Putifabsent java что это
Интерфейс Map представляет отображение или иначе говоря словарь, где каждый элемент представляет пару «ключ-значение». При этом все ключи уникальные в рамках объекта Map. Такие коллекции облегчают поиск элемента, если нам известен ключ — уникальный идентификатор объекта.
Следует отметить, что в отличие от других интерфейсов, которые представляют коллекции, интерфейс Map НЕ расширяет интерфейс Collection.
Среди методов интерфейса Map можно выделить следующие:
- void clear() : очищает коллекцию
- boolean containsKey(Object k) : возвращает true, если коллекция содержит ключ k
- boolean containsValue(Object v) : возвращает true, если коллекция содержит значение v
- Set> entrySet() : возвращает набор элементов коллекции. Все элементы представляют объект Map.Entry
- boolean equals(Object obj) : возвращает true, если коллекция идентична коллекции, передаваемой через параметр obj
- boolean isEmpty : возвращает true, если коллекция пуста
- V get(Object k) : возвращает значение объекта, ключ которого равен k. Если такого элемента не окажется, то возвращается значение null
- V getOrDefault(Object k, V defaultValue) : возвращает значение объекта, ключ которого равен k. Если такого элемента не окажется, то возвращается значение defaultVlue
- V put(K k, V v) : помещает в коллекцию новый объект с ключом k и значением v. Если в коллекции уже есть объект с подобным ключом, то он перезаписывается. После добавления возвращает предыдущее значение для ключа k, если он уже был в коллекции. Если же ключа еще не было в коллекции, то возвращается значение null
- V putIfAbsent(K k, V v) : помещает в коллекцию новый объект с ключом k и значением v, если в коллекции еще нет элемента с подобным ключом.
- Set keySet() : возвращает набор всех ключей отображения
- Collection values() : возвращает набор всех значений отображения
- void putAll(Map map) : добавляет в коллекцию все объекты из отображения map
- V remove(Object k) : удаляет объект с ключом k
- int size() : возвращает количество элементов коллекции
Чтобы положить объект в коллекцию, используется метод put , а чтобы получить по ключу — метод get . Реализация интерфейса Map также позволяет получить наборы как ключей, так и значений. А метод entrySet() возвращает набор всех элементов в виде объектов Map.Entry .
Обобщенный интерфейс Map.Entry представляет объект с ключом типа K и значением типа V и определяет следующие методы:
- boolean equals(Object obj) : возвращает true, если объект obj, представляющий интерфейс Map.Entry , идентичен текущему
- K getKey() : возвращает ключ объекта отображения
- V getValue() : возвращает значение объекта отображения
- V setValue(V v) : устанавливает для текущего объекта значение v
- int hashCode() : возвращает хеш-код данного объекта
При переборе объектов отображения мы будем оперировать этими методами для работы с ключами и значениями объектов.
Классы отображений. HashMap
Базовым классом для всех отображений является абстрактный класс AbstractMap , который реализует большую часть методов интерфейса Map. Наиболее распространенным классом отображений является HashMap , который реализует интерфейс Map и наследуется от класса AbstractMap.
Пример использования класса:
import java.util.*; public class Program < public static void main(String[] args) < Mapstates = new HashMap(); states.put(1, "Germany"); states.put(2, "Spain"); states.put(4, "France"); states.put(3, "Italy"); // получим объект по ключу 2 String first = states.get(2); System.out.println(first); // получим весь набор ключей Set keys = states.keySet(); // получить набор всех значений Collection values = states.values(); //заменить элемент states.replace(1, "Poland"); // удаление элемента по ключу 2 states.remove(2); // перебор элементов for(Map.Entry item : states.entrySet()) < System.out.printf("Key: %d Value: %s \n", item.getKey(), item.getValue()); >Map people = new HashMap(); people.put("1240i54", new Person("Tom")); people.put("1564i55", new Person("Bill")); people.put("4540i56", new Person("Nick")); for(Map.Entry item : people.entrySet()) < System.out.printf("Key: %s Value: %s \n", item.getKey(), item.getValue().getName()); >> > class Person < private String name; public Person(String value)< name=value; >String getName() >
Чтобы добавить или заменить элемент, используется метод put, либо replace, а чтобы получить его значение по ключу — метод get. С помощью других методов интерфейса Map также производятся другие манипуляции над элементами: перебор, получение ключей, значений, удаление.
Какие значения возвращают мутаторы Map?
• Методы put ( put , putIfAbsent ) возвращают старое значение.
