Руководство. Создание модели машинного обучения в Power BI
В этом руководстве вы используете автоматизированное машинное обучение для создания и применения двоичной модели прогнозирования в Power BI. Вы создаете поток данных Power BI и используете сущности, определенные в потоке данных, для обучения и проверки модели машинного обучения непосредственно в Power BI. Затем вы используете эту модель для оценки новых данных и создания прогнозов.
Во-первых, вы создаете модель машинного обучения двоичного прогнозирования для прогнозирования намерения покупки онлайн-покупателей на основе набора их атрибутов онлайн-сеанса. Для этого упражнения используется семантическая модель машинного обучения. После обучения модели Power BI автоматически создает отчет проверки, объясняющий результаты модели. Затем можно просмотреть отчет проверки и применить модель к данным для оценки.
В этом руководстве рассматриваются следующие шаги:
- Создайте поток данных с входными данными.
- Создание и обучение модели машинного обучения.
- Просмотрите отчет о проверке модели.
- Примените модель к сущности потока данных.
- Используйте результат оценки модели в отчете Power BI.
Создание потока данных с входными данными
Создайте поток данных с входными данными, выполнив следующие действия.
Получить данные
Первым шагом в создании потока данных является подготовка источников данных. В этом случае вы используете семантику машинного обучения из набора онлайн-сеансов, некоторые из которых завершились покупкой. Семантическая модель содержит набор атрибутов об этих сеансах, которые используются для обучения модели.
Вы можете скачать семантику модели на веб-сайте UC Irvine или скачать файл online_shoppers_intention.csv. Далее в этом руководстве вы подключаетесь к семантической модели, указав его URL-адрес.
Создание таблиц
Чтобы создать сущности в потоке данных, войдите в служба Power BI и перейдите в рабочую область.
- Если у вас нет рабочей области, создайте ее, выбрав рабочие области в области навигации Power BI слева и выбрав «Создать рабочую область«. На панели «Создание рабочей области» введите имя рабочей области и нажмите кнопку «Сохранить«.
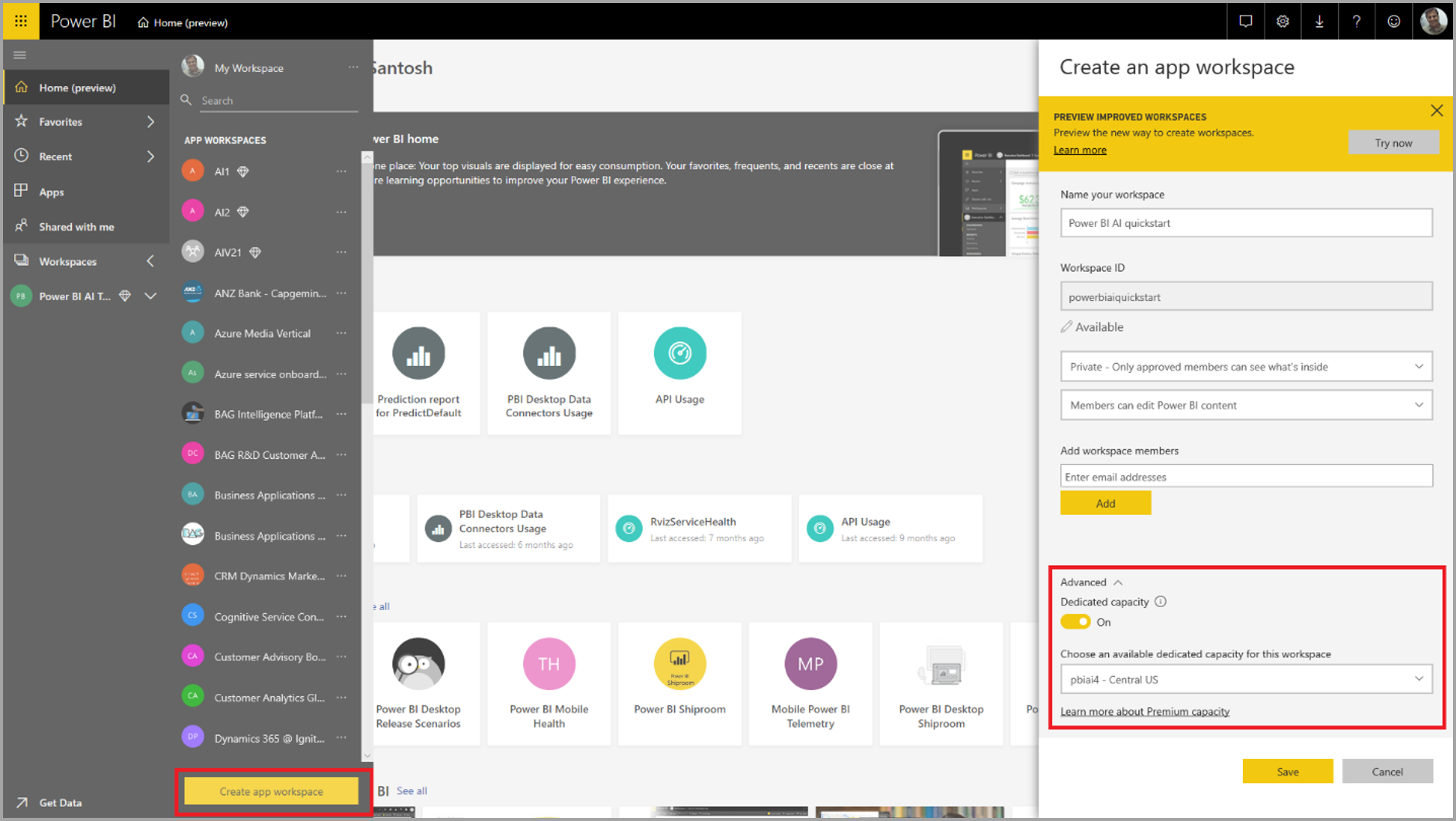
- Выберите «Создать» в верхней части новой рабочей области и выберите «Поток данных».
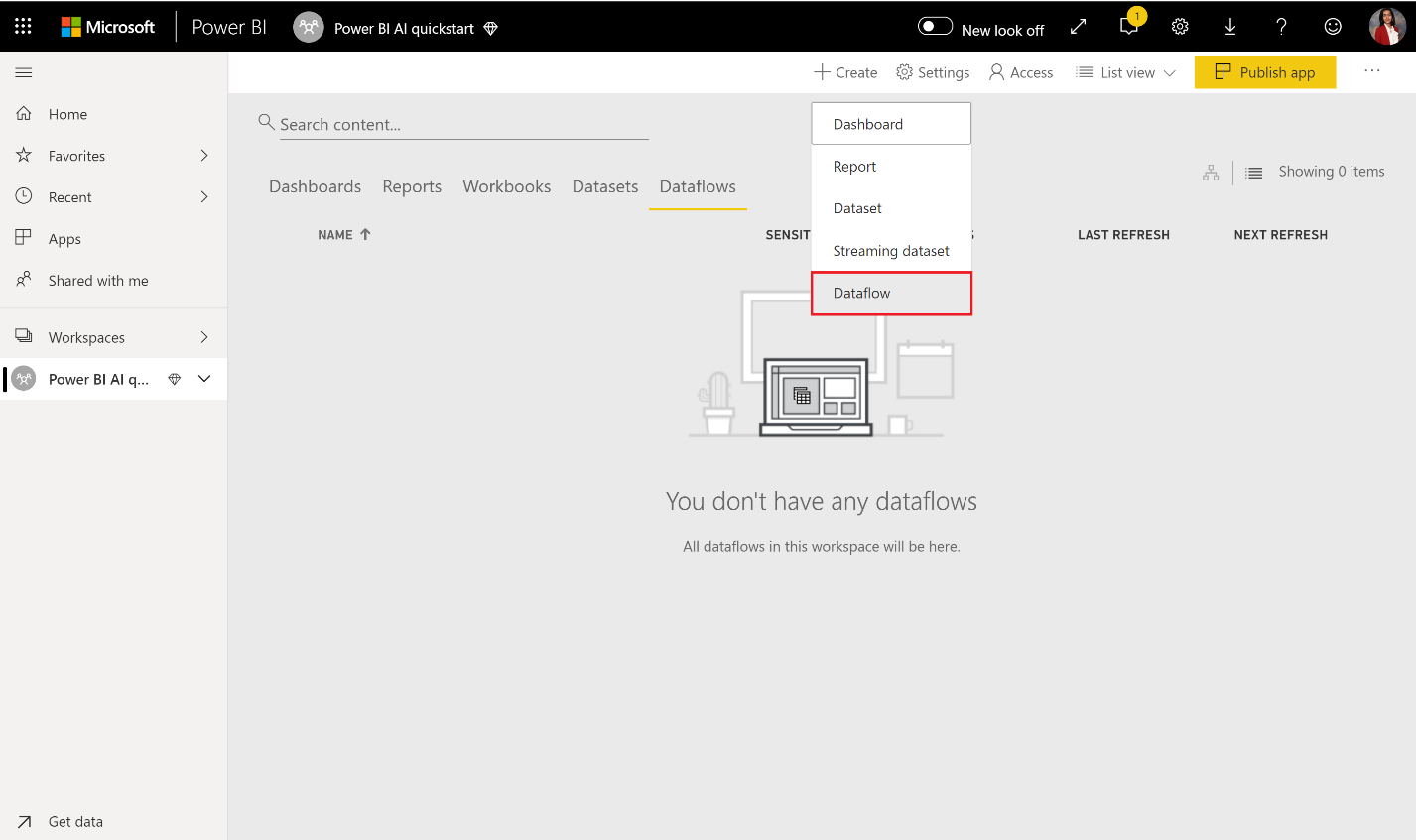
- Выберите » Добавить новые таблицы «, чтобы запустить редактор Power Query в браузере.
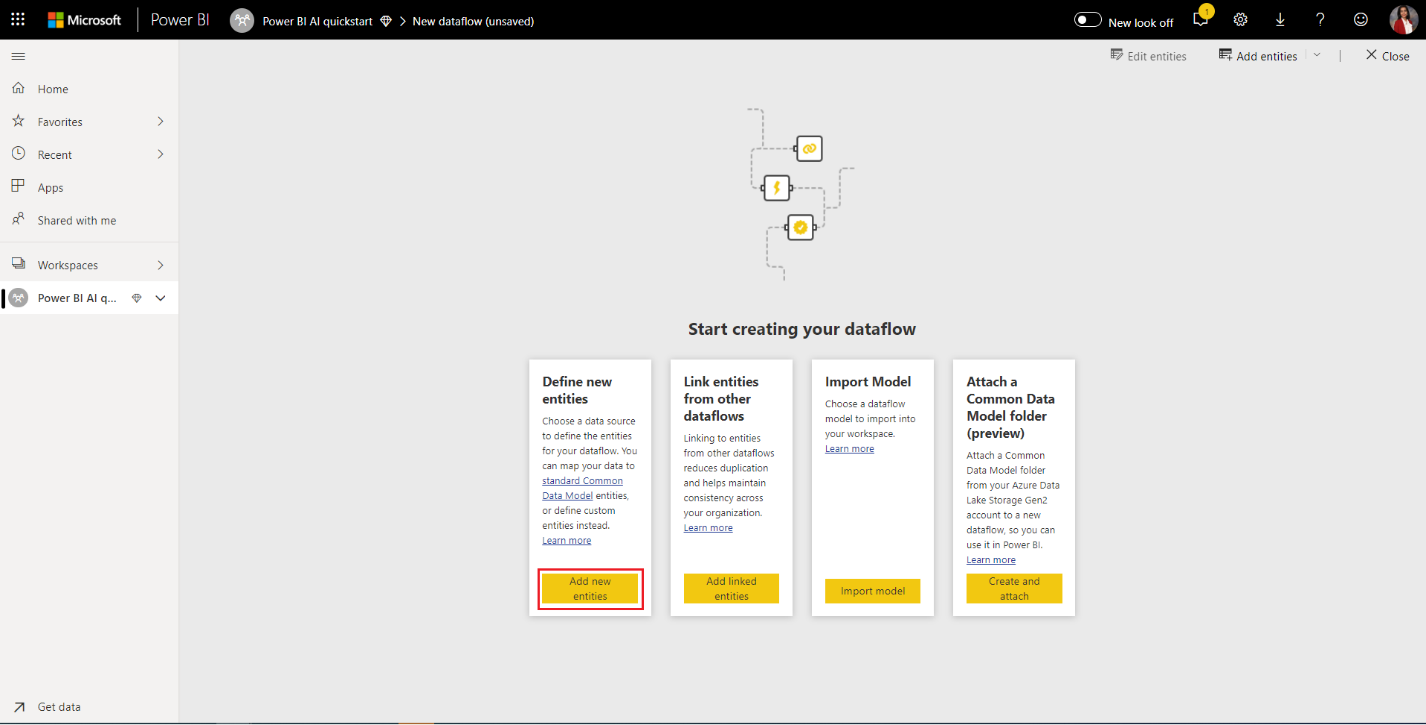
- На экране выбора источника данных выберите текст или CSV в качестве источника данных.
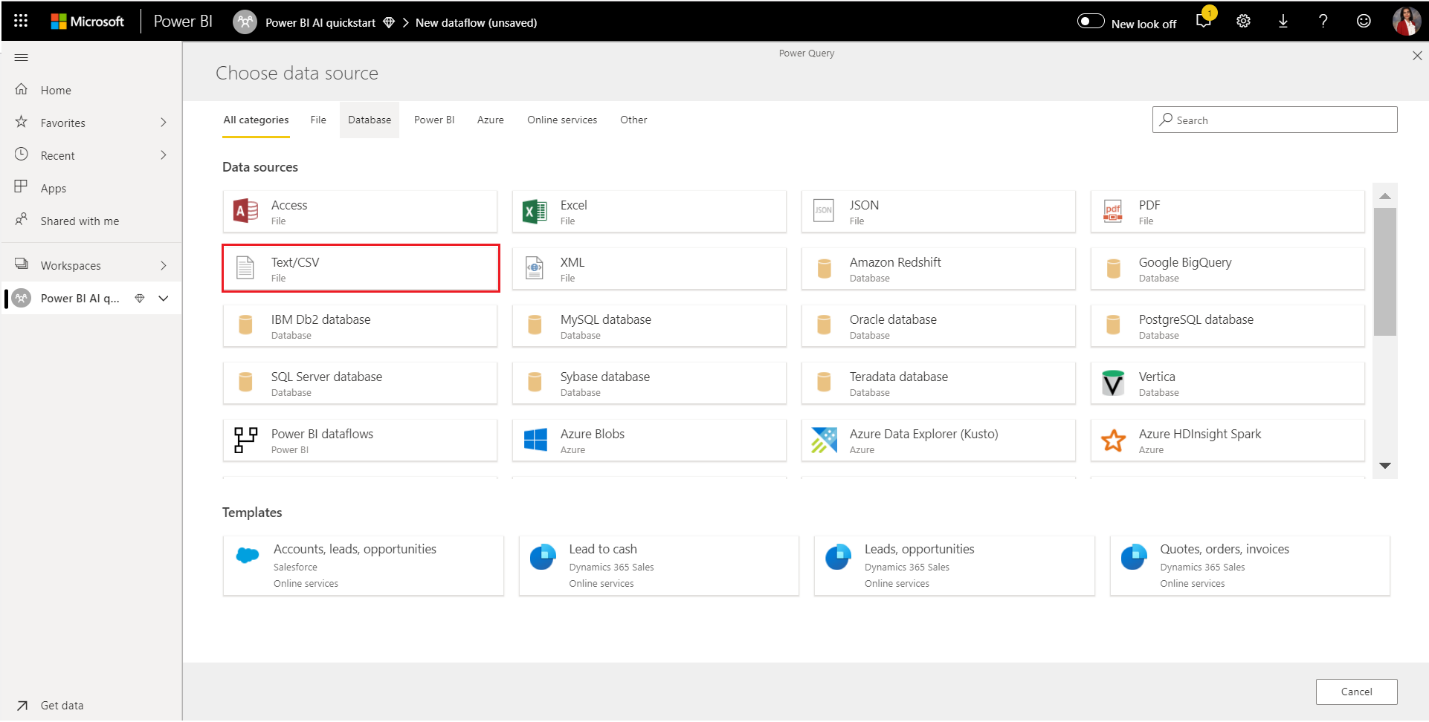
- На странице источника данных Подключение вставьте следующую ссылку на файл online_shoppers_intention.csv в поле «Путь к файлу» или «URL-адрес«, а затем нажмите кнопку «Далее«. https://raw.githubusercontent.com/santoshc1/PowerBI-AI-samples/master/Tutorial_AutomatedML/online_shoppers_intention.csv
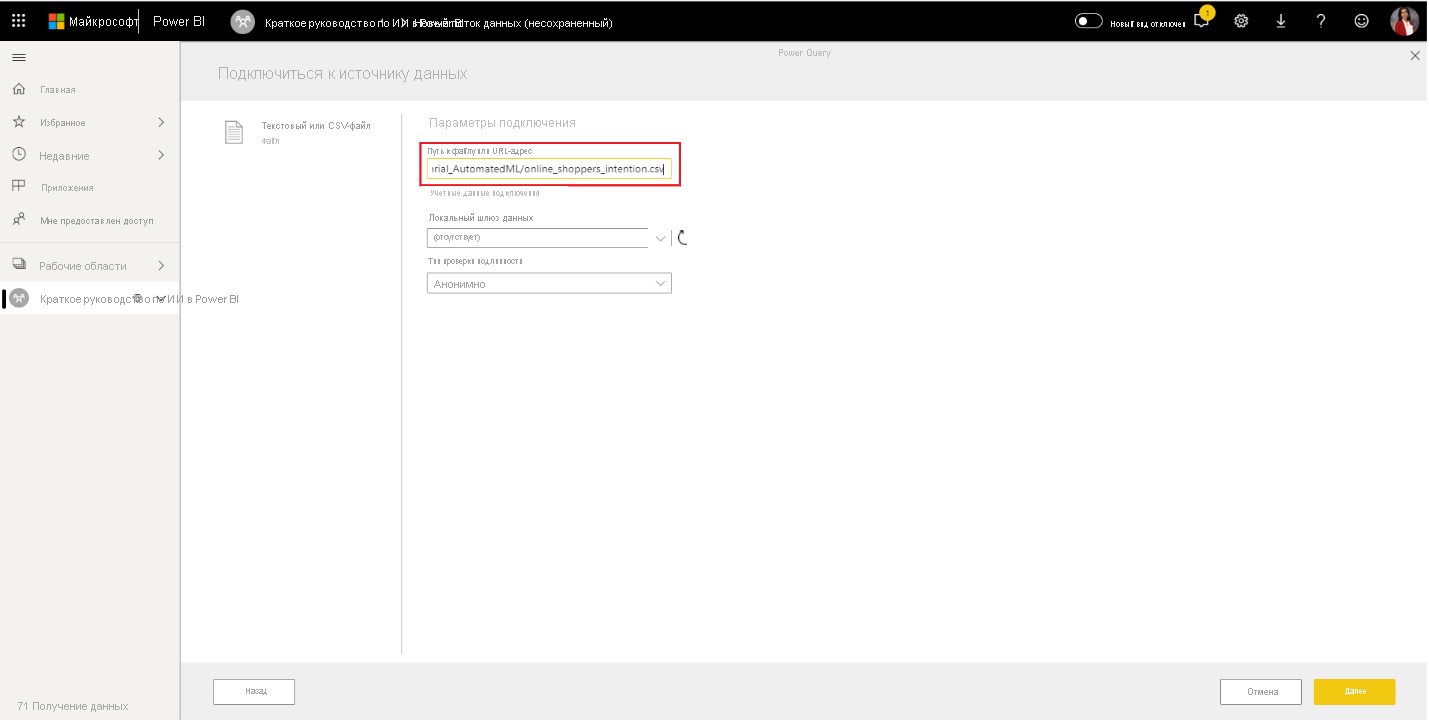
- В Редактор Power Query показан предварительный просмотр данных из CSV-файла. Чтобы внести изменения в данные перед загрузкой, выберите «Преобразовать данные«.
