Пишем API на Python (с Flask и RapidAPI)
Если вы читаете эту статью, вероятно, вы уже знакомы с возможностями, которые открываются при использовании API (Application Programming Interface).
Добавив в свое приложение один из многих открытых API, вы можете расширить функциональность этого приложения либо же дополнить его нужными данными. Но что, если вы разработали уникальную функцию, которой хотите поделиться с коммьюнити?
Ответ прост: нужно создать собственный API.
Несмотря на то, что это поначалу кажется сложной задачей, на самом деле всё просто. Мы расскажем, как это сделать с помощью Python.
Что нужно для начала работы
Для разработки API необходимы:
- Python 3;
- Flask — простой и легкий в использовании фреймворк для создания веб-приложений;
- Flask-RESTful — расширение для Flask, которое позволяет разработать REST API быстро и с минимальной настройкой.
pip install flask-restfulРекомендуем бесплатный интенсив по программированию для начинающих:
Разработка telegram-бота на C# — 26–28 августа. Бесплатный интенсив, который позволяет разобраться в том, как работают боты-помощники, в особенностях работы с API Telegram и прочих нюансах. Трое лучших участников получат от Skillbox 30 000 рублей.
Перед тем как начать
Мы собираемся разработать RESTful API с базовой CRUID-функциональностью.
Чтобы полностью понять задачу, давайте разберемся с двумя терминами, упомянутыми выше.
Что такое REST?
REST API (Representational State Transfer) — это API, которое использует HTTP-запросы для обмена данными.
REST API должны соответствовать определенным критериям:
- Архитектура клиент-сервер: клиент взаимодействует с пользовательским интерфейсом, а сервер — с бэкендом и хранилищем данных. Клиент и сервер независимы, любой из них может быть заменен отдельно от другого.
- Stateless — никакие клиентские данные не сохраняются на сервере. Состояние сеанса хранится на стороне клиента.
- Кэшируемость — клиенты могут кэшировать ответы сервера для улучшения общей производительности.
CRUD — концепция программирования, которая описывает четыре базовых действия (create, read, update и delete).
В REST API типы запросов и методы запроса отвечают за такие действия, как post, get, put, delete.
Теперь, когда мы разобрались с базовыми терминами, можно приступить к созданию API.
Разработка
Давайте создадим репозиторий цитат об искусственном интеллекте. ИИ — одна из наиболее активно развивающихся технологий сегодня, а Python — популярный инструмент для работы с ИИ.
С этим API разработчик Python сможет быстро получать информацию об ИИ и вдохновляться новыми достижениями. Если у разработчика есть ценные мысли по этой теме, он сможет добавлять их в репозиторий.
Начнем с импорта необходимых модулей и настройки Flask:
from flask import Flask from flask_restful import Api, Resource, reqparse import random app = Flask(__name__) api = Api(app)В этом сниппете Flask, Api и Resource — классы, которые нам нужны.
Reqparse — это интерфейс парсинга запросов Flask-RESTful… Также понадобится модуль random для отображения случайной цитаты.
Теперь мы создадим репозиторий цитат об ИИ.
Каждая запись репо будет содержать:
- цифровой ID;
- имя автора цитаты;
- цитату.
ai_quotes = [ < "id": 0, "author": "Kevin Kelly", "quote": "The business plans of the next 10,000 startups are easy to forecast: " + "Take X and add AI." >, < "id": 1, "author": "Stephen Hawking", "quote": "The development of full artificial intelligence could " + "spell the end of the human race… " + "It would take off on its own, and re-design " + "itself at an ever increasing rate. " + "Humans, who are limited by slow biological evolution, " + "couldn't compete, and would be superseded." >, < "id": 2, "author": "Claude Shannon", "quote": "I visualize a time when we will be to robots what " + "dogs are to humans, " + "and I’m rooting for the machines." >, < "id": 3, "author": "Elon Musk", "quote": "The pace of progress in artificial intelligence " + "(I’m not referring to narrow AI) " + "is incredibly fast. Unless you have direct " + "exposure to groups like Deepmind, " + "you have no idea how fast — it is growing " + "at a pace close to exponential. " + "The risk of something seriously dangerous " + "happening is in the five-year timeframe." + "10 years at most." >, < "id": 4, "author": "Geoffrey Hinton", "quote": "I have always been convinced that the only way " + "to get artificial intelligence to work " + "is to do the computation in a way similar to the human brain. " + "That is the goal I have been pursuing. We are making progress, " + "though we still have lots to learn about " + "how the brain actually works." >, < "id": 5, "author": "Pedro Domingos", "quote": "People worry that computers will " + "get too smart and take over the world, " + "but the real problem is that they're too stupid " + "and they've already taken over the world." >, < "id": 6, "author": "Alan Turing", "quote": "It seems probable that once the machine thinking " + "method had started, it would not take long " + "to outstrip our feeble powers… " + "They would be able to converse " + "with each other to sharpen their wits. " + "At some stage therefore, we should " + "have to expect the machines to take control." >, < "id": 7, "author": "Ray Kurzweil", "quote": "Artificial intelligence will reach " + "human levels by around 2029. " + "Follow that out further to, say, 2045, " + "we will have multiplied the intelligence, " + "the human biological machine intelligence " + "of our civilization a billion-fold." >, < "id": 8, "author": "Sebastian Thrun", "quote": "Nobody phrases it this way, but I think " + "that artificial intelligence " + "is almost a humanities discipline. It's really an attempt " + "to understand human intelligence and human cognition." >, < "id": 9, "author": "Andrew Ng", "quote": "We're making this analogy that AI is the new electricity." + "Electricity transformed industries: agriculture, " + "transportation, communication, manufacturing." >]Теперь нужно создать ресурсный класс Quote, который будет определять операции эндпоинтов нашего API. Внутри класса нужно заявить четыре метода: get, post, put, delete.