• Методы работы с множеством элементов ( putAll , replaceAll , clear ) не возвращают ничего.
• remove и replace с указанием не только ключа, но и старого значения, возвращают boolean ; без указания – это самое старое значение.
• Методы с коллбэками ( computeIfPresent , computeIfAbsent , compute , merge ) возвращают актуальное значение после вызова, оставшееся или новое.
Top 10 фич Java 8 о которых не говорят
О новых фичах Java 8 было сказано уже довольно много. В основном обсуждают замыкания, Stream’ы, новое API для работы со временем, default-методы в интерфейсах, класс Optional и отсутствие Permanent Generation.
Но помимо жирных фич, в Java 8 сильно изменилась стандартная библиотека по перифирии. В частности, в уже существующие классы было добавлено много методов существенно упрощающих ежедневные задачи. Об этом мы сегодня и поговорим.
Итак, Top 10 самых не обсуждаемых фич Java 8. Поехали.
String.join() Link to heading
Неужто свершилось?! 2014 год на дворе, а в стандартной библиотеке Java появился метод объединяющий набор строк в одну с заданным разделителем.
String.join(", ", "A", "B", "C"); // A, B, C Но лучше поздно чем никогда. Раньше приходилось или плясать со StringBuilder ‘ом. Ну или, самый разумный вариант, использовать Guava или commons-lang.
Ещё один вариант использовать Stream и Collectors.joining() :
CollectionString> strings = . ; strings.stream() .filter(i -> i != null || i.isEmpty()) .collect(Collectors.joining(", ")); В этом случае, появляется возможность предварительно отфильтровать пустые строки.
Map.computeIfAbsent()/getOrDefault()/merge()/putIfAbsent() Link to heading
Даю голову на отсечение, если вы пишете на Java, то у вас в проекте есть код похожий на этот:
MapString, Integer> data = . ; for (String s : strings) if (!data.containsKey(key)) data.put(key, 0); data.put(key, data.get(key) + 1); > Суть проста. Есть отображение из строки в счетчик, сколько раз мы встретили эту строку. Надо только не забывать инициализировать позиции Map ‘а нулем, а то виртуальная машина в вас NullPointerException кинет.
В Java 8 эта же задача решается проще:
for (String s : strings) data.merge(s, 1, (a, b) -> a + b); Meтод merge принимает ключ, значение и функцию которая объединяет заданное значение и уже существующее в отображении, если таковое имеется. Если в отображении под заданным ключем значения нет, то кладет туда указанное значение.
Для любителей однострочников, есть вариант похардкорней:
strings.forEach(s -> data.merge(s, 1, (a, b) -> a + b)); Аналогичную функциональность, но в другом контексте, дают методы:
- computeIfAbsent() – возвращает или значение из отображения по ключу, или создает его, если его не было;
- putIfAbsent() – добавляет значение в отображение, только если его там не было. Этот метод ранее имелся только у ConcurrentMap , теперь появился и у Map ‘а;
- getOrDefault() – название довольно красноречиво. Возвращает значение из отображения или переданное значение по-умолчанию. На мой взгляд, метод довольно не идиоматичен. Для работы с отсутствующими значениями был добавлен тип Optional , его и следовало использовать. Поэтому, я бы добавил метод: Optional getOptional(K key) . Но кто я такой…
ThreadLocal.withInitial() Link to heading
Тех, кто плотно работает с многопоточностью, ничем не пронять. Они как ветераны Вьетнама, и даже флешбеки по ночам так же мучают. И этой конструкцией их не напугаешь:
// Java 7 и ранее ThreadLocalObjectMapper> mapper = new ThreadLocal<>() @Override protected ObjectMapper initialValue() return new ObjectMapper(); > >; Но теперь, за счёт замыканий, стало проще:
// Java 8 ThreadLocalObjectMapper> mapper = withInitial(() -> new ObjectMapper()); Files.lines()/readAllLines()/BufferedReader.lines() Link to heading
В Java 8 стало возможным гораздо проще выполнить такую простую задачу как прочитать построчно файл. Это ещё одна задача, которая раньше требовала довольно много кода. Теперь так:
Минутка зануды. Метод возвращающий арифметическое среднее в классах SummaryStatistics называется getAverage() , хотя более точным было бы имя getMean() . Термин mean описывает именно арифметическое среднее, в то время как термин average относится к понятию среднего значения в целом и может относится к любой мере центральной тенденции (арифметическое среднее, медиана, геометрическое среднее, мода и т.д.). Примечательно, что даже в документации к методу getAverage() фигурирует именно понятие mean: “Returns the arithmetic mean of values recorded”.
