Node c что это
Что такое Node.js?
Node.js (или просто Node) — это серверная платформа для работы с JavaScript через движок V8. JavaScript выполняет действие на стороне клиента, а Node — на сервере. С помощью Node можно писать полноценные приложения. Node умеет работать с внешними библиотеками, вызывать команды из кода на JavaScript и выполнять роль веб-сервера.
В чём преимущество Node?
C Node проще масштабироваться. При одновременном подключении к серверу тысяч пользователей Node работает асинхронно, то есть ставит приоритеты и распределяет ресурсы грамотнее. Java же, например, выделяет на каждое подключение отдельный поток.
Откуда Node вообще взялся?
Node появился в 2009 году благодаря Райану Далу. До этого в серверах царил подход «один поток на каждое соединение», а Дал придумал использовать систему, которая ориентирована на события. То есть реагирует на действие или бездействие и выделяет под это ресурс. Главная цель Node — построение масштабируемых сетевых серверов.
Кто-то из крупных компаний использует Node?
Конечно, вот неполный список:
eBay постепенно переходит на Node, как и веб-версия PayPal. В LinkedIn ещё в 2012 году переехали с Ruby On Rails на Node и сразу ощутили преимущества этой платформы: 27 серверов показали 20-кратное увеличение скорости работы.
Что я могу написать на Node?
Полноценную программу для веба, Linux, OS X и Windows.
А если подробнее?
Не вопрос. Node удобен для создания API — уже существуют удобные библиотеки вроде Loopback.
На этом языке можно писать кроссплатформенные приложения — в связке мобильный + десктоп Node помогает достигать синхронности. Например, когда вы пишете сообщение с телефона, оно сразу же появляется и на ноутбуке, и в вебе.
А что-нибудь модное Node умеет?
Конечно. Node — это родной дом всего «интернета вещей» (Internet of Things, IoT). Термостаты, фитнес-трекеры — всё это можно запрограммировать через Node.
Node случайно не теряет популярность?
Совсем наоборот. Вот график интереса к Node с 2009 года в поиске Google:
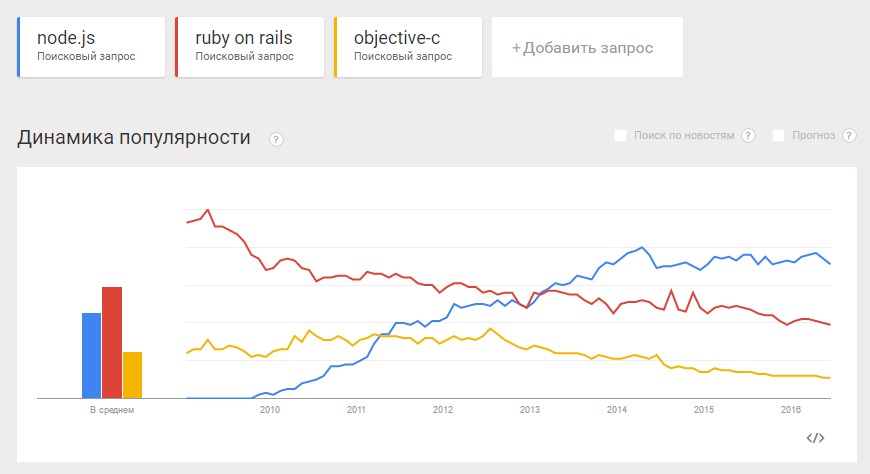
Интерес к Node стремительно растёт и уже обходит по этому показателю Ruby и Objective-C.
Убедили, хочу выучить Node. Что для этого нужно знать?
Перед тем, как осваивать Node, нужно знать JavaScript и в общих чертах понимать, как устроен клиент и сервер. Node — платформа для full-stack программистов, то есть для тех, кто может сделать приложение сам, а не специализируется на какой-то его части.
Односвязный список
О дносвязный список – структура данных, в которой каждый элемент (узел) хранит информацию, а также ссылку на следующий элемент. Последний элемент списка ссылается на NULL.
