9 структур данных, которые вам понадобятся

Еще в девяностые профессор Корейского университета передовых технологий Сонгчун Мун предложил Биллу Гейтсу назвать свой стартап Microdata, а не Microsoft. Мун указал на то, что данные и их структура — будущее программирования.
Структуры данных — способы хранения и извлечения информации. Правильный выбор структуры поможет эффективнее выполнить задачу. СД важны в разработке ПО, от них зависит, как будут работать алгоритмы.
Рассказываем о структурах данных, которые используются чаще всего.
#1. Массив (Array)
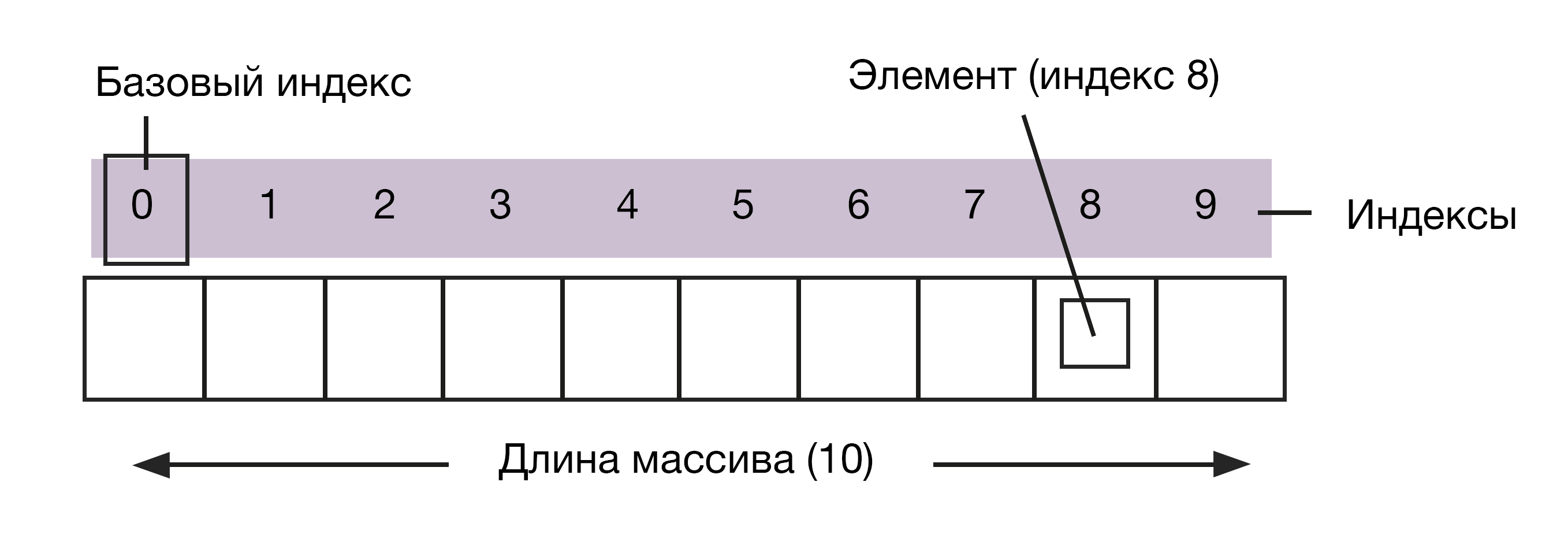
Массив — простая базовая структура. Стеки, очереди и списки — производные от массивов. Единице данных в массиве присваивается число или индекс, который указывает на ее расположение. Чтобы найти ячейку с информацией в массиве, нужно добавить к базовому элементу ее индекс. Базовый элемент, как правило, обозначается именем самого массива.
Представьте себе записную книжку со страницами, пронумерованными от 1 до 10. Каждая из них может содержать информацию или быть пустой. Блокнот — массив страниц, страницы — элементы массива «блокнот». Программно вы извлекаете информацию со страницы, обращаясь к ее индексу, то есть «блокнот+4» будет ссылаться на содержимое четвертой страницы.
Массив — это фиксированная структура, хранящая элементы одного типа в непрерывных ячейках памяти. Есть исключение — гетерогенные массивы, которые могут хранить данные разных типов. Массивы бывают одномерными и многомерными (массивы в массивах). Их размеры фиксированы, поэтому в уже созданный массив нельзя просто вставить новый элемент. Нужно скопировать старый массив и создать новый, увеличив размер.
#2. Матрица (Matrix)
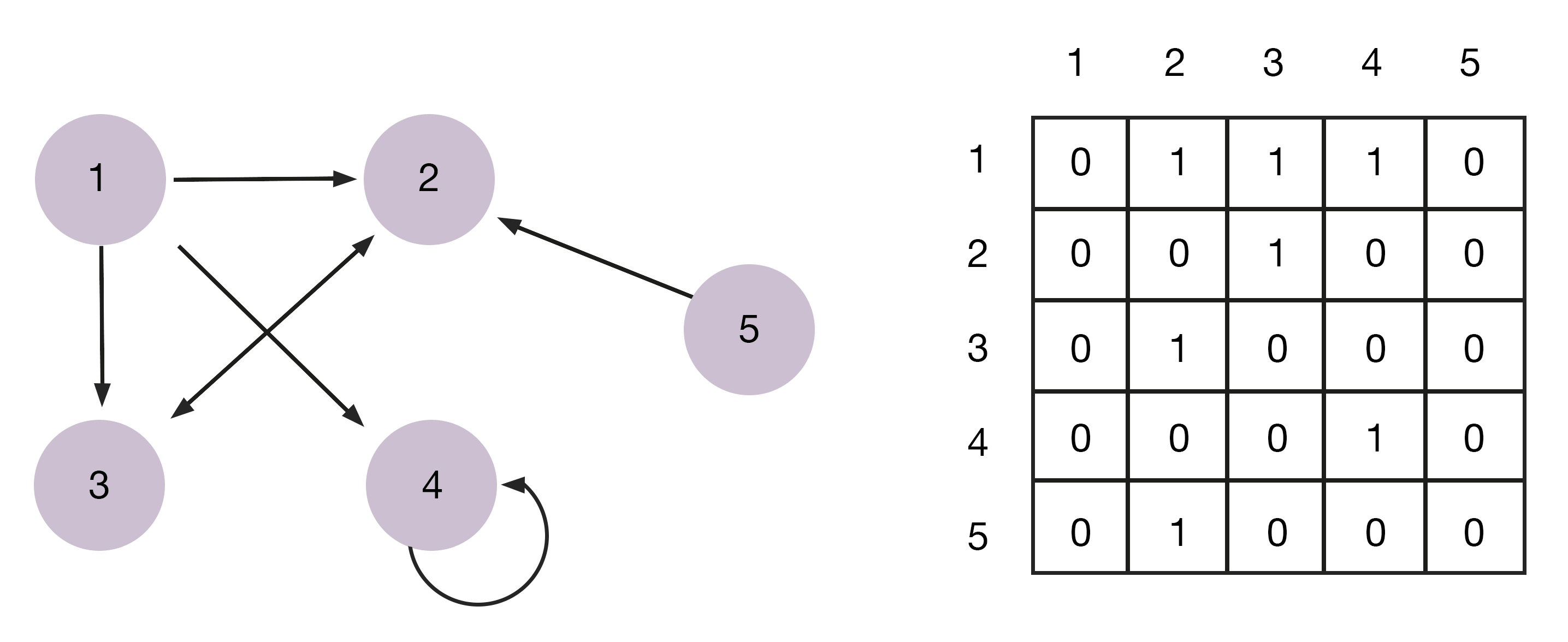
Матрица — двумерный массив, выглядящий как список столбцов и строк, на пересечении которых находятся элементы данных. Это прямоугольный массив, в котором количество строк и столбцов задает его размер. В математике их используют для компактной записи линейных алгебраических или дифференциальных уравнений.
