Логистическая регрессия и ROC-анализ — математический аппарат

Математический аппарат и назначение бинарной логистической регрессии — популярного инструмента для решения задач регрессии и классификации. ROC-анализ тесно связан с бинарной логистической регрессией и применяется для оценки качества моделей: позволяет выбрать аналитику модель с наилучшей прогностической силой, проанализировать чувствительность и специфичность моделей, подобрать порог отсечения.
Введение
Логистическая регрессия — полезный классический инструмент для решения задачи регрессии и классификации. ROC-анализ — аппарат для анализа качества моделей. Оба алгоритма активно используются для построения моделей в медицине и проведения клинических исследований.
Логистическая регрессия получила распространение в скоринге для расчета рейтинга заемщиков и управления кредитными рисками. Поэтому, несмотря на свое «происхождение» из статистики, логистическую регрессию и ROC-анализ почти всегда можно увидеть в наборе Data Mining алгоритмов.
Логистическая регрессия
Логистическая регрессия — это разновидность множественной регрессии, общее назначение которой состоит в анализе связи между несколькими независимыми переменными (называемыми также регрессорами или предикторами) и зависимой переменной. Бинарная логистическая регрессия применяется в случае, когда зависимая переменная является бинарной (т.е. может принимать только два значения). С помощью логистической регрессии можно оценивать вероятность того, что событие наступит для конкретного испытуемого (больной/здоровый, возврат кредита/дефолт и т.д.).
Все регрессионные модели могут быть записаны в виде формулы:
y = F (x_1,\, x_2, \,\dots, \, x_n)
В множественной линейной регрессии предполагается, что зависимая переменная является линейной функцией независимых переменных, т.е.:
Можно ли ее использовать для задачи оценки вероятности исхода события? Да, можно, вычислив стандартные коэффициенты регрессии. Например, если рассматривается исход по займу, задается переменная y со значениями 1 и 0, где 1 означает, что соответствующий заемщик расплатился по кредиту, а 0, что имел место дефолт.
Однако здесь возникает проблема: множественная регрессия не «знает», что переменная отклика бинарна по своей природе. Это неизбежно приведет к модели с предсказываемыми значениями большими 1 и меньшими 0. Но такие значения вообще не допустимы для первоначальной задачи. Таким образом, множественная регрессия просто игнорирует ограничения на диапазон значений для y .
Для решения проблемы задача регрессии может быть сформулирована иначе: вместо предсказания бинарной переменной, мы предсказываем непрерывную переменную со значениями на отрезке [0,1] при любых значениях независимых переменных. Это достигается применением следующего регрессионного уравнения (логит-преобразование):
где P — вероятность того, что произойдет интересующее событие e — основание натуральных логарифмов 2,71…; y — стандартное уравнение регрессии.
Зависимость, связывающая вероятность события и величину y , показана на следующем графике (рис. 1):
Поясним необходимость преобразования. Предположим, что мы рассуждаем о нашей зависимой переменной в терминах основной вероятности P , лежащей между 0 и 1. Тогда преобразуем эту вероятность P :
P’ = \log_e \Bigl(\frac\Bigr)
Это преобразование обычно называют логистическим или логит-преобразованием. Теоретически P’ может принимать любое значение. Поскольку логистическое преобразование решает проблему об ограничении на 0-1 границы для первоначальной зависимой переменной (вероятности), то эти преобразованные значения можно использовать в обычном линейном регрессионном уравнении. А именно, если произвести логистическое преобразование обеих частей описанного выше уравнения, мы получим стандартную модель линейной регрессии.
Существует несколько способов нахождения коэффициентов логистической регрессии. На практике часто используют метод максимального правдоподобия. Он применяется в статистике для получения оценок параметров генеральной совокупности по данным выборки. Основу метода составляет функция правдоподобия (likehood function), выражающая плотность вероятности (вероятность) совместного появления результатов выборки
L\,(Y_1,\,Y_2,\,\dots,\,Y_k;\,\theta) = p\,(Y_1;\, \theta)\cdot\dots\cdotp\,p\,(Y_k;\,\theta)
Согласно методу максимального правдоподобия в качестве оценки неизвестного параметра принимается такое значение \theta=\theta(Y_1,…,Y_k) , которое максимизирует функцию L .
Нахождение оценки упрощается, если максимизировать не саму функцию L , а натуральный логарифм ln(L) , поскольку максимум обеих функций достигается при одном и том же значении \theta :
L^*(Y;\,\theta) = \ln\,(L\,(Y;\,\theta)\,) \rightarrow \max
В случае бинарной независимой переменной, которую мы имеем в логистической регрессии, выкладки можно продолжить следующим образом. Обозначим через P_i вероятность появления единицы: P_i=Prob(Y_i=1) . Эта вероятность будет зависеть от X_iW , где X_i — строка матрицы регрессоров, W — вектор коэффициентов регрессии:
Логарифмическая функция правдоподобия равна:
где I_0 , I_1 — множества наблюдений, для которых Y_i=0 и Y_i=1 соответственно.
Можно показать, что градиент g и гессиан H функции правдоподобия равны:
g = \sum_i (Y_i\,-\,P_i)\,X_i
H=-\sum_i P_i\,(1\,-\,P_i)\,X_i^T\,X_i\,\leq 0
Гессиан всюду отрицательно определенный, поэтому логарифмическая функция правдоподобия всюду вогнута. Для поиска максимума можно использовать метод Ньютона, который здесь будет всегда сходиться (выполнено условие сходимости метода):
Логистическую регрессию можно представить в виде однослойной нейронной сети с сигмоидальной функцией активации, веса которой есть коэффициенты логистической регрессии, а вес поляризации — константа регрессионного уравнения (рис. 2).