Начнем с метода GET
Он дает возможность получить определенную цитату путем указания ее ID или же случайную цитату, если ID не указан.
class Quote(Resource): def get(self, if 0: return random.choice(ai_quotes), 200 for quote in ai_quotes: if(quote["id"] == id): return quote, 200 return "Quote not found", 404Метод GET возвращает случайную цитату, если ID содержит дефолтное значение, т.е. при вызове метода ID не был задан.
Если он задан, то метод ищет среди цитат и находит ту, которая содержит заданный ID. Если же ничего не найдено, выводится сообщение “Quote not found, 404”.
Помните: метод возвращает HTTP-статус 200 в случае успешного запроса и 404, если запись не найдена.
Теперь давайте создадим POST-метод для добавления новой цитаты в репозиторий
Он будет получать идентификатор каждой новой цитаты при вводе. Кроме того, POST будет использовать reqparse для парсинга параметров, которые будут идти в теле запроса (автор и текст цитаты).
def post(self, id): parser = reqparse.RequestParser() parser.add_argument("author") parser.add_argument("quote") params = parser.parse_args() for quote in ai_quotes: if(id == quote["id"]): return f"Quote with id already exists", 400 quote = < "id": int(id), "author": params["author"], "quote": params["quote"] >ai_quotes.append(quote) return quote, 201В коде выше POST-метод принял ID цитаты. Затем, используя reqparse, он получил автора и цитату из запроса, сохранив их в словаре params.
Если цитата с указанным ID уже существует, то метод выводит соответствующее сообщение и код 400.
Если цитата с указанным ID еще не была создана, метод создает новую запись с указанным ID и автором, а также другими параметрами. Затем он добавляет запись в список ai_quotes и возвращает запись с новой цитатой вместе с кодом 201.
Теперь создаем PUT-метод для изменения существующей цитаты в репозитории
def put(self, id): parser = reqparse.RequestParser() parser.add_argument("author") parser.add_argument("quote") params = parser.parse_args() for quote in ai_quotes: if(id == quote["id"]): quote["author"] = params["author"] quote["quote"] = params["quote"] return quote, 200 quote = < "id": id, "author": params["author"], "quote": params["quote"] >ai_quotes.append(quote) return quote, 201PUT-метод, аналогично предыдущему примеру, берет ID и input и парсит параметры цитаты, используя reqparse.
Если цитата с указанным ID существует, метод обновит ее с новыми параметрами, а затем выведет обновленную цитату с кодом 200. Если цитаты с указанным ID еще нет, будет создана новая запись с кодом 201.
Наконец, давайте создадим DELETE-метод для удаления цитаты, которая уже не вдохновляет
def delete(self, id): global ai_quotes ai_quotes = [qoute for qoute in ai_quotes if qoute["id"] != id] return f"Quote with id is deleted.", 200Этот метод получает ID цитаты при вводе и обновляет список ai_quotes, используя общий список.
Теперь, когда мы создали все методы, всё, что нам нужно, — просто добавить resource к API, задать путь и запустить Flask.
api.add_resource(Quote, "/ai-quotes", "/ai-quotes/", "/ai-quotes/") if __name__ == '__main__': app.run(debug=True)Наш REST API Service готов!
Далее мы можем сохранить код в файл app.py, запустив его в консоли при помощи команды:
python3 app.pyЕсли все хорошо, то мы получим нечто вроде этого:
* Debug mode: on
* Running on 127.0.0.1:5000/ (Press CTRL+C to quit)
* Restarting with stat
* Debugger is active!
* Debugger PIN: XXXXXXX
Тестируем API
После того как API создан, его нужно протестировать.
Сделать это можно при помощи консольной утилиты curl или клиента Insomnia REST либо же опубликовав API на Rapid API.
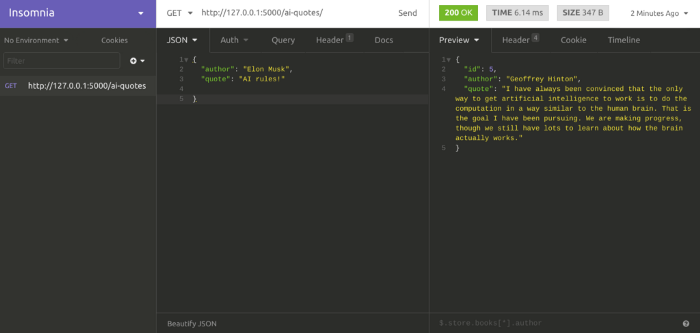
Публикуем наш API
RapidAPI — самый большой в мире маркетплейс с более чем 10 000 API (и около 1 млн разработчиков).
RapidAPI не только предоставляет единый интерфейс для работы со сторонними API, но и даtт возможность быстро и без проблем опубликовать ваш собственный API.
Для того чтобы сделать это, сначала нужно опубликовать его на каком-нибудь сервере в сети. В нашем случае воспользуемся Heroku. Работа с ним не должна вызвать никаких сложностей, (узнать о нём больше можно здесь).
Как опубликовать ваш API на Heroku
1. Устанавливаем Heroku.
Первым делом нужно зарегистрироваться и установить Heroku Command Line Interface (CLI). Это работает на Ubuntu 16+.
sudo snap install heroku —classic
heroku login
2. Добавляем необходимые файлы.
Теперь нужно добавить файлы для публикации в папку в нашем приложении:
- requirements.txt со списком необходимых Python модулей;
- Procfile, который указывает, какие команды должны быть выполнены для запуска приложения;
- .gitignore — для исключения файлов, которые не нужны на сервере.