Матрицы используют для описания вероятностей. Например, для ранжирования страниц в поиске Google при помощи алгоритма PageRank. В компьютерной графике — для работы с 3D-моделями и проецирования их на двумерный экран.
#3. Связный список (Linked list)
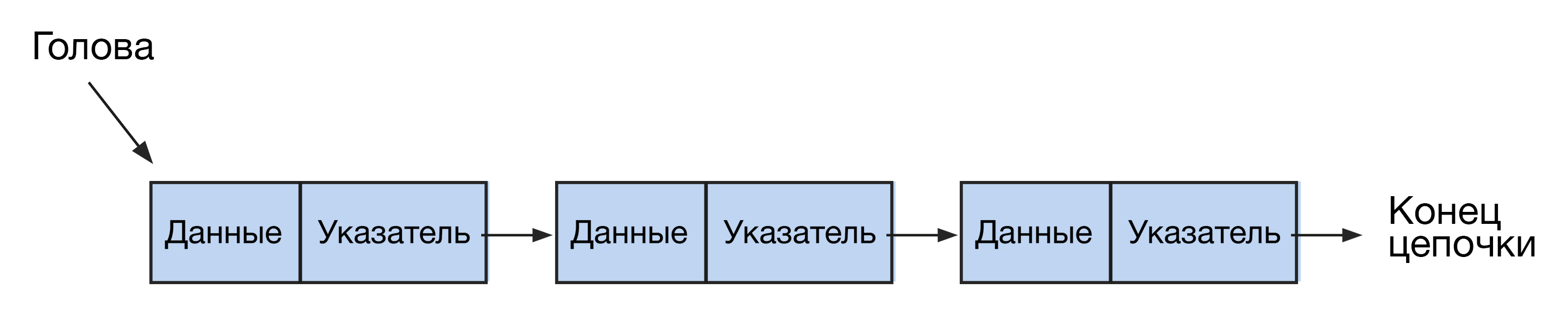
Списки схожи с массивами, но отличаются более гибкой структурой. Они выглядят как цепочки нод или узлов, где каждая нода содержит ссылку на следующую. Доступ к элементам в связном списке осуществляется последовательно, в отличие от массивов с произвольным доступом. Списки бывают односвязными и двусвязными.
Начальный элемент этой структуры называется головой, а все последующие узлы цепочки — хвостом. Хвост состоит из элементов двух типов: с информацией (info) и с указанием на следующий узел (next). Конец цепочки обозначается как null.
#4. Стек (Stack)
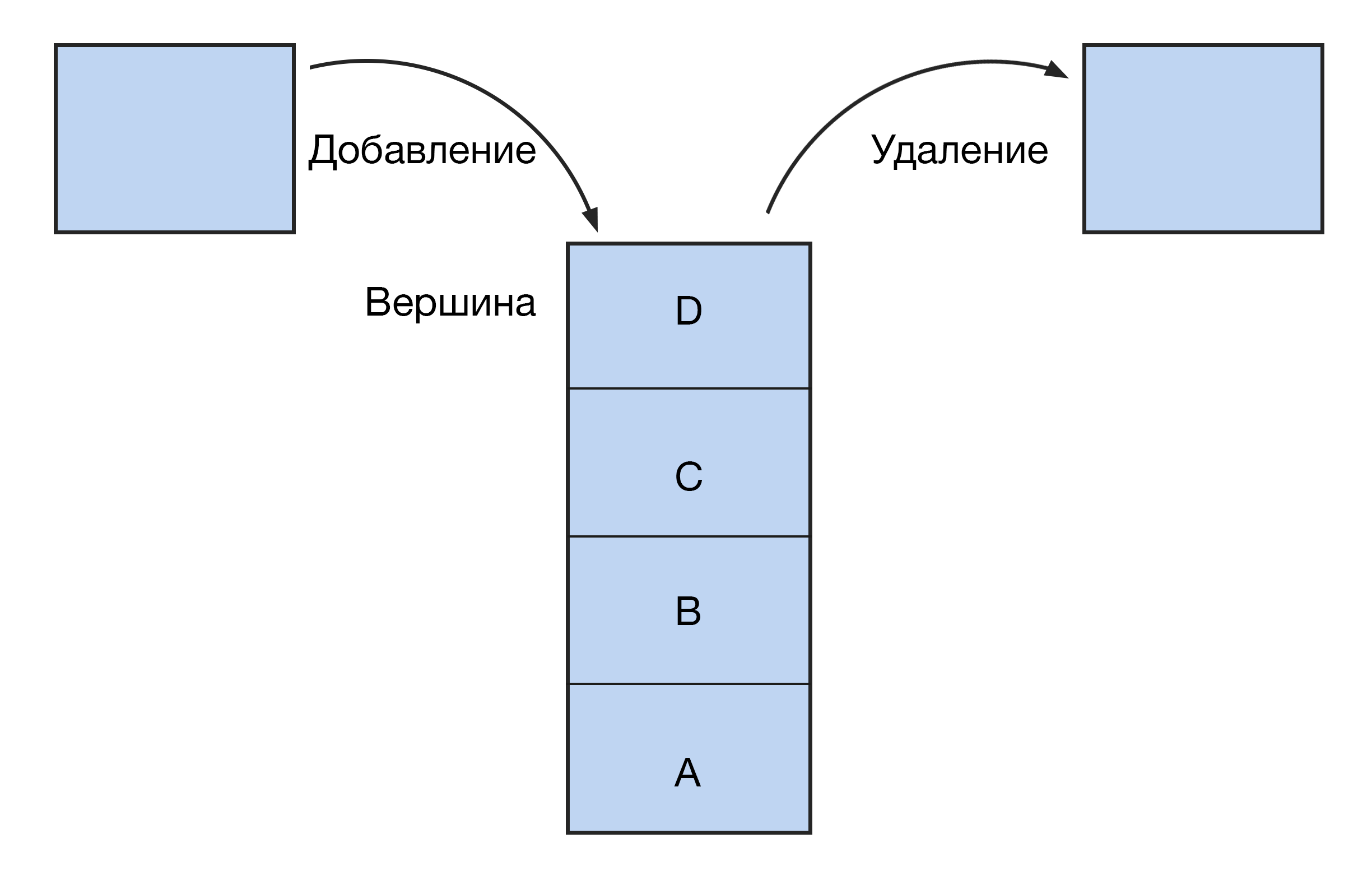
Это вертикальный столбец с блоками, доступ к которым можно получить только с одного конца: сверху или снизу. Как в стопке книг — чтобы добраться до нижней, нужно сначала убрать все книги сверху.