Однослойная нейронная сеть может успешно решить лишь задачу линейной сепарации. Поэтому возможности по моделированию нелинейных зависимостей у логистической регрессии отсутствуют. Однако для оценки качества модели логистической регрессии существует эффективный инструмент ROC-анализа, что является несомненным ее преимуществом.
Для расчета коэффициентов логистической регрессии можно применять любые градиентные методы: метод сопряженных градиентов, методы переменной метрики и другие.
ROC-анализ
ROC-кривая (Receiver Operator Characteristic) — кривая, которая наиболее часто используется для представления результатов бинарной классификации в машинном обучении. Название пришло из систем обработки сигналов. Поскольку классов два, один из них называется классом с положительными исходами, второй — с отрицательными исходами. ROC-кривая показывает зависимость количества верно классифицированных положительных примеров от количества неверно классифицированных отрицательных примеров.
В терминологии ROC-анализа первые называются истинно положительным, вторые — ложно отрицательным множеством. При этом предполагается, что у классификатора имеется некоторый параметр, варьируя который, мы будем получать то или иное разбиение на два класса. Этот параметр часто называют порогом, или точкой отсечения (cut-off value). В зависимости от него будут получаться различные величины ошибок I и II рода.
В логистической регрессии порог отсечения изменяется от 0 до 1 — это и есть расчетное значение уравнения регрессии. Будем называть его рейтингом.
Для понимания сути ошибок I и II рода рассмотрим четырехпольную таблицу сопряженности (confusion matrix), которая строится на основе результатов классификации моделью и фактической (объективной) принадлежностью примеров к классам.
| Модель | Фактически положительно | Фактически отрицательно |
|---|---|---|
| Положительно | TP | FP |
| Отрицательно | FN | TN |
- TP (True Positives) — верно классифицированные положительные примеры (так называемые истинно положительные случаи).
- TN (True Negatives) — верно классифицированные отрицательные примеры (истинно отрицательные случаи).
- FN (False Negatives) — положительные примеры, классифицированные как отрицательные (ошибка I рода). Это так называемый «ложный пропуск» — когда интересующее нас событие ошибочно не обнаруживается (ложно отрицательные примеры).
- FP (False Positives) — отрицательные примеры, классифицированные как положительные (ошибка II рода). Это ложное обнаружение, т.к. при отсутствии события ошибочно выносится решение о его присутствии (ложно положительные случаи).
Что является положительным событием, а что — отрицательным, зависит от конкретной задачи. Например, если мы прогнозируем вероятность наличия заболевания, то положительным исходом будет класс «Больной пациент», отрицательным — «Здоровый пациент». И наоборот, если мы хотим определить вероятность того, что человек здоров, то положительным исходом будет класс «Здоровый пациент», и так далее.
При анализе чаще оперируют не абсолютными показателями, а относительными — долями (rates), выраженными в процентах:
- Доля истинно положительных примеров (True Positives Rate): TPR = \frac\,\cdot\,100 \,\%
- Доля ложно положительных примеров (False Positives Rate): FPR = \frac\,\cdot\,100 \,\%
Введем еще два определения: чувствительность и специфичность модели. Ими определяется объективная ценность любого бинарного классификатора.
Чувствительность (Sensitivity) — это и есть доля истинно положительных случаев:
Специфичность (Specificity) — доля истинно отрицательных случаев, которые были правильно идентифицированы моделью:
Заметим, что FPR=100-Sp
Попытаемся разобраться в этих определениях.
Модель с высокой чувствительностью часто дает истинный результат при наличии положительного исхода (обнаруживает положительные примеры). Наоборот, модель с высокой специфичностью чаще дает истинный результат при наличии отрицательного исхода (обнаруживает отрицательные примеры). Если рассуждать в терминах медицины — задачи диагностики заболевания, где модель классификации пациентов на больных и здоровых называется диагностическим тестом, то получится следующее:
- Чувствительный диагностический тест проявляется в гипердиагностике — максимальном предотвращении пропуска больных.
- Специфичный диагностический тест диагностирует только доподлинно больных. Это важно в случае, когда, например, лечение больного связано с серьезными побочными эффектами и гипердиагностика пациентов не желательна.
ROC-кривая получается следующим образом:
- Для каждого значения порога отсечения, которое меняется от 0 до 1 с шагом d_x (например, 0,01) рассчитываются значения чувствительности Se и специфичности Sp . В качестве альтернативы порогом может являться каждое последующее значение примера в выборке.
- Строится график зависимости: по оси Y откладывается чувствительность Se , по оси X — FPR=100-Sp — доля ложно положительных случаев.
Канонический алгоритм построения ROC-кривой
Входы: L — множество примеров f[i] — рейтинг, полученный моделью, или вероятность того, что i -й пример имеет положительный исход; min и max — минимальное и максимальное значения, возвращаемые f ; d_x — шаг; P и N — количество положительных и отрицательных примеров соответственно.
- t=min
- повторять
- FP=TP=0
- для всех примеров i принадлежит L
- если f[i]>=t тогда // этот пример находится за порогом
- если i положительный пример тогда
- иначе // это отрицательный пример
- >
- Se=TP/P*100
- point=FP/N // расчет (100 минус Sp )
- Добавить точку (point, Se) в ROC-кривую
- t=t+d_x
- пока (t>max)
В результате вырисовывается некоторая кривая (рис. 3).
График часто дополняют прямой y=x .
Заметим, что имеется более экономичный способ расчета точек ROC-кривой, чем тот, который приводился выше, т.к. его вычислительная сложность нелинейная и равна O(n^2) : для каждого порога необходимо «пробегать» по записям и каждый раз рассчитывать TP и FP . Если же двигаться вниз по набору данных, отсортированному по убыванию выходного поля классификатора (рейтингу), то можно за один проход вычислить значения всех точек ROC-кривой, последовательно обновляя значения TP и FP .
