Исследование расщепленного мозга (split-brain research)
Начало систематическим И. р. м. положили работы Роджера Сперри. Лабораторное животное или пациент с «расщепленным мозгом» — продукт перерезки главного связующего звена между двумя полушариями головного мозга. Это связующее звено, состоящее из мн. миллионов нервных волокон, наз. мозолистым телом (corpus callosum). Наблюдения за больными людьми и лабораторными животными с разъединенными таким способом полушариями практически не выявили сколько-нибудь заметных нарушений в функционировании мозга, однако эксперименты Сперри и др. показали, что расщепленный мозг функционирует не вполне нормально. Напр., при перерезке мозолистого тела у эксперим. животных было обнаружено, что информ., усвоенная благодаря функционированию одного полушария мозга, не передавалась в др. полушарие. Последующие опыты с использованием задач на зрительное и осязательное различение, а тж на моторное научение, подтвердили этот осн. результат.
Есть данные, указывающие на превосходство правого полушария над левым в том, что касается пространственной, двигательной и др. невербальной активности. Накоплены тж доказательства в поддержку вывода о том, что левое полушарие мозга большинства людей связано с числовыми, аналитическими и лингвистическими операциями.
См. также Головной мозг, Латерализация головного мозга, Латеральное доминирование, Нейропсихология, Психохирургия
- Исследование психотерапии (psychotherapy research)
- Исследование социального климата (social climate research)
Развертывание разделенной системы DNS с помощью политики DNS
С помощью этого раздела вы узнаете, как настроить политику DNS в Windows Server® 2016 для развертываний DNS с разделением мозга, где существует две версии одной зоны — одна для внутренних пользователей в интрасети организации и одна для внешних пользователей, которые обычно являются пользователями в Интернете.
Сведения о том, как использовать политику DNS для развертывания DNS с разделением мозга с интегрированными зонами DNS Active Directory, см. в статье «Использование политики DNS для разбиения мозга DNS в Active Directory».
Ранее этот сценарий требовал, чтобы администраторы DNS поддерживали два разных DNS-сервера, каждый из которых предоставляет службы для каждого набора пользователей, внутренних и внешних. Если только несколько записей внутри зоны были разделены мозгом или оба экземпляра зоны (внутренние и внешние) были делегированы одному родительскому домену, это стало запутано управлением.
Другой сценарий конфигурации для развертывания разбиения мозга — выборочное управление рекурсией для разрешения DNS-имен. В некоторых случаях dns-серверы Enterprise должны выполнять рекурсивное разрешение через Интернет для внутренних пользователей, в то время как они также должны выступать в качестве доверенных серверов имен для внешних пользователей и блокировать рекурсию для них.
Эта тема описана в следующих разделах.
- Пример развертывания разделенного мозга DNS
- Пример элемента управления выборочной рекурсии DNS
Пример развертывания разделенного мозга DNS
Ниже приведен пример использования политики DNS для выполнения ранее описанного сценария разделенного мозга DNS.
Этот раздел содержит следующие подразделы.
- Как работает развертывание разделенного мозга DNS
- Настройка развертывания разбиения DNS в мозг
В этом примере используется одна вымышленная компания Contoso, которая поддерживает веб-сайт карьеры на www.career.contoso.com.
Сайт имеет две версии, один для внутренних пользователей, где доступны внутренние публикации заданий. Этот внутренний сайт доступен по локальному IP-адресу 10.0.0.39.
Вторая версия — это общедоступная версия того же сайта, которая доступна по общедоступному IP-адресу 65.55.39.10.
В отсутствие политики DNS администратор должен разместить эти две зоны на отдельных DNS-серверах Windows Server и управлять ими отдельно.
Теперь с помощью политик DNS эти зоны можно разместить на одном DNS-сервере.
На следующем рисунке показан этот сценарий.
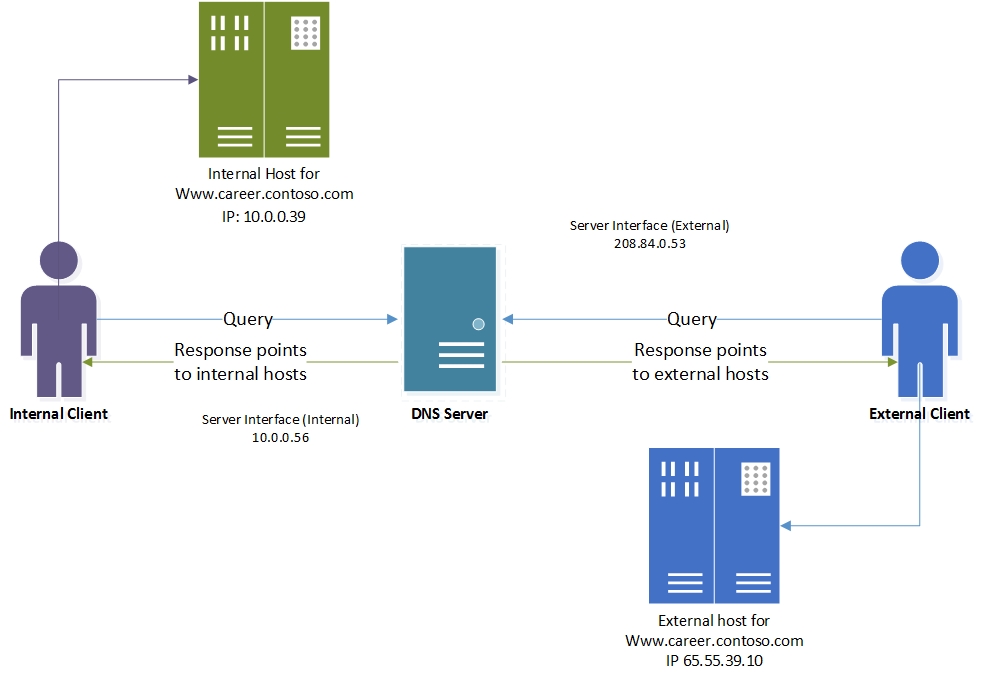
Как работает развертывание разделенного мозга DNS
Если DNS-сервер настроен с необходимыми политиками DNS, каждый запрос разрешения имен вычисляется по политикам на DNS-сервере.
Интерфейс сервера используется в этом примере в качестве критериев для различения внутренних и внешних клиентов.
Если интерфейс сервера, на котором получен запрос, соответствует любой из политик, связанная зона область используется для реагирования на запрос.
Таким образом, в нашем примере DNS-запросы для www.career.contoso.com, полученных на частном IP-адресе (10.0.0.56), получают DNS-ответ, содержащий внутренний IP-адрес, а запросы DNS, полученные на общедоступном сетевом интерфейсе, получают DNS-ответ, содержащий общедоступный IP-адрес в зоне по умолчанию область (это то же самое, что и обычное разрешение запросов).
Настройка развертывания разбиения DNS в мозг
Чтобы настроить развертывание разбиения DNS в мозг с помощью политики DNS, необходимо выполнить следующие действия.
- Создание областей зоны
- Добавление записей в области зоны
- Создание политик DNS
В следующих разделах приведены подробные инструкции по настройке.
В следующих разделах приведены примеры команд Windows PowerShell, которые содержат примеры значений для многих параметров. Перед выполнением этих команд замените примеры значений в этих командах значениями, подходящими для развертывания.
Создание областей зоны
Зона область является уникальным экземпляром зоны. Зона DNS может иметь несколько область зоны, при этом каждая зона область содержит собственный набор записей DNS. Одна и та же запись может присутствовать в нескольких область с разными IP-адресами или одинаковыми IP-адресами.
