Типы таблиц
Таблица определяет сведения, которые вы хотите отслеживать, в форме строк (записей), которые обычно включают столбцовые данные такие как название компании, местоположение, продукты, адрес электронной почты, телефон и т. д.
Таблицы в Power Apps бывают следующих типов:
- Стандартные: несколько стандартных таблиц, также известных как готовые таблицы, входят в комплект поставки среды Power Platform, включающей в себя Microsoft Dataverse. Таблицы учетных записей, бизнес-подразделений, контактов, задач и пользователей являются примерами стандартных таблиц в Dataverse. Большинство стандартных таблиц, включенных в Dataverse, можно настроить. Таблицы, импортированные как часть управляемого решения и заданные как настраиваемые, также отображаются как стандартные таблицы. Любой пользователь с соответствующими привилегиями может настроить эти таблицы, для которых свойство «таблица» имеет настраиваемое значение true.
- Таблицы действий: особый тип таблиц, который лучше всего подходят для строк, содержащих основанный на действиях элемент, который может включать тему, время начала, время окончания, дату выполнения и продолжительность. В комплект Dataverse входит несколько готовых таблиц действий, таких как встреча, задача, сообщение электронной почты и звонок. Дополнительные сведения: Таблицы действий
- Виртуальные: используются, когда вам нужно, чтобы таблица заполнялась данными из внешнего источника (за пределами Dataverse).
- Эластичные: предназначены для случаев, когда в таблице будет храниться очень большой набор данных, объем которого превышает десятки миллионов строк.
Таблицы действий
Действия можно рассматривать как любое действие, для которого можно сделать запись в календаре. Действие имеет временные измерения (время начала, остановки, срок, продолжительность) и помогает определить, когда произошло или произойдет действие. Действия также содержат данные, помогающие определить, какое действие представлено действием, например тема и описание. Любое действие можно открыть, отменить или выполнить. Завершенный статус действия будет иметь несколько вложенных значений статуса, связанных с ним, чтобы указать на способ выполнения действия.
Таблицы действий — это особый вид таблиц, которые могут принадлежать только пользователю или группе, но не могут принадлежать организации. При создании таблицы вы можете указать ее как стандартную таблицу или таблицу действий.
В следующей таблице перечислены таблицы действий, доступные в среде по умолчанию.
| Полное имя | Описание | Отображение в меню действий | Справка |
|---|---|---|---|
| Встреча | Обязательство, представляющее временной интервал с временем начала и окончания, а также длительностью. | Да | Встреча |
| Электронная почта | Действие, передаваемое с помощью протоколов электронной почты. | Да | Эл. почта |
| Факс | Действие, отслеживающее результаты звонков и число страниц в факсе и дополнительно хранящее электронную копию документа. | Да | Факс |
| Письмо | Действие, отслеживающее доставку письма. Действие, содержащее электронную копию письма. | Да | Письмо |
| Звонок | Действие для отслеживания телефонного звонка. | Да | PhoneCall |
| Повторяющаяся встреча | Главная встреча или ряд повторяющихся встреч. | Да | RecurringAppointmentMaster |
| Задача | Универсальное действие, представляющее работу, которую необходимо выполнить. | Да | Задача |
Когда можно создать новую настраиваемую таблицу действия, можно создать ее, чтобы читать сообщения с помощью мгновенных сообщений. Создание таблицы действия отличается от создания таблицы, не связанной с действием, потому что основной столбец не задается. Все таблицы действий имеют для столбца Основное поле заданное значение Тема и другие стандартные столбцы, определенные таблицей «Действие». Это позволяет отображать в представлении, где отображаются только стандартные столбцы, все типы действий.
Чтобы создать настраиваемую таблицу действий, откройте раздел Дополнительные параметры на панели Создать таблицу, выберите параметр Таблица действий из раскрывающегося списка Тип. После выбора этот значения вы увидите, что выбрано Отображать в меню действий. Это дает возможность создавать этот тип действия в меню действий. Оно не выбрано для действий, которые обычно связаны с конкретными событиями и созданы без использования кода или бизнес-процесса. Сохранив таблицу, изменить эти параметры нельзя.
Включение действий для таблицы
Включите действия для добавления действий в таблицу и используйте подстановку «В отношении» в таблице.
- Чтобы включить действия, войдите в Power Apps.
- На левой панели навигации выберите Таблицы, а затем откройте нужную таблицу.
- Выберите Свойства.
- Разверните Дополнительные параметры, а затем выберите Создание нового действия.
Важно! После включения этот параметр не может быть отключен.
Тип собственности таблицы
Существует два разных типа владения стандартными и пользовательскими таблицами. При создании пользовательской таблицы варианты владения будут Пользователь или рабочая группа или Организация. После создания таблицы изменить тип собственности будет невозможно.
| Ответственность | Описание |
|---|---|
| Предприятие | Данные принадлежат организации. Доступ к данным контролируется на уровне организации. |
| Пользователь или рабочая группа | Данные принадлежат пользователю или рабочей группе. Действия, которые могут быть выполнены для этих строк, можно контролировать на уровне пользователя. |
Обратите внимание, что есть несколько системных таблиц Dataverse, которые похожи на стандартные таблицы, но имеют другой тип собственности, отличный от организации и пользователя или рабочей группы:
- Нет. Некоторые системные таблицы не имеют владельца, например таблица привилегий.
