Почему для кодирования одного символа нужен именно 1 байт?
Почему для кодирования 1-го символа нужен именно 1 байт? Я прекрасно понимаю, что минимальная единица информации — 1 бит и чтобы выразить 255 символов в двоичном коде надо использовать 8 бит. И по таблице брать двоичный код и по нему находить нужный символ, но почему каждый символ обязательно занимает 1 байт? Зачем записывать число именно вот так 0000001 , а не просто 1 , тем самым заняв всего 1 бит информации и по таблице взять ему соответствующий символ.
Отслеживать
51.6k 201 201 золотой знак 63 63 серебряных знака 245 245 бронзовых знаков
задан 1 авг 2018 в 17:23
Никита Антонов Никита Антонов
125 1 1 серебряный знак 9 9 бронзовых знаков
Байт — минимальная адресуемая единица информации. Хранить каждый символ меньше чем в одном байте неэффективно по скорости доступа. А для длительного хранения (при сохранении в файл, например) никто не мешает применить сжатие.
1 авг 2018 в 17:27
@insolor, Use the answer form, Luke!
– user207618
1 авг 2018 в 17:34
Символы не хранят в одном байте уже лет тридцать 🙂
1 авг 2018 в 17:36
А вообще теоретически использовать один бит не разрешает, только вот 11111111 — это один символ (число 255) или восемь символов 1 ? Придётся добавлять дополнительную информацию, поясняющую, как правильно интерпретировать эти единицы. Ну и да, использовать число битов меньшее чем «минимальная адресуемая единица информации» банально неудобно, ибо именно под восьмибитный байт спроектированы все современные компьютеры
1 авг 2018 в 17:39
@andreymal, о спасибо большое! Теперь дошло! Только вот еще вопрос тоесть большие последовательности в зависимости от кодировки делятся на определенное количество байт (1, 2 и тд) и уже по таблице находится определенные символы ?
1 авг 2018 в 17:42
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
Не обязательно 1 ..есть кодировки (например utf-16, utf-32 ) где символы по 2 , по 4 байта. тут еще многое зависит от количества кодируемых символов. не всегда хватает 256 вариантов. часто нужно больше.то есть битность напрямую зависит от числа символов в таблице символов. Если влезть в ассемблер, то можно сделать свою таблицу символов. проблема будет только в том что твою кодировку будет понимать только твоя программа. А так просто принятый стандарт, и все. по поводу же адресации, да — опять же стандарт. хотя есть системы , которые работают и 9-ю битами ( старые советские системы связи) , где 9-й бит был или контрольным или знак передавал.
Отслеживать
ответ дан 1 авг 2018 в 17:35
Сергей Петрашко Сергей Петрашко
1,493 7 7 серебряных знаков 15 15 бронзовых знаков
Я наверное неправильно задал вопрос имею в виду почему все символы имеют 1 и тот же размер(тоесть 2 байта или 1), а не так чтобы 1 символ весит больше, а другой меньше, если все равно старшие разряды заполнены нулями (00000001 к примеру)
1 авг 2018 в 17:38
@НикитаАнтонов в кодировке UTF-8 длина одного символа может быть 1, 2, 3 или 4 байта 🙂 А использовать число бит, не кратное восьми, неудобно из-за архитектуры современных компьютеров, заточенных именно на 8 бит
1 авг 2018 в 17:40
будут проблемы с синхронизацией. такая проблема есть в азбуке морзе. то есть трудно понять где закончился один символ и начался второй. поэтому и принято использовать такие битности.
Символы Unicode: о чём должен знать каждый разработчик

Если вы пишете международное приложение, использующее несколько языков, то вам нужно кое-что знать о кодировке. Она отвечает за то, как текст отображается на экране. Я вкратце расскажу об истории кодировки и о её стандартизации, а затем мы поговорим о её использовании. Затронем немного и теорию информатики.
Введение в кодировку
Компьютеры понимают лишь двоичные числа — нули и единицы, это их язык. Больше ничего. Одно число называется байтом, каждый байт состоит из восьми битов. То есть восемь нулей и единиц составляют один байт. Внутри компьютеров всё сводится к двоичности — языки программирования, движений мыши, нажатия клавиш и все слова на экране. Но если статья, которую вы читаете, раньше была набором нулей и единиц, то как двоичные числа превратились в текст? Давайте разберёмся.
Краткая история кодировки
На заре своего развития интернет был исключительно англоязычным. Его авторам и пользователям не нужно было заботиться о символах других языков, и все нужды полностью покрывала кодировка American Standard Code for Information Interchange (ASCII).
ASCII — это таблица сопоставления бинарных обозначений знакам алфавита. Когда компьютер получает такую запись:
01001000 01100101 01101100 01101100 01101111 00100000 01110111 01101111 01110010 01101100 01100100 то с помощью ASCII он преобразует её во фразу «Hello world».
Один байт (восемь бит) был достаточно велик, чтобы вместить в себя любую англоязычную букву, как и управляющие символы, часть из которых использовалась телепринтерами, так что в те годы они были полезны (сегодня уже не особо). К управляющим символам относился, например 7 (0111 в двоичном представлении), который заставлял компьютер издавать сигнал; 8 (1000 в двоичном представлении) — выводил последний напечатанный символ; или 12 (1100 в двоичном представлении) — стирал весь написанный на видеотерминале текст.
В те времена компьютеры считали 8 бит за один байт (так было не всегда), так что проблем не возникало. Мы могли хранить все управляющие символы, все числа и англоязычные буквы, и даже ещё оставалось место, поскольку один байт может кодировать 255 символов, а для ASCII нужно только 127. То есть неиспользованными оставалось ещё 128 позиций в кодировке.
Вот как выглядит таблица ASCII. Двоичными числами кодируются все строчные и прописные буквы от A до Z и числа от 0 до 9. Первые 32 позиции отведены для непечатаемых управляющих символов.