Для нас односвязный список полезен тем, что
- 1) Он очень просто устроен и все алгоритмы интуитивно понятны
- 2) Односвязный список – хорошее упражнение для работы с указателями
- 3) Его очень просто визаулизировать, это позволяет «в картинках» объяснить алгоритм
- 4) Несмотря на свою простоту, односвязные списки часто используются в программировании, так что это не пустое упражнение.
- 5) Эта структуру данных можно определить рекурсивно, и она часто используется в рекурсивных алгоритмах.
Для простоты рассмотрим односвязный список, который хранит целочисленное значение.
Односвязный список
Односвязный список состоит из узлов. Каждый узел содержит значение и указатель на следующий узел, поэтому представим его в качестве структуры
typedef struct Node < int value; struct Node *next; >Node;
Чтобы не писать каждый раз struct мы определили новый тип.
Теперь наша задача написать функцию, которая бы собирала список из значений, которые мы ей передаём. Стандартное имя функции – push, она должна получать в качестве аргумента значение, которое вставит в список. Новое значение будет вставляться в начало списка. Каждый новый элемент списка мы должны создавать на куче. Следовательно, нам будет удобно иметь один указатель на первый элемент списка.
Node *head = NULL;
Вначале списка нет и указатель ссылается на NULL.
Для добавления нового узла необходимо
- 1) Выделить под него память.
- 2) Задать ему значение
- 3) Сделать так, чтобы он ссылался на предыдущий элемент (или на NULL, если его не было)
- 4) Перекинуть указатель head на новый узел.
1) Создаём новый узел
Создали новый узел, на который ссылается локальная переменная tmp
2) Присваиваем ему значение
Присвоили ему значение
3) Присваиваем указателю tmp адрес предыдущего узла
Перекинули указатель tmp на предыдущий узел
4) Присваиваем указателю head адрес нового узла
Перекинули указатель head на вновь созданный узел tmp
5) После выхода из функции переменная tmp будет уничтожена. Получим список, в который будет вставлен новый элемент.
Новый узел добавлен
void push(Node **head, int data) < Node *tmp = (Node*) malloc(sizeof(Node)); tmp->value = data; tmp->next = (*head); (*head) = tmp; >
Так как указатель head изменяется, то необходимо передавать указатель на указатель.
Теперь напишем функцию pop: она удаляет элемент, на который указывает head и возвращает его значение.
Если мы перекинем указатель head на следующий элемент, то мы потеряем адрес первого и не сможем его удалить и тем более вернуть его значения. Для этого необходимо сначала создать локальную переменную, которая будет хранить адрес первого элемента
Локальная переменная хранит адрес первого узла
Уже после этого можно удалить первый элемент и вернуть его значение
Перекинули указатель head на следующий элемент и удалили узел
int pop(Node **head) < Node* prev = NULL; int val; if (head == NULL) < exit(-1); >prev = (*head); val = prev->value; (*head) = (*head)->next; free(prev); return val; >
Не забываем, что необходимо проверить на NULL голову.
Таким образом, мы реализовали две операции push и pop, которые позволяют теперь использовать односвязный список как стек. Теперь добавим ещё две операции — pushBack (её ещё принято называть shift или enqueue), которая добавляет новый элемент в конец списка, и функцию popBack (unshift, или dequeue), которая удаляет последний элемент списка и возвращает его значение.
Для дальнейшего разговора необходимо реализовать функции getLast, которая возвращает указатель на последний элемент списка, и nth, которая возвращает указатель на n-й элемент списка.
Так как мы знаем адрес только первого элемента, то единственным способом добраться до n-го будет последовательный перебор всех элементов списка. Для того, чтобы получить следующий элемент, нужно перейти к нему через указатель next текущего узла
Node* getNth(Node* head, int n) < int counter = 0; while (counter < n && head) < head = head->next; counter++; > return head; >
Переходя на следующий элемент не забываем проверять, существует ли он. Вполне возможно, что был указан номер, который больше размера списка. Функция вернёт в таком случае NULL. Сложность операции O(n), и это одна из проблем односвязного списка.