- Подразделение. Несколько системных таблиц принадлежат компании. Сюда относятся таблицы «Подразделение», «Календарь», «Группа» и «Роль безопасности».
После создания пользовательской таблицы изменить владение невозможно. Перед созданием таблицы убедитесь, что выбран нужный тип владения. Если позже будет установлено, что пользовательская таблица должна иметь другой тип, придется удалять ее и создавать новую.
Виртуальные таблицы
Виртуальная таблица — это настраиваемая таблица в Dataverse, которая имеет столбцы, содержащие данные из внешнего источника данных. Виртуальные таблицы в приложении выглядят для пользователей как обычные строки таблицы, но содержат данные, динамически получаемые из внешней базы данных во время выполнения, например базы данных SQL Azure. Строки, основанные на виртуальных таблицах, доступны для всех клиентов, включая настраиваемые клиенты, разработанные с помощью веб-служб Dataverse. Дополнительные сведения: Создание и изменение виртуальных таблиц, содержащих данные из внешнего источника данных
Эластичные таблицы
Эластичные таблицы обеспечивают более высокую производительность по сравнению со стандартными таблицами, если таблица содержит очень большой набор данных. Эластичные таблицы работают на базе Azure Cosmos DB. Дополнительные сведения: Создание и изменение эластичных таблиц (предварительная версия)
См. также
Каковы ваши предпочтения в отношении языка документации? Пройдите краткий опрос (обратите внимание, что этот опрос представлен на английском языке).
Опрос займет около семи минут. Личные данные не собираются (заявление о конфиденциальности).
Обратная связь
Отправить и просмотреть отзыв по
Объединение двух или нескольких таблиц
Вы можете объединить строки из одной таблицы в другую, просто вклеив данные в первые пустые ячейки под целевой таблицей. Таблица увеличится в размере, чтобы включить в нее новые строки. Если строки в обеих таблицах совпадают, вы можете объединить столбцы одной таблицы с другой, вклеив их в первые пустые ячейки справа от таблицы. В этом случае таблица также увеличится вместить новые столбцы.
Слияние строк на самом деле очень просто, но слияние столбцов может быть непросто, если строки одной таблицы не соответствуют строкам в другой таблице. Некоторых проблем с выравниванием можно избежать, если воспользоваться функцией ВПР.
Объединение двух таблиц с помощью функции ВЛОП
В приведенного ниже примере вы увидите две таблицы с другими именами: «Синяя» и «Оранжевая». В таблице «Синяя» каждая строка представляет собой позицию заказа. Например, заказ № 20050 содержит две позиции, № 20051 — одну, № 20052 — три и т. д. Мы хотим объединить столбцы «Код продажи» и «Регион» с таблицей «Синяя» с учетом соответствия значений в столбце «Номер заказа» таблицы «Оранжевая».
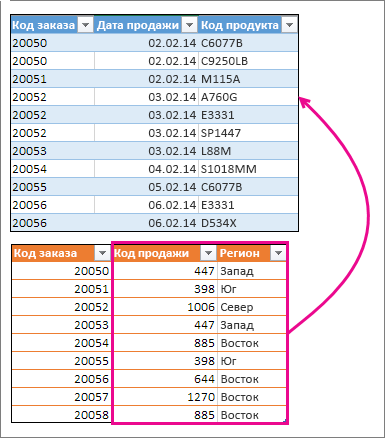
Значения «ИД заказа» повторяются в таблице «Синяя», но значения «ИД заказа» в таблице «Оранжевая» уникальны. Если просто скопировать и ввести данные из таблицы «Оранжевая», значения «ИД продаж» и «Регион» для второй строки заказа 20050 будут отключены на одну строку, что изменит значения в новых столбцах таблицы «Синяя».
Вот данные для таблицы «Синяя», которую можно скопировать на пустой лист. После в таблицы нажмите CTRL+T, чтобы преобразовать ее в таблицу, а затем переименуйте таблицу Excel синюю.
Вот данные для таблицы «Оранжевая». Скопируйте его на тот же самый таблицу. После в таблицы нажмите CTRL+T, чтобы преобразовать ее в таблицу, а затем переименуйте таблицу в Оранжевая.
Нам необходимо обеспечить правильное выравнивание значений «ИД продаж» и «Регион» для каждого заказа с каждым уникальным элементом строки заказа. Для этого впустим заголовки таблицы «ИД продажи» и «Регион» в ячейки справа от таблицы «Синяя», а затем с помощью формулЫ ВЗ ПРОСМОТР выберем правильные значения из столбцов «ИД продажи» и «Регион» таблицы «Оранжевая».
Вот как это сделать.
- Скопируйте заголовки «ИД продажи» и «Регион» в таблице «Оранжевая» (только эти две ячейки).
