Использование данных из кубов OLAP на языке R
olapR — это пакет R в Службах машинного обучения SQL Server, который позволяет выполнять запросы многомерных выражений для получения данных из кубов OLAP. При использовании этого пакета вам не нужно создавать связанные серверы или очищать плоские наборы строк; данные OLAP можно получать напрямую из R.
В этой статье описывается этот API, а также приводятся общие сведения об OLAP и многомерных выражениях для пользователей R, которые не знакомы с базами данных многомерных кубов.
Экземпляр Analysis Services может поддерживать либо стандартные многомерные кубы, либо табличные модели. Одновременная поддержка обоих типов моделей невозможна. Соответственно, прежде чем пытаться выполнить запрос многомерного выражения к кубу, убедитесь, что ваш экземпляр Analysis Services содержит многомерные модели.
Что представляет собой куб OLAP?
OLAP — это технология интерактивной аналитической обработки данных. Решения OLAP часто используются для сбора и хранения критически важных данных. Многие инструменты, панели мониторинга и визуализации используют данные OLAP для бизнес-аналитики. Дополнительные сведения см. в разделе Интерактивная аналитическая обработка.
Корпорация Майкрософт предлагает службы Analysis Services, с помощью которых вы можете разрабатывать, развертывать и запрашивать данные OLAP в форме кубов или табличных моделей. Куб — это многомерная база данных. Измерения аналогичны аспектам данных или факторам в R: с помощью измерений определяется конкретное подмножество данных, которые требуется суммировать или анализировать. Например, одним из важнейших измерений является время, в связи с чем в большинстве решений OLAP по умолчанию определено множество разных календарей, которые применяются при создании срезов и суммировании данных.
В целях оптимизации производительности в базе данных OLAP часто заранее рассчитываются сводки (или агрегаты), которые сохраняются для более быстрого извлечения в дальнейшем. Сводки основываются на мерах, представляющих формулы, которые могут применяться к числовым данным. Таким образом, с помощью измерения определяется подмножество данных, для которого затем вычисляется мера. Например, с помощью меры можно рассчитать общую сумму продаж определенной линейки продуктов за несколько кварталов за вычетом налогов, средние затраты на доставку для конкретного поставщика, общий объем выплат по заработной плате с начала года на текущую дату и т. д.
Для выполнения запросов к кубам используются многомерные выражения. Многомерное выражение как правило содержит определение данных, которое включает одно или несколько измерений и как минимум одну меру. Тем не менее, этим возможности таких выражений не ограничиваются, и они могут включать скользящие интервалы, совокупные средние значения, суммы, ранги или процентили.
Ниже приводятся некоторые другие термины, которые могут быть полезны при работе с многомерными выражениями:
- При создании срезов получается подмножество данных куба с использованием значений из одного измерения.
- Присегментировании создается вложенный куб посредством указания диапазона значений для нескольких измерений.
- Детализация позволяет перейти от сводки к подробностям.
- Подъем позволяет перейти от подробностей к более высокому уровню статистической обработки.
- Свертка дает сводные данные по данным в измерении.
- Сводка поворачивает куб или выбранные данные.
Создание запросов многомерных выражений с помощью olapR
В следующей статье подробно описывается синтаксис, используемый при создании или выполнении запросов к кубу:
API olapR
Пакет OlapR поддерживает два метода создания запросов многомерных выражений:
- Использование конструктора многомерных выражений. Использование функций R в пакете для создания простого запроса многомерного выражения посредством выбора куба и последующей настройки осей и срезов. Это простой способ создания допустимых запросов многомерных выражений при отсутствии доступа к традиционным средствам OLAP или нехватке опыта работы с языком многомерных выражений. Этот способ подходит не для всех запросов, поскольку многомерные выражения могут быть сложными. Тем не менее, этот API поддерживает большинство наиболее распространенных и полезных операций, включая срезы, сегментирование, детализацию, свертку и сводку в N измерениях.
- Копирование и вставка готового многомерного выражения. Вы можете вручную создать и затем вставить любой запрос многомерных выражений. Этот вариант является оптимальным, если существуют запросы многомерных выражений, которые вы хотите использовать повторно, или если вы хотите создать запрос, который слишком сложен для обработки в olapR. После создания многомерного выражения с помощью любой клиентской программы, например SSMS или Excel, сохраните строку запроса. Укажите эту строку многомерного выражения в качестве аргумента для обработчика запросов SSAS в пакете olapR. Поставщик отправит запрос на указанный сервер служб Analysis Services и передаст результаты в R.
Примеры создания запроса многомерных выражений или запуска существующего запроса см. в разделе Создание запросов многомерных выражений с помощью R.
Известные проблемы
В этом разделе представлены некоторые известные проблемы, а также часто задаваемые вопросы, связанные с пакетом olapR.
Поддержка табличных моделей
При подключении к экземпляру Analysis Services, который содержит табличную модель, функция explore сообщает об успешном выполнении операции и возвращает значение TRUE. Тем не менее, объекты табличной модели отличаются от многомерных, а структура многомерной базы данных отличается от структуры табличной модели.
В табличных моделях как правило используется язык DAX (выражения анализа данных), тем не менее вы можете создавать допустимые запросы многомерных выражений к табличной модели, если вы уже знакомы с такими выражениями. Для построения допустимых запросов многомерных выражений к табличной модели нельзя использовать конструкторы olapR.
Извлечение данных из табличной модели с помощью запросов многомерных выражений неэффективно. Если вам необходимо получить данные из табличной модели для использования в R, рассмотрите следующие способы:
- Активируйте DirectQuery для модели и добавьте сервер в качестве связанного сервера в SQL Server.
- Если табличная модель построена на основе реляционного киоска данных, получите данные непосредственно из источника.
Как определить, содержит ли экземпляр табличные или многомерные модели?
Один экземпляр служб Analysis Services может содержать несколько моделей, но все они должны быть одного типа. Это связано с принципиальными различиями в способах хранения и обработки данных между табличными и многомерными моделями. Например, табличные модели хранятся в памяти и используют индексы columnstore для максимального ускорения вычислений. В многомерных моделях данные хранятся на диске, а агрегаты определяются заранее и извлекаются с использованием запросов многомерных выражений.
