Получение данных веб-страницы путем предоставления примеров
Получение данных с веб-страницы позволяет пользователям легко извлекать данные из веб-страниц. Однако часто данные на веб-страницах не находятся в простых таблицах, которые легко извлекать. Получение данных из таких страниц может быть сложным, даже если данные структурированы и согласованы.
Есть решение. С помощью функции «Получить данные из Интернета» можно по сути отображать данные Power Query, которые необходимо извлечь, предоставив один или несколько примеров в диалоговом окне соединителя. Power Query собирает другие данные на странице, которая соответствует вашим примерам. С помощью этого решения можно извлечь все виды данных из веб-страниц, включая данные, найденные в таблицах и других не табличных данных.
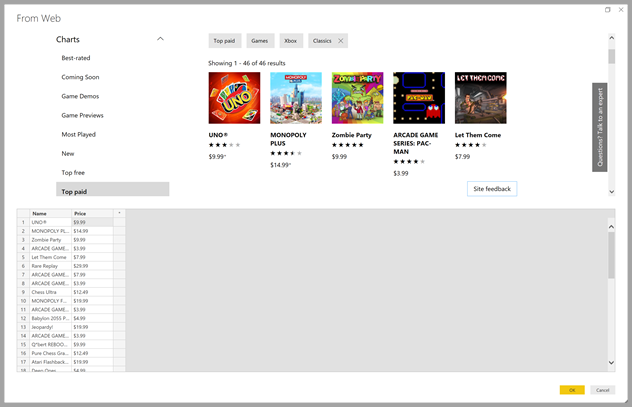
Цены, перечисленные в изображениях, являются только для целей.
Использование получения данных из Интернета по примеру
Выберите веб-параметр в выборе соединителя, а затем выберите Подключение, чтобы продолжить.
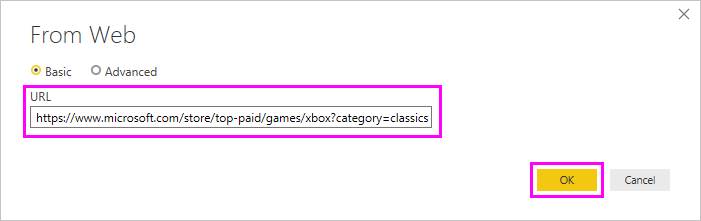
