Фильтрация или удаление повторяющихся значений
Фильтрация уникальных значений и удаление повторяющихся — это две тесно связанные друг с другом задачи, поскольку в результате их выполнения отображается список уникальных значений. Однако между этими двумя задачами существует важное различие. При фильтрации уникальных значений повторяющиеся значения временно скрываются, тогда как в ходе удаления повторяющихся значений они удаляются без возможности восстановления. Значение считается повторяющимся, если все значения в одной строке полностью совпадают со значениями в другой. Повторяющиеся значения определяются значением, которое отображается в ячейке, а не тем, которое в ней хранится. Например, если в различных ячейках содержатся одинаковые значения даты в разных форматах («08.12.2010» и «8 дек 2010»), они считаются уникальными. Рекомендуется сначала отфильтровать уникальные значения или применить к ним условное форматирование, чтобы перед удалением повторяющихся значений убедиться в том, что будет получен ожидаемый результат.
Примечание: Если формулы в ячейках разные, а значения одинаковые, такие значения считаются повторяющимися. Например, если в ячейке A1 содержится формула =2-1, а в ячейке A2 — формула =3-2 и к ячейкам применено одинаковое форматирование, такие значения считаются повторяющимися. Одинаковые значения, к которым применены различные числовые форматы, не считаются повторяющимися. Например, если значение в ячейке A1 имеет формат 1,00, а в ячейке A2 — формат 1, эти значения не являются повторяющимися.
Фильтрация уникальных значений

- Выделите диапазон ячеек или убедитесь в том, что активная ячейка находится в таблице.
- На вкладке Данные в группе Сортировка и фильтр нажмите кнопку Дополнительно.
- Выполните одно из указанных ниже действий.
| Задача | Необходимые действия |
|---|---|
| Фильтрация диапазона ячеек или таблицы на месте | Выделите диапазон ячеек и щелкните Фильтровать список на месте. |
| Копирование результатов фильтрации в другое место | Выделите диапазон ячеек, щелкните Скопировать результат в другое место, а затем в поле Копировать в введите ссылку на ячейку. |
Примечание: При копировании результатов фильтрации в другое место будут скопированы уникальные значения из выбранного диапазона. Исходные данные при этом не изменятся.
Дополнительные параметры
Удаление повторяющихся значений
При удалении повторяющихся значений данные удаляются только из выделенного диапазона ячеек или таблицы. Любые другие значения, которые находятся за пределами этого диапазона ячеек или таблицы, не изменяются и не перемещаются. Так как данные удаляются без возможности восстановления, перед удалением повторяющихся записей рекомендуется скопировать исходный диапазон ячеек или таблицу на другой лист или в другую книгу.
Примечание: Нельзя удалить повторяющиеся значения, если выделенные фрагмент содержит структурированные данные или промежуточные итоги. Перед удалением повторяющихся значений нужно удалить структуру и промежуточные итоги.
- Выделите диапазон ячеек или убедитесь в том, что активная ячейка находится в таблице.
- На вкладке Данные в разделе Работа с данными нажмите кнопку Удалить дубликаты.
- Установите один или несколько флажков, соответствующих столбцам таблицы, и нажмите кнопку Удалить дубликаты.
Совет: Если в диапазоне ячеек или таблице содержится много столбцов, а нужно выбрать только несколько из них, снимите флажок Выделить все и выделите только нужные столбцы.
Применение условного форматирования к уникальным или повторяющимся значениям
Для наглядного отображения уникальных или повторяющихся значений к ним можно применить условное форматирование. Например, выделение повторяющихся данных определенным цветом помогает найти и (при необходимости) удалить их.
- Выделите одну или несколько ячеек в диапазоне, таблице или отчете сводной таблицы.
- На вкладке Главная в группе Стили щелкните Условное форматирование, наведите указатель на пункт Правила выделения ячеек и выберите Повторяющиеся значения.
- В диалоговом окне Создать правило форматирования выберите нужные параметры и нажмите кнопку ОК.
Применение правил расширенного условного форматирования к уникальным или повторяющимся значениям
Вы можете создать правило для выделения уникальных или повторяющихся значений на листе определенным цветом. Это особенно полезно, когда в данных содержится несколько наборов повторяющихся значений.
