Односвязный список Python: определение и особенности

Односвязный список Python — это последовательность узлов информации, где каждый отдельный узел указывает только на следующий узел. Такой список можно легко исследовать от начала и до конца списка. В обратном порядке исследовать список о чень непросто.
Как выглядит односвязный список Python в коде:
# Объявляем класс узла
class myNode:
# Объявляем функцию, которая будет инициализировать создание узлов
def __init__(self, data):
self.data = data # Назначаем дату
self.nextnode = None # Инициализируем следующий узел как «null»
a = myNode(1) # Объявляем дату для каждого узла
b = myNode(2)
c = myNode(3)
a.nextmynode = b # объединяем первый узел со вторым
b.nextmynode = c # объединяем второй узел с третьим
a.next.value # вернет значение следующего узла, то есть «b = 2»
Односвязный список Python: операции над узлами
- Добавление узла в список. Данная операция осуществляется при помощи функции «add_list_item()». При этом нужно помнить, что узел добавляется в конец списка. Если в списке вообще нет узлов, тогда объявленный таким образом узел в станет в начало списка и будет его возглавлять.
- Поиск по списку. Это действие возможно при помощи функции «unordered_search()». Поиск начинается с первого узла списка и далее по порядку. При осуществлении поиска одновременно подсчитывается количество узлов. В результате выполнения этого метод а м ы получаем список узлов, в которых обнаружено совпадение с искомой информацией.
- Удаление узла из списка. При удалении узла обязательно нужно откорректировать ссылку, которая указывает на удаляемый узел, так как теперь она должна указывать на узел, следующий после удаляемого. Это действие осуществляется при помощи функции «remove_list_item_by_id()». Узел удаляется по его номеру.
Зачем использовать связный список
Односвязный или двусвязный спис ки в Python чем-то похожи на массивы , п оэтому иногда возникает вопрос: «Зачем использовать связный список, если можно использовать массив?». Проблема в том, что массив имеет ограниченный или заданный размер , п оэтому , когда в массив нужно добавить дополнительный элемент, превышающий его размер, это вызывает лишние трудности и проблемы.
Программисты не любят проблем с кодом, поэтому иногда используют связный список, а не массив. Если взглянуть на реализацию, тогда становится понятным, что связный список в Python чем-то похож на динамический массив , о днако все они имеют собственные преимущества и недостатки.
Заключение
Односвязный список в Python — это последовательность элементов, связанных в одном направлении. Он удобен, когда нужно сохранить неопределенное количество информации, связанной между собой. Добавлять новый узел в связный список Python легче и «дешевле», если сравнивать даже с динамическим массивом.
Мы будем очень благодарны
если под понравившемся материалом Вы нажмёте одну из кнопок социальных сетей и поделитесь с друзьями.
16. Связные списки¶
Мы уже видели примеры атрибутов, которые ссылаются на другие объекты. Ссылки на объекты использует и широко известная структура данных связный список.
Связные списки состоят из узлов, каждый из которых содержит ссылку на следующий узел в списке. Кроме того, каждый узел содержит какие-то полезные данные.
Связный список относится к рекурсивным структурам данных, поскольку его определение рекурсивно.
Связный список представляет собой либо
- пустой список, представленный значением None , либо
- узел, содержащий данные и ссылку на связный список.
Рекурсивные структуры данных могут обрабатываться рекурсивными методами.
16.2. Класс Node ¶
Как обычно при определении нового класса, мы начнем с инициализирующего метода и метода __str__ , обеспечив возможность создания и отображения объектов нового класса:
class Node: def __init__(self, cargo=None, next=None): self.cargo = cargo self.next = next def __str__(self): return str(self.cargo)
Параметры инициализирующего метода опциональны. По умолчанию и данные, cargo , и ссылка, next , получают значения None .
Строковым представлением узла будет строковое представление данных этого узла. Поскольку функции str можно передать любое значение, в нашем узле можно хранить любое значение.