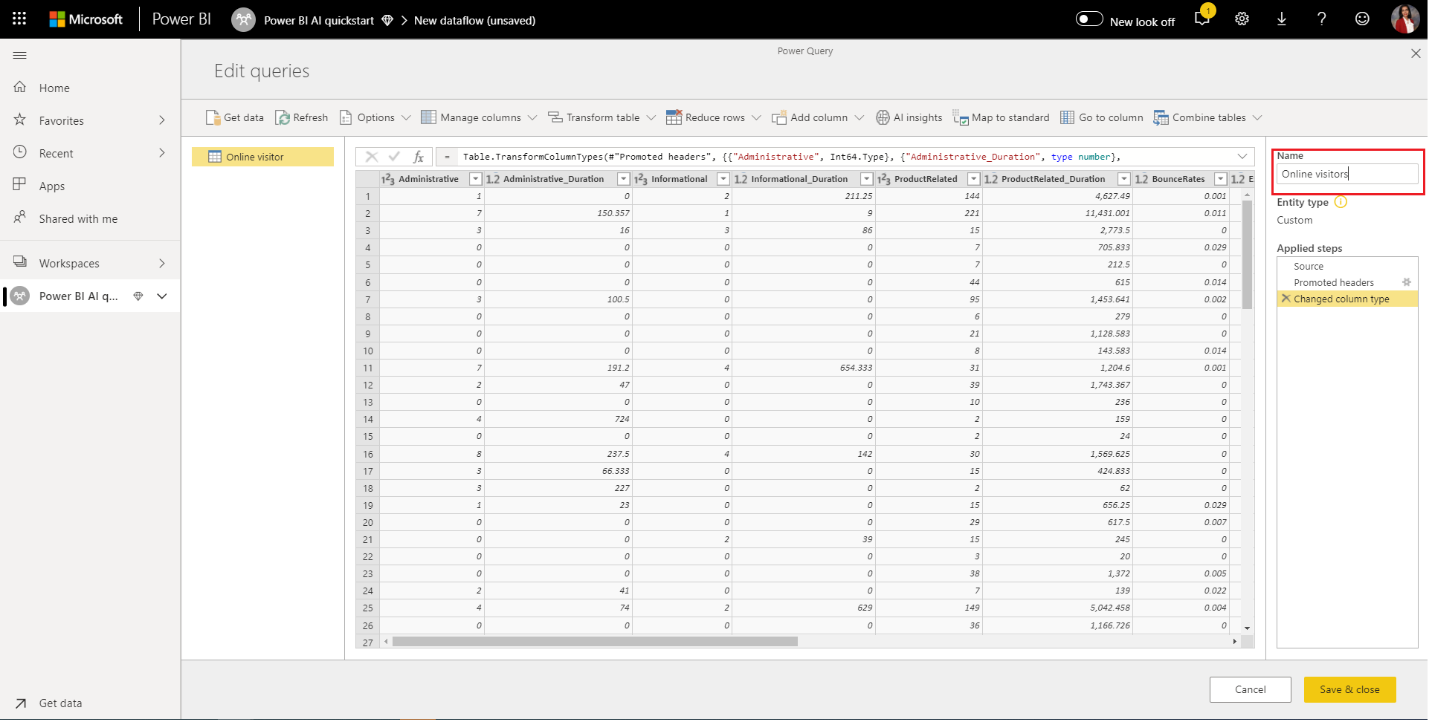
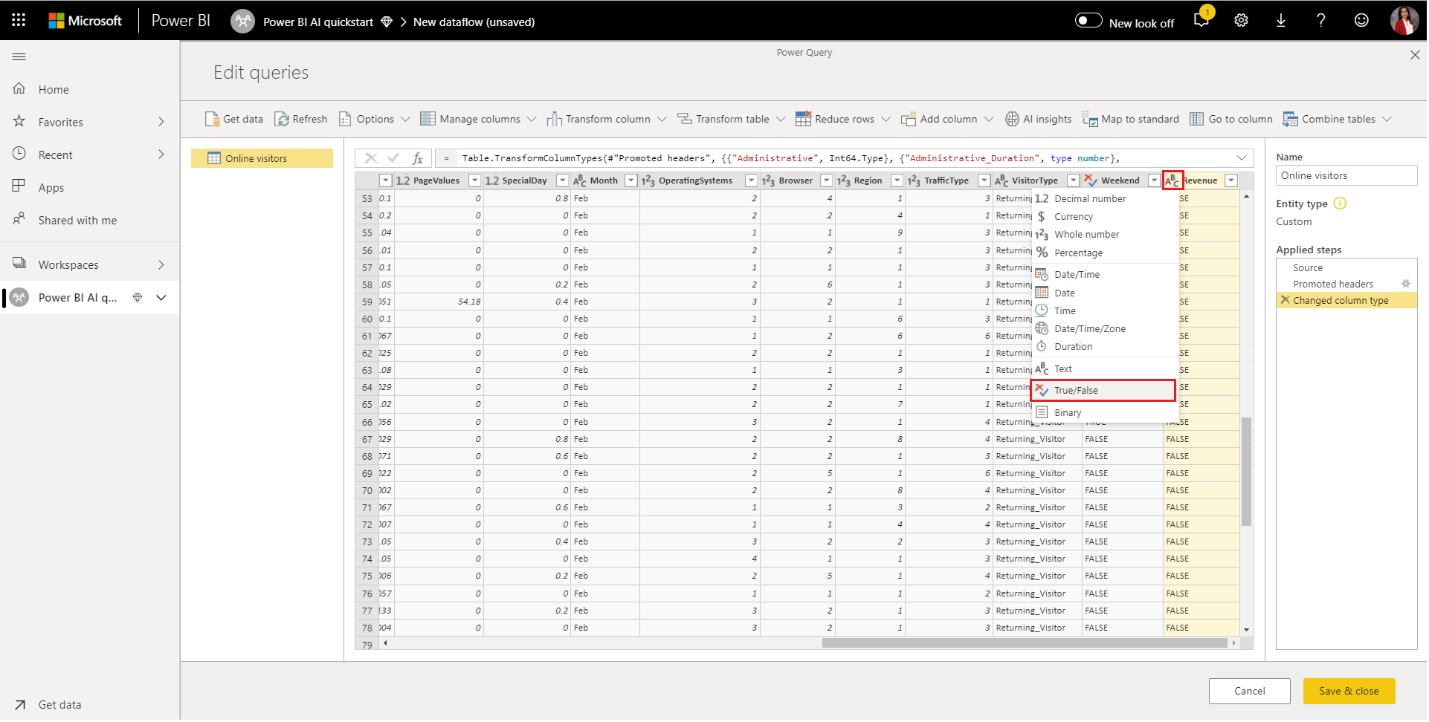
- Power Query автоматически выводит типы данных столбцов. Вы можете изменить типы данных, выбрав значок типа атрибута в верхней части заголовков столбцов. Измените тип столбца «Доход» на True/False. Вы можете переименовать запрос в более дружественное имя, изменив значение в поле «Имя » в правой области. Измените имя запроса на посетителей в Интернете.
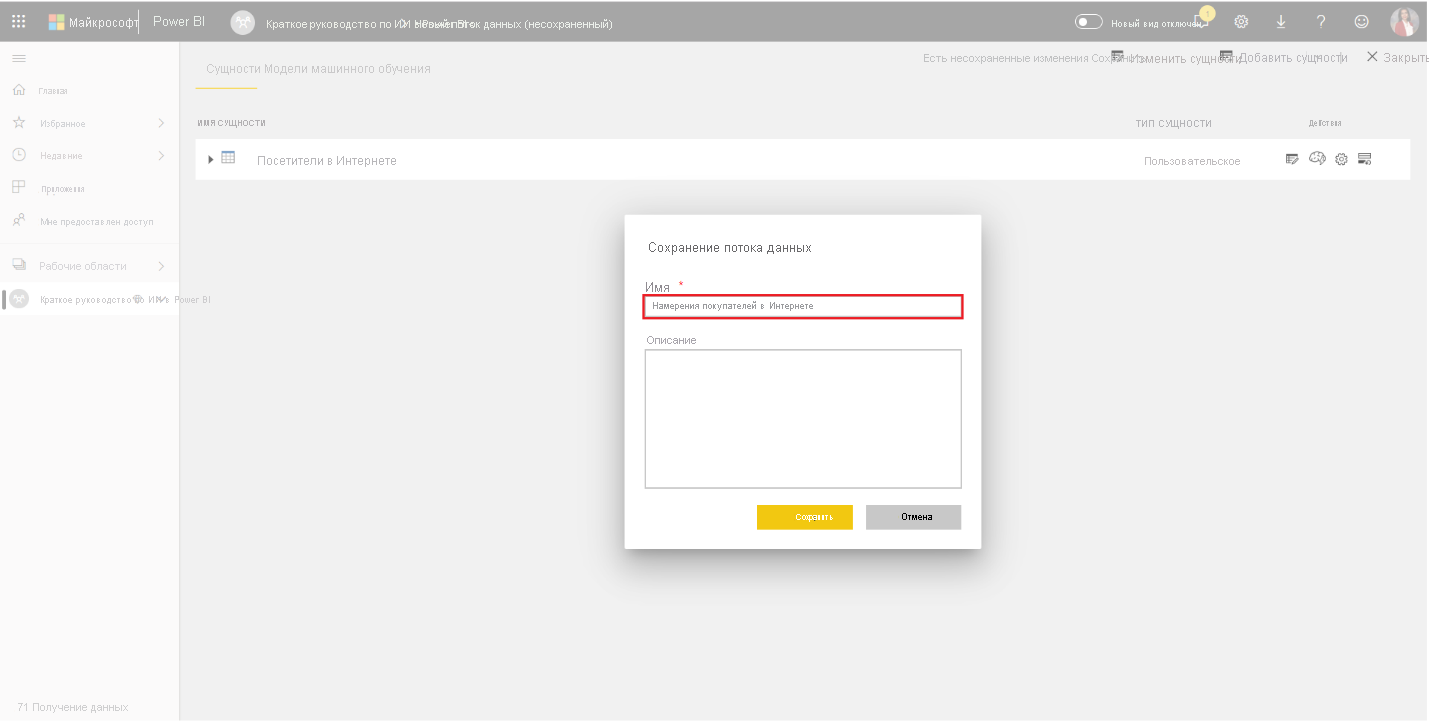
- Нажмите кнопку «Сохранить & « и в диалоговом окне укажите имя потока данных и нажмите кнопку «Сохранить«.
Создание и обучение модели машинного обучения
Чтобы добавить модель машинного обучения, выполните приведенные действия.
- Щелкните значок «Применить модель машинного обучения» в списке «Действия» для таблицы, содержащей данные обучения и сведения о метках, а затем нажмите кнопку «Добавить модель машинного обучения».
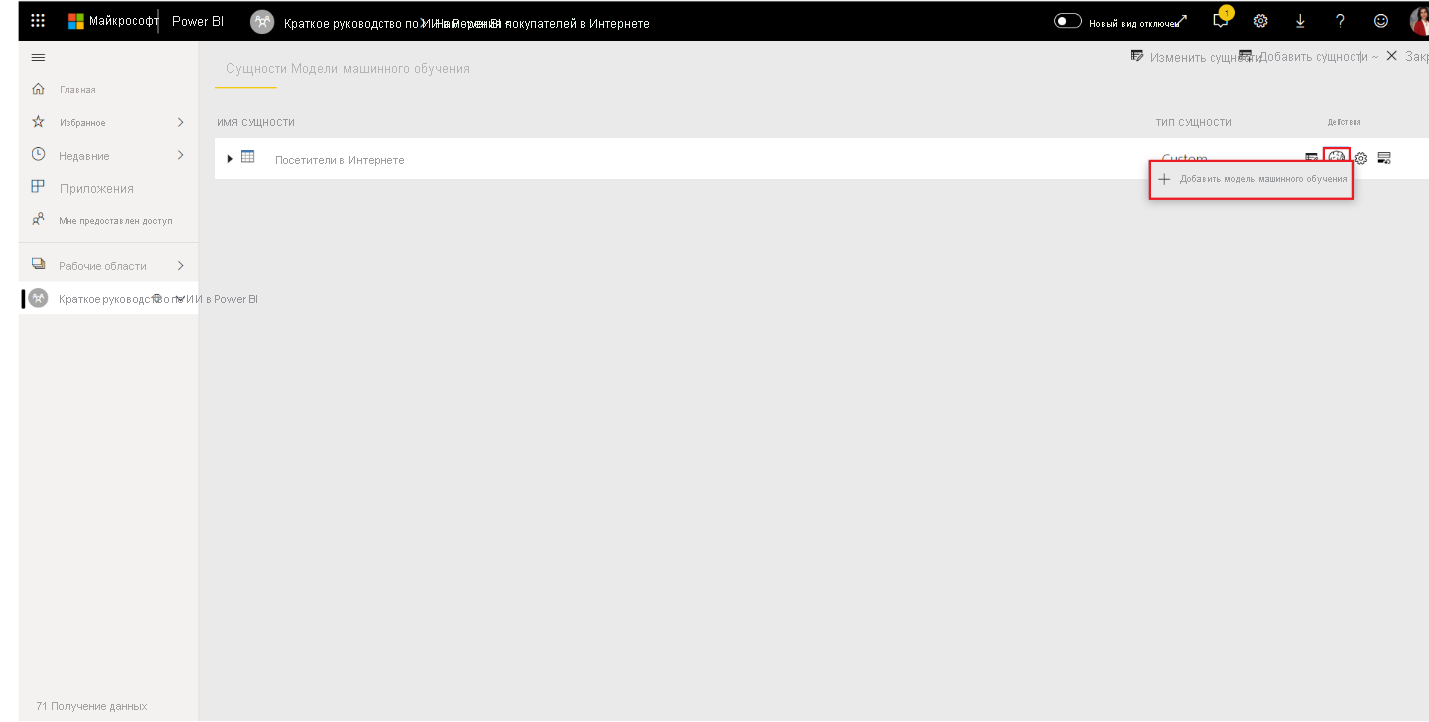
- Первым шагом для создания модели машинного обучения является определение исторических данных, включая поле результатов, которое требуется прогнозировать. Модель создается путем обучения из этих данных. В этом случае вы хотите предсказать, собираются ли посетители делать покупку. Результат, который вы хотите предсказать, находится в поле «Доход «. Выберите «Доход» в качестве значения столбца «Результат» и нажмите кнопку «Далее«.