При подключении к Analysis Services с помощью клиента, такого как SQL Server Management Studio, вы можете определить поддерживаемый тип модели по значку базы данных.
Также для определения типа модели, который поддерживает экземпляр, можно просмотреть и запросить свойства сервера. Свойство Режим сервера поддерживает два значения: Многомерный и Табличный.
Общие сведения об этих типах моделей см. в следующей статье:
Дополнительные сведения о запросе свойств сервера см. в следующей статье:
Обратная запись не поддерживается
Запись результатов пользовательских вычислений R в куб невозможна.
В общем случае, даже если куб допускает обратную запись, поддерживаются только некоторые операции и при этом может потребоваться дополнительная настройка. Для таких операций рекомендуется использовать многомерные выражения.
- Измерения, доступные для записи
- Секции, доступные для записи
- Настраиваемый доступ к данным ячейки
Долго выполняющиеся запросы многомерных выражений, блокирующие процессы обработки куба
Несмотря на то, что пакет olapR осуществляет только операции чтения, долго выполняющиеся запросы многомерных выражений могут создавать блокировки, препятствующие процессам обработки куба. Всегда заранее тестируйте свои запросы многомерных выражений, чтобы точно знать возвращаемый ими объем данных.
При попытке подключиться к заблокированному кубу вы можете получить сообщение об ошибке, связанной с недоступностью хранилища данных SQL Server. В таком случае вы можете включить удаленные подключения, проверить имя экземпляра сервера и попробовать другие способы. Тем не менее, рекомендуется проверить наличие ранее открытых подключений.
Администратор SSAS может предотвращать связанные с блокировкой проблемы, определяя и завершая открытые сеансы. Также на уровне сервера к запросам многомерных выражений можно применить свойство, задающее время ожидания. Это позволит при необходимости принудительно завершать долго выполняющиеся запросы.
Ресурсы
Если вы впервые сталкиваетесь с OLAP или запросами многомерных выражений, см. следующие статьи в Википедии:
- Кубы OLAP
- Запросы многомерных выражений
Библиотека python для работы с ssas
Есть библиотека olap.xmla на PyPI, вот достаточно подробный пример её применения.
Помимо этого есть вариант использования IronPython и соответствующих DLL, небольшой пример можно посмотреть здесь.
Отслеживать
ответ дан 25 мая 2019 в 7:24
9,848 5 5 золотых знаков 29 29 серебряных знаков 58 58 бронзовых знаков
- python
- python-3.x
- olap
- ssas
-
Важное на Мете
Похожие
Подписаться на ленту
Лента вопроса
Для подписки на ленту скопируйте и вставьте эту ссылку в вашу программу для чтения RSS.
Дизайн сайта / логотип © 2024 Stack Exchange Inc; пользовательские материалы лицензированы в соответствии с CC BY-SA . rev 2024.1.3.2953
Нажимая «Принять все файлы cookie» вы соглашаетесь, что Stack Exchange может хранить файлы cookie на вашем устройстве и раскрывать информацию в соответствии с нашей Политикой в отношении файлов cookie.
Организация OLAP куба средствами Python
Добрый день, уважаемые читатели. Сегодня я расскажу вам о том, как можно построить простенькую систему анализа данных на Python. В этом мне помогут framework cubes и пакет cubesviewer .
Сubes представляет собой framework’ом для работы с многомерными данными с помощью Python. Кроме того он включает в себя OLAP HTTP-сервер для упрощенной разработки приложений отчетности и общего просмотра данных.
Сubesviewer представляет собой web-интерфейс для работы с вышеуказанным сервером.
Установка и настройка cubes
Для начала надо установить библиотеки, необходимые для работы пакета:
pip install pytz python-dateutil jsonschema pip install sqlalchemy flask Далее устанавливаем сам пакет cubes :
pip install cubes Как показала практика, лучше использовать версию (1.0alpha2) из текущего репозитория .
Доп настройки под windows
Если вы планируете работать под Windows необходимо в файле PYTHON_DIR\Lib\site-packages\dateutil\tz.py заменить 40 строку:
return myfunc(*args, **kwargs).encode() return myfunc(*args, **kwargs) Затем, вне зависимости от платформы на которой вы работаете, нужно добавить следующий fix для корректной работы json-парсера. Вносить его надо в PYTHON_DIR\Lib\site-packages\cubes-1.0alpha-py2.7.egg\cubes\metadata.py начиная с 90 строки:
# TODO: same hack as in _json_from_url return read_model_metadata_bundle(source)
Описание настройки куба и процесс его разворачивания
Для примера возьмем OLAP-куб, который идет в поставке с cubes . Он находится в папке examples/hello_world (ее можно взять с репозитория). Наибольший интерес для нас представляют 2 файла:
- slicer.ini — файл настроек http сервера нашего куба
- model.json — файл с описание модели куба
Остановимся на них поподробнее. Начнем с файла slicer.ini , который может включать следующие разделы:
- [workspace] – конфигурация рабочего места
- [server] — параметры сервера (адрес, порт и тд.)
- [models] — список моделей для загрузки
- [datastore] или [store] – параметры хранилища данных
- [translations] — настройки локализации для модели.
Итак разберем из нашего тестового файла видно, что сервер будет располагаться на локальной машине и будет работать по 5000 порту. В качестве хранилища будет использоваться локальная база SQLite под названием data.sqlite.
Подробнее о конфигурировании сервера можно прочитать в документации. Также из файла видно, что описание модели нашего куба находиться в файле model.json , описание структуры которого мы сейчас и займемся. Файл описания модели, это json -файл, который включает следующие логические разделы:
- name – имя модели
- label – метка
- description – описание модели
- locale – локаль для модели (если задана локализация)
- cubes – список метаданных кубов
- dimensions – список метаданных измерений
- public_dimensions – список доступных измерений. По умолчанию все измерения доступны.
