UTF-8 — что это и зачем нужна кодировка символов
Машины и люди говорят «на разных языках», однако пользователи видят на экране компьютера понятный им текст, даже если в памяти устройства он хранится в виде чисел. При создании веб-сайта разработчику необходимо помнить, что возможность его использовать должна быть не только у сервера, но и у конечного пользователя. Для преобразования числового представления информации в ее символьный вид используют кодировки. Долгое время разработчики использовали разные схемы для трансформации текста, и если на другом устройстве работала иная кодировка, часть информации не могла быть распознана и терялась. Ситуация исправилась с появлением Юникода. В нашем материале отвечаем на вопросы: UTF-8 — что это? Для чего служит? Какие преимущества и недостатки имеет стандарт?
Что такое UTF-8
UTF-8 (Unicode Transformation Format, 8-bit) — это система кодирования, работающая по стандарту Unicode. В библиотеке Юникода хранится более миллиона символов. Каждому из них присваивается уникальный код — кодовая точка. Например, для «!» кодовой точкой будет U+0021. UTF-8 преобразовывает символы Unicode в компьютерный текст — двоичные строки. Кроме того, кодировка работает и в обратную сторону: от двоичных строк к символам.

UTF-8 входит в семейство кодировок Unicode, каждая из которых уникальна. Особенность UTF-8 заключается в том, что она представляет символы в однобайтовых единицах. Один байт содержит в самом простом виде восемь бит информации, что нашло отражение в названии кодировки.
Для чего нужна кодировка символов
Компьютеры обрабатывают информацию в двоичной системе. Чтобы разобраться в текстовом сообщении, им необходимо обработать последовательность нулей и единиц. Например, английская литера А — это 01000001. Человеку для понимания текста этого недостаточно, он воспринимает данные, записанные с помощью букв, цифр и других символов, кроме того ему потребуется знание языка, на котором написано сообщение. Чтобы текст, передаваемый компьютером, стал доступен для пользователя, необходимо преобразовать его числовое представление в символьное. Инструментом для трансформации являются кодировки, которые содержат набор правил по преобразованию одного способа представления информации в другой.
Компьютер говорит на языке битов и байтов. Информация в двоичной системе измеряется с помощью битов. Если объем данных достигает 8 битов, то для удобства подсчетов используют большую единицу измерения — байт, далее следуют килобайты, мега- и гигабайты. Каждый символ текста записывается в компьютерной системе в виде строки битов.
Человек говорит на языке символов. Одним из первых наиболее универсальных стандартов кодирования является ASCII. Он имеет библиотеки, в которых систематизированы элементы двух языков — байтового и символьного. Буквам, знакам пунктуации, цифрам присваиваются индивидуальные числовые коды. Например, литере «B» в верхнем регистре по стандарту кодирования ASCII присваивается код «066». Затем данное обозначение соотносится с двоичной системой: «066» — это 01000010 при записи в нулях и единицах. В результате каждому идентификатору принадлежит свой символ и его байтовый аналог.
Стандарт ASCII содержит данные о самых востребованных символах и работает для передачи текста, написанного латинскими буквами. Однако пользователи веб-ресурсов, приложений, программного обеспечения и других ИТ-продуктов рассредоточены по всему миру. Поэтому для кодирования всех языков человечества и вообще любого символа, который когда-либо использовался, включая эмотиконы, появился стандарт с более широкими возможностями по хранению символов и соответствующих им кодов — Unicode. Его понимают большинство компьютеров на планете и носители основных мировых языков. Юникод хранит результаты преобразования информации, выполненного через систему кодирования UTF-8, UTF-16 или UTF-32.
Преимущества и недостатки
Юникод — это набор символов, взятых из всех языков мира, глифов и эмодзи. Семейство кодировок UTF определяет, как символ будет представлен в двоичной системе. UTF-8 позволяет пользователям работать в совместимой со всеобщими стандартами и принятой по всему миру многоязычной среде.
Языки программирования (ЯП) по-разному поддерживают и используют кодировки. Иногда они могут искажать Unicode. Недостатки Юникода для разных ЯП и программ:
- PHP. Данный язык программирования поддерживает 256 символов, то есть воспринимает 1 символ в строке за 1 байт информации. Так происходит, даже если символ в строке весит больше одного байта. Например, смайл может весить четыре байта, а для PHP все равно один. Однако это можно исправить, настроив многобайтовые функции. Тогда при подсчете длины строки PHP будет обращаться к памяти, а не считать символ за байт.
- JavaScript. Работает с кодировкой UTF-16. Сложные символы требуют две кодовых точки для ссылки.
- MySQL. Система управления базами данных не поддерживает UTF-8 в его стандартном виде. MySQL недостаточно 24 битов, чтобы представить один символ. СУБД поддерживает расширенную версию кодировки — UTF-8mb4.
Максимальный потенциал
С помощью UTF-8 можно записать код любой длины. Однако, для того чтобы работа алгоритма была эффективной и надежной, лучше ограничить размер кода. Unicode 6.х является действующим стандартом и предполагает использование кода до четырех байт в UTF-8.
Сравнение UTF-8 и UTF-16
UTF-8 и UTF-16 — две самые широко используемые кодировки в стандарте Unicode. Они обе обладают переменной длинной кодирования. Один символ в них может быть представлен разным количеством байт. В Юникоде все данные хранятся в таблице и отсортированы по количеству байт, которое они имеют в двоичной системе. В начале стандарта символы могут занимать всего 1 байт, поэтому и UTF-8 зашифрует их с помощью 1 байта. Если данные требуют двух байтов, то и в UTF-8 они будут весить два байта. UTF-8 кодирует символ в двоичную строку от одного до четырех байтов. Так, для шифрования латинских символов достаточно одного байта, а для кириллических — двух. Для данных языков максимального потенциала UTF-8 достаточно.
