Вывод списка без квадратных скобок
Все равно выдает ошибку — Traceback (most recent call last): File «test.py», line 2, in
19 июн 2020 в 7:56
Ну очевидно, что это проблема в том, как вы запускаете, а не в этом коде
19 июн 2020 в 7:56
Предлагаю задать новый вопрос, описав ваше окружение, т.е. файлы и команды, которые вы используете для запуска
19 июн 2020 в 7:57
Нужно настроть вывод с помощью » «join(s) или print(*s, sep=’ ‘) Вот код:
s = [1, 2, 3] def reverse(lst): return lst[::-1] print(*reverse(s), sep=' ') #или print(" ".join(reverse(s))) Отслеживать
ответ дан 19 июн 2020 в 7:50
55 7 7 бронзовых знаков
К сожалению, тест не проходит
19 июн 2020 в 8:11
@user394620 возможно дело в типе данних, но я сомневаюсь
26 июн 2020 в 14:49
Самый простой способ
reverse(s) for elem in s_new: print(elem, end=" ") Изменено: по ошибке ImportError: cannot import name ‘recursive_reverse, предполагаю, что вы где-то неправильно импортировали recursive_reverse (я не знаю, что это)
Отслеживать
ответ дан 19 июн 2020 в 8:20
Руслан Мамедов Руслан Мамедов
669 4 4 серебряных знака 19 19 бронзовых знаков
ребят прост добавьте *
x = [] print(*x) Отслеживать
7,797 13 13 золотых знаков 25 25 серебряных знаков 55 55 бронзовых знаков
ответ дан 24 окт 2022 в 18:13
В текущем виде ваш ответ непонятен. Пожалуйста, нажмите править под сообщением, чтобы добавить больше подробностей, которые помогут другим понять, как он отвечает на заданный вопрос. Вы можете найти больше информации о том, как писать хорошие ответы в Справке.
24 окт 2022 в 18:15
Ответ от Васи уже содержит данное решение
24 окт 2022 в 18:16
-
Важное на Мете
Похожие
Подписаться на ленту
Лента вопроса
Для подписки на ленту скопируйте и вставьте эту ссылку в вашу программу для чтения RSS.
Дизайн сайта / логотип © 2024 Stack Exchange Inc; пользовательские материалы лицензированы в соответствии с CC BY-SA . rev 2024.1.3.2953
Нажимая «Принять все файлы cookie» вы соглашаетесь, что Stack Exchange может хранить файлы cookie на вашем устройстве и раскрывать информацию в соответствии с нашей Политикой в отношении файлов cookie.
Как вывести список без скобок в Python

Python — это высокоуровневый язык программирования, который часто используется для работы со списками. При выводе списков в Python по умолчанию скобки используются для обозначения списка. Однако иногда возникает необходимость вывода списка без скобок для различных целей. В этой статье мы рассмотрим несколько способов вывода списка без скобок в Python.
Использование функции join()
Функция join() в Python позволяет объединить элементы списка в строку, используя заданный разделитель. Мы можем использовать эту функцию, чтобы вывести элементы списка без скобок.
Принцип работы функции join() заключается в том, что она принимает в качестве аргумента разделитель (или строку-разделитель), а затем объединяет элементы списка в одну строку, вставляя указанный разделитель между ними.
Для вывода элементов списка без скобок и разделителя, мы можем использовать функцию join() с пустой строкой в качестве разделителя.
Вот пример использования функции join() :
my_list = ["apple", "banana", "cherry"] result = "".join(my_list) print(result)Этот код выведет следующий результат:
applebananacherryКак видим, все элементы списка были объединены в одну строку без использования скобок и разделителей. Если нам необходимо разделить элементы списка запятой, необходимо использовать соответствующий разделитель:
my_list = ["apple", "banana", "cherry"] result = ", ".join(my_list) print(result)Этот код выведет следующий результат:
apple, banana, cherryИспользование функции print() вместе с оператором ‘ * ‘
Для вывода элементов списка без скобок можно использовать функцию print() вместе с оператором распаковки * .
Оператор * перед списком в функции print() позволяет передать каждый элемент списка в качестве отдельного аргумента функции. По умолчанию разделителем между элементами будет пробел. Если вам необходимо вывести все элементы из списка через запятую, вам необходимо указать соответствующий разделитель:
my_list = [1, 2, 3, 4, 5] print(*my_list, sep=', ')В данном случае, оператор * передает элементы списка в функцию print() в качестве отдельных аргументов, а параметр sep=’, ‘ указывает разделитель.
В результате выполнения данного кода будет выведено:
1, 2, 3, 4, 5Python: коллекции, часть 4/4: Все о выражениях-генераторах, генераторах списков, множеств и словарей
Заключительная часть моего цикла, посещенного работе с коллекциями. Данная статья самостоятельная, может изучаться и без предварительного изучения предыдущих.
Эта статья глубже и детальней предыдущих и поэтому может быть интересна не только новичкам, но и достаточно опытным Python-разработчикам.
Будут рассмотрены: выражения-генераторы, генераторы списка, словаря и множества, вложенные генераторы (5 вариантов), работа с enumerate(), range().
А также: классификация и терминология, синтаксис, аналоги в виде циклов и примеры применения.
Я постарался рассмотреть тонкости и нюансы, которые освещаются далеко не во всех книгах и курсах, и, в том числе, отсутствуют в уже опубликованных на Habrahabr статьях на эту тему.
Оглавление:
1. Определения и классификация
1.1 Что и зачем
- Генераторы выражений предназначены для компактного и удобного способа генерации коллекций элементов, а также преобразования одного типа коллекций в другой.
- В процессе генерации или преобразования возможно применение условий и модификация элементов.
- Генераторы выражений являются синтаксическим сахаром и не решают задач, которые нельзя было бы решить без их использования.
1.2 Преимущества использования генераторов выражений
- Более короткий и удобный синтаксис, чем генерация в обычном цикле.
- Более понятный и читаемый синтаксис чем функциональный аналог сочетающий одновременное применение функций map(), filter() и lambda.
- В целом: быстрее набирать, легче читать, особенно когда подобных операций много в коде.
