Введение в соединения
Соединение (JOIN) — одна из самых важных операций, выполняемых реляционными системами управления базами данных (РСУБД). РСУБД используют соединения для того, чтобы сопоставить строки одной таблицы строкам другой таблицы. Например, соединения можно использовать для сопоставления продаж — клиентам или книг — авторам. Без соединений, имелись бы раздельные списки продаж и клиентов или книг и авторов, но невозможно было бы определить, какие клиенты что купили, или какой из авторов был заказан.
Можно соединить две таблицы явно, перечислив обе таблицы в предложении FROM запроса. Также можно соединить две таблицы, используя для этого всё разнообразие подзапросов. Наконец, SQL Server во время оптимизации может добавить соединение в план запроса, преследуя свои цели.
Это первая из серии статей, которые я планирую посвятить соединениям. Эту статью я собираюсь посвятить азам соединений, описав назначение логических операторов соединениё, поддерживаемых SQL Server. Вот они:
- Inner join
- Outer join
- Cross join
- Cross apply
- Semi-join
- Anti-semi-join
Для иллюстрации каждого соединения я буду использовать простую схему и набор данных:
create table Customers (Cust_Id int, Cust_Name varchar(10)) insert Customers values (1, 'Craig') insert Customers values (2, 'John Doe') insert Customers values (3, 'Jane Doe') create table Sales (Cust_Id int, Item varchar(10)) insert Sales values (2, 'Camera') insert Sales values (3, 'Computer') insert Sales values (3, 'Monitor') insert Sales values (4, 'Printer')Внутренние соединения
Внутренние соединения — самый распространённый тип соединений. Внутреннее соединение просто находит пары строк, которые соединяются и удовлетворяют предикату соединения. Например, показанный ниже запрос использует предикат соединения «S.Cust_Id = C.Cust_Id», позволяющий найти все продажи и сведения о клиенте с одинаковыми значениями Cust_Id:
select * from Sales S inner join Customers C on S.Cust_Id = C.Cust_Id Cust_Id Item Cust_Id Cust_Name ----------- ---------- ----------- ---------- 2 Camera 2 John Doe 3 Computer 3 Jane Doe 3 Monitor 3 Jane DoeПримечания:
Cust_Id = 3 купил два наименования, поэтому он фигурирует в двух строках результирующего набора.
Cust_Id = 1 не купил ничто и потому не появляется в результате.
Для Cust_Id = 4 тоже был продан товар, но поскольку в таблице нет такого клиента, сведения о такой продаже не появились в результате.
Внутренние соединения полностью коммутативны. «A inner join B» и «B inner join A» эквивалентны.
Внешние соединения
Предположим, что мы хотели бы увидеть список всех продаж; даже тех, которые не имеют соответствующих им записей о клиенте. Можно составить запрос с внешним соединением, которое покажет все строки в одной или обеих соединяемых таблицах, даже если не будет существовать соответствующих предикату соединения строку. Например:
select * from Sales S left outer join Customers C on S.Cust_Id = C.Cust_Id Cust_Id Item Cust_Id Cust_Name ----------- ---------- ----------- ---------- 2 Camera 2 John Doe 3 Computer 3 Jane Doe 3 Monitor 3 Jane Doe 4 Printer NULL NULLОбратите внимание, что сервер возвращает вместо данных о клиенте значение NULL, поскольку для проданного товара ‘Printer’ нет соответствующей записи клиента. Обратите внимание на последнюю строку, у которой отсутствующие значения заполнены значением NULL.
Используя полное внешнее соединение, можно найти всех клиентов (независимо от того, покупали ли они что-нибудь), и все продажи (независимо от того, сопоставлен ли им имеющийся клиент):
select * from Sales S full outer join Customers C on S.Cust_Id = C.Cust_Id Cust_Id Item Cust_Id Cust_Name ----------- ---------- ----------- ---------- 2 Camera 2 John Doe 3 Computer 3 Jane Doe 3 Monitor 3 Jane Doe 4 Printer NULL NULL NULL NULL 1 CraigСледующая таблица показывает, строки какой из соединяемых таблиц попадут в результирующий набор (у оставшейся таблицы возможны замены NULL), она охватывает все типы внешних соединений:
A left outer join B
A right outer join B
A full outer join B
Все строки A и B
Полные внешние соединения коммутативны. Кроме того, «A left outer join B » и «B right outer join A» является эквивалентным.
Перекрестные соединения
Перекрестное соединение выполняет полное Декартово произведение двух таблиц. То есть это соответствие каждой строки одной таблицы — каждой строке другой таблицы. Для перекрестного соединения нельзя определить предикат соединения, используя для этого предложение ON, хотя для достижения практически того же результата, что и с внутренним соединением, можно использовать предложение WHERE.
Перекрестные соединения используются довольно редко. Никогда не стоит пересекать две большие таблицы, поскольку это задействует очень дорогие операции и получится очень большой результирующий набор.
select * from Sales S cross join Customers C Cust_Id Item Cust_Id Cust_Name ----------- ---------- ----------- ---------- 2 Camera 1 Craig 3 Computer 1 Craig 3 Monitor 1 Craig 4 Printer 1 Craig 2 Camera 2 John Doe 3 Computer 2 John Doe 3 Monitor 2 John Doe 4 Printer 2 John Doe 2 Camera 3 Jane Doe 3 Computer 3 Jane Doe 3 Monitor 3 Jane Doe 4 Printer 3 Jane DoeCROSS APPLY
В SQL Server 2005 мы добавили оператор CROSS APPLY, с помощью которого можно соединять таблицу с возвращающей табличное значение функцией (table valued function — TVF), причём TVF будет иметь параметр, который будет изменяться для каждой строки. Например, представленный ниже запрос возвратит тот же результат, что и показанное ранее внутреннее соединение, но с использованием TVF и CROSS APPLY:
create function dbo.fn_Sales(@Cust_Id int) returns @Sales table (Item varchar(10)) as begin insert @Sales select Item from Sales where Cust_Id = @Cust_Id return end select * from Customers cross apply dbo.fn_Sales(Cust_Id) Cust_Id Cust_Name Item ----------- ---------- ---------- 2 John Doe Camera 3 Jane Doe Computer 3 Jane Doe MonitorТакже можно использовать внешнее обращение — OUTER APPLY, позволяющее нам найти всех клиентов независимо от того, купили ли они что-нибудь или нет. Это будет похоже на внешнее соединение.
select * from Customers outer apply dbo.fn_Sales(Cust_Id) Cust_Id Cust_Name Item ----------- ---------- ---------- 1 Craig NULL 2 John Doe Camera 3 Jane Doe Computer 3 Jane Doe MonitorПолусоединение и анти-полусоединение
Полусоединение — semi-join возвращает строки только одной из соединяемых таблиц, без выполнения соединения полностью. Анти-полусоединение возвращает те строки таблицы, которые не годятся для соединения с другой таблицей; т.е. они в обычном внешнем соединении выдавали бы NULL.
В отличие от других операторов соединений, не существует явного синтаксиса для указания исполнения полусоединения, но SQL Server, в целом ряде случаев, использует в плане исполнения именно полусоединения. Например, полусоединение может использоваться в плане подзапроса с EXISTS:
select * from Customers C where exists ( select * from Sales S where S.Cust_Id = C.Cust_Id ) Cust_Id Cust_Name ----------- ---------- 2 John Doe 3 Jane DoeВ отличие от предыдущих примеров, полусоединение возвращает только данные о клиентах.
В плане запроса видно, что SQL Server действительно использует полусоединение:
|—Nested Loops(Left Semi Join, WHERE:([S].[Cust_Id]=[C].[Cust_Id]))
|—Table Scan(OBJECT:([Customers] AS [C]))
|—Table Scan(OBJECT:([Sales] AS [S]))
Существуют левые и правые полусоединения. Левое полусоединение возвращает строки левой (первой) таблицы, которые соответствуют строкам из правой (второй) таблицы, в то время как правое полусоединение возвращает строки из правой таблицы, которые соответствуют строкам из левой таблицы.
Подобным образом может использоваться анти-полусоединение для обработки подзапроса с NOT EXISTS.
Дополнение
Во всех представленных в статье примерах использовались предикаты соединения, который сравнивали, являются ли оба столбца каждой из соединяемых таблицы равными. Такой тип предикатов соединений принято называть «соединением по эквивалентности». Другие предикаты соединений (например, неравенства) тоже возможны, но соединения по эквивалентности распространены наиболее широко. В SQL Server заложено много альтернативных вариантов оптимизации соединений по эквивалентности и оптимизации соединений с более сложными предикатами.
SQL Server более гибок в выборе порядка соединения и его алгоритма при оптимизации внутренних соединений, чем при оптимизации внешних соединений и CROSS APPLY. Таким образом, если взять два запроса, которые отличаются только тем, что один использует исключительно внутренние соединения, а другой использует внешние соединения и/или CROSS APPLY, SQL Server сможет найти лучший план исполнения для запроса, который использует только внутренние соединения.
- sql server
- операторы в плане запроса
- SQL
- Microsoft SQL Server
Соединения (SQL Server)
SQL Server выполняет операции сортировки, взаимодействия, объединения и разности с помощью технологии сортировки и хэш-соединения в памяти. С помощью этого типа плана запросов SQL Server поддерживает секционирование вертикальных таблиц.
SQL Server реализует операции логического соединения, как определено синтаксисом Transact-SQL:
- внутреннее соединение,
- левое внешнее соединение.
- Правое внешнее соединение
- Полное внешнее соединение
- Перекрестное соединение
Дополнительные сведения о синтаксисе соединения см. в разделе Предложение FROM и JOIN, APPLY, PIVOT (Transact-SQL).
SQL Server использует четыре типа операций физического соединения для выполнения операций логического соединения:
- Соединения вложенных циклов
- Соединения слиянием.
- Хэш-соединения.