Для нас представляют интерес разделы cubes и dimensions , т.к. все остальные опциональны. Элемент списка dimensions , содержит следующие метаданные:
Элемент списка cubes , содержит следующие метаданные:
Исходя из выше описанного, можно понять, что у нас в модели в будет 2 измерения ( item, year ). У измерения “ item ” 3 уровня измерений:
- category . Отображаемое имя “Category”, поля “category”, “category_label”
- subcategory . Отображаемое имя “Sub-category”, поля “subcategory”, “subcategory_label”
- line_item . Отображаемое имя “Line Item”, поле “line_item”
В качестве меры в нашем кубе будет выступать поле “amount” , для которой выполняются функции суммы и подсчета кол-ва строк. Подробнее о разметке модели куба можно почитать в документации После того, как мы разобрались с настройками, надо создать нашу тестовую базу. Для того, чтобы это сделать, необходимо запустить скрипт prepare_data.py :
python prepare_data.py Теперь осталось только запустить наш тестовый сервер с кубом, который называется slicer :
slicer serve slicer.ini После этого можно проверить работоспособность нашего куба. Для этого в строке браузера можно ввести: http://localhost:5000/cube/irbd_balance/aggregate?drilldown=year В ответ мы получим json-объект с результатом агрегации наших данных. Подробнее о формате ответа сервера можно почитать тут .
Установка cubesviewer
Когда мы настроили наш куб, можно приступить к установке сubesviewer . Для этого надо скопировать репозиторий себе на диск:
git clone https://github.com/nonsleepr/cubesviewer.git А потом просто переместить содержимое папки /src в нужный место.
Надо отметить, что сubesviewer является Django-приложением, поэтому для его работы необходим Django (не выше версии 1.4) , а также пакеты requests и django-piston . Т.к. данная версия Django уже устарела, то выше я привел ссылку откуда можно взять сubesviewer для версии Django 1.6.
Установка ее немного отличается от оригинала тем, что в файл конфигурации сервера slicer.ini в раздел [server] нужно добавить строку allow_cors_origin: http://localhost:8000
После этого надо настроить приложение в файле CUBESVIEWER_DIR/web/cvapp/settings.py . Указав ему настройки БД, адрес OLAP сервера (переменная CUBESVIEWER_CUBES_URL ) и адрес просмоторщика ( CUBESVIEWER_BACKEND_URL )
Осталось внести небольшой fix в dajno-piston
Теперь можно синхронизировать наше приложение с БД. Для этого из CUBESVIEWER_DIR/web/cvapp нужно выполнить:
python manage.py syncdb Осталось запустить локальный сервер Django
python manage.py runserver Теперь осталось зайти на указанный в CUBESVIEWER_BACKEND_URL адрес через браузер. И наслаждаться готовым результатом.
Заключение
Для иллюстрации работы я взял самый простой пример. Надо отметить что для производственных проектов cubes можно развернуть например на apache или uswgi . Ну а подключить к нему сubesviewer с помощью этой статьи не составит труда.
Если тема будет интересна сообществу, то я раскрою ее в одной из будущих статей.
Как создать Minecraft на Python? Обзор библиотеки Ursina Engine
В статье делимся основами работы с библиотекой Ursina Engine и показываем, как с помощью нее создать мир из кубов.

Среди любителей Minecraft много энтузиастов: пока одни просто играют, другие запускают целые серверы и пишут модификации. А кто-то идет дальше и разрабатывает собственные песочницы. Последнее достаточно просто сделать на Python.
В статье делимся основами работы с библиотекой Ursina Engine и показываем, как с помощью нее создать мир из кубов.
Пояснения внутри кодовых вставок — неотъемлемая часть статьи. Обращайтесь к ним, если что-то непонятно.
Первый чанк: основные элементы библиотеки
Ursina Engine — это полноценный движок под Windows, Linux и Mac, написанный на Panda3D, Pillow и Pyperclip. Его можно использовать для создания 2D- и 3D-игр. В комплекте библиотеки — готовые шейдеры, геометрические примитивы и анимации.
Движок будто консолидирует рутинную работу: разработчику нужно просто импортировать необходимые объекты и проработать логику игры.
# Инициализация окна игры from ursina import * app = Ursina() # здесь будет описана игровая логика app.run()Игровая сцена и наблюдатель: объекты типов Entity, FirstPersonController
Дисклеймер: Все, что описано в этом подразделе, лучше использовать для сцен с небольшим количеством объектов. Для более сложных полигонов генерацию нужно оптимизировать — об этом подробнее в следующих разделах. Но пропускать этот блок не советую: здесь объясняю принцип работы с ключевыми элементами библиотеки.
Для наполнения карты нужно использовать объект Entity. По сути, на базе него построены все внутриигровые сущности. Это могут быть как объекты игровой сцены — геометрические примитивы вроде кубов, сфер, квадратов и другого, так и, например, модели мобов.
# Генерация платформы 16x16 из блоков типа Entity. . app = Ursina() # создаем объекты модели cube, с текстурой white_cube и заданными координатами for x in range(16): for z in range(16): Entity(model="cube", texture="white_cube", position=Vec3(x,0,z)) app.run()После запуска программы на экране появится двумерная картинка. Чтобы увидеть площадку из блоков в 3D, нужно добавить наблюдателя. Это можно сделать с помощью встроенного объекта FirstPersonController.
# Активация FirstPersonController # импортируем объект from ursina.prefabs.first_person_controller import FirstPersonController . # добавляем персонажа player = FirstPersonController() # активируем невесомость, чтобы персонаж не упал в пустоту player.gravity = 0.0 app.run() . После запуска программы вы увидите простую площадку из блоков. И хоть пока что она выглядит скучно, по ней уже можно перемещаться.

По умолчанию персонажем можно управлять с помощью мышки и кнопок W, A, S, D. Но есть «фича»: если переключиться на русскую раскладку, то при нажатии кнопки сработает исключение TypeError. Поэтому лучше добавить автоматическое переключение раскладки при запуске программы — например, с помощью win32api.
Текстурирование и кастомные объекты
Кроме встроенных текстур и моделей, Ursina Engine позволяет добавлять собственные. Примеры таких кастомных объектов ищите в репозитории на GitHub.
Текстурирование блоков. Первым делом, мне кажется, лучше добавить и текстурировать блоки. Для этого нужно сделать Blender-модель, заготовить текстуру и импортировать объект в программу.
