Нейронные сети, перцептрон
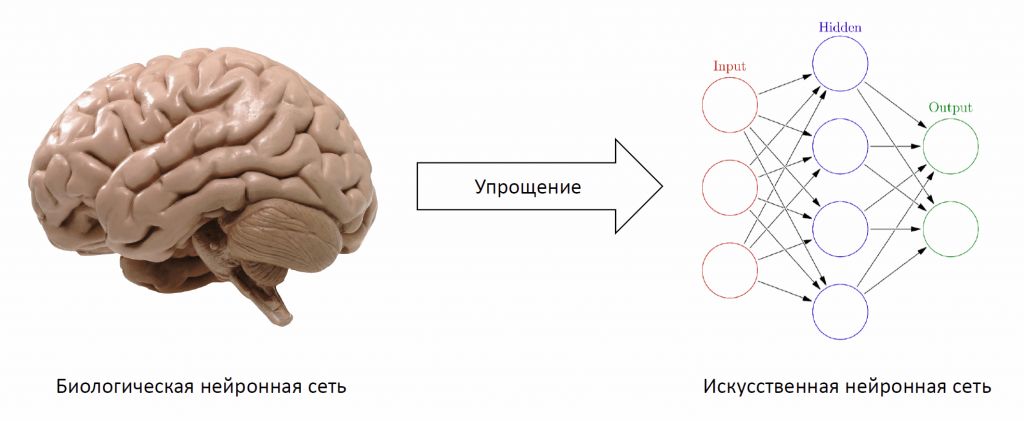
Искусственная нейронная сеть (ИНС) (англ. Artificial neural network (ANN)) — упрощенная модель биологической нейронной сети, представляющая собой совокупность искусственных нейронов, взаимодействующих между собой.
Основные принципы работы нейронных сетей были описаны еще в 1943 году Уорреном Мак-Каллоком и Уолтером Питтсом [1] . В 1957 году нейрофизиолог Фрэнк Розенблатт разработал первую нейронную сеть [2] , а в 2010 году большие объемы данных для обучения открыли возможность использовать нейронные сети для машинного обучения.
На данный момент нейронные сети используются в многочисленных областях машинного обучения и решают проблемы различной сложности.
Структура нейронной сети
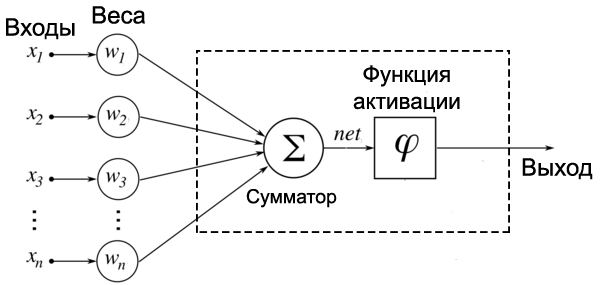
Рисунок 2. Схема искусственного нейрона
Хорошим примером биологической нейронной сети является человеческий мозг. Наш мозг — сложнейшая биологическая нейронная сеть, которая принимает информацию от органов чувств и каким-то образом ее обрабатывает (узнавание лиц, возникновение ощущений и т.д.). Мозг же, в свою очередь, состоит из нейронов, взаимодействующих между собой.
Для построения искусственной нейронной сети будем использовать ту же структуру. Как и биологическая нейронная сеть, искусственная состоит из нейронов, взаимодействующих между собой, однако представляет собой упрощенную модель. Так, например, искусственный нейрон, из которых состоит ИНС, имеет намного более простую структуру: у него есть несколько входов, на которых он принимает различные сигналы, преобразует их и передает другим нейронам. Другими словами, искусственный нейрон — это такая функция [math]\mathbb^n \rightarrow \mathbb[/math] , которая преобразует несколько входных параметров в один выходной.
Как видно на рисунке справа, у нейрона есть [math]n[/math] входов [math]x_i[/math] , у каждого из которого есть вес [math]w_i[/math] , на который умножается сигнал, проходящий по связи. После этого взвешенные сигналы [math]x_i \cdot w_i[/math] направляются в сумматор, который аггрегирует все сигналы во взвешенную сумму. Эту сумму также называют [math]net[/math] . Таким образом, [math]net = \sum_^ w_i \cdot x_i = w^T \cdot x[/math] .
Просто так передавать взвешенную сумму [math]net[/math] на выход достаточно бессмысленно — нейрон должен ее как-то обработать и сформировать адекватный выходной сигнал. Для этих целей используют функцию активации, которая преобразует взвешенную сумму в какое-то число, которое и будет являться выходом нейрона. Функция активации обозначается [math]\phi(net)[/math] . Таким образом, выходов искусственного нейрона является [math]\phi(net)[/math] .
Для разных типов нейронов используют самые разные функции активации, но одними из самых популярных являются:
- Функция единичного скачка. Если [math]net \gt threshold[/math] , [math]\phi(net) = 1[/math] , а иначе [math]0[/math] ;
- Сигмоидальная функция. [math]\phi(net) = \frac[/math] , где параметр [math]a[/math] характеризует степень крутизны функции;
- Гиперболический тангенс. [math]\phi(net) = tanh(\frac)[/math] , где параметр [math]a[/math] также определяет степень крутизны графика функции;
- Rectified linear units (ReLU). [math]ReLU(x) = \begin x & x \geq 0 \\ 0 & x \lt 0 \end = \max(x, 0)[/math] .
Виды нейронных сетей
Разобравшись с тем, как устроен нейрон в нейронной сети, осталось понять, как их в этой сети располагать и соединять.
Как правило, в большинстве нейронных сетей есть так называемый входной слой, который выполняет только одну задачу — распределение входных сигналов остальным нейронам. Нейроны этого слоя не производят никаких вычислений. В остальном нейронные сети делятся на основные категории, представленные ниже.
Однослойные нейронные сети

Рисунок 3. Схема однослойной нейронной сети
Однослойная нейронная сеть (англ. Single-layer neural network) — сеть, в которой сигналы от входного слоя сразу подаются на выходной слой, который и преобразует сигнал и сразу же выдает ответ.
Как видно из схемы однослойной нейронной сети, представленной справа, сигналы [math]x_1, x_2, \ldots x_n[/math] поступают на входной слой (который не считается за слой нейронной сети), а затем сигналы распределяются на выходной слой обычных нейронов. На каждом ребре от нейрона входного слоя к нейрону выходного слоя написано число — вес соответствующей связи.
Многослойные нейронные сети

Рисунок 4. Схема многослойной нейронной сети
Многослойная нейронная сеть (англ. Multilayer neural network) — нейронная сеть, состоящая из входного, выходного и расположенного(ых) между ними одного (нескольких) скрытых слоев нейронов.
Помимо входного и выходного слоев эти нейронные сети содержат промежуточные, скрытые слои. Такие сети обладают гораздо большими возможностями, чем однослойные нейронные сети, однако методы обучения нейронов скрытого слоя были разработаны относительно недавно.
Работу скрытых слоев нейронов можно сравнить с работой большого завода. Продукт (выходной сигнал) на заводе собирается по стадиям на станках. После каждого станка получается какой-то промежуточный результат. Скрытые слои тоже преобразуют входные сигналы в некоторые промежуточные результаты.
Сети прямого распространения
Сети прямого распространения (англ. Feedforward neural network) (feedforward сети) — искусственные нейронные сети, в которых сигнал распространяется строго от входного слоя к выходному. В обратном направлении сигнал не распространяется.
Все сети, описанные выше, являлись сетями прямого распространения, как следует из определения. Такие сети широко используются и вполне успешно решают определенный класс задач: прогнозирование, кластеризация и распознавание.
Однако сигнал в нейронных сетях может идти и в обратную сторону.
Сети с обратными связями
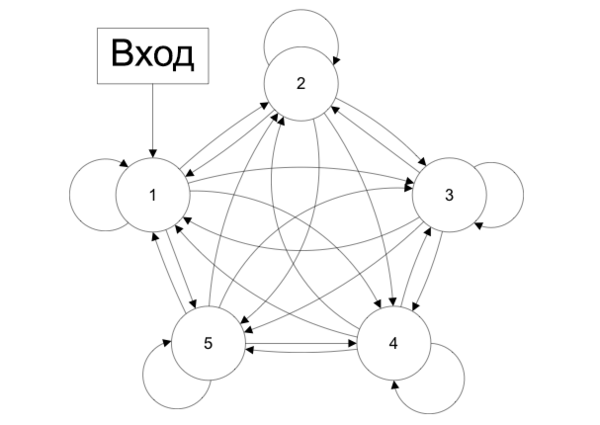
Рисунок 5. Схема сети с обратными связями
Сети с обратными связями (англ. Recurrent neural network) — искусственные нейронные сети, в которых выход нейрона может вновь подаваться на его вход. В более общем случае это означает возможность распространения сигнала от выходов к входам.
В сетях прямого распространения выход сети определяется входным сигналом и весовыми коэффициентами при искусственных нейронах. В сетях с обратными связями выходы нейронов могут возвращаться на входы. Это означает, что выход какого-нибудь нейрона определяется не только его весами и входным сигналом, но еще и предыдущими выходами (так как они снова вернулись на входы).
Обучение нейронной сети
Обучение нейронной сети — поиск такого набора весовых коэффициентов, при котором входной сигнал после прохода по сети преобразуется в нужный нам выходной.
Это определение «обучения нейронной сети» соответствует и биологическим нейросетям. Наш мозг состоит из огромного количества связанных друг с другом нейросетей, каждая из которых в отдельности состоит из нейронов одного типа (с одинаковой функцией активации). Наш мозг обучается благодаря изменению синапсов — элементов, которые усиливают или ослабляют входной сигнал.
Если обучать сеть, используя только один входной сигнал, то сеть просто «запомнит правильный ответ», а как только мы подадим немного измененный сигнал, вместо правильного ответа получим бессмыслицу. Мы ждем от сети способности обобщать какие-то признаки и решать задачу на различных входных данных. Именно с этой целью и создаются обучающие выборки.
Обучающая выборка — конечный набор входных сигналов (иногда вместе с правильными выходными сигналами), по которым происходит обучение сети.
После обучения сети, то есть когда сеть выдает корректные результаты для всех входных сигналов из обучающей выборки, ее можно использовать на практике. Однако прежде чем сразу использовать нейронную сеть, обычно производят оценку качества ее работы на так называемой тестовой выборке.
Тестовая выборка — конечный набор входных сигналов (иногда вместе с правильными выходными сигналами), по которым происходит оценка качества работы сети.
Само обучение нейронной сети можно разделить на два подхода: обучение с учителем [на 28.01.19 не создан] и обучение без учителя [на 28.01.19 не создан] . В первом случае веса меняются так, чтобы ответы сети минимально отличались от уже готовых правильных ответов, а во втором случае сеть самостоятельно классифицирует входные сигналы.
Перцептрон
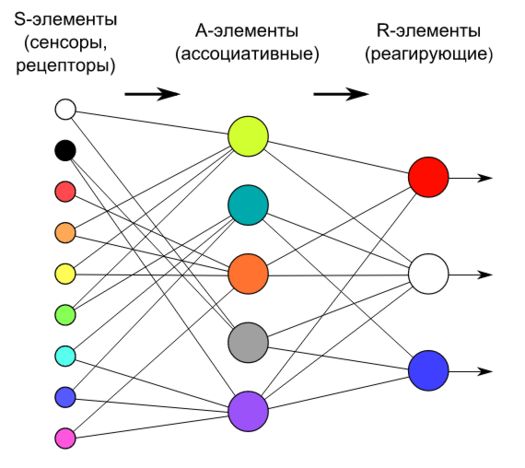
Рисунок 6. Схема перцептрона
Перцептрон (англ. Perceptron) — простейший вид нейронных сетей. В основе лежит математическая модель восприятия информации мозгом, состоящая из сенсоров, ассоциативных и реагирующих элементов.
История
Идею перцептрона предложил нейрофизиолог Фрэнк Розенблатт. Он предложил схему устройства, моделирующего процесс человеческого восприятия, и назвал его «перцептроном» (от латинского perceptio — восприятие). В 1960 году Розенблатт представил первый нейрокомпьютер — «Марк-1», который был способен распознавать некоторые буквы английского алфавита.
Таким образом перцептрон является одной из первых моделей нейросетей, а «Марк-1» — первым в мире нейрокомпьютером.
Описание
В основе перцептрона лежит математическая модель восприятия информации мозгом. Разные исследователи по-разному его определяют. В самом общем своем виде (как его описывал Розенблатт) он представляет систему из элементов трех разных типов: сенсоров, ассоциативных элементов и реагирующих элементов.
Принцип работы перцептрона следующий:
- Первыми в работу включаются S-элементы. Они могут находиться либо в состоянии покоя (сигнал равен 0), либо в состоянии возбуждения (сигнал равен 1);
- Далее сигналы от S-элементов передаются A-элементам по так называемым S-A связям. Эти связи могут иметь веса, равные только -1, 0 или 1;
- Затем сигналы от сенсорных элементов, прошедших по S-A связям, попадают в A-элементы, которые еще называют ассоциативными элементами;
- Одному A-элементу может соответствовать несколько S-элементов;
- Если сигналы, поступившие на A-элемент, в совокупности превышают некоторый его порог [math]\theta[/math] , то этот A-элемент возбуждается и выдает сигнал, равный 1;
- В противном случае (сигнал от S-элементов не превысил порога A-элемента), генерируется нулевой сигнал;
- Далее сигналы, которые произвели возбужденные A-элементы, направляются к сумматору (R-элемент), действие которого нам уже известно. Однако, чтобы добраться до R-элемента, они проходят по A-R связям, у которых тоже есть веса (которые уже могут принимать любые значения, в отличие от S-A связей);
- R-элемент складывает друг с другом взвешенные сигналы от A-элементов, а затем
- если превышен определенный порог, генерирует выходной сигнал, равный 1;
- eсли порог не превышен, то выход перцептрона равен -1.
Для элементов перцептрона используют следующие названия:
- S-элементы называют сенсорами;
- A-элементы называют ассоциативными;
- R-элементы называют реагирующими.