По умолчанию область зоны существуют в зонах DNS. Эта зона область имеет то же имя, что и зона, а устаревшие операции DNS работают над этим область. Эта зона по умолчанию область будет размещать внешнюю версию www.career.contoso.com.
Следующую команду можно использовать для секционирования зоны область contoso.com для создания внутренней зоны область. Внутренняя зона область будет использоваться для хранения внутренней версии www.career.contoso.com.
Add-DnsServerZoneScope -ZoneName «contoso.com» -Name «internal»
Дополнительные сведения см. в разделе Add-DnsServerZoneScope
Добавление записей в области зоны
Следующим шагом является добавление записей, представляющих узел веб-сервера, в две зоны область — внутренние и стандартные (для внешних клиентов).
В область внутренней зоны запись www.career.contoso.com добавляется с IP-адресом 10.0.0.39, который является частным IP-адресом, а в зоне по умолчанию область той же записи, www.career.contoso.com, добавляется с IP-адресом 65.55.39.10.
Параметр —ZoneScope указан в следующих примерах команд при добавлении записи в зону по умолчанию область. Это аналогично добавлению записей в зону ванили.
Add-DnsServerResourceRecord -ZoneName «contoso.com» -A -Name «www.career» -IPv4Address «65.55.39.10» Add-DnsServerResourceRecord -ZoneName «contoso.com» -A -Name «www.career» -IPv4Address «10.0.0.39” -ZoneScope «internal»
Дополнительные сведения см. в разделе Add-DnsServerResourceRecord.
Создание политик DNS
После определения интерфейсов сервера для внешней сети и внутренней сети и создания область зоны необходимо создать политики DNS, которые подключают внутренние и внешние область зоны.
В этом примере интерфейс сервера используется в качестве критериев для различения внутренних и внешних клиентов. Другой способ различать внешние и внутренние клиенты — использовать подсети клиента в качестве критерия. Если можно определить подсети, к которым принадлежат внутренние клиенты, можно настроить политику DNS для различения на основе подсети клиента. Сведения о настройке управления трафиком с помощью условий подсети клиента см. в статье «Использование политики DNS для управления трафиком на основе геолокации с основными серверами».
Когда DNS-сервер получает запрос в частном интерфейсе, ответ DNS-запроса возвращается из внутренней зоны область.
Для сопоставления зоны по умолчанию область не требуются политики.
В следующем примере команды 10.0.0.56 является IP-адресом частного сетевого интерфейса, как показано на предыдущем рисунке.
Add-DnsServerQueryResolutionPolicy -Name «SplitBrainZonePolicy» -Action ALLOW -ServerInterface «eq,10.0.0.56» -ZoneScope «internal,1» -ZoneName contoso.com
Пример элемента управления выборочной рекурсии DNS
Ниже приведен пример использования политики DNS для выполнения ранее описанного сценария выборочного рекурсии DNS.
Этот раздел содержит следующие подразделы.
- Как работает элемент управления выборочной рекурсии DNS
- Настройка элемента управления выборочной рекурсии DNS
В этом примере используется та же вымышленная компания, что и в предыдущем примере Contoso, которая поддерживает веб-сайт карьеры на www.career.contoso.com.
В примере развертывания разделенного мозга DNS один и тот же DNS-сервер отвечает как на внешние, так и внутренние клиенты и предоставляет им различные ответы.
Для некоторых развертываний DNS может потребоваться тот же DNS-сервер для рекурсивного разрешения имен для внутренних клиентов в дополнение к роли доверенного сервера имен для внешних клиентов. Это обстоятельство называется элементом управления выборочной рекурсии DNS.
В предыдущих версиях Windows Server включение рекурсии означает, что она была включена на всем DNS-сервере для всех зон. Так как DNS-сервер также прослушивает внешние запросы, рекурсия включена как для внутренних, так и для внешних клиентов, что делает DNS-сервер открытым сопоставителя.
DNS-сервер, настроенный как открытый сопоставитель, может быть уязвим к исчерпанию ресурсов и может быть злоупотреблять вредоносными клиентами для создания атак отражения.
Из-за этого администраторы DNS Contoso не хотят, чтобы DNS-сервер contoso.com выполнять рекурсивное разрешение имен для внешних клиентов. Существует только необходимость в управлении рекурсией для внутренних клиентов, а управление рекурсией может быть заблокировано для внешних клиентов.
На следующем рисунке показан этот сценарий.
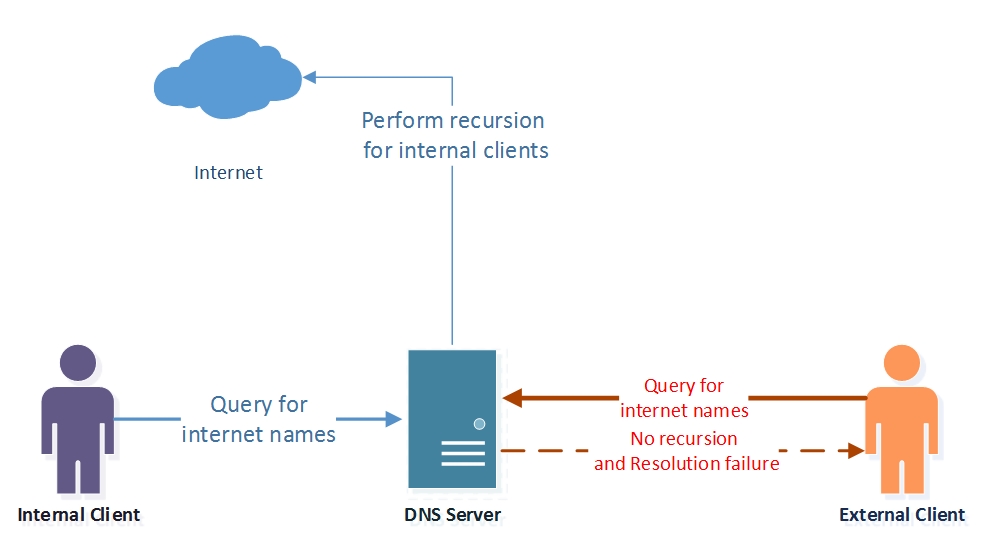
Как работает элемент управления выборочной рекурсии DNS
Если получен запрос, для которого DNS-сервер Contoso не является доверенным, например https://www.microsoft.comдля, то запрос разрешения имен вычисляется по политикам на DNS-сервере.
Так как эти запросы не попадают в любую зону, политики уровня зоны (как определено в примере с разделением мозга) не оцениваются.
DNS-сервер оценивает политики рекурсии, а запросы, полученные в частном интерфейсе, соответствуют SplitBrainRecursionPolicy. Эта политика указывает на рекурсию область, где включена рекурсия.
Затем DNS-сервер выполняет рекурсию, чтобы получить ответ https://www.microsoft.com из Интернета и кэширует ответ локально.
Если запрос получен во внешнем интерфейсе, политики DNS не совпадают, а параметр рекурсии по умолчанию , который в данном случае отключен, применяется.
Это запрещает серверу выступать в качестве открытого сопоставителя для внешних клиентов, хотя он выступает в качестве сопоставителя кэширования для внутренних клиентов.
Настройка элемента управления выборочной рекурсии DNS
Чтобы настроить элемент управления выборочной рекурсией DNS с помощью политики DNS, необходимо выполнить следующие действия.
- Создание областей рекурсии DNS
- Создание политик рекурсии DNS
Создание областей рекурсии DNS
Область рекурсии — это уникальные экземпляры группы параметров, которые управляют рекурсией на DNS-сервере. Рекурсия область содержит список пересылки и указывает, включена ли рекурсия. DNS-сервер может иметь множество рекурсий область.