- В ячейку справа от заголовка «ИД товара» таблицы «Синяя». Теперь таблица «Синяя» содержит пять столбцов, включая новые — «Код продажи» и «Регион».
- В таблице «Синяя», в первой ячейке столбца «Код продажи» начните вводить такую формулу: =ВПР(
- В таблице «Синяя» выберите первую ячейку столбца «Номер заказа» — 20050. Частично заполненная формула выглядит так:
 Выражение [@[Номер заказа]] означает, что нужно взять значение в этой же строке из столбца «Номер заказа». Введите точку с запятой и выделите всю таблицу «Оранжевая» с помощью мыши. В формулу будет добавлен аргумент Оранжевая[#Все].
Выражение [@[Номер заказа]] означает, что нужно взять значение в этой же строке из столбца «Номер заказа». Введите точку с запятой и выделите всю таблицу «Оранжевая» с помощью мыши. В формулу будет добавлен аргумент Оранжевая[#Все]. - Введите точку с запятой, число 2, еще раз точку с запятой, а потом 0, вот так: ;2;0
- Нажмите клавишу ВВОД, и законченная формула примет такой вид:
 Выражение Оранжевая[#Все] означает, что нужно просматривать все ячейки в таблице «Оранжевая». Число 2 означает, что нужно взять значение из второго столбца, а 0 — что возвращать значение следует только в случае точного совпадения. Обратите внимание: Excel заполняет ячейки вниз по этому столбцу, используя формулу ВПР.
Выражение Оранжевая[#Все] означает, что нужно просматривать все ячейки в таблице «Оранжевая». Число 2 означает, что нужно взять значение из второго столбца, а 0 — что возвращать значение следует только в случае точного совпадения. Обратите внимание: Excel заполняет ячейки вниз по этому столбцу, используя формулу ВПР. - Вернитесь к шагу 3, но в этот раз начните вводить такую же формулу в первой ячейке столбца «Регион».
- На шаге 6 вместо 2 введите число 3, и законченная формула примет такой вид:
 Между этими двумя формулами есть только одно различие: первая получает значения из столбца 2 таблицы «Оранжевая», а вторая — из столбца 3. Теперь все ячейки новых столбцов в таблице «Синяя» заполнены значениями. В них содержатся формулы ВПР, но отображаются значения. Возможно, вы захотите заменить формулы ВПР в этих ячейках фактическими значениями.
Между этими двумя формулами есть только одно различие: первая получает значения из столбца 2 таблицы «Оранжевая», а вторая — из столбца 3. Теперь все ячейки новых столбцов в таблице «Синяя» заполнены значениями. В них содержатся формулы ВПР, но отображаются значения. Возможно, вы захотите заменить формулы ВПР в этих ячейках фактическими значениями. - Выделите все ячейки значений в столбце «Код продажи» и нажмите клавиши CTRL+C, чтобы скопировать их.
- На вкладке Главная щелкните стрелку под кнопкой Вставить.
- В коллекции параметров вставки нажмите кнопку Значения.
- Выделите все ячейки значений в столбце «Регион», скопируйте их и повторите шаги 10 и 11. Теперь формулы ВПР в двух столбцах заменены значениями.
Дополнительные сведения о таблицах и функции ВПР
- Как добавить или удалить строку или столбец в таблице
- Использование структурированных ссылок в формулах таблиц Excel
- Использование функции ВПР (учебный курс)
Дополнительные сведения
Вы всегда можете задать вопрос эксперту в Excel Tech Community или получить поддержку в сообществах.
Столбцы таблиц также известны как
Для выборки данных из БД в MySQL применяется команда SELECT . В упрощенном виде она имеет следующий синтаксис:
SELECT список_столбцов FROM имя_таблицы
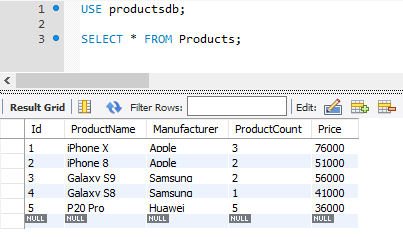
Например, пусть ранее была создана таблица Products, и в нее добавлены некоторые начальные данные:
CREATE TABLE Products ( Id INT AUTO_INCREMENT PRIMARY KEY, ProductName VARCHAR(30) NOT NULL, Manufacturer VARCHAR(20) NOT NULL, ProductCount INT DEFAULT 0, Price DECIMAL ); INSERT INTO Products (ProductName, Manufacturer, ProductCount, Price) VALUES ('iPhone X', 'Apple', 3, 76000), ('iPhone 8', 'Apple', 2, 51000), ('Galaxy S9', 'Samsung', 2, 56000), ('Galaxy S8', 'Samsung', 1, 41000), ('P20 Pro', 'Huawei', 5, 36000);
Получим все объекты из этой таблицы:
SELECT * FROM Products;
Символ звездочка * указывает, что нам надо получить все столбцы.
