Объем памяти, занимаемый текстом

Для представления текстовой (символьной) информации в компьютере используется алфавит мощностью 256 символов. Один символ из такого алфавита несет 8 бит информации (2 8 =256). 8 бит =1 байту, следовательно, двоичный код каждого символа в компьютерном тексте занимает 1 байт памяти.
Уровень «3»
- Сколько бит памяти займет слово «Микропроцессор»?([1],c.131, пример 1)
Решение:
Слово состоит из 14 букв. Каждая буква – символ компьютерного алфавита, занимает 1 байт памяти. Слово занимает 14 байт =14*8=112 бит памяти.
Ответ: 112 бит
- Текст занимает 0, 25 Кбайт памяти компьютера. Сколько символов содержит этот текст? ([1],c.133, №31)
Решение:
Переведем Кб в байты: 0, 25 Кб * 1024 =256 байт. Так как текст занимает объем 256 байт, а каждый символ – 1 байт, то в тексте 256 символов.
Ответ: 256 символов
- Текст занимает полных 5 страниц. На каждой странице размещается 30 строк по 70 символов в строке. Какой объем оперативной памяти (в байтах) займет этот текст? ([1],c.133, №32)
Решение:
30*70*5 = 10500 символов в тексте на 5 страницах. Текст займет 10500 байт оперативной памяти.
Ответ: 10500 байт
- Считая, что каждый символ кодируется одним байтом, оцените информационный объем следующего предложения из пушкинского четверостишия:
Певец-Давид был ростом мал, Но повалил же Голиафа! (ЕГЭ_2005. демо, уровень А)
| 1) | 400 бит | 2) | 50 бит | 3) | 400 байт | 4) | 5 байт |
Решение:
В тексте 50 символов, включая пробелы и знаки препинания. При кодировании каждого символа одним байтом на символ будет приходиться по 8 бит, Следовательно, переведем в биты 50*8= 400 бит.
Ответ: 400 бит
- 5.Считая, что каждый символ кодируется одним байтом, оцените информационный объем следующего предложения в кодировке КОИ-8: Сегодня метеорологи предсказывали дождь. (ЕГЭ_2005, уровень А)
Решение:
В таблице КОИ-8 каждый символ закодирован с помощью 8 бит. См. решение задачи №4.
Ответ: 320 бит
- Считая, что каждый символ кодируется 16 битами, оцените информационный объем следующего предложения в кодировкеUnicode:
Каждый символ кодируется 8 битами.
(ЕГЭ_2005, уровень А)
Решение:
34 символа в предложении. Переведем в биты: 34*16=544 бита.
Ответ: 544 бит
- Каждый символ закодирован двухбайтным словом. Оцените информационный объем следующего предложения в этой кодировке:
В одном килограмме 100 грамм.
(ЕГЭ_2005, уровень А)
Решение:
19 символов в предложении. 19*2 =38 байт
Ответ: 38 байт
Уровень «4»
- Текст занимает полных 10 секторов на односторонней дискете объемом 180 Кбайт. Дискета разбита на 40 дорожек по 9 секторов. Сколько символов содержит текст? ([1],c.133, №34)
Решение:
- 40*9 = 360 -секторов на дискете.
- 180 Кбайт : 360 * 10 =5 Кбайт – поместится на одном секторе.
- 5*1024= 5120 символов содержит текст.
Ответ: 5120 символов
- Сообщение передано в семибитном коде. Каков его информационный объем в байтах, если известно, что передано 2000 символов.
Решение:
Если код символа содержит 7 бит, а всего 2000 символов, узнаем сколько бит займет все сообщение. 2000 х 7=14000 бит.
Переведем результат в байты. 14000 : 8 =1750 байт
Ответ: 1750 байт.
Уровень «5»
- Сколько секунд потребуется модему, передающему сообщение со скоростью 28800 бит/с, чтобы передать 100 страниц текста в 30 строк по 60 символов каждая, при условии, что каждый символ кодируется одним байтом? (ЕГЭ_2005, уровень В)
Решение:
- Найдем объем сообщения. 30*60*8*100 =1440000 бит.
- Найдем время передачи сообщения модемом. 1440000 : 28800 =50 секунд
Ответ: 50 секунд
- Сколько секунд потребуется модему, передающему сообщения со скоростью 14400 бит/с, чтобы передать сообщение длиной 225 Кбайт? (ЕГЭ_2005, уровень В)
Решение:
- Переведем 225 Кб в биты.225 Кб *1024*8 = 1843200 бит.
- Найдем время передачи сообщения модемом. 1843200: 14400 =128 секунд.
Ответ: 128 секунд
Сколько места в куче занимают 100 миллионов строк в Java?
При работе с естественным языком и лингвистическом анализе текстов нам часто приходится оперировать огромным количеством уникальных коротких строк. Счёт идёт на десятки и сотни миллионов — именно столько в языке существует, к примеру, осмысленных сочетаний из двух слов. Основной платформой для нас является Java и мы не понаслышке знаем о её прожорливости при работе с таким большим количеством мелких объектов.
Чтобы оценить масштаб бедствия, мы решили провести простой эксперимент — создать 100 миллионов пустых строк в Яве и посмотреть, сколько придётся заплатить за них оперативной памяти.
Внимание: В конце статьи приведён опрос. Будет интересно, если вы попробуете ответить на него до прочтения статьи, для самоконтроля.
Правилом хорошего тона при проведении любых замеров считается опубликовать версию виртуальной машины и параметры запуска теста:
> java -version java version "1.8.0_101" Java(TM) SE Runtime Environment (build 1.8.0_101-b13) Java HotSpot(TM) 64-Bit Server VM (build 25.101-b13, mixed mode) Сжатие указателей включено (читай: размер кучи меньше 32 Гб):
java -Xmx12g -Xms12g -XX:+UseConcMarkSweepGC -XX:NewSize=4g -XX:+UseCompressedOops . ru.habrahabr.experiment.HundredMillionEmptyStringsExperiment Сжатие указателей выключено (читай: размер кучи больше 32 Гб):
java -Xmx12g -Xms12g -XX:+UseConcMarkSweepGC -XX:NewSize=4g -XX:-UseCompressedOops . ru.habrahabr.experiment.HundredMillionEmptyStringsExperiment Исходный код самого теста:
package ru.habrahabr.experiment; import org.apache.commons.lang3.time.StopWatch; import java.util.ArrayList; import java.util.List; public class HundredMillionEmptyStringsExperiment < public static void main(String[] args) throws InterruptedException < Listlines = new ArrayList<>(); StopWatch sw = new StopWatch(); sw.start(); for (int i = 0; i < 100_000_000L; i++) < lines.add(new String(new char[0])); >sw.stop(); System.out.println("Created 100M empty strings: " + sw.getTime() + " millis"); // чтобы не сохранять лишнего и было проще анализировать снимок кучи System.gc(); // защита от оптимизаций while (true) < System.out.println("Line count: " + lines.size()); Thread.sleep(10000); >> > Ищем идентификатор процесса с помощью утилиты jps и делаем снимок кучи (heap dump) с помощью jmap:
> jps 12777 HundredMillionEmptyStringsExperiment > jmap -dump:format=b,file=HundredMillionEmptyStringsExperiment.bin 12777 Dumping heap to E:\jdump\HundredMillionEmptyStringsExperiment.bin . Heap dump file created Анализируем снимок кучи, используя Eclipse Memory Analyzer (MAT):

Для второго теста с выключенным сжатием указателей снимки не приводим, но мы честно провели эксперимент и просим поверить на слово (оптимально: воспроизвести тест и убедиться самим).
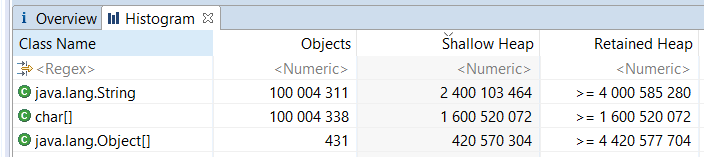
- 2.4 Гб занимает обвязка объектов класса String + указатели на массивы символов + хэши.
- 1.6 Гб занимает обвязка массивов символов.
- 400 Мб занимают указатели на строки.
- 3.2 Гб занимает обвязка объектов класса String + указатели на массивы символов + хэши.
- 2.4 Гб занимает обвязка массивов символов.
- 800 Мб занимают указатели на строки.
