5. Основные элементы программирования
Большинство программ создаются для решения какой-либо задачи. В процессе решения задачи на компьютере пользователю нужно ввести обрабатываемые данные, указать, как их обрабатывать, задать способ вывода полученных результатов. Поэтому как программист вы должны знать:
• как ввести информацию в память (ввод);
• как хранить информацию в памяти (данные);
• как указать правильные команды для обработки данных (операции);
• как передать обратно данные из программы пользователю (вывод). Вы должны упорядочить команды таким образом, чтобы:
• некоторые из них выполнялись только в том случае, если соблюдается некоторое условие или ряд условий (условное выполнение);
• другие выполнялись повторно некоторое число раз (циклы);
• третьи выделялись в отдельные части, которые могут быть неоднократно выполнены в разных местах программы (подпрограммы).
Таким образом, как программист вы должны уметь использовать семь основных элементов программирования: ввод, данные, операции, вывод, условное выполнение, циклы и подпрограммы и на их основе строить программы.
Этот список не является исчерпывающим, однако он содержит те элементы, которые обычно присущи всем программам (и процедурным языкам программирования). Многие языки программирования, в том числе и Паскаль, имеют еще дополнительные средства, которые вы изучите далее. Ниже дается краткое описание каждого элемента.
Ввод означает считывание значений, поступающих с клавиатуры, с диска, из порта ввода-вывода.
Данные — это константы, переменные и структуры, содержащие числа (целые и вещественные), текст (символы и строки) или адреса (переменных и структур).
Операции осуществляют присваивание значений, их комбинирование сложение, деление и т. д. ) и сравнение значений (равные, неравные и т.д.).
Вывод означает запись информации на экран, на диск или в порт ввода-вывода.
Условное выполнение предполагает выполнение набора команд в случае, если удовлетворяется (является истинным) некоторое условие (если это условие не удовлетворяется, то эти команды пропускаются или же выполняется другой набор команд) или если некоторый элемент данных имеет некоторое специальное значение или значение из некоторого спектра.
Благодаря циклам некоторый набор команд выполняется повторно или фиксированное число раз, или пока является истинным некоторое условие, или пока некоторое условие не стало истинным.
Подпрограмма представляет собой набор команд, который имеет имя и может быть неоднократно вызван из любого места программы по его имени.
6. Общая структура языков программирования введение
Практически каждый (алгоритмический) язык программирования (ЯП) предназначен для записи некоторого множества алгоритмов. Соответственно, учитывая, что алгоритмом, как правило, называют набор инструкций, понятных исполнителю, и то, что исполнителем в данном случае является ЭВМ, легко определить набор механизмов (средств управления исполнителем), которыми обязан обладать каждый язык программирования. Знание этих базовых механизмов позволяет программисту довольно легко переходить с одного языка на другой (хотя бы по той простой причине, что в любом новом языке эффективнее искать известные вещи, чем натыкаться на неизвестные). Кроме того, зачастую оно (знание) позволяет легче понять структуру языка в целом.
Основные структуры данных. Матчасть. Азы
Все чаще замечаю, что современным самоучкам очень не хватает матчасти. Все знают языки, но мало основы, такие как типы данных или алгоритмы. Немного про типы данных.
Еще в далеком 1976 швейцарский ученый Никлаус Вирт написал книгу Алгоритмы + структуры данных = программы.
40+ лет спустя это уравнение все еще верно. И если вы самоучка и надолго в программировании пробегитесь по статье, можно по диагонали. Можно код кофе.

В статье так же будут вопросы, которое вы можете услышать на интервью.
Что такое структура данных?
Структура данных — это контейнер, который хранит данные в определенном макете. Этот «макет» позволяет структуре данных быть эффективной в некоторых операциях и неэффективной в других.
Какие бывают?
Линейные, элементы образуют последовательность или линейный список, обход узлов линеен. Примеры: Массивы. Связанный список, стеки и очереди.
Нелинейные, если обход узлов нелинейный, а данные не последовательны. Пример: граф и деревья.
Основные структуры данных.
- Массивы
- Стеки
- Очереди
- Связанные списки
- Графы
- Деревья
- Префиксные деревья
- Хэш таблицы
Массивы
Массив — это самая простая и широко используемая структура данных. Другие структуры данных, такие как стеки и очереди, являются производными от массивов.
Изображение простого массива размера 4, содержащего элементы (1, 2, 3 и 4).