- Адаптивные соединения (начиная с SQL Server 2017 (14.x))
Основные принципы соединения
С помощью соединения можно получать данные из двух или нескольких таблиц на основе логических связей между ними. Соединения указывают, как SQL Server должен использовать данные из одной таблицы для выбора строк в другой таблице.
Соединение определяет способ связывания двух таблиц в запросе следующим образом:
- для каждой таблицы указываются столбцы, используемые в соединении. В типичном условии соединения указывается внешний ключ из одной таблицы и связанный с ним ключ из другой таблицы;
- Указывается логический оператор (например, = или <>), используемый для сравнения значений из столбцов.
Соединения выражаются логически с помощью следующего синтаксиса Transact-SQL:
- ВНУТРЕННЕЕ СОЕДИНЕНИЕ
- LEFT [ OUTER ] JOIN
- RIGHT [ OUTER ] JOIN
- FULL [ OUTER ] JOIN
- CROSS JOIN
Внутренние соединения можно задавать в предложениях FROM и WHERE . Внешние соединения и перекрестные соединения можно задавать только в предложении FROM . Условия соединения сочетаются с условиями поиска WHERE и HAVING для управления строками, выбранными из базовых таблиц, на которые ссылается предложение FROM .
То, что условия соединения задаются в предложении FROM , помогает отделить их от условий поиска, которые могут быть заданы в предложении WHERE . Объединение рекомендуется задавать именно таким способом. Ниже приведен упрощенный синтаксис соединения с использованием предложения FROM стандарта ISO:
FROM first_table < join_type >second_table [ ON ( join_condition ) ] Join_type указывает, какой тип соединения выполняется: внутреннее, внешнее или перекрестное соединение. join_condition определяет предикат, который будет вычисляться для каждой пары соединяемых строк. Ниже приведен пример предложения FROM с заданным соединением:
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor ON ( ProductVendor.BusinessEntityID = Vendor.BusinessEntityID ) Ниже приведена простая инструкция SELECT , использующая это соединение:
SELECT ProductID, Purchasing.Vendor.BusinessEntityID, Name FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor ON (Purchasing.ProductVendor.BusinessEntityID = Purchasing.Vendor.BusinessEntityID) WHERE StandardPrice > $10 AND Name LIKE N'F%'; GO Инструкция SELECT возвращает наименование продукта и сведения о поставщике для всех сочетаний запчастей, поставляемых компаниями с названиями на букву F и стоимостью продукта более 10 долларов.
Если один запрос содержит ссылки на несколько таблиц, то все ссылки столбцов должны быть однозначными. В предыдущем примере как таблица ProductVendor , так и таблица Vendor содержат столбец с именем BusinessEntityID . Имена столбцов, совпадающие в двух или более таблицах, на которые ссылается запрос, должны уточняться именем таблицы. Все ссылки на столбец Vendor в этом примере являются полными.
Если имя столбца не дублируется в двух или более таблицах, указанных в запросе, то ссылки на него уточнять именем таблицы не обязательно. Это показано в предыдущем примере. Подобное предложение SELECT иногда трудно понять, поскольку в нем нет ничего, что указывало бы на таблицы, из которых берутся столбцы. Запрос гораздо легче читать, если все столбцы указаны с именами соответствующих таблиц. Запрос будет читаться еще легче, если используются псевдонимы таблиц, особенно когда имена таблиц сами должны уточняться именами базы данных и владельца. Ниже приведен тот же пример, но чтобы упростить чтение, используются псевдонимы таблиц, уточняющие названия столбцов.
SELECT pv.ProductID, v.BusinessEntityID, v.Name FROM Purchasing.ProductVendor AS pv INNER JOIN Purchasing.Vendor AS v ON (pv.BusinessEntityID = v.BusinessEntityID) WHERE StandardPrice > $10 AND Name LIKE N'F%'; В предыдущем примере условие соединения задается в предложении FROM , что является рекомендуемым способом. В следующем запросе это же условие соединения указывается в предложении WHERE :
SELECT pv.ProductID, v.BusinessEntityID, v.Name FROM Purchasing.ProductVendor AS pv, Purchasing.Vendor AS v WHERE pv.BusinessEntityID=v.BusinessEntityID AND StandardPrice > $10 AND Name LIKE N'F%'; Список SELECT для соединения может ссылаться на все столбцы в соединяемых таблицах или на любое подмножество этих столбцов. Список SELECT не обязательно должен содержать столбцы из каждой таблицы в соединении. Например, в соединении из трех таблиц связующим звеном между одной из таблиц и третьей таблицей может быть только одна таблица, при этом список выборки не обязательно должен ссылаться на столбцы средней таблицы. Это так называемое антиполусоединение.
Хотя обычно в условиях соединения для сравнения используется оператор равенства (=), можно указать другие операторы сравнения или реляционные операторы, равно как другие предикаты. Дополнительные сведения см. в статьях «Операторы сравнения» (Transact-SQL) и WHERE (Transact-SQL).
При присоединении к SQL Server оптимизатор запросов выбирает наиболее эффективный метод (из нескольких возможностей) обработки соединения. Это включает выбор наиболее эффективного типа физического соединения, порядок объединения таблиц и даже использование типов операций логического соединения, которые нельзя выразить напрямую с помощью синтаксиса Transact-SQL, например полусоединения и анти-полусоединения. При физическом выполнении различных соединений можно использовать много разных оптимизаций, поэтому их нельзя надежно прогнозировать. Дополнительные сведения о полусоединениях и антиполусоединениях см. в справочнике по логическим и физическим операторам Showplan.
Столбцы, используемые в условии соединения, не обязательно должны иметь одинаковые имена или одинаковый тип данных. Однако если типы данных не совпадают, то они должны быть совместимыми или допускать в SQL Server неявное преобразование. Если типы данных не допускают неявное преобразование, то условия соединения должны явно преобразовывать эти типы данных с помощью функции CAST . Дополнительные сведения о неявных и явных преобразованиях см. в разделе «Преобразование типов данных» (ядро СУБД).
Большинство запросов, использующих соединение, можно переписать с помощью вложенных запросов и наоборот. Дополнительные сведения о вложенных запросах см. в разделе Вложенные запросы.
Таблицы невозможно соединять непосредственно по столбцам ntext, text или image. Однако соединить таблицы по столбцам ntext, text или image можно косвенно, с помощью SUBSTRING . Например, SELECT * FROM t1 JOIN t2 ON SUBSTRING(t1.textcolumn, 1, 20) = SUBSTRING(t2.textcolumn, 1, 20) выполняет двух табличное внутреннее соединение на первых 20 символов каждого текстового столбца в таблицах t1 и t2 .
Другая возможность сравнения столбцов ntext и text из двух таблиц заключается в сравнении длины столбцов с предложением WHERE , например: WHERE DATALENGTH(p1.pr_info) = DATALENGTH(p2.pr_info)
Общие сведения о соединениях вложенных циклов
Если один вход соединения имеет небольшой размер (менее десяти строк), а другой вход сравнительно большой и индексирован по соединяемым столбцам, индексное соединение вложенных циклов является самой быстрой операцией соединения, так как для нее потребуется наименьшее количество операций сравнения и ввода-вывода.
Соединение вложенных циклов, называемое также вложенной итерацией, использует один ввод соединения в качестве внешней входной таблицы (на графической схеме выполнения она является верхним входом), а второй в качестве внутренней (нижней) входной таблицы. Внешний цикл использует внешнюю входную таблицу построчно. Во внутреннем цикле для каждой внешней строки производится сканирование внутренней входной таблицы и вывод совпадающих строк.
В простейшем случае во время поиска целиком просматривается таблица или индекс; это называется упрощенным соединением вложенных циклов. Если при поиске используется индекс, то такой поиск называется индексным соединением вложенных циклов. Если индекс создается в качестве части плана запроса (и уничтожается после завершения запроса), то он называется временным индексным соединением вложенных циклов. Все эти варианты учитываются оптимизатором запросов.
Соединение вложенных циклов является особенно эффективным в случае, когда внешние входные данные сравнительно невелики, а внутренние входные данные велики и заранее индексированы. Во многих небольших транзакциях, работающих с небольшими наборами строк, индексное соединение вложенных циклов превосходит как соединения слиянием, так и хэш-соединения. Однако в больших запросах соединения вложенных циклов часто являются не лучшим вариантом.
Если для атрибута OPTIMIZED оператора соединения вложенными циклами задано значение True, это означает, что оптимизированные соединения вложенными циклами (или пакетная сортировка) используются для уменьшения количества операций ввода-вывода, когда внутренняя таблица имеет большой размер, независимо от того, выполняется ли ее параллельная обработка. Такая оптимизация в этом плане выполнения может быть не слишком очевидна при анализе плана, если сама сортировка выполняется как скрытая операция. Но изучив XML-код плана для атрибута OPTIMIZED, можно обнаружить, что соединение вложенными циклами, возможно, попытается изменить порядок входных строк, чтобы повысить производительность операций ввода-вывода.
Соединения слиянием.
Если два входа соединения достаточно велики, но отсортированы по соединяемым столбцам (например, если они были получены просмотром отсортированных индексов), то наиболее быстрой операцией соединения будет соединение слиянием. Если оба входа соединения велики и имеют сходные размеры, соединение слиянием с предварительной сортировкой и хэш-соединение имеют примерно одинаковую производительность. Однако операции хэш-соединения часто выполняются быстрее, если два входа значительно отличаются по размеру.
Соединение слиянием требует сортировки обоих наборов входных данных по столбцам слияния, которые определены предложениями равенства (ON) предиката объединения. Оптимизатор запросов обычно просматривает индекс, если для соответствующего набора столбцов такой существует, или устанавливает оператор сортировки под соединением слиянием. В редких случаях может быть несколько предложений равенства, но столбцы слияния берутся только из некоторых доступных предложений равенства.
Так как каждый набор входных данных сортируется, оператор Merge Join получает строку из каждого набора входных данных и сравнивает их. Например, для операций внутреннего соединения строки возвращаются в том случае, если они равны. Если они не равны, строка с меньшим значением не учитывается, и из этого набора входных данных берется другая строка. Этот процесс повторяется, пока не будет выполнена обработка всех строк.
