Анализ производительности ВМ в VMware vSphere. Часть 2: Memory

В этой статье поговорим про счетчики производительности оперативной памяти (RAM) в vSphere.
Вроде бы с памятью все более однозначно, чем с процессором: если на ВМ возникают проблемы с производительностью, их сложно не заметить. Зато если они появляются, справиться с ними гораздо сложнее. Но обо всем по порядку.
Немного теории
Оперативная память виртуальных машин берется из памяти сервера, на которых работают ВМ. Это вполне очевидно:). Если оперативной памяти сервера не хватает для всех желающих, ESXi начинает применять техники оптимизации потребления оперативной памяти (memory reclamation techniques). В противном случае операционные системы ВМ падали бы с ошибками доступа к ОЗУ.
Какие техники применять ESXi решает в зависимости от загруженности оперативной памяти:
| Состояние памяти | Граница | Действия |
| High | 400% от minFree | После достижения верхней границы, большие страницы памяти разбиваются на маленькие (TPS работает в стандартном режиме). |
| Clear | 100% от minFree | Большие страницы памяти разбиваются на маленькие, TPS работает принудительно. |
| Soft | 64% от minFree | TPS + Balloon |
| Hard | 32% от minFree | TPS + Compress + Swap |
| Low | 16% от minFree | Compress + Swap + Block |
minFree — это оперативная память, необходимая для работы гипервизора.
До ESXi 4.1 включительно minFree по умолчанию было фиксированным — 6% от объема оперативной памяти сервера (процент можно было поменять через опцию Mem.MinFreePct на ESXi). В более поздних версиях из-за роста объемов памяти на серверах minFree стало рассчитываться исходя из объема памяти хоста, а не как фиксированное процентное значение.
Значение minFree (по умолчанию) считается следующим образом:
| Процент памяти, резервируемый для minFree | Диапазон памяти |
| 6% | 0-4 Гбайт |
| 4% | 4-12 Гбайт |
| 2% | 12-28 Гбайт |
| 1% | Оставшаяся память |
Например, для сервера со 128 Гбайт RAM значение MinFree будет таким:
MinFree = 245,76 + 327,68 + 327,68 + 1024 = 1925,12 Мбайт = 1,88 Гбайт
Фактическое значение может отличаться на пару сотен МБайт, это зависит от сервера и оперативной памяти.
| Процент памяти, резервируемый для minFree | Диапазон памяти | Значение для 128 Гбайт |
| 6% | 0-4 Гбайт | 245,76 Мбайт |
| 4% | 4-12 Гбайт | 327,68 Мбайт |
| 2% | 12-28 Гбайт | 327,68 Мбайт |
| 1% | Оставшаяся память (100 Гбайт) | 1024 Мбайт |
Обычно для продуктивных стендов нормальным можно считать только состояние High. Для стендов для тестирования и разработки приемлемыми могут быть состояния Clear/Soft. Если оперативной памяти на хосте осталось менее 64% MinFree, то у ВМ, работающих на нем, точно наблюдаются проблемы с производительностью.
В каждом состоянии применяются определенные memory reclamation techniques начиная с TPS, практически не влияющего на производительность ВМ, заканчивая Swapping’ом. Расскажу про них подробнее.
Transparent Page Sharing (TPS). TPS — это, грубо говоря, дедупликация страниц оперативной памяти виртуальных машин на сервере.
ESXi ищет одинаковые страницы оперативной памяти виртуальных машин, считая и сравнивая hash-сумму страниц, и удаляет дубликаты страниц, заменяя их ссылками на одну и ту же страницу в физической памяти сервера. В результате потребление физической памяти снижается и можно добиться некоторой переподписки по памяти практически без снижения производительности.
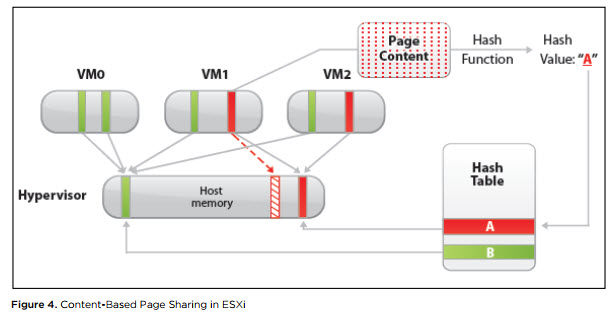
Источник
Данный механизм работает только для страниц памяти размером 4 Кбайт (small pages). Страницы размером 2 МБайт (large pages) гипервизор дедуплицировать даже не пытается: шанс найти одинаковые страницы такого размера не велик.
По умолчанию ESXi выделяет память большим страницам. Разбивание больших страниц на маленькие начинается при достижении порога состояния High и происходит принудительно, когда достигается состояние Clear (см. таблицу состояний гипервизора).
Если же вы хотите, чтобы TPS начинал работу, не дожидаясь заполнения оперативной памяти хоста, в Advanced Options ESXi нужно установить значение “Mem.AllocGuestLargePage” в 0 (по умолчанию 1). Тогда выделение больших страниц памяти для виртуальных машин будет отключено.
С декабря 2014 во всех релизах ESXi TPS между ВМ по умолчанию отключен, так как была найдена уязвимость, теоретически позволяющая получить из одной ВМ доступ к оперативной памяти другой ВМ. Подробности тут. Информация про практическую реализацию эксплуатации уязвимости TPS мне не встречалось.
Политика TPS контролируется через advanced option “Mem.ShareForceSalting” на ESXi:
0 — Inter-VM TPS. TPS работает для страниц разных ВМ;
1 – TPS для ВМ с одинаковым значением “sched.mem.pshare.salt” в VMX;
2 (по умолчанию) – Intra-VM TPS. TPS работает для страниц внутри ВМ.
Однозначно имеет смысл выключать большие страницы и включать Inter-VM TPS на тестовых стендах. Также это можно использовать для стендов с большим количеством однотипных ВМ. Например, на стендах с VDI экономия физической памяти может достигать десятков процентов.
Memory Ballooning. Ballooning уже не такая безобидная и прозрачная для операционной системы ВМ техника, как TPS. Но при грамотном применении с Ballooning’ом можно жить и даже работать.
Вместе с Vmware Tools на ВМ устанавливается специальный драйвер, называемый Balloon Driver (он же vmmemctl). Когда гипервизору начинает не хватать физической памяти и он переходит в состояние Soft, ESXi просит ВМ вернуть неиспользуемую оперативную память через этот Balloon Driver. Драйвер в свою очередь работает на уровне операционной системы и запрашивает свободную память у нее. Гипервизор видит, какие страницы физической памяти занял Balloon Driver, забирает память у виртуальной машины и возвращает хосту. Проблем с работой ОС не возникает, так как на уровне ОС память занята Balloon Driver’ом. По умолчанию Balloon Driver может забрать до 65% памяти ВМ.
Если на ВМ не установлены VMware Tools или отключен Ballooning (не рекомендую, но есть KB:), гипервизор сразу переходит к более жестким техникам отъема памяти. Вывод: следите, чтобы VMware Tools на ВМ были.

Работу Balloon Driver’а можно проверить из ОС через VMware Tools.
Memory Compression. Данная техника применяется, когда ESXi доходит до состояния Hard. Как следует из названия, ESXi пытается сжать 4 Кбайт страницы оперативной памяти до 2 Кбайт и таким образом освободить немного места в физической памяти сервера. Данная техника значительно увеличивает время доступа к содержимому страниц оперативной памяти ВМ, так как страницу надо предварительно разжать. Иногда не все страницы удается сжать и сам процесс занимает некоторое время. Поэтому данная техника на практике не очень эффективна.
Memory Swapping. После недолгой фазы Memory Compression ESXi практически неизбежно (если ВМ не уехали на другие хосты или не выключились) переходит к Swapping’у. А если памяти осталось совсем мало (состояние Low), то гипервизор также перестает выделять ВМ страницы памяти, что может вызвать проблемы в гостевых ОС ВМ.
Вот как работает Swapping. При включении виртуальной машины для нее создается файл с расширением .vswp. По размеру он равен незарезервированной оперативной памяти ВМ: это разница между сконфигурированной и зарезервированной памятью. При работе Swapping’а ESXi выгружает страницы памяти виртуальной машины в этот файл и начинает работать с ним вместо физической памяти сервера. Разумеется, такая такая “оперативная” память на несколько порядков медленнее настоящей, даже если .vswp лежит на быстром хранилище.
В отличие от Ballooning’а, когда у ВМ отбираются неиспользуемые страницы, при Swapping’e на диск могут переехать страницы, которые активно используются ОС или приложениями внутри ВМ. В результате производительность ВМ падает вплоть до подвисания. ВМ формально работает и ее как минимум можно правильно отключить из ОС. Если вы будете терпеливы 😉
Если ВМ ушли в Swap — это нештатная ситуация, которую по возможности лучше не допускать.
Основные счетчики производительности памяти виртуальной машины
Вот мы и добрались до главного. Для мониторинга состояния памяти в ВМ есть следующие счетчики:
Active — показывает объем оперативной памяти (Кбайт), к которому ВМ получила доступ в предыдущий период измерения.
Usage — то же, что Active, но в процентах от сконфигурированной оперативной памяти ВМ. Рассчитывается по следующей формуле: active ÷ virtual machine configured memory size.
Высокий Usage и Active, соответственно, не всегда является показателем проблем производительности ВМ. Если ВМ агрессивно использует память (как минимум, получает к ней доступ), это не значит, что памяти не хватает. Скорее это повод посмотреть, что происходит в ОС.
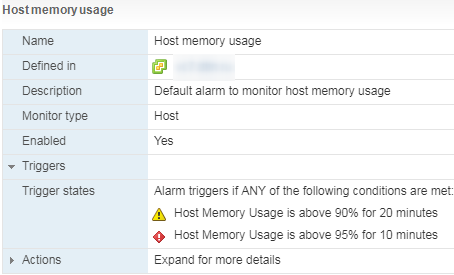
Есть стандартный Alarm по Memory Usage для ВМ:

Shared — объем оперативной памяти ВМ, дедуплицированной с помощью TPS (внутри ВМ или между ВМ).