Каждому элементу данных присваивается положительное числовое значение (индекс), который соответствует позиции элемента в массиве. Большинство языков определяют начальный индекс массива как 0.
Бывают
Одномерные, как показано выше.
Многомерные, массивы внутри массивов.
Основные операции
- Insert-вставляет элемент по заданному индексу
- Get-возвращает элемент по заданному индексу
- Delete-удаление элемента по заданному индексу
- Size-получить общее количество элементов в массиве
Вопросы
- Найти второй минимальный элемент массива
- Первые неповторяющиеся целые числа в массиве
- Объединить два отсортированных массива
- Изменение порядка положительных и отрицательных значений в массиве
Стеки
Стек — абстрактный тип данных, представляющий собой список элементов, организованных по принципу LIFO (англ. last in — first out, «последним пришёл — первым вышел»).
Это не массивы. Это очередь. Придумал Алан Тюринг.
Примером стека может быть куча книг, расположенных в вертикальном порядке. Для того, чтобы получить книгу, которая где-то посередине, вам нужно будет удалить все книги, размещенные на ней. Так работает метод LIFO (Last In First Out). Функция «Отменить» в приложениях работает по LIFO.
Изображение стека, в три элемента (1, 2 и 3), где 3 находится наверху и будет удален первым.

Основные операции
- Push-вставляет элемент сверху
- Pop-возвращает верхний элемент после удаления из стека
- isEmpty-возвращает true, если стек пуст
- Top-возвращает верхний элемент без удаления из стека
Вопросы
- Реализовать очередь с помощью стека
- Сортировка значений в стеке
- Реализация двух стеков в массиве
- Реверс строки с помощью стека
Очереди
Подобно стекам, очередь — хранит элемент последовательным образом. Существенное отличие от стека – использование FIFO (First in First Out) вместо LIFO.
Пример очереди – очередь людей. Последний занял последним и будешь, а первый первым ее и покинет.
Изображение очереди, в четыре элемента (1, 2, 3 и 4), где 1 находится наверху и будет удален первым

Основные операции
- Enqueue—) — вставляет элемент в конец очереди
- Dequeue () — удаляет элемент из начала очереди
- isEmpty () — возвращает значение true, если очередь пуста
- Top () — возвращает первый элемент очереди
Вопросы
- Реализовать cтек с помощью очереди
- Реверс первых N элементов очереди
- Генерация двоичных чисел от 1 до N с помощью очереди
Связанный список
Связанный список – массив где каждый элемент является отдельным объектом и состоит из двух элементов – данных и ссылки на следующий узел.
Принципиальным преимуществом перед массивом является структурная гибкость: порядок элементов связного списка может не совпадать с порядком расположения элементов данных в памяти компьютера, а порядок обхода списка всегда явно задаётся его внутренними связями.
Бывают
Однонаправленный, каждый узел хранит адрес или ссылку на следующий узел в списке и последний узел имеет следующий адрес или ссылку как NULL.
Двунаправленный, две ссылки, связанные с каждым узлом, одним из опорных пунктов на следующий узел и один к предыдущему узлу.
Круговой, все узлы соединяются, образуя круг. В конце нет NULL. Циклический связанный список может быть одно-или двукратным циклическим связанным списком.
Самое частое, линейный однонаправленный список. Пример – файловая система.

Основные операции
- InsertAtEnd — Вставка заданного элемента в конец списка
- InsertAtHead — Вставка элемента в начало списка
- Delete — удаляет заданный элемент из списка
- DeleteAtHead — удаляет первый элемент списка
- Search — возвращает заданный элемент из списка
- isEmpty — возвращает True, если связанный список пуст
Вопросы
- Реверс связанного списка
- Определение цикла в связанном списке
- Возврат N элемента из конца в связанном списке
- Удаление дубликатов из связанного списка
Графы
Граф-это набор узлов (вершин), которые соединены друг с другом в виде сети ребрами (дугами).
