Как использовать Pandas Get Dummies — pd.get_dummies
Часто в статистике наборы данных, с которыми мы работаем, включают категориальные переменные .
Это переменные, которые принимают имена или метки. Примеры включают:
- Семейное положение («замужем», «холост», «разведен»).
- Статус курения («курящий», «некурящий»)
- Цвет глаз («голубой», «зеленый», «ореховый»)
- Уровень образования (например, «средняя школа», «бакалавр», «магистр»)
При подборе алгоритмов машинного обучения (таких как линейная регрессия , логистическая регрессия , случайные леса и т. д.) мы часто преобразовываем категориальные переменные в фиктивные переменные , которые представляют собой числовые переменные, используемые для представления категориальных данных.
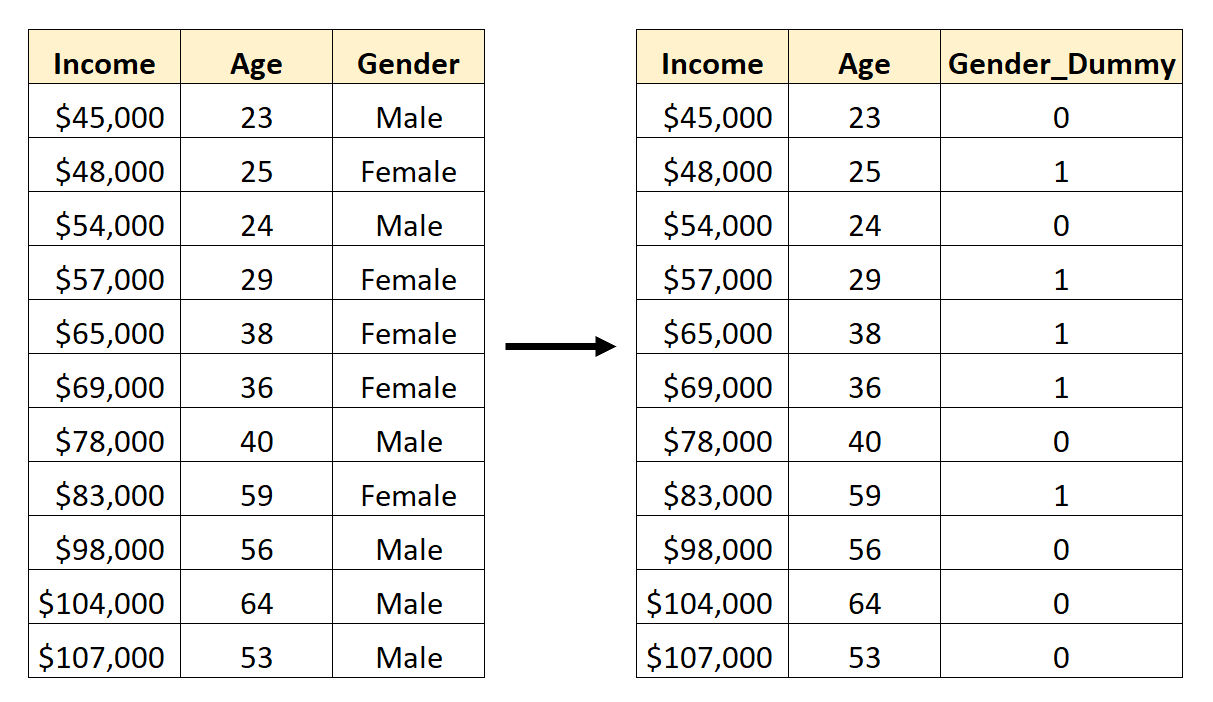
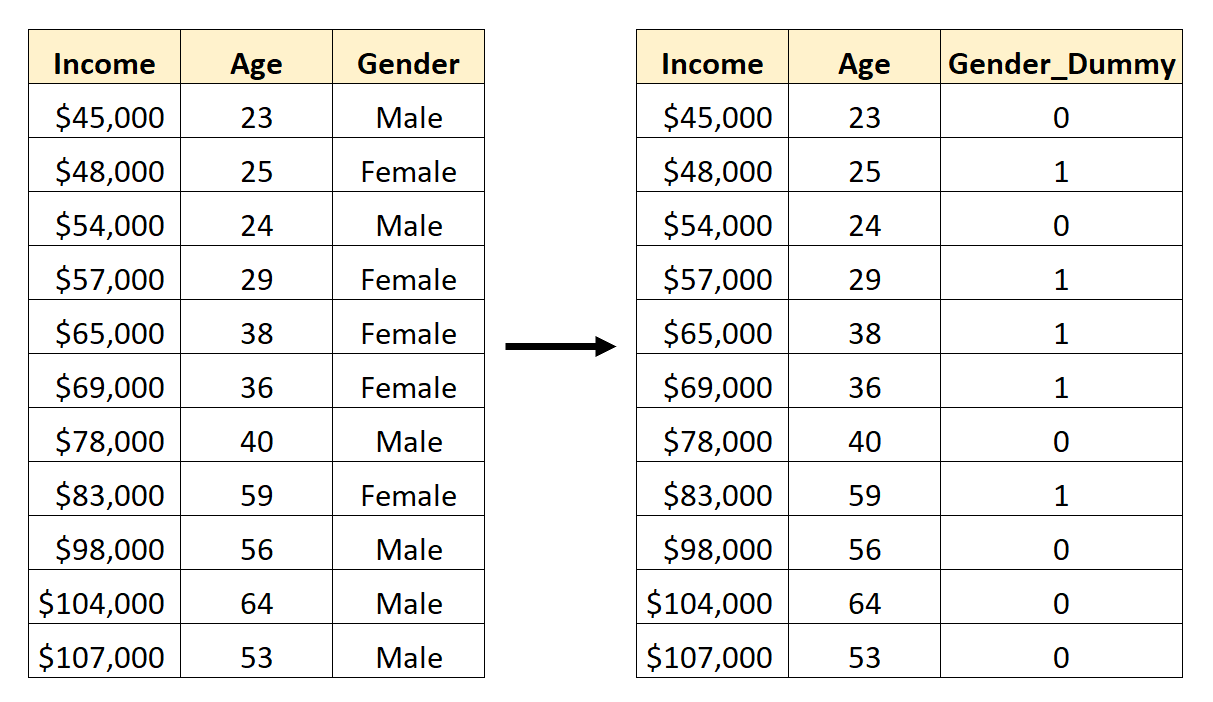
Например, предположим, что у нас есть набор данных, содержащий категориальную переменную Gender.Чтобы использовать эту переменную в качестве предиктора в регрессионной модели, нам сначала нужно преобразовать ее в фиктивную переменную.
Чтобы создать эту фиктивную переменную, мы можем выбрать одно из значений («Мужской») для представления 0, а другое значение («Женский») для представления 1:
Как создать фиктивные переменные в Pandas
Чтобы создать фиктивные переменные для переменной в кадре данных pandas, мы можем использовать функцию pandas.get_dummies() , которая использует следующий базовый синтаксис:
pandas.get_dummies (данные, префикс = нет, столбцы = нет, drop_first = ложь)
- data : имя Pandas DataFrame
- prefix : строка, которая добавляется в начало нового столбца фиктивной переменной.