Устаревший параметр рекурсии и список пересылки называются область рекурсии по умолчанию. Невозможно добавить или удалить область рекурсии по умолчанию, определяемую точкой имени («.»).
В этом примере параметр рекурсии по умолчанию отключен, а новый область рекурсии для внутренних клиентов создается, где включена рекурсия.
Set-DnsServerRecursionScope -Name . -EnableRecursion $False Add-DnsServerRecursionScope -Name "InternalClients" -EnableRecursion $True Дополнительные сведения см. в разделе Add-DnsServerRecursionScope
Создание политик рекурсии DNS
Политики рекурсии DNS-сервера можно создать для выбора рекурсии область для набора запросов, соответствующих определенным критериям.
Если DNS-сервер не является доверенным для некоторых запросов, политики рекурсии DNS-сервера позволяют управлять разрешением запросов.
В этом примере внутренняя рекурсия область с включенной рекурсией связана с частным сетевым интерфейсом.
Для настройки политик рекурсии DNS можно использовать следующую команду.
Add-DnsServerQueryResolutionPolicy -Name "SplitBrainRecursionPolicy" -Action ALLOW -ApplyOnRecursion -RecursionScope "InternalClients" -ServerInterfaceIP "EQ,10.0.0.39" Теперь DNS-сервер настраивается с необходимыми политиками DNS для сервера имен разбиения мозга или DNS-сервера с выборочным элементом управления рекурсией, включенным для внутренних клиентов.
Вы можете создавать тысячи политик DNS в соответствии с требованиями к управлению трафиком, и все новые политики применяются динамически , не перезапуская DNS-сервер в входящих запросах.
Дополнительные сведения см . в руководстве по сценарию политики DNS.
«Защита от split-brain при создании 2-х нодового кластера PostgreSQL» — Видеозапись доклада
В ноябре 2017 года состоялась конференция о системах, платформах и инструментах — «Linux Piter». С докладами выступили эксперты из США, Германии, Австрии, Швеции, Финляндии и конечно же из России. Компанию Postgres Professional представил старший администратор баз данных Игорь Косенков. Игорь выступил с докладом «Защита от split-brain при создании 2-х нодового кластера PostgreSQL».
Сегодня видеозаписи всех докладов уже доступны на сайте конференции «Linux Piter». А мы делимся здесь видеозаписью доклада Игоря Косенкова на русском языке и с английским переводом.
Русская версия:
Английская версия:
О докладе:
Split-brain является главным недостатком на пути использования двух-узлового кластера PostgreSQL. Многие известные механизмы защиты от split-brain не всегда могут быть применимы. В докладе Игорь Косенков расскажет об известных механизмах, и предложит свой механизм защиты от split-brain. Также вы узнаете о практическом использовании двух-узлового кластера в современных кластерах.
О докладчике:
Игорь Косенков старший администратор баз данных в компании Постгресс Профессиональный. Участвовал в разработке отечественной операционной системы военного назначения на базе Linux — ОС МСВС. Является специалистом в области построения отказоустойчивых решений для СУБД PostgreSQL.
7 типичных ошибок при разворачивании кластера
Разберём 7 основных ошибок, которые часто допускают при внедрении отказоустойчивого кластера. Содержание статьи не направлено на конкретную технологию и подойдёт под любой стек.

Мы обсудим следующие проблемы:
- Кластер ради кластера.
- Единые точки отказа.
- Нарушение принципов majority.
- Несимметричный кластер.
- Перегруженный кластер.
- Непротестированный кластер.
- Беспризорный кластер (без обслуживания и мониторинга).
Для подготовки материала мы использовали вебинар «10 типичных ошибок при разворачивании кластера». В выступлении спикер разобрал ещё три проблемы, а также ответил на вопросы зрителей. Если интересно, можно посмотреть вебинар, кликнув на его название.
1. Кластер ради кластера
Распространённая ошибка — разворачивать кластер тогда, когда он… Не нужен.
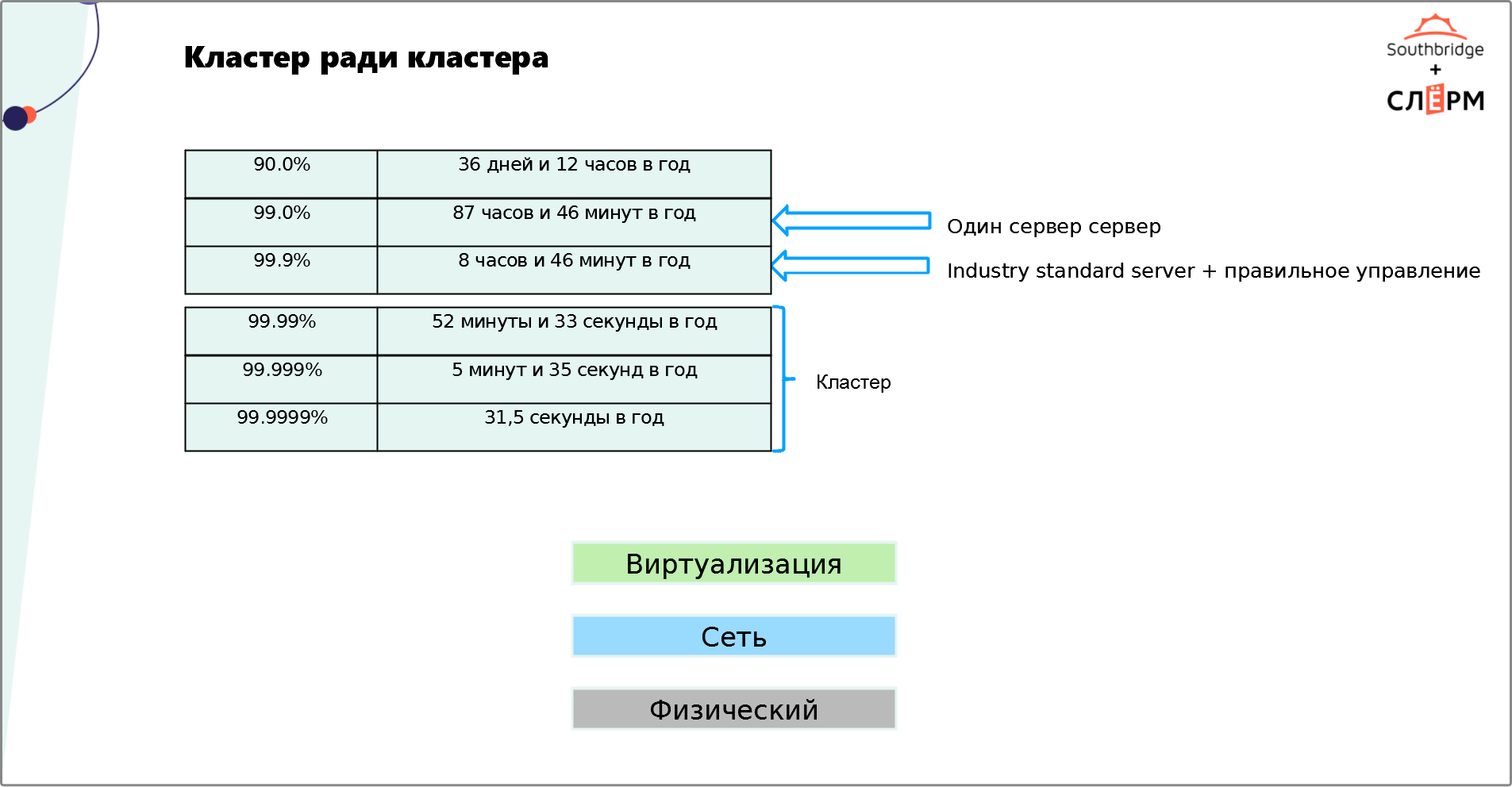
Считается, что кластер — универсальный инструмент, который обеспечивает надёжность и отказоустойчивость системы. Отказоустойчивость в «айтишном» мире измеряют девятками:
- Одна девятка = доступность 90%. Это означает, что сервис может не работать 36 дней и 12 часов в год.
