Мониторинг использования CPU в Zabbix
Приведу пример мониторинга использования каждого ядра процессора используя Zabbix.
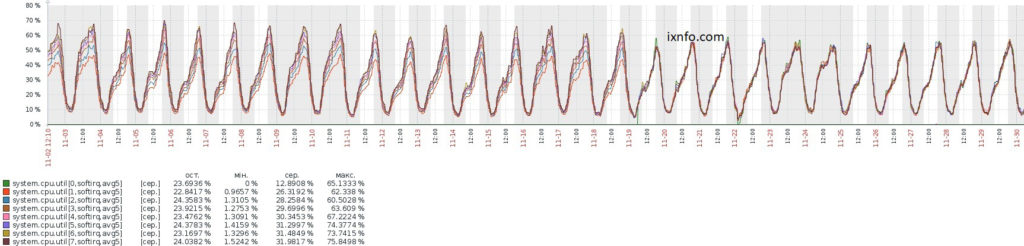
Допустим на высоконагруженном NAT сервере основная нагрузка от softirq, присутствует один процессор с 8 ядрами, а также на сервере установлен Zabbix агент.
И чтобы увидеть равномерно ли распределены прерывания сетевого адаптера по ядрам процессора, создадим элементы данных на Zabbix сервере, в которых укажем:
Тип: Zabbix агент
Тип информации: Числовой (с плавающей точкой)
Единица измерения: %
А также ключ:
system.cpu.util[0,softirq,avg5]
Где 0 — номер процессора, softirq — тип нагрузки, avg5 — средняя нагрузка за 5 минут. Аналогично создадим элементы данных для других ядер процессора с ключами, а также добавим их на один график:
system.cpu.util[1,softirq,avg5] system.cpu.util[2,softirq,avg5] system.cpu.util[3,softirq,avg5] .
Вместо softirq можно указать idle, nice, user (по умолчанию для Linux), system (по умолчанию для Windows), iowait, interrupt, softirq, steal, guest, guest_nice.
А вместо avg5 можно указать: avg1 (среднее за одну минуту, по умолчанию) или avg15 (среднее за 15 минут).
Чтобы не указывать ядра процессоров вручную, можно создать правило обнаружения:
system.cpu.discovery
И указать в нем элемент данных, например:
system.cpu.util[,softirq,avg5]
Также можно создать триггер, чтобы узнать когда значение будет больше 90:
Ниже приведу примеры элементов данных, которые отображают различную информацию о CPU, кстати эти элементы данных по умолчанию присутствуют в шаблоне «Template OS Linux».
Processor load (1 min average per core):
system.cpu.load[percpu,avg1]
Processor load (5 min average per core):
system.cpu.load[percpu,avg5]
Processor load (15 min average per core):
system.cpu.load[percpu,avg15]
Interrupts per second:
system.cpu.intr
Context switches per second:
system.cpu.switches
system.cpu.util[,idle]
CPU interrupt time:
system.cpu.util[,interrupt]
CPU iowait time:
system.cpu.util[,iowait]
system.cpu.util[,nice]
CPU softirq time:
system.cpu.util[,softirq]
system.cpu.util[,steal]
CPU system time:
system.cpu.util[,system]
system.cpu.util[,user]
Смотрите другие мои статьи в категории Zabbix.
- Нажмите, чтобы открыть на Facebook (Открывается в новом окне)
- Нажмите, чтобы поделиться на Twitter (Открывается в новом окне)
- Нажмите, чтобы поделиться записями на Pinterest (Открывается в новом окне)
- Нажмите, чтобы поделиться на LinkedIn (Открывается в новом окне)
- Нажмите, чтобы поделиться записями на Tumblr (Открывается в новом окне)
- Нажмите, чтобы поделиться в Telegram (Открывается в новом окне)
- Ещё
- Нажмите, чтобы поделиться записями на Pocket (Открывается в новом окне)
- Нажмите, чтобы поделиться на Reddit (Открывается в новом окне)
- Нажмите, чтобы поделиться в WhatsApp (Открывается в новом окне)
- Нажмите для печати (Открывается в новом окне)
2 Выражение триггера
Используемые в триггерах выражения являются очень гибкими. Вы можете использовать их для создания сложных логических тестов, учитывая статистику по мониторингу.
Простое полезное выражение может выглядеть примерно так:
:.()>оператор>константа>Функции
Функции триггеров позволяют ссылаться на собранные значения, текущее время и другие факторы.
Параметры функций
Большинство числовых функций принимают количество секунд в качестве параметра.
