Как построить дендрограмму в excel
Argument ‘Topic id’ is null or empty
Сейчас на форуме
© Николай Павлов, Planetaexcel, 2006-2023
info@planetaexcel.ru
Использование любых материалов сайта допускается строго с указанием прямой ссылки на источник, упоминанием названия сайта, имени автора и неизменности исходного текста и иллюстраций.
| ООО «Планета Эксел» ИНН 7735603520 ОГРН 1147746834949 |
ИП Павлов Николай Владимирович ИНН 633015842586 ОГРНИП 310633031600071 |
Как построить дендрограмму в excel
Как построить дендрограмму.
Atly: 1. Открываем по ссылке http://www.mymcgee.com/tools/yutility.html?mode=ftdna_mode 2. В открывшемся окне, слева под заголовком СОЗДАНИЕ ТАБЛИЦ убираем галочки, кроме TMRCA иGenerate PHYLIP data. 3. Вероятность ставим 95%. 4. Частоту мутаций среднее значение const 0,0022, или другой вариант FTDNA , McDonald’ на усмотрение. 5. Под заголовком: Вставьте гаплотип окно в которую нужно вставить интересующие гаплотипы. 6. Но прежде нужно подготовить гаплотипы: (проще всего в http://www.semargl.me/ru/dna/ydna/ открыть сравнение гаплотипов, занести интересуюшие гаплотипы и скопировать их в Microsoft Excel убрать все кроме № кита и str 290524 13 25 15 11 11 14 12 12 11 12 11 30. 290254 13 25 15 11 11 14 12 12 10 12 11 29. «очищенные» гаплотипы копируете и заносите в окно Вставьте гаплотип 7. Нажимаем выполнить жмем ОК и таблица готова, вернее две, копируем нижнюю и переходим к Mega6.05 8. Скачиваем MEGA6.05_setup (1).exe по ссылке http://update.megasoftware.net/MEGA6.05_setup.exe. 9. Создаем на рабочем столе текстовый документ (на раб. столе правую клавишу мышки — создать-текстовый документ) переименовываем текст. док. в 1 9-а. Скачиваем и устанавливаем на диск С Philip-3.695 http://evolution.genetics.washington.edu/phylip.html 10. Жмем пуск — компьютер — диск С — Philip-3.695 — exe в открывшееся окно курсором мышки перетаскиваем с рабочего стола текстовый документ 1. 11. Открываем текст. док. 1 заносим таблицу (п.7) и сохраняем. 12. Открываем в том же окне fitch — набираем 1.txt — жмем ок -j-ок -9 -ок -11 -ок — Y -ок. 13. Чуть ниже в том же окне появиться файл outree — переименовать и к outree допишем .tre получиться outree.tre -ок открываем outree.tre и все, дерево готово. Перед каждым построением дерева удаляю старые outree.tre и outfile иначе показывает ошибку.
Ответов — 19
Amigo: Спасибо Атлы Начну осваивать.
Atly: Amigo пишет: Начну осваивать. Амиго, всегда пожалуйста , напиши если будут проблемы.
Сары: Уважаемый Atly , есть несколько вопросов по твоему мануалу. Atly пишет: 1. Открываем по ссылке http://www.mymcgee.com/tools/yutility.html?mode=ftdna_mode Насколько корректно использование бета-версии калькулятора? Atly пишет: 4. Частоту мутаций const 0.0022. Чем обосновано именно это значение а не, например, «FTDNA 0.004..0.0075»? Применительно к карачаевцам какое значение возраста поколения лучше использовать — 25,30 лет или другое значение? Atly пишет: 10. Жмем пуск — компьютер — диск С — Philip-3.695 — exe в открывшееся окно курсором мышки перетаскиваем с рабочего стола текстовый документ 1. Неясно, что такое «Philip-3.695», я так понял 10-й пункт описывает запуск MEGA 6.05 Atly пишет: 12. Открываем в том же окне fitch — набираем 1.txt — жмем ок -j-ок -9 -ок -11 -ок — Y -ок. 13. Чуть ниже в том же окне появиться файл outree — наводим курсор, жмем правую клавишу мыши — переименовать и к outree допишем .tre получиться outree.tre -ок и все, дерево готово По этим пунктам вообще ничего непонятно. Облазил все пункты меняю, интуитивно-непонятным методом попытался построить дерево, но увы.
