Как увеличить скорость работы Python с Numba
Python – это интерпретируемый язык. Это означает, что код Python не компилируется напрямую в машинный код, а интерпретируется в режиме реального времени другой программой, называемой интерпретатором (в большинстве случаев CPython).
Это одна из причин, почему Python обеспечивает такую большую гибкость (динамическая типизация, работает везде и т.д.) по сравнению с компилируемыми языками. Однако именно поэтому Python медленный.
На самом деле существует несколько способов разогнать код на Python. Самыми популярными из них являются:
- использование Cython;
- использование PyPy;
- расширение Python с использованием C/C++.
Cython позволяет напрямую вызывать библиотечные функции C и эффективно работать с большими данными. Но обладает и минусами, главными из которых являются «свой» синтаксис, который предполагает знание C, и сложности в отладке. Код Python можно ускорить, написав нативный код, но тогда использование Cython не даст прироста скорости близкой к известному PyPy.
PyPy использует технику, известную как мета-трассировка, которая преобразует интерпретатор в компилятор трассировки JIT (Just-in-time), т.е. выполнение кода включает в себя компиляцию. PyPy имеет высокую скорость, которая не уступает Cython, рационально обращается с памятью, но несмотря на совместимость со многими базовыми библиотеками Python, PyPy поддерживает далеко не все из них, и к тому же для выполнения Python-кода могут потребоваться его некоторые изменения.
Расширение Python с помощью C/C++ дает возможность добавлять новые встроенные модули в Python без труда, однако требует умения программировать на C. С помощью таких модулей можно реализовывать новые встроенные типы объектов и вызывать библиотечные функции C.
Вышеупомянутые методы требуют использования языка, отличного от Python, или компиляции кода для его работы с Python. Эти варианты не самые удобные и не всегда просты в настройке. Возникает вопрос, как быть тем, кто абсолютно не знаком с C/C++ и не желает такого знакомства. К счастью, выход есть всегда, и пакет Numba — прекрасное решение, которое поможет значительно ускорить код, не отказываясь от дружелюбного Python.
Numba & JIT compilation
Numba – это компилятор с открытым исходным кодом, использующий подход LLVM (Low Level Virtual Machine). Numba использует компиляцию JIT (Just-in-time) – это означает, что компиляция выполняется во время выполнения кода Python, а не раньше!
Установлю Numba с помощью pip.
pip install numba
Рассмотрю простой пример с проверкой числа на простоту.
Для использования Numba нужно просто импортировать декоратор (@njit) и добавить его к функции.
import math #Импортируем njit from numba import njit def isPrime(n): for i in range(2, int(math.sqrt(n)+1)): if n % i == 0: return False return n>1 def test(n): for i in range(n): isPrime(n) #добавим numba декоратор, чтобы функция работала быстрее @njit def isPrime(n): for i in range(2, int(math.sqrt(n)+1)): if n % i == 0: return False; return n>1; @njit def test_with_numba(n): for i in range(n): isPrime(n)
Посмотрю на результаты:
В таком представлении Numba смотрится слишком хорошим, чтобы быть правдой. Но у него наверняка есть свои недостатки.
Первый вызов функции, декорированной с использованием Numba, запускается долго. Это связано с тем, что Numba пытается выяснить типы параметров и скомпилировать функцию при первом её выполнении. Чтобы уменьшить затраты времени на компиляцию при каждом вызове программы на Python, можно записать результат компиляции функции в файловый кэш. Сделать это можно, добавив в аргументы к декоратору @njit(cache=True), и тогда последующие запуски кода будут быстрыми.
Не весь код на Python будет скомпилирован с Numba. Например, если вы используете смешанные типы для одной и той же переменной или для элементов списка, вы получите ошибку. Для контроля типов переменных в numba есть способ, позволяющий сразу определить тип функции и типы входящих переменных, например, добавив строку с нужными типами в декоратор. Проиллюстрирую типизацию на примере функции сложения с декоратором @vectorize:
import numpy as np from numba import vectorize, int64, int32, float32, float64 @vectorize([float64(float64, float64)]) def sum_numbers(x, y): return x + y
Передавая несколько типов, следует помнить, что порядок передачи последовательности типов должен следовать от наиболее конкретных к наименее (т. е. тип с плавающей запятой одинарной точности должен описываться раньше типа с плавающей запятой двойной точности), иначе диспетчеризация на основе типов не будет работать должным образом.