Для идеального классификатора график ROC-кривой проходит через верхний левый угол, где доля истинно положительных случаев составляет 100% или 1,0 (идеальная чувствительность), а доля ложно положительных примеров равна нулю. Поэтому чем ближе кривая к верхнему левому углу, тем выше предсказательная способность модели. Наоборот, чем меньше изгиб кривой и чем ближе она расположена к диагональной прямой, тем менее эффективна модель. Диагональная линия соответствует «бесполезному» классификатору, т.е. полной неразличимости двух классов.
При визуальной оценке ROC-кривых расположение их относительно друг друга указывает на их сравнительную эффективность. Кривая, расположенная выше и левее, свидетельствует о большей предсказательной способности модели. Так, на рис. 4 две ROC-кривые совмещены на одном графике. Видно, что модель «A» лучше.
Визуальное сравнение кривых ROC не всегда позволяет выявить наиболее эффективную модель. Своеобразным методом сравнения ROC-кривых является оценка площади под кривыми. Теоретически она изменяется от 0 до 1,0, но, поскольку модель всегда характеризуются кривой, расположенной выше положительной диагонали, то обычно говорят об изменениях от 0,5 («бесполезный» классификатор) до 1,0 («идеальная» модель).
Эта оценка может быть получена непосредственно вычислением площади под многогранником, ограниченным справа и снизу осями координат и слева вверху — экспериментально полученными точками (рис. 5). Численный показатель площади под кривой называется AUC (Area Under Curve). Вычислить его можно, например, с помощью численного метода трапеций:
AUC = \int f(x)\,dx = \sum_i \Bigl[ \frac\,+\,X_i>\Bigr]\,\cdot \,(Y_\,-\, Y_i)
С большими допущениями можно считать, что чем больше показатель AUC , тем лучшей прогностической силой обладает модель. Однако следует знать, что:
- показатель AUC предназначен скорее для сравнительного анализа нескольких моделей;
- AUC не содержит никакой информации о чувствительности и специфичности модели.
В литературе иногда приводится следующая экспертная шкала для значений AUC , по которой можно судить о качестве модели:
| Интервал AUC | Качество модели |
|---|---|
| 0,9-1,0 | Отличное |
| 0,8-0,9 | Очень хорошее |
| 0,7-0,8 | Хорошее |
| 0,6-0,7 | Среднее |
| 0,5-0,6 | Неудовлетворительное |
Идеальная модель обладает 100% чувствительностью и специфичностью. Однако на практике добиться этого невозможно, более того, невозможно одновременно повысить и чувствительность, и специфичность модели. Компромисс находится с помощью порога отсечения, т.к. пороговое значение влияет на соотношение Se и Sp . Можно говорить о задаче нахождения оптимального порога отсечения (optimal cut-off value).
Порог отсечения нужен для того, чтобы применять модель на практике: относить новые примеры к одному из двух классов. Для определения оптимального порога нужно задать критерий его определения, т.к. в разных задачах присутствует своя оптимальная стратегия. Критериями выбора порога отсечения могут выступать:
- Требование минимальной величины чувствительности (специфичности) модели. Например, нужно обеспечить чувствительность теста не менее 80%. В этом случае оптимальным порогом будет максимальная специфичность (чувствительность), которая достигается при 80% (или значение, близкое к нему «справа» из-за дискретности ряда) чувствительности (специфичности).
- Требование максимальной суммарной чувствительности и специфичности модели, т.е. Cutt\underlineoff_o = \max_k (Se_k\,+\,Sp_k)
- Требование баланса между чувствительностью и специфичностью, т.е. когда Se \approx Sp : Cutt\underlineoff_o = \min_k \,\bigl |Se_k\,-\,Sp_k \bigr |
Второе значение порога обычно предлагается пользователю по умолчанию. В третьем случае порог есть точка пересечения двух кривых, когда по оси X откладывается порог отсечения, а по оси Y — чувствительность или специфичность модели (рис. 6).
Существуют и другие подходы, когда ошибкам I и II рода назначается вес, который интерпретируется как цена ошибок. Но здесь встает проблема определения этих весов, что само по себе является сложной, а часто не разрешимой задачей.
- Цыплаков А. А. Некоторые эконометрические методы. Метод максимального правдоподобия в эконометрии. Учебное пособие.
- Fawcett T. ROC Graphs: Notes and Practical Considerations for Researchers // 2004 Kluwer Academic Publishers.
- Zweig M.H., Campbell G. ROC Plots: A Fundamental Evaluation Tool in Clinical Medicine // Clinical Chemistry, Vol. 39, No. 4, 1993.
- Davis J., Goadrich M. The Relationship Between Precision-Recall and ROC Curves // Proc. Of 23 International Conference on Machine Learning, Pittsburgh, PA, 2006.
Другие материалы по теме:
Как легко понять логистическую регрессию
Логистическая регрессия является одним из статистических методов классификации с использованием линейного дискриминанта Фишера. Также она входит в топ часто используемых алгоритмов в науке о данных. В этой статье суть логистической регрессии описана так, что она станет понятна даже людям не очень близким к статистике.

Основная идея логистической регрессии
В отличие от обычной регрессии, в методе логистической регрессии не производится предсказание значения числовой переменной исходя из выборки исходных значений. Вместо этого, значением функции является вероятность того, что данное исходное значение принадлежит к определенному классу. Для простоты, давайте предположим, что у нас есть только два класса (см. Множественная логистическая регрессия для задач с большим количеством классов) и вероятность, которую мы будем определять, вероятности того, что некоторое значение принадлежит классу «+». И конечно . Таким образом, результат логистической регрессии всегда находится в интервале [0, 1].