UTF-16 оперирует данными из двух и четырех байт. Кодировка подходит для восточных языков.
Заключение
UTF-8 является самым распространенным методом кодирования в Сети, поскольку позволяет хранить текст, содержащий любой символ. Он способен перевести символы, содержащиеся в библиотеке Юникода, в байты, а затем выполнить обратный процесс.
UTF-8: Кодирование и декодирование
Причиной разобраться в том, как же работает UTF-8 и что такое Юникод заставил тот факт, что VBScript не имеет встроенных функций работы с UTF-8. А так как ничего рабочего не нашел, то пришлось писть/дописывать самому. Опыт на мой взгляд полезный в любом случае. Для лучшего понимания начну с теории.
О Юникоде
- Всего 255 символов, да и то часть из них не графические;
- Возможность открыть документ не с той кодировкой, в которой он был создан;
- Шрифты необходимо создавать для каждой кодировки.
О UTF-8
Когда-то я думал что есть Юникод, а есть UTF-8. Позже я узнал, что ошибался.
UTF-8 является лишь представлением Юникода в 8-битном виде. Символы с кодами меньше 128 представляются одним байтом, а так как в Юникоде они повторяют ASCII, то текст написанный только этими символами будет являться текстом в ASCII. Символы же с кодами от 128 кодируются 2-мя байтами, с кодами от 2048 — 3-мя, от 65536 — 4-мя. Так можно было бы и до 6-ти байт дойти, но кодировать ими уже ничего.
0x00000000 — 0x0000007F: 0xxxxxxx 0x00000080 — 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 — 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 — 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Кодируем в UTF-8
- Каждый символ превращаем в Юникод.
- Проверяем из какого символ диапазона.
- Если код символа меньше 128, то к результату добавляем его в неизменном виде.
- Если код символа меньше 2048, то берем последние 6 бит и первые 5 бит кода символа. К первым 5 битам добавляем 0xC0 и получаем первый байт последовательности, а к последним 6 битам добавляем 0x80 и получаем второй байт. Конкатенируем и добавляем к результату.
- Похожим образом можем продолжить и для больших кодов, но если символ за пределами U+FFFF придется иметь дело с UTF-16 суррогатами.
Function EncodeUTF8(s) Dim i, c, utfc, b1, b2, b3 For i=1 to Len(s) c = ToLong(AscW(Mid(s,i,1))) If c < 128 Then utfc = chr( c) ElseIf c < 2048 Then b1 = c Mod &h40 b2 = (c - b1) / &h40 utfc = chr(&hC0 + b2) & chr(&h80 + b1) ElseIf c < 65536 And (c < 55296 Or c >57343) Then b1 = c Mod &h40 b2 = ((c - b1) / &h40) Mod &h40 b3 = (c - b1 - (&h40 * b2)) / &h1000 utfc = chr(&hE0 + b3) & chr(&h80 + b2) & chr(&h80 + b1) Else ' Младший или старший суррогат UTF-16 utfc = Chr(&hEF) & Chr(&hBF) & Chr(&hBD) End If EncodeUTF8 = EncodeUTF8 + utfc Next End Function Function ToLong(intVal) If intVal < 0 Then ToLong = CLng(intVal) + &H10000 Else ToLong = CLng(intVal) End If End Function Декодируем UTF-8
- Ищем первый символ вида 11xxxxxx
- Считаем все последующие байты вида 10xxxxxx
- Если последовательность из двух байт и первый байт вида 110xxxxx, то отсекаем приставки и складываем, умножив первый байт на 0x40.
- Аналогично для более длинных последовательностей.
- Заменяем всю последовательность на нужный символ Юникода.
Function DecodeUTF8(s) Dim i, c, n, b1, b2, b3 i = 1 Do While i &h80 Then Exit Do End If n = n + 1 Loop If n = 2 and ((c and &hE0) = &hC0) Then b1 = asc(mid(s,i+1,1)) and &h3F b2 = c and &h1F c = b1 + b2 * &h40 Elseif n = 3 and ((c and &hF0) = &hE0) Then b1 = asc(mid(s,i+2,1)) and &h3F b2 = asc(mid(s,i+1,1)) and &h3F b3 = c and &h0F c = b3 * &H1000 + b2 * &H40 + b1 Else ' Символ больше U+FFFF или неправильная последовательность c = &hFFFD End if s = left(s,i-1) + chrw( c) + mid(s,i+n) Elseif (c and &hC0) = &h80 then ' Неожидаемый продолжающий байт s = left(s,i-1) + chrw(&hFFFD) + mid(s,i+1) End If i = i + 1 Loop DecodeUTF8 = s End Function Ссылки
UPD: Обработка ошибочных последовательностей и ошибка с типом Integer, который возвращает AscW.
UTF — универсальная кодировка для всего
В прошлый раз мы рассказали про Юникод — универсальную таблицу символов, в которой есть знаки почти всех языков. Вот краткое содержание:
- Когда компьютеры только появились, у них была кодировка только для букв латинского алфавита и некоторых знаков — всего 7 бит и 128 символов.
- С развитием технологий многие страны сделали себе альтернативные восьмибитные кодировки — в них можно было хранить уже 256 символов.
