Уменьшение размерности
Под уменьшением размерности (англ. dimensionality reduction) в машинном обучении подразумевается уменьшение числа признаков набора данных. Наличие в нем признаков избыточных, неинформативных или слабо информативных может понизить эффективность модели, а после такого преобразования она упрощается, и, соответственно, уменьшается размер набора данных в памяти и ускоряется работа алгоритмов ML на нем. Уменьшение размерности может быть осуществлено методами выбора признаков (англ. feature selection) или выделения признаков (англ. feature extraction).
| Определение: |
| Объекты описаны признаками $F = (f_1, . . . , f_n)$. Задачей является построить множество признаков $G = (g_1, . , g_k) : k < n$ (часто $k |
Зачем нужно
- Ускорение обучения и обработки
- Борьба с шумом и мультиколлинеарностью
- Интерпретация и визуализация данных
Когда применяется
- Нужно использовать меньше памяти для хранения данных
- Нужно уменьшить время обработки
- Нужно увеличить качество обработки
- Нужно понять природу признаков
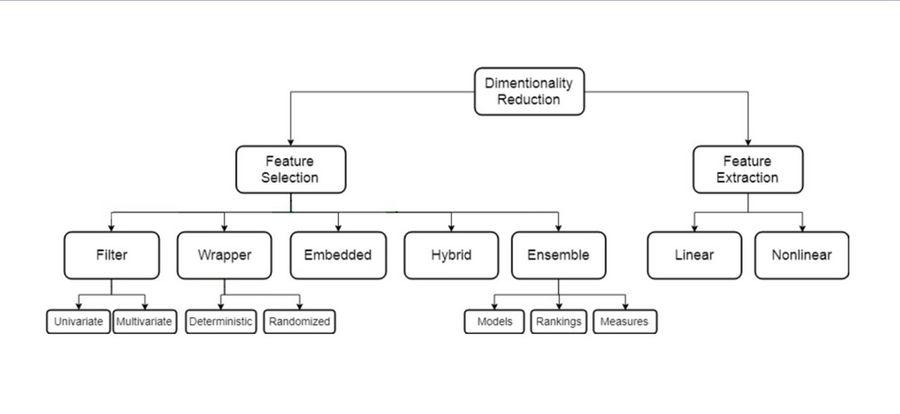
Методы уменьшения размерности
Замечание:
Уменьшение размерности — шаг в предобработке данных
Два основных подхода уменьшения размерности
Выбор признаков (feature selection) включает методы, для которых $G ⊂ F$. Они:
- Быстро работают;
- Не могут «выдумывать» сложных признаков.
Извлечение признаков (feature extraction) включает все другие методы (в том числе даже те, у которых $k > n$).
- В целом, дольше работают;
- Могут извлекать сложные признаки.
Цели извлечения и выбора признаков
- Уменьшение числа ресурсов, требуемых для обработки больших наборов данных
- Поиск новых признаков
- Эти признаки могут быть линейными и нелинейными относительно исходных
Цели выбора признаков:
- Уменьшение переобучения и улучшение качества предсказания
- Улучшение понимания моделей
Типы ненужных признаков
Существуют также два типа признаков, которые не являются необходимыми:
- Избыточные (redundant) признаки не привносят дополнительной информации относительно существующих
- Нерелевантные (irrelevant) признаки просто неинформативны
Встроенные методы
| Определение: |
| Встроенные методы (embedded methods) — это методы выбора |
признаков, при которых этот выбор осуществляется в процессе работы других алгоритмов (классификаторов и регрессоров)

Процесс работы встроенных методов
Группа встроенных методов (англ. embedded methods) очень похожа на оберточные методы, но для выбора признаков используется непосредственно структуру некоторого классификатора. В оберточных методах классификатор служит только для оценки работы на данном множестве признаков, тогда как встроенные методы используют какую-то информацию о признаках, которую классификаторы присваивают во время обучения.
Одним из примеров встроенного метода является реализация на случайном лесе: каждому дереву на вход подаются случайное подмножество данных из датасета с каким-то случайным набор признаков, в процессе обучения каждое из деревьев решений производит «голосование» за релевантность его признаков, эти данные агрегируются, и на выходе получаются значения важности каждого признака набора данных. Дальнейший выбор нужных нам признаков уже зависит от выбранного критерия отбора.
Встроенные методы используют преимущества оберточных методов и являются более эффективными, при этом на отбор тратится меньше времени, уменьшается риск переобучения, но т.к. полученный набор признаков был отобран на основе знаний о классификаторе, то есть вероятность, что для другого классификатора это множество признаков уже не будет настолько же релевантным.
Классификация методов выбора признаков
- Встроенные методы (embedded)
- Фильтрующие методы (filter)
- Одномерные (univariate)
- Многомерные (multivariate)
- Детерминированные (deterministic)
- Стохастические (stochastic)
Пример: Cлучайный лес 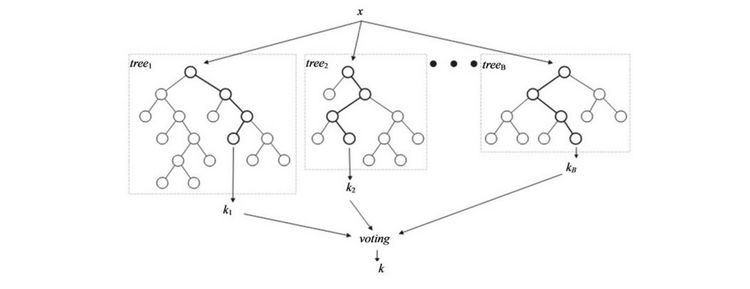
Случайный лес
Основная статья: Дерево решений и случайный лесМетоды-обертки

Процесс работы оберточных методов
Метод-обертка (wrapper method) использует алгоритм (классификатор или регрессор) для оценки качества получаемого подмножества признаков и использует алгоритмы дискретной оптимизации для поиска оптимального подмножества признаков.
