Как исправить: нет модуля с именем plotly
Одна распространенная ошибка, с которой вы можете столкнуться при использовании Python:
ModuleNotFoundError: No module named 'plotly' Эта ошибка возникает, когда Python не обнаруживает библиотеку Plotly в вашей текущей среде.
В этом руководстве представлены точные шаги, которые вы можете использовать для устранения этой ошибки.
Шаг 1: pip установить сюжетно
Поскольку Plotly не устанавливается автоматически вместе с Python, вам нужно будет установить его самостоятельно.
Самый простой способ сделать это — использовать pip , менеджер пакетов для Python.
Вы можете запустить следующую команду pip для установки сюжета:
pip install plotly Для python 3 вы можете использовать:
pip3 install numpy Затем вы можете запустить следующий код, чтобы убедиться, что Plotly был успешно установлен:
pip list | grep plotly plotly 5.3.1 Если plotly отображается с номером версии, это означает, что он был успешно установлен.
В большинстве случаев это исправит ошибку.
Шаг 2: Установите пип
Если вы все еще получаете сообщение об ошибке, вам может потребоваться установить pip. Используйте эти шаги , чтобы сделать это.
Вы также можете использовать эти шаги для обновления pip до последней версии, чтобы убедиться, что он работает.
Затем вы можете запустить ту же команду pip, что и раньше, чтобы установить Plotly:
pip install plotly На этом этапе ошибка должна быть устранена.
Шаг 3: проверьте версию сюжета
После успешной установки Plotly вы можете использовать следующую команду для отображения версии Plotly в вашей среде:
pip show plotly Name: plotly Version: 5.3.1 Summary: An open-source, interactive data visualization library for Python Home-page: https://plotly.com/python/ Author: Chris P Author-email: chris@plot.ly License: MIT Location: /srv/conda/envs/notebook/lib/python3.7/site-packages Requires: six, tenacity Required-by: Note: you may need to restart the kernel to use updated packages. Дополнительные ресурсы
В следующих руководствах объясняется, как исправить другие распространенные проблемы в Python:
Lets Analyse it!
Блог Владимира Степанова об аналитике. Публикую свои подходы и кейсы по анализу данных, визуализации и работе с дата-инструментами.
Создаем интерактивные чарты с Plotly
- Получить ссылку
- Электронная почта
- Другие приложения
На дворе 2020. Неужели мы не заслужили чего-то лучшего, чем Matplotlib для построения визуализаций? Конечно же, да! Тогда знакомьтесь — Plotly! Потрясающая и супер гибкая библиотека для создания красивых дата-визуализаций.

Собственно Plotly — это javascript -библиотека (plotly.js), построенная поверх D3.js — тоже javascript-библиотеки, которая заточена на отрисовку визуализаций в HTML-документах (читай web-страницах). А уже plotly.py — это python-библиотека, которая взаимодействует с plotly.js и позволяет задавать различные параметры для наших чартов, что и делает возможности визуализации гораздо более широкими и гибкими.
Есть два основных преимущества использования Plotly по сравнению с другими библиотеками Python, способными создавать графики, такими как Matplotlib и Seaborn. Это:
- Простота использования — создание интерактивных графиков, 3D-графиков и другой сложной графики уместится всего в несколько строк кода. Сделать то же самое в других библиотеках потребует гораздо больше работы.
- Больше возможностей — поскольку Plotly построен на основе D3.js, его возможности построения графиков намного больше, чем у аналогов. Финансовые, статистические, научные чарты, свечные диаграммы, гео-карты. На момент написания поста около 40 типов графиков доступно в Plotly. Смотрите полный список здесь.
pip install plotly==4.14.1
или через пакетный менеджер conda:
conda install -c plotly plotly=4.14.1
Далее мы потренируемся создать визуализации на основе датасета о ценах на жилье, который вы можете скачать из Kaggle.
Импорт данных
Для начала импортируем plotly и его внутренний компонент графических объектов.
А также pandas для загрузки наших данных в датафрейм.
Скаттер плот
Построим график зависимости года продажи объекта(Sales Price) от года постройки (YearBuilt). Для этого мы создадим Scatter graph object и поместим его в trace.
По сути задание характеристик для чарта выполняется в виде создания объекта с парой ключ-значение.
Приведенная выше команда откроет в вашем браузере новую вкладку с чартом.

