Мы же всё протестировали, откуда баги на проде? Разбор от QA с 10+ годами опыта
Это сообщение в рабочем мессенджере, пожалуй, самый страшный сон тестировщика.
Почему они всё-таки могут просочиться на прод? Каков порядок действий? Расскажу коммьюнити dev.by.
Кто пишет: Александра Ерёмина, QA Lead Engineer с опытом работы на 40+ проектах, преподаватель и автор блога «Всё о тестировании и QA».
Если вы хотите поделится необычными практиками, которые вы используете в работе с коммьюнити, пишите на [email protected] .
Дисклеймер. В этой статье рассматриваем ситуации, когда:
- В команде есть тестировщик/QA-специалиста.
- Тестировщик — не стажёр/джун (или джун, но помимо него, в команде тестирования есть еще тестировщики уровня middle и/или выше).
- В команде есть договоренность о том, что тестирование проводится до релиза на прод.
Автоматизация тестирования и баги, связанные с ней, в этот обзор включаться не будут.
Команда решила зарелизить новый или изменить существующий функционал, не поставив в известность тестировщиков
Резонный вопрос: как в принципе это может случиться и кому в здравом уме и трезвой памяти такое может прийти в голову? Ответ: и может, и приходит.
Я не сталкивалась с такими ситуациями на крупных серьёзных проектах в аутсорсе. Проблема больше характерна для стартапов, где не всегда сильные проджект- и продакт-менеджеры, и процессы зачастую отсутствуют или саботируются в силу разных причин.
В одном из таких стартапов я столкнулась с подобной ситуацией. Придя в понедельник на работу, я случайно узнала, что в выходные на проде был обнаружен критичнейший баг: когда пользователь выводил деньги на свой кошелек, с его баланса в нашем приложении эта сумма списывалась. Но на кошелек поступала сумма в 2 раза больше.
Как так могло получиться? Ведь мы ничего нового не релизили, а эта проверка входит в смоук-тест и успешно была пройдена при прошлом релизе. Откуда баг?
Выяснилось, что релиз всё-таки был. Проджект-менеджер договорился с командой разработки залить его на прод в обход команды тестирования.
Команда разработки делала рефакторинг кода. По договоренности с проджект-менеджером задача под это в Jira не заводилась и на общих дейликах это не озвучивалось. Разработчики самостоятельно провели тестирование и подтвердили, что всё работает. В пятницу вечером, по окончании рабочего дня новый код выкатили на прод.
А в субботу утром выяснились две новости.
Хорошая: в приложении произошел внезапный прирост новых пользователей, которые не только успели пополнить свои балансы в приложении, но и опробовали вывод денег с баланса на кошелёк.
Плохая: почему-то при этом в кошельке компании баланс уменьшился на пятизначную сумму. В долларах. И продолжает быстро уменьшаться.
В результате вывод денег заморозили, часть средств компании удалось вернуть, а дев-лид все выходные провел на работе.
На мой вопрос «А зачем вы это сделали?» был ответ: «Если бы мы вам [тестировщикам] сказали о релизе, вы бы его тестили, еще бы и регрессию сделали, нашли баги, релиз бы затормозился, мы бы потеряли время»…
Здесь хочу всем напомнить: задача тестировщика — зарепортать найденные баги, предоставить объективную и подкрепленную фактами информацию о текущем качестве фич/приложения.
Но не тестировщик решает:
- какой приоритет у багов;
- какие баги и в какие сроки должны быть пофикшены;
- может ли фича уйти в релиз с текущими багами или нет.
Это ответственность менеджера, не тестировщика.
Выводы:
- заранее информировать о фичах в релизе всю команду;
- регулярно обновлять статус этих фич;
- если тестирование фичи завершено со статусом «Failed» из-за найденных багов, то «уполномоченное лицо» должно аппрувнуть, какие из багов должны быть пофикшены до релиза, а какие могут быть отложены или отменены;
- регулярно обсуждать и обновлять приоритет/статус багов, найденных в релизных фичах;
- спорные вопросы (например, если тестировщик считает, что продакт-менеджер недооценил критичность бага) должны быть обсуждены на отдельном митинге с привлечением необходимых лиц (например, ВА, дев-лида и т. д.).