Оберточные методы (англ. wrapper methods) находят подмножество искомых признаков последовательно, используя некоторый классификатор как источник оценки качества выбранных признаков, т.е. этот процесс является циклическим и продолжается до тех пор, пока не будут достигнуты заданные условия останова. Оберточные методы учитывают зависимости между признаками, что является преимуществом по сравнению с фильтрами, к тому же показывают большую точность, но вычисления занимают длительное время, и повышается риск переобучения.
Существует несколько типов оберточных методов: детерминированные, которые изменяют множество признаков по определенному правилу, а также рандомизированные, которые используют генетические алгоритмы для выбора искомого подмножества признаков.
Классификация методов-оберток
- Детерминированные:
- SFS (sequential forward selection)
- SBE (sequential backward elimination)
- SVM-RFE
- Перестановочная полезность (Permutation importance)
- Поиск восхождением на холм
- Генетические алгоритмы
Анализ методов-оберток
- Более высокая точность, чем у фильтров
- Используют отношения между признаками
- Оптимизируют качество предсказательной модели в явном виде
- Очень долго работают
- Могут переобучиться при неправильной работе с разбиением набора данных
Фильтры
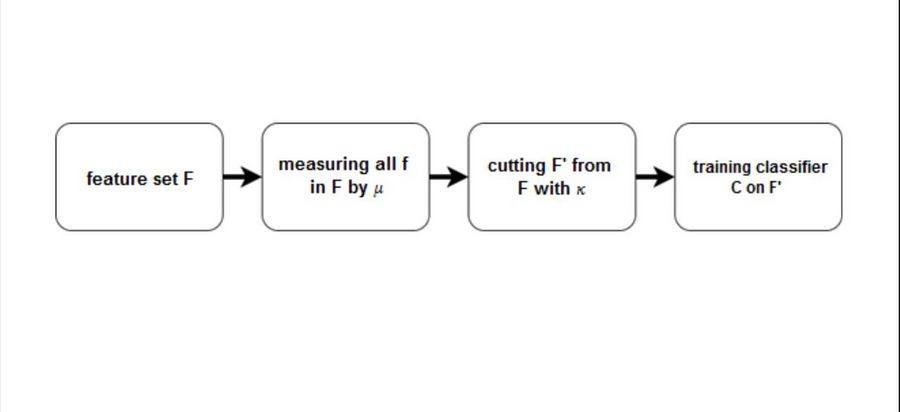
Процесс работы фильтрующих методов
Фильтры (англ. filter methods) измеряют релевантность признаков на основе функции $\mu$, и затем решают по правилу $\kappa$, какие признаки оставить в результирующем множестве.
Фильтры могут быть:
- Одномерные (англ. univariate) — функция $\mu$ определяет релевантность одного признака по отношению к выходным меткам. В таком случае обычно измеряют «качество» каждого признака и удаляют худшие. Одномерные метрики делятся на 3 части:
- Сравнивают два категориальных признака
- Сравнивают категориальный и числовой признаки
- Сравнивают два числовых признака
Преимуществом группы фильтров является простота вычисления релевантности признаков в наборе данных, но недостатком в таком подходе является игнорирование возможных зависимостей между признаками.
Фильтры (filter methods) оценивают качество отдельных признаков или подмножеств признаков и удаляют худшие.
- мера значимости признаков $\mu$
- правило обрезки κ определяет, какие признаки удалить на основе $\mu$
Классификация фильтрующих методов
- Одномерные (univariate):
- Евклидово расстояние
- Коэффициент корреляции (Пирсона или Спирмена)
- Попарные расстояния (внутренние или внешние)
- Условная дисперсия
- Прирост информации (IG)
- Индекс Джини
- $\chi^2$
- Выбор признаков на основе корреляций (CFS)
- Фильтр марковского одеяла (MBF)
Коэффициент корреляции Пирсона
Замечание Важно помнить, что мы смотрим не на корреляцию, а на модуль корреляции.
Коэффициент корреляции Спирмана
- Отсортировать объекты двумя способами (по каждому из признаков).
- Найти ранги объектов для каждой сортировки.
- Вычислить корреляцию Пирсона между векторами рангов.
Information gain [1] :
$IG(T, C)=\displaystyle -\sum_^kp(c_i)\log_2+\sum_^p(t_i)\sum_^kp(c_j|t_i)\log_2$Правило подрезки $k$
- Число признаков
- Порог значимости признаков
- Интегральный порог значимости признаков
- Метод сломанной трости
- Метод локтя
Анализ одномерных фильтров
Преимущества:
- Исключительно быстро работают
- Позволяют оценивать значимость каждого признака
- Порог значимости признаков
- Игнорируют отношения между признаками и то, что реально использует предсказательная модель
Анализ многомерных фильтров
Преимущества:
- Работают достаточно быстро
- Учитывают отношения между признаками
- Работают существенно дольше фильтров
- Не учитывают то, что реально использует предсказательная модель
Гибриды и ансамбли
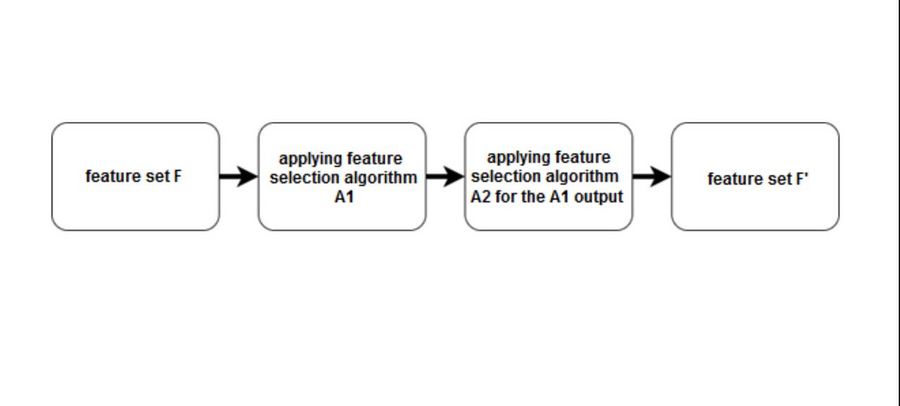
Схема процесса работы гибридного подхода
Гибридный подход
Гибридные методы (англ. hybrid methods) комбинируют несколько разных методов выбора признаков, например, некоторое множество фильтров, а потом запускают оберточный или встроенный метод. Таким образом, гибридные методы сочетают в себе преимущества сразу нескольких методов, и на практике повышают эффективность выбора признаков.