Классификация перцептронов
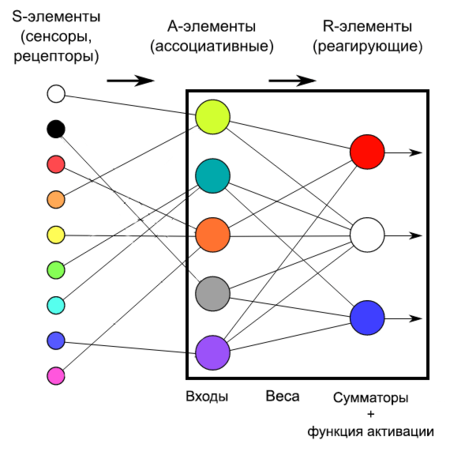
Рисунок 7. Схема однослойного перцептрона
Перцептрон с одним скрытым слоем (элементарный перцептрон, англ. elementary perceptron) — перцептрон, у которого имеется только по одному слою S, A и R элементов.
Однослойный персептрон (англ. Single-layer perceptron) — перцептрон, каждый S-элемент которого однозначно соответствует одному А-элементу, S-A связи всегда имеют вес 1, а порог любого А-элемента равен 1. Часть однослойного персептрона соответствует модели искусственного нейрона.
Его ключевая особенность состоит в том, что каждый S-элемент однозначно соответствует одному A-элементу, все S-A связи имеют вес, равный +1, а порог A элементов равен 1. Часть однослойного перцептрона, не содержащая входы, соответствует искусственному нейрону, как показано на картинке. Таким образом, однослойный перцептрон — это искусственный нейрон, который на вход принимает только 0 и 1.
Однослойный персептрон также может быть и элементарным персептроном, у которого только по одному слою S,A,R-элементов.
Многослойный перцептрон по Розенблатту (англ. Rosenblatt multilayer perceptron) — перцептрон, который содержит более 1 слоя А-элементов.
Многослойный перцептрон по Румельхарту (англ. Rumelhart multilater perceptron) — частный случай многослойного персептрона по Розенблатту, с двумя особенностями:
- S-A связи могут иметь произвольные веса и обучаться наравне с A-R связями;
- Обучение производится по специальному алгоритму, который называется обучением по методу обратного распространения ошибки.
Обучение перцептрона
Задача обучения перцептрона — подобрать такие [math]w_0, w_1, w_2, \ldots, w_n[/math] , чтобы [math]sign(\sigma(w_0 + w_1 \cdot x_1 + w_2 \cdot x_2 + \ldots + w_n \cdot x_n))[/math] как можно чаще совпадал с [math]y(x)[/math] — значением в обучающей выборке (здесь [math]\sigma[/math] — функция активации). Для удобства, чтобы не тащить за собой свободный член [math]w_0[/math] , добавим в вектор $x$ лишнюю «виртуальную размерность» и будем считать, что [math]x = (1, x_1, x_2, \ldots, x_n)[/math] . Тогда [math]w_0 + w_1 \cdot x_1 + w_2 \cdot x_2 + \ldots + w_n \cdot x_n[/math] можно заменить на [math]w^T \cdot x[/math] .
Чтобы обучать эту функцию, сначала надо выбрать функцию ошибки, которую потом можно оптимизировать градиентным спуском. Число неверно классифицированных примеров не подходит на эту кандидатуру, потому что эта функция кусочно-гладкая, с массой разрывов: она будет принимать только целые значения и резко меняться при переходе от одного числа неверно классифицированных примеров к другому. Поэтому использовать будем другую функцию, так называемый критерий перцептрона: [math]E_P(w) = -\sum_ y(x)(\sigma(w^T \cdot x))[/math] , где [math]M[/math] — множество примеров, которые перцептрон с весами [math]w[/math] классифицирует неправильно.
Иначе говоря, мы минимизируем суммарное отклонение наших ответов от правильных, но только в неправильную сторону; верный ответ ничего не вносит в функцию ошибки. Умножение на [math]y(x)[/math] здесь нужно для того, чтобы знак произведения всегда получался отрицательным: если правильный ответ −1, значит, перцептрон выдал положительное число (иначе бы ответ был верным), и наоборот. В результате у нас получилась кусочно-линейная функция, дифференцируемая почти везде, а этого вполне достаточно.
Теперь [math]E_P(w)[/math] можно оптимизировать градиентным спуском. На очередном шаге получаем: [math]w^ = w^ − \eta\triangledown_w E_P(w)[/math] .
Алгоритм такой — мы последовательно проходим примеры [math]x_1, x_2, \ldots[/math] из обучающего множества, и для каждого [math]x_n[/math] :
- если он классифицирован правильно, не меняем ничего;
- а если неправильно, прибавляем [math]\eta \triangledown_w E_P(w)[/math] .
Ошибка на примере [math]x_n[/math] при этом, очевидно, уменьшается, но, конечно, совершенно никто не гарантирует, что вместе с тем не увеличится ошибка от других примеров. Это правило обновления весов так и называется — правило обучения перцептрона, и это было основной математической идеей работы Розенблатта.
Применение
- Решение задач классификации, если объекты классификации обладают свойством линейной разделимости;
- Прогнозирование и распознавание образов;
- Управление агентами [3] .
Примеры кода
Пример использования с помощью scikit-learn [4]
Будем классифицировать с помощью перцептрона датасет MNIST [5] .
# Load required libraries from sklearn import datasets from sklearn.preprocessing import StandardScaler from sklearn.linear_model import Perceptron #Single-layer perceptron from sklearn.neural_network import MLPClassifier #Multilayer perceptron from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score import numpy as np
# Load the mnist dataset mnist = datasets.load_digits()
# Create our X and y data n_samples = len(mnist.images) X = mnist.images.reshape((n_samples, -1)) y = mnist.target
# Split the data into 70% training data and 30% test data X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# Train the scaler, which standarizes all the features to have mean=0 and unit variance sc = StandardScaler() sc.fit(X_train)
# Apply the scaler to the X training data X_train_std = sc.transform(X_train)
# Apply the SAME scaler to the X test data X_test_std = sc.transform(X_test)
# Create a single-layer perceptron object with the parameters: 40 iterations (epochs) over the data, and a learning rate of 0.1 ppn = Perceptron(n_iter=40, eta0=0.1, random_state=0) # Create a multilayer perceptron object mppn = MLPClassifier(solver='lbfgs', alpha=1e-5, hidden_layer_sizes=(256, 512, 128), random_state=1)
# Train the perceptrons ppn.fit(X_train_std, y_train) mppn.fit(X_train_std, y_train)
# Apply the trained perceptrons on the X data to make predicts for the y test data y_pred = ppn.predict(X_test_std) multi_y_pred = mppn.predict(X_test_std)
# View the accuracies of the model, which is: 1 - (observations predicted wrong / total observations) print('Single-layer perceptron accuracy: %.4f' % accuracy_score(y_test, y_pred)) print('Multilayer perceptron accuracy: %.4f' % accuracy_score(y_test, multi_y_pred))
Single-layer perceptron accuracy: 0.9574 Multilayer perceptron accuracy: 0.9759
Пример использования с помощью tensorflow [6]
Будем классифицировать цифры из того же датасета MNIST.
# Load required libraries import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data
#Load MNIST dataset mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
#placeholder for test data x = tf.placeholder(tf.float32, [None, 784]) #placeholder for weights and bias W = tf.Variable(tf.zeros([784, 10])) b = tf.Variable(tf.zeros([10])) #tensorflow model y = tf.nn.softmax(tf.matmul(x, W) + b) #loss function y_ = tf.placeholder(tf.float32, [None, 10]) cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
#gradient descent step train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
init = tf.initialize_all_variables() sess = tf.Session() sess.run(init) for i in range(1000): batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step, feed_dict=) correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) print("Accuracy: %s" % sess.run(accuracy, feed_dict=))

Рисунок 8.
Правильные метки — 5, 4, 9, 7.
Результат классификации — 6, 6, 4, 4.
Accuracy: 0.9164
На рисунке справа показаны четыре типичных изображения, на которых классификаторы ошибаются. Согласитесь, случаи действительно тяжелые.
Пример на языке Java
Пример классификации с применением weka.classifiers.functions.MultilayerPerceptron [7]
nz.ac.waikato.cms.weka weka-stable 3.8.0
import weka.classifiers.functions.MultilayerPerceptron; import weka.core.converters.CSVLoader; import java.io.File;
// read train & test datasets and build MLP classifier var trainds = new DataSource("etc/train.csv"); var train = trainds.getDataSet(); train.setClassIndex(train.numAttributes() - 1); var testds = new DataSource("etc/test.csv"); var test = testds.getDataSet(); test.setClassIndex(test.numAttributes() - 1); var mlp = new MultilayerPerceptron(); mlp.buildClassifier(train); // Test the model var eTest = new Evaluation(train); eTest.evaluateModel(mlp, test); // Print the result à la Weka explorer: var strSummary = eTest.toSummaryString(); System.out.println(strSummary);
См. также
- Сверточные нейронные сети
- Рекуррентные нейронные сети
- Рекурсивные нейронные сети [на 28.01.19 не создан]
Примечания
- ↑Artificial neuron, Wikipedia
- ↑Perceptron, Wikipedia
- ↑Применения перцептрона, Wikipedia
- ↑Библиотека scikit-learn для Python
- ↑Датасет MNIST
- ↑Библиотека tensorflow для Python
- ↑Weka, MLP
Источники информации
- Сергей Николенко, Артур Кадурин, Екатерина Архангельская. Глубокое обучение. Погружение в мир нейронных сетей. — «Питер», 2018. — С. 93-123.
- Нейронные сети — учебник
АЛГОРИТМ РАЗДЕЛЕНИЯ МОНОЛИТНОЙ НЕЙРОННОЙ СЕТИ ДЛЯ РЕАЛИЗАЦИИ ТУМАННЫХ ВЫЧИСЛЕНИЙ В УСТРОЙСТВАХ НА ПРОГРАММИРУЕМОЙ ЛОГИКЕ Текст научной статьи по специальности «Компьютерные и информационные науки»
Аннотация научной статьи по компьютерным и информационным наукам, автор научной работы — Бахтин В.В.
В проектах, где нет возможности использовать нейронную сеть в рамках одного устройства, целесообразно применять метод синтеза каскада из устройств, который бы позволял реализовать распределенную (блочную) нейронную сеть. Целью исследования является разработка метода синтеза устройств реализации искусственных нейронных сетей на программируемой логике , ориентированных на туманные вычисления . Основой для создания рассматриваемых устройств выступает искусственная нейронная сеть, которую требуется разделить на несколько блоков. Каждый из этих вычислительных блоков исполняется на отдельном физическом устройстве. Связь между блоками осуществляется с помощью стандартных каналов и протоколов. Методика исследования базируется на математическом моделировании нейронной сети, которая будет пригодной для работы в режиме туманных вычислений, методах алгоритмизации и программирования, которые позволят реализовать необходимые алгоритмические структуры. В результате исследования формируется алгоритм разделения монолитной нейронной сети на каскад блоков нейронной сети, адаптированной для туманных вычислений в устройствах на программируемой логике , который позволит реализовать метод синтеза устройств нейросетевого распознавания. В статье рассмотрена математическая модель, ставшая отправной точкой для алгоритмов . Сформулирован и реализован алгоритм : разделения монолитной нейронной сети на каскад блоков нейронной сети, адаптированной для туманных вычислений в устройствах на программируемой логике и вычисления результатов работы нейронной сети в новом формате, адаптированный для туманных вычислений . Предложен оригинальный формат хранения нейронной сети, созданный для предлагаемых алгоритмов .
i Надоели баннеры? Вы всегда можете отключить рекламу.
Похожие темы научных работ по компьютерным и информационным наукам , автор научной работы — Бахтин В.В.
МЕТОД СИНТЕЗА УСТРОЙСТВ НЕЙРОСЕТЕВОГО РАСПОЗНАВАНИЯ НА ПРОГРАММИРУЕМОЙ ЛОГИКЕ ДЛЯ РЕАЛИЗАЦИИ РЕЖИМА FOG COMPUTING
МАТЕМАТИЧЕСКАЯ МОДЕЛЬ ИСКУССТВЕННОЙ НЕЙРОННОЙ СЕТИ ДЛЯ УСТРОЙСТВ НА ПЛИС И МИКРОКОНТРОЛЛЕРАХ, ОРИЕНТИРОВАННЫХ НА ТУМАННЫЕ ВЫЧИСЛЕНИЯ
Модель инструментального средства автоматизированного синтеза аппаратных ускорителей сверточных нейронных сетей для программируемых логических интегральных схем
Устройство на основе ПЛИС для распознавания рукописных цифр на изображениях
АНАЛИТИЧЕСКИЙ ОБЗОР МЕТОДОВ ПОСТРОЕНИЯ ТУМАННЫХ ВЫЧИСЛЕНИЙ
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
i Надоели баннеры? Вы всегда можете отключить рекламу.
ALGORITHM FOR DECOMPOSITION OF A MONOLITHIC NEURAL NETWORK FOR IMPLEMENTED FOG COMPUTING IN DEVICES BASED ON PROGRAMMABLE LOGIC
In projects where it is not possible to use a neural network within a single device, a method of synthesizing a cascade of devices that would implement a distributed (block) neural network would be useful. The aim of the study is to develop a method for synthesizing devices for implementing artificial neural networks based on programmable logic, focused on fog computing. The basis for the creation of the devices in question will be an artificial neural network, which will need to be divided into several blocks. Each of these computing units will be executed on a separate physical device, communication between them will be carried out using standard channels and protocols. The research methodology is based on mathematical modelling of a neural network that will be suitable for operation in the mode of foggy calculations, algorithmization and programming methods that will allow implementing the necessary algorithmic structures. As a result of the research, it is planned to obtain an algorithm for dividing a monolithic neural network into a cascade of neural network blocks adapted for fog computing in devices based on programmable logic. This algorithm will allow the implementation of a method for synthesizing neural network recognition devices. The article considers a mathematical model as the starting point for algorithms. The following algorithms are formulated and implemented: the separation of a monolithic neural network into a cascade of neural network blocks adapted for fog computing in devices based on programmable logic and the calculation of the neural network results in a new format adapted for fog computing. The original neural network storage format created for the proposed algorithms is proposed.