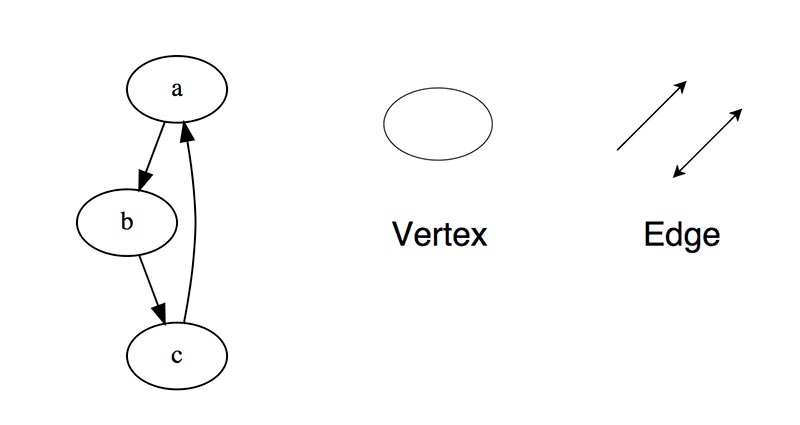
Бывают
Ориентированный, ребра являются направленными, т.е. существует только одно доступное направление между двумя связными вершинами.
Неориентированные, к каждому из ребер можно осуществлять переход в обоих направлениях.
Смешанные
Встречаются в таких формах как
- Матрица смежности
- Список смежности
Общие алгоритмы обхода графа
- Поиск в ширину – обход по уровням
- Поиск в глубину – обход по вершинам
Вопросы
- Реализовать поиск по ширине и глубине
- Проверить является ли граф деревом или нет
- Посчитать количество ребер в графе
- Найти кратчайший путь между двумя вершинами
Деревья
Дерево-это иерархическая структура данных, состоящая из узлов (вершин) и ребер (дуг). Деревья по сути связанные графы без циклов.
Древовидные структуры везде и всюду. Дерево скилов в играх знают все.
- N дерево
- Сбалансированное дерево
- Бинарное дерево
- Дерево Бинарного Поиска
- AVL дерево
- 2-3-4 деревья
«Бинарное дерево — это иерархическая структура данных, в которой каждый узел имеет значение (оно же является в данном случае и ключом) и ссылки на левого и правого потомка. » — Procs
Три способа обхода дерева
- В прямом порядке (сверху вниз) — префиксная форма.
- В симметричном порядке (слева направо) — инфиксная форма.
- В обратном порядке (снизу вверх) — постфиксная форма.
Вопросы
- Найти высоту бинарного дерева
- Найти N наименьший элемент в двоичном дереве поиска
- Найти узлы на расстоянии N от корня
- Найти предков N узла в двоичном дереве
Trie ( префиксное деревое )
Разновидность дерева для строк, быстрый поиск. Словари. Т9.
Вот как такое дерево хранит слова «top», «thus» и «their».

Слова хранятся сверху вниз, зеленые цветные узлы «p», «s» и «r» указывают на конец «top», «thus « и «their» соответственно.
Вопросы
- Подсчитать общее количество слов
- Вывести все слова
- Сортировка элементов массива с префиксного дерева
- Создание словаря T9
Хэш таблицы
Хэширование — это процесс, используемый для уникальной идентификации объектов и хранения каждого объекта в заранее рассчитанном уникальном индексе (ключе).
Объект хранится в виде пары «ключ-значение», а коллекция таких элементов называется «словарем». Каждый объект можно найти с помощью этого ключа.
По сути это массив, в котором ключ представлен в виде хеш-функции.
Эффективность хеширования зависит от

- Функции хеширования
- Размера хэш-таблицы
- Метода борьбы с коллизиями
Пример сопоставления хеша в массиве. Индекс этого массива вычисляется через хэш-функцию.
Вопросы
- Найти симметричные пары в массиве
- Найти, если массив является подмножеством другого массива
- Описать открытое хеширование
Список ресурсов
- medium.freecodecamp.org/the-top-data-structures-you-should-know-for-your-next-coding-interview-36af0831f5e3
- www.geeksforgeeks.org/commonly-asked-data-structure-interview-questions-set-1
- prog-cpp.ru/data-list
- habr.com/post/267855
- habr.com/post/273687
- habr.com/post/150732
- ruhighload.com/%D0%A7%D1%82%D0%BE+%D1%82%D0%B0%D0%BA%D0%BE%D0%B5+%D1%85%D0%B5%D1%88-%D1%82%D0%B0%D0%B1%D0%BB%D0%B8%D1%86%D1%8B+%D0%B8+%D0%BA%D0%B0%D0%BA+%D0%BE%D0%BD%D0%B8+%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%B0%D1%8E%D1%82
- ru.wikipedia.org
Вместо заключения
Матчасть так же интересна, как и сами языки. Возможно, кто-то увидит знакомые ему базовые структуры и заинтересуется.
Спасибо, что прочли. Надеюсь не зря потратили время =)
PS: Прошу извинить, как оказалось, перевод статьи уже был тут и очень недавно, я проглядел.