Вы можете использовать префикс #, чтобы указать что этот параметр должен иметь другой смысл:
| ВЫЗОВ ФУНКЦИИ | СМЫСЛ |
|---|---|
| sum(600) | Сумма всех значений за 600 секунд |
| sum(#5) | Сумма последних 5 значений |
Функция last использует другой смысл для значений, когда начинается с решетки — она дает выбрать n-ое предыдущее значение, так что с учетом значений 3, 7, 2, 6, 5 (от наиболее нового до наиболее старого), при last(#2) вернется 7 и при last(#5) вернется 5.
Несколько функций поддерживают дополнительный, второй параметр сдвиг_времени . Этот параметр позволят ссылаться на данные из периода времени в прошлом. Например, для avg(1h,1d) будет возвращено среднее значение за час днем ранее.
Вы можете использовать поддерживаемые единицы измерений в выражениях триггеров, например, ‘5m’ (минут) вместо ‘300’ секунд или ‘1d’ (день) вместо ‘86400’ секунд. ‘1K’ будет состоять из ‘1024’ байт.
Операторы
Следующие операторы поддерживаются для триггеров (представлены по убыванию приоритета выполнения):
| ПРИОРИТЕТ | ОПЕРАТОР | ОПРЕДЕЛЕНИЕ | |
|---|---|---|---|
| 1 | / | Деление | |
| 2 | *** |Умножение | |3** | — | Арифметический минус |
| 4 | + | Арифметический плюс | |
| 5 | Менее чем. Этот оператор может быть представлен в виде: A | ||
| 6 | > | Более чем. Этот оператор может быть представлен в виде: A>B ⇔ (A>=B+0.000001) |
|
| 7 | # | Не равенство. Этот оператор может быть представлен в виде: A#B ⇔ (A<=B-0.000001) | (A>=B+0.000001) |
|
| 8 | = | Равенство. Этот оператор может быть представлен в виде: A=B ⇔ (A>B-0.000001) & (A | |
| 9 | & | Логическое И | |
| 10 | | | Логическое ИЛИ | |
Кэширование значений
Значения, которые требуются для вычисления триггеров, кэшируются Zabbix сервером. По этой причине такое вычисление триггеров на некоторое время приводит к более высокой загрузке базы данных после перезапуска сервера. Кэш значений не очищается, когда значения истории элементов данных удаляются (либо вручную, либо при помощи автоматической очистки истории), поэтому сервер будет использовать кэшированные значения пока они не станут старше, чем периоды времени, которые заданы в функциях триггеров, либо пока сервер не будет перезапущен.
Примеры триггеров
Пример 1
Высокая загрузка процессора на www.zabbix.com.
‘www.zabbix.com:system.cpu.load[all,avg1]’ представляет короткое имя наблюдаемого параметра. Эта строка указывает, что сервер — ‘www.zabbix.com’ и наблюдаемый ключ — ‘system.cpu.load[all,avg1]’. Используя функцию ‘last()’, мы ссылаемся на самое последнее значение. И наконец ‘>5’ означает, что триггер перейдет в состояние ПРОБЛЕМА всякий раз, когда самое новое измерение загрузки процессора на сервере www.zabbix.com будет превышать 5.
Пример 2
Это выражение будет истинным, когда либо текущая загрузка процессора станет более 5, либо загрузка процессора больше 2 за последние 10 минут.
Пример 3
Изменился файл /etc/passwd
Используется функция diff:
Это выражение будет истинным, когда предыдущее значение контрольной суммы файла /etc/passwd отличается от самого нового значения.
Аналогичные выражения могут быть полезны для мониторинга изменений в важных файлах, таких как /etc/passwd, /etc/inetd.conf, /kernel и других.
Пример 4
Кто-то скачивает большой файл из Интернет
Используется функция min:
>100KЭто выражение будет истинным, когда количество полученных байт на eth0 превышает 100 КБ за последних 5 минут.
Пример 5
Оба узла кластера SMTP серверов недоступны
Примечание, в выражении используются два разных узла сети:
Это выражение будет истинным, когда оба SMTP сервера недоступны на обоих smtp1.zabbix.com и smtp2.zabbix.com.
Пример 6
Zabbix агент нуждается в обновлении
Используется функция str():
Это выражение будет истинным, когда версия Zabbix агента содержит в себе ‘beta8’ (возможно 1.0beta8).
Пример 7
Это выражение будет истинным, если узел сети “zabbix.zabbix.com» недоступен более 5 раз за последние 30 минут.