- flask
- flask-restful
- gunicorn
Procfile будет содержать:
web: gunicorn app:app
*.pyc __pycache__/Теперь, когда созданы файлы, давайте инициализируем git-репо и закоммитим:
git init git add git commit -m "First API commit"3. Создаем новое Heroku-приложение.
heroku createОтправляем master branch в удаленный репо Heroku:
git push heroku masterТеперь можно начать, открыв API Service при помощи команд:
heroku ps:scale web=1 heroku open Как добавить ваш Python API в маркетплейс RapidAPI
После того как API-сервис опубликован на Heroku, можно добавить его к Rapid API. Здесь подробная документация по этой теме.
1. Создаем аккаунт RapidAPI.

Регистрируем бесплатную учетную запись — это можно сделать при помощи Facebook, Google, GitHub.
2. Добавляем API в панель управления.
3. Далее вводим общую информацию о своем API.
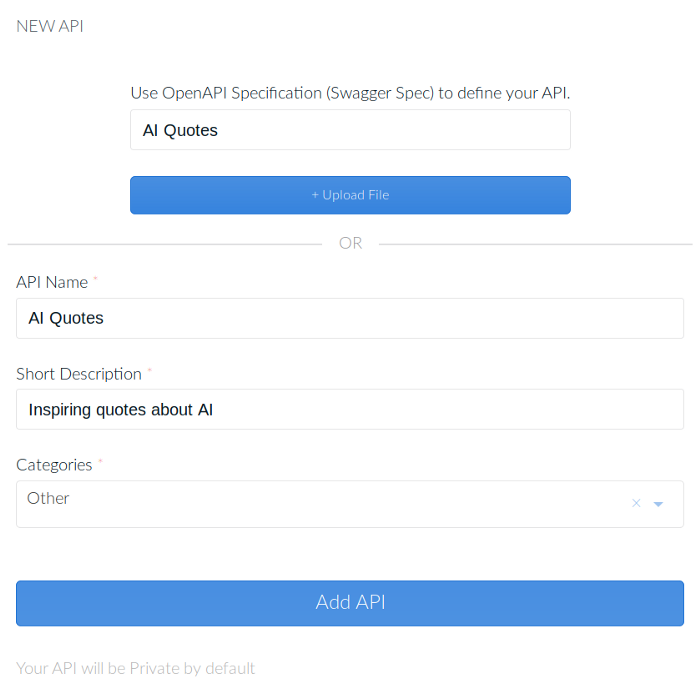
4. После нажатия “Add API” появляется новая страничка, где можно ввести информацию о нашем API.
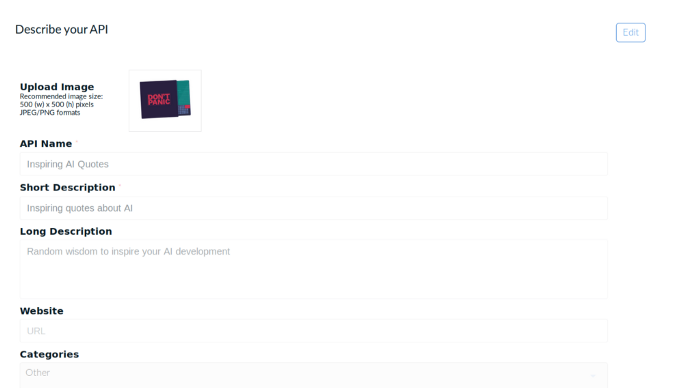
5. Теперь можно либо вручную ввести эндпоинты API, либо загрузить swagger-file при помощи OpenAPI.
Ну а теперь нужно задать эндпоинты нашего API на странице Endpoints. В нашем случае эндпоинты соответствуют концепции CRUD (get, post, put, delete).
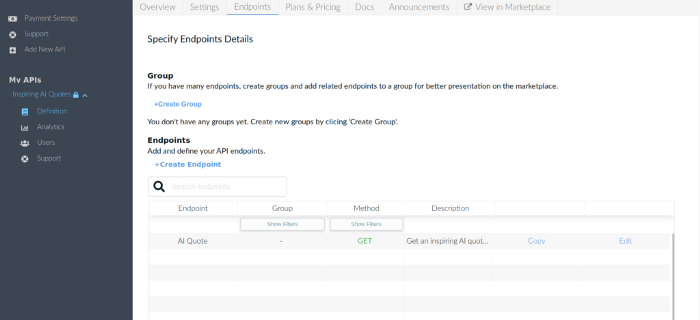
Далее нужно создать эндпоинт GET AI Quote, который выводит случайную цитату (в том случае, если ID дефолтный) или цитату для указанного ID.
Для создания эндпоинта нужно нажать кнопку “Create Endpoint”.

Повторяем этот процесс для всех других эндпоинтов API. На этом всё! Поздравляю, вы опубликовали ваш API!
Если все хорошо, страничка API будет выглядеть как-то так:
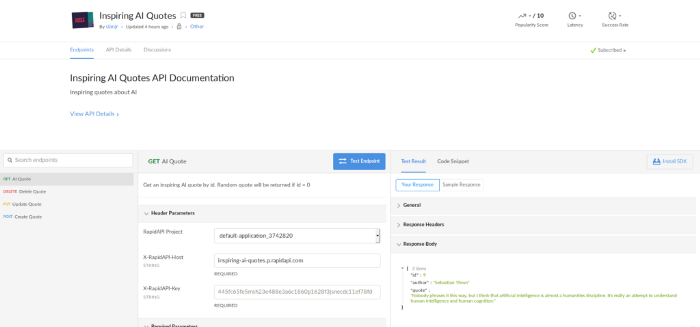
Заключение
В этой статье мы изучили процесс создания собственного RESTful API Service на Python, вместе с процессом публикации API в облаке Heroku и добавлением его в каталог RapidAPI.
Но в тестовом варианте были показаны только базовые принципы разработки API — такие нюансы, как безопасность, отказоустойчивость и масштабируемость, не рассматривались.