Основная идея логистической регрессии заключается в том, что пространство исходных значений может быть разделено линейной границей (т.е. прямой) на две соответствующих классам области. Итак, что же имеется ввиду под линейной границей? В случае двух измерений — это просто прямая линия без изгибов. В случае трех — плоскость, и так далее. Эта граница задается в зависимости от имеющихся исходных данных и обучающего алгоритма. Чтобы все работало, точки исходных данных должны разделяться линейной границей на две вышеупомянутых области. Если точки исходных данных удовлетворяют этому требованию, то их можно назвать линейно разделяемыми. Посмотрите на изображение.

Указанная разделяющая плоскость называется линейным дискриминантом, так как она является линейной с точки зрения своей функции, и позволяет модели производить разделение, дискриминацию точек на различные классы.
Если невозможно произвести линейное разделение точек в исходном пространстве, стоит попробовать преобразовать векторы признаков в пространство с большим количеством измерений, добавив дополнительные эффекты взаимодействия, члены более высокой степени и т.д. Использование линейного алгоритма в таком пространстве дает определенные преимущества для обучения нелинейной функции, поскольку граница становится нелинейной при возврате в исходное пространство.
Но каким образом используется линейная граница в методе логистической регрессии для количественной оценки вероятности принадлежности точек данных к определенному классу?
Как происходит разделение
Во-первых, давайте попробуем понять геометрический подтекст «разделения» исходного пространства на две области. Возьмем для простоты (в отличие от показанного выше 3-мерного графика) две исходные переменные — и , тогда функция, соответствующая границе, примет вид:
Важно отметить, что и и являются исходными переменными, а выходная переменная не является частью исходного пространства в отличие от метода линейной регрессии.
Рассмотрим точку . Подставляя значения и в граничную функцию, получим результат . Теперь, в зависимости от положения следует рассмотреть три варианта:
- лежит в области, ограниченной точками класса «+». Тогда , будет положительной, находясь где-то в пределах (0,). С математической точки зрения, чем больше величина этого значения, тем больше расстояние между точкой и границей. А это означает большую вероятность того, что принадлежит классу «+». Следовательно, будет находиться в пределах (0,5, 1].
- лежит в области, ограниченной точками класса «-«. Теперь, будет отрицательной, находясь в пределах (-, 0). Но, как и в случае с положительным значением, чем больше величина выходного значения по модулю, тем больше вероятность, что принадлежит классу «-«, и находится в интервале [0, 0.5).
- лежит на самой границе. В этом случае, . Это означает, что модель действительно не может определить, принадлежит ли к классу «+» или к классу «-«. И в результате, будет равняться 0,5.
Обозначим вероятностью происходящего события . Тогда, отношение шансов () определяется из , а это — отношение вероятностей того, произойдет ли событие или не произойдет. Очевидно, что вероятность и отношение шансов содержат одинаковую информацию. Но, в то время как находится в пределах от 0 до 1, находится в пределах от 0 до .
Это значит, что необходимо еще одно действие, так как используемая нами граничная функция выдает значения от — до . Далее следует вычислить логарифм , что называется логарифмом отношения шансов. В математическом смысле, имеет пределы от 0 до , а — от — до .
Таким образом, мы получили способ интерпретации результатов, подставленных в граничную функцию исходных значений. В используемой нами модели граничная функция определяет логарифм отношения шансов класса «+». В сущности, в нашем двухмерном примере, при наличии точки , алгоритм логистической регрессии будет выглядеть следующим образом:
- Шаг 1. Вычислить значение граничной функции (или, как вариант, функцию отношения шансов). Для простоты обозначим эту величину .
- Шаг 2. Вычислить отношение шансов: . (так как является логарифмом ).
- Шаг 3. Имея значение , вычислить с помощью простой зависимости.
Получив значение в шаге 1, можно объединить шаги 2 и 3:
Правая часть уравнения, указанного выше, называется логистической функцией. Отсюда и название, данное этой модели обучения.
Как обучается функция
Остался не отвеченным вопрос: «Каким образом обучается граничная функция ?» Математическая основа этого выходит за рамки статьи, но общая идея заключается в следующем:
Рассмотрим функцию , где — точка данных обучающей выборки. В простой форме можно описать так:
если является частью класса «+», (здесь — выходное значение, полученное из модели логистической регрессии). Если является частью класса «-«, .
Функция проводит количественную оценку вероятности того, что точка обучающей выборки классифицируется моделью правильным образом. Поэтому, среднее значение для всей обучающей выборки показывает вероятность того, что случайная точка данных будет корректно классифицирована системой, независимо от возможного класса.
Скажем проще — механизм обучения логистической регрессии старается максимизировать среднее значение . А название этого метода — метод максимального правдоподобия. Если вы не математик, то вы сможете понять каким образом происходит оптимизация, только если у вас есть хорошее представление о том, что именно оптимизируется.
Конспект
- Логистическая регрессия — одно из статистических методов классификации с использованием линейного дискриминанта Фишера.
- Значением функции является вероятность того, что данное исходное значение принадлежит к определенному классу.
- механизм обучения логистической регрессии старается максимизировать среднее значение .
- логистическая регрессия
- регрессия
- статистика
- аналитика
Логистическая регрессия
Логистическая регрессия (англ. logistic regression) — метод построения линейного классификатора, позволяющий оценивать апостериорные вероятности принадлежности объектов классам.
Описание
Логистическая регрессия применяется для прогнозирования вероятности возникновения некоторого события по значениям множества признаков. Для этого вводится зависимая переменная $y$, принимающая значения $0$ и $1$ и множество независимых переменных [math]x_1, . x_n[/math] на основе значений которых требуется вычислить вероятность принятия того или иного значения зависимой переменной.
