Извлечение всех ссылок web-сайта с помощью Python

Одна из задач, которая стояла в рамках проекта, нацеленного на исследование мер поисковой оптимизации (SEO, search engine optimization) информационных ресурсов дочерних структур организации, предполагала поиск всех ссылок и выявление среди них так называемых «мертвых (битых) ссылок», отсылающих на несуществующий сайт, страницу, файл, что в свою очередь понижает рейтинг информационного ресурса.
В этом посте я хочу поделиться одним из способов извлечения всех ссылок сайта (внутренних и внешних), который поможет при решении подобных задач.
Посмотрим, как можно создать инструмент извлечения ссылок в Python, используя пакет requests и библиотеку BeautifulSoup. Итак,
pip install requests bs4Импортируем необходимые модули:
import requests from urllib.parse import urlparse, urljoin from bs4 import BeautifulSoupЗатем определим две переменные: одну для всех внутренних ссылок (это URL, которые ссылаются на другие страницы того же сайта), другую для внешних ссылок вэб-сайта (это ссылки на другие сайты).
# Инициализировать набор ссылок (уникальные ссылки) int_url = set() ext_url = set()Далее создадим функцию для проверки URL – адресов. Это обеспечит правильную схему в ссылке — протокол, например, http или https и имя домена в URL.
# Проверяем URL def valid_url(url): parsed = urlparse(url) return bool(parsed.netloc) and bool(parsed.scheme)На следующем шаге создадим функцию, возвращающую все действительные URL-адреса одной конкретной веб-страницы:
# Возвращаем все URL-адреса def website_links(url): urls = set() # извлекаем доменное имя из URL domain_name = urlparse(url).netloc # скачиваем HTML-контент вэб-страницы soup = BeautifulSoup(requests.get(url).content, "html.parser")Теперь получим все HTML теги, содержащие все ссылки вэб-страницы.
for a_tag in soup.findAll("a"): href = a_tag.attrs.get("href") if href == "" or href is None: # href пустой тег continue
В итоге получаем атрибут href и проверяем его. Так как не все ссылки абсолютные, возникает необходимость выполнить соединение относительных URL-адресов и имени домена. К примеру, когда найден href — «/search» и URL — «google.com» , то в результате получим «google.com/search».
# присоединить URL, если он относительный (не абсолютная ссылка) href = urljoin(url, href)В следующем шаге удаляем параметры HTTP GET из URL-адресов:
parsed_href = urlparse(href) # удалить параметры URL GET, фрагменты URL и т. д. href = parsed_href.scheme + "://" + parsed_href.netloc + parsed_href.path Если URL-адрес недействителен/URL уже находится в int_url , следует перейти к следующей ссылке.
Если URL является внешней ссылкой, вывести его и добавить в глобальный набор ext_url и перейдти к следующей ссылке.
И наконец, после всех проверок получаем URL, являющийся внутренней ссылкой; выводим ее и добавляем в наборы urls и int_url
if not valid_url(href): # недействительный URL continue if href in int_url: # уже в наборе continue if domain_name not in href: # внешняя ссылка if href not in ext_url: print(f"[!] External link: ") ext_url.add(href) continue print(f"[*] Internal link: ") urls.add(href) int_url.add(href) return urls
Напоминаю, что эта функция захватывает ссылки одной вэб-страницы.
Теперь создадим функцию, которая сканирует весь веб-сайт. Данная функция получает все ссылки на первой странице сайта, затем рекурсивно вызывается для перехода по всем извлеченным ссылкам. Параметр max_urls позволяет избежать зависания программы на больших сайтах при достижении определенного количества проверенных URL-адресов.
# Количество посещенных URL-адресов visited_urls = 0 # Просматриваем веб-страницу и извлекаем все ссылки. def crawl(url, max_urls=50): # max_urls (int): количество макс. URL для сканирования global visited_urls visited_urls += 1 links = website_links(url) for link in links: if visited_urls > max_urls: break crawl(link, max_urls=max_urls) Итак, проверим на сайте, к которому имеется разрешение, как все это работает:
if __name__ == "__main__": crawl("https://newtechaudit.ru") print("[+] Total External links:", len(ext_url)) print("[+] Total Internal links:", len(int_url)) print("[+] Total:", len(ext_url) + len(int_url))Вот фрагмент результата работы программы:
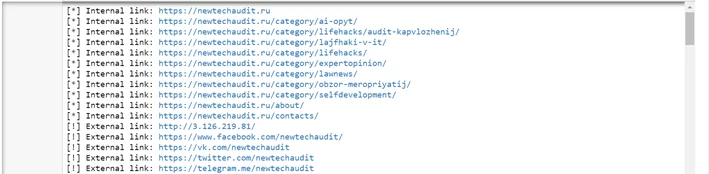
Обратите внимание, что многократный запрос к одному и тому же сайту за короткий промежуток времени может привести к тому, что ваш IP-адрес будет заблокирован. Ссылка на оригинал поста.
