Жизненный цикл ML-модели
Всем привет! Меня зовут Максим, и в Ситимобил я занимаюсь машинным обучением. Сегодня я расскажу вам, как мы разрабатываем устойчивые ML-модели в суровых условиях изменчивого мира.

Зачем моделям нужен жизненный цикл
Будем называть ML-моделью объект, возвращающий прогноз для входящего набора признаков. Пусть для простоты это будет модель бинарной классификации.
Представим, что модель уже разработана, метрика на out of time выборке (отложенной во времени) нас устраивает, и мы выкатываем модель в production. Получаем положительный результат в первый месяц работы, но потом качество сильно падает. Сколько нужно ждать, прежде чем предпринимать какие-либо действия в отношении модели? Стоит ли сразу же пытаться актуализировать её или же подождать, так как через день-два метрики снова станут стабильными? В идеальном мире ответ должен быть до развёртывания в production. И жизненный цикл поможет нам ответить на этот и другие вопросы по работе модели.

Когда вы начнёте искать информацию по планированию жизненного цикла модели, в большинстве случаев найдёте статьи по поддержке существующего алгоритма переобучения средствами DevOps и MLOps. Но как сделать алгоритм, который нужно поддерживать, переобучать и валидировать?
Принципы разработки жизненного цикла модели
Чтобы модель стабильно работала в будущем, нужно на этапе разработки эмулировать её работу на достаточно большом наборе данных. На каждой итерации можно менять один или несколько параметров. Этот процесс напоминает классический подбор гиперпараметров, поэтому нам нужно точно оценивать результат каждой отдельной симуляции по целевой метрике. Только в нашем случае гиперпараметры не типизированы и мы сами решаем, что именно менять в каждой конфигурации.

Какие параметры нужно учитывать, чтобы оценить жизненный цикл:
- периодичность переобучения модели;
- необходимый объём обучающей выборки;
- поведение целевой метрики во времени в стабильных и экстремальных условиях;
- как учитывать различные смещения целевой переменной и модельных признаков;
- прочие вопросы, характерные для отрасли применения модели.
Рассмотрим отдельно каждый из этих пунктов.
Периодичность переобучения модели
Так как мир не стоит на месте и всё постоянно меняется, модель может устаревать и терять качество (в единицах целевой метрики). Поэтому нужно проверить, через сколько часов, дней, месяцев качество начинает ухудшаться. Для этого мы проводим симуляцию, в которой движемся скользящим окном по всем доступным датам и оцениваем модель на несколько интервалов вперед.
Так мы сможем оценить потенциальное ухудшение качества модели во времени и принять решение о частоте её переобучения.
Оценка объема обучающей выборки
По аналогии с изменением объёма тестовых данных мы можем менять объём обучающей выборки. Мотивация может быть разная:
- на небольшом промежутке времени на обучающей выборке модель может переобучиться;
- в распределении целевой переменной есть сезонность;
- модель вносит смещение в распределение целевой переменной;
- объёма данных может быть недостаточно для выявления ключевых зависимостей.
Чтобы понять, сколько данных нам достаточно для стабильной работы модели, нужно также пройтись скользящим окном по доступным датам, но уже в обратную сторону, постепенно увеличивая обучающий набор данных.
Итогом этой симуляции будет n оценок модели на одном и том же наборе тестовых данных, что позволит точно понять, какая конфигурация оказалась лучшей.
Изменение распределения целевой переменной
Часто бывает так, что поведение целевой переменной нестабильно во времени. Ещё больше нестабильности вносит тот факт, что модель прямо влияет на её распределение (в нашем примере).
Здесь видно, как зона распределения условной целевой переменной постепенно увеличивается с течением времени. Это означает, что применение ML-модели в новой области, которой не было в обучающей выборке, может быть непредсказуемо.
Частично эту проблему должно решать правило частоты переобучения модели. Но ещё на этапе моделирования мы можем оценить влияние нестабильного поведения предсказываемой переменной на целевую метрику. Для этого нужно провести симуляцию, в которой мы искусственно будем уменьшать или увеличивать на n% баланс положительного класса. Таким образом мы сможем сделать выводы о стабильности нашего жизненного цикла при нетипичном изменении (таком, которого не было в обучающей выборке) целевой переменной.