Операция соединения слиянием может быть как обычной, так и операцией типа «многие ко многим». Соединение слиянием «многие ко многим» использует временную таблицу для хранения строк. При наличии повторяющихся значений из каждого входного элемента один из входных данных должен перемыкаться к началу дубликата по мере обработки каждого дубликата из другого ввода.
При наличии остаточного предиката все строки, удовлетворяющие предикату слияния, определяют остаточный предикат, и возвращаются только те строки, которые ему соответствуют.
Соединение слиянием — очень быстрая операция, но она может оказаться ресурсоемкой, если требуется выполнение операций сортировки. Однако если том данных имеет большой объем, и необходимые данные могут быть получены из существующих индексов сбалансированного дерева с выполненной предварительной сортировкой, соединение слиянием является самым быстрым из доступных алгоритмов соединения.
Хэш-соединения.
Хэш-соединения могут эффективно обрабатывать большие, несортированные и неиндексированные входы. Они полезны для получения промежуточных результатов в сложных запросах из-за следующего.
- Промежуточные результаты не индексированы (если только они явным образом не сохранены на диске, а затем проиндексированы) и часто отсортированы не так, как требуется для следующей операции в плане запроса.
- Оптимизаторы запросов оценивают только размеры промежуточных результатов. Так как для сложных запросов оценки могут быть очень неточны, алгоритмы обработки промежуточных результатов должны быть не только эффективными, но и правильно вырождаться, если объем промежуточных результатов оказался гораздо большим, чем ожидалось.
Хэш-соединение позволяет уменьшить денормализацию. Денормализация обычно используется для получения более высокой производительности при уменьшении количества операций соединения, несмотря на издержки, вызываемые избыточностью данных, например несогласованных обновлений. Хэш-соединения снижают потребность в денормализации и позволяют осуществлять вертикальное секционирование (представляющее группы столбцов, содержащиеся в одной таблице, в отдельных файлах или индексах) в качестве доступной возможности при реализации физической структуры базы данных.
Хэш-соединение имеет два входа: конструктивный и пробный. Оптимизатор запросов распределяет роли таким образом, при котором меньшему входу присваивается значение «конструктивный».
Хэш-соединения используются во многих операциях совпадающих множеств: внутреннее соединение; левое, правое и полное внешнее соединение; левое и правое полусоединение; пересечение; соединение; разность. Дополнительно модификация хэш-соединения применяется для двойного удаления и группирования, например SUM(salary) GROUP BY department . В указанной модификации используется общий вход как для конструктивной, так и для пробной ролей.
В представленных ниже разделах описываются различные типы хэш-соединений: хэш-соединения в памяти, поэтапные и рекурсивные хэш-соединения.
Хэш-соединение в памяти
Перед проведением хэш-соединения производится просмотр или вычисление входного конструктивного значения, а затем в памяти создается хэш-таблица. Каждая строка помещается в сегмент хэша согласно значению, вычисленному для хэш-ключа. В случае если конструктивное входное значение имеет размер, меньший объема доступной памяти, то все строки данных могут быть занесены в хэш-таблицу. После описанного конструктивного этапа предпринимается пробный этап. Производится построковое считывание или вычисление пробного входного значения, для каждой строки вычисляется значение хэш-ключа, затем происходит сканирование сегмента хэша и поиск совпадений.
Хэш-соединение грейс
Если размер конструктивного входного значения превышает максимально допустимый объем памяти, то хэш-соединение проводится в несколько шагов. Указанный процесс называется плавным хэш-соединением. Каждый шаг состоит из конструктивной и пробной частей. Исходные конструктивные и пробные входные данные разбиваются на несколько файлов (для этого используются хэш-функции ключей). При использовании хэш-функции для хэш-ключей обеспечивается гарантия нахождения соединяемых записей в общей паре файлов. Таким образом, задача соединения двух объемных входных значений разбивается на несколько более мелких задач. Затем хэш-соединение применяется к каждой паре разделенных файлов.
Рекурсивное хэш-соединение
Если объем информации, поступающей на конструктивный вход, настолько велик, что для использования обычного внешнего слияния требуется несколько уровней, то операцию разбиения необходимо проводить за несколько шагов на нескольких уровнях. Дополнительные шаги разбиения используются только для секций большого объема. Чтобы максимально ускорить проведение всех шагов разбиения, используются емкие асинхронные операции ввода-вывода, в результате чего один поток может занимать сразу несколько жестких дисков.
В случае незначительного превышения допустимого объема памяти конструктивными входными данными происходит совмещение элементов хэш-соединения в памяти и поэтапных хэш-соединений в общий этап. В результате получается гибридное хэш-соединение.
В процессе оптимизации не всегда удается определить тип используемого хэш-соединения. Поэтому в SQL Server в первую очередь используются хэш-соединения в памяти, а затем, в зависимости от объемов входной конструктивной информации, осуществляется переход на поэтапное или рекурсивное хэш-соединение.
В случае неверного определения конструктивного и пробного входов в оптимизаторе запросов их переключение осуществляется динамически. При использовании хэш-соединения осуществляется контроль использования меньшего файла в качестве конструктивного входа. Данная функция называется «переключением ролей». Переключение ролей происходит внутри хэш-соединения после сброса информации на диск.
Переключение ролей происходит независимо от указаний запроса или структуры запроса. Событие «переключение ролей» не отображается в плане запроса, и сообщение о нем выдается пользователю непосредственно после выполнения.
Хэш-спасение
Термин «аварийная остановка хэша» иногда используется для описания поэтапных и рекурсивных хэш-соединений.
Наличие рекурсивных хэш-соединений и аварийных остановок снижает производительность сервера. Если в трассировке содержится много «событий-предупреждений хэша», необходимо произвести обновление статистических данных соединяемых столбцов.
Дополнительные сведения об аварийных остановках хэша см. в разделе Класс событий Hash Warning.
Адаптивные соединения
Адаптивные соединения в пакетном режиме позволяют отложить выбор метода Хэш-соединение или Соединение вложенными цикламидо завершения сканирования первых входных данных. Оператор адаптивного соединения определяет пороговое значение, по которому принимается решение о переключении на план вложенного цикла. Таким образом, во время выполнения план запроса может динамически переключаться на более эффективную стратегию соединения без перекомпиляции.
Наиболее полезной эта функция будет для рабочих нагрузок с частыми переключениями между просмотрами входных данных мелких и крупных соединений.
Решение для среды выполнения зависит от следующего:
- Если число строк во входных данных соединения сборки настолько мало, что соединение вложенными циклами будет эффективнее хэш-соединения, план переключается на алгоритм вложенных циклов.
- Если число строк во входных данных соединения сборки превышает порог, переключение не выполняется и план продолжает использовать хэш-соединение.
Следующий запрос используется в качестве наглядного примера адаптивного соединения:
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity] FROM [Fact].[Order] AS [fo] INNER JOIN [Dimension].[Stock Item] AS [si] ON [fo].[Stock Item Key] = [si].[Stock Item Key] WHERE [fo].[Quantity] = 360; Этот запрос возвращает 336 строк. Если включить функцию Статистика активных запросов, отобразится следующий план:
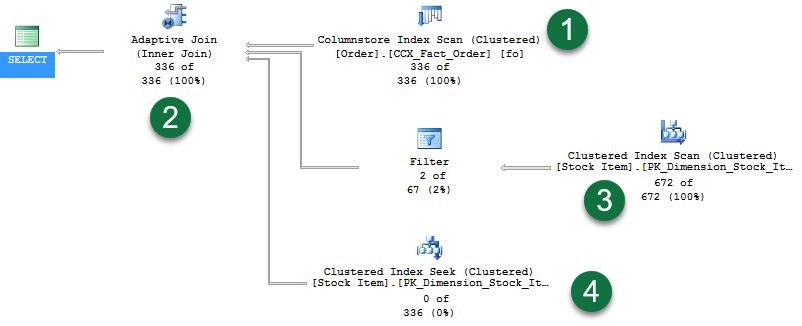
Обратите внимание на следующие моменты в плане:
- Просмотр индекса columnstore, используемый с целью предоставления строк для этапа сборки хэш-соединения.
- Новый оператор адаптивного соединения. Он определяет пороговое значение, по которому принимается решение о переключении на план вложенного цикла. В этом примере порог равен 78 строкам. Если число строк >= 78, будет использоваться хэш-соединение. Если значение меньше порога, будет использоваться соединение вложенными циклами.
- Так как запрос возвращает 336 строк, это превысило пороговое значение, поэтому вторая ветвь представляет этап проверки стандартной операции соединения хэша. Обратите внимание, что статистика активных запросов показывает строки, передаваемые через операторы — в данном случае это «672 из 672».
- И последняя ветвь — поиск кластеризованного индекса, используемый соединением вложенными циклами, если порог не был превышен. Обратите внимание, что мы видим число строк «0 из 336» (ветвь не используется).
Теперь контрастируйте план с тем же запросом, но если Quantity значение имеет только одну строку в таблице:
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity] FROM [Fact].[Order] AS [fo] INNER JOIN [Dimension].[Stock Item] AS [si] ON [fo].[Stock Item Key] = [si].[Stock Item Key] WHERE [fo].[Quantity] = 361; Запрос возвращает одну строку. Если включить функцию «Статистика активных запросов», отобразится следующий план:
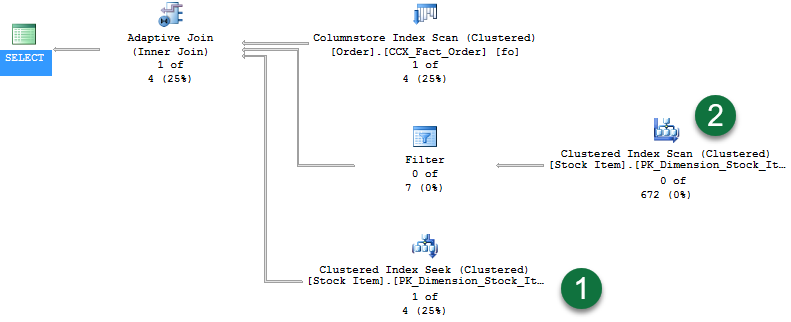
Обратите внимание на следующие моменты в плане:
- При возврате одной строки видно, что теперь через поиск кластеризованного индекса передаются строки.