Для тестирования создадим объект Node и выведем его на печать:
>>> node = Node("test") >>> print node test
Чтобы было интереснее, нам нужен список с более чем одним узлом:
>>> node1 = Node(1) >>> node2 = Node(2) >>> node3 = Node(3)
Этот код создает три узла, но у нас нет списка, так как ни один узел не связан с другим. Посмотрите на рисунок:
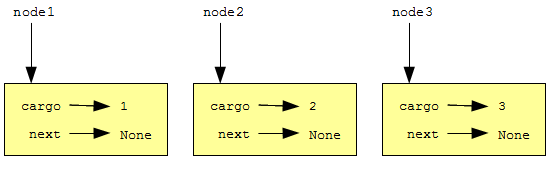
Чтобы связать узлы, нам нужно заставить первый узел ссылаться на второй, а второй — на третий:
>>> node1.next = node2 >>> node2.next = node3
Ссылка в третьем узле имеет значение None , что означает конец списка.
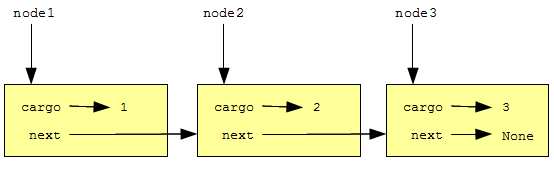
Теперь вы знаете, как создавать узлы и связывать их в списки. Но, возможно, пока не понимаете, зачем это нужно.
16.3. Списки как коллекции¶
Списки полезны, поскольку дают возможность собрать многочисленные объекты в единую сущность, иногда называемую коллекцией. В примере выше, первый узел списка может служить ссылкой на весь список.
Чтобы передать связный список в качестве аргумента, достаточно передать ссылку на первый узел. Например, функция print_list принимает один узел в качестве аргумента. Начиная с первого узла списка, она выводит на печать каждый узел, пока не достигнет конца списка:
def print_list(node): while node: print node, node = node.next print
Вызовем функцию, передав ей ссылку на первый узел:
>>> print_list(node1) 1 2 3
Хотя у print_list есть ссылка на первый узел списка, внутри функции нет переменных, ссылающихся на другие узлы. Функция получает ссылку на следующий узел, используя значение атрибута next каждого узла.
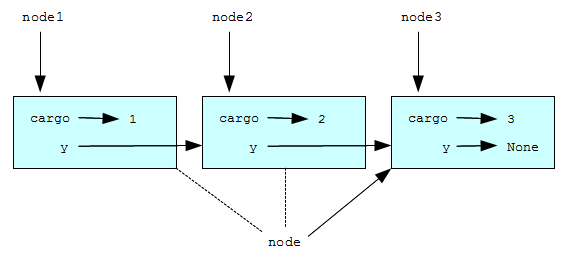
Чтобы пройти весь связный список, обычно используют переменную цикла вроде node , которая последовательно получает значения, ссылающиеся на узлы списка.
16.4. Списки и рекурсия¶
Многие операции над списком естественно реализовать с помощью рекурсивных методов. Вот рекурсивный алгоритм для вывода на печать списка в обратном порядке:
- Разделить список на две части: первый узел (голова) и все остальные (хвост).
- Распечатать хвост в обратном порядке.
- Распечатать голову.
Разумеется, шаг 2, рекурсивный вызов, предполагает, что у нас имеется способ распечатать список в обратном порядке. Но если мы примем, что рекурсивный вызов работает – нужно в это поверить – то мы можем убедиться в том, что алгоритм работает.
Все, что нам нужно, это простейший случай списка (базовый случай) и доказательство того, что, какой бы список мы ни взяли, наш алгоритм в конце концов приведет нас к этому базовому случаю. Имея рекурсивное определение списка, приведенное выше, в качестве базового случая возьмем пустой список, представленный значением None :
def print_backward(list): if list == None: return head = list tail = list.next print_backward(tail) print head,
Первая строка обрабатывает базовый случай. Две следующие строки кода разделяют список на head (англ.: голова) и tail (англ.: хвост). Две последние строки кода выводят список на печать. Запятая в конце последней строки удерживает Python от перевода строки после печати каждого узла.
Вызовем функцию так же, как вызывали print_list :
>>> print_backward(node1) 3 2 1
В результате на печать выведен список в обратном порядке.
Возможно, вы недоумеваете, почему print_list и print_backward являются функциями, а не методами класса Node . Причина в том, что мы используем None для представления пустого списка, а вызвать метод для None нельзя. Это ограничение не позволяет написать чистый объектно-ориентированный код для манипулирования списком.