Проблемы с ASCII
Позиции со 128 по 255 были пустыми. Общественность задумалась, чем их заполнить. Но у всех были разные идеи. Американский национальный институт стандартов (American National Standards Institute, ANSI) формулирует стандарты для разных отраслей. Там утвердили позиции ASCII с 0 по 127. Их никто не оспаривал. Проблема была с остальными позициями.
Вот чем были заполнены позиции 128-255 в первых компьютерах IBM:

Какие-то загогулины, фоновые иконки, математические операторы и символы с диакретическим знаком вроде é. Но разработчики других компьютерных архитектур не поддержали инициативу. Всем хотелось внедрить свою собственную кодировку во второй половине ASCII.
Все эти различные концовки назвали кодовыми страницами.
Что такое кодовые страницы ASCII?
Здесь собрана коллекция из более чем 465 разных кодовых страниц! Существовали разные страницы даже в рамках какого-то одного языка, например, для греческого и китайского. Как можно было стандартизировать этот бардак? Или хотя бы заставить его работать между разными языками? Или между разными кодовыми страницами для одного языка? В языках, отличающихся от английского? У китайцев больше 100 000 иероглифов. ASCII даже не может всех их вместить, даже если бы решили отдать все пустые позиции под китайские символы.
Эта проблема даже получила название Mojibake (бнопня, кракозябры). Так говорят про искажённый текст, который получается при использовании некорректной кодировки. В переводе с японского mojibake означает «преобразование символов».

Пример бнопни (кракозябров).
Безумие какое-то.
Именно! Не было ни единого шанса надёжно преобразовывать данные. Интернет — это лишь монструозное соединение компьютеров по всему миру. Представьте, что все страны решили использовать собственные стандарты. Например, греческие компьютеры принимают только греческий язык, а английские отправляют только английский. Это как кричать в пустой пещере, тебя никто не услышит.
ASCII уже не удовлетворял жизненным требованиям. Для всемирного интернета нужно было создать что-то другое, либо пришлось бы иметь дело с сотнями кодовых страниц.
��� Если только ������ вы не хотели ��� бы ��� читать подобные параграфы. �֎֏0590��׀ׁׂ׃ׅׄ׆ׇ
Так появился Unicode
Unicode расшифровывают как Universal Coded Character Set (UCS), и у него есть официальное обозначение ISO/IEC 10646. Но обычно все используют название Unicode.
Этот стандарт помог решить проблемы, возникавшие из-за кодировки и кодовых страниц. Он содержит множество кодовых пунктов (кодовых точек), присвоенных символам из языков и культур со всего мира. То есть Unicode — это набор символов. С его помощью можно сопоставить некую абстракцию с буквой, на которую мы хотим ссылаться. И так сделано для каждого символа, даже египетских иероглифов.
Кто-то проделал огромную работу, сопоставляя каждый символ во всех языках с уникальными кодами. Вот как это выглядит:
«Hello World» U+0048 : латинская прописная H U+0065 : латинская строчная E U+006C : латинская строчная L U+006C : латинская строчная L U+006F : латинская строчная O U+0020 : пробел U+0057 : латинская прописная W U+006F : латинская строчная O U+0072 : латинская строчная R U+006C : латинская строчная L U+0064 : латинская строчная DПрефикс U+ говорит о том, что это стандарт Unicode, а число — это результат преобразования двоичных чисел. Стандарт использует шестнадцатеричную нотацию, которая является упрощённым представлением двоичных чисел. Здесь вы можете ввести в поле что угодно и посмотреть, как это будет преобразовано в Unicode. А здесь можно полюбоваться на все 143 859 кодовых пунктов.
Уточню на всякий случай: речь идёт о большом словаре кодовых пунктов, присвоенных всевозможным символам. Это очень большой набор символов, не более того.
Осталось добавить последний ингредиент.
Unicode Transform Protocol (UTF)
UTF — протокол кодирования кодовых пунктов в Unicode. Он прописан в стандарте и позволяет кодировать любой кодовый пункт. Однако существуют разные типы UTF. Они различаются количеством байтов, используемых для кодировки одного пункта. В UTF-8 используется один байт на пункт, в UTF-16 — два байта, в UTF-32 — четыре байта.
Но если у нас есть три разные кодировки, то как узнать, какая из них применяется в конкретном файле? Для этого используют маркер последовательности байтов (Byte Order Mark, BOM), который ещё называют сигнатурой кодировки (Encoding Signature). BOM — это двухбайтный маркер в начале файл, который говорит о том, какая именно кодировка тут применена.
В интернете чаще всего используют UTF-8, она также прописана как предпочтительная в стандарте HTML5, так что уделю ей больше всего внимания.

Этот график построен в 2012-м, UTF-8 становилась доминирующей кодировкой. И всё ещё ею является.

График показывает распространённость UTF-8.
Что такое UTF-8 и как она работает?
UTF-8 кодирует с помощью одного байта каждый кодовый пункт Unicode с 0 по 127 (как в ASCII). То есть если вы писали программу с использованием ASCII, а ваши пользователи применяют UTF-8, они не заметят ничего необычного. Всё будет работать как задумано. Обратите внимание, как это важно. Нам нужно было сохранить обратную совместимость с ASCII в ходе массового внедрения UTF-8. И эта кодировка ничего не ломает.
Как следует из названия, кодовый пункт состоит из 8 битов (один байт). В Unicode есть символы, которые занимают несколько байтов (вплоть до 6). Это называют переменной длиной. В разных языках удельное количество байтов разное. В английском — 1, европейские языки (с латинским алфавитом), иврит и арабский представлены с помощью двух байтов на кодовый пункт. Для китайского, японского, корейского и других азиатских языков используют по три байта.
Если нужно, чтобы символ занимал больше одного байта, то применяется битовая комбинация, обозначающая переход — он говорит о том, что символ продолжается в нескольких следующих байтах.
