Алгоритм сортировки Timsort
Timsort, в отличии от всяких там «пузырьков» и «вставок», штука относительно новая — изобретен был в 2002 году Тимом Петерсом (в честь него и назван). С тех пор он уже стал стандартным алгоритмом сортировки в Python, OpenJDK 7 и Android JDK 1.5. А чтобы понять почему — достаточно взглянуть на вот эту табличку из Википедии.
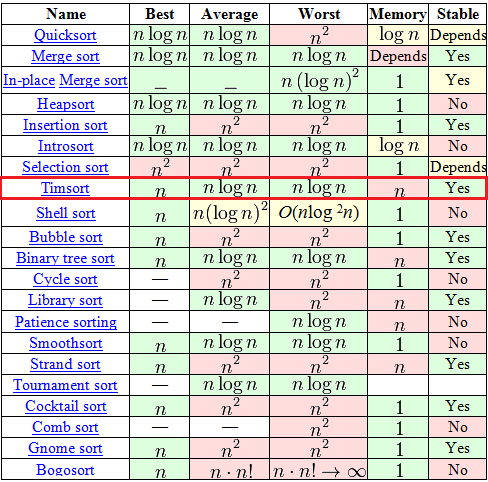
Среди, на первый взгляд, огромного выбора в таблице есть всего 7 адекватных алгоритмов (со сложностью O(n logn) в среднем и худшем случае), среди которых только 2 могут похвастаться стабильностью и сложностью O(n) в лучшем случае. Один из этих двух — это давно и хорошо всем известная «Сортировка с помощью двоичного дерева». А вот второй как-раз таки Timsort.
Алгоритм построен на той идее, что в реальном мире сортируемый массив данных часто содержат в себе упорядоченные (не важно, по возрастанию или по убыванию) подмассивы. Это и вправду часто так. На таких данных Timsort рвёт в клочья все остальные алгоритмы.
Сразу к сути
- По специальному алгоритму разделяем входной массив на подмассивы.
- Сортируем каждый подмассив обычной сортировкой вставками.
- Собираем отсортированные подмассивы в единый массив с помощью модифицированной сортировки слиянием.
Алгоритм
Используемые понятия

- N — размер входного массива
- run — упорядоченный подмассив во входном массиве. Причём упорядоченный либо нестрого по возрастанию, либо строго по убыванию. Т.е или «a0 a1 > a2 > . »
- minrun — как было сказано выше, на первом шаге алгоритма входной массив будет поделен на подмассивы. minrun — это минимальный размер такого подмассива. Это число рассчитывается по определённой логике из числа N.
Шаг 0. Вычисление minrun.
- Оно не должно быть слишком большим, поскольку к подмассиву размера minrun будет в дальнейшем применена сортировка вставками, а она эффективна только на небольших массивах
- Оно не должно быть слишком маленьким, поскольку чем меньше подмассив — тем больше итераций слияния подмассивов придётся выполнить на последнем шаге алгоритма.
- Хорошо бы, чтобы N \ minrun было степенью числа 2 (или близким к нему). Это требование обусловлено тем, что алгоритм слияния подмассивов наиболее эффективно работает на подмассивах примерно равного размера.
int GetMinrun(int n) < int r = 0; /* станет 1 если среди сдвинутых битов будет хотя бы 1 ненулевой */ while (n >= 64) < r |= n & 1; n >>= 1; > return n + r; >
Шаг 1. Разбиение на подмассивы и их сортировка.
- Ставим указатель текущего элемента в начало входного массива.
- Начиная с текущего элемента, ищем во входном массиве run (упорядоченный подмассив). По определению, в этот run однозначно войдет текущий элемент и следующий за ним, а вот дальше — уже как повезет. Если получившийся подмассив упорядочен по убыванию — переставляем элементы так, чтобы они шли по возрастанию (это простой линейный алгоритм, просто идём с обоих концов к середине, меняя элементы местами).
- Если размер текущего run’а меньше чем minrun — берём следующие за найденным run-ом элементы в количестве minrun — size(run). Таким образом, на выходе у нас получается подмассив размером minrun или больше, часть которого (а в идеале — он весь) упорядочена.
- Применяем к данному подмассиву сортировку вставками. Так как размер подмассива невелик и часть его уже упорядочена — сортировка работает быстро и эффективно.
- Ставим указатель текущего элемента на следующий за подмассивом элемент.