В интернете введите URL-адрес веб-страницы, из которой вы хотите извлечь данные. В этой статье мы будем использовать веб-страницу Microsoft Store и покажем, как работает этот соединитель.
Если вы хотите продолжить, можно использовать URL-адрес Microsoft Store, который мы используем в этой статье:
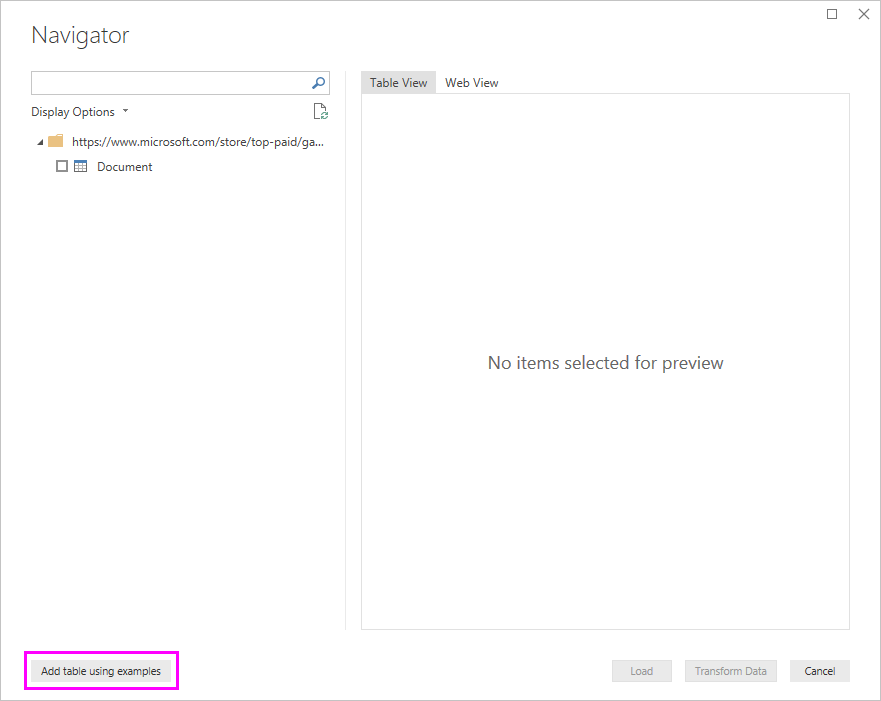
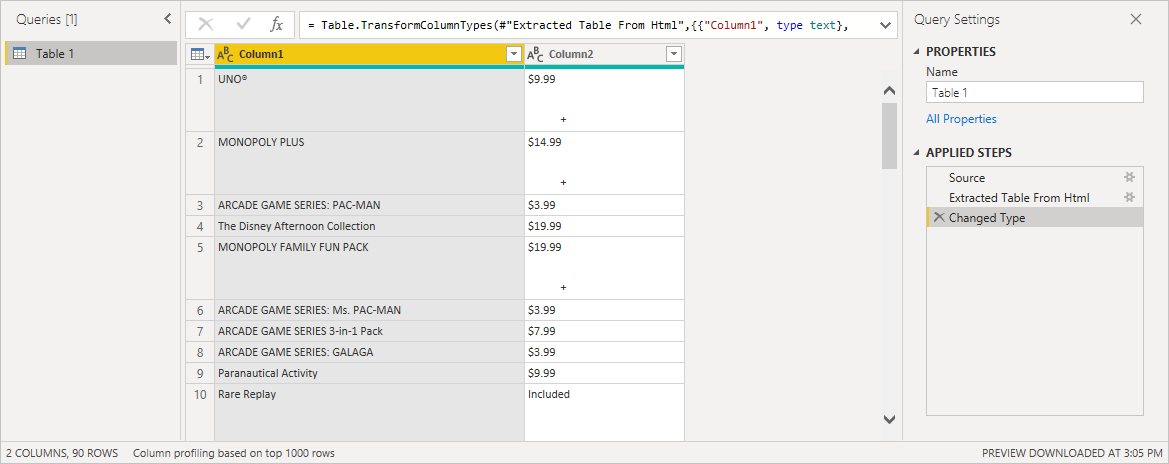
При нажатии кнопки «ОК» вы перейдете в диалоговое окно «Навигатор» , где отображаются все автоматически заданные таблицы на веб-странице. В приведенном ниже примере таблицы не найдены. Выберите » Добавить таблицу», используя примеры .
Добавление таблицы с помощью примеров представляет интерактивное окно, в котором можно просмотреть содержимое веб-страницы. Введите примеры значений данных, которые требуется извлечь.
В этом примере вы извлеките имя и цену для каждой игры на странице. Это можно сделать, указав несколько примеров на странице для каждого столбца. При вводе примеров Power Query извлекает данные, соответствующие шаблону примеров записей с помощью алгоритмов интеллектуального извлечения данных.
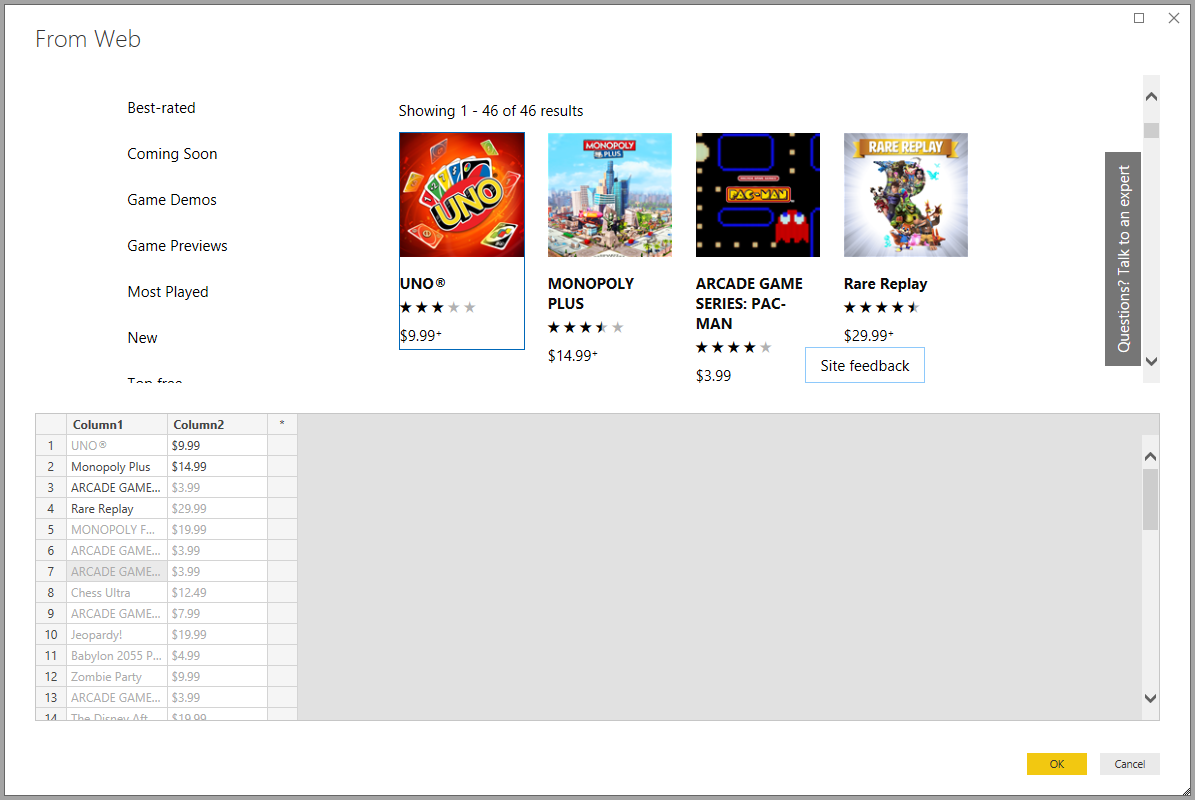
Предложения по значению включают только значения меньше или равно 128 символам длины.