И теперь мы, как по волшебству, пришли к соглашению, как закодировать шумерскую клинопись (Хабр её не отображает), а также значки emoji!
Подытожив сказанное: сначала читаем BOM, чтобы определить версию кодировки, затем преобразуем файл в кодовые пункты Unicode, а потом выводим на экран символы из набора Unicode.
Напоследок про UTF
Коды являются ключами. Если я отправлю ошибочную кодировку, вы не сможете ничего прочесть. Не забывайте об этом при отправке и получении данных. В наших повседневных инструментах это часто абстрагировано, но нам, программистам, важно понимать, что происходит под капотом.
Как нам задавать кодировку? Поскольку HTML пишется на английском, и почти все кодировки прекрасно работают с английским, мы можем указать кодировку в начале раздела .
Важно сделать это в самом начале , поскольку парсинг HTML может начаться заново, если в данный момент используется неправильная кодировка. Также узнать версию кодировки можно из заголовка Content-Type HTTP-запроса/ответа.
Если HTML-документ не содержит упоминания кодировки, спецификация HTML5 предлагает такое интересное решение, как BOM-сниффинг. С его помощью мы по маркеру порядка байтов (BOM) можем определить используемую кодировку.
Это всё?
Unicode ещё не завершён. Как и в случае с любым стандартом, мы что-то добавляем, убираем, предлагаем новое. Никакие спецификации нельзя назвать «завершёнными». Обычно в год бывает 1-2 релиза, найти их описание можно здесь.
Если вы дочитали до конца, то вы молодцы. Предлагаю сделать домашнюю работу. Посмотрите, как могут ломаться сайты при использовании неправильной кодировки. Я воспользовался этим расширением для Google Chrome, поменял кодировку и попытался открывать разные страницы. Информация была совершенно нечитаемой. Попробуйте сами, как выглядит бнопня. Это поможет понять, насколько важна кодировка.

Заключение
При написании этой статьи я узнал о Майкле Эверсоне. С 1993 года он предложил больше 200 изменений в Unicode, добавил в стандарт тысячи символов. По состоянию на 2003 год он считался самым продуктивным участником. Он один очень сильно повлиял на облик Unicode. Майкл — один из тех, кто сделал интернет таким, каким мы его сегодня знаем. Очень впечатляет.
Надеюсь, мне удалось показать вам, для чего нужны кодировки, какие проблемы они решают, и что происходит при их сбоях.
- Блог компании VK
- Веб-разработка
- Проектирование и рефакторинг
- Терминология IT
- Хранение данных
Юникод и байты
Про Юникод написано много, но мне кажется, что это одна из тем, про которую «чисто ради интереса» никто читать не полезет. Поэтому я решил поделиться здесь одной штукой, которая, как я в разговорах со многими замечал, не всем известна. Речь о том, «сколько байт занимает юникод».
Старые кодировки (например WINDOWS-1251, KOI8-R) совершенно четко определяют, какие конкретные значения одного байта используются для кодирования одного символа (человеческого или служебного). И отсюда вытекает их известная проблема с тем, что они не могут кодировать больше 256 символов. Для того, чтобы с этой проблемой бороться универсально, был придуман Юникод.
Вот дальше идет то самое частое, потому что очень логичное, заблуждение о том, что Юникод — это кодировка, где для каждого символа отводится 2 байта, а значит она может кодировать 65536 символов. Больше того, хоть я и не смотрел специально, кажется именно так она и была задумана в самом начале. Но сейчас все совсем не так.
Довольно быстро возникла необходимость кодировать гораздо больше, чем 65536 символов (чуть больше миллиона сейчас) и, что главное, появилась необходимость кодировать их по-разному. Поэтому в отличие от старых кодировок стандарт Юникода полностью разделяет две вещи:
- номера, присваиваемые символам
- какими байтами эти номера представляются
Номера, присваиваемые символам, полностью абстрактны. Это не байты, не двубайты, а просто числа. Например символу «Заглавная кириллическая буква А» назначен номер 1040, он же — 410 в шестнадцатеричной системе. И формально в Юникоде это принято записывать как U+0410.
А вот способов представлять это число в памяти или записывать в файлы существует больше одного. Называются они «». Вот наиболее распространенные.
UTF’ы
Есть несколько форм кодирования, которые официально входят в стандарт.
В этой форме юникодные символы кодируются одиночными байтами. Но поскольку одного байта для кодирования миллиона символов слегка мало, разные символы кодируются разным количеством байтов. Те, которые входят в старый ASCII, кодируются одним байтом и их значения полностью с ASCII совпадают. Русские и, например, западноевропейские символы кодируются двумя байтами, японские катакана и хирагана — тремя, а есть еще всякая экзотика, где могут быть и четыре байта.
UTF-8 совместим со старым софтом и протоколами, потому что в такой строке не может встретиться байт 0x00 , который бы ее обрывал. Также в большинстве текстов файлов конфигураций и исходников программ, которые традиционно состоят в основном из ASCII, он не занимает сильно больше места, чем ASCII — тот же байт на символ. Еще один плюс — у него нет разных вариантов для разных платформ, он везде одинаковый.
Самый существенный его минус — это то, что по количеству байт в строке невозможно определить ее длину в символах.
UTF-16 (или, что почти одно и то же — UCS-2)
Это, собственно, то, с чего начинался Юникод: для кодирования одного символа используются двухбайтовые целые. Этого хватает для того, чтобы хранить большинство нужных и распространенных на практике символов. И только для редких символов, включенных в Юникод позднее, используются пары двухбайтовых целых.
Кстати, UCS-2 — это как раз UTF-16 без этих дополнительных символов, то есть строго символ = 2 байта.
На практике редкие символы действительно редки (часто встречались с древнегреческой музыкальной грамотой?), поэтому во многих системах для внутреннего представления символов используется именно UTF-16, например в NTFS для имен файлов, в Delphi для WideString’ов, и Java, насколько я знаю, тоже внутри вся в UTF-16 работает со строками.