HTML::LinkExtractor — Парсер внешних и внутренних ссылок с указанного сайта
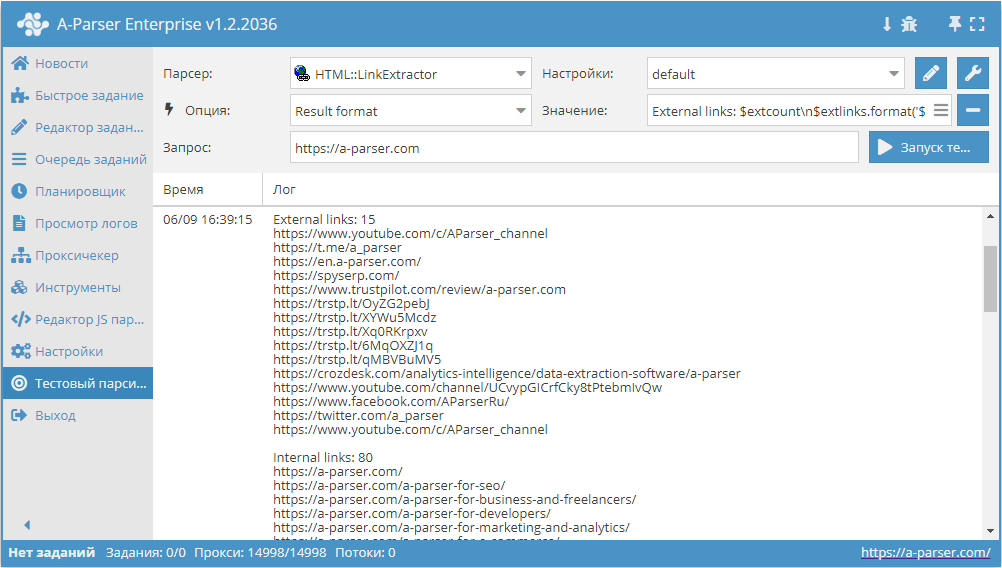
 HTML::LinkExtractor – парсер внешних и внутренних ссылок с указанного сайта. Поддерживает многостраничный парсинг и переход по внутренним страницам сайта до указанной глубины, что позволяет пройтись по всем страницам сайта, собирая внутренние и внешние ссылки. Имеет встроенные средства обхода защиты CloudFlare и также возможность выбора Chrome в качестве движка для парсинга почт со страниц, данные на которых подгружаются скриптами. Способен развивать скорость до 2000 запросов в минуту – это 120 000 ссылок за час.
HTML::LinkExtractor – парсер внешних и внутренних ссылок с указанного сайта. Поддерживает многостраничный парсинг и переход по внутренним страницам сайта до указанной глубины, что позволяет пройтись по всем страницам сайта, собирая внутренние и внешние ссылки. Имеет встроенные средства обхода защиты CloudFlare и также возможность выбора Chrome в качестве движка для парсинга почт со страниц, данные на которых подгружаются скриптами. Способен развивать скорость до 2000 запросов в минуту – это 120 000 ссылок за час.
