HTTP сервер за 15 минут
За минимальное время написать HTTP сервер, который после запуска сможет корректно ответить браузеру и отдать простую HTML страничку (минимальное время, чтобы кода было мало, чтобы новичку вникать было проще).
У меня это заняло около 15 минут. Сервер вроде справляется с поставленной задачей.
Суть примера — показать что такое Socket, ServerSocket, InputStream, OutputStream, и Thread.
Решение
import java.net.ServerSocket; import java.net.Socket; import java.io.InputStream; import java.io.OutputStream; import java.io.InputStreamReader; import java.io.BufferedReader; /** * Created by yar 09.09.2009 */ public class HttpServer < public static void main(String[] args) throws Throwable < ServerSocket ss = new ServerSocket(8080); while (true) < Socket s = ss.accept(); System.err.println("Client accepted"); new Thread(new SocketProcessor(s)).start(); >> private static class SocketProcessor implements Runnable < private Socket s; private InputStream is; private OutputStream os; private SocketProcessor(Socket s) throws Throwable < this.s = s; this.is = s.getInputStream(); this.os = s.getOutputStream(); >public void run() < try < readInputHeaders(); writeResponse("Hello from Habrahabr
"); > catch (Throwable t) < /*do nothing*/ >finally < try < s.close(); >catch (Throwable t) < /*do nothing*/ >> System.err.println("Client processing finished"); > private void writeResponse(String s) throws Throwable < String response = "HTTP/1.1 200 OK\r\n" + "Server: YarServer/2009-09-09\r\n" + "Content-Type: text/html\r\n" + "Content-Length: " + s.length() + "\r\n" + "Connection: close\r\n\r\n"; String result = response + s; os.write(result.getBytes()); os.flush(); >private void readInputHeaders() throws Throwable < BufferedReader br = new BufferedReader(new InputStreamReader(is)); while(true) < String s = br.readLine(); if(s == null || s.trim().length() == 0) < break; >> > > >
Сервер
Для работы с сервером и протоколом http в Node.js используется модуль http.
Чтобы создать сервер, следует вызвать метод http.createServer() :
const http = require("http"); const server = http.createServer();
Метод createServer() возвращает объект http.Server . Для обработки подключений в метод createServer передается функция-обработчик:
const http = require("http"); const server = http.createServer(function(request, response)< response.end("Hello METANIT.COM!"); >);
Эта функция принимает два параметра:
- request : хранит информацию о запросе
- response : управляет отправкой ответа
В примере выше с помощью метода response.end() в ответ клиенту посылается строка «Hello METANIT.COM!».
Но чтобы сервер мог прослушивать и обрабатывать входящие подключения, у объекта сервера необходимо вызвать метод listen() . Данный метод может принимать различный набор параметров. Но обычно в качестве первого параметра передается номер порта, по которому запускается сервер.
const http = require("http"); const server = http.createServer(function(request, response)< response.end("Hello METANIT.COM!"); >); server.listen(3000);
В данном случае сервер запускается по адресу 3000. Также дополнительно можно передать в метод listen функцию, которая будет срабатывать при запуске сервера:
const http = require("http"); const server = http.createServer(function(request, response)< response.end("Hello METANIT.COM!"); >); server.listen(3000, function()< console.log("Сервер запущен по адресу http://localhost:3000")>);
Например, запустим приложение, и после успешного запуска мы увидим на консоли соответствующее сообщение:
c:\app> node app.js Сервер запущен по адресу http://localhost:3000
Поскольку сервер запущен на порту 3000, то мы можем обратиться к нашему приложению в браузере по адресу http://localhost: 3000
Request
Параметр request позволяет получить информацию о запросе и представляет объект http.IncomingMessage . Отметим некоторые основные свойства этого объекта:
- headers : возвращает заголовки запроса
- method : тип запроса (GET, POST, DELETE, PUT)
- url : представляет запрошенный адрес
Например, определим следующий файл app.js:
const http = require("http"); http.createServer(function(request, response)< console.log("Url:", request.url); console.log("Тип запроса:", request.method); console.log("User-Agent:", request.headers["user-agent"]); console.log("Все заголовки"); console.log(request.headers); response.end(); >).listen(3000, function()< console.log("Сервер запущен по адресу http://localhost:3000")>);
Запустим его и обратимся в браузере по адресу http://localhost:3000/ , и консоль выведет нам информацию о запросе:
c:\app> Сервер запущен по адресу http://localhost:3000 Url: / Тип запроса: GET User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Все заголовки < host: 'localhost:3000', connection: 'keep-alive', 'sec-ch-ua': '"Google Chrome";v="119", "Chromium";v="119", "Not?A_Brand";v="24"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"macOS"', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36', 'sec-purpose': 'prefetch;prerender', purpose: 'prefetch', accept: 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7', 'sec-fetch-site': 'none', 'sec-fetch-mode': 'navigate', 'sec-fetch-user': '?1', 'sec-fetch-dest': 'document', 'accept-encoding': 'gzip, deflate, br', 'accept-language': 'ru-RU,ru;q=0.9,en-US;q=0.8,en;q=0.7,fr;q=0.6,de;q=0.5,tr;q=0.4,zh-CN;q=0.3,zh;q=0.2,bg;q=0.1' >
Response
Параметр response управляет отправкой ответа и представляет объект http.ServerResponse . Среди его функциональности можно выделить следующие методы:
- statusCode : устанавливает статусный код ответа
- statusMessage : устанавливает сообщение, отправляемое вместе со статусным кодом
- setHeader(name, value) : добавляет в ответ один заголовок
- write : пишет в поток ответа некоторое содержимое
- writeHead : добавляет в ответ статусный код и набор заголовков
- end : сигнализирует серверу, что заголовки и тело ответа установлены, в итоге ответ отсылается клиента. Данный метод должен вызываться в каждом запросе.