Как бороться
Существуют две основные стратегии для экономии ресурсов:
-
Для большого количества дублирующихся строк можно использовать интернирование (string interning) или дедупликацию (string deduplication). Суть механизма такая: поскольку строки в Яве неизменяемые, то можно хранить их в отдельном пуле и при повторе ссылаться на существующий объект вместо создания новой строки. Такой подход не бесплатен — он стоит и памяти и процессорного времени для хранения структуры пула и поиска в нём.
Чем отличается интернирование от дедупликации, какие есть вариации последней, и чем чревато использование метода String.intern() смотрите в замечательном докладе Алексея Шипилёва (ссылка), начиная с 31:52.
На посмотреть
Горячо рекомендуем посмотреть доклад Алексея Шипилёва из Oracle под громким названием «Катехизис java.lang.String» (спасибо periskop за наводку). Там он говорит по проблеме статьи на 4:26 и про интернирование/дедупликацию строк, начиная с 31:52.
В заключение
Решение любой проблемы начинается с оценки её масштабов. Теперь вы эти масштабы знаете и можете учитывать накладные расходы при работе с большим количеством строк в своих проектах.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Сколько места в куче занимают 100 миллионов пустых строк в Java? (Java 8, сжатие указателей включено, считаем только сами объекты, без учёта указателей на них)
7 класс – 2 четверть
Устно: Прочитать параграф 1.5 учебника “Двоичное кодирование”. Выучить все степени двойки от нулевой до десятой!
Письменно: пока не задано.
ДЗ на вторую неделю 2-й четверти.
Устно: Повторить параграф 1.5 учебника “Двоичное кодирование”. Выучить все степени двойки от нулевой до десятой!
Письменно в тетради к учебнику Босовой: выполнить обязательные письменные задания к параграфу 1.5 под номерами: №36, 37, 38, 39 и 40 (пять заданий на стр. 28 и 29 тетради).
Обязательное письменное домашнее задание, выполнить в рабочей тетради! У всех вариантов начальное условие одинаковое: Вы — министр образования племени Мульти-Пульти. Вождь этого племени поручил Вам разработать кодировку (двоичный код) для всех символов, которые есть в алфавите у племени. Алфавит в разных вариантах включает разные символы (см. свой вариант). Министр согласился за четвёрку создать новую кодировку, а за пять баллов закодировать при помощи новой кодировки предложение и измерить в битах и Байтах полученный результат (см. свой вариант с текстом), т.е. измерить информационный вес в битах и Байтах. Пример оформления и частичного решения задания приведен ниже.
ДЗ для варианта А
Задание на четвёрку: в алфавите племени Мульти-Пульти есть только такие символы как ‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’, ‘a’, ‘b’, ‘c’, ‘d’, ‘e’, ‘f’, ‘g’, ‘ ‘, ‘.’ Последние 2 символа — пробел и точка. Каждый символ с двух сторон выделен кавычками. Нужно создать кодировку (или кодировочную таблицу, что просто удобнее) для этого алфавита.
Задание на пятёрку: после выполнения задания на 4 балла следует при помощи полученной кодировочной таблицы закодировать такой текст:
Da Be. Af Cafe. Cafe FE FE FE…
Конечный результат кодирования 32-х символов следует измерить в битах и Байтах.
ДЗ для варианта B
Задание на четвёрку: в алфавите племени Мульти-Пульти есть только такие символы как ‘A’, ‘B’, ‘E’, ‘J’, ‘K’, ‘L’, ‘M’, ‘a’, ‘b’, ‘e’, ‘j’, ‘k’, ‘l’, ‘m’, ‘ ‘, ‘.’ Последние 2 символа — пробел и точка. Каждый символ с двух сторон выделен кавычками. Нужно создать кодировку (или кодировочную таблицу, что просто удобнее) для этого алфавита.
Задание на пятёрку: после выполнения задания на 4 балла следует при помощи полученной кодировочной таблицы закодировать такой текст:
Ja Be. Am Ba ke. Makaka BE BE BE.
Конечный результат кодирования 33-х символов следует измерить в битах и Байтах.
ДЗ для варианта С
Задание на четвёрку: в алфавите племени Мульти-Пульти есть только такие символы как ‘A’, ‘B’, ‘O’, ‘J’, ‘K’, ‘N’, ‘P’, ‘a’, ‘b’, ‘o’, ‘j’, ‘k’, ‘n’, ‘p’, ‘ ‘, ‘.’ Последние 2 символа — пробел и точка. Каждый символ с двух сторон выделен кавычками. Нужно создать кодировку (или кодировочную таблицу, что просто удобнее) для этого алфавита.
Задание на пятёрку: после выполнения задания на 4 балла следует при помощи полученной кодировочной таблицы закодировать такой текст:
Koba PaPa. JaPaNkA. Kaban Ajbo Pan.
Конечный результат кодирования 35-ти символов следует измерить в битах и Байтах.
ДЗ для варианта D
Задание на четвёрку: в алфавите племени Мульти-Пульти есть только такие символы как ‘A’, ‘B’, ‘V’, ‘W’, ‘X’, ‘Y’, ‘Z’, ‘a’, ‘b’, ‘v’, ‘w’, ‘x’, ‘y’, ‘z’, ‘ ‘, ‘.’ Последние 2 символа — пробел и точка. Каждый символ с двух сторон выделен кавычками. Нужно создать кодировку (или кодировочную таблицу, что просто удобнее) для этого алфавита.
Задание на пятёрку: после выполнения задания на 4 балла следует при помощи полученной кодировочной таблицы закодировать такой текст:
ZabaVa. Xa Xa Xa. VaWazyBaya baza.
Конечный результат кодирования 34-х символов следует измерить в битах и Байтах.
Пример оформления и частичного выполнения ДЗ
Дано: алфавит ‘A’, ‘B’, ‘С’, ‘a’, ‘b’, ‘с’, ‘ ‘, ‘.’
Найти: кодир. таблицу
Решение: строим двоичное дерево.
Рисунок дерева: (здесь должен быть рисунок).
Ответ: Искомая таблица (здесь должна быть таблица, а не строка с символами) такая: ‘A’ = 000 ‘В’ = 001 ‘С’ = 010 ‘a’ = … ‘b’ = … ‘c’ = … ‘ ‘ = … ‘.’ = …
Дано: кодировочная таблица из предыдущего задания и исходный текст:
ABAaba cababa.
Найти: код и его инф. вес — ?
Решение: 000001000………..
Ответ: информационный вес кода составит 42 бита, или 6 Байт (округление производим в бОльшую сторону).
ДЗ на третью неделю 2-й четверти.
Устно: прочитать параграф 1.6 учебника “Измерение информации”.
Письменно в тетради к учебнику Босовой: выполнить обязательные письменные задания к параграфу 1.5 под номерами: №41, 42, 43, 44 (четыре задания на стр. 30 и 31 тетради).
В тетради: обязательное письменное задание: решить 2 задачи . Условие двух задач для всех вариантов одинаковое. Отличаются только значения переменных K, L, W, X, Y, Z (см. свой вариант). Пример оформления будет показан ниже.
Первая задача: определите количество информации в битах и Байтах в сообщении из К символов алфавита мощностью L (на троечку).
Вторая задача: племя Мульти с алфавитом мощностью W написало письмо длиной X символов. Племя Пульти с алфавитом Y написало письмо длиной Z символов. Какое из писем займёт больше места на флешке? Поместятся ли оба письма на дискете объёмом 1,44 МегаБайта? В одном МегаБайте 1024 КилоБайт, а в одном КилоБайте ровно 1024 Байт (вместе с первой задачей — на пятёрку, только вторая задача — на четвёрку).
Значения переменных для варианта А
K = 1000 символов, L = 64 символа, W = 16 символов, X = 20 000 000 символов, Y = 4 символа, Z = 1 000 000 символов.
Значения переменных для варианта B
K = 2000 символов, L = 32 символа, W = 32 символа, X = 10 000 000 символов, Y = 4 символа, Z = 1 000 000 символов.
Значения переменных для варианта С
K = 4000 символов, L = 16 символов, W = 16 символов, X = 10 000 000 символов, Y = 4 символа, Z = 1 000 000 символов.
Значения переменных для варианта D
K = 8000 символов, L = 8 символов, W = 32 символа, X = 20 000 000 символов, Y = 4 символа, Z = 1 000 000 символов.
Пример оформления и выполнения ДЗ
Первая задача (на «4»)
Дано: алфавит из 8 символов и письмо, содержащее 10 символов.
Найти: инф.вес I в битах и Байтах письма — ?