Кейсы по применению парсера
Сбор всех внешних ссылок с сайта
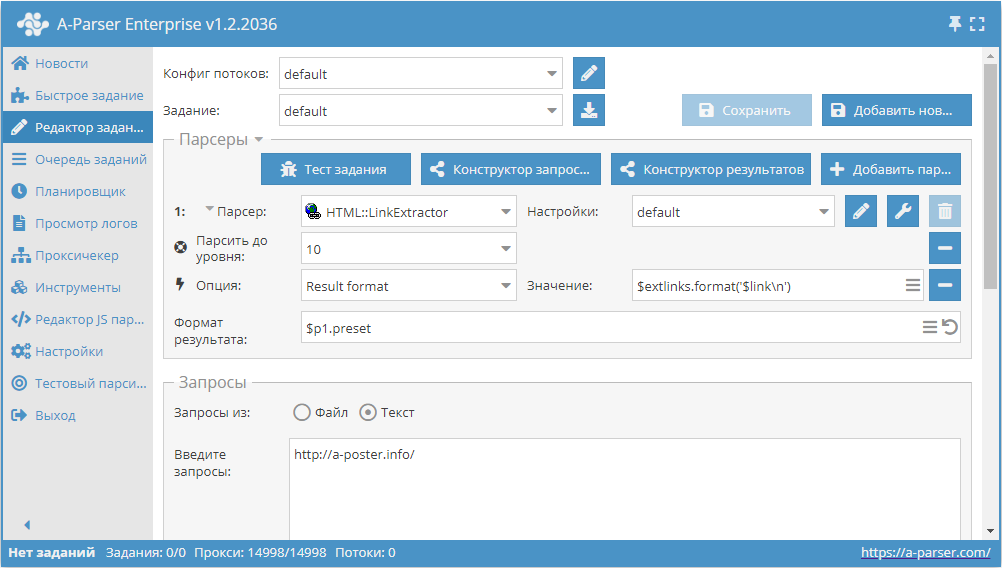
- Добавить опцию Парсить до уровня, в списке выбрать значение 10 (переход по соседним страницам до 10-ого уровня).
- Добавить опцию Result format, в качестве значения указать $extlinks.format(‘$link\n’) (вывод внешних ссылок).
- В разделе Запросы поставить галочку на опцию Уникальные запросы .
- В разделе Результаты поставить галочку на опцию Уник по строке .
- В качестве запроса указать ссылку на сайт, с которого требуется спарсить внешние ссылки.
Скачать пример
eJxtU01v2zAM/S9CgK5AlrSHXnxLgwZb4dZdm57SHISYztTIoirRWQrD/32U7NjJ 1ptIvsfHL9WCpN/5JwceyItkVQsb3yIRORSy0iTGwkrnwYXwSvxYPqRJkiqzuzuQ kxtCx4geWwv6tMBstKTQeI6pnM2YIoU9aPbspa4Yc33VnOD34JzK4Ugo0JWSuJa2 hI4iRnAgzeJ+0gK+XYyC+fZmLi5Fs16PRUvxixgODHs96Xrqgy9yD0sMKkrD4F6w 9SjLqJNLghA96lxO6BAyyDxXoTOpW4UwlUH11aiPWKcnp8yW8Ww6BX7hsGQ3QUwS nJ/HCldiFG3BaarI/9VyREKugrHwXO1Cci15Hyik9hxRBE7yBrJu2Ekt0My0joMe YDH9baV0zlucFUz62RG/hmT/5Wj6Dk+leGV/HNfQZ4nWbfYwsHJMccuNG+S2tSoV se3nWJmwmyt27gBsP7bHACvRQS/TZe7U+VAtmHAfw9ZmdnCdtXG2mXPnBk2htll3 c0dkZZb8GzIzx9JqCH2ZSmveiofn4UJmvltDMIYC/yXPo8TZPyJE7e9f2lKtU3yB N6HAkid5qtql3EitX5/T04gYLoqN30Q2mU7ld4ueFzpRpsCpCESCLfJFcVvNuv+/ /S+vv/zFSd3wwt79U4sO3QUs+3hMnrfBP7b5C6wbebo= Парсинг всех ссылок на сайте
Тема в разделе «Делимся опытом», создана пользователем Iura, 8 янв 2014 .
Поделиться этой страницей
Служба поддержки
- Опубликовать новый тикет
- База знаний
О нас
A-Parser разрабатывается с прицелом на парсинг и обработку больших объемов информации. Мы стремимся выпускать качественный и лучший на рынке продукт, который объединяет в себе более 10 лет опыта работы в индустрии парсинга. A-Parser активно развивается используя передовые технологии, что в конечном итоге дает вам больше результатов еще быстрее.
Быстрая навигация
Поддержка
Есть вопросы? Не стесняйтесь написать нам, мы отвечаем на все вопросы!