- columns : Имя столбца (столбцов) для преобразования в фиктивную переменную.
- drop_first : Отбрасывать или нет первый столбец фиктивной переменной.
В следующих примерах показано, как использовать эту функцию на практике.
Пример 1. Создание одной фиктивной переменной
Предположим, у нас есть следующие Pandas DataFrame:
import pandas as pd #create DataFrame df = pd.DataFrame() #view DataFrame df income age gender 0 45 23 M 1 48 25 F 2 54 24 M 3 57 29 F 4 65 38 F 5 69 36 F 6 78 40 M Мы можем использовать функцию pd.get_dummies() , чтобы превратить пол в фиктивную переменную:
#convert gender to dummy variable pd.get_dummies (df, columns=['gender'], drop_first= True ) income age gender_M 0 45 23 1 1 48 25 0 2 54 24 1 3 57 29 0 4 65 38 0 5 69 36 0 6 78 40 1 Половая колонка теперь является фиктивной переменной, где:
- Значение 0 представляет «женщину».
- Значение 1 представляет «Мужской».
Пример 2. Создание нескольких фиктивных переменных
Предположим, у нас есть следующие Pandas DataFrame:
import pandas as pd #create DataFrame df = pd.DataFrame() #view DataFrame df income age gender college 0 45 23 M Y 1 48 25 F N 2 54 24 M N 3 57 29 F N 4 65 38 F Y 5 69 36 F Y 6 78 40 M Y Мы можем использовать функцию pd.get_dummies() для преобразования пола и колледжа в фиктивные переменные:
#convert gender to dummy variable pd.get_dummies (df, columns=['gender', 'college'], drop_first= True ) income age gender_M college_Y 0 45 23 1 1 1 48 25 0 0 2 54 24 1 0 3 57 29 0 0 4 65 38 0 1 5 69 36 0 1 6 78 40 1 1 Половая колонка теперь является фиктивной переменной, где:
- Значение 0 представляет «женщину».