Если хотите, чтобы графики открывали прямо в ноутбуке, то для начала установите пакет ipywidgets.
pip install «ipywidgets>=7.2»
Через conda:
conda install «ipywidgets>=7.2»
А сам код будет выглядеть следующим образом:
import plotly.graph_objects as go
fig = go.Figure(data=go.Bar(y=[2, 3, 1]))
fig.show()
Интерактивность автоматически встроена в Plotly. Все команды находятся в правом верхнем углу браузера:

- При наведении на каждую точку отображаются ее значения в осях x и y.
- График можно зумить
- Можно выделять часть графика с помощью прямоугольника или лассо.
- Вы можете передвигаться по чарту, чтобы лучше рассмотреть его участки детально
- Вы можете скачать чарт в виде изображения
Рисуем бокс-плот
Процесс примерно такой же. Мы создадим graph object, поместим его в trace, поменяем только тип графика:

- Медиана
- 1 и 3 квартили
- Минимум и Максимум значений
- Верхний и нижний предел, увидеть если есть выбросы в данных

Тепловая карта (хитмэп)
Тепловые карты — еще один мощный инструмент визуального анализа данных. Они особенно эффективны для отображения корреляций между несколькими переменными на одном графике.
Давайте построим корреляционную матрицу нашего набора данных о ценах на жилье в виде тепловой карты. Сначала определяем x и y как имена столбцов, а z как значения в матрице.

После выполнения команды получим вот такой чарт:
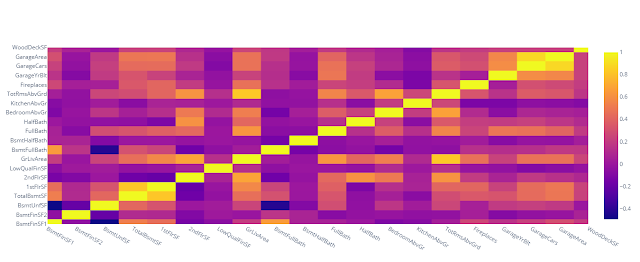
Те же хитмэпы в Matplotlib могут быть сложноваты для восприятия, поскольку вы не можете увидеть точное значение в каждой ячейке. Вы можете только предугадать по цвету. Да, можно написать дополнительно код, чтобы вывести эту информацию, но писать код для Matplotlib — это то еще удовольствие.

Plotly же дает нам интерактивность прямо из коробки, поэтому, когда мы строим тепловую карту, мы получаем не только интуитивно понятный обзор, но также возможность при необходимости проверять точные значения. А возможность фокусироваться на отдельной части большого графика позволяет легко погрузиться в детали все это безупречно с визуальной точки зрения!
Сегодня мы познакомились только с базовыми возможностями этой библиотеки. В следующих постах я планирую рассказать чуть больше про структуру основных объектов библиотеки и способах задания параметров для ваших чартов.
- Получить ссылку
- Электронная почта
- Другие приложения
Комментарии
Отправить комментарий
Популярные сообщения из этого блога
Быстрый импорт в базу данных с помощью DBeaver

Сегодня расскажу про небольшой лайфхак о том, как можно быстро загрузить вашу дату в базу данных используя минимум кодинга. Но сначала опишем суть проблемы, которую данный лайфхак решает. Итак, у нас есть некая дата, которая хранится во внешних файлах (например, в csv). Нам нужно загрузить дату в базу данных (далее БД), причем в самой БД нет таблиц предназначенных для загрузки. Делаем по старинке Классическим решением будет провести анализ содержимого таблиц, выписать названия полей и их формат. Затем создать с помощью SQL запроса сами таблицы. Это будет выглядеть примерно вот так: А затем нужно будет сформировать INSERT запрос для каждой строки файла для вставки его в БД. Если в вашем файле 30 тысяч строк, то придется писать запрос для каждой строки. Здесь без Excel или Google Sheets не обойтись. Так как используется инструментарий таблиц для работы со строками можно ускорить процесс создания тела INSERT запроса. Итоговый запрос может выглядеть вот так: Остается только подключиться к
Jupyter-фишки, которые облегчат жизнь аналитику