При разработке реального API все это нужно учитывать.
- Блог компании Skillbox
- Python
- Программирование
- API
- Учебный процесс в IT
Обращение к API с помощью Python
Достаточно разговоров — пора сделать первый вызов API! Мы вызовем популярный API для генерации случайных пользовательских данных. Единственное, что нужно знать для начала работы с API — по какому URL-адресу его вызывать. В этом примере это https://randomuser.me/api/, и вот самый простой вызов API, с которого мы и начнем:

OAuth: начало работы
Другой распространенный стандарт аутентификации API — это OAuth. Это очень обширная тема, поэтому мы коснемся только самых основ.
Когда приложение или платформа позволяет зарегистрироваться или войти с помощью другого ресурса, например, Google или Facebook, поток аутенфикации обычно использует OAuth.
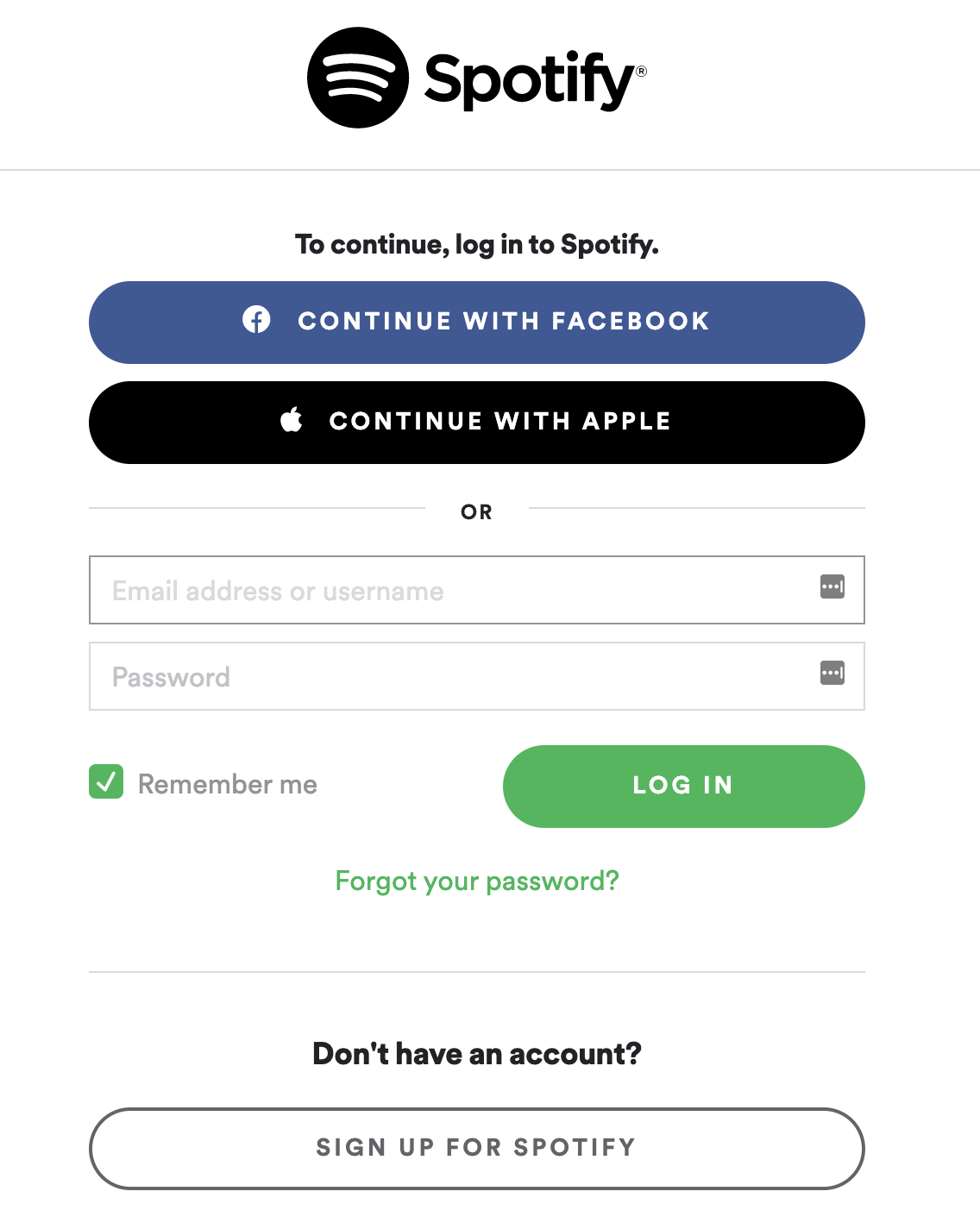
Вот пошаговое описание того, что происходит, когда мы нажимаем в приложении Spotify кнопку «Продолжить с Facebook»:
- Приложение Spotify запрашивает API Facebook запустить процесс аутентификации. Для этого приложение Spotify отправит идентификатор приложения ( client_id ) и URL-адрес ( redirect_uri ) для перенаправления пользователя после взаимодействия с API Facebook.
- Клиент будет перенаправлен на сайт Facebook, где нас попросят войти в систему с учетными данными. Приложение Spotify не увидит эти учетные данные и не получит к ним доступа. Это самое важное преимущество OAuth.
- Facebook отобразит данные профиля, запрашиваемые приложением Spotify, и попросит принять или отклонить обмен этими данными.
- Если вы согласитесь предоставить Spotify доступ к своим данным, вы будете перенаправлены обратно в приложение Spotify и получите доступ к системе.
При прохождении четвертого шага Facebook предоставит Spotify специальные учетные данные — токен доступа ( access_token ), который можно многократно использовать для получения информации. Этот токен входа в Facebook действителен в течение шестидесяти дней, но у других приложений могут быть другие сроки действия.