- Две девятки = доступность 99%. Сервис может не работать 87 часов и 46 минут в год.
- Три девятки = доступность 99.9%. Сервис может не работать 8 часов и 46 минут в год.
- Четыре девятки = доступность 99.99%. Сервис может не работать 52 минуты и 33 секунды в год.
- Пять девяток = доступность 99.999%. Сервис может не работать 5 минут и 35 секунд в год.
- Шесть девяток = доступность 99.9999%. Сервис может не работать всего 31,5 секунды в год.
Большинству бизнесов для стабильной работы сервиса хватит трёх девяток. Чтобы их достичь, можно:
- Использовать Industry standard server, у которых дублируются жёсткие диски, сетевые карты, источники питания.
- Правильно его обслуживать: мониторить и принимать меры, когда сервер выходит из строя.
- Обеспечить отказоустойчивость дополнительными средствами. Например, подключить два источника питания от разных подов в дата-центре; подсоединить серверы к разным свитчам разными линками; делать агрегацию; сделать виртуализацию — она позволит абстрагироваться от проблем с железом.
Ни один сервер не обеспечит отказоустойчивость больше трёх девяток. Для такой доступности приложения нужно разворачивать кластер. Однако часто не учитывают, что это дорогое и сложное решение, для которого требуются:
- Дополнительные траты на покупку или аренду железа и ПО. Высокая отказоустойчивость нуждается в избыточности ресурсов — в нескольких серверах, виртуальных машинах и т. д.
- Больше операционных затрат. Дублируются траты на обслуживание ресурсов — необходимо обновлять две ОС, защищать два сервера с двумя приложениями и т. д.
- Специалисты достаточно высокого уровня для поддержки кластера. Рядовой сисадмин с этим вряд ли справится.
Прежде чем внедрять кластер, следует:
- Понять, какая отказоустойчивость приложения необходима для вашего бизнеса.
- Посчитать, сколько денег вы теряете в случае простоя.
- Сопоставить траты на внедрение и содержание кластера с суммой, которую вы теряете при простое системы.
Если кластер стоит дороже времени простоя, то разворачивать его нерентабельно. Можно обойтись тремя девятками, укрепив отказоустойчивость средствами, о которых мы рассказали выше.
2. Единые точки отказа
- Один источник питания на все серверные стойки.
- Единое для всех серверов хранилище.
- Firewall и устройства, которые находятся в пограничной зоне между пользователями и кластером.
- Сетевое оборудование: свитчи, роутеры.
- Load balancers.
- Серверы. Если все виртуальные машины находятся на одном сервере, при его отказе приложение тоже упадёт.
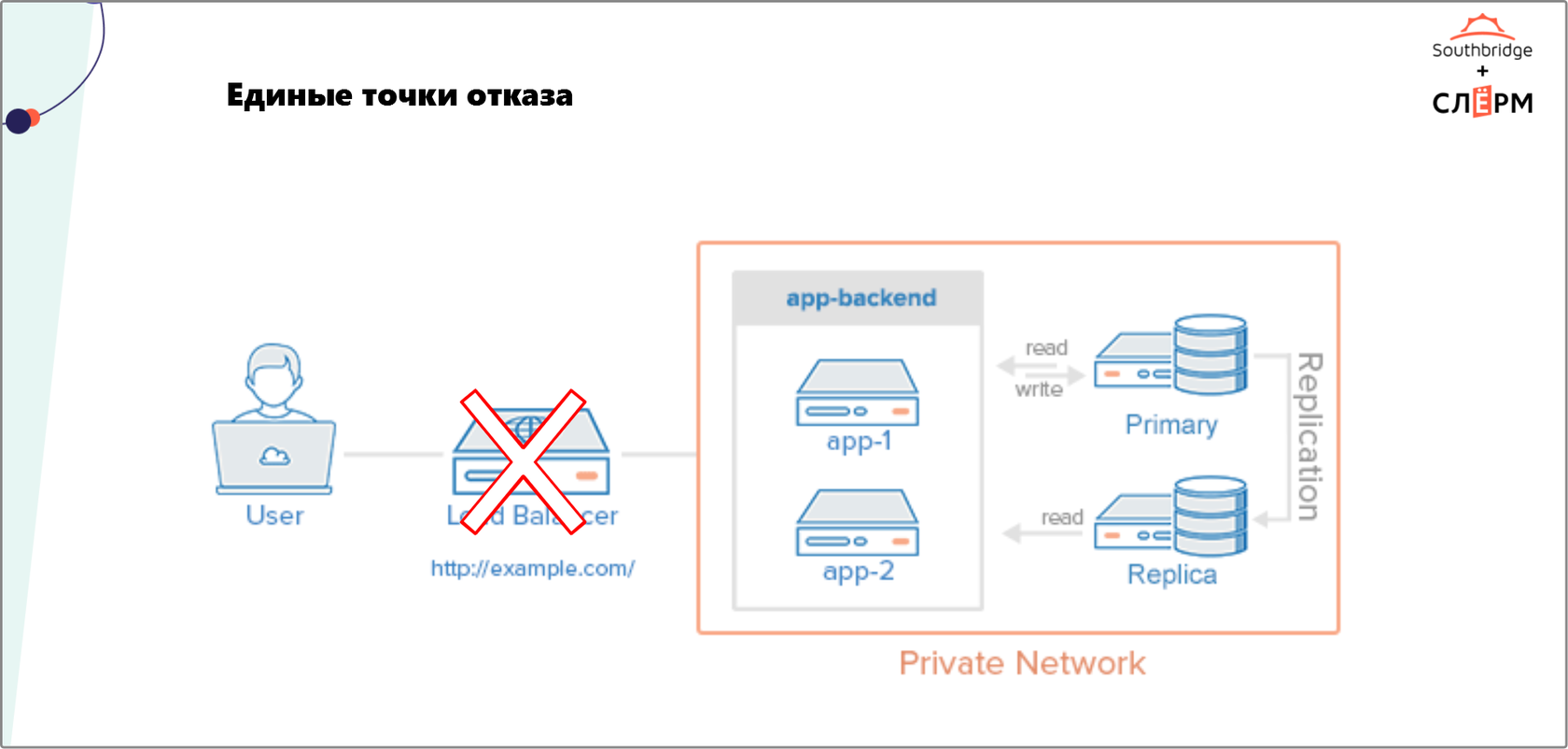
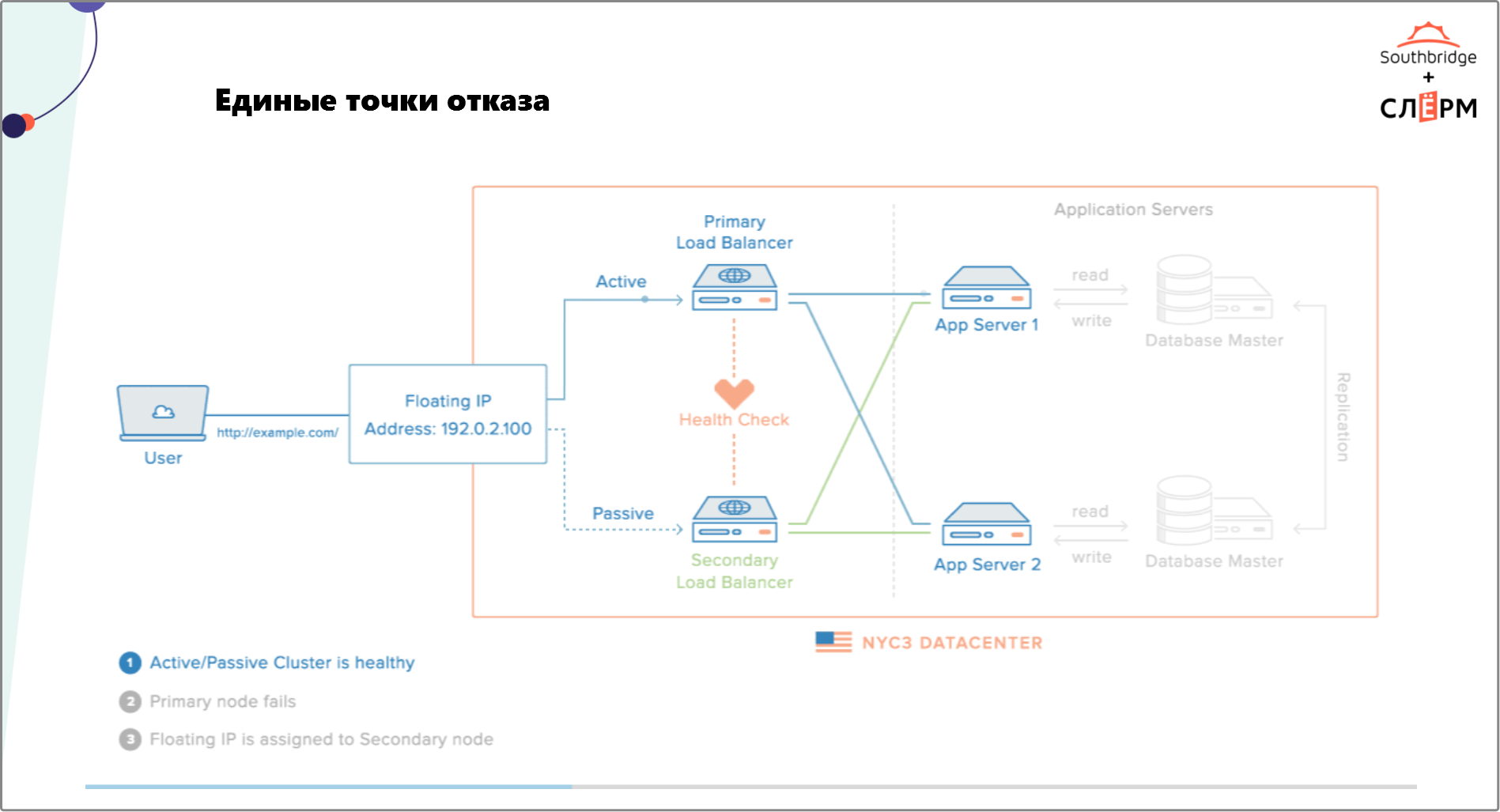
На Рис. 2 — кластер с высоким уровнем доступности. Здесь нет видимых точек отказа. IP-адрес плавает между Load balancers. Есть сервер приложения и кластеризованный сервер базы данных. Другие точки отказа на уровне инфраструктуры закрывает дата-центр.
3. Нарушение принципов majority
Чтобы кластер автоматически отработал отказ узла, ему необходимо понять, что произошло. Нода упала или стала изолированной? Порвалась сеть? Чтобы это определить, большинство кластеров используют принцип majority. У каждой ноды есть «голос». Работать останется та часть кластера, у которой больше голосов.
На Рис. 3 — кластер из трёх нод, распределённых по двум зонам отказа. В Зоне 1 — две ноды, следовательно, у этой зоны два «голоса». В Зоне 2 — одна нода и один «голос». Если вторая зона откажет, то кластер продолжит обслуживать Зона 1.
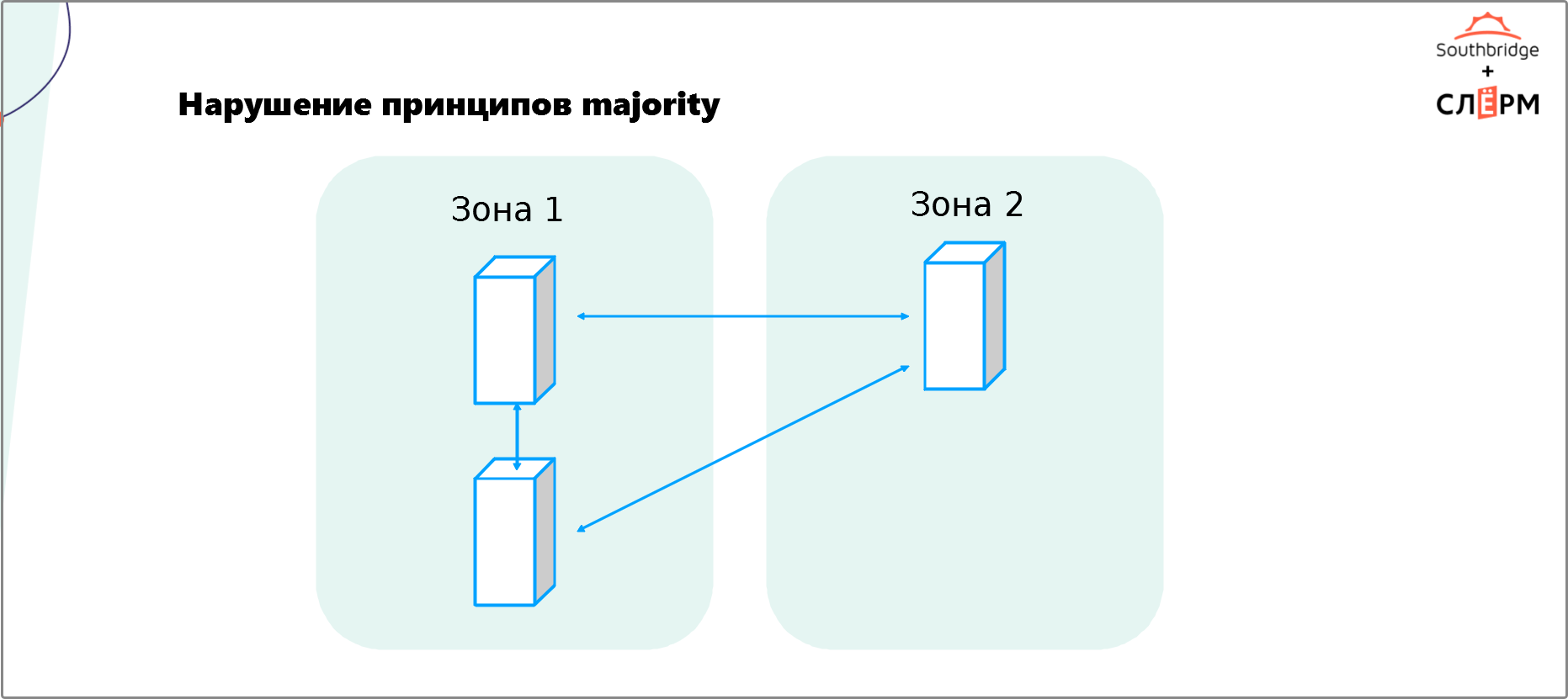
Кажется, что такая архитектура хорошо работает. Это не так — здесь нарушен принцип majority. Потеряв соединение с Зоной 1, Зона 2 не получит majority, посчитает себя изолированной от кластера и отключит сервис — приложение станет недоступным. Включать его придётся вручную, а на это потребуется время.
Если кластер состоит из чётного количества узлов, которые распределены в две зоны отказа, то разрыв соединения между ними приведёт к сплит-брейну (Split Brain). Кластер посчитает, что всё нормально и обе его части работают корректно, хотя это не так и зоны не «общаются» друг с другом.
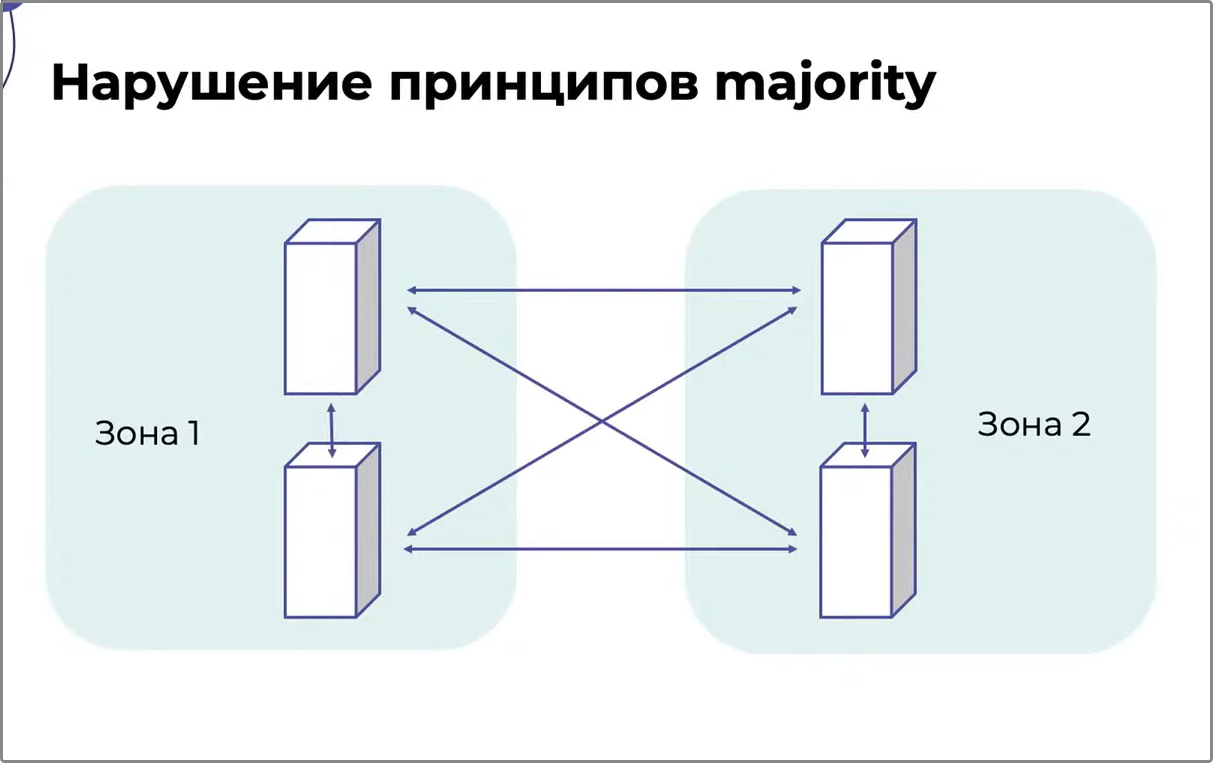
Сплит-брейн легко устраняется восстановлением соединения и не приводит к серьёзным последствиям при условии, что он произошёл не на кластере базы данных. В противном случае при обрыве сети кластер продолжает параллельно сохранять данные в обеих зонах и, когда между узлами снова появляется связь, начинается путаница — приходится долго разбираться, что записалось, а что потерялось; какие данные нужно удалить, а какие совместить. В связи с этим кластеры, особенно те, что хранят данные, рекомендуется дробить на нечётное количество зон отказа.
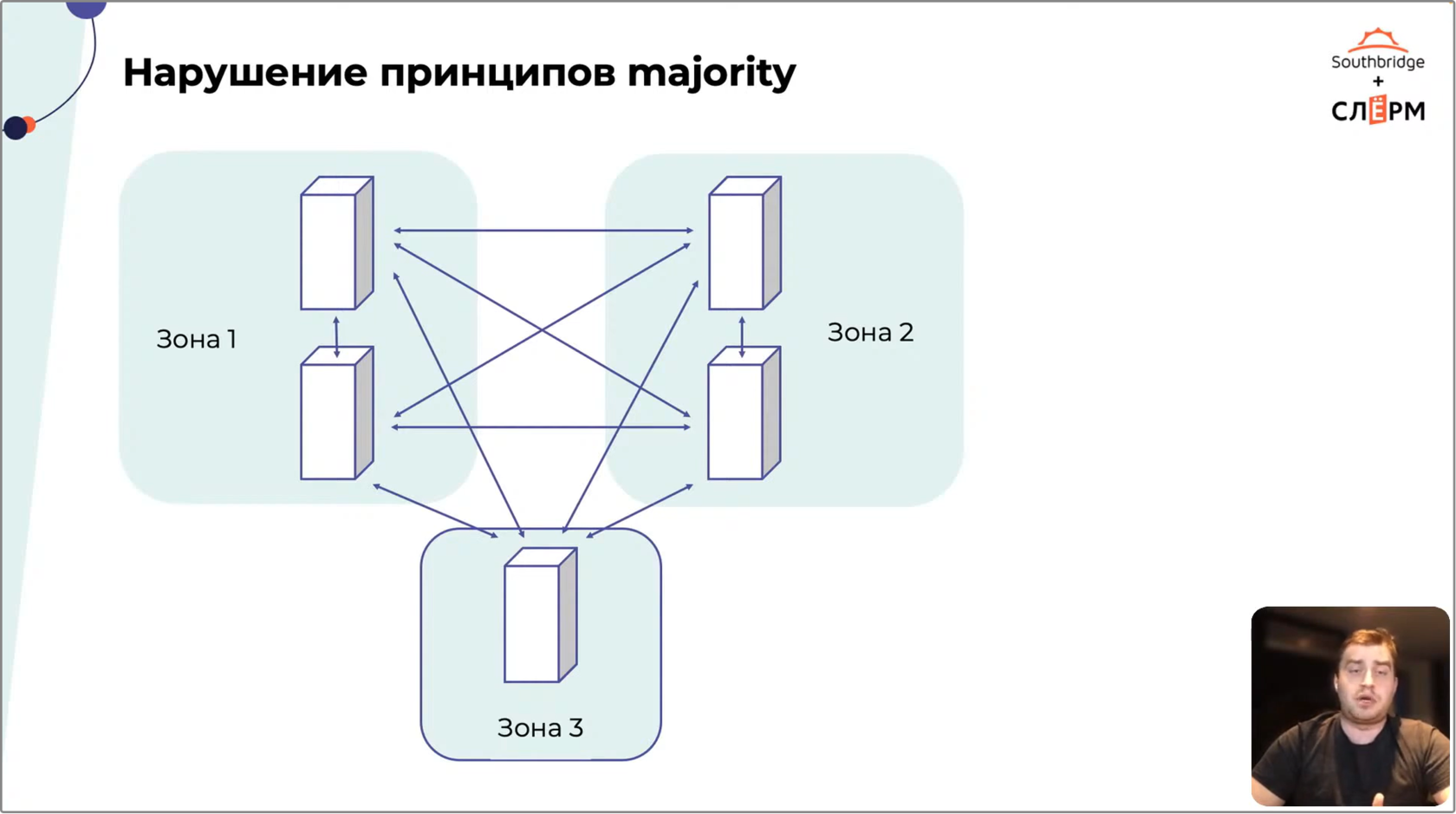
На Рис. 5 — кластер, в котором соблюдается принцип majority. Он состоит из 5 нод, распределённых по трём зонам отказа. Если первая зона отключится, Зона 2 продолжит видеть Зону 3 и наоборот, и кластер будет работать.