Прочие отраслевые вопросы
Самый простой пример: а что будет, если бизнес нашей компании вырастет на 20 % за n дней? Останется ли наш алгоритм стабильным, если завтра все входные признаки для модели увеличатся или уменьшатся на 20 %?
Алгоритм проверки аналогичен тому, что описан выше. Проводим симуляцию и проверяем, как увеличение или уменьшение того или иного признака влияет на стабильность целевой метрики. Если она ухудшается, то, возможно, стоит ещё раз пересмотреть частоту переобучения модели.
Все названные параметры могут как зависеть друг о друга, так и быть независимыми. Поэтому следует учитывать это при симуляции жизненного цикла. Идеальным решением подбора конфигурации будет оптимизация всех параметров сразу по сетке (как это происходит при подборе классических гиперпараметров).
Мы разработали правила жизненного цикла, что дальше?
Вот мы и получили набор правил работы ML-модели. Половина дела сделана, осталось запустить жизненный цикл в production и мониторить его работу.
Поскольку ещё на этапе моделирования мы предусмотрели большинство но не все потенциальных проблем, то можно ожидать стабильной работы модели некоторе время без внешнего вмешательства.
P.S. Проводя симуляции, не забывайте фиксировать random seed!
Что такое модель машинного обучения?
Моделью машинного обучения называется файл, который обучен распознаванию определенных типов закономерностей. Вы обучаете модель на основе набора данных, предоставляя ей алгоритм, который она может использовать для анализа и обучения на основе этих данных.
Завершив обучение модели, вы сможете применить ее для принятия решений и выполнения прогнозов по данным, которые ранее не встречались. Предположим, вам нужно создать приложение для распознавания эмоций пользователя по его выражению лица. Вы можете обучить модель по набору изображений лиц, каждое из которых отмечено тегом определенной эмоции, а затем применить эту модель в приложении для распознавания эмоций пользователя. Примером такого приложения служит Emoji8.
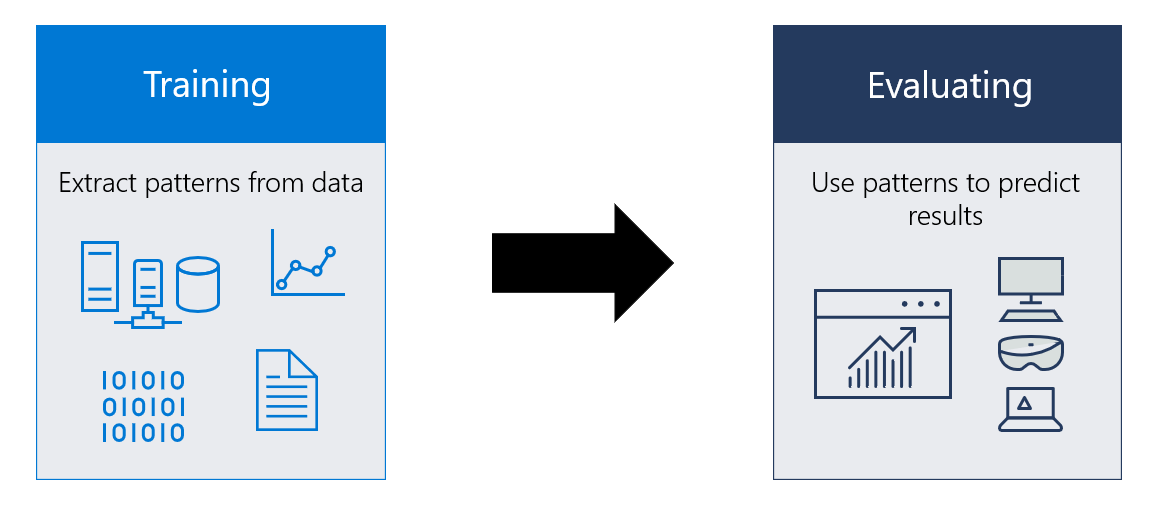
Когда использовать Машинное обучение
Продуманные сценарии машинного обучения обычно имеют следующие общие свойства:
- Они предполагают периодическое принятие решений или оценку, которую необходимо автоматизировать для получения согласованных результатов.