// на входе файл в формате "одна строка - одно число" // раcсчитываем среднее всех чисел int mean = lines(new File("file").toPath()) .mapToInt(Integer::parseInt) .summaryStatistics() .getAverage(); Аналогичный метод был добавлен в класс BufferedReader , поэтому теперь Stream’ы доступны поверх любого InputStream ‘а.
Парадокс Comparator’а Link to heading
Допустим вам надо написать имплементацию Comparator ‘а для сортировки объектов по-возрастанию. Обычно, компаратор выглядит следующим образом:
public class ByScoreComparator implements ComparatorUser> @Override public int compare(User u1, User u2) return (int) signum(o2.getAge() - o1.getAge()); > > Вопрос лишь в том, что от чего надо отнимать, чтобы получить верный порядок сортировки? Наука говорит, что если вы будете выбирать вариант случайно, то угадаете примерно в половине случаев. В конце концов, варианта всего два: или от u2 отнять u1 или наоборот.
Парадокс заключается в том, что написать компаратор правильно с первого раза не получается практически никогда. Заканчивается всё всегда одинаково, — флегматичным замечанием: “Ах да, я же тут отнял неверно!”.
Благо, теперь это и не требуется. Компаратор можно собрать из говна и палок, а точнее из ссылок на методы, которые возвращают Comparable типы или примитивы по которым мы хотим сортировать.
ComparatorUser> comparator = Comparator .comparingDouble(User::getAge) .thenComparing(User::getName); ListUser> hList = . ; hList.sort(comparator); PrimitiveIterator Link to heading
Одно из ограничений Java предыдущих версий заключалось в том, что в них не было стандартных итераторов над примитивными типами. Только над ссылочными. Теперь таковые появились в виде интерфейса PrimitiveIterator , а также его наследников: PrimitiveIterator.Of[Int|Long|Double] . Вместе с функциональными интерфейсами над примитивными типами это дает хорошую основу для работы с коллекциями примитивных типов без autobox’а.
List.replaceAll() Link to heading
Довольно удобный метод, который позволяет модифицировать все элементы списка. Если вы хотите список строк привести к нижнему регистру, раньше надо было писать что-то вроде:
ListString> list = . ; for (int i = 0; i list.size(); i++) list.set(i, list.get(i).toLowerCase()); Или более продвинутый вариант:
ListIteratorString> i = list.listIterator(); while (i.hasNext()) li.set(i.next().toLowerCase()); Сейчас же можно сделать следующим образом:
list.replaceAll(String::toLowerCase); Random.ints() Link to heading
Ещё одна возможность, о которой практически нет упоминаний, — это то что Random может создавать Stream ‘ы случайных чисел нужного типа и диапазона:
// Выведет 10 случайных числел от 20 до 100 new Random().ints(10, 20, 100).forEach(System.out::println); Есть методы для создания double ‘ов ( doubles() ) и long ‘ов ( longs() ).
LongAccumulator/LongAdder Link to heading
Два класса, которые представляют собой более производительные замены для AtomicLong . Класс LongAdder позволяет выполнять атомарные арифметические операции над типом long . LongAccumulator принимает произвольную функцию аккумуляции результатов. Эта функция принимает текущее значение, аргумент переданный в метод accumulate() и возвращает результат логического объединения (accumulate) двух значений.
// ранвосильно new LongAdder() LongAccumulator a = new LongAccumulator((a, b) -> a + b, 0); a.accumulate(1); a.accumulate(2); a.accumulate(3); a.accumulate(4); a.longValue(); // 10 При получении результата все элементы редуцируются в один общий результат. Вся эта кухня намекает нам, что функция аккумуляции должна быть коммутативна и ассоциативна. В противном случае результат будет зависеть от физического порядка выполнения операций, который данный класс не гарантирует.
При высоком contention’е два данных класса будут быстрее AtomicLong ‘а за счёт того, что операции выполняются не над общим элементом, а над группой элементов по отдельности. Благодаря чему, “гусары не подерутся из-за женщин”.
Аналогичная пара классов есть для типа Double ( DoubleAdder , DoubleAccumulator ).
Java Flight Recorder Link to heading
Последнее по порядку, но не по важности, — это новые инструменты диагностики, которые предоставила Oracle в Java 8. А именно, Java Flight Recorder. Технически JFR появился в версии 7u40, но это настолько важный инструмент, что не упомянуть о нем я не могу.