Но можем ли мы доказать, что print_backward всегда завершится? Другими словами, всегда ли алгоритм приведет нас к базовому случаю? На самом деле, ответ отрицательный. Некоторые списки сломают наш метод.
16.5. Бесконечные списки¶
Нет ничего, что помешало бы некоторому узлу ссылаться на узел, который идет в списке раньше этого узла, или ссылаться на самого себя. Например, этот рисунок показывает список с двумя узлами, один из которых ссылается на себя!
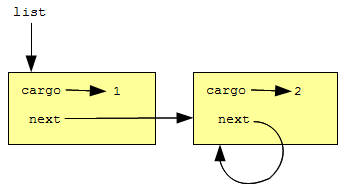
Если вызвать print_list с этим списком, функция зациклится. Если вызвать print_backward , возникнет бесконечная рекурсия. Таким образом, работа с бесконечными списками сопряжена с определенными сложностями.
Тем не менее, иногда бесконечные списки полезны. Например, можно представить число как список цифр, и воспользоваться бесконечным списком для представления дробного периода этого числа.
И все же тот факт, что мы не можем доказать, что print_list и print_backward завершатся, представляет проблему. Лучшее, что мы можем сделать, это выдвинуть гипотезу: Если список не содержит циклов, то эти методы завершатся. Такого рода утверждения называются предусловием. Предусловие налагает ограничение на параметры и описывает поведение функции в случае, когда это ограничение выполняется. Вскоре мы встретимся с другими примерами предусловий.
16.6. Неоднозначность ссылки на узел списка¶
Следующий фрагмент print_backward может вызвать удивление:
head = list tail = list.next
После выполнения первого предложения присваивания head и list имеют один и тот же тип и одно и то же значение. В таком случае, зачем мы создаем новую переменную?
Причина в том, что эти две переменные играют разные роли. Мы думаем о head как о ссылке на один узел, а о list – как о ссылке на первый узел списка. Эти роли не являются частью программы; они существуют в уме программиста.
В общем случае, глядя на код программы, мы не можем сказать, какую роль играет та или иная переменная. Эта неоднозначность может быть полезной, но также может затруднить чтение программы. Часто, чтобы подчеркнуть роль, которую играет переменная, мы используем переменные с “говорящими” именами, например, node и list , а иногда создаем дополнительные переменные с этой целью.
Можно переписать print_backward без переменных head и tail , что сделает функцию более компактной, но менее ясной:
def print_backward(list) : if list == None : return print_backward(list.next) print list,
Глядя на два вызова функции, нужно помнить, что print_backward рассматривает свой аргумент как коллекцию, а print – как единичный объект.
Если же взять ссылку на узел связного списка вне контекста, то ее семантика неоднозначна. Ссылка на узел связного списка может рассматриваться как ссылка на один узел или как ссылка на список.
16.7. Изменение списков¶
Можно изменить список двумя способами. Очевидно, что мы можем изменить данные одного из узлов. Но более интересны операции по добавлению, удалению и перестановке узлов.
В качестве примера давайте напишем функцию, которая удаляет второй узел из списка и возвращает ссылку на удаленный узел:
def remove_second(list): if list == None: return first = list second = list.next # make the first node refer to the third first.next = second.next # separate the second node from the rest of the list second.next = None return second
Здесь мы вновь используем временные переменные для того, чтобы сделать код яснее. Воспользуемся этой функцией:
>>> print_list(node1) 1 2 3 >>> removed = remove_second(node1) >>> print_list(removed) 2 >>> print_list(node1) 1 3
Следующий рисунок иллюстрирует результат работы функции remove_second :
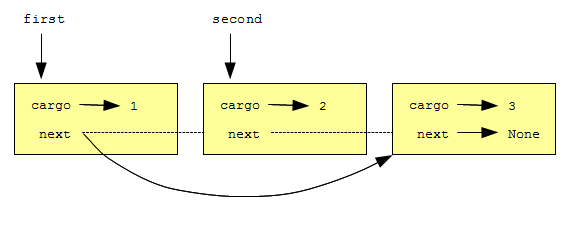
А что случится, если вызвать эту функцию со списком из одного элемента? С пустым списком? Существует ли предусловие для этой функции? Если да, то добавьте в функцию проверку предусловия и обработку его нарушения.