Ааа Эльграндов: Сары пишет Применительно к карачаевцам какое значение возраста поколения лучше использовать — 25,30 лет или другое значение? лет 30 наверно, т.к. женились у нас не очень рано и имели много детей. Младшие сыновья вообще могли быть когда отцу за сорок, старшие 20 с лишним. Ну 30 думаю в самый раз в среднем.
Atly: Есть косяк добавил пункт 9-а, надо установить Philip-3.695. По использованию тех или других версий программы Y-Utility — надо разбираться, думаю большой разницы нет. Скорости мутаций можно пробовать на разных вариантах, результат примерно одинаковый. Эти скорости рассчитаны на поколение равное 30 годам, если менять поколение, то надо менять и скорость мутаций, поэтому смысла в изменении возраста нет, это величина постоянная бери хоть 10 хоть 60 лет за поколение.
Сары: Atly пишет: 12. Открываем в том же окне fitch — набираем 1.txt — жмем ок -j-ок -9 -ок -11 -ок — Y -ок. Что не так? Кстати, а что это за параметры J 9 11? Может в них причина ошибки? Input file , то бишь 1.txt прилагаю.
Сары: Всё, разобрался. Важные замечания к мануалу. 1. Файл 1.txt должен ОБЯЗАТЕЛЬНО находится в одной папке с программой fitch.exe 2. Пункт 2 следует читать: «В открывшемся окне, слева под заголовком «Generate Tables» убираем галочки, кроме TMRCA и Generate PHYLIP data». Именно тогда во всплывающем окошке браузера появится таблица «PHYLIP compatible TMRCA table» содержимое которой в полном объеме и нужно копировать в пустой файл 1.txt. 3. Новая версия web-калькулятора Y-Utility работает, правда и результат немного отличается от предыдущей версии. 4. При использовании параметра «Mutation Rate = FTDNA» собственно сам этот параметр становится плавающим (см. табл. «Setup Data») в зависимости от маркера, что субъективно более точно отразилось на вычислениях.
Atly: Сары пишет: Что не так? Кстати, а что это за параметры J 9 11? Может в них причина ошибки? Input file , то бишь 1.txt прилагаю. J 9 11 это поправки на возвратные мутации и др. То что у тебя в текстовом документе 1 должно быть занесено в окно под Paste haplotype rows here (without marker headers): предварительно нужно убрать тире кавычки и пр. Удобнее в екселе один маркер одна ячейка не должно быть 12-14-15-16 или 35-39 в одной ячейке. В первом столбце номер кита дальше по порядку str-ы. Копируй составленную таблицу и в окно под Paste haplotype rows here (without marker headers): нажмешь Execute всплывет окно нажми ок откроется новое окно и внизу этого окна будет PHYLIP compatible TMRCA table чуть ниже таблица: 12 modal 0 900 1020 1260 1500 1140 1380 780 1020 900 1260 900 277360Abae 900 0 1260 1260 1770 1650 1380 1260 1380 1260 1380 1380 309709Tokh 1020 1260 0 1500 1650 1380 1500 1380 1650 1500 2010 1650 247851Bash 1260 1260 1500 0 1890 1770 1500 1650 1380 1500 1770 1770 321258Karc 1500 1770 1650 1890 0 660 1260 1650 1770 1650 1770 1890 321260Sarb 1140 1650 1380 1770 660 0 1260 1650 1770 1650 1650 1770 321253Misa 1380 1380 1500 1500 1260 1260 0 1650 1770 1500 1890 1770 321263Ayda 780 1260 1380 1650 1650 1650 1650 0 780 780 1500 1140 291808Karm 1020 1380 1650 1380 1770 1770 1770 780 0 540 1260 1140 321256Dzha 900 1260 1500 1500 1650 1650 1500 780 540 0 1140 1020 294587Katc 1260 1380 2010 1770 1770 1650 1890 1500 1260 1140 0 1020 275622Khub 900 1380 1650 1770 1890 1770 1770 1140 1140 1020 1020 0 ее и заноси в текстовый документ 1
Сары: Еще один мануал по построению филогенетического древа от Молгена http://forum.molgen.org/index.php/topic,19.0.html
Сары: И еще один мануал построения с помощью проги MURKA http://e1b1.org/rforum/viewtopic.php?f=7&t=80