Пример 8
Нет данных за последние 3 минуты
Используется функцию nodata():
Для того, чтобы этот триггер заработал, элемент данных ‘tick’ должен быть задан как элемент данных типа Zabbix траппер. Узел сети должен периодически отправлять данные этому элементу данных, используя zabbix_sender. Если не было получено данных за последние 180 секунд, значением триггера станет ПРОБЛЕМА.
Обратие внимание, что ‘nodata’ можно использовать с любым типом элементов данных.
Пример 9
Активность CPU в ночное время
Используется функция time():
>2& >000000& 060000Триггер может изменить свое состояние в истинное только в ночное время (00:00-06:00).
Пример 10
Проверка синхронизации времени на клиенте со временем на Zabbix сервере
Используется функция fuzzytime():
Триггер изменит состояние на проблему тогда, когда локальное время на сервере MySQL_DB и Zabbix сервере различаются более чем на 10 секунд.
Пример 11
Сравнение средней загрузки сегодня со средним значением загрузки за это же время вчера (использование второго параметра сдвиг_времени ).
Триггер изменит свое состояние на проблему, если средняя загрузка за последний час будет в два раза больше чем за аналогичный период времени вчера.
1 Гистерезис
Иногда триггер должен иметь различные условия для разных состояний. Например, мы хотим определить триггер, который перейдет в состояние ПРОБЛЕМА, если температура в серверной комнате поднимется выше 20C. При этом триггер должен оставаться в состоянии ПРОБЛЕМА, пока температура не опустится ниже 15C.
Для того, чтобы сделать это, мы определим следующий триггер:
Пример 1
Температура в серверной комнате слишком высокая.
( =0& >20)| ( =1& >15)Обратите внимание, используется макрос . Он возвращает текущее состояние триггера.
Пример 2
Очень мало свободного места на диске
Проблема: если меньше 10ГБ за последние 5 минут
Восстановление: если больше 40ГБ за последние 10 минут
( =0&Обратите внимание, используется макрос . Он возвращает текущее состояние триггера.
2 Обнаружение CPU и ядер CPU
Аналогично обнаружению файловых систем, также имеется возможность обнаружения CPU и ядер CPU.
Ключ элемента данных
Ключом элемента данных, который используется в правиле обнаружения является
system.cpu.discoveryЭтот ключ поддерживается начиная с Zabbix агента 2.4.
Поддерживаемые макросы
Этот ключ обнаружения возвращает два макроса — и , идентифицирующие порядковый номер CPU и состояние соответственно. Отметим, нельзя сделать четкого различия между действительными, физическими процессорами, ядрами и hyperthread. на Linux, UNIX и BSD системах возвращают состояние процессора, которое может быть как «online», так и «offline». На Windows системах, этот же макрос может представлять собой третье значение — «unknown» — которое указывает на то, что процессор был обнаружен, но информация по нему еще не собрана.
Обнаружение CPU основано на процессе коллектора агента, чтобы поддерживать соответствие с данными, которые поставляются коллектором и сохранить ресурсы на получение данных. Такое поведение дает эффект, что этот ключ элемента данных не работает с флагом командой строки тестирования (-t) бинарного файла, который возвращает состояние NOT_SUPPORTED и сопутствующее сообщение о том, что процесс коллектора не запущен.
Примеры прототипов элементов данных, которые вы мозможно захотите создать на основе обнаружения CPU включают, например:
Мониторинг использования CPU на сервере Linux
Объем памяти, размер кеша, скорость чтения и записи на диск, скорость и доступность вычислительной мощности – это ключевые элементы, влияющие на производительность любой инфраструктуры.
Данное руководство ознакомит с базовыми понятиями мониторинга CPU. Вы узнаете, как использовать утилиты uptime и top, чтобы узнать о нагрузке и использовании ЦП.
Требования
- Сервер Linux.
- Утилиты uptime и top должны быть установлены по умолчанию. Если это не так, установите их вручную.
Основные понятия
Прежде чем приступить к работе с утилитами, нужно понять, как измеряется использование ЦП и к каким результатам нужно стремиться.
Загрузка и использование ЦП
Загрузка (CPU Load) и использование процессора (CPU Utilization) – два разных способа взглянуть на использование вычислительной мощности компьютера.