- Значение 1 представляет «Мужской».
А столбец колледжа теперь является фиктивной переменной, где:
- Значение 0 представляет колледж «Нет».
- Значение 1 представляет колледж «Да».
Несовпадение размеров матриц при обучении предиктивной модели и предсказания
Имеется 2 pd.frame (Почему RF модель показала точность 0%? Что делать, если при преобразовании Pd.get_dummies нарушает соответствие размерности матриц(изначально фреймы равны) ? попытка предсказания:
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import numpy as np from scipy.stats import norm from sklearn.preprocessing import StandardScaler from scipy import stats import warnings warnings.filterwarnings('ignore') %matplotlib inline from sklearn.model_selection import train_test_split from sklearn import preprocessing from sklearn import linear_model df_train = pd.read_csv('D:\Kaggle\House prices/train.csv') df_test = pd.read_csv('D:\Kaggle\House prices/test.csv') total = df_train.isnull().sum().sort_values(ascending=False) percent = (df_train.isnull().sum()/df_train.isnull().count()).sort_values(ascending=False) missing_data_train = pd.concat([total, percent], axis=1, keys=['Total', 'Percent']) df_train = df_train.drop((missing_data_train[missing_data_train['Total'] > 1]).index,1) df_train = df_train.drop(df_train.loc[df_train['Electrical'].isnull()].index) df_test = df_test.drop((missing_data_train[missing_data_train['Total'] > 1]).index,1) df_test = df_test.drop(df_test.loc[df_test['Electrical'].isnull()].index) saleprice_scaled = StandardScaler().fit_transform(df_train['SalePrice'][:,np.newaxis]); df_test.fillna(method='ffill', inplace=True) df_test = df_test.astype(int, errors='ignore') df_train.sort_values(by = 'GrLivArea', ascending = False)[:2] df_train = df_train.drop(df_train[df_train['Id'] == 1299].index) df_train = df_train.drop(df_train[df_train['Id'] == 524].index) df_train['SalePrice'] = np.log(df_train['SalePrice']) data_features = df_train.drop("Id", axis = 1) X, y = data_features.drop (["SalePrice"], axis = 1), df_train["SalePrice"] FF = pd.get_dummies(X) Xnp = np.array(FF) ynp = np.array(y) X_train, X_test, y_train, y_test = train_test_split (Xnp, ynp, test_size=0.5) lab_enc = preprocessing.LabelEncoder() tsy = lab_enc.fit_transform(y_train) data_features2 reg = linear_model.Ridge(alpha=.5) pred=reg.fit(X_train,y_train) data_features2 = df_test.drop("Id", axis = 1) FF2 = pd.get_dummies(data_features2) FF2 Xnp2 = np.array(FF2) an=pred.predict(Xnp2) ValueError: shapes (1459,205) and (219,) not aligned: 205 (dim 1) != 219 (dim 0) Отслеживать
149k 12 12 золотых знаков 59 59 серебряных знаков 132 132 бронзовых знака
задан 4 авг 2019 в 19:42
user234183 user234183
чтобы дать ответ на данный вопрос надо создать небольшой пример исходного DataFrame, потом показать как вы делаете PIVOT, чтобы помочь воспроизвести ошибку. Если мы сделаем это за вас, то очень высока вероятность того, что данное решение не будет работать для ваших данных по причине различия структуры исходных данных.
Pandas / scikit-learn: get_dummies test / train sets – ValueError: фигуры не выровнены
Я использовал функцию panda get_dummies для генерации фиктивных столбцов для категориальных переменных для использования с scikit-learn, но заметил, что иногда это работает не так, как я ожидаю.