- Явно описать схему или критерии при принятии решения очень сложно или невозможно.
- У вас есть помеченные данные или существующие примеры, в которых вы можете описать ситуацию и сопоставить ее с правильным результатом.
Windows Machine Learning использует для своих моделей формат ONNX (Open Neural Network Exchange). Вы можете скачать предварительно обученную модель или обучить собственную. Дополнительные сведения о получении моделей ONNX для Windows ML см. в этой статье.
Начало работы
Вы можете начать работу с Windows Machine Learning, пройдя один из наших учебников или сразу перейдя к примерам Windows Machine Learning.
Используйте следующие ресурсы для получения справки по машинному обучению в Windows:
- Чтобы задать технические вопросы о машинном обучении в Windows или ответить на них, используйте тег windows-machine-learning в Stack Overflow.
- Сообщить об ошибке можно в нашем репозитории GitHub.
Модели машинного обучения: объясняем пятилетнему ребенку
Специалисты компании Sociaro подготовили перевод очередной статьи, которая поможет разобраться в том, что такое Машинное обучение.
Статья Megan Dibble с Medium Towards Data Science это максимально простое объяснение работы ML моделей.
Если вы новичок в data science, заголовок не был направлен на то, чтобы вас обидеть. Это мой второй пост на тему популярного вопроса на интервью, который звучит примерно так: «объясните мне [вставить техническую тему], как вы бы объяснили пятилетнему ребенку.»
Выходит, достичь уровня понимания пятилетнего ребенка довольно сложно. Так что, хоть эта статья может быть не совсем ясна детсадовцу, она будет понятна тому, кто практически не имеет опыта в data science (и если вы поймете, что это не так, пожалуйста, напишите об этом в комментариях).
Я начну с объяснения понятия машинного обучения, а также его различных типов, а затем перейду к объяснению простых моделей. Я не буду особо вдаваться в математику, но подумываю сделать это в своих будущих статьях. Наслаждайтесь!
Определение Машинного Обучения
Illustration of Machine Learning
Машинное обучение – это когда вы загружаете большое количество данных в компьютерную программу и выбираете модель, которая «подгонит» эти данные так, чтобы компьютер (без вашей помощи) мог придумывать прогнозы. Компьютер строит модели, используя алгоритмы, которые варьируются от простых уравнений (например, уравнение прямой) до очень сложных систем логики/математики, которые позволяют компьютеру сделать самые лучшие прогнозы.
Название – машинное обучение — очень удачное, потому что как только вы выбираете модель, которую будете использовать и настраивать (другими словами, улучшать с помощью корректировок), машина будет пользоваться моделью для изучения закономерностей в ваших данных. Затем вы можете добавить новые условия (наблюдения) и она предскажет результат!
Определение машинного обучения с учителем
Обучение с учителем — это тип машинного обучения, в котором данные, которые вы засовываете в модель «помечаются». Пометка просто означает, что результат наблюдения (то есть ряд данных) известен. Например, если ваша модель пытается предсказать пойдут ли ваши друзья играть в гольф или нет, у вас могут быть такие переменные, как погода, день недели и так далее. Если ваши данные помечены, то ваша переменная будет иметь значение 1, в том случае если ваши друзья пошли играть в гольф, и значение 0, если они не пошли.
Определение машинного обучения без учителя
Как вы наверно могли угадать, когда речь идет о помеченных данных, обучение без учителя является противоположностью обучения с учителем. В обучении без учителя, вы не можете знать пошли ваши друзья играть в гольф или нет – только компьютер может найти закономерности с помощью модели, чтобы угадать, что уже произошло или предсказать, что произойдет.