16.8. Обертки и помощники¶
Если нам понадобится вывести связный список в обратном порядке, заключенный в квадратные скобки, то, как вариант, мы можем воспользоваться функцией print_backward чтобы вывести 3 2 1 , и отдельно вывести открывающую и закрывающую скобки. Назовем новую функцию print_backward_nicely :
def print_backward_nicely(list) : print "[", print_backward(list) print "]",
В любом месте программы можно вызвать функцию print_backward_nicely , а она, в свою очередь, вызовет print_backward . Здесь print_backward_nicely работает как обертка, используя функцию print_backward в качестве помощника.
16.9. Класс LinkedList ¶
У нашей реализации связных списков есть одна проблема, неочевидная на первый взгляд. Поменяв местами причину и следствие, предложим вначале альтернативную реализацию, а затем рассмотрим, какую проблему она решает.
Создадим новый класс LinkedList . Его атрибутами будут целое число, представляющее длину списка, и ссылка на первый узел списка. С помощью объектов LinkedList удобно манипулировать списками объектов Node :
class LinkedList: def __init__(self): self.length = 0 self.head = None
Класс LinkedList оказывается удобным местом для помещения в него таких функций, как print_backward_nicely , и превращения их в методы этого класса:
class LinkedList: . def print_backward(self): print "[", if self.head != None: self.head.print_backward() print "]", class Node: . def print_backward(self): if self.next != None: tail = self.next tail.print_backward() print self.cargo,
Мы переименовали print_backward_nicely , и теперь у нас два метода с именами print_backward : один в классе Node (помощник), и один в классе LinkedList (обертка). Когда метод-обертка вызывает self.head.print_backward , он вызывает метод-помощник, поскольку self.head ссылается на объект Node .
Еще один плюс класса LinkedList состоит в том, что он облегчает добавление и удаление первого элемента списка. Например, следующий метод add_first класса LinkedList принимает в качестве аргумента данные для узла и помещает новый узел с этими данными в начало списка:
class LinkedList: . def add_first(self, cargo): node = Node(cargo) node.next = self.head self.head = node self.length += 1
Создадим связный список, добавим в него три узла и выведем его на печать в обратном порядке:
>>> linkedlist = LinkedList() >>> linkedlist.add_first(1) >>> linkedlist.add_first(2) >>> linkedlist.add_first(3) >>> linkedlist.print_backward() [ 1 2 3 ]
Поскольку каждый раз новый узел добавляется в начало списка, то последовательно добавленные нами узлы со значениями 1 , 2 , 3 расположились в обратном порядке, и метод print_backward вывел узлы в порядке их добавления.
В качестве упражнений вам будет предложено добавить другие полезные методы в класс LinkedList и поэкспериментировать с ними.
16.10. Инварианты¶
Некоторые списки построены правильно; другие нет. Например, если список содержит цикл, он сломает многие из наших методов. Поэтому мы можем потребовать, чтобы списки не содержали циклов. Другое разумное требование состоит в том, чтобы значение length в объекте LinkedList всегда равнялось реальному числу узлов в списке.
Требования, подобные этим, называются инвариантами, поскольку, в идеале, они должны выполняться для каждого объекта в любой момент времени. Указание инвариантов для объектов — полезный прием программирования. Он облегчает доказательство корректности кода, проверку целостности структур данных, и способствует обнаружению ошибок.
Заметим, что в отдельные моменты времени инварианты все же не выполняются. Например, в середине метода addFirst , после того, как мы добавили узел, но перед тем, как мы увеличили length , инвариант оказывается нарушенным. Такого рода нарушение приемлемо; действительно, часто невозможно изменить объект, не нарушая инвариант хотя бы ненадолго. Достаточно потребовать, чтобы метод, который нарушает инвариант, восстанавливал его.
Если имеется значительный участок кода, в котором инвариант нарушен, важно отразить это в комментариях. Чтобы операции, зависящие от инварианта, не выполнялись, пока инвариант не восстановлен.