Новые элементы стека заменяют старые. Принцип работы такой структуры — LIFO (last in — first out, «последним пришел — первым ушел»). Поэтому стек еще называют магазином — по аналогии с огнестрельным оружием: выстрелит патрон, который был заряжен последним.
Эта структура данных реализована в функции «отменить» (undo). Программа сохраняет статус работы так, что последнее действие становится первым в очереди на отмену. В стеке возможны всего три операции: добавление элемента (push), удаление (pop), чтение (peek).
Стек может быть реализован в виде связного списка или одномерного массива. В первом случае, каждый элемент содержит ссылку на следующий, во втором — упорядочен индексом.
Существует похожая СД — дек (deque — double ended queue, «двусторонняя очередь»). Это стек с двусторонним доступом.
#5. Очередь (Queue)
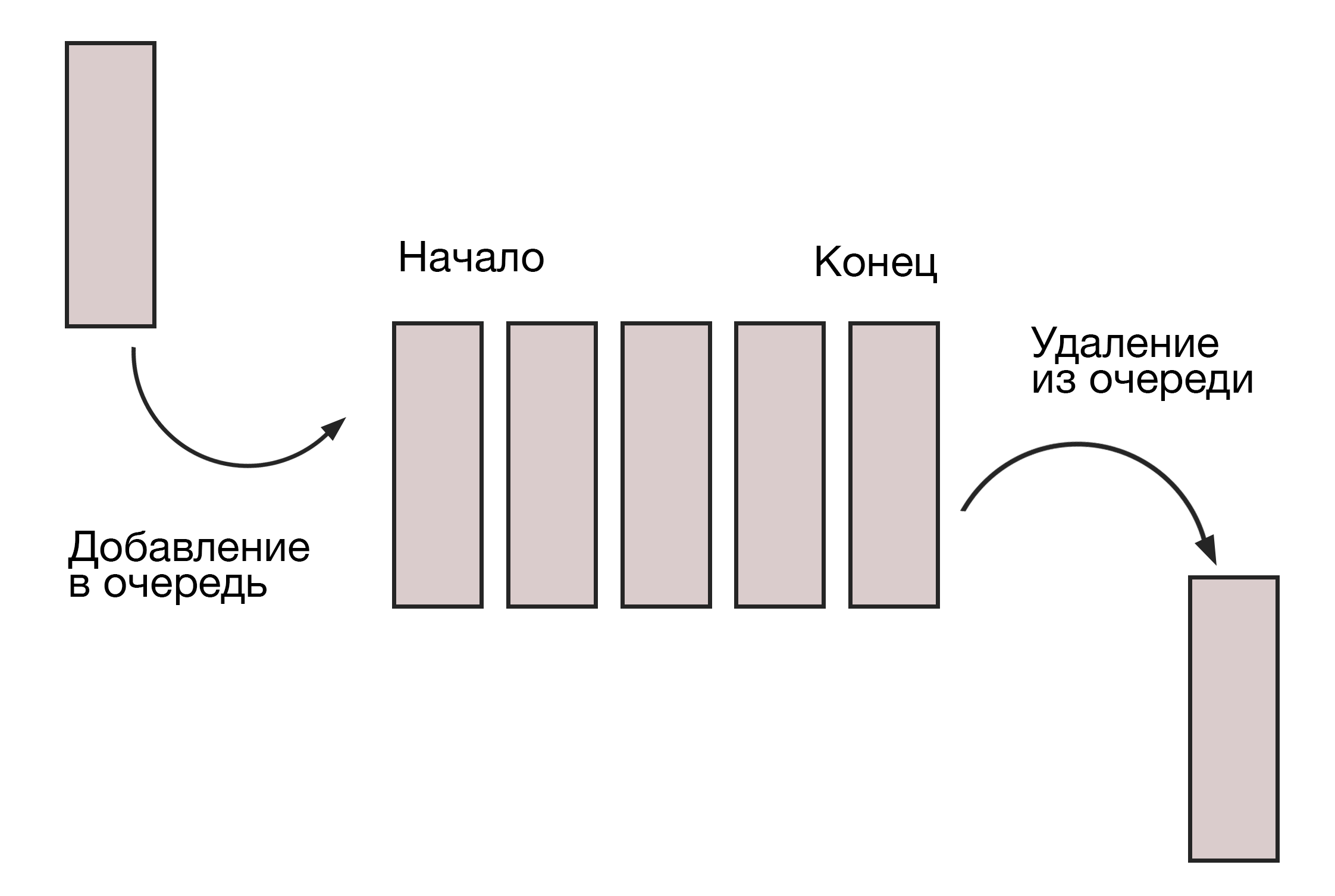
Этот тип СД напоминает стеки, но принцип работы реализован как FIFO (first in — first out, «первым пришел — первым ушел»). Как в супермаркете: первым покупки унесет домой тот, кто раньше всех займет очередь.
Очереди используются, когда ресурс нужно распределить между несколькими потребителями (работа ЦП, пропускная способность роутера). Или когда данные передаются асинхронно, то есть скорости приема и отдачи — разные.
В этой СД можно выполнить две операции: добавление элемента в конец очереди (enqueue) и удаление первого элемента (dequeue). Очереди бывают в виде связных списков или массивов, по аналогии со стеками.