Сары: Первые впечатления «чайника» от установки и «работы» древостроитльных программ PHILIP и MURKA: Общий алгоритм работы с прогами примерно схож — вытаскиваются исходные данные и конвертируются в нужный формат, затем производятся сами вычисления и результат выводится через графический формат. Но это в общем. В частности, конечно же нюансов установки достаточно и, если в ФИЛИПЕ особой «квалификации» не нужно, то с МУРКОЙ уже очень желателен навык работы в командной строке. К сожалению одного лишь технического осознания как все это «хозяйство» работает недостаточно, и тут, увы нужны более глубокие теоретические познания ДНК-генеалогии , особенно в МУРКЕ (набор ключей командной строки впечатляет — видно автор этой проги действительно профи в своем деле). Понятно что алгоритмы расчета в PHILIP и MURKA разные, но почему-то деревья при одних и тех же вводных данных получаются уж совершенно разные. И если топология древа расчитанная в ФИЛИПЕ как то похожа на известную топологию генеалогического древа, то в МУРКЕ топологий несколько и все они совершенно произвольные, хотя самих данных (в коих простой обыватель ни-ни) выводится очень много — красиво и непонятно Поэтому для себя решил, лучше начать с простого, т.е. Филипа и Меги, хотя и тут сразу вопросов конечно же возникает куча, например, почему ветви исходящие от общего предка имеют разный возраст и или ветвь с более длинным возрастом «вложена» в более «короткую», от чего логика как-то теряется? По какому признаку ветви группируются и т.д.? Понимаю, что прежде чем задавать «идиотские» вопросы, конечно же нужно «поглубже» подсесть в эту тему, но ничем не отличаясь от простого смертного хочется «всего много, здесь и сразу».
Atly: Насколько я понимаю есть несколько моментов, которые влияют на возраст отдельных гаплотипов. — невозможность точно определить модальный гаплотип — случайность мутаций — разная скорость мутаций на маркерах — гомоплазия Немножко дорогой, но верный способ построения дерева это исследование Y-DNA компанией Full Genomes или Big-Y от Ftdna. По снипам строится дерево, а по STR рассчитывается возраст общего предка веток и гаплотипов. Вот к примеру дерево z2123 от YFull http://yfull.com/tree/R-Z2123/
IK: Салам Алейкум! Я только начал интересоваться этой темой, поэтому у меня есть несколько вопросов. Буду признателен, если у Вас найдется время ответить на них. Суть вопроса в следующем: При построении дендрограммы по выше указанной инструкции, за которую отдельное спасибо автору, у меня возник вопрос по поводу участие на древе «модального» гаплотиппа. Не совсем понятно для чего он там нужен? Ведь, как я понимаю, он ошибочно принимается программой за «предковый», что не есть правильно. В связи с этим, я попытался просто-напросто удалить его, но, как вы понимаете, проблемы это не решило, ибо программа стала ругать и вовсе отказалась строить древо. В сети часто встречал подобные деревья, на которых модального гаплотиппа не было, но как подобное происходит с технической точки зрения пока не могу понять.
IK: И еще один вопрос. Умеет ли данная программа считать возраст? Если да, то каким образом заставить ее это делать?)))
Atly: IK пишет: Салам Алейкум! Я только начал интересоваться этой темой, поэтому у меня есть несколько вопросов. Буду признателен, если у Вас найдется время ответить на них. Суть вопроса в следующем: При построении дендрограммы по выше указанной инструкции, за которую отдельное спасибо автору, у меня возник вопрос по поводу участие на древе «модального» гаплотиппа. Не совсем понятно для чего он там нужен? Ведь, как я понимаю, он ошибочно принимается программой за «предковый», что не есть правильно. В связи с этим, я попытался просто-напросто удалить его, но, как вы понимаете, проблемы это не решило, ибо программа стала ругать и вовсе отказалась строить древо. В сети часто встречал подобные деревья, на которых модального гаплотиппа не было, но как подобное происходит с технической точки зрения пока не могу понять. Алейкум Салам! Да можно не обращать внимание на модал. Если построил дендограмму, то слева панель инструментов, можно выделить любой участок дендограммы без модала, там же фунция определения возраста отдельных гаплотипов или веток как сумма возрастов составляющих ветку гаплотипов.