Для нахождение последнего элемента будем передирать друг за другом элементы до тех пор, пока указатель next одного из элементов не станет равным NULL
Node* getLast(Node *head) < if (head == NULL) < return NULL; >while (head->next) < head = head->next; > return head; >
Теперь добавим ещё две операции — pushBack (её ещё принято называть shift или enqueue), которая добавляет новый элемент в конец списка, и функцию popBack (unshift, или dequeue), которая удаляет последний элемент списка и возвращает его значение.
Для вставки нового элемента в конец сначала получаем указатель на последний элемент, затем создаём новый элемент, присваиваем ему значение и перекидываем указатель next старого элемента на новый
void pushBack(Node *head, int value) < Node *last = getLast(head); Node *tmp = (Node*) malloc(sizeof(Node)); tmp->value = value; tmp->next = NULL; last->next = tmp; >
Односвязный список хранит адрес только следующего элемента. Если мы хотим удалить последний элемент, то необходимо изменить указатель next предпоследнего элемента. Для этого нам понадобится функция getLastButOne, возвращающая указатель на предпоследний элемент.
Node* getLastButOne(Node* head) < if (head == NULL) < exit(-2); >if (head->next == NULL) < return NULL; >while (head->next->next) < head = head->next; > return head; >
Функция должна работать и тогда, когда список состоит всего из одного элемента. Вот теперь есть возможность удалить последний элемент.
void popBack(Node **head) < Node *lastbn = NULL; //Получили NULL if (!head) < exit(-1); >//Список пуст if (!(*head)) < exit(-1); >lastbn = getLastButOne(*head); //Если в списке один элемент if (lastbn == NULL) < free(*head); *head = NULL; >else < free(lastbn->next); lastbn->next = NULL; > >
Удаление последнего элемента и вставка в конец имеют сложность O(n).
Можно написать алгоритм проще. Будем использовать два указателя. Один – текущий узел, второй – предыдущий. Тогда можно обойтись без вызова функции getLastButOne:
int popBack(Node **head) < Node *pFwd = NULL; //текущий узел Node *pBwd = NULL; //предыдущий узел //Получили NULL if (!head) < exit(-1); >//Список пуст if (!(*head)) < exit(-1); >pFwd = *head; while (pFwd->next) < pBwd = pFwd; pFwd = pFwd->next; > if (pBwd == NULL) < free(*head); *head = NULL; >else < free(pFwd->next); pBwd->next = NULL; > >
Теперь напишем функцию insert, которая вставляет на n-е место новое значение. Для вставки, сначала нужно будет пройти до нужного узла, потом создать новый элемент и поменять указатели. Если мы вставляем в конец, то указатель next нового узла будет указывать на NULL, иначе на следующий элемент
void insert(Node *head, unsigned n, int val) < unsigned i = 0; Node *tmp = NULL; //Находим нужный элемент. Если вышли за пределы списка, то выходим из цикла, //ошибка выбрасываться не будет, произойдёт вставка в конец while (i < n && head->next) < head = head->next; i++; > tmp = (Node*) malloc(sizeof(Node)); tmp->value = val; //Если это не последний элемент, то next перекидываем на следующий узел if (head->next) < tmp->next = head->next; //иначе на NULL > else < tmp->next = NULL; > head->next = tmp; >
Покажем на рисунке последовательность действий
Создали новый узел и присвоили ему значение
После этого делаем так, чтобы новый элемент ссылался на следующий после n-го
Теперь значение next нового узла хранит адрес того же узла, что и элемент, на который ссылается head
Перекидываем указатель next n-го элемента на вновь созданный узел
Теперь узел, адрес которого хранит head, указывает на новый узел tmp
Функция удаления элемента списка похожа на вставку. Сначала получаем указатель на элемент, стоящий до удаляемого, потом перекидываем ссылку на следующий элемент за удаляемым, потом удаляем элемент.
int deleteNth(Node **head, int n) < if (n == 0) < return pop(head); >else < Node *prev = getNth(*head, n-1); Node *elm = prev->next; int val = elm->value; prev->next = elm->next; free(elm); return val; > >
Рассмотрим то же самое в картинках. Сначала находим адреса удаляемого элемента и того, который стоит перед ним
Для удаления узла, на который ссылается elm необходим предыдущий узел, адрес которого хранит prev
После чего прокидываем указатель next дальше, а сам элемент удаляем.