Решение: запишем рабочие формулы: I = K * i N = 2**i
Подставим числовые значения в данные формулы: 8 = 2**i откуда i = 3 бита/символ
I = 10 * 3 = 30 бит, или 4 Байта (округляем в бОльшую сторону).
Ответ: I = 30 бит или 4 Байта.
Вторая задача (на «5»)
Дано: алф. W = 4 симв., длина X = 100 симв., алф. Y = 128 симв., длина Z = 1000 симв. Iдискеты = 1.44 МБ
Найти: инф. вес обоих писем в битах и Байтах I1 — ? I2 — ? I1 v I2 — ? I1+I2 v 1.44 МБ — ?
Решение: запишем рабочие формулы: I = K * i N = 2**i
Подставим числовые значения в данные формулы: 4 = 2**i откуда i1 = 2 бита/символ
I1 = 100 * 2 = 200 бит, или с учётом того, что 1Б=8бит, I1 = 25 Байт (округляем в бОльшую сторону).
Аналогично отыщем i2 и I2. 128 = 2**i откуда i2 = 7 бит/символ. I2 = 1000 * 7 = 7000 бит, или 875 Байт.
Ответ: I1 = 200 бит, или 25 Байт, I2 = 7000 бит, или 875 Байт. I1
ДЗ на четвёртую неделю 2-й четверти.
Устно: повторить параграф 1.6 учебника “Измерение информации”. Знать единицы измерения информации и соотношения между ними. Повторить степени двойки. Готовимся к контрольному тестированию.
Письменно в тетради к учебнику Босовой: выполнить обязательные письменные задания к параграфу 1.6 под номерами: №55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66 (12 заданий на стр. 36, 37, 38 и 39 тетради). За выполнение этого задания будет выставлено две пятёрки (большой объём. ).
В тетради: обязательное письменное задание согласно вашему варианту . Посмотрите на шахматную доску. На ней ровно 64 поля .

Вам нужно придумать способ закодировать позицию из шахматной партии при помощи двоичного кода. При этом Ваш код должен однозначно задавать положение любой фигуры на шахматной доске. Названия фигур и их изображения показаны на рисунке ниже. Белых и чёрных фигур по 6 (всего 12) и ещё понадобится одно обозначение для пустого поля (подсказка: пустое поле можно закодировать как «0000» и ещё останется несколько вакантных мест, их можно НЕ кодировать):

Минимальное задание на тройку: придумать способ закодировать информацию о шести шахматных фигурах и пустом поле.
Задание на четвёрку (выполняется после сделанного задания на тройку): придумать способ закодировать информацию о 64-х полях шахматной доски (подсказка: можно кодировать цифры отдельно и латинские символы отдельно, а можно закодировать все поля сразу).
Задание на пятёрку (выполняется после сделанного задания на четвёрку): согласно своему варианту следует закодировать информацию о шахматных фигурах согласно своему варианту и измерить полученные числовые данные в Байтах. Внимание! Данные о пустых клетках в тетрадь можно не записывать . На дополнительные два плюса (если вы знаете как ходят шахматные фигуры): найти и записать такой ход за белых, чтобы поставить мат чёрным (мат в один ход). Ещё по 2 плюса можно «заработать», решив шахматную задачу других вариантов (всего доступно 10 плюсиков).
Расположение фигур для варианта А
Белые фигуры: король G4, ладья А6, слон В6. Чёрные фигуры: Король F6, ферзь F7, ладья Е7, конь F3, слон D3.
Расположение фигур для варианта В
Белые фигуры: король А5, ферзь F5, слон Н3, пешка В6. Чёрные фигуры: король D8, ферзь В3, ладья G3, слон С6, пешка Е7.
Расположение фигур для варианта С
Белые фигуры: король Е8, ферзь D6, слон А3, конь С5. Чёрные фигуры: король С4, пешка Е3, пешка Е6.
Расположение фигур для варианта D
Белые фигуры: король G1, ладья G4, слон G7, пешка G2, пешка F2. Чёрные фигуры: король G7, ферзь В4, ладья А8, ладья F8, пешка А5, пешка F7, пешка Н7.
Расположение фигур для забывашек (или для тех, кому мало 4-х заданий)
Белые фигуры: король В1, ферзь В3, ладья G7, конь С6, пешка А2, пешка Н4, пешка G5. Чёрные фигуры: король А8, ферзь D2, слон С8, пешка А7, пешка В6, пешка Н5.
ДЗ на пятую неделю 2-й четверти.
Устно: прочитать параграф 2.1 учебника “Основные компоненты компьютера и их функции” и параграф 2.2 «Персональный компьютер».
Письменно (ПО ЖЕЛАНИЮ) в тетради к учебнику Босовой: выполнить задания к параграфу 1.6 под номерами: №72, 73, 74 и 75 (четыре задания на стр. 41 и 42 тетради).
В тетради: обязательное письменное задание для всех вариантов (таблицу перенести в тетрадь!) .
На четвёрку: заполните таблицу, найдя в сети Интернет информацию о первых семи носителях информации. Первую строку можно не переписывать, это образец.
На пятёрку: заполнить всю таблицу, найдя недостающую информацию в сети Интернет.
| Номер | Носитель информации | Максимальная ёмкость | Производитель | Современная стоимость |
| 0 | Диск mini-DVD | 5,32 ГигаБайта | Sony (можно взять любого производителя) | 300 руб. |
| 1 | Флешка | |||
| 2 | Жёсткий диск HDD | |||
| 3 | Жёсткий диск SSD | |||
| 4 | Диск CD | |||
| 5 | Диск DVD | |||
| 6 | Диск Blue-Ray | |||
| 7 | Дискета 3,5 дюйма | |||
| 8 | Дискета 5,25 дюйма | |||
| 9 | Дискета 8 дюймов | |||
| 10 | Карта памяти SD | |||
| 11 | Карта памяти microSD | |||
| 12 | Советская аудиокассета МК-60 |
ДЗ на шестую неделю 2-й четверти.
Устно: прочитать параграф 2.3 учебника «Программное обеспечение компьютера» и параграф 2.4 учебника «Файлы и файловые структуры».
Письменно в тетради к учебнику Босовой: выполнить обязательные письменные задания к параграфу 2.1 под номерами: №76, 78, 79, 80 (четыре задания на стр. 46 ,47 и 48 тетради).
В тетради: обязательное письменное задание, одинаковое для всех вариантов. Таблицу (или таблицы) перенести в тетрадь!
На четвёрку: заполните одну таблицу, найдя в сети Интернет информацию об одном струйном ИЛИ лазерном принтере.
На пятёрку: заполнить две таблицы, найдя недостающую информацию в сети Интернет об одном струйном И об одном лазерном принтере.
| Номер | Свойство принтера (указать краткое наименование) | Характеристики согласно документации |
| 1 | Достоинства | |
| 2 | Недостатки | |
| 3 | Полное наименование принтера | |
| 4 | Разрешение печати (качество печати) | |
| 5 | Скорость печати | |
| 6 | Объём встроенной памяти | |
| 7 | Способ(ы) подключения к компьютеру | |
| 8 | Формат(ы) бумаги | |
| 9 | Плотность (виды) бумаги | |
| 10 | Есть ли цветная печать | |
| 11 | Есть ли карта памяти (да, нет) | |
| 12 | Наименование картриджа (картриджей) | |
| 13 | Ресурс печати картриджа (картриджей), листов | |
| 14 | Число лотков для бумаги, шт. | |
| 15 | Ёмкость лотка (лотков), листов | |
| 16 | Стоимость принтера, руб. |
ДЗ на седьмую неделю 2-й четверти.
Устно: прочитать параграф 2.5 учебника «Пользовательский интерфейс».
Письменно в тетради к учебнику Босовой: выполнить обязательные письменные задания к параграфу 2.2 под номерами: №86, 87, 88, 89, 90, 91 (шесть заданий на стр. 52, 53 и 54 тетради).
В тетради письменно решить три задачи согласно своему варианту. Обратите внимание на пример оформления задачи, показанный ниже по тексту. Задачи выполняются по порядку. На троечку одну, на четвёрку две, на пятёрку — три задачи. Условие всех трёх задач для всех вариантов одинаковое. Отличаются только значения переменных K, L, T, W, X, Y, Z, A, B, C, D (см. свой вариант). Пример оформления и решения первой задачи показан ниже.
Задание на троечку: фотоальбом занимает весь жёсткий диск ёмкостью K. Сколько времени (в сутках) нужно потратить на просмотр фотоальбома, если каждое фото занимает L, а время просмотра одного фото составляет T секунд?