Как с помощью в Python извлечь все ссылки на веб‑сайты

Извлечение всех ссылок на веб-странице — обычная задача для веб-парсеров, полезно создавать продвинутые парсеры, которые сканируют каждую страницу определенного веб-сайта для извлечения данных, его также можно использовать для процесса диагностики SEO или даже на этапе сбора информации для проникновения. тестеры. В этом руководстве я расскажу, как с нуля на Python создать инструмент для извлечения ссылок, используя только запросы и библиотеки BeautifulSoup.
pip3 install requests bs4 colorama
Откроем новый файл Python и импортируем необходимые нам модули:
import requests from urllib.parse import urlparse, urljoin from bs4 import BeautifulSoup import colorama
Мы собираемся использовать colorama только для использования разных цветов при печати, чтобы различать внутренние и внешние ссылки:
# init the colorama module colorama.init() GREEN = colorama.Fore.GREEN GRAY = colorama.Fore.LIGHTBLACK_EX RESET = colorama.Fore.RESET YELLOW = colorama.Fore.YELLOW
Нам понадобятся две глобальные переменные, одна для всех внутренних ссылок сайта, а другая для всех внешних ссылок:
# initialize the set of links (unique links) internal_urls = set() external_urls = set()
- Внутренние ссылки — это URL-адреса, которые ведут на другие страницы того же веб-сайта.
- Внешние ссылки — это URL-адреса, которые ведут на другие веб-сайты.
Поскольку не все ссылки в тегах привязки (теги) действительны (я экспериментировал с этим), некоторые из них являются ссылками на части веб-сайта, некоторые — javascript, поэтому давайте наишем функцию для проверки URL-адресов:
def is_valid(url): """ Проверяет, является ли url допустимым """ parsed = urlparse(url) return bool(parsed.netloc) and bool(parsed.scheme)
Здесь проверяем наличие в URL-адресе правильной схемы (протокола, например http или https) и имени домена.
Теперь создадим функцию для возврата всех действительных URL-адресов веб-страницы:
def get_all_website_links(url): """ Возвращает все найденные URL-адреса на `url, того же веб-сайта. """ # все URL-адреса `url` urls = set() # доменное имя URL без протокола domain_name = urlparse(url).netloc soup = BeautifulSoup(requests.get(url).content, "html.parser")
Во-первых, инициализирована переменную urls набора URL-адресов, использован set Python, так-как нам не нужны лишние повторяющиеся ссылки.
Во-вторых, извлекается доменное имя из URL-адреса, которое понадобится для проверки полученных ссылок, на предмет внешних или внутренних.
В третьих, загружен HTML-контент веб-страницы, который обернул объектом soup для облегчения синтаксического анализа HTML.
Получим все HTML-теги (теги привязки, содержащие все ссылки на веб-страницы):
for a_tag in soup.findAll("a"): href = a_tag.attrs.get("href") if href == "" or href is None: # пустой тег href continue
Итак, мы получаем атрибут href и проверяем, есть ли там что-нибудь. В противном случае мы просто переходим к следующей ссылке.
Поскольку не все ссылки являются абсолютными, нам нужно будет объединить относительные URL-адреса с его доменным именем (например, когда href равен «/search», а url равен «google.com», результатом будет «google.com/search»):
# присоединяемся к URL, если он относительный (не абсолютная ссылка) href = urljoin(url, href)
Теперь нам нужно удалить параметры HTTP GET из URL-адресов, поскольку это приведет к избыточности в наборе, приведенный ниже код для этого:
parsed_href = urlparse(href) # удалить параметры URL GET, фрагменты URL и т. д. href = parsed_href.scheme + "://" + parsed_href.netloc + parsed_href.path
if not is_valid(href): # недействительный URL continue if href in internal_urls: # уже в наборе continue if domain_name not in href: # внешняя ссылка if href not in external_urls: print(f"[!] External link: ") external_urls.add(href) continue print(f"[*] Internal link: ") urls.add(href) internal_urls.add(href) return urls
В сухом остатке всё, что здесь сделано и проверяется:
- Если URL-адрес недействителен, перейдём к следующей ссылке.
- Если URL-адрес уже находится в internal_urls , нам он уже не нужен.
- Если URL-адрес является внешней ссылкой, распечатаем её серым цветом и добавив в наш глобальный набор external_urls , перейдём к следующей ссылке.
Наконец, после всех проверок URL будет внутренней ссылкой, распечатываем её и добавляем в наши наборы urls и internal_urls .