Решение о внесении изменений было сделано уже после завершения тестирования
Похожа на предыдущую. Разница в том, что тестировщики об изменениях узнают, когда времени на перепроверку уже не остается. Такая ситуация приключилась со мной на одном из проектов.
Релизили абсолютно новый функционал — менеджер задач. Работали над ним несколько месяцев. Все стори (больше 10) были протестированы, регрессия почти завершена. Релиз запланирован на послезавтра. И под конец регрессии абсолютно случайно замечаю, что одна из новых фич в статусе «Ready for Release» работает неправильно. А именно — находится в том состоянии, в котором нам ее впервые когда-то передали в тестирование: те же баги, функционал нерабочий и к релизу не готов.
Оказалось, что продакт-менеджер попросил разработчиков немного поправить внешний вид одного из полей ввода задачи. Поправили, залили, проверили. И выяснили, что допустили ошибку. Тогда, чтобы не задерживать релиз и не затевать тестирование, решили откатить это последнее изменение. Откатили, снова перепроверили: поле ввода задачи выглядело и работало, как раньше. Тестировщикам ничего говорить не стали.
Но, видимо что-то перепутали: в результате заодно откатились и изменения за последние несколько дней в других фичах. И никто этого не заметил.
Выводы:
- Код фриз (code freeze) — замораживание любых изменений на тестовом окружении, где уже проводится тестирование.
- Нужно обсуждать любые изменения и обязательно ставить в известность команду тестирования.
Баг обнаружен на окружении (браузер, ОС, девайс, разрешение экрана и т. д.), на котором тестирование не проводилось
На одном из крупных проектов я спросила про окружение. Lead Product Manager сбросил список браузеров, ОС и девайсов и даже указал приоритеты окружений.
Но, наблюдая за отчетами службы саппорта, я заметила, что в них довольно часто фигурировали баги, которые не воспроизводились на нашем тестовом окружении. Я решила уточнить, когда последний раз обновлялся список тестового окружения. Оказалось — почти 3 года назад.
Выяснилось, что, например, через десктопный браузер Mozilla FF (под Windows) в нашем приложении работает менее 2% пользователей. А этот браузер по приоритету у нас значился вторым после Google Chrome! Почти 15% юзеров пользовались приложением через мобильный браузер Safari, который вообще не входил в тестовое окружение.
Список тестового окружения актуализировали. С тех пор баги от пользователей мобильного браузера Safari нам больше не приходили.
Выводы:
- На новом проекте всегда спрашивайте про окружение, почему оно выбрано и когда список последний раз актуализировался.
Если заранее оговоренного тестового окружения нет (или на проекте нет продакт-менеджера), попросите того, кто отвечает за развитие продукта, это окружение вам предоставить. В крайнем случае составьте такой список сами и согласуйте с тем, кто отвечает за развитие продукта. - Уточняйте, на каком окружении обнаружен баг и насколько это популярно у пользователей.
- Если список тестового окружения большой и/или текущий проектный треугольник не позволяет постоянно проводить тестирование на всём запланированном окружении, то выберите 2-3 наиболее приоритетных. Остальные окружения вынесите в регулярно проводимую отдельную регрессию (например, 1 окружение 1 раз в месяц или реже).
Баг был обнаружен в той части функционала, которая не была покрыта тестами
Как-то меня попросили подключиться к проекту, где скопилась большая очередь задач на тестирование (больше 1000 задач на 2 тестировщика) и нужно было помочь коллегам эту очередь «расчистить».
На мой вопрос, как так получилось, мне рассказали предысторию.
Жил да был крупный европейский заказчик с интернет-магазином в 20+ странах. И нанял он подрядчика на разработку и поддержку этого интернет-магазина. А подрядчик нанял нашу компанию на работу в shadow mode. Наши тестировщики работали хорошо, а команда ВА+dev подрядчика — не очень, поэтому багов в каждой фиче находилось очень много.
И в какой-то момент европейский заказчик задал вопрос: «А почему это у нас зарепортано так много багов? У нас что, плохие разработчики?»
Подрядчик задумался, да и придумал: сократить количество багов можно… (барабанная дробь) сократив часть команды тестирования.