Будем комбинировать подходы, чтобы использовать их сильные стороны Самый частый вариант:
- сначала применим фильтр (или набор фильтров), отсеяв лишние признаки
- затем применим метод-обертку или встроенный метод
Ансамблирование в выборе признаков
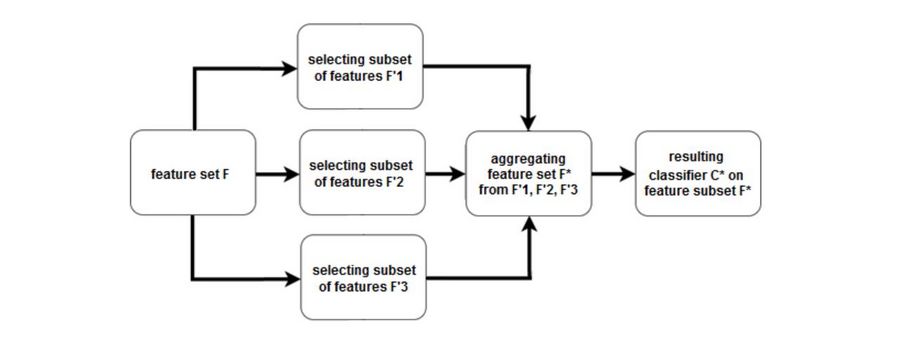
Ансамблирование в выборе признаков
Ансамблевые методы применяются больше для наборов данных с очень большим числом признаков. В данном подходе для начального множества признаков создается несколько подмножеств признаков, и эти группы каким-то образом объединяются, чтобы получить набор самых релевантных признаков. Это довольно гибкая группа методов, т.к. для нее можно применять различные способы выбора признаков и объединения их подмножеств.
Подход к ансамблированию состоит в построении ансамбля алгоритмов выбора признаков
- Строим ансамбль предсказательных моделей
- Объединяем ранжирования
- Объединяем меры значимости
Отбор признаков в машинном обучении
Как происходит процесс отбора подмножества значимых признаков для использования в построении модели в машинном обучении.
Даниил Дятченко
инженер-программист компании «Рексофт»В реальном мире данные не всегда такие чистые, как порой думают бизнес-заказчики. Именно поэтому востребован интеллектуальный анализ данных (data mining и data wrangling). Он помогает выявлять недостающие значения и паттерны в структурированных с помощью запросов данных, которые не может определить человек. Для того, чтобы найти и использовать эти паттерны для предсказания результатов с помощью обнаруженных связей в данных пригодится машинное обучение (Machine Learning).
Для понимания любого алгоритма необходимо просмотреть все переменные в данных и выяснить, что эти переменные представляют. Это крайне важно, потому что обоснование результатов основывается на понимании данных. Если данные содержат 5 или даже 50 переменных, можно изучить их все. А что если их 200? Тогда просто не хватит времени изучить каждую отдельную переменную. Более того, некоторые алгоритмы не работают для категориальных данных, и тогда придется привести все категориальные колонки к количественным переменным (они могут выглядеть количественными, но метрики покажут, что они категориальные), чтобы добавить их в модель. Таким образом, количество переменных увеличивается, и их становится около 500. Что теперь делать? Можно подумать, что ответом будет снижение размерности. Алгоритмы снижения размерности уменьшают число параметров, но негативно влияют на интерпретируемость. Что если существуют другие техники, которые исключают признаки и при этом позволяют легко понять и интерпретировать оставшиеся?
В зависимости от того, основан анализ на регрессии или классификации, алгоритмы отбора признаков могут отличаться, но главная идея их реализации остается одной и той же.
Сильно коррелированные переменные
Сильно коррелированные друг с другом переменные дают модели одну и ту же информацию, следовательно, для анализа не нужно использовать их все. Например, если набор данных (dataset) содержит признаки «Время в сети» и «Использованный трафик», можно предположить, что они будут в некоторой степени коррелированы, и мы увидим сильную корреляцию, даже если выберем непредвзятый образец данных. В таком случае в модели нужна только одна из этих переменных. Если использовать обе, то модель окажется переобучена (overfit) и предвзята относительно одного отдельного признака.
P-значения
В таких алгоритмах, как линейная регрессия, начальная статистическая модель — это всегда хорошая идея. Она помогает показать важность признаков с помощью их p-значений, которые были получены этой моделью. Установив уровень значимости, мы проверяем полученные p-значения, и если какое-то значение оказывается ниже заданного уровня значимости, то данный признак объявляется значимым, то есть изменение его значения, вероятно, приведет к изменению значения цели (target).