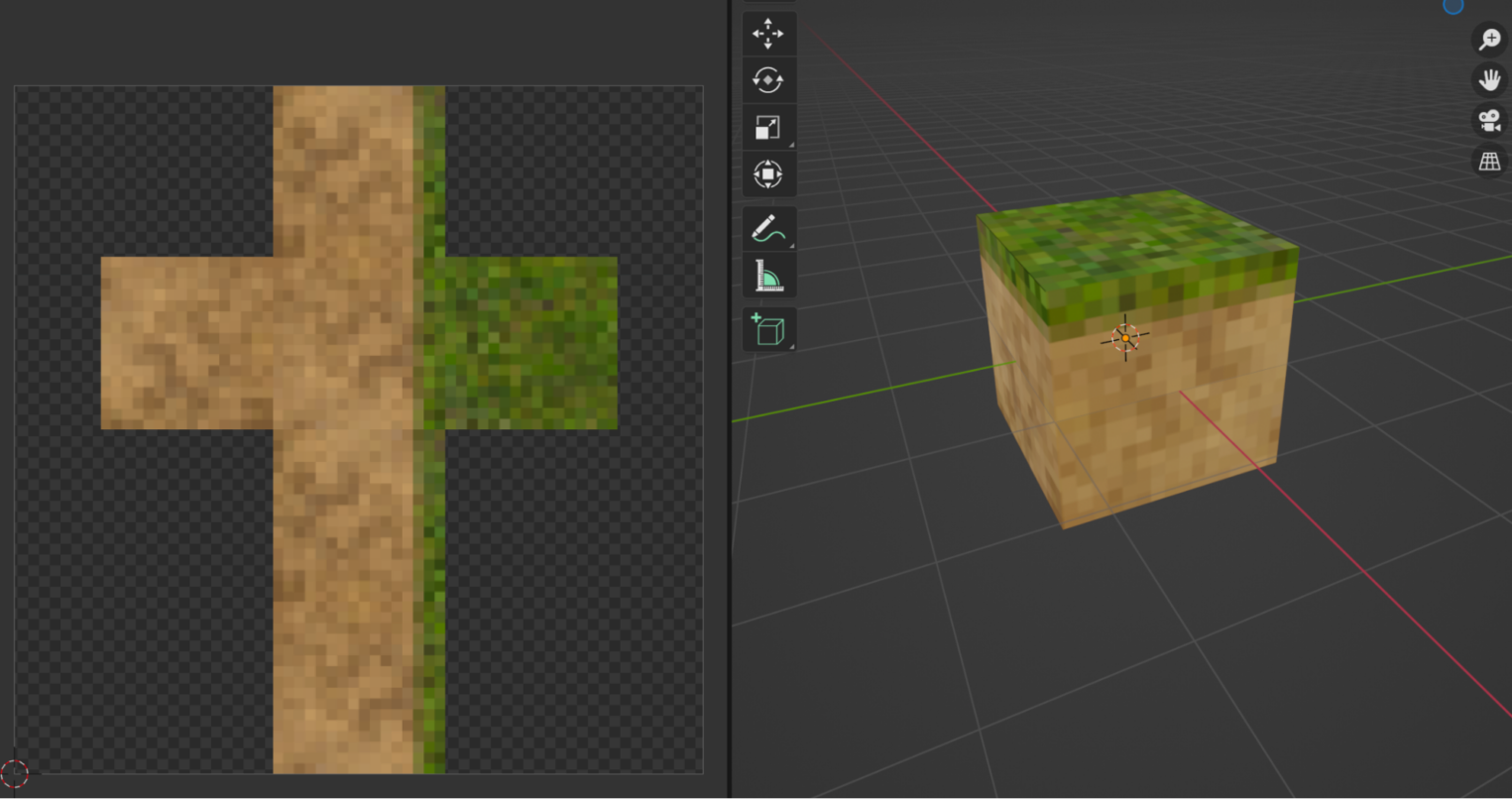
# Загрузка кастомного объекта block . # загружаем текстуру grass_texture = load_texture('assets/grass.png') for x_dynamic in range(16): for z_dynamic in range(16): # настраиваем объект Entity, загружаем модель block.obj Entity(model='assets/block', scale=0.5, texture=grass_texture, position=Vec3(x_dynamic,0,z_dynamic)) . После запуска программы вы увидите что-то похожее на оригинальную игру.

Текстурирование персонажа. Аналогичным образом можно добавить ту же руку персонажа. Сначала — заготовить текстуру для Blender-модели, а после — импортировать ее в программу через объект Entity. Чтобы закрепить руку рядом с камерой персонажа, нужно «подогнать» параметры — позицию и наклон.