1.3 Классификация и особенности
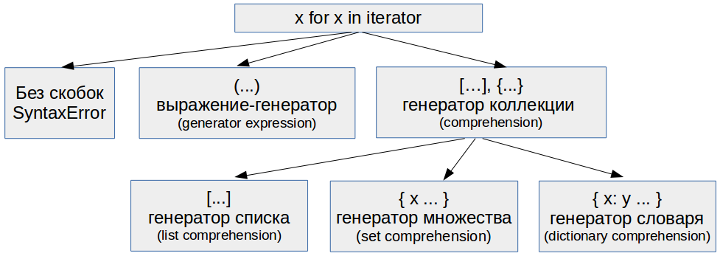
Сразу скажу, что существует некоторая терминологическая путаница в русских названиях того, о чем мы будем говорить.
В данной статье используются следующие обозначения:
- выражение-генератор (generator expression) — выражение в круглых скобках которое выдает создает на каждой итерации новый элемент по правилам.
- генератор коллекции — обобщенное название для генератора списка (list comprehension), генератора словаря (dictionary comprehension) и генератора множества (set comprehension).
В отдельных местах, чтобы избежать нагромождения терминов, будет использоваться термин «генератор» без дополнительных уточнений.
2. Синтаксис
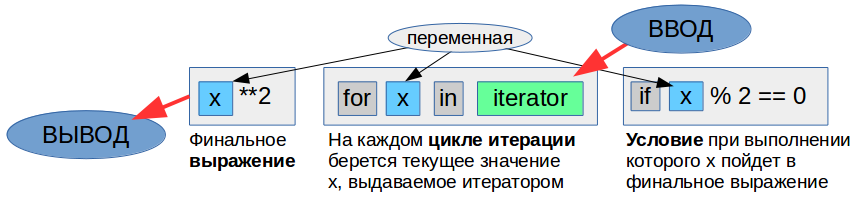
Для начала приведем иллюстрацию общего синтаксиса выражения-генератора.
Важно: этот синтаксис одинаков и для выражения-генератора и для всех трех типов генераторов коллекций, разница заключается, в каких скобках он будет заключен (смотрите предыдущую иллюстрацию).
Общие принципы важные для понимания:
- Ввод — это итератор — это может быть функция-генератор, выражение-генератор, коллекция — любой объект поддерживающий итерацию по нему.
- Условие — это фильтр при выполнении которого элемент пойдет в финальное выражение, если элемент ему не удовлетворяет, он будет пропущен.
- Финальное выражение — преобразование каждого выбранного элемента перед его выводом или просто вывод без изменений.
2.1 Базовый синтаксис
list_a = [-2, -1, 0, 1, 2, 3, 4, 5] # Пусть у нас есть исходный список list_b = [x for x in list_a] # Создадим новый список используя генератор списка print(list_b) # [-2, -1, 0, 1, 2, 3, 4, 5] print(list_a is list_b) # False - это разные объекты! По сути, ничего интересного тут не произошло, мы просто получили копию списка. Делать такие копии или просто перегонять коллекции из типа в тип с помощью генераторов особого смысла нет — это можно сделать значительно проще применив соответствующие методы или функции создания коллекций (рассматривались в первой статье цикла).
Мощь генераторов выражений заключается в том, что мы можем задавать условия для включения элемента в новую коллекцию и можем делать преобразование текущего элемента с помощью выражения или функции перед его выводом (включением в новую коллекцию).
2.2 Добавляем условие для фильтрации
Важно: Условие проверяется на каждой итерации, и только элементы ему удовлетворяющие идут в обработку в выражении.
Добавим в предыдущий пример условие — брать только четные элементы.
# if x % 2 == 0 - остаток от деления на 2 равен нулю - число четное list_a = [-2, -1, 0, 1, 2, 3, 4, 5] list_b = [x for x in list_a if x % 2 == 0] print(list_b) # [-2, 0, 2, 4] Мы можем использовать несколько условий, комбинируя их логическими операторами:
list_a = [-2, -1, 0, 1, 2, 3, 4, 5] list_b = [x for x in list_a if x % 2 == 0 and x > 0] # берем те x, которые одновременно четные и больше нуля print(list_b) # [2, 4] 2.3 Добавляем обработку элемента в выражении
Мы можем вставлять не сам текущий элемент, прошедший фильтр, а результат вычисления выражения с ним или результат его обработки функцией.
Важно: Выражение выполняется независимо на каждой итерации, обрабатывая каждый элемент индивидуально.
Например, можем посчитать квадраты значений каждого элемента:
list_a = [-2, -1, 0, 1, 2, 3, 4, 5] list_b = [x**2 for x in list_a] print(list_b) # [4, 1, 0, 1, 4, 9, 16, 25] Или посчитать длины строк c помощью функции len()
list_a = ['a', 'abc', 'abcde'] list_b = [len(x) for x in list_a] print(list_b) # [1, 3, 5] 2.4 Ветвление выражения
Обратите внимание: Мы можем использовать (начиная с Python 2.5) в выражении конструкцию if-else для ветвления финального выражения.
- Условия ветвления пишутся не после, а перед итератором.
- В данном случае if-else это не фильтр перед выполнением выражения, а ветвление самого выражения, то есть переменная уже прошла фильтр, но в зависимости от условия может быть обработана по-разному!
list_a = [-2, -1, 0, 1, 2, 3, 4, 5] list_b = [x if x < 0 else x**2 for x in list_a] # Если x-отрицательное - берем x, в остальных случаях - берем квадрат x print(list_b) # [-2, -1, 0, 1, 4, 9, 16, 25] Никто не запрещает комбинировать фильтрацию и ветвление:
list_a = [-2, -1, 0, 1, 2, 3, 4, 5] list_b = [x**3 if x < 0 else x**2 for x in list_a if x % 2 == 0] # вначале фильтр пропускает в выражение только четные значения # после этого ветвление в выражении для отрицательных возводит в куб, а для остальных в квадрат print(list_b) # [-8, 0, 4, 16] Этот же пример в виде цикла
list_a = [-2, -1, 0, 1, 2, 3, 4, 5] list_b = [] for x in list_a: if x % 2 == 0: if x < 0: list_b.append(x ** 3) else: list_b.append(x ** 2) print(list_b) # [-8, 0, 4, 16]2.5 Улучшаем читаемость
Не забываем, что в Python синтаксис позволяет использовать переносы строк внутри скобок. Используя эту возможность, можно сделать синтаксис генераторов выражений более легким для чтения:
numbers = range(10) # Before squared_evens = [n ** 2 for n in numbers if n % 2 == 0] # After squared_evens = [ n ** 2 for n in numbers if n % 2 == 0 ]3. Аналоги в виде цикла for и в виде функций
Как уже говорилось выше, задачи решаемые с помощью генераторов выражений можно решить и без них. Приведем другие подходы, которые могут быть использованы для решения тех же задач.