- А так как этап сборки хэш-соединения не продолжается, никакие строки через вторую ветвь не передаются.
Примечания к адаптивным соединениям
Адаптивные соединения предъявляют более высокие требования к памяти, чем эквивалентный план соединения вложенными циклами индекса. Дополнительная память запрашивается так, как если бы вложенный цикл был хэш-соединением. Существуют также издержки на этапе сборки, такие как стартстопная операция и эквивалентное потоковое соединение вложенными циклами. Эти дополнительные затраты обеспечивают гибкость для сценариев, где количество строк во входных данных сборки может меняться.
Адаптивные соединения в пакетном режиме используются для первого выполнения инструкции. После компиляции последовательные выполнения остаются адаптивными с учетом порога скомпилированных адаптивных соединений и строк времени выполнения, передаваемых через этап сборки внешних входных данных.
Если адаптивное соединение переключается на режим вложенного цикла, оно использует строки, уже считанные сборкой хэш-соединения. Этот оператор не считывает повторно строки по внешней ссылке.
Отслеживание действия адаптивного соединения
Оператор адаптивного соединения имеет следующие атрибуты оператора плана:
| Атрибут плана | Description |
|---|---|
| AdaptiveThresholdRows | Показывает пороговое значение, используемое для переключения с хэш-соединения на соединение вложенными циклами. |
| EstimatedJoinType | К какому типу, вероятнее всего, относится соединение. |
| ActualJoinType | В фактическом плане показывает, какой итоговый алгоритм соединения был выбран на базе порогового значения. |
Предполагаемый план показывает форму плана адаптивного соединения, а также определенное пороговое значение адаптивного соединения и предполагаемый тип соединения.
Хранилище запросов захватывает и может принудительно применить план адаптивного соединения в пакетном режиме.
Допустимые инструкции адаптивного соединения
Чтобы логическое соединение стало допустимым для адаптивного соединения в пакетном режиме, должны выполняться следующие условия:
- Уровень совместимости базы данных имеет значение 140 или больше.
- Запрос является инструкцией SELECT (инструкции для изменения данных сейчас недопустимы).
- Соединение может выполняться посредством как индексированного соединения вложенными циклами, так и физического алгоритма хэш-соединения.
- Хэш-соединение использует пакетный режим, включенный через наличие индекса columnstore в запросе в целом, индексированную таблицу columnstore, на которую ссылается непосредственно соединение, или с помощью режима пакетной службы в rowstore.
- Созданные альтернативные решения соединения вложенными циклами и хэш-соединения должны иметь одинаковый первый дочерний элемент (внешняя ссылка).
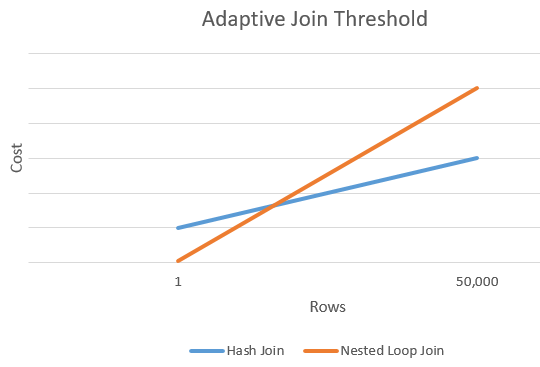
Строки адаптивного порогового значения
На приведенной ниже диаграмме показан пример пересечения между показателем затрат хэш-соединения и таким показателем альтернативного ему соединения вложенными циклами. В этой точке пересечения определяется пороговое значение, что, в свою очередь, определяет фактический алгоритм, используемый для операции соединения.
Отключение адаптивных соединений без изменения уровня совместимости
Адаптивные соединения можно отключить в области базы данных или инструкций, сохраняя уровень совместимости базы данных 140 и более поздних версий.
Чтобы отключить адаптивные соединения для всех запросов, поступающих из базы данных, выполните следующую команду в контексте соответствующей базы данных:
-- SQL Server 2017 ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = ON; -- Azure SQL Database, SQL Server 2019 and later versions ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = OFF; Чтобы снова включить адаптивные соединения для всех запросов, выполняемых из базы данных, выполните следующую команду в контексте соответствующей базы данных:
-- SQL Server 2017 ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = OFF; -- Azure SQL Database, SQL Server 2019 and later versions ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = ON; Вы также можете отключить адаптивные соединения для определенного запроса, назначив DISABLE_BATCH_MODE_ADAPTIVE_JOINS в качестве указания запроса USE HINT. Рассмотрим пример.
SELECT s.CustomerID, s.CustomerName, sc.CustomerCategoryName FROM Sales.Customers AS s LEFT OUTER JOIN Sales.CustomerCategories AS sc ON s.CustomerCategoryID = sc.CustomerCategoryID OPTION (USE HINT('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')); Указание запроса USE HINT имеет приоритет над конфигурацией, областью действия которой является база данных, или флагом трассировки.
Значения NULL и соединения
Если в столбцах, по которым производится соединение таблиц, есть значение NULL, значения NULL друг с другом совпадать не будут. Наличие таких значений в столбце одной из соединяемых таблиц возможно только при использовании внешнего соединения (если только предложение WHERE не исключает значение NULL).
Ниже приведены две таблицы, которые содержатся NULL в столбце, который будет участвовать в соединении:
table1 table2 a b c d ------- ------ ------- ------ 1 one NULL two NULL three 4 four 4 join4 Соединение, которое сравнивает значения столбца с столбцом c , не получает совпадение по столбцам со значениями NULL :
SELECT * FROM table1 t1 JOIN table2 t2 ON t1.a = t2.c ORDER BY t1.a; GO Возвращается только одна строка со значением 4 в столбцах a : c
a b c d ----------- ------ ----------- ------ 4 join4 4 four (1 row(s) affected) Значения NULL, возвращаемые из базовой таблицы, также сложно отличить от значений NULL, возвращаемых при внешнем соединении. Например, следующая инструкция SELECT выполняет левое внешнее соединение этих двух таблиц.
SELECT * FROM table1 t1 LEFT OUTER JOIN table2 t2 ON t1.a = t2.c ORDER BY t1.a; GO a b c d ----------- ------ ----------- ------ NULL three NULL NULL 1 one NULL NULL 4 join4 4 four (3 row(s) affected) Результаты не позволяют легко различать NULL данные из NULL данных, которые представляют собой ошибку соединения. Если значения NULL присутствуют в присоединении к данным, обычно предпочтительнее опустить их из результатов с помощью регулярного соединения.
Далее
- Справочник по логическим и физическим операторам Showplan
- Операторы сравнения (Transact-SQL)
- Преобразование типов данных (ядро СУБД)
- Вложенные запросы
- Адаптивное соединение
- Предложение FROM плюс JOIN, APPLY, PIVOT (Transact-SQL)
Что такое join в SQL и как с ним работать
Join — оператор для объединения данных из нескольких таблиц с общим ключом.
Анастасия Хамидулина
Автор статьи
9 июня 2022 в 18:11
SQL — Simple Query Language, то есть «простой язык запросов». Его создали, чтобы работать с реляционными базами данных. В таких базах данные представлены в виде таблиц. Зависимости между несколькими таблицами задают с помощью связующих — реляционных столбцов.
Когда запрашиваем данные из одной таблицы, работа со связующими столбцами не нужна. Но если нужно агрегировать данные из нескольких, стоит описать правила: как будут связаны строки на основе значений связующих столбцов. Тогда на помощь и приходит оператор join.
Что такое оператор join в SQL
Join — оператор, который используют, чтобы объединять строки из двух или более таблиц на основе связующего столбца между ними. Такой столбец еще называют ключом.
Чтобы разобраться в основах SQL, записывайтесь на курс
«Аналитик данных». Вы научитесь делать таблицы и составлять запросы для анализа. Узнаете, как соединять и обрабатывать несколько таблиц, использовать оконные функции.
Предположим, что у нас есть таблица заказов — Orders:
| OrderID | CustomerID | OrderDate |
| 304101 | 21 | 10-05-2021 |
| 304102 | 34 | 20-06-2021 |
| 304103 | 22 | 25-07-2021 |
И таблица клиентов — Customers:
| CustomerID | CustomerName | ContactName |
| 21 | Балалайка Сервис | Иван Иванов |
| 22 | Рога и копыта | Семён Семёнов |
| 23 | Редиска Менеджмент | Пётр Петров |
Столбец CustomerID в таблице заказов соотносится со столбцом CustomerID в таблице клиентов. То есть он — связующий двух таблиц. Чтобы узнать, когда, какой клиент и какой заказ оформил, составьте запрос:
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate FROM Orders JOIN Customers ON Orders.CustomerID=Customers.CustomerID;
Результат запроса будет выглядеть так:
| OrderID | CustomerName | OrderDate |
| 304101 | Балалайка Сервис | 10-05-2021 |
| 304103 | Рога и копыта | 25-07-2021 |
Общий синтаксис оператора join:
Python-разработчик: новая работа через 9 месяцев
Получится, даже если у вас нет опыта в IT

Соединять можно и больше двух таблиц: к запросу добавьте еще один оператор join. Например, в дополнение к предыдущим двум таблицам у нас есть таблица продавцов — Managers:
| OrderID | ManagerName | ContactDate |
| 304101 | Артём Лапин | 05-05-2021 |
| 304102 | Егор Орлов | 15-06-2021 |
| 304103 | Евгений Соколов | 20-07-2021 |
Таблица продавцов связана с таблицей заказов столбцом OrderID. Чтобы в дополнение к предыдущему запросу узнать, какой продавец обслуживал заказ, составьте следующий запрос:
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate, Managers.ManagerName FROM Orders JOIN Customers ON Orders.CustomerID=Customers.CustomerID JOIN Managers ON Orders.OrderId=Managers.OrderId
| OrderID | CustomerName | OrderDate | ManagerName |
| 304101 | Балалайка Сервис | 10-05-2021 | Артём Лапин |
| 304103 | Рога и копыта | 25-07-2021 | Евгений Соколов |
Внутреннее соединение INNER JOIN
Если использовать оператор INNER JOIN, в результат запроса попадут только те записи, для которых выполняется условие объединения. Еще одно условие — записи должны быть в обеих таблицах. В финальный результат из примера выше не попали записи с CustomerID=23 и OrderID=304102: для них нет соответствия в таблицах.