#6. Дерево (Tree)
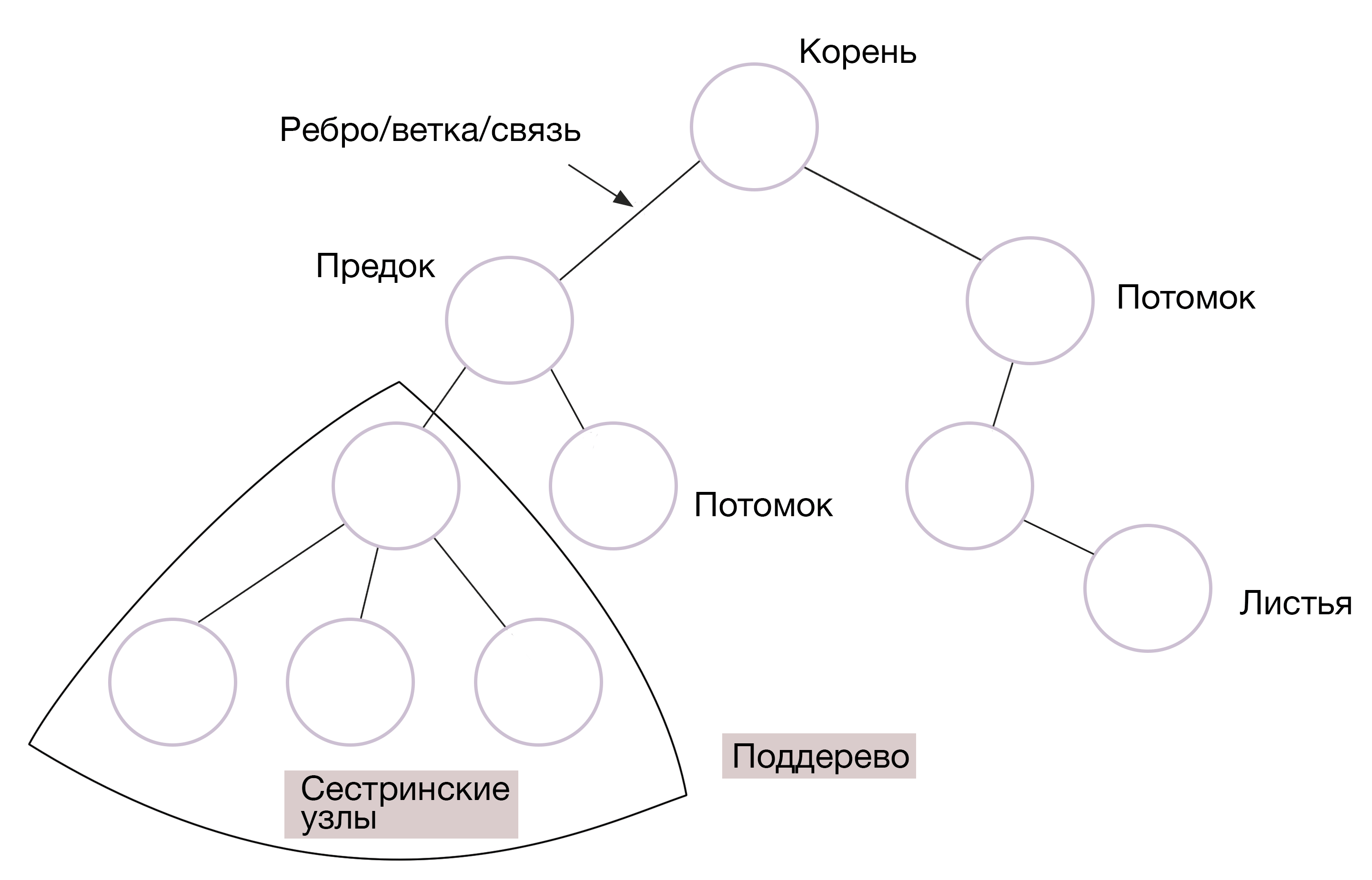
Деревья — структура, в которой данные связаны между собой узлами, и при этом расположены иерархически. Различают двоичное дерево поиска, расширенное, черно-красное и еще десяток видов.
Как и у настоящего дерева, тут есть корни, ветви и листья. Самый верхний узел в этой СД, не имеющий предков, называется корневым. Остальные узлы — потомками или дочерними элементами. Дочерние узлы с одним и тем же родителем — это узлы-братья. А листья — это узлы, не имеющие потомков.
Деревья используют, например, в разработке видеоигр. Они позволяют разделить пространство и быстро находить объекты. Так, дерево с четырьмя дочерними узлами (quadtree) — квадрант — используется для создания карты и ориентации по четырем сторонам света в игре.
Но деревья сложно хранить и у них невысокая скорость работы.
курсы по теме:
Data Science with Python
Типы структур данных в программировании
Зачем нужны? На сегодняшний день в программировании существуют различные типы структур данных, и уважающий себя специалист должен иметь представление о каждом из них. Это повысит качество работы и значительно сэкономит время.
Какой выбрать? Тот или иной тип структуры данных выбирается в зависимости от того, какой цели нужно достичь. То есть одни форматы для организации и хранения данных используются в решении простых задач, другие – более сложных.
В статье рассказывается:
- Понятие структуры данных
- Классификация структур данных
- Основные типы структур данных
- Массив
- Динамический массив
- Связанный список
Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.
Бесплатно от Geekbrains
Понятие структуры данных
Все люди используют различные данные в процессе своей жизнедеятельности. Они применяются в самых разных профессиях и областях.
В рамках программирования структуры данных представляют собой специальные контейнеры. Они хранят информацию в определённом формате, который придает структуре те или иные свойства. Именно эти качества отличают одну структуру данных от другой. Кроме того, они определяют ее пригодность для тех или иных сценариев применения.
Со структурой можно взаимодействовать разными способами: добавлять данные, извлекать их и обрабатывать (изменять, анализировать, сортировать и т.д.).
У каждой структуры свой алгоритм, поэтому программисту необходимо либо подобрать уже созданный, либо разработать свой.
Структуры отличаются тем, что любую единицу данных можно найти в определённом месте. Чтобы определить это место, необходимо знать нюансы конкретной структуры.
Как правило, в структуру можно добавлять элементы и извлекать их из неё. Однако это не всегда так. Существуют структуры, в которые нельзя вносить коррективы после создания.
В структуру может входить как множество данных, так и массив из одного единственного элемента.
Классификация структур данных
Различают физические и логические структуры. Физические отражают способ представления данных в памяти ЭВМ. Из-за этого их иногда называют внутренними.
Типы структур данных по составу:
- Простые. Они не делятся на составные части, которые больше, чем биты. Для простого типа четко определен размер и способ размещения структуры в памяти устройства.
- Сложные (интегрированные). Они включают в себя другие структуры, которые, в свою очередь, могут быть простыми или сложными.
Узнай, какие ИТ — профессии
входят в ТОП-30 с доходом
от 210 000 ₽/мес
Павел Симонов
Исполнительный директор Geekbrains
Команда GeekBrains совместно с международными специалистами по развитию карьеры подготовили материалы, которые помогут вам начать путь к профессии мечты.
Подборка содержит только самые востребованные и высокооплачиваемые специальности и направления в IT-сфере. 86% наших учеников с помощью данных материалов определились с карьерной целью на ближайшее будущее!
Скачивайте и используйте уже сегодня:

Павел Симонов
Исполнительный директор Geekbrains
Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда
Подборка 50+ бесплатных нейросетей для упрощения работы и увеличения заработка
Только проверенные нейросети с доступом из России и свободным использованием
ТОП-100 площадок для поиска работы от GeekBrains
Список проверенных ресурсов реальных вакансий с доходом от 210 000 ₽
Получить подборку бесплатно
Уже скачали 25512
Типы структур данных по наличию связи:
- несвязные структуры: массивы, векторы, строки, стеки (Last In, First Out), очереди (First In, First Out);
- связные структуры (например, связные списки).
Нельзя не упомянуть про так называемую изменчивость. Речь идёт об изменении числа элементов или связей между ними. В зависимости от уровня изменчивости выделяют:
- статические;
- полустатические;
- динамические.
В зависимости от признака упорядоченности элементов различают два типа структур организации данных:
- Нелинейные: деревья, графы, многосвязные списки.
- Линейные. В зависимости от типа распределения компонентов в памяти устройства они могут иметь последовательное распределение (строки, векторы, массивы, стеки, очереди) и произвольное связное распределение (односвязные и двусвязные списки).
При указании типа данных определяются следующие параметры:
- размер памяти, который необходимо для определенной структуры;
- способ размещения структуры в памяти;
- значения, которые могут применяться для этого типа данных;
- поддерживаемые операции.
Теперь поговорим о самых важных структурах данных, с помощью которых вы сможете решать те или иные задачи.