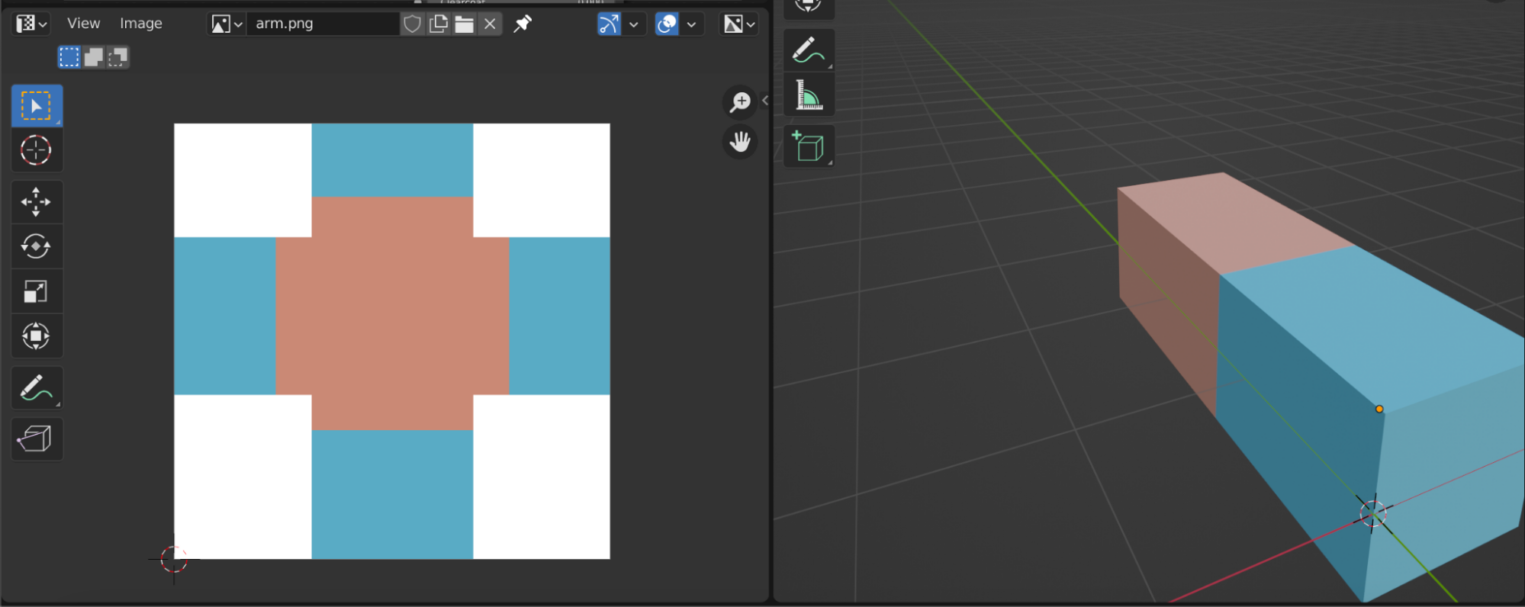
# Загрузка кастомного объекта hand . # загружаем текстуру руки arm_texture = load_texture('assets/arm_texture.png') # объявляем объект hand, привязываем к камере camera.ui, загружаем модель и размещаем ее в правом нижнем углу hand = Entity(parent = camera.ui, model = 'assets/arm', texture = arm_texture, scale = 0.2, rotation = Vec3(150, -10,0), position = Vec2(0.5,-0.6)) . 
Текстурирование неба. С помощью Entity также можно добавить небо — для этого нужно создать модель сферы и наложить на нее текстуру.
# Добавление объекта sky . sky_texture = load_texture('assets/sky_texture.png') sky = Entity( model = 'sphere', texture = sky_texture, scale = 1000, double_sided = True ) . 
Для создания перехода изо дня в ночь можно использовать функцию update. Она в параллельном потоке программы способна отслеживать время, координаты и другие параметры, а также — модифицировать объекты «на лету».
# Пример: функция параллельного вывода координат . def update(): print(player.x, player.y, player.z) . Серверы Shared Line
Арендуйте виртуальные машины за меньшую цену.
Основы взаимодействия с объектами
До этого раздела мы генерировали сцену и наполняли ее основными объектами. Но как с ними взаимодействовать?
Мониторинг действий через функцию input
Сначала нужно научиться отслеживать нажатия клавиш — для этого подходит функция input. С помощью нее можно, например, добавить режим быстрого бега при клике на шифт.
# Программирование режима ускорения . def input(key): if key == 'o': # кнопка выхода из игры quit() if key == 'shift': # кнопка быстрого бега global shift_click if shift_click % 2 == 0: player.speed = normal_speed + 3 # увеличиваем скорость при нажатии shift_click += 1 else: player.speed = normal_speed shift_click += 1 . Также ее можно использовать для удаления и установки блоков при нажатии ЛКМ и ПКМ соответственно.
Включение блоков типа Button
Но не все блоки можно «разрушать». Для того, чтобы добавить в игру взаимодействие с миром, нужно использовать специальный объект Button. Он поддерживает функцию input и метод destroy, который нужен для уничтожения блоков.
# Генерация платформы 16x16 из блоков типа Button . # создаем новый класс на базе Button и задаем стартовые параметры class Voxel(Button): def __init__(self, position=(0, 0, 0), texture=grass_texture): super().__init__( parent=scene, model='assets/block', scale=0.5, texture=texture, position=position, origin_y=0.5, color = color.color(0,0,random.uniform(0.9,1)) ) # добавляем input — встроенную функцию взаимодействия с блоком Voxel: # если нажали на ПКМ — появится блок # если нажали на ЛКМ — удалится def input(self, key): if self.hovered: if key == 'right mouse down': Voxel(position=self.position + mouse.normal, texture=texture) if key == 'left mouse down': destroy(self) # генерация платформы из блоков Voxel for x_dynamic in range(16): for z_dynamic in range(16): Voxel(position=(x_dynamic,0,z_dynamic)) . 
Супер — вы научились строить землянку. Попробуйте переплюнуть постройку с картинки.
Проблема оптимизации
Кажется, что статья подошла к концу: ландшафт из блоков готов, работу с объектами и обработку событий освоили. Но есть проблема с оптимизацией. Попробуйте сгенерировать полигон площадью в 1000 блоков — и вы заметите, как стремительно падает FPS.
Это связано с тем, что движок не умеет «безболезненно» загружать большое количество объектов Entity и Button. Конечно, можно последовательно генерировать чанки и удалять старые. Но у этого метода есть пара минусов.
- Не гарантирует стабильную работу. Внутри одного чанка с горной местностью может быть больше блоков, чем в нескольких с пологой.
- FPS все равно страдает. Чтобы подгружать дополнительные чанки незаметно, перед персонажем должно быть несколько сотен блоков. Это значит, что фреймрейт все равно просядет.
Поэтому рассмотренная механика хорошо подходит для создания именно небольших карт. А для генерации «бесконечных» миров лучше использовать объекты типа Mesh.
Погружение в Mesh
Я бы не написал этот раздел, если бы не канал Red Hen dev. К слову, на нем уже больше года выходят видео по Ursina Engine. Сегодня это лучшая неофициальная документация. Поэтому если вы хотите углубиться, например, в процедурную генерацию мира из Mesh-блоков, переходите по ссылке.
Модель Mesh позволяет генерировать один логический объект и отрисовывать его по заданным координатам, когда как Entity создает в каждой точке новые объекты. Так Mesh потребляет меньше памяти и производительности GPU.
