Как удалить все пробелы из строки в Python?
Нагуглил функцию strip() , но она удаляет только первый и последний пробел, а мне нужно все. Например, если a = ‘ sd dfsdf dfsfs’ , то нужно получить a = ‘sddfsdfdfsfs’ . Есть ли такая функция или надо через цикл как-то делать?
Отслеживать
6,373 5 5 золотых знаков 25 25 серебряных знаков 56 56 бронзовых знаков
задан 8 сен 2014 в 15:19
187 2 2 золотых знака 5 5 серебряных знаков 12 12 бронзовых знаков
3 ответа 3
Сортировка: Сброс на вариант по умолчанию
a.replace(' ', '') Отслеживать
ответ дан 8 сен 2014 в 15:20
4,676 16 16 серебряных знаков 15 15 бронзовых знаков
Спасибо, сейчас попробую.
8 сен 2014 в 15:21
strip() может удалить не только пробел, но и табы и другие символы, которые считаются пробелом, включая Юникодные пробелы, если strip() вызван для Юникодной строки:
>>> import string >>> string.whitespace '\t\n\x0b\x0c\r ' >>> string.whitespace.strip() '' >>> import sys >>> s = ''.join(unichr(i) for i in xrange(sys.maxunicode) if unichr(i).isspace()) >>> s[:15] u'\t\n\x0b\x0c\r\x1c\x1d\x1e\x1f \x85\xa0\u1680\u180e\u2000' >>> s.strip() u'' Поэтому аналог strip() , который удаляет пробел во всей строке: s = ».join(s.split()) .
Или, тоже самое, используя регулярные выражения: s = re.sub(r’\s+’, », s, flags=re.UNICODE) .
Или, в коде, где важна производительность, bytes.translate() может быть использован, чтобы удалить все стандартные ( string.whitespace в С локале) пробелы из ascii строки:
>>> b'a\tb\nc'.translate(None, b'\t\n\v\f\r ') 'abc' Какой метод нужен для удаления пробелов в строке python?
Если же лишние пробелы в середине строки, то придется сначала разбить строку на элементы списка с помощью метода split() , а потом собрать их обратно в строку через одиночный пробел и метод join() :
movie = 'Catch me if you can ' ' '.join(movie.split()) # 'Catch me if you can' Как убрать пробелы в строке python
Для этого можно использовать метод replace() . Взгляните на пример ниже:
>>> word = 'he x l et' >>> word.replace(' ', '') 'hexlet' Как удалять пробелы в Python и форматировать их
В Python есть несколько методов удаления пробелов в строках. Методы могут быть использованы при удалении пробелов во всем тексте, начале или конце.
Из-за того что строки являются неизменяемыми объектам каждая операция удаления или замены символов создает новую строку. Что бы сохранить новую строку мы должны будем присвоить ее переменной.
Навигация по посту
- Удаление пробелов в начале и конце строки со strip()
- Замена всех пробелов с replace()
- Удаление с join и split
- Использование translate()
- Использование регулярных выражений
Удаление пробелов в начале и конце строки со strip()
Для удаления пробелов в начале и конце строки можно использовать функцию strip(), как на примере ниже:
string = " My name is \n Alex " string = string.strip()
Для удаления символов в начале текста есть lstrip():
word = " My name is \n Alex " word = word.lstrip()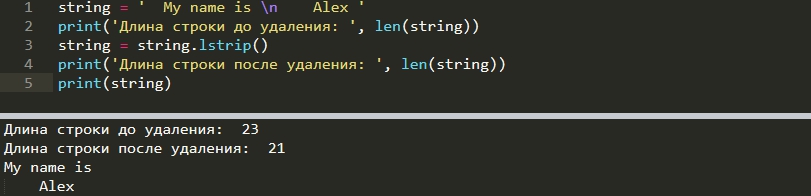
Противоположная операция — rstrip(), удалит символы только справа:
i = " My name is \n Alex " i = i.rstrip()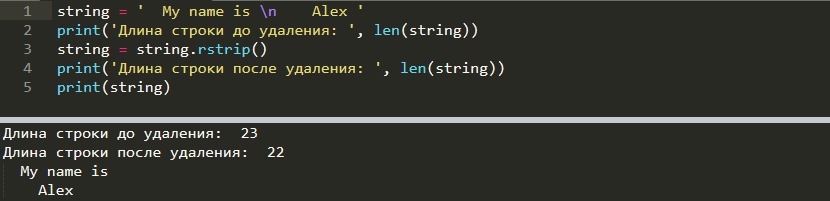
Замена всех знаков с replace()
Когда нужно удалить все нужные символы используйте replace():
d = " My name is \n Alex " d = d.replace(' ', '')
В отличие от методов strip с replace можно заменить задвоенные символы:
v = " My name is \n Alex " v = v.replace(' ', '')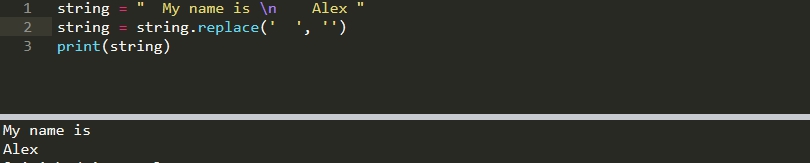
Удаление с join и split
Если нужно удалить все пробелы и символы новой строки ‘\n’ можно преобразовать строку в массив (используя пробелы как разделитель) и преобразовать массив обратно в строку уже добавив пробелы между значениями:
n = " My name is \n Alex " n = n.replace(' ', '')
Вам так же будет интересно:
Используем Python Pillow для вставки текста и изображения в картинку
Использование translate()
translate возвращает копию строки в которой все символы будут заменены в соответствии с таблицей. С помощью следующего способа эта операция пройдет с пробелами:
import string s = ' word1 word2 word3' s = s.translate()
Использование регулярных выражений
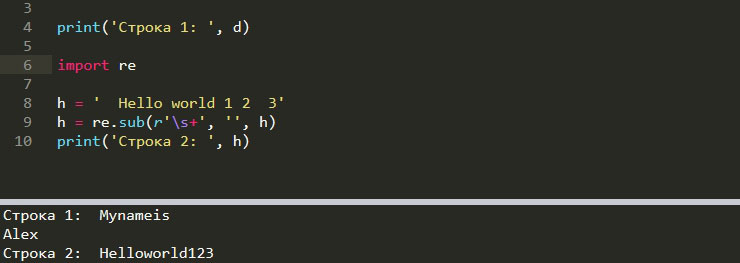
Используя регулярные выражения мы можем получить каждый из результатов полученных выше. Знак пробела, в регулярных выражениях, обозначается как ‘\s’. Знак ‘+’ говорит об одном или множестве повторений символа. В примере ниже будут заменены все символы пробела:
import re h = ' Hello world 1 2 3' h = re.sub(r'\s+', '', h)
Для замены указанных знаков в начале текста можно использовать знак ‘^’:
import re j = ' Hello world 1 2 3' j = re.sub(r'^\s+', '', j)
Конец текста обозначает знак ‘$’. С помощью его мы заменим нужные символы в конце строки в следующем примере:
import re string = ' Hello world 1 2 3 ' string = re.sub(r'\s+$', '', string)
Используя знак ‘|’, который в регулярных выражения работает как ‘or’, мы сможем заменить символы в начале и конце:
import re string = ' Hello world 1 2 3 ' string = re.sub(r'^\s+|\s+$', '', string)