Основные типы структур данных
Массив
Массив – это очень распространенная структура, отличающаяся своей простотой. Каждому элементу в массиве соответствует положительное целое число — индекс. Оно указывает на расположение элемента. Практически во всех языках программирования индексы начинаются с нуля (данный подход называют нумерацией на основе нуля).
Выделяют две разновидности массивов:
- Одномерные — простейшие линейные структуры.
- Многомерные — вложенные структуры, которые состоят из других массивов.
Как используются? За счёт своей простоты эти составные элементы более сложных структур (стеков, очередей и т.п.) применяются для хранения несложных связанных данных. Они также нужны для различных алгоритмов сортировки (сортировка вставок, сортировка пузырьком и т.д.).
Динамический массив
Размер обычного массива указывается заранее. Благодаря этому человек сразу понимает, какое количество индексов в него входит. Динамический массив отличается тем, что его размер не предопределён, он может меняться.
Для вас подарок! В свободном доступе до 14.01 —>
Скачайте ТОП-10
бесплатных нейросетей
для программирования
Помогут писать код быстрее на 25%
Чтобы получить подарок, заполните информацию в открывшемся окне
В процессе создания необходимо задать максимальную величину и число заполненных элементов. Если добавляются новые элементы, то они сначала заполняются по максимуму. Если же происходит превышение допустимой величины, то генерируется новый массив с увеличенным предельным размером.
Вы можете добавить сколько угодно элементов в динамический массив. Место размещения также выбирается произвольно. Но учтите, что если вставить их в середину, то остальные элементы нужно будет передвинуть. Это, как правило, занимает немало времени. Исходя из этого, рекомендуется добавлять элементы в конец такого массива.
Как используются? Динамические массивы играют роль блоков для структур данных. Их применяют в целях хранения неопределённого количества элементов.
Связанный список
Описание данного типа структуры данных будет следующим. Связанный список представляет собой набор элементов (узлов) в линейной последовательной структуре. Узел — это простой объект, имеющий 2 свойства: переменные для хранения данных и адреса памяти следующего узла в списке. Узел хранит информацию о типе данных, которые он содержит, а также о своем соседе. Благодаря этому можно создавать связанные списки, где все узлы будут связаны между собой.
Различают несколько разновидностей списков:
- Односвязный. Обходить элементы можно лишь в прямом направлении.
- Двусвязный. Кроме прямого, допускается ещё и обратное направление. Узлы включают дополнительный указатель(prev), который указывает на предыдущий узел.
- Круговые связанные. Так называют связанные списки, в которых предыдущий (prev) указатель «головы» указывает на «хвост», а следующий указатель «хвоста» указывает на «голову».
Как используются? Связанные списки играют роль строительных блоков сложных структур данных (очередей, стеков и некоторых разновидностей графиков). В динамических структурах они нужны для выделения памяти, а в ОС — для упрощения переключения вкладок. Кроме того, их используют в слайд-шоу изображений, так как картинки идут поочередно.
Стек
Стек представляет собой линейную структуру данных, которая формируется на базе массивов или связанных списков. Стек работает по принципу LIFO (от Last-In-First-Out — «первым на вход — последним на выход»). Проще говоря, первым элементом, который покинет стек, станет тот, который последний в него войдёт. Название «stack» переводится как «стопка». Дело в том, что данная структура может быть визуализирована как стопка книг, лежащих на столе.
Очередь
Очередь относится к линейному типу структуры данных так же, как и стек. Формируется она на основе массивов или связанных списков. Работает по принципу FIFO (First-In-First-Out — «первым на вход — первым на выход»). Иначе говоря, первым покинувшим очередь элементом будет тот, который первый в неё вошёл.
Как используются? Очереди применяются для обработки нескольких запросов на одном ресурсе. Кроме того, их можно использовать для управления потоками в многопоточных средах и регулирования нагрузки.
Множество
Во множестве данные не упорядочены и хранятся группой. При этом их нельзя структурировать, а иногда даже сортировать. Однако их можно использовать как обычные математические множества, например, объединять, искать пересечения, вычислять разность и смотреть, является ли одно множество подмножеством другого.
Дарим скидку от 60%
на обучение «Инженер-программист» до 14 января
Уже через 9 месяцев сможете устроиться на работу с доходом от 150 000 рублей
Как правило, в таких структурах размещаются объекты, которые имеют те или иные общие признаки. При этом порядок объектов может быть любым.
Как используются? Множества применяют для поддержания большого количества уникальных объектов. Их также используют для хранения данных, которые не требуется сортировать. Помимо этого, множества нужны для сравнения, объединения наборов данных и выполнения других прочих операций.
Карта (Map)
Внутри карт данные хранятся в паре «ключ/значение». Поэтому такие структуры называют ассоциативными массивами или словарями. При этом каждый ключ уникален, в отличие от значений, которые могут использоваться по несколько раз. Если вы знаете ключ, то поиск данных будет выполняться быстрее, нежели в других типах структур.
Как используются? Карты применяются для создания баз, в которых будут храниться уникальные соответствия между двумя множествами значений. Они размещаются в ключе. При этом структура контролирует отсутствие повторений этих ключей.
Рассмотрим яркий пример такой структуры данных — hash-map (хэш-таблица). В ней размещаются ключи и значения, а для их реализации добавляются индексы. С помощью хэш-функции можно вычислить индекс, зная ключ. Это позволяет отыскивать необходимые данные. Если в хэш-таблицу вставляют ту или иную информацию, то добавляют ключ и данные. После этого функция хэширует ключ, переводит его в число и записывает данные в ячейку, которая соответствует этому числу. Если требуется запросить данные, то следует ещё раз ввести ключ, чтобы хэш-функция выполнила поиск.
Только до 11.01
Скачай подборку материалов, чтобы гарантированно найти работу в IT за 14 дней
Список документов:

ТОП-100 площадок для поиска работы от GeekBrains
20 профессий 2023 года, с доходом от 150 000 рублей
Чек-лист «Как успешно пройти собеседование»
Чтобы зарегистрироваться на бесплатный интенсив и получить в подарок подборку файлов от GeekBrains, заполните информацию в открывшемся окне
Двоичное дерево поиска
Такой тип структуры данных представляет собой структуру, данные которой размещаются в узлах. При этом у каждого узла могут быть один или несколько дочерних и лишь один родитель. Таким образом, внешне они напоминают дерево. Существует несколько разновидностей таких структур.
Откройте для себя захватывающий мир IT! Обучайтесь со скидкой до 61% и получайте современную профессию с гарантией трудоустройства. Первый месяц – бесплатно. Выбирайте программу прямо сейчас и станьте востребованным специалистом.
Самыми популярными являются деревья поиска, у которых:
- каждый узел имеет не более 2-х дочерних;
- если новое значение меньше, то оно становится левым дочерним (или дочерним левого дочернего);
- если значение больше, то оно становится правым дочерним (либо дочерним правого дочернего).
Как используются? Деревья применяются для быстрого поиска данных и их хранения в отсортированном виде. При этом их можно быстро добавлять и удалять.
Префиксное дерево (бор, нагруженное дерево)
Отличается последовательностью хранения данных (каждый узел представляет собой префикс, с помощью которого можно найти следующие узлы).