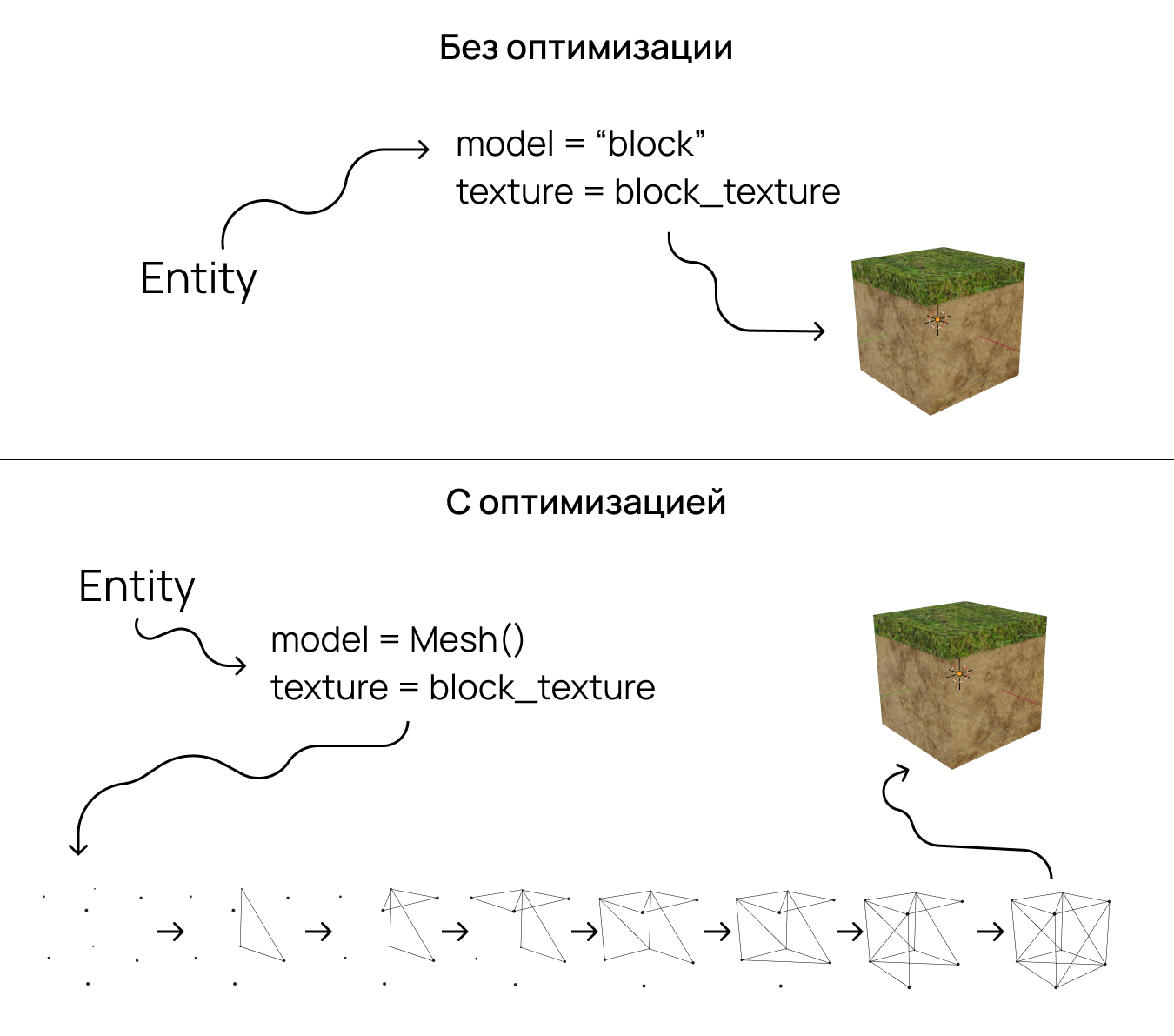
Однако с блоками типа Mesh работать сложнее. Сначала нужно создать объект Entity, загрузить модель Mesh, а после — «слепить» из нее прообраз Blender-объекта (блока). Посмотрите сами.
# Пример генерации площадки из блоков Mesh . # создаем объект Mesh e = Entity(model=Mesh(), texture=this.textureAtlas) # подгружаем конкретную ячейку из атласа текстур (с помощью масштабирования) # атлас текстур — это обычное изображение, в котором собраны текстуры разных блоков e.texture_scale *= 64/e.texture.width def genBlock(this, x, y, z): model = this.subsets[0].model uu = 8 uv = 7 model.uvs.extend([Vec2(uu, uv) + u for u in this.block.uvs]) def genTerrain(this): x = 0 z = 0 y = 0 o_width = int(this.subWidth*0.5) for x_dynamic in range(-o_width, o_width): for z_dynamic in range(-o_width, o_width): # обращаемся к genBlock(), генерируем блоки типа Mesh this.genBlock(x+x_dynamic, y, z+z_dynamic) this.subsets[0].model.generate() . Особенности Mesh
Генерация блоков Mesh — всего лишь одно из препятствий на пути к оптимизации. Есть и другие особенности, которые нужно учитывать.
- По умолчанию с Mesh-блоками нельзя взаимодействовать.
- Mesh-блоки не твердотельны.
Эти проблемы можно решить — например, написать собственные правила для удаления и установки блоков. Или управлять координатами персонажа таким образом, чтобы было ощущение перемещения по твердой поверхности.
Эти и другие решения уже есть — ищите их в GitHub-репозитории проекта Red Hen dev.
Генерация мира
Теперь, когда нет жестких ограничений на количество объектов внутри игровой сцены, можно сгенерировать Minecraft-подобный мир. Встроенные методы для этого не предусмотрены. Но есть простой способ — создать матрицу из шумов Перлина и последовательно «отрисовывать» ее внутри игры.
Матрица из шумов Перлина
Шум Перлина — это алгоритм процедурной генерации псевдослучайным методом. Механика такая: вы подаете на вход число seed, на базе которого генерируется текстура поверхности.