Однако двухбайтовость делает затруднительным использование UTF-16 для обмена данными из-за двух проблем: наличия нулевых байтов в строке и разночтения порядка следования старшего и младшего байтов на разных платформах.
UTF-32 (или, что почти одно и то же — UCS-4)
Это — форма для перфекционистов. Для представления символа используется строго 4 байта, которыми можно представить абсолютно любой юникодный символ. С недавнего времени тот же Python на большинстве платформ использует именно четырехбайтовое представление для юникодных строк.
Отличия от UCS-4 совсем умозрительные и непрактические.
Минус у этого представления, помимо плохой переносимости, как у UTF-16, еще и в том, что UTF-32 попросту занимает еще больше места.
Другие формы
Помимо UTF’ов, внесенных в стандарт Юникода, существует еще несколько знакомых многим способов представления юникодных номеров.
В первую очередь это XML и HTML со своими А и А . Такое представление, хоть и занимает места еще больше, чем UTF-32 (по 7 байт в двух предыдущих примерах), зато обладает несомненным плюсом в том смысле, что их можно использовать, даже если вы храните сам файл в старой однобайтовой кодировке. А вот если у вас файл и так хранится в одном из юникодных представлений (UTF-8 чаще всего), то в него можно вставлять все стрелочки и кавычечки прямо в UTF-8, которые можно либо взять из charmap’а, либо сам редактор может уметь обрабатывать всякие мудреные комбинации клавиш для этого. Оно и выглядит более читаемо при этом.
Ну и еще напоследок — представление в Javascript. Суть та же, что и у (X|HT)ML’а, только запись другая: \u0410 , \u0160 .
То, что я тут написал — довольно упрощенное прдставление, где я не касался всяких форм нормализации, символов, которые не символы, и прочих «высших и низших суррогатов». Хотя вчера успел совершенно замучить жену цитатами из стандарта Юникода, который читал, чтобы уточнить пару вещей для статьи. Штука, конечно, интересная, но удивительно запутанная. Если кого это все заинтересует, то лучше всего начать со статьи про Юникод в русской Wikipedia (очень хорошая).
Комментарии: 9
Есть ещё UTF-7, а у UTF-8 есть интересная особенность — всегда можно определить находимся ли мы посередине символа или в его начале. Ну и ещё ты забыл упомянуть, что наличие нулевого байта в строке это проблема языков, где строки хранятся как в Cи.
Спасибо, наконец-то я получил толковое объяснение почему так много кодировок называющих себя Юникодом. ))
Замечательный обзор, спасибо.
Зная, что Вы, Иван, знаете Python не понаслышке, хочу спросить о следующем:
В первую очередь это XML и HTML со своими А ;
Есть ли библиотечка, которая переводит все эти
привет питон
в «нормальный» вид, а вот как возник вопрос:
from mechanize import * from BeautifulSoup import * b = Browser() b.open("http://www.translate.ru/text.asp?lang=ru") b.select_form(nr=0) b["source"] = "hello python" html = b.submit().get_data() soup = BeautifulSoup(html) print soup.find("span", ).string А отличный рассказ про разные UTF есть тут
Pak поднял мучающий меня вопрос:) Как в Python перевести HTML и (особенно мучает:)) Javascript-коды в UTF8-строки?
Иван Сагалаев
Честно говоря, никогда не приходилось отдельно коды переводить. Если это HTML или XML, то он парсится парсерами (модуль htmllib и семейство модулей xml.* соответственно). А чтобы парсить javascript’овые строки есть, например, simplejson (с недавних пор включается в django.utils.simplejson, кстати). Делается примерно так:
from simplejson.decoder import JSONDecoder JSONDecoder().decode(r'"\\u0410"') Возвратит питоновскую юникодную строку.
Почему бы на ru.wikipedia.org Вам не добавить этот текст?
Иван Сагалаев
Мне показалось, что там тема проработана глубже, поэтому моя статья и не добавит ничего.
Интересная статья. Как раз столкнулся с проблемой — неизвестная четырехбайтовая кодировка. Первые 2 байта C3 90 или C3 91 (шестнадцатиричные), потом еще 2 байта (очевидно конкретно уточняющие символ). В общем выглядит примерно так — C3 90 C2 BA (один символ). Ни одна из имеющихся программ-перекодировщиков не смогла переварить такое. Не подскажите, что это может быть?
Представление символов, таблицы кодировок
В вычислительных машинах символы не могут храниться иначе, как в виде последовательностей бит (как и числа). Для передачи символа и его корректного отображения ему должна соответствовать уникальная последовательность нулей и единиц. Для этого были разработаны таблицы кодировок.
Количество символов, которые можно задать последовательностью бит длины [math]n[/math] , задается простой формулой [math]C(n) = 2^n[/math] . Таким образом, от нужного количества символов напрямую зависит количество используемой памяти.
Таблицы кодировок
На заре компьютерной эры на каждый символ было отведено по пять бит. Это было связано с малым количеством оперативной памяти на компьютерах тех лет. В эти [math]32[/math] символа входили только управляющие символы и строчные буквы английского алфавита.
С ростом производительности компьютеров стали появляться таблицы кодировок с большим количеством символов. Первой семибитной кодировкой стала ASCII7. В нее уже вошли прописные буквы английского алфавита, арабские цифры, знаки препинания. Затем на ее базе была разработана ASCII8, в которым уже стало возможным хранение [math]256[/math] символов: [math]128[/math] основных и еще столько же расширенных. Первая часть таблицы осталась без изменений, а вторая может иметь различные варианты (каждый имеет свой номер). Эта часть таблицы стала заполняться символами национальных алфавитов.
Но для многих языков (например, арабского, японского, китайского) [math]256[/math] символов недостаточно, поэтому развитие кодировок продолжалось, что привело к появлению UNICODE.