Granted — объем физической памяти хоста (Кбайт), который был отдан ВМ. Включает Shared.
Consumed (Granted — Shared) — объем физической памяти (Кбайт), которую ВМ потребляет с хоста. Не включает Shared.
Если часть памяти ВМ отдается не из физической памяти хоста, а из swap-файла или память отобрана у ВМ через Balloon Driver, данный объем не учитывается в Granted и Consumed.
Высокие значения Granted и Consumed — это совершенно нормально. Операционная система постепенно забирает память у гипервизора и не отдает обратно. Со временем у активно работающей ВМ значения данных счетчиков приближается к объему сконфигурированной памяти, и там остаются.
Zero — объем оперативной памяти ВМ (Кбайт), который содержит нули. Такая память считается гипервизором свободной и может быть отдана другим виртуальным машинам. После того, как гостевая ОС получила записала что-либо в зануленную память, она переходит в Consumed и обратно уже не возвращается.
Reserved Overhead — объем оперативной памяти ВМ, (Кбайт) зарезервированный гипервизором для работы ВМ. Это небольшой объем, но он обязательно должен быть в наличии на хосте, иначе ВМ не запустится.
Balloon — объем оперативной памяти (Кбайт), изъятой у ВМ с помощью Balloon Driver.
Compressed — объем оперативной памяти (Кбайт), которую удалось сжать.
Swapped — объем оперативной памяти (Кбайт), которая за неимением физической памяти на сервере переехала на диск.
Balloon и остальные счетчики memory reclamation techniques равны нулю.
Вот так выглядит график со счетчиками Memory нормально работающей ВМ со 150 ГБ оперативной памяти.
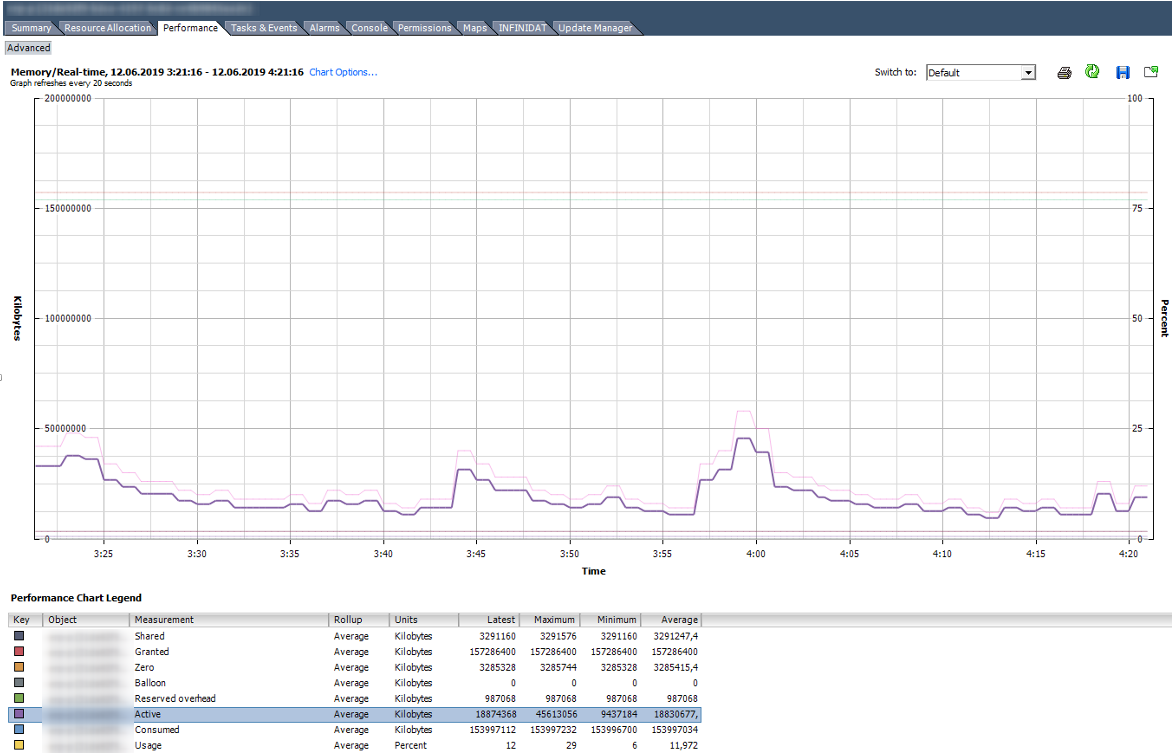
На графике ниже у ВМ явные проблемы. Под графиком видно, что для данной ВМ были использованы все описанные техники работы с оперативной памятью. Balloon для данной ВМ сильно больше, чем Consumed. По факту ВМ скорее мертва, чем жива.
ESXTOP
Как и с CPU, если хотим оперативно оценить ситуацию на хосте, а также ее динамику с интервалом до 2 секунд, стоит воспользоваться ESXTOP.
Экран ESXTOP по Memory вызывается клавишей «m» и выглядит следующим образом (выбраны поля B,D,H,J,K,L,O):

Интересными для нас будут следующие параметры:
Mem overcommit avg — среднее значение переподписки по памяти на хосте за 1, 5 и 15 минут. Если выше нуля, то это повод посмотреть, что происходит, но не всегда показатель наличия проблем.
В строках PMEM/MB и VMKMEM/MB — информация о физической памяти сервера и памяти доступной VMkernel. Из интересного здесь можно увидеть значение minfree (в МБайт), состояние хоста по памяти (в нашем случае, high).
В строке NUMA/MB можно увидеть распределение оперативной памяти по NUMA-нодам (сокетам). В данном примере распределение неравномерное, что в принципе не очень хорошо.
Далее идет общая статистика по серверу по memory reclamation techniques:
PSHARE/MB — это статистика TPS;
SWAP/MB — статистика использования Swap;
ZIP/MB — статистика компрессии страниц памяти;
MEMCTL/MB — статистика использования Balloon Driver.
По отдельным ВМ нас может заинтересовать следующая информация. Имена ВМ я скрыл, чтобы не смущать аудиторию:). Если метрика ESXTOP аналогична счетчику в vSphere, привожу соответствующий счетчик.
MEMSZ — объем памяти, сконфигурированный на ВМ (МБ).
MEMSZ = GRANT + MCTLSZ + SWCUR + untouched.
GRANT — Granted в МБайт.
TCHD — Active в МБайт.
MCTL? — установлен ли на ВМ Balloon Driver.
MCTLSZ — Balloon в МБайт.
MCTLGT — объем оперативной памяти (МБайт), который ESXi хочет изъять у ВМ через Balloon Driver (Memctl Target).
MCTLMAX — максимальный объем оперативной памяти (МБайт), который ESXi может изъять у ВМ через Balloon Driver.
SWCUR — текущий объем оперативной памяти (МБайт), отданный ВМ из Swap-файла.
SWGT — объем оперативной памяти (МБайт), который ESXi хочет отдавать ВМ из Swap-файла (Swap Target).
Также через ESXTOP можно посмотреть более подробную информацию про NUMA-топологию ВМ. Для этого нужно выбрать поля D,G:
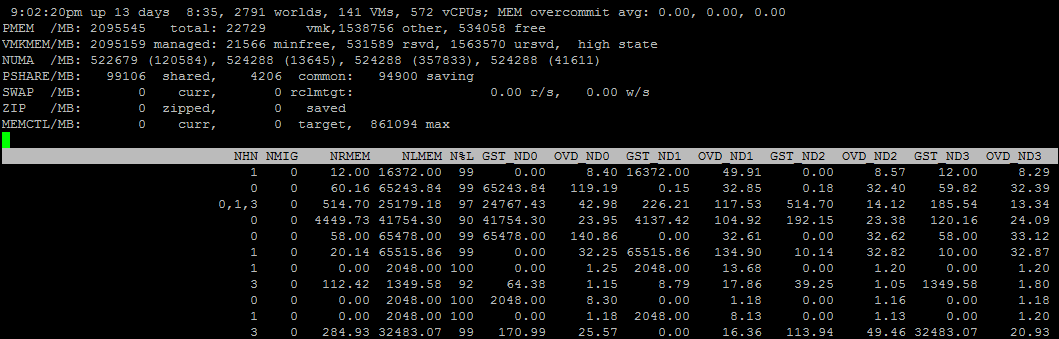
NHN – NUMA узлы, на которых расположена ВМ. Здесь можно сразу заметить wide vm, которые не помещаются на один NUMA узел.
NRMEM – сколько мегабайт памяти ВМ берет с удаленного NUMA узла.
NLMEM – сколько мегабайт памяти ВМ берет с локального NUMA узла.
N%L – процент памяти ВМ на локальном NUMA узле (если меньше 80% — могут возникнуть проблемы с производительностью).
Memory на гипервизоре
Если счетчики CPU по гипервизору обычно не представляют особого интереса, то с памятью ситуация обратная. Высокий Memory Usage на ВМ не всегда говорит о наличие проблемы с производительностью, а вот высокий Memory Usage на гипервизоре, как раз запускает работу техник управления памятью и вызывает проблемы с производительностью ВМ. За алармами Host Memory Usage надо следить и не допускать попадания ВМ в Swap.
