Как спарсить любой сайт?

Меня зовут Даниил Охлопков, и я расскажу про свой подход к написанию скриптов, извлекающих данные из интернета: с чего начать, куда смотреть и что использовать.
Написав тонну парсеров, я придумал алгоритм действий, который не только минимизирует затраченное время на разработку, но и увеличивает их живучесть, робастность, масштабируемость.
TL;DR
Чтобы спарсить данные с вебсайта, пробуйте подходы именно в таком порядке:
- Найдите официальное API,
- Найдите XHR запросы в консоли разработчика вашего браузера,
- Найдите сырые JSON в html странице,
- Отрендерите код страницы через автоматизацию браузера,
- Если ничего не подошло — пишите парсеры HTML кода.
Совет профессионалов: не начинайте с BS4/Scrapy
BeautifulSoup4 и Scrapy — популярные инструменты парсинга HTML страниц (и не только!) для Python.
Крутые вебсайты с крутыми продактами делают тонну A/B тестов, чтобы повышать конверсии, вовлеченности и другие бизнес-метрики. Для нас это значит одно: элементы на вебстранице будут меняться и переставляться. В идеальном мире, наш написанный парсер не должен требовать доработки каждую неделю из-за изменений на сайте.
Приходим к выводу, что не надо извлекать данные из HTML тегов раньше времени: разметка страницы может сильно поменяться, а CSS-селекторы и XPath могут не помочь. Используйте другие методы, о которых ниже. ⬇️
Используйте официальный API
�� Ого? Это не очевидно ��? Конечно, очевидно! Но сколько раз было: сидите пилите парсер сайта, а потом БАЦ — нашли поддержку древней RSS-ленты, обширный sitemap.xml или другие интерфейсы для разработчиков. Становится обидно, что поленились и потратили время не туда. Даже если API платный, иногда дешевле договориться с владельцами сайта, чем тратить время на разработку и поддержку.
Sitemap.xml — список страниц сайта, которые точно нужно проиндексировать гуглу. Полезно, если нужно найти все объекты на сайте. Пример: http://techcrunch.com/sitemap.xml
RSS-лента — API, который выдает вам последние посты или новости с сайта. Было раньше популярно, сейчас все реже, но где-то еще есть! Пример: https://habr.com/ru/rss/hubs/all/
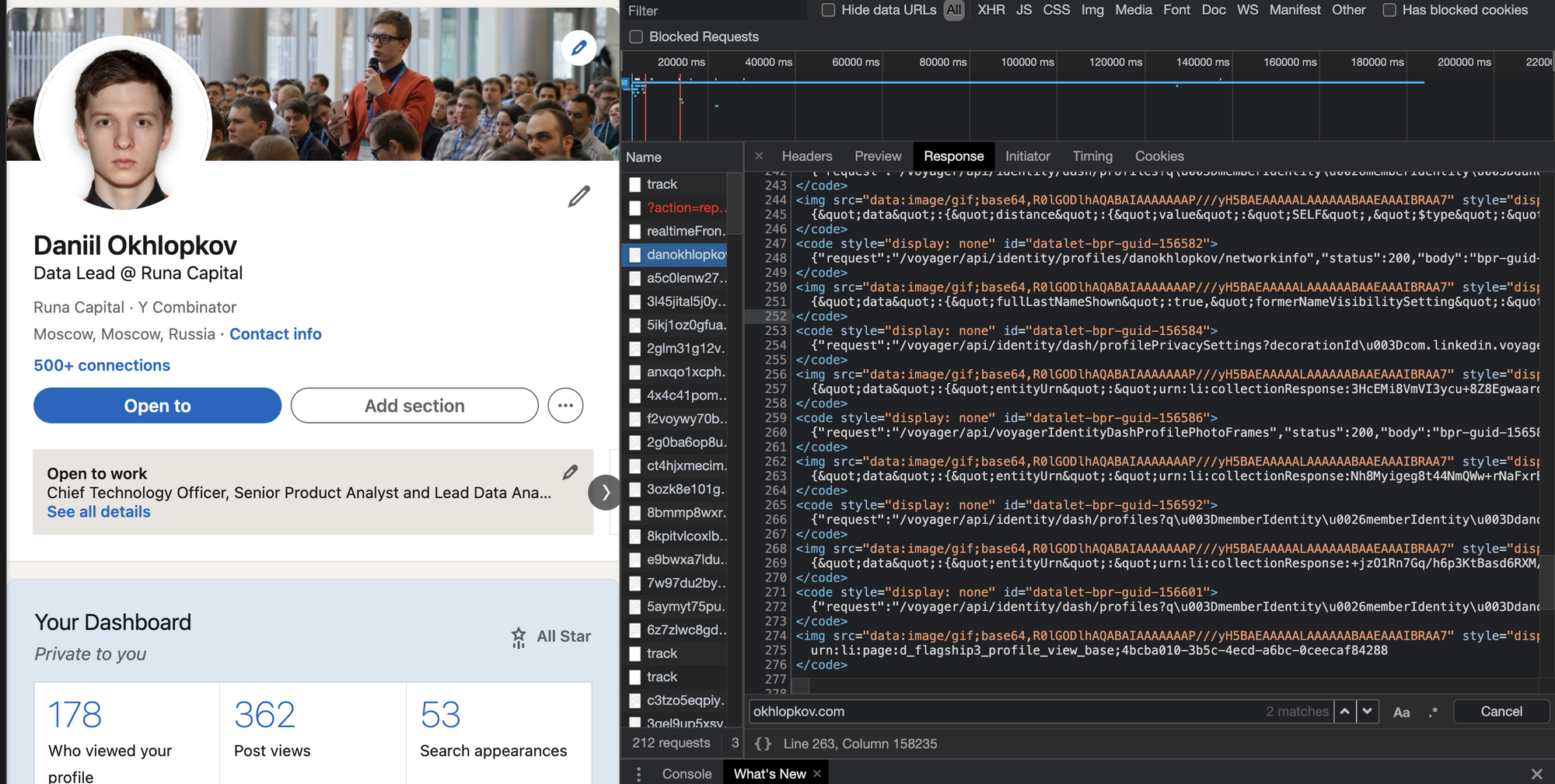
Поищите XHR запросы в консоли разработчика

Все современные вебсайты (но не в дарк вебе, лол) используют Javascript, чтобы догружать данные с бекенда. Это позволяет сайтам открываться плавно и скачивать контент постепенно после получения структуры страницы (HTML, скелетон страницы).

Обычно, эти данные запрашиваются джаваскриптом через простые GET/POST запросы. А значит, можно подсмотреть эти запросы, их параметры и заголовки — а потом повторить их у себя в коде! Это делается через консоль разработчика вашего браузера (developer tools).
В итоге, даже не имея официального API, можно воспользоваться красивым и удобным закрытым API. ☺️
Даже если фронт поменяется полностью, этот API с большой вероятностью будет работать. Да, добавятся новые поля, да, возможно, некоторые данные уберут из выдачи. Но структура ответа останется, а значит, ваш парсер почти не изменится.