В общем случае для отправки ответа достаточно вызвать метод end() , в который передаются отправляемые данные:
response.end("Hello METANIT.COM!");
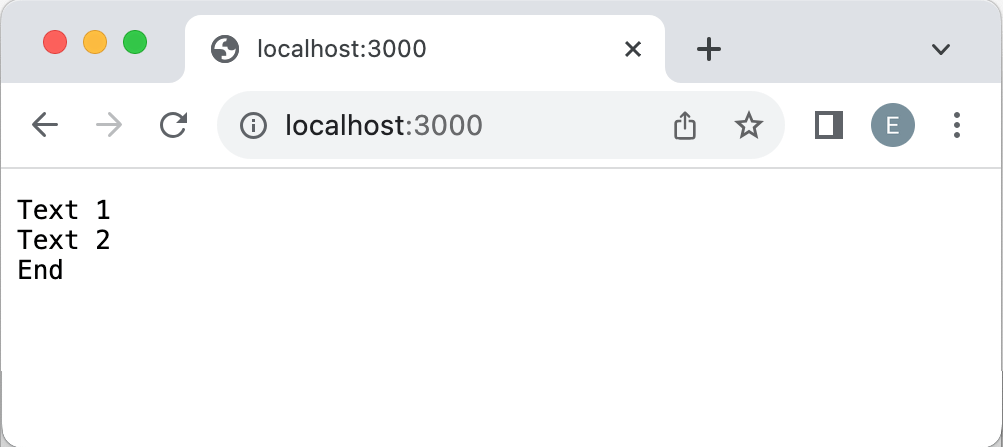
С помощью метода write() можно кусками добавить данные в ответ. Например, изменим файл app.js следующим образом:
const http = require("http"); http.createServer(function(request, response)< response.write("Text 1\n"); response.write("Text 2\n"); response.end("End"); >).listen(3000, function()< console.log("Сервер запущен по адресу http://localhost:3000")>);
Запустим файл и обратимся в браузере к приложению:
Можно через end() ничего не добавлять в ответ, но в любом случае этот метод следует вызывать при отправке ответа:
const http = require("http"); http.createServer(function(_, response)< response.write("Text 1\n"); response.write("Text 2\n"); response.end(); >).listen(3000, function()< console.log("Сервер запущен по адресу http://localhost:3000")>);
Отправка заголовков
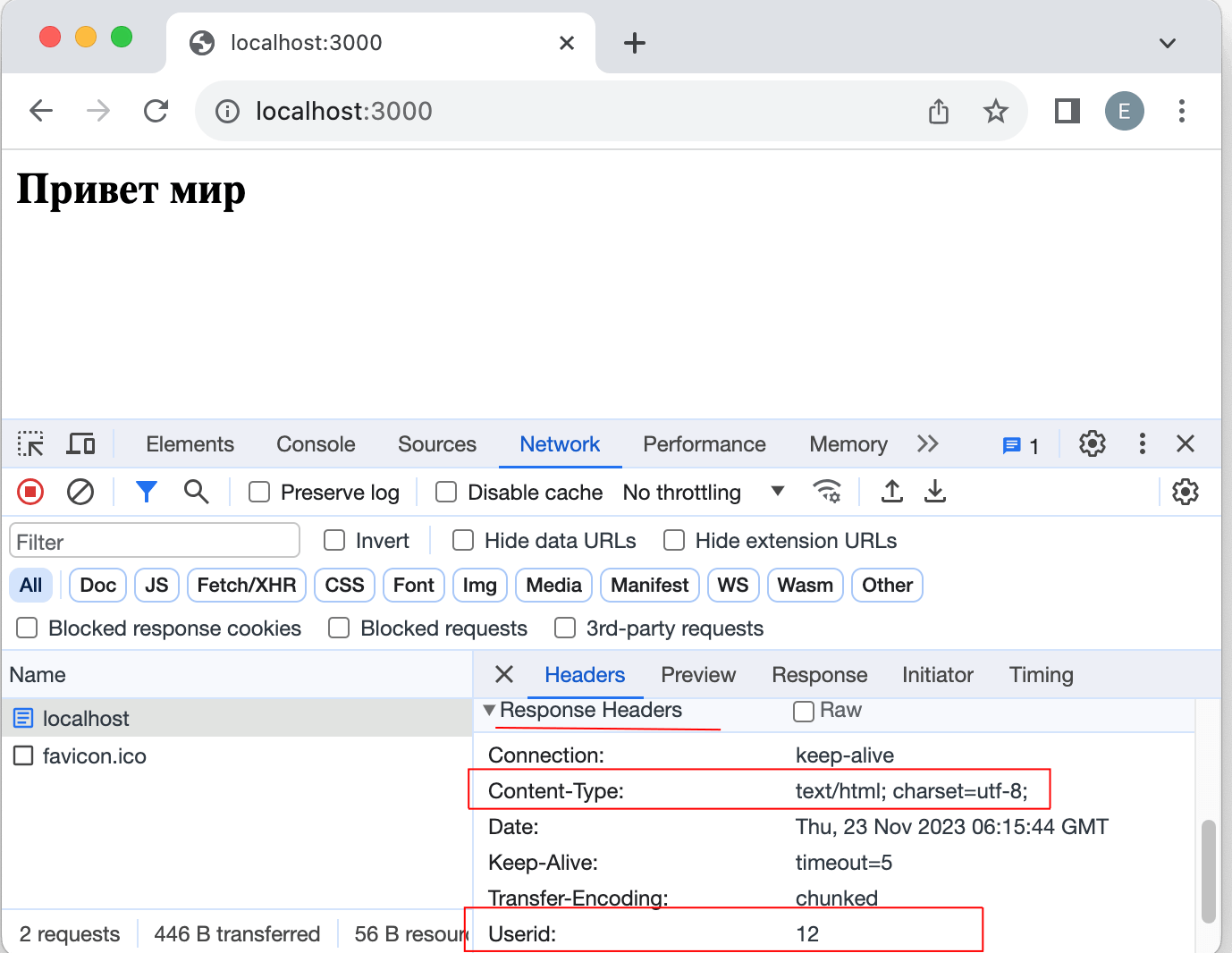
Метод setHeader() позволяет установить заголовки ответа:
const http = require("http"); http.createServer(function(_, response)< response.setHeader("UserId", 12); // установка кастомного заголовка response.setHeader("Content-Type", "text/html; charset=utf-8;"); response.write("Привет мир
"); response.end(); >).listen(3000, function()< console.log("Сервер запущен по адресу http://localhost:3000")>);
В данном случае для теста устанавливаем кастомный заголовок «UserId», пусть он равен 12. А чтобы отправляемый ответ интерпретировался браузером как код html, для заголовка «Content-Type» устанавливаем значение «text/html; charset=utf-8;». Результат работы:
Маршрутизация
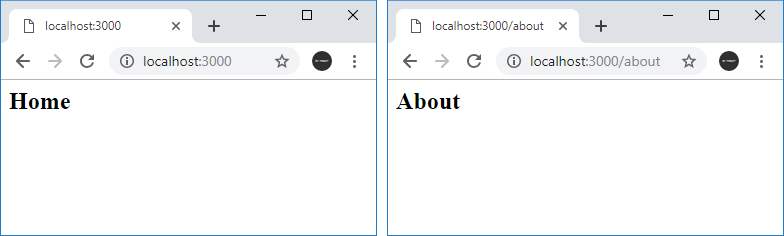
По умолчанию Node.js не имеет встроенной системы маршрутизации. Обычно она реализуется с помощью специальных фреймворков типа Express, о котором речь пойдет в следующей главе. Однако если необходимо разграничить простейшую обработку пары-тройки маршрутов, то вполне можно использовать для этого свойство url объекта Request. Например:
const http = require("http"); http.createServer(function(request, response)< response.setHeader("Content-Type", "text/html; charset=utf-8;"); if(request.url === "/home" || request.url === "/")< response.write("Home
"); > else if(request.url == "/about")< response.write("About
"); > else if(request.url == "/contact")< response.write("Contacts
"); > else< response.write("Not found
"); > response.end(); >).listen(3000);
В данном случае обрабатываются три маршрута. Если идет обрашение к корню сайта или по адресу localhost:3000/home , то пользователю выводится строка «Home». Ели обращение идет по адресу localhost:3000/about , то пользователю в браузере отображается строка About и так далее. Если запрошенный адрес не соответствует ни одному маршруту, то выводится заговлок «Not Found».
Однако опять же отмечу, что рамках специальных фреймворков, которые работают поверх Node.js, например, Express, есть более удобные способы для обработки маршрутов, которые нередко и используются.