С технической точки зрения вот что нам нужно знать при использовании API с использованием OAuth:
- Нам нужно создать приложение, которое будет иметь идентификатор ( app_id или client_id ) и некоторую секретную строку ( app_secret или client_secret ).
- У нас должен быть URL-адрес перенаправления ( redirect_uri ), который API будет использовать для отправки нам информации.
- В результате аутентификации мы получим код ( exchange_code ), который необходимо обменять на токен доступа ( access_token ).
Существуют различные вариации этого процесса, но большинство потоков OAuth содержат шаги, аналогичные описанным. Давайте попробуем OAuth на примере GitHub API.
OAuth: практический пример
Как мы видели выше, первое, с чего стоит начать — создать приложение. В документации GitHub есть отличное пошаговое объяснение, как это сделать. Чтобы не разворачивать отдельный сервер, в качестве адреса для перенаправления можно использовать адрес https://httpbin.org/anything. Эта веб-страница просто выводит все, что получает на входе.
Создадим приложение, скопируем и вставим Client_ID и Client_Secret вместе с указанным URL для переадресации в файл Python, который назовем github.py :

В API пагинация обычно обрабатывается с помощью двух параметров запроса:
- Атрибут page определяет номер запрашиваемой страницы
- Атрибут size определяет размер каждой страницы
Конкретные имена параметров запроса могут сильно различаться в зависимости от выбора разработчиков API. Некоторые провайдеры API могут также использовать HTTP-заголовки или JSON для возврата текущих фильтров разбивки на страницы.
Снова воспользуемся GitHub API. Параметр per_page= определяет количество возвращаемых элементов, а page= позволяет разбивать результат на отдельные страницы. Пример использования параметров:
>>> response = requests.get("https://api.github.com/events?per_page=1&page=0") >>> response.json()[0]["id"] '15315291644' >>> response = requests.get("https://api.github.com/events?per_page=1&page=1") >>> response.json()[0]["id"] '15316180831' >>> response = requests.get("https://api.github.com/events?per_page=1&page=2") >>> response.json()[0]["id"] '15316181822' Используя параметр запроса page= , мы получаем страницы без перегрузки API.
Ограничение скорости
Учитывая, что рассматриваемые API-интерфейсы являются общедоступными и могут использоваться кем угодно, ими пытаются злоупотреблять люди с плохими намерениями. Чтобы предотвратить такие атаки, используется метод, называемый ограничением скорости ( rate limit ). API ограничивает количество запросов, которые пользователи могут сделать за определенный период. В случае превышения лимита API-интерфейсы временно блокируют IP-адрес или API-ключ.
Некоторые API, такие как GitHub, даже включают в заголовки дополнительную информацию о текущем ограничении скорости и количестве оставшихся запросов. Это очень помогает избежать превышения установленного лимита.
Использование API с помощью Python: практические примеры
Теперь, когда мы поэкспериментировали с несколькими API, можно объединить полученные знания с помощью еще нескольких практических примеров.
Запрос наиболее популярных сейчас гифок
Как насчет создания небольшого скрипта, который извлекает три самых популярных сейчас GIF-файла с веб-сайта GIPHY? Начните с получения API-ключа:
- Создайте аккаунт на GIPHY
- Перейдите в панель разработчика и зарегистрируйте новое приложение.
- Получите ключ для соединения с API.
Ключ API используем в GIPHY API:
import requests API_KEY = "API_KEY" endpoint = "https://api.giphy.com/v1/gifs/trending" params = response = requests.get(ENDPOINT, params=params).json() for gif in response["data"]: title = gif["title"] trending_date = gif["trending_datetime"] url = gif["url"] print(f" | | ") Запуск этого кода выведет структурированный список со ссылками на гифки:
Excited Schitts Creek GIF by CBC | 2020-11-28 20:45:14 | https://giphy.com/gifs/cbc-schittscreek-schitts-creek-SiGg4zSmwmbafTYwpj Saved By The Bell Shrug GIF by PeacockTV | 2020-11-28 20:30:15 | https://giphy.com/gifs/peacocktv-saved-by-the-bell-bayside-high-school-dZRjehRpivtJsNUxW9 Schitts Creek Thank You GIF by CBC | 2020-11-28 20:15:07 | https://giphy.com/gifs/cbc-funny-comedy-26n79l9afmfm1POjC Получение подтвержденных случаев COVID-19 в каждой стране
API сайта, отслеживающего случаи заболевания COVID-19, не требует аутентификации. В следующем примере мы получим общее количество подтвержденных случаев до предыдущего дня:
import requests from datetime import date, timedelta today = date.today() yesterday = today - timedelta(days=1) country = "Russia" endpoint = f"https://api.covid19api.com/country//status/confirmed" params = response = requests.get(endpoint, params=params).json() total_confirmed = 0 for day in response: cases = day.get("Cases", 0) total_confirmed += cases print(f"Total Confirmed Covid-19 cases in : ") Total Confirmed Covid-19 cases in Russia: 4153735 В этом примере мы получаем общее количество подтвержденных случаев для всей страны. Однако вы также можете просмотреть документацию и получить данные для конкретного города.