IK: Atly пишет: Если построил дендограмму, то слева панель инструментов, можно выделить любой участок дендограммы без модала, там же фунция определения возраста отдельных гаплотипов или веток как сумма возрастов составляющих ветку гаплотипов. С модальным разобрался, сау бол. Теперь меня мучает вопрос с возрастами, уж очень странные числа получаются, типа, 23.7 и это у самого корня древа почти С эти числом никаких махинаций проводить не нужно случайно?
Atly: IK пишет: С модальным разобрался, сау бол. Теперь меня мучает вопрос с возрастами, уж очень странные числа получаются, типа, 23.7 и это у самого корня древа почти С эти числом никаких махинаций проводить не нужно случайно? можно менять скорость мутаций Constant: 0.0024 и точность расчета Probability 95% Таблица в помощь Таблица расчета времени жизни общего предка для двух гаплотипов http://www.rodstvo.ru/forum/index.php?act=attach&type=post&id=1021 Если не получится, скинь № гаплотипов посмотрим что выйдет.
IK: Atly пишет: Таблица расчета времени жизни общего предка для двух гаплотипов С этим более менее знаком. Меня больше интересует расчет по кластерам, если я правильно выразился. То есть время жизни общего предка, допустим, двух веток состоящих из нескольких гаплотиппов, как в таком случае высчитывают возраст? Для примера приведу древо по нашим R1a, которое выкладывал И.Рожанский. Вот меня, собственно, вычисление этих датировок интересует. Как, например, считался ВОБ для Гергокова и остальной ветки наших гаплотиппов?
Atly: IK пишет: С этим более менее знаком. Меня больше интересует расчет по кластерам, если я правильно выразился. То есть время жизни общего предка, допустим, двух веток состоящих из нескольких гаплотиппов, как в таком случае высчитывают возраст? Для примера приведу древо по нашим R1a, которое выкладывал И.Рожанский. Вот меня, собственно, вычисление этих датировок интересует. Как, например, считался ВОБ для Гергокова и остальной ветки наших гаплотиппов? Для разных кластеров эта программа не годится, есть программы с возможностью выделение отдельных кластеров, но по возрастам таких кластеров или субкладов лучше ориентироваться на снипы.
Как сделать кластерный анализ в Excel: сфера применения и инструкция
Кластерный анализ объединяет кластеры и переменные (объекты), похожие друг на друга. То есть классифицирует объекты. Часто при решении экономических задач, имеющих достаточно большое число данных, нужна многомерность описания. Один из простых методов многомерного анализа – кластерный анализ.
Кластерный анализ является количественным инструментом исследования социально-экономических процессов, для описания которых необходимо много характеристик. Он позволяет разбить выборку на несколько групп по исследуемому признаку, проанализировать группы (как группируются переменные), группировку объектов (как группируются объекты). С помощью метода решаются задачи сегментирования рынка, анализируются сельские хозяйства для сравнения производительности, например, прогнозируется конъюнктура рынка отдельных продуктов и т.д.
Многомерный кластерный анализ
По сути, кластерный анализ – это совокупность инструментов для классификации многомерных объектов. Метод подразумевает определение расстояния между переменными (дельты) и последующее выделение групп наблюдений (кластеров).
Техника кластеризации применяется в самых разнообразных областях. Главное задача – разбить многомерный ряд исследуемых значений (объектов, переменных, признаков) на однородные группы, кластеры. То есть данные классифицируются и структурируются.
Вопрос, который задает исследователь при использовании кластерного анализа, – как организовать многомерную выборку в наглядные структуры.
Примеры использования кластерного анализа:
- В биологии – для определения видов животных на Земле.
- В медицине – для классификации заболеваний по группам симптомов и способам терапии.
- В психологии – для определения типов поведения личности в определенных ситуациях.
- В экономическом анализе – при изучении и прогнозировании экономической депрессии, исследовании конъюнктуры.
- В разнообразных маркетинговых исследованиях.
Когда нужно преобразовать «горы» информации в пригодные для дальнейшего изучения группы, используют кластерный анализ.