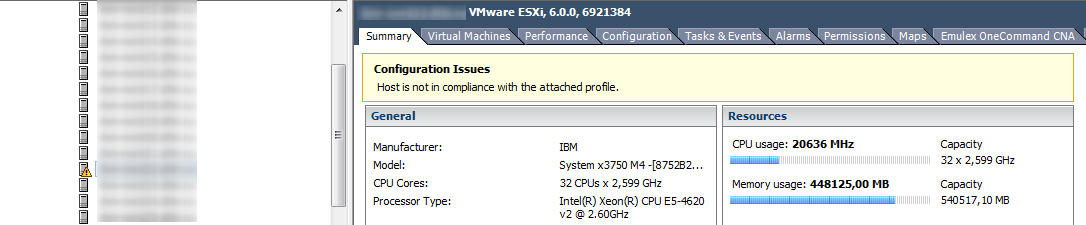
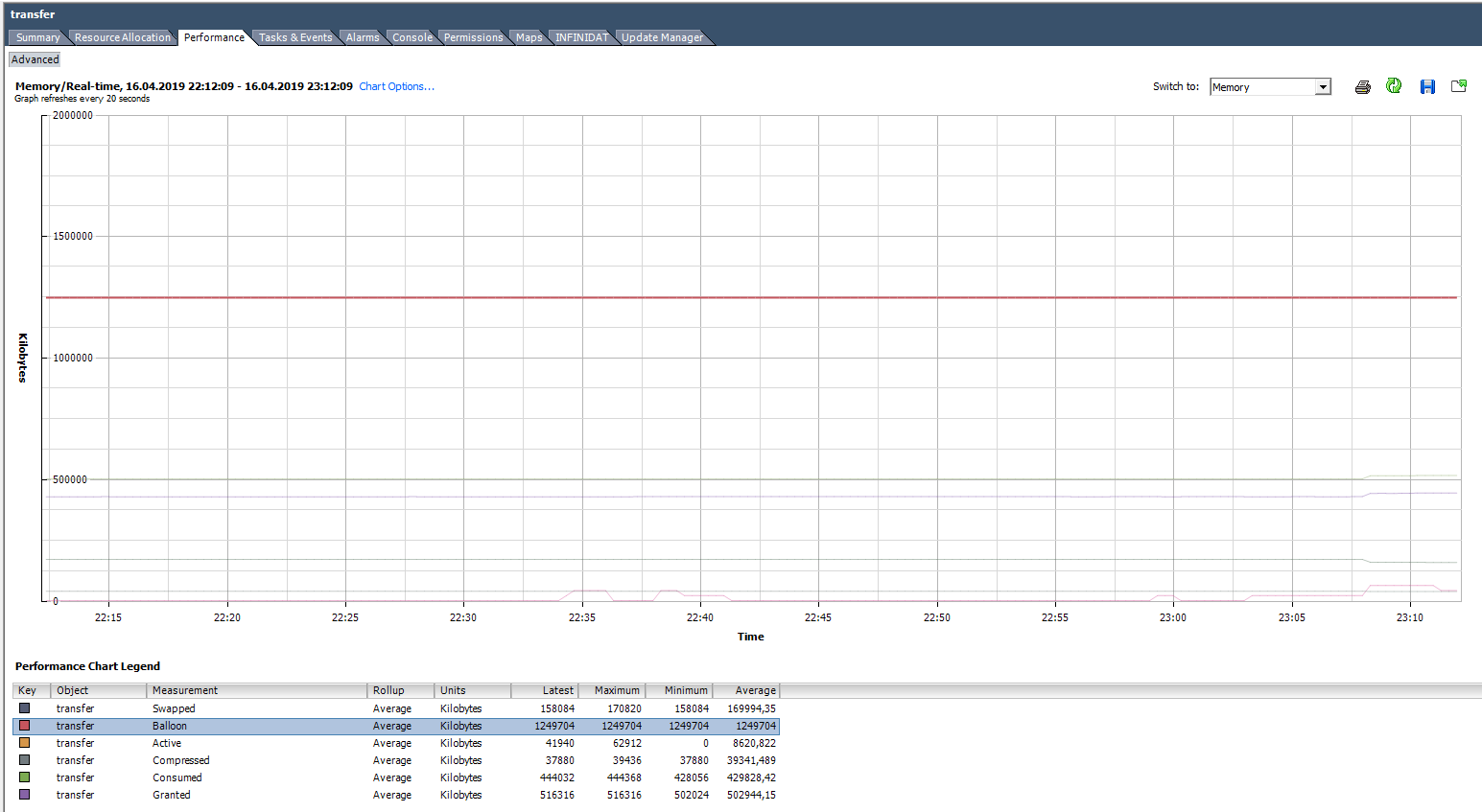
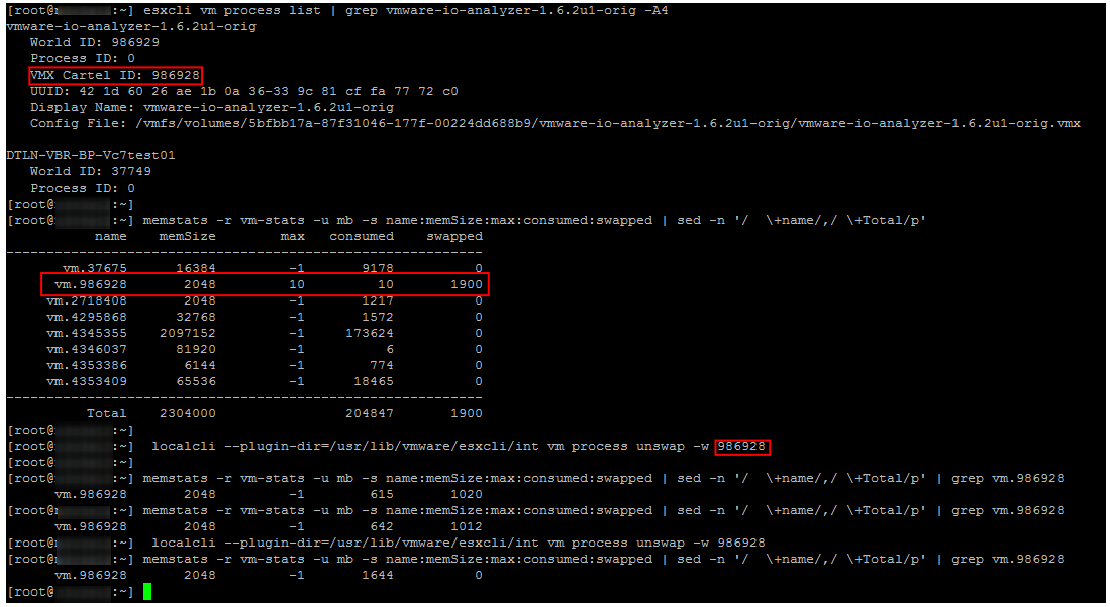
Unswap
Если ВМ попала в Swap, ее производительность сильно снижается. Следы Ballooning’а и компрессии быстро исчезают после появления свободной оперативной памяти на хосте, а вот возвращаться из Swap в оперативную память сервера виртуальная машина совсем не торопится.
До версии ESXi 6.0 единственным надежным и быстрым способ вывода ВМ из Swap была перезагрузка (если точнее выключение/включение контейнера). Начиная с ESXi 6.0 появился хотя и не совсем официальный, но рабочий и надежный способ вывести ВМ из Swap. На одной из конференций мне удалось пообщаться с одним из инженеров VMware, отвечающим за CPU Scheduler. Он подтвердил, что способ вполне рабочий и безопасный. В нашем опыте проблем с ним также замечено не было.
Собственно команды для вывода ВМ из Swap описал Duncan Epping. Не буду повторять подробное описание, просто приведу пример ее использования. Как видно на скриншоте, через некоторое время после выполнения указанной команд Swap на ВМ исчезает.
Советы по управлению оперативной памятью на ESXi
Напоследок приведу несколько советов, которые помогут вам избежать проблем с производительностью ВМ из-за оперативной памяти:
- Не допускайте переподписки по оперативной памяти в продуктивных кластерах. Желательно всегда иметь ~20-30% свободной памяти в кластере, чтобы у DRS ( и у администратора) было пространство для маневра, и при миграции ВМ не ушли в Swap. Также не забывайте про запас для отказоустойчивости. Неприятно, когда при выходе из строя одного сервера и перезагрузке ВМ с помощью HA часть машин еще и уходит в Swap.
- В инфраструктурах с высокой консолидацией старайтесь НЕ создавать ВМ с памятью больше половины памяти хоста. Это опять же поможет DRS’у без проблем распределять виртуальные машины по серверам кластера. Это правило, разумеется, не универсальное :).
- Следите за Host Memory Usage Alarm.
- Не забывайте ставить на ВМ VMware Tools и не выключайте Ballooning.
- Рассмотрите возможность включения Inter-VM TPS и выключения Large Pages в средах с VDI и тестовых средах.
- Если ВМ испытывает проблемы с производительностью, проверьте не использует ли она память с удаленной NUMA-ноды.
- Выводите ВМ из Swap как можно быстрее! Помимо всего прочего, если ВМ в Swap’е, по очевидным причинам страдает СХД.
Анализ производительности ВМ в VMware vSphere. Часть 1: CPU
Рассказываем, что и почему «тормозит» и как сделать так, чтобы не «тормозило».
23 мая 2019 • Алексей Дарченков

Если вы администрируете виртуальную инфраструктуру на базе VMware vSphere (или любого другого стека технологий), то наверняка часто слышите от пользователей жалобы: «Виртуальная машина работает медленно!». В этом цикле статей разберу метрики производительности и расскажу, что и почему «тормозит» и как сделать так, чтобы не «тормозило».
Буду рассматривать следующие аспекты производительности виртуальных машин:
Для анализа производительности нам понадобятся:
- vCenter Performance Counters – счетчики производительности, графики которых можно посмотреть через vSphere Client. Информация по данным счетчикам доступна в любой версии клиента (“толстый” клиент на C#, web-клиент на Flex и web-клиент на HTML5). В данных статьях мы будем использовать скриншоты из С#-клиента, только потому, что они лучше смотрятся в миниатюре:)
- ESXTOP – утилита, которая запускается из командной строки ESXi. С ее помощью можно получить значения счетчиков производительности в реальном времени или выгрузить эти значения за определенный период в .csv файл для дальнейшего анализа.