Стоит отметить, что применение звездочки * для получения данных считается не очень хорошей практикой, так как обычно необходимо получить данные по небольшому набору столбцов. Поэтому более оптимальный подход заключается в указании всех необходимых столбцов после слова SELECT. Исключение составляет тот случай, когда надо получить данные по абсолютно всем столбцам таблицы. Также использование символа * может быть предпочтительно тогда, когда названия столбцов не известны.
Если необходимо получить данные не из всех, а из каких-то конкретных столбцов, тогда спецификации этих столбцов перечисляются через запятую после SELECT:
SELECT ProductName, Price FROM Products;
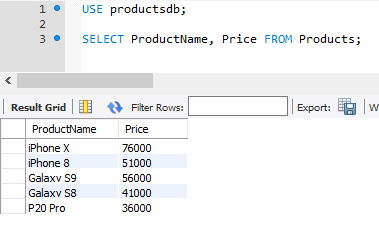
Спецификация столбца необязательно должна представлять его название. Это может быть любое выражение, например, результат арифметической операции. Так, выполним следующий запрос:
SELECT ProductName, Price * ProductCount FROM Products;
Здесь при выборке будут создаваться два столбца. Причем второй столбец представляет значение столбца Price, умноженное на значение столбца ProductCount, то есть совокупную стоимость товара.
С помощью оператора AS можно изменить название выходного столбца или определить его псевдоним:
SELECT ProductName AS Title, Price * ProductCount AS TotalSum FROM Products;
Здесь для первого столбца определяется псевдоним Title, хотя в реальности он будет представлять столбец ProductName. Второй столбец TotalSum хранит произведение столбцов ProductCount и Price.
Индексы в базе данных Oracle
Индексы Oracle обеспечивают быстрый доступ к строкам таблиц, сохраняя отсортированные значения указанных столбцов и используя эти отсортированные значения для быстрого нахождения ассоциированных строк таблицы . Индексы позволяют находить строку с определенным значением столбца, просматривая при этом лишь небольшую часть общего объема строк таблицы. Таким образом правильное использование индексов сокращает до минимума количество дорогостоящих операций ввода-вывода.
Применение индексов представляет собой компромисс между ускорением получения результатов запросов и замедлением обновлений и вставок данных. Первая часть этого компромисса – ускорение запросов – довольно очевидна: если поиск выполняется по отсортированному индексу вместо полного сканирования всей таблиц, то запрос проходит намного быстрее. Но всякий раз, когда вы обновляете, вставляете или удаляете строку таблицы с индексами, индексы также должны быть обновлены соответствующим образом. То есть такие операции на таблицах с индексами обходятся дороже.
Вообще говоря, если таблицы в основном используются для чтения (выборки) информации, как в хранилищах данных, то лучше иметь много индексов. Если база данных относится к типу OLTP, с большим количеством вставок, обновлений и удалений, то лучше обойтись меньшим числом индексов.
Если только вам не нужно обращаться к большинству сток таблицы, индексированные запросы обеспечивают более быстрое получение результатов, чем запросы, не использующие индексы. Не существует ограничений на количество индексов, которые могут относиться к одной таблице Oracle, но, как упоминалось ранее, от их количества зависит производительность. Индекс полностью прозрачен для пользователя – т.е. оператор SQL пользователя не должен изменяться в результате создания индексов. Однако разработчикам приложений для построения эффективных запросов следует хорошо представлять себе , что такое индексы и как они работают.
Индексы могут относиться к нескольким типам, наиболее важные из которых перечислены ниже:
- Уникальные и неуникальные индексы. Уникальные индексы основаны на уникальном столбце – обычно вроде номера карточки социального страхования сотрудника. Хотя уникальные индексы можно создавать явно, Oracle не рекомендует это делать. Вместо этого следует использовать уникальные ограничения. Когда накладывается ограничение уникальности на столбец таблицы, Oracle автоматически создает уникальные индексы по этим столбцам.
- Первичные и вторичные индексы. Первичные индексы – это уникальные индексы в таблице, которые всегда должны иметь какое-то значение и не могут быть равны null. Вторичные индексы – это прочие индексы таблицы, которые могут и не быть уникальными.
- Составные индексы – индексы, содержащие два или более столбца из одной и той же таблицы. Они также известны как сцепленные индексы (concatenated index). Составные индексы особенно полезны для обеспечения уникальности сочетания столбцов таблицы в тех случаях, когда нет уникального столбца, однозначно идентифицирующего строку.
Руководство по созданию индексов
Хотя хорошо известно, что индексы повышают производительность базы данных, следует знать, как их заставить работать должным образом. Добавление ненужных или неподходящих индексов к таблице может даже привести к снижению производительности. Ниже предоставлены некоторые рекомендации по созданию эффективных индексов в базе данных Oracle.
- Индекс имеет смысл, если нужно обеспечить доступ одновременно не более чем к 4-5% данных таблицы. Альтернативной использования индекса для доступа к данным строки является полное последовательное чтение таблицы от начала до конца, что называется полным сканированием таблицы. Полное сканирование таблицы больше подходит для запросов, которые требуют извлечения большего процента данных таблицы. Помните, что применение индексов для извлечения строк требует двух операций чтения: индекса и затем таблицы.