- позволяет разбивать многомерный ряд сразу по целому набору параметров;
- можно рассматривать данные практически любой природы (нет ограничений на вид исследуемых объектов);
- можно обрабатывать значительные объемы информации, резко сжимать их, делать компактными и наглядными;
- может применяться циклически (проводится до тех пор, пока не будет достигнут нужный результат; а после каждого цикла возможно значительное изменение направленности дальнейшего исследования).
Дельта-кластерный анализ имеет и свои недостатки:
- состав и количество кластеров зависит от заданного критерия разбиения;
- при преобразовании исходного набора данных в компактные группы исходная информация может искажаться, отдельные объекты могут терять свою индивидуальность;
- часто игнорируется отсутствие в анализируемой совокупности некоторых значений кластеров.
Как сделать кластерный анализ в Excel
Для примера возьмем шесть объектов наблюдения. Каждый имеет два характеризующих его параметра.
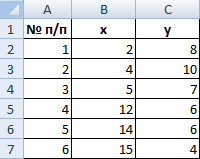
В качестве расстояния между объектами возьмем евклидовое расстояние. Формула расчета:
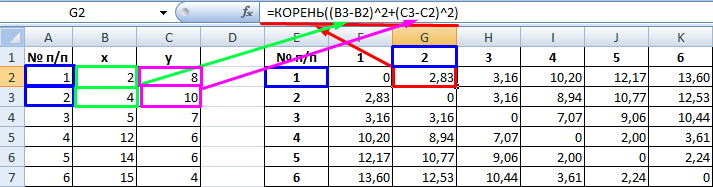
Рассчитанные данные размещаем в матрице расстояний.
Самыми близкими друг к другу объектами являются объекты 4 и 5. Следовательно, их можно объединить в одну группу – при формировании новой матрицы оставляем наименьшее значение.
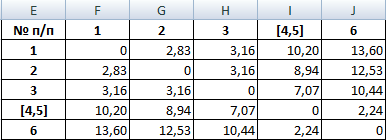
Из новой матрицы видно, что можно объединить в один кластер объекты [4, 5] и 6 (как наиболее близкие друг к другу по значениям). Оставляем наименьшее значение и формируем новую матрицу:
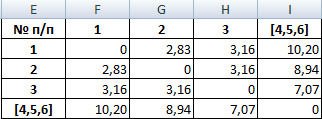
Объекты 1 и 2 можно объединить в один кластер (как наиболее близкие из имеющихся). Выбираем наименьшее значение и формируем новую матрицу расстояний. В результате получаем три кластера:
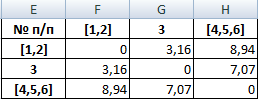
Самые близкие объекты – 1, 2 и 3. Объединим их.
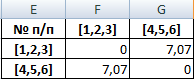
Мы провели кластерный анализ по методу «ближайшего соседа». В результате получено два кластера, расстояние между которыми – 7,07.
Огромное значение имеет кластерный анализ в экономическом анализе. Инструмент позволяет вычленять из громадной совокупности периоды, где значения соответствующих параметров максимально близки и где динамика наиболее схожа. Для исследования, к примеру, товарной и общехозяйственной конъюнктуры этот метод отлично подходит.
- Excel Formula Examples
- Создать таблицу
- Форматирование
- Функции Excel
- Формулы и диапазоны
- Фильтр и сортировка
- Диаграммы и графики
- Сводные таблицы
- Печать документов
- Базы данных и XML
- Возможности Excel
- Настройки параметры
- Уроки Excel
- Макросы VBA
- Скачать примеры
Как построить дендрограмму в excel
Шаг 102.
Введение в машинное обучение с использованием Python. Методы машинного обучения . . Кластеризация. Иерархическая кластеризация и дендрограммы
На этом шаге мы рассмотрим особенности и ограничения этой кластеризации .