Модели Машинного Обучения С Учителем
[Требуется присутствие взрослых]
Логистическая регрессия
Логистическая регрессия используется для решения проблемы классификации. Это значит, что ваша целевая переменная (та которую вы хотите предсказать) состоит из категорий. Эти категории могут быть да/нет, или что-то вроде числа от 1 до 10, которое обозначает удовлетворенность клиента. Модель логистической регрессии использует уравнение, чтобы создать кривую с вашими данными, а затем использует эту кривую, чтобы спрогнозировать результаты нового наблюдения.
Illustration of Logistic Regression
На графике выше, новое наблюдение получило бы в прогнозе 0, потому что оно попадает на левую часть кривой. Если посмотреть на данные, по которым построена кривая, это логично, потому что в области графика «прогнозируемое значение 0» большинство точек по оси y имеют значение 0.
Линейная Регрессия
Довольно часто линейная регрессия становится первой моделью машинного обучения, которую люди изучают. Связано это с тем, что ее алгоритм (проще говоря уравнение) достаточно просто понять, используя только одну переменную x – вы просто-напросто рисуете наиболее подходящую линию – концепция, которой учат еще в начальной школе. Наиболее подходящая линия затем используется для прогнозирования новых точек данных (см. иллюстрацию).
Illustration of Linear Regression
Линейная Регрессия чем-то напоминает логистическую регрессию, но используется, когда целевая переменная – непрерывная, а это значит, что она может принимать практически любое числовое значение. На самом деле, любая модель с непрерывной целевой переменной может быть классифицирована как «регрессия». Примером непрерывной переменной может служить цена продажи дома.
Линейная регрессия хорошо интерпретируется. Уравнение модели содержит коэффициенты для каждой переменной, и эти коэффициенты показывают, насколько сильно меняется целевая переменная при малейшем изменении независимой переменной (х-переменной). Если показывать это на примере цен на продажу дома, это означает, что вы могли бы посмотреть на уравнение регрессии и сказать что-то типа «о, это говорит мне о том, что за каждый дополнительный 1м2 от размера дома (х-переменная), цена продажи (целевая переменная) увеличивается на $25.»
K Ближайших Соседей (KNN)
Эта модель может быть использована для классификации или для регрессии. Название — «К Ближайших Соседей» не должно сбить вас с толку. Для начала модель выводит все данные на график. Часть «К» в названии относится к числу ближайших соседних точек данных, на которые модель смотрит, чтобы определить каким должно быть прогнозное значение (см. иллюстрацию ниже). Вы, как будущий data science специалист, выбираете значение K и можете поиграть с ним, чтобы увидеть, какое из значений дает лучшие прогнозы.
Illustration of K Nearest Neighbors
Все точки данных, находящиеся в круге K=__, получают “голос » относительно того, каким должно быть значение целевой переменной для этой новой точки данных. Значение, которое получает большинство голосов – это значение, которое KNN прогнозирует для новой точки данных. В иллюстрации выше, 2 ближайших соседей – class 1, в то время как 1 соседей – class 2. Таким образом, модель бы спрогнозировала class 1 для этой точки данных. Если модель предсказывает числовое значение, а не категорию, то все «голоса» — числовые значения, которые усредняются, чтобы получить прогноз.
Метод опорных Векторов (SVMs)
Принцип работы опорных векторов заключается в том, что они устанавливают границы между точками данных, где большинство из одного класса падает на одну сторону границы (как пример, в двумерном пространстве это будет линия) и большинство из другого класса падает на другую сторону границы.
Illustration of Support Vector Machines
Способ работы также заключается в том, что машина стремится найти границу с наибольшим пределом. Предел определяется расстоянием между границей и ближайшими точками каждого класса (см. иллюстрацию). Новые точки данных затем строятся и помещаются в определенный класс, в зависимости от того, на какую сторону границы они попадают.
Я объясняю эту модель на примере классификации, но вы также можете ее использовать для регрессии!
Деревья Решений & Случайные Леса
Про это я уже рассказывала в предыдущей статья, вы можете найти ее здесь (Деревья Решений и Случайные Леса ближе к концу):
Модели Машинного Обучения Без Учителя
[Читайте с осторожностью]
Теперь мы готовы перейти к машинному обучению без учителя. Напомню, это значит, что наш датасет не помеченный, так что мы не знаем результаты наших наблюдений.