Переадресация
Переадресация предполагает отправку статусного кода 301 (постоянная переадресация) или 302 (временная переадресация) и заголовка Location , который указывает на новый адрес. Например, выполним переадресацию с адреса localhost:3000/ на адрес localhost:3000/newpage
const http = require("http"); http.createServer(function(request, response) < response.setHeader("Content-Type", "text/html; charset=utf-8;"); if(request.url === "/")< response.statusCode = 302; // временная переадресация // на адрес localhost:3000/newpage response.setHeader("Location", "/newpage"); >else if(request.url == "/newpage") < response.write("New address"); >else < response.statusCode = 404; // адрес не найден response.write("Not Found"); >response.end(); >).listen(3000);
Реализация сервера — JS: HTTP Server
Перед тем, как бросаться в омут и смотреть на реализацию бэкэнда, нам придётся поговорить о теоретической базе, скрывающейся за несколькими строчками кода. Небольшого введения должно хватить для старта, но в будущем нужно будет браться за соответствующие книги и углубляться в тему. Конечно же, это верно для тех, кто хочет стать хорошим разработчиком. Пугаться этих книжек не стоит, даже наоборот, после них вы можете почувствовать кураж, потому что огромное число вещей, которые для вас сейчас представляются черным ящиком, на поверку окажутся достаточно простыми концепциями с понятным устройством внутри.
Операционная система (ОС)
Основой основ для программиста можно считать ОС. Да, у нас есть еще железо и архитектуру ЭВМ никто не отменял, но прикладному разработчику достаточно иметь общее понимание того, как работает железо, а вот от ОС не уйти совсем.
Процесс
Базовой единицей исполнения в ОС является процесс. Каждый раз, когда вы запускаете какую-либо программу, то запускается минимум один процесс. Кстати, может быть и больше, отсюда следует что программа != процесс. Список запущенных процессов можно посмотреть так:
-xf PID TTY STAT TIME COMMAND 29 pts/1 S 0:00 bash 30 pts/1 S+ 0:00 \_ top 22 pts/0 S 0:00 bash 32 pts/0 R+ 0:00 \_ ps xf Каждая строчка на рисунке выше – это информация о каком-либо процессе. Как видно, ОС содержит в себе различную информацию о каждом из процессов. На текущий момент нас интересует только один параметр, который называется PID . PID, как ни странно, расшифровывается как process identifier и фактически представляет из себя целое число, однозначно определяющее то, о каком процессе идет речь.
Сети
Основным (высокоуровневым) способом коммуникации между машинами является семейство протоколов TCP/IP . Большинство людей, которые пользуются интернетом или сетями в целом так или иначе слышали выражение ip адрес . Этот адрес (для версии IPv4 ) может выглядеть так: 10.0.152.23 . Он указывает на какое-то устройство в сети, которое не обязательно представлено компьютером в привычном понимании этого слова.
Интерфейсы
По правде говоря, этот адрес связан даже не с самим устройством, а с конкретным интерфейсом устройства. Например, каждая сетевая карта будет представлена в системе как отдельный интерфейс. Кроме того, интерфейсы бывают виртуальными, то есть у них отсутствует физический элемент. Зачем это нужно? Самый тривиальный пример это так называемая обратная петля (loopback). Интерфейс, который присутствует по умолчанию в большинстве ОС. Любой трафик, посланный в этот интерфейс, тут же принимается им же.
Этот интерфейс позволяет обращаться к серверному приложению, расположенному на той же машине, без активного подключения к сети. Такая возможность особенно полезна для тестирования служб и их разработки. Адрес этого интерфейса всегда 127.0.0.1 . Так же к нему можно обращаться по имени localhost .
Domain Name System
DNS — система доменных имён, благодаря которой нам необходимо запоминать только буквенные имена сайтов без необходимости знать конкретный ip адрес машины, на которую надо пойти. Общий принцип работы довольно прост. Каждый раз, когда в браузер вводится имя сайта, он обращается к специальным серверам и спрашивает их: ‘Какой ip адрес у hexlet.io?’. Дальше происходит немного магии, и, в конце концов, эта система возвращает (если найдёт) этот адрес. Затем браузер устанавливает tcp соединение и начинает свою работу.
Порты
Когда происходит общение удаленных машин друг с другом по tcp , то в реальности между собой общаются процессы ОС, а не компьютеры в целом. Отсюда возникает вопрос: каким образом, зная только ip адрес, постучаться на чужую машину в интересующую нас программу. Конкретно в этом курсе нас интересует веб-сервер. Короткий ответ: никак. И действительно, одного ip адреса недостаточно.
В tcp существует такое понятие, как порт. Это целое число, означающее точку входа в процесс запущенной программы. То есть при получении данных по tcp ОС смотрит то, для какого порта они предназначены. Затем она находит процесс, соответствующий этому порту, и передает данные в него. Важным следствием этого подхода становится тот факт, что невозможно занять уже занятый порт. Иначе это ввело бы неоднозначность. И действительно, при старте сервера, который пытается слушать занятый другой программой порт, будет получена такая ошибка:
Мы можем даже посмотреть на того, кто занял этот порт:
-i :4000 COMMAND PID USER TYPE NODE NAME node 40726 mokevnin IPv6 TCP *:terabase (LISTEN) Суммируя вышесказанное, делаем вывод, что любое серверное приложение при старте должно начать слушать определенный порт для возможности получать данные по сети.
Если вернуться к браузеру, то может возникнуть вопрос: почему мы не указываем порт, когда загружаем сайты, откуда браузер знает, куда стучаться на сервер? Ответ на этот вопрос крайне прост: браузер действительно знает порт, на который нужно идти. И по умолчанию это порт с номером 80 .
Веб-сервер
Начнём с иллюстрации:
// server.js import http from 'http'; const server = http.createServer((request, response) => // content-length формируется автоматически! response.write('hello, world!'); response.end(); >); const port = 4000; server.listen(port, () => console.log('Server has been started'); >); - Импортируется модуль http . Он встроен в node.js и позволяет создать веб-сервер (и не только).
- Создаётся веб-сервер. В функцию createServer передается обработчик запросов. Он будет вызываться на каждый входящий запрос.
- Сервер вешается на порт.
Обработки запроса в данном примере как таковой нет. Сервер будет отвечать по http фразой hello, world! на любой входящий запрос. Делается это с помощью объекта response , который представляет собой http-ответ. В примере выше мы используем две функции интерфейса response . Функцию write , которая позволяет передать текст в теле http ответа, и функцию end , которая означает, что мы закончили формирование ответа. Обратите внимание: нам не пришлось руками выставлять заголовок content-length , модуль http самостоятельно вычисляет размер тела и подставляет необходимый заголовок.
Для запуска нашего сервера необходимо набрать команду:
# blocking Запуск приводит к блокировке. Сервер запущен и работает. Чтобы его остановить, надо нажать комбинацию ctrl+c .
Теперь можно выполнить запрос к серверу:
Проделав данную процедуру, можно будет сказать, что вы запустили свой первый сайт на node.js 😉
Но дальше нас поджидает сюрприз. Если попробовать поменять код сервера, и писать в ответ my first web server , то без перезапуска сервера ничего не изменится. После того, как сервер запущен, он больше не перечитывает файлы с диска и не
Открыть доступ
Курсы программирования для новичков и опытных разработчиков. Начните обучение бесплатно
- 130 курсов, 2000+ часов теории
- 1000 практических заданий в браузере
- 360 000 студентов
Наши выпускники работают в компаниях:
Пишем свой веб-сервер на Python: протокол HTTP
Подпишись на обновления блогa, чтобы не пропустить следующий пост!
Оглавление
- Введение
- Задача HTTP-сервера
- Структура HTTP-сервера
- Пару слов о кодировке
- Стратегия разбора запроса
- Разбор request line
- Разбор заголовков запроса
- Обработка запроса
- Отправка ответа
- Чтение тела запроса
- Повторное использование TCP-соединений
- Заключение
- Ссылки по теме
Введение
На данный момент мы умеем отправлять и принимать данные по сети и организовывать обработку запросов на сервере. Настало время перейти на более высокий уровень — реализовать свой HTTP сервер.
Для начала определимся, что же такое HTTP. Hypertext Transfer Protocol (HTTP) — это протокол прикладного уровня, предназначенный для передачи гипертекстовых данных в распределенных информационных системах. Ух, сложнааа. А на самом деле нет. Давайте разбираться!
Протокол — это не более, чем соглашение между двумя или более участниками некоторого взаимодействия. Когда речь идет о сетевом взаимодействии, протоколы принято условно разделять на уровни. В самом низу находятся протоколы физического уровня, определяющие как данные передаются в физических средах, т.е. по проводам, оптоволокну, и т.п. Знакомые нам из первой части протоколы IP и TCP — это протоколы сетевого и транспортного уровня, соответственно. Они определяют более высокоуровневые детали взаимодействия, в частности, IP отвечает за адресацию компьютеров/узлов в сети, а TCP — за надежную передачу данных произвольной (т.е. в общем случае превышающей размер одного IP-пакета) длины между узлами. HTTP же располагается на самом высоком уровне — прикладном. От нижележащих протоколов HTTP ожидает гарантий надежности доставки данных, а сам концентрируется на определении понятий запросов и ответов (сообщений) и их семантике. Фактически, HTTP является основным протоколом передачи данных в вебе, а сами данные являются гипертекстом, зачастую представленным в формате HTML-страниц.

До версии HTTP/2, появившейся в 2015 году, HTTP был простым текстовым протоколом. Во второй версии протокол претерпел значительные доработки, стал эффективнее и приобрел новые возможности, но в то же время реализация клиентов и серверов усложнилась. На декабрь 2021 только 46.8% сайтов Интернет используют HTTP/2, но наблюдается устойчивый восходящий тренд.
В этой статье мы рассмотрим, как можно реализовать простейший HTTP-сервер на Python. Ради простоты, мы будем работать с версией протокола HTTP/1.1, а код сервера будет скорее служить образовательным целям, нежели являться полнофункциональным веб-сервером.
Задача HTTP-сервера
HTTP-сервер — это (в большинстве случаев) развитие идеи уже хорошо нам известного TCP-сервера. Задача HTTP-сервера — принимать входящие HTTP-запросы от клиентов, обрабатывать их и отправлять HTTP-ответы.
Простейший HTTP-запрос выглядит следующим образом:
GET / HTTP/1.1 Host: example.com То, что мы видим выше — это так называемое сообщение HTTP message. Опуская вопрос кодировки данных, сообщение HTTP/1.1 — это обычный текст, который состоит из строк, разделенных символами CRLF, т.е. \r\n . Первая строка запроса называется request line. Она определяет метод method, цель target и версию протокола. Далее идут заголовки запроса. В ранних версиях протокола секция заголовков могла отсутствовать полностью, но в HTTP/1.1 заголовок Host является обязательным.
Назначение вышеописанных элементов мы рассмотрим чуть позже, а сейчас перейдем к примеру HTTP-ответа:
HTTP/1.1 200 OK HTTP-ответы также представлены сообщениями. Первая строка ответа называется status line. Она состоит из версии, трехзначного кода статуса status-code и опционального текста причины.
Как и в случае с TCP-сервером, для того, чтобы начать обрабатывать HTTP-запросы, наш сервер должен создать слушающий (listening) сокет. На каждое входящее соединение, сервер должен прочитывать текст HTTP-запроса, вызывать соответствующий обработчик, и, получив от него ответ, отсылать данные клиенту. TCP-соединение может быть как завершено непосредственно после отправки ответа, так и сохранено для повторного использования клиентом.
Структура HTTP-сервера
Реализация полнофункционального HTTP/1.1-сервера требует учета всех требований протокола, определенных группой RFC (RFC7230 «Message Syntax and Routing», RFC7231 «Semantics and Content», RFC7232 «Conditional Requests», RFC7233 «Range Requests», RFC7234 «Caching», RFC7235 «Authentication»). Мы же скорее хотим сфокусироваться на самом подходе к реализации. Исходный код в этой статье не готов для боевого использования, и не гарантируется, что его логика строго следует спецификации протокола.
В качестве основы будущего HTTP-сервера мы будем использовать следующий класс:
# python3 import socket import sys class MyHTTPServer: def __init__(self, host, port, server_name): self._host = host self._port = port self._server_name = server_name def serve_forever(self): serv_sock = socket.socket( socket.AF_INET, socket.SOCK_STREAM, proto=0) try: serv_sock.bind((self._host, self._port)) serv_sock.listen() while True: conn, _ = serv_sock.accept() try: self.serve_client(conn) except Exception as e: print('Client serving failed', e) finally: serv_sock.close() def serve_client(self, conn): try: req = self.parse_request(conn) resp = self.handle_request(req) self.send_response(conn, resp) except ConnectionResetError: conn = None except Exception as e: self.send_error(conn, e) if conn: conn.close() def parse_request(self, conn): pass # TODO: implement me def handle_request(self, req): pass # TODO: implement me def send_response(self, conn, resp): pass # TODO: implement me def send_error(self, conn, err): pass # TODO: implement me if __name__ == '__main__': host = sys.argv[1] port = int(sys.argv[2]) name = sys.argv[3] serv = MyHTTPServer(host, port, name) try: serv.serve_forever() except KeyboardInterrupt: pass Код сервера максимально упрощен, чтобы иметь возможность сфокусироваться именно на работе с протоколом HTTP. Обработка запросов происходит синхронно, т.е. возможно обслуживать не более одного клиента в один момент времени. Сервер в бесконечном цикле осуществляет прием входящих соединений, выполняя serv_sock.accept() . Каждое соединение conn является клиентским сокетом. Прием очередного соединения инициирует обработку HTTP-запроса serve_client(conn) . Обработка же заключается в чтении и разборе aka синтаксическом анализе HTTP-запроса parse_request(conn) , непосредственно обработке handle_request(req) и отправке ответа send_response(conn, resp) . В случае же ошибки на любом из этапов, обработка заканчивается отправкой сообщения об ошибке send_error(conn, err) .
Запустить сервер можно, сохранив код в файле server.py и выполнив команду:
python3 server.py 127.0.0.1 53210 example.local Для отправки тестовых HTTP-запросов удобно пользоваться консольной утилитой netcat:
nc localhost 53210 > GET / HTTP/1.1 > Host: example.local > Пару слов о кодировке
В соответствии со спецификацией, одно сообщение HTTP может одновременно содержать данные, представленные в различных кодировках. В то же время, служебные данные, такие как request line, status line и заголовки должны быть преставлены некоторым надмножеством однобайтовой ASCII кодировки, определенном в стандарте ISO/IEC 8859-1. Почему существует такое требование становится очевидно при попытке реализации собственного HTTP-сервера. Как мы уже видели выше, HTTP-запрос — это обычный текст, а текст в компьютерном мире — это последовательность байт плюс дополнительное знание, в какой кодировке эти байты должны быть интерпретированы. Без знания кодировки в общем случае невозможно (и зачастую небезопасно) каким-либо образом интерпретировать текстовые данные, представленные последовательностью байт. Так как никакой предварительной фазы обмена информацией о кодировке в протоколе не предусмотрено, логичным решением является заранее договориться, что все данные по умолчанию передаются в одной и той же кодировке, и такой кодировкой была выбрана ASCII. В таком случае, у сервера всегда существует возможность произвести разбор запроса на составляющие, т.е. отделить request line от блока заголовков, а заголовки друг от друга.
Ограничение ASCII к счастью не распространяется на тело запроса. Имея возможность прочитать заголовки, из них возможно получить информацию о наличии, размере и кодировке тела запроса. Далее сервер должен прочитать заданное количество «сырых» байт из сокета и лишь потом декодировать их в строку с использованием договоренной кодировки (или кодировки по умолчанию).
Если же существует очень большое желании использовать не-ASCII символы в значениях заголовков, то проткол предлагает кодировать данные в MIME, хотя поддержка и использование этой возможности не является широко распространенной практикой.
Стратегия разбора запроса
Разбор запроса состоит из следующих шагов:
- Читаем первую строку, т.е. request line, разбираем ее на метод, цель и версию и сохраняем их в некоторую структуру данных.
- Читаем построчно заголовки, разбираем их на имя и значение и сохраняем в словаре (aka ассоциативном массиве) с именем заголовка в качестве ключа. Индикатором конца секции заголовков служит пустая строка.
- На основе метода и заголовков определяем, содержит ли запрос тело. Если да, поточно читаем байты из соединения до тех пор, пока прочитанное количество не равно ожидаемому размеру тела запроса. Техника чтения может отличаться в зависимости от типа запроса, подробнее см. секцию Чтение тела запроса.
Как было отмечено ранее, чтение строк должно осуществляться с использованием кодировки ISO/IEC 8859-1. Применение других кодировок возможно только к значениям элементов сообщения (т.е. к значениям заголовков или телу запроса).
Разбор request line
В качестве разминки выполним разбор request line, самой первой строки HTTP-запроса. Прежде всего, из соединения необходимо прочитать строку, т.е. последовательность байт, заканчивающуюся комбинацией \r\n . Простейший способ — это читать данные байт за байтом, сохраняя их в некотором буфере, пока не будет найдена необходимая комбинация:
class MyHTTPServer: def parse_request(self, conn): buf = '' while '\r\n' not in buf: byte = conn.recv(1) # возвращает тип bytes buf += str(byte, 'iso-8859-1') # . Однако, такой подход достаточно неэффективен, так как каждый вызов conn.recv() приводит к системному вызову, а значит имеет высокие накладные расходы. К счастью, благодаря широчайшим возможностям стандартной библиотеки Python, сокет предоставляет возможность создать вокруг него некоторую обертку, которая предоставляет file object интерфейс:
MAX_LINE = 64*1024 class MyHTTPServer: def parse_request(self, conn): rfile = conn.makefile('rb') raw = rfile.readline(MAX_LINE + 1) # эффективно читаем строку целиком if len(raw) > MAX_LINE: raise Exception('Request line is too long') req_line = str(raw, 'iso-8859-1') req_line = req_line.rstrip('\r\n') words = req_line.split() # разделяем по пробелу if len(words) != 3: # и ожидаем ровно 3 части raise Exception('Malformed request line') method, target, ver = words if ver != 'HTTP/1.1': raise Exception('Unexpected HTTP version') return Request(method, target, ver, rfile) class Request: def __init__(self, method, target, version, rfile): self.method = method self.target = target self.version = version self.rfile = rfile Так как мы фокусируемся только на версии HTTP/1.1, код разбора получился достаточно коротким и простым. Все, что мы сделали — это прочитали строку из соединения и разбили ее по пробелу на составляющие — метод, цель и версию, сохранив их в структуре Request.
Разбор заголовков запроса
Перейдем к следующему шагу — разбору HTTP-заголовков. Запрос с заголовками выглядит следующим образом:
GET /foo/bar HTTP/1.1 Host: example.local Accept: text/html User-Agent: Mozilla/5.0 # пустая строка выше - индикатор конца блока заголовков Таким образом, необходимо читать строку за строкой, до тех пор, пока не будет встречена первая пустая строка. Выполним небольшой рефакторинг кода нашего сервера, выделив разбор request line и разбор заголовков в отдельные методы:
MAX_HEADERS = 100 class MyHTTPServer: def parse_request(self, conn): rfile = conn.makefile('rb') method, target, ver = self.parse_request_line(rfile) headers = self.parse_headers(rfile) return Request(method, target, ver, headers, rfile) def parse_headers(self, rfile): headers = [] while True: line = rfile.readline(MAX_LINE + 1) if len(line) > MAX_LINE: raise Exception('Header line is too long') if line in (b'\r\n', b'\n', b''): # завершаем чтение заголовков break headers.append(line) if len(headers) > MAX_HEADERS: raise Exception('Too many headers') return headers def parse_request_line(self, rfile): pass # . В результате, мы получили список отдельных заголовков headers вида:
[b'Host: example.local\r\n', b'Accept: text/html\r\n', b'User-Agent: Mozilla/5.0\r\n'] В то же время, мы планировали сохранять заголовки HTTP-сообщений в ассоциативном массиве, где ключами бы являлись ключи заголовков (например, Host, Accept или User-Agent), а значениями — соответствующие значения полей. Одним из вариантов было бы продолжить разбор, разбивая каждый элемент списка по символу : и сохраняя левую часть в качестве ключа, а правую — в качестве значения в некотором dict:
def parse_headers(self, rfile): headers = [] # . read headers lines from rfile hdict = <> for h in headers: h = h.decode('iso-8859-1') k, v = h.split(':', 1) hdict[k] = v return hdict Однако, существует достаточно большое количество частных случаев, которые подход выше не учитывает. Например, в одном сообщении может быть несколько заголовков с одинаковым именем, т.е. в общем случае по ключу в hdict должен находиться скорее список, а не одна строка; значения заголовков могут быть представлены в MIME-кодировке; и пр.