Прекидываем указатель на следующий за удалённым узел и освобождаем память
Кроме создания списка необходимо его удаление. Так как самая быстрая функция у нас этот pop, то для удаления будем последовательно выталкивать элементы из списка.
void deleteList(Node **head) < while ((*head)->next) < pop(head); *head = (*head)->next; > free(*head); >
Вызов pop можно заменить на тело функции и убрать ненужные проверки и возврат значения
void deleteList(Node **head) < Node* prev = NULL; while ((*head)->next) < prev = (*head); (*head) = (*head)->next; free(prev); > free(*head); >
Осталось написать несколько вспомогательных функций, которые упростят и ускорят работу. Первая — создать список из массива. Так как операция push имеет минимальную сложность, то вставлять будем именно с её помощью. Так как вставка произойдёт задом наперёд, то массив будем обходить с конца к началу:
void fromArray(Node **head, int *arr, size_t size) < size_t i = size - 1; if (arr == NULL || size == 0) < return; >do < push(head, arr[i]); >while(i--!=0); >
И обратная функция, которая возвратит массив элементов, хранящихся в списке. Так как мы будем создавать массив динамически, то сначала определим его размер, а только потом запихнём туда значения.
int* toArray(const Node *head) < int leng = length(head); int *values = (int*) malloc(leng*sizeof(int)); while (head) < values[--leng] = head->value; head = head->next; > return values; >
И ещё одна функция, которая будет печатать содержимое списка
void printLinkedList(const Node *head) < while (head) < printf("%d ", head->value); head = head->next; > printf("\n"); >
Теперь можно провести проверку и посмотреть, как работает односвязный список
void main() < Node* head = NULL; int arr[] = ; //Создаём список из массива fromArray(&head, arr, 10); printLinkedList(head); //Вставляем узел со значением 333 после 4-го элемента (станет пятым) insert(head, 4, 333); printLinkedList(head); pushBack(head, 11); pushBack(head, 12); pushBack(head, 13); pushBack(head, 14); printLinkedList(head); printf("%d\n", pop(&head)); printf("%d\n", popBack(&head)); printLinkedList(head); //Удаляем пятый элемент (индексация с нуля) deleteNth(&head, 4); printLinkedList(head); deleteList(&head); getch(); >
Сортировка односвязного списка
Сортировать список будем слиянием. Этот метод очень похож на сортировку слиянием для массива. Для его реализации нам понадобятся две функции: одна буде делить список пополам, а другая будет объединять два упорядоченных односвязных списка, не создавая при этом новых узлов. Наша реализация не будет оптимальной, однако, некоторые решения, которые мы применим, могут быть использованы и в других алгоритмах.
Вспомогательная функция – слияние двух отсортированных списков. Функция не должна создавать новых узлов, так что будем использовать только имеющиеся. Для начала проверим, если хоть один из списков пуст, то вернём другой.
Node tmp; *c = NULL; if (a == NULL) < *c = b; return; >if (b == NULL)
После этого нужно, чтобы наша локальная переменная стала хранить адрес большего из узлов двух списков, от него и будем танцевать дальше
if (a->value < b->value) < *c = a; a = a->next; > else < *c = b; b = b->next; >
Теперь сохраним указатель c, так как в дальнейшем он будет использоваться для прохода по списку
tmp.next = *c;
После этого проходим по спискам, сравниваем значения и перекидываем их
while (a && b) < if (a->value < b->value) < (*c)->next = a; a = a->next; > else < (*c)->next = b; b = b->next; > (*c) = (*c)->next; >
В конце, может остаться один список, который пройден не до конца. Добавим его узлы
if (a) < while (a) < (*c)->next = a; (*c) = (*c)->next; a = a->next; > > if (b) < while (b) < (*c)->next = b; (*c) = (*c)->next; b = b->next; > >
Теперь указатель c хранит адрес последнего узла, а нам нужна ссылка на голову. Она как раз хранится во второй переменной tmp
*c = tmp.next;
void merge(Node *a, Node *b, Node **c) < Node tmp; *c = NULL; if (a == NULL) < *c = b; return; >if (b == NULL) < *c = a; return; >if (a->value < b->value) < *c = a; a = a->next; > else < *c = b; b = b->next; > tmp.next = *c; while (a && b) < if (a->value < b->value) < (*c)->next = a; a = a->next; > else < (*c)->next = b; b = b->next; > (*c) = (*c)->next; > if (a) < while (a) < (*c)->next = a; (*c) = (*c)->next; a = a->next; > > if (b) < while (b) < (*c)->next = b; (*c) = (*c)->next; b = b->next; > > *c = tmp.next; >
Ещё одна важная функция – нахождение середины списка. Для этих целей будем использовать два указателя. Один из них — fast – за одну итерацию будет два раза изменять значение и продвигаться по списку вперёд. Второй – slow, всего один раз. Таким образом, если список чётный, то slow окажется ровно посредине списка, а если список нечётный, то второй подсписок будет на один элемент длиннее.