Если интересно, вот она, спасибо Hokum, буду внимательнее.
- Программирование
- Алгоритмы
Элементы функционального программирования в R

Всем привет. Меня зовут Дмитрий Володин, я Analytics Engineer в TrafficStars. Сегодня я хочу рассказать вам о приёмах ФП в R. Исходить я постараюсь из более-менее реальных задач, а не учебных, чтобы показать, что элементам ФП вполне есть место в вашем ящике с инструментами.
Структуры данных в R
Списки ведут себя немного иначе. Списки — это коллекция векторов (все датафреймы и прочее — просто вариации списков по сути). Список — сам по себе занимает область памяти, в которой хранятся ссылки на элементы списка. Если изменить элемент списка — и элемент и сам список сменят прописку. Неизменённые объекты останутся на своих местах. Довольно похоже на привычную вещь в ФП: объекты по большей части имутабельны.
Всё это ведёт к тому, что менять что-то поэлементно с последующим постоянным присваиванием в переменную крайне неэффективно. Потому что хоть в R и есть сборщик мусора, но он может не успевать вычищать все области, на которые не ссылается ни один объект в вашей текущей сессии. Тут на помощь приходит ФП с отображениями списков, рекурсиями и прочими заменами циклов.
*Надо оговориться, что под капотом в любом случае (если не явно, то на уровне машины) у вас будет цикл. Но цикл оптимизированный и написанный со знанием дела специалистами в области computer science. Можно и нужно им довериться.
Функции высших порядков
Если мы посмотрим на синтаксис создания функции в R
my_func то заметим, что они создаются также, как и другие объекты: оператором присваивания. Функции в R — граждане первого класса и с ними можно делать тоже самое, что и с другими объектами. Например, передавать в качестве аргументов в другие функции. Функции, которые используют другие функции в качестве аргументов, называются функциями высшего порядка.
В R есть классические функции высших порядков: Map, Reduce, Filter. Я специально не буду рассматривать *apply функции, потому что про них довольно много сказано.
- Map(f, . ) (можно перевести как отображение) — применение функции f к элементам списков в . поэлементно. Возвращает список длиной согласно правилам рециркуляции векторов.
- Reduce(f, x, init, right = FALSE, accumulate = FALSE) — редукция списка x через функцию f. Функция принимает два аргумента. Первый — результат вычисления функции на предыдущей операции, второй — текущий элемент списка. Проще понять будет на примере.
- Filter(f, x) — фильтрация списка. Остаются только те элементы, для которых результат применения f возвращает TRUE.
Большинство функций в R векторизовано. То есть применяется поэлементно и так. Например складывать два вектора не надо в цикле поэлементно. Достаточно просто написать v1 + v2 и элементы векторов сложатся. Но существуют функции, которые принимают один аргументы. Именно для таких случаев и существуют функции высших порядков. Как всегда, проще на примере.
# созадим сразу список с результатами кластеризации по списку с количеством центроидов kmeans_results К этому списку потом можно применять плечевой метод и на его результатах выбрать подходящее количество центроидов.
Знающие люди могут спросить: "Но ведь если посмотреть исходный код функций, там всё равно будут циклы? И если так, зачем вот эти сложные концепции, когда можно просто написать цикл в лоб?". Ну во-первых, написать цикл в лоб не так просто, как кажется, особенно учитывая работу с памятью в R. Наверняка на цикл её уйдёт больше, а может ещё и времени тоже. А во-вторых, писать цикл просто-напросто дольше.
Можно посчитать с помощью пакета microbenchmark. В целом решения с циклом и без него одинаковы по времени. Но вариант с Map выглядит намного проще, лаконичнее и понятнее. По крайней мере с опытом точно проще писать мапы, а не циклы.
Map(kmeans, list(mtcars), 1:6) my_func return(cl_list) > microbenchmark( Map(kmeans, list(mtcars), 1:6), my_func(mtcars, 6) ) %>% as_tibble() %>% mutate(time = time / 10e9) %>% ggplot(aes(x = expr, y = time, fill = expr))+ geom_boxplot()+ coord_flip()+ scale_fill_manual(values = c('#FF9E18', '#7D62F4'))+ theme_bw()+ theme(legend.position = 'bottom', axis.text.y.left = element_blank()) 
Теперь о Reduce. Если нужно вычислить вектор, где каждый последующий элемент вычисляется на основе расчёта предыдущего, то можно и нужно использовать Reduce. Например при расчёте факториала используются результаты на предыдущих итерациях: факториал 5 равен 5, умноженному на факториал 4.