Поиск в Google Книгах
Воспользуемся API Google Книг для поиска информации об интересующей нас книге. Вот простой фрагмент кода для поиска названия книги Моби Дик во всем каталоге с выдачей трех первых записей:
import requests endpoint = "https://www.googleapis.com/books/v1/volumes" query = "Моби Дик" params = response = requests.get(endpoint, params=params).json() for book in response["items"]: volume = book["volumeInfo"] title = volume["title"] published = volume.get("publishedDate", "год издания неизвестен") description = volume.get("description", "описание отсутствует") print(f" () | ") Моби Дик (год издания неизвестен) | «Моби Дик» — самый известный роман американского писателя Германа Мелвилла (1819–1891), романтика, путешественника, философа, поэта, автора морских повестей и психологических рассказов. В настоящем издании «Моби Дик». Моби Дик (2018-01-03) | Моби Дик — это не кит, это человек… Он одинок и у него нет никого и ничего, кроме работы, составляющей всю его жизнь. И лишь настоящие чувства, пробужденные в нем девушкой, изменяют смысл его жизни. Моби Дик (1961) | описание отсутствует Вы можете использовать свои знания OAuth и создать приложение, хранящее записи о книгах, которые читаете или хотите прочитать.
Заключение
Есть множество других вещей, которые вы ещё узнаете об API: другие заголовки, типы контента, методы аутентификации и так далее. Однако концепции и методы, которые мы рассмотрели в этом руководстве, позволят достаточно быстро разобраться и провзаимодействовать с помощью Python с любыми API.
Напоследок приведем список агрегаторов ссылок на публичные API, которые вы можете использовать в собственных проектах:
- Репозиторий GitHub со списком общедоступных API
- Public APIs
- Public API
- Any API
На Python создают прикладные приложения, пишут тесты и бэкенд веб-приложений, автоматизируют задачи в системном администрировании, его используют в нейронных сетях и анализе больших данных. Язык можно изучить самостоятельно, но на это придется потратить немало времени. Если вы хотите быстро понять основы программирования на Python, обратите внимание на онлайн-курс «Библиотеки программиста». За 30 уроков (15 теоретических и 15 практических занятий) под руководством практикующих экспертов вы не только изучите основы синтаксиса, но и освоите две интегрированные среды разработки (PyCharm и Jupyter Notebook), работу со словарями, парсинг веб-страниц, создание ботов для Telegram и Instagram, тестирование кода и даже анализ данных. Чтобы процесс обучения стал более интересным и комфортным, студенты получат от нас обратную связь. Кураторы и преподаватели курса ответят на все вопросы по теме лекций и практических занятий.
Источники
Работа с REST API на Python
В этой статье вы узнаете как выполнять запросы к REST API на Python 3 и обрабатывать ответы.
Если ваша цель — создание своего REST API — переходите к статье «Flask»
Прежде чем что-то устанавливать убедитесь, что вы знакомы с работой в виртуальном окружении Python.
Прочитать об этом можно в статье «Виртуальные окружения в Python»
Подготовка
Активируйте ваше виртуальное окружение и установите requests командой
python -m pip install requests
Изучите список установленных модулей
python -m pip list
Package Version ———- ——— certifi 2020.6.20 chardet 3.0.4 idna 2.10 pip 20.2.3 requests 2.24.0 setuptools 50.3.1 urllib3 1.25.10 wheel 0.35.1
requests подтягивает за собой requests, certifi , chardet, idna, urllib3
Проверить куда установился requests в этом окружении можно командой
python3 -m pip show requests
Name: requests Version: 2.24.0 Summary: Python HTTP for Humans. Home-page: https://requests.readthedocs.io Author: Kenneth Reitz Author-email: me@kennethreitz.org License: Apache 2.0 Location: /home/andrei/python/virtualenvs/answerit_env/lib/python3.8/site-packages Requires: certifi, chardet, urllib3, idna Required-by:
GET
Чтобы сделать GET запрос достаточно импортировать requests и выполнить requests. get
Создайте файл rdemo.py следующего содержания:
import requests r = requests. get (‘https://xkcd.com/353/’) print (r)
Запустите скрипт командой
Если получили 200 значит всё хорошо. Изменим наш код, чтобы узнать, какие действия мы можем произвести с объектом
dir(r) выдаст список доступных атрибутов и методов
import requests r = requests. get (‘https://topbicycle.ru/b/stels_pilot_950_md_26.php’) print (dir(r))
[‘__attrs__’, ‘__bool__’, ‘__class__’, ‘__delattr__’, ‘__dict__’, ‘__dir__’, ‘__doc__’, ‘__enter__’, ‘__eq__’, ‘__exit__’, ‘__format__’, ‘__ge__’, ‘__getattribute__’, ‘__getstate__’, ‘__gt__’, ‘__hash__’, ‘__init__’, ‘__init_subclass__’, ‘__iter__’, ‘__le__’, ‘__lt__’, ‘__module__’, ‘__ne__’, ‘__new__’, ‘__nonzero__’, ‘__reduce__’, ‘__reduce_ex__’, ‘__repr__’, ‘__setattr__’, ‘__setstate__’, ‘__sizeof__’, ‘__str__’, ‘__subclasshook__’, ‘__weakref__’, ‘_content’, ‘_content_consumed’, ‘_next’, ‘apparent_encoding’, ‘close’, ‘connection’, ‘content’, ‘cookies’, ‘elapsed’, ‘encoding’, ‘headers’, ‘history’, ‘is_permanent_redirect’, ‘is_redirect’, ‘iter_content’, ‘iter_lines’, ‘json’, ‘links’, ‘next’, ‘ok’, ‘raise_for_status’, ‘raw’, ‘reason’, ‘request’, ‘status_code’, ‘text’, ‘url’]
Более подробную информацию можно получить заменив dir(r) на help(r)
Если вам интересно — прочитайте статью requests help
Из этого документа можно узнать http статус содержится в атрибуте status_code
import requests r = requests. get (‘https://topbicycle.ru/b/stels_pilot_950_md_26.php’) print (r.status_code)
Если всё прошло успешно, то получите
ok вернёт True если ответ не 4XX или 5XX
headers возвращает заголовок ответа
Также из этого документа можно узнать что text возвращает содержимое ответа в формате unicode а content содержимое ответа в байтах
import requests r = requests. get (‘https://xkcd.com/353/’) print («content:») print («——«) print (r.content) print («——«) print («text:») print («——«) print (r.text)
И изучите разницу
Обычно content используют для работы с изображениями
Перейдите на TopBicycle.ru и найдите первое фото велосипеда.