Flight Recorder представляет собой инструментарий встроенный в JVM для сбора и диагностики самой виртуальной машины, а также приложений запущенных на ней. Запускается он командой jmc . У JFR есть несколько интересных особенностей:
- в зависимости от профиля собираемой информации, издержки на работу JFR могут быть очень низкими (менее 1% по утверждению Oracle, при конфигурации по-умолчанию). Это позволяет использовать этот инструмент в “боевых условиях” и под нагрузкой;
- JFR, в отличии от инструментов вроде VisualVM, может вести постоянную запись диагностической информации в ring buffer, и имеет настраиваемые политики dump’а информации на диск. Это позволяет настроить виртуальную машину таким образом, чтобы она постоянно вела диагностический лог, а сохраняла его только в случае возникновения проблем (например, при систематической нехватке CPU). Такой подход позволяет получать “черные ящики” описывающие состояние виртуальной машины и приложения непосредственно в момент проявления проблемы. До JFR единственный способ локализовать проблему был, — поймать её на production’е что называется “за руку”.
Какую информацию может собирать JFR? Её очень много, основные моменты, которые я считаю полезными:
- результаты семплинга кода (какие классы и методы заняли больше всего процессорного времени, в каких потоках);
- информация по всем GC циклам (сколько памяти было высвобождено, сколько времени заняла каждая сборка мусора);