@vectorize([int32(int32, int32), int64(int64, int64), float32(float32, float32), float64(float64, float64)]) def sum_numbers_multitype(x, y): return x + y
Функция будет работать для указанных типов, однако с другими типами выдаст ошибку:
Numba создан специально с учетом Numpy и очень удобен для массивов Numpy. Как известно, Pandas основан на Numpy: поддерживает конвертацию структур данных Numpy в свои собственные структуры и наоборот. Данная особенность позволяет использовать Numba не только в паре с Numpy, но и с Pandas. Это приводит к сумасшедшей оптимизации при использовании пользовательских функций или даже при выполнении различных операций в любимой многими структуре данных pandas.DataFrame.
Рассмотрю ещё два примера:
import numpy as np import pandas as pd n = 1_000_000 df = pd.DataFrame(< 'x': np.random.random(n), 'y': 100 * np.random.random(n) >)
Воспользуюсь декоратором @vectorize, он позволяет использовать функции Python, принимающие скалярные входные аргументы, в качестве ufuncs.
Вычислю квадрат Х в наборе данных:
from numba import vectorize def squared_without_numba(x): return x ** 2 @vectorize def squared_with_numba(x): return x ** 2
Также посмотрю на применение Numba с методом @njit(parallel=True), который позволяет автоматически распараллелить выполнение кода в функции на разных ядрах CPU, но там, где это возможно.
from numba import njit @njit(parallel=True) def test_with_numba(x, y): n = len(x) result = np.empty(n, dtype=»float64″) for i, (x, y) in enumerate(zip(x, y)): result[i] = x**2 + y ** 2 return result
Приведенные примеры показали, что Numba позволяет сократить время выполнения кода и является простым способом сделать ваш код намного быстрее без особых усилий.
Попробуйте и убедитесь в этом лично!
Увеличиваем скорость работы Python до уровня C++ с Numba
Повышаем скорость работы Python с использованием библиотеки Numba и сравниваем с «плюсами» на примере простенького алгоритма.
В этой статье автор разобрался, как увеличить скорость работы Python, и продемонстрировал реализацию на реальном примере.
Прим. ред. Это перевод. Мнение редакции может не совпадать с мнением автора оригинала.
Тест базовой скорости
Для сравнения базовой скорости Python и C++ я буду использовать алгоритм генерации случайных простых чисел.
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Реализация на Python
import math from time import per_counter def is_prime(num): if num == 2: return True; if num Реализация на C++
#include #include #include using namespace std; bool isPrime(int num) < if (num == 2) return true; if (num return true; > int main() < int N = 10000000; clock_t start,end; start = clock(); for (int i; i < N; i++) isPrime(i); end = clock(); cout Результат
- Python: скорость выполнения 80,137 секунд;
- C++: скорость выполнения 3,174 секунды.
Комментарий
Как и ожидалось, программа на C++ выполняется в 25 раз быстрее, чем на Python. Ожидания подтвердились, потому что:
- Python — это динамически типизированный язык;
- GIL(Global Interpreter Lock) — не поддерживает параллельное программирование.
Благодаря тому, что Python это гибкий универсальный язык, наш результат можно улучшить. Один из лучших способов увеличить скорость Python — Numba.
Numba
Чтобы начать использовать Numba, просто установите её через консоль:
pip install numba Реализация на Python с использованием Numba
import math from time import per_counter from numba import njit, prange @njit(fastmath=True, cache=True) def is_prime(num): if num == 2: return True; if num Как вы могли заметить, в коде добавились декораторы njit:
- parallel=True — включает параллельное выполнение программы на процессоре;
- fastmath=True — разрешает использование небезопасных преобразований с плавающей точкой;
- cache=True — позволяет сократить время компиляции функции, если она уже была скомпилирована.
Итоговая скорость Python
- Python: скорость выполнения 1,401 секунды;
- C++: скорость выполнения 3,174 секунды.