Для примера возьмем простую задачу — сделаем из списка чисел список квадратов четных чисел и решим ее с помощью трех разных подходов:
3.1 Решение с помощью генератора списка
numbers = range(10) squared_evens = [n ** 2 for n in numbers if n % 2 == 0] print(squared_evens) # [0, 4, 16, 36, 64]3.2. Решение c помощью цикла for
Важно: Каждый генератор выражений можно переписать в виде цикла for, но не каждый цикл for можно представить в виде такого выражения.
numbers = range(10) squared_evens = [] for n in numbers: if n % 2 == 0: squared_evens.append(n ** 2) print(squared_evens) # [0, 4, 16, 36, 64]В целом, для очень сложных и комплексных задач, решение в виде цикла может быть понятней и проще в поддержке и доработке. Для более простых задач, синтаксис выражения-генератора будет компактней и легче в чтении.
3.3. Решение с помощью функций.
Для начала, замечу, что выражение генераторы и генераторы коллекций — это тоже функциональный стиль, но более новый и предпочтительный.
Можно применять и более старые функциональные подходы для решения тех же задач, комбинируя map(), lambda и filter().
numbers = range(10) squared_evens = map(lambda n: n ** 2, filter(lambda n: n % 2 == 0, numbers)) print(squared_evens) # print(list(squared_evens)) # [0, 4, 16, 36, 64] # Примечание: в Python 2 в переменной squared_evens окажется сразу список, а в Python 3 «map object», который мы превращаем в список с помощью list()Несмотря на то, что подобный пример вполне рабочий, читается он тяжело и использование синтаксиса генераторов выражений будет более предпочительным и понятным.
4. Выражения-генераторы
Выражения-генераторы (generator expressions) доступны, начиная с Python 2.4. Основное их отличие от генераторов коллекций в том, что они выдают элемент по-одному, не загружая в память сразу всю коллекцию.
UPD: Еще раз обратите внимание на этот момент: если мы создаем большую структуру данных без использования генератора, то она загружается в память целиком, соответственно, это увеличивает расход памяти Вашим приложением, а в крайних случаях памяти может просто не хватить и Ваше приложение «упадет» с MemoryError. В случае использования выражения-генератора, такого не происходит, так как элементы создаются по-одному, в момент обращения.
list_a = [-2, -1, 0, 1, 2, 3, 4, 5] my_gen = (i for i in list_a) # выражение-генератор print(next(my_gen)) # -2 - получаем очередной элемент генератора print(next(my_gen)) # -1 - получаем очередной элемент генератораОсобенности выражений-генераторов
-
Генаратор нельзя писать без скобок — это синтаксическая ошибка.
# my_gen = i for i in list_a # SyntaxError: invalid syntaxlist_a = [-2, -1, 0, 1, 2, 3, 4, 5] my_sum = sum(i for i in list_a) # my_sum = sum((i for i in list_a)) # так тоже можно print(my_sum) # 12# my_len = len(i for i in list_a) # TypeError: object of type 'generator' has no len()print(my_gen) # at 0x7f162db32af0> list_a = [-2, -1, 0, 1, 2, 3, 4, 5] my_gen = (i for i in list_a) print(sum(my_gen)) # 12 print(sum(my_gen)) # 0import itertools inf_gen = (x for x in itertools.count()) # бесконечный генератор от 0 to бесконечности!Будьте осторожны в работе с такими генераторами, так как при не правильном использовании «эффект» будет как от бесконечного цикла.
list_a = [-2, -1, 0, 1, 2, 3, 4, 5] my_gen = (i for i in list_a) my_gen_sliced = my_gen[1:3] # TypeError: 'generator' object is not subscriptable5. Генерация стандартных коллекций
5.1 Создание коллекций из выражения-генератора
Создание коллекций из выражения-генератора с помощью функций list(), tuple(), set(), frozenset()
Примечание: Так можно создать и неизменное множество и кортеж, так как неизменными они станет уже после генерации.
Внимание: Для строки такой способ не работает! Синтаксис создания генератора словаря таким образом имеет свои особенности, он рассмотрен в следующем под-разделе.
-
Передачей готового выражения-генератора присвоенного переменной в функцию создания коллекции.
list_a = [-2, -1, 0, 1, 2, 3, 4, 5] my_gen = (i for i in list_a) # выражение-генератор my_list = list(my_gen) print(my_list) # [-2, -1, 0, 1, 2, 3, 4, 5]list_a = [-2, -1, 0, 1, 2, 3, 4, 5] my_list = list(i for i in list_a) print(my_list) # [-2, -1, 0, 1, 2, 3, 4, 5]То же самое для кортежа, множества и неизменного множества
# кортеж my_tuple = tuple(i for i in list_a) print(my_tuple) # (-2, -1, 0, 1, 2, 3, 4, 5) # множество my_set = set(i for i in list_a) print(my_set) # # неизменное множество my_frozenset = frozenset(i for i in list_a) print(my_frozenset) # frozenset()5.2 Специальный синтаксис генераторов коллекций
В отличии от выражения-генератора, которое выдает значение по-одному, не загружая всю коллекцию в память, при использовании генераторов коллекций, коллекция генерируется сразу целиком.