- Избегайте создания индексов для сравнительно небольших таблиц. Для таких таблиц больше подходит полное сканирование. В случае маленьких таблиц нет необходимости в хранении данных и таблиц, и индексов.
- Создавайте первичные ключи для всех таблиц. При назначении столбца в качестве первичного колюча Oracle автоматически создаст индекс по этому столбцу.
- Индексируйте столбцы, участвующие в многотабличных операциях соединения.
- Индексируйте столбцы, которые часто используются в конструкциях WHERE.
- Индексируйте столбцы, участвующие в операциях ORDER BY и GROUP BY или других операциях, таких как UNION и DISTINCT, включающих сортировку. Поскольку индексы уже отсортированы, объем работы по выполнению необходимой сортировки данных для упомянутых операций будет существенно сокращен.
- Столбцы, стоящие из длинно-символьных строк, обычно плохие кандидаты на индексацию.
- Столбцы, которые часто обновляются, в идеале не должны быть индексированы из-за связанных с этим накладных расходов.
- Индексируйте таблицы в которых мало строк имеют одинаковые значения.
- Сохраняйте количество индексов небольшим.
- Составные индексы могут понадобиться там, где одностолбцовые значения сами по себе не уникальны. В составных индексах первым столбцом ключа должен быть столбец в котором количество строк с одинаковым значением минимально.
Всегда помните золотое правило индексации таблиц: индекс таблицы должен быть основан на типах запросов, которые будут выполняться над столбцами этой таблицы. На таблице можно создавать более одного индекса: например, можно создать индекс на столбце X, или столбце Y, или обоих сразу, а также один составной индекс на обоих столбцах. Принимая правильное решение относительно того, какие индексы следует создавать, подумайте о наиболее часто используемых типах запросов данных таблицы.
Схемы индексации Oracle
Oracle предлагает несколько схем индексации, соответствующих требованиям различных типов приложений. На фазе проектирования после тщательного анализа конкретных требований приложения, необходимо выбрать правильный тип индекса.
(B*tree)
В реализации индексов на основе B-деревьев используется концепция сбалансированного (на что указывает буква ‘B’ (balanced)) дерева поиска в качестве основы структуры индекса. В Oracle имеется собственный вариант B-дерева. Это обычные индексы, создаваемые по умолчанию, когда вы применяете оператора CREATE INDEX.
Индексы на основе B-деревьев структурированы в форме обратного дерева, где блоки верхнего уровня называются блоками ветвей (branch blocks), а блоки нижнего уровня – листовыми блоками (leaf blocks). В иерархии узлов все узлы кроме вершины, или корневого узла, имеют родительский узел и могут иметь ноль или более дочерних узлов. Если глубина древовидной структуры , т.е. количество уровней, одинакова от каждого листового блока до корневого узла, то такое дерево называется сбалансированным, или B-деревом.
B-деревья автоматически поддерживают необходимый уровень индекса по размеру таблицы. B-деревья также гарантируют, что индексные блоки всегда будут заполнены не меньше, чем наполовину, и менее, чем на 100%. B-деревья допускают операции выборки, вставки и удаления с очень небольшим количеством операций ввода-вывода на один оператор. Большинство B-деревьев имеет всего три и менее уровней. При использовании B-дерева нужно читать только блоки B-дерева, так что количество операций ввода-вывода будет ограничено числом уровней B-дерева (скажем, тремя) плюс две операции ввода-вывода на выполнение обновления или удаления (одна для чтения и одна для записи). Для выполнения поиска по B-дереву понадоисят всего три или менее обращений к диску.
Реализация B-дерева от Oracle – всегда сохраняет дерево сбалансированным. Листовые блоки содержат по два элемента: индексированные значения столбца и соответствующий идентификатор ROWID для строки, которая содержит это значение столбца. ROWID – уникальный указатель Oracle, идентифицирующий физическое местоположение строки и обеспечивающий самый быстрый способ доступа к строке в базе данных Oracle. Сканирование индекса быстро дает ROWID строки, и отсюда можно быстро получить к ней доступ непосредственно. Если запрос нуждается лишь в значении индексированного столбца, то конечно, последний шаг исключается, поскольку извлекать дополнительные данные, кроме прочитанных из индекса, не потребуется.
Оценка размера индекса
Для оценки размера нового индекса можно использовать пакет DBMS_SPACE. Процедуре CREATE_INDEX_COST этого пакета потребуется передать оператор DDL, создающий индекс, в качестве атрибута.
SET SERVEROUTPUT ON DECLARE l_index_ddl varchar2(1000); l_used_bytes NUMBER; l_allocated_bytes NUMBER; BEGIN DBMS_SPACE.create_index_cost ( ddl => 'create index repsons_idx on EMP(ENAME)', used_bytes => l_used_bytes, alloc_bytes => l_allocated_bytes); DBMS_OUTPUT.PUT_LINE ('RESULT:'); DBMS_OUTPUT.PUT_LINE ('used_bytes = ' || l_used_bytes || ' byte'); DBMS_OUTPUT.PUT_LINE ('alloc_bytes = ' || l_allocated_bytes || ' byte'); END; / Обратите внимание на отличие между атрибутами, касающимися размера, в процедуре CREATE_INDEX_COST:
- Used_bytes показывает количество байт, которыми представлены данные индекса;
- Alloc_bytes показывает количество байт, которое займет индекс в табличном пространстве после его создания.