- Если конец входного массива не достигнут — переход к пункту 2, иначе — конец данного шага.
Шаг 2. Слияние.

На данном этапе у нас имеется входной массив, разбитый на подмассивы, каждый из которых упорядочен. Если данные входного массива были близки к случайным — размер упорядоченных подмассивов близок к minrun, если в данных были упорядоченные диапазоны (а исходя из рекомендаций по применению алгоритма, у нас есть основания на это надеяться) — упорядоченные подмассивы имеют размер, превышающий minrun.
Теперь нам нужно объединить эти подмассивы для получения результирующего, полностью упорядоченного массива. Причём по ходу этого объединения нужно выполнить 2 требования:
- Объединять подмассивы примерно равного размера (так получается эффективнее).
- Сохранить стабильность алгоритма — т.е. не делать бессмысленных перестановок (например, не менять два последовательно стоящих одинаковых числа местами).
Достигается это таким образом.
- Создаем пустой стек пар -. Берём первый упорядоченный подмассив.
- Добавляем в стек пару данных — для текущего подмассива.
- Определяем, нужно ли выполнять процедуру слияния текущего подмассива с предыдущими. Для этого проверяется выполнение 2 правил (пусть X, Y и Z — размеры трёх верхних в стеке подмассивов):
X > Y + Z
Y > Z - Если одно из правил нарушается — массив Y сливается с меньшим из массивов X и Z. Повторяется до выполнения обоих правил или полного упорядочивания данных.
- Если еще остались не рассмотренные подмассивы — берём следующий и переходим к пункту 2. Иначе — конец.
Цель этой хитрой процедуры — сохранение баланса. Т.е. изменения будут выглядеть вот так:
а значит, размеры подмассивов в стеке эффективны для дальнейшей сортировки слиянием. Представьте себе идеальный случай: у нас есть подмассивы размера 128, 64, 32, 16, 8, 4, 2, 2 (забудем на секунду о наличии требования «размер подмассива >= minrun»). В этом случае никаких слияний не будет выполнятся пока не встретятся 2 последних подмассива, а вот после этого будут выполнены 7 идеально сбалансированных слияний.
Процедура слияния подмассивов

Как Вы помните, на втором шаге алгоритма мы занимаемся слиянием двух подмассивов в один упорядоченный. Мы всегда соединяем 2 последовательных подмассива. Для их слияния используется дополнительная память.
- Создаём временный массив в размере меньшего из соединяемых подмассивов.
- Копируем меньший из подмассивов во временный массив
- Ставим указатели текущей позиции на первые элементы большего и временного массива.
- На каждом следующем шаге рассматриваем значение текущих элементов в большем и временном массивах, берём меньший из них и копируем его в новый отсортированный массив. Перемещаем указатель текущего элемента в массиве, из которого был взят элемент.
- Повторяем 4, пока один из массивов не закончится.
- Добавляем все элементы оставшегося массива в конец нового массива.
Модификация процедуры слияния подмассивов
- Начинаем процедуру слияния, как было показано выше.
- На каждой операции копирования элемента из временного или большего подмассива в результирующий запоминаем, из какого именно подмассива был элемент.
- Если уже некоторое количество элементов (в данной реализации алгоритма это число жестко равно 7) было взято из одного и того же массива — предполагаем, что и дальше нам придётся брать данные из него. Чтобы подтвердить эту идею, мы переходим в режим «галопа», т.е. бежим по массиву-претенденту на поставку следующей большой порции данных бинарным поиском (мы помним, что массив упорядочен и мы имеем полное право на бинарный поиск) текущего элемента из второго соединяемого массива. Бинарный поиск эффективнее линейного, а потому операций поиска будет намного меньше.
- Найдя, наконец, момент, когда данные из текущего массива-поставщика нам больше не подходят (или дойдя до конца массива), мы можем, наконец, скопировать их все разом (что может быть эффективнее копирования одиночных элементов).
- Первые 7 итераций мы сравниваем числа 1, 2, 3, 4, 5, 6 и 7 из массива A с числом 20000 и, убедившись, что 20000 больше — копируем элементы массива A в результирующий.
- Начиная со следующей итерации переходим в режим «галопа»: сравниваем с числом 20000 последовательно элементы 8, 10, 14, 22, 38, n+2^i, . 10000 массива A. Как видно, таких сравнение будет намного меньше 10000.