void split(Node *src, Node **low, Node **high) < Node *fast = NULL; Node *slow = NULL; if (src == NULL || src->next == NULL) < (*low) = src; (*high) = NULL; return; >slow = src; fast = src->next; while (fast != NULL) < fast = fast->next; if (fast != NULL) < fast = fast->next; slow = slow->next; > > (*low) = src; (*high) = slow->next; slow->next = NULL; >
Очевидно, что можно было один раз узнать длину списка, а потом передавать размер в каждую функцию. Это было бы проще и быстрее. Но мы не ищем лёгких путей)))
Теперь у нас есть функция, которая позволяет разделить список на две части и функция слияния отсортированных списков. С их помощью реализуем функцию сортировки слиянием.
Сортировка слиянием для односвязного списка
Функция рекурсивно вызывает сама себя, передавая части списка. Если в функцию пришёл список длинной менее двух элементов, то рекурсия прекращается. Идёт обратная сборка списка. Сначала из двух списков, каждый из которых хранит один элемент, создаётся отсортированный список, далее из таких списков собирается новый отсортированный список, пока все элементы не будут включены.
void mergeSort(Node **head) < Node *low = NULL; Node *high = NULL; if ((*head == NULL) || ((*head)->next == NULL)) < return; >split(*head, &low, &high); mergeSort(&low); mergeSort(&high); merge(low, high, head); >
Если Вы желаете изучать этот материал с преподавателем, советую обратиться к репетитору по информатике
ru-Cyrl 18- tutorial Sypachev S.S. 1989-04-14 sypachev_s_s@mail.ru Stepan Sypachev students

Всё ещё не понятно? – пиши вопросы на ящик
Как работает функция struct в C?
Объясните на пальцах — как она работает?
В частности я не могу понять как работает строка struct node* next;
Первую строку я понимаю, объявляется переменная int с именем n, также понимаю как ее использовать, например —
node number; number.n = 3;- Вопрос задан более трёх лет назад
- 1860 просмотров
Комментировать
Решения вопроса 1

Самый лучший программист
Вообщето это обьявление типа данных — структура. Описание работы со структурами есть — тут
Строка struct node* next; это обьявление члена структуры типа указатель, на данные такого же типа структуры.
Rukovodstvo
статьи и идеи для разработчиков программного обеспечения и веб-разработчиков.
Как создавать надстройки C / C ++ в Node
Node.js хорош по многим причинам, одна из которых — скорость, с которой вы можете создавать значимые приложения. Однако, как мы все знаем, это происходит за счет производительности (по сравнению с собственным кодом). Чтобы обойти это, вы можете написать свой код для взаимодействия с более быстрым кодом, написанным на C или C ++. Все, что нам нужно сделать, это сообщить Node, где найти этот код и как с ним взаимодействовать. Есть несколько способов решить эту проблему в зависимости от того, какой уровень абстракции вы хотите. Мы начнем с
Время чтения: 7 мин.
Node.js хорош по многим причинам, одна из которых — скорость, с которой вы можете создавать значимые приложения. Однако, как мы все знаем, это происходит за счет производительности (по сравнению с собственным кодом). Чтобы обойти это, вы можете написать свой код для взаимодействия с более быстрым кодом, написанным на C или C ++. Все, что нам нужно сделать, это сообщить Node, где найти этот код и как с ним взаимодействовать.