Если ты работаешь аналитиком или пока еще изучаешь предмет, наверняка, твой основной рабочий инструмент — Jupyter Notebook. И все дело в том, что аналитики используют Python немного по-другому, в отличие от Python-программистов. Конечно, можно делать исследования и в какой-нибудь навороченной IDE, но работа в Jupyter уже давно стала стандартом для аналитиков. А сегодня посмотрим на фишки Jupyter, которые помогут сделать твою работу еще более продуктивной и интересной. Конечно ты знаешь такие pandas команды для обзора датафрейма, как info и describe . Но что, если можно было бы одной командой узнать гораздо больше информации и причем сразу вывести ее в интерактивном чарте? Pandas profiling Эта библиотека позволяет выводить расширенную информацию о датафрейме, которую , кстати, можно сохранить в HTML-файл. Установка Устанавливать Pandas profiling советую не через pip, а через conda. Причем, лучше сразу указывать последнюю версию. Мне по умолчанию conda поставила версию 1.4.1, которая
Два способа загрузить свой датасет в Python

Если вы только начинаете осваивать анализ данных, то наверняка задавались вопросом, как загрузить данные в Python, чтобы начать их анализ. В этой статье покажу 2 способа, как это можно сделать. Способ 1. Загружаем данные с помощью модуля csv Для примера возьмем датасет с рейтингом отзывов по производителям рамена. Рамен — это популярная еда в Азии, лапша быстрого приготовления с различными вкусами. В дальнейших постах мы будет работать именно с этим датасетом. Посмотрим как он выглядит с помощью редактора Notepad++ Используя следующий код мы получим данные из нашего датасета используя CSV модуль При таком способе загрузки CSV модуль загружает данные из датасета в список построчно. Каждый элемент списка будет представлять одну строку нашего датасета, которая в свою очередь тоже будет списком с элементами строки. Т.е это будет список списков. Такой способ выглядит довольно громоздко и является малоэффективным для обработки больших датасетов. Поэтому, мы воспользуемся вторым способом дл
5 приемов при работе с модулем datetime в Python

Сегодня посмотрим на Python-библиотеку datetime — незаменимый набор инструментов для обработки данных с датой и временем. Я дам обзор пяти основных приемов этой библиотеки, которые закроют большинство ваших проблем при обработки дат и времени. Поехали! Понимание что такое объект datetime в Python. Прежде чем приступить к разбору самих приемов полезно посмотреть, как устроены дата и время в datetime. Основным строительным блоком является объект datetime. И вполне логично, что это комбинация объекта даты и объекта времени (привет, кэп Очевидность!) Объект даты — это просто набор значений года, месяца, дня плюс набор функций, которые умеют их обрабатывать. Аналогичным образом устроен объект времени. Он включает значения часа, минут, секунд, микросекунд и часового пояса. Любое время может быть представлено соответствующим выбором этих значений. 1. combine() import datetime # (часы, минуты) start_time = datetime.time(20, 0) # (год, месяц, день) # Создаем объект datetimet start_date
Чистка и препроцессинг данных. Готовим датасет для ML.