- Мы дошли до конца массива A и знаем, что он весь меньше B (мы могли также остановиться где-то посередине). Копируем нужные данные из массива A в результирующий, идём дальше.
Материалы по теме
- Timsort на Википедии (русской версии нет)
- Представление алгоритма от его создателя
- Обсуждение алгоритма на Stackoverflow
- Красивая визуализация алгоритма
Алгоритм сортировки Timsort
Для сортировки в CPython используется алгоритм Timsort, который его создатель Тим Петерс застенчиво назвал в честь себя. Timsort — это комбинация сортировки вставками и сортировки слиянием, заточенная под работу с реальными данными. Дело в том, что на практике массивы, которые нужно сортировать, часто бывают частично упорядочены и Timsort пользуется этим предположением для ускорения работы.
Логика работы Timsort на самом деле довольно прозрачная:
- Timsort делит входной массив на подмассивы;
- сортирует подмассивы вставками;
- объединяет их попарно сортировкой слиянием;
- и возвращает отсортированный массив.
Но дьявол кроется в деталях.
Делим на подмассивы
Части, на которые алгоритм делит входной массив, в описании алгоритма автор называет run’ами. Так на какое количество run’ов следует разделить входной массив? Здесь два соображения. Во-первых, части должны быть достаточно короткими, чтобы их было выгодно сортировать вставками. А еще мы хотим, чтобы пары последовательностей, которые позже поступят в сортировку слиянием, были примерно одинаковой длины. Дальше происходит магия, которая учитывает эти соображения и выбирает длину подпоследовательности minrun между 32 и 64 элементами. При этом если входной массив короче 64 элементов, то на части он не делится.
Сортируем run’ы
Перед тем, как приступить к сортировке подмассива, алгоритм ищет изначально упорядоченные участки. Если они слишком короткие и не дотягивают до минимального размера, то алгоритм удлинняет их бинарной сортировкой (http://www.geneffects.com/briarskin/theory/binary/index.html). Бинарная сортировка — это разновидность сортировки вставками, которая помещает элементы на свои места, используя двоичный поиск. Сортировки вставками как раз эффективны в случаях небольших частично упорядоченных массивов. Сам Петерс пишет, что это лучшее, что можно было выбрать, учитывая ограничения более утонченных алгоритмов.
Сливаем подмассивы
По мере того, как упорядоченные run’ы формируются, сортировкой слияния они объединяются попарно во всё более крупные отсортированные куски. При этом, если алгоритм при слиянии последовательностей встречает два участка вида
a = [1, 2, 3, 4] b = [5, 6, 7, 8]
то по понятным причинам может объединить их быстрее, чем поэлементным перебором. Эта модификация сортировки называется galloping, поскольку в этом режиме алгоритм переносит на новое место не один элемент, а сразу несколько. Досортировки и слияния повторяются до тех пор, пока не достигается полная упорядоченность входного массива.
Вывод
Объем алгоритма в исходнике примерно 2к строк и, как можно догадаться по описанию, код довольно запутанный. Зато за счет использования упорядоченности в реальных данных сложность Timsort в лучшем случае линейная. В худшем случае, если входные данные случайные, timsort справится за O(n log n), а это неплохо для сортировки. Кстати, несмотря на то, что Timsort изначально был придуман в Python-сообществе, сейчас он используется еще в Java, Swift и Android platform.
Вот что нужно запомнить о Timsort:
- Timsort это гибридный алгоритм сортировки, сочетающий модифицированные варианты сортировки вставками и сортировки слиянием;
- Timsort пользуется тем, что реальные данные часто бывают частично упорядочены;
- В лучшем случае сложность O(n), в худшем — O(n log n)).
Визуализацию работы алгоритма можно посмотреть здесь:
Timsort — самый быстрый алгоритм сортировки, о котором вы никогда не слышали

Timsort: Очень быстрый, O(n log n), стабильный алгоритм сортировки, созданный для реального мира, а не для академических целей.
Timsort — это алгоритм сортировки, который эффективен для реальных данных, а не создан в академической лаборатории. Tim Peters создал Timsort для Python в 2001 году.
Timsort сначала анализирует список, который он пытается отсортировать, и на его основе выбирает наилучший подход. С момента его появления он используется в качестве алгоритма сортировки по умолчанию в Python, Java, платформе Android и GNU Octave.
Нотация Big O для Timsort — это O(n log n). Чтобы узнать о нотации Big O, прочтите это.