- Кроме латиницы, в таких кодировках записывали буквы национальных алфавитов и другие нужные символы.
- Это сработало в тех странах, где алфавит состоит из небольшого числа букв (20—40), но не решило проблему с иероглифами. Тогда страны Азии сделали свои кодировки.
- В итоге всё это привело к тому, что файл с одного компьютера мог не прочитаться на другом компьютере, если там не было нужной кодировки.
- Для решения этих проблем сделали Юникод — универсальную таблицу, в которую можно поместить 1 112 064 символа.
- Сейчас в Юникоде записаны символы почти всех языков мира, но свободных позиций там осталось ещё около 80%.
Получается, что Юникод — универсальное решение проблемы совместимости текста. Текстовый файл, записанный в таком формате, можно прочитать на любом современном компьютере. Поддержка Юникода есть во всех новых операционных системах последних лет.
Чтобы пользоваться Юникодом, нужна была новая кодировка, которая бы определяла правила хранения информации о каждом символе. Такой кодировкой стала UTF — про неё и поговорим. Она сложно устроена: будет интересно всем, кто интересуется компьютерами.
UTF — универсальная кодировка для хранения символов
Юникод как таковой отвечает на вопрос «Как мы храним символы?». Он объясняет, каким символам мы присваиваем какие коды; по какому принципу выделяем эти коды; какие символы используем, а какие нет.
Но также нам нужно знать, как хранить и передавать данные о символах Юникода. Вот это и есть UTF.
UTF (Unicode Transformation Format) — это стандарт кодирования символов Unicode. Разберём на куски:
- Стандарт — то есть всеобщая договорённость. Разработчик в России и Мексике открывают одну и ту же документацию и одинаково понимают, как им работать с данными. Договорились такие.
- Кодирование — то есть как мы представляем эти данные на компьютере. Это одно большое число? Несколько чисел поменьше? Сколько байтов выделять на эти символы? Нужно ли специально говорить компьютеру, что сейчас будут символы Юникода?
Что такое UTF-8?
Сейчас самая популярная разновидность UTF-кодировки — это UTF-8.
Чаще всего упоминание UTF-8 можно встретить в самом начале HTML-кода, когда мы объявляем кодировку в заголовке страницы. Строчка как раз говорит браузеру, что всё текстовое содержимое страницы нужно отображать по формату UTF-8.
Число 8 означает, что для хранения данных используются 8 бит информации. Ещё есть 16- и 32-битные кодировки: UTF-16 и UTF-32.
Проблема нулевых байтов
Сейчас немного информатики, потерпите.
Компьютер кодирует числа с помощью единиц и нулей в двоичной системе счисления. Она позволяет закодировать любое число, если дать ей достаточно места в памяти. Эти места измеряются в битах. Одним битом можно закодировать 0 или 1; двумя битами — числа от 0 до 3; восемью битами — от 0 до 255 и так далее. Биты слишком мелкие, поэтому для удобства хранения и обработки компьютеры группируют их по 8 бит, это называется байтом. В памяти можно выделять только байты, а не отдельные биты.
Максимальное количество символов в Юникоде — 1 112 064. Для хранения числа такого размера нам нужен 21 бит. Получается, что кодировка должна уметь работать с 21-битными числами.
Самое простое решение — выделить на каждый символ по 3 байта, то есть 24 бита. Например, символ с номером 998 536 в двоичной системе счисления выглядит так:
Если мы разобьём это на три байта и добавим впереди нужное количество нулей до трёх байтов, то получится такое:
00001111 00111100 10001000
Кажется, что мы сразу нашли способ кодирования: просто выделяй на все символы по три байта и кайфуй.
Но что, если нам нужен, например, символ под номером 150?
Разобьем снова на три байта:
00000000 00000000 10010110
У нас получилось в самом начале два нулевых байта. Проблема в том, что многие системы передачи данных воспринимают нулевые байты как конец передачи. Если они встретят такую последовательность, то решат, что передача окончена, а всё, что идёт дальше, — лишний шум, который обрабатывать не нужно. Если в нашем Юникод-тексте много символов из начала таблицы (например, всё на английском), то с чтением такого файла возникнут проблемы.
Чтобы выйти из этой ситуации, придумали UTF-8 — кодировку с плавающим количеством символов.
Как устроена кодировка UTF-8
В UTF-8 каждый символ кодируется разным количеством байтов — всё зависит от того, какой длины исходное число. Сначала расскажем теорию, потом нарисуем, как это работает.
До 7 бит — выделяется один байт, первый бит всегда ноль: 0xxxxxxxx. Иксы — это биты нашего числа. Например, буква A стоит на 65-м месте в таблице, а если перевести 65 в двоичный код, получится 1000001. Ставим эти 7 бит в наш шаблон и получаем нужный юникод-байт: 01000001.
Ноль здесь — признак того, что перед нами символ из первых 128 символов таблицы. Они совпадают с таблицей ASCII, поэтому одним байтом можно закодировать все стандартные математические символы, знаки препинания и буквы латинского алфавита.
Если первым в символе идёт ноль, кодировка понимает, что перед нами — один восьмибитный символ. Двух-, трёх- и четырёхбайтные символы всегда начинаются с единицы.
8—11 бит: выделяется два байта — 110xxxxx 10xxxxxx. Две единицы в начале говорят, что перед нами символ из двух байтов. Последовательность 10 в начале второго байта — признак того, что это продолжение предыдущего байта.