Ниже в статье расскажу немного про ESXTOP и приведу несколько полезных ссылок на документацию и статьи по теме.
Немного теории
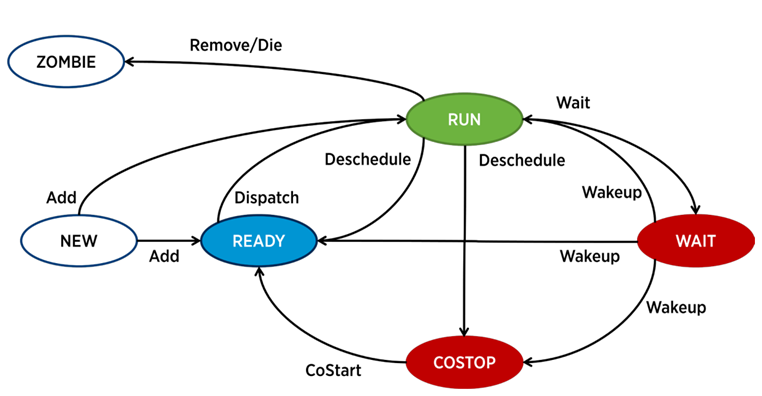
Диаграмма состояний процесса в ESXi. Источник
В ESXi за работу каждого vCPU (ядра виртуальной машины) отвечает отдельный процесс – world в терминологии VMware. Также есть служебные процессы, но с точки зрения анализа производительности ВМ они менее интересны.
Процесс в ESXi может находиться в одном из четырех состояний:
- Run – процесс выполняет какую-то полезную работу.
- Wait – процесс не выполняет никакой работы (idle) либо ждет ввода/вывода.
- Co-stop – состояние, которое возникает в многоядерных виртуальных машинах. Оно возникает, когда планировщик CPU гипервизора (ESXi CPU Scheduler) не может запланировать одновременное исполнение на физических ядрах сервера всех активных ядер виртуальной машины. В физическом мире все ядра процессора работают параллельно, гостевая ОС внутри ВМ рассчитывает на аналогичное поведение, поэтому гипервизору приходится замедлять ядра ВМ, у которых есть возможность закончить такт быстрее. В современных версиях ESXi планировщик CPU использует механизм, который называется relaxed co-scheduling: гипервизор считает разрыв между самым «быстрым» и самым “медленным» ядром виртуальной машины (skew). Если разрыв превышает определенный порог, «быстрое» ядро переходит в состояние co-stop. Если ядра ВМ проводят много времени в этом состоянии, это может вызвать проблемы с производительностью.
- Ready – процесс переходит в данное состояние, когда у гипервизора нет возможности выделить ресурсы для его исполнения. Высокие значения ready могут вызвать проблемы с производительностью ВМ.
Основные счетчики производительности CPU виртуальной машины
CPU Usage, %. Показывает процент использования CPU за заданный период.
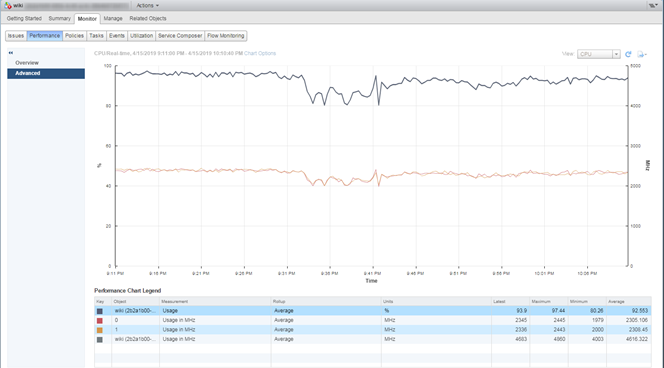
Как анализировать? Если ВМ стабильно использует CPU на 90% или есть пики до 100%, то у нас проблемы. Проблемы могут выражаться не только в «медленной» работе приложения внутри ВМ, но и в недоступности ВМ по сети. Если система мониторинга показывает, что ВМ периодически отваливается, обратите внимание на пики на графике CPU Usage.
Есть стандартный Аlarm, который показывает загрузку CPU виртуальной машины:

Что делать? Если у ВМ постоянно зашкаливает CPU Usage, то можно задуматься об увеличении количества vCPU (к сожалению, это не всегда помогает) или переносе ВМ на сервер с более производительными процессорами.
CPU Usage in Mhz
В графиках на vCenter Usage в % можно посмотреть только по всей виртуальной машине, графиков по отдельным ядрам нет (в Esxtop значения в % по ядрам есть).
По каждому ядру можно посмотреть Usage in MHz.
Как анализировать? Бывает, что приложение не оптимизировано под многоядерную архитектуру: использует на 100% только одно ядро, а остальные простаивают без нагрузки. Например, при дефолтных настройках бэкапа MS SQL запускает процесс только на одном ядре. В итоге резервное копирование тормозит не из-за медленной скорости дисков (именно на это изначально пожаловался пользователь), а из-за того, что не справляется процессор. Проблема была решена изменением параметров: резервное копирование стало запускаться параллельно в несколько файлов (соответственно, в несколько процессов).
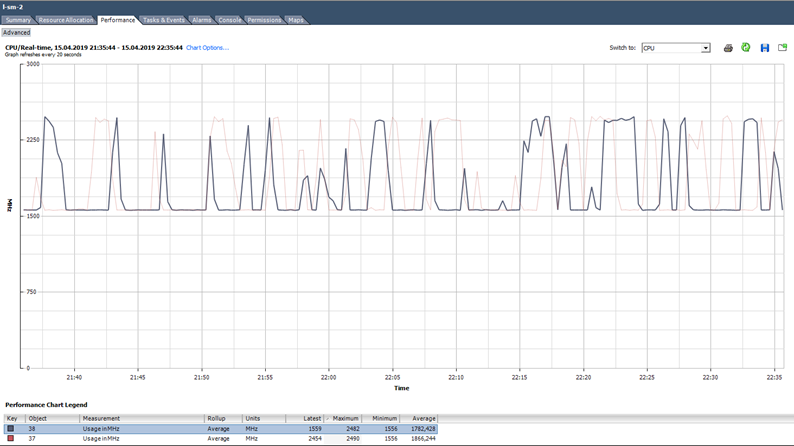
Пример неравномерной нагрузки ядер
Также бывает ситуация (как на графике выше), когда ядра нагружены неравномерно и на некоторых из них есть пики в 100%. Как и при загрузке только одного ядра, alarm по CPU Usage не сработает (он по всей ВМ), но проблемы с производительностью будут.
Что делать? Если ПО в виртуальной машине нагружает ядра неравномерно (использует только одно ядро или часть ядер), нет смысла увеличивать их количество. В таком случае лучше переместить ВМ на сервер с более производительными процессорами.
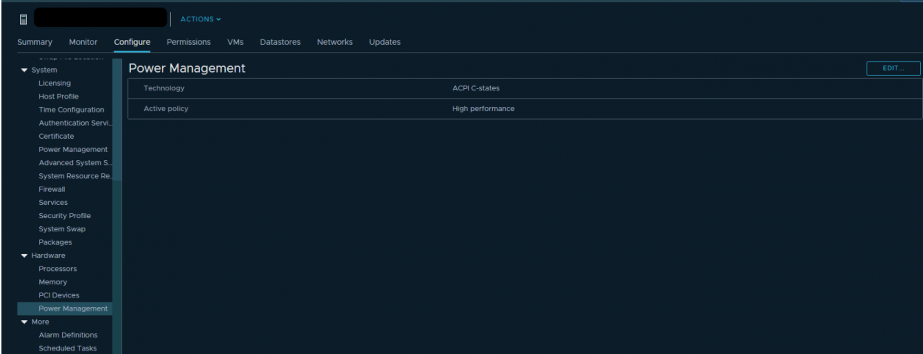
Также можно попробовать проверить настройки энергопотребления в BIOS сервера. Многие администраторы включают в BIOS режим High Performance и тем самым отключают технологии энергосбережения C-states и P-states. В современных процессорах Intel используется технология Turbo Boost, которая увеличивает частоту отдельных ядер процессора за счет других ядер. Но она работает только при включенных технологиях энергосбережения. Если мы их отключаем, то процессор не может уменьшить энергопотребление ядер, которые не нагружены.
VMware рекомендует не отключать технологии энергосбережения на серверах, а выбирать режимы, которые максимально отдают управление энергопотреблением гипервизору. При этом в настройках энергопотребления гипервизора нужно выбрать High Performance.
Если у вас в инфраструктуре отдельные ВМ (или ядра ВМ) требуют повышенную частоту CPU, корректная настройка энергопотребления может значительно улучшить их производительность.
CPU Ready (Readiness)
Если ядро ВМ (vCPU) находится в состоянии Ready, оно не выполняет полезную работу. Такое состояние возникает, когда гипервизор не находит свободное физическое ядро, на которое можно назначить процесс vCPU виртуальной машины.
Как анализировать? Обычно если ядра виртуальной машины находятся в состоянии Ready больше 10% времени, то вы заметите проблемы с производительностью. Проще говоря, больше 10% времени ВМ ждет доступности физических ресурсов.
В vCenter можно посмотреть 2 счетчика, связанных с CPU Ready:
Значения обоих счетчиков можно посмотреть как по всей ВМ, так и по отдельным ядрам.
Readiness показывает значение сразу в процентах, но только в Real-time (данные за последний час, интервал измерений 20 секунд). Этот счетчик лучше использовать только для поиска проблем «по горячим следам».
Значения счетчика Ready можно посмотреть также в исторической перспективе. Это полезно, если нужно установить закономерности и для более глубокого анализа проблемы. Например, если у виртуальной машины начинаются проблемы с производительностью в какое-то определенное время, можно сопоставить интервалы повешенного значения CPU Ready с общей нагрузкой на сервер, где данная ВМ работает, и принять меры по снижению нагрузки (если DRS не справился).