- информация по аллокации памяти (из какого потока, класса и метода было выделено больше всего памяти, под какой тип данных выделяли больше всего памяти, скорость выделения по времени);
- информация по сетевому и дисковому вводу/выводу;
- какие Exception’ы и Error’ы были сгенерированы приложением;
- профиль блокировки потоков (какие потоки чаще всего блокируются, на каких локах/мониторах, какие потоки на момент блокировки владеют этими локами/мониторами чаще всего).
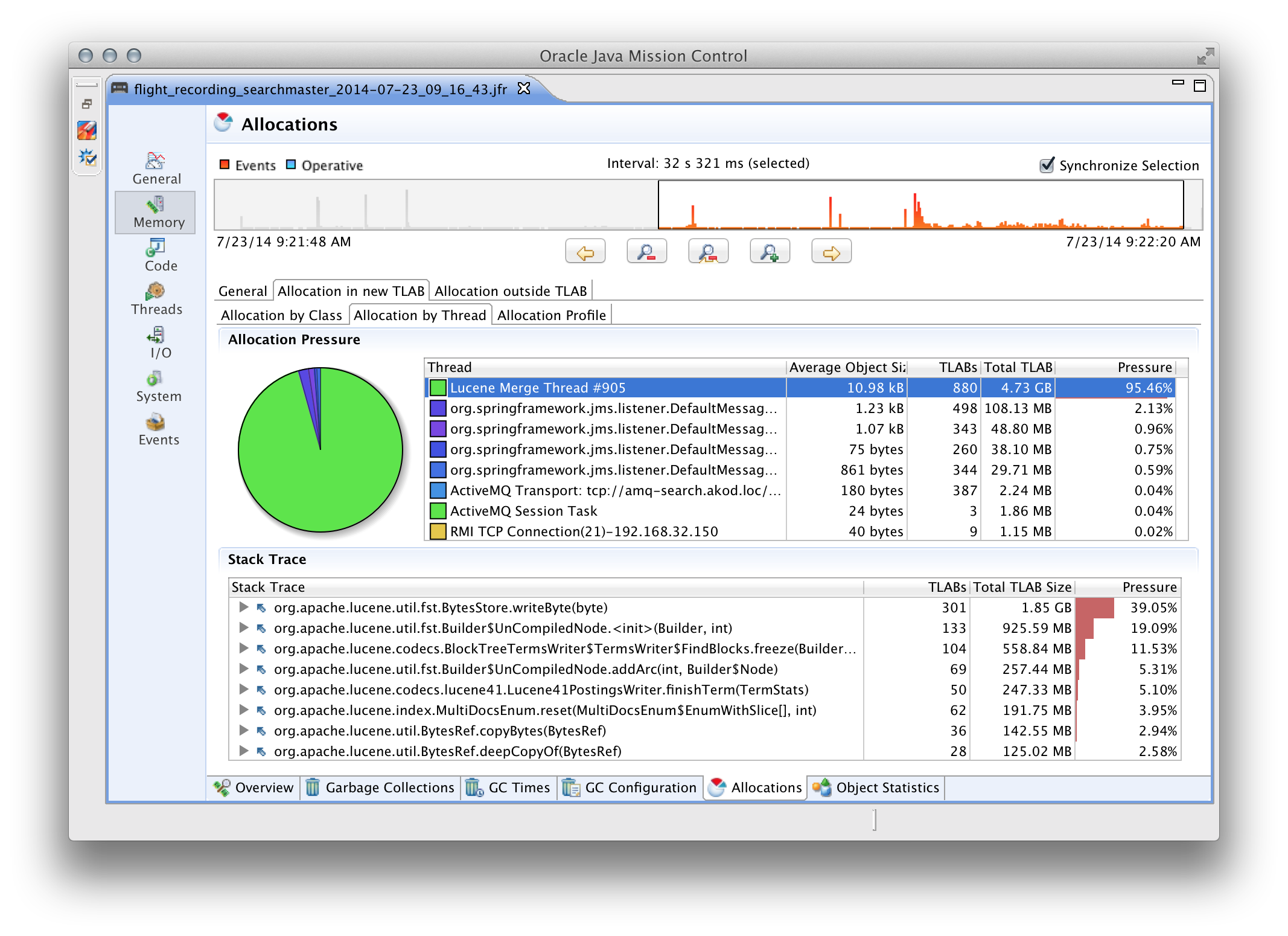
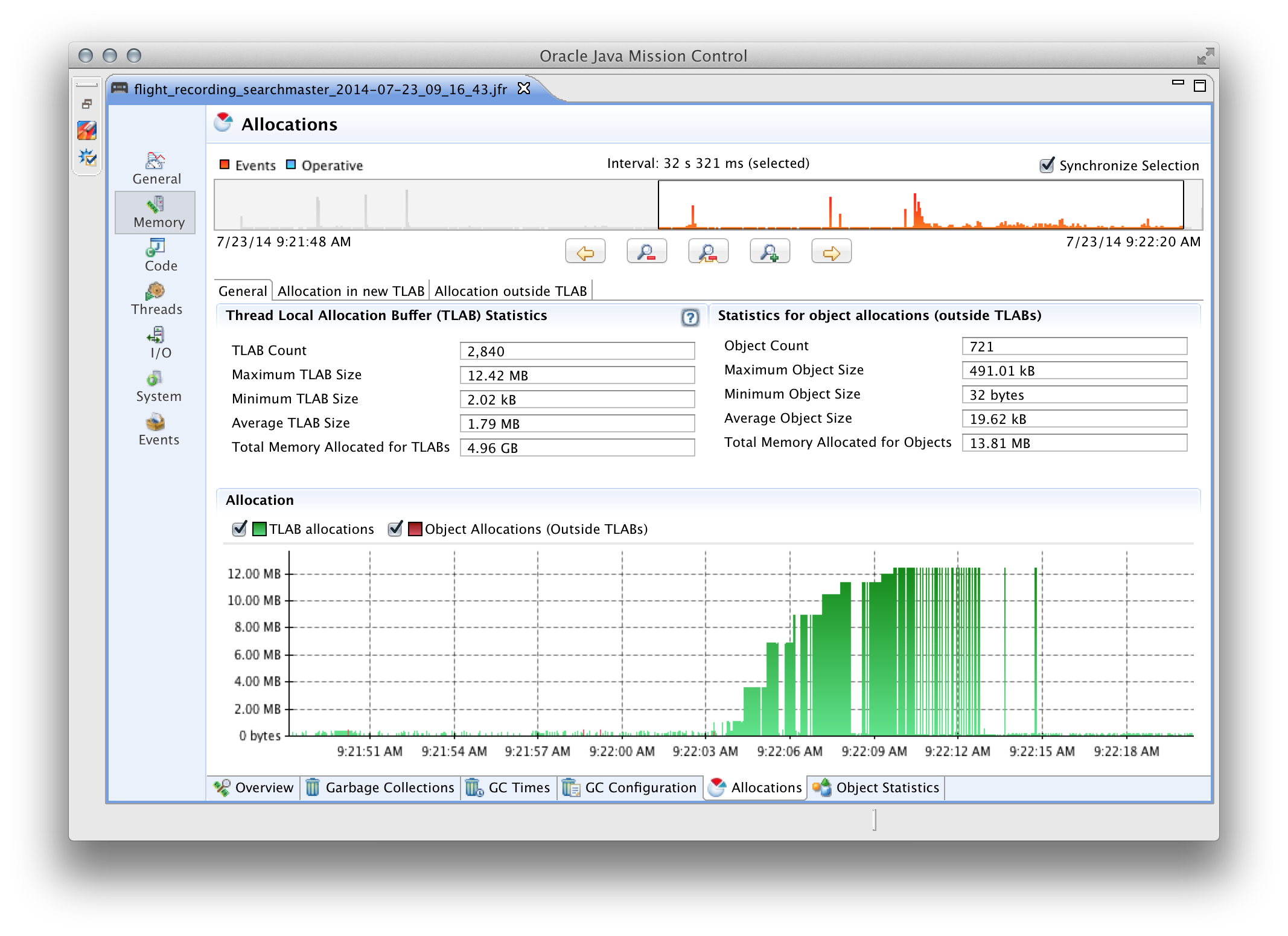
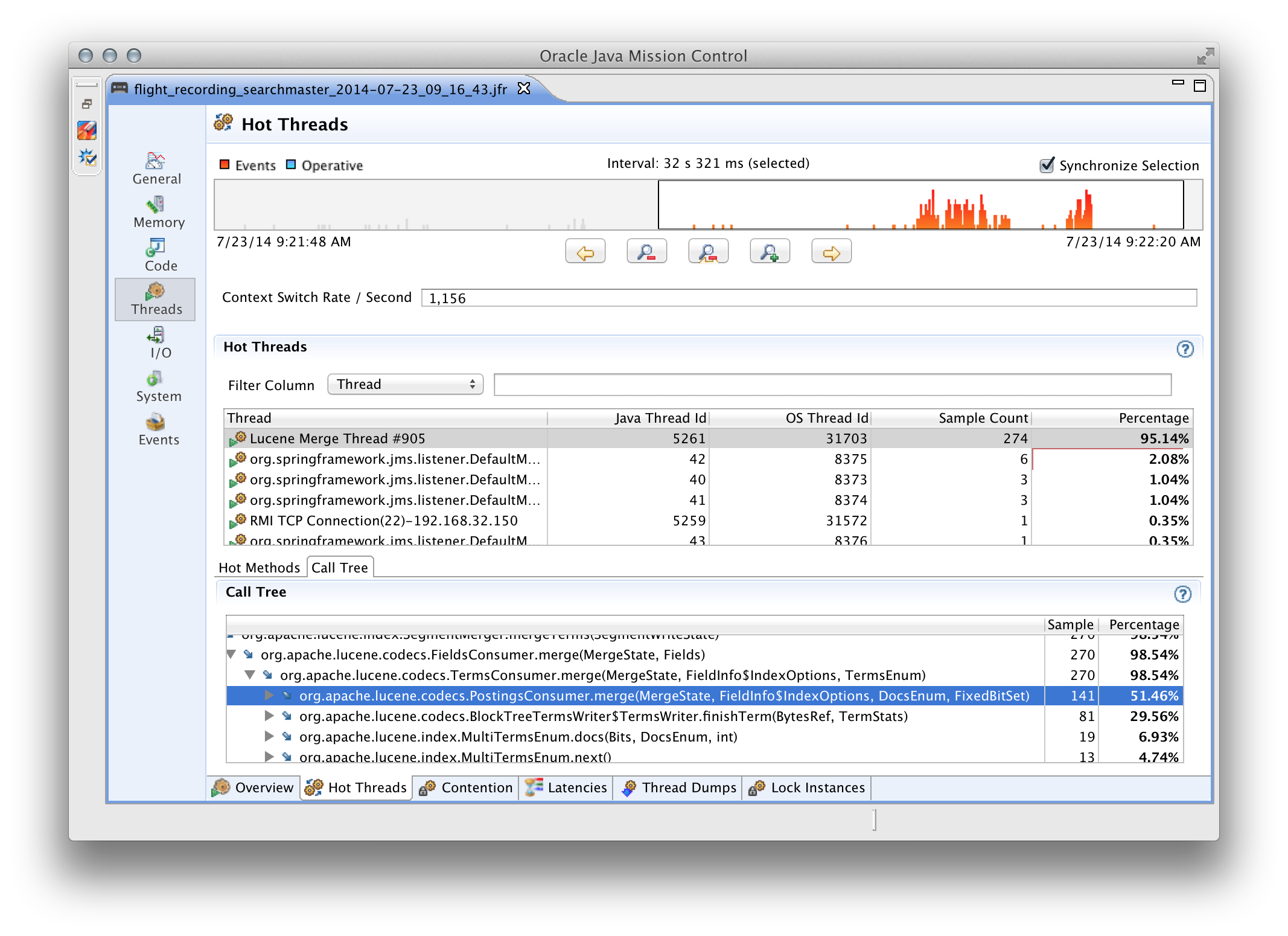
Список можно было бы продолжить, но в рамках этого поста я не смогу достаточно полно описать JFR. Поэтому, всем заинтересованым лицам настоятельно рекомендую потратить время на изучение этого крайне полезного инструмента.