12—16 бит: тут уже три байта — 1110xxxx 10xxxxxx 10xxxxxx. Три единицы в начале — признак трёхбайтного символа. Каждый байт продолжения начинается с 10.
17—21 бит: для кодирования нужно четыре байта: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx.
Короче: в кодировке UTF договорились, что много байтов выделяют только на те символы, которые стоят где-то в глубине таблицы, то есть всякие сложные национальные кодировки, эмодзи и иконки. Чем ближе к началу таблицы символ, тем меньше байтов на него выделяют. А чтобы компьютер понимал, сколько байтов выделено на каждый конкретный символ, сначала ставят специальные маркеры-подсказки.
Практика: кодируем символы в UTF-8
Закодируем в UTF-8 такой Юникод-символ — �� с порядковым номером 66376.
Для этого сначала переведём число 66376 в двоичный формат:
Здесь 17 бит, поэтому для кодирования в UTF-8 нам понадобится 4 байта. Вот шаблон, который нам нужно будет заполнить:

Подготовим наше двоичное число к заполнению по этому шаблону. Для этого разобьем его справа налево на те же группы: 3—6—6—6 символов:
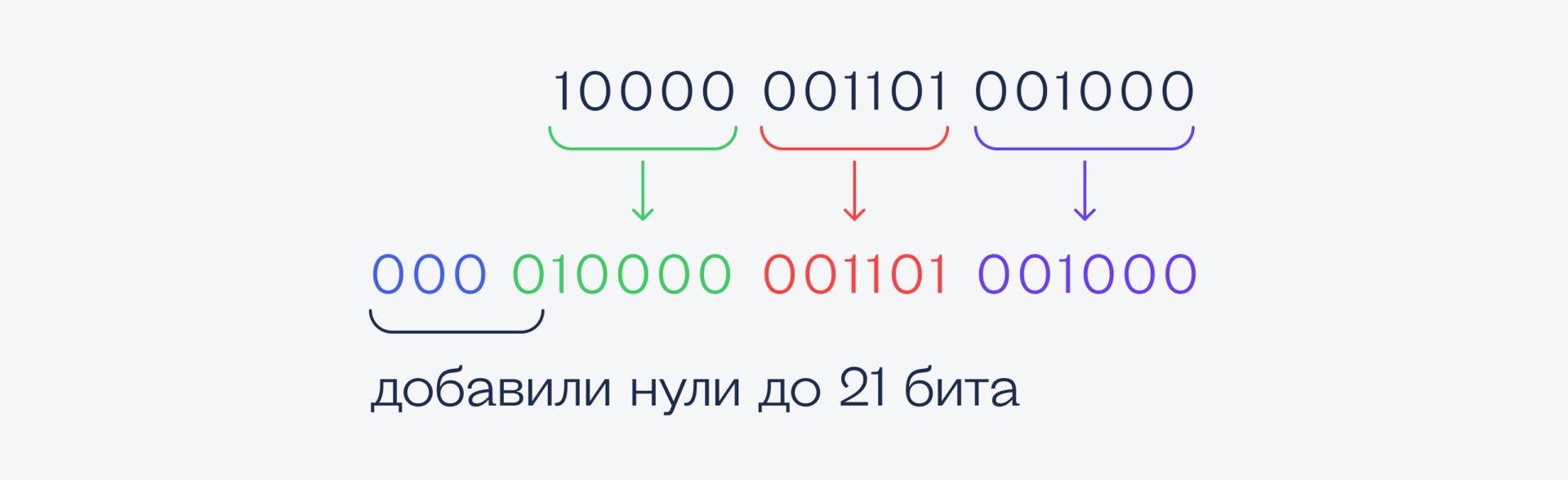
Теперь подставим эти значения в наш четырёхбитный шаблон:

И переведём в шестнадцатеричную систему счисления:

Получается, что символ �� закодируется в четырёх байтах как F0 90 8D 88.
Почему нельзя просто всё кодировать одинаковым количеством бит
Можно, причём так часто делают в некоторых системах. Для этого там используют кодировки UTF-16 и UTF-32 — в них на каждый символ отводится сразу 2 или 4 байта.
Проблема такого подхода в том, что это увеличивает объём памяти, нужный для хранения данных. Проще говоря, те символы, на которых в UTF-8 хватило бы одного байта, здесь занимают в 2–4 раза больше.
С другой стороны, такие кодировки иногда проще в обработке, поэтому их, например, используют как штатные кодировки операционных систем. Так, UTF-16 — стандартная кодировка файловой системы NTFS в Windows.
Проблемы с безопасностью
Так как Юникод с помощью UTF-8 сам преобразует символы в последовательность байтов и наоборот, есть ситуации, когда это может навредить системе и привести к взлому.
Например, пользователю могут прислать файл, который называется otchetexe. txt — кажется, что это обычный текстовый файл, который можно смело открывать. Но на самом деле файл называется otchet[U+202E]txt.exe, а U+202E — это специальный юникод-символ, который включает написание справа налево. После того как Юникод встречает этот символ, он выводит всё написанное после него в обратном порядке. Так простой текстовый файл превращается в исполняемый .exe-файл для Windows. Если его запустить с правами администратора, он может натворить много всякого.
Ещё пример — использование Юникода в разных SQL- и PHP-запросах. Из-за сложных преобразований может произойти переполнение стека — а этим уже могут воспользоваться злоумышленники, чтобы внедрить нужный код для выполнения.
На самом деле Юникод с этой точки зрения — большая дыра в безопасности любой системы, поэтому при работе с ним в критичных ситуациях используют белые списки, то есть те символы, которые использовать безопасно.