Теперь вы знаете что Python способен обогнать C++. О других способах увеличения скорости работы Python читайте в статьях про пять проектов, которые помогают ускорить код на Python и про количество памяти, которое занимают разные типы данных в Python.
Python (+numba) быстрее си — серьёзно?! Часть 2. Практика
Это вторая часть статьи про numba. В первой было историческое введение и краткая инструкция по эксплуатации numba. Здесь я привожу слегка модифицированный код задачи из статьи про хаскелл «Быстрее, чем C++; медленнее, чем PHP» (там сравнивается производительность реализаций одного алгоритма на разных языках/компиляторах) с более детальными бенчмарками, графиками и пояснениями. Сразу оговорюсь, что я видел статью Ох уж этот медленный C/C++ и, скорее всего, если внести в код на си эти правки, картина несколько изменится, но даже в этом случае то, что питон способен превысить скорость си хотя бы в таком варианте, само по себе является примечательным.

Заменил питоновский список на numpy-массив (и, соответственно, v0[:] на v0.copy() , потому что в numpy a[:] возвращает view вместо копирования).
Чтобы понять характер поведения быстродействия сделал «развёртку» по количеству элементов в массиве.
В питоновском коде заменил time.monotonic на time.perf_counter , поскольку он точнее (1us против 1ms у monotonic).
Поскольку в numba используется jit-компиляция, эта самая компиляция должна когда-то происходить. По умолчанию она происходит при первом вызове функции и неизбежно влияет на результаты бенчмарков (правда, если берётся мин время из трёх запусков этого можно не заметить), а также сильно ощущается в практическом использовании. Есть несколько способов борьбы с этим явлением:
1) кэшировать результаты компиляции на диск:
@njit(cache=True) def lev_dist(s1: AnyStr, s2: AnyStr) -> int:тогда компиляция произойдёт при первом вызове программы, а при последующих будет подтягиваться с диска.
2) указывать сигнатуру
Компиляция будет происходить в момент, когда питон парсит определение функции и первый запуск будет уже быстрым.
В оригинале передаётся строка (точнее, bytes), но поддержка строк добавлена недавно, поэтому сигнатура достаточно монструозная (см. ниже). Обычно сигнатуры пишутся попроще:
@njit(nb.int64(nb.uint8[:], nb.uint8[:])) def lev_dist(s1, s2):но тогда придётся заранее преобразовать bytes в numpy-массив:
s1_py = [int(x) for x in b"a" * 15000] s1 = np.array(s1_py, dtype=np.uint8)s1 = np.full(15000, ord('a'), dtype=np.uint8)А можно оставить bytes как есть и указать сигнатуру вот в таком виде:
@njit(nb.int64(nb.bytes(nb.uint8, nb.1d, nb.C), nb.bytes(nb.uint8, nb.1d, nb.C))) def lev_dist(s1: AnyStr, s2: AnyStr) -> int:Скорость выполнения для bytes и numpy-массива из uint8 (в данном случае) одинаковая.
3) подогревать кэш
s1 = b"a" * 15 # 15 вместо 15000 s2 = s1 s3 = b"b" * 15 exec_time = -clock() print(lev_dist(s1, s2)) print(lev_dist(s1, s3)) exec_time += clock() print(f"Finished in s", file=sys.stderr)
Тогда компиляция произойдёт на первом вызове, а второй уже будет быстрым.