Задание на четвёрку: первые компьютеры имели довольно маленький объём оперативной памяти. Сколько страниц текста можно разместить в оперативной памяти такого компьютера объёмом W, если на странице помещается X строк, в каждой строке можно разместить Y символов. Мощность алфавита составляет Z символов.
Задание на пятёрку: средняя скорость передачи данных по некоторому каналу связи равна A. Определите какое время (в секундах) понадобится для передачи по такому каналу В страниц текста, каждая из которых содержит в среднем С символов, а информационный вес каждого символа равен D.
Значения переменных для варианта А
K = 100 ГигаБайт, L = 2048 Килобит, T = 4 секунды; W = 16 КилоБайт, X = 128 строк, Y = 32 символа, Z = 64 символа; A = 128 Килобит/секунду, B = 64 страницы, C = 32 символа, D = 16 бит/символ.
Значения переменных для варианта B
K = 200 ГигаБайт, L = 2048 Килобит, T = 2 секунды; W = 16 КилоБайт, X = 64 строки, Y = 64 символа, Z = 64 символа; A = 128 Килобит/секунду, B = 128 страниц, C = 32 символа, D = 8 бит/символ.
Значения переменных для варианта С
K = 400 ГигаБайт, L = 2048 Килобит, T = 1 секунду; W = 16 КилоБайт, X = 32 строки, Y = 128 символов, Z = 64 символа; A = 128 Килобит/секунду, B = 128 страниц, C = 16 символов, D = 16 бит/символ.
Значения переменных для варианта D
K = 50 ГигаБайт, L = 2048 Килобит, T = 8 секунд; W = 16 КилоБайт, X = 128 строк, Y = 32 символа, Z = 64 символа; A = 128 Килобит/секунду, B = 32 страницы, C = 64 символа, D = 16 бит/символ.
Пример оформления ДЗ
Первая задача (на «3»)
Дано: K = 500 ГБ, L = 128 кбит/фото, T = 20 сек.
Найти: Tобщ (суток) — ?
Решение: запишем рабочие формулы: K = N * L Tобщ = N * T
Подставим числовые значения в данные формулы, переведя всё в Байты:
500 ГБ = 500 * 1024 МБ = 500 * 1024 * 1024 КБ = 500 * 1024 * 1024 * 1024 Байт = 536870912000 Байт.
128 кбит = 16 килоБайт = 16384 Байт/фото.
Найдём число фотографий в альбоме: N = K / L = 536870912000/16384 = 32768000 фотографий.
Найдём время просмотра в секундах: Тобщ = 32768000*20 = 655360000 секунд. В сутках 24*3600 = 86400 секунд, значит Tобщ = 655360000/86400 = 7585,185 суток. Округляем в бОльшую сторону до 7586 суток.
Ответ: Тобщ = 7586 суток, или чуть более 20 лет.
В тетради: дополнительное письменное задание на вторую пятёрку, одинаковое для всех вариантов: разработать интерфейс приложения «Аудиокнига» для мобильного телефона, который состоял бы из трёх-пяти окон. Рисунки интерфейса следует выполнить в тетради!
ДЗ на восьмую неделю 2-й четверти. Готовимся к контрольной работе по теме «Компьютер».
Это пробный тест для 7 класса перед контрольной. Тест НЕ на отметку.
Подготовительный (перед контрольной работой по главе 1 и 2 учебника) пробный тест для 7 класса. Этот тест, в отличие от контрольного, можно проходить сколько угодно раз. Чтобы начать пробный тест просто нажмите «Начать тест». Чтобы пройти тест повторно — обновите страницу ��

Начать тест
Какой размер оперативной памяти занимает произвольный символ алфавита
Spiral group
Строки в Java . JDK 1.6.
Статья опубликована: 31.01.2007
Последнее изменение: 1 8 .0 3 .2007
Строковый тип (в программировании) — это тип данных, значениями которого является произвольная последовательность символов алфавита. Каждая переменная такого типа может иметь произвольную длину.
Представление строк в памяти связано со следующими проблемами:
— строки могут иметь достаточно существенный размер (до нескольких десятков мегабайт);
— изменяющийся со временем размер – возникают трудности с добавлением и удалением символов.
Введение в строки
В представлении строк в памяти компьютера существует два принципиально разных подхода: представление массивом символов и представление с помощью завершающего байта.
Представление массивом символов.
В этом подходе строки представляются массивом символов ; при этом размер массива хранится в отдельной (служебной) области. От названия языка Pascal , где этот метод был впервые реализован, данный метод получил название Pascal Strings .
Преимущества:
— программа в каждый момент времени «знает» о размере строки, и операции копирования и получения размера строки выполняются достаточно быстро;
— каждый символ строки может изменяться;
— на программном уровне можно следить за выходом за границы строки при её обработке;
— возможно быстрое выполнение операции вида «взятие N-ого символа с конца строки».
Недостатки:
— проблемы с хранением и обработкой символов произвольной длины;
— увеличение затрат на хранение строк — значение «длина строки» так же занимает место и в случае большого количества строк маленького размера может существенно увеличить требования алгоритма к оперативной памяти;
— ограничение максимального размера строки. В современных языках программирования это ограничение скорее теоретическое, так как обычно размер строки хранится в 32-битовом поле, что даёт максимальный размер строки в 2 147 483 647 байт (2 гигабайта).
Представление с помощью «завершающего байта» .
Одно из возможных значений символов алфавита (как правило, это символ с кодом 0) выбирается в качестве признака конца строки, и строка хранится как последовательность байтов от начала до конца. Есть системы, в которых в качестве признака конца строки используется не символ 0, а байт 0xFF (255) или код символа «$».
Метод имеет три названия — ASCIIZ (символы в кодировке ASCII с нулевым завершающим байтом), C-strings (наибольшее распространение метод получил именно в языке Си) и метод нуль-терминированных строк.
Преимущества:
— отсутствие дополнительной служебной информации о строке (кроме завершающего байта);
— возможность представления строки без создания отдельного типа данных;
— отсутствие ограничения на максимальный размер строки;
— экономное использование памяти;
— простота получения суффикса строки;
— возможность использовать алфавит с произвольным размером символа (например, UTF -8).
Недостатки:
— долгое выполнение операций получения длины и конкатенации строк;
— отсутствие средств контроля над выходом за пределы строки, в случае повреждения завершающего байта возможность повреждения больших областей памяти, что может привести к непредсказуемым последствиям — потере данных, краху программы и даже всей системы;
— невозможность использовать символ завершающего байта в качестве элемента строки.
В языке Java применяется первый вид представления в виде массива символов и две его разновидности:
— представление в виде массива символов, инкапсулированного в объект специально предназначенного класса для работы со строками.
— представление в виде массива байтов, которые выражают коды символов (применяется только для восьмибитной кодировки, которая заранее известна). Используется крайне редко, только в определенных ситуациях для повышения производительности.
Представления символов в зависимости от кодировки
Представление символов строки можно реализовать различными способами. До последнего времени один символ всегда кодировался одним байтом (8 двоичных битов; применялись также кодировки с 7 битами на символ), что позволяло представлять 256 (128 при семибитной кодировке) возможных значений. Однако для полноценного представления символов алфавитов нескольких языков (многоязыковых документов, типографских символов — несколько видов кавычек, тире, нескольких видов пробелов и для написания текстов на иероглифических языках — китайском, японском и корейском) 256 символов недостаточно. Для решения этой проблемы существует несколько методов:
— Использование двух или более байт для представления каждого символа ( UTF -16, UTF -32). Главным недостатком этого метода является потеря совместимости с предыдущими библиотеками для работы с текстом при представлении строки как ASCIIZ. Например, концом строки должен считаться уже не байт со значением 0, а два или четыре подряд идущих нулевых байта, в то время как одиночный байт «0» может встречаться в середине строки, что сбивает библиотеку «с толку».
— Использование кодировки с переменным размером символа. Например, в UTF -8 часть символов представляется одним байтом, часть двумя, тремя или четырьмя. Этот метод позволяет сохранить частичную совместимость со старыми библиотеками (нет символов 0 внутри строки и поэтому 0 можно использовать как признак конца строки), но приводит к невозможности прямой адресации символа в памяти по номеру его позиции в строке.
В языке Java , в отличие от некоторых других языков, ни строка, ни массив типа char не заканчиваются ‘\ u 0000’ (символом NUL ). Внутреннее представление символов строки в Java хранится в кодировке Unicode , и, поскольку, основной недостаток (завершающий символ) отсутствует, то это является наилучшим вариантом.