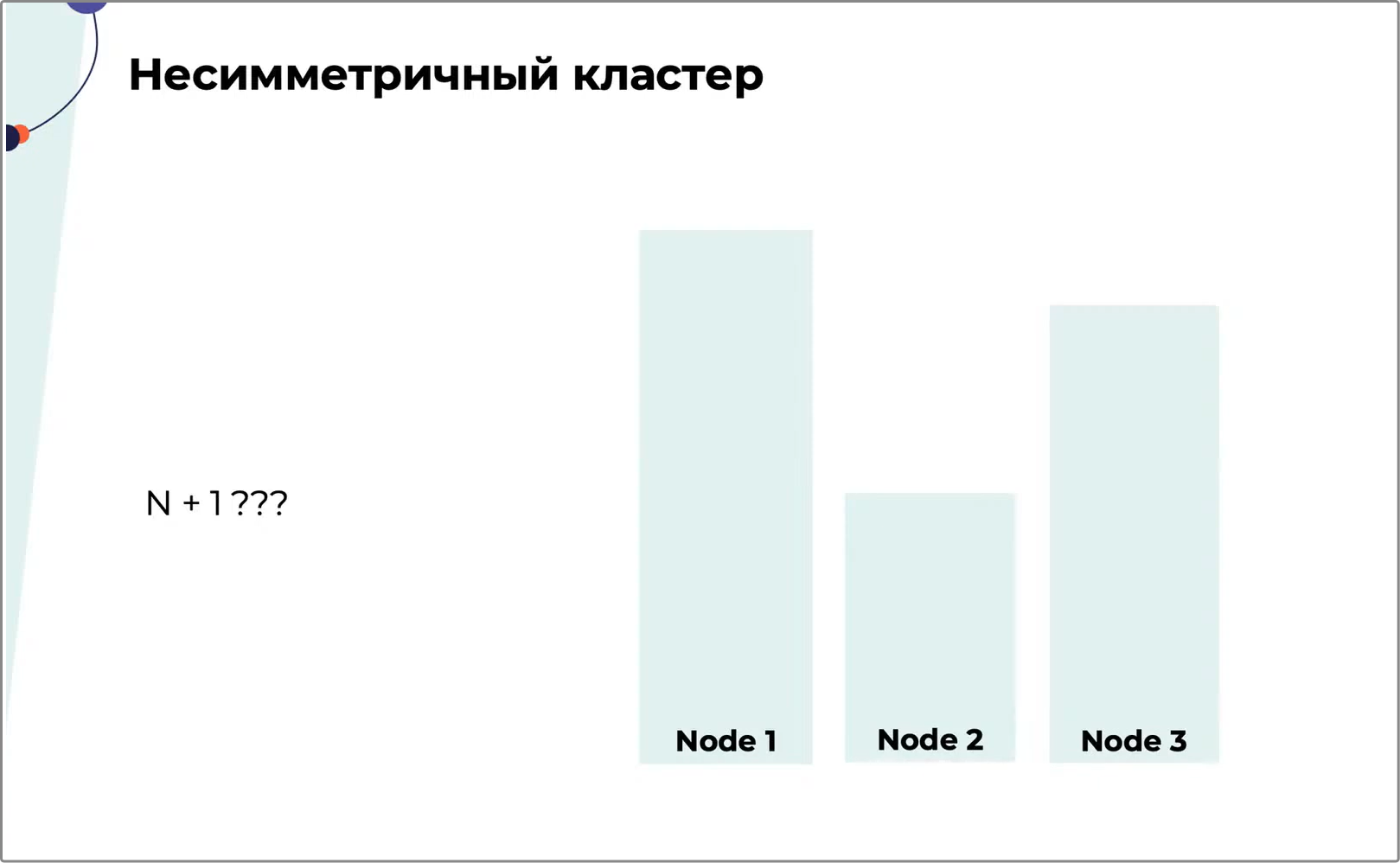
4. Несимметричный кластер
При внедрении кластера нужно позаботиться о его симметричности и выделить каждой ноде одинаковое количество ресурсов: ЦПУ, дисков, памяти и т. д. Так будет гораздо легче обеспечить отказоустойчивость и не загрузить кластер на 100% при отказе одной или нескольких нод. Приложение на 100% загруженном кластере работает так себе — в лучшем случае оно подтормаживает. В худшем — вообще не загружается.
На Рис. 6 — несимметричный кластер. При падении второй ноды её ресурсы распределятся между нодами 1 и 3, и это не перегрузит кластер. Если откажет нода 1, её ресурсы не поместятся в ноды 2 и 3 — из строя выйдет весь кластер.
5. Перегруженный кластер
Эта ошибка связана с предыдущей. Выше мы уже говорили, что отказоустойчивый кластер требует избыточности. Это значит, что нужно не только равномерно распределить по нодам ЦПУ, диски, память и т. д., но и выделить на них некоторое количество ресурсов, которые не будут использоваться. Необязательно закладывать в два или три раза больше ресурсов. Их должно быть столько, чтобы хватило на рост нагрузки в случае отказа одной или нескольких нод и осталось ещё немного.
На Рис. 7 — кластер из пяти нод. Мы хотим обеспечить N + 2 — сделать так, чтобы при отказе двух нод кластер продолжил работать. Сейчас кластер сможет распределить нагрузку при отказе одной ноды (Рис. 8), а вот двух — уже нет (Рис. 9).