Прямой отбор
Прямой отбор — это техника, заключающаяся в применении пошаговой регрессии. Построение модели начинается с полного нуля, то есть пустой модели, а затем каждая итерация добавляет переменную, которая вносит улучшение в строящуюся модель. То, какая переменная добавляется в модель, определяется ее значимостью. Это может быть рассчитано с использованием различных метрик. Самым распространенным способом является применение p-значений, полученных в изначальной статистической модели с использованием всех переменных. Иногда прямой отбор может приводить к переобучению модели, потому что в модели могут оказаться сильно коррелированные переменные, даже если они предоставляют одну и ту же информацию модели (но модель при этом показывает улучшение).
Обратный отбор
Обратный отбор тоже заключается в пошаговом исключении признаков, однако в противоположном направлении по сравнению с прямым. В данном случае начальная модель включает в себя все независимые переменные. Затем переменные исключаются (по одной за итерацию), если они не несут ценности для новой регрессионной модели в каждой итерации. В основе исключения признаков лежат показатели p-значений начальной модели. В этом методе тоже присутствует неопределенность при удалении сильно коррелированных переменных.
Рекурсивное исключение признаков
RFE является широко используемой техникой/алгоритмом для выбора точного числа значимых признаков. Иногда метод используется, чтобы объяснить некоторое число «самых важных» признаков, влияющих на результаты; а иногда для уменьшения очень большого числа переменных (около 200-400), и оставляются только те, которые вносят хоть какой-то вклад в модель, а все остальные исключаются. RFE использует ранговую систему. Признакам в наборе данных выставляются ранги. Затем эти ранги используются для рекурсивного исключения признаков в зависимости от коллинеарности между ними и значимости этих признаков в модели. Кроме ранжирования признаков, RFE может показать, важны ли эти признаки или нет даже для заданного числа признаков (потому что очень вероятно, что выбранное число признаков может являться не оптимальным, и оптимальное число признаков может быть как больше, так и меньше выбранного).
Диаграмма важности признаков
Говоря об интерпретируемости алгоритмов машинного обучения, обычно обсуждают линейные регрессии (позволяющие проанализировать значимость признаков с помощью p-значений) и деревья решений (буквально показывающие важность признаков в форме дерева, а заодно и их иерархию). С другой стороны, в таких алгоритмах, как Random Forest, LightGBM и XG Boost, часто используется диаграмма значимости признаков, то есть строится диаграмма переменных и «количества их важности». Это особенно полезно, когда нужно предоставить структурированное обоснование важности признаков с точки зрения их влияния на бизнес.
Регуляризация
Регуляризация делается для контроля за балансом между предвзятостью (bias) и отклонением (variance). Предвзятость показывает, насколько модель переобучилась (overfit) на тренировочном наборе данных. Отклонение показывает, насколько различны были предсказания между тренировочным и тестовым датасетами. В идеале и предвзятость, и дисперсия должны быть маленькими. Тут на помощь приходит регуляризация! Существует две основных техники:
L1 Регуляризация — Лассо: Лассо штрафует весовые коэффициенты модели для изменения их важности для модели и может даже обнулить их (т.е. убрать эти переменные из конечной модели). Обычно Лассо используется, если набор данных содержит большое число переменных и требуется исключить некоторые из них, чтобы лучше понять, как важные признаки влияют на модель (т.е. те признаки, которые были выбраны Лассо и у которых установлена важность).
L2 Регуляризация — методом Ridge: Задачей Ridge является сохранение всех переменных и в то же время присвоение им важности на основе вклада в эффективность модели. Ridge будет хорошим выбором, если набор данных содержит небольшое число переменных и все они необходимы для интерпретации выводов и полученных результатов.
Так как Ridge оставляет все переменные, а Лассо лучше устанавливает их важность, был разработан алгоритм, объединяющий лучшие особенности обеих регуляризаций и известный как Elastic-Net.
Существует еще множество способов отбора признаков для машинного обучения, но главная идея всегда остается одной и той же: продемонстрировать важность переменных и затем исключить некоторые из них на основе полученной важности. Важность — это очень субъективный термин, так как это не одна, а целый набор метрик и диаграмм, который может использоваться для нахождения ключевых признаков.
Спасибо за чтение! Счастливого обучения!
Как выбрать признаки для машинного обучения

Критерий хи-квадрат (Chi-square Test)
Используется для категориальных признаков в датасете. Мы вычисляем хи-квадрат между каждым признаком и целью, после выбираем желаемое количество “фич” с лучшими показателями. Чтобы правильно применить критерий для проверки связи между различными функциями в наборе данных и целевой переменной, должны быть выполнены следующие условия: категориальные переменные, которые выбираются независимо, и частота значений > 5.
import pandas as pd import numpy as np from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import chi2 # Преобразование в категориальные данные путем преобразования в целые числа. # Где X, y - входные и выходные данные соответственно. X_categorical = X.astype(int) # Выбираем 3 признака с наивысшим "хи-квадрат". chi2_features = SelectKBest(chi2, k = 3) X_kbest_features = chi2_features.fit_transform(X_categorical, y) # Вывод "до и после" print("Количество признаков до преобразования:", X_categorical.shape[1]) print("Количество признаков после преобразования:", X_kbest_features.shape[1])Критерий Фишера (F-тест)
Критерий Фишера – один из наиболее широко используемых методов контролируемого выбора признаков. Алгоритм, который мы будем использовать, возвращает ранги переменных на основе оценки критерия в порядке убывания, после чего уже следует их отбор.
import pandas as pd import numpy as np from skfeature.function.similarity_based import fisher_score import matplotlib.pyplot as plt # Вычисляем критерий # Где X, y - входные и выходные данные соответственно. ranks = fisher_score.fisher_score(X, y) # Делаем график наших "фич" # Где data - ваш датасет feature_importances = pd.Series(ranks, data.columns[0:len(data.columns)-1]) feature_importances.plot(kind='barh', color='teal') plt.show()Коэффициент корреляции
Корреляция – это мера линейной связи двух или более переменных. При её помощи мы можем предсказать одну переменную через другую. Логика использования этого метода для выбора характеристик заключается в том, что “хорошие” переменные сильно коррелируют с нашей целью.