Как используются? Префиксные деревья применяются в целях хранения данных, которые нужно выдавать по цепочке. К примеру, слова для функции автозаполнения на мобильном устройстве: пользователь вбивает одну букву, и дерево предлагает следующие. Кроме того, префиксные деревья используются для хранения данных, у которых есть повторяющиеся участки (к примеру, IP-адресов).
Граф (Graph)
Граф представляет собой структуру данных, состоящую из нескольких узлов (вершин), связанных между собой. Пару (x,y) называют ребром. Таким образом, вершина x соединена с вершиной y. Ребро может определять вес/стоимость (стоимость прохождения по пути между двумя вершинами).
Графы представляют собой более общие случаи деревьев, которые, в свою очередь, нередко называют ациклическими графами. Можно выделить две особенности, которые отличают одну структуру от другой:
- В графе могут быть циклы (когда «ребенок» является «родителем» для того же объекта).
- Ребра могут нести смысловую нагрузку (необходимо сохранять их значения).
Различают два вида граф: ориентированные и неориентированные. В первом случае у рёбер между узлами есть направление. Поэтому для ориентированных граф имеет значение порядок элементов. У неориентированных разновидностей нет направлений. Следовательно, их можно читать и обходить как угодно.
Популярные статьи





Стоит отметить, что графы нередко представляют как матрицы смежности. При этом каждая строка или столбец – узел. Если в ячейке появилось значение «1», то между узлами есть связь, а если «0», то связь отсутствует. Учтите, что если у связей (рёбер графа) есть вес, то его можно разместить в ячейке.
Как используются? Графы полезны для хранения данных, которые связаны между собой сложными соотношениями. Кроме того, эти структуру используются для формирования маршрутов из точки А в точку Б, а также для выполнения анализа соотносящейся между собой информации.
Как же определить нужный тип данных структуры? Необходимо ориентироваться на конкретные цели. К примеру, для решения простых задач могут использоваться массивы, а для более сложных (при создании очереди, истории запросов и т.д.) подойдут двоичные деревья. Если вы будете знать все типы данных, то всегда сможете подобрать наилучший вариант.
Структуризацию данных в программировании можно выполнять самыми разными методами. Если вы будете знать, как устроены структуры, то сможете улучшить ПО. Кроме того, процесс написания кода станет проходить гораздо быстрее. Еще на стадии формирования спецификаций и требований следует обращать внимание на особенности поставленных задач. Это позволит правильно выбрать формат данных.
Структура данных
Структура данных в программировании — это объект-контейнер, в котором хранится информация. Данные внутри контейнера структурированы по особой системе — она различается в зависимости от вида структуры. Так разработчики оптимизируют доступ к информации.

Освойте профессию «Data Scientist»
Структуру данных можно представить как переменную, в которой хранится не одно значение, а несколько. Через эту переменную можно по определенному алгоритму получить доступ к каждому из значений — или почти к каждому. Какие типы могут быть у этих переменных, как именно они будут структурированы — зависит от конкретной сущности.
Основными структурами данных пользуются практически все разработчики. Такие структуры есть почти во всех современных языках программирования, просто могут называться по-разному.
Профессия / 24 месяца
Data Scientist
Дата-сайентисты решают поистине амбициозные задачи. Научитесь создавать искусственный интеллект, обучать нейронные сети, менять мир и при этом хорошо зарабатывать. Программа рассчитана на новичков и плавно введет вас в Data Science.

Для чего нужны структуры данных
Современные программы могут работать с большим количеством информации, причем иногда довольно разнообразной. Было бы сложно выделять для каждой единицы таких данных отдельную переменную: это лишняя трата памяти, к тому же в обилии переменных тогда было бы слишком легко запутаться.
Поэтому разработчики используют структуры данных — единые объекты, которые хранят в себе набор информации. Правила доступа к этой информации могут быть разными — для этого есть специальные операции, порой специфичные для конкретного структурного типа. Каждая структура подходит для своих сценариев использования: есть задачи, в которых ее будет удобно использовать, а есть те, где это излишне.
Пользоваться базовыми структурами данных должен уметь каждый разработчик. Они упрощают написание кода и делают возможным решение задач, которые очень сложно выполнить без структурированных данных.
Характеристики структуры данных
Описание структуры данных можно условно поделить на интерфейс и реализацию. Интерфейс — это набор операций, который описывает поведение конкретной структуры. То есть это то, что можно сделать с конкретной структурой данных. А реализация — то, как данные структурированы внутри.
Кроме того, типичная структура данных отвечает нескольким критериям:
- корректность, то есть грамотная реализация своего технического описания;
- пространственная сложность — реализация должна занимать минимум места;
- временная сложность — операции должны выполняться за минимум времени.
«Минимум места» и «минимум времени» могут различаться для разных структур. Это нормально: у каждой из них свое назначение и оптимальный способ использования.
Какими бывают структуры данных
Структуры данных в общем можно разделить на линейные и нелинейные. Разница в том, как они хранят свои элементы — данные, которые в них расположены.
- В линейных структурах элементы расположены как бы «по цепочке», друг за другом. Они выстраиваются в последовательность. Например, слово можно представить как линейную структуру данных, где данные — буквы.
- В нелинейных элементы могут ветвиться, образовывать таблицы или схемы. Пример нелинейной структуры данных из жизни — схема дорог.
Ниже мы коротко расскажем о наиболее популярных структурах данных: их особенностях, операциях с ними и ситуациях, когда их следует применять.
Массивы
Это наиболее простой пример структуры данных. Массив — это линейная последовательность значений, у каждого из которых есть свой номер. Номера называются индексами — по ним можно получить доступ к любому элементу массива.
Индексы идут последовательно. Это целые числа, последовательность которых начинается с 0.
Можно выделить одномерные и многомерные массивы. Одномерные — это просто ряд пронумерованных значений. Многомерные — матрица: каждое из значений массива само является массивом. Соответственно, доступ к элементу возможен по двум индексам — строки и столбца.
Классические массивы — статические, то есть у них конечная и неизменная длина. Если такой массив создать с длиной 5 — там всегда будет место ровно для 5 элементов, не больше и не меньше. Еще бывают динамические массивы: их длина изменяется в зависимости от того, сколько значений в них «положили».
Как правило, в массиве могут лежать данные только одного типа. Например, массив чисел или массив строк.
Операции. К массиву можно добавить элемент или несколько — в конец или в определенный участок ряда. Также можно вернуть элемент по индексу, в некоторых случаях — удалить. По прямому обращению к элементу по индексу его можно изменить. Существуют также операции, позволяющие узнать длину массива, и операции, выдающие весь массив целиком.
Применение. Массивы применяют в большинстве ситуаций, где требуется организованное хранение данных. Не используют их только в сложных структурах: там логичнее будет применить другой формат. Но и тут массивы нужны как строительные «кирпичики» для реализации более комплексных структур.