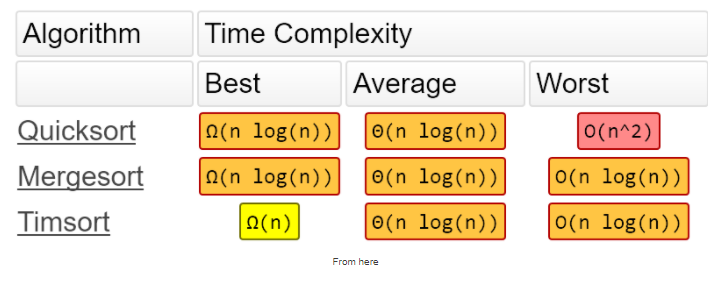
Время сортировки Timsort такое же, как и у Mergesort, что быстрее, чем у большинства других известных сортировок. Timsort фактически использует сортировку вставкой как и Mergesort. Вы это скоро увидите.
Peters разработал Timsort для использования уже упорядоченных элементов, которые существуют в большинстве реальных наборов данных. Он называет эти упорядоченные элементы «natural runs» (естественные пробеги). Они итеративно перебирают данные, собирая элементы в пробеги и одновременно объединяя несколько этих пробегов в один.

Если массив (array), который мы пытаемся отсортировать, содержит менее 64 элементов, Timsort выполняет сортировку вставкой.
Сортировка вставкой — это простая сортировка, которая наиболее эффективна для небольших списков. Она функционирует довольно медленно при работе с большими списками, но при этом быстро работает с маленькими списками. Идея сортировки вставкой заключается в следующем:
- Просматривать элементы по одному
- Построить отсортированный список, вставляя элемент в нужное место
Вот таблица, показывающая, как сортировка вставкой сортирует список [34, 10, 64, 51, 32, 21].
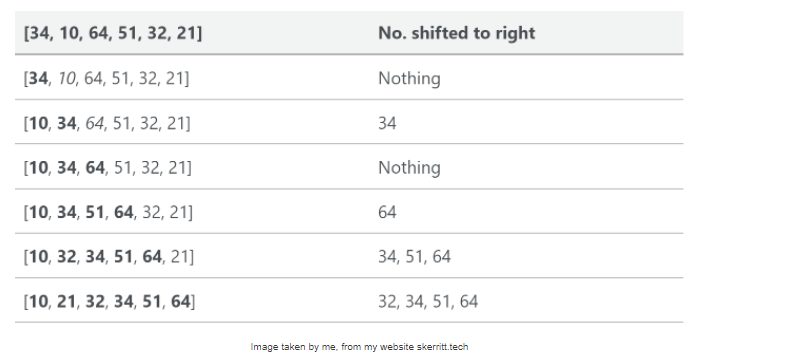
В данном случае мы вставляем только что отсортированные элементы в новый подмассив (sub-array), который начинается от начала массива.
Вот gif, показывающий сортировку вставкой:
Больше о пробегах
Если список больше 64 элементов, то алгоритм сделает первый проход (pass) по списку в поисках частей, которые строго возрастают или убывают. Если какая-либо часть является убывающей, то она будет изменена.
Таким образом, если пробег уменьшается, он будет выглядеть следующим образом (пробег выделен жирным шрифтом):

Если не происходит уменьшение, то это будет выглядеть следующим образом:

Minrun — это размер, который определяется на основе размера массива. Алгоритм выбирает его таким образом, чтобы большинство пробегов в произвольном массиве были или становились длиной minrun. Слияние двух массивов более эффективно, когда число пробегов равно или чуть меньше степени числа 2. Timsort выбирает minrun, чтобы попытаться обеспечить эту эффективность, убедившись, что minrun равен или меньше степени числа 2.
Алгоритм выбирает minrun из диапазона от 32 до 64 включительно, таким образом, чтобы длина исходного массива при расчете была меньше или равна степени числа 2.
Если длина пробега меньше minrun, необходимо рассчитать длину этого пробега относительно minrun. Используя это новое число выполняется сортировка вставкой для создания нового пробега.
Итак, если minrun равен 63, а длина пробега равна 33, вы выполняете вычитание: 63-33 = 30. Затем вы берете 30 элементов из run[33], и делаете сортировку вставкой для создания нового пробега.
После завершения этой части должно появиться множество отсортированных пробегов в списке.