Ваш первый язык программирования: бесплатный гид для начинающих
Скачайте бесплатный гид от журнала «Код», чтобы ответить на все вопросы о старте в ИТ




Получите ИТ-профессию
В «Яндекс Практикуме» можно стать разработчиком, тестировщиком, аналитиком и менеджером цифровых продуктов. Первая часть обучения всегда бесплатная, чтобы попробовать и найти то, что вам по душе. Дальше — программы трудоустройства.
UTF-8
UTF-8 — это кодировка символов переменной длины, что, в данном случае, означает длину от 1 до 4 байт на символ. Первый байт UTF-8 используется для кодирования ASCII, что означает, что данный набор символов полностью обратно совместим с ASCII. UTF-8 означает, что символы ASCII и Latin полностью взаимозаменяемы с небольшим увеличением размера данных, так как используется только первый байт. Пользователи восточных алфавитов, например, японского, которым назначили диапазон с большим числом байт несчастливы, так как это приводит к 50-процентной избыточности в их данных.
- 1 Кодировки символов
- 1.1 Что такое кодировка символов?
- 1.2 История кодировок символов
- 1.3 Что такое Юникод?
- 1.4 Что UTF-8 может сделать
- 2.1 Поиск или создание локалей UTF-8
- 2.2 Настройка локали
- 2.3 Альтернатива: Использование eselect для настройки локали
- 3.1 (V)FAT
- 3.2 Имена файлов
- 3.3 Системная консоль
- 3.4 Ncurses и Slang
- 3.5 KDE, GNOME и Xfce
- 3.6 X11 и шрифты
- 3.7 Диспетчеры окон и эмуляторы терминалов
- 3.8 Vim, emacs, xemacs и nano
- 3.9 Командные оболочки
- 3.10 Irssi
- 3.11 Mutt
- 3.12 links и elinks
- 3.13 Samba
- 3.14 Проверка работоспособности
- 4.1 Системные конфигурационные файлы (в /etc)
Кодировки символов
Что такое кодировка символов?
Компьютеры неспособны воспринимать текст как человек. Вместо этого они каждый символ представляют как число. Традиционно каждый набор чисел, используемый для представления алфавитов и символов (известный как кодировка или набор символов), ограничен по размеру в силу ограничений оборудования.
История кодировок символов
Самой распространенной (или, по крайней мере, наиболее принятой повсеместно) кодировкой является ASCII (Американский стандартный код для обмена информацией, American Standard Code for Information Interchange). Часто считается, что ASCII — наиболее успешный программный стандарт из когда-либо созданных. Современный ASCII стандартизован в 1986 году (ANSI X3.4, RFC 20, ISO/IEC 646:1991, ECMA-6) Американским национальным институтом по стандартизации (American National Standards Institute, ANSI).
ASCII является строго семибитной кодировкой, из чего следует, что она использует семь двоичных цифр, то есть интервал от 0 до 127. Сюда входят 33 невидимых управляющих символа с кодами от 0 до 31 и управляющим символом DEL (или delete) с кодом 127. Символы в диапазоне от 32 до 126 видимы — это пробел, знаки препинания, латинские буквы и цифры.
Восьмой бит в ASCII изначально использовался как бит контроля четности для проверки ошибок при передаче информации. Если проверка на ошибки не важна, то он остается равным 0. Это означает, что в ASCII каждый символ занимал один байт.
Хотя ASCII было достаточно для передачи информации на английском, для других европейских языков, содержащих символы с диакритическими знаками, это было не так просто. Для них был разработаны стандарты семейства ISO 8859. Они были обратно совместимы с ASCII, но использовали восьмой бит для дополнения таблицы дополнительными 128 символами (32 управляющих и 96 видимых) для каждой кодировки. Скоро стали видны и ограничения ISO 8859. На данный момент существует 15 вариантов стандарта ISO 8859 (с 8859-1 по 8859-15). Зачастую для каждого символа вне ASCII-совместимого диапазона между этими стандартами возникал конфликт. И словно этого было мало, для ещё большей путаницы корпорация Microsoft ввела собственную кодировку Windows-1252, использовавшуюся для западноевропейских языков в некоторых версиях Microsoft Windows. Набор видимых символов этой кодировки является надстройкой надстройкой ISO 8859-1, обладающий, однако, собственными изменениями; тем не менее, все эти наборы сохранили совместимость с ASCII.
Необходимость разработки совершенно отличных от ASCII однобайтовых кодировок для нелатинских алфавитов, как например EUC (Extended Unix Coding), используемый в японском и корейском (и в меньшей степени китайском) алфавитах, породила еще большую неразбериху с кодировками. Ряд операционных систем все еще использует различные наборы символов для одного и того же языка, например японские Shift-JIS и ISO-2022-JP. А пользователи, желающие видеть кириллицу, вынуждены были выбирать между KOI8-R (для русского и болгарского языков) и KOI8-U (для украинского языка), неудачной ISO 8859-5 и популярной Windows-1251. Все три семейства кодировок не полностью совместимы с ASCII. Хотя надо отметить, в KOI8 фонетически созвучные кириллические символы расположены так же, как и латинские, благодаря чему даже при отбрасывании восьмого бита текст оставался читабельным в ASCII-терминалах в виде транслита.
Все это привело к путанице и почти полной невозможности многоязычного общения; в особенности с использованием различных алфавитов. Переходим к Юникоду.
Что такое Юникод?