Когда вы довольны данными, извлеченными на веб-странице, нажмите кнопку «ОК«, чтобы перейти к Редактор Power Query. Затем можно применить дополнительные преобразования или сформировать данные, например объединение этих данных с другими источниками данных.
См. также
- Добавление столбца из примеров
- Фигура и объединение данных
- Получение данных
- Устранение неполадок соединителя Power Query Web
Как вытащить данные из сайта?
Всем привет! Нужно вытащить информацию с сайта.Подробнее: результаты футбольных матчей с сайта myscore.ru Выслушаю любые принадлежности.
Отслеживать
задан 23 окт 2012 в 12:55
Владимир92 Владимир92
25 1 1 золотой знак 2 2 серебряных знака 4 4 бронзовых знака
Если нет АПИ, то только ручной парсинг регулярками и тд, с которым связано масса проблем.
23 окт 2012 в 13:03
на каком языке программирования-то хоть? можно и просто сохранить страницу и блокнотом скопировать нужные данные))
23 окт 2012 в 16:16
2 ответа 2
Сортировка: Сброс на вариант по умолчанию
Я делаю это на python’е с помощью модуля lxml.html. Точнее, с помощью пары функций из него. Одна называется document_fromstring. Она делает DOM-дерево из ответа http-сервера. Другая же делает к этому дереву xpath-запрос, который возвращает нужный элемент. Общая идея примерно такова:
from lxml.html import document_fromstring doc = document_fromstring(response.text) tbl = doc.xpath('//table[descendant::tr[position()=1]/th[text()="Заголовок"]]') (Этот код вылавливает из документа такую таблицу, у которой первая строка содержит заголовочную ячейку с текстом «Загловок».)
Веб-скрейпинг: как бесплатно спарсить и извлечь данные с сайта

можно ли одним способом, например, RegExp, заменить все остальные модели получения данных?, не совсем понятна логика выбора, от чего к чему переходить, выбирая надежный вариант. насколько я знаю, способ XPath дает больше всего ошибок/расхождений.
Admin
29.08.2022 09:28:03
Здравствуйте, с одной стороны регулярные выражения самые распространенные и самые гибкие в использовании, но и с другой самые медленные. На счет точности работы XPath не могу ничего сказать, но примеров по нему в интернете достаточно.
Чтобы оставить комментарий необходимо авторизоваться.
Как извлечь данные с любого сайта?
Мы живем в эпоху, когда принятие бизнес-решений на основе данных является приоритетом номер один для многих компаний. Для поддержки этих решений компании отслеживают и собирают соответствующие данные 24/7, например осуществляют мониторинг цен товаров конкурентов . К счастью, на серверах разных сайтов хранится много данных.
Для различных компаний стало обычным делом извлекать данные для целей своего бизнеса. Тем не менее, это не один из тех процессов, которые вы можете реализовать в своей повседневной деятельности.
Если вы чувствуете, что еще слишком рано думать об использовании парсинга для вашего бизнеса, потому что вам нужны дополнительные знания в этой области, мы собрали статью, которая поможет вам понять, как извлекать данные с веб-сайта и какие задачи вас ожидают.
Зачем извлекать данные ?
Парсинг данных — новое модное словосочетание в мире бизнеса. Он включает в себя различные процессы, выполняемые с несколькими целями — получение значимого понимания, выявление тенденций, моделей и прогнозирование экономических условий. Например, парсинг данных о недвижимости помогает проанализировать существенные влияния в этой отрасли.
Различные компании извлекают данные с помощью парсинга, чтобы сделать собственные данные более актуальными и конкуретными. Эта практика часто распространяется и на другие отрасли без исключения. Чем больше данных, тем лучше, так как они предоставляют больше опорных точек для анализа.