К счастью, формат HTTP-сообщений, как и email-сообщений, следует спецификации Internet Message Format. Стандартная библиотека Python предоставляет модуль email, который в частности может быть использован для разбора HTTP-заголовков. Нам понадобится внести лишь минимальное изменение в метод parse_headers() , чтобы воспользоваться стандартным парсером:
from email.parser import Parser class MyHTTPServer: def parse_headers(self, rfile): headers = [] # . read headers lines from rfile sheaders = b''.join(headers).decode('iso-8859-1') return Parser().parsestr(sheaders) Возвращаемое значение метода Parser.parsestr() — это объект email.message.Message , который напоминает OrderedDict . Ключи в Message — это отсортированные в порядке появления ключи заголовков.
Последнее, что мы сделаем в рамках задачи разбора заголовков — это проверим наличие и соответствие заголовка Host:
class MyHTTPServer: def parse_request(self, conn): # . headers = self.parse_headers(rfile) host = headers.get('Host') if not host: raise Exception('Bad request') if host not in (self._server_name, f':'): raise Exception('Not found') return Request(method, target, ver, headers, rfile) # terminal 1 python3 server.py 127.0.0.1 53210 example.local # terminal 2 nc localhost 53210 > GET / HTTP/1.1 > Host: example.local # terminal 3 nc localhost 53210 > GET / HTTP/1.1 > Host: iximiuz.com Обработка запроса
Настало время заняться непосредственно обработкой HTTP-запросов, т.е. бизнес-логикой нашего сервера. Одной из традиционных задач, выполняемых HTTP-сервером, является отдача статического контента, т.е. файлов и директорий из некоторой корневой директории. Мы же опустим эту функцию и сфокусируемся на кастомной логике приложения.
Представим, что мы хотим создать сервис, который позволяет регистрировать пользователей, получать список ID зарегистрированных пользователей, а также информацию о каждом пользователе по его ID. Опишем API нашего сервиса:
# Создание нового пользователя POST /users?name=Vasya&age=42 # Получение списка пользователей GET /users # Получение профиля пользователя GET /users/123 Дополнительно, в зависимости от заголовка запроса Accept, сервер будет возвращать данные либо в формате HTML, либо JSON.
Прежде, чем приступать непосредственно к обработке, давайте расширим возможности класса Request, чтобы впоследствии код обработки получился чуть более высокоуровневым. Добавим полезные методы path и query , которые будут разбивать цель вида /users?name=Vasya&age=42 на /users и , соответственно:
from functools import lru_cache from urllib.parse import parse_qs, urlparse class Request: def __init__(self, method, target, version, headers, rfile): self.method = method self.target = target self.version = version self.headers = headers self.rfile = rfile @property def path(self): return self.url.path @property @lru_cache(maxsize=None) def query(self): return parse_qs(self.url.query) @property @lru_cache(maxsize=None) def url(self): return urlparse(self.target) Обработка запросов начинается в методе handle_request() . Сам метод занимается скорее диспетчеризацией запросов на основе метода и цели, чем непосредственно обработкой:
from urllib.parse import parse_qs class MyHTTPServer: def __init(self, *args): # . self._users = <> def handle_request(self, req): if req.path == '/users' and req.method == 'POST': return self.handle_post_users(req) if req.path == '/users' and req.method == 'GET': return self.handle_get_users(req) if req.path.startswith('/users/'): user_id = req.path[len('/users/'):] if user_id.isdigit(): return self.handle_get_user(req, user_id) raise Exception('Not found') def handle_post_users(self, req): pass def handle_get_users(self, req): pass def handle_get_user(self, req, user_id): pass Давайте посмотрим на метод создания пользователя handle_post_users() :
class MyHTTPServer: def handle_post_users(self, req): user_id = len(self._users) + 1 self._users[user_id] = return Response(204, 'Created') Все очень просто — на основании данных из запроса создаем новый объект пользователя и сохраняем его на сервере. Ответом на такой запрос является лишь строка статуса HTTP/1.1 204 Created\r\n . Класс Response можно определить следующим образом:
class Response: def __init__(self, status, reason, headers=None, body=None): self.status = status self.reason = reason self.headers = headers self.body = body Следующий функция нашего приложения — это возвращение списка зарегистрированных пользователей handle_get_users() . В данном случае нам понадобится полноценный ответ, содержащий в себе перечисление всех пользователей на сервере. А в качестве дополнительной возможности, наш сервер будет поддерживать два формата данных — text/html и application/json:
-
‘ for u in self._users.values(): body += f’
- # , ‘ body += ‘
Важно обратить внимание на способ представления body . Так как наш ответ содержит символы кириллицы, ASCII кодировка нам не подходит. Мы работаем с body как со строкой в кодировке UTF-8. Однако, прежде чем создать объект ответа, мы кодируем строку в последовательность байт, а заголовок Content-Length, представляющий собой размер ответа, принимает значение длины уже в байтах. Заголовок Content-Type при этом содержит секцию ; charset=utf-8 , по которой клиенты нашего сервера могут определить кодировку тела ответа.