Есть несколько способов решить эту проблему в зависимости от того, какой уровень абстракции вы хотите. Мы начнем с самой низкой абстракции, а именно с Node Addon .
Дополнения
Аддон работает, обеспечивая связь между библиотеками Node и C / C ++. Для типичного разработчика Node это может быть немного сложно, так как вам придется фактически написать код C / C ++ для настройки интерфейса. Однако между этой статьей и документацией по Node вы сможете заставить работать несколько простых интерфейсов.
Есть несколько вещей, которые нам нужно сделать, прежде чем мы сможем приступить к созданию аддонов. Прежде всего, нам нужно знать, как компилировать (о чем разработчики Node к счастью забывают) собственный код. Это делается с помощью node-gyp . Затем мы кратко поговорим о nan , который помогает обрабатывать различные версии Node API.
узел-гипс
Существует множество различных типов процессоров (x86, ARM, PowerPC и т. Д.) И даже больше операционных систем, с которыми приходится иметь дело при компиляции кода. К счастью, за вас все это node-gyp Как описано на их странице Github, node-gyp — это «кроссплатформенный инструмент командной строки, написанный на Node.js для компиляции собственных дополнительных модулей для Node.js». По сути, node-gyp — это просто оболочка вокруг gyp , созданная командой Chromium.
В README проекта есть отличные инструкции по установке и использованию пакета, поэтому вам следует прочитать их для получения более подробной информации. Короче говоря, чтобы использовать node-gyp вам нужно сделать следующее.
Перейдите в каталог вашего проекта:
$ cd my_node_addon
Сгенерируйте соответствующие файлы сборки с помощью команды configure , которая создаст либо Makefile (в Unix), либо vcxproj (в Windows):
$ node-gyp configure
И наконец, соберите проект:
$ node-gyp build
Это создаст /build содержащий, среди прочего, скомпилированный двоичный файл.
Даже при использовании более высоких абстракций, таких как ffi , все же хорошо понимать, что происходит под капотом, поэтому я рекомендую вам потратить время на изучение тонкостей node-gyp .
нан
nan (собственные абстракции для Node) — это модуль, о котором легко забыть, но он избавит вас от многих часов разочарования. Между версиями Node v0.8 , v0.10 и v0.12 используемые версии V8 претерпели некоторые большие изменения (в дополнение к изменениям внутри самого узла), поэтому nan помогает скрыть эти изменения от вас и обеспечивает приятный согласованный интерфейс. .
Эта собственная абстракция работает, предоставляя объекты / функции C / C ++ в файле заголовка #include
Чтобы использовать его, установите пакет nan
$ npm install --save nan
Добавьте эти строки в свой файл binding.gyp:
"include_dirs" : [ "
И вы готовы использовать методы / функции из nan.h в своих хуках вместо исходного кода #include Я очень рекомендую вам использовать nan . В этом случае нет особого смысла изобретать колесо.
Создание аддона
Перед тем, как начать работу над аддоном, убедитесь, что у вас есть время, чтобы ознакомиться со следующими библиотеками:
- Библиотека V8 JavaScript C ++, которая используется для фактического взаимодействия с JavaScript (например, для создания функций, вызова объектов и т. Д.).
- Примечание: node.h файл по умолчанию предлагается, но на самом деле nan.h следует использовать вместо
В оставшейся части этого раздела я покажу вам реальный пример. В этом случае мы создадим перехватчик функции pow библиотеки Поскольку вы почти всегда должны использовать nan , я буду использовать его во всех примерах.
В этом примере в вашем проекте аддона должны присутствовать как минимум следующие файлы:
- pow.cpp
- binding.gyp
- package.json
Файл C ++ не обязательно называть pow.cpp , но имя обычно отражает либо то, что это надстройка, либо его конкретная функция.