Есть веские причины для сбора данных. Сначала важно наладить этот процесс непрерывно, чтобы сбор данных исключал человеческий фактор, а как следствие ошибки. Вместо бесконечного копирования, ваши сотрудники смогут сосредоточиться на более насущных вопросах.
Инструменты парсинга также упрощают управление данными и агрегируют данные, чтобы вы могли их легко понять.
Как работает сбор данных ?
Если вы не разбираетесь в технологиях, извлечение данных может показаться очень сложным и непонятным вопросом. На самом деле, не так сложно понять весь процесс. У нас есть даже руководство по парсинга для начинающих.
Процесс извлечения данных с веб-сайтов называется парсингом. Иногда вы можете найти его также как веб-скраппинг данных, веб-скрейпинг — «web-scrapping» (этот термин используют в западных странах). Парсинг обычно относится к процессам извлечения данных с использованием бота (скрипта) или расширения для вашего браузера. Мы пройдем шаг за шагом, чтобы полностью понять, как работает извлечение данных.
Что делает возможным извлечение данных
У нас есть HTML, чтобы иметь возможность извлечения данных с веб-страниц. HTML — это текстовый язык разметки. Он определяет структуру содержимого веб-сайта с помощью различных компонентов, включая такие теги, как «параграф», «таблица» и «заголовок страницы».
Благодаря структурированной природе веб-страниц HTML разработчики могут создавать сценарии, которые проходят через них и извлекают данные из определенных тегов HTML.
Создание сценариев извлечения данных
Все начинается с создания сценариев извлечения данных. Программисты, владеющие определенными языками программирования, такими как Python, могут разрабатывать скрипты или плагины извлечения данных, так называемые «парсеры». Эти сценарии способны полностью автоматизировать извлечение данных. Они отправляют запрос на сервер, переходят на веб-сайт, просматривают все ранее определенные страницы, теги HTML и компоненты. Затем они получают данные из них.
Разработка различных шаблонов сканирования данных
Скрипты или плагины извлечения данных могут быть адаптированы для извлечения данных только из определенных компонентов HTML. Данные, которые вам нужно извлечь, зависят от ваших бизнес-целей и задач. Нет необходимости извлекать все, когда вы можете использовать только те данные, которые нужны вам. Это также уменьшит нагрузку на ваши серверы, уменьшит требования к объему памяти и облегчит обработку данных.
Настройка серверной среды
Чтобы постоянно запускать ваши созданные парсеры, вам нужен сервер. Следующим шагом в этом процессе является инвестирование в серверную инфраструктуру или аренда серверов у существующей компании. Серверы необходимы, так как они позволяют вам запускать сценарии извлечения данных 24/7 и оптимизировать хранение данных.
Обеспечение достаточного места для хранения
Результатом сценариев извлечения данных являются данные. Крупномасштабные операции сопровождаются высокими требованиями к объему хранилища. Извлечение данных с нескольких веб-сайтов приводит к тысячам таблицам, изображениям, инструкциям и так далее. Поскольку процесс непрерывный, вы получите огромное количество данных. Очень важно обеспечить достаточно места для хранения, чтобы успешно завершить операции в процессе парсинга.
Обработка данных
Большинство сервисов извлечения данных также поставляются с сервисами обработки данных, потому что это абсолютно необходимо. Когда вы извлекаете данные с сайтов, они поступают в необработанном виде. Вы не можете извлечь информацию из необработанных данных, поэтому они должны быть кластеризованы, объединены и обработаны.
Какие данные собираются при парсинге?
Как мы упоминали ранее, понятно, что не все данные являются целью извлечения. Ваши бизнес-цели, потребности и цели должны служить основными ориентирами при принятии решения, какие данные извлекать .
Когда мы говорим о целях данных, вы должны знать, что нет никаких ограничений. Вы можете получить описания и характеристики товаров, цены, отзывы и оценки например, страницы часто задаваемых вопросов, практические руководства и многое другое. Вы также можете настроить скрипты извлечения данных для новых продуктов и услуг.
Парсинг для бизнеса крайне необходим, чтобы оставаться конкурентоспособным на рынке.
Какие проблемы извлечения данных ?
Извлечение данных с сайта не обходится без проблем. Наиболее распространенные из них:
Сбор данных требует много ресурсов.
Если компании решают начать парсинг сайтов таких как интернет-магазины или популярные маркетплейсы отечественные или зарубежные, им необходимо разработать определенную инфраструктуру, написать код парсера и контролировать весь процесс. Требуется команда разработчиков, системных администраторов и других специалистов.