Создание индекса
Индекс создается с помощью оператора CREATE INDEX
CREATE INDEX employee_id ON employee(employee_id) TABLESPACE MY_INDEXES; По умолчанию Oracle допускает дублирование значения в столбцах индекса, которые также называются ключевыми столбцами. Однако можно специфицировать уникальный индекс, что исключит дублирование значений столбца в нескольких строках.
Для создания уникального индекса служит оператор CREATE UNIQUE INDEX.
Специальные типы индексов
Нормальный или типовой индекс, который создается в базе данных, называется индексом кучи (heap index), или неупорядоченным индексом. Oracle также предоставляет несколько специальных типов индексов для специфических нужд.
Битовые индексы (bitmap indexes)
Битовые индексы используют битовые карты для указания значения индексированного столбца. Это идеальный индекс для столбца с низкой кардинальностью (число уникальных записей в таблице мало) при при большом размере таблицы. Эти индексы обычно не годятся для таблиц с интенсивным обновлением, но хорошо подходят для приложений хранилищ данных.
Битовые индексы состоят из битового потока (единиц и нулей) для каждого столбца индекса. Битовые индексы очень компактны по сравнению с нормальными индексами на основе B-деревьев.
| Индексы B-деревьев | Битовые индексы |
| Хороши для данных с высокой кардинальностью | Хороши для данных с низкой кардинальностью |
| Хороши для баз данных OLTP | Хороши для приложений хранилищ данных OLAP |
| Занимают много места | Используют, относительно мало места |
| Легко обновляются | Трудно обновляются |
Для создания битового индекса используется оператор
CREATE BITMAP INDEX gender_dx ON employee(gender) TABLESPACE MY_INDEXES; Иногда можно наблюдать значительное повышение производительности при замене обычных индексов B-дерева на битовые в некоторых очень крупных таблицах. Однако каждый элемент битового индекса открывает огромное количество строк в таблице, так что когда данные обновляются,вставляются или удаляются из таблицы, то необходимые обновления битового индекса очень велики., и сам индекс может существенно увеличиться в размере. Единственный способ обойти это увеличение размера индекса с последующим падением производительности заключается в регулярной его перестройке. Битовый индекс – не слишком разумная альтернатива для таблиц, подвергающихся большому количеству вставок, удалений и обновлений.
Индексы с реверсированным ключом
Индексы с реверсированным ключом – это, по сути, то же самое, что и индексы B-деревьев, за исключением того, что байты данных ключевого столбца при индексации меняют порядок на противоположный. Порядок столбцов остается нетронутым, меняется только порядок байтов. Самое большое преимущество применения индексов с реверсивным ключом состоит в том, что они исключают неприятные последствия упорядоченной вставки значений в индекс. Вот как создается индекс с реверсированным ключом:
SQL> CREATE INDEX reverse_idx ON employee(emp_id) REVERSE; При использовании индекса с реверсированным ключом базы данных не сохраняет ключи индекса друг за другом в лексикографическом порядке. Таким образом, когда в запросе присутствует предикат неравенства, ответ получается медленнее, поскольку база данных вынуждена выполнять полное сканирование таблицы. При индексе с реверсированным ключом база данных не может запустить запрос по диапазону ключа индекса.
Индексы со сжатым ключом
Сэкономить пространство хранения индекса вместе с повышением производительности можно за счет создания индекса со сжатым ключом. Всякий раз, когда индексируемый ключ имеет повторяющийся компонент, или же создается уникальный многостолбцовый индекс, получается выигрыш от использования сжатия ключа. Вот пример:
SQL> CREATE INDEX emp_indx1 ON employees(ename) TABLESPACE MY_INDEXES COMPRESS 1; Приведенный выше оператор сжимает все дублированные вхождения индексированного ключа в листовом блоке индекса (на уровне 1).
Индексы на основе функций
Индексы на основе функций предварительно вычисляют значения функций по заданному столбцы и сохраняют результат в индексе. Когда конструкция WHERE содержит вызовы функций, то основанные на функциях индексы являются идеальным способом индексирования столбца.
Ниже показано, как создать индекс на основе функции LOWER
SQL> CREATE INDEX lastname _idx ON employees(LOWER(l_name)); Этот оператор CREATE INDEX создаст индекс по столбцу l_name, хранящему фамилии сотрудников в верхнем регистре. Однако этот индекс будет основан на функции, поскольку база данных создаст его по столбцу l_name, применив к нему предварительно функцию LOWER для преобразования его значения в нижний регистр.
Секционированные индексы
Секционированные индексы используются для индексации секционированных таблиц. Oracle предлагает два типа индексов для таких таблиц: локальные и глобальные.