Но количество новых фич осталось прежним. Пришлось отказаться от глубокого и широкого тестового покрытия.
Плюсы: по результатам тестирования зарепортанных багов теперь, действительно, резко стало меньше.
Минусы: зато теперь больше багов стали находить пользователи. На проде.
А «бонусом» проектная команда получила еще и bottleneck в тестировании новых фич. И теперь уже к тестированию пришлось подключать самих разработчиков. Естественно, качество тестирования таких фич стало еще хуже.
И вот уже европейский заказчик пришёл с новым вопросом: «А как так получается, что у нас выросло количество багов на проде?»
Подрядчик снова задумался… и вот так на проекте временно появилась я.
Выводы:
- Заранее и честно информируйте проджект-менеджера и команду о том, в какие реальные сроки может быть протестирован принятый скоуп задач при широком и глубоком тестовом покрытии.
Если сроки и скоуп меняться не будут, то:
- Согласуйте, насколько глубоко и широко можно успеть протестировать все фичи за утвержденный срок силами текущей команды тестирования. Например, будет проведен только смоук-тест, а тест критического пути и расширенное тестирование проводиться не будут.
Чек-лист проверок нужно пошарить на всех ключевых членов команды: проджект-менеджер, продакт-менеджер/ВА, лида команды разработки, — и попросить их в течение какого-то разумного срока указать те критичные проверки, которые необходимо добавить вместо существующих (или в дополнение к ним). И согласовать, иначе ваш чек-лист будет считаться аппрувнутым по умолчанию. - Если первый вариант не подходит, согласуйте, какие именно фичи целиком может проверить команда тестирования, а тестирование каких фич целиком могут взять на себя другие члены проектной команды.
- Если на проектах постоянно не хватает рук, то имеет смысл написать краткую тест-стратегию и зафиксировать в ней договоренность о глубине/ширине тестирования, а также о том, кто будет в нем участвовать.
- Если на проекте ведётся детализированная документация, можно всей командой тестировать одну фичу. Например, смоук-тест проводят разработчики, тест критического пути — QA, а расширенное тестирование — BA.
Тестовые данные отличаются от реальных данных с прода
История из жизни. И снова крупный заказчик. На этот раз в сфере консалтинга. Приложение работает с огромными массивами данных ритейл-компаний.
Понимая, что данные могут быть весьма специфичными, согласовываем с заказчиком возможность генерации похожих данных. Заказчик соглашается и предоставляет данные, по его словам, похожие на данные с прода (к проду команда доступа не имела).
После каждого релиза с прода приходят баги, которые не воспроизводятся на точно таком же тестовом окружении. Анализируем, оказывается, что проблема в данных: на проде они реальные и поэтому образуют такие комбинации, существование которых команда просто не может предугадать. Не говоря уже об их проверке при разработке и тестировании.
Заказчику были предложены варианты:
- Передать для тестирования данные с прода, изменив или удалив информацию о компаниях, датах и прочую информацию, по которой можно было бы «вычислить» компании, людей, счета и т. д.
- Дать доступ к проду хотя бы кому-то из команды разработки и/или тестирования (даже с подписанием дополнительного договора о неразглашении).
- Включить в команду представителя компании-заказчика, который мог бы проверять тестовые сценарии на предмет добавления дополнительных проверок исходя из возможных особенностей в текущих продовских данных.
Заказчик отверг все варианты. Понимая причину появления багов на проде, заказчик согласился, что эти баги допустимые и будут исправляться по мере фидбэка от пользователей.
Мы по мере обнаружения новых багов обновляли и дополняли свои тестовые данные. Приблизительно через полгода количество багов, которые обнаруживали пользователи на проде из-за разницы между сгенерированными и реальными данными, существенно уменьшилось.
Выводы:
- Всегда согласовывайте с продакт-менеджером или другим лицом, отвечающим за развитие продукта, откуда команда может брать данные для тестирования и разработки; насколько они соответствуют реальным бизнес- и пользовательским данным и какие специфичные наборы данных могут быть в реальности.
- По мере обнаружения багов, связанных с разницей в данных на тестовом стенде и проде, обновляйте и дополняйте свои тестовые данные, а также добавляйте чек-проверки или тест-кейсы для них.