Юникод отбрасывает лимит традиционных однобайтовых кодировок. Он использует 17 «плоскостей», содержащих по 65 536 кодов символов. Таким образом, максимальное возможное число символов равно 1 114 112. Поскольку в первой плоскости («Basic Multilingual Plane» или BMP) содержится почти всё, что может понадобиться, многие ошибочно посчитали, что Юникод это 16-битный набор символов.
Юникод реализован несколькими способами, но распространены только два UTF (Unicode Transformation Format) и UCS (Universal Character Set). Число после UTF обозначает число бит на каждый символ, когда как число после UCS обозначает число байт. UTF-8 стала наиболее распространенной при обмене текста Юникод из-за своей явной ориентированности на размер в 8 бит; поэтому является основной темой данного документа.
Что UTF-8 может сделать
UTF-8 позволяет пользователям работать в совместимой со всеобщими стандартами и принятой по всему миру многоязычной среде, правда с небольшим увеличением размера данных. Это наилучший способ для передачи не-ASCII символов через интернет, будь то электронная почта, IRC-сети или что-нибудь еще. Несмотря на это, множество людей расценивают использование UTF-8 при передаче данных неприличным и неуважительным. Всегда следует выяснять, поддерживает ли определенный канал, группа Usenet или список рассылки UTF-8 перед тем, как использовать символы из не-ASCII диапазона UTF-8.
Настройка UTF-8 в Gentoo Linux
Поиск или создание локалей UTF-8
Теперь, когда принципы лежащие в основе Unicode были изложены, начнем использовать UTF-8 на локальной системе!
Пользователям, которым нужна более детальная информация, могут найти ее в статье Руководство Gentoo по локализации.
Далее, нужно определить, доступна ли локаль UTF-8 для нашего языка или придется создать её.
user $ locale -a | grep 'en_GB'
en_GB en_GB.utf8
На выходе этой команды мы должны получить хотя бы одну строку, содержащую суффикс .UTF-8 . Если таковых нет, то нам придётся создать локаль, совместимую с UTF-8.
Команда выше перечисляет суффикс в нижнем регистре без дефисов, glibc понимает обе формы суффикса, многие другие программы — нет. Наиболее распространённым примером является Xorg. Поэтому лучше всегда использовать UTF-8 вместо utf8.
Заметка
Запускайте следующую команду, если в система не имеет UTF-8 локали для выбранного языка.Замените «en_GB», если нужна какая-то другая локаль:
root # localedef -i en_GB -f UTF-8 en_GB.UTF-8
Другим способом включить локаль UTF-8 является добавление её в файл /etc/locale.gen и генерация нужных локалей с помощью команды locale-gen . Локали будут записаны в архив локалей /usr/lib/locale/locale-archive .
КОД Строка в /etc/locale.gen
en_GB.UTF-8 UTF-8
root # locale-gen
* Generating 1 locales (this might take a while) with 1 jobs * (1/1) Generating en_GB.UTF-8 . [ ok ] * Generation complete
Настройка локали
Есть одна переменная среда, которую необходимо настроить, чтобы использовать UTF-8 локали: LC_CTYPE (также, можно изменить переменную LANG , чтобы изменить системный язык). Есть множество способов сделать это. Некоторые системные администраторы предпочитают использовать UTF-8 только для определенного пользователя, поэтому они устанавливают эту переменную в своём ~/.profile ( /bin/sh > для пользователей Bourne shell), ~/.bash_profile или ~/.bashrc ( /bin/bash для пользователей Bourne again shell). Больше информации, а также наилучшие способы локализации можно найти в Руководстве по локализации.
Другие же предпочитают установить локаль глобально. Есть по крайней один весомый аргумент в пользу этого подхода - при использовании /etc/init.d/xdm , так как init-скрипт запускают диспетчер окон до того, как будут загружены конфигурационные файлы командной оболочки. Другими словами, это выполняется до того момента, как какие-либо переменные попадут в окружение пользователя.
Настройка локали глобально делается с помощью файла /etc/env.d/02locale . Он должен выглядеть следующим образом:
ФАЙЛ /etc/env.d/02locale Демонстрация для en_GB.UTF-8
## (Как обычно, замените "en_GB.UTF-8" соответствующее значение локали; каждый язык имеет своё значение!) LANG="en_GB.UTF-8"
Заметка
Можно использовать LC_CTYPE вместо переменной LANG . За дополнительными сведениями о категориях, на которые влияет использование LC_CTYPE , обращайтесь к странице локалей GNU.Далее, следует обновить среду переменных, запустив следующую команду:
root # env-update
>>> Regenerating /etc/ld.so.cache.
root # source /etc/profile
Теперь запустите locale без аргументов, чтобы увидеть, что верные переменные были загружены в окружающую среду переменных:
root # locale
LANG=en_GB.utf8 LC_CTYPE="en_GB.utf8" LC_NUMERIC="en_GB.utf8" LC_TIME="en_GB.utf8" LC_COLLATE="en_GB.utf8" LC_MONETARY="en_GB.utf8" LC_MESSAGES="en_GB.utf8" LC_PAPER="en_GB.utf8" LC_NAME="en_GB.utf8" LC_ADDRESS="en_GB.utf8" LC_TELEPHONE="en_GB.utf8" LC_MEASUREMENT="en_GB.utf8" LC_IDENTIFICATION="en_GB.utf8" LC_ALL=
Значения переменных окружения локали, которые были явно установлены, например, при помощи «export» (в bash), перечислены без двойных кавычек. Те переменные, чьи значения были унаследованы от других переменных окружения локали, содержат свои значения в двойных кавычках.