Код на python
#!/usr/bin/env python3 import sys import time from numba import njit import numpy as np, numba as nb from time import perf_counter as clock @njit(nb.int64(nb.uint8[::1], nb.uint8[::1])) def lev_dist(s1, s2): m = len(s1) n = len(s2) # Edge cases. if m == 0: return n elif n == 0: return m v0 = np.arange(n + 1) v1 = v0.copy() for i, c1 in enumerate(s1): v1[0] = i + 1 for j, c2 in enumerate(s2): subst_cost = v0[j] if c1 == c2 else (v0[j] + 1) del_cost = v0[j + 1] + 1 ins_cost = v1[j] + 1 min_cost = min(subst_cost, del_cost, ins_cost) v1[j + 1] = min_cost v0, v1 = v1, v0 return v0[n] if __name__ == "__main__": fout = open('py.txt', 'w') for n in 1000, 2000, 5000, 10000, 15000, 20000, 25000: s1 = np.full(n, ord('a'), dtype=np.uint8) s2 = s1 s3 = np.full(n, ord('b'), dtype=np.uint8) exec_time = -clock() print(lev_dist(s1, s2)) print(lev_dist(s1, s3)) exec_time += clock() print(f' ', file=fout)Код на си (clang -O3 -march=native)
#include #include #include #include static long lev_dist (const char *s1, unsigned long m, const char *s2, unsigned long n) < // unsigned long m, n; unsigned long i, j; long *v0, *v1; long ret, *temp; /* Edge cases. */ if (m == 0) < return n; >else if (n == 0) < return m; >v0 = malloc (sizeof (long) * (n + 1)); v1 = malloc (sizeof (long) * (n + 1)); if (v0 == NULL || v1 == NULL) < fprintf (stderr, "failed to allocate memory\n"); exit (-1); >for (i = 0; i memcpy (v1, v0, sizeof(long) * (n + 1)); for (i = 0; i < m; ++i) < v1[0] = i + 1; for (j = 0; j < n; ++j) < const long subst_cost = (s1[i] == s2[j]) ? v0[j] : (v0[j] + 1); const long del_cost = v0[j + 1] + 1; const long ins_cost = v1[j] + 1; #if !defined(__GNUC__) || defined(__llvm__) if (subst_cost < del_cost) < v1[j + 1] = subst_cost; >else < v1[j + 1] = del_cost; >#else v1[j + 1] = (subst_cost < del_cost) ? subst_cost : del_cost; #endif if (ins_cost < v1[j + 1]) < v1[j + 1] = ins_cost; >> temp = v0; v0 = v1; v1 = temp; > ret = v0[n]; free (v0); free (v1); return ret; > int main () < char s1[25001], s2[25001], s3[25001]; int lengths[] = ; FILE *fout; fopen_s(&fout, "c.txt", "w"); for(int j = 0; j < sizeof(lengths)/sizeof(lengths[0]); j++)< int len = lengths[j]; int i; clock_t start_time, exec_time; for (i = 0; i < len; ++i) < s1[i] = 'a'; s2[i] = 'a'; s3[i] = 'b'; >s1[len] = s2[len] = s3[len] = '\0'; start_time = clock (); printf ("%ld\n", lev_dist (s1, len, s2, len)); printf ("%ld\n", lev_dist (s1, len, s3, len)); exec_time = clock () - start_time; fprintf(fout, "%d %.6f\n", len, ((double) exec_time) / CLOCKS_PER_SEC); fprintf (stderr, "Finished in %.3fs\n", ((double) exec_time) / CLOCKS_PER_SEC); > return 0; >Сравнение проводил под windows (windows 10 x64, python 3.7.3, numba 0.45.1, clang 9.0.0, intel m5-6y54 skylake): и под linux (debian 4.9.30, python 3.7.4, numba 0.45.1, clang 9.0.0).
По x размер массива, по y время в секундах.