Соответственно, вместо особенности выражений-генераторов перечисленных выше, такая коллекция будет обладать всеми стандартными свойствами характерными для коллекции данного типа.
Обратите внимание, что для генерации множества и словаря используются одинаковые скобки, разница в том, что у словаря указывается двойной элемент ключ: значение.
-
Генератор списка (list comprehension)
list_a = [-2, -1, 0, 1, 2, 3, 4, 5] my_list = [i for i in list_a] print(my_list) # [-2, -1, 0, 1, 2, 3, 4, 5]Не пишите круглые скобки в квадратных!
list_a = [-2, -1, 0, 1, 2, 3, 4, 5] my_list = [(i for i in list_a)] print(my_list) # [ at 0x7fb81103bf68>]list_a = [-2, -1, 0, 1, 2, 3, 4, 5] my_set= print(my_set) # - порядок случаенdict_abc = dict_123 = print(dict_123) # # Обратите внимание, мы потеряли "с"! Так как значения были одинаковы, # то когда они стали ключами, только последнее значение сохранилось.Словарь из списка:
list_a = [-2, -1, 0, 1, 2, 3, 4, 5] dict_a = print(dict_a) #
Важно! Такой синтаксис создания словаря работает только в фигурных скобках, выражение-генератор так создать нельзя, для этого используется немного другой синтаксис (благодарю longclaps за подсказку в комментариях):
# dict_gen = (x: x**2 for x in list_a) # SyntaxError: invalid syntax dict_gen = ((x, x ** 2) for x in list_a) # Корректный вариант генератора-выражения для словаря # dict_a = dict(x: x**2 for x in list_a) # SyntaxError: invalid syntax dict_a = dict((x, x ** 2) for x in list_a) # Корректный вариант синтаксиса от @longclaps5.3 Генерация строк
Для создания строки вместо синтаксиса выражений-генераторов используется метод строки .join(), которому в качестве аргументов можно передать выражение генератор.
Обратите внимание: элементы коллекции для объединения в строку должны быть строками!
list_a = [-2, -1, 0, 1, 2, 3, 4, 5] # используем генератор прямо в .join() одновременно приводя элементы к строковому типу my_str = ''.join(str(x) for x in list_a) print(my_str) # -2-10123456. Периодичность и частичный перебор
6.1 Работа с enumerate()
Иногда в условиях задачи в условии-фильтре нужна не проверка значения текущего элемента, а проверка на определенную периодичность, то есть, например, нужно брать каждый третий элемент.
Для подобных задач можно использовать функцию enumerate(), задающую счетчик при обходе итератора в цикле:
for i, x in enumerate(iterable)здесь x — текущий элемент i — его порядковый номер, начиная с нуля
Проиллюстрируем работу с индексами:
list_a = [-2, -1, 0, 1, 2, 3, 4, 5] list_d = [(i, x) for i, x in enumerate(list_a)] print(list_d) # [(0, -2), (1, -1), (2, 0), (3, 1), (4, 2), (5, 3), (6, 4), (7, 5)]Теперь попробуем решить реальную задачу — выберем в генераторе списка каждый третий элемент из исходного списка:
list_a = [-2, -1, 0, 1, 2, 3, 4, 5] list_e = [x for i, x in enumerate(list_a, 1) if i % 3 == 0] print(list_e) # [0, 3]Важные особенности работы функции enumerate():
- Возможны два варианта вызова функции enumerate():
- enumerate(iterator) без второго параметра считает с 0.
- enumerate(iterator, start) — начинает считать с значения start. Удобно, например, если нам надо считать с 1, а не 0.
- enumerate() возвращает кортеж из порядкового номера и значения текущего элемента итератора. Кортеж в выражении-генераторе результате можно получить двумя способами:
- (i, j) for i, j in enumerate(iterator) — скобки в первой паре нужны!
- pair for pair in enumerate(mylist) — мы работаем сразу с парой
- Индексы считаются для всех обработанных элементов, без учета прошли они в дальнейшем условие или нет!
first_ten_even = [(i, x) for i, x in enumerate(range(10)) if x % 2 == 0] print(first_ten_even) # [(0, 0), (2, 2), (4, 4), (6, 6), (8, 8)]6.2 Перебор части итерируемого.
Иногда бывает задача из очень большой коллекции или даже бесконечного генератора получить выборку первых нескольких элементов, удовлетворяющих условию.
Если мы используем обычное генераторное выражение с условием ограничением по enumerate() индексу или срез полученной результирующей коллекции, то нам в любом случае придется пройти всю огромную коллекцию и потратить на это уйму компьютерных ресурсов.
Выходом может быть использование функции islice() из пакета itertools.
import itertools first_ten = (itertools.islice((x for x in range(1000000000) if x % 2 == 0), 10)) print(list(first_ten)) # [0, 2, 4, 6, 8, 10, 12, 14, 16, 18]Для сомневающихся: проверяем время выполнения
import time import itertools # На генераторе с малым количеством элементов start_time = time.time() first_ten = (itertools.islice((x for x in range(100) if x % 2 == 0), 10)) print(list(first_ten)) # [0, 2, 4, 6, 8, 10, 12, 14, 16, 18] elapsed_time = time.time() - start_time print(elapsed_time) # 3.409385681152344e-05 # На генераторе с огромным количеством элементов start_time = time.time() first_ten = (itertools.islice((x for x in range(100000000) if x % 2 == 0), 10)) print(list(first_ten)) # [0, 2, 4, 6, 8, 10, 12, 14, 16, 18] elapsed_time = time.time() - start_time print(elapsed_time) # 1.1205673217773438e-05 # То есть максимальное количество элементов в генераторе range() мы увеличили на 6 порядков, # а время исполнения осталось того же порядка 7. Вложенные циклы и генераторы
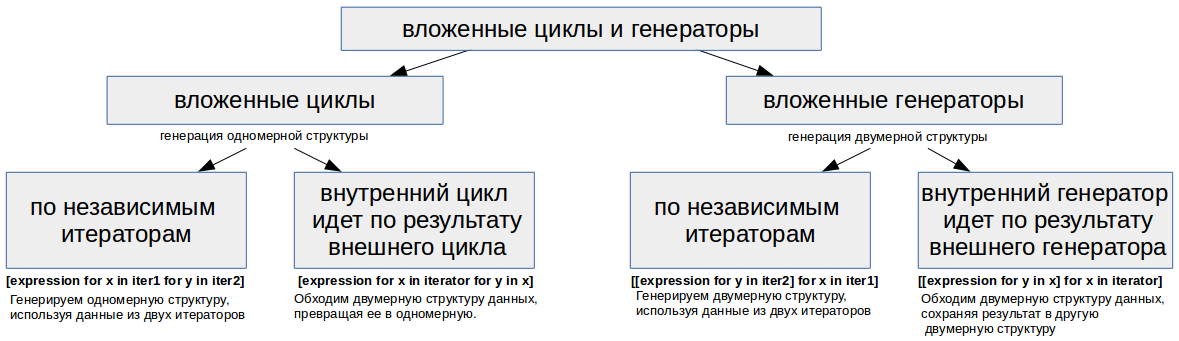
Рассмотрим более комплексные варианты, когда у нас циклы или сами выражения-генераторы являются вложенными. Тут возможны несколько вариантов, со своими особенностями и сферой применения, чтобы не возникало путаницы, рассмотрим их по-отдельности, а после приведем общую схему.