Если хотите составлять запросы на объединение данных, приходите на курс «Анализ данных». Научитесь работать с простыми и сложными запросами и использовать разные комбинации для решения реальных задач. А еще получите диплом установленного образца и сможете хорошо зарабатывать.
Общий синтаксис запроса INNER JOIN:
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;
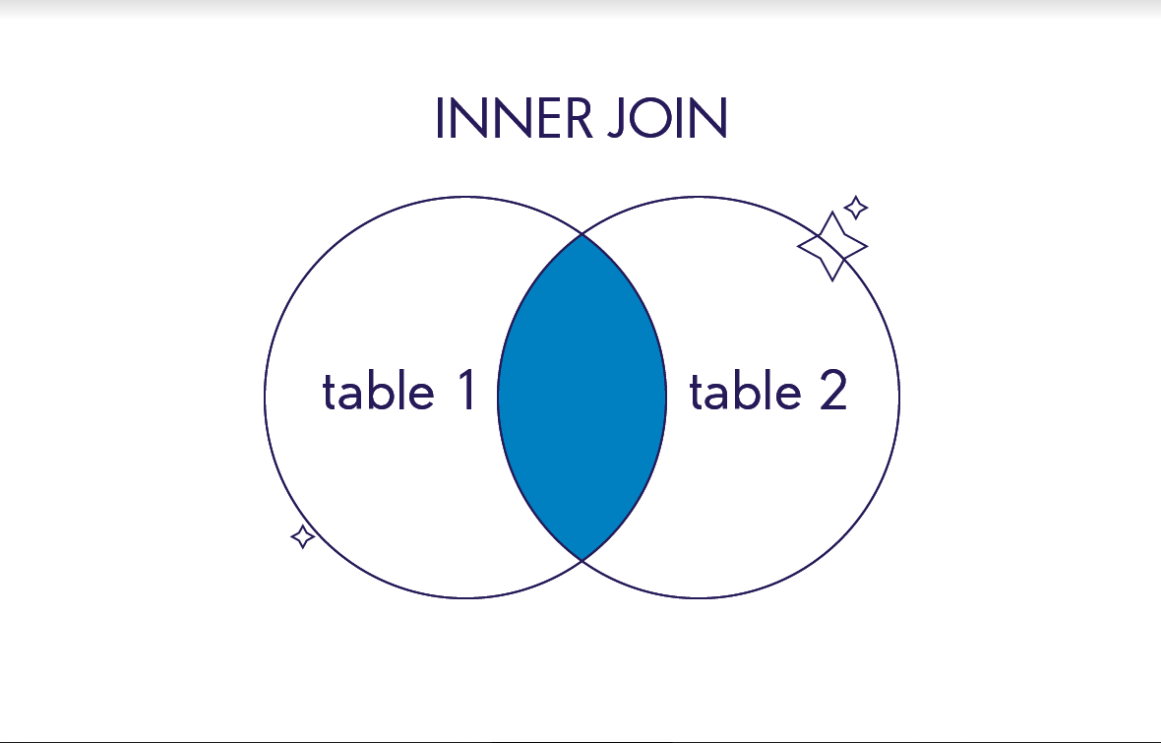
Иллюстрация работы INNER JOIN
Слово INNER в запросе можно опускать, тогда общий синтаксис запроса будет выглядеть так:
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;
Внешние соединения OUTER JOIN
Если использовать внешнее соединение, то в результат запроса попадут не только записи с совпадениями в обеих таблицах, но и записи одной из таблиц целиком. Этим внешнее соединение отличается от внутреннего.
Указание таблицы, из которой нужно выбрать все записи без фильтрации, называется направлением соединения.
LEFT OUTER JOIN / LEFT JOIN
В финальный результат такого соединения попадут все записи из левой, первой таблицы. Даже если не будет ни одного совпадения с правой. И записи из второй таблицы, для которых выполняется условие объединения.
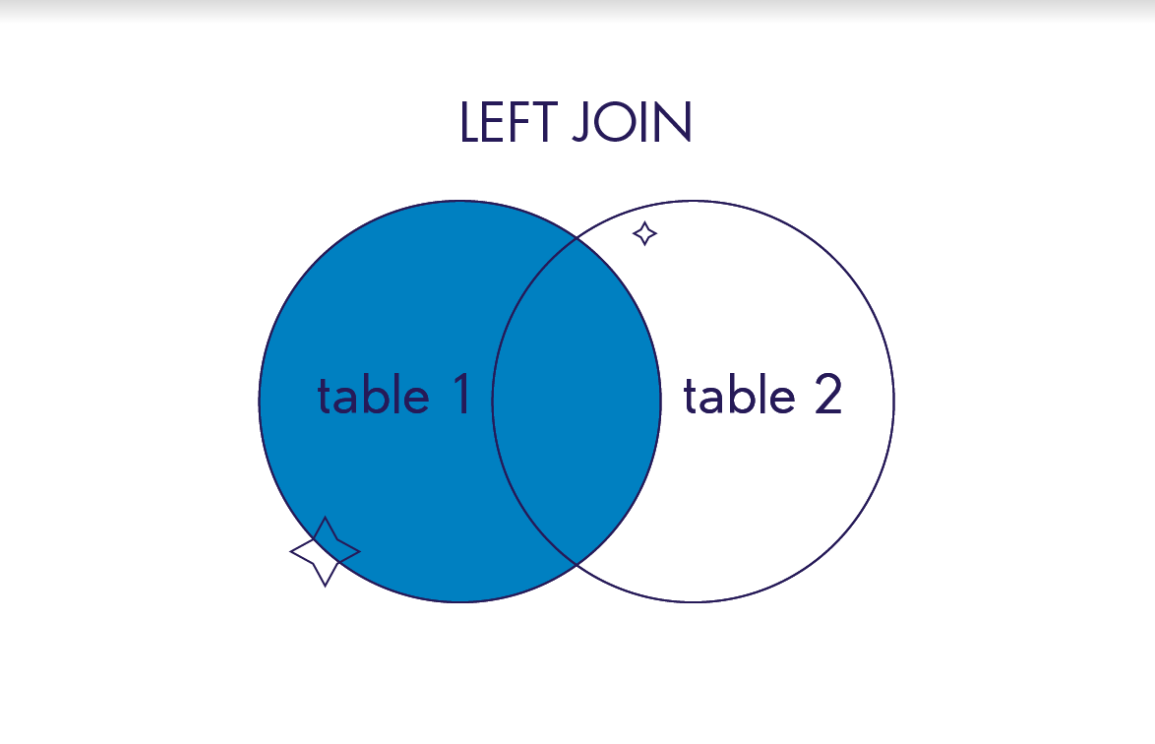
Иллюстрация работы LEFT JOIN
Синтаксис:
SELECT column_name(s) FROM table1 LEFT JOIN table2 ON table1.column_name = table2.column_name;
Пример:
| OrderID | CustomerID | OrderDate |
| 304101 | 21 | 10-05-2021 |
| 304102 | 34 | 20-06-2021 |
| 304103 | 22 | 25-07-2021 |
| CustomerID | CustomerName | ContactName |
| 21 | Балалайка Сервис | Иван Иванов |
| 22 | Рога и копыта | Семён Семёнов |
| 23 | Редиска Менеджмент | Пётр Петров |
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate FROM Orders LEFT JOIN Customers ON Orders.CustomerID=Customers.CustomerID;
| OrderID | CustomerName | OrderDate |
| 304101 | Балалайка Сервис | 10-05-2021 |
| 304102 | null | 20-06-2021 |
| 304103 | Рога и копыта | 25-07-2021 |
RIGHT OUTER JOIN / RIGHT JOIN
В финальный результат этого соединения попадут все записи из правой, второй таблицы. Даже если не будет ни одного совпадения с левой. И записи из первой таблицы, для которых выполняется условие объединения.