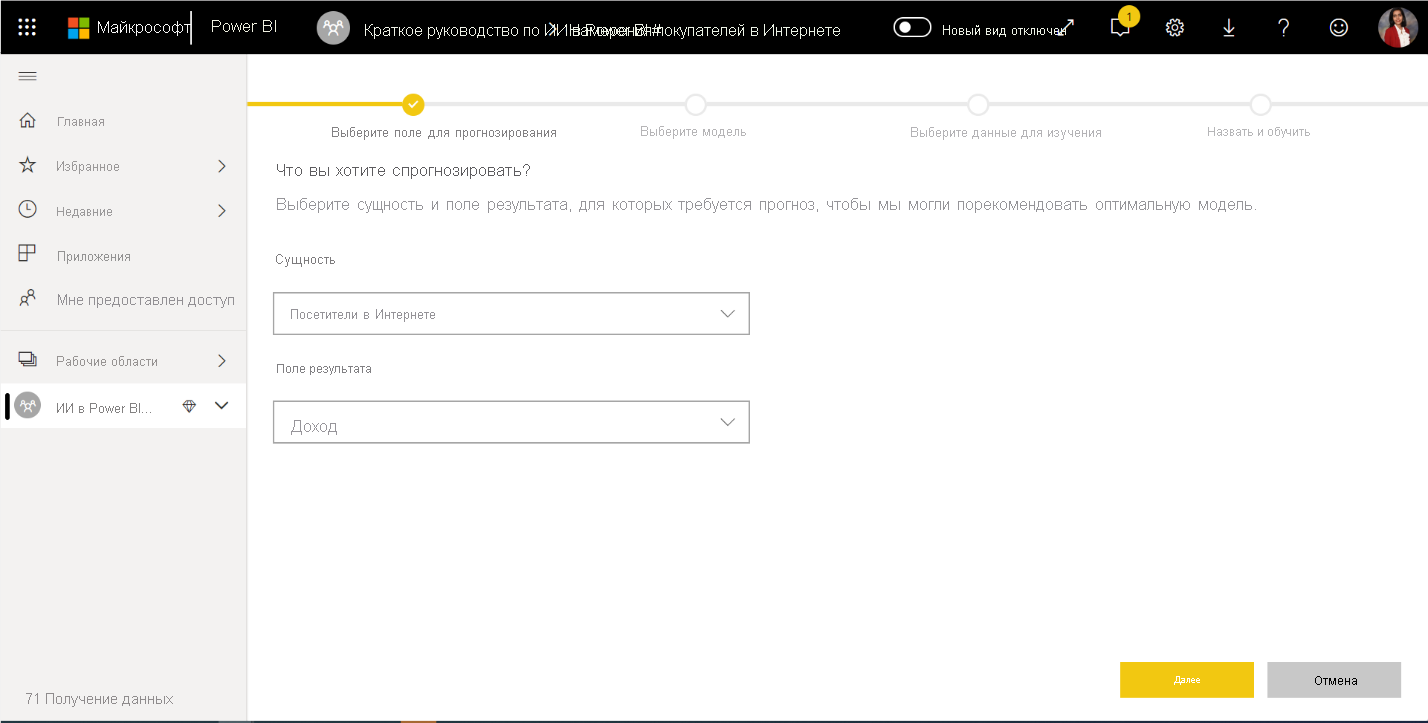
- Затем выберите тип модели машинного обучения для создания. Power BI анализирует значения в поле результатов, которое вы определили, и предлагает типы моделей машинного обучения, которые он может создать для прогнозирования этого поля. В этом случае, так как вы хотите предсказать двоичный результат того, собирается ли посетитель приобрести, Power BI рекомендует двоичное прогнозирование. Так как вы заинтересованы в прогнозировании посетителей, которые собираются сделать покупку, выберите true в разделе «Выбор целевого результата«. Вы также можете указать различные метки, используемые для результатов в автоматически созданном отчете, который суммирует результаты проверки модели. Затем выберите Далее.
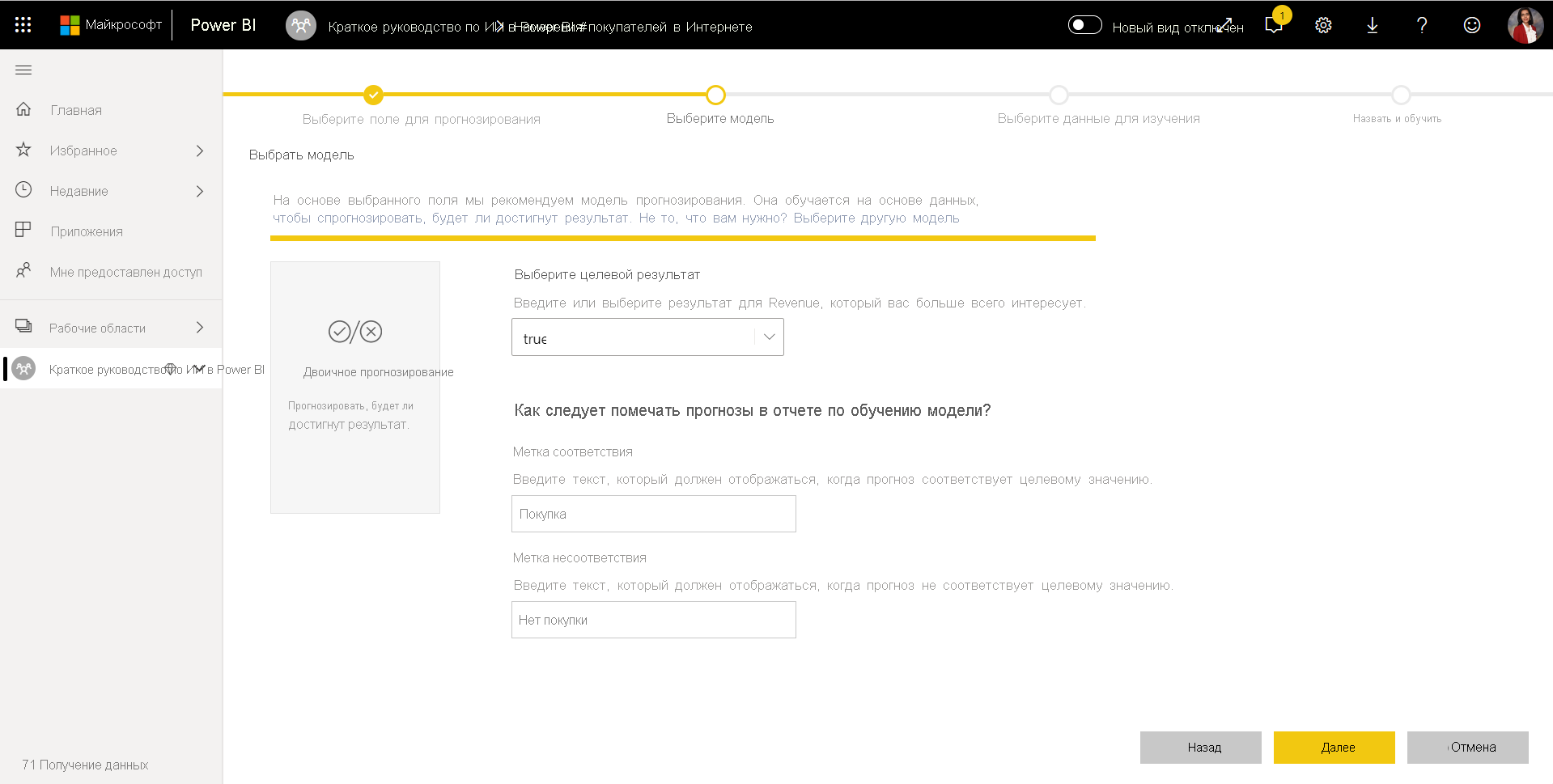
- Power BI выполняет предварительную проверку образца данных и предлагает входные данные, которые могут создавать более точные прогнозы. Если Power BI не рекомендует столбец, он объясняет, почему не рядом с столбцом. Вы можете изменить выбранные элементы, чтобы включить только поля, которые нужно изучать модели, выбрав или отменив выбор полей проверка boxes рядом с именами столбцов. Нажмите кнопку «Рядом «, чтобы принять входные данные.
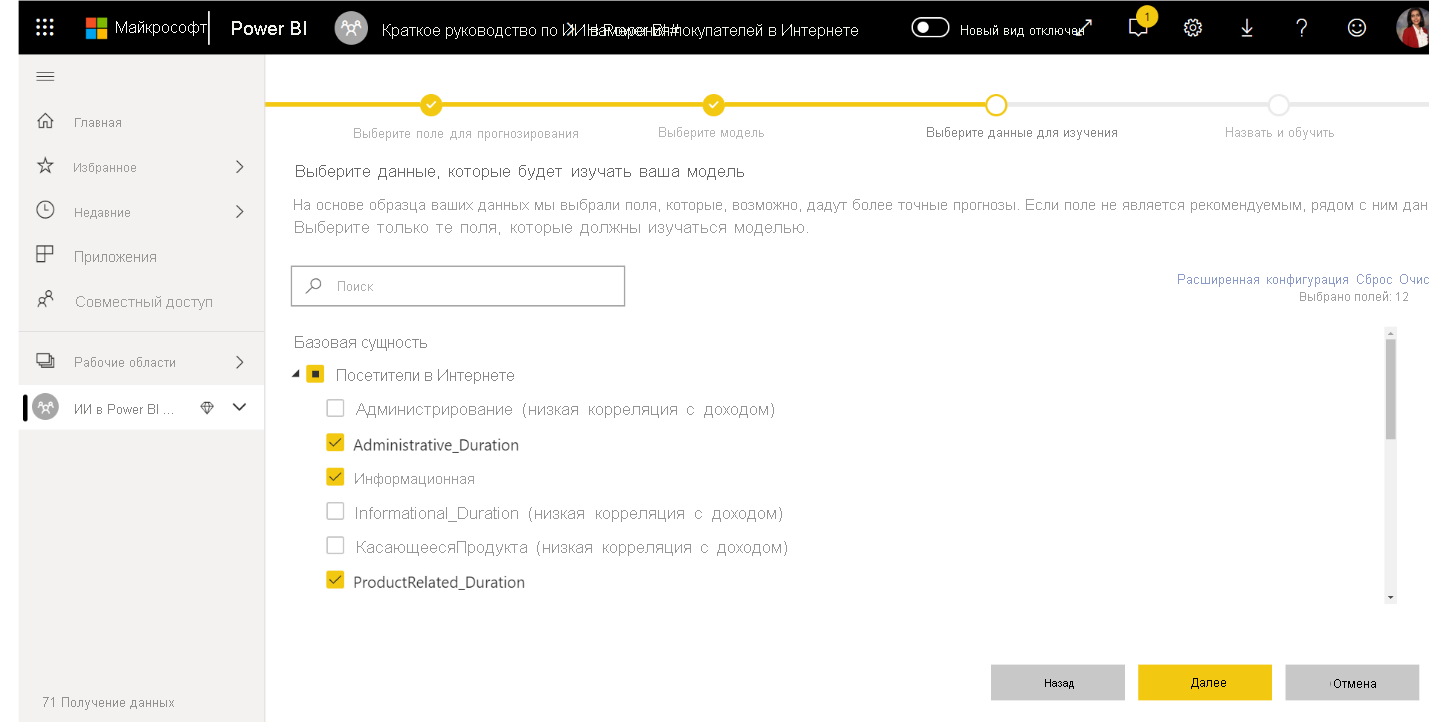
- На последнем шаге назовите прогноз намерения покупки модели и выберите время для обучения. Вы можете сократить время обучения, чтобы увидеть быстрые результаты или увеличить время, чтобы получить лучшую модель. Затем нажмите кнопку «Сохранить и обучить «, чтобы начать обучение модели.
Если вы получаете ошибку, аналогичную учетным данным, не найденной для источника данных, необходимо обновить учетные данные, чтобы Power BI могли оценить данные. Чтобы обновить учетные данные, выберите дополнительные параметры . в строке заголовка и выберите Параметры > Параметры.
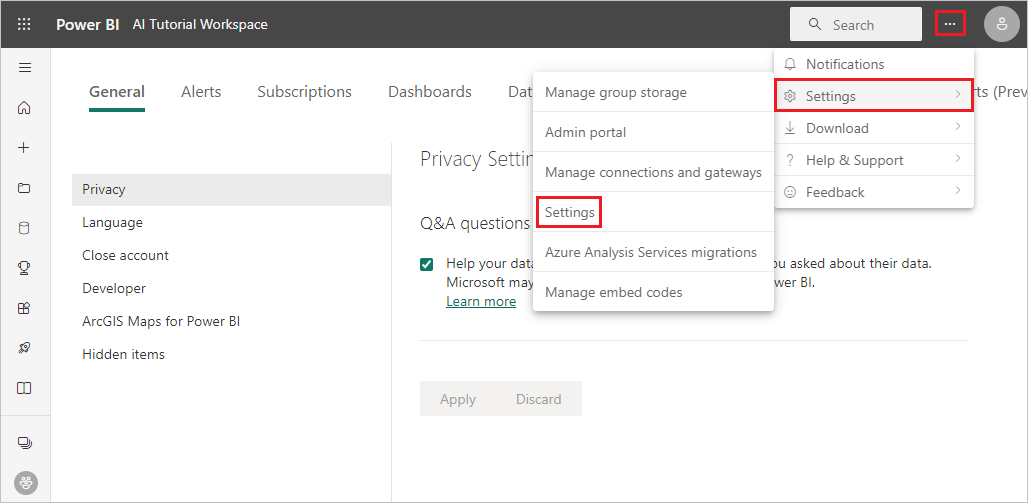
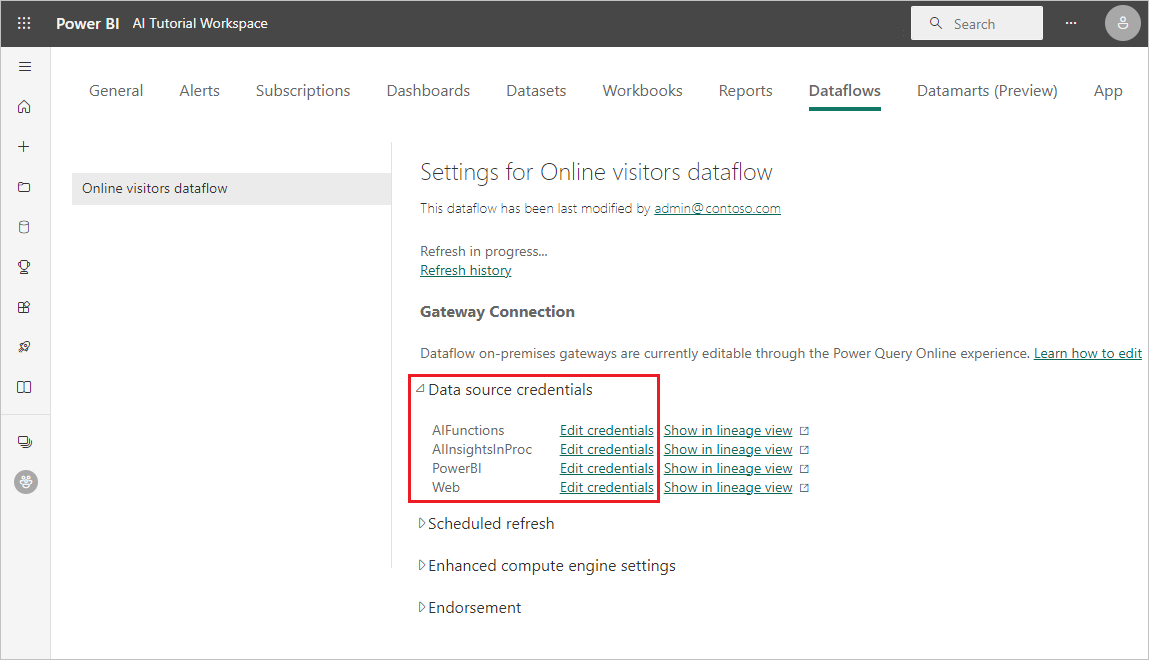
Выберите поток данных в потоках данных, разверните учетные данные источника данных и выберите пункт «Изменить учетные данные».