16.11. Глоссарий¶
инвариант Утверждение, которое должно выполняться для объекта в любое время (за исключением того времени, когда объект изменяется). обертка Метод, который выступает посредником между вызывающим кодом и методом-помощником; способствует упрощению и повышению надежности кода. помощник Метод, не вызываемый непосредственно, а используемый вызываемым методом для выполнения части работы. предусловие Утверждение, которое должно быть справедливым, для того чтобы функция выполнялась корректно. связный список Структура данных, реализующая коллекцию, используя последовательность связанных узлов. узел списка Элемент списка, обычно реализуемый как объект, содержащий ссылку на объект того же типа и некоторые полезные данные.
16.12. Упражнения¶
- Традиционно списки выводятся на печать в скобках, с запятыми между элементами, например: [1, 2, 3] . Добавьте в класс LinkedList метод print_list так, чтобы он возвращал список в таком формате.
- Добавьте в класс LinkedList метод last , который вернет последний узел в списке или None в случае, когда список пуст. Протестируйте работу метода для пустого и непустого списков.
- Добавьте в класс LinkedList метод append(self, cargo) для добавления узла в конец списка. Используйте метод list из предыдущего упражнения для получения узла, к которому будет добавляться новый узел. Протестируйте работу метода.
- Добавьте в класс LinkedList метод find(self, cargo) для поиска в списке узла с cargo , ближайшего к началу списка. Протестируйте метод для пустого списка, списка, содержащего узел с искомым cargo , и для списка, не содержащего такого узла.
- Добавьте в класс LinkedList метод __contains__(self, cargo) чтобы реализовать оператор in для LinkedList . Используйте метод find из предыдущего упражнения в методе __contains__ . Протестируйте работу оператора in для пустого списка, списка, содержащего узел с cargo , и списка, не содержащего такого узла.
Просмотр
© Copyright 2009, 2012, Джеффри Элкнер, Аллен Б. Дауни, Крис Мейерс, Андрей Трофимов. При создании использован Sphinx 1.1.3.
Связный список на Python: что это такое и как его реализовать
Давайте поговорим немного о связных списках. Вероятно, вы о них слышали. Скажем, на лекциях по структурам данных. И возможно, вы думали, что это как-то сильно заумно. Почему бы не использовать массив? На самом деле связные списки имеют некоторые преимущества перед массивами и простыми списками. Поначалу эта тема может показаться сложной, но не волнуйтесь: мы все разберем.
Если вы представите себе фотографию людей, взявшихся за руки в хороводе, вы получите примерное представление о такой структуре, как связный список. Это некоторое количество отдельных узлов, связанных между собой ссылками, т. е. ссылками на другие узлы. Связные списки бывают двух видов: однонаправленные и двунаправленные (односвязные и двусвязные).
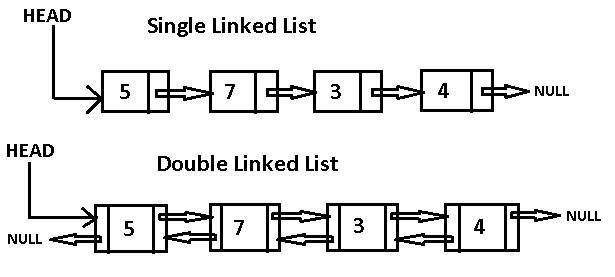
В односвязных списках каждый узел имеет одну стрелку, указывающую вперед, а в двусвязных узлы имеют еще и стрелки, указывающие назад. Но на собеседованиях в вопросах, касающихся связных списков, чаще всего имеются в виду односвязные. Почему? Их проще реализовать. Да, у вас не будет возможности перемещаться по списку в обратном направлении, но для отслеживания узлов хватит и однонаправленных связей.
Давайте попробуем реализовать связный список на Python. Возможно, вы бы начали с class Linked_list , а затем создали в нем узлы, но все можно сделать куда проще. Представьте цепочку из скрепок. Мы берем кучку скрепок и соединяем их, цепляя друг за дружку.

Цепочку создают отдельные скрепки плюс тот факт, что они сцеплены между собой. Поэтому вместо создания класса Linked_list мы просто создадим класс Node и позволим отдельным узлам связываться друг с другом.
class Node:
Далее, как обычно при создании класса на Python, мы создаем метод __init__ . Этот метод инициализирует все поля, например, переменные в классе, при создании каждого нового объекта Node .