- Выделите одну или несколько ячеек в диапазоне, таблице или отчете сводной таблицы.
- На вкладке Главная в группе Стили щелкните Условное форматирование и выберите пункт Создать правило.
- В списке Стиль выберите пункт Классический, а затем в списке Форматировать только первые или последние значения выберите пункт Форматировать только уникальные или повторяющиеся значения.
- В списке значения в выбранном диапазоне выберите пункт уникальные или повторяющиеся.
- В списке Форматировать с помощью выберите нужный вариант форматирования уникальных или повторяющихся значений.
Изменение правил расширенного условного форматирования
Вы можете отредактировать существующее правило, чтобы изменить условное форматирование, применяемое к уникальным или повторяющимся данным.
- Выделите одну или несколько ячеек в диапазоне, таблице или отчете сводной таблицы.
- На вкладке Главная в группе Стили щелкните Условное форматирование и выберите пункт Управление правилами.
- Убедитесь, что в списке Показать правила форматирования для выбран соответствующий лист или таблица.
- Выберите правило и нажмите кнопку Изменить правило.
- Выберите нужные параметры и нажмите кнопку ОК.
Фильтрация уникальных значений
- Выделите диапазон ячеек или убедитесь в том, что активная ячейка находится в таблице.
- На вкладке Данные в разделе Сортировка и фильтр щелкните стрелку рядом с элементом Фильтр и выберите пункт Расширенный фильтр.
- Выполните одно из указанных ниже действий.
| Задача | Необходимые действия |
|---|---|
| Фильтрация диапазона ячеек или таблицы на месте | Выделите диапазон ячеек и щелкните Фильтровать список на месте. |
| Копирование результатов фильтрации в другое место | Выделите диапазон ячеек, щелкните Скопировать результат в другое место, а затем в поле Копировать в введите ссылку на ячейку. |
Примечание: При копировании результатов фильтрации в другое место будут скопированы уникальные значения из выбранного диапазона. Исходные данные при этом не изменятся.
Дополнительные параметры
Удаление повторяющихся значений
При удалении повторяющихся значений данные удаляются только из выделенного диапазона ячеек или таблицы. Любые другие значения, которые находятся за пределами этого диапазона ячеек или таблицы, не изменяются и не перемещаются. Так как данные удаляются без возможности восстановления, перед удалением повторяющихся записей рекомендуется скопировать исходный диапазон ячеек или таблицу на другой лист или в другую книгу.
Примечание: Нельзя удалить повторяющиеся значения, если выделенные фрагмент содержит структурированные данные или промежуточные итоги. Перед удалением повторяющихся значений нужно удалить структуру и промежуточные итоги.
- Выделите диапазон ячеек или убедитесь в том, что активная ячейка находится в таблице.
- На вкладке Данные в разделе Сервис нажмите кнопку Удалить дубликаты.
- Установите один или несколько флажков, соответствующих столбцам таблицы, и нажмите кнопку Удалить дубликаты. Появится либо сообщение о том, сколько повторяющихся значений было удалено и сколько уникальных осталось, либо сообщение о том, что ни одного повторяющегося значения не было удалено.
Совет: Если в диапазоне ячеек или таблице содержится много столбцов, а нужно выбрать только несколько из них, снимите флажок Выделить все и выделите только нужные столбцы.
Применение условного форматирования к уникальным или повторяющимся значениям
Для наглядного отображения уникальных или повторяющихся значений к ним можно применить условное форматирование. Например, выделение повторяющихся данных определенным цветом помогает найти и (при необходимости) удалить их.
- Выделите одну или несколько ячеек в диапазоне, таблице или отчете сводной таблицы.
- На вкладке Главная в разделе Формат щелкните стрелку рядом с элементом Условное форматирование, выберите пункт Правила выделения ячеек, а затем — пункт Повторяющиеся значения.
- Выберите нужные параметры и нажмите кнопку ОК.
Применение правил расширенного условного форматирования к уникальным или повторяющимся значениям
Вы можете создать правило для выделения уникальных или повторяющихся значений на листе определенным цветом. Это особенно полезно, когда в данных содержится несколько наборов повторяющихся значений.
- Выделите одну или несколько ячеек в диапазоне, таблице или отчете сводной таблицы.