В этом посте посмотрим на основные шаги в процессе чистки и подготовки данных для последующего ML-моделирования. В зависимости от структуры аналитического департамента и его размера, чисткой данных могут заниматься как аналитики, так и сами дата-сайентисты. В любом случае, на сырых данных не строится ни одно исследование. По заявлениям экспертов в индустрии, на процесс очистки данных может уходить до 70% рабочего времени аналитиков. Импорт библиотек Первое, что вам нужно сделать, это импортировать библиотеки для предварительной обработки данных. Доступно множество библиотек, но наиболее популярными и важными библиотеками Python для работы с данными являются Numpy, Matplotlib и Pandas. Numpy — это библиотека, используемая для всех математических вещей. Pandas — лучший инструмент для импорта и манипуляций с датасетами. Matplotlib (Matplotlib.pyplot) — это библиотека для создания диаграмм. Альтернативными решениями для Matplotlib могут выступать библиотеки Seaborn и Plotly. Как правило,
Как установить библиотеку plotly в anaconda

Комментарии
Популярные По порядку
Не удалось загрузить комментарии.
ЛУЧШИЕ СТАТЬИ ПО ТЕМЕ
ООП на Python: концепции, принципы и примеры реализации
Программирование на Python допускает различные методологии, но в его основе лежит объектный подход, поэтому работать в стиле ООП на Python очень просто.
Пишем свою нейросеть: пошаговое руководство
Отличный гайд про нейросеть от теории к практике. Вы узнаете из каких элементов состоит ИНС, как она работает и как ее создать самому.
Программирование на Python: от новичка до профессионала
Пошаговая инструкция для всех, кто хочет изучить программирование на Python (или программирование вообще), но не знает, куда сделать первый шаг.
Как настроить визуализацию в Python: Matplotlib и Plotly
Data Scientist работает с огромным объемом данных, который необходимо проанализировать и обработать. Одним из подходов к анализу данных является их визуализация с использованием графического представления.
Сегодня существует множество библиотек для визуализации данных в Python. Одной из самых популярных является Matplotlib, однако этот инструмент создавался задолго до бурного развития Data Science, и в большей мере ориентирован на отображение массивов NumPy и параметрических функций SciPy. В то же время в Data Science распространен обобщенный тип объектов – датасеты, крупные таблицы с разнородными данными. Для визуализации подобных данных разрабатываются новые библиотеки визуализации, например, Plotly.
Далее предложим вашему вниманию сравнительный анализ библиотек Matplotlib и Plotly.
Сравнение проведем на данных, полученных при решении задачи оптимизации электронно-лучевого процесса. Подробней задача описана в отчете о научно-исследовательской работе «математическое и алгоритмическое обеспечение процесса электронно-лучевой сварки тонкостенных конструкций аэрокосмического назначения». Результаты работы модели сильно зависят от начальных параметров, которые варьируются в широком диапазоне, поэтому для экспресс-анализа полученных данных целесообразно использовать графическое представление переменных и целевой функции.
Программная реализация описанной задачи разбита на два модуля:
- module_1 содержит функции T_1, T_2, ψ (описание функций приведено ниже);
- module_2 выполняет расчет распределения температур (T_1 + T_2) по заданным параметрам с последующим графическим выводом в отдельном окне с возможностью сохранения графика в файл.
Для визуализации математического моделирования тепловых процессов необходимо установить библиотеки Plotly и Matplotlib. Plotly не входит ни в Anaconda, ни в стандартный пакет, поэтому устанавливаем через командную строку:
pip install plotly
Устанавливаем Matplotlib в Jupyter notebook с помощью кода:
!pip install matplotlib
Также для работы понадобятся библиотеки NumPy, SciPy, Pandas, Math и Csv для работы с сырыми данными:
import plotly import plotly.graph_objs as go import plotly.express as px from plotly.subplots import make_subplots import numpy as np import pandas as pd import os,sys,inspect import random import math import scipy.integrate import matplotlib.pyplot as plt import math import scipy.integrate import csv import svs
Ниже представлена функция для импортирования настроек из конфигурационного csv файла, принимает 1 аргумент — число — номер модуля, сам csv файл размещен в репозитории.
def import_csv_cofigs(module_num): try: # Начальная температура изделия T_n = 0 # Время t_ = 0 # Мощность q_ = 0 # Теплоемкость материала cp_ = 0 # Коэффициент температуропроводности alpha_ = 0 # Скорость сварки v_ = 0 # Коэффициент теплопроводности lambda_ = 0 # Толщина delta_ = 0 mainDialect = csv.Dialect mainDialect.doublequote = True mainDialect.quoting = csv.QUOTE_ALL mainDialect.delimiter = ‘;’ mainDialect.lineterminator = ‘\n’ mainDialect.quotechar = ‘»‘ module_dir = ‘/’.join(sys.path[0].split(‘\\’)) with open(f’
Ниже представлено описание и код этих двух модулей, начнем с module_1:
import sys # Формула для состояния температурного поля при воздействии быстро движущегося точечного источника def T_1(T_n, V_, t_, q_, cp_, a_, v_): «»» T_n — начальная температура изделия x_ — координата x t_ — время q_ — мощность cp_ — теплоемкость материала a_ — коэффициент температуропроводности v_ — скорость сварки R_ — длина радиус-вектора «»» R_ = math.sqrt(V_.x_**2 + V_.y_**2 + V_.z_**2) # Функция — подинтегральное выражение def f_(t_1): tau_ = t_1 return math.exp((-v_**2 * tau_)/(4*a_) — (R_**2)/(4*a_*tau_))*(1/(tau_**(3/2))) i_ = scipy.integrate.quad(f_, 0, t_, limit=1) return T_n + ((2*q_)/(cp_*math.sqrt((4*math.pi*a_)**3))) * math.exp((-v_*V_.x_)/(2*a_)) * i_[0] # Формула для состояния температурного поля при воздействии быстро движущегося линейного источника def T_2(T_n, V_, t_, q_, cp_, a_, v_, lambda_, delta_): «»» T_n — начальная температура изделия x_ — координата x t_ — время q_ — мощность cp_ — теплоемкость материала a_ — коэффициент температуропроводности v_ — скорость сварки lambda_ — коэффициент теплопроводности delta_ — толщина «»» # Функция — подинтегральное выражение def f_(t_1): tau_ = t_1 return math.exp( (-v_**2 * tau_)/(4*a_) — (2*lambda_*tau_)/(cp_*delta_) — (V_.x_**2+V_.y_**2)/(4*a_*tau_) ) * (1/tau_) i_ = scipy.integrate.quad(f_, 0, t_, limit=1) return T_n + ((q_)/(4*math.pi*lambda_*delta_)) * math.exp((-v_*V_.x_)/(2*a_)) * i_[0] # Функция ψ(x, y, z, v, t, q) def PSI_xyzvtq(T_n, V_, t_, q_, cp_, a_, v_, lambda_, delta_): «»» T_n — начальная температура изделия x_ — координата x t_ — время q_ — мощность cp_ — теплоемкость материала a_ — коэффициент температуропроводности v_ — скорость сварки lambda_ — коэффициент теплопроводности delta_ — толщина T_t — температура в стадии теплонасыщения «»» T_1_result = T_1(T_n, V_, t_, q_, cp_, a_, v_) T_2_result = T_2(T_n, V_, t_, q_, cp_, a_, v_, lambda_, delta_) T_t = (T_1_result + T_2_result) * 0.9 return (T_t — T_n)/(T_1_result+T_2_result-T_n)
Дальше рассмотрим module_2:
from module_1.module_1 import T_1, T_2, PSI_xyzvtq, V_xyz, import_csv_cofigs work_configs = import_csv_cofigs(2) # Начальная температура изделия T_n = work_configs[0] # Время t_ = work_configs[1] # Мощность q_ = work_configs[2] # Теплоемкость материала cp_ = work_configs[3] # Коэффициент температуропроводности alpha_ = work_configs[4] # Скорость сварки v_ = work_configs[5] # Коэффициент теплопроводности lambda_ = work_configs[6] # Толщина delta_ = work_configs[7] def main(): show_matrix = [[], [], []] for i in range(-50,100,5): for j in range(-50,100,5): V_ = V_xyz(i/100,j/100,0) tmp_ = T_2(T_n, V_, t_, q_, cp_, alpha_, v_, lambda_, delta_) + T_1(T_n, V_, t_, q_, cp_, alpha_, v_) show_matrix[0].append(V_.x_) show_matrix[1].append(V_.y_) show_matrix[2].append(tmp_) if __name__ == «__main__»: main()