7.1 Вложенные циклы
В результате генерации получаем одномерную структуру.
Важно! При работае с вложенными циклами внутри генератора выражений порядок следования инструкций for in будет такой же (слева-направо), как и в аналогичном решении без генератора, только на циклах (сверху-вниз)! Тоже справедливо и при более глубоких уровнях вложенности.
7.1.1 Вложенные циклы for где циклы идут по независимым итераторам
Общий синтаксис: [expression for x in iter1 for y in iter2]
Применение: генерируем одномерную структуру, используя данные из двух итераторов.
Например, создадим словарь, используя кортежи координат как ключи, заполнив для начала его значения нулями.
rows = 1, 2, 3 cols = 'a', 'b' my_dict = <(col, row): 0 for row in rows for col in cols>print(my_dict) #
Дальше можем задавать новые значения или получать их
my_dict['b', 2] = 10 # задаем значение по координатному ключу-кортежу print(my_dict['b', 2]) # 10 - получаем значение по координатному ключу-кортежуТоже можно сделать и с дополнительными условиями-фильтрами в каждом цикле:
rows = 1, 2, 3, -4, -5 cols = 'a', 'b', 'abc' # Для наглядности разнесем на несколько строк my_dict = < (col, row): 0 # каждый элемент состоит из ключа-кортежа и нулевого знаечния for row in rows if row >0 # Только положительные значения for col in cols if len(col) == 1 # Только односимвольные > print(my_dict) #
Эта же задача решенная с помощью цикла
rows = 1, 2, 3, -4, -5 cols = 'a', 'b', 'abc' my_dict = <> for row in rows: if row > 0: for col in cols: if len(col) == 1: my_dict[col, row] = 0 print(my_dict) #
7.1.2 Вложенные циклы for где внутренний цикл идет по результату внешнего цикла
Общий синтаксис: [expression for x in iterator for y in x].
Применение: Стандартный подход, когда нам надо обходить двумерную структуру данных, превращая ее в «плоскую» одномерную. В данном случае, мы во внешнем цикле проходим по строкам, а во внутреннем по элементам каждой строки нашей двумерной структуры.
Допустим у нас есть двумерная матрица — список списков. И мы желаем преобразовать ее в плоский одномерный список.
matrix = [[0, 1, 2, 3], [10, 11, 12, 13], [20, 21, 22, 23]] # Решение с помощью генератора списка: flattened = [n for row in matrix for n in row] print(flattened) # [0, 1, 2, 3, 10, 11, 12, 13, 20, 21, 22, 23]Таже задача, решенная с помощью вложенных циклов
flattened = [] for row in matrix: for n in row: flattened.append(n) print(flattened)UPD:Изящные решения из комментариев
import itertools flattened = list(itertools.chain.from_iterable(matrix)) # от @iMrDron # Данный подходнамного быстрее генератора списков # и рекомендован к использованию для подобных задач. flattened = sum(a, []) # от @YuriM1983 # sum(a, []) имеет квадратическую сложность(O(n^2)) # и потому совсем не рекомендуется к использованию для таких целей7.2 Вложенные генераторы
Вложенными могут быть не только циклы for внутри выражения-генератора, но и сами генераторы.
Такой подход применяется когда нам надо строить двумерную структуру.
Важно!: В отличии от примеров выше с вложенными циклами, для вложенных генераторов, вначале обрабатывается внешний генератор, потом внутренний, то есть порядок идет справа-налево.
Ниже рассмотрим два варианта подобного использования.
7.2.1 — Вложенный генератор внутри генератора — двумерная из двух одномерных
Общий синтаксис: [[expression for y in iter2] for x in iter1]
Применение: генерируем двумерную структуру, используя данные из двух одномерных итераторов.
Для примера создадим матрицу из 5 столбцов и 3 строк и заполним ее нулями:
w, h = 5, 3 # зададим ширину и высотку матрицы matrix = [[0 for x in range(w)] for y in range(h)] print(matrix) # [[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]]Создание этой же матрицы двумя вложенными циклами - обратите внимание на порядок вложения
matrix = [] for y in range(h): new_row = [] for x in range(w): new_row.append(0) matrix.append(new_row) print(matrix) # [[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]]Примечание: После создания можем работать с матрицей как с обычным двумерным массивом
# теперь можно добавлять значения по координатам (координаты - индексы в списке списков) matrix[0][0] = 1 matrix[1][3] = 3 print(matrix) # [[1, 0, 0, 0, 0], [0, 0, 0, 3, 0], [0, 0, 0, 0, 0]] # Получаем значение по произвольным координатам x, y = 1, 3 print(matrix[x][y]) # 37.2.2 — Вложенный генератор внутри генератора — двумерная из двумерной
Общий синтаксис: [[expression for y in x] for x in iterator]
Применение: Обходим двумерную структуру данных, сохраняя результат в другую двумерную структуру.
matrix = [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]Возведем каждый элемент матрицы в квадрат:
squared = [[cell**2 for cell in row] for row in matrix] print(squared) # [[1, 4, 9, 16], [25, 36, 49, 64], [81, 100, 121, 144]] Эта же операция в виде вложенных циклов
squared = [] for row in matrix: new_row = [] for cell in row: new_row.append(cell**2) squared.append(new_row) print(squared) # [[1, 4, 9, 16], [25, 36, 49, 64], [81, 100, 121, 144]] Обобщим все вышеперечисленные варианты в одной схеме (полный размер по клику):
7.3 — Генератор итерирующийся по генератору
Так как любой генератор может использоваться как итератор в цикле for, это так же можно использовать и для создания генератора по генератору.