Мы будем принимать переменную data — это значение, которое мы хотим сохранять в узле. Также нам нужно определить ссылку, направленную вперед, она традиционно называется next . Сначала узел не связан ни с чем, поэтому мы устанавливаем next в None .
class Node: def __init__(self, data): self.data = data self.next = None
Это почти все, что нам нужно. Можно оставить, как есть, но в книге «Cracking the Coding Interview» также реализуется метод appendToTail() , который создает новый узел и добавляет его в конец списка, проходя его, так что нам не приходится делать это вручную.
Начнем с определения этого метода в классе Node . Метод будет принимать значение, которое мы хотим поместить в новый узел, и ключевое слово self (это специфично для Python).
class Node: def __init__(self, data): self.data = data self.next = None def append(self, val): pass
Первое, что мы делаем, это создаем новый узел с заданным значением. Назовем его end .
def append(self, val): end = Node(val)
Затем мы создаем указатель (поинтер). Это может звучать слишком технически, но по сути мы создаем ссылку на головной элемент ( head ) нашего списка. Мы делаем так, потому что хотим проходить по списку, не переназначая в нем ничего. Итак, мы делаем ссылку на первый узел, self , и сохраняем его в переменной n .
def append(self, val): end = Node(val) n = self
Наконец, мы проходим список. Как мы это делаем? Нам нужно всего лишь перемещаться к следующему узлу, если он есть. А если следующего узла нет, мы поймем, что мы уже в конце списка. Для прохождения списка до предпоследнего узла мы используем простой цикл while .
def append(self, val): end = Node(val) n = self while (n.next): n = n.next
Наконец, мы указываем на последний узел, за которым нет следующего узла. Мы просто берем end — наш новый узел — и устанавливаем n.next = end .
def append(self, val): end = Node(val) n = self while (n.next): n = n.next n.next = end
Вот и все! Вот как выглядит наш класс полностью:
class Node: def __init__(self, data): self.next = None self.data = data def append(self, val): end = Node(val) n = self while (n.next): n = n.next n.next = end
Проверяем наш связный список
Давайте все это проверим. Начнем с создания нового объекта Node. Назовем его ll (две латинские буквы «l» в нижнем регистре как сокращение Linked List). Назначим ему значение 1.
ll = Node(1)
Поскольку мы написали такой классный метод append() , мы можем вызывать его для добавления в наш список новых узлов.
ll.append(2) ll.append(3)
Как нам увидеть, как выглядит наш список? Теоретически, выглядеть он должен следующим образом:
[1] --> [2] --> [3]
Но нет способа вывести его именно в таком виде. Нам нужно пройти список, выводя каждое значение. Вы же помните, как проходить список? Мы только что это делали. Повторим:
- Создаем переменную, указывающую на head .
- Если есть следующий узел, перемещаемся к этому узлу.
И просто выводим data в каждом узле. Мы начинаем с шага № 1: создаем новую переменную и назначаем ее головным элементом списка.
node = ll
Далее мы выводим первый узел. Почему мы не начали с цикла while? Цикл while проитерируется только дважды, потому что только у двух узлов есть next (у последнего узла его нет). В информатике это называется ошибкой на единицу (когда нужно сделать что-то Х раз плюс 1). Это можно представить в виде забора. Вы ставите столб, затем секцию забора, и чередуете пару столб + секция столько раз, сколько нужно по длине.

Но вы не можете оставить последнюю секцию забора висящей в воздухе. Ограда должна закончиться столбом, а не секцией. Поэтому вам приходится либо добавлять еще один столб в конце, либо (что в информатике более распространено) начать с постановки столба, а затем добавлять пары секция + столб . Это мы и сделаем.
Для начала мы выведем первый узел, а затем запустим цикл while для вывода всех последующих узлов.
node = ll print(node.data) while node.next: node = node.next print(node.data)
Запустив это для нашего предыдущего списка, мы получим в консоли:
1 2 3
Ура! Наш связный список работает.
Зачем уметь создавать связный список на Python?
Зачем вообще может понадобиться создавать собственный связный список на Python? Это хороший вопрос. Использование связных списков имеет некоторые преимущества по сравнению с использованием просто списков Python.
Традиционно вопрос звучит как «чем использование связного списка лучше использования массива». Основная идея в том, что массивы в Java и других ООП-языках имеют фиксированный размер, поэтому для добавления элемента приходится создавать новый массив с размером N + 1 и помещать в него все значения из предыдущего массива. Пространственная и временная сложность этой операции — O(N). А вот добавление элемента в конец связного списка имеет постоянную временную сложность (O(1)).