Ready в отличие от Readiness показывается не в процентах, а миллисекундах. Это счетчик типа Summation, то есть он показывает, сколько времени за период измерения ядро ВМ находилось в состоянии Ready. Перевести данное значение в проценты можно по несложной формуле:
(CPU ready summation value / (chart default update interval in seconds * 1000)) * 100 = CPU ready %
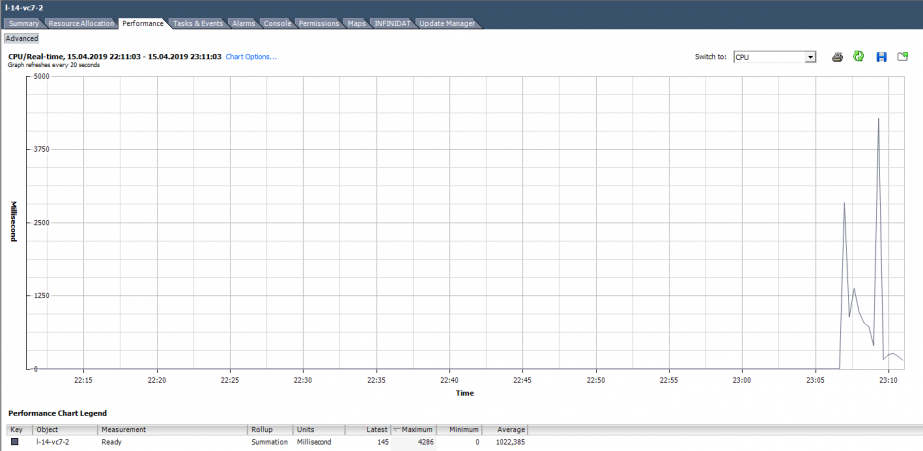
Например, для ВМ на графике ниже пиковое значение Ready на всю виртуальную машину получится следующим:
При подсчете значения Ready в процентах стоит обращать внимание на два момента:
- Значение Ready по всей ВМ – это сумма Ready по ядрам.
- Интервал измерения. Для Real-time – это 20 секунд, а, например, на дневных графиках – это 300 секунд.
При активном траблшутинге эти простые моменты можно легко упустить и потратить ценное время на решение несуществующих проблем.
Рассчитаем Ready на основе данных из графика ниже. (324474/(20*1000))*100 = 1622% на всю ВМ. Если смотреть по ядрам получится уже не так страшно: 1622/64 = 25% на ядро. В данном случае обнаружить подвох довольно просто: значение Ready нереалистичное. Но если речь идет о 10–20% на всю ВМ с несколькими ядрами, то по каждому ядру значение может быть в пределах нормы.
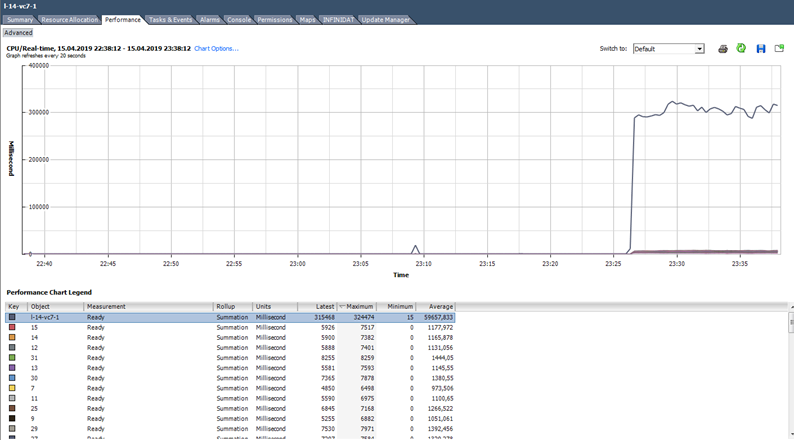
Что делать? Высокое значение Ready говорит о том, что серверу не хватает ресурсов процессора для нормальной работы виртуальных машин. В такой ситуации остается только уменьшить переподписку по процессору (vCPU:pCPU). Очевидно, этого можно добиться, уменьшив параметры существующих ВМ или путем миграции части ВМ на другие серверы.
Co-stop
Как анализировать? Данный счетчик также имеет тип Summation и переводится в проценты аналогично Ready:
(CPU co-stop summation value / ( * 1000)) * 100 = CPU co-stop %
Здесь также нужно обращать внимание на количество ядер на ВМ и на интервал измерения.
В состоянии Costop ядро таже не выполняет полезную работу. При правильном подборе размера ВМ и нормальной нагрузке на сервер счетчик со-stop должен быть близок к нулю.
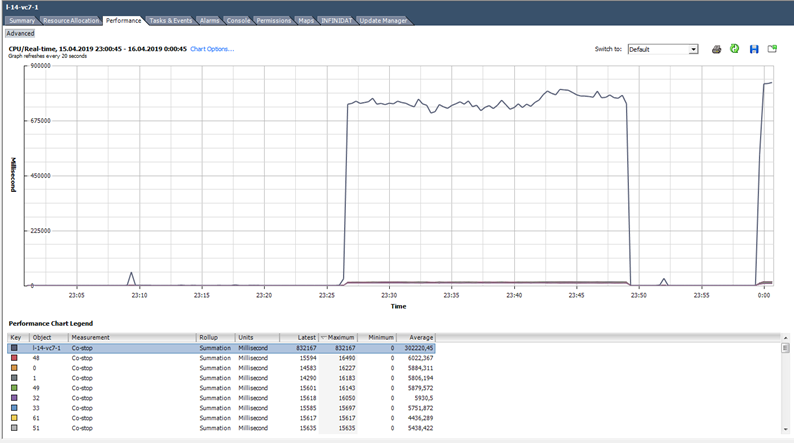
В данном случае нагрузка явно ненормальная 🙂
Что делать? Если на одном гипервизоре работают несколько ВМ с большим количеством ядер и есть переподписка по CPU, то счетчик co-stop может вырасти, что приведет к проблемам с производительностью данных ВМ.
Также co-stop вырастет, если для активных ядер одной ВМ используются треды на одном физическом ядре сервера со включенным hyper-treading. Такая ситуация может возникнуть, например, если у ВМ больше ядер, чем физически есть на сервере, где она работает, или если для ВМ включена настройка «preferHT». Про эту настройку можно прочитать здесь.
Чтобы избежать проблем с производительностью ВМ из-за высокого Co-stop, выбирайте размер ВМ в соответствии с рекомендациями производителя ПО, которое работает на этой ВМ, и с возможностями физического сервера, где работает ВМ.
Не добавляйте ядра про запас, это может вызвать проблемы с производительностью не только самой ВМ, но и ее соседей по серверу.
Другие полезные метрики CPU
Run – сколько времени (мс) за период измерения vCPU находился в состоянии RUN, то есть собственно выполнял полезную работу.
Idle – сколько времени (мс) за период измерения vCPU находился в состоянии бездействия. Высокие значения Idle – это не проблема, просто vCPU было «нечего делать».
Wait – сколько времени (мс) за период измерения vCPU находился в состоянии Wait. Так как в данный счетчик включается IDLE, высокие значения Wait также не говорят о наличии проблемы. А вот если при высоком Wait IDLE низкий, значит ВМ ждала завершения операций ввода/вывода, а это, в свою очередь, может говорить о наличии проблемы с производительностью жесткого диска или каких-либо виртуальных устройств ВМ.
Max limited – сколько времени (мс) за период измерения vCPU находился в состоянии Ready из-за установленного лимита по ресурсам. Если производительность необъяснимо низкая, то полезно проверить значение данного счетчика и лимит по CPU в настройках ВМ. У ВМ действительно могут оказаться выставлены лимиты, о которых вы не знаете. Например, так происходит, когда ВМ была склонирована из шаблона, на котором был установлен лимит по CPU.
Swap wait – сколько времени за период измерения vCPU ждал операции с VMkernel Swap. Если значения данного счетчика выше нуля, то у ВМ точно есть проблемы с производительностью. Подробнее про SWAP поговорим в статье про счетчики оперативной памяти.
ESXTOP
Если счетчики производительности в vCenter хороши для анализа исторических данных, то оперативный анализ проблемы лучше производить в ESXTOP. Здесь все значения представлены в готовом виде (не нужно ничего переводить), а минимальный период измерения 2 секунды.
Экран ESXTOP по CPU вызывается клавишей «c» и выглядит следующим образом:

Для удобства можно оставить только процессы виртуальных машин, нажав Shift-V.
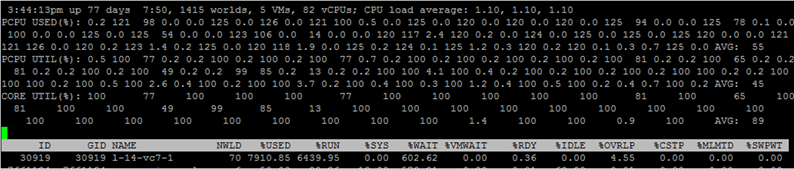
Чтобы посмотреть метрики по отдельным ядрам ВМ, нажмите «e» и вбейте GID интересующей ВМ (30919 на скриншоте ниже):
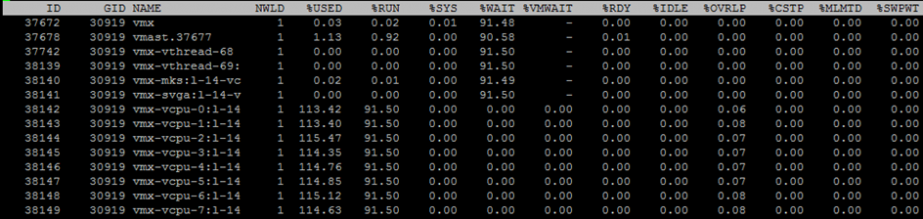
Кратко пройдусь по столбцам, которые представлены по умолчанию. Дополнительные столбцы можно добавить, нажав «f».