Предпосылки
import pandas as pd
import numpy as np
from sklearn import linear_model
импортировать панд как pd импортировать numpy как np из sklearn import linear_model
Допустим, у нас есть следующие обучающие и тестовые наборы:
Обучающий набор
train = pd.DataFrame(< "letter" :[ "A" , "B" , "C" , "D" ], "value" : [ 1 , 2 , 3 , 4 ]>)
X_train = train.drop([ «value» ], axis= 1 )
X_train = pd.get_dummies(X_train)
y_train = train[ «value» ]
train = pd.DataFrame () X_train = train.drop ( [«Значение»], ось = 1) X_train = pd.get_dummies (X_train) y_train = train [«значение»]
Тестовый набор
test = pd.DataFrame(< "letter" :[ "D" , "D" , "B" , "E" ], "value" : [ 4 , 5 , 7 , 19 ]>)
X_test = test.drop([ «value» ], axis= 1 )
X_test = pd.get_dummies(X_test)
y_test = test[ «value» ]
test = pd.DataFrame ()) X_test = test.drop ( [«Значение»], ось = 1) X_test = pd.get_dummies (X_test) y_test = test [«value»]
Теперь предположим, что мы хотим обучить линейную модель на нашем обучающем наборе, а затем использовать ее для прогнозирования значений в нашем наборе испытаний:
Тренируй модель
lr = linear_model.LinearRegression()
model = lr.fit(X_train, y_train)
Протестируйте модель
model.score(X_test, y_test)
ValueError: shapes ( 4 , 3 ) and ( 4 ,) not aligned: 3 (dim 1 ) != 4 (dim 0 )
Хм, это не пошло в план. Если мы напечатаем X_train и X_test, это может помочь пролить некоторый свет:
Проверка поездных / тестовых наборов данных
print(X_train)
letter_A letter_B letter_C letter_D
print(X_test)
letter_B letter_D letter_E
Они действительно имеют разные формы и несколько разных имен столбцов, потому что тестовый набор содержал некоторые значения, которых не было в обучающем наборе.
Мы можем исправить это, сделав поле ‘letter’ категориальным, прежде чем запустить метод get_dummies над фреймом данных. На данный момент поле имеет тип «объект»:
pandas.get_dummies#
Convert categorical variable into dummy/indicator variables.
Each variable is converted in as many 0/1 variables as there are different values. Columns in the output are each named after a value; if the input is a DataFrame, the name of the original variable is prepended to the value.
Parameters : data array-like, Series, or DataFrame
Data of which to get dummy indicators.
prefix str, list of str, or dict of str, default None
String to append DataFrame column names. Pass a list with length equal to the number of columns when calling get_dummies on a DataFrame. Alternatively, prefix can be a dictionary mapping column names to prefixes.
prefix_sep str, default ‘_’
If appending prefix, separator/delimiter to use. Or pass a list or dictionary as with prefix .
dummy_na bool, default False
Add a column to indicate NaNs, if False NaNs are ignored.
columns list-like, default None
Column names in the DataFrame to be encoded. If columns is None then all the columns with object , string , or category dtype will be converted.
sparse bool, default False
Whether the dummy-encoded columns should be backed by a SparseArray (True) or a regular NumPy array (False).
drop_first bool, default False
Whether to get k-1 dummies out of k categorical levels by removing the first level.
dtype dtype, default bool
Data type for new columns. Only a single dtype is allowed.
Dummy-coded data. If data contains other columns than the dummy-coded one(s), these will be prepended, unaltered, to the result.
Convert Series of strings to dummy codes.
Convert dummy codes to categorical DataFrame .
Reference the user guide for more examples.
>>> s = pd.Series(list('abca'))
>>> pd.get_dummies(s) a b c 0 True False False 1 False True False 2 False False True 3 True False False
>>> s1 = ['a', 'b', np.nan]
>>> pd.get_dummies(s1) a b 0 True False 1 False True 2 False False
>>> pd.get_dummies(s1, dummy_na=True) a b NaN 0 True False False 1 False True False 2 False False True
>>> df = pd.DataFrame('A': ['a', 'b', 'a'], 'B': ['b', 'a', 'c'], . 'C': [1, 2, 3]>)
>>> pd.get_dummies(df, prefix=['col1', 'col2']) C col1_a col1_b col2_a col2_b col2_c 0 1 True False False True False 1 2 False True True False False 2 3 True False False False True
>>> pd.get_dummies(pd.Series(list('abcaa'))) a b c 0 True False False 1 False True False 2 False False True 3 True False False 4 True False False
>>> pd.get_dummies(pd.Series(list('abcaa')), drop_first=True) b c 0 False False 1 True False 2 False True 3 False False 4 False False
>>> pd.get_dummies(pd.Series(list('abc')), dtype=float) a b c 0 1.0 0.0 0.0 1 0.0 1.0 0.0 2 0.0 0.0 1.0