Итак, пусть объекты задаются $n$ числовыми признаками $f_j : X \to R, j = 1 . n$ и пространство признаковых описаний в таком случае $X = R^n$. Пусть $Y$ — конечное множество меток классов и задана обучающая выборка пар «объект-ответ» [math]X^m = \.[/math]
Рассмотрим случай двух классов: $Y = \$. В логистической регрессии строится линейный алгоритм классификации $a: X \to Y$ вида
[math]a(x, w) = \mathrm\left(\sum\limits_^n w_j f_j(x) — w_0 \right)=\mathrm\left\lt x, w\right\gt [/math] ,
где $w_j$ $-$ вес $j$-го признака, $w_0$ $-$ порог принятия решения, $w=\left(w_0, . w_n\right)$ $-$ вектор весов, $\left$ $-$ скалярное произведение признакового описания объекта на вектор весов. Предполагается, что искусственно введён нулевой признак: $f_(x)=-1$.
Задача обучения линейного классификатора заключается в том, чтобы по выборке $X^m$ настроить вектор весов $w$. В логистической регрессии для этого решается задача минимизации эмпирического риска с функцией потерь специального вида: [math]Q(w) = \sum\limits_^m \ln\left( 1 + \exp( -y_i \langle x_i,w \rangle ) \right) \to \min_[/math] ,
После того, как решение $w$ найдено, становится возможным не только вычислять классификацию $a(x) = \mathrm\langle x,w \rangle$ для произвольного объекта $x$, но и оценивать апостериорные вероятности его принадлежности классам:
[math]\mathbb\ = \sigma\left( y \langle x,w \rangle\right),\;\; y\in Y[/math] ,
где $\sigma(z) = \frac1>$ — сигмоидная функция.
Обоснование
Наиболее строгое обоснование логистической регрессии опирается на следующую теорему
- выборка прецедентов $\mathrm^l=\<\left(x_1, y_1\right), . ,\left(x_l, y_l\right)\>$ получена согласно вероятностному распределению с плотностью
[math]p\left(x, y\right)=\mathrm_yp_y\left(x\right)=\mathrm\left(y|x\right)p\left(x\right)[/math] где $\mathrm_y$ — априорные вероятности, $p_y(x)$ $-$ функции правдоподобия, принадлежащие экспонентному семейству плотностей (т.е. $p_y(x) = \exp \left( \langle\theta,x\rangle \cdot a(\delta) + b(\delta,\theta) + d(x,\delta) \right)$, где $a, b, d$ $-$ произвольные функции);
- функции правдоподобия имеют равные знаения параметра разброса $\delta$ и отличаются только значениями параметра сдвига $\theta_y$;
- среди признаков есть константа, скажем, $f_0(x) = -1$;
- линейный классификатор является оптимальным байесовским классификатором;
- апостериорные вероятности классов оценивается по формуле [math]\mathbb\ = \sigma\left( y \langle x,w \rangle\right),\;\; y\in Y[/math] .
Напомним, что оптимальный байесовский классификатор для двух классов выглядит следущим образом:
[math]a\left(x\right)= \mathrm\left(\lambda_+\mathrm\left(+1|x\right)-\lambda_-\mathrm\left(-1|x\right)\right)= \mathrm\left(\frac<\mathrm\left(+1|x\right)><\mathrm\left(-1|x\right)>-\frac<\lambda_-><\lambda_+>\right)[/math] ,
Рассмотрим отношение апостериорных вероятностей классов
и распишем функции правдоподобия, используя экспонентную формулу с параметрами $\theta_y$ и $\delta$:
[math]\frac<\mathrm _-p_-(x)> = \exp\left(\langle\left(c_+(\delta)\theta_+-c_-(\delta)\theta_-\right), x\rangle+b_+(\delta, \theta_+)-b_-(\delta, \theta_-) + \ln\frac<\mathrm _+><\mathrm _->\right)[/math] , Рассмотрим получившуюся под экспонентой сумму: _+><\mathrm _-> = \mathrm\left(x\right)$. Можно считать данные слагаемые аддитивной добавкой к коэффициенту при признаке. Но так как свободные коэффициенты настраиваются по обучающей выборке, вычислять эту добавку не имеет смысла и ее можно включить в $\langle w, x\rangle$. Разделяющая поверхность в байесовском решающем правиле определяется уравнением [math]\lambda_- \mathrm\left(-1|x\right) = \lambda_+ \mathrm\left(+1|x\right)[/math] , Следовательно, разделяющая поверхность линейна и первый пункт теоремы доказан. Используя формулу полной вероятности получаем следующее равенство [math]\mathrm\left(+1|x\right) + \mathrm\left(-1|x\right) = \sigma\left(+\langle w ,x\rangle\right) + \sigma\left(-\langle w ,x\rangle\right) = 1[/math] , Классификатор sklearn.linear_model.LogisticRegression имеет несколько параметров, например: Пример логистической регрессии с применением smile.classification.LogisticRegression [1] Основная статья: Примеры кода на