Кодировки стандарта ASCII
| Определение: |
| ASCII — таблицы кодировок, в которых содержатся основные символы (английский алфавит, цифры, знаки препинания, символы национальных алфавитов(свои для каждого региона), служебные символы) и длина кода каждого символа [math]n = 8[/math] бит. |
- ASCII7 — первая кодировка, пригодная для работы с текстом. Помимо маленьких букв английского алфавита и служебных символов, содержит большие буквы английского языка, цифры, знаки препинания и другие символы.
Кодировки стандарта ASCII ( [math]8[/math] бит):
- ASCII — первая кодировка, в которой стало возможно использовать символы национальных алфавитов.
- КОИ8-R — первая русская кодировка. Символы кириллицы расположены не в алфавитном порядке. Их разместили в верхнюю половину таблицы так, чтобы позиции кириллических символов соответствовали их фонетическим аналогам в английском алфавите. Это значит, что даже при потере старшего бита каждого символа, например, при проходе через устаревший семибитный модем, текст остается «читаемым».
- CP866 — русская кодировка, использовавшаяся на компьютерах IBM в системе DOS.
- Windows-1251 — русская кодировка, использовавшаяся в русскоязычных версиях операционной системы Windows в начале 90-х годов. Кириллические символы идут в алфавитном порядке. Содержит все символы, встречающиеся в типографике обычного текста (кроме знака ударения).
Структурные свойства таблицы
- Цифры 0-9 представляются своими двоичными значениями (например, [math]5=0101_2[/math] ), перед которыми стоит [math]0011_2[/math] . Таким образом, двоично-десятичные числа (BCD) превращаются в ASCII-строку с помощью простого добавления слева [math]0011_2[/math] к каждому двоично-десятичному полубайту.
- Буквы A-Z верхнего и нижнего регистров различаются в своём представлении только одним битом, что упрощает преобразование регистра и проверку на диапазон. Буквы представляются своими порядковыми номерами в алфавите, записанными в двоичной системе счисления, перед которыми стоит [math]0100_2[/math] (для букв верхнего регистра) или [math]0110_2[/math] (для букв нижнего регистра).
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | TAB | LF | VT | FF | CR | SO | SI |
| 1 | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2 | ! | « | # | $ | % | & | ‘ | ( | ) | * | + | , | — | . | / | |
| 3 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | = | > | ? | |
| 4 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ |
| 6 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7 | p | q | r | s | t | u | v | w | x | y | z | | | > | ~ | DEL |
Кодировки стандарта UNICODE
Юникод или Уникод (англ. Unicode) — это промышленный стандарт обеспечивающий цифровое представление символов всех письменностей мира, и специальных символов.
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc.). Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей. Стандарт состоит из двух основных разделов: универсальный набор символов (англ. UCS, universal character set) и семейство кодировок (англ. UTF, Unicode transformation format). Универсальный набор символов задаёт однозначное соответствие символов кодам — элементам кодового пространства, представляющим неотрицательные целые числа.Семейство кодировок определяет машинное представление последовательности кодов UCS.
Коды в стандарте Unicode разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F. Часть кодов зарезервирована для использования в будущем.
Кодовое пространство
Хотя формы записи UTF-8 и UTF-32 позволяют кодировать до [math]2^[/math] [math](2\ 147\ 483\ 648)[/math] кодовых позиций, было принято решение использовать лишь [math]1\ 112\ 064[/math] для совместимости с UTF-16. Впрочем, даже и этого на текущий момент более чем достаточно — в версии 6.0 используется чуть менее [math]110\ 000[/math] кодовых позиций ( [math]109\ 242[/math] графических и [math]273[/math] прочих символов).
Кодовое пространство разбито на [math]17[/math] плоскостей (англ. planes) по [math]2^[/math] [math](65\ 536)[/math] символов. Нулевая плоскость называется базовой, в ней расположены символы наиболее употребительных письменностей. Первая плоскость используется, в основном, для исторических письменностей, вторая — для для редко используемых иероглифов китайского письма, третья зарезервирована для архаичных китайских иероглифов. Плоскости [math]15[/math] и [math]16[/math] выделены для частного употребления.
Для обозначения символов Unicode используется запись вида «U+xxxx» (для кодов [math]0000_..FFFF_[/math] ) или «U+xxxxx» (для кодов [math]10000_..FFFFF_[/math] ) или «U+xxxxxx» (для кодов [math]100000_..10FFFF_[/math] ), где xxx — шестнадцатеричные цифры. Например, символ «я» (U+044F) имеет код [math]044F_ = 1103_[/math] .
| Плоскости Юникода | ||
|---|---|---|
| Плоскость | Название | Диапазон символов |
| Plane 0 | Basic multilingual plane (BMP) | U+0000…U+FFFF |
| Plane 1 | Supplementary multilingual plane (SMP) | U+10000…U+1FFFF |
| Plane 2 | Supplementary ideographic plane (SIP) | U+20000…U+2FFFF |
| Planes 3-13 | Unassigned | U+30000…U+DFFFF |
| Plane 14 | Supplementary special-purpose plane (SSP) | U+E0000…U+EFFFF |
| Planes 15-16 | Supplementary private use area (S PUA A/B) | U+F0000…U+10FFFF |
Модифицирующие символы
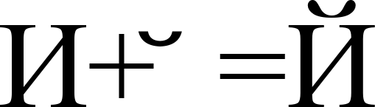
Графические символы в Юникоде делятся на протяжённые и непротяжённые. Непротяжённые символы при отображении не занимают дополнительного места в строке. К примеру, к ним относятся знак ударения. Протяжённые и непротяжённые символы имеют собственные коды, но последние не могут встречаться самостоятельно. Протяжённые символы называются базовыми (англ. base characters), а непротяженные — модифицирующими (англ. combining characters). Например символ «Й» (U+0419) может быть представлен в виде базового символа «И» (U+0418) и модифицирующего символа « ̆» (U+0306).
Способы представления
Юникод имеет несколько форм представления (англ. Unicode Transformation Format, UTF): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт.