Reduce(`*`, 1:5) 1 * 2 == 2 2 * 3 == 6 6 * 4 == 24 24 * 5 == 120После самого вызова Reduce я раскрыл, как именно происходит расчёт. Заодно разберёмся, что за функция используется в первом аргументе.
В Reduce необходимо передавать функцию от двух аргументов: первый является результатом расчёта Reduce на предыдущем шаге, а второй - текущим элементом из исходного вектора. И к ним применяется функция f. В данном случае функция - бинарный оператор перемножения. Все операторы в R по сути своей функции, потому мы спокойно можем писать их вот как ниже или использовать в функциях высшего порядка (только окружить бэктиками надо)
`*`(24, 5)Ну а под вызовом Reduce я расписал, что происходит на каждом шаге. Сначала перемножаются первые два элемента (получается 2). Этот результат затем перемножается с третьим элементом (получается 6). И так далее.
Если в Reduce передать в аргумент accumulate значение TRUE, то Reduce вернёт все промежуточные результаты. А если передать в аргумент init какое-то значение, то оно будет использоваться в качестве первого аргумента в первом расчёте.
Filter(\(x) x %% 2 == 0, x = as.numeric(1:20)) |> Reduce(`*`, x = _, accumulate = TRUE)Здесь заодно есть и оператор конвейера ( |> ) и лямбда ( \(x) ). Об этом и поговорим в следующем разделе.
Немного про Filter. Пример выше исключительно учебный и фильтровать простые векторы так не стоит совсем. В индекс вектора можно передавать logical вектор такой же длины, тогда результатом будет вектор, состоящий из элементов исходного, для индексов которых значения в logical векторе TRUE
# вот так гораздо лучше x Конвейер, лямбда и снижение количества переменных.
Пример выше преобразует изначальный вектор 1:20 в произведение всех чётных его членов с сохранением промежуточных элементов. Подведу к конвейерам издалека на этом примере. Начнём с того, что наделаем кучу переменных.
starting_vector На самом деле это хрестоматийно плохой код, но проработать будущие ошибки лучше до мёрджа их в мастер.
Итак, мы тут создали три переменные, единственный смысл существования которых - расчёт четвёртой. Да, их можно удалить потом функцией rm. И сборщик мусора в какой-то момент освободит область памяти, которую они занимали. Но это дополнительная сложность в написании кода, с которой незачем сталкиваться аналитикам.
Теперь вспомним, что в аргументы функций можно передавать не просто значение или переменную с подходящим значением, а прямо результат вызова другой функции.
# здесь в фильтр сразу передаём вектор с изменённым типом, просто пример Filter(\(x) x %% 2 == 0, as.numeric(1:20)) # а это финал, тут в аргумент x передаём предыдущую строчку reduced_vector Итак можно делать со сколь угодно глубокой вложенностью. К сожалению, так сильно страдает читаемость кода, потому что в основном люди читают сверху вниз и слева направо. И получается, что этот вызов будет прочитан с конца: сначала Reduce, а уже потом Filter. Для композиции из большого количества вызовов это превратится в жуткое нечитаемое месиво. Зато здесь создаётся только одна переменная.
Чтобы наш код был также понятен, как в первом примере, но при этом не имел кучи промежуточных переменных, существует оператор конвейера. До четвёртой версии R он был только в дополнительных пакетах (пусть и очень популярных; в этой же статье я использую %>% из пакета magrittr), но сейчас есть в стандартном наборе инструментов: |>.
f(g(h(x))) # тоже самое, что и x |> h() |> g() |> f() # для передачи предыдщуего результата в конкретный аргумент # следующей функции используется placeholder _ # без такого явного указания значение из вызова слева передаётся # в первый аргумент TRUE |> sum(c(NA, 1:10), na.rm = _)Анонимные функции я добавил в этот же раздел потому, что они тоже позволяют создавать меньше сущностей. Анонимной функцией (или лямбдой в качестве дани уважения лямбда-исчислению) называется такая функция, аргументы и тело которой не присваивается ни в какую переменную.
function(x) x + 1 # или \(x) x + 1Сверху вариант анонмной функции на свободном выпасе. Толку от такой записи мало, потому что она должна быть вызвана, а здесь она пропадает сразу после объявления. И есть три варианта использования (для экономии чернил я буду использовать второй вариант синтаксиса, они абсолютно равнозначны):
# традиционный: присваиваем в переменную succ Что нужно знать про анонимные функции:
- В отличие от того же Python, лямбды в R могут состоять из более чем одной строчки, если тело функции обернуть в фигурные скобки.