K Значит Кластеризация
Когда вы используете K кластеризацию, вы должны начать с предположения, что в вашем датасете присутствует K кластеров. Поскольку вы не знаете, сколько групп на самом деле в ваших данных, вы должны попробовать различные значения K и с помощью визуализации и метрик понять, какое значение K подходит. Метод K средних лучше всего работает с круговыми кластерами одинаковых размеров.
Этот алгоритм сначала выбирает лучшие точки данных K, чтобы сформировать центр каждого K кластера. Затем, он повторяет 2 следующих шага для каждой точки:
1. Присваивает точку данных ближайшему центру кластера
2. Создает новый центр, взяв среднее значение всех точек данных из этого кластера
ML-разработка
Ещё в XVII веке известный математик Г.В. Лейбниц полагал, что любую мысль человека можно представить математическими формулами и элементарными символами. Идея наделить человеческим интеллектом неодушевлённые предметы прослеживалась в древней мифологии, в средневековой литературе. С развитием компьютерных технологий разработка искусственного интеллекта стала одним из самых активных направлений математической науки.
В середине XX века шла активная работа над обучением компьютеров. Долгое время это было прерогативой научных центров и институтов.
В последнее десятилетие технология вышла на новый уровень. Применять систему смогли разработчики всего мира не только в научных целях, но и для решения современных задач производства, продвижения, маркетинга, развлечения.
Видеозвонки в SberJazz
Общайтесь с друзьями и близкими везде, где есть Интернет
Попробовать сейчас
Что такое Machine Learning
Процессы машинного обучения называются также общим английским термином Machine Learning. Его суть — в передаче компьютерам определённых знаний и алгоритмов их анализа, на основе которых машина может:
- обучаться;
- выявлять закономерности;
- накапливать опыт для решения задач;
- строить прогнозы;
- собирать аналитические, статистические данные.
Технология позволяет обрабатывать данные и выполнять различные операции без инструкций программиста.
Итог Machine Learning — определённая модель, которая при правильно введённых параметрах способна решать задачи на уровне, близком к человеческому.
В отличие от образного человеческого представления, модели анализируют данные по конкретным признакам. Например, человек воспринимает образ перед ним в целом, он просто знает, что видит кошку, собаку, мышь или другое животное. Компьютер сделает вывод по длине хвоста, шерсти на ушах, размеру лап и так далее.
Потребность в машинном обучении
Machine Learning — это давно больше, чем виртуальный соперник по игре в шашки и шахматы. Например, когда компьютер проверяет тексты на грамматические ошибки, это воспринимается как нечто привычное. А стриминговые сервисы благодаря алгоритмам понимают предпочтения пользователей.
Чем больше в жизни человека удобства при решении задач, тем выше запрос на дальнейшую оптимизацию и цифровизацию. Для бизнеса создание моделей машинного обучения — способ автоматизировать производственную рутину и привлечь аудиторию. Разные типы алгоритмов позволяют, к примеру, сделать онлайн-игры ещё интереснее: система отследит поведение игрока и сформирует для него индивидуальное предложение.
Зачем и когда учить машины?
Способы машинного обучения делят на три общих типа:
- С учителем, или supervised learning. Цель — помочь компьютеру понять, почему процесс происходит именно так, выявить закономерности, последовательность действий в системе. Ответ известен заранее, поэтому алгоритм концентрируется на этапах его получения. Итоговая модель способна строить прогнозы.
- Без учителя, или unsupervised learning, — позволяет машине научиться самостоятельно выявлять закономерности при обработке массива загруженных данных. По выявленным закономерностям компьютер способен работать над задачами с новыми данными.
- C подкреплением, или reinforcement learning, — даёт машине возможность среди различных сценариев выбрать оптимальный. Иными словами, это метод проб и ошибок, при котором компьютер определяет последствия выбора и их связь с результатом.
Любой из способов приводит к разработке рабочего механизма, который оказывается в чём-то эффективнее человека:
- не устаёт, работает круглосуточно;
- совершает меньше ошибок;
- обрабатывает большие объёмы информации;
- оценивает данные непредвзято.