NWLD (Number of Worlds) – количество процессов в группе. Чтобы раскрыть группу и увидеть метрики для каждого процесса (например, для каждого ядра многоядерной ВМ), нажмите “e”. Если в группе больше одного процесса, то значения метрик для группы равны сумме метрик для отдельных процессов.
%USED – сколько циклов CPU сервера использует процесс или группа процессов.
%RUN – сколько времени за период измерения процесс находился в состоянии RUN, т.е. выполнял полезную работу. Отличается от %USED тем, что не учитывает hyper-threading, frequency scaling и время, затраченное на системные задачи (%SYS).
%SYS – время, затраченное на системные задачи, например: обработку прерываний, ввода/вывода, работу сети и пр. Значение может быть высоким, если на ВМ большой ввод/вывод.
%OVRLP – сколько времени физическое ядро, на котором выполняется процесс ВМ, потратило на задачи других процессов.
Данные метрики соотносятся между собой следующим образом:
%USED = %RUN + %SYS — %OVRLP.
Обычно метрика %USED является более информативной.
%WAIT – сколько времени за период измерения процесс находился в состоянии Wait. Включает IDLE.
%IDLE – cколько времени за период измерения процесс находился в состоянии IDLE.
%SWPWT – сколько времени за период измерения vCPU ждал операции с VMkernel Swap.
%VMWAIT – сколько времени за период измерения vCPU находилось в состояния ожидания события (обычно ввода/вывода). Аналогичного счетчика нет в vCenter. Высокие значения говорят о проблемах с вводом/выводом на ВМ.
%WAIT = %VMWAIT + %IDLE + %SWPWT.
Если ВМ не использует VMkernel Swap, то при анализе проблем с производительностью целесообразно смотреть на %VMWAIT, так как данная метрика не учитывает время, когда ВМ ничего не делала (%IDLE).
%RDY – cколько времени за период измерения процесс находился в состоянии Ready.
%CSTP – cколько времени за период измерения процесс находился в состоянии Co-stop.
%MLMTD – сколько времени за период измерения vCPU находился в состоянии Ready из-за установленного лимита по ресурсам.
%WAIT + %RDY + %CSTP + %RUN = 100% – ядро ВМ все время находится в каком-то из этих четырех состояний.
CPU на гипервизоре
В vCenter есть также счетчики производительности CPU для гипервизора, но они не представляют из себя ничего интересного – это просто сумма счетчиков по всем ВМ на сервере.
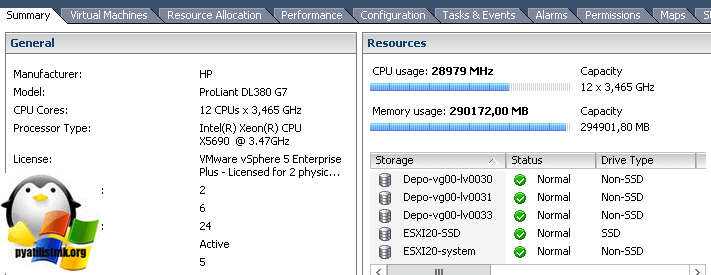
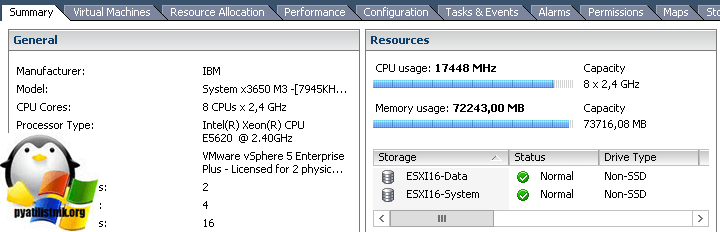
Удобнее всего смотреть состояние CPU на сервере на вкладке Summary:

Для сервера, как и для виртуальной машины, есть стандартный Alarm:
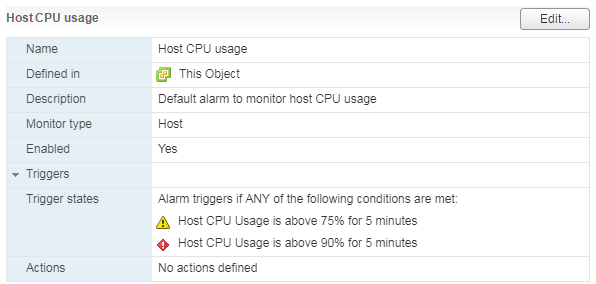
При высокой нагрузке на CPU сервера у ВМ, работающих на нем, начинаются проблемы с производительностью.
В ESXTOP данные о загрузке CPU сервера представлены в верхней части экрана. Помимо стандартного CPU load, который малоинформативен для гипервизоров, есть еще три метрики:
CORE UTIL(%) – загрузка ядра физического сервера. Данный счетчик показывает, сколько времени за период измерения ядро выполняло работу.
PCPU UTIL(%) – если включен hyper-threading, то на каждое физическое ядро приходится два потока (PCPU). Данная метрика показывает, сколько времени каждый поток выполнял работу.
PCPU USED(%) – то же, что PCPU UTIL(%), но учитывает frequency scaling (либо снижение частоты ядра в целях энергосбережения, либо повышение частоты ядра за счет технологии Turbo Boost) и hyper-threading.
PCPU_USED% = PCPU_UTIL% * эффективную частоту ядра / номинальную частоту ядра.
На этом скриншоте для некоторых ядер из-за работы Turbo Boost’а значение USED больше 100%, так как частота ядра выше номинальной
Пара слов о том, как учитывается hyper-threading. Если процессы исполняются 100% времени на обоих потоках физического ядра сервера, при этом ядро работает на номинальной частоте, то:
- CORE UTIL для ядра будет 100%,
- PCPU UTIL для обоих потоков будет 100%,
- PCPU USED для обоих потоков будет 50%.
Если оба потока не работали 100% времени за период измерения, то в те периоды, когда потоки работали параллельно, PCPU USED для ядер делится пополам.
В ESXTOP также есть экран с параметрами энергопотребления CPU сервера. Здесь можно посмотреть, используются ли сервером технологии энергосбережения: C-states и P-states. Вызывается клавишей «p»:

Стандартные проблемы производительности CPU
Напоследок пробегусь по типичным причинам возникновения проблем с производительностью CPU ВМ и дам короткие советы их решению:
- Не хватает тактовой частоты ядра. Если нет возможности перевести ВМ на более производительные ядра, можно попробовать изменить настройки энергопотребления, чтобы Turbo Boost работал эффективнее.
- Неправильный сайзинг ВМ (слишком много/мало ядер). Если поставить мало ядер, будет высокая загрузка CPU ВМ. Если много, словите высокий co-stop.
- Большая переподписка по CPU на сервере. Если на ВМ высокий Ready, снизьте переподписку по CPU.
- Неправильная NUMA-топология на больших ВМ. NUMA-топология, которую видит ВМ (vNUMA), должна соответствовать NUMA-топологии сервера (pNUMA). Про диагностику и возможные варианты решения данной проблемы написано, например, в книге «VMware vSphere 6.5 Host Resources Deep Dive». Если не хотите углубляться и у вас нет лицензионных ограничений по ОС, установленной на ВМ, делайте на ВМ много виртуальных сокетов по одному ядру. Много не потеряете:)
На этом про CPU у меня все. Задавайте вопросы. В следующей части расскажу про оперативную память.
Полезные статьи по теме:
Host CPU usage и host memory usage


Добрый день уважаемые читатели и подписчики, продолжаем изучать виртуализацию и гипервизор компании VMware. В прошлый раз я вам рассказывал, как установить wmware tools в linux, сегодняшняя тема будет, так же про ошибки и предупреждения и разберем мы с вами вот такие «host CPU usage и host memory usage», что это такое и чем это чревато для вашей инфраструктуры.
Предупреждения о ОЗУ и CPU
Данные предупреждения и алерты, вы можете обнаружить как в vCenter server, так и на отдельном хосте ESXI. Выглядят эти алерты вот так:
- Host memory usage на вкладке Alarms
- Host CPU usage на вкладке Alarms
Если вы перейдет на вкладку «Summary», то в пункте «Resources» увидите шкалу загрузки по процессору
и оперативной памяти.
Пути решения данной ситуации такие:
- Вы ограничиваете потребление ресурсов для прожорливой виртуальной машины
- Либо более правильно перераспределяете их и дорабатываете план планирования, это дольше, но лучше, так как будет возможность предусмотреть будущий рост
Что плохого несут в себе эти предупреждения
Если у вас появились сообщения «Host CPU usage и host memory usage», это чревато тем что:
- Ваш сервер быстрее изнашивается, так как при правильно планировании, он не должен использовать более 90 процентов ресурсов.
- Идет борьба за ресурсы между виртуальными машинами, в следствии чего уменьшается их производительность.
- Может привести к зависанию хоста или виртуальной машины
Популярные Похожие записи:
- Ошибка Unable to apply DRS resource settings on host
 Ошибка миграции между кластерами ESXI и VDS
Ошибка миграции между кластерами ESXI и VDS- Ошибка Cannot initialize SFTP protocol. Is the host running an SFTP server
 Ошибка 0x00002740: only one usage of each socket address
Ошибка 0x00002740: only one usage of each socket address Как включить буфер обмена в vSphere Client (HTML5)
Как включить буфер обмена в vSphere Client (HTML5) Ошибка System Chassis 1 Chassis intro на ESXI хосте
Ошибка System Chassis 1 Chassis intro на ESXI хосте
Как найти проблему с производительностью ВМ на VMware ESXi
Рассказываем, как проверять ресурсы ВМ на ошибки и даем ключевые метрики, на которые можно опираться.