Отслеживание состояния обучения
Учебный процесс начинается с выборки и нормализации исторических данных и разделения семантической модели на две новые сущности: Приобретение данных обучения прогнозирования намерений и данных прогнозирования намерений покупки.
В зависимости от размера семантической модели процесс обучения может занять от нескольких минут до выбранного времени обучения. Вы можете убедиться, что модель обучена и проверена с помощью состояния потока данных. Состояние отображается как обновление данных на вкладке «Семантические модели + потоки данных» рабочей области.
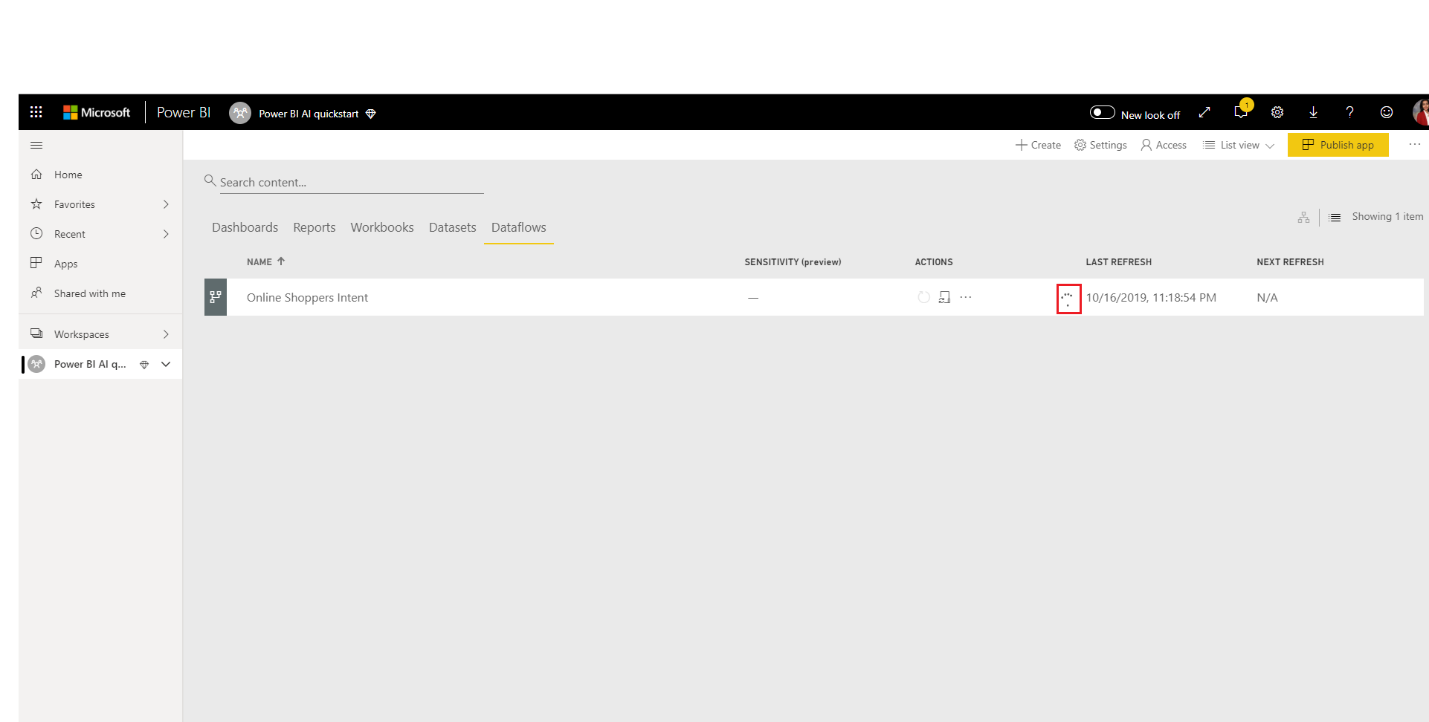
Модель отображается на вкладке моделей машинного обучения потока данных. Состояние указывает, включена ли модель в очередь для обучения, находится под обучением или обучена. После завершения обучения модели поток данных отображает обновленное время последнего обучения и состояние обученного .
Просмотр отчета о проверке модели
Чтобы просмотреть отчет о проверке модели, на вкладке «Модели машинного обучения» щелкните значок «Просмотр обучающий отчет» в разделе «Действия«. В этом отчете описывается, как модель машинного обучения, скорее всего, будет выполняться.
На странице «Производительность модели» отчета выберите «Просмотреть основные прогнозаторы», чтобы просмотреть лучшие прогнозаторы для модели. Вы можете выбрать один из прогнозаторов, чтобы узнать, как распределение результатов связано с этим прогнозатором.
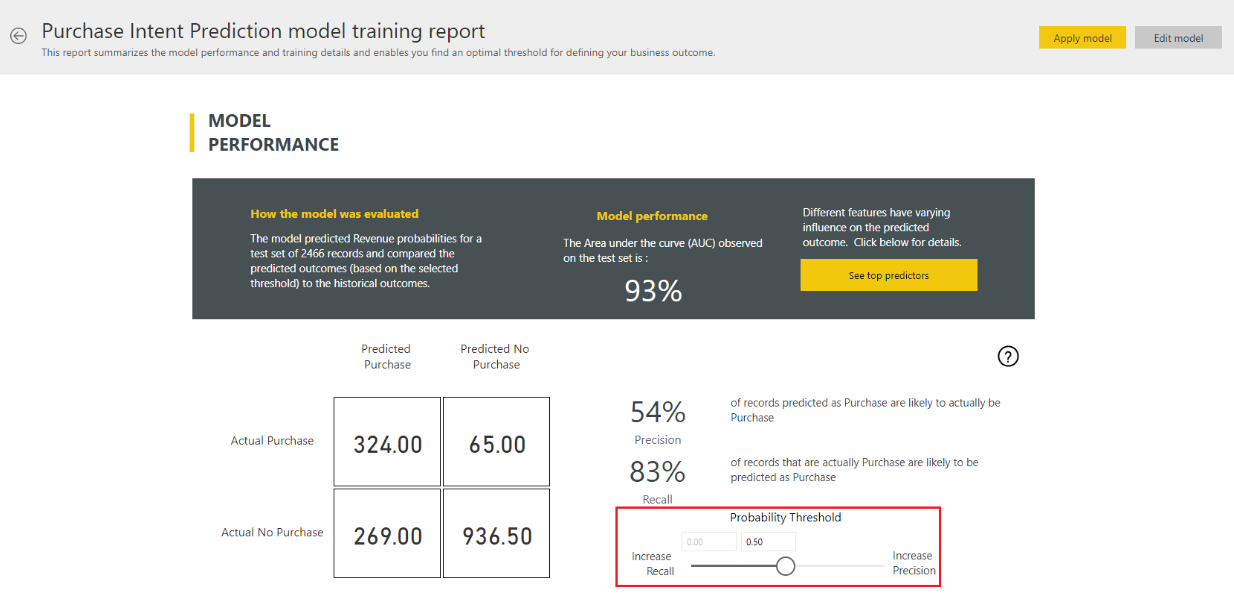
Срез порога вероятности можно использовать на странице «Производительность модели» для изучения влияния точности модели и отзыва на модель.
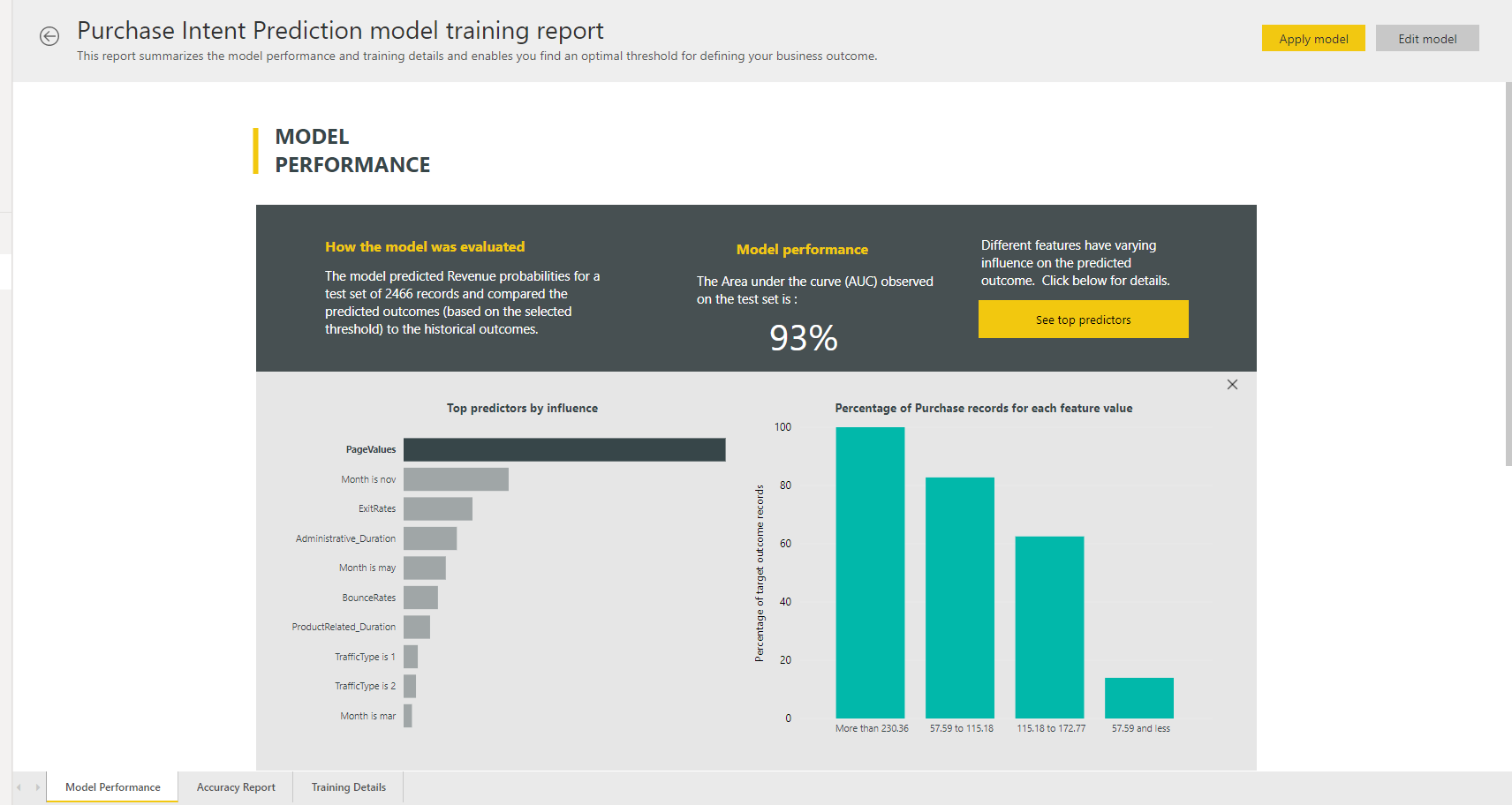
На других страницах отчета описываются статистические метрики производительности для модели.
Отчет также содержит страницу сведений об обучении, описывающую выполнение итерации, способ извлечения признаков из входных данных и гиперпараметров для используемой конечной модели.
Применение модели к сущности потока данных
Нажмите кнопку «Применить модель« в верхней части отчета, чтобы вызвать эту модель. В диалоговом окне «Применить» можно указать целевую сущность с исходными данными для применения модели. Затем нажмите кнопку «Сохранить и применить«.
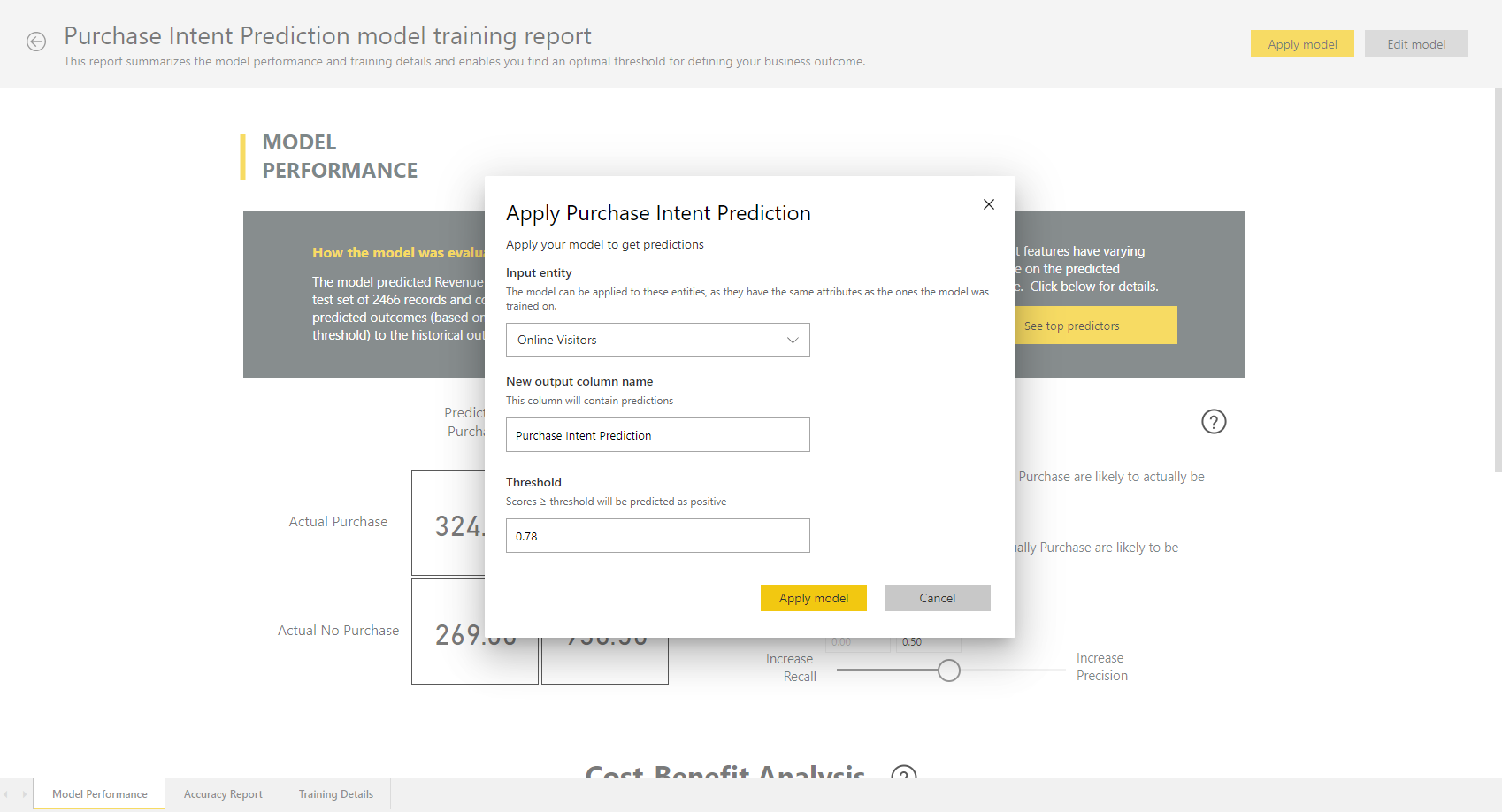
Применение модели создает две новые таблицы с суффиксами, обогащенными обогащенными > объяснениями. В этом случае применение модели к таблице посетителей Online создает следующее:
- Онлайн-посетители обогащены прогноз намерения покупки, который включает прогнозируемые выходные данные модели.
- Онлайн-посетители обогатили объяснения намерений покупки, которые содержат основные факторы влияния для прогнозирования с учетом записей.
Применение двоичной модели прогнозирования добавляет четыре столбца: Результаты, PredictionScore, PredictionExplanation и ExplanationIndex, каждый из которых имеет префикс прогнозирования намерения покупки.