Вышеупомянутая функция будет захватывать только ссылки одной конкретной страницы, что, если мы хотим извлечь все ссылки всего веб-сайта? Сделаем это:
# количество посещенных URL-адресов будет сохранено здесь total_urls_visited = 0 def crawl(url, max_urls=30): """ Сканирует веб-страницу и извлекает все ссылки. Все ссылки будут в глобальных переменных набора external_urls и internal_urls. параметры: max_urls (int): максимальное количество URL-адресов для сканирования, по умолчанию 30 """ global total_urls_visited total_urls_visited += 1 print(f"[*] Crawling: ") links = get_all_website_links(url) for link in links: if total_urls_visited > max_urls: break crawl(link, max_urls=max_urls)
Эта функция сканирует веб-сайт, что означает, что она получает все ссылки первой страницы, а затем рекурсивно вызывает себя, чтобы перейти по всем ранее извлеченным ссылкам. Однако это может вызвать некоторые проблемы, программа будет зависать на крупных веб-сайтах (на которых есть много ссылок), таких как google.com, поэтому, добавлен параметр max_urls для выхода, когда мы достигаем определенного количества проверенных URL.
Хорошо, давайте проверим и убедимся, что вы используете это на веб-сайте, на который вы авторизованы, в противном случае я не несу ответственности за любой вред, который вы причиняете.
if __name__ == "__main__": crawl("https://www.thepythoncode.com") print("[+] Total Internal links:", len(internal_urls)) print("[+] Total External links:", len(external_urls)) print("[+] Total URLs:", len(external_urls) + len(internal_urls)) print("[+] Total crawled URLs:", max_urls)
Тестирую на этом сайте. Тем не менее, я настоятельно рекомендую вам не делать этого, это вызовет много запросов, приведет к переполнению веб-сервера и может заблокировать ваш IP-адрес.
Вот часть вывода:
Тут нужна картинка
После завершения сканирования будет выведено общее количество извлеченных и просканированных ссылок:
[+] Total Internal links: 90 [+] Total External links: 137 [+] Total URLs: 227 [+] Total crawled URLs: 30
Классно, правда? Я надеюсь, что этот рецепт будет вам полезен и вдохновит на создание подобных инструментов с использованием Python.
Я собрал все фрагменты и немного отредактировал код для сохранения найденных URL-адресов в файле, а также для получения URL-адреса из аргументов командной строки функции main, посмотрите содержимое файла link_extractor.py.
import requests from urllib.parse import urlparse, urljoin from bs4 import BeautifulSoup import colorama # запускаем модуль colorama colorama.init() GREEN = colorama.Fore.GREEN GRAY = colorama.Fore.LIGHTBLACK_EX RESET = colorama.Fore.RESET YELLOW = colorama.Fore.YELLOW # инициализировать set's для внутренних и внешних ссылок (уникальные ссылки) internal_urls = set() external_urls = set() total_urls_visited = 0 def is_valid(url): """ Проверка url """ parsed = urlparse(url) return bool(parsed.netloc) and bool(parsed.scheme) def get_all_website_links(url): """ Возвращает все найденные URL-адреса на `url, того же веб-сайта. """ # все URL-адреса `url` urls = set() # доменное имя URL без протокола domain_name = urlparse(url).netloc soup = BeautifulSoup(requests.get(url).content, "html.parser") for a_tag in soup.findAll("a"): href = a_tag.attrs.get("href") if href == "" or href is None: # пустой тег href continue # присоединяемся к URL, если он относительный (не абсолютная ссылка) href = urljoin(url, href) parsed_href = urlparse(href) # удалить параметры URL GET, фрагменты URL и т. д. href = parsed_href.scheme + "://" + parsed_href.netloc + parsed_href.path if not is_valid(href): # неверный URL continue if href in internal_urls: # уже в наборе continue if domain_name not in href: # внешняя ссылка if href not in external_urls: print(f"[!] Внешняя ссылка: ") external_urls.add(href) continue print(f"[*] Внутреннея ссылка: ") urls.add(href) internal_urls.add(href) return urls def crawl(url, max_urls=30): """ Сканирует веб-страницу и извлекает все ссылки. Вы найдете все ссылки в глобальных переменных набора external_urls и internal_urls. параметры: max_urls (int): максимальное количество URL-адресов для сканирования, по умолчанию 30. """ global total_urls_visited total_urls_visited += 1 print(f"[*] Проверено: ") links = get_all_website_links(url) for link in links: if total_urls_visited > max_urls: break crawl(link, max_urls=max_urls) if __name__ == "__main__": import argparse """ parser = argparse.ArgumentParser(description="Link Extractor Tool with Python") parser.add_argument("url", help="The URL to extract links from.") parser.add_argument("-m", "--max-urls", help="Number of max URLs to crawl, default is 30.", default=30, type=int) args = parser.parse_args() url = args.url max_urls = args.max_urls """ url = 'https://alumnus.susu.ru' max_urls = 500 crawl(url, max_urls=max_urls) print("[+] Total Internal links:", len(internal_urls)) print("[+] Total External links:", len(external_urls)) print("[+] Total URLs:", len(external_urls) + len(internal_urls)) print("[+] Total crawled URLs:", max_urls) domain_name = urlparse(url).netloc # сохранить внутренние ссылки в файле with open(f"_internal_links.txt", "w") as f: for internal_link in internal_urls: print(internal_link.strip(), file=f) # сохранить внешние ссылки в файле with open(f"_external_links.txt", "w") as f: for external_link in external_urls: print(external_link.strip(), file=f)