Стоит отметить, что переменные должны коррелировать с целевым показателем, но не должны между собой. В примере ниже мы будем использовать корреляцию Пирсона.
import seaborn as sns import matplotlib.pyplot as plt # Матрица корреляции # Где data - ваш датасет correlation_matrix = data.corr() # Выводим признаки на тепловую карту plt.figure(figsize= (10, 6)) sns.heatmap(correlation_matrix, annot = True)Абсолютное отклонение (Mean Absolute Difference, MAD)
Эта техника позволяет нам вычислить абсолютное отклонение от среднего.
import pandas as pd import numpy as np import matplotlib as plt # Вычисляем MAD # Где X - входные данные mean_absolute_difference = np.sum(np.abs(X - np.mean(X, axis = 0)), axis = 0) / X.shape[0] # Наш график признаков plt.bar(np.arange(X.shape[1]), mean_absolute_difference, color = 'teal')2. Методы обертки (wrapper methods)
Особенность этих методов – поиск всех возможных подмножеств признаков и оценка их качества путем “прогонки” через модель.
Процесс выбора функции основан на конкретном алгоритме машинного обучения, который мы используем. Он следует подходу жадного поиска, оценивая все возможные комбинации функций по определенному критерию. Методы оболочки обычно обеспечивают лучшую точность прогнозирования чем методы фильтрации.
Прямой отбор признаков
Это крайне прямолинейный метод, в котором мы начинаем с наиболее эффективной переменной по отношению к цели. Затем мы выбираем другую переменную, которая дает лучшую производительность в сочетании с первой. Этот процесс продолжается до тех пор, пока не будет достигнут заданный критерий.
from sklearn.linear_model import LogisticRegression from mlxtend.feature_selection import SequentialFeatureSelector lr = LogisticRegression(class_weight = 'balanced', solver = 'lbfgs', random_state=42, n_jobs=-1, max_iter=50e) ffs = SequentialFeatureSelector(lr, k_features='best', forward = True, n_jobs=-1) ffs.fit(X, Y) # X, y – входные и выходные данные соответственно. # X_train – входные данные с обучающейся выборки, # y_pred – выходные данные предиктора features = list(ffs.k_feature_names_) features = list(map(int, features)) y_pred = lr.predict(X_train[features])Последовательный отбор признаков
Этот метод работает прямо противоположно методу прямого выбора характеристик. Здесь мы начинаем со всех доступных функций и строим модель. Затем мы используем переменную из модели, которая дает наилучшее значение меры оценки. Этот процесс продолжается до тех пор, пока не будет достигнут заданный критерий.
from sklearn.linear_model import LogisticRegression from mlxtend.feature_selection import SequentialFeatureSelector lr = LogisticRegression(class_weight = 'balanced', solver = 'lbfgs', random_state=42, n_jobs=-1, max_iter=50e) lr.fit(X, y) bfs = SequentialFeatureSelector(lr, k_features='best', forward = False, n_jobs=-1) bfs.fit(X, y) features = list(bfs.k_feature_names_) features = list(map(int, features)) lr.fit(X_train[features], y_train) y_pred = lr.predict(x_train[features])Исчерпывающий выбор признаков
Это самый надежный метод выбора функций из всех существующих. Его суть – оценка каждого подмножества функций методом перебора. Это означает, что метод пропускает все возможные комбинации переменных через алгоритм и возвращает наиболее эффективное подмножество.
from mlxtend.feature_selection import ExhaustiveFeatureSelector from sklearn.ensemble import RandomForestClassifier # создаем ExhaustiveFeatureSeLlector объект. efs = ExhaustiveFeatureSelector(RandomForestClassifier(), min_features=4, max_features=8, scoring='roc_auc', cv=2) efs = efs.fit(X, Y) # выводим выбранные признаки selected_features = X_train.columns[list(efs.best_idx_)] print(selected_features) # выводим финальную оценку прогнозирования. print(efs.best_score_)Рекурсивное исключение признаков
Сначала модель обучается на начальной выборке признаков, и важность каждой функции определяется либо с помощью атрибута coef_ или feature _importances_ . Затем наименее важные “фичи” удаляются из текущего набора. Процедура рекурсивно повторяется для сокращенного набора до тех пор, пока в конечном итоге не будет достигнуто желаемое количество признаков для выбора.
from sklearn.linear_model import LogisticRegression from sklearn.feature_selection import RFE lr = LogisticRegression(class_weight = 'balanced', solver = 'lbfgs', random_state=42, n_jobs=-1, max_iter=50e) rfe = RFE(lr, n_features_to_select=7) rfe.fit(X_train, y_train) # X_train, y_train - входные и выходные данные с обучающей выборки соответственно. y_pred = rfe.predict(X_train)3. Встроенные методы (embedded methods)
Эти методы включают в себя преимущества первых двух, а также уменьшают вычислительные затраты. Отличительной особенностью встроенных методов является извлечение “фич” на этапе конкретной итерации.