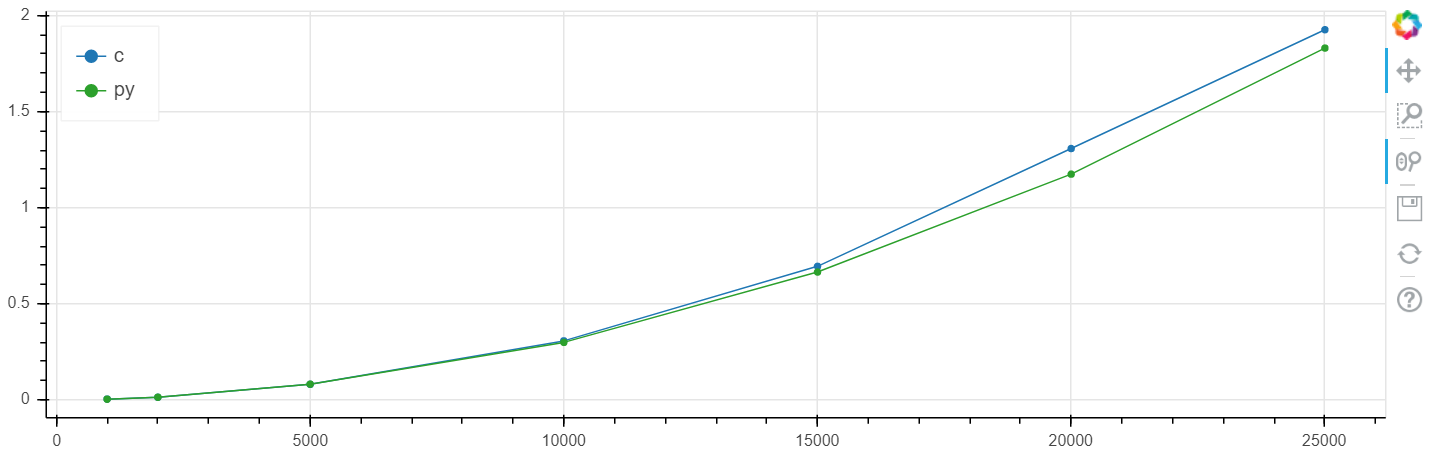
Windows, линейный масштаб:
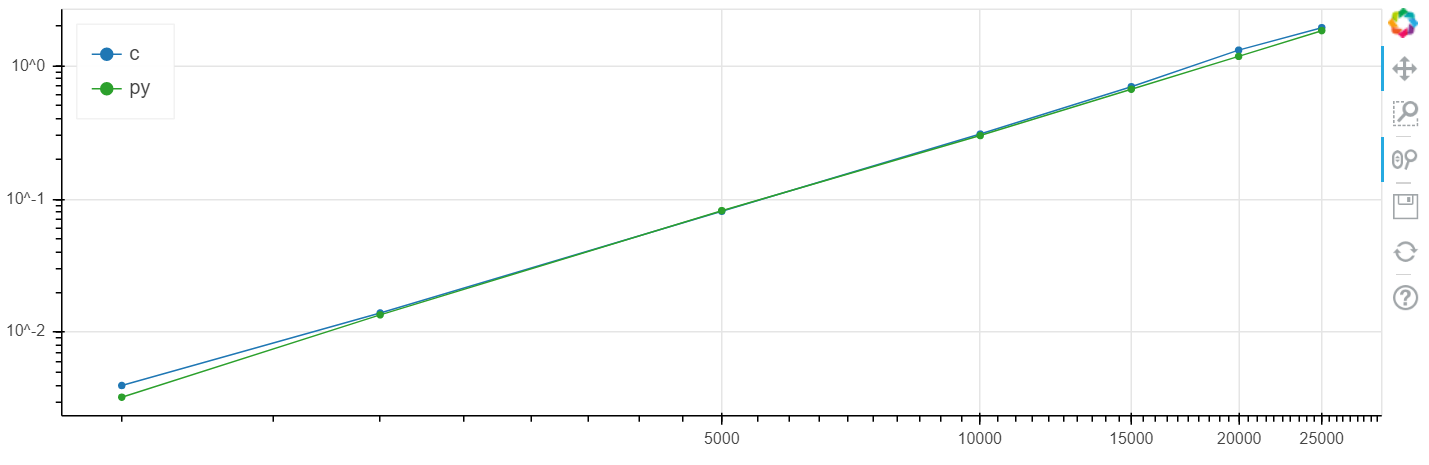
Windows, логарифмический масштаб:

Linux, линейный масштаб:
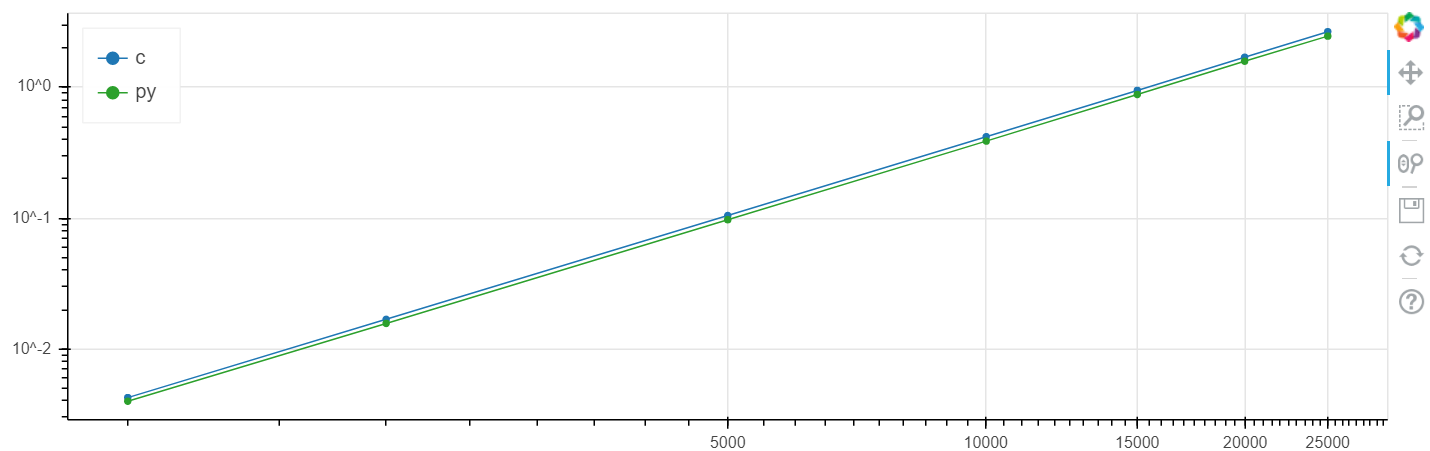
Linux, логарифмический масштаб
На данной задаче получился прирост в скорости по сравнению с clang на уровне нескольких процентов, что в общем-то выше статистической ошибки.
Я неоднократно проводил это сравнение на разных задачах и, как правило, если numba может что-то разогнать, она это разгоняет до скорости, в пределах погрешности совпадающей со скоростью C (без использования ассемблерных вставок).
Повторюсь, что если внести в код на С правки из Ох уж этот медленный C/C++ ситуация может измениться.
Буду рад услышать вопросы и предложения в комментариях.
PS При указании сигнатуры массивов лучше задать явно способ чередования строк/столбцов:
чтобы numba не раздумывала 'C' (си) это или 'A'(автораспознавание си/фортран) — почему-то это влияет на быстродействие даже для одномерных массивов, для этого есть вот такой оригинальный синтаксис: uint8[. ] это 'A' (автоопределение), nb.uint8[:, ::1] – это 'C' (си), np.uint8[::1, :] – это 'F' (фортран).
@njit(nb.int64(nb.uint8[::1], nb.uint8[::1])) def lev_dist(s1, s2):Python (+numba) быстрее си — серьёзно?! Часть 1. Теория