Этот список неполный, моя коллекция причин состоит из примерно 20 пунктов. Если статья понравится коммьюнити dev.by, с удовольствием напишу продолжение.
Делитесь в комментариях, почему же баги могут возникать на проде.
Первоначально этот текст был опубликован на habr.ru. Публикуем его с незначительными изменениями.
Мнение автора может не совпадать с мнением редакции.
dev.by, как и другим честным медиа, сегодня очень сложно: редакция работает за пределами страны, а наши рекламные доходы сократились в несколько раз. Но мы справляемся — с вашей помощью. Это вы делитесь с нами инфоповодами, мнениями, опытом, временем и вниманием. А 220 читателей поддерживают нас донатами.
В 2023 году мы хотим собрать 1000 читателей-подписчиков.
Что ещё почитать про тестирование:
- Тестирование — это не «простая точка входа в ИТ». Мифы разрушает Артём Русов;
- Как научиться тестировать самому и найти работу в трудные времена;
- Найдёт код, сымитирует собес, поможет с английским. 19 нейросеток для учёбы и работы (не ChatGPT);
Заморозка (программное обеспечение)
Замораживание в разработке программного обеспечения (заморозка, англ. freeze ) — момент времени, по достижению которого правила внесения изменений в исходный код ужесточаются. Замораживание помогает произвести выпуск (RTM) — обеспечить стадию разработки, для которой характерна стабильность.
- Анализ
- Проектирование
- Программирование
- Конструирование
- Тестирование
- Отладка
- Развёртывание
- Сопровождение
- Документирование
- Компилятор
- Отладчик
- Профилирование
- GUI-конструктор
- ИСР
- Автоматизация сборки
- Автоматизация релиза
- Инструменты тестирования
Распространённые типы замораживания:
- замораживание функциональных свойств (англ. feature freeze ), когда новые возможности не добавляются, а всё внимание переключается на исправление ошибок и тестирование, что позволяет улучшить стабильность программы перед релизом;
- замораживание кода (англ. code freeze ) [1] — состояние, при котором не разрешаются никакие изменения исходников; в больших проектах небольшие изменения могут сопровождаться ошибками в работе продукта, замораживание кода предотвращает допущение таких ошибок в последний момент, когда они могут быть незамеченными: код, который продолжительное время стабильно работал, попадает в ближайший выпуск; как правило, происходит перед выпуском релиз-кандидатов;
- замораживание требований и замораживание дизайна могут предшествовать стадии разработки [2] .
При разработке программного обеспечения вызванные замораживанием задержки решаются использованием системы управления версиями. Замораживанию подвергается только одна из ветвей (стабильная версия), а новые изменения реализуются в версии для разработчиков.
Oops something went wrong:
Без код-фриза были в стрессе и быстро выгорали: как мы внедрили замораживание кода и что оно дает

Замораживание кода или код-фриз (code freeze) может показаться рудиментом в мире, где активно используются agile-методы и принцип непрерывной разработки. Ведь этот подход предлагает сделать паузу для того, чтобы выделить время исключительно на тестирование. Как замораживание кода может помочь командам сегодня? Поделимся собственным опытом.
Детям из Мариуполя нужно 120 ноутбуков для обучения — подари старое «железо», пусть оно работает на будущее Украины

Подход предлагает сделать паузу, чтобы выделить время исключительно на тестирование
Какой была наша проблема до код-фриза
Постоянные форс-мажоры, когда недавно добавленный функционал переставал работать или ломал уже работающие участки приложения. Из-за того, что нужно было как можно скорее показать результат клиенту, нам часто не хватало времени на качественное тестирование. Иногда приходилось вносить изменения прямо перед презентацией клиенту, или же была ситуация, когда наш первый «платный» пользователь хотел купить премиум версию, но не смог этого сделать из-за механической ошибки в коде.
Такие проблемы часто воспринимаются как обычное дело, ведь в процессе работы могут случаться сбои.
Но разработка без код-фриза создавала лишний стресс, из-за которого увеличивалось количество ошибок и быстро наступало выгорание.