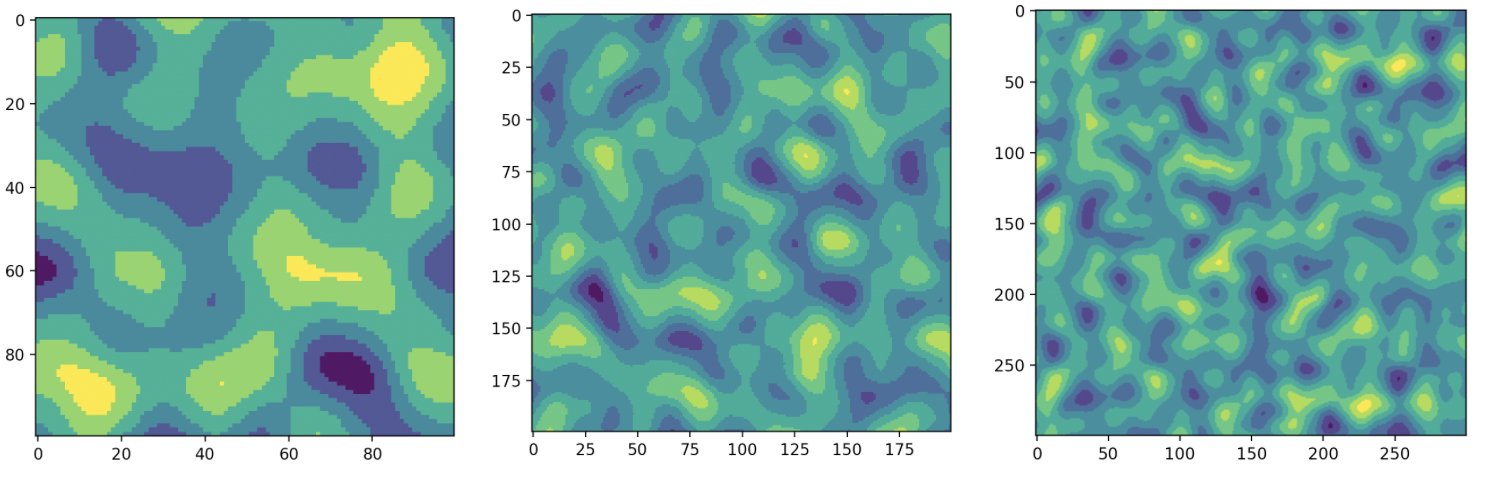
Если не менять внутренние параметры алгоритма, то при загрузке одного и того же значения seed шум будет одинаковым.
# Генерация «красивого» шума Перлина from numpy import floor from perlin_noise import PerlinNoise import matplotlib.pyplot as plt noise = PerlinNoise(octaves=2, seed=4522) amp = 6 freq = 24 terrain_width = 300 landscale = [[0 for i in range(terrain_width)] for i in range(terrain_width)] for position in range(terrain_width**2): x = floor(position / terrain_width) z = floor(position % terrain_width) y = floor(noise([x/freq, z/freq])*amp) landscale[int(x)][int(z)] = int(y) plt.imshow(landscale) plt.show()Генерация сложного ландшафта
По сути, шум Перлина формирует двумерный массив с плавными спадами и подъемами по координате y. Его достаточно просто перенести в игру.
# Генерация ландшафта . for x_dynamic in range(-o_width, o_width): for z_dynamic in range(-o_width, o_width): # генерация Mesh-блока в заданной точке, координату y берем из алгоритма Перлина this.genBlock(x+x_dynamic, this.landscale[x+x_dynamic][z+z_dynamic], z+z_dynamic) . Подобным образом возможно генерировать не только ландшафты, но и, например, шахты. Только в последнем случае используются черви Перлина. Подробнее о разных алгоритмах и принципах генерации мира можно узнать тут.

Элементы «атмосферы»: шейдеры и аудио
Игра до сих пор кажется плоской: ей не хватает музыки, звуков и чего-то «нового». Если другие блоки — песок, камень, дерево — добавить просто, то с анимированными объектами — например, водой — ситуация сложнее.
Добавление шейдеров
В Ursina Engine есть готовый набор шейдеров, которые можно импортировать из подмодуля ursina.shaders и подключить к нужным Entity-объектам. Это полезно, если нужно, например, показать объем объектов.
# Пример подключения шейдера from ursina.shaders import basic_lighting_shader . e = Entity(. shader = basic_lighting_shader) . Также к шейдерам можно причислить туманность, которая есть и в оригинальной игре. Она нужна, чтобы «сбить» фокус с дальних объектов.
# Добавление туманности . scene.fog_density=(0,95) # scene, как и window, тоже один из основных элементов библиотеки. Иногда его можно встретить в параметре наследования parent. Хотя, по моему опыту, его использование скорее опционально, чем обязательно. scene.fog_color=color.white . 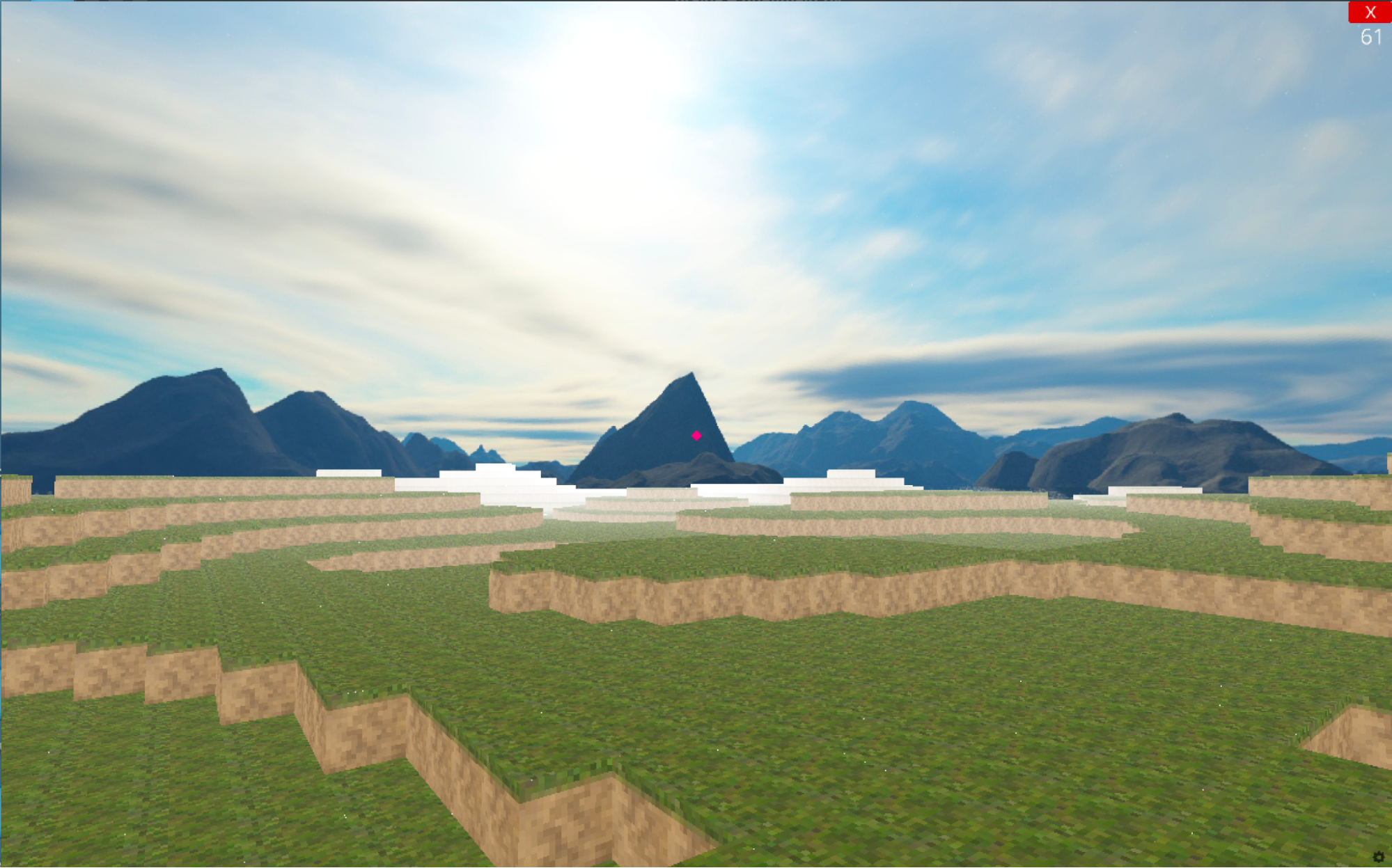
Ursina Lighting. В целом, это все, что нужно знать о встроенных шейдерах. Но есть аналог ursina.shaders — открытая библиотека Ursina Lighting. С помощью нее можно добавить даже воду.
# Подключение UrsinaLighting и добавление воды # импортируем основные объекты. Предварительно нужно развернуть репозиторий UrsinaLighting внутри своего проекта. from UrsinaLighting import LitObject, LitInit . # важно! нужно инициализировать главный объект. lit = LitInit() . # заполняем нижние уровни ландшафта водой (y = -1.1), создаем текстуру воды размером с ширину ландшафта. Проседать FPS не будет, тк water — это один объект, который просто «растянут» вдоль игровой сцены water = LitObject(position = (floor(terrain.subWidth/2), -1.1, floor(terrain.subWidth/2)), scale = terrain.subWidth, water = True, cubemapIntensity = 0.75, collider='box', texture_scale=(terrain.subWidth, terrain.subWidth), ambientStrength = 0.5) . 
Добавление звуков и музыки