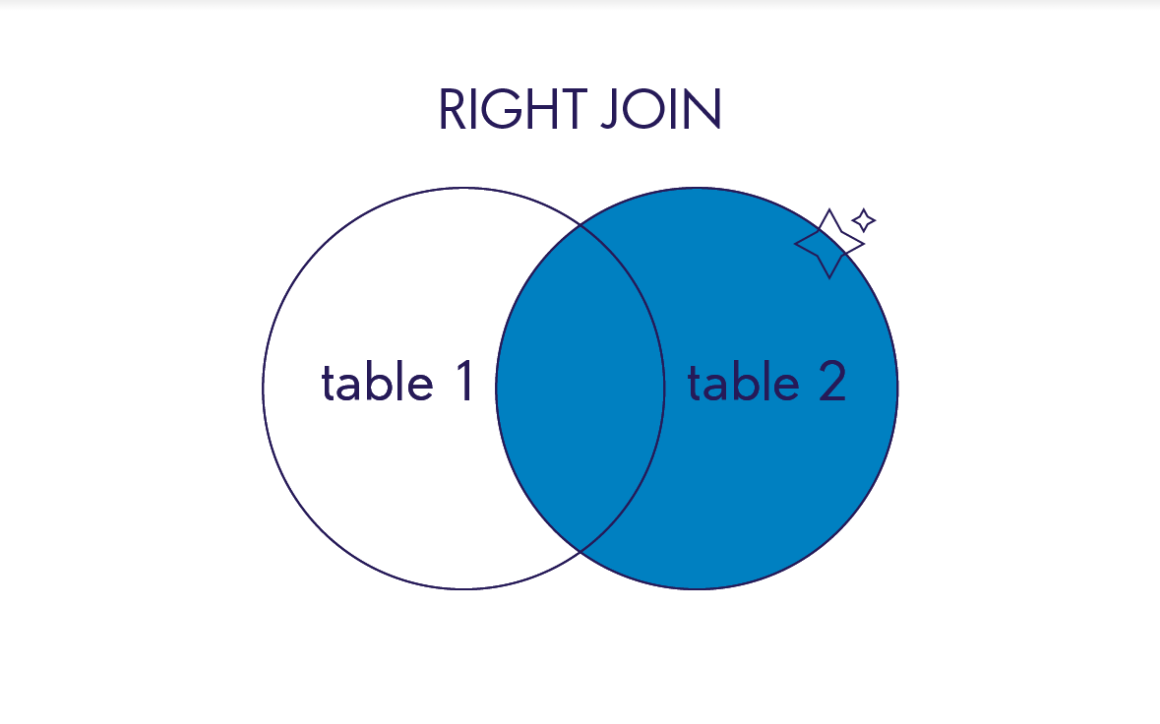
Иллюстрация работы RIGHT JOIN
Синтаксис:
SELECT column_name(s) FROM table1 RIGHT JOIN table2 ON table1.column_name = table2.column_name;
Пример:
| OrderID | CustomerID | OrderDate |
| 304101 | 21 | 10-05-2021 |
| 304102 | 34 | 20-06-2021 |
| 304103 | 22 | 25-07-2021 |
| CustomerID | CustomerName | ContactName |
| 21 | Балалайка Сервис | Иван Иванов |
| 22 | Рога и копыта | Семён Семёнов |
| 23 | Редиска Менеджмент | Пётр Петров |
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate FROM Orders RIGHT JOIN Customers ON Orders.CustomerID=Customers.CustomerID;
| OrderID | CustomerName | OrderDate |
| 304101 | Балалайка Сервис | 10-05-2021 |
| null | Редиска Менеджмент | null |
| 304103 | Рога и копыта | 25-07-2021 |
FULL OUTER JOIN / FULL JOIN
В финальный результат такого соединения попадут все записи из обеих таблиц. Независимо от того, выполняется условие объединения или нет.
Если хотите разобраться в нюансах join в SQL, приходите на курс
«Программирование для анализа данных». Вы узнаете, как работать с базами данных и таблицами: создавать их, объединять и обрабатывать. Выполните практические задания и получите ответы на вопросы от наставников.
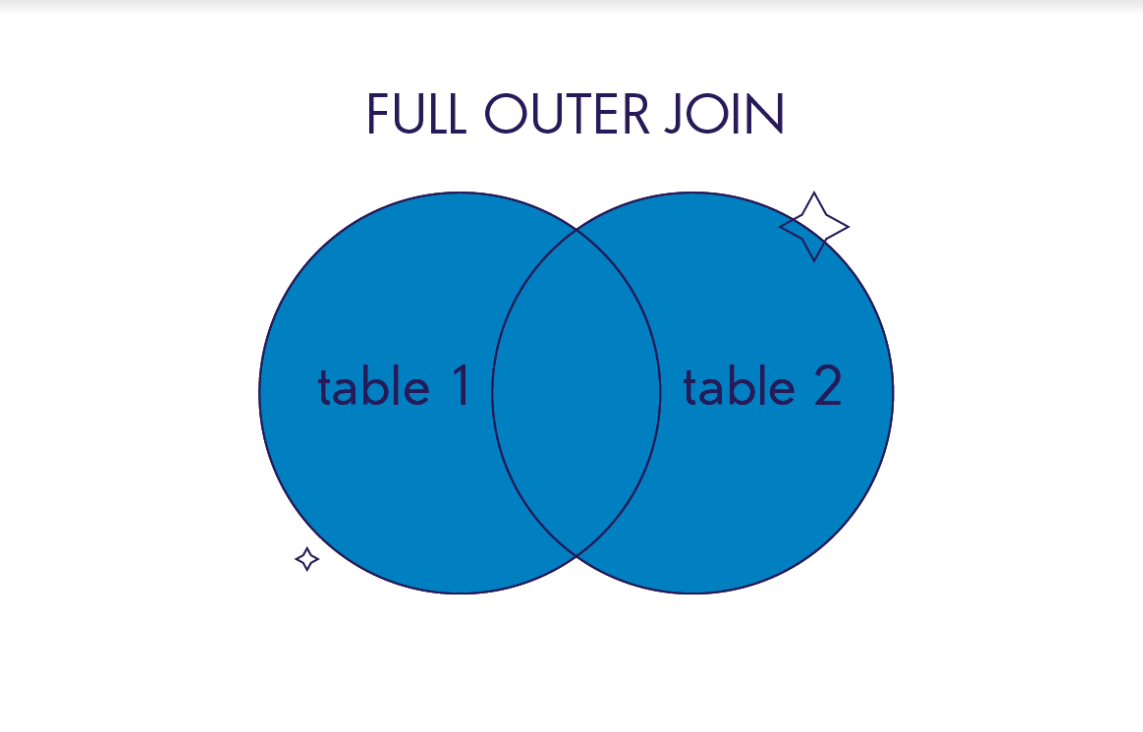
Иллюстрация работы FULL JOIN
Синтаксис:
SELECT column_name(s) FROM table1 FULL JOIN table2 ON table1.column_name = table2.column_name;
Пример:
| OrderID | CustomerID | OrderDate |
| 304101 | 21 | 10-05-2021 |
| 304102 | 34 | 20-06-2021 |
| 304103 | 22 | 25-07-2021 |
| CustomerID | CustomerName | ContactName |
| 21 | Балалайка Сервис | Иван Иванов |
| 22 | Рога и копыта | Семён Семёнов |
| 23 | Редиска Менеджмент | Пётр Петров |
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate FROM Orders FULL JOIN Customers ON Orders.CustomerID=Customers.CustomerID;
| OrderID | CustomerName | OrderDate |
| 304101 | Балалайка Сервис | 10-05-2021 |
| 304102 | null | 20-06-2021 |
| 304103 | Рога и копыта | 25-07-2021 |
| null | Редиска Менеджмент | null |
Перекрестное соединение CROSS JOIN
Этот оператор отличается от предыдущих операторов соединения: ему не нужно задавать условие объединения (ON table1.column_name = table2.column_name). Записи в таблице с результатами — это результат объединения каждой записи из левой таблицы с записями из правой. Такое действие называют декартовым произведением.
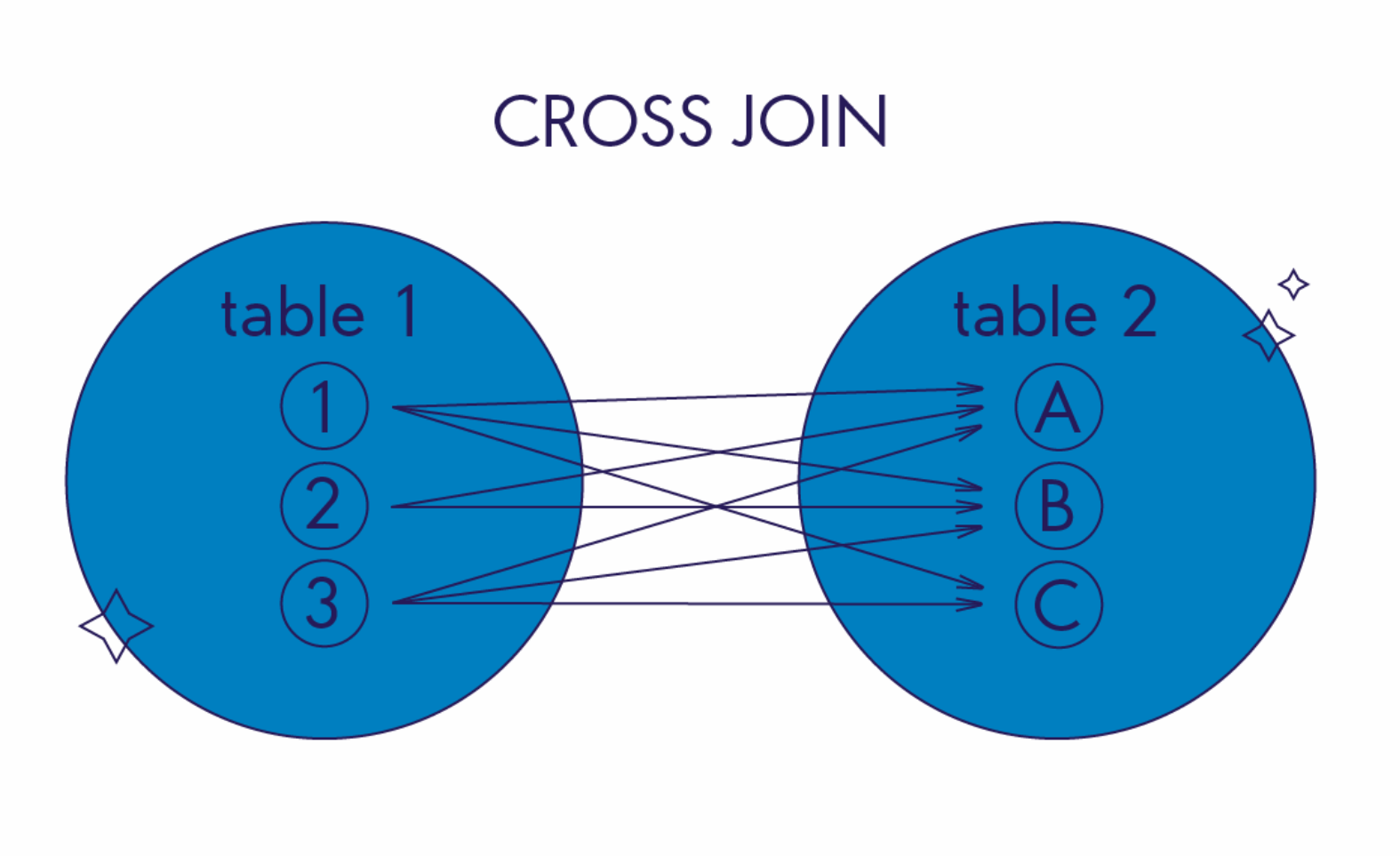
Иллюстрация работы CROSS JOIN
Синтаксис:
SELECT column_name(s) FROM table1 CROSS JOIN table2;
Пример:
| OrderID | CustomerID | OrderDate |
| 304101 | 21 | 10-05-2021 |
| 304102 | 34 | 20-06-2021 |
| 304103 | 22 | 25-07-2021 |
| CustomerID | CustomerName | ContactName |
| 21 | Балалайка Сервис | Иван Иванов |
| 22 | Рога и копыта | Семён Семёнов |
| 23 | Редиска Менеджмент | Пётр Петров |
</p> SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate FROM Orders CROSS JOIN Customers;
| OrderID | CustomerName | OrderDate |
| 304101 | Балалайка Сервис | 10-05-2021 |
| 304101 | Рога и копыта | 10-05-2021 |
| 304101 | Редиска Менеджмент | 10-05-2021 |
| 304102 | Балалайка Сервис | 20-06-2021 |
| 304102 | Рога и копыта | 20-06-2021 |
| 304102 | Редиска Менеджмент | 20-06-2021 |
| 304103 | Балалайка Сервис | 25-07-2021 |
| 304103 | Рога и копыта | 25-07-2021 |
| 304103 | Редиска Менеджмент | 25-07-2021 |
Соединение SELF JOIN
Его используют, когда в запросе нужно соединить несколько записей из одной и той же таблицы.