Данный код и соответствующий ему конфигурационные файлы размещены в репозитории (https://github.com/Saverona/codes.git).
Выполним визуализацию тепловых процессов. Получаем распределение температуры при сварке титанового сплава с учетом геометрических размеров изделия, заданных технологических параметров и заданном режиме ввода электронного луча.
Для визуализации данных с помощью Plotly используем код:
fig = go.Figure(data=[go.Mesh3d( x=show_matrix[0], y=(show_matrix[1]), z=(show_matrix[2]), opacity=0.5, color=’rgba(244,22,100,0.6)’ )]) fig.show()
Для визуализации данных с помощью Matplotlib используем код:
fig = plt.figure() ax = fig.add_subplot(111, projection=’3d’) ax.plot_trisurf(np.array(show_matrix[0]), np.array(show_matrix[1]), np.array(show_matrix[2]), cmap=’plasma’, linewidth=0, antialiased=False) plt.show()
В результате получаем графики распределения температуры на поверхности изделия, построенные с помощью Matplotlib (3D график изображен слева) и Plotly (графики изображены справа). В Plotly можем наблюдать распределение с разных осей, а также имеется возможность посмотреть значение в конкретной точке, в Matplotlib таких возможностей нет.
Simple plot – это график, который показывает динамику по одному или нескольким показателям. Его удобно применять, когда нужно сравнить, как меняются с течением времени разные наборы данных. Данные на таком графике отображаются в виде точек, которые соединены линиями. Выполним визуализацию Simple plot в Matplotlib и Plotply. График показывает равномерность нагрева изделия в процессе электронно-лучевой сварки.
fig, ax = plt.subplots() ax.plot(show_matrix[1], show_matrix[2]) ax.set(xlabel=’x’, ylabel=’y’, title=’Temp’) ax.grid() plt.show()
fig = px.line(x=show_matrix[1],y=show_matrix[2]) fig.show
При работе с Plotly есть возможность сохранять результат сразу в png (к сожалению, у анимационных графиков нет возможности сохранения в gif, что очень неудобно):
Scatter plots – математическая диаграмма, изображающая значения двух переменных в виде точек на декартовой плоскости. На Scatter plots каждому наблюдению соответствует точка, координаты которой равны значениям двух какого-то параметра этого наблюдения. Эти диаграммы используются для визуализации наличия или отсутствия корреляции между двумя переменными. Выполним визуализацию Scatter plots в Matplotlib и Plotply.
Код в Matplotlib:
fig, ax = plt.subplots() sizes = np.random.uniform(15, 80, len(show_matrix[1])) colors = np.random.uniform(15, 80, len(show_matrix[2])) ax.scatter(x=show_matrix[1], y=show_matrix[2], s=sizes, c=colors) plt.show()
fig = px.scatter(x=show_matrix[1],y=show_matrix[2]) fig.show()
В Plotly, есть возможность выделения конкретной области с помощью Lasso и Box select. В Matplotlib график изображен более красочно, по сравнению с Plotly:
Pie chart – это секторная диаграмма, которая предназначена для визуализации структуры статических совокупностей. Относительная величина каждого значения изображается в виде сектора круга, площадь которого соответствует вкладу этого значения в сумме значений. Этот вид визуализации очень удобно использовать, когда нужно показать долю каждой величины в общем объеме. Сектора могут отображаться как в общем круге, так и отдельно, расположенными на небольшом удалении друг от друга. Pie chart сохраняет наглядность только в том случае, если количество частей совокупности диаграммы небольшое. Если частей диаграммы много, то применение такой визуализации данных неэффективно по причине несущественного различия сравниваемых структур. Недостаток Pie chart – малая емкость, невозможно отразить более широкий объем полезной информации. Выполним визуализацию Pie chart в Matplotlib и Plotply.