17 января 2023 • DataLine

В этой статье мы расскажем, как искать иголку в стоге сена причину проблем с производительностью ВМ на ESXi. Главным способом будет то, что так не любят многие администраторы: планомерная проверка всех ресурсов на утилизацию, сатурацию и ошибки. Мы приведем ключевые метрики, на которые следует обратить внимание, их краткое описание и значения, на которые можно ориентироваться, как на норму. При этом важно понимать, что разные системы имеют разные требования к производительности. Следовательно, то, что приемлемо для одной системы, для другой может являться признаком аварийного состояния.
Кроме собственных наработок, мы использовали материалы из разных англоязычных источников. По некоторым вопросам описания тянут на отдельные статьи, поэтому на них приводим ссылки.
Нашим первым шагом должна быть быстрая базовая проверка основных параметров – ее сценарий описан в начале статьи. Если базовая проверка не нашла причины проблем, то, скорее всего, укажет направление, в котором мы запустим расширенную проверку. В любом случае, более глубокая расширенная проверка всех доступных параметров поможет в итоге найти корень проблем. С этим обнадеживающим фактом давайте приступим. Напоминаем, что проверяемые параметры стоит фиксировать скриншотами.
Выясняем симптомы проблемы
Вот краткий список ключевых вопросов, на которые нужно ответить:
1. Как проявляются проблемы производительности? Описываем словами, снимками, прикладываем графики.
2. Когда работало хорошо и когда начало работать плохо? Вспоминаем даты и время.
3. Были ли какие-то аппаратные, программные или нагрузочные изменения?
4. Охватывает ли проблема другие системы или только одну, например: ВМ, vApp, группу ВМ, кластер, группу кластеров и т. д.
Часть 1. Базовая проверка
Цель базовой проверки – быстро выяснить направление, в котором находится источник проблем производительности. Учитывайте, что графики в vSphere Client усредняют значения со временем, и лучше собирать максимум информации в любую стороннюю систему мониторинга (Prometeus, Zabbix, VMware vRealize Operation Manager и т. д.). Если такой системы нет, то воспроизводим проблему в реальном времени и наблюдаем за ней со стороны гипервизора. По результатам базовой проверки решаем, нужно ли дальнейшее расследование.
Проверяем ВМ из vSphere Client
- Triggered Alarms, Tasks и Events не должны содержать событий, коррелирующих с проблемой.
- CPU
- Usage не должен превышать 90%. Usage – процент активно задействованных мощностей виртуальных CPU. Это среднее значение загруженности CPU в виртуальной машине. Например, если виртуальная машина с одним виртуальным CPU работает на хосте, имеющем четыре физических CPU, и Usage виртуального CPU составляет 100%, то виртуальная машина полностью использует один физический CPU. Usage виртуального CPU = usagemhz / кол-во виртуальных CPU x частота ядра.
- Ready не должен превышать 10% на ядро. Ready показывает время, в течение которого виртуальная машина была готова к использованию, но не могла быть запущена на физическом CPU из-за нехватки ресурсов. Ready % зависит от количества виртуальных машин на хосте и загруженности их CPU.
- Ballooned должен быть равен 0. Этот параметр указывает на объем памяти, захваченной драйвером управления памятью ВМ (vmmemctl), который установлен в гостевую ОС вместе с VMware Tools. Данный объем перераспределяется от ВМ к гипервизору в условиях её нехватки. То же самое происходит, когда неверно выставлен Memory Limit на ВМ или ресурсный пул – это тоже ухудшает производительность ВМ.
- Swapped должен быть равен 0. Это текущий объем гостевой физической памяти, которую VMkernel выгрузил в файл подкачки ВМ. Выгруженная память остается на диске до тех пор, пока она не понадобится ВМ, либо пока не будет запущен принудительный механизм unswap. Подробнее расписано тут: https://www.yellow-bricks.com/2016/06/02/memory-pages-swapped-can-unswap/
- Нормально, если отсутствуют мгновенные снимки старше 24 часов.
- Highest latency не должен превышать приемлемых для приложения значений. Это наибольшее значение задержки среди всех дисков, используемых ВМ. Измеряет время, необходимое для обработки команды SCSI, которое гостевая ОС предоставила виртуальной машине. Задержка ядра – это время, которое требуется VMkernel для обработки запроса ввода/вывода. Задержка устройства – это время, которое требуется оборудованию для обработки запроса. Есть прямая зависимость от размера блока ввода/вывода (Write request size и Read request size) с временем задержки, за которое этот блок будет обработан подсистемой хранения.
- Write request size и Read request size не должны коррелировать с Highest latency. Важным нюансом этой метрики является то, что vSphere не отображает размеры блока более 512 КБ: вы увидите рост задержек вследствие роста размера блока выше 512 КБ, но при этом не будете видеть рост размера самого блока. Увидеть его можно только через утилиту хоста ESXi vscsiStats. Подробнее о vscsiStats здесь: https://communities.vmware.com/t5/Storage-Performance/Using-vscsiStats-for-Storage-Performance-Analysis/ta-p/2796805 Здесь можно превратить вывод команды в гистограмму: https://www.virten.net/vmware/vscsistats-grapher/
- Average commands issued per second не должен превышать IOPS Limit.
- Commands aborted и Bus resets должны равняться 0.
- Usage не должен достигать предела (vmnic хоста, политик коммутирующего оборудования или маршрутизатора). Этот параметр отображает объем данных, переданных и полученных всеми виртуальными сетевыми картами, подключенными к виртуальной машине.
- Receive packets dropped и Transmit packets dropped должен равняться 0.
- Packets received и Packets transmitted не должны содержать скачков, коррелирующих с проблемой в разбивке по типам Broadcast, Unicast и Multicast.
Проверяем хост из vSphere Client
- Triggered Alarms, Tasks и Events не должны содержать событий, коррелирующих с проблемой.
- CPU
- Usage по всему хосту не должен превышать 80%.
- Ready не должен превышать 10% на ядро (как перевести из summation в проценты подробно читайте тут: https://kb.vmware.com/s/article/2002181).
- Balloned должен равняться 0. Это сумма значений vmmemctl для всех включенных ВМ и служб vSphere на хосте. Если целевой размер balloon (дословно переводится как «шар») больше, чем текущий, VMkernel «раздувает» balloon внутри ВМ, в результате чего освобождается больше памяти хоста. Если целевой размер balloon меньше, чем текущий, VMkernel «сдувает» balloon, что позволяет процессам внутри ВМ при необходимости использовать больше памяти. Подробнее про ballooning тут: https://docs.vmware.com/en/VMware-vSphere/8.0/vsphere-resource-management/GUID-2B1086F3-B3F5-426C-9162-3C3CDD23A5DF.html
- Swap consumed должен быть равен 0. Это объем памяти, которая используется для подкачки всех включенных ВМ и служб vSphere на хосте.
- Page-fault latency должно равняться 0. Это время ожидания виртуальной машиной доступа к сжатой памяти или файлу подкачки.
- Write rate и Read rate не должны превышать пропускную способность vmhba, коммутирующего оборудования до хранилища или пропускной способности хранилища.
- Write latency и Read latency должны примерно равняться по всем активным vmhba. Если какая-то из vmhba сильно выбивается по задержкам или нагрузке, то следует удостовериться, что политика мультипасинга выставлена корректно. Подробнее о политиках тут: https://kb.vmware.com/s/article/1011340. Большинство современных хранилищ позволяют применять политику Round Robin. После проверки политики стоит обратить внимание на качество соединения.
- Usage не должен превышать пределов vmnic Это суммарный объем данных, которые передают и получают все физические сетевые карты, подключенные к хосту.
- Receive packets dropped и Transmit packets dropped должны равняться 0.
- Packets received и Packets transmitted недолжны содержать скачков, коррелирующих с проблемой в разбивке по типам Broadcast, Unicast и Multicast.
Часть 2. Расширенная проверка
Если результаты базовой проверки не указали на главную причину проблем с производительностью, делаем расширенную проверку.
Проверяем ВМ и хост
Здесь большая часть метрик берется из утилиты хоста ESXi esxtop. Очень кстати вывод esxtop можно записывать в csv-файл. Формат csv позволяет открыть его, к примеру, в PerfMon на Windows и проанализировать не только мгновенные значения, но и их изменение во времени.
Запись одной тысячи точек с шагом раз в две секунды можно выполнить так:
esxtop -a -b -d 2 -n 1000 > esxtop-output.csv- Должны отсутствовать ошибки в vmware.log ВМ, vmkernel.log хоста, в журнале IPMI хоста и во внешних системах журналирования по объектам, релевантным проблеме.
- CPU в esxtop (клавиша ‘c’)
- CPU load average не должен превышать 1. Это среднее арифметическое значение загрузки CPU за 1 минуту, 5 минут и 15 минут, основанное на 6-секундных выборках.
- %USED не должен превышать 90 на ядро. Это процент физического процессорного времени, приходящийся на world. В эту величину входит метрика %RUN, обозначающая процент времени, когда world вычислялся на физическом CPU. Дополнительно сюда засчитывается %SYS, обозначающая процент времени, при котором VMkernel обрабатывал прерывания и выполнял иные системные действия для данного world. Метрика же %OVRLP вычитается из данной и отражает процент времени, которое world провел в очереди на выполнение, ожидая завершения системных действий в отношении других world. %USED = %RUN + %SYS — %OVRLP.
- %RDY не должен превышать 10. Это процент времени, в течение которого world был готов к запуску. Поясню: world, который стоит в очереди, ожидает, пока планировщик разрешит ему запуск на физическом CPU. %RDY – процент от этого времени, поэтому он всегда меньше 100%. Если в настройках ресурсов ВМ установлен CPU Limit, то планировщик не станет размещать ВМ на физическом CPU, когда она израсходует выделенный ей ресурс CPU. Это может произойти даже при наличии большого количества свободных тактов CPU. Время, в течение которого планировщик намеренно удерживает ВМ, отображается в параметре %MLMTD, который мы опишем дальше. Обратите внимание, что параметр %RDY включает в себя %MLMTD. Для определения задержки процессора мы будем использовать формулу: %RDY – %MLMTD. Поэтому, если показатель %RDY – %MLMTD высокий, например больше 10%, вы можете столкнуться с проблемой нехватки мощностей CPU. Рекомендуемый порог зависит от обстоятельств. Для пробы можно начать с 10%. Если скорость работы приложения в ВМ в порядке, то оставьте порог как есть. В противном случае – снизьте порог. Закономерный вопрос: а что составляет 100% времени? World может находиться в разных состояниях: он запланирован к запуску, готов к запуску, но не запланирован, или не готов к запуску, то есть ожидает какое-либо событие. 100% = %RUN + %RDY + %CSTP + %WAIT.