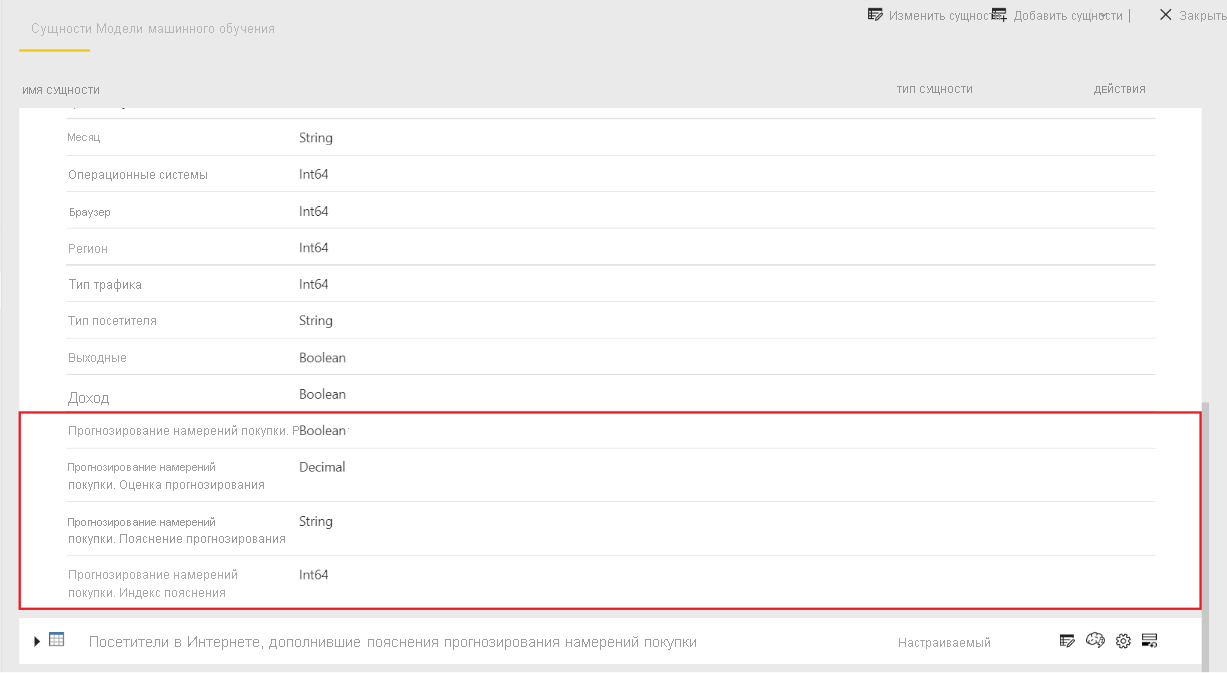
После завершения обновления потока данных можно выбрать таблицу прогнозирования намерений покупки в Интернете, чтобы просмотреть результаты.
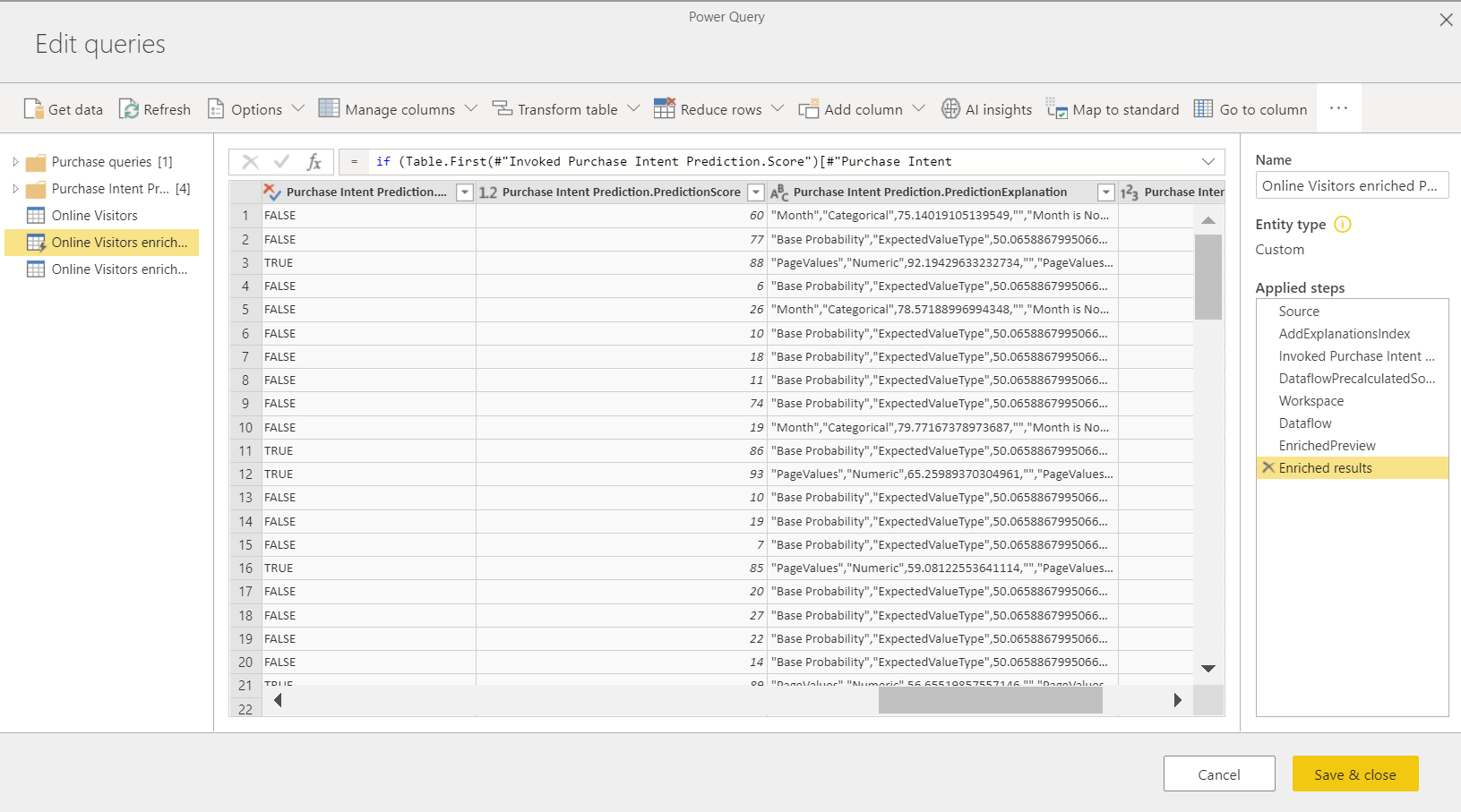
Вы также можете вызвать любую автоматизированную модель машинного обучения в рабочей области непосредственно из Редактор Power Query в потоке данных. Чтобы получить доступ к моделям автоматизированного машинного обучения, выберите «Изменить » для таблицы, которую вы хотите дополнить аналитическими сведениями из модели автоматизированного машинного обучения.
В Редактор Power Query выберите аналитику ИИ на ленте.
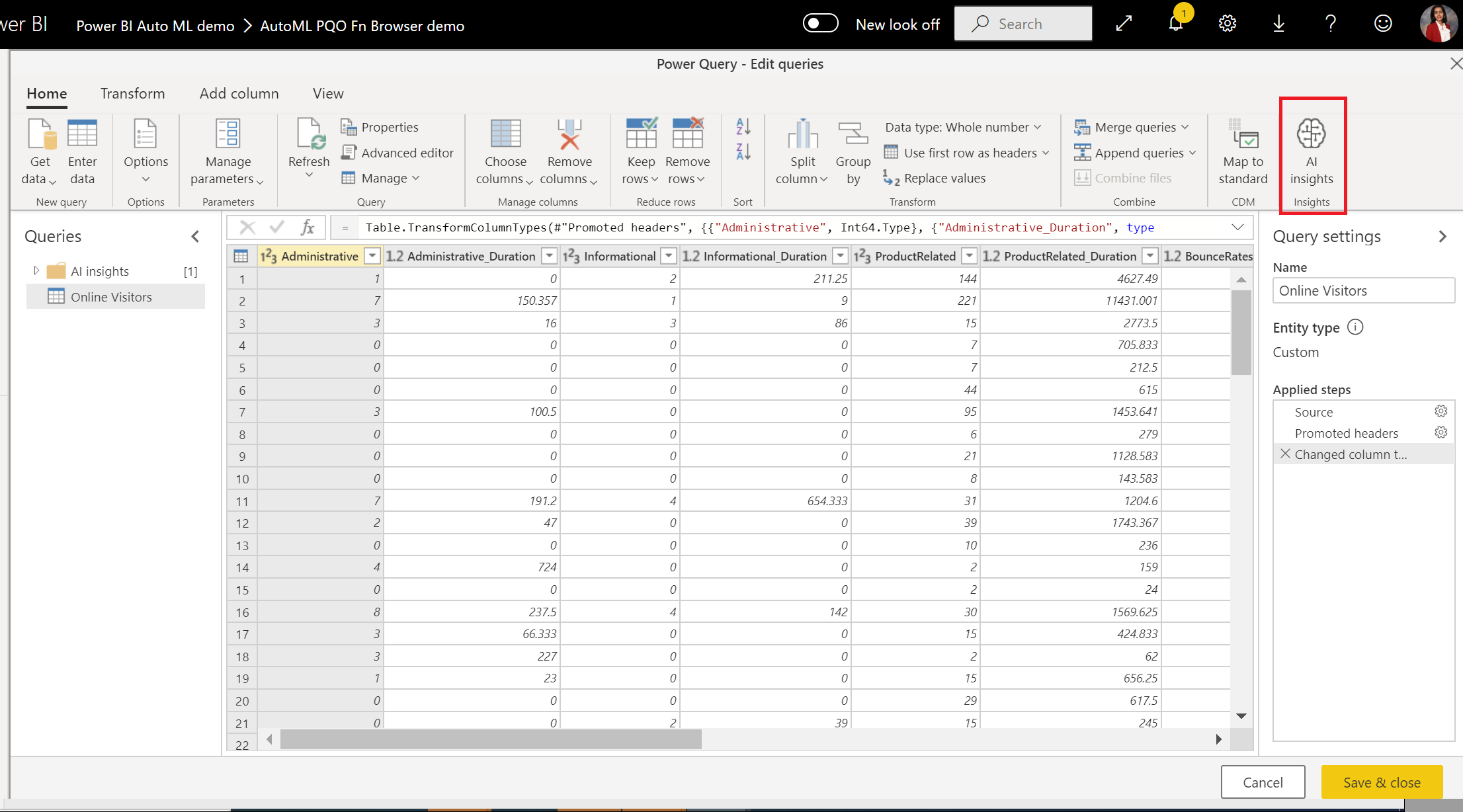
На экране аналитики ИИ выберите папку Power BI Машинное обучение Models в области навигации. В списке показаны все модели машинного обучения, к которых у вас есть доступ к функциям Power Query. Входные параметры модели машинного обучения автоматически сопоставляют с параметрами соответствующей функции Power Query. Автоматическое сопоставление параметров происходит только в том случае, если имена и типы данных параметра совпадают.
Чтобы вызвать модель машинного обучения, можно выбрать любой из столбцов выбранной модели в качестве входных данных в раскрывающемся списке. Можно также указать константное значение для использования в качестве входных данных, переключив значок столбца рядом с входной строкой.
Выберите «Применить» , чтобы просмотреть предварительный просмотр выходных данных модели машинного обучения в виде новых столбцов в таблице. Вы также увидите вызов модели в разделе «Примененные действия » для запроса.
После сохранения потока данных модель автоматически вызывается при обновлении потока данных для любых новых или обновленных строк в таблице сущностей.
Использование оценки выходных данных модели в отчете Power BI
Чтобы использовать оцененные выходные данные из модели машинного обучения, вы можете подключиться к потоку данных из Power BI Desktop с помощью соединителя потоков данных. Теперь вы можете использовать таблицу прогнозирования намерений покупки в Интернете, чтобы включить прогнозы из модели в отчеты Power BI.
Ограничения
Существуют некоторые известные проблемы с использованием шлюзов с автоматизированным машинным обучением. Если вам нужно использовать шлюз, лучше всего создать поток данных, который импортирует необходимые данные через шлюз. Затем создайте другой поток данных, который ссылается на первый поток данных для создания или применения этих моделей.
Если искусственный интеллект работает с потоками данных, может потребоваться включить быстрое объединение при использовании ИИ с потоками данных. После импорта таблицы и перед добавлением функций ИИ выберите «Параметры» на ленте «Главная» и в окне, которое отображается, выберите поле проверка box рядом с разрешением объединения данных из нескольких источников, чтобы включить эту функцию, а затем нажмите кнопку «ОК«, чтобы сохранить выбор. Затем вы можете добавить функции ИИ в поток данных.
Следующие шаги
В этом руководстве вы создали и применили двоичную модель прогнозирования в Power BI, выполнив следующие действия.
- Создан поток данных с входными данными.
- Создана и обучена модель машинного обучения.
- Просмотр отчета о проверке модели.
- Применяет модель к сущности потока данных.
- Узнайте, как использовать оцененные выходные данные из модели в отчете Power BI.
Дополнительные сведения о автоматизации Машинное обучение в Power BI см. в статье «Автоматизированное машинное обучение» в Power BI.
Классификация, регрессия и другие алгоритмы Data Mining с использованием R
Классификация – наиболее часто встречающаяся задача машинного обучения, и заключается в построении моделей, выполняющих отнесение интересующего нас объекта к одному из нескольких известных классов. Существуют сотни методов классификации (см. Fernandez-Delgado et al., 2014), которые можно использовать для предсказания значения отклика с двумя и более классами. Возникает вопрос: отвечает ли такое множество потребностям реально решаемых задач?
Попробуем выделить основные характерные черты, отличающие эти методы. Во-первых, многое зависит от того, что является поставленной целью исследования: объяснение внутренних механизмов изучаемых процессов или только прогнозирование отклика. Если ставится задача “вскрытия” структуры взаимосвязей между независимыми переменными и откликом, то создаваемая модель должна в явном виде отображать их в виде наглядной схемы, либо осуществлять сравнительную оценку силы влияния отдельных переменных. Примерами хорошо интерпретируемых моделей классификации являются деревья решений, логистическая регрессия и модели дискриминации.
Если же основной задачей является достижение высокой общей точности предсказаний (overall accuracy) значения целевого признака \(y\) для объекта \(a\) , то представление модели в явном виде не требуется. Изучаемый процесс, который часто имеет объективно сложный характер, представляется в виде “черного ящика”, а решающие процедуры могут иметь большое (до десятков тысяч) или неопределенное число трудно интерпретируемых параметров. Эффективными методами прогнозирования классов являются случайные леса, бустинг, бэггинг, искусственные нейронные сети, машины опорных векторов, групповой учет аргументов МГУА и др.
Во-вторых, некоторую систематичность в типизацию моделей классификации может внести их связь с тремя основными парадигмами машинного обучения: геометрической, вероятностной и логической. Обычно множество объектов имеет некую геометрическую структуру: каждый из них, описанный числовыми признаками, можно рассматриваться как точка в многомерной системе координат. Геометрическая модель разделения на классы строится в пространстве признаков с применением таких геометрических понятий, как прямые, плоскости и криволинейные поверхности (в общем виде “гиперплоскости”). Примеры моделей, реализующих геометрическую парадигму: логистическая регрессия, метод опорных векторов и дискриминантный анализ. Другим важным геометрическим понятием является функция расстояния между объектами, которая приводит к классификатору по ближайшим соседям.
Вероятностный подход заключается в предположении о существовании некоего случайного процесса, который порождает значения целевых переменных, подчиняющиеся вполне определенному, но неизвестному нам распределению вероятностей. Примером модели вероятностного характера является байесовский классификатор, формирующий решающее правило по принципу апостериорного максимума. Модели логического типа по своей природе наиболее алгоритмичны, поскольку легко выражаются на языке правил, понятных человеку, таких как: if = 1 then Y = . Примером таких моделей являются ассоциативные правила и деревья классификации. Некоторые авторы (Mount, Zumel, 2014, р. 91) подчеркивают различие терминов “предсказание” (prediction) и “прогнозирование” (forecasting). Предсказание лишь озвучивает результат (например, «Завтра будет дождь»), а при прогнозировании итог связывается с вероятностью события («Завтра с шансом 80% будет дождь»). Мы считаем, что на практике трудно провести между этими терминами четкую границу. К тому же, часто эта разница в совершенно не принципиальна – главное понимать контекст задачи.