Регуляризация LASSO (L1)
Регуляризация состоит в добавлении штрафа (penalty) к различным параметрам модели во избежание чрезмерной подгонки. При регуляризации линейной модели штраф применяется к коэффициентам, умножающим каждый из предикторов. Lasso-регуляризация обладает свойством, позволяющим уменьшить некоторые коэффициенты до нуля. Следовательно, такие “фичи” можно будет просто удалить из модели.
from sklearn.linear_model import LogisticRegression from sklearn.feature_selection import SelectFromModel # Устанавливаем наш параметр регуляризации C=1 logistic = LogisticRegression(C=1, penalty="l1", solver='liblinear', random_state=7).fit(X, y) # Где X, y - входные и выходные данные соответственно. model = SelectFromModel(logistic, prefit=True) X_new = model.transform(X) # Выбираем нужные нам столбцы из датасета без нулевых данных # Где “selected_features” - предварительно выбранные нами признаки (см. по предыдущим методам) selected_columns = selected_features.columns[selected_features.var() != 0] print(selected_columns)Метод с использованием Случайного Леса (Random Forest Importance)
Стратегии на основе дерева, используемые случайными лесами , естественным образом ранжируются по тому, насколько хорошо они улучшают чистоту модели в плане данных. Таким образом, “обрезая” деревья ниже определенного коэффициента, мы можем подобрать наиболее важные признаки.
import numpy as np import pandas as pd from sklearn.ensemble import RandomForestClassifier # создаем случайное дерево с вашими гипер параметрами model = RandomForestClassifier(n_estimators=340) # Обучаем модель на вашей выборке; Где X, y - входные и выходные данные соответственно. model.fit(X, y) # Подбираем самые важные признаки importances = model.feature_importances_ # Создаем отдельный датасет для визуализации final_df = pd.DataFrame() final_df.set_index('Importances') # Сортируем их по возрастанию для лучшей визуализации final_df = final_df.sort_values('Importances') # Выводим на график final_df.plot.bar(color = 'teal')Заключение
Эффективный отбор необходимых “фич” для модели приводит к наибольшему увеличению производительности. Это та проблема, за решением которой дата-сайентисты проводят большую часть времени. Разумеется, без построения признаков (feature engineering) у нас не будет материала для дальнейшего отбора.
Правильные преобразования зависят от многих факторов: типа и структуры данных, их объема. Не стоит также забывать о доступных ресурсах нашего компьютера или облака. Взяв на вооружение обе техники из этого цикла статей, вы будете чувствовать себя гораздо увереннее в мире науки о данных.
Выбор алгоритмов машинного обучения Azure
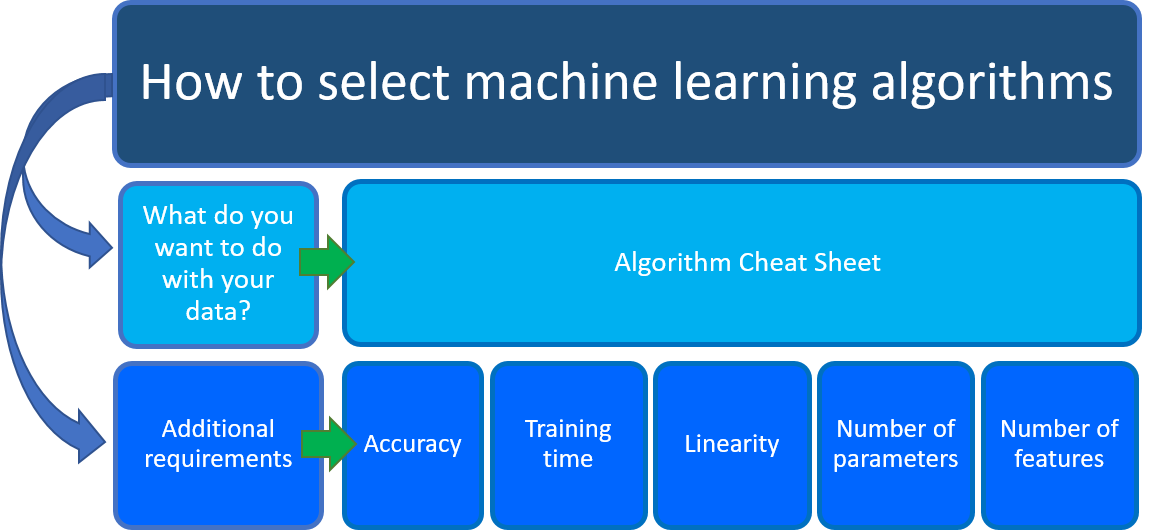
Распространенный вопрос: «Какой алгоритм машинного обучения следует использовать?» Выбранный алгоритм зависит, в основном, от двух различных аспектов сценария обработки и анализа данных:
- Что вы хотите сделать с данными? В частности, каков бизнес-вопрос, на который вы хотите ответить при обучении по прошлым данным?
- Каковы требования к сценарию обработки и анализа данных? В частности, какова точность, время обучения, линейность, количество параметров и функций, поддерживаемых вашим решением?
Конструктор поддерживает два типа компонентов, классические предварительно созданные компоненты (версии 1) и пользовательские компоненты (версия 2). Эти два типа компонентов несовместимы.
Классические предварительно созданные компоненты предоставляют предварительно созданные компоненты, главным образом для обработки данных и традиционных задач машинного обучения, таких как регрессия и классификация. Этот тип компонента по-прежнему поддерживается, но новые компоненты добавляться не будут.
Пользовательские компоненты позволяют упаковывать собственный код в качестве компонента. Она поддерживает совместное использование компонентов между рабочими областями и простой разработки в интерфейсах Studio, CLI версии 2 и ПАКЕТА SDK версии 2.
Для новых проектов мы настоятельно рекомендуем использовать настраиваемый компонент, совместимый с AzureML версии 2 и сохраняющий получение новых обновлений.
Эта статья относится к классическим предварительно созданным компонентам и не совместим с CLI версии 2 и пакетом SDK версии 2.