Слияние
Теперь Timsort использует сортировку слиянием, чтобы объединить пробеги. Однако Timsort следит за тем, чтобы сохранить стабильность и баланс слияния во время сортировки.
Для поддержания стабильности мы не должны менять местами два одинаковых числа. Это не только сохраняет их исходные позиции в списке, но и позволяет алгоритму работать быстрее. В ближайшее время мы обсудим баланс слияния.
Когда Timsort находит пробеги, он добавляет их в стек. Простой стек выглядит следующим образом:

Представьте себе стопку тарелок. Вы не можете взять тарелки снизу, поэтому вам приходится брать их сверху. То же самое можно сказать и о стеке.
Timsort пытается сбалансировать две конкурирующие задачи при сортировке слиянием. С одной стороны, мы хотели бы отложить слияние на как можно дольше, чтобы использовать паттерны, которые могут появиться позже, но еще больше нам хотелось бы произвести слияние как можно быстрее, чтобы воспользоваться тем, что только что найденный пробег все еще находится наверху в иерархии памяти. Мы также не можем откладывать слияние «слишком надолго», потому что на запоминание еще не объединенных пробегов расходуется память, а стек имеет фиксированный размер.
Чтобы добиться компромисса, Timsort отслеживает три последних элемента в стеке и создает два правила, которые должны выполняться для этих элементов:
Где A, B и C — три самых последних элемента в стеке.
По словам Tim Peters:
Хорошим компромиссом оказалось то, что сохраняет два варианта для записей в стеке, где A, B и C — длины трех самых правых еще не объединенных частей.
Обычно объединить соседние пробеги разной длины очень сложно. Еще сложнее то, что мы должны поддерживать стабильность. Чтобы обойти эту проблему, Timsort выделяет временную память. Он помещает меньший (называя оба пробега A и B) из двух побегов в эту временную память.
Galloping*
*Модификация процедуры слияния подмассивов
Пока Timsort объединяет A и B, обнаруживается, что один пробег «выигрывает» много раз подряд. Если бы оказалось, что A состоял из гораздо меньших чисел, чем B, то A оказался бы на прежнем месте. Слияние этих двух пробегов потребовало бы много работы c нулевым результатом.
Чаще всего данные имеют некоторую уже существующую внутреннюю структуру. Timsort предполагает, что если многие значения пробега A меньше, чем значения пробега B, то, скорее всего, A будет и дальше содержать меньшие значения, чем B.
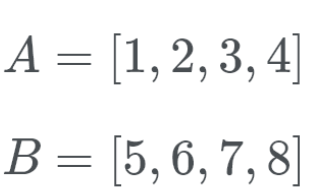
Затем Timsort переходит в режим galloping. Вместо того чтобы сверять A[0] и B[0] друг с другом, Timsort выполняет бинарный поиск соответствующей позиции b[0] в a[0]. Таким образом, Timsort может полностью переместить A. Затем Timsort ищет соответствующее местоположение A[0] в B. После этого Timsort также может полностью перемещает B.
Давайте посмотрим на это в действии. Timsort проверяет B[0] (который равен 5) и, используя бинарный поиск, ищет соответствующее место в A.
Итак, B[0] находится в конце списка A. Теперь Timsort проверяет A[0] (который равен 1) в правильном месте B. Итак, мы ищем, где находится число 1. Это число находится в начале B. Теперь мы знаем, что B находится в конце A, а A — в начале B.
Оказывается, что действие не имеет смысла, если подходящее место для B[0] находится очень близко к началу A (или наоборот), поэтому режим gallop быстро завершается, если он не приносит результатов. Кроме того, Timsort принимает это к сведению и усложняет вход в режим gallop, увеличивая количество последовательных «побед» только в A или только в B. Если режим gallop приносит результаты, Timsort облегчает его повторный запуск.
Если говорить коротко, Timsort делает две вещи невероятно хорошо:
- Обеспечивает высокую производительность при работе с массивами с уже существующей внутренней структурой
- Создает возможность поддерживать стабильную сортировку
А раньше, чтобы добиться стабильной сортировки, вам нужно было сжать элементы списка в целые числа и отсортировать его как массив кортежей.
Код
Если вас не интересует код, смело пропускайте эту часть. Под этим разделом есть дополнительная информация.
Если вы хотите увидеть оригинальный исходный код Timsort во всей его красе, посмотрите его здесь. Timsort официально реализован на C, а не на Python.