Классы для работы со строками в Java
Строки в Java являются стандартными объектами со встроенной языковой поддержкой. Пакет java.lang содержит несколько классов для работы со строками: String , StringBuffer , StringBuilder .
Класс String
Класс String представляет собой строку в формате UTF -16, в которой дополнительные символы представлены в виде суррогатной пары (см. класс Character ). Значения индексов ссылаются кодовые блоки char , так как дополнительный символ использует две позиции в строке типа String .
Класс String снабжен методами для работы с кодовыми точками Unicode (так называемыми символами) и в дополнении к этим методам имеет методы для работы с кодовыми блоками Unicode (так называемыми значениями символа). Начиная с JDK версии 1.5 класс String поддерживает 32 битные коды символов Unicode .
Данный класс используется для строк фиксированной длины, которые не будут изменяться в процессе работы программы. Нельзя ни вставить новые символы в уже существующую строку, ни поменять в ней одни символы на другие. Добавить одну строку в конец другой тоже нельзя.
В этом классе есть методы, которые позволяют сравнивать строки, осуществлять в них поиск и извлекать определенные символы и подстроки, создавать копию строки с приведением всех символов к верхнему или нижнему регистру.
Данный класс является наиболее употребимым для создания строк.
Класс StringBuffer
Класс StringBuffer представляет собой потокозащищенную, изменяемую последовательность символов. StringBuffer используется для строк переменной длины, которые могут изменяться во время работы программы.
Строки типа StringBuffer является защищенной при использовании нескольких потоков. Это означает, что операция со строкой одним потоком гарантированно завершится до того момента, как другой поток начнет оперировать с этой же строкой.
Наиболее важными методами данного класса являются семейства методов append и insert , которые перегружены для поддержки основных типов.
Каждая строка типа StringBuffer имеет емкость и длину. Эти понятия различны по своей сути. Если длина символьной последовательности содержащейся в строке – это количество символов, то емкость – это количество места в символах, выделяемого для строки в оперативной памяти. Если длина не превышает емкости, то нет необходимости выделять новое пространство в памяти для хранения символьной последовательности. Если внутренний буфер переполняется, то он автоматически расширяется.
Класс StringBuilder
Синхронизация для защиты объекта, при одновременном доступе потоков к нему, исключает состояние неопределенности, но оказывается дорогой с точки зрения вычислительных ресурсов. Поэтому в JDK 1.5 был добавлен еще один класс StringBuilder для работы со строками в одном потоке, в отличие от класса StringBuffer , который может использоваться в многопоточном режиме. Этот класс идентичен StringBuffer и поддерживает все методы класса StringBuffer , но выполняется в ряде случаев быстрее при отсутствии синхронизации.
Достаточно большое количество аспектов программирования в Java на каком-либо этапе подразумевает использование классов String , StringBuffer , StringBu ilder . Они необходимы при отладке, работе с текстом, указании имен файлов и адресов URL и часто выступают в качестве аргументов методов.
String , StringBuffer и String Builder объявлены как final , что означает, что ни от одного из этих классов нельзя производить подклассы. Это было сделано для того, чтобы можно было применить некоторые виды оптимизации, позволяющие увеличить производительность при выполнении операций обработки строк.
Экземпляр любого из этих классов по определению нельзя воспринимать как массив символов. Другими словами следующие переменные s 1 и s 2
это различные по своей сути переменные. Хотя если заглянуть в исходные коды классов для работы со строками, можно увидеть, что они содержат внутри себя символьный массив и многие операции внутри этих классов оперируют символами этого массива. Но, тем не менее, экземпляры классов для строк не являются массивами и не могут применить для возврата символ с заданным индексом с помощью оператора [] . Поэтому операция
будет неверной и вместо этого следует использовать метод charAt(int) , который есть во всех трех классах. Принимая целое значение индекса символа в строке, он возвращает этот символ. Следует помнить, что индексация строки начинается с нуля. Например,
возвратит первый символ непустой строки.
Символьные последовательности и строки
Работая со строками, мы неизменно подразумеваем под строкой некоторую символьную последовательность. Как было описано ранее, в Java символьную последовательность можно реализовать не только с помощью строк, но и другими способами, например, в виде массива символов или массива байтов с кодами символов. Следует принять к сведению, что в Java понятие строки, символьного массива и символьной последовательности имеют между собой ряд отличий.
Символьная последовательность — это абстрагированное понятие. Однако символьная последовательность может быть реализована в форме символьного массива или строки-объекта с заданным типом. Иными словами, символьная последовательность это символы в чистом виде, которые можно занести в массив символов типа char , в объекты-строки или даже занести преобразованные коды символов в массив байтов типа byte .
Не следует приравнивать понятие символьной последовательности к интерфейсу CharSequence , который реализуют классы String , StringBuffer , StringBuilder .
Однако следует учесть еще один очень важный аспект. Понятие символьной последовательности подразумевает то, что вы знаете заранее кодировку символов, из которых состоит данная символьная последовательность. Поэтому, символьная последовательность без сведен ия о ее кодировке не несет никакой информативной нагрузки.
Как было описано выше, строки являются стандартными объектами одного из типов: String , StringBuffer , StringBuilder , но массив символов типа char это уже не объект-строка. Не смотря на то, что символьные последовательности, которые заложены и в массив и в объект-строку могут быть одинаковыми, сам массив и объект-строка не являются эквивалентными между собой.
В языке Java , объект типа String является неизменяемым ( immutable ), то есть никогда не меняется содержимое символьной последовательности, заключенной в этом объекте. Изменение содержимого возможно только через создание нового объекта типа String , что нельзя назвать прямым изменением. В то же время, массив символов типа char имеет элементы, значения которых могут многократно изменяться.
Массив символов типа char используется для повышения быстродействия, когда доминируют операции с отдельными символами символьной последовательности с фиксированной длиной и большая часть времени затрачивается на посимвольные операции. Кроме того, используя массив символов, можно многократно изменять отдельные символы символьной последовательности, чего не всегда можно эффективно сделать в строках типа StringBuffer и StringBuilder , а в строках типа String , как было описано выше, прямым изменением сделать это вообще невозможно.
Фиксированная длина массива позволяет вести обработку массива в простом цикле. Быстродействие же, при использовании массива символов типа char объясняется тем, что элементы массива имеют примитивный тип. А, как известно, примитивные типы в Java лежат вне дерева наследования классов и все операции с ними производятся быстрее, поскольку не требуют создания объекта и связанных с объектом операций. Более того, заглянув в исходные коды классов String , StringBuffer , StringBuilder можно заметить, что в них создается массив символов типа char из параметра конструктора, и многие внутренние операции проделываются уже на этом массиве.
Слабой стороной массива символов является отсутствие возможности использования готовых методов для работы со строками (эту возможность предоставляют строки типа String , StringBuffer и StringBuilder ), а также отсутствие возможности динамически изменять длину массива по определению. Однако возможно неявное изменение длины массива через создание нового массива. Такой способ используется внутри StringBuffer и StringBuilder и нет смысла лишний раз пользоваться массивом, а лучше воспользоваться этими классами для экономии и ясности исходного кода.
По поводу массивов символов можно добавить то, что сам массив символов char (но не его элементы) является объектом и поэтому для него доступны методы, относящиеся к классу java . util . Arrays , которые позволяют сортировать, искать производить заполнение в массивах. Кроме этого, класс java . lang . System предоставляет метод для копирования массива.
Подводя итог, можно сделать следующие выводы:
— если операции с символьной последовательностью не критичны по времени, строка не претерпевает многократных изменений, то лучше использовать реализацию в виде строки;
— если операции с символьной последовательностью критичны по времени, ожидается многократное изменение строки, возможна работа с кодовыми блоками кодовых точек Unicode , то лучше использовать StringBuffer (в многопоточном режиме) и StringBuilder (в однопоточном режиме).
— в том случае, если операции с символьной последовательностью критичны по времени, работа с кодовыми блоками кодовых точек Unicode не требует существенных затрат, предстоящие операции не имеют эквивалентных методов в классах-строках, то следует прибегать к массивам char ;
— в том случае, если операции с символьной последовательностью критичны по времени, операции проводятся с кодами символов, кодировка символов заранее известна и позволяет уместить все виды символов в размерность типа byte , то можно прибегать к массивам типа byte .