Бизнес-сценарии и краткий справочник по Машинному обучению
Краткий справочник по Машинному обучению Azure в первую очередь позволяет ответить на вопрос: что нужно сделать с данными? На листе Машинное обучение алгоритма найдите задачу, которую вы хотите выполнить, а затем найдите алгоритм конструктора Машинное обучение Azure для решения прогнозной аналитики.
Конструктор Машинного обучения предоставляет комплексный портфель алгоритмов, таких как лес решений с несколькими классами, системы рекомендаций, регрессия нейронных сетей, многоклассовая нейронная сеть и кластеризация методом k-средних. Каждый алгоритм предназначен для решения определенного типа проблем, связанных с машинным обучением. Полный список, а также описание работы каждого алгоритма и настройки параметров для оптимизации алгоритма см. в Справочнике по модулям и алгоритмам для конструктора Машинного обучения Azure.
Вместе с рекомендациями, приведенными в кратком справочнике по алгоритмам Машинного обучения, следует учитывать другие требования при выборе алгоритма Машинного обучения для принятия решения. Ниже приведены дополнительные факторы, которые следует учитывать, такие как точность, время обучения, линейность, количество параметров и функций.
Сравнение алгоритмов машинного обучения
Некоторые алгоритмы обучения делают определенные предположения о структуре данных или желаемых результатов. Если вы сможете найти тот алгоритм, который соответствует вашим потребностям, с ним вы сможете получить более точные результаты, более точные прогнозы и сократить время обучения.
В следующей таблице перечислены некоторые из наиболее важных характеристик алгоритмов из семейств классификации, регрессии и кластеризации.
Алгоритм Точность Время обучения Линейность Параметры Примечания Семейство классификации Двухклассовая логистическая регрессия Специалист Быстро Да 4 Двухклассовый лес принятия решений Отлично Умеренно No 5 Показывает меньшее время оценки. Предложение не работает с Многоклассовым классификатором «один — все» из-за более медленных оценок, вызванных блокировкой в накоплении прогнозов дерева Двухклассовое увеличивающееся дерево принятия решений Отлично Умеренно No 6 Большой объем памяти Двухклассовая нейронная сеть Специалист Умеренно No 8 Двухклассовое усредненное восприятие Специалист Умеренно Да 4 Двухклассовый метод опорных векторов Специалист Быстро Да 5 Подходит для больших наборов функций Многоклассовая логистическая регрессия Специалист Быстро Да 4 Многоклассовый лес принятия решений Отлично Умеренно No 5 Показывает меньшее время оценки Мультиклассовое увеличивающееся дерево принятия решений Отлично Умеренно No 6 Имеет тенденцию к повышению точности с небольшим риском меньшего объема Многоклассовая нейронная сеть Специалист Умеренно No 8 Многоклассовый классификатор «один — все» — — — — Просмотрите свойства выбранного двухклассового метода Семейство регрессии Линейная регрессия Специалист Быстро Да 4 Регрессия леса принятия решений Отлично Умеренно No 5 Регрессия увеличивающегося дерева принятия решений Отлично Умеренно No 6 Большой объем памяти Регрессия нейронной сети Специалист Умеренно No 8 Семейство кластеризации Кластеризация методом k-средних Отлично Умеренно Да 8 Алгоритм кластеризации Требования к сценарию обработки и анализа данных
После того как будет известно о том, что делать с данными, необходимо определить дополнительные требования для принятия решения.
Сделайте выбор и, возможно, найдите приемлемое решение для удовлетворения следующих требований.
- Правильность
- Время обучения
- Линейность
- Количество параметров
- Количество функций
Правильность
Точность машинного обучения позволяет измерить эффективность модели как пропорцию истинных результатов к общему числу вариантов. В конструкторе Машинного обучения компонент «Оценка модели» вычисляет набор отраслевых метрик оценки. Вы можете использовать этот компонент для измерения точности обученной модели.
Получение наиболее точного ответа возможно не всегда. Иногда достаточно приближенного ответа в зависимости от того, для чего он используется. В этом случае можно значительно сократить время обработки, придерживаясь более приближенных методов. Кроме того, приблизительные методы, как правило, позволяют избежать лжевзаимосвязи.
Существует три способа использования компонента «Оценка модели»:
- Создание оценок для обучающих данных для оценки модели
- Создание оценок для модели, но со сравнением этих оценок с показателями в зарезервированном проверочном наборе
- Сравнение оценок для двух различных, но связанных моделей с использованием одного набора данных
Полный список метрик и подходов, которые можно использовать для оценки точности моделей машинного обучения, см. в компоненте «Оценка модели».
Время обучения
Контролируемое обучение обозначает использование исторических данных для построения модели машинного обучения, которая позволяет снизить ошибки до минимума. Количество минут или часов, необходимых для обучения модели, сильно отличается для различных алгоритмов. Время обучения часто тесно связано с точностью — одно обычно сопутствует другому.
Кроме того, некоторые алгоритмы более чувствительны к количеству точек данных, чем другие. Можно выбрать конкретный алгоритм, так как имеется ограничение по времени, особенно если набор данных большой.
В конструкторе Машинного обучения создание и использование модели машинного обучения, как правило, состоит из трех этапов:
- Необходимо настроить модель, выбрав определенный тип алгоритма и определив ее параметры или гиперпараметры.
- Предоставьте помеченный набор данных, который содержит данные, совместимые с алгоритмом. Подключите данные и модель к компоненту «Обучение модели».
- После завершения обучения используйте обученную модель с одним из компонентов оценки, чтобы создать прогнозы на основе новых данных.
Линейность
Линейность в статистике и машинном обучении означает, что между переменной и константой в наборе данных существует линейная связь. Например, алгоритмы линейной классификации предполагают, что классы могут быть разделены прямой линией (или ее аналогом для большего числа измерений).
