Основы работы с MySQL Workbench: быстрый старт, управление схемой данных
Веб-разработчик растёт вместе с проектами, которые он создаёт и развивает. С ростом проектов увеличивается сложность программной части, неизбежно возрастает количество обрабатываемых ею данных, а так же сложность схемы данных. Общение с другими вебщиками показывает, что огромной популярностью среди нас пользуются базы данных MySQL, а для управления ими — небезызвестный PHPMyAdmin. Переходя от маленьких проектов к большим, от cms к фреймворкам, многие, как и я, остаются верны MySQL. Однако для проектирования сложной базы данных с большим количеством таблиц и связей, возможностей PHPMyAdmin катастрофически не хватает. Поэтому я решил написать обзор MySQL Workbench — замечательной бесплатной десктопной программы для работы с MySQL.
В первой части обзора я расскажу о самых основах работы с программой, так что, можете использовать эту статью как руководство начинающего пользователя. Вторая часть будет посвящена использованию Workbench в бою при работе с удалённым сервером. В ней я дам базовые инструкции и рекомендации по настройке подключения сервера и синхронизации с ним.
MySQL Workbench — инструмент для визуального проектирования баз данных, интегрирующий проектирование, моделирование, создание и эксплуатацию БД в единое бесшовное окружение для системы баз данных MySQL.
Должен сказать, что программа действительно великолепная. Она позволяет быстро и с удовольствием накидывать схемы данных проекта, проектировать сущности и связи между ними, безболезненно внедрять изменения в схему и так же быстро и безболезненно синхронизировать её с удалённым сервером. А графический редактор EER-диаграмм, напоминающих забавных таракашек, позволяет увидеть общую картину модели данных и насладиться её лёгкостью и элегантностью 🙂 После первой же пробы этот инструмент становится незаменимым помощником в боевом арсенале веб-программиста.
Скачать MySQL Workbench
Дистрибутив MySQL Workbench доступен на этой странице. Самая свежая версия программы на момент написания статьи — Version 6.1. Перед скачиванием требуется выбрать одну из следующих платформ:
- Microsoft Windows (доступны MSI Installer и ZIP архив)
- Ubuntu Linux
- Fedora
- Red Hat Enterprise Linux / Oracle Linux
- Mac OS X
После выбора платформы вам предлагают зарегистрироваться или авторизоваться в Oracle. Если не хотите, внизу есть ссылка «No thanks, just start my download» — жмите на неё 😉
Начало работы
Стартовый экран программы отражает основные направления её функциональности — проектирование моделей баз данных и их администрирование:
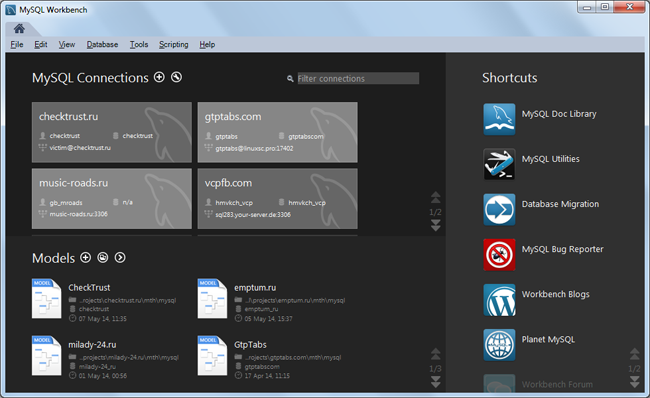
В верхней части экрана находится список подключений к MySQL серверам ваших проектов, а список последних открытых моделей данных — в нижней части экрана. Работа обычно начинается с создания схемы данных или загрузки существующей структуры в MySQL Workbench. Приступим к работе!
Создание и редактирование модели данных
Для добавления модели нажимаем плюсик рядом с заголовком «Models» или выбираем «File → New Model» (Ctrl + N):
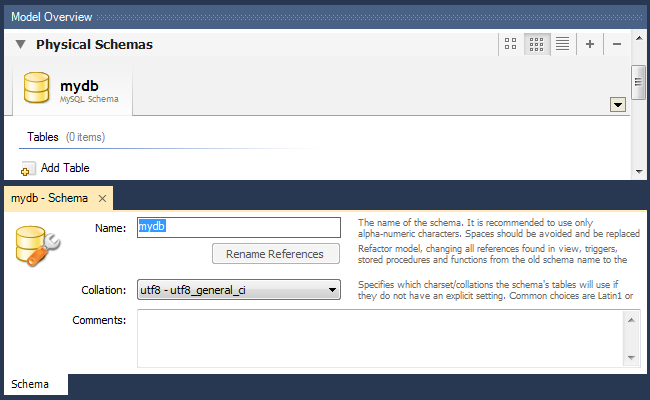
На этом экране вводим имя базы данных, выбираем кодировку по умолчанию и, если нужно, заполняем поле комментария. Можно приступать к созданию таблиц.
Добавление и редактирование таблицы
Список баз данных проекта и список таблиц в пределах базы данных будет располагаться во вкладке «Physical Schemas». Чтобы создать таблицу, дважды кликаем на «+Add Table»:
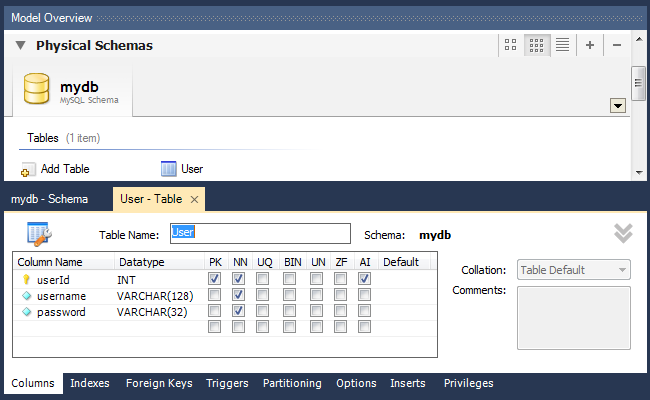
Откроется удобный интерфейс для редактирования списка полей и их свойств. Здесь мы можем задать название поля, тип данных, а так же установить для полей различные атрибуты: назначить поле первичным ключом (PK), пометить его Not Null (NN), бинарным (BIN), уникальным (UQ) и другие, установить для поля авто-инкремирование (AI) и значение по умолчанию (Default).
Управление индексами
Добавлять, удалять и редактировать индексы таблиц можно во вкладке «Indexes» интерфейса управления таблицей:
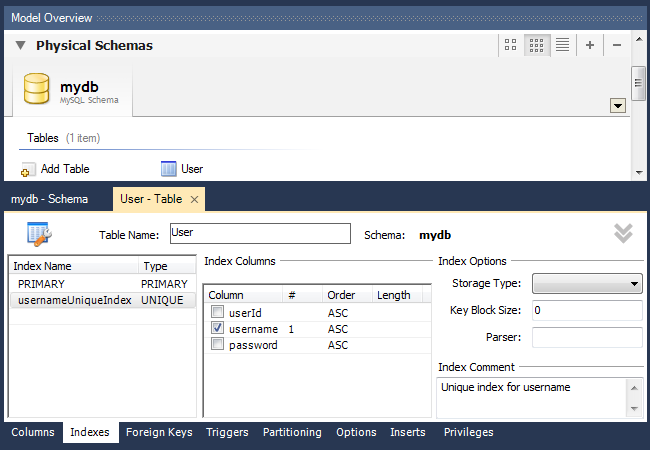
Вводим название индекса, выбираем его тип, затем галочками помечаем в нужном порядке список полей, участвующих в данном индексе. Порядок полей будет соответствовать порядку, в котором были проставлены галочки. В данном примере я добавил уникальный индекс к полю username.
Связи между таблицами
Установка внешних ключей и связывание таблиц возможно только для таблиц InnoDB (эта система хранения данных выбирается по умолчанию). Для управления связями в каждой таблице находится вкладка «Foreign Keys»:
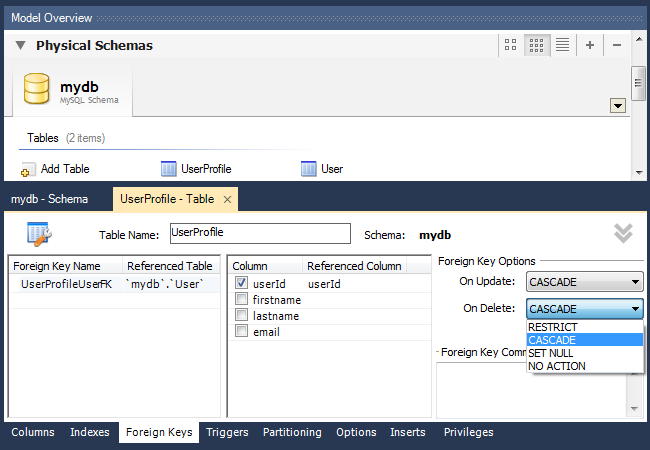
Для добавления связи открываем вкладку «Foreign Keys» дочерней таблицы, вводим имя внешнего ключа и выбираем таблицу-родителя. Далее в средней части вкладки в графе Column выбираем поле-ключ из дочерней таблицы, а в графе Referenced Column — соответствующее поле из родительской таблицы (тип полей должен совпадать). При создании внешних ключей в дочерней таблице автоматически создаются соответствующие индексы.
В разделе «Foreign Key Options» настраиваем поведение внешнего ключа при изменении соответствующего поля (ON UPDATE) и удалении (ON DELETE) родительской записи:
- RESTRICT — выдавать ошибку при изменении / удалении родительской записи
- CASCADE — обновлять внешний ключ при изменении родительской записи, удалять дочернюю запись при удалении родителя
- SET NULL — устанавливать значение внешнего ключа NULL при изменении / удалении родителя (неприемлемо для полей, у которых установлен флаг NOT NULL!)
- NO ACTION — не делать ничего, однако по факту эффект аналогичен RESTRICT
В приведённом примере я добавил к дочерней таблице UserProfile внешний ключ для связи с родительской таблицей User. При редактировании поля userId и удалении позиций из таблицы User аналогичные изменения будут автоматически происходить и со связанными записями из таблицы UserProfile.
Наполнение таблицы базовыми данными
При создании проекта в базу данных часто нужно добавлять стартовые данные. Это могут быть корневые категории, пользователи-администраторы и т.д. В управлении таблицами MySQL Workbench для этого существует вкладка «Inserts»:
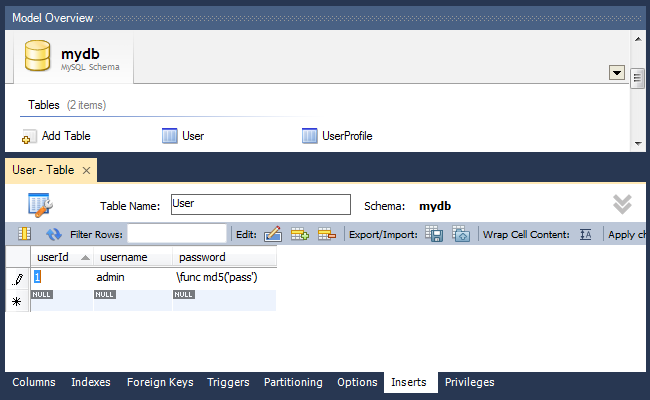
Как видно из примера, в случае, если перед записью в базу данных к данным нужно применить какую-то функцию MySQL, это делается с помощью синтаксиса \func functionName(‘data’), например, \func md5(‘password’).
После ввода данных необходимо сохранить их в локальную базу данных нажатием на кнопку «Apply Changes».
Создание EER диаграммы (диаграммы «сущность-связь»)
Для представления схемы данных, сущностей и их связей в графическом виде в MySQL Workbench существует редактор EER-диаграмм. Для создания диаграммы в верхней части экрана управления базой данных дважды кликаем на иконку «+Add Diagram»:
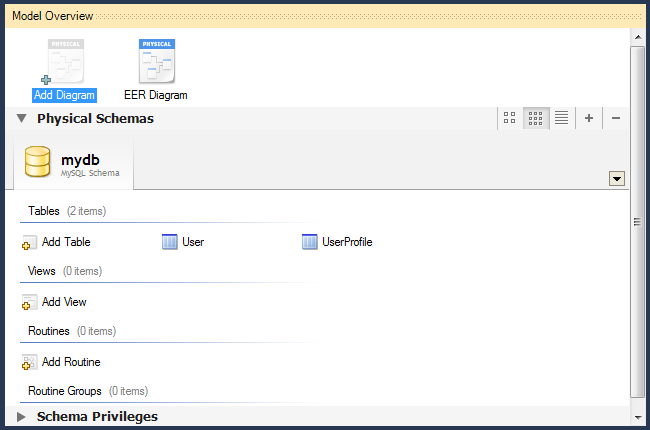
В его интерфейсе можно создавать и редактировать таблицы, добавлять между ними связи различных типов. Чтобы добавить уже существующую в схеме таблицу на диаграмму, просто перетащите её из панели «Catalog Tree».
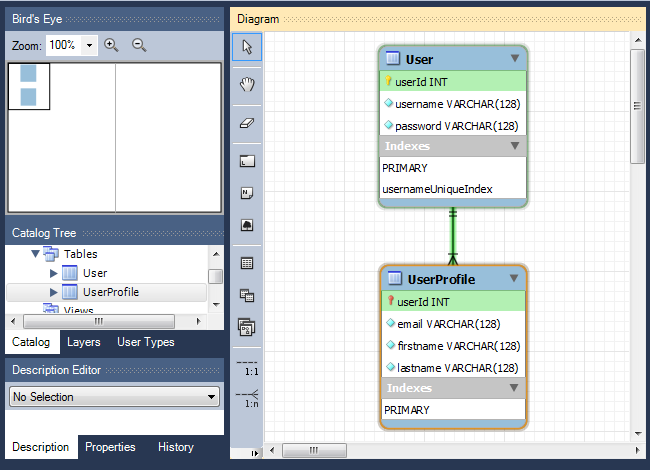
Для экспорта схемы данных в графический файл выберите «File → Export», а затем один из вариантов (PNG, SVG, PDF, PostScript File).
Импорт существующей схемы данных (из SQL дампа)
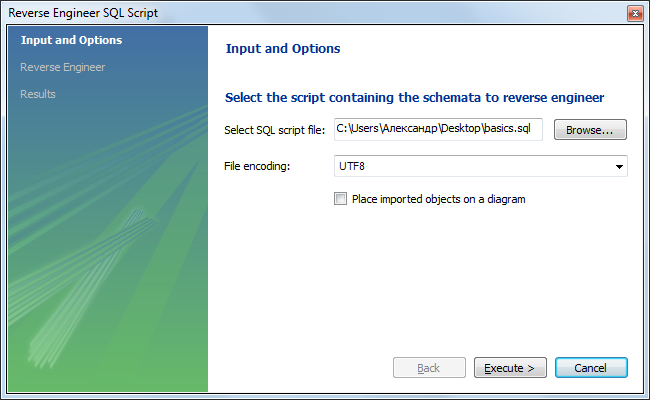
Если у нас уже есть схема данных, её можно без труда импортировать в MySQL Workbench для дальнейшей работы. Для импорта модели из SQL файла выбираем «File → Import → Reverse Engineer MySQL Create Script. «, после чего выбираем нужный SQL файл и жмём «Execute >»
В MySQL Workbench так же предусмотрен импорт и синхронизация модели данных нарямую с удалённым сервером. Для этого потребуется создать подключение удалённого доступа к MySQL, о которых я расскажу в продолжении данного обзора.
Демо-проект из статьи доступен для скачивания по этой ссылке. Желаю успехов и красивых таракашек схем!
Insert в MySQL — добавление данных в таблицу
В статье расскажем, для чего нужна команда INSERT в MySQL и покажем как ей пользоваться на десяти практических примерах.
Зачем нужна команда Insert
Команда INSERT используется для того, чтобы вставлять новые данные в таблицы. Общий и наиболее часто используемый синтаксис выглядит так:
INSERT into table_name [(column1, [, column2] . )] values (values_list) Минимальный набор обязательных параметров: название таблицы и список значений. Но часто также указывают список столбцов, в которые нужно вставить данные. Есть еще много других необязательных параметров и возможностей. Самую основную часть из них мы посмотрим в этой статье.
Создаем базу MySQL в облаке
Прежде чем начать работать с командой Insert, нам нужна база данных MySQL. Чтобы не заниматься долгой установкой и настройкой, мы создадим управляемую БД на платформе Selectel. Если сервер MySQL у вас уже установлен, можете сразу переходить к следующему разделу.
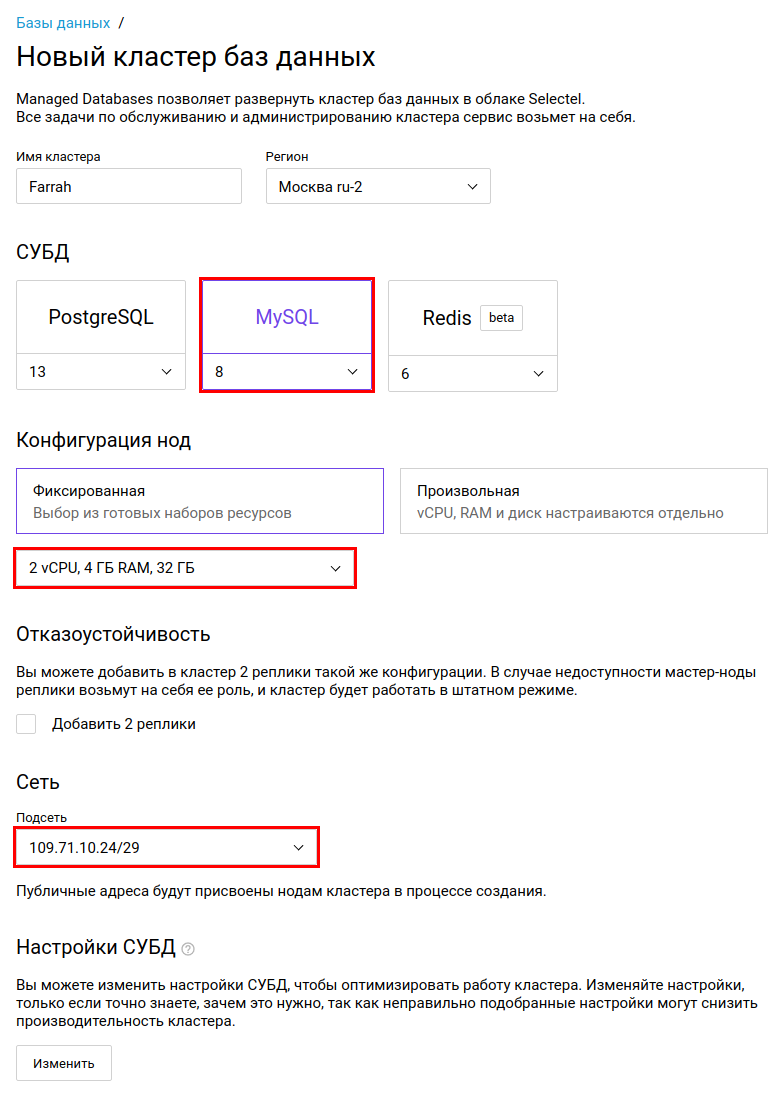
Заходим в личный кабинет, в разделе «Облачная платформа» переходим к «Базам данных». Нажимаем кнопку «Создать кластер».
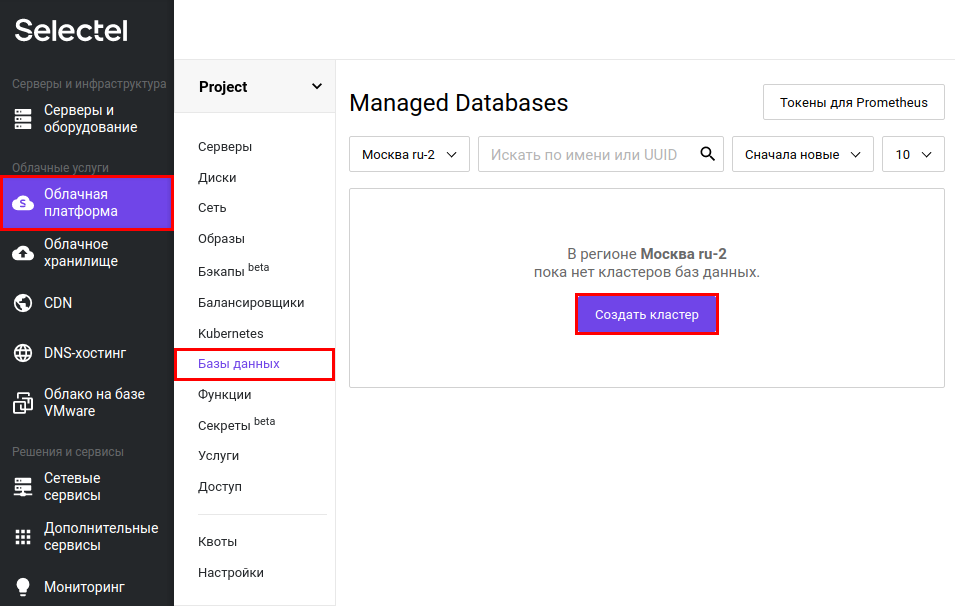
На следующем экране выбираем параметры новой базы. Выбираем «СУБД» — MySQL. Далее необходимо выбрать конфигурацию сервера: нам будет достаточно 2 vCPU, 4 ГБ оперативной памяти и 32 ГБ диска. Обратите внимание на раздел «Сеть» — у вас должна быть выбрана публичная сеть, чтобы к базе данных можно было подключиться из интернета. Остальные параметры можно оставить по умолчанию.
Немного подождем, пока сервер создается. Когда он перейдет в статус ACTIVE, выберите его и зайдите в раздел настроек. Сначала перейдем на вкладку «Пользователи» и создадим нового пользователя, который сможет подключаться к базе данных. Не забудьте записать имя пользователя и пароль, они будут нужны для подключения.
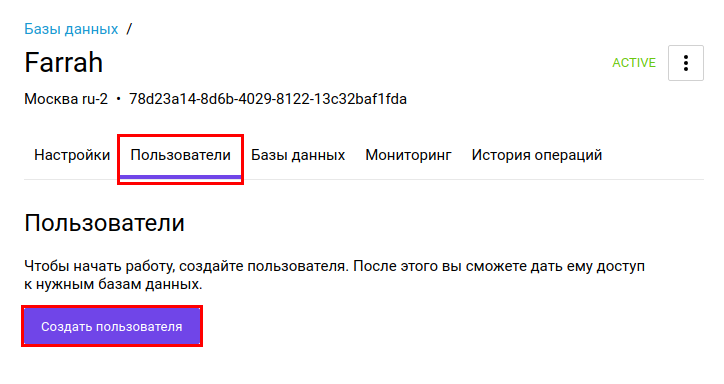
Затем перейдем на следующую вкладку — «Базы данных». Нам нужно создать базу, в которой мы будем работать. Для этого нажмем кнопку «Создать базу данных». Запишите название созданной БД, оно нам будет нужно для подключения.
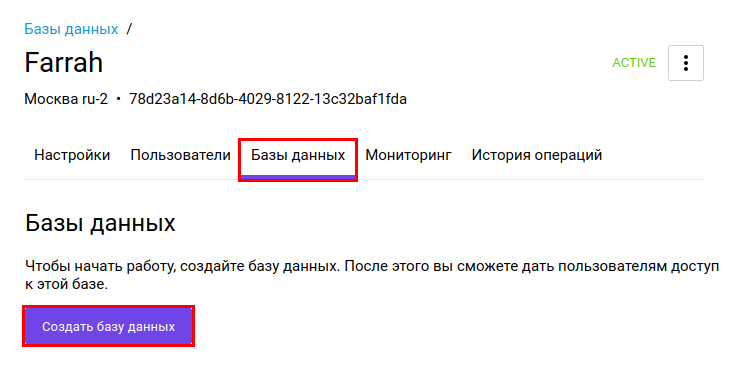
Когда база создастся, нужно дать нашему пользователю права на нее. На этой же вкладке нажмем кнопку «Добавить» и выберем недавно созданного пользователя.
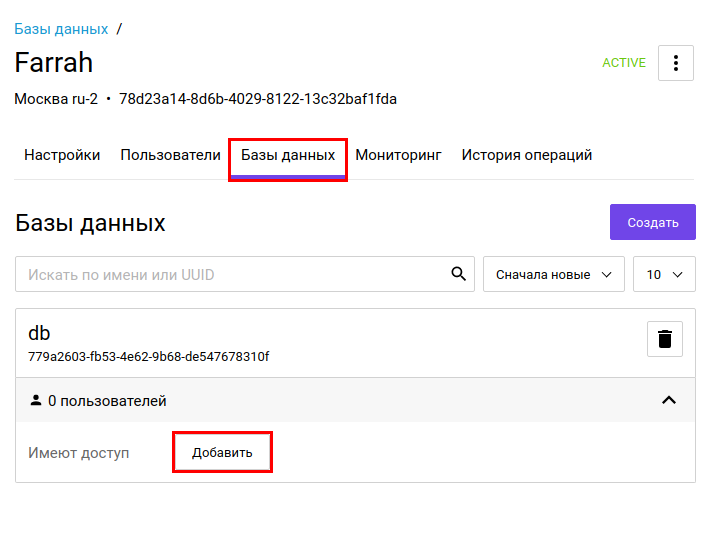
Все, БД настроена и к ней можно подключаться. Чтобы узнать параметры подключения, перейдите на вкладку «Настройки» и там в самом низу в разделе «Подключение» указаны нужные параметры. Вы можете пользоваться консольным клиентом или любой графической утилитой. Мы будем показывать на примере консольного клиента, поэтому строка для подключения будет выглядеть вот так:
mysql --host=109.71.10.30 \ --port=6033 \ --user=chrystal \ --password \ --database=db После ввода этой команды консоль попросит нас ввести пароль. Вот и все, мы подключились к БД.
Структура таблиц для примеров
Все дальнейшие команды мы будем показывать на простом примере из трех таблиц. Допустим, мы — сеть фруктовых магазинов. У нас есть таблица со списком магазинов, таблица со списком товаров (фруктов) и таблица, в которой мы записываем какой фрукт в каком магазине продается и по какой цене.
С помощью команды Insert мы будем вставлять в эти таблицы новые данные разными способами. Итак, вот описание наших таблиц и начальные данные в них:
+----+------------------+--------------+ | id | name | address | +----+------------------+--------------+ | 1 | Магазин 1 | Адрес 1 | | 2 | Магазин 2 | Адрес 2 | | 3 | Магазин 3 | Адрес 3 | +----+------------------+--------------+ +----+------------------+ | id | name | +----+------------------+ | 1 | Яблоко | | 2 | Мандарин | | 3 | Банан | +----+------------------+ - sale, таблица наличия товаров и цены:
+----------+----------+-------+-------+ | store_id | fruit_id | price | count | +----------+----------+-------+-------+ | 1 | 3 | 60 | 20 | | 2 | 2 | 80 | 10 | | 3 | 1 | 120 | 12 | +----------+----------+-------+-------+ Пример 1: базовое использование команды INSERT
Начнем с самого простого использования команды INSERT в MySQL. Добавим новый фрукт в справочник фруктов. Команда будет выглядеть так:
INSERT INTO fruits VALUES (4, 'Апельсин'); Проверяем таблицу фруктов и видим, что появилась новая запись:
+----+------------------+ | id | name | +----+------------------+ | 1 | Яблоко | | 2 | Мандарин | | 3 | Банан | | 4 | Апельсин | +----+------------------+ Мы не указывали названия столбцов, в которые хотим вставить данные. Поэтому они вставлялись по порядку, как они расположены в таблице. Поэтому нам нужно было указывать значения для всех столбцов, которые есть в таблице, даже если мы не хотим их заполнять.
Но если в таблице много столбцов, нам может быть неудобно указывать много пустых значений. Поэтому существует другой способ записи, в котором нужно явно указывать названия столбцов.
INSERT INTO stores (id, name) VALUES (4, 'Магазин 4'); Обратите внимание, что в таблице stores у нас еще есть столбец с адресом, но мы его не указали. Посмотрим, что вставилось в таблицу:
+----+------------------+--------------+ | id | name | address | +----+------------------+--------------+ | 1 | Магазин 1 | Адрес 1 | | 2 | Магазин 2 | Адрес 2 | | 3 | Магазин 3 | Адрес 3 | | 4 | Магазин 4 | NULL | +----+------------------+--------------+ Мы видим указанные нами значения, а в поле address вставилось значение NULL.
Пример 2: вставка нескольких строк
За один запрос можно добавлять сразу несколько элементов. Например, мы хотим добавить три новых фрукта. Вместо того, чтобы писать три отдельных команды INSERT, мы воспользуемся вот таким способом записи:
INSERT INTO fruits VALUES (5, 'Киви'), (6, 'Виноград'), (7, 'Груша'); Посмотрим результат. Видим, что появилось сразу три новых записи:
+----+------------------+ | id | name | +----+------------------+ | 1 | Яблоко | | 2 | Мандарин | | 3 | Банан | | 4 | Апельсин | | 5 | Киви | | 6 | Виноград | | 7 | Груша | +----+------------------+ Пример 3: использование SET
В команде INSERT мы обычно указываем отдельно столбцы и отдельно значения. Но есть способ записи, похожий на команду UPDATE: указывать столбцы и их значения через символ равенства. Такой способ может быть удобен, когда в таблице много полей и значений. Так сразу видно, в какое поле какое значение подставляется.
INSERT INTO sale SET store_id=1, fruit_id=1, price=89, count=3; Проверим, что числа вставились именно в те столбцы, которые мы указали:
+----------+----------+--------+-------+ | store_id | fruit_id | price | count | +----------+----------+--------+-------+ | 1 | 3 | 60 | 20 | | 2 | 2 | 80 | 10 | | 3 | 1 | 120 | 12 | | 1 | 1 | 89 | 3 | +----------+----------+--------+-------+ Пример 4: вставка с выражением
Во всех предыдущих примерах мы указывали явное значение для столбца. Но в MySQL можно использовать арифметические выражения, например сумму, разность, умножение и так далее. Допустим, мы хотим добавить запись в таблицу sale о том что в магазине № 2 продаются апельсины по 137 рублей. Но потом мы решаем, что хотим сделать скидку 6%. Чтобы не высчитывать ее самим, мы можем использовать такой запрос:
INSERT INTO sale VALUES (2, 4, 137*0.94, 5); Мы умножаем 137 рублей на 0.94, это и есть скидка 6%. Проверим что у нас получилось:
+----------+----------+--------+-------+ | store_id | fruit_id | price | count | +----------+----------+--------+-------+ | 1 | 3 | 60 | 20 | | 2 | 2 | 80 | 10 | | 3 | 1 | 120 | 12 | | 1 | 1 | 89 | 3 | | 2 | 4 | 128.78 | 1 | +----------+----------+--------+-------+ Пример 5: вставка данных из другой таблицы
В качестве источника данных для вставки можно использовать другую таблицу. Предположим, у нас есть таблица fruits_new, где хранится список фруктов, которые мы заказали у поставщиков, но эти фрукты еще не продаются в наших магазинах. И вот наконец-то нам привезли два новых фрукта, которые мы так давно ждали. Но вместо того, чтобы переписывать эти названия в команду INSERT, мы можем просто использовать таблицу fruits_new и загружать данные из нее. Для этого нам понадобится оператор SELECT:
INSERT INTO fruits SELECT * FROM fruits_new WHERE >Обратите внимание, что мы не указываем названия столбцов: из какого взять и в какой вносить. Поэтому такой способ подойдет только если структура таблиц одинакова, или в таблице-источнике меньше столбцов. Чаще всего используется другой синтаксис, когда столбцы указаны явно:
INSERT INTO fruits (name, id) SELECT name, id FROM fruits_new WHERE >Проверим результат. После выполнения этих двух команд у нас должно появиться две новых строки:
+----+------------------+ | id | name | +----+------------------+ | 1 | Яблоко | | 2 | Мандарин | | 3 | Банан | | 4 | Апельсин | | 5 | Киви | | 6 | Виноград | | 7 | Груша | | 8 | Ананас | | 9 | Вишня | +----+------------------+ Пример 6: вставка значения по умолчанию
Обычно, если в MySQL для столбца не указано значение, то команда INSERT INTO подставляет NULL. Но если при создании таблицы у этого столбца было указано значение по умолчанию (default), тогда подставится именно оно. В нашей таблице sale у столбца count значение по-умолчанию равно единице. Проверим это, вставив новую запись без указания этого столбца:
INSERT INTO sale (store_id, fruit_id, price) VALUES(4, 7, 50); Проверяем результат. Мы не указывали значение для столбца count, но автоматически подставлилось значение 1.
+----------+----------+--------+-------+ | store_id | fruit_id | price | count | +----------+----------+--------+-------+ | 1 | 3 | 60 | 20 | | 2 | 2 | 80 | 10 | | 3 | 1 | 120 | 12 | | 1 | 1 | 89 | 3 | | 2 | 4 | 128.78 | 5 | | 4 | 7 | 50 | 1 | +----------+----------+--------+-------+ Пример 7: вставка или обновление при дубликате
В MySQL нельзя добавить строку в таблицу, у которой дублируется первичный ключ (primary key). В наших таблицах stores и fruits поле id — это первичный ключ. Поэтому если мы попробуем добавить в таблицу fruit значение с то MySQL выдаст ошибку.
Но существует похожая на INSERT команда — REPLACE, которая умеет перезаписывать значения. Она работает как INSERT и UPDATE одновременно: если в таблице еще нет записи с таким первичным ключом, команда создаст новую запись; а если уже есть — заменит ее.
REPLACE INTO fruits VALUES (1, 'Лимон'); Проверяем результат и видим, что вместо яблока у нас появился лимон с тем же идентификатором.
+----+------------------+ | id | name | +----+------------------+ | 1 | Лимон | | 2 | Мандарин | | 3 | Банан | | 4 | Апельсин | | 5 | Киви | | 6 | Виноград | | 7 | Груша | | 8 | Ананас | | 9 | Вишня | +----+------------------+ Пример 8: игнорирование ошибки при вставке
Продолжим предыдущий пример. Допустим, записи в нашу таблицу вставляет бэкенд-сервис приложения. Мы хотим, чтобы сервис попробовал вставить новую запись, но если такой первичный ключ уже существует — ничего не обновлял и просто шел выполнять другой код. Но при совпадении ключей MySQL выдаст ошибку, а код на бэкенде прервется и ее нужно будет обрабатывать в сервисе. Гораздо проще добавить к команде INSERT ключевое слово IGNORE, чтобы при совпадении первичного ключа MySQL не генерировал ошибку:
INSERT IGNORE INTO stores VALUES (1, 'Магазин 10', 'Адрес 10'); Обратите внимание на сообщение, которое выдает MySQL, оно будет примерно таким: Query OK, 0 rows affected, 1 warning. Это значит, что запрос выполнился успешно, при этом он не затронул ни одну строки и есть одно предупреждение. Проверим результат: видим, что новых магазинов не появилось, а текущие не изменились.
+----+------------------+--------------+ | id | name | address | +----+------------------+--------------+ | 1 | Магазин 1 | Адрес 1 | | 2 | Магазин 2 | Адрес 2 | | 3 | Магазин 3 | Адрес 3 | | 4 | Магазин 4 | NULL | +----+------------------+--------------+ Пример 9: вставка записи в определенные партиции
Если таблица разбита на партиции, то при вставке данных можно сразу указать, в какой именно раздел вставлять запись. Наша таблица sales разбита на несколько партиций согласно условию:
- p0 для записей, у которых count от 0 до 100
- p1 для записей, у которых count от 101 до 150.
Чтобы вставить данные в первую партицию, воспользуемся командой:
INSERT INTO sale PARTITION (p0) VALUES (1, 9, 130, 10); Кроме того, в одной команде мы можем вставлять данные сразу в несколько партиций. Это делается так:
INSERT INTO sale PARTITION (p0, p1) VALUES (4, 8, 90, 10), (3, 7, 50, 120); Пример 10: изменение приоритета
В некоторых движках таблиц MySQL (например, в MyISAM, MEMORY и MERGE) можно изменить приоритет вставки данных. Например, можно сделать так, что если таблицу считывает команда SELECT, то команда INSERT будет ждать ее завершения. Это делается с помощью ключевого слова LOW_PRIORITY:
INSERT LOW_PRIORITY INTO sale VALUES (1, 6, 40, 3); Если же нужно наоборот поднять приоритет, используется такая команда:
INSERT HIGH_PRIORITY INTO sale VALUES (1, 6, 40, 3); Но нужно иметь ввиду, что если к таблице активно идут SELECT-запросы, то команда INSERT с низким приоритетом может ждать своей очереди довольно долго.
Заключение
Мы рассмотрели команду INSERT и познакомились с десятью самыми основными способами ее использования. Вы узнали, как с помощью SQL команды можно добавить новую строку в таблицу или обновить существующую. Зная эти основы, вы можете начать писать INSERT-запросы для своей структуры БД.
ALTER TABLE — изменение таблицы в SQL
Работа с командой UPDATE — как обновить данные в таблице MySQL
Зарегистрируйтесь в панели управления
И уже через пару минут сможете арендовать сервер, развернуть базы данных или обеспечить быструю доставку контента.
Читайте также:
Инструкция
Как создать веб-приложение на базе Telegram Mini Apps
Инструкция
Что делает команда chmod и как ее использовать в Linux
Инструкция
Как разработать gRCP-сервис на Go
Как создавать таблицы в MySQL (Create Table)
Рассказываем о типах данных, атрибутах, ограничениях и об изменениях в уже созданной таблице.
Эта инструкция — часть курса «MySQL для новичков».
Смотреть весь курс
Введение
В данной статье мы рассмотрим, как правильно создавать таблицы в MySQL. Для этого разберем основные типы данных, атрибуты, ограничения, и что можно исправить в уже созданной таблице. Чтобы сократить последующие изменения, стоит заранее продумать структуру таблицы и ее содержимое. Наиболее важные пункты:
- Названия таблиц и столбцов.
- Типы данных столбцов.
- Атрибуты и ограничения.
Ниже разберем подробнее, как реализовать этот короткий список для MySQL наиболее эффективно.
Синтаксис Create table в MySQL и создание таблиц
Поскольку наш путь в базы данных только начинается, стоит вспомнить основы. Реляционные базы данных хранят данные в таблицах, и каждая таблица содержит набор столбцов. У столбца есть название и тип данных. Команда создания таблицы должна содержать все вышеупомянутое:
CREATE TABLE table_name ( column_name_1 column_type_1, column_name_2 column_type_2, . column_name_N column_type_N, ); table_name — имя таблицы;
column_name — имя столбца;
column_type — тип данных столбца.
Теперь разберем процесс создания таблицы детально.
Названия таблиц и столбцов
Таблицы и столбцы стоит называть осмысленно и прозрачно, чтобы было понятно, как другому разработчику, так и вам самим спустя полгода. Даже если это учебная база только для вашего пользования, рекомендуем сразу привыкать делать правильно.
Имена могут содержать символы подчеркивания для большей наглядности. Классический пример непонятных названий — table1, table2 и т. п. Использование транслита, неясных сокращений и, разумеется, наличие орфографических ошибок тоже не приветствуется. Хороший пример коротких информативных названий: Customers, Users, Orders, так как по названию таблицы должно быть очевидно, какие данные таблица будет содержать. Эта же логика применима и к названию столбцов.
Максимальная длина названия и для таблицы, и для столбцов — 64 символа.
Типы данных столбцов
Для каждого столбца таблицы будет определен тип данных. Неправильное использование типов данных увеличивает как объем занимаемой памяти, так и время выполнения запросов к таблице. Это может быть незаметно на таблицах в несколько строк, но очень существенно, если количество строк будет измеряться десятками и сотнями тысяч, и это далеко не предел для рабочей базы данных. Проведем краткий обзор наиболее часто используемых типов.
Числовые типы
- INT — целочисленные значения от −2147483648 до 2147483647, 4 байта.
- DECIMAL — хранит числа с заданной точностью. Использует два параметра — максимальное количество цифр всего числа (precision) и количество цифр дробной части (scale). Рекомендуемый тип данных для работы с валютами и координатами. Можно использовать синонимы NUMERIC, DEC, FIXED.
- TINYINT — целые числа от −127 до 128, занимает 1 байт хранимой памяти.
- BOOL — 0 или 1. Однозначный ответ на однозначный вопрос — false или true. Название столбцов типа boolean часто начинается с is, has, can, allow. По факту это даже не отдельный тип данных, а псевдоним для типа TINYINT (1). Тип настолько востребован на практике, что для него в MySQL создали встроенные константы FALSE (0) или TRUE (1). Можно использовать синоним BOOLEAN.
- FLOAT — дробные числа с плавающей запятой (точкой).
Символьные
- VARCHAR(N) — N определяет максимально возможную длину строки. Создан для хранения текстовых данных переменной длины, поэтому память хранения зависит от длины строки. Наиболее часто используемый тип строковых данных.
- CHAR(N) — как и с varchar, N указывает максимальную длину строки. Char создан хранить данные строго фиксированной длины, и каждая запись будет занимать ровно столько памяти, сколько требуется для хранения строки длиной N.
- TEXT — подходит для хранения большого объема текста до 65 KB, например, целой статьи.
Дата и время
- DATE — только дата. Диапазон от 1000-01-01 по 9999-12-31. Подходит для хранения дат рождения, исторических дат, начиная с 11 века. Память хранения — 3 байта.
- TIME — только время — часы, минуты, секунды — «hh:mm:ss». Память хранения — 3 байта.
- DATETIME — соединяет оба предыдущих типа — дату и время. Использует 8 байтов памяти.
- TIMESTAMP — хранит дату и время начиная с 1970 года. Подходит для большинства бизнес-задач. Потребляет 4 байта памяти, что в два раза меньше, чем DATETIME, поскольку использует более скромный диапазон дат.
Бинарные
Используются для хранения файлов, фото, документов, аудио и видеоконтента. Все это хранится в бинарном виде.
Подробный разбор типов данных, включая более специализированные типы, например, ENUM, SET или BIGINT UNSIGNED, будет в отдельной тематической статье.
Практика с примерами
Для лучшего понимания приведем пример, создав простую таблицу для хранения данных сотрудников, где
- id — уникальный номер,
- name — ФИО,
- position — должность
- birthday — дата рождения
Синтаксис create table с основными параметрами:
CREATE TABLE Staff ( id INT, name VARCHAR(255) NOT NULL, position VARCHAR(30), birthday Date ); Тут могут появиться вопросы. Откуда MySQL знает, что номер уникален? Если еще нет должности для этого сотрудника, что будет, если оставить поле пустым?
Все это (как и многое другое) придется указать с помощью дополнительных параметров — атрибутов.
Часто таблицы создаются и заполняются скриптами. Если мы вызовем команду CREATE TABLE Staff, а таблица Staff уже есть в базе, команда выдаст ошибку. Поэтому перед созданием разумно проверить, содержит ли уже база таблицу Staff. Достаточно добавить IF NOT EXISTS, чтобы выполнить эту проверку в MySQL, то есть вместо
CREATE TABLE Staff CREATE TABLE IF NOT EXISTS Staff Повторный запуск команды выведет предупреждение:
1050 Table 'Staff' already exists Если таблица уже создана и нужно создать таблицу с тем же именем с «чистого листа», старую таблицу можно удалить командой:
DROP TABLE table_name; Облачные базы данных
Готовые к работе кластеры баз данных в облаке с развертыванием в несколько кликов.
Атрибуты (ATTRIBUTES) и ограничения (CONSTRAINTS)
PRIMARY KEY
Предназначение индексов — обеспечить быстрый доступ к табличным данным. Основная идея — существенное ускорение поиска. Создание первичного ключа, внешних ключей, определение уникальных значений в столбце — во всех этих случаях будут созданы индексы. Существуют определенные ограничения на построения индексов в зависимости от типов данных, но разбор этих нюансов будет в других статьях.
Пользы индексов на примерах: для поиска уникального значения среди 10000 строк придется проверить, в худшем случае, все 10000 без индекса, с индексом — всего 14. Поиск по миллиону записей займет не больше в 20 проверок — это реализация идеи бинарного поиска.
Создадим таблицу Staff с номером сотрудника в качестве первичного ключа. Первичный ключ гарантирует нам, что номер точно будет уникальным, а поиск по нему — быстрым.
CREATE TABLE Staff ( id INT PRIMARY KEY, name VARCHAR(255), position VARCHAR(30), birthday Date, has_children BOOLEAN ); NOT NULL
При заполнении таблицы мы утверждаем, что значение этого столбца должно быть установлено. Если нет явного указания NOT NULL, и этот столбец не PRIMARY KEY, то столбец позволяет хранить NULL, то есть хранение NULL — поведение по умолчанию. Для первичного ключа это ограничение можно не указывать, так как первичный ключ всегда гарантирует NOT NULL.
Изменим команду CREATE TABLE, добавив NOT NULL ограничения: таким образом, мы обозначим обязательные для заполнения столбцы (т.е. столбцы, поля в которых не могут оставаться пустыми при наличии записи в таблице):
CREATE TABLE Staff ( id INT PRIMARY KEY, name VARCHAR(255) NOT NULL, position VARCHAR(30), birthday DATE NOT NULL, has_children BOOLEAN NOT NULL ); DEFAULT
Можно указать значение по умолчанию, т.е. текст или число, которые будут сохранены, если не указано другое значение. Применяется не ко всем типам: BLOB, TEXT, GEOMETRY и JSON не поддерживают это ограничение.
Эта величина должна быть константой, функция или выражение не допустимы.
Продолжим изменять команду, установив ограничение DEFAULT для поля BOOLEAN.
CREATE TABLE Staff ( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(255) NOT NULL, position VARCHAR(30), birthday DATE NOT NULL, has_children BOOLEAN DEFAULT(FALSE) NOT NULL ); Для типа данных BOOLEAN можно использовать встроенные константы FALSE и TRUE. Вместо DEFAULT(FALSE) можно указать DEFAULT(0) — эти записи эквивалентны.
AUTO_INCREMENT
Каждый раз, когда в таблицу будет добавлена запись, значение этого столбца автоматически увеличится. На всю таблицу этот атрибут применим только к одному столбцу, причем этот столбец должен быть ключом. Рекомендуется использовать для целочисленных значений. Нельзя сочетать с DEFAULT.
CREATE TABLE Staff ( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(255) NOT NULL, position VARCHAR(30), birthday DATE NOT NULL, has_children BOOLEAN DEFAULT(FALSE) NOT NULL ); Теперь номер сотрудника будет автоматически последовательно увеличиваться при каждой новой записи в таблицу.
Интересно, что при CREATE TABLE MySQL не позволяет установить стартовое значение для AUTO_INCREMENT. Можно назначить стартовое значение для счетчика AUTO_INCREMENT уже созданной таблицы.
ALTER TABLE Staff AUTO_INCREMENT=10001; Первая запись после такой модификации получит >
UNIQUE
Это ограничение устанавливает, что все значения данного столбца будут уникальны в пределах таблицы, и создает индекс. Можно применять к столбцам с поддержкой NULL, но так как NULL будет считаться уникальным значением, возможна только одна NULL-запись.
CREATE TABLE Staff ( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(255) NOT NULL, position VARCHAR(30), birthday DATE NOT NULL, has_child BOOLEAN DEFAULT(0) NOT NULL, phone VARCHAR(20) UNIQUE NOT NULL ); CHECK
Позволяет установить дополнительную проверку данных для столбца или набора столбцов. Это тоже CONSTRAINT, так как накладывает ограничение.
На примере ограничим дату рождения сотрудника.
Синтаксис позволяет устанавливать CHECK как в описании столбца при CREATE TABLE:
birthday DATE NOT NULL CHECK (birthday > ‘1900-01-01’), так отдельно от описания столбцов:
CHECK (birthday > ‘1900-01-01’), В этих случаях название проверки будет определено автоматически. При вставке данных, не прошедших проверку, будет сообщение об ошибке Check constraint ‘staff_chk_1’ is violated. Ситуация усложняется, когда установлено несколько CHECK, поэтому рекомендуется давать понятное имя.
Воспользуемся полной командой для создания CHECK и определим не только ограничение даты рождения, но и допустимые форматы телефона через регулярное выражение.
CREATE TABLE Staff ( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(255) NOT NULL, position VARCHAR(30), birthday DATE NOT NULL, has_child BOOLEAN DEFAULT(0) NOT NULL, phone VARCHAR(20) UNIQUE NOT NULL, CONSTRAINT staff_chk_birthday CHECK (birthday > '1900-01-01'), CONSTRAINT staff_chk_phone CHECK (phone REGEXP '[+]?[0-9] ?\\(?[0-9]\\)? ?[0-9][0-9 -]+[0-9]') ); Для добавления ограничений используем оператор CONSTRAINT, при этом, все названия уникальны, как и имена таблиц. Учитывая, что по умолчанию названия включают в себя и имя таблицы, рекомендуем придерживаться этого правила. Если используется CONSTRAINT, мы обязаны дать имя ограничению, которое вводим.
FOREIGN KEY или внешний ключ
Внешний ключ — это ссылка на столбец или группу столбцов другой таблицы. Это тоже ограничение (CONSTRAINT), так как мы сможем использовать только значения, для которых есть соответствие по внешнему ключу. Таблицу с внешним ключом называют зависимой.
FOREIGN KEY (column_name1, column_name2) REFERENCES external_table_name(external_column_name1, external_column_name2) Сначала указывается выражение FOREIGN KEY и набор столбцов таблицы, откуда строим FOREIGN KEY. Затем ключевое слово REFERENCES указывает на имя внешней таблицы и набор столбцов этой внешней таблицы. В конце можно добавить операторы ON DELETE и ON UPDATE, с помощью которых настраивается поведение при удалении или обновлении данных в главной таблице. Это делать не обязательно, так как предусмотрено поведение по умолчанию. Поведение по умолчанию запрещает удалять или изменять записи из внешней таблицы, если на эти записи есть ссылки по внешнему ключу.
Возможные опции для ON DELETE и ON UPDATE:
CASCADE: автоматическое удаление/изменение строк зависимой таблицы при удалении/изменении связанных строк главной таблицы.
SET NULL: при удалении/изменении связанных строк главной таблицы будет установлено значение NULL в строках зависимой таблицы. Столбец зависимой таблицы должен поддерживать установку NULL, т.е. параметр NOT NULL в этом случае устанавливать нельзя.
RESTRICT: не даёт удалить/изменить строку главной таблицы при наличии связанных строк в зависимой таблице. Если не указана иная опция, по умолчанию будет использовано NO ACTION, что, по сути, то же самое, что и RESTRICT.
Рассмотрим пример:
Для таблицы Staff было определено текстовое поле position для хранения должности.
Так как список сотрудников в компании обычно больше, чем список занимаемых должностей, есть смысл создать справочник должностей.
CREATE TABLE Positions ( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(100) NOT NULL ); Поскольку из Staff мы будем ссылаться на Positions, таблица персонала Staff будет зависимой от Positions. Изменим синтаксис CREATE TABLE для таблицы Staff, чтобы должность была ссылкой на запись в таблице Positions.
CREATE TABLE Staff ( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(255) NOT NULL, position_id int, birthday DATE NOT NULL, has_child BOOLEAN DEFAULT(0) NOT NULL, phone VARCHAR(20) UNIQUE NOT NULL, FOREIGN KEY (position_id) REFERENCES Positions (id) ); При CREATE TABLE, чтобы не усложнять описание столбца, рекомендуется указывать внешний ключ и все его атрибуты после перечисления создаваемых столбцов.
Можно ли добавить внешний ключ, если таблица уже создана и в ней есть данные? Можно! Для внесения изменений в таблицу используем ALTER TABLE.
ALTER TABLE Staff ADD FOREIGN KEY (position_id) REFERENCES Positions(id); Или в развернутой форме, определяя имя ключа fk_position_id явным образом:
ALTER TABLE Staff ADD CONSTRAINT fk_position_id FOREIGN KEY (position_id) REFERENCES Positions(id); Главное условие в этом случае — согласованность данных. Это значит, что для всех записей внешнего ключа position_id должно найтись соответствие в целевой таблице Positions по столбцу id.
Создание таблиц на основе уже существующих, временные таблицы
Мы рассмотрели создание таблицы с «чистого листа», но есть два других способа:
LIKE
Создание таблицы на основе уже существующей таблицы. Копирует структуру — количество, названия и типы столбцов, индексы, все ограничения, кроме внешних ключей. Как мы помним, внешний ключ создает индекс. При создании через LIKE индексы в новой таблице будут построены также, как и в старой, но внешние ключи не скопируются. Таблица будет создана без записей и без счетчиков AUTO_INCREMENT.
CREATE TABLE new_table LIKE source_table; SELECT
Можно создать таблицу на основе SELECT-запроса — результат этой выборки будет записан в новую таблицу. Такая таблица не будет иметь индексов, ограничений и ключей. Все столбцы, с учетом порядка, типов данных и названий, будут взяты из запроса — поля из SELECT станут столбцами новой таблицы. При этом можно переопределить изначальные названия полей, что особенно актуально, когда в выборку попадают столбцы с одинаковыми названиями (на уровне таблицы названия столбцов всегда уникальны).
CREATE TABLE new_table [AS] SELECT * FROM source_table; Разберем пример создания новой таблицы через SELECT, используя две таблицы в выборке — Staff и Positions. В запросе определим три поля: id, staff, position — это будут столбцы новой таблицы StaffData211015 (срез сотрудников на определённую дату). Без присвоения псевдонимов (name as staff, name as position) в выборке получилось бы два одинаковых поля name, что не позволило бы создать таблицу из-за duplicate column name ошибки.
CREATE TABLE StaffData211015 SELECT s.Id, s.name as staff, p.name as position FROM Staff s JOIN Positions p ON s.position_id = p.id TEMPORARY
При подготовке отчетов или обработке данных на стороне базы, нередко может потребоваться сохранять промежуточные результаты в отдельные таблицы.
После завершения всех вычислений внутри скрипта эти вспомогательные таблицы нам будут уже не нужны. В таких ситуациях удобно использовать временные таблицы, которые будут существовать до завершения работы скрипта.
Чтобы обозначить таблицу как временную, нужно добавить TEMPORARY в CREATE TABLE:
CREATE TEMPORARY TABLE table_name; Работа с уже созданной таблицей
Когда таблица создана, работа с ней только начинается. Операторы и команды для работы с данными рассмотрены в другой статье, а сейчас посмотрим, что же можно исправить, если потребовалось внести изменения.
Переименование
Ключевая команда — RENAME.
- Изменить имя таблицы:
RENAME TABLE old_table_name TO new_table_name; - Изменить название столбца:
ALTER TABLE table_name RENAME COLUMN old_column_name TO new_column_name; Удаление данных
- DELETE FROM Staff; — удалит все записи из таблицы. Условие в WHERE позволит удалить только определенные строки, в примере ниже удалим только одну строку с DELETE FROM Staff WHERE TABLE Staff; — используется для полной очистки всей таблицы. При TRUNCATE счетчики AUTO_INCREMENT сбросятся. Если бы мы удалили все в строки командой DELETE, то новые строки учитывали бы накопленный за время жизни таблицы AUTO_INCREMENT.
- DROP TABLE Staff; — команда удаления таблицы.
Изменение структуры таблицы
Команда ALTER TABLE включает в себя множество опций, рассмотрим основные вместе с примерами на таблице Staff.
Добавление столбцов
Добавим три столбца: электронную почту, возраст и наличие автомобиля. Так как в таблице уже есть записи, мы не можем пока что отметить эти поля как NOT NULL, по умолчанию они будут позволять хранить NULL.
ALTER TABLE Staff ADD email VARCHAR(50), ADD age INT, ADD has_auto BOOLEAN; Удаление столбцов
Удалим столбец с возрастом, так как сейчас возраст сотрудников в базе всегда статичен, а должен быть вычисляемым полем в зависимости от текущей даты.
ALTER TABLE Staff DROP COLUMN age; Значение по умолчанию
Выставим значение по умолчанию для столбца has_auto:
ALTER TABLE Staff ALTER COLUMN has_auto SET DEFAULT(FALSE); Изменение типа данных столбца
Для столбца name изменим тип данных:
ALTER TABLE Staff MODIFY COLUMN name VARCHAR(500) NOT NULL; Максимальная длина поля была увеличена. Если не указать NOT NULL явно, то поле станет NULL по умолчанию.
Установка CHECK
Добавим ограничение формата для email через регулярное выражение:
ALTER TABLE Staff ADD CONSTRAINT staff_chk_email CHECK (email REGEXP '^[^@]+@[^@]+\\.[^@]$'); Заключение
Любой путь начинается с первых шагов. В работе с базами данных этими шагами является создание структуры таблиц. Продуманная композиция сущностей (таблиц) и связей между ними — основа проектирования любого вашего приложения от интернет-магазинов до мощных систем управления предприятиями.
Как заполнить таблицу в mysql workbench
Для упрощения работы с сервером MySQL в базовый комплект установки входит такой инструмент как MySQL Workbench . Он представляет графический клиент для работы с сервером, через который мы в удобном виде можем создавать, удалять, изменять базы данных и управлять ими. Так, на Windows после установки в меню Пуск мы можем найти значок программы и запустить ее:
Нам откроется следующее окно, где мы можем увидеть поле с названием запущенного локально экземпляра MySQL:

Нажмем на него, и нам отобразится окно для ввода пароля:
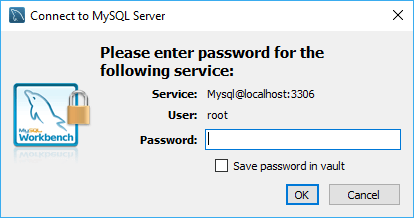
Здесь надо ввести пароль, который был установлен для пользователя root при установке MySQL.
После успешного логина нам откроется содержимое сервера:
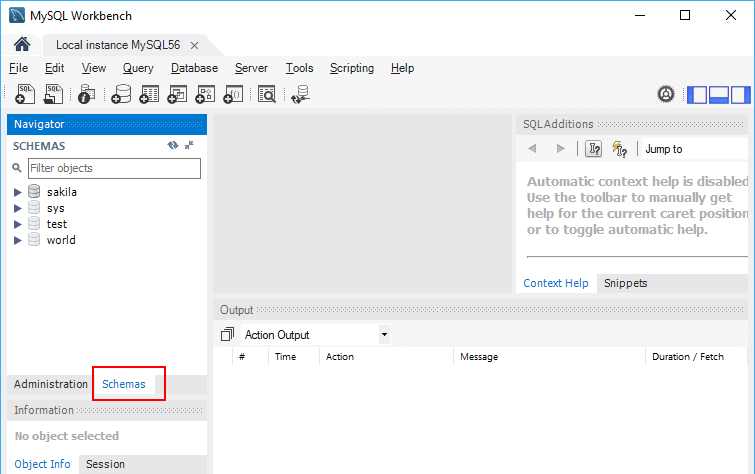
В частности, в левой части в окне SCHEMAS можно увидеть доступные базы данных.
Теперь посмотрим, как мы можем выполнять в этой программе запросы к бд. Вначале создадим саму БД. Для этого нажмем над списком баз данных на значок «SQL» с плюсом:
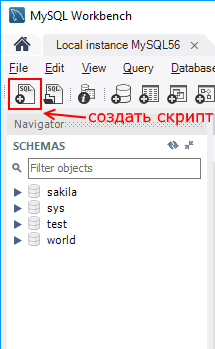
После этого в центральной части программы откроется окно для ввода скрипта SQL. Введем в него следующую команду:
CREATE DATABASE usersdb;
Данная команда создает базу данных usersdb.
Для выполнения скрипта в панели инструментов нажмем на значок молнии:
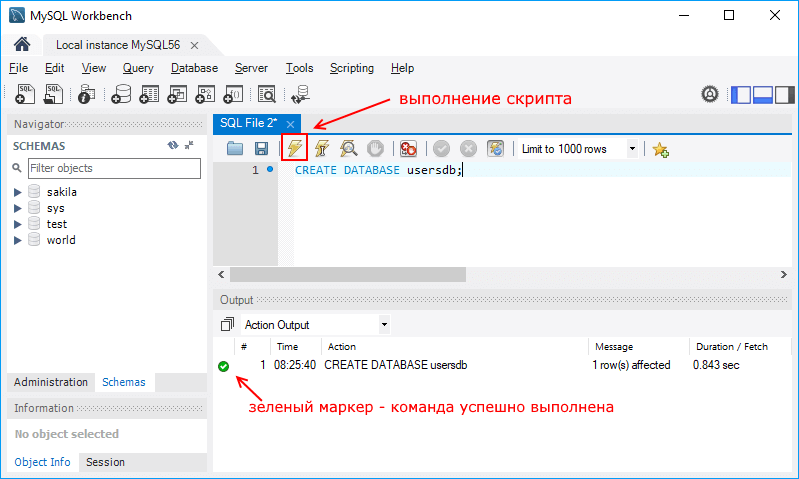
После этого внизу программы в поле вывода в случае удачного выполнения мы увидим зеленый маркер и отчет о выполнении.
Таким образом, бд создана. Теперь добавим в нее таблицу и какие-нибудь данные. Для этого изменим код в поле ввода скрипта на следующий:
USE usersdb; CREATE TABLE users ( id INTEGER AUTO_INCREMENT PRIMARY KEY, firstname VARCHAR(30), age INTEGER ); INSERT INTO users (firstname, age) VALUES ('Tom', 34);
Все команды отделяются друг от друга точкой с запятой. Первая комнда — USE устанавливает в качестве используемой базу данных usersdb, которая была создана выше. Вторая команда — CREATE TABLE создает в бд таблицу users, в которой будет три столбца: id, firstname и age. Третья команда — INSERT INTO добавляет в таблицу users одну строку. Для выполнения этих команд также нажмем на значок молнии.
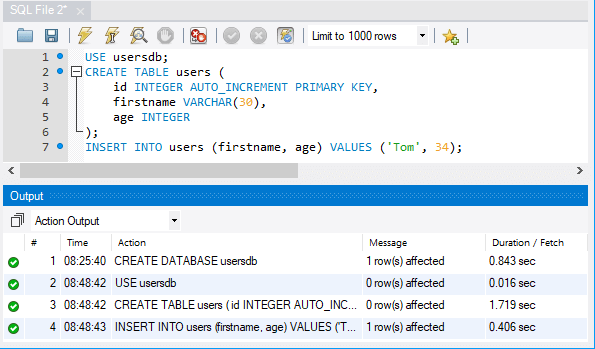
И в конце получим все данные из таблицы users с помощью следующих команд:
USE usersdb; SELECT * FROM users;
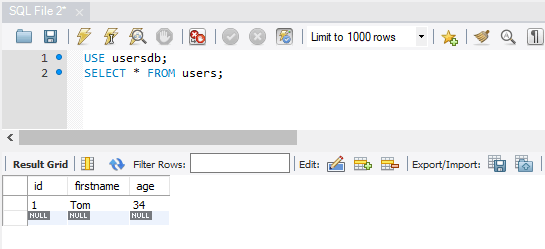
Таким образом, мы можем осуществлять запросы к БД в программе MySQL Workbench CE.