UTF-8
UTF-8 — представление Юникода, обеспечивающее наилучшую совместимость со старыми системами, использовавшими [math]8[/math] -битные символы. Текст, состоящий только из символов с номером меньше [math]128[/math] , при записи в UTF-8 превращается в обычный текст ASCII. И наоборот, в тексте UTF-8 любой байт со значением меньше [math]128[/math] изображает символ ASCII с тем же кодом. Остальные символы Юникода изображаются последовательностями длиной от двух до шести байт (на деле, только до четырех байт, поскольку в Юникоде нет символов с кодом больше [math]10FFFF_[/math] , и вводить их в будущем не планируется), в которых первый байт всегда имеет вид [math]11xxxxxx[/math] , а остальные — [math]10xxxxxx[/math] .
Символы UTF-8 получаются из Unicode cледующим образом:
| Unicode | UTF-8 | Представленные символы |
|---|---|---|
| 0x00000000 — 0x0000007F | 0xxxxxxx | ASCII, в том числе английский алфавит, простейшие знаки препинания и арабские цифры |
| 0x00000080 — 0x000007FF | 110xxxxx 10xxxxxx | кириллица, расширенная латиница, арабский алфавит, армянский алфавит, греческий алфавит, еврейский алфавит и коптский алфавит; сирийское письмо, тана, нко; Международный фонетический алфавит; некоторые знаки препинания |
| 0x00000800 — 0x0000FFFF | 1110xxxx 10xxxxxx 10xxxxxx | все другие современные формы письменности, в том числе грузинский алфавит, индийское, китайское, корейское и японское письмо; сложные знаки препинания; математические и другие специальные символы |
| 0x00010000 — 0x001FFFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | музыкальные символы, редкие китайские иероглифы, вымершие формы письменности |
| 111111xx | служебные символы c, d, e, f |
Несмотря на то, что UTF-8 позволяет указать один и тот же символ несколькими способами, только наиболее короткий из них правильный. Остальные формы, называемые overlong sequence, отвергаются по соображениям безопасности.
Принцип кодирования
Правила записи кода одного символа в UTF-8
1. Если размер символа в кодировке UTF-8 = [math]1[/math] байт
Код имеет вид (0aaa aaaa), где «0» — просто ноль, остальные биты «a» — это код символа в кодировке ASCII;
2. Если размер символа в кодировке в UTF-8 [math]\gt 1[/math] байт (то есть от [math]2[/math] до [math]6[/math] ):
2.1 Первый байт содержит количество байт символа, закодированное в единичной системе счисления;
2 — 11 3 — 111 4 — 1111 5 — 1111 1 6 — 1111 11
2.2 «0» — бит терминатор, означающий завершение кода размера 2.3 далее идут значащие байты кода, которые имеют вид (10xx xxxx), где «10» — биты признака продолжения, а «x» — значащие биты.
В общем случае варианты представления одного символа в кодировке UTF-8 выглядят так:
(1 байт) 0aaa aaaa (2 байта) 110x xxxx 10xx xxxx (3 байта) 1110 xxxx 10xx xxxx 10xx xxxx (4 байта) 1111 0xxx 10xx xxxx 10xx xxxx 10xx xxxx (5 байт) 1111 10xx 10xx xxxx 10xx xxxx 10xx xxxx 10xx xxxx (6 байт) 1111 110x 10xx xxxx 10xx xxxx 10xx xxxx 10xx xxxx 10xx xxxx
Определение длины кода в UTF-8
| Количество байт UTF-8 | Количество значащих бит |
|---|---|
| [math]1[/math] | [math]7[/math] |
| [math]2[/math] | [math]11[/math] |
| [math]3[/math] | [math]16[/math] |
| [math]4[/math] | [math]21[/math] |
| [math]5[/math] | [math]26[/math] |
| [math]6[/math] | [math]31[/math] |
В общем случае количество значащих бит [math]C[/math] , кодируемых [math]n[/math] байтами UTF-8, определяется по формуле:
[math]C = 7[/math] при [math]n=1[/math]
[math]C = n\cdot5+1[/math] при [math]n\gt 1[/math]
UTF-16
UTF-16 — один из способов кодирования символов (англ. code point) из Unicode в виде последовательности [math]16[/math] -битных слов (англ. code unit). Данная кодировка позволяет записывать символы Юникода в диапазонах U+0000..U+D7FF и U+E000..U+10FFFF (общим количеством [math]1\ 112\ 064[/math] ), причем [math]2[/math] -байтные символы представляются как есть, а более длинные — с помощью суррогатных пар (англ. surrogate pair), для которых и вырезан диапазон [math]D800_..DFFF_[/math] .
В UTF-16 символы кодируются двухбайтовыми словами с использованием всех возможных диапазонов значений (от [math]0000_[/math] до [math]FFFF_[/math] ). При этом можно кодировать символы Unicode в диапазонах [math]0000_..D7FF_[/math] и [math]E000_..10FFFF_[/math] . Исключенный отсюда диапазон [math]D800_..DFFF_[/math] используется как раз для кодирования так называемых суррогатных пар — символов, которые кодируются двумя [math]16[/math] -битными словами. Символы Unicode до [math]FFFF_[/math] включительно (исключая диапазон для суррогатов) записываются как есть [math]16[/math] -битным словом. Символы же в диапазоне [math]10000_..10FFFF_[/math] (больше [math]16[/math] бит) уже кодируются парой [math]16[/math] -битных слов. Для этого их код арифметически сдвигается до нуля (из него вычитается минимальное число [math]10000_[/math] ). В результате получится значение от нуля до [math]FFFFF_[/math] , которое занимает до [math]20[/math] бит. Старшие [math]10[/math] бит этого значения идут в лидирующее (первое) слово, а младшие [math]10[/math] бит — в последующее (второе). При этом в обоих словах старшие [math]6[/math] бит используются для обозначения суррогата. Биты с [math]11[/math] по [math]15[/math] имеют значения [math]11011_2[/math] , а [math]10[/math] -й бит содержит [math]0[/math] у лидирующего слова и [math]1[/math] — у последующего. В связи с этим можно легко определить к чему относится каждое слово.