Скопируйте его url
Теперь измените код так, чтобы сохранить изображение в файл
import requests r = requests. get ( «https://topbicycle.ru/b/img/stels_pilot_950_MD_26.jpg» ) with open(«bike.jpg», «wb») as f: f.write(r.content)
Если всё прошло успешно, в вашей папке появится следующее фото

GET с параметрами
Для проверки ваших навыков работы с REST API можно воспользоваться сайтом httpbin.org
Он будет возвращать вам обратно ваш запрос.
Изменим код rdemo.py :
Параметры можно записать сразу после url за знаком вопроса, но надёжнее оформить их в виде отдельного словаря (dictionary).
import requests payload = r = requests. get ( «https://httpbin.org/get» , params= payload) print (f»url: \n\ntext: \n «)
POST
Чтобы отправить и проверить POST запрос внесите небольшие изменения в код.
Очевидно, что GET нужно заменить на POST, также params нужно заменить на data или json
data – (optional) Dictionary, list of tuples, bytes, or file-like object to send in the body of the Request.
json – (optional) A JSON serializable Python object to send in the body of the Request.
import requests payload = r = requests. post (‘https://httpbin.org/post’, data= payload) print (f»url: \n\ntext: \n «)
Ответы, которые мы получили с httpbin приходили в формате json.
Для работы c json бывает удобно использовать встроенный метод .json()
В этом случае данные записываются в словарь и к ним очень легко обращаться.
Обратите внимание на «form» данные, которые были переданы возвращаются в этом поле.
Изменим код так, чтобы на экран выводились только эти данные
import requests payload = r = requests. post (‘https://httpbin.org/post’, data= payload) r_dict = r. json () print (r_dict[‘form’])
PUT
Всё аналогично POST просто замените post на put
Рассмотрим пример, в котором нужно передать в теле запроса json, а также использовать имеющийся токен для авторизации
import requests import json url = «http://eth1.ru» new_access_token = «sdlfjsljglkjfd;lkgjdlkhjlkjgdlkhjlkdjglkj» body = «»»[]»»» payload = json.loads(body) json_headers = < "Content-type" : "application/json" , "Authorization" : "Bearer %s" %new_access_token >r = requests.put(url, headers =json_headers, json =payload, verify =False)
Обратите внимание на следующие моменты
- При передаче JSON нужно обязательно указать заголовок ‘Content-type’: ‘application/json’
- Токен передаётся с помощью Bearer
- Можно легко преобразовать данные в JSON с помощью json.loads()
Обработка ответа
Рассмотрим приёмы, которые пригодятся при работе с полученными данными
Простейший ответ сервера, например 200 может вообще не содержать никаких данных
response = requests.delete ( url , headers=headers , verify= False ) print ( f»type(response): < type (response)>» ) print ( f»response.__repr__: < repr (response)>» ) print ( f»response.__str__: < str (response)>» ) print ( f»response.text: » )
Очень часто данные приходят в формате json.
Например, нужно извлечь из них токен, который хранится в access_token
Чтобы его получить, воспользуйтесь методом json() который возвращает словарь ().
И из этого словаря получите токен по ключевому слову access_token
r_dict = response.json() access_token = r_dict[ «access_token» ]
json.dumps
Если вы хотите сразу же изучить полученный json можно воспользоваться методом dumps()
import json print (json.dumps(response.json() , indent = 4 ))
Если вы получили не json а dict, json.dumps нужно использовать так:
import json print (json.dumps(resp.dict , indent = 4 , sort_keys = True ))
sort_keys делать не обязательно. Это я для примера показываю, что можно отсортировтаь ключевые слова.
Вытащить часть ответа
Часто интерес бывает не весь ответ, а только часть. О том как её грамотно выделить из ответа читайте в статье
Аутентификация
Рассмотрим базовую аутентификацию на сайте httpbin
Придумайте любое имя пользоватлея и пароль к нему.
Я придумал andrey с паролем heihei
Перейдите на httpbin.org . Убедитесь, что в адресной строке стоит basic-auth/andrey/heihei либо те логин и пароль, что придумали вы.

Введите ваши логин и пароль

Убедитесь, что аутентификация прошла успешно

Теперь проделаем такую же аутентификацию с помощью Python
Создайте файл auth_demo.py со следующим кодом
import requests r = requests. get ( ‘https://httpbin.org/basic-auth/andrey/heihei’ , auth= ( ‘andrey’ , ‘heihei’ ) ) print (r.text)
Ответ совпадает с тем что мы уже получали в браузере
Выполните такой же запрос, но с неправильным паролем. Убедитесь в том, что text ничего не содержит. Замените print (r.text) на print (r) и убедитесь, что полученный объект это
Задержка
Часто бывает нужно ограничить время ожидания ответа. Это можно сделать с помощью параметра timeout
Перейдите на httpbin.org раздел — / #/ Dynamic_data / delete_delay__delay_ и изучите документацию — если делать запрос на этот url можно выставлять время, через которое будет отправлен ответ.
Создайте файл timeout_demo.py следующего содержания
import requests r = requests. get (‘https://httpbin.org/delay/1’, timeout= 3) print (r)
Задержка равна одной секунде. А ждать ответ можно до трёх секунд.
Измените код так, чтобы ответ приходил заведомо позже чем наш таймаут в три секунды.
import requests r = requests. get (‘https://httpbin.org/delay/7’, timeout= 3) print (r)
Задержка равна семи секундам. А ждать ответ можно по-прежнему только до трёх секунд.