Это позволяет автоматизировать процессы, выявлять глубинные закономерности, оптимизировать работу сотрудников. Благодаря ML-разработке появилось огромное количество программ и сервисов, которые повышают качество жизни человека. Например, они помогают ориентироваться на местности, быстро находить любимые фильмы и музыку.
Сложные модели используются в промышленности, в сфере безопасности и различных крупных корпорациях. Благодаря разработкам происходит полная цифровая трансформация корпоративной культуры и делового взаимодействия в компании. К примеру, алгоритм может автоматически собирать, систематизировать, анализировать данные с датчиков оборудования на крупном производстве, а затем формировать отчёт.
Машинное обучение: принципы и задачи
В компьютер загружаются исходные данные (датасет) с метками и подробными разъяснениями. Программа анализирует все алгоритмы и закономерности, запоминает соотношение меток и сведений о них — таким образом формируется нейронная сеть. На основе полученной базы система может делать выводы, давать ответы, сопоставлять данные и делать выбор.
Чем больше действий совершит компьютер с базовой информацией, тем точнее будет анализ в последующем. ML предполагает непрерывное обучение.
Основа Machine Learning — работа с тремя составляющими:
- Данными как отправной точкой процесса. С них сеть начинает обучение и ими же непрерывно пополняет свою базу знаний.
- Признаками, которые служат метками, по которым модель может получать необходимые результаты и решать задачи.
- Алгоритмами, или методами, в соответствии с которыми компьютер совершает каждое действие. Они определяют форму модели, скорость её работы, точность ответов.
Machine Learning характеризуется тремя признаками:
- Инновационность. ML становится точкой роста и новым этапом развития в любой экономической сфере.
- Специфичность. Машинное обучение — сугубо IT-направление. Разработкой и внедрением занимаются люди, которые понимают языки программирования и умеют работать с IT-инструментами.
- Простота. ML позволяет создавать продукты, понятные любому пользователю вне зависимости от возраста, уровня знаний и умения работать с программами.
С помощью разработок Machine Learning бизнес решает задачи разного типа:
- Кластеризация — распределение данных на типы, группы и другие категории по заданным критериям.
- Классификация — ответ на вопрос по категории, например, есть ли на фотографии красные предметы.
- Уменьшение размерности — перевод от большего к меньшему, сжатие информации для дальнейшей визуализации.
- Регрессия — прогнозирование по различным признакам объектов в выборке, к примеру, прогноз стоимости объекта недвижимости через заданный период.
- Выявление аномалий — анализ процессов, выделение среди них нетипичных.
- Идентификация — выделение из общего массива данных только необходимых. Яркий пример — идентификация лица определённого человека среди всех распознанных системой.
- Прогнозирование — анализ существующих процессов и основанное на нём предсказание показателей через заданное время. Таким образом можно оценивать предположительную эффективность выбранной компанией стратегии развития.
Благодаря многозадачности ML становится универсальным инструментом в любой сфере — экономической, финансовой, производственной, социальной и других.
Инструменты ML
Применяемые в Machine Learning технологии связаны с тремя общими этапами разработки:
- система собирает и обрабатывает данные;
- ведётся обучение на основе полученных данных, формируется обученная модель;
- оценивается качество работы модели и развёртывается ПО для её использования.
Для разработки моделей используют готовые фреймворки и библиотеки на разных языках программирования. Они позволят быстро начать работу с собранным датасетом, для точной обработки данных необходимо отфильтровать ненужные.
Кроме того, понадобятся инструменты для визуализации на разных этапах, она поможет выделить важные признаки, аномалии, линейные закономерности. Готовая модель должна пройти тестирование.
ML-разработка становится удобнее и доступнее, если все необходимые инструменты собраны на одной платформе. Продукт ML Space позволяет работать над моделями командой в едином пространстве.