Заключение Link to heading
Реальный список гораздо больше. Если вам интересно что ещё добавили в Java 8, я настоятельно рекомендую поискать по стандартной библиотеке Java следующим regexp’ом: @since\s+1.8\s*\n . Вы найдете более 1000 вхождений. Ни один блог пост этого не покроет.
Оставляйте в комментариях, какие из фич Java 8 вы используете чаще всего.
#Назаметку. Осторожно, атомарные операции в ConcurrentHashMap
В Java с незапямятных времён есть замечательный интерфейс Map и его имплементации, в частности, HashMap. А начиная с Java 5 есть ещё и ConcurrentHashMap. Рассмотрим эти две реализации, их эволюцию и то, к чему эта эволюция может привести невнимательных разработчиков.
Warning: в статье использованы цитаты исходного кода OpenJDK 8, распространяемого под лицензией GNU General Public License version 2.
Времена до Java 8
Те, кто застал времена долгого-долгого ожидания сначала Java 7, а потом и Java 8 (не то что сейчас, каждые полгода новая версия), помнят, какие операции с Map были самыми востребованными. Это:
- V Map.put(K key, V value)
- V Map.get(Object key)
Но что делать, если требуется «ленивая» инициализация? Тогда появлялся код такого вида:
String getOrPut(String key) < String result = map.get(key); //(1) if (result == null) < //(2) result = createValue(key); //(3) map.put(key, result); //(4) >return result; > - получаем значение по ключу
- проверяем, найдено ли искомое значение
- если значения не обнаружено, то создаём его
- добавляем значение в коллекцию по ключу
До прихода Java 8 элегантных вариантов просто не было. Если требовалось увернуться от нескольких созданий значений, то приходилось использовать дополнительные блокировки.
С Java 8 всё стало проще. Казалось бы…
Java 8 к нам приходит…
Какая самая долгожданная фича пришла к нам с Java 8? Правильно, лямбды. И не просто лямбды, а их поддержка во всём разнообразии API стандартной библиотеки. Не обошли вниманием и структуры данных Map. В частности, там появились такие методы, как:
- computeIfAbsent
- computeIfPresent
- forEach
- и т.д.
String getOrPut(String key)
Понятно, что никто не откажется от возможности упростить свой код. Более того, в случае с ConcurrentHashMap метод computeIfAbsent ещё и выполняется атомарно. Т.е. createValue будет вызвано ровно один раз и только в том случае, если искомое значение будет отсутствовать.
IDE тоже не прошли мимо. Так IntelliJ IDEA предлагает автозамену старого варианта на новый:



Понятно, что и упрощение кода и подсказки от IDE стимулируют разработчиков использовать этот новый API. Как следствие тот же computeIfAbsent начал появляться в очень многих местах кода.
Пока…
Внезапно!
Пока не настала пора очередного нагрузочного тестирования. И тут обнаружилось страшное:

Приложение работало на следующей версии Java:
openjdk version "1.8.0_222" OpenJDK Runtime Environment (build 1.8.0_222-8u222-b10-1ubuntu1~18.04.1-b10) OpenJDK 64-Bit Server VM (build 25.222-b10, mixed mode)
Для тех, кто не знаком с таким замечательным инструментом, как YourKit.
На скриншоте горизонтальными широкими линиями отображается работа потоков приложения во времени. В зависимости от состояния потока в конкретный момент времени полоса раскрашивается в соответствующий цвет:
- жёлтый — поток бездействует, ожидая работы;
- зелёный — поток работает, выполняя програмный код;
- красный — данный поток заблокирован другим потоком.
Но постойте, как так? Ведь даже в документации к методу про блокировки говорится только в приложении к обновлению:
«If the specified key is not already associated with a value, attempts to compute its value using the given mapping function and enters it into this map unless null. The entire method invocation is performed atomically, so the function is applied at most once per key. Some attempted update operations on this map by other threads may be blocked while computation is in progress, so the computation should be short and simple, and must not attempt to update any other mappings of this map.»