В SQL нет отдельного оператора, чтобы описать SELF JOIN соединения. Поэтому, чтобы описать соединения данных из одной и той же таблицы, воспользуйтесь операторами JOIN или WHERE.
Если интересно разобраться в тонкостях работы с SQL, понять, как делать запросы и составлять таблицы, приходите на курс «Аналитик данных». Под руководством наставников вы попрактикуетесь в решении разных задач и сможете профессионально работать с одним из самых популярных языков запросов.
Учтите, что в одном запросе нельзя дважды использовать имя одной и той же таблицы: иначе запрос вернет ошибку. Поэтому, чтобы выполнить соединение таблицы SQL с самой собой, в запросе ей присваивают два разных временных имени — алиаса.
Синтаксис соединения SELF JOIN при использовании оператора JOIN:
SELECT column_name(s) FROM table1 a1 JOIN table1 a2 ON a1.column_name = a2.column_name;
Оператор JOIN может быть любым: используйте LEFT JOIN, RIGHT JOIN. Результат будет таким же, как когда объединяли две разные таблицы.
Синтаксис соединения SELF JOIN при использовании оператора WHERE:
SELECT column_name(s) FROM table1 a1, table1 a2 WHERE a1.common_col_name = a2.common_col_name;
Пример:
| StudentID | Name | CourseID | Duration |
| 1 | Артём | 1 | 3 |
| 2 | Пётр | 2 | 4 |
| 1 | Артём | 2 | 4 |
| 3 | Борис | 3 | 2 |
| 2 | Ирина | 3 | 5 |
Запрос с оператором WHERE:
SELECT s1.StudentID, s1.Name FROM Students AS s1, Students s2 WHERE s1.StudentID = s2.StudentID AND s1.CourseID <> s2.CourseID;
| StudentID | Name |
| 1 | Артём |
| 2 | Ирина |
| 1 | Артём |
| 2 | Пётр |
Запрос с оператором JOIN:
SELECT s1.StudentID, s1.Name FROM Students s1 JOIN Students s2 ON s1.StudentID = s2.StudentID AND s1.CourseID <> s2.CourseID GROUP BY StudentID;
| StudentID | Name |
| 1 | Артём |
| 2 | Ирина |
Соединение таблиц – операция JOIN и ее виды
Говоря про соединение таблиц в SQL, обычно подразумевают один из видов операции JOIN. Не стоит путать с объединением таблиц через операцию UNION. В этой статье я постараюсь простыми словами рассказать именно про соединение, чтобы после ее прочтения Вы могли использовать джойны в работе и не допускать грубых ошибок.
Соединение – это операция, когда таблицы сравниваются между собой построчно и появляется возможность вывода столбцов из всех таблиц, участвующих в соединении.
Придумаем 2 таблицы, на которых будем тренироваться.
Таблица «Сотрудники», содержит поля:
- id – идентификатор сотрудника
- Имя
- Отдел – идентификатор отдела, в котором работает сотрудник
| id | Имя | Отдел |
|---|---|---|
| 1 | Юлия | 1 |
| 2 | Федор | 2 |
| 3 | Алексей | NULL |
| 4 | Светлана | 2 |
Таблица «Отделы», содержит поля:
- id – идентификатор отдела
- Наименование
| id | Наименование |
|---|---|
| 1 | Кухня |
| 2 | Бар |
| 3 | Администрация |
Давайте уже быстрее что-нибудь покодим.
INNER JOIN
Самый простой вид соединения INNER JOIN – внутреннее соединение. Этот вид джойна выведет только те строки, если условие соединения выполняется (является истинным, т.е. TRUE). В запросах необязательно прописывать INNER – если написать только JOIN, то СУБД по умолчанию выполнить именно внутреннее соединение.
Давайте соединим таблицы из нашего примера, чтобы ответить на вопрос, в каких отделах работают сотрудники (читайте комментарии в запросе для понимания синтаксиса).
SELECT -- Перечисляем столбцы, которые хотим вывести Сотрудники.id, Сотрудники.Имя, Отделы.Наименование AS Отдел -- выводим наименование отдела и переименовываем столбец через as FROM -- таблицы для соединения перечисляем в предложении from Сотрудники -- обратите внимание, что мы не указали вид соединения, поэтому выполнится внутренний (inner) джойн JOIN Отделы -- условия соединения прописываются после ON -- условий может быть несколько, записанных через and, or и т.п. ON Сотрудники.Отдел = Отделы.id
Получим следующий результат:
| id | Имя | Отдел |
|---|---|---|
| 1 | Юлия | Кухня |
| 2 | Федор | Бар |
| 4 | Светлана | Бар |
Из результатов пропал сотрудник Алексей (id = 3), потому что условие «Сотрудники.Отдел = Отделы.id» не будет истинно для этой сроки из таблицы «Сотрудники» с каждой строкой из таблицы «Отделы». По той же логике в результате нет отдела «Администрация». Попробую это визуализировать (зеленные линии – условие TRUE, иначе линия красная):
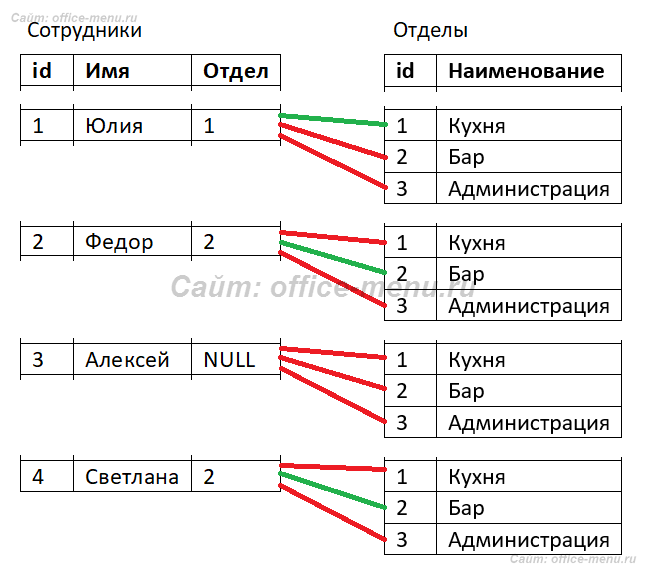
Если не углубляться в то, как внутреннее соединение работает под капотом СУБД, то происходит примерно следующее:
- Каждая строка из одной таблицы сравнивается с каждой строкой из другой таблицы
- Строка возвращается, если условие сравнения является истинным
Если для одной или нескольких срок из левой таблицы (в рассмотренном примере левой таблицей является «Сотрудники», а правой «Отделы») истинным условием соединения будут являться одна или несколько срок из правой таблицы, то строки умножат друг друга (повторятся). В нашем примере так произошло для отдела с поэтому строка из таблицы «Отделы» повторилась дважды для Федора и Светланы.
Перемножение таблиц проще ощутить на таком примере, где условие соединения будет всегда возвращать TRUE, например 1=1:
SELECT * FROM Сотрудники JOIN Отделы ON 1=1
В результате получится 12 строк (4 сотрудника * 3 отдела), где для каждого сотрудника подтянется каждый отдел.
Также хочу сразу отметить, что в соединении может участвовать сколько угодно таблиц, можно таблицу соединить даже саму с собой (в аналитических задачах это не редкость). Какая из таблиц будет правой или левой не имеется значения для INNER JOIN (для внешних соединений типа LEFT JOIN или RIGHT JOIN это важно. Читайте далее). Пример соединения 4-х таблиц:
SELECT * FROM Table_1 JOIN Table_2 ON Table_1.Column_1 = Table_2.Column_1 JOIN Table_3 ON Table_1.Column_1 = Table_3.Column_1 AND Table_2.Column_1 = Table_3.Column_1 JOIN Table_1 AS Tbl_1 -- Задаем алиас для таблицы, чтобы избежать неоднозначности -- Если в Table_1.Column_1 хранится порядковый номер какого-то объекта, -- то так можно присоединить следующий по порядку объект ON Table_1.Column_1 = Tbl_1.Column_1 + 1
Как видите, все просто, прописываем новый джойн после завершения условий предыдущего соединения. Обратите внимание, что для Table_3 указано несколько условий соединения с двумя разными таблицами, а также Table_1 соединяется сама с собой по условию с использованием сложения.