Станьте дата-сайентистом и решайте амбициозные задачи с помощью нейросетей
Очереди
Очередь похожа на массив. Это тоже линейная структура, состоящая из последовательности элементов. Разница в том, что доступ к этим элементам возможен только по принципу FIFO: First In, First Out. Это значит, что из очереди можно быстро и легко извлечь элемент, который расположен в самом ее начале и находится в ней дольше всего. А вот операций для доступа с конца или из середины может вообще не быть. Добавляются же элементы, наоборот, только в конец — как с реальной очередью в магазине.
Операции. Основные операции, характерные для очереди — добавление элемента в конец, получение элемента из начала без удаления или с удалением, а также проверка ее на пустоту.
Применение. Очереди применяют для организации многопоточных процессов, когда несколько действий выполняются одновременно. Эта структура данных позволяет задать действиям последовательность и очередность выполнения. Так балансируется нагрузка на программу и предотвращается зависание. По такому же принципу очереди используют при выполнении запросов — если их много, и они поступают очень быстро.
Стеки
Стек — структура, обратная очереди. Это последовательность, в которой доступ работает по принципу LIFO: Last In, First Out. Элементы добавляются в конец, а быстро получить и извлечь их можно опять же с конца. То есть чем позже элемент добавили в стек, тем легче до него добраться.
Английское слово stack означает «стопка», например, стопка бумаг. Так можно представить и стек: как стопку бумаг, где самый верхний элемент берется первым.
Операции. Среди операций специально для стеков — так называемый push, то есть добавление элемента в конец, и pop — извлечение элемента из конца. Извлечение означает, что элемент удаляется из стека, но возвращается как значение.
Также есть проверка пустоты стека и операция, возвращающая последний элемент без его удаления.
Применение. Стек используется при выделении памяти программам и процессам. Функции, работающие внутри программы, как бы «укладываются» в системный стек. Популярное выражение stack overflow — это распространенная ошибка, возникающая, когда стек переполняется из-за неправильного использования памяти. Чаще всего такое бывает при рекурсии.
Еще один вариант применения стека — история просмотров: доступ к данным, которые человек просмотрел последними, проще.
Деки
Деками называют двусторонние очереди: они объединяют возможности и очереди, и стека. Такие структуры данных могут работать и по принципу FIFO, и по принципу LIFO. Доступ к элементам возможен с любого конца.
Операции. Можно сказать, что деки объединяют в себе операции, характерные для очередей и стеков. В каком-то смысле эти структуры данных напоминают массивы и приближены к ним по функциональности.
Применение. Деки используют, когда важно обеспечить доступ и к первым, и к последним элементам. Например, при оптимизации выполнения процессов.
Связанные списки
Еще один распространенный пример линейной структуры данных. Это последовательность элементов, каждый из которых хранит данные и ссылку на следующий или предыдущий элемент. В результате от одного элемента можно быстро получить доступ к его «соседу».
Сами элементы, в отличие от массива, хранятся отдельно друг от друга. У них нет номеров. Последовательность достигается исключительно за счет указателей «следующий» и «предыдущий». Последний элемент будет указывать на «пустое» значение.
У односвязных списков есть ссылки только на следующий элемент, у двусвязных — и на следующий, и на предыдущий. Их еще называют однонаправленными или двунаправленными. Есть и круговые списки — они закольцовываются, и последний их элемент указывает на первый.
Первый элемент называется головой списка, последний — хвостом.
Операции. В список можно добавить элемент — в голову, хвост или заданный участок. Также можно обновить значение элемента или удалить его, провести поиск по структуре данных. Также есть операция-проверка, пуст ли список. Доступ к следующему элементу возможен с помощью указателя next, к предыдущему — prev.
Применение. Связанные списки используют для построения более сложных структур, например, графов и хэш-таблиц, которые мы рассмотрим позже. Кроме того, они бывают важны при выделении памяти программам в динамических процессах и операционных системах.
Множества
Множество — еще одна линейная структура данных. Ее особенность в том, что элементы не имеют четкого порядка, зато уникальны по значению. Ее можно представить не как последовательность или список, а как «облако тегов»: неупорядоченный набор уникальных значений. Это определение близко к математическому понятию множества. И работают с ним так же: не сортируют и не структурируют, но хранят, получают и анализируют данные.
Множество еще называют сетом. По-английски название звучит как Set.
Операции. Характерные для этой структуры данных операции рассчитаны на работу с двумя множествами. Например, это операции объединения множества, сравнения, поиска пересечений между двумя сетами. Похоже на круги Эйлера, но программно реализованные.
Также есть операция, которая возвращает только элементы множества, не пересекающиеся с другим, и операция поиска подмножества. Она показывает, содержится ли одно множество в другом.
Применение. Множества используют для хранения наборов данных, которые должны быть уникальными, но не нуждаются в упорядочивании. Обычно это наборы, с которыми нужно проводить определенные операции: искать в них подмножества, объединять, сравнивать с другими и выделять пересечения.
Карты
По-английски эта структура данных называется Map. Ее еще называют ассоциативным массивом или словарем. Она действительно похожа на массив, но вместо упорядоченных числовых индексов в ней используются «ключи» — заданные пользователем числа или строки. Весь массив — это набор пар из ключей и значений.
Можно представить эту структуру данных как телефонный справочник. Ключ — это имя, по которому человек ищет нужный номер. А само значение — собственно, номер телефона.
Разработчик сам задает ключи или генерирует их автоматически. Часто ключи строковые: это облегчает понимание и поиск информации.
Обычно в ассоциативных массивах можно хранить данные разных типов. Ключи тоже могут различаться.
Операции. С картами можно работать как с массивами, но доступ к ним осуществляется по названию ключа, а не индексу. Можно добавить пару ключ-значение, удалить ее или изменить значение. Также можно обратиться к элементу по его ключу.
У ассоциативных массивов иначе реализован проход по всей структуре, чем у обычных: тут не получится просто увеличивать индекс на 1 на каждом шаге, ведь ключ может быть каким угодно. Поэтому в языках программирования обычно предусмотрены специальные операции для прохода по словарю.
Применение. Ассоциативные массивы используют для хранения данных, которые нужно быстро найти по какому-то неизменному ключу. Еще они применяются для передачи данных — ключ выступает как название параметра, а в самом элементе хранится его значение. Например, когда человек заполняет форму на сайте и отправляет ее, на сервер приходят данные в виде словаря вроде такого:
Ключи name, phone и isAgree описывают, что именно передают: имя, телефон и наличие согласия на получение сообщений. А Ivan, true и номер — уже значения, которые приняли эти параметры.
Хэш-таблицы
Эта структура данных похожа на ассоциативный массив и иногда реализуется через него. Разница в том, что ключ для каждого значения задается автоматически с помощью специальной формулы — хэш-формулы. Эта формула применяется к самому значению — в результате генерируется ключ, основанный на нем.
С помощью хэш-таблицы можно генерировать ключи автоматически, например, в ситуациях, когда их название не должно нести полезной нагрузки. Это удобнее и быстрее, чем словарь, если речь идет о больших объемах данных. Кроме того, использование хэшей позволяет шифровать информацию — правда, одной таблицы для этого недостаточно.
При работе с хэш-таблицами важно избегать коллизий — ситуаций, когда применение формулы к разным значениям дает одинаковые ключи. Чтобы такого не было, нужно грамотно подбирать формулу для каждого случая. Также существуют специальные стратегии для предотвращения коллизий.