- В тело функции можно запихать всё, что угодно. Можно плюнуть на функциональный подход и налепить там чтения с диска, запись в файл, логирование и прочие побочные эффекты, что противоречит подходу "чистых функций"
- Но делать я так крайне не советую, лучше всё-таки функцию объявить заранее и использовать её к месту. Так вы возможно ещё и познаете прелести JIT компиляции в R.
Резюмирую: анонимные функции хороши, когда готовой нет, а писать и сохранять коротенькую функцию - нет смысла. Но длинные и сложные функции по всем правилам лучше сохранить в отдельную переменную для последующего вызова.
Функции возвращают функции
Напоминаю, что функции в R - граждане первого сорта. Значит их можно возвращать в результате выполнения других функций. Я ну буду использовать набивший оскомину вариант со сложением двух чисел или другими арифмитическими операциями. Вместо этого немного усложню
Map(\(x) \(df) kmeans(df, x), 1:6) %>% Map(\(f) f(mtcars), .)Здесь первая лямбда для каждого элемента вектора 1:10 возвращает функцию. Возвращаемая функция принимает в качестве аргумента датафрейм и применяет к нему метод k-средних с количеством центроидов, равных соответствующему значению элемента вектора 1:10. Ну а далее, чтобы не быть голословным, мы этот список функций отправим по конвейеру (уже из magrittr, он чуть более функциональный в общем плане) в следующее отображение, где применим эту функцию на датафрейм mtcars.
Функции, возвращающие функции, удобны для разработки. Написав вот так:
# Да, это классический вариант с add add add(1) # function(y) x + y #
вы получаете функцию, в которую можно передавать значение в один аргумент (вместо указанных двух) и она в итоге не вернёт ошибку, а вернёт функцию, в которую также можно передать значение.
add(1)(2) == 3Такая запись может быть даже проще читается, чем два подряд Map:
(\(df, n) \(n) kmeans(df, n))(mtcars) |> Map(f = _, 1:6)Здесь мы объявляем лямбдой функцию от двух переменных df и n, передаём в первый аргумент значение mtcars и получаем функцию от одного аргумента. Её отправляем по конвейеру в Map, где получаем список результатов kmeans по на набору центроидов.
Сокращение количества аргументов путём последовательного возвращения функций от одного аргумента называется каррированием или каррингом по имени математика Хаскеля Карри.
Синтаксис с лямбдами может быть не очень понятен, особенно начинающим (хотя чем раньше начнёшь, тем быстрее научишься). Для этого существуют вспомогательные функции, например из пакета purrr, который является воплощением ФП в R (частичным).
library(purrr) partial(kmeans, x = mtcars) %>% map(1:6, .)partial тоже является функцией высшего порядка (потмоу что принимает функцию в качестве аргумента). Передав по имени аргумента из функции значение, мы создадим новую функцию, количество аргументов в которой меньше на один. В partial можно передать сколько угодно аргументов, хоть все. И даже в этом случае вернётся функция. Останется её только вызвать без аргументов.
partial(kmeans, x = mtcars, centers = 5)()Последняя на сегодня функция высшего порядка - compose из purrr. По сути это замена конвейера. Но если у вас есть стандартный набор шагов, используемый в разных частях кода, стоит подумать над заворачиваением его в compose.
sum_of_addition Функция выше складывает два вектора поэлементно а затем результат суммирует.
Рекурсия
Говоря о ФП, невозможно обойти стороной рекурсию. Это довольно распространённый приём в преимущественно функциональных языках. Особенно в чистых, где вообще нет циклов и рекурсия является одним из немногих способов итерироваться (не считая функций высшего порядка). Концепцию рекурсии на курсе по Scala на курсере её создатель объясняет на втором уроке уже буквально. Я же этим блоком хочу сразу показать, что нельзя так огульно бросаться в ФП в R.