Альтернатива: Использование eselect для настройки локали
То, что было написано выше, достаточно, чтобы хорошо настроить систему, можно также проверить правильность настройки локали с помощью утилиты eselect .
Используйте команду eselect , чтобы получить список доступных локалей в системе:
root # eselect locale list
[1] C [2] POSIX * [3] en_GB.utf8 [ ] (free form)
Утилита eselect выводит список локалей. После того, как нужная локаль была определена, активируйте ее:
root # eselect locale set 3
Setting LANG to en_GB.utf8 .
root # eselect locale list
[1] C [2] POSIX [3] en_GB.utf8 * [ ] (free form)
В случае предпочтения использовать .UTF-8 заместо .utf8 в /etc/env.d/02locale , запустите соответствующую команду eselect:
root # eselect locale set en_GB.UTF-8
Setting LANG to en_GB.UTF-8 .
root # eselect locale list
[1] C [2] POSIX [3] en_GB.utf8 [4] en_GB.UTF-8 * [ ] (free form)
Запуск следующей команды обновит переменное окружение для shell:
root # env-update && source /etc/profile
>>> Regenerating /etc/ld.so.cache.
Вот и всё. Теперь система использует локаль UTF-8. Следующим этапом будет настройка повседневно используемых приложений.
Поддержка приложениями
Когда Юникод делал первые шаги в мире программного обеспечения, многобайтовые кодировки были плохо совместимы с таким языком программирования как C, на котором написаны многие из часто используемых программ. Даже сейчас некоторые программы не способны работать с UTF-8 как надо. К счастью, большинство распространенных программ поддерживают Юникод.
(V)FAT
Для настройки поддержки UTF-8 в файловых системах FAT смотрите статью FAT.
Имена файлов
Чтобы сменить кодировку имен файлов, используйте app-text/convmv .
root # emerge --ask app-text/convmv
Команда convmv имеет следующий формат:
root # convmv -f -t utf-8
Замените iso-8859-1 кодировкой, с которой хотите конвертировать:
root # convmv -f iso-8859-1 -t utf-8 имя_файла
Для изменения содержимого файлов, используйте утилиту iconv , поставляемую вместе с sys-libs/glibc и уже должна быть установлена в системе Gentoo. Замените iso-8859-1 кодировкой, с которой хотите конвертировать. После запуска команды убедитесь в нормальном выходе:
root # iconv -f iso-8859-1 -t utf-8 имя_файла
Чтобы конвертировать файл, нужно создать другой файл:
root # iconv -f iso-8859-1 -t utf-8 имя_файла > новый_файл
Также для перекодировки может быть использован пакет ( app-text/recode ).
Системная консоль
Для поддержки консолью локали UTF-8 нужно отредактировать /etc/rc.conf . Установите переменную UNICODE="yes" и прочтите комментарии в этом файле -- важно, чтобы в системе были шрифты с нужным диапазоном символов, если хотите выжать из Юникода всё. Чтобы это сработало, удостоверьтесь, что локаль Unicode была правильно создана.
В файле /etc/conf.d/keymaps переменная KEYMAP должна соответствовать раскладке Unicode.
КОД Выдержка из /etc/conf.d/keymaps
## (Замените uk на любимую раскладку) keymap="uk"
Ncurses и Slang
Заметка
Игнорируйте любые упоминания о Slang в этом разделе, если он не установлен или не нужен.Будет хорошим решением добавить unicode к глобальным USE-флагам в файле /etc/portage/make.conf , а затем при необходимости пересобрать sys-libs/ncurses и sys-libs/slang . Portage это сделает автоматически при обновлении системы, если он был запущен с опциями --changed-use или --newuse . Запустите следующую команду чтобы обновить пакеты:
root # emerge --update --deep --newuse @world
Также понадобится пересобрать пакеты, зависящие от них, чтобы изменения USE вступили в силу. Используемая утилита ( revdep-rebuild ) входит в пакет app-portage/gentoolkit .
root # revdep-rebuild --library libncurses.so.5
root # revdep-rebuild --library libslang.so.1KDE, GNOME и Xfce
Все основные графические оболочки полностью совместимы с Юникодом и не требуют дополнительной настройки, кроме той, что описана в этом документе. Все это благодаря тому, графические библиотеки (Qt и GTK+ 2) совместимы с UTF-8. Следовательно, все приложения, работающие на основе этих библиотек, также должны поддерживать UTF-8 без дополнительных настроек.
У приложений написанных на GTK, для ввода шестнадцатеричного Юникода нужно ввести Ctrl + Shift + u + . Например, символ Юникода ✔ , у которого Юникод номер U+2714, может быть введен как Ctrl + Shift + u + 2714 + ENTER , что после преобразования станет ✔ .
X11 и шрифты
Шрифты TrueType обычно совместимы с Юникодом, и большинство шрифтов, поставляемых с Xorg, имеют поддержку большинства кодировок, хотя не все глифы Юникода могут быть отображены для конкретного шрифта.
Также множество пакетов шрифтов в Portage совместимы с Юникодом. Смотрите страницу Fontconfig для более подробной информации о рекомендуемых шрифтах и настройках.
Диспетчеры окон и эмуляторы терминалов
Диспетчеры окон, не использующие GTK или Qt, обычно очень хорошо поддерживают Юникод, так как чаще всего для отображения шрифтов используют библиотеку Xft. Если диспетчер окон не использует Xft, то еще возможно использовать FontSpec, указанный в предыдущем разделе в качестве шрифта Юникода.