Есть некоторые веб-сайты, которые загружают большую часть своего контента с помощью JavaScript, в результате нам нужно вместо этого использовать библиотеку request_html , которая позволяет нам выполнять Javascript с помощью Chromium . Я уже написал для этого сценарий, добавив всего несколько строк (поскольку request_html очень похож на requests ). Вот посмотрите код записанный в файле link_extractor_js.py:
from requests_html import HTMLSession from urllib.parse import urlparse, urljoin from bs4 import BeautifulSoup import colorama # init the colorama module colorama.init() GREEN = colorama.Fore.GREEN GRAY = colorama.Fore.LIGHTBLACK_EX RESET = colorama.Fore.RESET YELLOW = colorama.Fore.YELLOW # initialize the set of links (unique links) internal_urls = set() external_urls = set() total_urls_visited = 0 def is_valid(url): """ Checks whether `url` is a valid URL. """ parsed = urlparse(url) return bool(parsed.netloc) and bool(parsed.scheme) def get_all_website_links(url): """ Returns all URLs that is found on `url` in which it belongs to the same website """ # all URLs of `url` urls = set() # domain name of the URL without the protocol domain_name = urlparse(url).netloc # initialize an HTTP session session = HTMLSession() # make HTTP request & retrieve response response = session.get(url) # execute Javascript try: response.html.render() except: pass soup = BeautifulSoup(response.html.html, "html.parser") for a_tag in soup.findAll("a"): href = a_tag.attrs.get("href") if href == "" or href is None: # href empty tag continue # join the URL if it's relative (not absolute link) href = urljoin(url, href) parsed_href = urlparse(href) # remove URL GET parameters, URL fragments, etc. href = parsed_href.scheme + "://" + parsed_href.netloc + parsed_href.path if not is_valid(href): # not a valid URL continue if href in internal_urls: # already in the set continue if domain_name not in href: # external link if href not in external_urls: print(f"[!] External link: ") external_urls.add(href) continue print(f"[*] Internal link: ") urls.add(href) internal_urls.add(href) return urls def crawl(url, max_urls=30): """ Crawls a web page and extracts all links. You'll find all links in `external_urls` and `internal_urls` global set variables. params: max_urls (int): number of max urls to crawl, default is 30. """ global total_urls_visited total_urls_visited += 1 print(f"[*] Crawling: ") links = get_all_website_links(url) for link in links: if total_urls_visited > max_urls: break crawl(link, max_urls=max_urls) if __name__ == "__main__": import argparse parser = argparse.ArgumentParser(description="Link Extractor Tool with Python") parser.add_argument("url", help="The URL to extract links from.") parser.add_argument("-m", "--max-urls", help="Number of max URLs to crawl, default is 30.", default=30, type=int) args = parser.parse_args() url = args.url max_urls = args.max_urls crawl(url, max_urls=max_urls) print("[+] Total Internal links:", len(internal_urls)) print("[+] Total External links:", len(external_urls)) print("[+] Total URLs:", len(external_urls) + len(internal_urls)) print("[+] Total crawled URLs:", max_urls) domain_name = urlparse(url).netloc # save the internal links to a file with open(f"_internal_links.txt", "w") as f: for internal_link in internal_urls: print(internal_link.strip(), file=f) # save the external links to a file with open(f"_external_links.txt", "w") as f: for external_link in external_urls: print(external_link.strip(), file=f)
Многократный запрос одного и того же веб-сайта за короткий период времени может привести к тому, что веб-сайт заблокирует ваш IP-адрес. В этом случае вам необходимо использовать прокси-сервер для таких целей.
Если вы хотите вместо этого получать изображения, проверьте это руководство: Как загрузить все изображения с веб-страницы в Python, или, если вы хотите извлечь таблицы HTML, проверьте это руководство.

Как с помощью в Python извлечь все ссылки на веб‑сайты , опубликовано К ВВ, лицензия — Creative Commons Attribution-NonCommercial 4.0 International.
Респект и уважуха