Timsort фактически встроен прямо в Python, поэтому этот код служит только в качестве пояснения. Чтобы использовать Timsort, просто напишите следующее:
list.sort()sorted(list)Если вы хотите узнать, как работает Timsort, и понять его суть, я настоятельно рекомендую вам попробовать применить его самостоятельно!
Эта статья основана на оригинальном вступлении Tim Peters к Timsort, которое можно найти здесь.
Если вам интересно узнать о курсе больше, приглашаем на день открытых дверей онлайн.
- алгоритмы
- программирование
- timsort
- алгоритм сортировки
Timsort — самый быстрый алгоритм сортировки, о котором вы никогда не слышали
Timsort: Очень быстрый, O(n log n), стабильный алгоритм сортировки, созданный для реального мира, а не для академических целей.
Timsort — это алгоритм сортировки, который эффективен для реальных данных, а не создан в академической лаборатории. Tim Peters создал Timsort для Python в 2001 году.
Timsort сначала анализирует список, который он пытается отсортировать, и на его основе выбирает наилучший подход. С момента его появления он используется в качестве алгоритма сортировки по умолчанию в Python, Java, платформе Android и GNU Octave.
Нотация Big O для Timsort — это O(n log n). Чтобы узнать о нотации Big O, прочтите это.
Время сортировки Timsort такое же, как и у Mergesort, что быстрее, чем у большинства других известных сортировок. Timsort фактически использует сортировку вставкой как и Mergesort. Вы это скоро увидите.
Peters разработал Timsort для использования уже упорядоченных элементов, которые существуют в большинстве реальных наборов данных. Он называет эти упорядоченные элементы «natural runs» (естественные пробеги). Они итеративно перебирают данные, собирая элементы в пробеги и одновременно объединяя несколько этих пробегов в один.
Если массив (array), который мы пытаемся отсортировать, содержит менее 64 элементов, Timsort выполняет сортировку вставкой.
Сортировка вставкой — это простая сортировка, которая наиболее эффективна для небольших списков. Она функционирует довольно медленно при работе с большими списками, но при этом быстро работает с маленькими списками. Идея сортировки вставкой заключается в следующем:
- Просматривать элементы по одному
- Построить отсортированный список, вставляя элемент в нужное место
Вот таблица, показывающая, как сортировка вставкой сортирует список [34, 10, 64, 51, 32, 21].
В данном случае мы вставляем только что отсортированные элементы в новый подмассив (sub-array), который начинается от начала массива.
Вот gif, показывающий сортировку вставкой:
Больше о пробегах
Если список больше 64 элементов, то алгоритм сделает первый проход (pass) по списку в поисках частей, которые строго возрастают или убывают. Если какая-либо часть является убывающей, то она будет изменена.
Таким образом, если пробег уменьшается, он будет выглядеть следующим образом (пробег выделен жирным шрифтом):
Если не происходит уменьшение, то это будет выглядеть следующим образом:
Minrun — это размер, который определяется на основе размера массива. Алгоритм выбирает его таким образом, чтобы большинство пробегов в произвольном массиве были или становились длиной minrun. Слияние двух массивов более эффективно, когда число пробегов равно или чуть меньше степени числа 2. Timsort выбирает minrun, чтобы попытаться обеспечить эту эффективность, убедившись, что minrun равен или меньше степени числа 2.
Алгоритм выбирает minrun из диапазона от 32 до 64 включительно, таким образом, чтобы длина исходного массива при расчете была меньше или равна степени числа 2.
Если длина пробега меньше minrun, необходимо рассчитать длину этого пробега относительно minrun. Используя это новое число выполняется сортировка вставкой для создания нового пробега.
Итак, если minrun равен 63, а длина пробега равна 33, вы выполняете вычитание: 63-33 = 30. Затем вы берете 30 элементов из run[33], и делаете сортировку вставкой для создания нового пробега.
После завершения этой части должно появиться множество отсортированных пробегов в списке.
Слияние
Теперь Timsort использует сортировку слиянием, чтобы объединить пробеги. Однако Timsort следит за тем, чтобы сохранить стабильность и баланс слияния во время сортировки.
Для поддержания стабильности мы не должны менять местами два одинаковых числа. Это не только сохраняет их исходные позиции в списке, но и позволяет алгоритму работать быстрее. В ближайшее время мы обсудим баланс слияния.