Итак, рекурсия - это обращение функции к самой себе. Это мощный и лаконичный приём, для понимания которого может понадобится время. Но как и всё мощное, надо к его использованию подходить с умом. Я приведу классические примеры с факториалом и вычислением n-ого элемента последовательности Фибоначчи.
straight_recursion_factorial # > straight_recursion_factorial(10) # [1] 3628800Здесь решение буквально в лоб. Факториал n равен факториалу (n-1) умноженному на n. Потому мы явно вызываем объявляемую функцию в её же теле. Давайте разберём это построчно
straight_recursion_factorial(10) == 10 * straight_recursion_factorial(9) straight_recursion_factorial(9) == 9 * straight_recursion_factorial(8) straight_recursion_factorial(8) == 8 * straight_recursion_factorial(7) straight_recursion_factorial(7) == 7 * straight_recursion_factorial(6) straight_recursion_factorial(6) == 6 * straight_recursion_factorial(5) straight_recursion_factorial(5) == 5 * straight_recursion_factorial(4) straight_recursion_factorial(4) == 4 * straight_recursion_factorial(3) straight_recursion_factorial(3) == 3 * straight_recursion_factorial(2) straight_recursion_factorial(2) == 2 * straight_recursion_factorial(1) straight_recursion_factorial(1) == 1Тоже самое, но с подстановкой значений (β-редукция для следующего чтения)
straight_recursion_factorial(10) == 10 * 9 * 8 * 7 * 6 * 5 * 4 * 3 * 2 * 1 straight_recursion_factorial(9) == 9 * 8 * 7 * 6 * 5 * 4 * 3 * 2 * 1 straight_recursion_factorial(8) == 8 * 7 * 6 * 5 * 4 * 3 * 2 * 1 straight_recursion_factorial(7) == 7 * 6 * 5 * 4 * 3 * 2 * 1 straight_recursion_factorial(6) == 6 * 5 * 4 * 3 * 2 * 1 straight_recursion_factorial(5) == 5 * 4 * 3 * 2 * 1 straight_recursion_factorial(4) == 4 * 3 * 2 * 1 straight_recursion_factorial(3) == 3 * 2 * 1 straight_recursion_factorial(2) == 2 * 1 straight_recursion_factorial(1) == 1Здесь сразу видно слабое место такой рекурсии: с увеличением n растёт и количество необходимых ресурсов для вычисления, потому что все промежуточные состояния до выхода из рекурсии заносятся в стек вызовов. И он вполне может переполниться
> straight_recursion_factorial(10000) Error: C stack usage 7954120 is too close to the limitДля оптимизации рекурсии есть вариант написать "хвостовую рекурсию". Его главное отличие - возвращается последний вызов рекурсивной функции, а не первый. Что может заметно ускорить выполнение и затребовать меньше памяти. А в функциональных языках такая рекурсия компилятором или интерпретатором преобразуется в итерацию, что избавляет от проблемы переполненного стека вызовов. К сожалению, R так не умеет, хотя это не означает, что не надо пытаться оптимизирвоать свою рекурсивную функцию.
Для хвостовой рекурсии характерно наличие некоего "аккумулятора", который вбирает в себя результаты вызовов, чтобы на последнем вызове стать возвращаемым значением. Приведу пример с тем же факториалом:
tail_recursion_factorial
Попробуем вызвать эту функцию и применить редукцию.
tail_recursion_factorial(n = 5, total = 1) == tail_recursion_factorial(n = 4, total = 5 * 1) tail_recursion_factorial(n = 4, total = 5 * 1) == tail_recursion_factorial(n = 3, total = 4 * 5 * 1) tail_recursion_factorial(n = 3, total = 4 * 5 * 1) == tail_recursion_factorial(n = 2, total = 3 * 4 * 5 * 1) tail_recursion_factorial(n = 2, total = 3 * 4 * 5 * 1) == tail_recursion_factorial(n = 1, total = 2 * 3 * 4 * 5 * 1) tail_recursion_factorial(n = 1, total = 2 * 3 * 4 * 5 * 1) == 2 * 3 * 4 * 5 * 1Здесь мы видим, что при каждом вызове значение total умножалось на соответствующее n и к последнему вызову, когда происходит выход из рекурсии, проходить обратно по всему стеку для вычисления значения не надо, total уже весь посчитан, остаётся его вернуть. Тем не менее интерпретатор должен умень с этим работать и не забивать стек. В R это не так и это можно увидеть на бенчмарках двух факториалов (прямого и хвостового)

Здесь хвостовая рекурсия по времени выполнения даже хуже обычной. Но есть и обратные примеры. Напишем функцию вычисления n-ого элемента последовательности Фибоначчи. Считаем что первый и второй элементы последовательности равны одному.
straight_recursion_fibonacci tail_recursion_fibonacci

А вот здесь разница огромная. Скорость вычисления в хвостовом варианте выше примерно в 3 раза. И это даже без оптимизации интерпретатором.
