Как войти на сайт с помощью Requests?
Нужно с помощью requests авторизоваться на сайте https://ctr.ru/ и получить данные со страниц типа https://ctr.ru/?event=detail&i=983 (страница доступна только для авторизованных пользователей). Пытаюсь вытащить cookie с Google Chrome (в браузере я авторизован):
import browser_cookie3 import requests cj = browser_cookie3.chrome() r = requests.get('https://ctr.ru/?event=detail&i=983', cookies=cj) Но requests получает страницу https://ctr.ru/, сайт перенаправляет неавторизованных пользователей. Предполагаю, что это происходит из-за того, что протокол сайта HTTPS. Что ещё можно сделать для авторизации? Заранее спасибо!
Отслеживать
задан 20 мар 2018 в 15:05
hohokibeza hohokibeza
105 1 1 золотой знак 3 3 серебряных знака 10 10 бронзовых знаков
2 ответа 2
Сортировка: Сброс на вариант по умолчанию
Проанализировал, что отправляется на сайт при авторизации, и оказалось, что кроме логина и пароля на сайт отправляется параметр a_event со значением _login. Этот код заработал (программа авторизуется и заходит на страницы, доступные только для авторизованных пользователей):
import requests s = requests.Session() data = url = 'https://ctr.ru/' r = s.post(url, data=data) r = requests.get('https://ctr.ru/?event=detail&i=984', cookies=s.cookies) Отслеживать
ответ дан 20 мар 2018 в 16:44
hohokibeza hohokibeza
105 1 1 золотой знак 3 3 серебряных знака 10 10 бронзовых знаков
Чтобы сохранить cookies используй Session(), например:
import requests username = 'user' password = 'password' url = 'https://www.example.com' sess = requests.Session() sess.verify = False resp = sess.post(url + '/login', data=) resp.raise_for_status() resp = sess.get(url + '/index.html') resp.raise_for_status() print(resp) Парсинг сайта с применением авторизации

Любой, кто когда-либо пытался парсить сайты на python начинал с простого запроса «get» библиотеки «requests». Запрос «get» выгружает html код страницы, который можно обрабатывать под свои нужды.
Но иногда данные доступны только после авторизации на ресурсе. В этом посте я покажу, как можно подключаться, используя логин-пароль и библиотеку «requests».
Использование сессий дает преимущества в скорости парсинга данных и исключает блокировку учетной записи. Если приходится выгружать данные — страницу сайта за страницей, при каждом новом запросе будет создаваться новый запрос с новым подключением к сайту, при использовании сессии она создается один раз и используется на всем протяжении работы.
Возьмем сайт https://ivi.ru/ и попытаемся залогиниться.
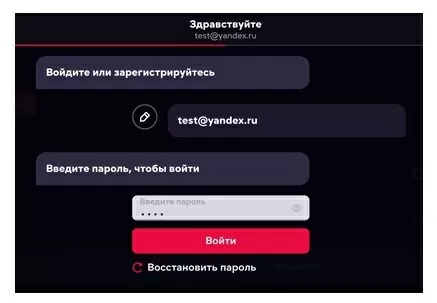
Для авторизации требуется ввести email и пароль. В библиотеке requests есть метод «POST», с помощью которого реализуются отправки данных на сервер. Общий вид использования метода: «requests.post(url, headers, data)». «url» ссылка на ресурс, «headers» заголовки запроса, «data» данные запроса, которые мы будем передавать.
Импорт, авторизация и исходные параметры
pip install requestsПрежде всего, нужно узнать, откуда брать данные «headers» и «data». Для этого запустим инструмент разработчика. Переходим во вкладку СЕТЬ и обновляем страницу. Здесь видим все активности сети.
На главной странице сайта входим в профиль. Открывается форма авторизации, вводим логин-пароль и нажимаем кнопку ВОЙТИ. Ищем нашу ссылку.
Чтобы быстрее находить нужную строку в отображении полей нужно добавить поле «Method» и по нему отсортировать столбец. Данные на авторизацию отправляются в «POST» запросах.
Находим строку v5/

Смотрим информацию по этой строке
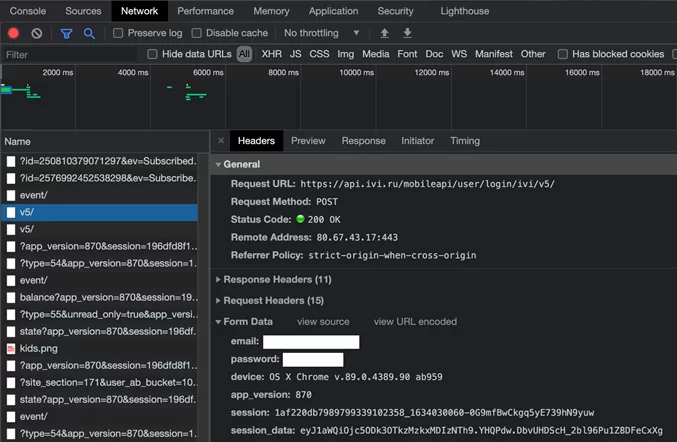
Во вкладке «headers» находим «General» в нем возьмем «url», в «Request Headers» нас интересует только «User-Agent», который пропишем в «headers», в «Form Data» данные для запроса «data».
import requestsurl = 'https://api.ivi.ru/mobileapi/user/login/ivi/v5/'headers = < 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36' >data =
Создаем сессию, она будет держать наше соединение с сайтом, и мы сможем с ним работать.
session = requests.Session() session.headers.update(headers) response = session.post(url, data=data) Смотрим статус ответа
response
Ответ 200 означает успешный ответ от сервера.
Посмотрим, что возвратил наш запрос
response.json(), 'email': 'test@yandex.ru', 'email_real': 1, 'msisdn': '', 'confirmed': 1, 'storageless': False, 'is_debug': False, 'children': [], 'basic': '0.0000', 'bonus': '0.0000'>> Здесь важная строка «session», которая указывает на наш номер сессии. Дальше в примере будет видно, что, если бы мы не создали сессию, изменить данные нам бы не удалось.
Попробуем поменять данные профиля. Нажимаем на кнопку редактировать и меняем имя.
Ищем в инструменте разработчика нашу строку. Чтобы не было много записей, можно сразу же после нажатия кнопки сохранить остановить загрузку страницы, «POST» запрос на изменение будет идти первым, только после этого происходит загрузка страницы с обновленными данными.
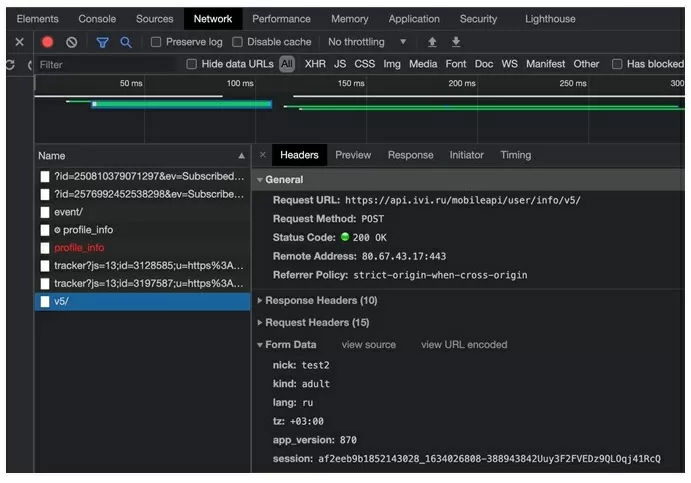
Записываем «url» и копируем «data». Необходимо обратить внимание на строку «session», где нужно передать наш номер сессии. Номер берем из ответа сервера.
url_change_nick = 'https://api.ivi.ru/mobileapi/user/info/v5/'session_id = response.json()['result']['session'] data =
response = session.post(url_change_nick, data=data)Чтобы удостовериться в работе нашего кода обновляем страницу в браузере.

Наш код успешно сработал.
Использование учетных данных WINDOWS
Также бывают редкие случаи, когда нужно использовать логин-пароль от учетной записи Windows. Для этого можно использовать библиотеку «requests-negotiate-sspi». Она становится особенно полезной, когда часто меняется пароль от учетной записи.
Устанавливаем и импортируем библиотеку, нам нужен метод «HttpNegotiateAuth»
pip install requests_negotiate_sspi from requests_negotiate_sspi import HttpNegotiateAuth Повторяем все, что делали выше: прописываем «headers», заполняем «data» и поднимаем сессию. Попробуем получить дату и время сервера.
Вначале сделаем запрос без передачи данных авторизации
xml_request = ''' ''' headers = < 'Host': host_name, 'Content-Type': 'text/xml; charset=utf-8', 'Content-Length': str(len(xml_request)) >session.headers = headers response = session.post('http://' + host_name + '/ServerService.asmx?WSDL', data=xml_request) response Посмотрим текст ответа
response.text401 - Unauthorized: Access is denied due to invalid credentials. Как мы видим ошибка авторизации.
Повторяем запрос с использованием «HttpNegotiateAuth»
response = session.post('http://' + host_name + '/ServerService.asmx?WSDL', auth=HttpNegotiateAuth(), data=xml_request) response.text 44298.576980902777 Ответ на запрос даты и времени сервера получен успешно.
Sessions позволяет вам использовать requests более эффективно и решать проблемы с подключением к аккаунту, ускорять работу выполнения запросов и исключать блокировку при ограничении количества соединений.
Как залогиниться на сайте при помощи python requests?
День добрый
Есть задача спарсить сайт https://www.strava.com, для парсинга используем Python.
Парсить надо внутренние пользовательские данные сайта. Для этого надо залогинеца, а с этим проблема. Что бы мы не пробовали пока результат отрицательный. Нужна помощь специалиста в этом вопросе.
Заранее спасибо
from bs4 import BeautifulSoup import requests from fake_useragent import UserAgent from time import sleep def authorize(): headers = < 'User-Agent': UserAgent().chrome, ># utf8: ✓ # 'utf8': '✓', login_data = < 'utf8': '✓', 'plan': '', 'email': 'mail@ru', 'password': 'pass', >with requests.Session() as s: s.get('https://www.strava.com') s.verify = False url = 'https://www.strava.com/login/' r = s.get(url) soup = BeautifulSoup(r.text, 'html5lib') login_data['authenticity_token'] = str(soup.find('input', attrs=)['value']) headers['X-CSRF-Token'] = soup.select_one('meta[name="csrf-token"]')['content'] headers['cookie'] = '; '.join([x.name + '=' + x.value for x in s.cookies]) sleep(1) r2 = s.post(url, data=login_data, headers=headers) r3 = s.get('https://www.strava.com/clubs/225082/members') sleep(1) print(r3.text) def main(): authorize() if __name__ == '__main__': main()- Вопрос задан более трёх лет назад
- 3435 просмотров
Комментировать
Решения вопроса 1

Сергей Карбивничий @hottabxp Куратор тега Python
Сначала мы жили бедно, а потом нас обокрали..
Да тут делов на 2минуты:
import requests from bs4 import BeautifulSoup import time headers = data = url = 'https://www.strava.com/session' session = requests.Session() # Сессия def get_token():# Метод, для получения токена response = session.post(url,headers=headers) soup = BeautifulSoup(response.text,"html.parser") token = soup.find('input',).get('value') return token # Возвращает токен def auth(): # Метод, для авторизации response = session.post(url,headers=headers,data=data) return response.text data['authenticity_token'] = get_token() # Вызывает метод для получения токена, и результат заносим в словарь time.sleep(2) # Пауза 2 сек :) html = auth() # Авторизируемся. В html будет наш ответ после авторизации if 'Log Out' in html: # Если строка 'Log Out' есть в html, значит авторизация прошла успешно print('Login OK!') else: print('Login Error!')Если что не понятно, пишите.
Ответ написан более трёх лет назад
Нравится 4 1 комментарий
Павел Иванов @Ivanov_pv Автор вопроса
Спасибо большое за помощь, все работает
Ответы на вопрос 1

Назар Тропанец @nazartropanets
изучаю deep learning и ML(Python)
Попробуйте промониторить через Network вход в аккаунт(нажимаете f12 и выбираете Network), логинитесь и отсылаете форму. Во вкладке Network должны были отослатся данные входа на сервер, посмотрите что передается, вероятнее всего вместе с паролем и именем передается какой-то токен, и из-за этого не получается выполнить авторизацию. Для авторизации нужно передавать все данные которые должны передаватся, а не только юзернейм и пароль.
Ответ написан более трёх лет назад
Павел Иванов @Ivanov_pv Автор вопроса
Да токен тоже предается в коде он он добавляется тут
. login_data['authenticity_token'] = str(soup.find('input', attrs=)['value']) . Промониторить через Network в гуглхроме, вот вся выдача что была с post запросом
В коде формируется первые шесть строчек с реализацией токена, а что еще добавлять?
Подскажите если не сложно?
utf8: ✓ authenticity_token: YW0S8lRJ/EqPqkS/wTUj5qCRExIgpzIn9Ryd/A3xuJQQVSKaoozomMDW2LDnDkdrD0UShE8S3FGKWv8199ws3w== plan: email: mail@.ru password: pass event: pageview metadata: initial_referrer: https://www.strava.com/login is_iframe: false user_language: ru open_app: false has_app_websdk: false feature: journeys callback_string: branch_view_callback__1 data: source: web-sdk branch_key: key_live_lmpPsfj2DP8CflI4rmzfiemerte7sgwm session_id: 792280983689258684 identity_id: 791901031512693012 sdk: web2.53.1 browser_fingerprint_id: 707829489312081104 event: web-login metadata: initial_referrer: https://www.strava.com/login browser_fingerprint_id: 707829489312081104 identity_id: 791901031512693012 sdk: web2.53.1 session_id: 792353521164926825 branch_key: key_live_lmpPsfj2DP8CflI4rmzfiemerte7sgwm identity_id: 792353521173559587 identity: 58983723 browser_fingerprint_id: 707829489312081104 sdk: web2.53.1 session_id: 792353521164926825 branch_key: key_live_lmpPsfj2DP8CflI4rmzfiemerte7sgwm
Назар Тропанец @nazartropanets
Павел Иванов, да, вы передаете все параметры, но я не могу понять в чем проблема
Попробуйте выввести все параметры, которые вы передаете, и проверьте в чем может быть проблема
Возможно в plan нужно передовать — » «, вместо — «»
Автоматизированная система входа на сайт с Python и Selenium WebDriver
В сегодняшней статье мы рассмотрим как с помощью вебдрайвера Selenium и Python, автоматически залогиниться на сайте. Нам понадобится скачать Selenium WebDriver для браузера Chrome c сайта https://chromedriver.chromium.org/downloads, а также модуль selenium для работы с драйвером через Python. Версия драйвера должна соответствовать версии браузера Chrome. Для проверки версии Chrome в адресной строке вводим: chrome://settings/help. Далее скачиваем файл в виде .zip архива. Создаем на диске C папку chromedriver и положим в нее извлеченный файл chromedriver.exe.
# установка модуля для взаимодействия с веб-драйвером
pip install selenium==4.*
Создадим файл main.py:
# импорт модулей time и selenium
from selenium import webdriver
from selenium.webdriver.common.by import By
# инициализация веб-драйвера с полным путем к исполняемому драйверу
driver = webdriver.Chrome(‘C:\chromedriver\chromedriver.exe’)
# засыпание программы на 2 миллисекунды
time.sleep(2)
# открытие драйвером сайта
driver.get(«https://myrusakov.ru/»)
time.sleep(1)
# поиск элементов формы по описанию в html коде
login = driver.find_element(By.NAME, «login»)
password = driver.find_element(By.NAME, «password»)
# отправка данных в найденные формы
login.send_keys(«login»)
password.send_keys(«password»)
# кнопка регистрации ищется драйвером по CSS селектору, указывающему путь в CSS коде к данному элементу
submit_button = driver.find_element(By.CSS_SELECTOR , «#auth input[type=\»submit\»]»).click()
# метод click выполняет нажатие по кнопке формы
# окончание работы драйвера
driver.quit()
В результате, при существующем логине и пароле, сайт аутентифицирует нас. Далее возможно автовыполнение некоторых рутинных действий. Драйвер имеет методы поиска не только по имени но и по другим атрибутам html
Следует иметь в виду, что используемые здесь атрибуты не подойдут на других сайтах.
Таким образом, с помощью веб-драйвера Selenium и Python можно выполнять множество действий на сайте.

![]()
Создано 02.06.2022 13:36:28
Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov.ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Порекомендуйте эту статью друзьям:
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
- Кнопка:
Она выглядит вот так: - Текстовая ссылка:
Она выглядит вот так: Как создать свой сайт - BB-код ссылки для форумов (например, можете поставить её в подписи):
Комментарии ( 0 ):
Для добавления комментариев надо войти в систему.
Если Вы ещё не зарегистрированы на сайте, то сначала зарегистрируйтесь.
Copyright © 2010-2024 Русаков Михаил Юрьевич. Все права защищены.