Когда Timsort находит пробеги, он добавляет их в стек. Простой стек выглядит следующим образом:
Представьте себе стопку тарелок. Вы не можете взять тарелки снизу, поэтому вам приходится брать их сверху. То же самое можно сказать и о стеке.
Timsort пытается сбалансировать две конкурирующие задачи при сортировке слиянием. С одной стороны, мы хотели бы отложить слияние на как можно дольше, чтобы использовать паттерны, которые могут появиться позже, но еще больше нам хотелось бы произвести слияние как можно быстрее, чтобы воспользоваться тем, что только что найденный пробег все еще находится наверху в иерархии памяти. Мы также не можем откладывать слияние «слишком надолго», потому что на запоминание еще не объединенных пробегов расходуется память, а стек имеет фиксированный размер.
Чтобы добиться компромисса, Timsort отслеживает три последних элемента в стеке и создает два правила, которые должны выполняться для этих элементов:
Где A, B и C — три самых последних элемента в стеке.
По словам Tim Peters:
Хорошим компромиссом оказалось то, что сохраняет два варианта для записей в стеке, где A, B и C — длины трех самых правых еще не объединенных частей.
Обычно объединить соседние пробеги разной длины очень сложно. Еще сложнее то, что мы должны поддерживать стабильность. Чтобы обойти эту проблему, Timsort выделяет временную память. Он помещает меньший (называя оба пробега A и B) из двух побегов в эту временную память.
Galloping*
*Модификация процедуры слияния подмассивов
Пока Timsort объединяет A и B, обнаруживается, что один пробег «выигрывает» много раз подряд. Если бы оказалось, что A состоял из гораздо меньших чисел, чем B, то A оказался бы на прежнем месте. Слияние этих двух пробегов потребовало бы много работы c нулевым результатом.
Чаще всего данные имеют некоторую уже существующую внутреннюю структуру. Timsort предполагает, что если многие значения пробега A меньше, чем значения пробега B, то, скорее всего, A будет и дальше содержать меньшие значения, чем B.
Затем Timsort переходит в режим galloping. Вместо того чтобы сверять A[0] и B[0] друг с другом, Timsort выполняет бинарный поиск соответствующей позиции b[0] в a[0]. Таким образом, Timsort может полностью переместить A. Затем Timsort ищет соответствующее местоположение A[0] в B. После этого Timsort также может полностью перемещает B.
Давайте посмотрим на это в действии. Timsort проверяет B[0] (который равен 5) и, используя бинарный поиск, ищет соответствующее место в A.
Итак, B[0] находится в конце списка A. Теперь Timsort проверяет A[0] (который равен 1) в правильном месте B. Итак, мы ищем, где находится число 1. Это число находится в начале B. Теперь мы знаем, что B находится в конце A, а A — в начале B.
Оказывается, что действие не имеет смысла, если подходящее место для B[0] находится очень близко к началу A (или наоборот), поэтому режим gallop быстро завершается, если он не приносит результатов. Кроме того, Timsort принимает это к сведению и усложняет вход в режим gallop, увеличивая количество последовательных «побед» только в A или только в B. Если режим gallop приносит результаты, Timsort облегчает его повторный запуск.
Если говорить коротко, Timsort делает две вещи невероятно хорошо:
- Обеспечивает высокую производительность при работе с массивами с уже существующей внутренней структурой
- Создает возможность поддерживать стабильную сортировку
А раньше, чтобы добиться стабильной сортировки, вам нужно было сжать элементы списка в целые числа и отсортировать его как массив кортежей.
Код
Если вас не интересует код, смело пропускайте эту часть. Под этим разделом есть дополнительная информация.
Если вы хотите увидеть оригинальный исходный код Timsort во всей его красе, посмотрите его здесь. Timsort официально реализован на C, а не на Python.
Timsort фактически встроен прямо в Python, поэтому этот код служит только в качестве пояснения. Чтобы использовать Timsort, просто напишите следующее:
list.sort()sorted(list)Если вы хотите узнать, как работает Timsort, и понять его суть, я настоятельно рекомендую вам попробовать применить его самостоятельно!
Эта статья основана на оригинальном вступлении Tim Peters к Timsort, которое можно найти здесь.
Перевод статьи подготовлен в рамках курса «Алгоритмы и структуры данных».
Если вам интересно узнать о курсе больше, приглашаем на день открытых дверей онлайн.