Наконец, третьим основанием для группировки методов является природа наблюдаемых признаков, которые можно разделить на четыре типа: бинарные (0/1), категориальные, счетные и метрические. Имеются определенные нюансы при использовании перечисленных типов признаков в качестве предикторов, которые оговариваются нами ниже в рекомендациях по применению каждого метода моделирования. Например, бинарное пространство переменных некорректно использовать для линейного дискриминантного анализа. Однако принципиально важное значение имеет, к какому типу признаков относится отклик: задача классификации предполагает, что он измерен в бинарных, категориальных или, отчасти, порядковых шкалах.
Бинарный классификатор формирует некоторое диагностическое правило и оценивает, к какому из двух возможных классов следует отнести изучаемый объект (согласно медицинской терминологии условно назовем эти классы “норма” или “патология”). Группы точек “патология/норма” в заданном пространстве предикторов, как правило, статистически неразделимы: например, повышение температуры тела до 37.5C часто свидетельствует о заболевании, хотя не всегда болезнь может сопровождаться высокой температурой. Поэтому при тестировании модели вероятны ошибочные ситуации, такие как пропуск положительного (патологического) заключения FN или его “гипердиагностика” FP , т.е. отнесение нормального состояния к патологическому.
Результаты теста на некоторой контрольной выборке можно представить обычной таблицей сопряженности, которую часто называют матрицей неточностей (confusion matrix):
| Результаты теста: | ||
|---|---|---|
| Истинное состояние тест-объектов: | Предсказана патология (1) | Предсказана норма (0) |
| Патология (1) | Истинно-положительные TP (True positives) | Ложно-отрицательные FN (False negatives) |
| Норма (1) | Ложно-положительные FP (False positives) | Истинно-отрицательные TN (True negatives) |
В этих обозначениях объективная ценность рассматриваемого бинарного классификатора определяется следующими показателями:
- Чувствительность (sensitivity) \(SE = Err_ = TP / (TP + FN)\) , определяющая насколько хорош тест для выявления патологических экземпляров;
- Специфичность (specificity) \(SP = Err_ = FP / (FP + TN)\) , показывающая эффективность теста для правильной диагностики отклонений от нормального состояния;
- Точность (accuracy) \(AC = (TP + TN) / (TP + FP + FN + TN)\) , определяющая общую вероятность теста давать правильные результаты.
По аналогии с классической проверкой статистических гипотез специфичность \(Err_I\) определяет ошибку I рода и, соответственно, вероятность нулевой гипотезы, тогда как чувствительность \(Err_\) — мощность теста. Точность является, безусловно, наиболее широко известной мерой производительности классификатора, которая становится катастрофически некорректной в случае несбалансированных частот классов. Если, например, число пациентов, заболевших лихорадкой, составляет менее 1% от числа обследованных, то полный пропуск патологии даст вполне приличный результат тестирования 99%.
Рассмотрим популярный пример выделения спама (“spam” от слияния двух слов — “spiced” и “ham”, или “пряная ветчина”, как образец некачественного пищевого продукта) в электронных письмах в зависимости от встречаемости тех или иных слов (всего 58 частотных показателей). Выборка по спаму представлена в обширной коллекции наборов данных Центра машинного обучения и интеллектуальных систем Калифорнийского университета (UCI Machine Learning Repository) и после некоторой предварительной обработки используется для иллюстрации в книге Mount, Zumel (2014). Скачаем этот файл с сайта ее авторов и разделим исходные данные в соотношении 10:1 на обучающую и проверочную выборки:
spamD read.table('https://raw.github.com/WinVector/zmPDSwR/master/Spambase/spamD.tsv', header = TRUE, sep = '\t') dim(spamD)## [1] 4601 59spamTrain subset(spamD, spamD$rgroup >= 10) spamTest subset(spamD, spamD$rgroup 10) c(nrow(spamTrain), nrow(spamTest))## [1] 4143 458# Составляем список переменных и объект типа "формула" spamVars setdiff(colnames(spamD), list('rgroup', 'spam')) spamFormula as.formula(paste('spam=="spam"', paste(spamVars, collapse = ' + '), sep = ' ~ ')) spamModel glm(spamFormula, family = binomial(link = 'logit'), data = spamTrain) # Добавляем столбец со значениями вероятности спама: spamTrain$pred predict(spamModel, newdata = spamTrain, type = 'response') spamTest$pred predict(spamModel,newdata = spamTest, type = 'response')Компоненты матрицы неточностей и перечисленные показатели легко получить с использованием обычной функции table() — например, так:
# На обучающей выборке: (cM.train table(Факт = spamTrain$spam, Прогноз = spamTrain$pred > 0.5))## Прогноз ## Факт FALSE TRUE ## non-spam 2396 114 ## spam 178 1455# На проверочной выборке: (cM table(Факт = spamTest$spam, Прогноз = spamTest$pred > 0.5))## Прогноз ## Факт FALSE TRUE ## non-spam 264 14 ## spam 22 158c(Точность (cM[1, 1] + cM[2, 2])/sum(cM), Чувствительность cM[1, 1]/(cM[1, 1] + cM[2, 1]), Специфичность cM[2, 2]/(cM[2, 2] + cM[1, 2]))## [1] 0.9213974 0.9230769 0.9186047Иногда предпочтительнее использовать функцию confusionMatrix(y, pred) из пакета caret :
library(caret) library(e1071) pred ifelse(spamTest$pred > 0.5, "spam", "non-spam") confusionMatrix(spamTest$spam, pred)## Confusion Matrix and Statistics ## ## Reference ## Prediction non-spam spam ## non-spam 264 14 ## spam 22 158 ## ## Accuracy : 0.9214 ## 95% CI : (0.8928, 0.9443) ## No Information Rate : 0.6245 ## P-Value [Acc > NIR] : Выбрать другой класс в качестве положительного исхода можно, задав аргумент positive = "spam" . Функция предоставляет пользователю такие статистики, как доверительные интервалы и р-значение для точности, результаты теста \(\chi^2\) по Мак-Немару, вероятностный индекс \(\kappa\) (каппа) Дж. Коэна, а также еще шесть других критериев оценки эффективности классификатора, интересных, по всей вероятности, ограниченному кругу специалистов:
- прогностическая ценность (prevalence) PV = (TP + FN)/(TP + FP + FN + TN) ;
- положительная прогностическая ценность (вероятность фактической патологии при положительном диагнозе) PPV = SE*PV/(SE*PV + (1- SP)*(1 - PV)) ;
- отрицательная прогностическая ценность (вероятность отсутствия патологии при негативном результате теста) NPV = SP*(1 - PV)/(PV*(1 - SE) + SP*(1 - PV)) ;
- частота выявления (detection rate) DR = TP/( TP + FP + FN + TN) ;
- частота распространения (detection drevalence) DP = (TP + FP)/(TP + FP + FN + TN) ; сбалансированная точность (balanced accuracy) BAC = (SE + SP)^2 .
Эффективность классификатора может также оцениваться с использованием информационных критериев - энтропии \(E = \sum -p_i\log_2 p_i\) , где \(p_i\) - вероятности каждого возможного исхода, и условной энтропии (conditional entropy). Эти меры могут быть рассчитаны с использованием функций:
entropy function(x) x[x > 0] scaled xpos/sum(xpos) ; sum(-scaled*log(scaled, 2)) > print(entropy(table(spamTest$spam))) ## [1] 0.9667165conditionalEntropy function(t) < (sum(t[, 1])*entropy(t[, 1]) + sum(t[, 2])*entropy(t[, 2]))/sum(t) > print(conditionalEntropy(cM))## [1] 0.3971897Исходная энтропия Е = entropy(table(y)) определяет среднее количество информации, измеряемой в битах, которую мы приобретаем, если извлечь из выборки очередной экземпляр того или иного класса. Условная энтропия conditionalEntropy(table(y, pred)) показывает, насколько эта мера информации уменьшается из-за ошибок предсказания для различных категорий.
Общепринятым графоаналитическим методом оценки качества теста и интерпретации перечисленных показателей является ROC-анализ (от “Receiver Operator Characteristic” - функциональная характеристика приемника), название которого взято из методологии оценки качества сигнала при радиолокации.
ROC-кривая получается следующим образом (Goddard, Hinberg, 1989). Пусть мы имеем выборку значений независимого количественного показателя, который варьирует от xmin до xmax, и сопряженного с ним бинарного отклика (1 – патология, 0 – норма). Любое произвольное значение \(х\) на этом диапазоне может считаться классификационным порогом, или точкой отсечения (cutt-off value), делящим вектор \(y\) на два подмножества, и для этого разбиения можно рассчитать значения чувствительности \(SE\) и специфичности \(SP\) . Если выполнить сканирование всех возможных значений \(x_ <\max>\geq x \geq x_<\min>\) , то можно построить график зависимости, где по оси Y откладывается \(SE\) , а по оси X - \((1 - SP)\) . Реализация этой процедуры в R может привести к ступенчатой или сглаженной кривой следующего вида (рис. 2.8):
# ROC кривая: library(pROC) m_ROC.roc roc(spamTest$spam, spamTest$pred) plot(m_ROC.roc, grid.col = c("green", "red"), grid = c(0.1, 0.2), print.auc = TRUE, print.thres = TRUE) plot(smooth(m_ROC.roc), col = "blue", add = TRUE, print.auc = FALSE)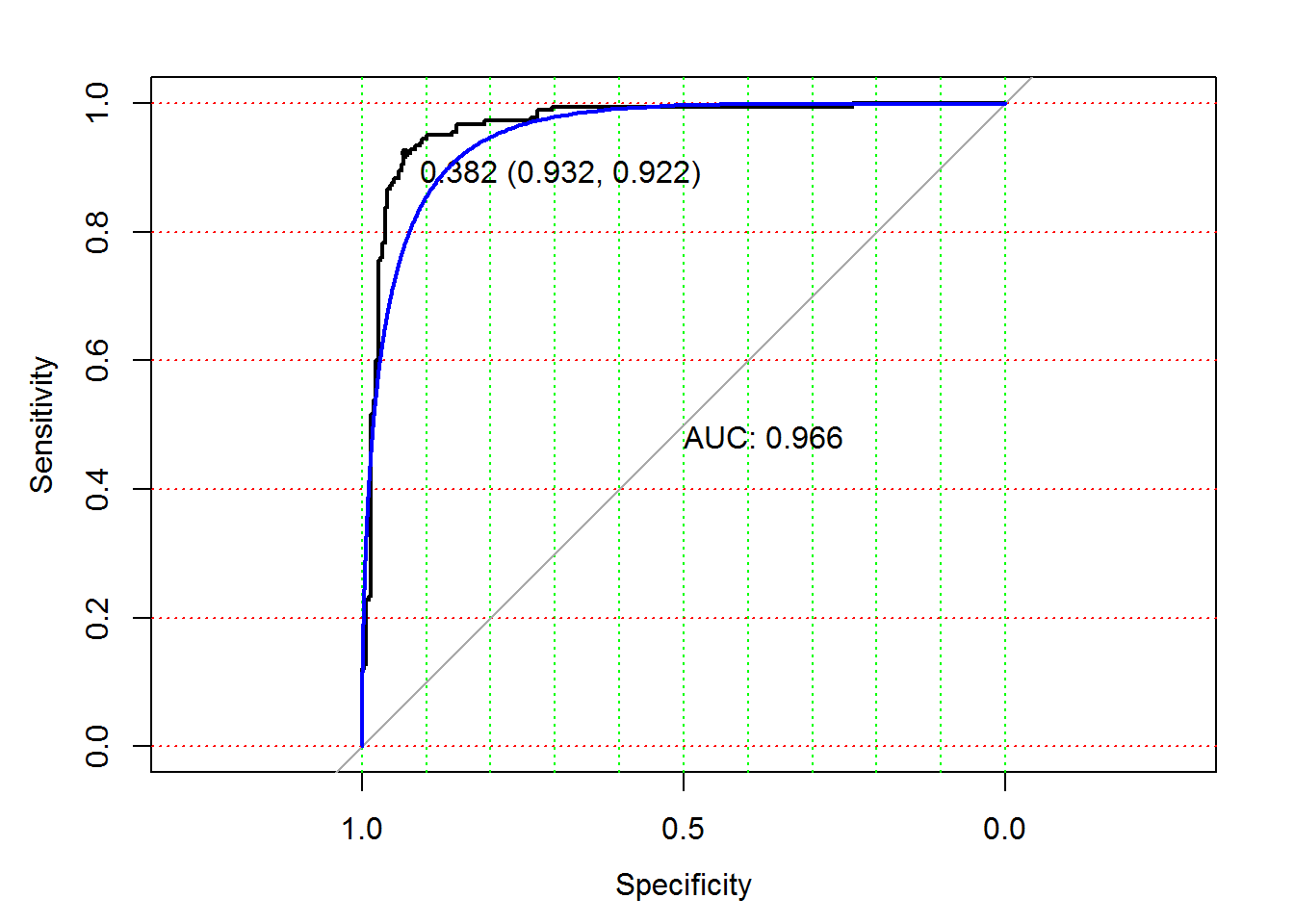
Рисунок 2.8: ROC-кривая для оценки вероятности спама
В случае идеального классификатора ROC-кривая проходит вблизи верхнего левого угла, где доля истинно-положительных случаев равна 1, а доля ложно-положительных примеров равна нулю. Поэтому чем ближе кривая к верхнему левому углу, тем выше предсказательная способность модели. Наоборот, главная диагональная линия соответствует “бесполезному” классификатору, который “угадывает” классовую принадлежность случайным образом. Следовательно, близость ROC-кривой к диагонали говорит о низкой эффективности построенной модели.
Для нахождения оптимального порога, соответствующего наиболее безошибочному классификатору, через крайнюю точку ROC-кривой проводят линию максимальной точности, параллельную главной диагонали. На приведенном графике такая точка, соответствующая значению х = 0.382 , имеет наилучшую комбинацию значений чувствительности SE = 0.932 и специфичности SP = 0.922 . Обратите внимание, что в качестве значений \(х\) фигурирует оценка вероятности отнесения к спаму и, видимо, мы совершенно напрасно принимали ранее в качестве порога величину 0.5.
Полезным показателем является численная оценка площади под ROC-кривыми AUC (Area Under Curve). Практически она изменяется от 0.5 (“бесполезный” классификатор) до 1.0 (“идеальная” модель). Показатель AUC предназначен исключительно для сравнительного анализа нескольких моделей, поэтому связывать его величину с прогностической силой можно только с большими допущениями.
В нашем примере в качестве классификатора писем со спамом мы использовали модель логистической регрессии, полагая, что бинарный отклик имеет биномиальное распределение. Напомним, что в случае обобщенных линейных моделей GLM вместо минимизации суммы квадратов отклонений ищется экстремум логарифма функции максимального правдоподобия (log maximum likelihood), вид которой зависит от характера распределения данных. В нашем случае логарифм функции правдоподобия LL численно равен сумме логарифмов вероятностей классов, которые модель правильно предсказывает для каждого наблюдения:
(LL logLik(spamModel))## 'log Lik.' -807.0323 (df=58)Как и в случае гауссова распределения (см. раздел 2.1), оценка адекватности биномиальной модели осуществляется с использованием девианса D = -2(LL - S) , где S = 0 - правдоподобие “насыщенной модели” с минимальным уровнем байесовской ошибки. Исходя из априорной вероятности одного из классов, можно рассчитать логарифм правдоподобия и девианс для нулевой модели D.null . Эффективность классификатора определяется соотношением девианса остатков D и нуль-девианса D.null , что соответствует псевдо-коэффициенту детерминации Rsquared модели. Статистическую значимость разности девиансов ( D.null - D ) можно оценить по критерию \(\chi^2\) :
df with(spamModel, df.null - df.residual) c(D.null spamModel$null.deviance, D spamModel$deviance, Rsquared = 1 - D/D.null, pchisq(D.null - D, df, lower.tail = FALSE))## Rsquared ## 5556.3602041 1614.0646078 0.7095104 0.0000000Мы получили модель, вполне адекватную по отношению к имеющимся данным. Разумеется, все эти вычисления могут быть выполнены с использованием базовых функций summary() и anova() :
summary(spamModel)Null_Model glm(spam ~ 1, family = binomial(link = 'logit'), data = spamTrain)anova(spamModel, Null_Model , test = "Chisq")Мы не станем приводить здесь длинные протоколы с результатами этих процедур, включающие статистический анализ 58 коэффициентов модели. Отложим также для специального раздела обсуждение возможных путей решения проблемы поиска оптимального состава предикторов.