Алгорим действий такой:

- Открывайте вебстраницу, которую хотите спарсить
- Правой кнопкой -> Inspect (или открыть dev tools как на скрине выше)
- Открывайте вкладку Network и кликайте на фильтр XHR запросов
- Обновляйте страницу, чтобы в логах стали появляться запросы
- Найдите запрос, который запрашивает данные, которые вам нужны
- Копируйте запрос как cURL и переносите его в свой язык программирования для дальнейшей автоматизации.
Вы заметите, что иногда эти XHR запросы включают в себя огромные строки — токены, куки, сессии, которые генерируются фронтендом или бекендом. Не тратьте время на ревёрс фронта, чтобы научить свой парсер генерировать их тоже.
Вместо этого попробуйте просто скопипастить и захардкодить их в своем парсере: очень часто эти строчки валидны 7-30 дней, что может быть окей для ваших задач, а иногда и вообще несколько лет. Или поищите другие XHR запросы, в ответе которых бекенд присылает эти строчки на фронт (обычно это происходит в момент логина на сайт). Если не получилось и без куки/сессий никак, — советую переходить на автоматизацию браузера (Selenium, Puppeteer, Splash — Headless browsers) — об этом ниже.
Поищите JSON в HTML коде страницы
Как было удобно с XHR запросами, да? Ощущение, что ты используешь официальное API. �� Приходит много данных, ты все сохраняешь в базу. Ты счастлив. Ты бог парсинга.
Но тут надо парсить другой сайт, а там нет нужных GET/POST запросов! Ну вот нет и все. И ты думаешь: неужели расчехлять XPath/CSS-selectors? ��♀️ Нет! ��♂️
Чтобы страница хорошо проиндексировалась поисковиками, необходимо, чтобы в HTML коде уже содержалась вся полезная информация: поисковики не рендерят Javascript, довольствуясь только HTML. А значит, где-то в коде должны быть все данные.
Современные SSR-движки (server-side-rendering) оставляют внизу страницы JSON со всеми данные, добавленный бекендом при генерации страницы. Стоп, это же и есть ответ API, который нам нужен! ������
Вот несколько примеров, где такой клад может быть зарыт (не баньте, плиз):

Алгоритм действий такой:
- В dev tools берете самый первый запрос, где браузер запрашивает HTML страницу (не код текущий уже отрендеренной страницы, а именно ответ GET запроса).
- Внизу ищите длинную длинную строчку с данными.
- Если нашли — повторяете у себя в парсере этот GET запрос страницы (без рендеринга headless браузерами). Просто requests.get .
- Вырезаете JSON из HTML любыми костылямии (я использую html.find(«= <") ).
Отрендерите JS через Headless Browsers
Если XHR запросы требуют актуальных tokens, sessions, cookies. Если вы нарываетесь на защиту Cloudflare. Если вам обязательно нужно логиниться на сайте. Если вы просто решили рендерить все, что движется загружается, чтобы минимизировать вероятность бана. Во всех случаях — добро пожаловать в мир автоматизации браузеров!
Если коротко, то есть инструменты, которые позволяют управлять браузером: открывать страницы, вводить текст, скроллить, кликать. Конечно же, это все было сделано для того, чтобы автоматизировать тесты веб интерфейса. I’m something of a web QA myself.
После того, как вы открыли страницу, чуть подождали (пока JS сделает все свои 100500 запросов), можно смотреть на HTML страницу опять и поискать там тот заветный JSON со всеми данными.
driver.get(url_to_open) html = driver.page_sourceSelenoid — open-source remote Selenium cluster
Для масштабируемости и простоты, я советую использовать удалённые браузерные кластеры (remote Selenium grid).
Недавно я нашел офигенный опенсорсный микросервис Selenoid, который по факту позволяет вам запускать браузеры не у себя на компе, а на удаленном сервере, подключаясь к нему по API. Несмотря на то, что Support team у них состоит из токсичных разработчиков, их микросервис довольно просто развернуть (советую это делать под VPN, так как по умолчанию никакой authentication в сервис не встроено). Я запускаю их сервис через DigitalOcean 1-Click apps: 1 клик — и у вас уже создался сервер, на котором настроен и запущен кластер Headless браузеров, готовых запускать джаваскрипт!
Вот так я подключаюсь к Selenoid из своего кода: по факту нужно просто указать адрес запущенного Selenoid, но я еще зачем-то передаю кучу параметров бразеру, вдруг вы тоже захотите. На выходе этой функции у меня обычный Selenium driver, который я использую также, как если бы я запускал браузер локально (через файлик chromedriver).
def get_selenoid_driver( enable_vnc=False, browser_name="firefox" ): capabilities = < "browserName": browser_name, "version": "", "enableVNC": enable_vnc, "enableVideo": False, "screenResolution": "1280x1024x24", "sessionTimeout": "3m", # Someone used these params too, let's have them as well "goog:chromeOptions": , "prefs": < "credentials_enable_service": False, "profile.password_manager_enabled": False >, > driver = webdriver.Remote( command_executor=SELENOID_URL, desired_capabilities=capabilities, ) driver.implicitly_wait(10) # wait for the page load no matter what if enable_vnc: print(f"You can view VNC here: ") return driverЗаметьте фложок enableVNC . Верно, вы сможете смотреть видосик с тем, что происходит на удалённом браузере. Всегда приятно наблюдать, как ваш скрипт самостоятельно логинится в Linkedin: он такой молодой, но уже хочет познакомиться с крутыми разработчиками.
Парсите HTML теги
Мой единственный совет: постараться минимизировать число фильтров и условий, чтобы меньше переобучаться на текущей структуре HTML страницы, которая может измениться в следующем A/B тесте.

Даниил Охлопков — Data Lead @ Runa Capital
Подписывайтесь на мой Телеграм канал, где я рассказываю свои истории из парсинга и сливаю датасеты.
Надеюсь, что-то из этого было полезно! Я считаю, что в парсинге важно, с чего ты начинаешь. С чего начать — я рассказал, а дальше ваш ход ��
Почему стоит научиться «парсить» сайты, или как написать свой первый парсер на Python

Для начала давайте разберемся, что же действительно означает на первый взгляд непонятное слово — парсинг. Прежде всего это процесс сбора данных с последующей их обработкой и анализом. К этому способу прибегают, когда предстоит обработать большой массив информации, с которым сложно справиться вручную. Понятно, что программу, которая занимается парсингом, называют — парсер. С этим вроде бы разобрались.
Перейдем к этапам парсинга.
- Поиск данных
- Извлечение информации
- Сохранение данных
И так, рассмотрим первый этап парсинга — Поиск данных.
Так как нужно парсить что-то полезное и интересное давайте попробуем спарсить информацию с сайта work.ua.
Для начала работы, установим 3 библиотеки Python.
pip install beautifulsoup4
Без цифры 4 вы ставите старый BS3, который работает только под Python(2.х).
pip install requests
pip install pandas
Теперь с помощью этих трех библиотек Python, можно проанализировать нашу веб-страницу.
Второй этап парсинга — Извлечение информации.