Создание строк
Строковые объекты могут создаваться явно, с помощью конструктора. Кроме этого строки могут создаваться и неявным образом:
— при помощи строкового литерала;
— за счет выполнения оператора конкатенации + над двумя объектами String ;
— за счет выполнения оператора конкатенации с присваиванием += над двумя объектами String .
Строковый литерал состоит из ноля или большего количества символов, заключенных в двойные кавычки. Java создает объект для каждого стокового литерала, однако внешне это никак не проявляется.
Итак, строка типа String может быть создана непосредственно строковым литералом,
String str = » World «;
что эквивалентно созданию строки с помощью конструктора:
String str = new String( «World»);
Строка может быть создана с помощью конкатенации строковых литералов:
String s = " + "world!";
String s = "Hello ";
s += "world!
В строках можно использовать все управляющие последовательности, а также восьмеричные/шестнадцатиричные формы записи, которые определены для символьных литералов и отражены в следующей таблице.
Восьмеричный символ (ddd)
Шестнадцатиричный символ UNICODE (xxxx)
Обратная косая черта
Возврат каретки (carriage return)
Перевод строки (line feed, new line)
Перевод страницы (form feed)
Горизонтальная табуляция (tab)
Возврат на шаг (backspace)
public static void main(String[] args)
String s = «\»column1\» \t \»column2\» \t \»column3\» \r\n»;
s += «\u0061 \t\t \u0062 \t\t \u0063»;
Поскольку конкатенация строк является неотъемлемой частью создания строк, то стоит упомянуть о некоторых вариациях конкатенации отдельно.
В ряде случаев, когда строка имеет большую длину, удобно записывать конкатенацию построчно. Это может пригодиться для динамического формирования HTML и XML кода, XSD строк, XPATH и SQL запросов и т.п. При этом следует учитывать, что с трочные литералы в Java обязательно должны начинаться и заканчиваться в одной и той же строке исходного кода. В Java , в отличие от многих других языков, нет управляющей последовательности для продолжения строкового литерала на новой строке.
Например:
class StringConcatenateDemo
public static void main(String[] args)
String s = " SELECT title"
+ " FROM table1, table1"
+ " WHERE N_ID = 5"
+ " LIMIT "
System.out.println(s);
Можно создавать строку и путем конкатенации с присваиванием, но это не всегда продуктивно, кроме того, увеличивается исходный код и требуется следить за тем, чтобы каждая строка заканчивалась точкой с запятой, в отличие от предыдущего варианта:
class StringConcatenateDemo
public static void main(String[] args)
String s = " SELECT title";
s += " FROM table1, table1";
s += " WHERE N_ID = 5";
s += " LIMIT ";
s += n;
System.out.println(s);
При применении конкатенации следует отличать оператор + для конкатенации строк и оператор + для арифметического сложения. Например, результатом вывода следующей программы
class StringConcatenateDemo 2
public static void main(String[] args)
int region_number = 112;
String post_code1 = «The post code1: » + prefix + region_number;
String post_code2 = «The post code2: » + (prefix + region_number);
The post code1: 83112
The post code 2: 195
Вывод свидетельствует о том, что в выражении ( prefix + region _ number ) оператор + воспринят компилятором как оператор сложения из-за принципа старшинства операций ( ). В то же время, при отсутствии скобок оператор + воспринимается как оператор конкатенации строк.
Создание строк с помощью строкового литерала, и операторов конкатенации возможно только для класса String и не распространяется на класс StringBuffer и StringBuilder . Строки этих дух типов создаются с помощью оператора new . Конкатенация для строк типа StringBuilder или StringBuffer осуществляется с помощью метода append () . Следует отметить, что ф орма создания короткой строки с помощью оператора + и += более удобна в чтении, чем ее эквивалент, записанный с явными вызовами методов append () . Тем не менее, при создании больших строк с помощью конкатенации, рекомендуется создавать строки с помощью классов StringBuilder или StringBuffer и производить конкатенацию методом append () , поскольку в этих строках не требуется промежуточное создание нового объекта из слагаемых строк.
Возникает закономерный вопрос: “А почему нельзя обойтись одним классом String , позволив ему вести себя примерно так же, как StringBuffer ?” Все дело в производительности. Тот факт, что объекты типа String в Java неизменны, позволяет транслятору быстро выполнять ряд операций. Примером такой операции может служить возврат длины строки, которую вычислять не нужно, поскольку строка неизменна (вернее нужно, но только единожды при ее создании).
Для изменяемых строк длина может меняться многократно, что требует дополнительных вычислительных затрат, но это с лихвой компенсируется появлением операций удаления, добавления, замены в рамках одной и той же строки без создания нового объекта.
Пустая строка и null
Не следует забывать разницу между пустой строкой «» , не содержащей ни одного символа, и пустой ссылкой null , не указывающей ни на какую строку и не являющейся объектом. В языке Java null является нулевой ссылкой, представляемой пустым литеральным указателем, который сформирован из символов ASCII.
public static void main(String[] args)
String s1 = null;
Пустую строку можно создать и с помощью конструктора без параметров, а также с помощью конструктора с аргументом «» , поэтому следующие три строки кода приведут к одинаковому результату:
String s1 = new String( );
String s2 = new String( «»);
В случае, если ваша строковая переменная присваивается значению null , необходимо в дальнейшем коде внимательно следить, чтобы не вызывался метод строкового класса, иначе закономерно произойдет выброс исключения NullPointerExeption (ситуация вызова метода для несуществующего объекта) . Данной ситуации можно избежать, проинициализировав переменную перед вызовом метода, или (если вам сильно необходимо именно null ) создать условный блок проверки для обхода кода с вызовом метода для строковой переменной.
Кроме того, строковая переменная может быть не инициализирована, и любые действия с ней могут привести к ошибке компиляции.
public static void main(String[] args)
int len1, len2, len3;
String s 2 = null ;
//Следующие три строки приведут
//к одинаковому результату — созданию пустой строки
//String s2 = new String( );
//String s2 = new String( «»);
//len1 = s1.length( ); // Приведет к ошибке компиляции :
//variable s1 might not have been initialized
// len 2 = s 2. length (); //Приведет к выбросу исключения
// java . lang . NullPointerException на этапе выполнения
len 3 = s 3. length ( ); //(пустая строка, длина равна 0)
//Следующая строка выполнится только в JDK 1.6
// if( s3.isEmpty()) System.out.println(«s3 is empty»);
Не допускается создание строки с помощью конструктора, в который в качестве аргумента передается null . Это приведет к выбросу исключения NullPointerException на этапе выполнения программы. Например ,
public static void main(String[] args)
String s1 = null;
String s2 = new String( s1);
Создание строк типа String с помощью конструкторов
Класс S tring предоставляет следующие конструкторы:
S tring( ) — создает объект с пустой строкой;
Следующие конструкторы, используют массив байтов в качестве аргумента, предназначены для создания Unicode-строки из массива байтов с определенной кодировкой символов. Такая ситуация возникает при чтении файлов, извлечении информации из базы данных или при передаче информации по сети.
String ( byte [] bytes )
Создает объект String , декодируя указанный массив байтов используя платформенный набор символов по-умолчанию.
String(byte[] byte s , String charsetName ) — создает объект String , декодируя указанный массив байтов в указанный набор символов.
String(byte[] byte s , Charset charset ) — создает объект String , декодируя указанный массив байтов в указанный набор символов.
String (byte [] byteArray, int offset, int count)
Создает объект String из части массива байтов используя платформенную кодировку по умолчанию;
String ( byte [] bytes , int offset , int count , String charsetName ) — создает объект String , декодируя часть массива байтов в указанный набор символов.
String ( byte [] bytes , int offset , int count , Charset charset ) — создает объект String , декодируя часть массива байтов в указанный набор символов.
Следующие конструкторы создают объект String из массива символов Unicode;
String (char [] charArray) — создает объект String из массива символов Unicode;
String (char [] charArray, int offset, int count) — создает объект String из части массива символов Unicode;
Следующий пример демонстрирует один из этих конструкторов:
char chars[] = < 'a', 'b', 'с', 'd', 'e', 'f' >;
String s = new
System.out.println(s);
Этот фрагмент выведет :
Следующий конструктор создает объект String из массива кодовых точек.
String (int[] codePoints, int offset, int count)
Создает объект String , который содержит символы из подмассива кодовых точек Unicode . Аргумент offset является индексом первой кодовой точки подмассива, а аргумент count определяет длину подмассива. Содержимое подмассива конвертируется в символы типа char . Последующее изменение массива кодовых точек не влияет на новую созданную строку.