Вероятностные модели логита, как и иные детерминированные классификаторы, выполняют предсказание класса каждого тестируемого объекта, но при этом возвращают также оцененную вероятность такой принадлежности. При этом весьма полезно проанализировать график плотности распределения вероятностей обоих классов, особенно при подборе оптимальных пороговых значений классификатора. Следующая команда R обеспечивает построение такого графика:
ggplot(data = spamTest) + geom_density(aes(x = pred, color = spam, linetype = spam))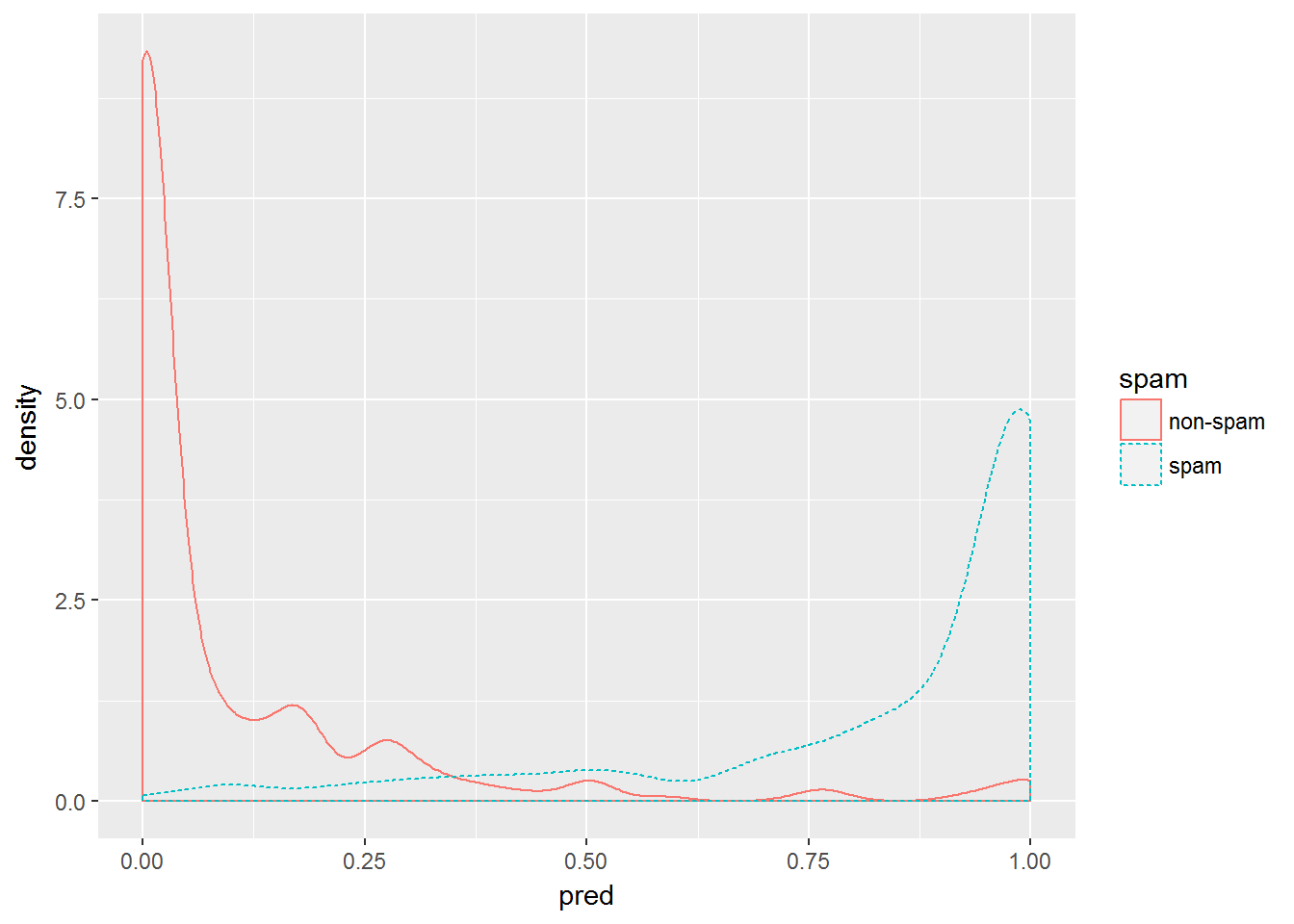
Рисунок 2.9: Кривые плотности апостериорной вероятности принадлежности объектов к двум классам: электронным письмам с наличием спама и без него
Машинное обучение при создании развивающих языковых видеоигр Текст научной статьи по специальности «Математика»
В данной статье представлено использование техник машинного обучения и анализа данных для создания адаптивных схем выбора уровней для языковых видеоигр . Описаны предпосылки к созданию подобной системы, а также проведён статистический анализ эффективности построенной схемы на основе данных, собранных с выборки студентов Астраханского государственного университета. Приведено сравнение с более простыми схемами, использованными ранее в процессе разработки, с помощью как классических частотных методов (критерий согласия Пирсона), так и с помощью байесовских методов.
i Надоели баннеры? Вы всегда можете отключить рекламу.
Похожие темы научных работ по математике , автор научной работы — Сидоров К.С., Ермилов Н.О.
Применение физических признаков видео к задаче классификации
Случайные леса: обзор
Регуляризованные ортогональные модели вероятностных характеристик с условием выполнения их основных свойств
Распознавание дорожных знаков с помощью метода опорных векторов и гистограмм ориентированных градиентов
Метод повышения интерпретируемости регрессионных моделей на основе трехступенчатой модели развития мышления
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
i Надоели баннеры? Вы всегда можете отключить рекламу.
MACHINE LEARNING IN DEVELOPMENT OF VIDEO GAMES FOR LANGUAGE LEARNING
This article presents the use of machine learning and data analysis techniques in development of adaptive level selection schemes for video games for language learning. The prerequisites for the development of such a system are described in the paper, as well as a statistical analysis of the effectiveness of the constructed scheme based on data collected from a sample of students of the Astrakhan State University. The comparison is made with the simpler schemes used earlier in the development process, using both classical frequency methods (Pearson consensus test) and Bayesian methods.
Текст научной работы на тему «Машинное обучение при создании развивающих языковых видеоигр»
DOI: https://doi.org/10.23670/IRJ.2017.66.137 Сидоров К.С.1, Ермилов Н.О.2
:ORCID: 0000-0003-0395-286X, студент, 2Старший преподаватель кафедры математики и методики её
ФГБОУ ВО «Астраханский государственный университет».
МАШИННОЕ ОБУЧЕНИЕ ПРИ СОЗДАНИИ РАЗВИВАЮЩИХ ЯЗЫКОВЫХ ВИДЕОИГР
В данной статье представлено использование техник машинного обучения и анализа данных для создания адаптивных схем выбора уровней для языковых видеоигр. Описаны предпосылки к созданию подобной системы, а также проведён статистический анализ эффективности построенной схемы на основе данных, собранных с выборки студентов Астраханского государственного университета. Приведено сравнение с более простыми схемами, использованными ранее в процессе разработки, с помощью как классических частотных методов (критерий согласия Пирсона), так и с помощью байесовских методов.
Ключевые слова: машинное обучение, анализ данных, высшее образование, видеоигры, статистика.
Sidorov K.S.1, Ermilov N.O.2
:ORCID: 0000-0003-0395-286X, student, 2 Senior professor of department of mathematics and its teaching methodology, Federal State Budget Educational Institution of Higher Professional Education "Astrakhan State University" MACHINE LEARNING IN DEVELOPMENT OF VIDEO GAMES FOR LANGUAGE LEARNING
This article presents the use of machine learning and data analysis techniques in development of adaptive level selection schemes for video games for language learning. The prerequisites for the development of such a system are described in the paper, as well as a statistical analysis of the effectiveness of the constructed scheme based on data collected from a sample of students of the Astrakhan State University. The comparison is made with the simpler schemes used earlier in the development process, using both classical frequency methods (Pearson consensus test) and Bayesian methods.
Keywords: machine learning, data analysis, higher education, video games, statistics.
Как и в любом университете, в Астраханском государственном университете учатся студенты из разных стран, и уровень знания русского языка, разумеется, у них разный. Поскольку для успешного усвоения материала требуется знание русского языка, одна из задач, стоящих перед университетом - подготовить иностранных студентов так, чтобы языковой барьер не мешал им учиться.
С этой целью в АГУ была разработана обучающая видеоигра, основанная на следующей известной идее: игроку выдаётся слово, его задача - за ограниченное время составить как можно больше слов из выданных ему букв. Подобных приложений на рынке, разумеется, представлено много, но они не заточены под обучение языку (в частности, в них отсутствуют продуманные системы уровней).
Как уже было отмечено, уровни сложности игры необходимо градуировать. В то же время простые схемы, неполно учитывающие специфику слова, работали некачественно (понятие качественной модели будет уточнено в разделе «Статистическое сравнение результатов»). Поэтому для построения более эффективной схемы градирования уровней по согласованным с разработчиком техническим заданиям были собраны данные о прохождении игры с разными словами и настройками времени, по которой средствами машинного обучения была построена схема градирования, успешно работающая на практике.
Как уже упоминалось, разрабатываемый продукт основан на составлении как можно большего числа анаграмм заданного слова за ограниченное время. На момент написания статьи интерфейс программы выглядел так, как показано на рис. 1:
Правильный ответ i 11рави льный ответ 2
Ошибки Всего очков
Рис. 1 - образец интерфейса приложения 137
Остаётся неясным, как построить уровни, если зафиксировано время прохождения игры и разыгрываемое слово. Другими словами, нас интересует проблема того, как по заданному слову выбрать пороговые количества слов 11,12,13 так, чтобы они могли адекватно задавать степень сложности игры в том смысле, что количество дошедших до того или иного уровня было бы примерно одинаковым.
Насколько нам известно, осознанных попыток решить подобную задачу не предпринималось. В одной из статей на Хабрахабре была попытка учитывать специфику слова для построения системы наград, но она не была подкреплена анализом данных, и некоторые идеи из той статьи будут рассмотрены далее вместе с обоснованием их неэффективности. [1] Описание выборки
Для дальнейшего анализа была собрана выборка данных о прохождении игры. Более подробно, она содержит 989 записей, каждая из которых содержит: разыгрываемое слово;
максимальное возможное количество слов, которое можно в нём найти; время прохождения; количество найденных слов.
Пять первых записей выборки приведены в таблице 1.
Таблица 1 - Образец формата записей в выборке
Слово Максимальное Время на игру, Результат
математика 129 7 13
геометрия 229 7 15
графика 77 5 24
Как можно видеть уже по первым записям, выборка достаточно вариативна - например, разыгрывались слова разной длины и с разным потенциалом на поиск слов.
В то же время можно заметить, что большинство игроков не угадывают очень много возможных слов (см. рис. 2). С одной стороны, это объясняется ограниченностью времени, а с другой - наличием редких слов, неизвестных даже многим носителям языка
Распределение процентного отношения напоенных слов
Рис. 2 - гистограмма распределения процентного отношения найденных слов
Как видим, основная масса не находит больше 15% слов, а больше 50% было найдено только в 1 игре (напомним, что в выборке их 989).
Для дальнейшего анализа нам понадобится математическая модель зависимости количества найденных слов от времени. Для этого мы будем использовать модель, известную из ядерной физики как простейшую модель числа нераспавшихся частиц [2]. А именно, будем считать, что если всего в слове можно найти 5тиж слов, то в момент времени £ игрок найдёт 5(£) = 5тиж(1 — слов. На качественном уровне это можно понимать так: сначала игрок находит слова с постоянной скоростью Я, после чего приходит «насыщение», и он начинает находить слова всё медленнее и медленнее, но асимптотически при £ ^ +оо игрок находит все слова.
Параметр Я в данной модели отражает, как уже упоминалось, скорость «прорешивания» слова. Заметим, что для более опытных игроков этот параметр будет больше - это будет существенно для построения системы уровней на основе данной модели.
Эту модель пока что нельзя использовать напрямую, потому что есть скрытый параметр Я, поэтому дальнейшее изложение будет разворачиваться вокруг оценки этого параметра. Поскольку в нашей выборке хранятся только параметры 5, 5тиж, £, то мы можем построить эмпирическую оценку на скрытый параметр следующим образом:
Настройка параметров с помощью машинного обучения
Как уже отмечалось, мы ищем зависимость от параметров слова. Предлагается искать эту зависимость в классе
параметрических зависимостей вида
где - вектор параметров слова (содержащий, в частности,
максимальное доступное количество слов), а - пока что неизвестные параметры, задающие зависимость. Именно такой вид зависимости обосновывается графиком, представленном на рис. 3.
Рис. 3 - диаграмма рассеяния для зависимости - = £ от максимального числа слов
Как можно видеть на приведённой диаграмме, зависимость от можно хотя бы с точностью до случайного шума считать линейной. Из этого возникает следующая задача машинного обучения: по выборке, состоящей из параметров слова и оценки --= £, построить линейную модель для предсказания £ по остальным переменным. Для
ясности, в таблице 2 приводим примерный вид выборки в том формате, в котором она используется при применении алгоритмов машинного обучения (использованы те же объекты в том же порядке, что и в таблице 1).
Таблица 2 - Образец формата записей в выборке, составленной для поиска модели для (для простоты указана
лишь одна свободная переменная)
Максимальное £, эмпирическая оценка
В такой постановке получается стандартная задача линейной регрессии, для решения которой существует множество инструментов [3]. Перед применением алгоритма, впрочем, оказалось нужным для каждого слова удалить все объекты, не находящиеся между 25-ой и 75-ой процентилью по количеству найденных слов. Таким образом, из выборки были удалены нетипично слабые и нетипично сильные игроки - из-за очень большой разнородность уровня знаний игроков в области лексики русского языка данные получились очень зашумлёнными, без подобной процедуры очистки построить полезные выводы не представлялось возможным. В результате подобной очистки в выборке осталось лишь 563 объекта.
К оставшимся объектам была применена стандартная модель линейной регрессии с Ь х-регуляризатором [4]. На кросс-валидации с 3 проходами модель показала среднее значение коэффициента детерминации 0,539. Это можно интерпретировать следующим образом: модель смогла «объяснить» 53,9% дисперсии в данных (для сравнения, константная модель по определению данного коэффициента объясняет 0% дисперсии) [5]. С учётом того, что данные остались достаточно зашумлёнными даже после удаления части данных (рис. 3 был построен именно на сокращённой
выборке), это можно расценивать как положительный результат, который можно использовать далее для других задач (например, для оценки порогов уровней).
В конечном итоге была найдена следующая зависимость: Яе тр =---. В данной зависимости фигурирует
только одна свободная переменная - 5таж, чему есть строгое обоснование. Поскольку Ъ^регуляризатор обладает свойством удаления признаков, не объясняющих вариативность данных [4], то во время исследования в модель добавлялись признаки, которые могут косвенным образом объяснять сложность слова - например, его длина, количество гласных, отношение количества гласных к длине слова. Все подобные признаки моделью отклонялись как несущественные (если точнее, модель выставляла им нулевые коэффициенты), что говорит о том, что такие признаки не имеют значения для игроков при условии, что известно максимально количество слов. В частности, это опровергает схемы из упомянутых статей на Хабрахабре и позволяет перейти к решению основной поставленной задачи.
Реализация уровней сложности
Как уже упоминалось, большие значения параметра скорости при прочих равных в нашей модели задают более высокий уровень мастерства игрока. Поэтому возможна следующая реализация уровней: пусть зафиксировано слово и время По параметрам слова (как было показано выше) оцениваем Яетр. Сделав это, вычисляем величину 5 (£) , используя Я = Яетр - это будет средний уровень сложности. Лёгкий (трудный) уровень теперь получаются подстановкой меньшего (большего) значения в выражение для .
Отметим, что эмпирически величина 1 п Я распределена нормально, что отражено на Q-Q графике [6] на рис. 4, построенном с помощью оценок Хетр для всех объектов выборки.
Квантили норма л и не го распределения
Рис. 4 - Q-Q график для квантилей нормального распределения и значений исследуемой величины
Из графика видно, что соответствующие квантили двух распределений - нормального и эмпирического - очень похожи (особенно в зоне типичных значений), что означает, что хотя бы приближённо можно считать нормально распределённой.
Соответственно, если считать, что , то тогда при выборе подходящего значения
, , окажутся (соответственно) первым, вторым и третьим квартилем распределения, то есть
поделят игроков на четыре примерно равные группы в зависимости от степени опыта - как раз то, что и должна делать хорошая схема построения уровней.
Переходя от логарифмов к исходным величинам, получаем формулы для построения лёгкого, среднего и трудного
уровней получаются выбором Я соответственно К Яетр, Яе тр и Яе™р для некоторого К (в наших экспериментах неплохие результаты давало ).
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
Статистическое сравнение результатов
Ранее в приложении использовалась следующая схема уровней (далее будем называть её жёсткой - в противовес мягкой, адаптивной схеме, разработанной выше): для прохождения лёгкого уровня требовалось найти ,
Поскольку нашим основным требованием к уровням сложности является равное разделение игроков по группам, то был проведён следующий тест: для каждого слова были выписаны уровни в соответствии с обеими схемами, после чего для каждого слова было рассчитано количество игроков, дошедших до того или иного уровня (всего для каждого слова получилось 4 числа).