Существенное различие между ними заключается в том, что локальные индексы основаны на разделах таблицы, по которой они созданы. Если таблица секционирована на 12 разделов по диапазонам дат, то индексы также будут распределены по тем же 12 разделам. Другими словами, между разделами индексов и разделами таблиц существует соответствие «один к одному». Такого соответствия нет между глобальными индексами и разделами таблицы, потому что глобальные индексы секционируются независимо от базовых таблиц.
В следующих разделах будут раскрыт важные различия между управлением глобального секционированными индексами и локально секционированными индексами.
Глобальные индексы
Глобальные индексы на секционированных таблицах могут быть как секционированными, так и несекционированными. Глобальные несекционированные индексы подобны обычным индексам Oracle для несекционированных таблиц. Для создания таких индексов применяется обычный синтаксис CREATE INDEX.
Ниже приведен пример глобального индекса на таблице ticket_sales:
SQL> CREATE INDEX tickersales_idx ON ticket_sales(month) GLOBAL PARTITION BY range(month) (PARTITION ticketsales1_idx VALUES LESS THAN (3) PARTITION ticketsales1_idx VALUES LESS THAN (6) PARTITION ticketsales2_idx VALUES LESS THAN (9) PARTITION ticketsales3_idx VALUES LESS THAN (MAXVALUE); Обратите внимание, что управление глобально секционированными индексами требует серьезных усилий. Всякий раз, когда происходит какое-т о действие DDL над секционированной таблицей, ее глобальные индексы требуют перестройки. Действия DDL над лежащей в основе таблице помечают глобальные индексы как недействительные. По умолчанию любая операция обслуживания секционированной таблицы делает недействительными глобальные индексы.
Давайте в качестве примера воспользуемся таблицей ticket_sales, чтобы разобраться, почему это так. Предположим, что вы ежеквартально уничтожаете самый старый раздел, чтобы освободить место для нового раздела, в который поступят данные за новый квартал. Когда уничтожается раздел, относящийся к таблице ticket_sales, глобальные индексы могут стать недействительными, потому что часть данных, на которые они указывают, перестают существовать. Чтобы предотвратить такое объявление недействительным индекса из-за уничтожения раздела, необходимо использовать опцию UPDATE GLOBAL INDEXES вместе с оператором DROP PARTITION:
SQL> ALTER TABLE ticket_sales DROP PARTITION sales_quarter01 UPDATE GLOBAL INDEXES; Если не включить оператор UPDATE GLOBAL INDEXES, то все глобальные индексы станут недействительными. Опцию UPDATE GLOBAL INDEXES можно также использовать при добавлении, объединении, обмене, слиянии, перемещении, разделении или усечении секционированных таблиц. Разумеется, с помощью ALTER INDEX..REBUILD можно перестраивать любой индекс, который становится недействительным, но эта опция также требует дополнительных затрат времени и обслуживания.
При небольшом количестве листовых блоков индекса, что приводит к высокой конкуренции Oracle рекомендует использовать глобальные индексы с хэш-секционированием. Синтаксис для создания хэш-секционированного глобального индекса подобен тому, что применяется для хэш-секционированной таблицы. Например, следующий оператор создает хэш-секционированный глобальный индекс:
SQL> CREATE INDEX hgidx ON tab (c1,c2,c3) GLOBAL PARITION BY HASH (c1,c2) ( PARTITION p1 TABLESPACE tsb_1, PARTITION p2 TABLESPACE tsb_2, PARTITION p3 TABLESPACE tsb_3, PARTITION p4 TABLESPACE tsb_4, ); Локальные индексы
Локально секционированные индексы, в отличие от глобально секционированных индексов, имею отношение «один к одному» с разделами таблицы. Локально секционированные индексы можно создавать в соответствии с разделами и даже подразделами. База данных конструирует индекс таким образом, чтобы он был секционирован так же, как и его таблица. При каждой модификации раздела таблицы база автоматически сопровождает это соответствующей модификацией раздела индекса. Это, наверное, самое большое преимущество использования локально секционированных индексов – Oracle автоматически перестраивает их всегда, когда уничтожается раздел или над ним выполняется какая-то другая операция DDL.
Ниже приведен простой пример создания локально секционированного индекса на секционированной таблице:
SQL> CREATE INDEX ticket_no_idx ON Ticket_sales(ticket_no) LOCAL TABLESPACE localidx_01; Невидимые индексы
По умолчанию оптимизатор «видит» все индексы. Тем не менее, можно создать невидимый индекс, который оптимизатор не обнаруживает и не принимает во внимание при создании плана выполнения оператора. Невидимый индекс можно применять в качестве временного индекса для определенных операций или его тестирования перед тем, как сделать его «официальным». Вдобавок, иногда объявления индекса невидимым можно использовать в качестве альтернативы уничтожению индекса или объявлению его недоступным. Сделать индекс невидимым можно временно, чтобы протестировать эффект от его уничтожения.
База данных поддерживает невидимый индекс точно так же, как и нормальный (видимый) индекс. После объявления индекса невидимым, его и все прочие невидимые индексы можно сделать вновь видимым для оптимизатора, установив значение параметра optimizer_use_invisible_index равным TRUE на уровне сеанса или всей системы. Значением этого параметра по умолчанию является FALSE, а это означает, что оптимизатор по умолчанию не может использовать невидимые индексы.