Как мы вводили код-фриз
Осознав, что разработка как можно большего количества новых фич увеличивает скорость, но на практике же снижает качество и нашу эффективность, мы попробовали альтернативный способ использования времени.
Курс Python basic.
Після курсу ви зможете впевнено працювати з чатботами, скриптами, вбудованими системами, веб- та мобільними застосунками, а також навіть ігровими програмами.
Перестать вносить изменения хотя бы на несколько дней
Первым делом вся команда договорилась выделять несколько дней, когда мы перестаем вносить любые изменения в код, который планируется заливать в следующем релизе. Даже если очень хочется и «мне всего пару строк поменять».
На момент введения код-фриза, вопрос планирования времени и овертаймов уже был наболевшим, мы понимали, что нужно больше времени на тестирование, поэтому такое решение было воспринято позитивно. Впрочем, все равно иногда хотелось «быстро добить» какие-то мелочи, но очень важно не соблазняться на подобные «улучшения», так как они могут привести к очередному сбою на продакшене.
Планировать спринты с учетом времени на заморозку кода
Следующим шагом было планирование спринтов с учетом времени на заморозку кода. Наши спринты длились две недели и теперь, вместо активного тестирования в последний момент, мы установили четкие временные рамки.
На разработку нового функционала выделили 1,5 недели, а остальную часть — исключительно на код-фриз.
Понять, готовы ли заливать обновления
После того, как все было проверено, последним шагом оставалось решить, готовы ли мы заливать обновления с учетом текущего состояния приложения. В нашем случае могло быть три варианта развития событий:
- Если ошибок нет или они некритичны и действительно могут быть легко исправлены — фиксим все, что можно пофиксить, делаем проверку исправлений и готовим релиз.
- Если новый функционал частично работает не так, как этого ожидается, можно попробовать согласовать текущее поведение с клиентом и принять решение о релизе.
- Если же нашли критичные ошибки или регрессию, тогда новый релиз будет содержать только исправления багов из предыдущего или вообще будет отменен: «не ломай то, что уже хорошо работает».
Что нам дал код-фриз?
- Мы стали значительно лучше планировать работу, ведь код-фриз приводит к ситуации «все или ничего», когда нужно рассчитать время так, чтобы на начало код-фриза была завершена работа над задачами текущего спринта. Все, что не успели — идет в следующий релиз.
Курс Англійської.
Обери викладача за своїми вимогами серед 1100+ фахівців в Englishdom.
Недостатки код-фриза
В общем, это универсальный инструмент, ведь это о планировании времени, а не о тонкостях написания кода.
Единственное, такой подход, вероятно, не очень хорошо сработает в условиях постоянной неопределенности, как, например, в стартапах, где срочные задания могут влиять на спланированный процесс.
Тем не менее, когда нам нужно внедрить ключевые обновления, которые влияют на поведение всего продукта, мы «замораживаем» код и много-много тестируем.
Также вначале может быть тяжело принять то, что теперь вы ставите меньшее количество задач на спринт. Представьте ситуацию, когда вы договорились встретиться с товарищем, он приходит раньше и спрашивает, через сколько вы будете. Допустим вам реально идти 12-15 минут. Если вы скажете «через 10 минут» — это то, как мы работали раньше. Нужно чтобы или все пошло идеально, или очень спешить. Теперь же мы отвечаем «20 минут» и точно укладываемся в установленный срок без спешки.
Неправильное планирование — одна из главных причин срыва дедлайнов. Задержки приводят к финансовым убыткам, а разработка в стрессе — к большему количеству ошибок и регрессии. Если подобное хотя бы частично касается вашей команды, код-фриз может стать отличным решением, так как приближает к главной цели любой парадигмы построения процессов — выполнять задания вовремя и качественно.
Курс Управління командою в бізнесі.
Онлайн-курс для ефективного управління командою, спрямований на створення проактивних та самостійних команд, де мікроменеджмент не потрібний.
If you have found a spelling error, please, notify us by selecting that text and pressing Ctrl+Enter.
Цикл выпуска версий
Каждая версия проходит через следующие четыре периода разработки.