Текст научной работы на тему «АЛГОРИТМ РАЗДЕЛЕНИЯ МОНОЛИТНОЙ НЕЙРОННОЙ СЕТИ ДЛЯ РЕАЛИЗАЦИИ ТУМАННЫХ ВЫЧИСЛЕНИЙ В УСТРОЙСТВАХ НА ПРОГРАММИРУЕМОЙ ЛОГИКЕ»
2022 Электротехника, информационные технологии, системы управления № 41 Научная статья
Б01: 10.15593/2224-9397/2022.1.06 УДК 004.89
Пермский национальный исследовательский политехнический университет,
АЛГОРИТМ РАЗДЕЛЕНИЯ МОНОЛИТНОЙ НЕЙРОННОЙ СЕТИ ДЛЯ РЕАЛИЗАЦИИ ТУМАННЫХ ВЫЧИСЛЕНИЙ В УСТРОЙСТВАХ НА ПРОГРАММИРУЕМОЙ ЛОГИКЕ
В проектах, где нет возможности использовать нейронную сеть в рамках одного устройства, целесообразно применять метод синтеза каскада из устройств, который бы позволял реализовать распределенную (блочную) нейронную сеть. Целью исследования является разработка метода синтеза устройств реализации искусственных нейронных сетей на программируемой логике, ориентированных на туманные вычисления. Основой для создания рассматриваемых устройств выступает искусственная нейронная сеть, которую требуется разделить на несколько блоков. Каждый из этих вычислительных блоков исполняется на отдельном физическом устройстве. Связь между блоками осуществляется с помощью стандартных каналов и протоколов. Методика исследования базируется на математическом моделировании нейронной сети, которая будет пригодной для работы в режиме туманных вычислений, методах алгоритмизации и программирования, которые позволят реализовать необходимые алгоритмические структуры. В результате исследования формируется алгоритм разделения монолитной нейронной сети на каскад блоков нейронной сети, адаптированной для туманных вычислений в устройствах на программируемой логике, который позволит реализовать метод синтеза устройств нейросетевого распознавания. В статье рассмотрена математическая модель, ставшая отправной точкой для алгоритмов. Сформулирован и реализован алгоритм: разделения монолитной нейронной сети на каскад блоков нейронной сети, адаптированной для туманных вычислений в устройствах на программируемой логике и вычисления результатов работы нейронной сети в новом формате, адаптированный для туманных вычислений. Предложен оригинальный формат хранения нейронной сети, созданный для предлагаемых алгоритмов.
Ключевые слова: алгоритм, искусственная нейронная сеть, программируемая логика, туманные вычисления, принятие решений, устройство нейросетевого распознавания, метод синтеза, математическая модель.
Perm National Research Polytechnic University, Perm, Russian Federation
ALGORITHM FOR DECOMPOSITION OF A MONOLITHIC NEURAL NETWORK FOR IMPLEMENTED FOG COMPUTING IN DEVICES BASED ON PROGRAMMABLE LOGIC
In projects where it is not possible to use a neural network within a single device, a method of synthesizing a cascade of devices that would implement a distributed (block) neural network would be useful. The aim of the study is to develop a method for synthesizing devices for implementing artificial neural networks based on programmable logic, focused on fog computing. The basis for the creation of the devices in question will be an artificial neural network, which will need to be divided into several blocks. Each of these computing units will be executed on a separate physical device, communication between them will be carried out using standard channels and protocols. The research methodology is based on mathematical modelling of a neural network that will be suitable for operation in the mode of foggy calculations, algorithmization and programming methods that will allow implementing the necessary algorithmic structures. As a result of the research, it is planned to obtain an algorithm for dividing a monolithic neural network into a cascade of neural network blocks adapted for fog computing in devices based on programmable logic. This algorithm will allow the implementation of a method for synthesizing neural network recognition devices. The article considers a mathematical model as the starting point for algorithms. The following algorithms are formulated and implemented: the separation of a monolithic neural network into a cascade of neural network blocks adapted for fog computing in devices based on programmable logic and the calculation of the neural network results in a new format adapted for fog computing. The original neural network storage format created for the proposed algorithms is proposed.
Keywords: algorithm; artificial neural network; FPGA; microcontrollers; fog computing; decision making; neural network recognition device; synthesis method, programmable logic, mathematical model.
Иссделования в области создания нейронных сетей, ориентированных на туманные вычисления, сегодня имеют высокую актуальность, в различных научных коллективах мира ведутся разработки в данном направлении. Проблемы создания распределенных НС исследуются в работах Bradley McDanel, Surat Teerapittayanon, H.T. Kung [1], Andrzej Sobecki, Julian Szymanski, David Gil [2], Yuchen Liang, W.D. Li, Zhi-Cong Chen [3] и других современных ученых. Однако на текущий момент по-прежнему не решена задача использования нейронных сетей на нескольких физически распределенных устройствах в ситуации небольших вычислительных ресурсов каждого из одиночных устройств. Это создает предпосылки для создания нового поколения туманных вычислений, которые поддерживают искусственный интеллект и используют архитектуру, подходящую для интеллектуальных реше-
ний, с малыми требованиями к вычислительной мощности отдельных устройств. В результате исследования планируется получить метод декомпозиции нейронной сети на блоки, которые будут работать на оконечных устройствах, также будет проведено испытание данного метода на тестовом каскаде вычислительных устройств. Данный подход важен тем, что позволяет отойти от оптимизации сети в пользу разделения вычислительной нагрузки между устройствами [4].
У проблемы высокой ресурсоемкости нейросетевых вычислений могут быть различные решения [5], которые должны учитывать также влияние на окружающую среду [6]. Возможным решением данной проблемы, которое мы хотели бы предложить в данной работе, является разделение монолитной нейронной сети на каскад блоков, последовательно выполняемых на связанных между собой вычислителях [7]. Раскроем предполагаемое решение в терминах предметной области.
Нейронную сеть, все слои которой производят свои вычисления на одном и том же вычислительном устройстве, назовем монолитной нейронной сетью. Если перед нами стоит задача получения нейронной сети, которая может проводить свои вычисления на нескольких связанных между собой устройствах, то нам потребуется разделить слои этой нейронной сети на блоки последовательных, идущих друг за другом слоев. Каждый из этих блоков будет выполнен на отдельном вычислительном устройстве, а промежуточные результаты будут переданы по сети между ними. Нейронную сеть, разбитую на набор подобных блоков, назовем блочной нейронной сетью. Именно метод преобразования монолитной нейронной сети к виду блочной нейронной сети, адаптированной для выполнения туманных вычислений [8], и является ключом к созданию каскадов из нескольких не очень мощных вычислительных устройств на программируемой логике, которые будут сопоставимы с более производительными вычислительными устройствами и будут иметь достаточную производительность для работы нейронных сетей.
Подробное описание сущности и методов функционирования облачных и туманных вычислений представлены в работах [9-11]. Туманные вычисления — это метод распределения вычислительных задач в виде небольших блоков на небольшие устройства, которые обрабатывают информацию в процессе ее передачи от отправителя к получателю [12]. Именно на такие блоки предлагается разбивать монолитную
нейронную сеть, чтобы выполнение ее вычислений стало возможным на небольших промежуточных устройствах. Это позволит осуществлять нейросетевые вычисления на нескольких вычислительных устройствах небольшой мощности, а значит, использовать нейронные сети в системах управления или принятия решений, которые ограничены в вычислительных мощностях [13].
Исходя из представленных предположений, можно сформулировать цель представленной работы: разработка метода синтеза устройств реализации искусственных нейронных сетей на ПЛИС и микроконтроллерах, ориентированных на туманные вычисления. В предыдущей статье была сформулирована математическая модель искусственной нейронной сети для устройств на плис и микроконтроллерах, ориентированных на туманные вычисления [1], т.е. была решена первая задача исследования. В данной статье будут сформулированы два алгоритма: алгоритм разделения монолитной нейронной сети на каскад блоков нейронной сети, адаптированной для туманных вычислений в устройствах на программируемой логике, главными особенностями которого являются учет входных параметров: мощности устройств, оптимального объема передаваемых между устройствами данных, пропорциональности по слоям или по нейронам. А также алгоритм вычисления результатов работы нейронной сети в новом формате, адаптированный для туманных вычислений в устройствах на программируемой логике, главными особенностями которого являются возможность выполнения алгоритма как на программируемой логике, так и на процессорных системах и встроенный словарь функций активации нейрона, который может быть расширен новыми функциями, если этого потребует задача. Предлагаемые алгоритмы являются следующим шагом к созданию оригинального метода синтеза устройств нейросетевого распознавания.
1. Математическая модель искусственной нейронной сети, ориентированной на туманные вычисления
В данной статье описывается работа с уже обученными нейронными сетями, т.е. к моменту разделения на блочные нейронные сети веса синапсов уже будут известны и зафиксированы [14]. Как было отмечено ранее, при построении предсказательных моделей исходные данные обычно разбиваются на обучающую и контрольную выборки.
Обучающая выборка используется для обучения модели, тогда как контрольная выборка служит для получения оценки прогнозных свойств модели на новых данных [15].
В описываемом исследовании важно, чтобы к моменту синтеза устройства нейросетевого распознавания обучение было завершено и веса синапсов стабилизированы, это ограничение временное и его можно преодолеть в будущем. Также в приведенном исследовании рассматриваются именно многослойные нейронные сети, так как в полных нейронных сетях слишком много связей и их сложно разделить на независимые кластеры, которые могли бы выполняться на различных физических устройствах. В данной статье будет рассматриваться математическая модель разделения нейронной сети без обратных связей, в будущем в рамках исследования возможна доработка, которая позволит разделять сети с обратными связями.
Дано: монолитная многослойная нейронная сеть X, результат работы которой — последовательность сигналов
Найти: последовательность нейронных сетей |Х0. Хох|, где
результат вычисления Х1 . ^ Х0 , совпадает с результатом
Процесс преобразования монолитной ИНС в каскад блочных ИНС, результат вычисления которого совпадает с результатами монолитной нейронной сети, назовем декомпозицией искусственной нейронной сети. Начнем создание математической модели искусственной нейронной сети, ориентированной на туманные вычисления, с того, что воспользуемся общепринятыми определениями функционирования нейронных сетей. Это и станет отправной точкой наших изысканий (рисунок).
Рис. Математический нейрон
где х — вход синапса, у. — выход синапса, ^^^ — вес синапса [16].
Тогда функция работы ИНС на примере многослойного персеп-трона:
где х(0) — входные ИНС, у)к’ — выход /-го нейрона к-го слоя,
число нейронов на данные слое к — 1 , ‘ — функция активации нейрона [17].
Разделение на подсети может осуществляться различными способами. Рассмотрим простой пример деления монолитной нейронной сети на блочные нейронные сети, когда в каждой блочной нейронной сети содержится одинаковое количество слоев.
Ответ: общая рекуррентная формула описания каждой из полученных блочных нейронных сетей, где массив
(2 *=„ ь’ = ^ Ьк _1лл! к,, ^к у ^ :„ Ьк—^
где Б — число устройств, на которые размещаются блоки, К — общее число слоев монолитной нейронной сети.
Существуют различные варианты входных параметров, в зависимости от которых будут реализовываться конкретные способы разделения монолитной ИНС на части:
1) Разделение на блоки с равным количеством слоев на узле.
Для самого частого случая, когда К не кратно Б, количество слоев Ьи которые должны быть переданы на устройство Д-, вычисляется по формуле:
Поскольку применяется округление в меньшую сторону для получения целого числа, количество слоев нейронной сети, которое будет на последнем вычислителе с номером D — 1, вычисляется по формуле:
2) Разделение пропорционально производительности устройств (слои). Для разделения пропорционально производительности (по количеству слоев нейронной сети) нужно сделать массив мощностей , выраженных в некоторых абсолютных единицах (результатах тестов производительности, тактовых частотах, объемах оперативной памяти), и распределить число слоев пропорционально значениям массива.
3) Разделение на блоки с равным количеством нейронов на узле. Берем сумму всех нейронов на всех слоях монолитной нейронной сети. На каждом слое всего Нъ нейронов, тогда желаемое число нейронов в каждой из блочных ИНС будет равно сумме всех нейронов на слоях, деленной на число устройств.
4) Разделение пропорционально производительности устройств (нейроны) осуществляется модификацией метода выше для разделения по числу нейронов, а не слоев нейронной сети.
5) Разделение с условием минимизации передаваемых по сети данных осуществляется с учетом нахождения минимальных по размеру векторов данных, которые потребуется передать между двумя блоками нейронной сети.
2. Формат файла, описывающего нейронную сеть ANN
Для работы с нейронными сетями в унифицированном виде на устройствах с программируемой логикой потребовалось создать несложный формат хранения нейронной сети в файле, чтобы иметь возможность читать и записывать нейронные сети при разделении на блоки из постоянной памяти вычислительного устройства. Формат файлов
получил расширение .ann — сокращенное от artificial neural network. Нейронная сеть в этом файле хранится в следующем формате:
— в первой строке единственное целое число — количество слоев в нейронной сети K;
— далее в каждой строке описывается отдельный слой нейронной сети. В описании слоя части разделяются литерой «,». Сначала идут два целых числа — порядковый номер слоя и число нейронов на слое, затем через разделитель располагаются описания каждого из нейронов;
— в описании нейрона части разделяются литерой «;». Описание состоит из пяти частей. Два целых числа вначале обозначают номер нейрона на слое и номер функции активации данного нейрона в справочнике функций. Далее идут три массива: массив констант для вычислений, массив весов связей и массив номеров нейронов предыдущего слоя, с которыми связан данный нейрон. Для разделения элементов массива используется символ пробела.
Описание небольшой нейронной сети в предлагаемом в статье формате представлено в примере 1.
1,3,0;10;1;1 1;0 1,1;10;1;1 1;1 2,2;10;1;1 1;0 2
2,1,0;11;0;1 1 1;0 1 2
Пример 1. Нейронная сеть, использованная при классификации терминов в программном продукте TSBuilder.
Это исходное состояние нейронной сети, которая была использована в наших предыдущих исследованиях [18]. Преимуществом такого способа хранения является его компактность, недостаток выходит из преимущества — данное представление, даже в случае небольшой нейронной сети, сложно читается человеком.
Перейдем непосредственно к рассмотрению алгоритма разд е-ления монолитной нейронной сети на каскад блочных нейронных сетей для туманных вычислений на устройствах с программируемой логикой.