При этом синтаксически это может записываться в два выражения или объединяться во вложенный генератор.
Проиллюстрирую и такую возможность.
Допустим у нас есть два таких генератора списков:
list_a = [x for x in range(-2, 4)] # Так сделано для дальнейшего примера синтаксиса, # конечно в подобной задаче досточно только range(-2, 4) list_b = [x**2 for x in list_a]Тоже самое можно записать и в одно выражение, подставив вместо list_a его генератор списка:
list_c = [x**2 for x in [x for x in range(-2, 4)]] print(list_c) # [4, 1, 0, 1, 4, 9]UPD от longclaps: Преимущество от комбинирования генераторов на примере сложной функции f(x) = u(v(x))
list_c = [t + t ** 2 for t in (x ** 3 + x ** 4 for x in range(-2, 4))]8. Использование range()
Говоря о способах генерации коллекций, нельзя обойти вниманием простую и очень удобную функцию range(), которая предназначена для создания арифметических последовательностей.
Особенности функции range():
-
Наиболее часто функция range() применяется для запуска цикла for нужное количество раз. Например, смотрите генерацию матрицы в примерах выше.
- range(stop) — в данном случае с 0 до stop-1;
- range(start, stop) — Аналогично примеру выше, но можно задать начало отличное от нуля, можно и отрицательное;
- range(start, stop, step) — Добавляем параметр шага, который может быть отрицательным, тогда перебор в обратном порядке.
- range(. ) которая аналогична выражению list(range(. )) в Python 3 — то есть она выдавала не итератор, а сразу готовый список. То есть все проблемы возможной нехватки памяти, описанные в разделе 4 актуальны, и использовать ее в Python 2 надо очень аккуратно!
- xrange(. ) — которая работала аналогично range(. ) в Python 3 и из 3 версии была исключена.
print(list(range(5))) # [0, 1, 2, 3, 4] print(list(range(-2, 5))) # [-2, -1, 0, 1, 2, 3, 4] print(list(range(5, -2, -2))) # [5, 3, 1, -1]9. Приложение 1. Дополнительные примеры
9.1 Последовательный проход по нескольким спискам
import itertools l1 = [1,2,3] l2 = [10,20,30] result = [l*2 for l in itertools.chain(l1, l2)] print(result) # [2, 4, 6, 20, 40, 60] 9.2 Транспозиция матрицы
(Преобразование матрицы, когда строки меняются местами со столбцами).
matrix = [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]Сделаем ее транспозицию с помощью генератора выражений:
transposed = [[row[i] for row in matrix] for i in range(len(matrix[0]))] print(transposed) # [[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]] Эта же транспозиция матрицы в виде цикла
transposed = [] for i in range(len(matrix[0])): new_row = [] for row in matrix: new_row.append(row[i]) transposed.append(new_row) print(transposed) # [[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]] И немного черной магии от @longclaps
transposed = list(map(list, zip(*matrix))) print(transposed) # [[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]] 9.3 Задача выбора только рабочих дней
# Формируем список дней от 1 до 31 с которым будем работать days = [d for d in range(1, 32)] # Делим список дней на недели weeks = [days[i:i+7] for i in range(0, len(days), 7)] print(weeks) # [[1, 2, 3, 4, 5, 6, 7], [8, 9, 10, 11, 12, 13, 14], [15, 16, 17, 18, 19, 20, 21], [22, 23, 24, 25, 26, 27, 28], [29, 30, 31]] # Выбираем в каждой неделе только первые 5 рабочих дней, отбрасывая остальные work_weeks = [week[0:5] for week in weeks] print(work_weeks) # [[1, 2, 3, 4, 5], [8, 9, 10, 11, 12], [15, 16, 17, 18, 19], [22, 23, 24, 25, 26], [29, 30, 31]] # Если нужно одним списком дней - можно объединить wdays = [item for sublist in work_weeks for item in sublist] print(wdays) # [1, 2, 3, 4, 5, 8, 9, 10, 11, 12, 15, 16, 17, 18, 19, 22, 23, 24, 25, 26, 29, 30, 31] Можно убрать выходные еще более изящно, используя только индексы
# Формируем список дней от 1 до 31 с которым будем работать days = [d for d in range(1, 32)] wdays6 = [wd for (i, wd) in enumerate(days, 1) if i % 7 != 0] # Удаляем каждый 7-й день # Удаляем каждый 6 день в оставшихся после первого удаления: wdays5 = [wd for (i, wd) in enumerate(wdays6, 1) if i % 6 != 0] print(wdays5) # [1, 2, 3, 4, 5, 8, 9, 10, 11, 12, 15, 16, 17, 18, 19, 22, 23, 24, 25, 26, 29, 30, 31] # Обратите внимание, что просто объединить два условия в одном if не получится, # как минимум потому, что 12-й день делится на 6, но не выпадает на последний 2 дня недели! # Шикарное короткое решение от @sophist: days = [d + 1 for d in range(31) if d % 7 < 5] 10. Приложение 2. Ссылки по теме
Иллюстрация из статьи:
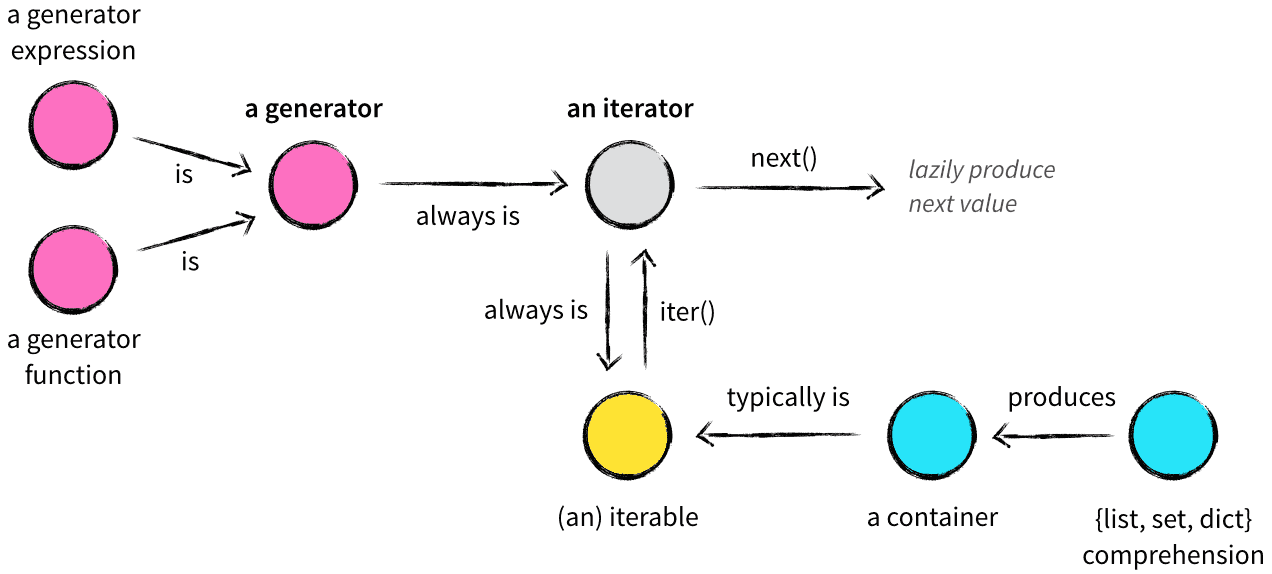
Например так:
squared_evens = [n ** 2 # SELECT for n in numbers # FROM if n % 2 == 0] # WHEREПриглашаю к обсуждению:
- Если я где-то допустил неточность или не учёл что-то важное — пишите в комментариях, важные комментарии будут позже добавлены в статью с указанием вашего авторства.
- Если какие-то моменты не понятны и требуется уточнение — пишите ваши вопросы в комментариях — или я или другие читатели дадут ответ, а дельные вопросы с ответами будут позже добавлены в статью.
- Python
- Программирование
Переформатирование, изменение формы — Python: Numpy-массивы
Часто разработчикам приходится изменять размеры массивов. Например, переформатировать исходные данные, чтобы разделить их на подмассивы. В некоторых случаях требуется еще и объединять многомерные данные в единый массив значений. Чтобы решать такие задачи, массивы numpy.ndarray предоставляют набор методов, самым популярным из которых является метод reshape() .
В этом уроке разберем, как работать с размерами массивов numpy.ndarray и как получать их производные. Еще поговорим об ограничениях размерности и узнаем, как они помогают оптимизировать работу.
Как изменить размер массива
Представим, что нам нужно увеличить размер массива numpy.ndarray . Для этого будем идти по следующим шагам:
- Узнаем размер массива и индексы вдоль оси
- Изменим размер массива
Рассмотрим каждый этап подробнее.
Как узнать размер массива и индексы вдоль оси
Чтобы изменить размер numpy.ndarray , нужно узнать его значение. Для этого используют атрибут shape :
import numpy as np one_dimension_array = np.array( [0,1,2,3,4,5,6,7,8,9,10,11] ) print(one_dimension_array.shape) # => (12,) two_dimensions_array = np.array( [ [0,1,2], [3,4,5], [6,7,8], [9,10,11] ] ) print(two_dimensions_array.shape) # => (4, 3) three_dimensions_array = np.array( [ [ [0,1], [2,3], ], [ [4,5], [6,7], ], [ [8,9], [10,11] ] ] ) print(three_dimensions_array.shape) # => (3, 2, 2) В примере выше атрибут shape возвращает кортеж целых чисел. Длина кортежа указывает на размерность массива:
- (12,) — одномерный массив
- (4, 3) — двумерный массив
- (3, 2, 2) — трехмерный массив
Числа в кортеже означают количество элементов по конкретной оси индексов:
- (12,) — 12 значений
- (4, 3) — четыре блока значений по три значения в каждом
- (3, 2, 2) — три блока значений, каждый из которых состоит из двух блоков по два значения
Название ось индексов отсылает к декартовой системе координат. Вспомним ее основные правила:
- Чтобы построить отрезок или другой одномерный объект, достаточно одной координатной оси
- Чтобы построить квадрат или другой двумерный объект, необходима координатная плоскость из двух перпендикулярных осей
- Чтобы построить куб или другой трехмерный объект, нужно три ортогональные оси координат
Теперь, когда мы знаем размер исходного массива, можно изменять его форму. Для этого используем метод reshape() .
Как изменить размер массива с помощью метода reshape()
В Python используется метод reshape() , с помощью которого можно получить двухмерный и трехмерный массив из одномерного. Этот обязательный параметр ожидает новый размер данных, к которому нужно переформатировать исходный массив.
Попробуем получить двумерный массив two_dimensions_array из одномерного массива one_dimension_array . Для этого используем метод reshape() с новым размером данных (4, 3) :
print(one_dimension_array.reshape((4, 3))) # => [[ 0 1 2] # [ 3 4 5] # [ 6 7 8] # [ 9 10 11]] Чтобы получить трехмерный массив three_dimensions_array , достаточно также указать нужный размер:
print(one_dimension_array.reshape((3, 2, 2))) # => [[[ 0 1] # [ 2 3]] # [[ 4 5] # [ 6 7]] # [[ 8 9] # [10 11]]] Изменять форму массива можно не только от данных меньшей размерности к данным большей размерности. Это можно делать и в обратную сторону.