Давно собирался написать статью о numba и о сравнении её быстродействия с си. Статья про хаскелл «Быстрее, чем C++; медленнее, чем PHP» подтолкнула к действию. В комментариях к этой статье упомянули о библиотеке numba и о том, что она магическим образом может приблизить скорость выполнения кода на питоне к скорости на си. В данной статье — чуть более подробный разбор этой ситуации (часть 2) и рекомендации по «приручению» numba (часть 1).

Главным недостатком питона принято считать его скорость. Разгонять python с переменным успехом стали чуть ли не с первых дней его существования: shedskin , nutika , pythran , parakeet , theano , cython , pypy , numba . На сегодняшний день самыми востребованными являются последние три. Cython (не путать с cpython) — довольно сильно отличается семантически от обычного питона. Фактически это отдельный язык — некий гибрид си и python. Что касается pypy (альтернативная реализация транслятора python с использованием jit-компиляции) и numba (библиотека для транскомпиляции кода в llvm) – они пошли разными путями. В pypy изначально была заявлена поддержка всех конструкций python. В numba же исходили из того, что чаще всего требует ускорения (cpu bound) — математические вычисления, соответственно, они выделили часть языка, связанную с вычислениями и начали разгонять её, постепенно увеличивая «охват» (например, до недавнего времени не было поддержки строк, сейчас она появилась). Соответственно, в numba разгоняется не вся программа, а отдельные функции, это позволяет совместить высокую скорость и обратную совместимость с библиотеками, которые numba (пока) не поддерживает. Numpy поддерживается (с незначительными ограничениями) и в pypy , и в numba .