- На вкладке Главная в разделе Формат щелкните стрелку рядом с кнопкой Условное форматирование и выберите пункт Создать правило.
- Во всплывающем меню Стиль выберите пункт Классический, а затем во всплывающем меню Форматировать только первые или последние значения выберите пункт Форматировать только уникальные или повторяющиеся значения.
- В меню значения в выбранном диапазоне выберите уникальные или повторяющиеся.
- В меню Форматировать с помощью выберите нужный вариант форматирования уникальных или повторяющихся значений.
Изменение правил расширенного условного форматирования
Вы можете отредактировать существующее правило, чтобы изменить условное форматирование, применяемое к уникальным или повторяющимся данным.
- Выделите одну или несколько ячеек в диапазоне, таблице или отчете сводной таблицы.
- На вкладке Главная в разделе Формат щелкните стрелку рядом с кнопкой Условное форматирование и выберите пункт Управление правилами.
- Убедитесь, что в меню Показать правила форматирования для выбран соответствующий лист или таблица.
- Выберите правило и нажмите кнопку Изменить правило.
- Выберите нужные параметры и нажмите кнопку ОК.
Как в sql выбрать уникальные значения
С помощью DISTINCT можно получить только уникальные значения из столбца таблицы.
SELECT DISTINCT first_name FROM users; first_name ------------ Roman Sean Alex Michal Britney Кроме того, DISTINCT можно использовать и с несколькими полями сразу:
SELECT DISTINCT first_name, last_name FROM users; first_name | last_name ------------+--------------- Bruce | Williss Sean | Connery Robin | Williams Извлечение уникальных элементов из диапазона
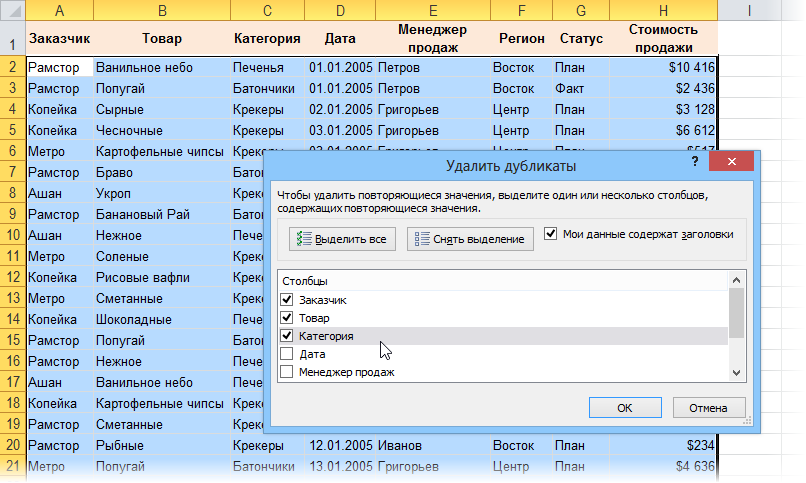
Начиная с 2007-й версии функция удаления дубликатов является стандартной — найти ее можно на вкладке Данные — Удаление дубликатов (Data — Remove Duplicates) : В открывшемся окне нужно с помощью флажков задать те столбцы, по которым необходимо обеспечивать уникальность. Т.е. если включить все флажки, то будут удалены только полностью совпадающие строки. Если включить только флажок заказчик, то останется только по одной строке для каждого заказчика и т.д.
Способ 2. Расширенный фильтр
- Выделяем наш список компаний в Исходный диапазон (List Range) .
- Ставим переключатель в положение Скопировать результат в другое место (Copy to another location) и указываем пустую ячейку.
- Включаем (самое главное!) флажок Только уникальные записи(Uniqe records only) и жмем ОК.
Получите список без дубликатов:
Если требуется искать дубликаты не по одному, а по нескольким столбцам, то можно предварительно склеить их в один, сделав, своего рода, составной ключ с помощью функции СЦЕПИТЬ (CONCATENATE) :
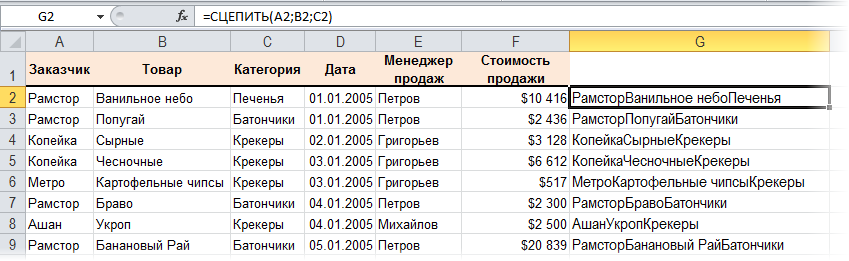
Тогда дальнейшая задача будет сводиться к поиску дубликатов уже в одном столбце.