Строки, которые выведутся запросом, должны совпасть по всем условиям. Например:
- Строка из Table_1 соединилась со строкой из Table_2 по условию первого JOIN. Давайте назовем ее «объединенной строкой» из двух таблиц;
- Объединенная строка успешно соединилась с Table_3 по условию второго JOIN и теперь состоит из трех таблиц;
- Для объединенной строки не нашлось строки из Table_1 по условию третьего JOIN, поэтому она не выводится вообще.
На этом про внутреннее соединение и логику соединения таблиц в SQL – всё. Если остались неясности, то спрашивайте в комментариях.
Далее рассмотрим отличия остальных видов джойнов.
LEFT JOIN и RIGHT JOIN
Левое и правое соединения еще называют внешними. Главное их отличие от внутреннего соединения в том, что строка из левой (для LEFT JOIN) или из правой таблицы (для RIGHT JOIN) попадет в результаты в любом случае. Давайте до конца определимся с тем, какая таблица левая, а какая правая.
Левая таблица та, которая идет перед написанием ключевых слов [LEFT | RIGHT| INNER] JOIN, правая таблица – после них:
SELECT * FROM Левая_таблица AS lt LEFT JOIN Правая_таблица AS rt ON lt.c = rt.c
Теперь изменим наш SQL-запрос из самого первого примера так, чтобы ответить на вопрос «В каких отделах работают сотрудники, а также показать тех, кто не распределен ни в один отдел?»:
SELECT Сотрудники.id, Сотрудники.Имя, Отделы.Наименование AS Отдел FROM Сотрудники LEFT JOIN Отделы -- добавляем только left ON Сотрудники.Отдел = Отделы.id
Результат запроса будет следующим:
| id | Имя | Отдел |
|---|---|---|
| 1 | Юлия | Кухня |
| 2 | Федор | Бар |
| 3 | Алексей | NULL |
| 4 | Светлана | Бар |
Как видите, запрос вернул все строки из левой таблицы «Сотрудники», дополнив их значениями из правой таблицы «Отделы». А вот строка для отдела «Администрация» не показана, т.к. для нее не нашлось совпадений слева.
Это мы рассмотрели пример для левого внешнего соединения. Для RIGHT JOIN будет все тоже самое, только вернутся все строки из таблицы «Отделы»:
| id | Имя | Отдел |
|---|---|---|
| 1 | Юлия | Кухня |
| 2 | Федор | Бар |
| 4 | Светлана | Бар |
| NULL | NULL | Администрация |
Алексей «потерялся», Администрация «нашлась».
Вопрос для Вас. Что надо изменить в последнем приведенном SQL-запросе, чтобы результат остался тем же, но вместо LEFT JOIN, использовался RIGHT JOIN?
Ответ. Нужно поменять таблицы местами:
SELECT Сотрудники.id, Сотрудники.Имя, Отделы.Наименование AS Отдел FROM Отделы RIGHT JOIN Сотрудники ON Сотрудники.Отдел = Отделы.id
В одном запросе можно применять и внутренние соединения, и внешние одновременно, главное соблюдать порядок таблиц, чтобы не потерять часть записей (строк).
FULL JOIN
Еще один вид соединения, который осталось рассмотреть – полное внешнее соединение.
Этот вид джойна вернет все строки из всех таблиц, участвующих в соединении, соединив между собой те, которые подошли под условие ON.
Давайте посмотрим всех сотрудников и все отделы из наших тестовых таблиц:
SELECT Сотрудники.id, Сотрудники.Имя, Отделы.Наименование AS Отдел FROM Сотрудники FULL JOIN Отделы ON Сотрудники.Отдел = Отделы.id
| id | Имя | Отдел |
|---|---|---|
| 1 | Юлия | Кухня |
| 2 | Федор | Бар |
| 3 | Алексей | NULL |
| 4 | Светлана | Бар |
| NULL | NULL | Администрация |
Теперь мы видим все, даже Алексея без отдела и Администрацию без сотрудников.
Вместо заключения
Помните о порядке выполнения соединений и порядке таблиц, если используете несколько соединений и используете внешние соединения. Можно выполнять LEFT JOIN для сохранения всех строк из самой первой таблицы, а последним внутренним соединением потерять часть данных. На маленьких таблицах косяк заметить легко, на огромных очень тяжело, поэтому будьте внимательны.
Рассмотрим последний пример и введем еще одну таблицу «Банки», в которой обслуживаются наши придуманные сотрудники:
| id | Наименование |
|---|---|
| 1 | Банк №1 |
| 2 | Лучший банк |
| 3 | Банк Лидер |
В таблицу «Сотрудники» добавим столбец «Банк»:
| id | Имя | Отдел | Банк |
|---|---|---|---|
| 1 | Юлия | 1 | 2 |
| 2 | Федор | 2 | 2 |
| 3 | Алексей | NULL | 3 |
| 4 | Светлана | 2 | 4 |
Теперь выполним такой запрос:
SELECT Сотрудники.id, Сотрудники.Имя, Отделы.Наименование AS Отдел, Банки.Наименование AS Банк FROM Сотрудники LEFT JOIN Отделы ON Сотрудники.Отдел = Отделы.id INNER JOIN Банки ON Сотрудники.Банк = Банки.id
В результате потеряли информацию о Светлане, т.к. для нее не нашлось банка с (такое происходит из-за неправильной проектировки БД):
| id | Имя | Отдел | Банк |
|---|---|---|---|
| 1 | Юлия | Кухня | Лучший банк |
| 2 | Федор | Бар | Лучший банк |
| 3 | Алексей | NULL | Банк Лидер |
Хочу обратить внимание на то, что любое сравнение с неизвестным значением никогда не будет истинным (даже NULL = NULL). Эту грубую ошибку часто допускают начинающие специалисты. Подробнее читайте в статье про значение NULL в SQL.
Пройдите мой тест на знание основ SQL. В нем есть задания на соединения таблиц, которые помогут закрепить материал.
Дополнить Ваше понимание соединений в SQL могут схемы, изображенные с помощью кругов Эйлера. В интернете много примеров в виде картинок.
Если какие нюансы джойнов остались не раскрытыми, или что-то описано не совсем понятно, что-то надо дополнить, то пишите в комментариях. Буду только рад вопросам и предложениям.
Привожу простыню запросов, чтобы Вы могли попрактиковаться на легких примерах, рассмотренных в статье:
-- Создаем CTE для таблиц из примеров WITH Сотрудники AS( SELECT 1 AS id, 'Юлия' AS Имя, 1 AS Отдел, 2 AS Банк UNION ALL SELECT 2, 'Федор', 2, 2 UNION ALL SELECT 3, 'Алексей', NULL, 3 UNION ALL SELECT 4, 'Светлана', 2, 4 ), Отделы AS( SELECT 1 AS id, 'Кухня' AS Наименование UNION ALL SELECT 2, 'Бар' UNION ALL SELECT 3, 'Администрация' ), Банки AS( SELECT 1 AS id, 'Банк №1' AS Наименование UNION ALL SELECT 2, 'Лучший банк' UNION ALL SELECT 3, 'Банк Лидер' ) -- Если надо выполнить другие запросы, то сначала закоментируй это запрос с помощью /**/, -- а нужный запрос расскоментируй или напиши свой. -- Это пример внутреннего соединения SELECT Сотрудники.id, Сотрудники.Имя, Отделы.Наименование AS Отдел FROM Сотрудники JOIN Отделы ON Сотрудники.Отдел = Отделы.id /* -- Пример левого джойна SELECT Сотрудники.id, Сотрудники.Имя, Отделы.Наименование AS Отдел FROM Сотрудники LEFT JOIN Отделы ON Сотрудники.Отдел = Отделы.id */ /* -- Результат этого запроса будет аналогичен результату запроса выше, хотя соединение отличается SELECT Сотрудники.id, Сотрудники.Имя, Отделы.Наименование AS Отдел FROM Отделы RIGHT JOIN Сотрудники ON Сотрудники.Отдел = Отделы.id */ /* -- Правое соединение SELECT Сотрудники.id, Сотрудники.Имя, Отделы.Наименование AS Отдел FROM Сотрудники RIGHT JOIN Отделы ON Сотрудники.Отдел = Отделы.id */ /* -- Пример с использованием разных видов JOIN SELECT Сотрудники.id, Сотрудники.Имя, Отделы.Наименование AS Отдел FROM Отделы RIGHT JOIN Сотрудники ON Сотрудники.Отдел = Отделы.id LEFT JOIN Банки ON Банки.id = Сотрудники.Банк */ /* -- Полное внешние соединение SELECT Сотрудники.id, Сотрудники.Имя, Отделы.Наименование AS Отдел FROM Сотрудники FULL JOIN Отделы ON Сотрудники.Отдел = Отделы.id */ /* -- Пример с потерей строки из-за последнего внутреннего соединения SELECT Сотрудники.id, Сотрудники.Имя, Отделы.Наименование AS Отдел, Банки.Наименование AS Банк FROM Сотрудники LEFT JOIN Отделы ON Сотрудники.Отдел = Отделы.id INNER JOIN Банки ON Сотрудники.Банк = Банки.id */ /* -- Запрос с условием, которое всегда будет True SELECT * FROM Сотрудники JOIN Отделы ON 1=1 */
- Объединение таблиц – UNION
- Соединение таблиц – операция JOIN и ее виды
- Тест на знание основ SQL
Если материалы office-menu.ru Вам помогли, то поддержите, пожалуйста, проект, чтобы я мог развивать его дальше.