UTF-16LE и UTF-16BE
Один символ кодировки UTF-16 представлен последовательностью двух байт или двух пар байт. Который из двух байт в словах идёт впереди, старший или младший, зависит от порядка байт. Подробнее об этом будет сказано ниже.
UTF-32
UTF-32 — один из способов кодирования символов из Юникод, использующий для кодирования любого символа ровно [math]32[/math] бита. Остальные кодировки, UTF-8 и UTF-16, используют для представления символов переменное число байт. Символ UTF-32 является прямым представлением его кодовой позиции (англ. code point).
Главное преимущество UTF-32 перед кодировками переменной длины заключается в том, что символы Юникод непосредственно индексируемы. Получение [math]n[/math] -ой кодовой позиции является операцией, занимающей одинаковое время. Напротив, коды с переменной длиной требует последовательного доступа к [math]n[/math] -ой кодовой позиции. Это делает замену символов в строках UTF-32 простой, для этого используется целое число в качестве индекса, как обычно делается для строк ASCII.
Главный недостаток UTF-32 — это неэффективное использование пространства, так как для хранения символа используется четыре байта. Символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства редко используются в большинстве текстов. Поэтому удвоение, в сравнении с UTF-16, занимаемого строками в UTF-32 пространства не оправдано.
Хотя использование неменяющегося числа байт на символ удобно, но не настолько, как кажется. Операция усечения строк реализуется легче в сравнении с UTF-8 и UTF-16. Но это не делает более быстрым нахождение конкретного смещения в строке, так как смещение может вычисляться и для кодировок фиксированного размера. Это не облегчает вычисление отображаемой ширины строки, за исключением ограниченного числа случаев, так как даже символ «фиксированной ширины» может быть получен комбинированием обычного символа с модифицирующим, который не имеет ширины. Например, буква «й» может быть получена из буквы «и» и диакритического знака «крючок над буквой». Сочетание таких знаков означает, что текстовые редакторы не могут рассматривать [math]32[/math] -битный код как единицу редактирования. Редакторы, которые ограничиваются работой с языками с письмом слева направо и составными символами (англ. Precomposed character), могут использовать символы фиксированного размера. Но такие редакторы вряд ли поддержат символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства и вряд ли смогут работать одинаково хорошо с символами UTF-16.
Порядок байт
В современной вычислительной технике и цифровых системах связи информация обычно представлена в виде последовательности байт. В том случае, если число не может быть представлено одним байтом, имеет значение в каком порядке байты записываются в памяти компьютера или передаются по линиям связи. Часто выбор порядка записи байт произволен и определяется только соглашениями.
В общем случае, для представления числа [math]M[/math] , большего [math]255[/math] (здесь [math]255=2^8-1[/math] — максимальное целое число, записываемое одним байтом), приходится использовать несколько байт. При этом число [math]M[/math] записывается в позиционной системе счисления по основанию [math]256[/math] :
[math]M = \sum_^A_i\cdot 256^i=A_0\cdot 256^0+A_1\cdot 256^1+A_2\cdot 256^2+\dots+A_n\cdot 256^n.[/math]
Набор целых чисел [math]A_0,\dots,A_n[/math] , каждое из которых лежит в интервале от [math]0[/math] до [math]255[/math] , является последовательностью байт, составляющих [math]M[/math] . При этом [math]A_0[/math] называется младшим байтом, а [math]A_n[/math] — старшим байтом числа [math]M[/math] .
Варианты записи
Порядок от старшего к младшему
Порядок от старшего к младшему (англ. big-endian): [math]A_n,\dots,A_0[/math] , запись начинается со старшего и заканчивается младшим. Этот порядок является стандартным для протоколов TCP/IP, он используется в заголовках пакетов данных и во многих протоколах более высокого уровня, разработанных для использования поверх TCP/IP. Поэтому, порядок байт от старшего к младшему часто называют сетевым порядком байт (англ. network byte order). Этот порядок байт используется процессорами IBM 360/370/390, Motorola 68000, SPARC (отсюда третье название — порядок байт Motorola, Motorola byte order).
В этом же виде (используя представление в десятичной системе счисления) записываются числа индийско-арабскими цифрами в письменностях с порядком знаков слева направо (латиница, кириллица). Для письменностей с обратным порядком (арабская) та же запись числа воспринимается как «от младшего к старшему».
Порядок байт от старшего к младшему применяется во многих форматах файлов — например, PNG, FLV, EBML.
Порядок от младшего к старшему
Порядок от младшего к старшему (англ. little-endian): [math]A_0,\dots,A_n[/math] , запись начинается с младшего и заканчивается старшим. Этот порядок записи принят в памяти персональных компьютеров с x86-процессорами, в связи с чем иногда его называют интеловский порядок байт (по названию фирмы-создателя архитектуры x86).
В противоположность порядку big-endian, соглашение little-endian поддерживают меньше кросс-платформенных протоколов и форматов данных; существенные исключения: USB, конфигурация PCI, таблица разделов GUID, рекомендации FidoNet.
Переключаемый порядок
Многие процессоры могут работать и в порядке от младшего к старшему, и в обратном, например, ARM, PowerPC (но не PowerPC 970), DEC Alpha, MIPS, PA-RISC и IA-64. Обычно порядок байт выбирается программно во время инициализации операционной системы, но может быть выбран и аппаратно перемычками на материнской плате. В этом случае правильнее говорить о порядке байт операционной системы. Переключаемый порядок байт иногда называют англ. bi-endian.
Смешанный порядок
Смешанный порядок байт (англ. middle-endian) иногда используется при работе с числами, длина которых превышает машинное слово. Число представляется последовательностью машинных слов, которые записываются в формате, естественном для данной архитектуры, но сами слова следуют в обратном порядке.