Среди преимуществ решения:
- ML-разработка полного цикла на высокопроизводительной инфраструктуре с использованием мощностей суперкомпьютеров Christofari и Christofari Neo;
- командная работа на каждом этапе;
- более 1700 GPU для распределённого обучения и артефактов на маркетплейсах DataHub и AI Services;
- удобный интерфейс, множество встроенных популярных библиотек, утилит и других привычных инструментов с модулем Environments;
- Data Catalog для работы с ML-артефактами;
- инструмент для тестирования и развёртывания Deployments;
- сервисы автоматического построения моделей, обработки данных AutoML и Pipelines;
- доступ при разработке к предобученным моделям, датасетам и контейнерам в модуле DataHub.
Платформа учитывает специфику российского рынка, в том числе законодательство о защите персональных данных.
Платформа для совместной ML-разработки полного цикла на базе суперкомпьютеров Christofari и Christofari Neo
Практическое применение ML-технологий
Робототехника
Функциональность физических роботов может ограничиваться простыми действиями, основанными на контроллерах, датчиках, сенсорах. Самые простые образцы работают по строго заданным координатам, но этого не всегда достаточно. Иногда необходимо, чтобы робот мог решать более сложные задачи по выученным алгоритмам.
Machine Learning позволяет роботам:
- видеть и распознавать речь;
- определять заданные объекты;
- отслеживать перемещающиеся объекты;
- сегментировать содержимое видимой картинки;
- оценивать расстояния, обходить препятствия на пути;
- ориентироваться в пространстве;
- захватывать объекты, манипулировать ими;
Для реализации различных функций необходим большой объём вычислительного пространства и высокопроизводительные GPU.
Маркетинг
Алгоритмы разного типа позволяют маркетологам обрабатывать большие массивы данных, превращать их в знания, на основе которых строятся прогнозы и стратегии развития. Machine Learning даёт возможность сегментировать целевую аудиторию, прогнозировать поведение клиентов, корректировать действия в реальном времени.
Безопасность
Интеллектуальный анализ записей с камер видеонаблюдения помогает в режиме реального времени отслеживать различные физические угрозы. Крупные компании используют распознавание лиц сотрудников вместо традиционных пропусков, а системы умного города позволяют быстро искать преступников.
Модели эффективны в кибербезопасности. Компьютер обучается на базе предсказуемых действий, которые выполняются при определённом процессе в сети. Например, параметры работы сотрудников с корпоративной почтой будут иметь стабильный характер — одинаковое время открытия и закрытия, фиксированные действия, привязка к устройствам и локации.
Любые отклонения воспринимаются как угроза, о которой система проинформирует пользователя.
Финансовый сектор и страхование
Один из ярких примеров применения методов Machine Learning в банковском секторе — автоматическая оценка кредитного потенциала заявителя. В страховании интеллектуальный анализ позволяет оценить степень страховых рисков по направлениям. На рынке ценных бумаг разработки ML позволяют прогнозировать рост или падение акций по результатам анализа финансовых новостей и текущих торгов.
Общественное питание
Насущный вопрос сферы общепита — контроль производственных процессов, обслуживания клиентов. Компьютерное зрение как область Machine Learning способно анализировать окружающее пространство, распознавать объекты, действия, перемещения.
Система сможет определить, есть ли на сотрудниках перчатки, головные уборы, верно ли упакован заказ. Это позволит выявить слабые места, провести дополнительное обучение, продумать новые маркетинговые ходы.
Медицина
Интеллектуальный анализ способен упростить работу врача. На основе оцифрованных результатов различных обследований и анализов модель сможет дать предварительную оценку состояния здоровья пациента, определит вектор дальнейшего поиска проблем.
Добыча полезных ископаемых
Машинное зрение упрощает процессы в горнодобывающей промышленности. Так, на стадии дробления руды до более мелких фракций система может отслеживать в идущих по конвейеру обломках слишком крупные либо инородные предметы. Она подаст сигнал оператору или вовсе остановит процесс, чтобы не дать элементам неподходящего размера и состава застрять в оборудовании. Аналогичным образом отслеживается целостность конвейерных лент.
ML-модели — новый этап цифровизации бизнеса и жизни человека. Работа с Big Data стала проще, а доступ к технологии получили новые пользователи. Единая платформа для ML-разработки ML Space позволяет создавать собственные персонализированные модели для внедрения в бизнес-процессы.