1. Разморозка кода (code thaw) После выхода предыдущей версии Друпала, Drupal HEAD открывается для добавления новых возможностей. Мы называем этот период разморозкой кода. В этой периоде, название игры — мировое доминирование. Всё разрешено. Исправление ошибок, переписывание Form API, перенос полезных дополнительных модулей в ядро, удаление ненужных модулей из ядра, изменение API ядра, добавление и удаление шаблонов, в общем всё, о чём вы мечтаете. Капля всегда движется и размороженный код, это шанс сделать реальностью все свои дикие мечты. Когда разморозка заканчивается, мы получаем состояние заморозки кода (code freeze) и после этого начинаем скрупулёзно обрабатывать принятые патчи. 2. Скрепление кода (code slush) Этот период добавлен в Друпал 7, так как Друпал 7 имел такой нетипично долгий период с размороженным кодом. В этом периоде, который имеет точные временные рамки, разработчики ядра определяют важные возможности, которые уже завершены и(или) очень важны для будущего проекта и делают необходимые изменения для этого набора (и только его).
Это период «последней минуты» для изменения API и добавления связанных с существующими возможностей, которые уже реализованы в процессе разморозки кода. Никаких других новых возможностей. Никаких других изменений в API или дополнений.
В конце этой фазы, мы объявляем о заморозке API и больше никакие изменения в API не разрешены (за исключением исправления критических ошибок, которые могут обнаружиться позднее и блокируют выход стабильной версии). Изменения API включают изменение подписей функций, добавление или удаление хуков, добавление или исключение файлов шаблонов или переменных шаблонов и что-либо ещё, что очень важно сделать до выхода финальной версии.
3. Полировка кода (polish phase) Теперь наступает время для вещей, которые не получили внимания, когда все с сумасшествием ломали Друпал и набивали его новыми возможностями. Здесь мы работаем над оптимизацией быстродействия, эргономики, документированием и изменением строк интерфейса. Это отличное время чтобы убедиться, что справочные страницы Друпала содержат корректную информацию или почистить разметку кода.
В конце этого периода, мы объявляем о заморозке строк и интерфейса. Также как и с заморозкой API, это означает, что мы больше не изменяем строки интерфейса или другие аспекты интерфейса (за исключением критических ошибок, которые могут обнаружиться позднее блокируют выход стабильной версии).
4. Публикация версий (release phase) Наконец, наступает период публикации версий. В этом периоде выпускаются альфа, бета, RC -версии и стабильная версия системы.
В этой фазе усилия сосредоточены на исправлении критических ошибок и доведении их количества до нуля. После того, как количество критических ошибок будет доведено до нуля (или близко к нему), выходит RC-версия. После того, как все критические ошибки в RC-версиях будут исправлены и не будут появляться новые критические ошибки, будет выпущена финальная версия системы. Всё шумят, хлопают друг дружку по спине и потом мы снова переходим к разморозке кода.
Все эти периоды легко показать в виде воронки:
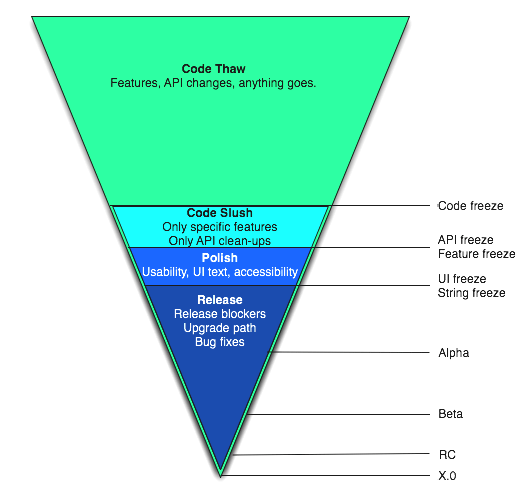
Здесь мы видим, что каждый период цикла получает всё меньшее и меньшее количество типов патчей и все изменения всё больше замыкаются на разработчиков ядра.