Способ 3. Выборка уникальных записей формулой
Чуть более сложный способ, чем первые два, но зато — динамический, т.е. с автоматическим пересчетом, т.е. если список редактируется или в него дописываются еще элементы, то они автоматически проверяются на уникальность и отбираются. В предыдущих способах при изменении исходного списка нужно будет заново запускать Расширенный фильтр или жать на кнопку Удаление дубликатов.
Итак, снова имеем список беспорядочно повторяющихся элементов. Например, такой:
Первая задача — пронумеровать всех уникальных представителей списка, дав каждому свой номер (столбец А на рисунке). Для этого вставляем в ячейку А2 и копируем затем вниз до упора следующую формулу:
=ЕСЛИ(СЧЁТЕСЛИ(B$1:B2;B2)=1;МАКС(A$1:A1)+1;»»)
В английской версии это будет:
=IF(COUNTIF(B$1:B2;B2)=1;MAX(A$1:A1)+1;»»)
Эта формула проверяет сколько раз текущее наименование уже встречалось в списке (считая с начала), и если это количество =1, т.е. элемент встретился первый раз — дает ему последовательно возрастающий номер.
Для упрощения адресации дадим нашим диапазонам (например, исходя из того, что в списке может быть до 100 элементов) имена. Это можно сделать в новых версиях Excel на вкладке Формулы — Диспетчер имен (Formulas — Name manager) или в старых версиях — через меню Вставка — Имя — Присвоить (Insert — Name — Define) :
- диапазону номеров (A1:A100) — имя NameCount
- всему списку с номерами (A1:B100) — имя NameList
Теперь осталось выбрать из списка NameList все элементы имеющие номер — это и будут наши уникальные представители. Сделать это можно в любой пустой ячейке соседних столбцов, введя туда вот такую формулу с известной функцией ВПР (VLOOKUP) и скопировав ее вниз на весь столбец:
или в английской версии Excel:
=IF(MAX(NameCount)
Эта формула проходит сверху вниз по столбцу NameCount и выводит все позиции списка с номерами в отдельную таблицу:
Ссылки по теме
- Выделение дубликатов по одному или нескольким столбцам в списке цветом
- Запрет ввода повторяющихся значений
- Извлечение уникальных значений при помощи надстройки PLEX
Pandas: как найти уникальные значения в столбце
Самый простой способ получить список уникальных значений в столбце pandas DataFrame — использовать функцию unique() .
В этом руководстве представлено несколько примеров использования этой функции со следующими пандами DataFrame:
import pandas as pd #create DataFrame df = pd.DataFrame() #view DataFrame df team conference points 0 A East 11 1 A East 8 2 A East 10 3 B West 6 4 B West 6 5 C East 5 Найти уникальные значения в одном столбце
Следующий код показывает, как найти уникальные значения в одном столбце DataFrame:
df.team.unique () array(['A', 'B', 'C'], dtype=object) Мы видим, что уникальные значения в столбце команды включают «A», «B» и «C».
Найти уникальные значения во всех столбцах
Следующий код показывает, как найти уникальные значения во всех столбцах DataFrame:
for col in df: print(df[col]. unique ()) ['A' 'B' 'C'] ['East' 'West'] [11 8 10 6 5] Поиск и сортировка уникальных значений в столбце
Следующий код показывает, как найти и отсортировать уникальные значения в одном столбце DataFrame:
#find unique points values points = df.points.unique () #sort values smallest to largest points. sort () #display sorted values points array([ 5, 6, 8, 10, 11]) Найти и подсчитать уникальные значения в столбце
В следующем коде показано, как найти и подсчитать появление уникальных значений в одном столбце DataFrame:
df.team.value_counts () A 3 B 2 C 1 Name: team, dtype: int64