R Логистическая регрессия — это алгоритм классификации в машинном обучении для прогнозирования вероятности категориально зависимой переменной. В логистической регрессии зависимые переменные — это двоичные (бинарные) переменные, содержащие 1 (да, успех, и так далее) или 0 — нет, неудача, и так далее. Другими словами, логистическая регрессия прогнозирует P(Y=1) как функцию от X. Подробный и ясный пример — к старту нашего флагманского курса по Data Science. Допущения логистической регрессии: Имея в виду эти допущения, посмотрим на набор данных. Набор данных из реозитория UCI Machine Learning связан с целевыми маркетинговыми компаниями (телефонными звонками) Португальского банка. Задача классификации — спрогнозировать (0/1), то есть откроет ли клиент срочный вклад (переменная y). Загрузить набор можно отсюда. Набор посвящён клиентам банка и содержит 41188 записей с 21 полем: Входные переменные Наша цель — прогноз переменной Y, то есть того, есть ли у клиента срочный вклад? (0 — нет, 1 — да). У поля об образовании (education) много категорий. Чтобы сделать модель лучше, количество этих категорий нужно сократить: Для этого сгруппируем «basic.4y», «basic.9y» и «basic.6y», назовём их «Basic»: Вот поля после группировки: Классы наших данных не сбалансированы, а соотношение клиентов без вклада и с вкладом составляет 89 к 11. До балансировки классов проведём ещё несколько исследований: Вот новые наблюдения: Чтобы чётче представлять данные, рассчитаем категориальное среднее других категориальных переменных, таких как образование и семейное положение. Частота открытия депозита во многом зависит от должности клиента, а значит, эта категориальная переменная может служить хорошим фактором прогнозирования. Семейное положение сильным фактором прогнозирования не выглядит: Также хорошим фактором прогнозирования выглядит категория образования: А день недели — нет: Хорошим фактором прогнозирования может быть месяц: Большинству клиентов банка в этом наборе данных от 30 до 40 лет. Наконец, хорошим фактором прогнозирования выглядит Poutcome. Эти переменные содержат только значения 0 и 1. И последние поля: Я увеличу выборку данных о клиентах без вклада при помощи алгоритма SMOTE (Synthetic Minority Oversampling Technique). На высоком уровне он работает так: Теперь данные сбалансированы идеально! Вы могли заметить, что я увеличила выборки только тренировочных данных; никакая информация из тестовых данных не используется для генерации синтетических наблюдений, то есть никакая информация тестового набора не утечёт в обучающие данные. Рекурсивные устранение признаков построено на идее повторяющегося конструирования модели и выбора лучших и худших в смысле производительности признаков, а затем отбрасывания признака и повторения процесса до исчерпания всех данных. Цель — выбирать признаки, рекурсивно рассматривая всё меньшие и меньшие их множества. Метод помог выбрать следующие признаки: «euribor3m», «job_blue-collar», «job_housemaid», «marital_unknown», «education_illiterate», «default_no», «default_unknown», «contact_cellular», «contact_telephone», «month_apr», «month_aug», «month_dec», «month_jul», «month_jun», «month_mar», «month_may», «month_nov», «month_oct», «poutcome_failure», «poutcome_success». p-значение большинства переменных меньше 0,05, кроме четырёх, которые мы удалим: Прогноз на тестовом наборе и расчёт точности: Точность классификатора логистической регрессии на тестовом наборе: 0,74 У нас 6124+5170 верных и 2505+1542 неверных прогнозов. Точность — это отношение tp/(tp + fp), где tp — число истинных и ложных срабатываний, а интуитивно — это способность модели не отмечать истинные примеры как ложные. Полнота — это отношение tp/(tp + fn), то есть числа истинных и ложных срабатываний, а интуитивно — способность модели найти все истинные примеры. Оценку F-beta можно понимать как взвешенное гармоническое среднее точности и полноты. Лучшее значение оценки — 1, худшее — 0. Эта оценка взвешивает полноту тщательнее точности, умножая её на коэффициент бета. Бета, равная 1.0, означает одинаковую важность полноты и точности. Носитель — это количество вхождений каждого класса в y_test. Рабочая характеристика