Результатом агломеративной кластеризации является иерархическая кластеризация (hierarchical clustering) . Кластеризация выполняется итеративно, и каждая точка совершает путь от отдельной точки-кластера до участника итогового кластера. На каждом промежуточном шаге происходит кластеризация данных (с разным количеством кластеров). Иногда полезно сразу взглянуть на все возможные кластеризации. Следующий пример (рисунок 1) показывает наложение всех возможных кластеризаций, показанных на рисунке 1 101 шага и дает некоторое представление о том, как каждый кластер распадается на более мелкие кластеры:
[In 62]: mglearn.plots.plot_agglomerative()
Рис.1. Иерархическое присвоение кластеров (показаны в виде линий), полученное с помощью алгоритма агломеративной кластеризации, точки данных пронумерованы (см. рисунок 2)
Хотя эта визуализация дает достаточно детализированное представление о результатах иерархической кластеризации, она опирается на двумерную природу данных и не может быть использована для наборов данных, которые имеют более двух характеристик. Однако есть еще один инструмент для визуализации результатов иерархической кластеризации, называемый дендрограммой (dendrogram) и позволяющий обрабатывать многомерные массивы данных.
К сожалению, на данный момент в scikit-learn нет инструментов, позволяющих рисовать дендрограммы. Однако вы легко можете создать их с помощью SciPy . По сравнению с алгоритмами кластеризации scikit-learn алгоритмы кластеризации SciPy имеют немного другой интерфейс. В SciPy используется функция, которая принимает массив данных X в качестве аргумента и вычисляет массив связей (linkage array) с записанными сходствами между кластерами. Затем мы можем скормить этот массив функции SciPy dendrogram() , чтобы построить дендрограмму (рисунок 2):
[In 63]: # импортируем функцию dendrogram и функцию кластеризации ward из SciPy from scipy.cluster.hierarchy import dendrogram, ward X, y = make_blobs(random_state=0, n_samples=12) # применяем кластеризацию ward к массиву данных X # функция SciPy ward возвращает массив с расстояниями # вычисленными в ходе выполнения агломеративной кластеризации linkage_array = ward(X) # теперь строим дендрограмму для массива связей, содержащего расстояния # между кластерами dendrogram(linkage_array) # делаем отметки на дереве, соответствующие двум или трем кластерам ax = plt.gca() bounds = ax.get_xbound() ax.plot(bounds, [7.25, 7.25], '--', c='k') ax.plot(bounds, [4, 4], '--', c='k') ax.text(bounds[1], 7.25, ' два кластера', va='center', fontdict='size': 15>) ax.text(bounds[1], 4, ' три кластера', va='center', fontdict='size': 15>) plt.xlabel("Индекс наблюдения") plt.ylabel("Кластерное расстояние")
Рис.2. Дендрограмма для кластеризации, показанной на рисунке 1, линии обозначают расщепления на два и три кластера
Точки данных показаны в нижнеи части дендрограммы (пронумерованы от 0 до 11). Затем строится дерево с этими точками (представляющими собой кластеры-точки) в качестве листьев, и для каждых двух объединенных кластеров добавляется новый узел-родитель.
Чтение дендрограммы происходит снизу вверх. Точки данных 1 и 4 объединяются первыми (как вы уже могли видеть на рисунке 1 101 шага). Затем в кластер объединяются точки 6 и 9 и т.д. На самом верхнем уровне остаются две ветви, одна ветвь состоит из точек 11, 0, 5, 10, 7, 6 и 9, а вторая — из точек 1, 4, 3, 2 и 8. Они соответствуют двум крупнейшим кластерам.
Ось у в дендрограмме указывает не только момент объединения двух кластеров в ходе работы алгоритма агломеративной кластеризации. Длина каждой ветви показывает, насколько далеко друг от друга находятся объединенные кластеры. Самыми длинными ветвями в этой дендрограмме являются три линии, отмеченные пунктирной чертой с надписью «три кластера». Тот факт, что эти линии являются самыми длинными ветвями, указывает на то, что переход от трех кластеров к двум сопровождался объединением некоторых сильно удаленных друг от друга точек. Мы снова видим это в самой верхней части графика, когда объединение двух оставшихся кластеров в единый кластер подразумевает относительно большое расстояние между точками.
К сожалению, алгоритм агломеративной кластеризации по-прежнему не в состоянии обработать сложные данные типа набора two_moons . Чего нельзя сказать о DBSCAN , следующем алгоритме, который мы рассмотрим.
На следующем шаге мы рассмотрим алгоритм DBSCAN .