Эмуляторы терминала, использующие Xft и поддерживающие Юникод найти сложнее. Кроме Konsole и GNOME Terminal, лучшим выбором в Portage будет x11-terms/rxvt-unicode , x11-terms/xfce4-terminal , gnustep-apps/terminal , x11-terms/mlterm или просто x11-terms/xterm , собранный с USE-флагом unicode и запускаемый как uxterm . app-misc/screen тоже поддерживает UTF-8, если запускается с параметром screen -U , или в файле ~/.screenrc есть следующая строчка:
КОД ~/.screenrc для UTF-8
defutf8 on
Vim, emacs, xemacs и nano
Vim полностью поддерживает UTF-8 и к тому же автоматически определяет файлы с UTF-8. Для более детальной информации используйте в Vim :help mbyte.txt .
GNU Emacs с версии 23 и XEmacs версии 21.5 имеют полную поддержку UTF-8. GNU Emacs 24 также поддерживает редактирование текста в обоих направлениях.
Nano полностью поддерживает UTF-8 начиная с версии 1.3.6.
Командные оболочки
На данный момент Bash полностью поддерживает Юникод через библиотеку GNU readline. Z Shell поддерживает Unicode при использовании USE-флага unicode .
Оболочки C, tcsh и ksh не поддерживают UTF-8.
Irssi
Irssi полностью поддерживает UTF-8, хотя для этого требуется дополнительная настройка пользователем.
[irssi] set term_charset UTF-8
Для каналов, где не-ASCII символы чаще всего передаются в не-UTF-8 кодировках, может пригодиться команда /recode для перекодировки символов. Наберите /help recode для большего количества информации.
Mutt
Почтовый агент Mutt очень хорошо справляется с Юникодом. Чтобы использовать UTF-8 в Mutt, не надо что-либо добавлять в конфигурационные файлы. Mutt будет работать с Юникодом без модификаций, при условии, что все конфигурационные файлы (включая подпись) сохранены в UTF-8.
Заметка
Если всё ещё видите '?' в письмах при чтении с помощью Mutt? Это случается из-за того, что некоторые люди используют почтовые клиенты, которые не указывают используемую кодировку письма. Мало что можно сделать в этом случае, кроме как попросить их правильно настроить свои клиенты.Для более детальной информации см. Mutt Wiki.
links и elinks
Это самые популярные текстовые браузеры, и вы узнаете, как установить поддержку UTF-8 для них. В elinks и links есть два способа сделать это — через меню Setup (Установки) браузера или отредактировав конфигурационный файл. Чтобы настроить параметры в самом браузере, откройте какой-нибудь сайт с помощью elinks или links и нажмите Alt + S для входа в меню настроек (Setup Menu), после чего выберите параметры терминала (Terminal options), или нажмите T . Пролистайте вниз и выберите последний параметр UTF-8 I/O , нажав на Enter . Затем сохраните и выйдите из меню. В links можно сделать тоже самое, нажав Alt + S , а затем S для сохранения. Пример конфигурационного файла показан ниже.
КОД Включение UTF-8 в elinks/links
## (Для elinks добавьте в /etc/elinks/elinks.conf или ~/.elinks/elinks.conf следующую строку) set terminal.linux.utf_8_io = 1 ## (Для links, добавьте в ~/.links/links.cfg следующую строку) terminal "xterm" 0 1 0 us-ascii utf-8
Samba
Samba — это набор программ, реализующих протокол SMB (Server Message Block) для UNIX-систем (Mac, Linux и FreeBSD). Этот протокол также иногда упоминается как Common Internet File System (CIFS). Samba содержит также систему NetBIOS, используемую для предоставления доступа к файлам в Windows-сетях.
Добавьте следующие строки в раздел [global] :
root # nano -w /etc/samba/smb.conf
dos charset = 1255 unix charset = UTF-8 display charset = UTF-8
Проверка работоспособности
Есть множество сайтов, использующих UTF-8 и большинство популярных веб-браузеров в Gentoo полностью поддерживают UTF-8.
При использовании текстовых браузеров, удостоверьтесь, что используется совместимый с Юникодом терминал.
Если некоторые символы отображаемые как квадратики с буквами или цифрами внутри, то это значит, что в текущем шрифте нет соответствующего символа или глифа для этого символа. Вместо этого, он отображает квадрат с шестнадцатеричным кодом символа UTF-8.
- unicode-table.com
- тестовая страница UTF-8 W3C
- тестовая страничка UTF-8 от Университета Франкфурта
Известные проблемы
Системные конфигурационные файлы (в /etc)
Большинство системных конфигурационных файлов (например, /etc/fstab ) не поддерживают UTF-8. Рекомендуется придерживаться набора символов ASCII при работе с этими файлами.
Внешние ресурсы
- статья в Википедии про Юникод (ru)
- статья в Википедии про UTF-8 (ru)
- Unicode.org
- UTF-8.com
- RFC 3629
- RFC 2277
- символы и байты
- библиотека GNU C: локали и интернационализация
- unifoundry.com - руководство по unicode
- Описание USE-флага unicodeThis page is based on a document formerly found on our main website gentoo.org.
The following people contributed to the original document: Thomas Martin, Alexander Simonov, Shyam Mani,
They are listed here because wiki history does not allow for any external attribution. If you edit the wiki article, please do not add yourself here; your contributions are recorded on each article's associated history page.