Массив констант хранится в справочнике, в нашем случае -в файле NeuronFunctions.java. Сейчас он представлен 13 функциями. Этот список функций может быть расширен. В данном файле инкапсулируется выбор функции для вычисления в конкретном нейроне.
public enum NeuronFunctions
Здесь представлены следующие функции: сумма входных параметров, максимум среди входных параметров, сигмоида, линейная функция активации нейрона, пороговая функция, булева функция «ИЛИ», булева функция «И», гиперболический тангенс, функция подсчета максимальной частоты входных параметров, эквивалентность и авторские функции активации, которые использовались нами на начальных этапах исследования в нейронной сети продукта TSBuilder [18-23].
3. Алгоритм разделения МНС на блоки БНС
Алгоритм был реализован на языке программирования Java. Возможны различные сочетания входных параметров алгоритма разделения, мы рассмотрим вариант, когда монолитная нейронная сеть, имеющая в своем составе K слоев, разделяется на D различных блочных нейронных сетей. В представленном варианте алгоритма мы ориентируемся на равномерное распределение нагрузки на все вычислительные узлы, если это возможно, т.е. мы пытаемся распределить на каждое устройство одинаковое число слоев из исходной нейронной сети. Для того чтобы алгоритм учитывал различные вычислительные мощности вычислительных устройств, достаточно поменять методику расчёта количества слоев для каждого устройства с равномерной на пропорциональную. Рассмотрим предлагаемый алгоритм разделения по шагам.
1. Создается объект класса NNetwork. Объекты этого класса описывают как монолитные, так и блочные нейронные сети. Такие классы называются унифицированными классами.
2. В созданный объект считывается исходная монолитная нейронная сеть из файла.
NNetwork monoNetwork = NNetwork.ReadNNFromFile(«/TSNetwork.ann»);
3. Создается объект класса Separator, который отвечает непосредственно за разделение нейронной сети.
Separator separator = new Separator();
4. Вызывается метод splitOnEqualNumberOfLayers объекта separator, реализующий разделение на блочные нейронные сети с равномерным распределением слоев исходной нейронной сети. На вход методу передаются нейронная сеть monoNetwork и число устройств D, на которые требуется разделить нейронную сеть.
ArrayList blockNetworks = separa-tor.splitOnEqualNumberOfLayers(monoNetwork, D);
5. Дальнейшие операции производятся внутри метода splitOnEqualNumberOfLayers. Инициализируется список для хранения создаваемых блочных нейронных сетей blockNetworks.
ArrayList blockNetworks = new ArrayList();
6. Подсчитывается число слоев, которое будет передано на каждую блочную нейронную сеть, кроме последней. Для этого осуществим целочисленное деление числа слоев K на число устройств D.
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
int numberOfLayers = network.K / D;
7. В цикле с итератором i от 0 до D-2: создается массив слоев, которые будут переданы в очередную блочную нейронную сеть.
ArrayList layers = new
8. В цикле с итератором j добавляются слои, которые будут переданы в блочную сеть, номера слоев считаются, начиная с i*numberOfLayers. Окончание цикла по итератору j.
9. Создается новая блочная нейронная сеть, ей передается число слоев и непосредственно слои монолитной нейронной сети layers. Нейронная сеть добавляется в список blockNetworks.
blockNetworks.add(new NNetwork(numberOfLayers, layers));
10. Окончание цикла по итератору i. Подсчитывается число слоев в последней блочной нейронной сети. Оно может быть отличным от numberOfLayers и получается вычитанием числа слоев во всех предыдущих слоях из общего числа слоев K.
int numberOfLastLayers = network.K — (D-1)*numberOfLayers;
11. Копируются все оставшиеся в монолитной нейронной сети слои, создается последняя нейронная сеть. Ей передаются слои lastLayers, и сеть добавляется в общий список blockNetworks.
ArrayList lastLayers = new
for (int j = (D-1)*numberOfLayers; j < network.K; j++)
blockNetworks.add(new NNetwork(network.K -(D-1)*numberOfLayers, lastLayers));
12. Блочные нейронные сети полностью готовы, они сохраняются в файлы. На вход функции сохранения подаются список нейронных сетей blockNetworks и предпочитаемое название файлов.
NNetwork.SaveNNToFile (blockNetworks, «TSNetworks»).
Каждая нейронная сеть сохраняется на диск в отдельном файле. Название файла формируется из переданной в функцию строки, номера нейронной сети в каскаде и расширения .ann. Например, TSNetworksl.ann для первой блочной нейронной сети.
4. Алгоритм запуска и работы распределенной нейронной сети
Также был реализован алгоритм вычисления результатов работы нейронной сети в предложенном формате. Для начала рассмотрим алгоритм запуска и работы нейронной сети, которая получена из одного конкретного *.ann файла:
1. Получен входной вектор данных float[] nums.
2. Создается объект класса NNetwork, объекты этого класса описывают как монолитные, так и блочные нейронные сети. Такие классы называются унифицированными классами.
3. В этот объект считывается нейронная сеть из файла.
4. Вызвать метод объекта NNetwork для вычисления результата работы нейронной сети computing.
float[] result = network.computing(nums);
5. Дальнейшие операции производятся внутри метода computing (NNetwork). Инициализируем векторы для хранения результатов работы текущего слоя actualVector и результатов работы предыдущего слоя lastVector, изначально инициализируем его входным вектором nums, полученным на вход нейронной сети.
float[] lastVector = nums; float[] actualVector;
6. В цикле, который проходит итератором по всем элементам списка слоев нейронной сети LayersList, запускаем соответствующий метод вычисления результатов слоя computing для каждого слоя layer.
7. Дальнейшие операции производятся внутри метода computing (Layer). Инициализируем результирующий вектор resultVector, каждое из значений в котором будет результатом вычисления конкретного нейрона, поэтому его размерность NeuronsCount (число нейронов на слое).
float[] resultVector = new float[NeuronsCount];
8. В цикле с итератором i от 0 до NeuronsCount-1 получаем из списка нейронов соответствующий нейрон get(i) и запускаем для нейрона метод computing.
9. Дальнейшие операции производятся внутри метода computing (Neuron). Вызывается метод вычисления результатов для класса Functions, отвечающего за работу всех функций активации нейронов. На вход подается номер функции активации f, константа для функции с, вектор весов синапсов weightsList, вектор номеров нейронов предыдущего слоя, с которыми связан данный нейрон, sinapses и вектор результатов работы предыдущего слоя lastVector.
return Functions.computing(f, c, weightsList, sinapses, lastVector);
10. Дальнейшие операции производятся внутри метода computing (Functions). Инициализируем переменную для результата result и вектор, который пойдет на вход функции активации нейрона. В цикле с итератором i от 0 до weightsList.length-1 умножаем вес синапса weightsList[i] на входной сигнал, пришедший по соответствующему синапсу lastVector[sinapses[i]].
float result = 0; float[] inputVector = new float[weightsList.length];
11. Вызываем функцию calculate, передав ей номер функции, константу и входной вектор для функции активации inputVector.
result = calculate(f, c, inputVector);
12. В функции calculate выбирается по номеру функции соответствующая реализация функции активации. Вызывается функция программного кода, которая реализует данную функцию активации с нужными ей параметрами.
private static float calculate(NeuronFunctions f, float c, float[] inputVector)
13. Возвращаем result из класса Functions, далее возвращаем этот же результат из класса Neuron.
14. Затем в классе Layer этот результат попадает в результирующий вектор с соответствующим номером resultVector[i], и этот вектор возвращается в класс NNetwork.
15. После прохождения итератора по всему списку LayersList последнее значение в векторе lastVector и является результатом работы нейронной сети. Возвращаем его на уровень выше и осуществляем дальнейшую обработку полученного результата.
Описанный алгоритм работает для распределенного случая на каждом из вычислителей с тем дополнением, что между вычислителями необходимо наладить каналы связи по unicast socket, по которым будет передаваться результат работы каждого из блоков блочной нейронной сети.
Результирующий вектор первого блока станет вектором входных данных для второго блока и так далее, пока последний блок не выдаст результат работы всего каскада устройств.
5. Результаты и предлагаемые дальнейшие шаги исследования
В результате проделанной работы был сформулирован и реализован алгоритм разделения монолитной нейронной сети на каскад блоков нейронной сети, адаптированной для туманных вычислений в устройствах на программируемой логике. Главными особенностями этого алгоритма являются: учет входных параметров, т.е. его можно настраивать под различные задачи, а также то, что исходная и блочные нейронные сети хранятся в одинаковом формате *.ann. Данный алгоритм описан на языке программирования высокого уровня.
Вторым важным результатом является алгоритм вычисления результатов работы нейронной сети в новом формате, адаптированный для туманных вычислений в устройствах на программируемой логике. Главными особенностями данного алгоритма являются: возможность его выполнения, как на программируемой логике, так и на процессорных системах, а также встроенный словарь функций активации нейрона, который может быть расширен новыми функциями.
По итогам оценки сложности предлагаемых алгоритмов были получены следующие результаты:
— алгоритм декомпозиции МНС:
— алгоритм вычисления результатов работы НС в формате *.ann:
Порядок сложности вычислений результатов блока на устройстве будет рассчитываться аналогично, с поправкой на то, что в блок войдет лишь часть слоев нейронной сети.
Поэтому оценим сложность вычислений, проводимых одним вычислительным устройством на программируемой логике:
Первая задача исследования уже была решена: математическая модель, подходящая для создания метода синтеза устройств нейросе-тевого распознавания на программируемой логике, представлена в предыдущей статье [1]. Вторая задача исследования — реализация необходимых для метода синтеза алгоритмов также успешно решена, полученные алгоритмы представлены выше. Из полученных вариантов
входных параметров для алгоритма декомпозиции для непосредственного моделирования и реализации на физических устройствах была выбрана разновидность алгоритма, которая осуществляет разделение на блоки с равным количеством слоев на узле. Выбрано разделение на блоки с такими входными ограничениями по той причине, что вычислители, которые будут использованы в дальнейших экспериментах, будут иметь одинаковые параметры вычислительной мощности.
Существуют архитектуры ИНС и варианты использования блоков, которые совпадут в каскадах различных монолитных ИНС после декомпозиции, в которых последовательность блочных ИНС будет превращаться в граф вычислений [24], потенциально возможны даже асинхронные реализации подобных графов нейронных сетей [25].
Следующим шагом станет формализация метода синтеза устройств. Уже реализованы и зарегистрированы в Роспатенте программные продукты NNSplitter и NNImplementer, которые реализовывают алгоритм декомпозиции и алгоритм работы распределенной нейронной сети соответственно.
Целью исследования являлась разработка метода синтеза устройств реализации искусственных нейронных сетей на программируемой логике, ориентированных на туманные вычисления. В результате исследования создан алгоритм декомпозиции монолитной нейронной сети на каскад блоков нейронной сети, адаптированной для туманных вычислений в устройствах на программируемой логике. Также сформулирован алгоритм вычисления результатов работы нейронной сети в новом формате, адаптированный для туманных вычислений в устройствах на программируемой логике. Оба предложенных алгоритма реализованы на языке программирования JAVA.
Научная новизна представленных результатов состоит том, что разработанные алгоритмы помогают сформировать распределенные блочные нейронные сети для использования их в устройствах на программируемой логике, а также запускать блоки нейронной сети в каскаде на физически распределенных устройствах. Дальнейшие шаги исследования завершатся формулированием полного метода синтеза устройств нейросетевого распознавания для реализации туманных вычислений и моделированием работы подобных каскадов устройств в САПР Proteus.
Определены параметры, с которыми будут осуществляться декомпозиция и тестирование работы распределенной блочной нейронной сети как при виртуальном, так и при физическом моделировании. Осуществление подобного решения задачи блочного синтеза устройств нейро-сетевого распознавания позволит использовать нейронные сети для решения различных задач в системах управления или диагностики в тех случаях, где использование нейронной сети в рамках одного устройства недоступно в силу низкой вычислительной мощности устройств.
1. Teerapittayanon S., McDanel B., Kung H.T. Distributed deep neural networks over the cloud, the edge and end devices // IEEE 37th International Conference on Distributed Computing Systems (ICDCS). — 2017. -P. 328-339. DOI: 10.1109/ICDCS.2017.226
2. Deep learning in the fog / A. Sobecki, J. Szymanski, D. Gil, H. Mora // International Journal of Distributed Sensor Networks. — 2019. -Vol. 15, iss. 8. DOI: 10.1177/1550147719867072
3. An efficient binary convolutional neural network with numerous skip connections for fog computing / L. Wu, X. Lin, Z. Chen, J. Huang, H. Liu, Y. Yang // IEEE Internet of Things Journal. — 2021. -Vol. 8, № 14. — P. 11357-11367. DOI: 10.1109/JI0T.2021.3052105
4. Бахтин В.В. Математическая модель искусственной нейронной сети для устройств на плис и микроконтроллерах, ориентированных на туманные вычисления // Вестник Пермского национального исследовательского политехнического университета. Электротехника. Информационные технологии, системы управления. — 2021. — № 40. — С. 109-129.
5. Akhmetzyanov K., Yuzhakov A. Waste sorting neural network architecture optimization // International Russian Automation Conference (RusAutoCon). — 2019. — P. 1-5. DOI: 10.1109/RUSAUT0C0N.2019.8867749
6. Akhmetzyanov K.R., Yuzhakov A.A., Kokoulin A.N. Neural network development based on knowledge about environmental influence // IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (EIConRus). — 2020. — P. 218-221. DOI: 10.1109/EIConRus49466.2020.9039226
7. Бахтин В.В. Модификация алгоритма идентификации и категоризации научных терминов с использованием нейронной сети // Нейрокомпьютеры: разработка, применение. — 2019. — Т. 21, № 3. -С.14-19.
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
8. Aazam Mohammad, Zeadally Sherali, Harras Khaled. Fog computing architecture, evaluation, and future research directions // IEEE Communications Magazine. — 2018. — № 56. — P. 46-52. DOI: 10.1109/MCOM.2018.1700707
9. Surbiryala J., Rong C. Cloud Computing: History and Overview // IEEE Cloud Summit. — 2019. — P. 1-7. DOI: 10.1109/CloudSummit47114.2019.00007
10. Zhang W., Xiao K. Communication mode of computer cluster network in cloud environment based on neural computing // 5th International Conference on Computing Methodologies and Communication (ICCMC).
— 2021. — P. 48-52. DOI: 10.1109/ICCMC51019.2021.9418350
11. An application placement technique for concurrent iot applications in edge and fog computing environments / M. Goudarzi, H. Wu, M. Palaniswami, R. Buyya // IEEE Transactions on Mobile Computing. — 2021.
— Vol. 20, № 4. — P. 1298-1311. DOI: 10.1109/TMC.2020.2967041
12. Fog computing: a comprehensive architectural survey / P. Habibi, M. Farhoudi, S. Kazemian, S. Khorsandi, A. Leon-Garcia // IEEE Access. — 2020. — Vol. 8. — P. 69105-69133. DOI: 10.1109/ACCESS.2020.2983253
13. Priyabhashana H.M.B., Jayasena K.P.N. Data analytics with deep neural networks in fog computing using tensorflow and Google cloud platform // 14th Conference on Industrial and Information Systems (ICIIS). -2019. — P. 34-39. DOI: 10.1109/ICIIS47346.2019.9063284
14. Гафаров Ф.М., Галимянов А.Ф. Искусственные нейронные сети и приложения: учеб. пособие. — Казань: Изд-во Казан. ун-та, 2018. — С. 121.
15. Fast deep neural networks with knowledge guided training and predicted regions of interests for real-time video object detection / W. Cao, J. Yuan, Z. He, Z. Zhang, Z. He // IEEE Access. — 2018. — Vol. 6. -P. 8990-8999. DOI: 10.1109/ACCESS.2018.2795798
16. Yasnitsky L.N., Yasnitsky V.L. Technique of design of integrated economic and mathematical model of mass appraisal of real estate property
by the example of Yekaterinburg housing market // Journal of Applied Economic Sciences. — 2016. — Vol. 11, № 8. — P. 1519-1530.
17. Ясницкий Л.Н. Интеллектуальные системы. — М.: Лаборатория знаний, 2016.
18. Bakhtin V., Isaeva E. Developing an algorithm for identification and categorization of scientific terms in natural language text through the elements of artificial intelligence // 14th International Scientific-Technical Conference on Actual Problems of Electronic Instrument Engineering (APEIE) — 44894. Proceedings. — Novosibirsk, 2018. — P. 384-390.
19. Isaeva E., Bakhtin V., Tararkov A. Collecting the database for the neural network deep learning implementation // Digital Science. DSIC18 2018. Advances in Intelligent Systems and Computing / T. Antipova, A. Rocha (eds). — 2019. — Vol. 850. — P. 12-18. Springer, Cham. DOI: 10.1007/978-3-030-02351-5_2
20. Bakhtin V.V., Isaeva E.V. New TSBuilder: shifting towards cognition // IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (EIConRus). — 2019. — P. 179-181. DOI: 10.1109/EIConRus.2019.8656917
21. Bakhtin V.V., Isaeva E.V., Tararkov A.V. TSBuilder 2.0: improving the identification accuracy due to synonymy // IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (EIConRus). — 2020. — P. 225-228. DOI: 10.1109/EIConRus49466.2020.9039207
22. Bakhtin V.V., Isaeva E.V., Tararkov A.V. TSMiner: from TSBuilder to ecosystem // IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (ElConRus). — 2021. — P. 221-224. DOI: 10.1109/ElConRus51938.2021.9396569
23. Isaeva E., Bakhtin V., Tararkov A. Formal cross-domain ontologization of human knowledge // Information Technology and Systems. ICITS 2020. Advances in Intelligent Systems and Computing / A. Rocha, C. Ferras, C. Montenegro Marin, V. Medina Garcia (eds). — 2020. — Vol. 1137. — P. 94-103. Springer, Cham. DOI: 10.1007/978-3-030-40690-5_10
24. Бахтин В.В., Подлесных И.А. Алгоритм построения графа совместной работы каскадов устройств нейросетевого распознавания, реализующих блочные нейронные сети // Сб. матер. IX Междунар. науч. конф., посв. 85-лет. проф. В.И. Потапова. — Омск, 2021. — С. 277-278.
25. Каменских А.Н., Тюрин С.Ф. Методика комбинированного резервирования асинхронных нейронных сетей // Нейрокомпьютеры: разработка, применение. — 2016. — № 8. — С. 36-40.
1. Teerapittayanon S., McDanel B., Kung H.T. Distributed deep neural networks over the cloud, the edge and end devices. IEEE 37th International Conference on Distributed Computing Systems (ICDCS), 2017, pp. 3280339. DOI: 10.1109/ICDCS.2017.226
2. Sobecki A., Szymanski J., Gil D., Mora H. Deep learning in the fog. International Journal of Distributed Sensor Networks, 2019, vol. 15, iss. 8. DOI: 10.1177/1550147719867072
3. Wu L., Lin X., Chen Z., Huang J., Liu H., Yang Y. An Efficient Binary Convolutional Neural Network with Numerous Skip Connections for Fog Computing. IEEE Internet of Things Journal, 2021, vol. 8, no. 14, pp. 11357-11367. DOI: 10.1109/JIOT.2021.3052105
4. Bakhtin V.V. Matematicheskaia model’ iskusstvennoi neironnoi seti dlia ustroistv na plis i mikrokontrollerakh, orientirovannykh na tumannye vychisleniia [Mathematical model of an artificial neural network for fpga devices and microcontrollers focused on fog computing]. Vestnik Permskogo natsional’nogo issledovatel’skogo politekhnicheskogo universiteta. Elektrotekhnika. Informatsionnye tekhnologii, sistemy upravleniia, 2021, no. 40, pp. 109-129.
5. Akhmetzyanov K., Yuzhakov A. Waste Sorting Neural Network Architecture Optimization. International Russian Automation Conference (RusAutoCon), 2019, pp. 1-5. DOI: 10.1109/RUSAUTOCON.2019.8867749
6. Akhmetzyanov K.R., Yuzhakov A.A., Kokoulin A.N. Neural network development based on knowledge about environmental influence. IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (EIConRus), 2020, pp. 218-221. DOI: 10.1109/EIConRus49466.2020.9039226
7. Bakhtin V.V. Modifikatsiia algoritma identifikatsii i kategorizatsii nauchnykh terminov s ispol’zovaniem neironnoi seti [Modification of the algorithm for identification and categorization of scientific terms using a neural network]. Neirokomp’iutery: razrabotka, primenenie, 2019, vol. 21, no. 3, pp. 14-19.
8. Aazam Mohammad, Zeadally Sherali, Harras Khaled. Fog Computing Architecture, Evaluation, and Future Research Directions. IEEE Communications Magazine, 2018, no. 56, pp. 46-52. DOI: 10.1109/MCOM.2018.1700707
9. Surbiryala J., Rong C. Cloud Computing: History and Overview. IEEE Cloud Summit, 2019, pp. 1-7. DOI: 10.1109/CloudSummit47114.2019.00007
10. Zhang W., Xiao K. Communication Mode of Computer Cluster Network in Cloud Environment based on Neural Computing. 5th International Conference on Computing Methodologies and Communication (ICCMC), 2021, pp. 48-52. DOI: 10.1109/ICCMC51019.2021.9418350
11. Goudarzi M., Wu H., Palaniswami M., Buyya R. An Application Placement Technique for Concurrent IoT Applications in Edge and Fog Computing Environments. IEEE Transactions on Mobile Computing, 2021, vol. 20, no. 4, pp. 1298-1311. DOI: 10.1109/TMC.2020.2967041
12. Habibi P., Farhoudi M., Kazemian S., Khorsandi S., Leon-Garcia A. Fog Computing: A Comprehensive Architectural Survey. IEEE Access, 2020, vol. 8, pp. 69105-69133. DOI: 10.1109/ACCESS.2020.2983253
13. Priyabhashana H.M.B., Jayasena K.P.N. Data Analytics with Deep Neural Networks in Fog Computing Using TensorFlow and Google Cloud Platform. 14th Conference on Industrial and Information Systems (ICIIS), 2019, pp. 34-39. DOI: 10.1109/ICIIS47346.2019.9063284
14. Gafarov F.M., Galimianov A.F. Iskusstvennye neironnye seti i prilozheniia [Artificial neural networks and applications]. Kazan’: Kazanskii universitet, 2018, 121 p.
15. Cao W., Yuan J., He Z., Zhang Z., He Z. Fast Deep Neural Networks With Knowledge Guided Training and Predicted Regions of Interests for Real-Time Video Object Detection. IEEE Access, 2018, vol. 6, pp. 89908999. DOI: 10.1109/ACCESS.2018.2795798
16. Yasnitsky L.N., Yasnitsky V.L. Technique of design of integrated economic and mathematical model of mass appraisal of real estate property by the example of Yekaterinburg housing market. Journal of Applied Economic Sciences, 2016, vol. 11, no. 8, pp. 1519-1530.
17. Iasnitskii L.N. Intellektual’nye sistemy [Intelligent systems]. Moscow: Laboratoriia znanii, 2016.
18. Bakhtin V., Isaeva E. Developing an Algorithm for Identification and Categorization of Scientific Terms in Natural Language Text through
the Elements of Artificial Intelligence. 14th International Scientific-Technical Conference on Actual Problems of Electronic Instrument Engineering (APEIE) — 44894. Proceedings. Novosibirsk, 2018, pp. 384-390.
19. Isaeva E., Bakhtin V., Tararkov A. Collecting the Database for the Neural Network Deep Learning Implementation. Digital Science. DSIC18 2018. Advances in Intelligent Systems and Computing. T. Antipova, A. Rocha (eds), 2019, vol. 850, pp. 12-18. Springer, Cham. DOI: 10.1007/978-3-030-02351-5_2
20. Bakhtin V.V., Isaeva E.V. New TSBuilder: Shifting towards Cognition. IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (EIConRus), 2019, pp. 179-181. DOI: 10.1109/EIConRus.2019.8656917
21. Bakhtin V.V., Isaeva E.V., Tararkov A.V. TSBuilder 2.0: Improving the Identification Accuracy Due to Synonymy. IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (EIConRus), 2020, pp. 225-228. DOI: 10.1109/EIConRus49466.2020.9039207
22. Bakhtin V.V., Isaeva E.V., Tararkov A.V. TSMiner: from TSBuilder to Ecosystem. IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (ElConRus), 2021, pp. 221-224. DOI: 10.1109/ElConRus51938.2021.9396569
23. Isaeva E., Bakhtin V., Tararkov A. Formal Cross-Domain Ontologization of Human Knowledge. Information Technology and Systems. ICITS 2020. Advances in Intelligent Systems and Computing. Rocha A., Ferras C., Montenegro Marin C., Medina Garcia V. (eds), 2020, vol. 1137, pp. 94-103. Springer, Cham. DOI: 10.1007/978-3-030-40690-5_10
24. Bakhtin V.V., Podlesnykh I.A. Algoritm postroeniia grafa sovmestnoi raboty kaskadov ustroistv neirosetevogo raspoznavaniia, realizuiushchikh blochnye neironnye seti [Algorithm for constructing a graph of collaboration of cascades of neural network recognition devices implementing block neural networks]. Sbornik materialov IX Mezhdunarodnoi nauchnoi konferentsii, posviashchennoi 85-letiiu professora V.I. Potapova. Omsk, 2021, pp. 277-278.
25. Kamenskikh A.N., Tiurin S.F. Metodika kombinirovannogo rezervirovaniia asinkhronnykh neironnykh setei [A technique for combined redundancy of asynchronous neural networks]. Neirokomp’iutery: razrabotka, primenenie, 2016, no. 8, pp. 36-40.
Сведения об авторах
Бахтин Вадим Вячеславович (Пермь, Россия) — аспирант, младший научный сотрудник кафедры «Автоматика и телемеханика» Пермского национального исследовательского политехнического университета (614990, Пермь, Комсомольский пр., 29, e-mail: bakhtin_94@bk.ru).
About the authors
Vadim V. Bakhtin (Perm, Russian Federation) — Graduate Student, junior researcher of the Department of Automation and Telemechanics Perm National Research Polytechnic University (614990, Perm, 29, Komsomolsky pr., e-mail: bakhtin_94@bk.ru).
Принята к публикации 20.06.2022
Финансирование. Исследование проводится при поддержке РФФИ на средства гранта № 20-37-90036 Аспиранты «Метод синтеза устройств нейросетевого распознавания для реализации режима Fog computing».
Конфликт интересов. Конфликт интересов по отношению к статье отсутствует.
Как работает нейронная сеть: разбираемся с основами

Мария Жарова Эксперт по Python и математике для Data Science, ментор одного из проектов на курсе по Data Science.
Сейчас на слуху «творчество нейросетей»: сгенерированные машиной тексты и стихи, несуществующие картины и фотографии людей, почти похожие на настоящие. Для человека вне IT это выглядит как чудо. Но на самом деле нейронные сети хорошо объясняются математически, хотя результат их работы действительно невозможно предсказать.
Что такое нейросети?
Нейросети — математические модели и их программное воплощение, основанные на строении человеческой нервной системы. Самую простую нейронную сеть, перцептрон (модель восприятия информации мозгом), вы сможете легко самостоятельно написать и запустить на своем компьютере, не используя сторонние мощности и дополнительные устройства. Пройдите наш тест и узнайте, какой контент подготовил искусственный интеллект, а какой — реальный человек. Чтобы лучше понять, что это такое, попробуем сначала разобраться, как работают биологические нейронные сети — те, что находятся внутри нашего организма. Именно они стали прообразом для машинных нейронных сетей. Биологические нейронные сети. Нервная система живого существа состоит из нейронов — клеток, которые накапливают и передают информацию в виде электрических и химических импульсов. У нейронов есть аксон — основная часть клетки, и дендрит — длинный отросток на ее конце, который может достигать сантиметра в длину. Дендриты передают информацию с одной клетки на другую и работают как «провода» для нервных импульсов. С помощью специальных шипов они цепляются за другие нейроны, и так сигналы передаются по всей нервной системе.

Освойте профессию «Data Scientist» на курсе с МГУ
Data Scientist с нуля до PRO
Освойте профессию Data Scientist с нуля до уровня PRO на углубленном курсе совместно с академиком РАН из МГУ. Изучите продвинутую математику с азов, получите реальный опыт на практических проектах и начните работать удаленно из любой точки мира.

25 месяцев
Data Scientist с нуля до PRO
Создавайте ML-модели и работайте с нейронными сетями
6 224 ₽/мес 11 317 ₽/мес

В качестве примера можно привести любое осознанное действие. Например, человек решает поднять руку: импульс сначала появляется в его мозгу, потом через сеть нейронов информация передается от одной клетки к другой. По пути она преобразуется и в конечном итоге достигает клеток в руке. Рука поднимается. Так работает большинство процессов в организме — тех, которые управляются мозгом. Но главная особенность нейронных сетей — способность обучаться. И именно она легла в основу машинных нейросетей. Первые машинные нейросети. В сороковых годах прошлого века люди впервые попытались описать сеть нейронов математически. Затем, в пятидесятых, — воссоздать ее модель с помощью кода. Получилась та самая структура, которую назвали перцептрон. На графиках и иллюстрациях ее обычно рисуют как набор кругов и прямых, их соединяющих — это и есть нейроны, образующие сетку. Перцептрон был проще современных нейросетей. Он имел всего один слой и три типа элементов: первый тип принимал информацию, второй обрабатывал и создавал ассоциативные связи, третий выдавал результат. Но даже элементарная структура уже могла обучаться и более-менее точно решать простые задачи. Например, перцептрон мог ответить, есть ли на картинке предмет, который его научили распознавать. Он был способен отвечать только на вопросы, где есть два варианта ответов: «да» и «нет». После этого развитие нейросетей замедлилось. Существующих на тот момент технологий было недостаточно, чтобы создать мощную систему. Наработки шли неторопливо, но чем больше развивалась компьютерная отрасль, тем больше интереса вызывал концепт. Современные нейронные сети. Когда компьютеры развились до современных мощностей, концепция нейронной сети снова стала привлекательной. К тому моменту ученые успели описать много алгоритмов, которые помогали распространять информацию по нейронам, и предложили несколько структур. Это были как однослойные, так и многослойные сети, однонаправленные и рекуррентные — подробнее мы расскажем о классификации далее. Чем более продвинутыми становились компьютеры, тем больше сложных и интересных задач могли реализовать нейронные сети. Мощность системы играет важную роль, т.к. каждый нейрон постоянно выполняет ресурсоемкие вычисления. Чтобы решить сложную задачу, обычно нужно много нейронов, их масштабная структура и множество математических функций. Понятно, что для этого понадобится очень сильный компьютер.
Как работает нейросеть?
Структуру нейрона воссоздают при помощи кода. В качестве «аксона» используется ячейка, которая хранит в себе ограниченный диапазон значений. Информация о как бы «нервных импульсах» хранится в виде математических формул и чисел. Связи между нейронами тоже реализованы программно. Один из них передает другому на вход какую-либо вычисленную информацию, тот получает ее, обрабатывает, и затем передает результат уже своих вычислений дальше. Таким образом, информация распространяется по сети, коэффициенты внутри нейронов меняются — происходит процесс обучения.

Станьте дата-сайентистом на курсе с МГУ и решайте амбициозные задачи с помощью нейросетей
Как работает обучение?
Предоставление информации. Когда нейросеть обучают, ей «показывают» данные, по которым необходимо что-то предсказать, и эталонные правильные ответы для них — это называется обучающей выборкой. Информации должно быть много — считается, что минимум в десять раз больше, чем количество нейронов в сети. Во время обучения нейросети показывают какую-либо информацию и говорят, что это такое, т.е. дают ответ. Все данные представляются не посредством слов, а с помощью формул и числовых коэффициентов. Например, изображению женщины соответствует «1», а изображению мужчины — «0». Это простой пример; реальные сети устроены сложнее. Преобразования. Входные нейроны получают информацию, преобразуют ее и передают дальше. Содержание информации автоматически обрабатывается с помощью формул и превращается в математические коэффициенты. Примерно как то, что мы видим глазами, превращается в нервные импульсы и передается в мозг. Он их обрабатывает, и человек понимает, что находится вокруг него. Здесь принцип похож.
Науки о данных
Онлайн-магистратура МФТИ.
Приобретите опыт на реальных проектах и выйдите на новый уровень в профессии и карьере.
Обработка и выводы. У каждого нейрона есть «вес» — число внутри него, рассчитанное по особым алгоритмам. Он показывает, насколько показания нейрона значимы для всей сети. Соответственно, во время обучения веса нейронов автоматически меняются и балансируются. В результате складывается ситуация, когда определенные нейроны реагируют, например, на силуэт человека — и выдают информацию, которая преобразуется в ответ: «Это человек». При этом человека не нужно описывать как набор математических фигур — во время обучения нейронная сеть сама задает значения весов, которые определяют его. Результат. Выводом нейронной сети становится набор формул и чисел, которые преобразуются в ответ. Например, если изображение мужчины — «0», а женщины — «1», то результат 0,67 будет означать что-то вроде «Скорее всего, это женщина». Нейросеть из-за своей структуры не может дать абсолютно точный ответ — только вероятность. И из-за закрытости и нестабильности нейронов ее показания могут различаться даже для одинаковых выборок.
Читайте также Как написать свою первую нейросеть на Python
Особенности нейронных сетей
Из архитектуры и режима работы нейросети следует несколько особенностей, ключевых для понимания направления. Нейросети закрыты. Мы не можем сказать, по каким критериям программа «решает», что на картинке изображен человек или что текст является стихотворением. Все это происходит автоматически; задача разработчика — правильно описать структуру и задать формулы. Примерно так же мы не можем достоверно сказать, что именно происходит в человеческом мозгу, почему он понимает, что собака — это собака, даже если впервые видит незнакомую породу. Если у собаки не будет хвоста, она окажется бесшерстной или покрашенной в неестественный цвет, мы все равно определим ее как собаку — по ряду характеристик, которые до конца не осознаем сами. Нейроны в сетях независимы. Каждый нейрон никак не связан с процессом работы других. Да, они получают друг от друга информацию, но их внутренняя деятельность не зависит от других элементов. Поэтому даже если один нейрон выйдет из строя, другой продолжит работать — это важно в вопросе отказоустойчивости. Подобная устойчивость свойственна и биологическим нейронным сетям, которые продолжают работать, даже если оказываются повреждены. Но у независимости есть и недостаток: из-за нее решения оказываются многоступенчатыми и порой хаотичными, их сложно предсказать и повлиять на них.
Начните карьеру в Data Science.
Онлайн-магистратура МФТИ с практикой на реальных проектах
Нейросети очень гибкие. Так как нейроны сами подбирают критерии и не зависят друг от друга, нейросети более гибкие, чем другие модели машинного обучения. Их архитектура унаследовала важные свойства биологической нервной системы: способность самообучаться и приспосабливаться к новым данным, возможность игнорировать «шумы» и неважные детали входной информации. Как живой человек сможет различить знакомого в толпе, так нейросеть можно научить выделять нужное и отбрасывать ненужное. Гибкость проявляется не только в этом. Нейросети способны решать широкий спектр задач, и их можно адаптировать практически под любые обстоятельства. Нейросети приблизительны. Мы уже говорили: любой результат, выданный нейронной сетью, приблизителен и неточен. Например, сеть, которая распознает картинки, может сказать «Здесь изображена корова» только с определенной вероятностью. И эта вероятность всегда будет меньше единицы, то есть ниже ста процентов. Более того: если два раза показать нейросети одну и ту же картинку, она может выдать разные вероятности в качестве ответа. Различаться они, конечно, будут на сотые и тысячные доли, но это все же неодинаковый, недетерминированный результат. Нейросети могут ошибаться. Любой искусственный интеллект уступает человеческому. Это происходит из-за того, что мощности нашего мозга до сих пор невозможно повторить. В теле человека 86 миллиардов нейронов, и еще не создана сеть, которая хотя бы немного приблизилась к этому числу. В современных нейросетях содержится примерно 10 миллиардов нейронов. Даже при наличии продвинутых формул искусственная нейросеть все равно остается упрощенной моделью — например, в ней нет понятия силы импульса, которое есть в биологических нервах. У биологических нейронных сетей, конечно, тоже бывают ошибки. Но для нейросетей они проявляются более ярко за счет их упрощенной структуры. Читайте также: Искусственный интеллект против сценаристов: как нейросети создают истории
Ошибки нейросетей: какими они бывают
Существует три основных проблемы работы с сетями — это явления забывчивости и переобучения, а также непредсказуемость. В биологических нейронных сетях они тоже есть, но мы их корректируем. В искусственных нейросетях аналогично применяются методы корректировки, но это сложнее и не всегда может быть эффективно. Забывчивость. Представьте, что вы попали сразу в несколько незнакомых ситуаций, опыта для которых ранее не было. Скорее всего, вам будет тяжело эффективно работать. Даже простые, но отличающиеся действия будут вызывать стресс, вы будете допускать больше ошибок. В теории нейронных сетей это называется забывчивостью: программы плохо реагируют на большое разнообразие ситуаций. Если обстоятельства все время меняются, нейросеть будет пытаться подстроиться под каждое из них, и в результате точность решений упадет. Но если человек еще может сориентироваться в незнакомой обстановке, то программе это сделать сложнее, ведь она — «вещь в себе», лишенная нейропластичности. Переобучение. Это явление, когда модель хорошо объясняет только примеры из обучающей выборки, адаптируясь к примерам оттуда, вместо того, чтобы учиться классифицировать что-то другое, не участвующее в обучении. Если вы когда-нибудь смотрели на автомобиль и видели, что фары похожи на глаза, а решетка радиатора — на рот, вы понимаете, как это работает. Нейросеть точно так же начинает путаться. Но ресурсов человеческого мозга хватает, чтобы понять, что машина — не настоящее лицо. Программа понять это не может и в подобной ситуации способна действительно выдать результат, что на картинке изображен человек. Еще один пример переобучения можно привести для сетей, которые создают что-то новое, например стиль. Вы, наверное, замечали, что у реальных художников и писателей есть свои характерные приемы, а их произведения со временем становятся все более похожими друг на друга. Это тоже пример переобучения — и генерирующие контент нейросети также ему подвержены. Непредсказуемость. Это прямое следствие закрытости и автономности нейронов. Сложно предугадать результат работы нейросети, будет ли она корректно работать в решении той или иной задачи. И если с предыдущими ошибками можно бороться благодаря правильным алгоритмам обучения, то непредсказуемость не пропадает. Это не стандартная программа, которая выдает известный результат для каждой ситуации. С непредсказуемостью тоже борются: точность можно повысить, если использовать подходящую архитектуру. Не обязательно более сложную — с некоторыми задачами хорошо справляются, наоборот, более простые сети. Но это дополнительно усложняет работу над нейросетями, особенно когда результат работы критичен.
Для чего нужны нейронные сети?
Нейросети используются в огромном количестве сфер, в первую очередь в тех, где от машины нужна функциональность сродни человеческой. То есть в ситуациях, где нет четко заданного скрипта, описывающего каждый конкретный случай; входные данные могут быть любыми, поэтому нужно уметь обрабатывать все возможные варианты. Хороший пример — робот-ассистент или подсказки в поле поиска. В свое время именно поисковые системы дали толчок развитию методов искусственного интеллекта. Пока с нейронными сетями работают в основном большие компании и холдинги. Для того чтобы создать нейросеть, способную достаточно грамотно работать в сложных условиях, нужны мощные машины и большие наборы обучающих данных. Такие ресурсы могут себе позволить только крупные корпорации. Еще есть стартапы — они в основном работают на арендованных мощностях и концентрируются на создании нейросети под конкретные задачи. Пример — знаменитое приложение Prisma. Отрасль может быть любой. Во всех сферах есть задачи, которые в силах решить нейросеть. Рассмотрим основные области задач, для решения которых используются нейросети. Классификация. Нейросеть получает объект и относит его к определенному классу. Самая первая сеть, перцептрон, решала именно задачи классификации, но очень простые. Сейчас возможности шире: сети могут классифицировать клиентов и выделять аудитории по интересам — вы сталкиваетесь с этой возможностью каждый день, когда ваш электронный почтовый ящик определяет (классифицирует) некоторые письма как спам. Но это не единственный пример: автоматический скоринг в банках, контекстная реклама — это все касается классификации. Распознавание. Задача поставлена иначе: она не в том, чтобы отнести объект к одному из классов, а в том, чтобы найти нужное среди множества данных — например, лицо на картинке. «Умные» фильтры для фотографий работают именно так. Можно вспомнить многочисленные нейросети, которые превращают фотографии в картины маслом или постеры, — они тоже сначала распознают, что находится на изображении. Распознавать можно и текстовые данные, например приложения для определения названия музыкальных треков. Но распознавание — это не только приложения. Это и поиск по картинке, и чтение текста с изображения, и работа «умных» камер слежения. Разнообразные программы для людей с ограниченными возможностями тоже используют возможности распознавания. Сюда же относятся голосовые ассистенты, которые распознают речь. Сейчас нейросети начинают активно применяться в медицине, например распознают информацию на снимках, что облегчает диагностику. Прогнозирование. Третий вариант — нейросети, которые получают входные данные и на их основе что-то предсказывают. Их часто применяют в аналитике, например в финансовом секторе такая сеть может предсказывать поведение рынка, а в маркетинге — тренды и аудитории. Нейросетевые программы, которые дописывают текст или дорисовывают изображение, тоже по сути занимаются прогнозированием. Так же работают поисковые системы: вы начинаете вводить фразу, а вам предлагают ее завершение. Это тоже задача прогнозирования, причем интересная — с учетом смысла предыдущих слов. Генерация. Нейронные сети могут сами генерировать контент. Пока он далек от идеального, но программы становятся умнее. Сейчас нейросети могут писать музыку, создавать изображения, и со временем они становятся все больше похожими на настоящие. Это комплексная задача, которая может состоять из нескольких предыдущих. Например, «дорисовка» человека на фотографии — задача распознавания и прогнозирования одновременно. Генерация текста в определенном стиле — классификация плюс прогнозирование.
Какими бывают нейронные сети?
У нейросетей есть общие черты — например, наличие входного слоя, который принимает информацию на вход. Но много и различий. Для каждой из перечисленных выше задач потребуется своя нейронная сеть. У них будут различаться структуры, архитектура, типы нейронов и многое другое. Создать универсальный алгоритм невозможно, по крайней мере пока, поэтому сети отдельно оптимизируют под определенные спектры задач. Однонаправленные. Нейросети работают в одном направлении — как оригинальный перцептрон. Это значит, что у них нет «памяти», а поток информации передается только в одну сторону. Структура выходит более простой, чем в случае с рекуррентными сетями, о которых мы поговорим ниже. Но это не плохо: для решения некоторых задач простые структуры подходят лучше. Однонаправленные сети хорошо подходят для задач распознавания. Суть примерно та же, что и в случае с восприятием окружающего мира реальным мозгом. Органы чувств получают информацию и передают ее в одном направлении, та в процессе трансформируется и распознается. Мозг делает вывод: «я вижу собаку», «слышна рок-музыка», «на улице холодно». Однонаправленная модель работает по тому же принципу, но более упрощенно. Еще один вариант применения — прогнозирование. Принцип такой же: «На улице тучи — значит, пойдет дождь». Но критерии, по которым нейросети делают выводы, до конца непонятны. Рекуррентные. У этих сетей есть эффект «памяти» благодаря тому, что данные передаются в двух направлениях, а не в одном. В результате они воспринимают предыдущую полученную информацию и могут глубже ее «анализировать». Это полезно, если перед сетью стоит сложная задача вроде перевода текста. Однонаправленная нейросеть переведет каждое слово по отдельности, и получится бессвязная «каша». Рекуррентная сможет учесть контекст и перевести, например, apple tree не как «яблоко дерево», а как «яблоня». Или более сложный пример: идиома that’s a piece of cake в контексте переведется не как «это кусок торта», а как «проще простого» в зависимости от стиля текста. На это сейчас способны не все переводчики. Задачи для рекуррентной сети можно сформулировать так: это работа с большим объемом данных, которые надо разбить на более мелкие и обработать. Причем с учетом связей между друг другом. Правильно настроенная рекуррентная нейронная сеть способна отличать контекст одной ситуации от другой. Это важно, например, при создании «говорящих» ботов: вспомните, как «обижаются» голосовые помощники, если сказать им что-то грубое. Сверточные. Это отдельная категория нейронных сетей, менее закрытая, чем другие, благодаря принципиальной многослойности. Многослойными называются нейронные сети, в которых нейроны сгруппированы в слои. При этом каждый нейрон предыдущего слоя связан со всеми нейронами следующего слоя, а внутри слоев связи между нейронами отсутствуют. Сверточные сети используют для распознавания образов. У них особая структура слоев: часть занимается «свертыванием», преобразованием картинки, а часть — группировкой и распознаванием маленьких дискретных элементов, созданных на сверточных слоях. Таких слоев несколько. Результат — более высокая точность и качественное восприятие информации. Интересный факт: как обычные нейросети были основаны на нейронах в головном мозгу, так сверточные — на структуре зрительной коры. Это та часть мозга, которая отвечает за восприятие картинок. В ней чередуются «простые» и «сложные» клетки: первые реагируют на определенные линии и очертания, вторые — на активацию конкретных простых клеток. Так происходит процесс распознавания образов в мозгу, и примерно так же устроена сверточная нейросеть. Сверточные слои «воспринимают» отдельные элементы картинки как простые клетки — линии. Особые слои, называемые субдискретизирующими, реагируют на конкретные найденные элементы. Чем больше слоев, тем более абстрактные детали способна заметить и определить сеть. На результат работы промежуточных слоев можно посмотреть, если заглянуть в файлы нейросети. Поэтому она и считается менее закрытой. Результат больше всего напоминает карту признаков из машинного обучения.
Нейронные сети — это машинное обучение?
Не совсем. Нейронные сети относят к глубокому обучению (Deep Learning), которое является частью машинного, но от классического ML подход сильно отличается. В стандартном машинном обучении программе предварительно рассказывают, как выглядит то, что она должна сделать. Например, если нужно отличить мужчину от женщины, потребуется «объяснить» модели, в чем принципиальные различия между фигурами. Это делается с помощью математических формул и абстракций, которые будут описывать параметры. Выше мы говорили про понятие карты признаков — по сути, это она и есть. При обучении нейросети такой задачи не стоит. Признаки сеть находит сама, их не нужно описывать. Необходимо только задать коэффициенты и результаты, соответствующие каждому возможному исходу. Это и хорошо, и плохо. Плохо — потому что приводит к уже описанной выше непредсказуемости. Хорошо — потому что дает больше гибкости: два необученных исходника одной и той же сети можно обучить на выполнение двух разных задач. Не понадобится писать другой алгоритм и задавать новые параметры. Можно оставить ту же архитектуру, главное — чтобы она изначально была оптимальной для этого типа задач.
То есть нейронная сеть может заменить человека?
Нейросети действительно используются для решения задач, похожих на те, которые решает человеческий мозг. Но даже мощная нейросеть может ошибиться. И в некоторых случаях цена этой ошибки может быть крайне велика, а ее вероятность намного больше, чем если задачу решает человек. Поэтому сейчас нейронные сети используются скорее для ассистирования, чем для полномасштабной самостоятельной работы. Существуют проблемы, в решении которых машины действительно могут заменить человека. Это некоторые аналитические задачи, а также те, которые связаны с более-менее однообразными действиями. Например, с помощью нейросети может работать робот-почтальон. Но далеко не все задачи можно решить вот так. Например, робот может ответить на более менее стандартные вопросы в банковском приложении, но не поймет, что делать, если человек задаст что-то неочевидное.
Примеры популярных нейронных сетей
| Нейросеть | Описание |
|---|---|
| Convolutional Neural Network (CNN) | Используется для обработки изображений и распознавания паттернов в них. Применяется в компьютерном зрении. |
| Recurrent Neural Network (RNN) | Подходит для работы с последовательными данными, такими как текст и аудио. Применяется в языковых моделях. |
| Generative Adversarial Network (GAN) | Используется для генерации новых данных, таких как изображения и звуки. Применяется в синтезе контента. |
| Transformer | Базовая архитектура для моделей обработки естественного языка, таких как BERT и GPT. |
| Deep Q-Network (DQN) | Применяется в обучении с подкреплением для игр и задач управления. |
| U-Net | Широко используется в сегментации изображений, включая медицинское изображение. |
| YOLO (You Only Look Once) | Одна из популярных архитектур для реального времени обнаружения объектов на изображении. |
| ResNet | Известная архитектура с нейронными блоками остаточных связей, обычно используется для классификации. |
| ChatGPT | Мощная языковая модель, разработанная OpenAI. Основана на архитектуре GPT (Generative Pre-trained Transformer). ChatGPT способна генерировать тексты и поддерживать разговоры с пользователем, делая ее популярным инструментом для задач генерации текста и чат-ботов. |
А что с творчеством нейронных сетей?
Нейросеть не осознает свои действия. Даже если она генерирует контент — она делает это машинально, на основе предыдущих данных, а не благодаря собственному мышлению. Вряд ли нейронная сеть, даже сложная, сможет догадаться, что созданное ей предложение абсурдно и не имеет смысла. Для нее нет такого понятия, как «смысл». Творчество нейросетей — примерно как «речь» говорящего попугая или «китайская комната». Поэтому есть мнение, что книга или картина, написанные нейросетью, не смогут заменить человеческие, даже если алгоритмы будут очень хорошо имитировать наше творчество. Вряд ли много кто захочет читать книгу, если точно известно, что автор не вкладывал туда никаких мыслей. Правда, пока создавать с нуля контент, похожий на настоящий, могут немногие системы. Но вы можете внести свой вклад в их развитие — если освоите, как они работают. Сейчас это направление востребовано как никогда. Тест: нейросеть или человек — сможете определить?
Как производятся вычисления в нейроне
Дата публикации: 23 августа 2023
Время чтения: 11 минут
Во власти искусственного интеллекта: что такое нейросеть и как она работает
Ключевой элемент искусственного интеллекта — нейросети. Они способны анализировать данные, извлекать сложные закономерности и даже принимать решения на основе полученных знаний. В статье подробно расскажем, что такое нейросеть, как она работает и обучается. Также узнаете, где и как ее применяют, какие преимущества и недостатки.

Редакция iConText Group
Центр управления бизнесом
Оглавление
- Основные компоненты нейросети.
- Принцип передачи и обработки данных.
- Процесс обучения нейронной сети.
- Виды обучения.
- В зависимости от структуры.
- В зависимости от сферы применения.
- Преимущества.
- Недостатки.
- В области медицины.
- В финансовой сфере.
- В технологических приложениях.
- Примеры использования.
- Влияние нейросетей на рынок труда.
- Преимущества и ограничения замены человеческого труда.
Что такое нейросеть
Представим, что у компьютера есть мозг. Этот мозг состоит из маленьких частей — нейронов. Каждый нейрон принимает информацию, обдумывает ее и после выдает ответ. Это может быть ответ на вопрос, определение картинки, создание музыки и пр. Что важно — нейроны работают вместе, передавая друг другу информацию, чтобы решить сложную задачу.
Нейронная сеть — это математическая модель, имитирующая работу человеческого мозга. Используется для анализа данных, распознавания образов, принятия решений, а также выполнения других простых и сложных задач.
Идея нейронных сетей базируется на функционировании нервной системы живых организмов, где нейроны обрабатывают информацию, передавая электрические импульсы между собой. Искусственные нейроны имитируют этот процесс, но используют математические операции для вычисления и передачи данных.
Как работает нейросеть
Основные компоненты нейросети
- Нейроны. Базовые вычислительные единицы, которые принимают входные данные, выполняют вычисления, а затем передают результаты следующим нейронам. Говоря простыми словами, нейроны — маленькие помощники в мозге компьютера. Каждый из них получает, анализирует информацию, а затем говорит другим нейронам, что думает об этом.
- Веса. Числовые коэффициенты, определяющие силу связи между нейронами. Дают понимание, насколько входные данные повлияют на результат, который выдает нейрон. Веса похожи на наши предпочтения. Принимая информацию, нейрон говорит: «Это важнее, а вот это менее важно».
- Функции активации. Это как переключатели включения, выключения нейронов. Когда информация и веса перемешиваются, функция активации решает, будет ли нейрон активирован, т. е. «включен», и передаст ли информацию дальше.
- Слои. Нейроны объединяются в слои, где каждый слой выполняет определенные вычисления. Входной слой принимает входные данные, скрытые слои выполняют более сложные вычисления, а выходной слой выдает результат.
Принцип передачи, обработки данных
Рассмотрим на простом примере, как информация передается, а затем обрабатывается в нейросети. За основу возьмем нейросеть, которая умеет распознавать, кто нарисован на картинке: кошка или собака.
-
Входные данные. Картинка — это набор пикселей определенного цвета. Нейросеть берет этот набор пикселей в качестве входных данных.
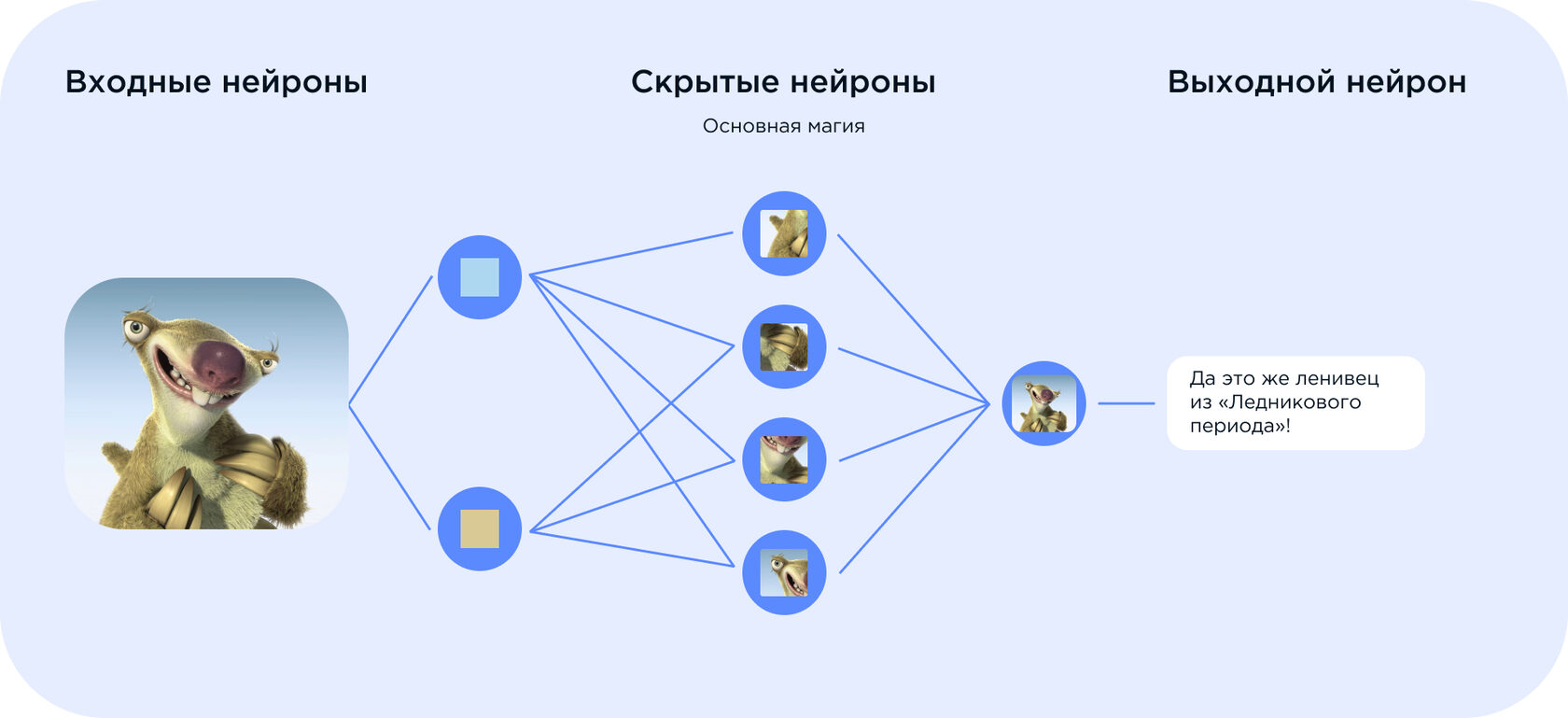
Таким образом, нейросеть «смотрит» на картинку, разбирается в мельчайших деталях, чтобы потом сделать вывод. Этот процесс подобен тому, как наш мозг обрабатывает информацию.
Как нейросеть обучается
Процесс обучения нейронной сети
Для примера возьмем ту же ситуацию: нейронка учится распознавать, что изображено на картинке: кошка или собака. Как происходит процесс обучения:
-
Подготовка данных. Сначала мы подбираем много картинок кошек и собак. При этом на каждой делаем пометки, что именно изображено. Это поможет нейросети понять разницу между животными.