// pow.cpp #include #include void Pow(const Nan::FunctionCallbackInfo& info) < if (info.Length() < 2) < Nan::ThrowTypeError("Wrong number of arguments"); return; >if (!info[0]->IsNumber() || !info[1]->IsNumber()) < Nan::ThrowTypeError("Both arguments should be numbers"); return; >double arg0 = info[0]->NumberValue(); double arg1 = info[1]->NumberValue(); v8::Local num = Nan::New(pow(arg0, arg1)); info.GetReturnValue().Set(num); > void Init(v8::Local exports) < exports->Set(Nan::New("pow").ToLocalChecked(), Nan::New(Pow)->GetFunction()); > NODE_MODULE(pow, Init)Обратите внимание, что в конце NODE_MODULE нет точки с запятой ( ; ). Это сделано намеренно, поскольку NODE_MODULE самом деле не функция
Приведенный выше код поначалу может показаться немного устрашающим для тех, кто не писал на C ++ какое-то время (или когда-либо), но на самом деле это не так уж сложно понять. Функция Pow - это основа кода, в котором мы проверяем количество переданных аргументов, типы аргументов, вызываем встроенную pow и возвращаем результат в приложение Node. info объект содержит все, что нам нужно знать о вызове, включая аргументы (и их типы) и место для возврата результата.
Функция Init основном просто связывает функцию Pow
имя "pow", а NODE_MODULE фактически обрабатывает регистрацию надстройки в Node.package.json мало чем отличается от обычного модуля Node. Хотя это не кажется обязательным, в большинстве модулей Addon установлено значение "gypfile": true , но процесс сборки, кажется, все еще работает без него. Вот что я использовал для этого примера:
< "name": "addon-hook", "version": "0.0.0", "description": "Node.js Addon Example", "main": "index.js", "dependencies": < "nan": "^2.0.0" >, "scripts": < "test": "node index.js" >>Затем этот код необходимо встроить в файл «pow.node», который является двоичным файлом аддона. Для этого вам нужно указать node-gyp какие файлы ему нужно скомпилировать, и имя файла, полученного в результате двоичного файла. Хотя есть много других опций / конфигураций, которые вы можете использовать с node-gyp , для этого примера нам не нужно много. binding.gyp может быть таким простым, как:
Теперь, используя node-gyp , сгенерируйте соответствующие файлы сборки проекта для данной платформы:
$ node-gyp configureИ наконец, соберите проект:
$ node-gyp buildЭто должно привести к pow.node файла pow.node, который будет находиться в каталоге build/Release/ Для того, чтобы использовать этот крюк в коде приложения, просто require в pow.node файл (без «.node» расширение):
var addon = require('./build/Release/pow'); console.log(addon.pow(4, 2)); // Prints '16'Интерфейс внешней функции узла
Примечание . Пакет ffi ранее назывался node-ffi . Обязательно добавьте новое ffi в свои зависимости, чтобы избежать путаницы во время npm install 🙂
Хотя функциональность Addon, предоставляемая Node, дает вам всю необходимую гибкость, не всем разработчикам / проектам она понадобится. Во многих случаях такая абстракция, как ffi подойдет и обычно требует очень небольшого программирования на C / C ++ или вообще не требует его.
ffi загружает только динамические библиотеки, что может быть ограничивающим для некоторых, но также значительно упрощает настройку хуков.
var ffi = require('ffi'); var libm = ffi.Library('libm', < 'pow': [ 'double', [ 'double', 'double' ] ] >); console.log(libm.pow(4, 2)); // 16Приведенный выше код работает, указывая библиотеку для загрузки (libm) и, в частности, какие методы загружать из этой библиотеки (pow). [ 'double', [ 'double', 'double' ] ] строка говорит ffi , что тип возвращаемого значения и параметры метода в том, что в этом случае состоит из двух double параметров и double вернулся.
Заключение
Хотя сначала это может показаться пугающим, создание аддона на самом деле не так уж и плохо после того, как у вас будет возможность самостоятельно проработать такой небольшой пример. По возможности я бы предложил подключиться к динамической библиотеке, чтобы значительно упростить создание интерфейса и загрузку кода, хотя для многих проектов это может быть невозможно или лучший выбор.
Есть ли примеры библиотек, для которых вы хотели бы видеть привязки? Дайте нам знать об этом в комментариях!
Licensed under CC BY-NC-SA 4.0