Классический пример middle-endian — представление [math]4[/math] -байтных целых чисел на [math]16[/math] -битных процессорах семейства PDP-11 (известен как PDP-endian). Для представления двухбайтных значений (слов) использовался порядок little-endian, но [math]4[/math] -хбайтное двойное слово записывалось от старшего слова к младшему.
В процессорах VAX и ARM используется смешанное представление для длинных вещественных чисел.
Различия

Существенным достоинством little-endian по сравнению с big-endian порядком записи считается возможность «неявной типизации» целых чисел при чтении меньшего объёма байт (при условии, что читаемое число помещается в диапазон). Так, если в ячейке памяти содержится число [math]00000022_[/math] , то прочитав его как int16 (два байта) мы получим число [math]0022_[/math] , прочитав один байт — число [math]22_[/math] . Однако, это же может считаться и недостатком, потому что провоцирует ошибки потери данных.
Обратно, считается что у little-endian, по сравнению с big-endian есть «неочевидность» значения байт памяти при отладке (последовательность байт (A1, B2, C3, D4) на самом деле значит [math]D4C3B2A1_[/math] , для big-endian эта последовательность (A1, B2, C3, D4) читалась бы «естественным» для арабской записи чисел образом: [math]A1B2C3D4_[/math] ). Наименее удобным в работе считается middle-endian формат записи; он сохранился только на старых платформах.
Для записи длинных чисел (чисел, длина которых существенно превышает разрядность машины) обычно предпочтительнее порядок слов в числе little-endian (поскольку арифметические операции над длинными числами производятся от младших разрядов к старшим). Порядок байт в слове — обычный для данной архитектуры.
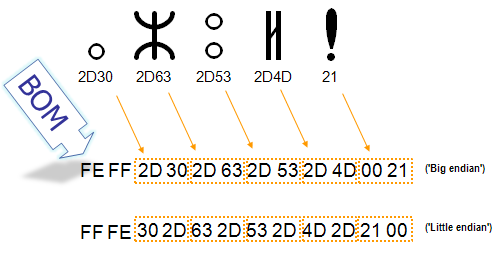
Маркер последовательности байт
Для определения формата представления Юникода в начало текстового файла записывается сигнатура — символ U+FEFF (неразрывный пробел с нулевой шириной), также именуемый маркером последовательности байт (англ. byte order mark (BOM)). Это позволяет различать UTF-16LE и UTF-16BE, поскольку символа U+FFFE не существует.
| Кодирование | Представление (Шестнадцатеричное) |
|---|---|
| UTF-8 | EF BB BF |
| UTF-16 (BE) | FE FF |
| UTF-16 (LE) | FF FE |
| UTF-32 (BE) | 00 00 FE FF |
| UTF-32 (LE) | FF FE 00 00 |
В кодировке UTF-8, наличие BOM не является существенным, поскольку, нет альтернативной последовательности байт. Когда BOM используется на страницах или редакторах для контента закодированного в UTF-8, иногда он может представить пробелы или короткие последовательности символов, имеющие странный вид (такие как ). Именно поэтому, при наличии выбора, для совместимости, как правило, лучше упустить BOM в UTF-8 контенте.Однако BOM могут еще встречаться в тексте закодированном в UTF-8, как побочный продукт перекодирования или потому, что он был добавлен редактором. В этом случае BOM часто называют подписью UTF-8.
Когда символ закодирован в UTF-16, его [math]2[/math] или [math]4[/math] байта можно упорядочить двумя разными способами (little-endian или big-endian). Изображение справа показывает это. Byte order mark указывает, какой порядок используется, так что приложения могут немедленно расшифровать контент. UTF-16 контент должен всегда начинатся с BOM.
BOM также используется для текста обозначенного как UTF-32. Аналогично UTF-16 существует два варианта четырёхбайтной кодировки — UTF-32BE и UTF-32LE. К сожалению, этот способ не позволяет надёжно различать UTF-16LE и UTF-32LE, поскольку символ U+0000 допускается Юникодом
Проблемы Юникода
В Юникоде английское «a» и польское «a» — один и тот же символ. Точно так же одним символом (но отличающимся от «a» латинского) считаются русское «а» и сербское «а». Такой принцип кодирования не универсален; по-видимому, решения «на все случаи жизни» вообще не может существовать.
Примеры
Если записать строку ‘hello мир’ в файл exampleBOM, а затем сделать его hex-дамп, то можно убедиться в том, что разные символы кодируются разным количеством байт. Например, английские буквы,пробел, знаки препинания и пр. кодируются одним байтом, а русские буквы — двумя
Код на python
#!/usr/bin/env python #coding:utf-8 import codecs f = open('exampleBOM','w') b = u'hello мир' f.write(codecs.BOM_UTF8) f.write(b.encode('utf-8')) f.close()
hex-дамп файла exampleBOM
| Символ | BOM | h | e | l | l | o | Пробел | м | и | р | |||||
| Код в UNICODE | EF | BB | BF | 68 | 65 | 6C | 6C | 6F | 20 | D0 | BC | D0 | B8 | D1 | 80 |
| Код в UTF-8 | 11101111 | 10111011 | 10111111 | 01101000 | 01100101 | 01101100 | 01101100 | 01101111 | 00100000 | 11010000 | 10111100 | 11010000 | 10111000 | 11010001 | 10000000 |
См. также
- Представление целых чисел: прямой код, код со сдвигом, дополнительный код
- Представление вещественных чисел
Источники информации
- Wikipedia — таблица ASCII
- Wikipedia — стандарт UNICODE
- Wikipedia — Byte order mark
- Wikipedia — Порядок байтов
- Wikipedia — Юникод
- Wikipedia — Windows-1251
- Wikipedia — UTF-8
- Wikipedia — UTF-16
- Wikipedia — UTF-32