- В процессе разморозки кода, патчам API уделяется больше внимания, чем шлифовке кода и тексту интерфейса
- В процессе полировки, патчи шлифующие код и текст интерфейса получают полное внимание, а патчи изменяющие API не применяются
- В процессе публикации версий, мы концентрируем всё внимание на критических ошибках и других ошибках, которые нужно исправить до выхода стабильной версии. Патчи, которые делают полировку или исправляют некритические ошибки API переносятся в следующую основную версию системы и следующий цикл разморозки кода
Что такое изменение API
В общем смысле, изменение API означает всё, что затрагивает разработчиков модулей, тем или что-то, что связано с написанием документации к новой версии Друпала и что потребует её серьёзного переписывания. Изменение подписей функций или хуков; добавление и удаление функций и хуков; добавление, удаление и изменение функций тем; добавление, удаление и изменение файлов шаблонов или переменных шаблонов и так далее.
Как только объявляется заморозка кода, мы вносим только такие изменения в API, которые исправляют критические ошибки. Если есть способ исправить ошибку уровня «major» или «normal» без изменения API, мы идём на это, так же, как мы делаем это в стабильных версиях.
Что такое критическая ошибка
Критическая ошибка это что-то такое, что нарушает работу Друпала так сильно, что это затрагивает так много пользователей, что мы не можем использовать текущую версию без исправления этой ошибки. Посмотрите статью о приоритете уровней в сообщениях.
В общем виде, критические ошибки это:
- Ошибки связанные с обновлением
- Ошибки вызывающие потерю данных
- Ошибки создающие угрозу безопасности
- Ошибки, которые не дают закончить тест тест-ботам
- Нарушение поведения чего-либо, что работало в предыдущей версии
Окончательно, что является критическим, а что нет, решают разработчики ядра.
Здесь ещё можно привести очень длинный список вещей, которые не являются критическими:
- Неприятные проблемы, которые так же существуют и в предыдущих версиях. Если они не настолько плохи, чтобы блокировать выход предыдущих версий Друпала, то они не будут блокировать и выход следующих
- Крайние случаи, которые несмотря на свою ужасность, затрагивают небольшое количество пользователей
- DX -проблемы, которые не мешают использованию Друпала
- UX -проблемы, которые не мешают использованию Друпала
- TX -проблемы, которые не мешают использованию Друпала
What’s the harm in letting in API changes late?
There are consequences every time we deviate from the overall release plan:
- Takes time and focus away from critical, release-blocking issues: Since none of us are being paid to work on Drupal core, we need to allocate our attention and focus in the most efficient way. That generally means focusing on critical, release-blocking bugs first, everything else second.
- Sends a signal to all other core contributors that we’re still in «polish» phase: All of us have our own pet niggles with Drupal that we really wish were better than we were. Tweaking a theme function here. Adding a hook there. If the core maintainers send up the signal that these sorts of patches are still on the table, suddenly everyone wants to jump in and add their own pet project, too. Which means critical issues aren’t being looked at, and core maintainers need to divide their attention.
- Creates morale issues and dissent: The flip side of the above. When people perceive favouritism or special treatment (contributor X’s «polish phase» patches are getting committed during release phase while contributor Y’s were bumped to Drupal 8), it builds resentment and mistrust. It also builds this feeling when the vast majority of the team is working hard on the «core» issues leading directly to release, but there are other people off in the sidelines scratching their own itches.
- Makes the release cycle even longer: Each one of these patches are not something that happens for free. Each patch that goes into core needs to be read, evaluated, reviewed, tested, tweaked, tested again, given final look-over by a core maintainer, and finally committed. This is all time not being spent on the «core» issues that get the release out the door. Additionally, every time code changes, it opens up the possibility for follow-up issues, or at the very least re-rolls in other patches to fix tests or whatnot.
- Eliminates incentive to join with community at appropriate times: If we don’t ever end code thaw, and we don’t ever end polish phase, what on earth is the incentive for helping out during those times when we as a community really need people to rally? If we are changing APIs and the theme system months after we declared an API/markup freeze, what’s the incentive for porting modules and themes during code freeze? Much safer to wait until the next version actually ships, which inevitably leads to a major core release with 0 contributed module support, which isn’t good for anyone.
Will one little patch like this end the world? No, of course not. But it’s death by a thousand cuts. So core maintainers and major core contributors tend to give more and more pushback the later in the cycle major changes are introduced.
- 5980 просмотров