Ursina Engine умеет воспроизводить аудиофайлы формата mp3 и wav. Так, например, можно добавить музыку C418 и разные звуки.
# Добавление музыки и звуков удара . punch_sound = Audio('assets/punch_sound',loop = False, autoplay = False) . class Voxel(Button): . def input(key): if key == 'left mouse down': punch_sound.play() . Меню игры: основные элементы GUI
На базе Entity делают не только 3D, но и полноценные графические интерфейсы. Логично, ведь все элементы GUI — это двумерные объекты, с которыми Ursina Engine также работает хорошо.
Движок поддерживает элементы типа Text и ButtonList. Последний автоматически создает кнопки и привязывает к ним функции, которые срабатывают при нажатии.
Ниже — пример программирования простого меню игры.
# Примитивный GUI на базе Ursina Engine # в отдельном файле menu.py from ursina import * app = Ursina(title='Minecraft-Menu') # создаем объект на базе Entity, настраиваем камеру и бэкграунд class MenuMenu(Entity): def __init__(self, **kwargs): super().__init__(parent=camera.ui, ignore_paused=True) self.main_menu = Entity(parent=self, enabled=True) self.background = Sky(model = "cube", double_sided = True, texture = Texture("textures/skybox.jpg"), rotation = (0, 90, 0)) # стартовая надпись Minecraft Text("Minecraft", parent = self.main_menu, y=0.4, x=0, origin=(0,0)) def switch(menu1, menu2): menu1.enable() menu2.disable() # вместо print_on_screen можно вписать lambda-функцию для запуска игры ButtonList(button_dict=< "Start": Func(print_on_screen,"You clicked on Start button!", position=(0,.2), origin=(0,0)), "Exit": Func(lambda: application.quit()) >,y=0,parent=self.main_menu) main_menu = MenuMenu() app.run()Смотрим, что получилось
Код из статьи доступен на GitHub. Делайте «форк» и используйте его в качестве референса, а также предлагайте свои улучшения.
Получившийся проект издалека напоминает ранние версии Minecraft. Хотя и превосходит их по качеству шейдеров и текстур.
На самом деле, это лишь небольшая доля того, что можно сделать на базе Ursina Engine. Энтузиасты со всего мира создают на этом движке шутеры, платформеры и другие игры. И это оправдано: время разработки на Ursina Engine меньше, чем на чистом OpenGL. А качество игры выше, чем на том же PyGame.
Но несмотря на позитивный результат, хочу отметить и негативные моменты в работе с библиотекой.
Проблемы Ursina Engine
Нет подробной документации. О назначении некоторых параметров остается только догадываться. Документация ограничивается небольшим лендингом и репозиторием с примерами. Последнего недостаточно, чтобы полностью понять механику работы с объектами.
«Сырая» кроссплатформенность. На MacOS трудно управлять камерой персонажа: курсор постоянно слетает, а иногда и вовсе не перемещается. Некоторые элементы из UrsinaLighting не поддерживаются. Это нужно учитывать, если вы разрабатываете полноценный проект.
Не хватает элементов. Например, взаимодействие с объектами типа Mesh нужно программировать самостоятельно.