Линейность используется во многих алгоритмах машинного обучения. В конструкторе «Машинное обучение» Azure они включают:
- Многоклассовая логистическая регрессия
- Двухклассовая логистическая регрессия
- Поддержка векторных компьютеров
Алгоритмы линейной регрессии предполагают, что тренды данных следуют прямой линии. Это предположение полезно для решения некоторых проблем, но для других снижает точность. Несмотря на недостатки, линейные алгоритмы распространены в качестве первой стратегии. Обычно они алгоритмически просты и быстро осваиваются.
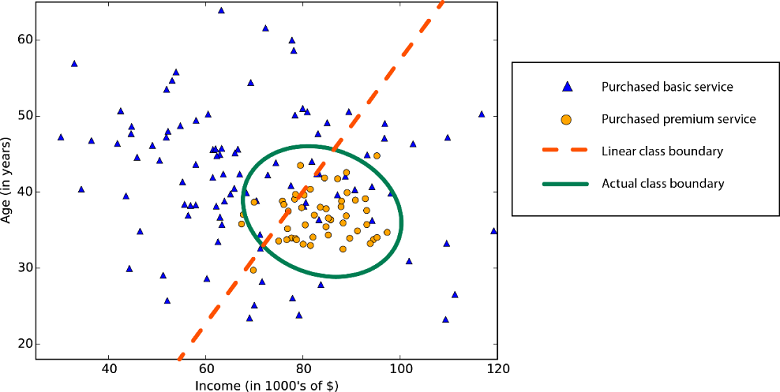
Граница нелинейного класса — использование алгоритма линейной классификации приведет к снижению точности.
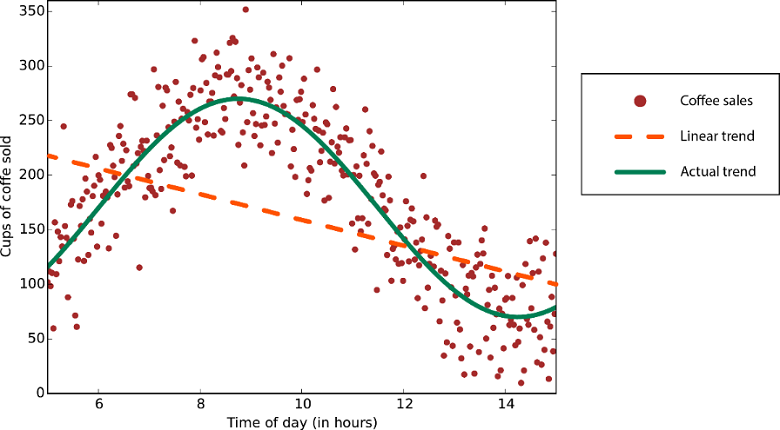
Данные с нелинейным трендом — использование метода линейной регрессии приведет к появлению гораздо большего количества ошибок, чем необходимо.
Количество параметров
Параметры являются теми регуляторами, которые специалист по данным поворачивает при настройке алгоритма. Это числа, которые влияют на поведение алгоритма, например чувствительность к ошибкам или количество итераций, либо на варианты поведения алгоритма. Время обучения и точность алгоритма иногда могут быть чувствительными к точности задания параметров. Как правило, алгоритмы с большим числом параметров требуют большого количества проб и ошибок, чтобы определить удачное сочетание параметров.
Кроме того, конструктор Машинного обучения содержит компонент «Настройка гиперпараметров модели». Цель этого компонента — определить оптимальные гиперпараметры для модели машинного обучения. Модуль создает и тестирует несколько компонентов, используя различные сочетания параметров. Он сравнивает метрики по всем моделям, чтобы получить сочетания параметров.
Хотя это отличный способ убедиться в том, что вы заполнили пространство параметров, с увеличением количества параметров экспоненциально возрастает время, необходимое для обучения модели. Плюсом является то, что наличие большого количества параметров обычно означает, что алгоритм имеет большую гибкость. Часто это позволяет достичь очень хорошей точности при условии, что вы можете найти правильное сочетание настроек параметров.
Количество функций
В машинном обучении компонент — это количественная переменная, которую вы пытаетесь проанализировать. Для некоторых типов данных количество функций может быть очень большим по сравнению с количеством точек данных. Это часто происходит с генетическими или текстовыми данными.
Большое количество функций для некоторых алгоритмов обучения может привести к тому, что они увязнут и время обучения станет недопустимо большим. Метод опорных векторов особенно хорошо подходит для сценариев с большим количеством функций. По этой причине они использовались во многих областях применения: от извлечения информации до классификации текста и изображения. Методы опорных векторов можно использовать как для задач классификации, так и регрессии.
Как правило, выбор признаков обозначает процесс применения статистических тестов к входным данным с учетом конкретных выходных данных. Цель состоит в том, чтобы определить столбцы, которые лучше других позволяют прогнозировать эти выходные данные. Компонент «Выбор признаков с помощью фильтра» в конструкторе Машинного обучения предоставляет несколько алгоритмов выбора признаков. Данный компонент включает такие методы корреляции, как корреляция Пирсона и значения хи-квадрат.
Кроме того, можно воспользоваться компонентом «Важность признака перестановки», чтобы вычислить набор оценок важности признаков для вашего набора данных. Используйте эти оценки при определении наиболее подходящих признаков в модели.
Следующие шаги
- Подробнее о конструкторе Машинного обучения Azure
- Описание всех алгоритмов машинного обучения, доступных в конструкторе Машинного обучения Azure, см. в Справочнике по алгоритмам и компонентам для конструктора Машинного обучения
- Сведения о связи между глубоким обучением, машинным обучением и искусственным интеллектом см. в статье Глубокое обучение и Машинное обучение