Моё знакомство с Numba началось в 2015 году вот с этого вопроса на stackoverflow про скорость умножения матриц на питоне: Efficient outer product in python
╔═══════════╦═══════════╦═════════╗ ║ method ║ time(ms)* ║ version ║ ╠═══════════╬═══════════╬═════════╣ ║ numba ║ 9.77 ║ 0.16.0 ║ ║ np.outer ║ 9.79 ║ 1.9.1 ║ ║ cython ║ 10.1 ║ 0.21.2 ║ ║ parakeet ║ 11.6 ║ 0.23.2 ║ ║ pypy ║ 16.36 ║ 2.4.0 ║ ║ np.einsum ║ 16.6 ║ 1.9.1 ║ ║ theano ║ 17.4 ║ 0.6.0 ║ ╚═══════════╩═══════════╩═════════╝ * less time = faster
С тех пор произошло много событий в каждой из библиотек, но качественно картина в отношении numba / cython / pypy не изменилась: numba обгоняет cython за счёт использования нативных процессорных инструкций ( cython не умеет jit), а pypy – за счёт более эффективного выполнения байткода llvm.
Использую numba в научных вычислениях и при обучении питону в НГУ.
как ускорять
Чтобы ускорить функцию, надо перед её определением вписать декоратор njit:
from numba import njit @njit def f(n): s = 0 for i in range(n): s += i return sпосле этого f(n) начинает выполняться быстрее – бывает, на пару порядков. Для экспериментов рекомендую взять функцию посложнее, поскольку в данном случае numba распознаёт сумму арифметической прогрессии(!) и вычисляет её за O(1).
Раньше был актуален режим просто @jit (а не @njit ). Смысл в том, что в этом режиме можно использовать неподдерживаемые нумбой операции: нумба на большой скорости доходит до первой такой операции, затем замедляется и до конца функции исполнение продолжается с обычной питоновской скоростью, даже если больше в функции ничего «запретного» не встречается (т.н. object mode), что, очевидно, нерационально. Сейчас от @jit постепенно отказываются, рекомендуется всегда пользоватся @njit (или в полной форме @jit(nopython=True) ): в этом режиме нумба ругается исключениями на такие места – всё равно лучше их переписать, чтобы не потерять в скорости.
что умеет разгонять
В разогнанных функциях можно использовать только часть функционала питона и нумбы. Все операторы, функции и классы делятся в отношении нумбы на две части: те, которые нумба «понимает» и те, которые она «не понимает».
В документации по numba есть два таких списка (с примерами):
- подмножество функционала питона, знакомое нумбе и
- подмножество функционала numpy, знакомое нубме.
Из примечательного в этих списках:
- нумба «понимает» питоновские списки с быстрым (амортизированное O(1)) добавлением в конец, которые «не понимает» numpy (правда, только однородные – из элементов одного типа),
- numpy'евские массивы, которые отсутствуют в базовом питоне. Понимает также
- кортежи (tuples): они могут, как и в обычном питоне, содержать элементы разных типов.
- с недавних пор str и bytes, правда, только в качестве входных параметров, создавать их (пока?) нельзя.
Никакие другие библиотеки (в частности, scipy и pandas) она не понимает совсем.
Но даже того подмножества языка, которое она понимает, достаточно, чтобы разогнать большую часть кода для научных приложений, на которые numba в первую очередь и ориентирована.
важно!
Из разогнанных функций можно вызывать только разогнанные, не разогнанные нельзя.
(хотя разогнанные функции можно вызывать и из разогнанных и из не разогнанных).
globals
В разогнанных функциях глобальные переменные становятся константами: их значение фиксируется на момент компиляции функции (пример). => Не используйте глобальные переменные в разогнанных функциях (кроме констант).