приёмника — другой распространённый в бинарной классификации инструмент. Пунктирная линия здесь представляет кривую рабочей характеристики приёмника для чисто случайного классификатора, при этом график хорошего классификатора держится от пунктира как можно дальше, к левому верхнему углу. Интерактивный блокнот для этого поста лежит здесь. Мне будет приятно получить отзыв или вопрос в комментариях. Научим вас аккуратно работать с данными, чтобы вы прокачали карьеру и стали востребованным IT-специалистом. Новогодняя акция — скидка 45% по промокоду HABR: Краткий каталог курсов Data Science и Machine Learning Python, веб-разработка Мобильная разработка Java и C# От основ — в глубину А также
Примеры кода
scikit-learn
from sklearn.linear_model import LogisticRegression from sklearn import datasets from sklearn.model_selection import train_test_split
iris = datasets.load_iris() X = iris.data y = iris.target X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
clf = LogisticRegression(random_state=0, solver='lbfgs', multi_class='multinomial') model = clf.fit(X_train, y_train)
y_pred = model.predict(X_test) model.score(X_test, y_test)
Пример кода на Scala
Пример на языке Java
import smile.data.AttributeDataset; import smile.data.NominalAttribute; import smile.classification.LogisticRegression; import smile.data.parser.ArffParser;
var arffParser = new ArffParser(); arffParser.setResponseIndex(4); var iris = arffParser.parse(smile.data.parser.IOUtils.getTestDataFile("weka/iris.arff")); var logClf = new LogisticRegression(iris.x(), iris.labels()); logClf.predict(testX);
Пример на языке R
# reading data rdata "input.csv", sep = ',', header = FALSE) # evaluating model model = glm(formula = target ~ x + y + z, data = rdata, family = binomial) # printing summary print(summary(model))
См. также
Источники информации
Логистическая регрессия на Python

Данные
import pandas as pd import numpy as np from sklearn import preprocessing import matplotlib.pyplot as plt plt.rc("font", size=14) from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split import seaborn as sns sns.set(style="white") sns.set(style="whitegrid", color_codes=True)

data['education']=np.where(data['education'] =='basic.9y', 'Basic', data['education']) data['education']=np.where(data['education'] =='basic.6y', 'Basic', data['education']) data['education']=np.where(data['education'] =='basic.4y', 'Basic', data['education'])
Исследование данных

count_no_sub = len(data[data['y']==0]) count_sub = len(data[data['y']==1]) pct_of_no_sub = count_no_sub/(count_no_sub+count_sub) print("percentage of no subscription is", pct_of_no_sub*100) pct_of_sub = count_sub/(count_no_sub+count_sub) print("percentage of subscription", pct_of_sub*100)



Визуализация
%matplotlib inline pd.crosstab(data.job,data.y).plot(kind='bar') plt.title('Purchase Frequency for Job Title') plt.xlabel('Job') plt.ylabel('Frequency of Purchase') plt.savefig('purchase_fre_job')
table=pd.crosstab(data.marital,data.y) table.div(table.sum(1).astype(float), axis=0).plot(kind='bar', stacked=True) plt.title('Stacked Bar Chart of Marital Status vs Purchase') plt.xlabel('Marital Status') plt.ylabel('Proportion of Customers') plt.savefig('mariral_vs_pur_stack')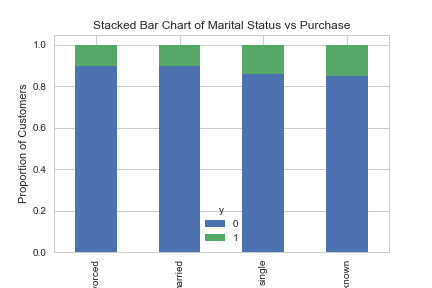
table=pd.crosstab(data.education,data.y) table.div(table.sum(1).astype(float), axis=0).plot(kind='bar', stacked=True) plt.title('Stacked Bar Chart of Education vs Purchase') plt.xlabel('Education') plt.ylabel('Proportion of Customers') plt.savefig('edu_vs_pur_stack')pd.crosstab(data.day_of_week,data.y).plot(kind='bar') plt.title('Purchase Frequency for Day of Week') plt.xlabel('Day of Week') plt.ylabel('Frequency of Purchase') plt.savefig('pur_dayofweek_bar')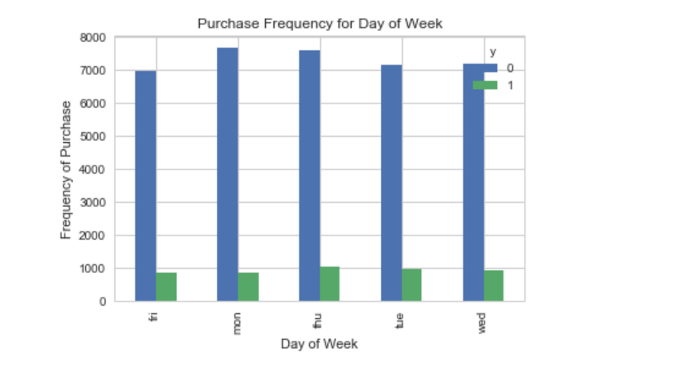
pd.crosstab(data.day_of_week,data.y).plot(kind='bar') plt.title('Purchase Frequency for Day of Week') plt.xlabel('Day of Week') plt.ylabel('Frequency of Purchase') plt.savefig('pur_dayofweek_bar')
data.age.hist() plt.title('Histogram of Age') plt.xlabel('Age') plt.ylabel('Frequency') plt.savefig('hist_age')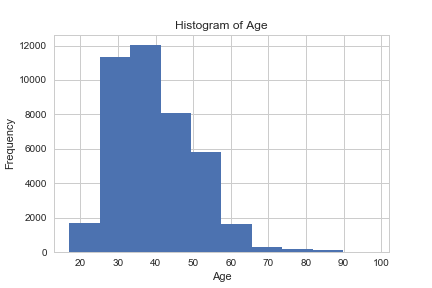