Код в Matplotlib:
fig = plt.pie(np.array(show_matrix[2]), explode=None, labels=None, colors=None, autopct=None, pctdistance=0.6, shadow=False, labeldistance=1.1, startangle=0, radius=1, counterclock=True, wedgeprops=None, textprops=None, center=(0, 0), frame=False, rotatelabels=False, normalize=True, data=None)
fig = px.pie(show_matrix[2]) fig.update_layout(uniformtext_minsize=12, uniformtext_mode=’hide’) fig.show()
Сравним результаты. в Plotly есть возможность выбрать конкретное количество значений, которые нам можно или нужно посмотреть, а в Matplotlib невозможно проанализировать данный график.
Styling Markers – это особый способ обработки маркеров, он используется как функцией разброса, так и для построения точечных диаграмм. Выполним визуализацию Styling Markers в Matplotlib и Plotply.
Код в Matplotlib:
fig = plt.figure() plt.plot(np.array(show_matrix[2]), marker = ‘o’, ms = 20, mec = ‘hotpink’, mfc = ‘hotpink’)
fig = px.scatter(x = show_matrix[1], y = show_matrix[2]) fig.update_traces(marker=dict(size=7, line=dict(width=6, color=’hotpink’)), selector=dict(mode=’markers’)) fig.show()
У Plotly есть функционал выделения области разными вариантами, удобен просмотр расположения маркера, а также есть возможность посмотреть конкретное значение маркера. В свою очередь у Matlotlib очень приятная визуализация.
А еще в Plotly можем более точно рассмотреть значения распределения температурного поля, как видим в самой верхней точке происходит нагрев при температуре 1914,4. Так же можем выбирать, какой график нам отображать первым или же можем совсем наложить их друг на друга для более точного анализа, ниже представлен код и визуализация:
fig = go.Figure() fig.add_trace(go.Scatter(x=show_matrix[1], y=show_matrix[2], mode=’lines+markers’, name=’Нагрев’, marker=dict(color=show_matrix[2], colorbar=dict(title=»Температура»), colorscale=’Inferno’, size=50))) fig.add_trace(go.Scatter(visible=’legendonly’, x=show_matrix[1], y=show_matrix[2], name=’T1+T2′)) fig.update_layout(legend_orientation=»h», legend=dict(x=.5, xanchor=»center»), margin=dict(l=0, r=0, t=0, b=0)) fig.update_traces(hoverinfo=»all», hovertemplate=»Температура») fig.show()
Так же в Plotly есть возможность реализовать анимационный график с express. Функции express принимают на вход датафреймы, вам лишь нужно указать колонки, по которым производится агрегация данных. И можно сразу строить и тепловые карты, и анимации очень небольшим количеством кода, как в этом примере:
import plotly.express as px df = px.data.gapminder() fig = px.scatter(df, x=»gdpPercap», y=»lifeExp», animation_frame=»year», animation_group=»country», size=»pop», color=»continent», hover_name=»country», log_x=True, size_max=55, range_x=[100,100000], range_y=[25,90]) fig.show()
Также хочется отметить, что у Plotly очень удобная и понятная документация, можно легко найти какой вариант визуализации нужен для работы, но к сожалению, нет описания параметров, которые используются для построения. В документации Matplotlib имеется описание каждого параметра, что очень упрощает реализацию.
По сравнению с Matplotlib, Plotly предлагает обширный список вариантов построения графиков, начиная с обычных и заканчивая анимационными или графическими картами.
На наш взгляд, Plotly является более информативной и удобной библиотекой для визуализации данных. Библиотека имеет однострочный код для красочной визуализации датасетов, интерактивные элементы для выделения и исследования данных, возможность существенной детализации отображаемой информации.
Желаем приятной работы при визуализации данных!