На деле же получается всё не совсем так. Если заглянуть в исходный код этого метода, то получается, что он содержит два весьма толстых синхронизирующих блока:
Реализация ConcurrentHashMap.computeIfAbsent
public V computeIfAbsent(K key, Function mappingFunction) < if (key == null || mappingFunction == null) throw new NullPointerException(); int h = spread(key.hashCode()); V val = null; int binCount = 0; for (Node[] tab = table;;) < Nodef; int n, i, fh; if (tab == null || (n = tab.length) == 0) tab = initTable(); else if ((f = tabAt(tab, i = (n - 1) & h)) == null) < Noder = new ReservationNode(); synchronized (r) < if (casTabAt(tab, i, null, r)) < binCount = 1; Nodenode = null; try < if ((val = mappingFunction.apply(key)) != null) node = new Node(h, key, val, null); > finally < setTabAt(tab, i, node); >> > if (binCount != 0) break; > else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); else < boolean added = false; synchronized (f) < if (tabAt(tab, i) == f) < if (fh >= 0) < binCount = 1; for (Nodee = f;; ++binCount) < K ek; V ev; if (e.hash == h && ((ek = e.key) == key || (ek != null && key.equals(ek)))) < val = e.val; break; >Node pred = e; if ((e = e.next) == null) < if ((val = mappingFunction.apply(key)) != null) < added = true; pred.next = new Node(h, key, val, null); > break; > > > else if (f instanceof TreeBin) < binCount = 2; TreeBint = (TreeBin)f; TreeNode r, p; if ((r = t.root) != null && (p = r.findTreeNode(h, key, null)) != null) val = p.val; else if ((val = mappingFunction.apply(key)) != null) < added = true; t.putTreeVal(h, key, val); >> > > if (binCount != 0) < if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); if (!added) return val; break; > > > if (val != null) addCount(1L, binCount); return val; > Из приведённого примера видно, что результат может быть сформирован только в шести точках, и почти все эти места находятся внутри синхронизирующих блоков. Весьма неожиданно. Тем более, что простой get вообще не содержит синхронизации:
Реализация ConcurrentHashMap.get
public V get(Object key) < Node[] tab; Node e, p; int n, eh; K ek; int h = spread(key.hashCode()); if ((tab = table) != null && (n = tab.length) > 0 && (e = tabAt(tab, (n - 1) & h)) != null) < if ((eh = e.hash) == h) < if ((ek = e.key) == key || (ek != null && key.equals(ek))) return e.val; >else if (eh < 0) return (p = e.find(h, key)) != null ? p.val : null; while ((e = e.next) != null) < if (e.hash == h && ((ek = e.key) == key || (ek != null && key.equals(ek)))) return e.val; >> return null; > Так что же делать? По сути, есть только два варианта: или возвращаться к первоначальному коду, или использовать его же, но в чуть модифицированном варианте:
String getOrPut(String key)
Заключение
Вообще такие фатальные последствия от, казалось бы, банального рефакторинга оказались весьма неожиданными. Ситуацию спасло только наличие нагрузочного теста, который удачно выявил деградацию.
К счастью в более новых версиях Java эту проблему поправили: JDK-8161372.
Так что будьте бдительны, не доверяйте заманчивым подсказкам и пишите тесты. Особенно нагрузочные.
UPD1: как правильно заметили coldwind, проблема известна: JDK-8161372. И, вроде как, исправлялась для Java 9. Но при этом на момент публикации статьи и в Java 8, и в Java 11, и даже в Java 13 этот метод остался без изменений.
UPD2: vkovalchuk подловил меня на невнимательности. Действительно для Java 9 и более новых проблема исправлена добавлением ещё одного условия с возвращением результата без блокировки:
else if (fh == h // check first node without acquiring lock && ((fk = f.key) == key || (fk != null && key.equals(fk))) && (fv = f.val) != null) return fv;
Изначально я напаролся на ситуацию в следующей версии Java:
openjdk version "1.8.0_222" OpenJDK Runtime Environment (build 1.8.0_222-8u222-b10-1ubuntu1~18.04.1-b10) OpenJDK 64-Bit Server VM (build 25.222-b10, mixed mode)
А когда смотрел на исходники более поздних версий, то честно проморгал эти строки, что ввело меня в заблуждение.
Так что ради справедливости подправил основной текст статьи.
- Блог компании НПО Криста
- Программирование
- Java