Пример выборки, построенной для статистического анализа - в таблице 3.
Таблица 3 - Количество дошедших до того или иного уровня (по жёсткой схеме) для первых 5 слов выборки
Слово Не дошло до 1 Дошло до 1, но не до 2 Дошло до 2, но не до 3 Дошло до 3
уровня уровня уровня уровня
математика 1 4 31 27
алгебра 1 8 24 30
геометрия 2 20 27 14
логика 0 4 12 40
графика 0 3 6 47
Поскольку перед нами стоит требование равномерности, разумно применить ко всем словам критерий согласия Пирсона [7]. (Требуемый уровень значимости везде - 5%). В результате применения критерия к жёсткой схеме только для одного слова - «розетка» - нельзя отклонить нулевую гипотезу (которая в критерии согласия Пирсона формулируется как равномерность исследуемого распределения). В мягкой схеме нулевая гипотеза не отклоняется уже для шести слов - «геометрия», «розетка», «монетизация», «линолеум», «клавиатура», «праздничный». Учитывая, что выборка содержит очень большое количество шума, это уже позволяет сделать вывод о том, что мягкая схема представляет собой качественное улучшение по сравнению с жёсткой.
Также был проведён ещё один тест, в котором напрямую оценивалась энтропия полученных распределений игроков - из наших рассуждений следует, что чем выше энтропия разбиения, тем лучше работает схема построения уровней.
Для этого использовалась следующая вероятностная модель:
а = (а1( . ак) р | а ~ Dir (а) х | р ~ Cat (р)
а= (а 1(.. . ,а fc) - гиперпараметр, отвечающий за априорное знание о количестве объектов (мы использовали а = (1 ,1 ,1 ,1 ) );
р - вероятностное распределение, задающую вероятность увидеть игрока, дошедшего до соответствующего уровня;
- конкретное «наблюдение», то есть уровень, до которого дошёл игрок.
Пусть мы увидели N = (V,. . ., V) игроков, дошедших до того или иного уровня. (Это ровно те числа, которые приведены в таблице 3). Тогда, как известно, по правилу Байеса можно получить апостериорное распределение на р , которое будет равно р ~ Dir (а + N) - вновь распределение Дирихле, но с другими параметрами [8].
Далее мы провели следующий эксперимент: для каждой из схем построили указанное байесовское апостериорное распределение, после чего построили случайную выборку для величины Н (р ) - энтропии Шеннона [9] - и эмпирически оценили 95%-ный доверительный интервал для неё. (Поскольку апостериорное распределение мы получили в явном виде, то для эмпирической оценки мы могли использовать достаточно много значений - в наших экспериментах результаты перестали меняться после того, как размер выборки превысил 10 миллионов).
В результате для шести слов - «логика», «графика», «монетизация», «линолеум», «клавиатура», «праздничный» -доверительный интервал для энтропии мягкой схемы лежал целиком правее, чем доверительный интервал для жёсткой схемы, что можно интерпретировать следующим образом: мягкая схема на этих словах устойчиво даёт статистически значимо более равномерное распределение. Обратной ситуации не возникало ни разу; более того, точечные оценки на энтропию мягкой схемы были больше для 14 слов из 16. Полные результаты запуска - в таблице 4.
Таблица 4 - Эмпирические доверительные интервалы для двух схем.
Слово Доверительный Доверительный Статистически
интервал жесткой интервал мягкой эффективная схема
математика [0.85, 1.15] [0.94, 1.26] -
алгебра [0.94, 1.21] [0.94, 1.19] -
геометрия [1.07, 1.29] [1.24, 1.28] -
логика [0.65, 1.03] [1.18, 1.37] Мягкая схема
графика [0.43, 0.88] [1.04, 1.31] Мягкая схема
розетка [1.21, 1.37] [1.24, 1.38] -
монетизация [0.77, 1.09] [1.22, 1.38] Мягкая схема
потолок [0.75, 1.07] [0.75, 1.07] -
аудитория [1.04, 1.27] [1.10, 1.33] -
краска [0.61, 0.97] [0.93, 1.23] -
линолеум [0.95, 1.25] [1.28, 1.38] Мягкая схема
куртка [1.12, 1.31] [1.16, 1.35] -
компьютер [0.96, 1.25] [0.97, 1.27] -
сковорода [1.04, 1.31] [1.00, 1.29] -
клавиатура [0.74, 1.08] [1.25, 1.38] Мягкая схема
праздничный [0.82, 1.18] [1.20, 1.37] Мягкая схема
Отметим, что ещё одним достоинством представленной схемы (как видно по таблице 4) является её устойчивость - даже когда мягкая схема в чём-то проигрывала жёсткой, её всё равно удавалось производить достаточно сбалансированные разбиения.
В данной статье была рассмотрена, построена и проанализирована система уровней, способная адаптироваться под параметры конкретного слова и (после модификации алгоритма с учётом возникающей специфики задачи online learning [10]) к специфике игроков.
Всё исследование было подкреплено конкретными данными и статистическими оценками, построенными на них, что подтверждает работоспособность данной модели в рассматриваемой задаче.
В качестве дальнейших улучшений рассматривается расширение данной схемы на выбор не только интересных уровней сложности, но и интересных временных интервалов (построение быстрых или длинных игр в зависимости от слова). Также рассматривается построение системы наград на основе данных, что может также быть очень полезно при геймификации приложения и, как следствие, вовлечении пользователей в процесс изучения лексики.
Список литературы / References
1. Создание игры «Слова из Слова» [Электронный ресурс] // Habrahabr. - 2016. - URL: https://habrahabr.ru/post/308256/ (дата обращения: 16.11.2017).
2. Rutherford E. A comparative study of the radioactivity of radium and thorium. / Ernest Rutherford, Frederick Soddy // Philosophical Magazine - 1903. - Vol. 5 - P. 445-457 - doi:10.1080/14786440309462943
3. Pedregosa F. Scikit-leam: Machine Learning in Python. / Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort and others // Journal of Machine Learning Research - 2011. - Vol. 12 - P. 2825-2830.
4. Tibshirani R. Regression Shrinkage and Selection via the Lasso. / Robert Tibshirani // Journal of the Royal Statistical Society. Series B (Methodological) - 1996. - Vol. 58 - P. 267-288.
5. Glantz S. Primer of Applied Regression and Analysis of Variance. / Stanton A. Glantz, Bryan K. Slinker. - McGraw-Hill, 1990 - 949 p.
6. NIST/SEMATECH e-Handbook of Statistical Methods, 1.3.3.24. Quantile-Quantile Plot [Электронный ресурс] // National Institute of Standards and Technology. - 2012. - URL: http://www.itl.nist.gov/div898/handbook/eda/section3/qqplot.htm (дата обращения: 16.11.2017).
7. Pearson K. On the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling. / Karl Pearson // The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science - 1900. - Vol. 50 - P. 157-175 -doi:10.1080/14786440009463897
8. Agresti A. Bayesian inference for categorical data analysis. / Alan Agresti, David B. Hitchcock // Statistical Methods and Applications - 2005. - Vol. 14 - P. 297-330 - doi:10.1007/s10260-005-0121-y
9. Shannon C. E. A Mathematical Theory of Communication. / Claude E. Shannon // Bell System Technical Journal -1948. - Vol. 27 - P. 379-423 - doi:10.1002/j.1538-7305.1948.tb01338.x
10. Bottou L. Online Learning and Stochastic Approximations. / Léon Bottou - 1998.
Список литературы на английском языке / References in English
1. Sozdanie igry «Slova iz Slova» [Creation of the game "Words from Words"] [Electronic resource] // Habrahabr. -2016. - URL: https://habrahabr.ru/post/308256/ (accessed: 16.11.2017). [in Russian]
2. Rutherford E. A comparative study of the radioactivity of radium and thorium. / Ernest Rutherford, Frederick Soddy // Philosophical Magazine - 1903. - Vol. 5 - P. 445-457 - doi:10.1080/14786440309462943
3. Pedregosa F. Scikit-learn: Machine Learning in Python. / Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort and others // Journal of Machine Learning Research - 2011. - Vol. 12 - P. 2825-2830.
4. Tibshirani R. Regression Shrinkage and Selection via the Lasso. / Robert Tibshirani // Journal of the Royal Statistical Society. Series B (Methodological) - 1996. - Vol. 58 - P. 267-288.
5. Glantz S. Primer of Applied Regression and Analysis of Variance. / Stanton A. Glantz, Bryan K. Slinker. - McGraw-Hill, 1990 - 949 p.
6. NIST/SEMATECH e-Handbook of Statistical Methods, 1.3.3.24. Quantile-Quantile Plot [Electronic resource] // National Institute of Standards and Technology. - 2012. - URL: http://www.itl.nist.gov/div898/handbook/eda/section3/qqplot.htm (accessed: 16.11.2017).
7. Pearson K. On the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling. / Karl Pearson // The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science - 1900. - Vol. 50 - P. 157-175 -doi:10.1080/14786440009463897
8. Agresti A. Bayesian inference for categorical data analysis. / Alan Agresti, David B. Hitchcock // Statistical Methods and Applications - 2005. - Vol. 14 - P. 297-330 - doi:10.1007/s10260-005-0121-y
9. Shannon C. E. A Mathematical Theory of Communication. / Claude E. Shannon // Bell System Technical Journal -1948. - Vol. 27 - P. 379-423 - doi:10.1002/j.1538-7305.1948.tb01338.x
10. Bottou L. Online Learning and Stochastic Approximations. / Léon Bottou - 1998.
Создаём первую модель машинного обучения: используем Colab, Pandas и Sklearn

Кандидат философских наук, специалист по математическому моделированию. Пишет про Data Science, AI и программирование на Python.
Возьмём данные о предпочтениях туристов, обучим на них популярную модель машинного обучения и сделаем предсказание — в точности как настоящие дата-сайентисты, разрабатывающие рекомендательные системы.
- Сформируем тренировочный датасет в виде датафреймовPandas (наша статья об этой библиотеке).
- Обучим модель из библиотеки Sklearn на получившемся датасете.
- Напишем код на Python для дальнейших предсказаний (прочитайте статью про Python-минимум для занятий data science).
В исходной таблице собраны данные о тысяче туристов: возраст, доходы, предпочтения. Ключевая колонка называется target — это город, который конкретный турист выбрал в итоге для поездки. Наша модель научится предсказывать именно её значение — уже для новых туристов.

Основная часть таблицы содержит только числа, что удобно для модели. Например, если в колонке city_Екатеринбург стоит единица, а в остальных колонках, названия которых начинаются с city_, — нули, это означает, что этот турист екатеринбуржец.
Скачайте таблицу по этой ссылке на компьютер и загрузите её в свой Google Colab — сервис, позволяющий писать код и работать с данными прямо в браузере, без установки программ на компьютер. Предварительно прочитайте статью о том, как с ним работать.
Читаем данные
Данные нужно прочитать из файла и преобразовать в подходящий для работы формат. Для этого в колабе добавим новую кодовую ячейку с помощью кнопки «+ Код» вверху и напишем в ней:
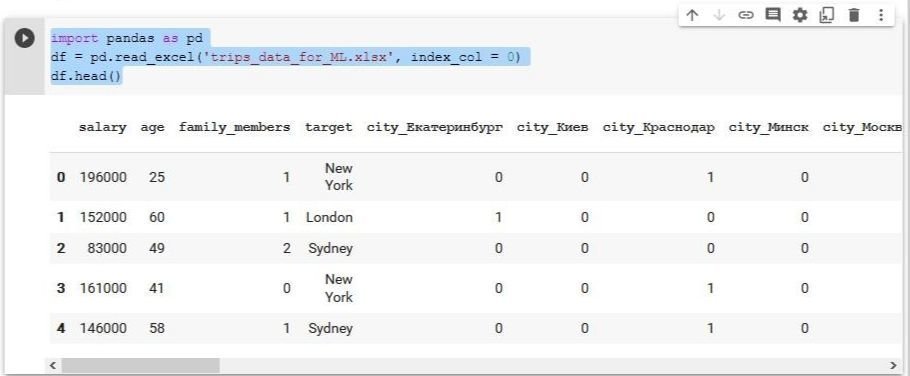
Он показывает первые строки свежесозданного датафрейма (по умолчанию 5). Этим удобно пользоваться, если нужно убедиться, что данные прочитались правильно.
Создаём датасет
Теперь датафрейм с нашими данными надо превратить в датасет, на котором модель машинного обучения сможет тренироваться.
Для этого разобьём df на две части, которые обозначим как X и y. Идея в том, чтобы в Х содержались все данные туристов, кроме колонки target, то есть выбранных ими городов, а в y — только колонка target c этими городами.
Это похоже на задачник: в одной, большой части находятся условия задач (данные туристов), а в другой части, поменьше, — правильные ответы (города, которые они выбрали). Модель будет учиться именно по этому «задачнику».
Добавляем ячейку кода и пишем:
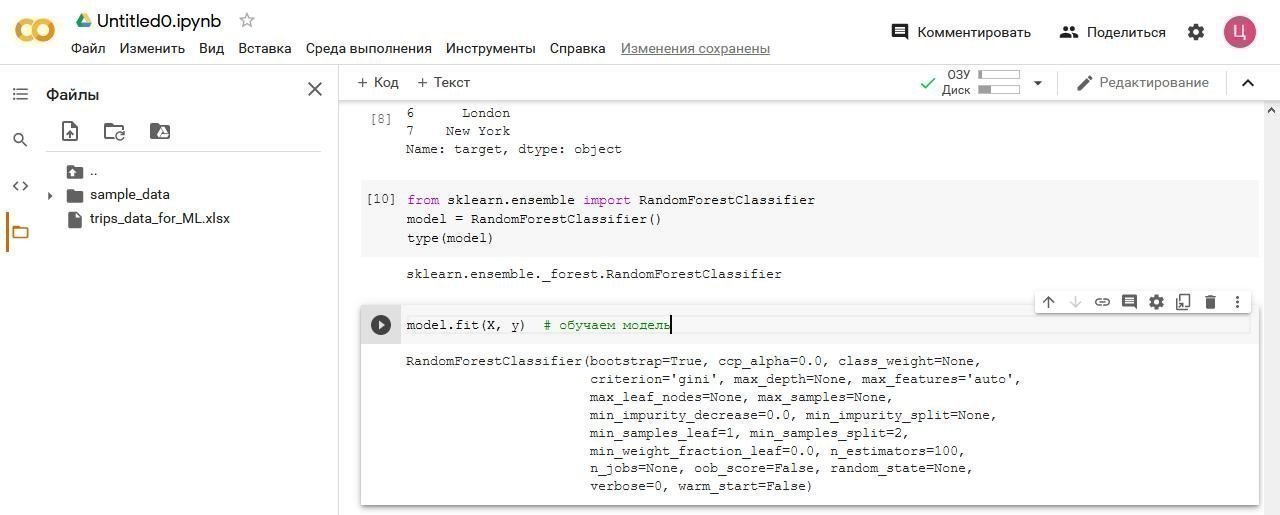
Пора приступать к предсказанию.
Турист — это словарь
С точки зрения нашей модели любой турист выглядит примерно так:
example = 'age': [31], 'city_Екатеринбург': [0], 'city_Киев': [0], 'city_Краснодар': [1], 'city_Минск': [0], 'city_Москва': [0], 'city_Новосибирск': [0], 'city_Омск': [0], 'city_Петербург': [0], 'city_Томск': [0], 'city_Хабаровск': [0], 'city_Ярославль': [0], 'family_members': [0], 'salary': [130000], 'transport_preference_Автомобиль': [1], 'transport_preference_Космический корабль': [0], 'transport_preference_Морской транспорт': [0], 'transport_preference_Поезд': [0], 'transport_preference_Самолет': [0], 'vacation_preference_Архитектура': [0], 'vacation_preference_Ночные клубы': [0], 'vacation_preference_Пляжный отдых': [0], 'vacation_preference_Шопинг': [1]>
Переменная example содержит словарь — структуру данных языка Python, состоящую из пар «ключ — значение». Видим, что ключу 'age' в нашем словаре соответствует значение [31], и догадываемся, что здесь имеется в виду возраст: 31 год. И поскольку ключу 'city_Краснодар' соответствует единица, а всем остальным city-ключам нули, то делаем вывод, что наш новый турист — из Краснодара.
Скопируйте код выше в новую ячейку и запустите его. Тем самым вы одновременно и объявите переменную example, и поместите в неё словарь, описывающий нового туриста.