Попробуем получить исходный одномерный массив one_dimension_array из двумерного массива two_dimensions_array :
print(two_dimensions_array.reshape((12,))) # => [ 0 1 2 3 4 5 6 7 8 9 10 11] А тут переформатируем three_dimensions_array в two_dimensions_array :
print(three_dimensions_array.reshape((4,3))) # => [[ 0 1 2] # [ 3 4 5] # [ 6 7 8] # [ 9 10 11]] Необязательно уменьшать размер последовательно. Например, можно из трехмерного массива получить сразу одномерный:
print(three_dimensions_array.reshape((12,))) # => [ 0 1 2 3 4 5 6 7 8 9 10 11] С помощью атрибута shape можно узнать размерность массива numpy.ndarray . А метод reshape поможет ее уменьшить или увеличить. Однако у этого массива есть ограничения по размеру данных — его нужно соблюдать, чтобы оптимизировать выполнения методов над массивами.
Какие размеры массива допустимы
У массива numpy.ndarray есть ограничения по размеру данных — по осям индексов должны быть данные одного размера. Это ограничение позволяет оптимизировать выполнения методов над массивами. Рассмотрим на примере.
Допустим, нам нужно сконвертировать список из списков длиной три и два:
np.array( [ [0,1,2], [3,4,], ] ) # => [list([0, 1, 2]) list([3, 4])] На первый взгляд у нас получился массив numpy.ndarray . Но если внимательно посмотреть на элементы, мы увидим, что получились списки, а не ожидаемые целочисленные массивы. Это ограничит дальнейшую работу с данными, потому что поведение многих методов меняется.
Попробуем найти в данном массиве максимальный элемент 4 . Это приведет к такому результату:
print(np.array( [ [0,1,2], [3,4,], ] ).max()) # => [3, 4] В этом примере мы получили не тот результат, которого ожидали.
Numpy старается предотвращать некорректные действия — для этого в нем есть система предупреждений и подсказок. Но это не значит, что не нужно следить за размером массива. Он играет важную роль в реализации методов библиотеки Numpy, поэтому рекомендуем обращать внимание на этот момент.
В случае с методом reshape() Numpy вообще не дает совершить некорректную конвертацию массива из 12 элементов в массив из 15 элементов — три блока по пять значений. В этом случае он вызывает исключение:
one_dimension_array.reshape(3,5) # => ValueError: cannot reshape array of size 12 into shape (3,5) Ограничения по размеру могут добавить неудобств, когда мы увеличиваем или уменьшаем размерность массива. При этом они позволяют не указывать некоторые значения размера, когда мы хотим его изменить.
Как сделать автоматический расчет размера массива
Ограничения на размер массива позволяют не указывать некоторые размеры в методе reshape() . Это можно оставить на автоматический расчет. Для этого нужное значение размерности поменяем на -1 :
print(one_dimension_array.reshape((4,3))) print(one_dimension_array.reshape(((4, -1)))) print(one_dimension_array.reshape(((-1, 3)))) # => [[ 0 1 2] # [ 3 4 5] # [ 6 7 8] # [ 9 10 11]] Все преобразования в примере выше дают одинаковый результат. Необходимый размер рассчитывается автоматически, исходя из количества элементов.
Для массивов большей размерности это работает по такому же принципу:
print(one_dimension_array.reshape((3, 2, 2))) print(one_dimension_array.reshape((-1, 2, 2))) print(one_dimension_array.reshape((3, -1, 2))) print(one_dimension_array.reshape((3, 2, -1))) # => [[[ 0 1] # [ 2 3]] # [[ 4 5] # [ 6 7]] # [[ 8 9] # [10 11]]] Чтобы получить одномерный массив и использовать автоматический расчет, не нужно находить количество элементов. Строки в примере ниже дают одинаковый результат:
print(three_dimensions_array.reshape((12,))) print(three_dimensions_array.reshape((-1,))) # => [ 0 1 2 3 4 5 6 7 8 9 10 11] Теперь вы знаете, как определять размерность массива. Вы умеете изменять размер и рассчитывать его автоматически. Чтобы закрепить знания на практике, рассмотрим еще один пример.
Как размер массива меняется на практике
Изменение формы массива помогает подготовить исходные данные — после такой обработки их будет удобнее анализировать и преобразовывать.
Представим сервис платформы продаж, который логирует данные по сетевым магазинам в конце рабочего дня в определенном порядке. Аналитики выгрузили данные из закрытого контура платформы. Так они получили 24 значения недельных продаж сети:
orders = [7, 1, 7, 8, 4, 2, 4, 5, 3, 5, 2, 3, 8, 12, 8, 7, 15, 11, 13, 9, 21, 18, 17, 21, 25, 16, 25, 17,] shops_number = 4 orders_matrix = np.array(orders) orders_matrix = orders_matrix.reshape(-1, shops_number) print(orders_matrix) # => [[ 7 1 7 8] # [ 4 2 4 5] # [ 3 5 2 3] # [ 8 12 8 7] # [15 11 13 9] # [21 18 17 21] # [25 16 25 17]] print(orders_matrix.shape) # => (7, 4) Полученный массив данных можно визуализировать в виде такой таблицы:
| День | Магазин №1 | Магазин №2 | Магазин №3 | Магазин №4 |
|---|---|---|---|---|
| 0 | 7 | 1 | 7 | 8 |
| 1 | 4 | 2 | 4 | 5 |
| 2 | 3 | 5 | 2 | 3 |
| 3 | 8 | 12 | 8 | 7 |
| 4 | 15 | 11 | 13 | 9 |
| 5 | 21 | 18 | 17 | 21 |
| 6 | 25 | 16 | 25 | 17 |
Выводы
Метод shape — важный атрибут для структурного описания массива numpy.ndarray . Он помогает узнать размер вдоль каждой оси.
Открыть доступ
Курсы программирования для новичков и опытных разработчиков. Начните обучение бесплатно
- 130 курсов, 2000+ часов теории
- 1000 практических заданий в браузере
- 360 000 студентов
Наши выпускники работают в компаниях: