[Конспект админа] Домены, адреса и Windows: смешивать, но не взбалтывать

В очередном «конспекте админа» остановимся на еще одной фундаментальной вещи – механизме разрешения имен в IP-сетях. Кстати, знаете почему в доменной сети nslookup на все запросы может отвечать одним адресом? И это при том, что сайты исправно открываются. Если задумались – добро пожаловать под кат. .
Для преобразования имени в IP-адрес в операционных системах Windows традиционно используются две технологии – NetBIOS и более известная DNS.
Дедушка NetBIOS
NetBIOS (Network Basic Input/Output System) – технология, пришедшая к нам в 1983 году. Она обеспечивает такие возможности как:
- регистрация и проверка сетевых имен;
- установление и разрыв соединений;
- связь с гарантированной доставкой информации;
- связь с негарантированной доставкой информации;
- поддержка управления и мониторинга драйвера и сетевой карты.
В рамках этого материала нас интересует только первый пункт. При использовании NetBIOS имя ограниченно 16 байтами – 15 символов и спец-символ, обозначающий тип узла. Процедура преобразования имени в адрес реализована широковещательными запросами.
Небольшая памятка о сути широковещательных запросов.
Широковещательным называют такой запрос, который предназначен для получения всеми компьютерами сети. Для этого запрос посылается на специальный IP или MAC-адрес для работы на третьем или втором уровне модели OSI.
Для работы на втором уровне используется MAC-адрес FF:FF:FF:FF:FF:FF, для третьего уровня в IP-сетях адрес, являющимся последним адресом в подсети. Например, в подсети 192.168.0.0/24 этим адресом будет 192.168.0.255
Интересная особенность в том, что можно привязывать имя не к хосту, а к сервису. Например, к имени пользователя для отправки сообщений через net send.
Естественно, постоянно рассылать широковещательные запросы не эффективно, поэтому существует кэш NetBIOS – временная таблица соответствий имен и IP-адреса. Таблица находится в оперативной памяти, по умолчанию количество записей ограничено шестнадцатью, а срок жизни каждой – десять минут. Посмотреть его содержимое можно с помощью команды nbtstat -c, а очистить – nbtstat -R.
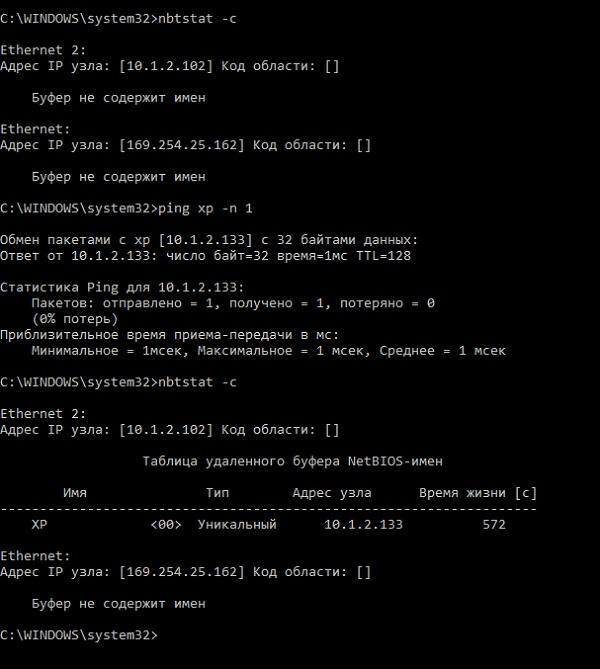
Пример работы кэша для разрешения имени узла «хр».
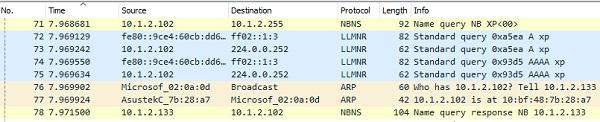
Что происходило при этом с точки зрения сниффера.
В крупных сетях из-за ограничения на количество записей и срока их жизни кэш уже не спасает. Да и большое количество широковещательных запросов запросто может замедлить быстродействие сети. Для того чтобы этого избежать, используется сервер WINS (Windows Internet Name Service). Адрес сервера администратор может прописать сам либо его назначит DHCP сервер. Компьютеры при включении регистрируют NetBIOS имена на сервере, к нему же обращаются и для разрешения имен.
В сетях с *nix серверами можно использовать пакет программ Samba в качестве замены WINS. Для этого достаточно добавить в конфигурационный файл строку «wins support = yes». Подробнее – в документации.
В отсутствие службы WINS можно использовать файл lmhosts, в который система будет «заглядывать» при невозможности разрешить имя другими способами. В современных системах по умолчанию он отсутствует. Есть только файл-пример-документация по адресу %systemroot%\System32\drivers\etc\lmhost.sam. Если lmhosts понадобится, его можно создать рядом с lmhosts.sam.
Сейчас технология NetBIOS не на слуху, но по умолчанию она включена. Стоит иметь это ввиду при диагностике проблем.
Стандарт наших дней – DNS
DNS (Domain Name System) – распределенная иерархическая система для получения информации о доменах. Пожалуй, самая известная из перечисленных. Механизм работы предельно простой, рассмотрим его на примере определения IP адреса хоста www.google.com:
- если в кэше резолвера адреса нет, система запрашивает указанный в сетевых настройках интерфейса сервер DNS;
- сервер DNS смотрит запись у себя, и если у него нет информации даже о домене google.com – отправляет запрос на вышестоящие сервера DNS, например, провайдерские. Если вышестоящих серверов нет, запрос отправляется сразу на один из 13 (не считая реплик) корневых серверов, на которых есть информация о тех, кто держит верхнюю зону. В нашем случае – com.
- после этого наш сервер спрашивает об имени www.google.com сервер, который держит зону com;
- затем сервер, который держит зону google.com уже выдает ответ.
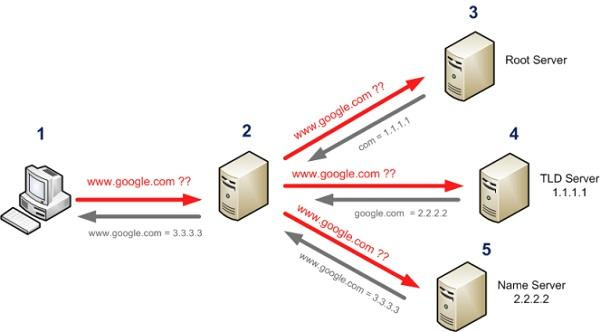
Наглядная схема прохождения запроса DNS.
Разумеется, DNS не ограничивается просто соответствием «имя – адрес»: здесь поддерживаются разные виды записей, описанные стандартами RFC. Оставлю их список соответствующим статьям.
Сам сервис DNS работает на UDP порту 53, в редких случаях используя TCP.
DNS переключается на TCP с тем же 53 портом для переноса DNS-зоны и для запросов размером более 512 байт. Последнее встречается довольно редко, но на собеседованиях потенциальные работодатели любят задавать вопрос про порт DNS с хитрым прищуром.
Также как и у NetBIOS, у DNS существует кэш, чтобы не обращаться к серверу при каждом запросе, и файл, где можно вручную сопоставить адрес и имя – известный многим %Systemroot%\System32\drivers\etc\hosts.
В отличие от кэша NetBIOS в кэш DNS сразу считывается содержимое файла hosts. Помимо этого, интересное отличие заключается в том, что в кэше DNS хранятся не только соответствия доменов и адресов, но и неудачные попытки разрешения имен. Посмотреть содержимое кэша можно в командной строке с помощью команды ipconfig /displaydns, а очистить – ipconfig /flushdns. За работу кэша отвечает служба dnscache.
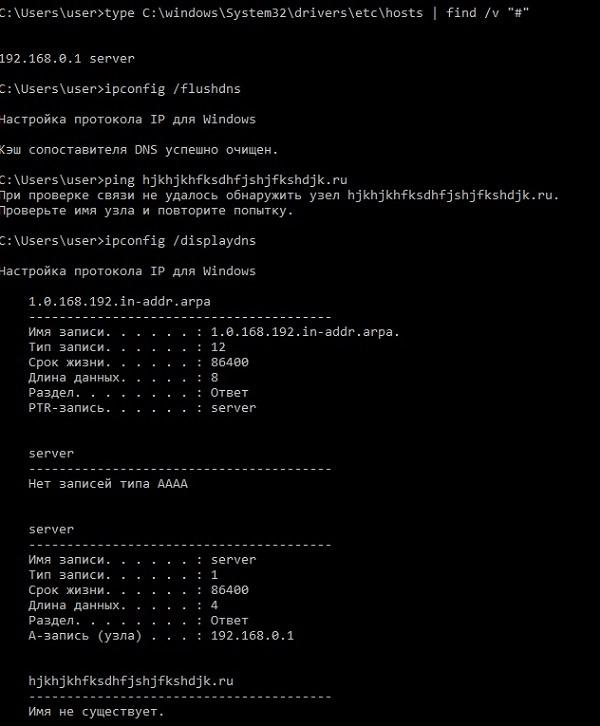
На скриншоте видно, что сразу после чистки кэша в него добавляется содержимое файла hosts, и иллюстрировано наличие в кэше неудачных попыток распознавания имени.
При попытке разрешения имени обычно используются сервера DNS, настроенные на сетевом адаптере. Но в ряде случаев, например, при подключении к корпоративному VPN, нужно отправлять запросы разрешения определенных имен на другие DNS. Для этого в системах Windows, начиная с 7\2008 R2, появилась таблица политик разрешения имен (Name Resolution Policy Table, NRPT). Настраивается она через реестр, в разделе HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Microsoft\Windows NT\DnsClient\DnsPolicyConfig или групповыми политиками.

Настройка политики разрешения имен через GPO.
При наличии в одной сети нескольких технологий, где еще и каждая – со своим кэшем, важен порядок их использования.
Порядок разрешения имен
Операционная система Windows пытается разрешить имена в следующем порядке:
- проверяет, не совпадает ли имя с локальным именем хоста;
- смотрит в кэш DNS распознавателя;
- если в кэше соответствие не найдено, идет запрос к серверу DNS;
- если имя хоста «плоское», например, «servername», система обращается к кэшу NetBIOS. Имена более 16 символов или составные, например «servername.domainname.ru» – NetBIOS не используется;
- если не получилось разрешить имя на этом этапе – происходит запрос на сервер WINS;
- если постигла неудача, то система пытается получить имя широковещательным запросом, но не более трех попыток;
- последняя попытка – система ищет записи в локальном файле lmhosts.
Для удобства проиллюстрирую алгоритм блок-схемой:
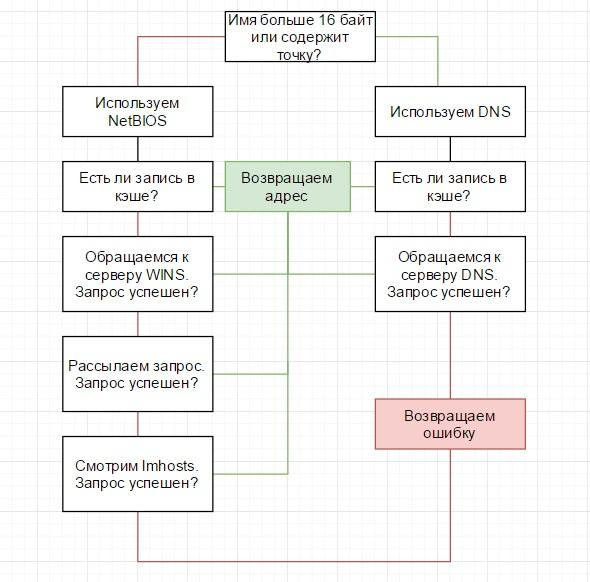
Алгоритм разрешения имен в Windows.
То есть, при запуске команды ping server.domain.com NetBIOS и его широковещательные запросы использоваться не будут, отработает только DNS, а вот с коротким именем процедура пойдет по длинному пути. В этом легко убедиться, запустив простейший скрипт:
@echo off echo %time% ping hjfskhfjkshjfkshjkhfdsjk.com echo %time% ping xyz echo %time% pauseВыполнение второго пинга происходит на несколько секунд дольше, а сниффер покажет широковещательные запросы.

Сниффер показывает запросы DNS для длинного имени и широковещательные запросы NetBIOS для короткого.
Отдельного упоминания заслуживают доменные сети – в них запрос с коротким именем отработает чуть по-другому.
Active Directory и суффиксы
Active Directory тесно интегрирована с DNS и не функционирует без него. Каждому компьютеру домена создается запись в DNS, и компьютер получает полное имя (FQDN — fully qualified domain name) вида name.subdomain.domain.com.
Для того чтоб при работе не нужно было вводить FQDN, система автоматически добавляет часть имени домена к хосту при различных операциях – будь то регистрация в DNS или получение IP адреса по имени. Сначала добавляется имя домена целиком, потом следующая часть до точки.
При попытке запуска команды ping servername система проделает следующее:
- если в кэше DNS имя не существует, система спросит у DNS сервера о хосте servername.subdomain.domain.com;
- если ответ будет отрицательный – система запросит servername.domain.com, на случай, если мы обращаемся к хосту родительского домена.
При этом к составным именам типа www.google.com суффиксы по умолчанию не добавляются. Это поведение настраивается групповыми политиками.
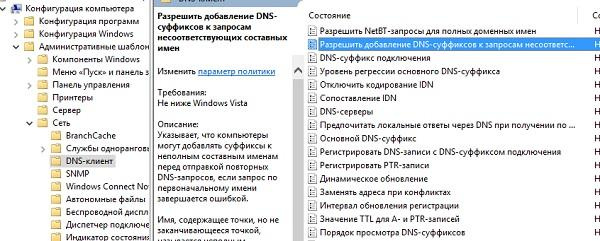
Настройка добавления суффиксов DNS через групповые политики.
Настраивать DNS суффиксы можно также групповыми политиками или на вкладке DNS дополнительных свойств TCP\IP сетевого адаптера. Просмотреть текущие настройки удобно командой ipconfig /all.
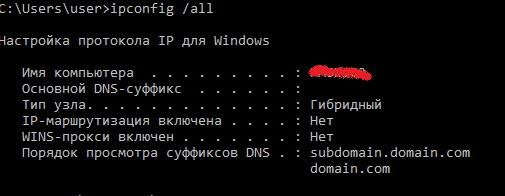
Суффиксы DNS и их порядок в выводе ipconfig /all.
Однако утилита nslookup работает немного по-другому: она добавляет суффиксы в том числе и к длинным именам. Посмотреть, что именно происходит внутри nslookup можно, включив диагностический режим директивой debug или расширенный диагностический режим директивой dc2. Для примера приведу вывод команды для разрешения имени ya.ru:
nslookup -dc2 ya.ru ------------ Got answer: HEADER: opcode = QUERY, rcode = NOERROR header flags: response, want recursion, recursion avail. questions = 1, answers = 1, authority records = 0, additional = 0 QUESTIONS: 4.4.8.8.in-addr.arpa, type = PTR, ANSWERS: -> 4.4.8.8.in-addr.arpa name = google-public-dns-b.google.com ttl = 86399 (23 hours 59 mins 59 secs) ------------ ╤хЁтхЁ: google-public-dns-b.google.com Address: 8.8.4.4 ------------ Got answer: HEADER: opcode = QUERY, rcode = NOERROR header flags: response, want recursion, recursion avail. questions = 1, answers = 1, authority records = 0, additional = 0 QUESTIONS: ya.ru.subdomain.domain.com, type = A, ANSWERS: -> ya.ru.subdomain.domain.com internet address = 66.96.162.92 ttl = 599 (9 mins 59 secs) ------------ Не заслуживающий доверия ответ: ------------ Got answer: HEADER: opcode = QUERY, rcode = NOERROR header flags: response, want recursion, recursion avail. questions = 1, answers = 0, authority records = 1, additional = 0 QUESTIONS: ya.ru.subdomain.domain.com, type = AAAA, AUTHORITY RECORDS: -> domain.com ttl = 19 (19 secs) primary name server = ns-2022.awsdns-60.co.uk responsible mail addr = awsdns-hostmaster.amazon.com serial = 1 refresh = 7200 (2 hours) retry = 900 (15 mins) expire = 1209600 (14 days) default TTL = 86400 (1 day) ------------ ╚ь : ya.ru.subdomain.domain.com Address: 66.96.162.92Из-за суффиксов утилита nslookup выдала совсем не тот результат, который выдаст например пинг:
ping ya.ru -n 1 Обмен пакетами с ya.ru [87.250.250.242] с 32 байтами данных: Ответ от 87.250.250.242: число байт=32 время=170мс TTL=52Это поведение иногда приводит в замешательство начинающих системных администраторов.
Лично сталкивался с такой проблемой: в домене nslookup выдавал всегда один и тот же адрес в ответ на любой запрос. Как оказалось, при создании домена кто-то выбрал имя domain.com.ru, не принадлежащее организации в «большом интернете». Nslookup добавляла ко всем запросам имя домена, затем родительский суффикс – com.ru. Домен com.ru в интернете имеет wildcard запись, то есть любой запрос вида XXX.com.ru будет успешно разрешен. Поэтому nslookup и выдавал на все вопросы один ответ. Чтобы избежать подобных проблем, не рекомендуется использовать для именования не принадлежащие вам домены.
При диагностике стоит помнить, что утилита nslookup работает напрямую с сервером DNS, в отличие от обычного распознавателя имен. Если вывести компьютер из домена и расположить его в другой подсети, nslookup будет показывать, что всё в порядке, но без настройки суффиксов DNS система не сможет обращаться к серверам по коротким именам.
Отсюда частые вопросы – почему ping не работает, а nslookup работает.
В плане поиска и устранения ошибок разрешения имен могу порекомендовать не бояться использовать инструмент для анализа трафика – сниффер. С ним весь трафик как на ладони, и если добавляются лишние суффиксы, то это отразится в запросах DNS. Если запросов DNS и NetBIOS нет, некорректный ответ берется из кэша.
Если же нет возможности запустить сниффер, рекомендую сравнить вывод ping и nslookup, очистить кэши, проверить работу с другим сервером DNS.
Кстати, если вспомните любопытные DNS-курьезы из собственной практики – поделитесь в комментариях.
Напишите программу, которая просит пользователя ввести фамилию.
Напишите программу, которая просит пользователя ввести фамилию, имя и год рождения. После чего приветствует пользователя и сообщает ему сколько лет он прожил.
Голосование за лучший ответ
name = input(«Ваша фамилия: «)
name1 = input(«Ваше имя: «)
name2 = input(«Год вашего рождения: «)
print(«Ваша фамилия,»,name)
print(«Ваше имя,»,name1)
print(«Вы родились,»,name2)
Дима ГолубецЗнаток (272) 2 года назад
лучший код, который я видел за эту жизнь
Похожие вопросы
Ваш браузер устарел
Мы постоянно добавляем новый функционал в основной интерфейс проекта. К сожалению, старые браузеры не в состоянии качественно работать с современными программными продуктами. Для корректной работы используйте последние версии браузеров Chrome, Mozilla Firefox, Opera, Microsoft Edge или установите браузер Atom.
Как узнать имя текущего пользователя
Узнать, под каким именем система знает текущего пользователя можно одним из следующих способов:
Способ 1: Скрипт
Скачайте и запустите файл: current_user.cmd
Способ 2: Сведения о системе
- Нажмите Win+R,
- введите команду msinfo32 ,
- нажмите «Ok».
- В открывшемся окне «Сведения о системе» найдите строку «Имя пользователя».
- Имя текущего пользователя будет находится сразу после символа «\».
Способ 3: Командная строка
- Нажмите сочетание клавиш Win+R,
- Введите в открывшемся окне cmd и нажмите Enter,
- В открывшемся окне Командной строки введите команду %username% .
- Результат работы команды — ваше текущее имя пользователя.
- Нет меток
Инструменты контента
Действует бесплатная лицензия Atlassian Confluence для сообществ, предоставленная пользователю Nobosibirsk State University. Возможности Confluence
- На платформе Atlassian Confluence 7.19.5
- Напечатано компанией Atlassian Confluence 7.19.5
- Сообщить об ошибке
- Новости Atlassian
Какая команда корректно узнает имя пользователя
Файловая система обеспечивает интерфейс доступа к данным на дисковых накопителях и в периферийных устройствах ввода/вывода. Одни и те же функции open(), read(0, write() могут использоваться при чтении/записи на диске и при выводе данных на принтер или терминал. Файловая система управляет правами доступа и привилегиями. Она обеспечивает перенаправление запросов, адресованных периферийным устройствам.
Система управления процессами ЭВМ, причем их число обычно превышает число ЦПУ. Специальной задачей ядра является планирование выполнением процессов (scheduler). Сюда входит управление ресурсами системы (временем ЦПУ, дисковым пространством, распределением памяти и т.д.). Данная система занимается созданием и удалением процессов, синхронизацией их работы и взаимодействием процессов (например, обменом данными).
Система ввода/вывода обслуживает запросы файловой системы и системы управления процессами для доступа к периферийным устройствам (дискам, лентам, печати, терминалам). Эта система организует взаимодействие с драйверами этих устройств.
Файловая система UNIX представляет собой древовидную структуру. Каждый файл имеет имя, которое определяет его место на дереве файловой системы. Корнем этой системы является корневой каталог с именем /.
В этом каталоге обычно содержатся каталоги:
Каталог наиболее популярных системных команд и утилит.
Каталог файлов для периферийных устройств, например дисковых накопителей (/dev/cdrom, /dev/mem, /dev/null или /dev/ttyp10).
Здесь находятся конфигурационные файлы и утилиты администрирования, среди них скрипты инициализации системы.
Каталог библиотечных файлов языка Си и других языков.
/lost+found
Каталог «потерянных» файлов. Ошибки при неправильном выключении ЭВМ могут привести к появлению безымянных файлов (содержимое корректно, но нет ссылок на этот файл ни в одном из каталогов).
Каталог для установления временных связей (монтирования) физических файловых систем с корневой системой. Обычно каталог пуст.
/home
Служит для размещения каталогов пользователей (в прежних версиях для этого служил каталог /usr.
Предназначен для размещения сервисных подкаталогов, например, электронной почты (/usr/spool), утилит UNIX (/usr/bin), программ, исполняемых на данной ЭВМ (/usr/local), файлов заголовков (/usr/include), системы справочника (/usr/man).
Служит для записи временных файлов.
Полные имена остальных файлов содержат путь — список каталогов, размещенных между / и данным файлом. По этой причине полное имя любого файла начинается с символа / (не содержит в отличие от Windows имени диска (например, CD), другого внешнего устройства или удаленной ЭВМ).
UNIX, тем не менее, не предполагает наличия лишь одной файловой системы. Число таких файловых систем в этой ОС не лимитировано, они могут располагаться на одном дисковом накопителе, на разных устройствах или даже на разных ЭВМ.
Каждый файл имеет сопряженные с ним метаданные, записанные в индексных дескрипторах — inode . Имя файла является указателем на его метаданные (метаданные не содержат указателя на имя файла). Существует 6 типов файлов:
- Обычный файл (regular)
- Каталог (directory)
- Файл внешнего устройства
- Канал с именем (FIFO)
- Связь (link)
- socket
Обычный файл является наиболее распространенным типом. Для операционной системы такой файл представляется простой последовательностью байтов. Интерпретация содержимого такого файла находится в зоне ответственности прикладной программы, которая с ним работает.
Каталог — это файл, содержащий имена находящихся в нем файлов и указатели на информацию, позволяющую ОС производить операции над этими файлами. Запись в каталог имеет право только ядро. Каталог представляет собой таблицу, каждая запись в которой соответствует некоторому файлу.
Файл внешнего устройства обеспечивает доступ к этому прибору. UNIX различает символьные и блочные файлы. Символьные файлы служат для не буферизованного обмена, а блочные предполагают обмен порциями данных фиксированной длины.
Каналы с именем (FIFO) — это файлы, служащие для связи между процессами.
Файловая система допускает наличие нескольких имен у одного файла. Связь имени файла с его метаданными называется жесткой связью. С помощью команды ln можно создать еще одно имя для файла. Особым типом файла является символическая связь, позволяющей косвенно обращаться к файлу. Символическая связь является особым типом файла.
Socket служит для взаимодействия между процессами. Интерфейс socket используется, например, для доступа к сети TCP/IP.
Любой файл имеет двух владельцев — собственно создателя и группу (chown, chgrp и chmod). Файл создается не пользователем, а процессом, им запущенным. Атрибуты этого процесс присваиваются и файлу (r, w и x). Имеется также несколько дополнительных атрибутов, среди них sticky bit , который требует сохранения образа \исполняемого файла в памяти после завершения его работы. Атрибуты SUID и GUID позволяют изменить права пользователя в направлении расширения (до уровня создателя файла) на время исполнения данной программы (это используется, например, в случае работы с файлом /etc/passwd) . В случае каталогов sticky bit позволяет стереть только файлы, которыми владеет пользователь.
Различается несколько типов процессов.
- Системные процессы являются частью ядра и резидентно размещены в оперативной памяти. Они запускаются при инициализации ядра системы. Системными процессами являются, например, kmadaemon (диспетчер памяти ядра), shed (диспетчер свопинга), bdfflush (диспетчер кэша), init (прародитель всех остальных процессов).
- Демоны — не интерактивные процессы, запускаемые путем загрузки в память соответствующих программ и выполняемые в фоновом режиме. Демоны не ассоциируются ни с одним из пользователей (они служат, например, для организации терминального ввода, печатающего устройства, сетевого доступа).
- Прикладные процессы — это остальные процессы принадлежащие, как правило, пользователям.
Процессы создаются процедурой fork и характеризуются набором атрибутов:
(Process ID) представляет собой уникальное имя процесса (идентификатор нового процесса характеризуется большим кодом, чем идентификатор предыдущего). После уничтожения процесса ликвидируется и его PID и этот идентификатор может быть присвоен новому процессу.
PPID
(Parent Process ID) — идентификатор процесса, породившего данный процесс.
Приоритет процесса
(Nice Number) учитывается планировщиком при определении очередности запуска процессов.
псевдотерминал, ассоциированный с процессом. Демоны не имеют псевдотерминала.
RID (Real ID)
пользователя, запустившего данный процесс. Эффективный идентификатор ( EUID ) служит для определения прав доступа процесса к системным ресурсам.
Для запуска задачи процесс должен выполнить системный вызов exec. При этом не порождается новый процесс, а код процесса замещается полностью кодом запускаемой программы.
Так, когда пользователь вводит команду ls , текущий процесс shell осуществляет вызов fork , порождая новый процесс — копию shell . Порожденный процесс осуществит вызов exec , указав в качестве параметра имя исполняемого файла ( ls ). Ls замещает shell , а по завершении работы процесс уничтожается.
Сигналы служат для того, чтобы передавать от одного процесса к другому или от ядра к какому-то процессу, уведомление о происхождении некоторого события. Примером такого события может быть нажатие клавиши мышки или нажатие клавиш (SIGINIT)или .
Для отправления сигнала служит команда kill pid, где sig_no — номер или символическое название сигнала, pid — идентификатор процесса, которому адресован сигнал. Для остановки процесса, выполняемого в фоновом режиме можно послать сигнал SIGTERM. Например, kill $!, где $! — переменная, где хранится идентификатор процесса (PID), запущенного последним.
Таблица 1. Сигналы
Имя сигнала
Функция по умолчанию
Описание
SIGABRT
Завершение + ядро
Результат системного вызова abort
SIGALRM
Завершение
Результат срабатывания таймера, установленного системными вызовом alarm или setitimer
SIGBUS
Завершение + ядро
Результат аппаратной ошибки. Сигнал посылается при обращении к виртуальному адресу, для которого отсутствует соответствующая физическая страница памяти.
SIGCHLD
Игнорирование
Сообщает родительскому процессу о завершении исполнения дочернего
SIGEGV
Завершение + ядро
Формируется при попытке обращения к неверному адресу или области памяти, для которой у процесса нет привилегий.
SIGFPE
Завершение + ядро
Сигнал возникает в случае деления на нуль или при переполнении в операциях с плавающей запятой.
SIGHUP
Завершение
Посылается хозяину сессии, связанной с консолью, когда ядро обнаружит, что терминал отключился. Сигнал передается всем процессам текущей группы при завершении сессии хозяина. Этот сигнал иногда используется для взаимодействия процессов, например, для уведомления демонов о необходимости обновления конфигурационных данных.
SIGILL
Завершение + ядро
Посылается ядром при попытке процесса выполнить недопустимую команду.
SIGINT
Завершение
Посылается ядром всем процессам при нажатии комбинации клавиш или .
SIGKILL
Завершение
Сигнал прерывает выполнение процесса. Перехват или игнорирование этого сигнала невозможно.
SIGPIPE
Завершение
Результат попытки записи в канал или сокет, когда получатель данных закрыл соответствующий дескриптор.
SIGPOLL
Завершение
Результат реализации определенного события для устройства, которое опрашивается.
SIGPWR
Игнорирование
Результат угрозы потери питания (при переключении на UPS).
SIGQUIT
Завершение + ядро
Посылается ядром всем процессам текущей группы при нажатии клавиш .
SIGSTOP
Стоп
Посылается всем процессам текущей группы при нажатии пользователем комбинации клавиш . Процесс останавливается.
SIGSYS
Завершение + ядро
Посылается ядром при попытке некорректного системного вызова
SIGTERM
Завершение
Предупреждение о скорой ликвидации процесса (ликвидировать временные файлы, прервать текущие обмены) Команда kill посылает именно этот сигнал.
SIGTTIN
Стоп
Формируется ядром при попытке фонового процесса выполнить чтение с консоли.
SIGTTOU
Стоп
Формируется ядром при попытке фонового процесса выполнить запись в консоль
SIGUSR1
Завершение
Предназначен для прикладных задач, как средство взаимодействия процессов.
SIGUSR2
Завершение
Предназначен для прикладных задач, как средство взаимодействия процессов.
Сигнал может игнорироваться, могут быть предприняты действия, предусмотренные по умолчанию, или процесс может взять на себя функцию обработки сигнала. Если процесс не остановился, существует способ заставить его выполнить это требование, послав команду:
Иногда и это может не помочь, например, в случае процессов зомби (процесса нет а запись о нем имеется), операции в NFS или с ленточным ЗУ.
Атрибуты пользователя в файле /etc/passwd (одна строка — одна запись):
имя уникальное регистрационное имя пользователя (вводится при login)
passwd-encod закодированный пароль пользователя. Часто пароль хранится в отдельном файле, а здесь вместо него проставляется символ х . Если в этом поле стоит символ *, то данный пользователь в систему войти не может (используется для псевдопользователей)
UID Идентификатор пользователя, который наследуется порожденными им процессами. ROOT имеет UID=0.
GID Идентификатор первичной группы пользователя, который соответствует идентификатору в файле /etc/group, где содержится список имен пользователей-членов группы.
Комментарии Обычно здесь записывается истинное имя пользователя, здесь может быть записана дополнительная информация, например, телефон или e-mail пользователя, считываемые программой finger .
home-dir Базовый каталог пользователя, где он оказывается после входа в систему.
Shell Название программы, используемой системой в качестве командного интерпретатора (например, /bin/sh). Разные интерпретаторы используют разные скрипты инициализации (. profole, .login и т.д.).
В первой строке скрипта помещается строка #! /bin/sh, указывающая на тип и размещения интерпретатора. Поскольку скрипт исполняется интерпретатором, работает он медленно. Значение PID сохраняется в переменной $$ , что можно использовать при формировании имен временных файлов, гарантируя их уникальность. Переменные $1, $2 и т.д. несут в себе значения параметров, переданных скрипту. Число таких параметров записывается в переменной $# . Результат работы скрипта заносится в переменную $? . Ненулевое значение $? свидетельствует об ошибке. В переменной $! Хранится PID последнего процесса, запущенного в фоновом режиме. Переменная $* хранит в себе все переменные, переданные скрипту в виде единой строки вида: «$1 $2 $3 .». Другое представление переданных параметров предлагает переменная $@= «$1» «$2» «$3» .
Таблица 2. Перенаправление потоков ввода/вывода
Обозначение
Выполняемая операция
> файл
Стандартный вывод перенаправляется в файл
>> файл
Данные из стандартного вывода добавляются в файл
Стандартный ввод перенаправляется в файл
p1|p2
Вывод программы p1 направляется на вход программы p2
n> файл
Перенаправление вывода из файла с идентификатором n в файл
n>> файл
Тоже, что и в предыдущей строке, но данные добавляются к содержимому файла
Объединение потоков с идентификаторами n и m
«Ввод здесь» — используется стандартный ввод до подстроки str. При этом осуществляется подстановка метасимволов интерпретатора
То же, что и в предшествующей строке, но без подстановки.
Символ | иногда называется конвейером. Например, команда:
ps — ef | grep proс
осуществляет вывод данных о конкретном процессе proс . Несколько более корректна команда:
ps — ef | grep proс grep -v grep
так как в потоке, формируемом командой ps , присутствуют две строки, содержащие proс — строка процесса proс и строка процесса grep с параметром proс.
Для запуска выполнения команды в фоновом режиме достаточно завершить ее символов &.
Виртуальная память процесса состоит из сегментов памяти. Размер, содержимое и размещение сегментов определяется самой программой (например, применением библиотек). Исполняемые файлы могут иметь формат COFF (Common Object File Format) и ELF (Executable and Linking Format).
Функция main() является первой, определенной пользователем. Именное ей будет передано управление после формирования соответствующего окружения запускаемой программы. Функция main определяется следующим образом.
main(int argc, char *argv[], char *envp[]);
Аргумент argc определяет число параметров, переданных программе. Указатели на эти параметры передаются с помощью массива argv[], так через argv[0] передается имя программы, argv[1] — несет в себе первый параметр и т.д. до argv[argc-1]. Массив envp[] несет в себе список указателей на переменные окружения, передаваемые программе. Переменные представляют собой строки имя=значение_переменной.
В среде UNIX существует два базовых интерфейса для файлового ввода/вывода.
- Интерфейс системных вызовов, непосредственно взаимодействующих с ядром ОС.
- Стандартная библиотека ввода-вывода.
С файлом ассоциируется дескриптор, который в свою очередь связан с файловым указателем смещения, начиная с которого будет произведена последующая операция чтения/записи. Каждая операция чтения или записи увеличивает этот указатель на число переданных байтов. При открытии файла указатель принимает значение нуль.
Процесс характеризуется набором атрибутов и идентификаторов. Важнейшим из них является идентификатор процесса PID и идентификатор родительского процесса PPID. PID является именем процесса в ОС. Существует еще 4 идентификатора, которые определяют доступ к системным ресурсам.
- Идентификатор пользователя — UID.
- Эффективный идентификатор пользователя — ЕUID
- Идентификатор группы GID
- Эффективный идентификатор группы ЕGID.
Процессы с идентификаторами SUID и SGID ни при каких обстоятельствах не должны порождать других процессов .
Процесс при реализации использует разные системные ресурсы — память, процессор, возможности файловой системы и ввод/вывод. ОС создает иллюзию одновременного исполнения нескольких процессов (предполагается, что имеется только один процессор), распределяя ресурсы между ними и препятствуя злоупотреблениям.
Выполнение процесса может происходить в двух режимах — в режиме ядра ( kernel mode ) и в режиме пользователя ( user mode ). В режиме пользователя процесс исполняет команды прикладной программы, доступные на непривилегированном уровне. Для получения каких-либо услуг ядра процесс делает системный вызов. При этом могут исполняться инструкции ядра, но от имени процесса, реализующего системный вызов. Выполнение процесса переходит в режим ядра, что защищает адресное пространство ядра. Следует иметь в виду, что некоторые инструкции, например, изменение содержимого регистров управления памятью, возможно только в режиме ядра.
По этой причине образ процесса состоит из двух частей: данных режима ядра и режима пользователя. Каждый процесс представляется в системе двумя основными структурами данных — proc и user, описанными в файлах и , соответственно. Структура proc является записью системной таблицы процессов, которая всегда находится в оперативной памяти. Запись этой таблицы для активного в данный момент процесса адресуется системной переменной curproc . Каждый раз при переключении контекста, когда ресурсы процессора передаются другому процессу, соответственно изменяется содержимое переменной curproc, которая теперь будет указывать на proc активного процесса.
Структура user, называемая также u-area или u block , содержит данные о процессе, которые нужны ядру при выполнении процесса. В отличие от структуры proc, адресуемой с помощью указателя curproc, данные user размещаются в определенном месте виртуальной памяти ядра и адресуются через переменную u . u area также содержит стек фиксированного размера — системный стек или стек ядра (kernel stack). При выполнении процесса в режиме ядра операционная система использует стек, а не стек процесса.
Современные процессоры поддерживают разбивку адресного пространства на области переменного размера — сегменты , и области фиксированного объема — страницы .
Процессоры Intel позволяют разделить память на несколько логических сегментов. Виртуальный адрес при этом состоит из двух частей — селектора сегмента и смещения в пределах сегмента. Поле селектора INDEX указывает на дескриптор сегмента, где записано его положение, размер и права доступа RPL (Descriptor Privilege Level).
При запуске программы командный интерпретатор порождает процесс, который наследует все 4 идентификатора и имеет те же права, что и shell.Так как в сеансе пользователя прародителем всех процессов является login shell, то их идентификаторы будут идентичны. При запуске программы сначала порождается новый процесс, а затем загружается программа.
Процесс порождается с помощью системного вызова fork :
Порожденный процесс (дочерний) является точной копией родительского процесса. Дочерний процесс наследует следующие атрибуты:
- идентификатор пользователя и группы
- все указатели и дескрипторы файлов
- диспозицию сигналов и их обработчики
- текущий и корневой каталог
- переменные окружения
- маску файлов
- ограничения, налагаемые на процесс
- управляющий терминал
Конфигурация виртуальной памяти также сохраняется (те же сегменты программ, данных, стека и пр.). После завершения вызова fork оба процесса будут выполнять одну и ту же инструкцию. Отличаются эти процессы PID, PPID (идентификатор родительского процесса), дочерний процесс не имеет сигналов, ждущих доставки, отличаются и код, возвращаемый системным вызовом fork (родителю возвращается PID дочернего процесса, а дочернему — 0). Если код =0, то возврат осуществляется только в родительский процесс.
Для загрузки исполняемого файла используется вызов exec (аргумент — запускаемая программа). При этом существующий процесс замещается новым, соответствующим исполняемому файлу.
- идентификаторы PID и PPID
- все указатели и дескрипторы файлов, для которых не установлен флаг FD_CLOEXEC
- идентификаторы пользователя и группы
- текущий и корневой каталог
- переменные окружения
- маску файлов
- ограничения, налагаемые на процесс
- управляющий терминал
Процессы могут уведомлять друг друга о произошедших событиях с помощью сигналов, каждый из которых имеет символьное имя и номер. Сигнал может инициировать попытка деления на 0 или обращение по недопустимому адресу.
ОС UNIX создает иллюзию одновременного исполнения процессов, стараясь эффективно распределять между ними имеющиеся ресурсы. Выполнение процесса возможно в режиме ядра (kernel mode) и в режиме задачи (user mode). В последнем случае процесс реализует инструкции прикладной программы, допустимые на непривилегированном уровне защиты процессора. При этом системные структуры данных недоступны. Для получения таких данных процесс делает системный вызов (на время происходит переход процесса в режим ядра).
Каждый процесс представляется в системе двумя основными структурами данных — proc и user , описанными в файлах < sys/proc.h >и < sys/user. h>. Структура proc представляет собой системную таблицу процессов, которая находится в оперативной памяти резидентно. Текущий процесс адресуется системной переменной curproc . Структура user размещается в виртуальной памяти. Область user содержит также системный стек и стек ядра.
Распределение оперативной памяти всегда бывает динамическим. Процессы выполняются в своем виртуальном адресном пространстве. Виртуальные адреса преобразуются в физические на аппаратном уровне при активном участии ОС. Объем виртуальной памяти может значительно превышать объем физической. Процессоры обычно поддерживают разделение адресного пространства области переменного размера — сегменты и фиксированного размера — страницы. Для каждой страницы может быть задано собственная схема преобразования виртуальных адресов в физические. Intel поддерживает работу с сегментами (сегментные регистры), где задается селектор сегмента (дескриптор) и смещение в пределах сегмента.
Распределение ресурсов процессора осуществляется планировщиком, который выделяет кванты времени каждому из активных процессов. Здесь приложения делятся на три класса:
- Интерактивные
- Фоновые
- Реального времени
Каждый процесс в UNIX имеет свой контекст (контекст сохраняется при прерывании процесса). Контекст определяется следующими составляющими:
- Адресное пространство процесса в режиме user
- Управляющая информация (proc и user).
- Окружение процесса (в виде пар переменная=значение).
- Аппаратный контекст (регистры процессора)
Работа планировщика UNIX основана на использовании приоритетов процессов. Если процесс имеет наивысший приоритет и готов к работе, планировщик прервет работу текущего процесса, если у него более низкий приоритет, даже при условии, что он не выбрал до конца свой квант времени. Работа программы ядра обычно не прерывается. Это касается и процессов user, если они в данный момент осуществляют системный вызов.
Каждый процесс имеет два атрибута приоритета — текущий и относительный (nice) . Первый служит для реализации планирования, второй присваивается при порождении процесса и воздействует на значение текущего приоритета. Текущий приоритет может характеризоваться кодами 0 (низший) — 127 (высший). Для режима user используются коды приоритета 0-65, а для ядра — 66-94 (системный диапазон).
Процессы с кодами 96-127 имеют фиксированный приоритет, который не может изменить ОС (обычно служат для процессов реального времени).
Процессу, ожидающему освобождения какого-то ресурса, система присваивает значение кода приоритета сна, выбираемое из диапазона системных приоритетов (в версии BSD большему коду соответствует меньший приоритет). Процессы типа «ожидание ввода с клавиатуры» имеют высокий приоритет сна и им сразу предоставляется ресурс процессора. Фоновые же процессы, забирающие много времени ЦПУ, получают относительно низкий приоритет.
p_cpu = p_cpu*(2*load)/(2*load+1), где load — среднее число процессов в очереди за последнюю секунду. В результате после долгого ожидания даже низкоприоритетный процесс имеет определенный шанс получить требуемый ресурс.
Ядро генерирует и посылает процессу сигнал в ответ на определенные события, вызванные самим процессом, другим процессом, прерыванием (например, терминальным) или внешним событием. Это могут быть Alarm, нарушение по выделенным квотам, особые ситуации, например деление на нуль и т.д. Некоторые сигналы можно заблокировать, отложить их обработку, или проигнорировать, для других (например, SIGKILL и SIGSTOP) это невозможно.
Взаимное влияние процессов в UNIX минимизировано (многозадачность!), но система была бы неэффективной, если бы она не позволяла процессам обмениваться данными и сигналами (IPC — Inter Process Communications). Для реализации этой задачи в UNIX предусмотрены:
- каналы
- сигналы
- FIFO (First-In-First-Out — именованные каналы)
- очереди сообщений
- семафоры
- совместно используемые области памяти
- сокеты >
Для создания канала используется системный вызов pipe int pipe(int *filedes); который возвращает два дескриптора файла filedes[0] — для записи в канал и filedes[1] для чтения из канала. Когда один процесс записывает данные в filedes[0], другой получает их из filedes[1]. Здесь уместен вопрос, как этот другой процесс узнает дескриптор filedes[1]?
Нужно вспомнить, что дочерний процесс наследует все дескрипторы файлов родительского процесса. Таким образом, к дескрипторам имеет доступ процесс, сформировавший канал, и все его дочерние процессы, что позволяет работать каналам только между родственными процессами. Для независимых процессов такой метод обмена недоступен. Канальный обмен может быть запущен и с консоли. Например:
cat file.txt | wc
Здесь символ | олицетворяет создание канала между выводом из файла file.txt и программой wc , подсчитывающей число символов в словах. Процессы эти не являются независимыми, так как оба порождены процессом shell .
Метод FIFO (в BSD не реализован) сходен с канальным обменом, так как также организует лишь однонаправленный обмен. Такие каналы имеют имена, что позволяет их применять при обмене между независимыми процессами. FIFO — это отдельный тип файла в файловой системе UNIX. Для формирования FIFO используется системный вызов mknod .
int mknod(char *pathname, int mode, int dev);
где pathname — имя файла ( FIFO ),
mode — флаги владения и прав доступа,
dev — при создании FIFO игнорируется.
Допускается создание FIFO и из командной строки: mknod name p .
FIFO также как и обычные канала работают с соблюдением следующих правил.
- Если из канала берется меньше байтов, чем там содержится, остальные остаются там для последующего чтения.
- При попытке прочесть больше байт, чем имеется в канале, читающий процесс должен соответствующим образом обработать возникшую ситуацию.
- Если в канале ничего нет и ни один процесс не открыл его на запись, при чтении будет получено нуль байтов. Если один или более процессов открыло канал на запись, вызов read будет заблокирован до появления данных.
- В случае записи в канал несколькими процессами, эти данные не перемешиваются.
- При попытке записать большее число байтов, чем это позволено каналом или FIFO, вызов write блокируется до освобождения нужного места. Если процесс предпринимает попытку записи в канал, не открытый ни одним из процессов для чтения, процессу посылается сигнал SIGPIPE, а вызов write присылает 0 с кодом ошибки errno=EPIPE.
Очереди сообщения являются составной частью UNIX System V. Процесс, заносящий сообщение в очередь, может не ожидать чтения этого сообщения каким-либо другим процессом. Сообщения имеют следующие атрибуты:
- Тип сообщения
- Длина данных в байтах
- Данные (если длина ненулевая)
Очередь сообщений имеет вид списка в адресном пространстве ядра. Для каждой очереди ядро формирует заголовок(msqid_ds), где размещаются данные о правах доступа к очереди (msg_perm), о текущем состоянии очереди (msg_cbytes — число байтов msg_qnum — число сообщений в очереди), а также указатели на первое и последнее сообщение. Создание новой очереди сообщений осуществляется посредством системного вызова msgget:
#include
#include
#include e
int msgget( key_t key, int msgflag );
Эта функция выдает дескриптор элемента очереди, или -1 — в случае ошибки. Процесс может с помощью оператора msgsnd поместить сообщение в очередь, получить сообщение из очереди посредством msgrcv и манипулировать сообщениями с помощью msgctl .
Для управления доступом нескольких процессов к разделяемым ресурсам используются семафоры. Семафоры являются одной из форм IPC (Inter-Process Communication). Для обеспечения работы нужно обеспечить выполнение следующих условий:
- Семафор должен быть доступен разным процессам и, по этой причине, находиться в адресной среде ядра.
- Операция проверки и изменения семафора должна быть реализована в режиме ядра.
Помимо значения семафора в структуре sem записывается идентификатор процесса, вызвавшего последнюю операцию над семафором, число процессов, ожидающих увеличения значения семафора.
Активное использование каналов, FIFO и очередей сообщений может привести к снижению производительности машины. Это сопряжено с тем, что передаваемые данные сначала из буфера передающего процесса в буфер ядра, и только затем в буфер принимающего процесса. Техника разделяемой памяти позволяет избавиться от этих потерь, предоставив доступ двум или более процессам доступ общей зоне памяти.
Пока один процесс читает данные из разделяемой памяти, другой не должен туда писать и наоборот. Такого рода согласование работы осуществляется посредством семафоров.
В настоящее время UNIX использует виртуальную файловую систему, которая допускает работу с несколькими физическими файловыми системами самых разных типов. Система S5FS занимает раздел диска и состоит из трех компонентов.
- Суперблока , где хранится общая информация о файловой системе, о ее архитектуре, числе блоков, и индексных дескрипторов (inode).
- Массива индексных дескрипторов (ilist), где записаны метаданные всех файлов системы. Индексный дескриптор содержит статусные данные о файле и информацию о расположении этих данных на диске. Ядро обращается к inode по индексу массива ilist. Один inode является корневым, через него происходит доступ к структуре каталогов и файлов после монтирования файловой системы.
- Блоки данных файлов и каталогов. Размер блока кратен 512 байтам.
Индексный дескриптор (inode) несет в себе информацию о файле, необходимую для обработки метаданных файла. Каждый файл ассоциируется с одним inode. При открытии файла ядро записывает копию inode в таблицу in-core inode.
Слабой точкой файловой системы F5FS является суперблок. Он записан на диске в одном экземпляре и по этой причине уязвим. Низкая производительность этой файловой системы связана с тем, что метаданные файлов размещены в начале диска, а данные на относительном расстоянии от них. Это вызывает постоянные перемещения считывающих головок, снижая быстродействие системы.
Имена файлов хранятся в специальных файлах, называемых каталогами. По этой причине любой реальный файл данных может иметь любое число имен. Каталог файловой системы представляет собой таблицу, каждый элемент которой имеет длину 16 байтов: 2 байта номер индексного дескриптора, 14 — его имя. Число inode не может превышать 65535. Имя файла в этой системе (S5FS) не должно превышать 14 символов.
При удалении имени файла из каталога номер соответствующего inode устанавливается равным 0. Ядро не удаляет свободные элементы, по этой причине размер каталога при удалении файлов не уменьшается.
Новая файловая система FFS (Berkeley Fast File System) использует те же структуры длинные имена файлов (до 255 символов). Записи каталога имеют следующую структуру:
d_namlen — Длина имени файла
d_name[] — Имя файла
Имя файла имеет переменную длину, дополняемую нулями до 4-байтовой границы. Метаданные активных файлов, на которые ссылаются один или более процессов, представлены в памяти в виде in-core inode. В виртуальной файловой системе в качестве in-core inode выступает vnode . Структура vnode одинакова для всех файлов и не зависит от типа файловой системы. vnode содержит данные, необходимые для работы виртуальной файловой системы, а также характеристики файла, такие как его тип.
Получение описания инструкций (Help): man
Уход из UNIX Ctrl-d или logout.