Попробуем получить структуру html-кода нашего сайта.
Давайте подключим наши новые библиотеки.
import requests from bs4 import BeautifulSoup as bs import pandas as pd И сделаем наш первый get-запрос.
URL_TEMPLATE = "https://www.work.ua/ru/jobs-odesa/?page=2" r = requests.get(URL_TEMPLATE) print(r.status_code) Статус 200 состояния HTTP — означает, что мы получили положительный ответ от сервера. Прекрасно, теперь получим код странички.
print(r.text) Получилось очень много, правда? Давайте попробуем получить названия вакансий на этой страничке. Для этого посмотрим в каком элементе html-кода хранится эта информация.
Комірник
У нас есть тег h2 с классом «add-bottom-sm», внутри которого содержится тег a. Отлично, теперь получим title элемента a.
soup = bs(r.text, "html.parser") vacancies_names = soup.find_all('h2', class_='add-bottom-sm') for name in vacancies_names: print(name.a['title']) Хорошо, мы получили названия вакансий. Давайте спарсим теперь каждую ссылку на вакансию и ее описание. Описание находится в теге p с классом overflow. Ссылка находится все в том же элементе a.
Some information about vacancy.
Получаем такой код.
vacancies_info = soup.find_all('p', class_='overflow') for name in vacancies_names: print('https://www.work.ua'+name.a['href']) for info in vacancies_info: print(info.text) И последний этап парсинга — Сохранение данных.
Давайте соберем всю полученную информацию по страничке и запишем в удобный формат — csv.
import requests from bs4 import BeautifulSoup as bs import pandas as pd URL_TEMPLATE = "https://www.work.ua/ru/jobs-odesa/?page=2" FILE_NAME = "test.csv" def parse(url = URL_TEMPLATE): result_list = r = requests.get(url) soup = bs(r.text, "html.parser") vacancies_names = soup.find_all('h2', class_='add-bottom-sm') vacancies_info = soup.find_all('p', class_='overflow') for name in vacancies_names: result_list['href'].append('https://www.work.ua'+name.a['href']) result_list['title'].append(name.a['title']) for info in vacancies_info: result_list['about'].append(info.text) return result_list df = pd.DataFrame(data=parse()) df.to_csv(FILE_NAME) После запуска появится файл test.csv — с результатами поиска.
Делаем парсер, чтобы массово тянуть с сайтов что угодно
Однажды мы рассказывали, как утащить что угодно с любого сайта, — написали свой парсер и забрали с чужого сайта заголовки статей. Теперь сделаем круче — покажем на примере нашего сайта, как можно спарсить вообще весь текст всех статей.
Парсинг — это когда вы забираете какую-то конкретную информацию с сайта в автоматическом режиме. Для этого пишется софт (скрипт или отдельная программа), софт настраивается под конкретный сайт, и дальше он ходит по нужным страницам и всё оттуда забирает.
После парсинга полученный текст можно передать в другие программы — например подстроить свои цены под цены конкурентов, обновить информацию на своём сайте, проанализировать текст постов или собрать бигдату для тренировки нейросетей.
Что делаем
Сегодня мы спарсим все статьи «Кода» кроме новостей и задач, причём сделаем всё так:
- Научимся обрабатывать одну страницу.
- Сделаем из этого удобную функцию для обработки.
- Найдём все адреса всех нужных страниц.
- Выберем нужные нам рубрики.
- Для каждой рубрики создадим отдельный файл, в который добавим всё текстовое содержимое всех статей в этой рубрике.
Чтобы потом можно было нормально работать с текстом, мы не будем парсить вставки с примерами кода, а ещё постараемся избавиться от титров, рекламных баннеров и плашек.
Будем работать поэтапно: сначала научимся разбирать контент на одной странице, а потом подгрузим в скрипт все остальные статьи.
Выбираем страницу для отладки
Технически самый простой парсинг делается двумя командами в Python, одна из которых — подключение сторонней библиотеки. Но этот код не слишком полезен для нашей задачи, сейчас объясним.
from urllib.request import urlopen inner_html_code = str(urlopen('АДРЕС СТРАНИЦЫ').read(),'utf-8')Когда мы заберём таким образом страницу, мы получим сырой код, в котором будет всё: метаданные, шапка, подвал и т. д. А нам нужно не только достать информацию из самой статьи (а не всей страницы), а ещё и очистить её от ненужной информации.
Чтобы скрипт научился отбрасывать ненужное, придётся ему прописать, что именно отбрасывать. А для этого нужно знать, что нам не нужно. А значит, нам нужно взять какую-то старую статью, в которой будут все ненужные элементы, и на этой одной странице всё объяснить.
Для настройки скрипта мы возьмём нашу старую статью. В ней есть всё нужное для отладки:
- текст статьи,
- подзаголовки,
- боковые ссылки,
- кат с кодом,
- просто вставки кода в текст,
- титры,
- рекламный баннер.
Получаем сырой текст
Вот что мы сейчас сделаем:
- Подключим библиотеку urlopen для обработки адресов страниц.
- Подключим библиотеку BeautifulSoup для разбора исходного кода страницы на теги.
- Получим исходный код страницы по её адресу.
- Распарсим его по тегам.
- Выведем текстовое содержимое распарсенной страницы.
На языке Python это выглядит так:
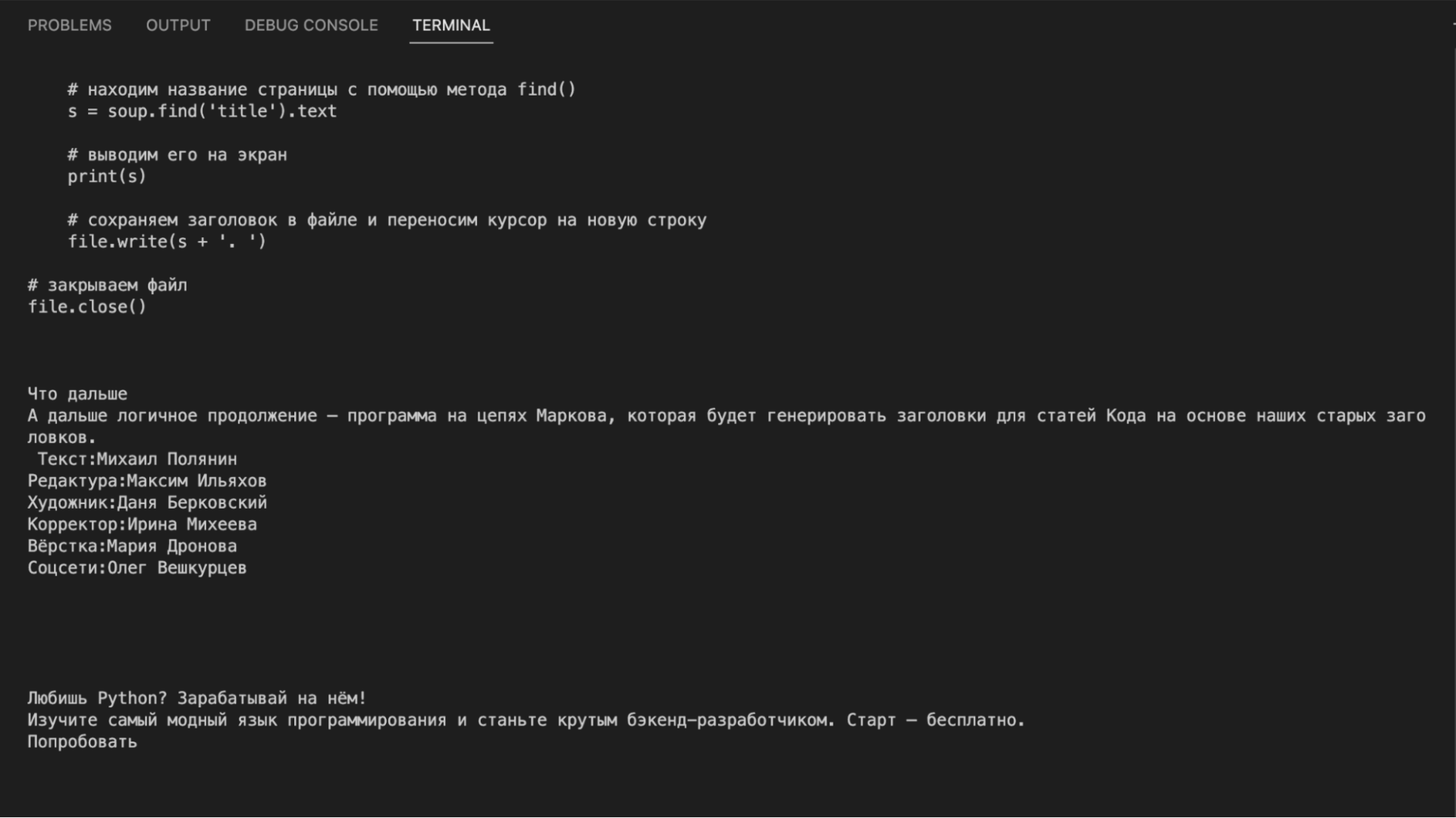
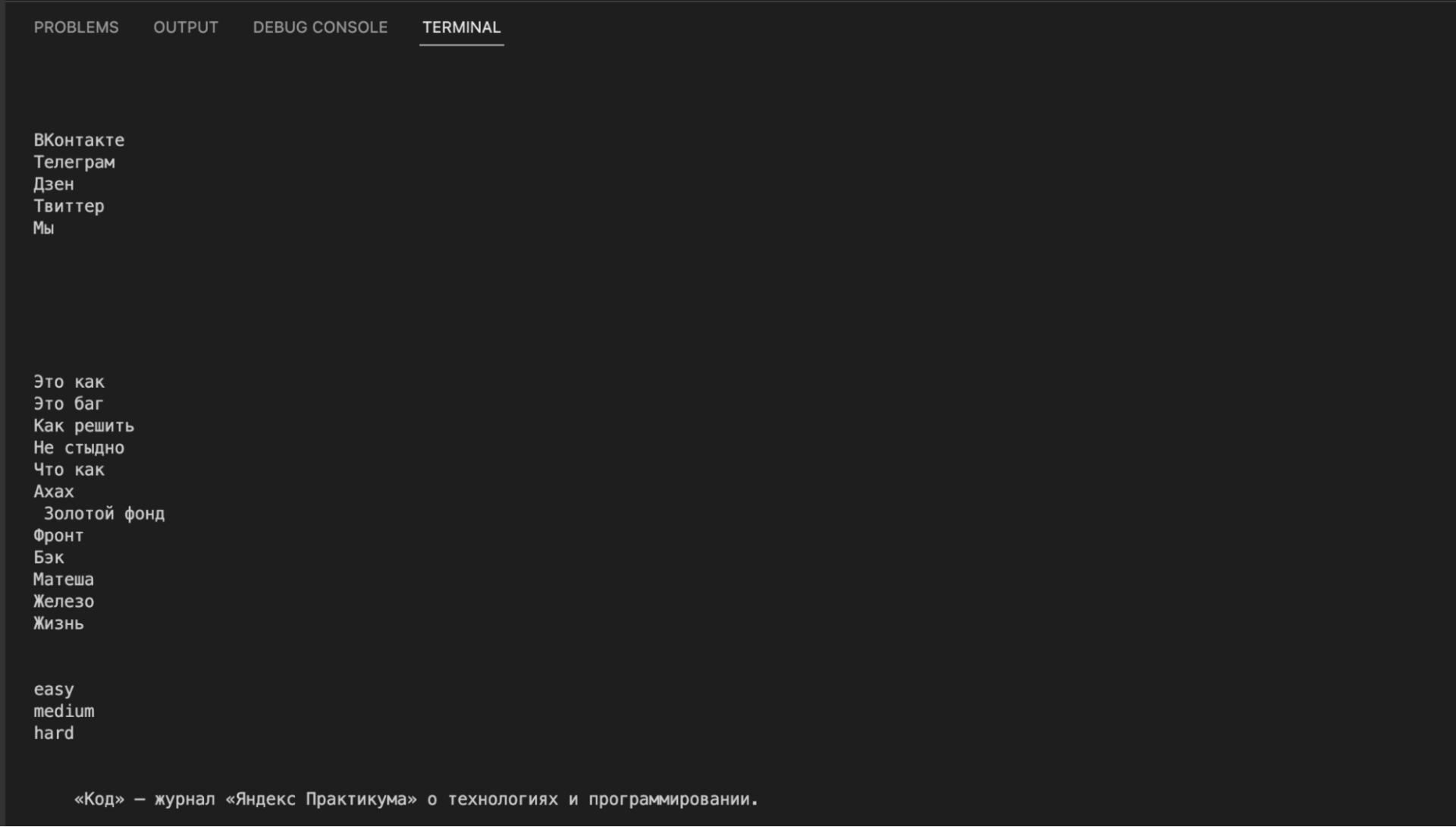
# подключаем urlopen из модуля urllib from urllib.request import urlopen # подключаем библиотеку BeautifulSoup from bs4 import BeautifulSoup # получаем исходный код страницы inner_html_code = str(urlopen('https://thecode.media/parsing/').read(),'utf-8') # отправляем исходный код страницы на обработку в библиотеку inner_soup = BeautifulSoup(inner_html_code, "html.parser") # выводим содержимое страницы print(inner_soup.get_text())Если посмотреть на результат, то видно, что в вывод пошло всё: и программный код из примеров, и текст статьи, и служебные плашки, и баннер, и ссылки с рекомендациями. Такой мусорный текст не годится для дальнейшего анализа:
Чистим текст
Так как нам требуется только сама статья, найдём раздел, в котором она лежит. Для этого посмотрим исходный код страницы, нажав Ctrl+U или ⌘+⌥+U. Видно, что содержимое статьи лежит в блоке , причём такой блок на странице один.

Чтобы из всего исходного кода оставить только этот блок, используем команду find() с параметром ‘div’, — она найдёт нужный нам блок, у которого есть характерный признак класса.
Добавим эту команду перед выводом текста на экран:
# оставляем только блок с содержимым статьи
inner_soup = inner_soup.find(‘div’, )
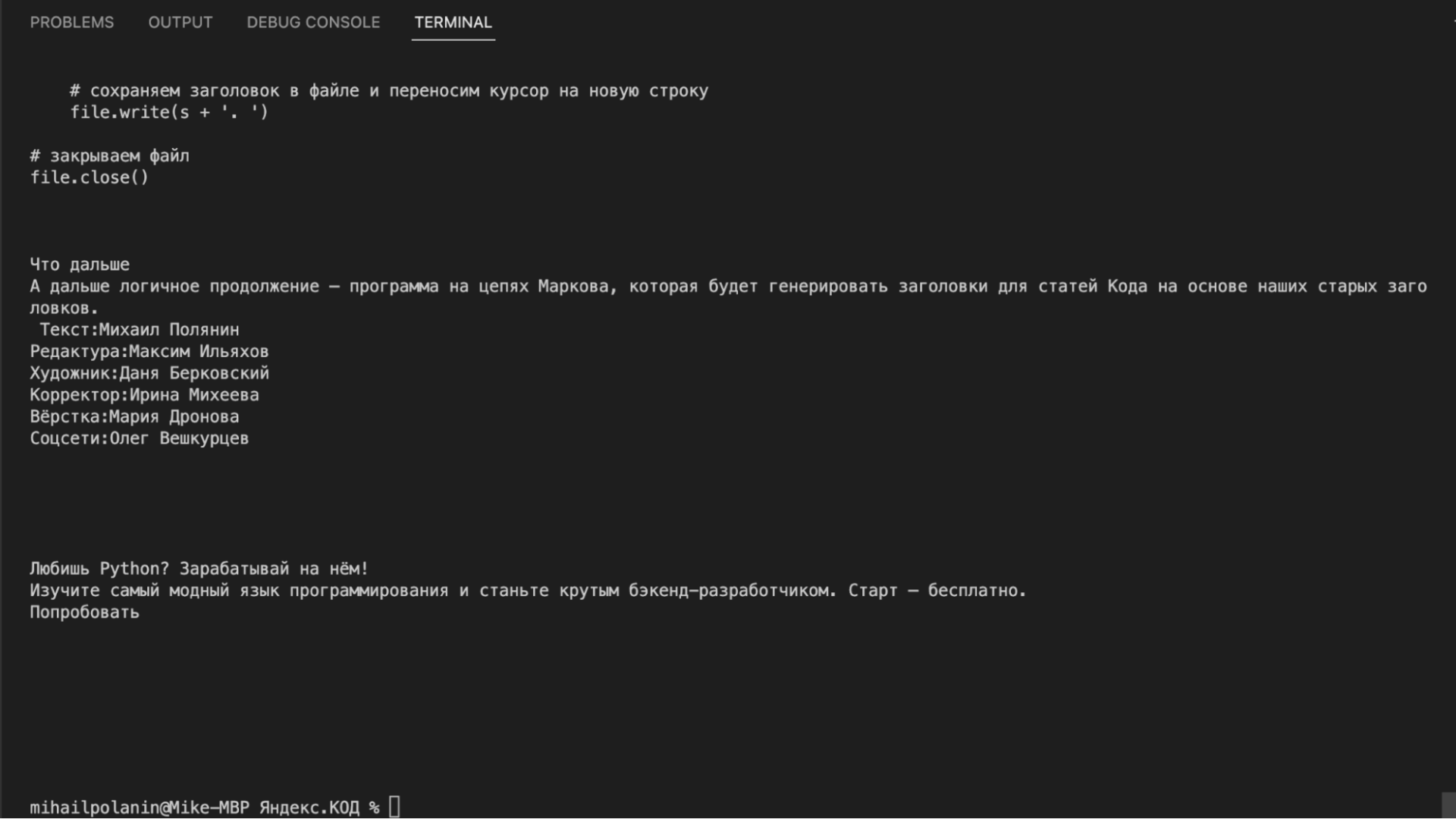
Стало лучше: нет мусора до и после статьи, но в тексте всё ещё много лишнего — содержимое ката с кодом, преформатированный код ( вот такой ), вставки с кодом, титры и рекламный баннер.
Чтобы избавиться и от этого, нам нужно знать, в каких тегах или блоках это лежит. Для этого нам снова понадобится заглянуть в исходный код страницы. Логика будет такая: находим фрагмент текста → смотрим код, который за него отвечает, → удаляем этот код из нашей переменной.Например, если мы хотим убрать титры, то находим блок, где они лежат, а потом в цикле удаляем его командой decompose() .

Сделаем функцию, которая очистит наш код от любых разделов и тегов, которые мы укажем в качестве параметра:
# очищаем код от выбранных элементов def delete_div(code,tag,arg): # находим все указанные теги с параметрами for div in code.find_all(tag, arg): # и удаляем их из кода div.decompose()А теперь добавим такой код перед выводом содержимого:
# удаляем титры delete_div(inner_soup, "div", )
Точно так же проанализируем исходный код и добавим циклы для удаления остального мусора:
# удаляем боковые ссылки delete_div(inner_soup, "div", ) # удаляем баннеры, перебирая все их возможные индексы в цикле (потому что баннеры в коде имеют номера от 1 до 99) for i in range(99): delete_div(inner_soup, "div", ) # удаляем кат delete_div(inner_soup, "div", ) # удаляем преформатированный код delete_div(inner_soup, 'pre','') # удаляем вставки с кодом delete_div(inner_soup,'code','')Теперь всё в порядке: у нас есть только текст статьи, без внешнего обвеса, лишнего кода и ссылок. Можно переходить к массовой обработке.
Собираем функцию
У нас есть скрипт, который берёт одну конкретную ссылку, идёт по ней, чистит контент и получает очищенный текст. Сделаем из этого функцию — на вход она будет получать адрес страницы, а на выходе будет давать обработанный и очищенный текст. Это нам пригодится на следующем шаге, когда будем обрабатывать сразу много ссылок.
Если запустить этот скрипт, получим тот же результат, что и в предыдущем разделе.
# подключаем urlopen из модуля urllib from urllib.request import urlopen # подключаем библиотеку BeautifulSout from bs4 import BeautifulSoup # очищаем код от выбранных элементов def delete_div(code,tag,arg): # находим все указанные теги с параметрами for div in code.find_all(tag, arg): # и удаляем их из кода div.decompose() # очищаем текст по указанному адресу def clear_text(url): # получаем исходный код страницы inner_html_code = str(urlopen(url).read(),'utf-8') # отправляем исходный код страницы на обработку в библиотеку inner_soup = BeautifulSoup(inner_html_code, "html.parser") # оставляем только блок с содержимым статьи inner_soup = inner_soup.find('div', ) # удаляем титры delete_div(inner_soup, "div", ) # удаляем боковые ссылки delete_div(inner_soup, "div", ) # удаляем баннеры for i in range(11): delete_div(inner_soup, "div", ) # удаляем кат delete_div(inner_soup, "div", ) # удаляем преформатированный код delete_div(inner_soup, 'pre','') # удаляем вставки с кодом delete_div(inner_soup,'code','') # возвращаем содержимое страницы return(inner_soup.get_text()) print(clear_text('https://thecode.media/parsing/'))Получаем адреса всех страниц
Одна из самых сложных вещей в парсинге — получить список адресов всех нужных страниц. Для этого можно использовать:
- карту сайта,
- внутренние рубрикаторы,
- разделы на сайте,
- готовые страницы со всеми ссылками.
В нашем случае мы воспользуемся готовой страницей — там собраны все статьи с разбивкой по рубрикам: https://thecode.media/all. Но даже в этом случае нам нужно написать код, который обработает эту страницу и заберёт оттуда только адреса статей. Ещё нужно предусмотреть, что нам не нужны ссылки из новостей и задач.
Идём в исходный код общей страницы и видим, что все ссылки лежат внутри списка:

При этом каждая категория статей лежит в своём разделе — именно это мы и будем использовать, чтобы обработать только нужные нам категории. Например, вот как рубрика «Ахах» выглядит на странице:
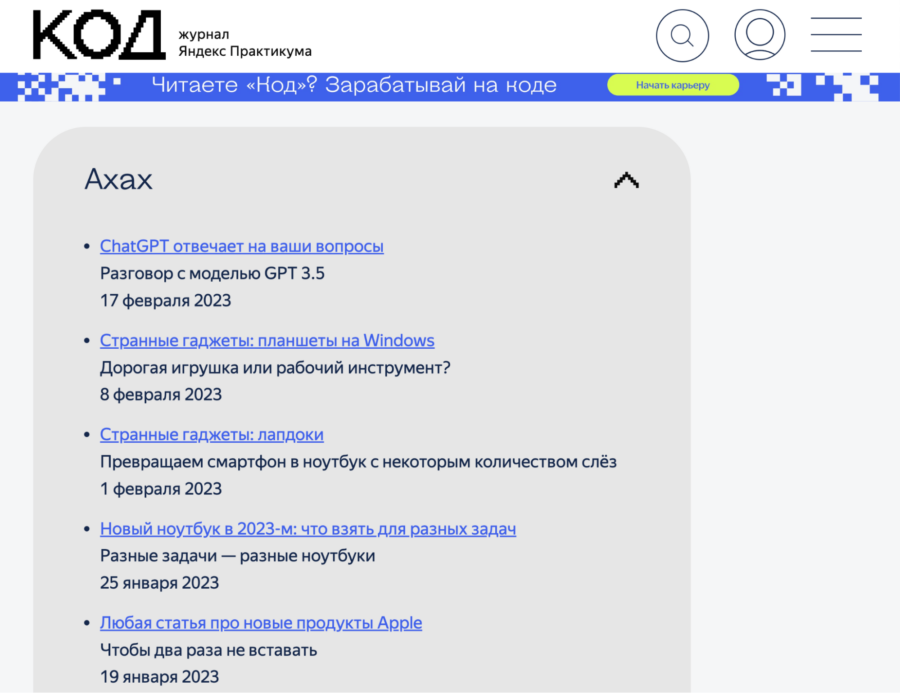
А вот она же — но в исходном коде. По названию легко понять, какой блок за неё отвечает:
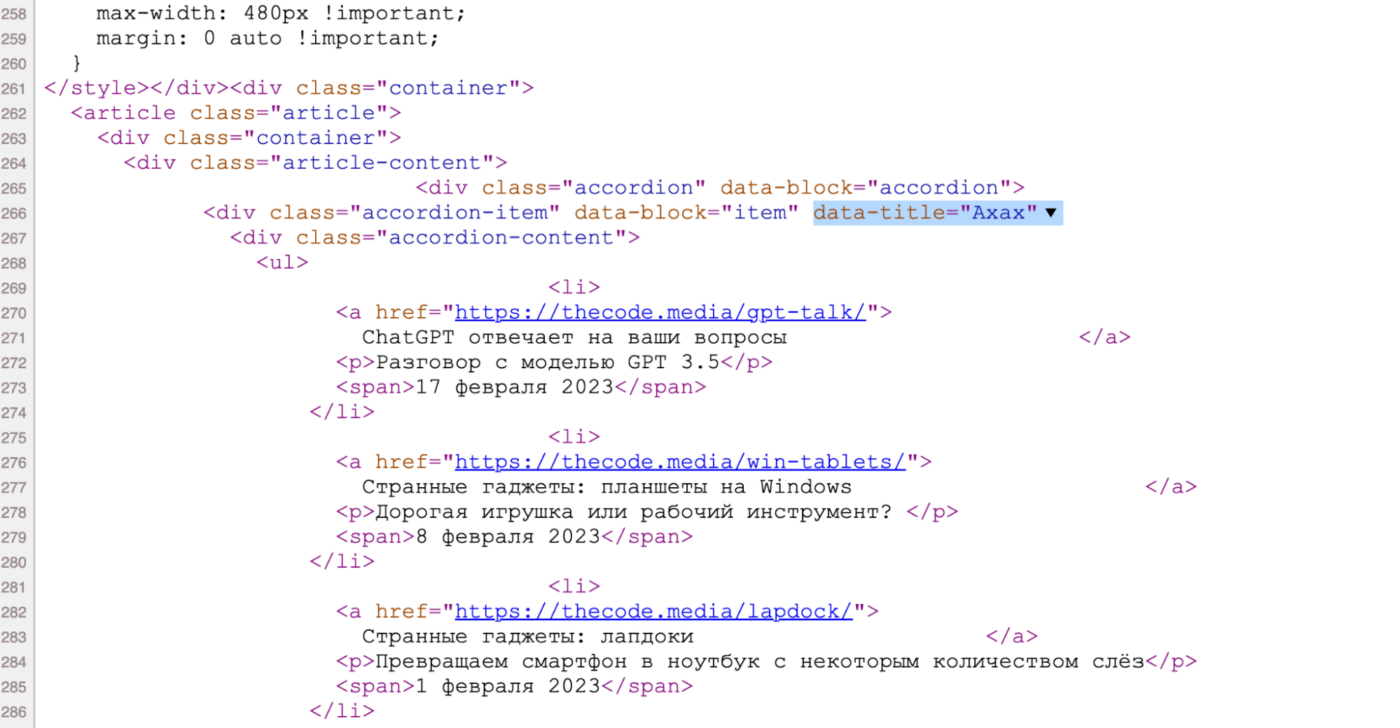
Чтобы найти раздел в коде по атрибуту, используем команду find() с параметром attrs — в нём мы укажем название рубрики. А чтобы найти адрес в ссылке — используем команду select(), в которой укажем, что ссылка должна лежать внутри элемента списка.
Теперь логика будет такая:
- Создаём список с названиями нужных нам рубрик.
- Делаем функцию, куда будем передавать эти названия.
- Внутри функции находим рубрику по атрибуту.
- Перебираем все элементы списка со ссылками.
- Находим там адреса и записываем в переменную.
- Для проверки — выводим переменную с адресами на экран.
def get_all_url(data_title): html_code = str(urlopen('https://thecode.media/all').read(),'utf-8') soup = BeautifulSoup(html_code, "html.parser") # находим рубрику по атрибуту s = soup.find(attrs=) # тут будут все найденные адреса url = [] # перебираем все теги ссылок, которые есть в списке for tag in s.select("li:has(a)"): # добавляем адрес ссылки в нашу общую переменную url.append(tag.find("a")["href"]) # выводим найденные адреса print(url) # названия рубрик, которые нам нужны division = ['Ахах','Не стыдно','Это баг','Это как'] # перебираем все рубрики for el in division: # и обрабатываем каждую рубрику отдельно get_all_url(el)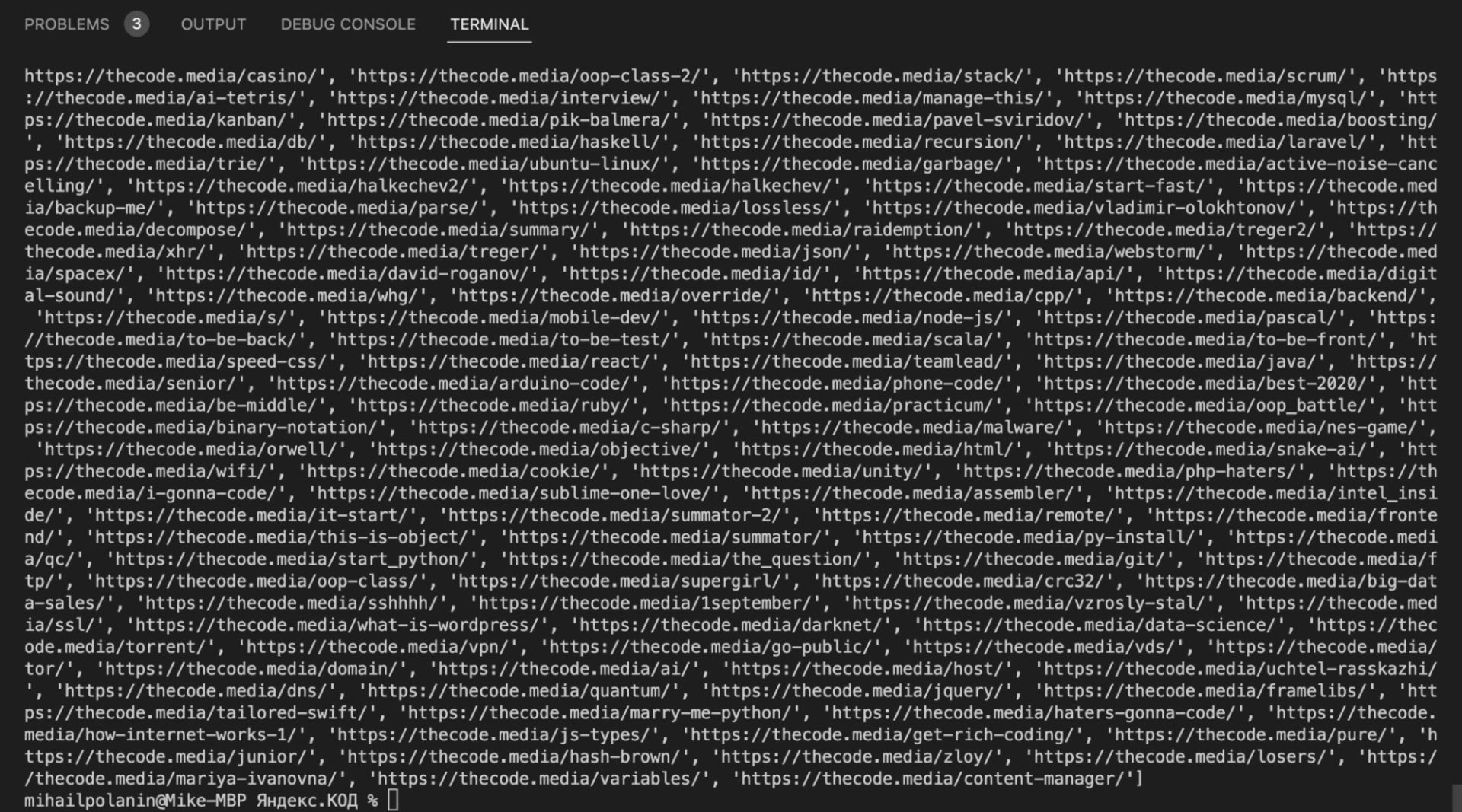
На выходе у нас все адреса страниц из нужных рубрик. Теперь объединим обе функции и научим их сохранять текст в файл.
Сохраняем текст в файл
Единственное, чего нам сейчас не хватает, — это сохранения в файл. Чтобы каждая рубрика хранилась в своём файле, привяжем имя файла к названию рубрики. Дальше логика будет такая:
- Берём функцию get_all_url(), которая формирует список всех адресов для каждой рубрики.
- В конец этой функции добавляем команду создания файла с нужным названием.
- Открываем файл для записи.
- Перебираем в цикле все найденные адреса и тут же отправляем каждый адрес в функцию clear_text().
- Результат работы этой функции — готовый контент — записываем в файл и переходим к следующему.
Так у нас за один прогон сформируются адреса, и мы получим содержимое страницы, которые сразу запишем в файл. Читайте комментарии, чтобы разобраться в коде:
# подключаем urlopen из модуля urllib from urllib.request import urlopen # подключаем библиотеку BeautifulSout from bs4 import BeautifulSoup # очищаем код от выбранных элементов def delete_div(code,tag,arg): # находим все указанные теги с параметрами for div in code.find_all(tag, arg): # и удаляем их из кода div.decompose() # очищаем текст по указанному адресу def clear_text(url): # получаем исходный код страницы inner_html_code = str(urlopen(url).read(),'utf-8') # отправляем исходный код страницы на обработку в библиотеку inner_soup = BeautifulSoup(inner_html_code, "html.parser") # оставляем только блок с содержимым статьи inner_soup = inner_soup.find('div', ) # удаляем титры delete_div(inner_soup, "div", ) # удаляем боковые ссылки delete_div(inner_soup, "div", ) # удаляем баннеры for i in range(11): delete_div(inner_soup, "div", ) # удаляем кат delete_div(inner_soup, "div", ) # удаляем преформатированный код delete_div(inner_soup, 'pre','') # удаляем вставки с кодом delete_div(inner_soup,'code','') # возвращаем содержимое страницы return(inner_soup.get_text()) # формируем список адресов для указанной рубрики def get_all_url(data_title): # считываем страницу со всеми адресами html_code = str(urlopen('https://thecode.media/all').read(),'utf-8') # отправляем исходный код страницы на обработку в библиотеку soup = BeautifulSoup(html_code, "html.parser") # находим рубрику по атрибуту s = soup.find(attrs=) # тут будут все найденные адреса url = [] # перебираем все теги ссылок, которые есть в списке for tag in s.select("li:has(a)"): # добавляем адрес ссылки в нашу общую переменную url.append(tag.find("a")["href"]) # имя файла для содержимого каждой рубрики content_file_name = data_title + '_content.txt' # открываем файл и стираем всё, что там было file = open(content_file_name, "w") # перебираем все адреса из списка for x in url: # сохраняем обработанный текст в файле и переносим курсор на новую строку file.write(clear_text(x) + '\n') # закрываем файл file.close() # названия рубрик, которые нам нужны division = ['Ахах','Не стыдно','Это баг','Это как'] # перебираем все рубрики for el in division: # и обрабатываем каждую рубрику отдельно get_all_url(el)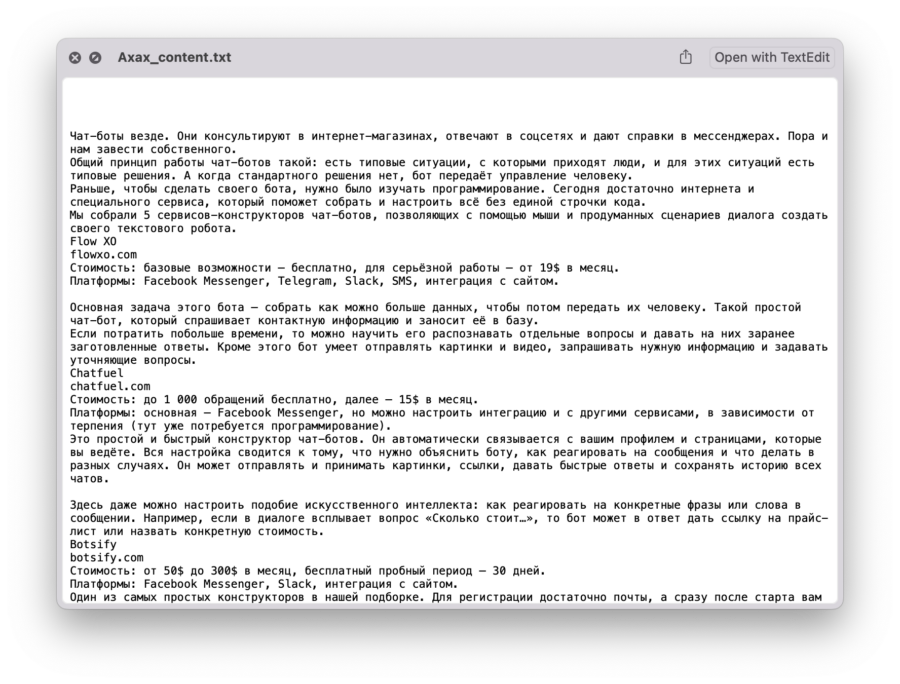
Что дальше
Теперь у нас есть все тексты всех статей. Как-нибудь проанализируем частотность слов в них (как в проекте с текстами Льва Толстого) или научим нейросеть писать новые статьи на основе старых.
Как написать парсер сайта на Python
В этой статье мы рассмотрим, как создать базовый парсер сайта на Python, используя библиотеки BeautifulSoup и requests. Он сможет спарсить информацию со страниц сайта и сохранять ее для последующего анализа.
Что такое веб-парсинг?
Парсинг — это процесс извлечения данных из веб-страниц. Эти данные могут включать любую информацию, доступную на веб-странице: текст, ссылки, изображения, метаданные и т.д. Веб-парсеры используются для различных задач, включая мониторинг цен, анализ социальных медиа, веб-майнинг, веб-аналитику и т.д.
Необходимые инструменты
Для начала, нам необходимо установить две библиотеки Python: requests и beautifulsoup4 . Это можно сделать при помощи pip :
pip install requests beautifulsoup4
Requests — это библиотека Python, что позволяет нам выполнять HTTP-запросы, а BeautifulSoup — мощная библиотека для парсинга HTML и XML документов.
Начало работы
Для демонстрации мы напишем простой веб-парсер, который соберет заголовки статей с главной страницы блога на условном домене example.com. Первым шагом будет получение HTML-кода страницы. Мы воспользуемся для этого библиотекой requests :
import requests url = 'https://example.com/blog/' response = requests.get(url)
Если все прошло гладко, response.text теперь содержит HTML-код главной страницы блога.
Парсинг HTML
Теперь, когда у нас есть HTML-код страницы, мы можем воспользоваться BeautifulSoup для его парсинга:
from bs4 import BeautifulSoup soup = BeautifulSoup(response.text, 'html.parser')
BeautifulSoup преобразует HTML-строку в объект, с которым легко работать, предоставляя различные методы для навигации и поиска в HTML-структуре.
Поиск данных
С помощью BeautifulSoup мы можем использовать CSS-селекторы для поиска элементов на странице. Например, давайте найдем все заголовки статей на странице. Просмотрев код страницы, мы видим, что заголовки находятся в тегах , которые имеют класс blog-title .
titles = soup.select('h2.blog-title')
select возвращает список всех найденных элементов. Если нам нужен только первый найденный элемент, мы можем использовать метод select_one .
Извлечение данных
Теперь, когда мы нашли наши заголовки, мы можем вытянуть из них текст:
for title in titles: print(title.get_text())
Используя метод get_text() , мы можем получить весь текст, который находится внутри элемента, включая все его дочерние элементы.
Сохранение данных
Последний шаг — это сохранение собранных данных. Мы можем сохранить их в файл, базу данных или любое другое место в зависимости от наших потребностей. Для простоты давайте сохраним их в текстовый файл:
with open('titles.txt', 'w') as f: for title in titles: f.write(title.get_text() + '\n')
Теперь у нас есть простой парсер, который собирает заголовки с сайта и сохраняет их в текстовый файл.
Итоги
В этой статье мы рассмотрели основы написания веб-парсера на Python с использованием библиотек requests и BeautifulSoup . Это базовый пример, но принципы, которые мы здесь использовали, могут быть применены для написания намного более сложных веб-парсеров. Благодаря Python и его прекрасным библиотекам, парсинг становится простым и доступным инструментом для сбора данных из Интернета.
Если вы хотите расширить свои знания и навыки в написании парсеров на Python, вот несколько рекомендаций:
- Изучить больше о CSS селекторах и их использовании в BeautifulSoup для поиска нужных элементов.
- Ознакомиться с различными методами для навигации по DOM-структуре, такими как .parent, .children, .next_sibling и другие.
- Рассмотреть использование других библиотек Python для веб-парсинга, таких как lxml, html5lib или PyQuery.
- Исследовать возможности использования веб-парсеров для автоматического заполнения форм, работы с авторизацией на сайтах и обхода защиты от парсинга (например, CAPTCHA).
Кроме того, при написании веб-парсеров важно учитывать этические аспекты и соблюдать правила использования веб-сайтов. Проверяйте, разрешен ли парсинг и уважайте ограничения на частоту запросов.
С опытом и соблюдением лучших практик, написание парсеров на Python станет неотъемлемой частью вашего набора навыков, которая поможет вам собирать и анализировать данные из Интернета для различных целей.
Освоить профессию python разработчика вы можете на нашем курсе Python с трудоустройством.