pd.crosstab(data.poutcome,data.y).plot(kind='bar') plt.title('Purchase Frequency for Poutcome') plt.xlabel('Poutcome') plt.ylabel('Frequency of Purchase') plt.savefig('pur_fre_pout_bar')
Переменные-заглушки
cat_vars=['job','marital','education','default','housing','loan','contact','month','day_of_week','poutcome'] for var in cat_vars: cat_list='var'+'_'+var cat_list = pd.get_dummies(data[var], prefix=var) data1=data.join(cat_list) data=data1 cat_vars=['job','marital','education','default','housing','loan','contact','month','day_of_week','poutcome'] data_vars=data.columns.values.tolist() to_keep=[i for i in data_vars if i not in cat_vars]data_final=data[to_keep] data_final.columns.values
Обогащение синтетическими данными через SMOTE
X = data_final.loc[:, data_final.columns != 'y'] y = data_final.loc[:, data_final.columns == 'y'] from imblearn.over_sampling import SMOTE os = SMOTE(random_state=0) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) columns = X_train.columns os_data_X,os_data_y=os.fit_sample(X_train, y_train) os_data_X = pd.DataFrame(data=os_data_X,columns=columns ) os_data_y= pd.DataFrame(data=os_data_y,columns=['y']) # we can Check the numbers of our data print("length of oversampled data is ",len(os_data_X)) print("Number of no subscription in oversampled data",len(os_data_y[os_data_y['y']==0])) print("Number of subscription",len(os_data_y[os_data_y['y']==1])) print("Proportion of no subscription data in oversampled data is ",len(os_data_y[os_data_y['y']==0])/len(os_data_X)) print("Proportion of subscription data in oversampled data is ",len(os_data_y[os_data_y['y']==1])/len(os_data_X))
Рекурсивное устранение признаков
data_final_vars=data_final.columns.values.tolist() y=['y'] X=[i for i in data_final_vars if i not in y] from sklearn.feature_selection import RFE from sklearn.linear_model import LogisticRegression logreg = LogisticRegression() rfe = RFE(logreg, 20) rfe = rfe.fit(os_data_X, os_data_y.values.ravel()) print(rfe.support_) print(rfe.ranking_)
cols=['euribor3m', 'job_blue-collar', 'job_housemaid', 'marital_unknown', 'education_illiterate', 'default_no', 'default_unknown', 'contact_cellular', 'contact_telephone', 'month_apr', 'month_aug', 'month_dec', 'month_jul', 'month_jun', 'month_mar', 'month_may', 'month_nov', 'month_oct', "poutcome_failure", "poutcome_success"] X=os_data_X[cols] y=os_data_y['y']Реализация модели
import statsmodels.api as sm logit_model=sm.Logit(y,X) result=logit_model.fit() print(result.summary2())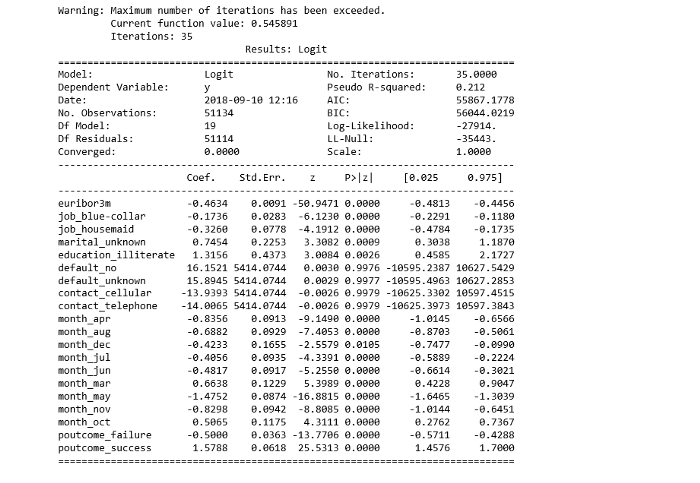
cols=['euribor3m', 'job_blue-collar', 'job_housemaid', 'marital_unknown', 'education_illiterate', 'month_apr', 'month_aug', 'month_dec', 'month_jul', 'month_jun', 'month_mar', 'month_may', 'month_nov', 'month_oct', "poutcome_failure", "poutcome_success"] X=os_data_X[cols] y=os_data_y['y'] logit_model=sm.Logit(y,X) result=logit_model.fit() print(result.summary2())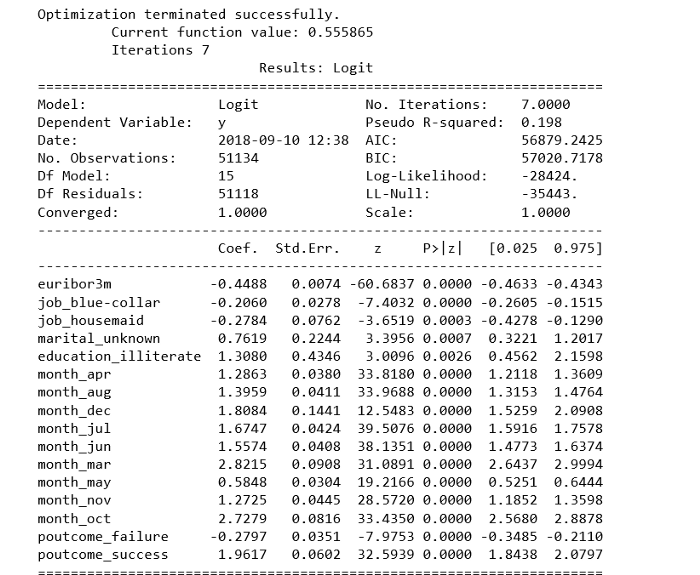
Обучение модели логистической регрессии
from sklearn.linear_model import LogisticRegression from sklearn import metrics X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) logreg = LogisticRegression() logreg.fit(X_train, y_train)
y_pred = logreg.predict(X_test) print('Accuracy of logistic regression classifier on test set: '.format(logreg.score(X_test, y_test)))Матрица путаницы
from sklearn.metrics import confusion_matrix confusion_matrix = confusion_matrix(y_test, y_pred) print(confusion_matrix)[[6124 1542] [2505 5170]]Расчёт точности, полноты, F-меры и носителя
from sklearn.metrics import classification_report print(classification_report(y_test, y_pred))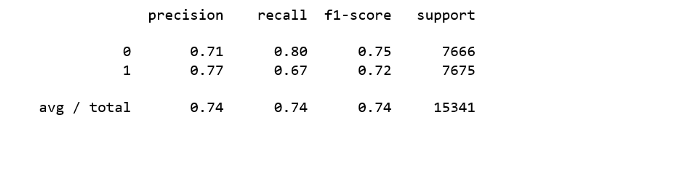
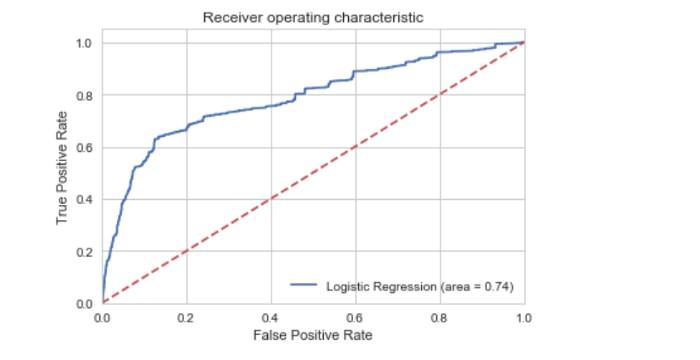
ROC-кривая
from sklearn.metrics import roc_auc_score from sklearn.metrics import roc_curve logit_roc_auc = roc_auc_score(y_test, logreg.predict(X_test)) fpr, tpr, thresholds = roc_curve(y_test, logreg.predict_proba(X_test)[:,1]) plt.figure() plt.plot(fpr, tpr, label='Logistic Regression (area = %0.2f)' % logit_roc_auc) plt.plot([0, 1], [0, 1],'r--') plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.title('Receiver operating characteristic') plt.legend(loc="lower right") plt.savefig('Log_ROC') plt.show()