сигнатуры
В нумбе каждой функции сопоставляется один или несколько типов входных и выходных аргументов, т.н. сигнатуры. При первом вызове функции сигнатура формируется и автоматически компилируется соответствующий бинарный код функции. При запуске с другими типами аргументов будут создаваться новые сигнатуры и новые бинарники (старые при этом сохраняются). Таким образом, «выход на режим» по скорости исполнения для каждой сигнатуры наступает начиная со второго запуска с этими типами аргументов. Так что надо либо
– «прогревать кэш», запуская с небольшими размерами входных массивов, либо
– указывать аргумент @jit(cache=True) для сохранения скомпилированного кода на диск с автоматической его загрузкой при последующих запусках программы (правда на практике на сегодняшний день этот первый запуск всё равно немного медленнее, чем последующие, но быстрее, чем без cache=True ).
Есть ещё третий способ. Сигнатуры можно задавать вручную:
from numba import int16, int32 @njit(int32(int16, int16)) def f(x, y): return x + y f.signatures [(int16, int16)]При запуске функции с сигнатурой, указанной в декораторе, уже первый запуск будет быстрым: компиляция произойдёт в тот момент, когда питон увидит определение функции, а не при первом запуске. Сигнатур может быть несколько, порядок их следования имеет значение.
Предупреждение: этот последний способ не future-safe. Авторы numba предупреждают о том, что синтаксис указания типов может измениться в будущем, @jit / @njit без сигнатур – более безопасный в этом плане вариант.
f.signatures начинают показывать сигнатуры только тогда, когда питон о них узнает, то есть после первого вызова функции, либо если они заданы вручную.
Кроме f.signatures сигнатуры можно посмотреть через f.inspect_types() – кроме типов входных параметров эта функция покажет типы выходных параметров, а также типы всех локальных переменных.
Кроме типов входных и выходных параметров, есть возможность вручную указать типы локальных переменных:
from numba import int16, int32 @njit(int32(int16, int16), locals=) def f(x, y): z = y + 10 return x + zint
В нумбе у целых чисел нет длинной арифметики как в «просто» питоне, но есть стандартные типы различной ширины от int8 до int64 . Есть ещё типы int_ (а также float_ ), используя которые вы предоставляете нумбе возможность выбрать оптимальную (с её точки зрения) ширину поля.
классы
Поддержка классов (@jitclass) вообще есть, но пока она экспериментальная, так что лучше пока избегать их использования (на текущий момент, по моему опыту, с ними сильно медленнее, чем без них).
custom dtypes
В numba поддерживается некая альтернатива классам из numpy – структурные массивы (structured array), или, иначе говоря, пользовательские dtype'ы. Они работают с той же скоростью, что и обычные массивы numpy, их чуть удобнее индексировать (например, a['y2'] более читаемо, чем a[3] ). Интересно, что в numba, в отличие от numpy, наряду с обычным синтаксисом a['y2'] допускается более лаконичный a.y2 . Но в целом их поддержка в numba оставляет желать лучшего, и некоторые очевидные даже в numpy операции с ними в нумбе записываются достаточно нетривиально.
GPU
Умеет выполнять разогнанный код на GPU, причём в отличие от того же, например, pycuda или pytorch, не только на nvidia, но и на amd'шных карточках. С этим пока разбирался мало. Вот статья на хабре 2016 года Сравнение производительности GPU-расчетов на Python и C. Там получилась сопоставимая с С скорость.
установка
Еще пару лет назад были проблемы с установкой, сейчас всё разрешилось: одинаково хорошо устанавливается и через pip, и через conda; llvm подтягивается и устанавливается автоматически.
ahead-of-time компиляция
В нумбе есть режим обычной (то есть не jit) компиляции (документация), но этот режим является не основным, я с ним не разбирался.
документация
Нумбе до сих пор не хватает толковой документации. Она есть, но в ней есть не всё.
оптимизация
Есть некоторая непредсказуемость при оптимизации кода вручную: unpythonic код зачастую работает быстрее, чем pythonic.
Заинтересовавшимся темой могу порекомендовать видео мастер-класса по numba с конференции scipy 2017 (есть исходники на гитхабе). Оно правда длинновато и частично устарело (например, строки уже поддерживаются), но общее представление получить помогает.
Во второй части рассмотрим применение numba на примере кода из упомянутой в начале статьи.