Создание невидимого индекса.
Чтобы сделать индекс невидимым, к оператору CRETE INDEX нужно добавить конструкцию INVISIBLE.
С помощью команды ALTER INDEX можно превратить существующий индекс в невидимый.
ALTER INDEX test_idx INVISIBLE; И обратная команда
ALTER INDEX test_idx VISIBLE; Приведенный ниже запрос к представлению DBA_INDEXES показывает состояние видимости индекса:
SQL> SELECT index_name, visibility FROM user_indexes WHERE index_name =’indx1’; Мониторинг использования индекса
Если вы сомневаетесь в использовании определенного индекса, можете попросить Oracle выполнить мониторинг его применения. Таким образом, если индекс окажется избыточным, его можно уничтожить и сэкономить место в хранилище, а также снизить накладные расходы на операции DML.
Опишем, что потребуется сделать для отслеживания индекса в базе данных. Предположим, что вы пытаетесь узнать, используется ли индекс p_key_sales в определенных запросах к таблице sales. Обеспечьте репрезентативный промежуток времени для оценки использования индекса. Для базы данных OLTP это промежуток может быть относительно коротким. Для хранилища данных может понадобится запустить тестовый мониторинг на несколько дней, чтобы точно проверить, как используется индекс.
Чтобы запустить мониторинг использования индекса, войдите в базу данный как владелец индекса p_keyPsales и запустите следующую команду:
SQL> ALTER INDEX p_key_sales MONITORING USAGE; Теперь запустите какие-нибудь запросы к таблице sales. Завершите мониторинг, применив следующую команду:
SQL> ALTER INDEX p_key_sales NOMONITORING USAGE; После этого можно запросить представление словаря данных V$OBJECT_USAGE для определения того, используется ли индекс p_key_sales.
SQL> SELECT index_nm, used FROM v$object_usage WHERE index_name=’P_KEY_SALES’; Причина по которой нельзя узнать количество случаев использования индекса, связана с тем, что база данных выполняет мониторинг его использования только на фазе разбора (parsing); если бы разбор производился при каждом выполнении, пострадала бы производительность.
Обслуживание индексов
Данные индекса постоянно изменяются из-за DML-действий, связанных с его таблицей. Индексы часто становятся слишком большими, если происходит много удалений сток, потому что пространство, занятое удаленными значениями, автоматически повторно индексом не используется. За счет периодического применения команды REBUILD можно реорганизовать индексы и сделать их более компактными, а потому и более эффективными. Команда REBUILD также служит для изменения параметров хранения, которые устанавливаются во время начального создания индекса.
ALTER INDEX sales_idx REBUILD; Перестройка индексов лучше уничтожения и воссоздания неудачного индекса, потому что при этой операции пользователи продолжают иметь доступ к индексу в процессе его перестройки. Однако индексы в процессе перестройки накладывают много ограничений на действия пользователя. Еще более эффективный способ перестройки индексов состоит в том, чтобы сделать это в оперативном (online) режиме, как показано в следующем примере. Во время оперативной перестройки индекса разрешено применение всех операций DML, но не операций DDL.
ALTER INDEX sales_idx REBUILD ONLINE; Оперативную перестройку индекса можно ускорить за счет добавления к показанному выше оператору ALTER INDEX конструкции ONLINE NOLOGGING. После добавления этой конструкции база данных не будет генерировать данные повторного выполнения для операции перестройки индекса.
Пример запроса который показывает на какие внешние ключи отсутствуют индексы
elect table_name, constraint_name, cname1 || nvl2(cname2,','||cname2,null) || nvl2(cname3,','||cname3,null) || nvl2(cname4,','||cname4,null) || nvl2(cname5,','||cname5,null) || nvl2(cname6,','||cname6,null) || nvl2(cname7,','||cname7,null) || nvl2(cname8,','||cname8,null) columns from ( select b.table_name, b.constraint_name, max(decode( position, 1, column_name, null )) cname1, max(decode( position, 2, column_name, null )) cname2, max(decode( position, 3, column_name, null )) cname3, max(decode( position, 4, column_name, null )) cname4, max(decode( position, 5, column_name, null )) cname5, max(decode( position, 6, column_name, null )) cname6, max(decode( position, 7, column_name, null )) cname7, max(decode( position, 8, column_name, null )) cname8, count(*) col_cnt from (select substr(table_name,1,30) table_name, substr(constraint_name,1,30) constraint_name, substr(column_name,1,30) column_name, position from user_cons_columns ) a, user_constraints b where a.constraint_name = b.constraint_name and b.constraint_type = 'R' group by b.table_name, b.constraint_name ) cons where col_cnt > ALL ( select count(*) from user_ind_columns i where i.table_name = cons.table_name and i.column_name in (cname1, cname2, cname3, cname4, cname5, cname6, cname7, cname8 ) and i.column_position cons.col_cnt group by i.index_name ) Tags: Oracle Database, Indexes