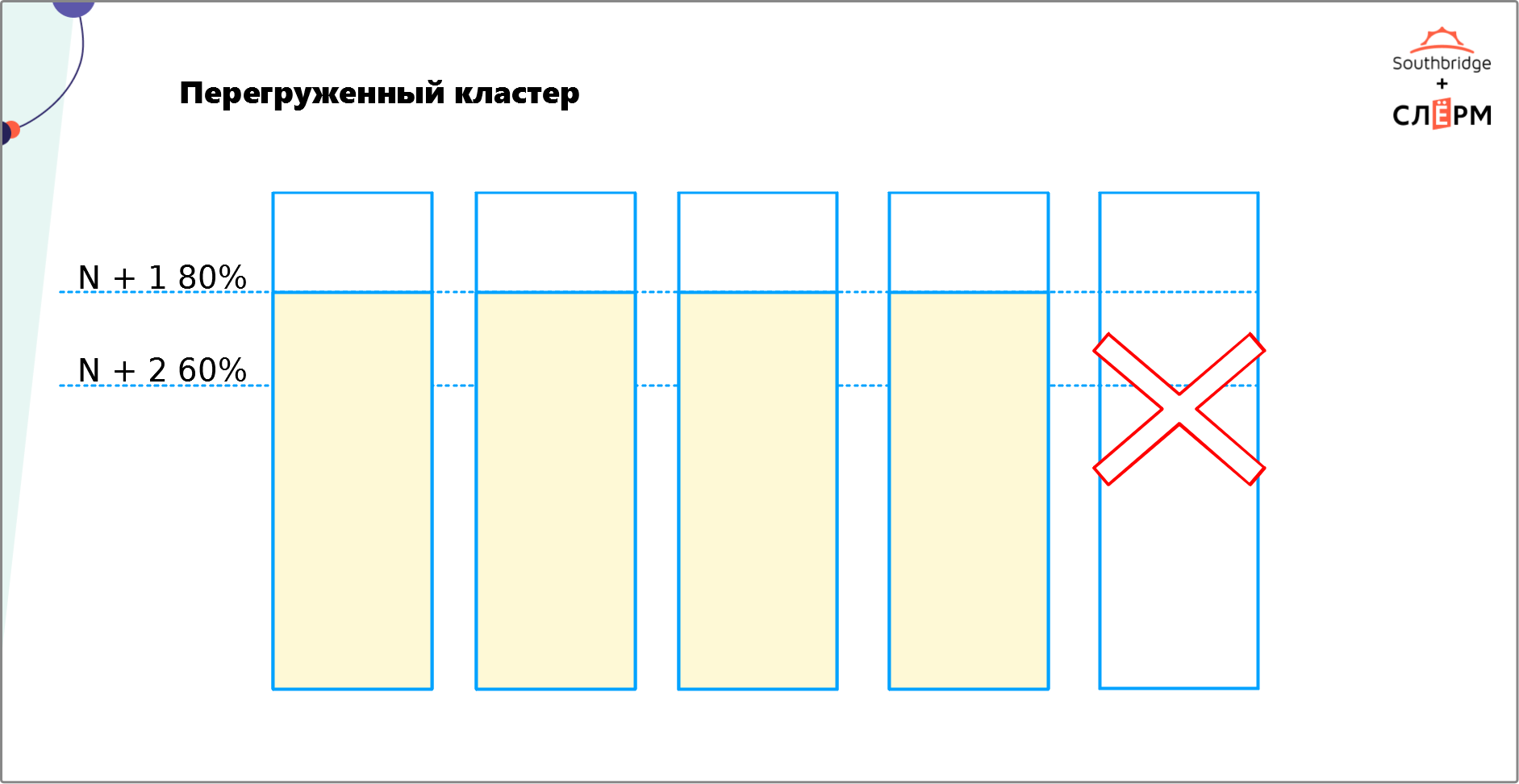
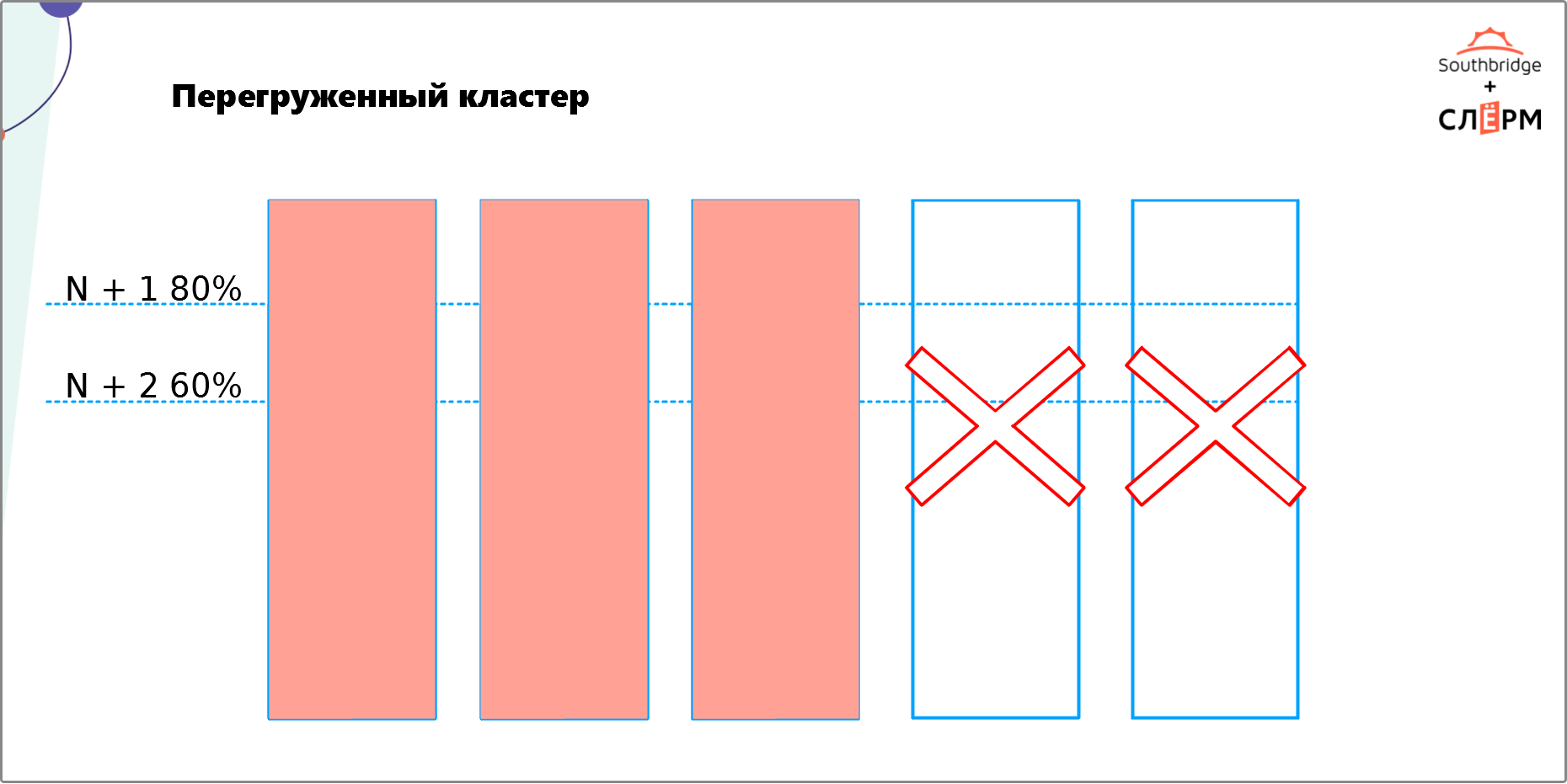
Чтобы обеспечить на таком кластере N + 2, нужно выделить столько ресурсов для каждой ноды, чтобы:
- при отказе одной ноды нагрузка на оставшиеся четыре составила не больше 60%;
- при отказе двух нод нагрузка на оставшиеся три составила не больше 80%.
6. Непротестированный кластер
Перед запуском следует протестировать кластер и убедиться, что он работает именно так, как мы ожидаем. В противном случае его поведение может стать неприятным сюрпризом — кластер может долго переключать сервис; падать, когда не должен; мешать решать другие задачи.
- Сработает ли кластеризация в случае отказа?
- Сколько времени займёт переключение сервиса?
- Как подготовиться к плановому обслуживанию?
- Что делать, если часть инфраструктуры станет недоступна?
- Есть ли в серверной провод, выдернув который мы выключим весь кластер?
7. Беспризорный кластер (без обслуживания и мониторинга)
- Выявить вышедший из строя компонент кластера раньше, чем из-за поломки сломается сам сервис.
- Доказать бизнесу, что деньги на кластер потрачены не зря и он обеспечивает ожидаемый уровень отказоустойчивости.
- Измерять и контролировать загрузку кластера, чтобы избежать несимметричности и перегруженности. Кластер не статичен. Со временем у него растёт загрузка, меняются версии и конфигурации.
Резюме
- Ответить на вопрос: «Действительно ли нужен кластер?» Иногда достаточный уровень отказоусточивости обеспечивается без этого инструмента.
- Протестировать кластер перед запуском в продакшн и понять, как система ведёт себя в разных условиях, нет ли у неё единых точек отказа и нарушений принципов majority, равномерно ли распределены ресурсы и т. д.
- Обеспечить кластеру мониторинг и обслуживание.