Рекурсия - сложная концепция, но позволяет писать простой и понятный код. Описать рекурсию можно меметичной фразой "сводим задачу к предыдущей". Хотя вариант с хвостовой рекурсией последовательнсоти Фибоначчи всё равно не самый очевидный.
Однако на практике почти всегда рекурсию можно заменить функциями высшего порядка. Я могу привести только один реальный пример, когда можно использовать рекурсию вместо цикла и невозможно использовать map или reduce. Я говорю о расчёте размера вклада после определённого периода с извлечением фиксированной суммы каждый месяц. Или с депозитом фиксированной суммы каждый месяц.
# рекурсивный вызов recursive_dep # рекурсивный вызов loop_dep deposit >Кстати, рекурсия сходу получается хвостовой (у нас накапливается deposit).

И хотя императивный стиль победил, вариант с рекурсией гораздо лаконичнее и даже элегантнее. Ну и в большинстве случаев разница совершенно незаметна.
Выводы
R не чистый функциональный язык. Он таковым и не задумывался. Однако это язык высокого уровня абстракции для профессионалов по работе с данными и статистиков. У таких специалистов иногда бывают сложности с пониманием устройства памяти и стандартных императивных алгоритмов. И именно для этого в R есть много элементов ФП. Нам буквально говорят: "Используйте декларативный стиль, пишите что нужно сделать, а не как. А интерпретатор позаботится о деталях."
Иногда даже кажется, что если убрать в R возможность писать циклы, ничего сверхстрашного не произойдёт.
В завершение хочу пригласить вас на бесплатный вебинар, который предназначен для всех, кто интересуется использованием R в своей работе с данными. В ходе вебинара вы познакомитесь с тремя популярными средствами разработки и анализа данных, которые помогут стать более продуктивным и эффективным при работе с R: Rstudio, Jupyter, VSCode.
- r
- функциональное программирование
Члены (Руководство по программированию на C#)
В классах и структурах есть члены, представляющие их данные и поведение. Члены класса включают все члены, объявленные в этом классе, а также все члены (кроме конструкторов и методов завершения), объявленные во всех классах в иерархии наследования данного класса. Закрытые члены в базовых классах наследуются, но недоступны из производных классов.
В следующей таблице перечислены виды членов, которые содержатся в классе или в структуре.
| Член | Описание |
|---|---|
| Поля | Поля являются переменными, объявленными в области класса. Поле может иметь встроенный числовой тип или быть экземпляром другого класса. Например, в классе календаря может быть поле, содержащее текущую дату. |
| Константы | Константы — это поля, значения которых устанавливаются во время компиляции и не изменяются. |
| Свойства | Свойства — это методы класса. Доступ к ним осуществляется так же, как если бы они были полями этого класса. Свойство может защитить поле класса от изменений (независимо от объекта). |
| Методы | Методы определяют действия, которые может выполнить класс. Методы могут принимать параметры, предоставляющие входные данные, и возвращать выходные данные посредством параметров. Методы могут также возвращать значения напрямую, без использования параметров. |
| События | События предоставляют другим объектам уведомления о различных случаях, таких как нажатие кнопки или успешное выполнение метода. События определяются и переключаются с помощью делегатов. |
| Инструкции | Перегруженные операторы считаются членами типа. При перегрузке оператора его следует определять как открытый статический метод в типе. Для получения дополнительной информации см. раздел Перегрузка операторов. |
| Индексаторы | Индексаторы позволяют индексировать объекты аналогично массивам. |
| Конструкторы | Конструкторы — это методы, которые вызываются при создании объекта. Зачастую они используются для инициализации данных объекта. |
| Методы завершения | Методы завершения очень редко используются в C#. Они являются методами, вызываемыми средой выполнения, когда объект нужно удалить из памяти. Они обычно применяются для правильной обработки ресурсов, которые должны быть высвобождены. |
| Вложенные типы | Вложенными типами являются типы, объявленные в другом типе. Вложенные типы часто применяются для описания объектов, использующихся только типами, в которых эти объекты находятся. |
См. также
- Руководство по программированию на C#
- Классы
Совместная работа с нами на GitHub
Источник этого содержимого можно найти на GitHub, где также можно создавать и просматривать проблемы и запросы на вытягивание. Дополнительные сведения см. в нашем руководстве для участников.