Списки в Python это не настоящие массивы, а скорее реализация динамического массива, что имеет свои преимущества и недостатки. В Википедии есть таблица со сравнением производительности связных списков, массивов и динамических массивов.
Если вопрос производительности вас не тревожит, тогда да, проще реализовать обычный список Python. Но научиться реализовывать собственный связный список все равно полезно. Это как изучение математики: у нас есть калькуляторы, но основные концепции мы все-таки изучаем.
В сообществе разработчиков постоянно ведутся горячие споры о том, насколько целесообразно давать на технических интервью задания, связанные с алгоритмами и структурами данных. Возможно, в этом и нет никакого смысла, но на собеседовании вас вполне могут попросить реализовать связный список на Python. И теперь вы знаете, как это сделать.
Задача: найти центральный элемент односвязного списка
Решаем задачи, которые дают программистам на собеседованиях в IT‑компаниях. Сегодня ищем центральный элемент односвязного списка.

Иллюстрация: Polina Vari для Skillbox Media

Дмитрий Зверев
Любитель научной фантастики и технологического прогресса. Хорошо сочетает в себе заумного технаря и утончённого гуманитария. Пишет про IT и радуется этому.

Сергей Голицын
Senior Java Developer в Covalent Inc. и преподаватель. Больше семи лет в Java-разработке. В свободное время судит хакатоны и делится опытом с начинающими программистами. Пишет статьи для «Хабра» и Medium. Ведёт телеграм-каналы «Полезные ссылки около Java» и Cracking code interview.
Условие. Дана голова односвязного списка — head. Необходимо вернуть его центральный элемент и все остальные элементы после него. Если в списке два центральных элемента, то вернуть второй и все элементы за ним.
Пояснение. Связный список — это список из объектов, которые связаны друг с другом. Каждый элемент состоит из двух компонентов: собственно данных и ссылки на следующий элемент. Головой (head) связного списка называют его первый элемент. Конечный элемент — это хвост. Главное отличие хвоста от остальных элементов в том, что его ссылка на следующий элемент — это null.
Ввод и вывод. Пример 1
Ввод: head = [1,2,3,4,5] Вывод: [3,4,5] Пояснение: центральный элемент — 3.
Пример 2
Ввод: head = [1,2,3,4,5,6] Вывод: [4,5,6] Пояснение: так как центральных элементов два — 3 и 4, мы возвращаем второй из них — 4.
Решить эту задачу самостоятельно и на разных языках программирования можно на LeetCode. Наше решение взято из телеграм-канала Сергея Cracking code interview.
Решение
Эта задача может быть немного каверзной. Но мы разберём два возможных решения.
Самым простым решением будет проитерировать весь список и посчитать количество элементов, а затем найти индекс центрального и вернуть его. Очень просто.
Второе решение чуть сложнее. Мы будем использовать способ с двумя указателями — медленным и быстрым. Оба будут пробегать по всему списку, пока не достигнут конца. А конец в нашем случае — это один из двух вариантов: первый — список имеет цикл, и бегунки встретятся, второй — мы будем иметь null в конце списка.
Пояснение: список будет зациклен, если его хвостовой элемент указывает не на null, а на индекс другого элемента. Получается, что мы будем бесконечно перебирать элементы списка и никогда не достигнем его конца.
Когда быстрый указатель достигнет конца, медленный будет как раз в середине списка.
При этом не стоит забывать и о границах списка. Мы должны проверять быстрый указатель, чтобы элемент, на который он указывает в текущий момент, и следующий за ним элемент не были равны null.
Давайте реализуем это в коде:
public ListNode middleNode(ListNode head) < ListNode slow = head; ListNode fast = head; while(fast != null && fast.next != null) < slow = slow.next; fast = fast.next.next; >return slow; >
Результаты
Временная сложность: O(n) — так как мы однократно проходимся по всему массиву.
Ёмкостная сложность: O(1) — нам нужно заранее определённое количество места в памяти.
Читайте также:
- Популярные вопросы и задачи на собеседованиях тестировщиков
- Тест: сможете отличить Zen of Python от философии Лао-цзы?
- Как сделать приложение для Android самостоятельно