Чтобы оценить основное различие между ними, попробуйте представить, что процессоры – это кассиры в продуктовом магазине, а задачи – это клиенты, которых нужно обслужить. Загрузка процессора – это, по сути, одна очередь, в которой клиенты ждут, пока освободиться один из кассиров. Нагрузка – это в данном случае количество клиентов в очереди, включая тех, что уже на кассе. Чем длиннее очередь, тем дольше ждать.
Использование ЦП оценивает исключительно занятость кассиров и не знает, сколько клиентов в очереди.
Если говорить конкретнее, задачи создают очередь за ресурсами процессоров. Когда подходит очередь той или иной задачи, она должна получить определенное количество времени обработки. Если задача была выполнена, он снимается; в противном случае она возвращается в конец очереди. После этого обрабатывается следующая задача в очереди.
Загрузка ЦП – это длина очереди запланированных задач, включая те, что находятся в обработке. Задачи могут переключаться в пределах миллисекунд, поэтому один снапшот загрузки не так полезен, как среднее значение из нескольких снапшотов, взятых за определенный период времени. Потому загрузка ЦП часто представляется как среднее значение.
Загрузка процессора отображает спрос на процессорное время. Высокий спрос может привести к сбоям и ухудшению производительности.
Использование ЦП сообщает, насколько загружены процессоры, не беря во внимание количество ожидающих задач. Мониторинг использования ЦП может отображать тенденции во времени, выделять пики использования процессора и выявлять нежелательную активность на сервере.
Ненормированные и нормированные значения
В одной процессорной системе общая емкость всегда равна 1. В многопроцессорной системе данные могут отображаться двумя разными способами. Суммарная емкость всех процессоров рассчитывается как 100% независимо от количества процессоров, такое значение считается нормированным. Другой вариант предлагает считать каждый процессор как единицу, так что 2-процессорная система в полном объеме имеет емкость 200%, 4-процессорная система в полном объеме имеет мощность 400% и т. д.
Чтобы правильно интерпретировать загрузку или использование CPU, нужно знать количество процессоров на сервере.
Отображение информации о ЦП
Чтобы узнать количество процессоров, можно использовать команду nproc с опцией –all. Без этого флага команда отобразит количество обрабатывающих блоков, доступных для текущего процесса, что будет меньше общего количества процессоров.
В большинстве современных дистрибутивов Linux также можно использовать команду lscpu, которая отображает не только количество процессоров, но и архитектуру, имя модели, скорость и многое другое:
lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 2
On-line CPU(s) list: 0,1
Thread(s) per core: 1
Core(s) per socket: 1
Socket(s): 2
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 63
Model name: Intel(R) Xeon(R) CPU E5-2650L v3 @ 1.80GHz
Stepping: 2
CPU MHz: 1797.917
BogoMIPS: 3595.83
Virtualization: VT-x
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 30720K
NUMA node0 CPU(s): 0,1
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good nopl eagerfpu pni pclmulqdq vmx ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm vnmi ept fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid xsaveopt arat
Знание точного количества процессоров важно для интерпретации результатов тех или иных утилит.
Оптимальные значения загрузки и использования ЦП
Оптимальное значение использования ЦП зависит от того, какую работу должен выполнять сервер. Стабильно высокое использование процессора негативно влияет на отзывчивость системы. Часто приложениям и пакетным заданиям с интенсивными вычислениями необходим весь или почти весь объем ЦП. Однако, если система должна обслуживать веб-страницы или поддерживать интерактивные сеансы сервисов (например, SSH), тогда может понадобиться свободная вычислительная мощность.
Как и во многих других аспектах производительности, ключом к оптимизации ресурсов является изучение потребностей сервисов системы и мониторинг непредвиденных изменений.
Мониторинг ЦП
Существует множество инструментов для получения данных о состоянии ЦП системы. Мы рассмотрим две команды: uptime и top. Обе утилиты являются частью стандартной установки большинства популярных дистрибутивов Linux и обычно используются для исследования загрузки и использования ЦП.
Примечание: Следующие примеры выполнены на 2-ядерном сервере.
Утилита uptime
Команда uptime позволяет отследить загрузку процессора. Она может быть полезна, если система медленно реагирует на интерактивные запросы (вероятно, ей не хватает системных ресурсов).