Реализацию последнего метода нашего приложения handle_get_user(user_id) можно посмотреть в полном исходном коде сервера в конце статьи.
Отправка ответа
Последний шаг, отделяющий нас от минимальной рабочей версии — это отправка HTTP-ответов. Код отправки достаточно прост. Прежде всего записываем в соединение status line вида HTTP/1.1 . Затем, построчно записываем заголовки и не забываем пустую строку, обозначающую конец секции заголовков. Все вышеперечисленные данные должны быть представлены в кодировке ISO/IEC 8859-1. При наличии тела ответа, ожидаем, что оно уже представлено последовательностью байт и просто отправляем его в сокет:
class MyHTTPServer: def send_response(self, conn, resp): wfile = conn.makefile('wb') status_line = f'HTTP/1.1 \r\n' wfile.write(status_line.encode('iso-8859-1')) if resp.headers: for (key, value) in resp.headers: header_line = f': \r\n' wfile.write(header_line.encode('iso-8859-1')) wfile.write(b'\r\n') if resp.body: wfile.write(resp.body) wfile.flush() wfile.close() В случае возникновения ошибки на сервере, нам также необходимо отправить ответ. Для этого реализуем метод send_error() , фактически являющийся оберткой вокруг метода send_response() :
class MyHTTPServer: def send_error(self, conn, err): try: status = err.status reason = err.reason body = (err.body or err.reason).encode('utf-8') except: status = 500 reason = b'Internal Server Error' body = b'Internal Server Error' resp = Response(status, reason, [('Content-Length', len(body))], body) self.send_response(conn, resp) Теперь мы можем ввести класс HTTPError(Exception) и заменить в коде сервера вхождения вида raise Exception(‘Not found’) на raise HTTPError(404, ‘Not found’) .
class HTTPError(Exception): def __init__(self, status, reason, body=None): super() self.status = status self.reason = reason self.body = body Запустим наш сервер:
# terminal 1 python3 server.py 127.0.0.1 53210 example.local И протестируем его, создав двух пользователей:
# terminal 2 nc localhost 53210 > POST /users?name=Vasya&age=42 HTTP/1.1 > Host: example.local > < HTTP/1.1 204 Created nc localhost 53210 >POST /users?name=Vasya&age=42 HTTP/1.1 > Host: example.local > < HTTP/1.1 204 Created Теперь попробуем получить информацию о зарегистрированных пользователях - в формате HTML и в формате JSON:
Также попробуем протестировать сообщения об ошибке:
# terminal 2 nc localhost 53210 > GET /users HTTP/1.1 > < HTTP/1.1 400 Bad request < Content-Length: 22 < < Host header is missing nc localhost 53210 >GET /foo HTTP/1.1 > Host: example.local > Accept: application/json > < HTTP/1.1 404 Not found < Content-Length: 9 < < Not found Чтение тела запроса
До настоящего момента, наш сервер не умел работал с телом запроса. Расширим класс Request, добавив тривиальную реализацию метода body() :
class Request: def body(self): size = self.headers.get('Content-Length') if not size: return None return self.rfile.read(size) Если абстрактно представить себе проблему передачи сообщений по сети, то задача чтения одного сообщения может быть непротиворечиво решена только если: сообщения всегда имеют фиксированную длину, сообщения имеют метаинформацию о размере, сообщения разделены некоторым набором символов. В случае протокола HTTP используется подход с передачей метаинформации в заголовоке Content-Length, определяющем длину тела сообщения.
Необходимо заметить, что не все типы запросов могут иметь тело. Например, запросы GET не должны иметь тела сообщения.
Протокол HTTP также предоставляет возможность передачи больших объемов данных, разбивая их на части (т.н. chunk-и). В таком случае добавляется специалльный заголовок Transfer-Encoding: chunked , а тело запроса (или ответа) представляется блоками байт, каждый из которых имеет префикс в виде длины блока. Подробнее тут Chunked transfer encoding.
Повторное использование TCP-соединений
Протокол HTTP поддерживает отправку нескольких последовательных (в версии HTTP2 поддерживается также мультиплексирование) HTTP-запросов в рамках одного TCP-соединения. Несмотря на то, что наш сервер мгновенно закрывает соединение после отправки ответа, поведением по умолчанию для протокола HTTP/1.1 является сохранение соединения открытым для повторного его использования клиентом. Это так называемый механизм HTTP keep-alive. В случае же, если клиент или сервер по каким-либо причинам не хотят реиспользовать соединение, необходимо добавить заголовок Connection: close .
Заключение
Реализованный нами HTTP-сервер объединяет в себе как непосредственно работу с протоколом, так и более высокоуровневую обработку HTTP-запросов, суть - бизнес-логику приложения. Очевидным развитием архитектуры веб-сервера является отделение редко меняющейся протокольной части от специфичной и волатильной бизнес-логики приложения. Более того, формализация программного интерфейса HTTP-сервера в виде некоторого стандарта позволила бы создавать переносимые между серверами приложения, избегая дублирования кода. Не удивительно, что Python-сообщество уже решило эту проблему, введя стандарт взаимодействия сервера и приложения WSGI. В следующей статье мы рассмотрим, что из себя представляет эта спецификация и как на уровне кода можно научить приложение взаимодействовать с любым WSGI-совместимым HTTP-сервером.
Исходный код сервера
-
' for u in self._users.values(): body += f'
- # , ' body += '
Ссылки по теме
- http.server модуль Python Standard Library
- Исходный код http.server на GitHub
- RFC7230 Message Syntax and Routing
- RFC7231 Semantics and Content
- RFC7232 Conditional Requests
- RFC7233 Range Requests
- RFC7234 Caching
- RFC7235 Authentication
Автор Ivan Velichko
Следовать в twitter @iximiuz