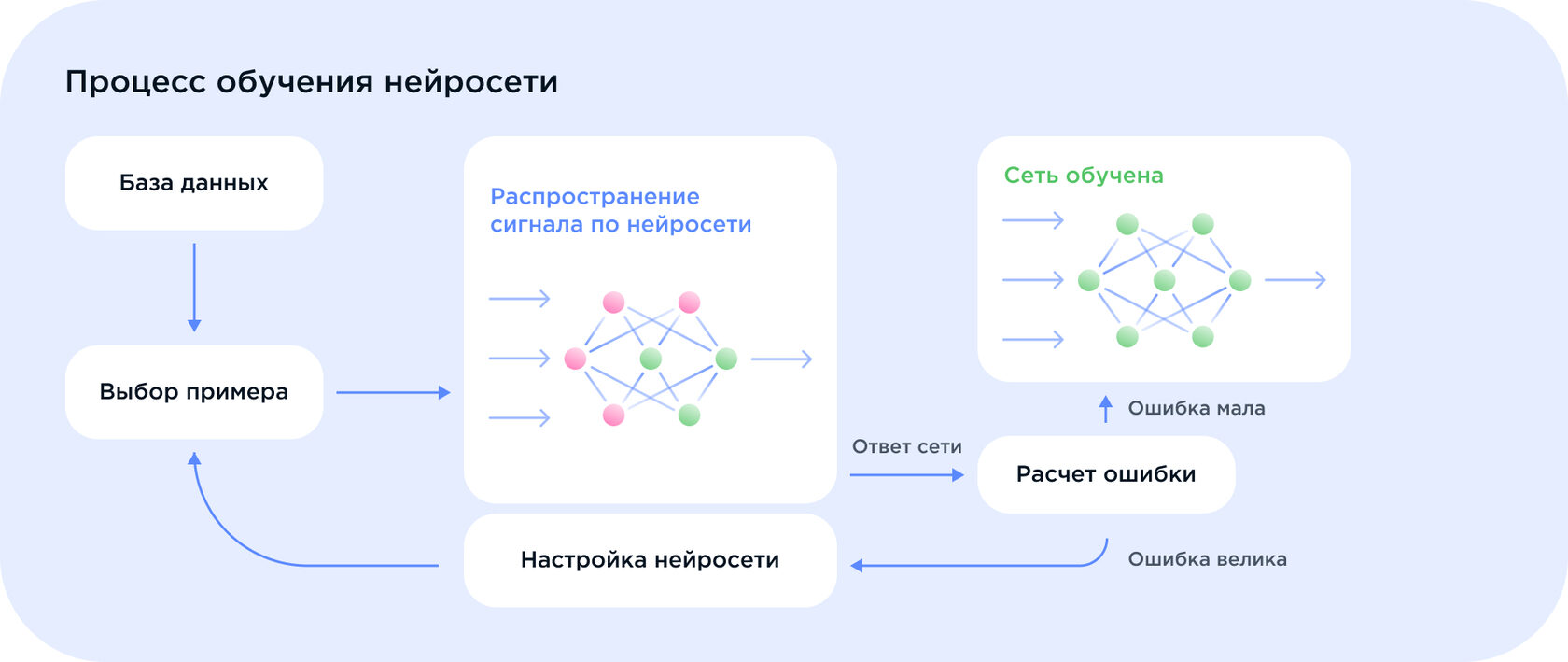
Виды обучения
- Обучение с учителем (Supervised Learning). Этот вид обучения похож на обучение в школе. Мы даем нейросети много примеров с правильными ответами. Например, показываем фотографии кошек, собак и говорим, кто есть кто. Нейронная сеть учится находить закономерности в данных и правильно определять ответы. Затем, когда видит новую картинку, пытается предсказать ответ самостоятельно.
Какие бывают нейронки
Виды нейросетей в зависимости от структуры
- Перцептроны. Это как базовые строительные блоки нейронных сетей. Они имитируют работу одного нейрона в мозгу и используются для создания более сложных сетей.
Виды нейросетей в зависимости от сферы применения
- Глубокие нейронные сети (Deep Learning). В таких нейросетях множество слоев нейронов, что позволяет анализировать данные на разных уровнях абстракции. Они распознают образы, голоса, переводят тексты на всевозможные языки и решают другие сложные задачи.
Преимущества и недостатки нейросетей
Преимущества нейросетей
- Высокая производительность. Нейросети умеют решать сложные задачи, обрабатывать большие объемы данных и выявлять закономерности, которые трудно обнаружить вручную.
- Автоматическое извлечение признаков. Нейросети самостоятельно извлекают важные признаки из информации, не требуя ручной настройки. Это полезно в случаях, когда сложно определить, какие признаки использовать.
Недостатки нейросетей
- Большие вычислительные ресурсы. Обучение, работа с глубокими нейронными сетями требуют существенных вычислительных ресурсов, включая мощные процессоры, графические карты. Это может быть дорого, а значит затруднит доступ к технологии.
Какие задачи решает нейросеть
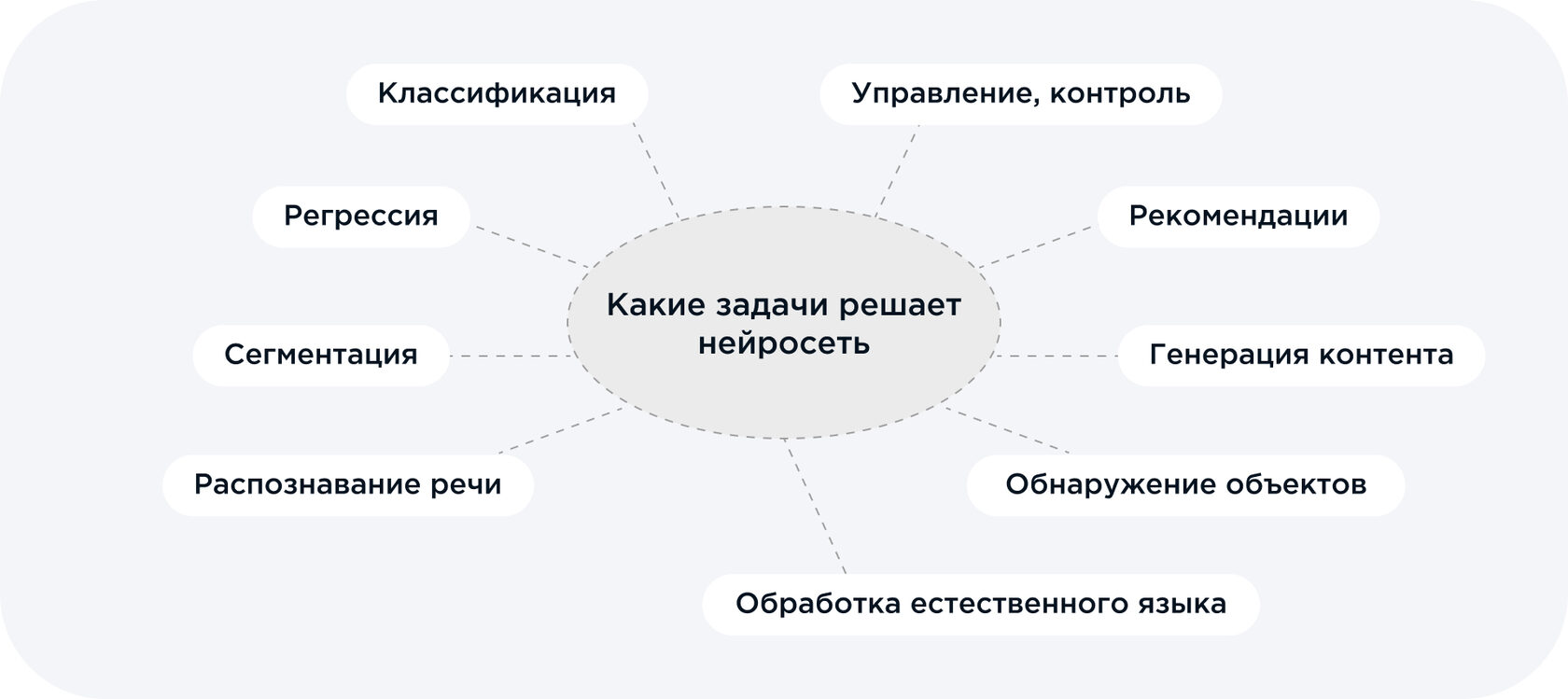
- Классификация. Определение принадлежности объекта к классу. Например, распознавание образов (что изображено на картинке: кошка или собака), классификация текстов (какая у текста тональность) и пр.
Где используются нейронки
В области медицины
В медицинских приложениях нейросети могут диагностировать болезни на основе изображений, например, обнаруживать рак на ранних стадиях. Они также помогают прогнозировать заболевания, оптимизировать лечение.
В финансовой сфере
Финансовая сфера использует нейронные сети для прогнозирования рыночных трендов, определения рисков, обнаружения мошенничества и даже для автоматизации торговых операций.
В технологических приложениях
Нейросети распознают речь, обрабатывают естественный язык, управляют автопилотами автомобилей. Также анализируют социальные медиа, создают голосовых помощников.
Примеры использования
-
Нейронка внутри ChatGPT по запросу составляет тексты на разных языках.

Алексей Курицын
Руководитель группы по работе с клиентами icontext
Уже сейчас ИИ выполняет несложные манипуляции с аналитическими данными, рутинную работу, которая мешает сотруднику смотреть на задачи шире и предлагать решения по продвижению клиентского бизнеса.
GPT не дает готовых решений, но может помочь генерировать гипотезы, которые потом дорабатываются менеджерами агентства и воплощаются в жизнь.
Мы идем к полной перестройке рабочих процессов внутри клиентского сервиса. За счет ИИ повысится востребованность сотрудников, способных выходить за рамки стандартного инструментария.

Ольга Черепякина
Руководитель направления performance icontext
ChatGPT полезен в работе с ключевыми словами, написании текстов на разных языках, проведении тестов, первичном анализе данных, мониторинге трендов и анализе целевой аудитории.
В итоге трудоемкие процессы превращаются в легко управляемые задачи. Нейронки автоматизируют рутинные процедуры и освобождают время на самое важное — повышение качества рекламных кампаний, развитие экспертизы сотрудников.
Это наше время, когда мы, объединяя усилия с ИИ, не просто следуем тенденциям, но устанавливаем новые стандарты в рекламной индустрии.
С помощью нейросетей также можно генерировать креативные решения для клиентов, внутренних задач, повседневных ситуаций.

Рустам Бродников
Арт-директор iConText Group
Когда мы только начали изучать нейросети, они не давали нужного результата. Но с каждой новой версией эта технология лучше и лучше генерирует, например, 3D-изображения. Теперь мы можем отказаться от фотостоков: детализация сгенерированных фотографий это позволяет. Кроме того, мы активно пользуемся AI-сервисами. Они значительно улучшают детализацию изображений. Это позволяет готовить макеты к печати без потери качества.
Могут ли нейросети заменить людей
Нейронные сети берут на себя все больше задач, которые раньше выполняли исключительно люди. Вопрос в том, к чему приведет их развитие: заменит ли искусственный интеллект некоторые профессии или останется играть роль помощника.
Влияние нейросетей на рынок труда
С одной стороны, способности нейронных сетей автоматизировать повторяющиеся задачи (обработка информации, сортировка, мониторинг) могут привести к сокращению рабочих мест, требующих выполнения стандартных операций. С другой, развитие искусственного интеллекта создает спрос на специалистов в области машинного обучения, анализа данных, разработки алгоритмов, технической поддержки.
Наравне с этим нейросети могут повысить производительность сотрудников. Но для этого потребуется более высокий уровень знаний, навыков. Например, освоение промпт-инжиниринга — навыка составления правильного запроса для нейронной сети. Можем предположить, что в дальнейшем это будет дополнительным преимуществом для каждого человека в маркетинге.

Милена Манаенко
Младший менеджер по маркетплейсам icontext
Генеративные нейросети вносят огромный вклад в нашу деятельность, открывая новые возможности и переворачивая традиционные подходы к работе с контентом, маркетингом.
Сейчас мы активно осваиваем промт-инжиниринг, чтобы гарантировать максимальное использование потенциала технологии. Один из основных вызовов — тонкая настройка промтов, чтобы они соответствовали нашим целям, интересам. Это требует технического понимания работы нейросетей, способности творчески подходить к задачам, учитывая контекст, конкретные цели.
Кроме того, внедрение нейросетей стимулирует создание новых видов бизнеса. Например, компании могут создавать продукты и сервисы на основе анализа больших данных или использования технологии ИИ для решения сложных задач.
Преимущества и ограничения замены человеческого труда
Преимущества. Первое — высокая производительность. Нейросети выполняют задачи быстрее, точнее, чем человек, особенно в случае рутинных, повторяющихся операций. В результате увеличивается производительность, эффективность, снижается число ошибок. А способность быстро обрабатывать данные позволяет оперативнее выявлять паттерны, тренды и зависимости.
Нейросети могут работать 24/7. Они не берут выходные, отпуск или больничный. Это особенно актуально для автоматизации процессов в сферах, где требуется постоянный мониторинг, анализ информации.
Ограничения. Нейронки не могут полностью заменить человека. Они ограничены программой и требуют человеческого вмешательства для настройки, обучения, интерпретации результатов. Кроме того, могут допускать ошибки, особенно, если работают с новыми или непредвиденными данными.

Денис Егоров
Старший владелец IT-продуктов второй категории в iConText Group
Действительно ли ИИ — универсальный «инструмент» для отрасли, покажет только время и опыт применения. Возлагать на него большие надежды не стоит, ведь технология еще сыра, как и понимание «зачем».
Сейчас ИИ как ребенок, который быстро растет вместе с целыми командами. Его ведут за ручку, но иногда он спотыкается и падает. А что вы можете доверить ребенку?
Но это не значит, что технологию нужно игнорировать. Те, кто лучше поймут «зачем» (и когда сойдется экономика от реального решения), будут захватывать рынки.
Какой вывод можно сделать? Нейросети — инструмент с большим потенциалом, но его применение требует баланса между автоматизацией и человеческим вмешательством.