- %CSTP не должен превышать 3. Это процент времени, в течение которого world находится в состоянии co-schedule. Состояние co-schedule применимо только для многопроцессорных виртуальных машин. Планировщик CPU ESXi намеренно переводит виртуальный CPU в это состояние, если этот виртуальный CPU опережает в вычислениях другие виртуальные CPU данной ВМ. Высокий показатель %CSTP означает, что ВМ неравномерно использует виртуальные CPU. Приложение использует CPU с высоким %CSTP внутри ВМ гораздо чаще, чем остальные её CPU.
- %MLMTD должен равняться 0. Это процент времени, в течение которого world был готов к запуску, но не запущен планировщиком из-за настроек CPU Limit. Обратите внимание, что параметр %MLMTD уже учтен в расчете %RDY. Показатель %MLMTD высок, когда ВМ не может быть запущена из-за настройки CPU Limit. Если вы хотите повысить производительность этой ВМ, то увеличьте этот лимит. В целом, использование CPU Limit не рекомендуется.
- %SWPWT должен равняться 0. Это процент времени, в течение которого world ожидает, пока VMkernel завершит подкачку памяти. Время %SWPWT (ожидание подкачки) включено в %WAIT.
- Memory хоста в состоянии High. Про memory state подробно написано здесь: https://www.yellow-bricks.com/2015/03/02/what-happens-at-which-vsphere-memory-state/.
- MCTLSZ должен равняться 0. Это объем гостевой физической памяти, перераспределенной balloon-драйвером. Высокий показатель MCTLSZ означает, что много гостевой физической памяти этой виртуальной машины «украдено», чтобы уменьшить нагрузку на память хоста. Как тогда узнать, что виртуальная машина работает в режиме ballooning? Если показатель MCTLSZ изменяется, balloon-драйвер активно освобождает память хоста, раздувая «шар памяти» в ВМ. Скорость ballooning в краткосрочной перспективе можно оценить по изменению MCTLSZ в какую-либо сторону.
- SWCUR должно равняться 0. Это общее количество мегабайт подкачки, которые используются в файле vswp ВМ или в системном файле подкачки, а также миграционном файле подкачки. ВМ в состоянии vMotion использует миграционный файл подкачки для удержания выгруженной памяти на целевом узле, если целевому узлу не хватает памяти. Для ВМ это текущий объем гостевой физической памяти, выгруженной в зарезервированное хранилище. Обратите внимание, что эта статистика относится к своппингу VMkernel, а не к своппингу гостевой ОС внутри ВМ. Высокий показатель SWCUR у ВМ означает, что гостевая физическая память ВМ находится не в оперативной памяти, а на диске. .
- N%L должен быть больше 80. Это процент объема виртуальной памяти ВМ, который находится в локальной для её виртуальных CPU NUMA Node. Низкий процент N%L означает, что, с высокой вероятностью, какие-то запросы виртуальных процессоров ВМ используют данные оперативной памяти ВМ через межпроцессорное соединение. Подробнее об этом можно почитать в цикле статей от Frank Denneman: https://frankdenneman.nl/2016/07/06/introduction-2016-numa-deep-dive-series/.
- LAT/rd и LAT/wr не должны превышать приемлемых для приложения значений.
- CMDS/s не должен достигать IOPS Limit.
- MBREAD/s + MBWRTN/s не должна достигать пределов vmhba.
- QAVG/cmd должно быть около 0 и не превышать KAVG/cmd. Это среднее время ожидания в очереди. QAVG должен входить в KAVG. Но при проблемах с физическим устройством или соединительными линиями QAVG может превышать KAVG. Если показатель QAVG высокий, то следует обратить внимание на глубину очередей на каждом уровне стека хранения.
- GAVG/cmd, KAVG/cmd и DAVG/cmd не должны превышать приемлемые значения для данного хранилища данных.
- GAVG – это круговая задержка для всех запросов ввода/вывода, которые гостевая система отправляет на виртуальное устройство хранения. Параметр GAVG = KAVG + DAVG.
- KAVG – этот параметр отслеживает задержки, связанные с работой VMkernel. Значение KAVG должно быть намного меньше значения DAVG и близко к нулю. Когда в ESXi много очередей, KAVG может быть таким же высоким или даже выше, чем DAVG. Если это произошло, проверьте статистику очередей и лимиты политики хранения или виртуального диска.
- DAVG – это задержка, наблюдаемая на уровне драйвера устройства. Она включает в себя время приема-передачи между HBA и хранилищем. DAVG – хороший индикатор производительности хранилища. Если есть подозрения, что задержки ввода/вывода являются причиной проблем с производительностью, то следует проверить DAVG. Сравните задержки ввода/вывода с соответствующими данными из массива. Если они сходятся, проверьте массив на предмет неправильной конфигурации или неисправностей. Если нет, то сравните DAVG с соответствующими данными из точек между массивом и сервером ESXi, например, FC-коммутаторов. Если эти промежуточные данные также совпадают со значениями DAVG, вероятно, приложению не хватает ресурсов для корректной работы в этом хранилище. В таких случаях может помочь добавление накопителей или изменение уровня RAID.
- MBREAD/s + MBWRTN/s не должна достигать пределов vmhba.
- FCMDS/s, ABRTS/s, RESETS/s должны равняться 0.
- FCMDS/s – это количество команд в секунду, завершившихся ошибкой. Может указывать на проблемы с контроллером хранения, состоянием соединения до хранилища или непосредственно с хранилищем.
- ABRTS/s – это количество прерванных команд в секунду. Параметр может указывать на то, что система хранения данных не удовлетворяет требованиям гостевой ОС. Гостевая система прерывает обработку команды, если хранилище не отвечает в течение приемлемого времени (может быть настроено в гостевой ОС, в том числе и в результате установки VMware Tools). Кроме того, гостевая ОС может прервать все команды, выполняемые на ее виртуальном SCSI-адаптере.
- RESETS/s – это количество сброшенных команд в секунду. Указывает на число отброшенных команд в результате сброса состояния адаптера. Сброс может быть вызван драйвером как реакция на какие-либо события в сети хранения данных.
- Вывод команды esxcli storage san fc stats get не должен содержать ошибок.
- Мониторинг портов сети хранения данных не должен содержать ошибок.
- в драйвере HBA глобально на хост: https://kb.vmware.com/s/article/1267
- на каждом LUN есть два параметра: https://kb.vmware.com/s/article/1268
- Device Max Queue Depth наследуется от Queue Depth драйвера HBA (предыдущий шаг). Однако может быть занижено такими технологиями, как SIOCv1 (включается в vSphere Client на Datastore) и Adaptive Queue Depth (подробнее тут: https://kb.vmware.com/s/article/1008113), которая включается расширенными настройками QFullSampleSize и QFullThreshold.
- No of outstanding IOs with competing worlds (DSNRO) по умолчанию равняется 32. Это глубина очереди к LUN, если с ним одновременно работают более одной ВМ.
- H:0x0 D:0x28 P:0x0 Valid sense data: 0x## 0x## 0x##
- H:0x0 D:0x08 P:0x0 Valid sense data: 0x## 0x## 0x##
- H:0x0 D:0x8 P:0x0 Valid sense data: 0x## 0x## 0x##
- MbTX/s, MbRX/s не должны превышать vmnic. Это мегабиты, передаваемые (MbTX) или принимаемые (MbRX) в секунду. В зависимости от рабочей нагрузки MbRX/s может не совпадать с PKTRX/s, потому что размер пакетов может быть разным. Средний размер пакета можно рассчитать по формуле: средний размер пакета = MbRX/s / PKTRX/s. Увеличение размера пакетов может повысить эффективность обработки пакетов процессором. Однако потенциально это также может увеличить задержку.
- %DRPTX, %DRPRX должны равняться 0. %DRPTX – это процент потерянных исходящих пакетов. %DRPTX = потерянные исходящие пакеты / (успешно отправленные исходящие пакеты + потерянные исходящие пакеты). Высокое значение %DRPTX обычно указывает на проблемы с отправкой данных. Проверьте, полностью ли используются возможности физических сетевых карт. Возможно, нужно заменить сетевые карты на карты с лучшей производительностью. Или вы можете подключить еще несколько сетевых карт и настроить политику балансировки нагрузки, чтобы равномерно распределить нагрузку по всем картам. %DRPRX – это процент потерянных входящих пакетов. Вычисляется по формуле: %DRPRX = потерянные входящие пакеты / (успешные принятые входящие пакеты + потерянные входящие пакеты). Высокое значение %DRPRX обычно указывает на проблемы с приемом входящего трафика. Стоит выделить больше ресурсов CPU для затронутой ВМ или увеличить размер ring buffer.
cd/net/portsets//ports// cat stats packet stats
Ненулевое значение droppedRx может означать превышение Rx Ring Buffers. Расследуем дальше:
cd /net/portsets/vSwitch0/ports//vmxnet3 cat rxSummary stats of a vmxnet3 vNICrx queue
В этой статье был приведен список ключевых точек для исследования при поиске проблем с производительностью ВМ и их краткое описание. Если требуется более глубокое погружение в материал, то рекомендуем обратиться к циклу наших прошлых статей по данной теме:
- Анализ производительности ВМ в VMware vSphere. Часть 1: CPU
- Анализ производительности ВМ в VMware vSphere. Часть 2: Memory
- Анализ производительности ВМ в VMware vSphere. Часть 3: Storage