IllegalArgumentException если найдена неверная кодовая точка Unicode в codePoints
При неправильном задании индексов offset , count во всех конструкторах, где они используются, возникает исключительная ситуация IndexOutOfBoundsException
S tring (String original )
Создает объект из другого , поэтому этот конструктор используется редко;
S tring (StringBuffer buffer )
Создает String объект из последовательности символов содержащейся в аргументе StringBuffer ;
S tring (StringBu ilder builder )
Создает String объект из последовательности символов содержащейся в аргументе StringBuilder . Содержимое строки StringBu ilder копируется; дальнейшее изменение StringBuilder не влияет на новую созданную строку.
Получать строку String из StringBuilder лучше с помощью метода toString () , поскольку выполняется быстрее.
Создание строк типа StringBuffer с помощью конструкторов
Объект StringBuffer можно создать без параметров, при этом в нем будет зарезервировано место для размещения 16 символов. Вы также можете передать конструктору целое число, для того чтобы явно задать требуемый размер буфера. И, наконец, вы можете передать конструктору строку, при этом она будет скопирована в объект и дополнительно к этому в нем будет зарезервировано место еще для 16 символов. Текущую длину StringBuffer можно определить, вызвав метод length() , а для определения всего места, зарезервированного под строку в объекте StringBuffer нужно воспользоваться методом capacity() . Ниже приведен пример , поясняющий это :
public static void main(String args[])
StringBuffer sb = new StringBuffer( «Hello»);
System.out.println( «buffer = » + sb);
System.out.println( «length = » + sb.length());
System.out. println( «capacity = » + sb.capacity());
Из вывода этой программы, видно, что в объекте StringBuffer для манипуляций со строкой зарезервировано дополнительное место.
Как было описано ранее, строка типа StringBuffer имеет емкость и длину, причем эти понятия разнятся между собой. Для управления длиной и емкостью подобной строки существуют методы ensureCapacity() и setLength() . Метод ensureCapacity() применяется в тех случаях, когда после создания объекта StringBuffer вы захотите зарезервировать в нем место для определенного количества символов. Это бывает полезно, когда вы заранее знаете, что вам придется добавлять к буферу.
Если вам вдруг понадобится в явном виде установить длину строки в буфере, воспользуйтесь методом setLength() . Если вы зададите значение, большее чем длина содержащейся в объекте строки, этот метод заполнит конец новой, расширенной строки символами с кодом 0.
Абстрактный класс CharBuffer
В JDK 1.4 был введен новый класс CharBuffer , который предназначен для ряда операций, которые несвойственны строковым классам, массивам char [] и byte []. Данный класс предназначен для эффективного и гибкого управления элементами типа char . Данный класс имеет огромное преимущество перед различными вариантами преобразований символов. Наряду с абстрактными классами java . nio . charset . Charset и java . nio . ByteBuffer он участвует в преобразованиях символьных и битовых массивов в обе стороны. При этом позволяет указывать кодировку, а так же указывать порядок следования байтов. Класс CharBuffer реализует интерфейс CharSequence , который позволяет принимать участие в символьно-ориентированных операциях, таких как регулярные выражения . к оторые отсутствовали раньше и также были введены в JDK 1.4.
Интерфейс CharSequence
В JDK 1.4 был введен новый интерфейс CharSequence , который описывает специфическую, неизменяемую последовательность символов. Этот новый интерфейс является абстракцией для разделения концепции последовательности символов от специфической реализации, содержащей эти символы. Строковые классы String , StringBuffer , StringBuilder в Java теперь настроены таким образом, что реализуют интерфейс CharSequence .
Интерфейс CharSequence дотаточно прост:
public interface CharSequence
char charAt (int index);
public String toString( );
CharSequence subSequence (int start, int end);
Интерфейс CharSequence является неизменяемым ( immutable ), поскольку не имеет методов, изменяющих символьную последовательность. Однако базовый объект, реализующий данный интерфейс может быть изменяемым. Поэтому методы CharSequence будут отражать текущее состояние базового объекта. Если его состояние изменяется, то информация, возвращаемая методами CharSequence будет также изменяться. Если вы зависите от CharSequence , и не знаете заранее тип базового объекта, то запускайте метод toString () , чтобы получить действительно неизменяемую копию символьной последовательности.
Следующая программа демонстрирует поведение java . lang . CharSequence , имплементируемое String , StringBuffer и CharBuffer .
* @author Ron Hitchens (ron@ronsoft.com)
public static void main (String [] argv)
StringBuffer stringBuffer = new StringBuffer («Hello World»);
CharBuffer charBuffer = CharBuffer.allocate (20);
CharSequence charSequence = «Hello World»;
// derived directly from a String
// derived from a StringBuffer
stringBuffer.append («Goodbye cruel world»);
// same «immutable» CharSequence yields different result
// Derive CharSequence from CharBuffer
charBuffer.put («Hello World»);
//Changing underlying CharBuffer is reflected in the
//read-only CharSequnce interface
private static void printCharSequence (CharSequence cs)
System.out.println («length=» + cs.length( )
length= 11, content=’Hello World’
length= 11, content=’Hello World’
length= 19, content=’Goodbye cruel world’
length= 11, content=’Hello World’
length= 11, content=’Seeya World’
length= 20, content=’Seeya Worldxxxxxxxxx’
Метод toString ()
Преобразование строки в строку типа String с помощью метода toString () возможно в любом из классов предназначенных для строк. Метод toString () присутствует также в любых других классах. Это обусловлено тем, что метод toString () определен в классе Object , который является вершиной иерархии классов и наследуется всеми классами Java .
Следует отметить, что String и CharSequence являются неизменяемыми ( immutable ), и поскольку CharSequence полностью описывает String , то метод toString () интерфейса CharSequence возвратит базовый объект String , а не его копию. Для объектов классов StringBuffer и CharSequence метод toString () создаст новую строку String , которая будет содержать копию символьной последовательности.
Производительность String и StringBuffer / StringBuilder при многократной конкатенации.
Создание строки во многом может зависеть от того, какие операции будут в дальнейшем проводиться с этой строкой. Многократная конкатенация при работе с большими строками является примером ситуации, где требуется осознанный выбор типа строки при ее создании.
Как было ранее описано, при создании больших строк с помощью конкатенации, вместо класса String рекомендуется создавать строки с помощью классов StringBuilder или StringBuffer и производить конкатенацию методом append () , поскольку в этих строках не требуется промежуточное создание нового объекта из слагаемых строк.
Следующий тест демонстрирует преимущество конкатенации в строке типа StringBuffer перед конкатенацией в строке типа String .
public static void main(String args[])
String-SBConcatenationDemo scd = new String- SBConcatenationDemo( );
System.out.println( «Execution time:» + (end-start));
System.out.println( «Execution time:» + (end-start));
public void appendString()
s += «<>@#KF :OEJNLDSKN DJSLDKmv dskv lskdv E(#*)FJ:L j jdfsl;kjf»;
public void appendStringBuffer()
StringBuffer s = new StringBuffer( «»);
s.append( «<>@#KF:OEJNLDSKN DJSLDKmv dskv lskdv E(#*)FJ:L j jdfsl;kjf»);
Добавляемые строки : «<>@#KF :OEJNLDSKN DJSLDKmv dskv lskdv E(#*)FJ:L j jdfsl;kjf»
Команда запуска : java -Xmx256m StringFamilyDemo
Операционная система : Windows XP Professional
Параметры компьютера : Pentium4 CPU 2 ,8 ГГц 512 Mb ОЗУ
Количество добавлений в цикле 10000 600000
Время выполнения для строки типа String : 10 082 281 мс не определено
Время выполнения для строки типа StringBuffer : 47 мс 1140 мс
Программа демонстрирует добавление в цикле подстрок к строкам типов String , StringBuffer . Для корректной работы программа запускается с выделением памяти в 256 Mb , поскольку значения по умолчанию в 64 Mb может быть недостаточно. Для разнообразия первая добавляемая строка подобрана таким образом, чтобы в ней присутствовали различные символы, остальные строки добавляются для многократного использования метода append () и оператора += с короткими строками. Скорость операций для строк String будет явно падать в десятки, сотни и более раз с ростом размера строки. Поскольку время выполнения для String слишком велико уже при 10000 добавлений, то им можно пренебречь.
Производительность StringBuffer и StringBuilder .