Утилита uptime сообщает следующие данные:
- системное время в момент выполнения команды;
- как долго работает сервер;
- сколько подключений пользователей обслуживает машина;
- средняя загрузка процессора за последние одну, пять и пятнадцать минут.
uptime
14:08:15 up 22:54, 2 users, load average: 2.00, 1.37, 0.63
В этом примере команда была запущена в 14:08 на сервере, который работал почти 23 часа. При запуске uptime подключились два пользователя. Этот сервер имеет 2 процессора. За минуту до запуска команды средняя загрузка процессора была 2,00, что означает, что в течение этой минуты процессоры использовали в среднем две задачи, а ожидающих задач не было. Среднее значение загрузки з а5 минут указывает на то, что в течение некоторого интервала времени один из процессоров бездействовал около 60% времени. Среднее за 15 минут значение указывает на то, что было доступно больше времени обработки. Вместе эти три значения показывают увеличение загрузки за последние пятнадцать минут.
Утилита uptime сообщает полезные средние значения загрузки ЦП, но для того, чтобы получить более подробную информацию, нужно использовать top.
Утилита top
Как и uptime, утилита top доступна как в Linux, так и в Unix-системах, но помимо отображения средних значений нагрузки для заданных временных интервалов она предоставляет информацию о потреблении ЦП в реальном времени, а также другие полезные показатели производительности. Если uptime запускается и сразу завершает работу, top работает на переднем плане и регулярно обновляется.
Заглавный блок
Первые пять строк содержат сводную информацию о процессах на сервере:
top — 18:31:30 up 1 day, 3:17, 2 users, load average: 0.00, 0.00, 0.00
Tasks: 114 total, 1 running, 113 sleeping, 0 stopped, 0 zombie
%Cpu(s): 7.7 us, 0.0 sy, 0.0 ni, 92.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.1 st
KiB Mem : 4046532 total, 3238884 free, 73020 used, 734628 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 3694712 avail Mem
Первая строка почти идентична выводу утилиты uptime. Здесь показаны средние значения за одну, пять и пятнадцать минут. Эта строка отличается от вывода uptime только тем, что вначале указывается утилита top и время последнего обновления данных.
Вторая строка предоставляет краткий обзор состояния задач: общее количество процессов, количество запущенных, спящих, остановленных и зависших процессов.
Третья строка говорит об использовании ЦП. Эти цифры нормируются и отображаются в процентах (без символа %), так что все значения в этой строке должны составлять до 100% независимо от количества процессоров.
Четвертая и пятая строки сообщают об использовании памяти и swap соответственно.
После заглавного блока следует таблица с информацией о каждом отдельном процессе, которую мы вскоре рассмотрим.
В нижеприведенном заглавном блоке среднее значение загрузки за одну минуту превышает число процессоров на .77, что указывает на короткую очередь с небольшим временем ожидания. Общая емкость процессора используется на 100%, и есть много свободной памяти.
top — 14:36:05 up 23:22, 2 users, load average: 2.77, 2.27, 1.91
Tasks: 117 total, 3 running, 114 sleeping, 0 stopped, 0 zombie
%Cpu(s): 98.3 us, 0.2 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.2 si, 1.3 st
KiB Mem : 4046532 total, 3244112 free, 72372 used, 730048 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 3695452 avail Mem
. . .
Давайте рассмотрим подробнее все компоненты строки CPU.
- us, user: время на un-niced процессы пользователя. Эта категория относится к пользовательским процессам, которые были запущены без явного приоритета планирования. Системы Linux используют команду nice для установки приоритета планирования процесса. «un-niced» означает, что приоритет по умолчанию не менялся с помощью nice. Значения user и nice учитывают все пользовательские процессы. Высокое использование ЦП в этой категории может указывать на неконтролируемый процесс. Вывод в таблице процессов может определить, действительно ли это так.
- sy, system: системные процессы. Большинство приложений имеют как пользовательские компоненты, так и компоненты ядра. Когда ядро Linux создает системные вызовы, проверяет привилегии или взаимодействует с устройствами от имени приложения, здесь отображается использование процессора. Когда процесс выполняется не ядром, он будет отображаться либо в показателе user, либо в nice, если его приоритет был задан с помощью nice.
- ni, nice: niced процессы пользователя. Как и user, это поле отображает задачи, не связанные с ядром. В отличие от user, приоритет планирования для этих задач был установлен с помощью nice. Уровень приоритета (niceness) процесса указан в четвертом столбце таблицы процессов в заголовке NI. Процессы со значением niceness от 1 до 20 имеют пониженный приоритет. Такие процессы, потребляющие много процессорного времени, обычно не создают проблем, потому что задачи с повышенным приоритетом получат вычислительную мощность своевременно. Однако, если задачи с повышенным приоритетом (между -1 и -20) занимают непропорциональное количество CPU, они могут легко повлиять на отзывчивость системы. Обратите внимание, что многие процессы с самым высоким приоритетом планирования (-19 или -20 в зависимости от системы) порождаются ядром для выполнения важных задач, которые влияют на стабильность системы. Если вы не уверены, что точно знаете все процессы, указанные в выводе, лучше исследуйте их, но не останавливайте.