Операции. В таблицу можно добавить элемент, удалить или найти по тому или иному признаку. При ее создании также можно и нужно задать формулу, по которой будут генерироваться хэши.
Применение. Хэш-таблицы используются для хранения больших объемов информации, в базах данных, а также для создания кэшей или при построении более сложных структур. Чаще всего таблицы используют, когда нужен быстрый доступ к информации.
Графы
Граф — нелинейная структура организации данных, которая состоит из «вершин» и «ребер» между ними. Каждая вершина — это значение, а ребра — пути, которые соединяют между собой вершины. Получается своеобразная «сетка», похожая на карту дорог или созвездие.
Графы бывают неориентированными, когда ребра не имеют конкретного направления, и ориентированными. Во втором случае по ребрам можно пройти только в одну сторону — как по дороге с односторонним движением. Есть смешанные графы, в которых есть и ориентированные, и неориентированные ребра.
Также существуют взвешенные графы, у ребер которых есть «вес» — то или иное значение. Например, в карте дорог весом ребра-дороги можно назвать его длину.
Графы обычно реализуют с помощью связанных списков или матриц — двумерных массивов.
Операции. С этими структурами есть базовые операции: добавление вершины или ребра, отображение вершины или графа целиком, оценка «стоимости» обхода взвешенного графа и так далее.
Существует несколько алгоритмов обхода графов для поиска информации или для нахождения кратчайшего пути от одной вершины до другой. Например, DFS, BFS, алгоритм Дейкстры и другие. Для них не всегда существуют отдельные команды, так что реализовать эти алгоритмы может понадобиться самостоятельно.
Применение. Графы активно используют для хранения моделей машинного обучения, а также при работе с картами, например, для построения маршрутов через онлайн-сервисы. Программное эмулирование электрических цепей — это тоже графы. Также теория графов применяется в поисковых алгоритмах и социальных сетях — например, так рассчитывается «охват» друзей одного человека. Графы можно использовать для распределения ресурсов внутри системы или при организации сложных вычислений.
Деревья
Деревья можно назвать частным случаем графов. Это тоже структуры из вершин и ребер, но имеющие древовидный формат. Вершины деревьев называются узлами. От одного узла может отходить несколько вершин-потомков, но предок у каждого узла может быть только один. Так и получается древовидная иерархическая структура.
В программировании применяют несколько видов деревьев. Большинство из них реализуют с помощью графов.
- Бинарные деревья поиска — самый распространенный формат деревьев. У каждого узла может быть не более двух потомков. Если значение узла-потомка меньше предка, он располагается слева. Если равно или больше — справа. С помощью таких деревьев удобно сортировать данные и искать в них нужное значение с помощью бинарного поиска.
- Префиксные деревья, они же нагруженные деревья или боры — это деревья, которые хранят данные «по цепочке». Узлы-предки — префиксы, которые нужны, чтобы перейти к потомкам. При прохождении дерева «собираются» полные данные. Например, в каждом узле — буква. При прохождении от начала до конца получаются слова. Обычно такие деревья используют для хранения повторяющихся данных или, например, для реализации автодополнения при вводе.
- Двоичные кучи — двоичные деревья, заполненные целиком. У каждого узла два потомка. Потомки в зависимости от типа дерева должны быть строго больше предков или меньше либо равны им.
Также существуют N-арные деревья, красно-черные деревья, AVL-деревья, сбалансированные, 2-3-4-деревья и так далее.
Операции. По деревьям можно проходить снизу вверх или сверху вниз, в ширину или в глубину. Для этого существуют специальные алгоритмы — как и для графов. Так как обычно в деревьях расположение узла зависит от его значения, произвольно добавить узел куда угодно не получится. Поэтому при добавлении, удалении или изменении узла происходит перебалансировка — изменение структуры с учетом добавленного значения.
Применение. Деревья используют для хранения информации, для которой важна иерархичность. Также их могут применять для эффективной сортировки, поиска нужных значений или хранения повторяющихся данных, как в случае с префиксными деревьями. Часто деревья встречаются в алгоритмах машинного обучения.
Структуры данных есть в любом языке программирования. Впервые вы встретитесь с ними еще в начале обучения, когда начнете проходить массивы. Постепенно программа будет усложняться, и вы будете сталкиваться и с другими структурами — а возможно, писать их собственные реализации.
Узнать больше о программировании и хранении данных вы можете на наших курсах. Записывайтесь — сделайте первый шаг к новой популярной профессии.
Data Scientist
Дата-сайентисты решают поистине амбициозные задачи. Научитесь создавать искусственный интеллект, обучать нейронные сети, менять мир и при этом хорошо зарабатывать. Программа рассчитана на новичков и плавно введет вас в Data Science.
Информатика. 10 класс (Повышенный уровень)
В информатике структура данных — программная единица, позволяющая хранить и обрабатывать данные, а также обеспечивающая их эффективное использование. Данные при этом должны быть однотипными или логически связанными.
Различные виды структур данных подходят для различных задач; некоторые из них имеют узкую специализацию, другие являются универсальными (пример 21.1).
При разработке программного обеспечения сложность реализации и качество работы программ существенно зависят не только от выбора алгоритма, но и от правильного выбора структур данных. Одни и те же данные можно сохранить в структурах, требующих различного объема памяти, а алгоритмы работы с разными структурами данных могут иметь различную эффективность. Структура данных, наиболее подходящая для решения конкретной задачи, позволяет выполнять большое количество различных операций, используя как можно меньший объем ресурсов.
Ни одна профессиональная программа сегодня не пишется без использования структур данных, поэтому многие из них содержатся в стандартных библиотеках современных языков программирования (например, STL для С++).
Структура данных представляет собой набор значений данных, отношения между ними, а также функции и (или) операции, которые могут быть применены к данным.
Структуры данных классифицируют по разным признакам. В примере 21.2 приведена классификация структур данных по организации взаимосвязей между элементами.
Пример 21.1. Примеры некоторых структур данных:
1. Массив (вектор в C++) — самая простая и широко используемая структура данных.
2. Запись (структура в С++) — совокупность элементов данных разного типа. Содержит постоянное количество элементов, которые называют полями.
3. Связный список (Linked List) представляет набор связанных узлов, каждый из которых хранит собственно данные и ссылку на следующий узел. В реальной жизни связный список можно представить в виде поезда, каждый вагон которого может содержать некоторый груз или пассажиров и при этом может быть связан с другим вагоном.
4. Граф — совокупность вершин (узлов) и связей между ними (ребер). В реальной жизни по такому принципу устроены социальные сети: узлы — это люди, а ребра — их отношения.
5. Множество — совокупность данных, значения которых не повторяются, реализация математического объекта множество, за исключением того, что множество в программировании конечно.
Пример 21.2. Классификация структур данных.
-
- массив;
- список;
- связанный список;
- стек;
- очередь;
- хэш-таблица.
Иерархические:
-
- двоичные деревья;
- n-арные деревья;
- иерархический список.
-
- неориентированный граф;
- ориентированный граф.
-
- таблица реляционной базы данных;
- двумерный массив.