Traceback (most recent call last): File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 421, in _make_request six.raise_from(e, None) File «», line 3, in raise_from File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 416, in _make_request httplib_response = conn.getresponse() File «/usr/lib/python3.8/http/client.py», line 1347, in getresponse response.begin() File «/usr/lib/python3.8/http/client.py», line 307, in begin version, status, reason = self._read_status() File «/usr/lib/python3.8/http/client.py», line 268, in _read_status line = str(self.fp.readline(_MAXLINE + 1), «iso-8859-1») File «/usr/lib/python3.8/socket.py», line 669, in readinto return self._sock.recv_into(b) File «/usr/lib/python3/dist-packages/urllib3/contrib/pyopenssl.py», line 326, in recv_into raise timeout(«The read operation timed out») socket.timeout: The read operation timed out During handling of the above exception, another exception occurred: Traceback (most recent call last): File «/usr/lib/python3/dist-packages/requests/adapters.py», line 439, in send resp = conn.urlopen( File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 719, in urlopen retries = retries.increment( File «/usr/lib/python3/dist-packages/urllib3/util/retry.py», line 400, in increment raise six.reraise(type(error), error, _stacktrace) File «/usr/lib/python3/dist-packages/six.py», line 703, in reraise raise value File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 665, in urlopen httplib_response = self._make_request( File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 423, in _make_request self._raise_timeout(err=e, url=url, timeout_value=read_timeout) File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 330, in _raise_timeout raise ReadTimeoutError( urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(host=’httpbin.org’, port=443): Read timed out. (read timeout=3) During handling of the above exception, another exception occurred: Traceback (most recent call last): File «timeout_demo.py», line 4, in r = requests.get(‘https://httpbin.org/delay/7’, timeout=3) File «/usr/lib/python3/dist-packages/requests/api.py», line 75, in get return request(‘get’, url, params=params, **kwargs) File «/usr/lib/python3/dist-packages/requests/api.py», line 60, in request return session.request(method=method, url=url, **kwargs) File «/usr/lib/python3/dist-packages/requests/sessions.py», line 533, in request resp = self.send(prep, **send_kwargs) File «/usr/lib/python3/dist-packages/requests/sessions.py», line 646, in send r = adapter.send(request, **kwargs) File «/usr/lib/python3/dist-packages/requests/adapters.py», line 529, in send raise ReadTimeout(e, request=request) requests.exceptions.ReadTimeout: HTTPSConnectionPool(host=’httpbin.org’, port=443): Read timed out. (read timeout=3)
Если хотите обработать исключение — измените код используя try except
import requests try : r = requests.get( ‘https://httpbin.org/delay/7’ , timeout= 3 ) print (r) except ( requests.exceptions.Timeout, requests.exceptions. ConnectionError ) as err: print ( ‘Response is taking too long.’ , err)
Response is taking too long. HTTPSConnectionPool(host=’httpbin.org’, port=443): Read timed out. (read timeout=3)
Работа с сертификатами
В Python по умолчанию используются не сертификаты системы, а сертификаты из модуля certif
Проверить где они расположены можно следуюущим образом
python >>> import certifi >>> certifi.where()
Как использовать Python для работы с REST API
Изучите основы работы с REST API с помощью Python и библиотеки Requests, чтобы легко взаимодействовать с веб-сервисами.

Алексей Кодов
Автор статьи
23 июня 2023 в 18:40
В этой статье мы рассмотрим, как использовать Python для работы с REST API. REST API (Representational State Transfer) — это стандартный способ взаимодействия между различными компонентами системы через HTTP(s) протокол. Многие веб-сервисы предоставляют API для доступа к своим данным и функционалу.
Библиотека Requests
Для работы с REST API в Python одной из наиболее популярных библиотек является Requests. Эта библиотека позволяет отправлять HTTP-запросы и обрабатывать ответы от сервера.
Для установки библиотеки Requests используйте следующую команду:
pip install requests Основы работы с Requests
Давайте рассмотрим основные методы, которые предоставляет библиотека Requests для работы с REST API:
GET-запрос
Пример отправки GET-запроса и обработки ответа:
import requests response = requests.get("https://jsonplaceholder.typicode.com/posts") if response.status_code == 200: data = response.json() print(data) else: print("Ошибка:", response.status_code)
POST-запрос
Пример отправки POST-запроса с данными:
import requests url = "https://jsonplaceholder.typicode.com/posts" data = < "title": "My new post", "body": "Hello, world!", "userId": 1 >response = requests.post(url, json=data) if response.status_code == 201: print("Данные успешно отправлены") print(response.json()) else: print("Ошибка:", response.status_code)
Python-разработчик: новая работа через 9 месяцев
Получится, даже если у вас нет опыта в IT

PUT-запрос
Пример отправки PUT-запроса для обновления данных:
import requests url = "https://jsonplaceholder.typicode.com/posts/1" data = < "title": "Updated post", "body": "New content", "userId": 1 >response = requests.put(url, json=data) if response.status_code == 200: print("Данные успешно обновлены") print(response.json()) else: print("Ошибка:", response.status_code)
DELETE-запрос
Пример отправки DELETE-запроса для удаления данных:
import requests url = "https://jsonplaceholder.typicode.com/posts/1" response = requests.delete(url) if response.status_code == 200: print("Данные успешно удалены") else: print("Ошибка:", response.status_code)
�� Теперь вы знаете основы работы с REST API с помощью Python и библиотеки Requests. Эти знания помогут вам взаимодействовать с различными веб-сервисами и получать доступ к их данным.
Для дополнительной информации и более сложных примеров работы с REST API, рекомендуем обратиться к документации библиотеки Requests: https://docs.python-requests.org/en/master/
Не забывайте практиковаться и экспериментировать с различными API. Удачи вам в изучении Python и работе с REST API! ��