Не совсем однозначная ситуация по времени выполнения выходит со строками StringBuffer и StringBuilder . Согласно документации, использование класса StringBuilder более предпочтительно чем StringBuffer . Как было описано ранее, для строк StringBuilder ряд операций выполняется быстрее из-за отсутствия синхронизации, а, следовательно, и отсутствием потоковой безопасности.
public static void main(String args[])
StringFamilyDemo sfd = new StringFamilyDemo( );
System.out.println( «Execution time:» + (end-start));
System.out.println( «Execution time:» + (end-start));
public void appendStringBuffer()
StringBuffer s = new StringBuffer( «»);
s.append( «<>@#KF:OEJNLDSKN DJSLDKmv dskv lskdv E(#*)FJ:L j jdfsl;kjf»);
public void appendStringBuilder()
StringBuilder s = new StringBuilder( «»);
s.append( «<>@#KF:OEJNLDSKN DJSLDKmv dskv lskdv E(#*)FJ:L j jdfsl;kjf»);
Добавляемые строки : «<>@#KF :OEJNLDSKN DJSLDKmv dskv lskdv E(#*)FJ:L j jdfsl;kjf»
Команда запуска : java -Xmx256m StringFamilyDemo
Операционная система : Windows XP Professional
Параметры компьютера : Pentium4 CPU 2 ,8 ГГц 512 Mb ОЗУ
Количество вызовов методов с конкатенацией: 100 1000
Время выполнения для строки типа StringBuffer : 102359 мс 1017828 мс
Время выполнения для строки типа StringBuilder : 102141 мс 1017594 мс
По результатам видно, что в однопоточном режиме многократная конкатенация показывает примерно одинаковые результаты. Показатели времени выполнения поменяются местами, если в методе main () поменять местами блоки с циклами вызовов методов appendStringBuilder () и appendStringBuffer () . Другими словами, производительность строк типа StringBuffer и StringBuilder одинаковая, разве что только имеет место слабая зависимость от очередности выполнения многократной конкатенации с различными типами строк.
Однако возникает следующий вопрос: “почему в однопоточном режиме строки StringBuffer и StringBuilder имеют одинаковую производительность, тогда как документация от Sun Microsystems настойчиво рекомендует StringBuilder ?”. Причину можно увидеть в следующих несложных примерах.
Первый пример содержит конкатенацию строк типа String
public void printStr ( String s )
System.out.println( «prefix » + s + » suffix»);
Второй пример содержит конкатенацию строк типа StringBuffer
public void printStr2(String s)
StringBuffer buf = new StringBuffer( «prefix»).append(s).append(» suffix»);
Откомпилируем и дезассемблируем первый пример, используя Java 1.4. x , запустив
javap – c ConcatenationDemo1
public void printStr(java.lang.String);
0: getstatic #2; //Field java/lang/System.out:Ljava/io/PrintStream;
3: new #3; //class java/lang/StringBuffer
7: invokespecial #4; //Method java/lang/StringBuffer.»»:()V
10: ldc #5; //String prefix
12: invokevirtual #6; //Method
java/lang/ StringBuffer .append: (Ljava/lang/String;) Ljava/lang/StringBuffer;
16: invokevirtual #6; //Method
java/lang/ StringBuffer .append: (Ljava/lang/String;) Ljava/lang/StringBuffer;
19: ldc #7; // String suffix
21: invokevirtual #6; //Method
java/lang/ StringBuffer .append: (Ljava/lang/String;) Ljava/lang/StringBuffer;
24: invokevirtual #8; //Method java/lang/ StringBuffer.toString: ()Ljava/lang/String;
27: invokevirtual #9; //Method java/io/ PrintStream.println: (Ljava/lang/String;)V
Откомпилируем и дезассемблируем второй пример, используя Java 1.4. x , запустив
javap – c ConcatenationDemo2
public void printStr2(java.lang.String);
0: new #3; //class java/lang/StringBuffer
4: ldc #10; //String prefix
6: invokespecial #11; //Method java/lang/StringBuffer.»»:(Ljava/lang/ String; ) V
10: invokevirtual #6; //Method
java/lang/ StringBuffer .append: (Ljava/lang/String;) Ljava/lang/StringBuffer;
13: ldc #7; // String suffix
15: invokevirtual #6; //Method
java/lang/ StringBuffer .append: (Ljava/lang/String;) Ljava/lang/StringBuffer;
19: getstatic #2; //Field java/lang/System.out:Ljava/io/PrintStream;
23: invokevirtual #8; //Method java/lang/ StringBuffer.toString: ()Ljava/lang/String;
26: invokevirtual #9; //Method java/io/ PrintStream.println: (Ljava/lang/String;)V
Реальное отличие первого исходного кода от второго в том, что во втором случае мы вручную создаем строку StringBuffer . Это не особо соответствует исходному коду, но приемлемо, поскольку неявно увеличивается производительность и конкатенация происходит без присваивания. Согласно спецификации языка, д ля примитивных объектов, реализация может также оптимизировать длительное создание объекта-оболочки, преобразуя непосредственно примитивный тип в строку.
Однако, что произойдет, если откомпилировать второй пример с помощью Java 1.5+? Дезассемблирование даст следующий результат:
public void printStr ( java . lang . String );
0: getstatic #2; //Field java/lang/System.out:Ljava/io/PrintStream;
3: new #3; //class java/lang/StringBuilder
7: invokespecial #4; // Method java/lang/StringBuilder.»»:() V
10: ldc #5; //String prefix
12: invokevirtual #6; //Method
java/lang/ StringBuilder.append: (Ljava/lang/String;)Ljava/lang/StringBuilder;
16: invokevirtual #6; //Method
java/lang/ StringBuilder.append: (Ljava/lang/String;)Ljava/lang/StringBuilder;
19: ldc #7; // String suffix
21: invokevirtual #6; //Method
java/lang/ StringBuilder.append: (Ljava/lang/String;)Ljava/lang/StringBuilder;
24: invokevirtual #8; //Method java/lang/ StringBuilder.toString: ()Ljava/lang/String;
27: invokevirtual #9; //Method java/io/ PrintStream.println: (Ljava/lang/String;)V
Мы получаем StringBuilder вместо StringBuffer , путем негласной перестройки байт-кода от Sun . Теперь становится вполне понятно, почему производительность StringBuffer и StringBuilder относительно исходного кода одинакова. Да потому что байт-код у них одинаковый!
По признаку лояльности к негласной оптимизации исходного кода при компиляции, всех разработчиков условно можно разделить на два типа:
— Сторонники. Программисты, пишущие код, который изолирован от другого кода (не имеющий влияния на другой код), не требует анализа, многократного прохождения тестов.
— Противники. Программисты, которым не один раз приходится анализировать написанный код на предмет утечки ресурсов, которые сталкиваются со взаимовлияющими блоками кода, которые проводят разностороннее тестирование, даже после незначительного изменения кода.
С одной стороны можно согласиться с Sun . В случае если вы отклоняетесь от рекомендаций, то “все будет сделано за Вас так как следует и так как хочет Sun ”. Но подобная практика приводит к тому, что программист все меньше и меньше может быть уверенным, что его программа делает то, что в ней написано и постоянно держать под рукой дизассемблер. В то время как здоровая практика программирования предусматривает два простых этапа: написание грамотного и ясно читаемого кода, использование профайлера для определения мест, где необходима оптимизация исходного кода. Для многих разработчиков, которые при утечках производительности не держат на взводе диассемблер javap , данная ситуация станет откровением.
Помните, что в проектах проще оптимизировать ясно функционирующий код, чем искать недочеты, отлаживая высоко оптимизированный код. Но если вы уже столкнулись с подобной ситуацией, то не следует сбрасывать со счетов, что различные компиляторы генерируют различный вывод. Тестируйте с одним компилятором, с которым вы будете делать сборку, но примите во внимание вывод Eclipse compiler , Jikes , GCJ , IBM и javac от Sun . Не попадите впросак, создавая код для одного компилятора.
Вернемся к вопросу потокозащищенности. Как известно, потокозащищенность объекта во время его изменения, может быть обеспечена в Java с помощью блока synchronized . Следующий тест, в двух вариантах исполнения (для строк StringBuffer и строк StringBuilder ), показывает потокозащищенность строк типа StringBuffer и потоконезащищенность строк типа StringBuilder .
public class ThreadSBDemo
public static void main(String args[])
StringBuffer sb = new StringBuffer( «»);
NewThread nt1 = new NewThread( sb, «a»);
NewThread nt2 = new NewThread( sb, «b»);
NewThread nt3 = new NewThread( sb, «c»);