- Id, idle: время, затраченное на обработчик простоя ядра. Этот показатель отображает процент времени, в течение которого ЦП был доступен и простаивал. Считается, что система разумно использует ЦП, если сумма user, nice и idle близка к 100%.
- wa, IO-wait: время ожидания завершения ввода-вывода. Показатель сообщает, когда процессор начал операцию чтения или записи и ожидает завершения операции ввода-вывода. Задачи чтения и записи для удаленных ресурсов (таких как NFS и LDAP) будут также учитываться. Как и в строке idle, прыжки здесь считаются нормой. Но если показатель сообщает о частых или продолжительных обработках, это может указывать на зависшую задачу или потенциальную проблему с жестким диском.
- hi: время на бслуживание аппаратных прерываний. Это время, затрачиваемое на физические прерывания, отправленные на процессор с периферийных устройств (дисков и аппаратных сетевых интерфейсов). Если значение аппаратного прерывания велико, одно из периферийных устройств может работать неправильно.
- si: время, затраченное на обслуживание программных прерываний. Программные прерывания отправляются процессами, а не физическими устройствами. В отличие от аппаратных прерываний, которые происходят на уровне ЦП, программные прерывания происходят на уровне ядра. Если этот показатель сообщает о высоком использовании вычислительной мощности, исследуйте процессы, которые используют CPU.
- st: время, которое использовал гипервизор. Значение steal сообщает, как долго виртуальный процессор ожидает ответа физического процессора, когда гипервизор обслуживает свои задачи или другой виртуальный процессор. По сути, объем использования ЦП в этом поле указывает, сколько мощности для обработки виртуальной машины готово к использованию, но недоступно приложению, поскольку оно используется физическим хостом или другой виртуальной машиной. Как правило, нормой значения steal считается до 10% в течение коротких периодов времени. Большее значение steal в течение более длительного периода времени указывает на то, что физический сервер имеет больший спрос на CPU, чем он может предоставить.
Таблица процессов
Все процессы, выполняемые на сервере, независимо от их состояния перечисляются под заглавным блоком вывода. Ниже приведены первые шесть строк таблицы процессов из предыдущего примера. По умолчанию таблица процессов сортируется по% CPU, поэтому в начале находятся процессы, которые потребляют больше CPU.
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9966 8host 20 0 9528 96 0 R 99.7 0.0 0:40.53 stress
9967 8host 20 0 9528 96 0 R 99.3 0.0 0:40.38 stress
7 root 20 0 0 0 0 S 0.3 0.0 0:01.86 rcu_sched
1431 root 10 -10 7772 4556 2448 S 0.3 0.1 0:22.45 iscsid
9968 root 20 0 42556 3604 3012 R 0.3 0.1 0:00.08 top
9977 root 20 0 96080 6556 5668 S 0.3 0.2 0:00.01 sshd
.
Столбец %CPU представлен как процентное значение, но он не нормируется, поэтому в этой двухъядерной системе общее количество всех значений в таблице процессов должно составлять до 200%, если оба процессора полностью используются.
Примечание: Если вы предпочитаете работать с нормированными значениями, вы можете нажать SHIFT + I, и отображение переключится с режима Irix в режим Solaris. Этот режим выводит ту же информацию, которая усредняется по всему количеству процессоров, так что используемая сумма не будет превышать 100%. Перейдя к режиму Solaris, вы получите краткое сообщение о том, что режим Irix выключен.
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10081 8host 20 0 9528 96 0 R 50.0 0.0 0:49.18 stress
10082 8host 20 0 9528 96 0 R 50.0 0.0 0:49.08 stress
1439 root 20 0 223832 27012 14048 S 0.2 0.7 0:11.07 snapd
1 root 20 0 39832 5868 4020 S 0.0 0.1 0:07.31 systemd
Заключение
Теперь вы умеете работать с утилитами uptime и top и интерпретировать их вывод.
Читайте также:
- Как выбрать правильный VPS для приложения?
- Мониторинг оповещений Zabbix с помощью Alerta в Ubuntu 16.04
- Мониторинг хостов и сервисов с помощью Icinga в Ubuntu 16.04
- Мониторинг системных метрик с помощью стека TICK в Ubuntu 16.04