Перенос базы данных PostgreSQL с помощью дампа и ее восстановление
Базу данных PostgreSQL можно извлечь в файл дампа с помощью pg_dump. Затем необходимо использовать pg_restore для восстановления базы данных PostgreSQL из файла архива, созданного pg_dump .
Предварительные требования
Прежде чем приступить к выполнению этого руководства, необходимы следующие компоненты:
- Сервер базы данных Azure для PostgreSQL с правилами брандмауэра, разрешающими доступ к этом серверу.
- Установленные программы командной строки pg_dump и pg_restore.
Создание файла дампа, содержащего необходимые для загрузки данные
Чтобы создать резервную копию базы данных PostgreSQL локально или на виртуальной машине, выполните следующую команду:
pg_dump -Fc -v --host= --username= --dbname= -f .dump Например, если имеется локальный сервер с базой данных testdb, запустите на нем следующее:
pg_dump -Fc -v --host=localhost --username=masterlogin --dbname=testdb -f testdb.dump Восстановление данных в целевую базу данных
После создания целевой базы данных можно воспользоваться командой pg_restore с параметром —dbname , чтобы восстановить данные в целевую базу данных из файла дампа.
pg_restore -v --no-owner --host= --port= --username= --dbname= .dump При включении параметра —no-owner все объекты, созданные во время восстановления, будут присвоены пользователю, отмеченному —username . Дополнительные сведения см. в документации по PostgreSQL.
На серверах базы данных Azure для PostgreSQL соединения TLS и SSL включены по умолчанию. Если сервер PostgreSQL требует соединения TLS или SSL, но не содержит их, задайте переменную среды PGSSLMODE=require чтобы утилита pg_restore могла подключаться с помощью TLS. Без протокола TLS может появиться ошибка «FATAL: SSL connection is required. Please specify SSL options and retry.» (Критическая ошибка: необходимо соединение SSL. Настройте SSL и повторите попытку). В командной строке Windows выполните команду SET PGSSLMODE=require перед выполнением команды pg_restore . В Linux или Bash выполните команду export PGSSLMODE=require перед выполнением команды pg_restore .
В этом примере необходимо восстановить данные из файла дампа testdb.dump в базу данных mypgsqldb на целевом сервере mydemoserver.postgres.database.azure.com.
Ниже приведен пример использования этого pg_restore для одиночного сервера:
pg_restore -v --no-owner --host=mydemoserver.postgres.database.azure.com --port=5432 --username=mylogin@mydemoserver --dbname=mypgsqldb testdb.dump Ниже приведен пример использования этого pg_restore для гибкого сервера:
pg_restore -v --no-owner --host=mydemoserver.postgres.database.azure.com --port=5432 --username=mylogin --dbname=mypgsqldb testdb.dump Оптимизация процесса миграции
Один из способов миграции существующей базы данных PostgreSQL в службу баз данных Azure для PostgreSQL — это резервное копирование базы данных в источнике и ее восстановление в Azure. Чтобы свести к минимуму время, необходимое для завершения миграции, можно использовать следующие параметры с командами резервного копирования и восстановления.
Подробные сведения о синтаксисе см. в статьях о pg_dump и pg_restore.
Для резервного копирования
Создайте резервную копию с использованием параметра -Fc , чтобы можно было выполнять восстановление параллельно. Это позволит ускорить процесс. Пример:
pg_dump -h my-source-server-name -U source-server-username -Fc -d source-databasename -f Z:\Data\Backups\my-database-backup.dump Для восстановления
- Переместите файл резервной копии на виртуальную машину Azure в том же регионе, в котором находится сервер базы данных Azure для PostgreSQL, на который выполняется миграция. Выполните pg_restore из этой виртуальной машины, чтобы снизить задержку в сети. Создание виртуальной машины с ускоренной сетью.
- Откройте файл дампа, чтобы убедиться в том, что инструкции создания индекса находятся после вставки данных. Если это не так, переместите инструкции создания индекса после вставленных данных. Это должно быть сделано по умолчанию, но рекомендуется дополнительно проверить и подтвердить.
- Восстановление с помощью переключателя -j N (где N представляет число) для параллелизации восстановления. Указанное вами число — это количество ядер на целевом сервере. Вы также можете попробовать установить вдвое большее количество ядер целевого сервера, чтобы оценить нагрузку. Ниже приведен пример использования этого pg_restore для одиночного сервера:
pg_restore -h my-target-server.postgres.database.azure.com -U azure-postgres-username@my-target-server -j 4 -d my-target-databasename Z:\Data\Backups\my-database-backup.dump
Ниже приведен пример использования этого pg_restore для гибкого сервера:
pg_restore -h my-target-server.postgres.database.azure.com -U azure-postgres-username -j 4 -d my-target-databasename Z:\Data\Backups\my-database-backup.dump
- Отключите отслеживание производительности запросов. Эти статистические данные не требуются во время миграции. Это можно сделать, установив для параметров pg_stat_statements.track , pg_qs.query_capture_mode и pgms_wait_sampling.query_capture_mode значение NONE .
- Используйте SKU с высоким объемом ресурсов вычисления и памяти, например модель 32 vCore Memory Optimized (32 виртуальных ядра с оптимизацией для операций в памяти), чтобы ускорить миграцию. Вы можете легко вернуться к предпочитаемому SKU после завершения восстановления. Чем выше номер SKU, тем большего параллелизма можно достичь, увеличив значение соответствующего параметра -j в команде pg_restore .
- Увеличьте число операций ввода-вывода в секунду на целевом сервере — это может улучшить производительность восстановления. Вы можете подготовить больше операций ввода-вывода в секунду, увеличив объем хранилища на сервере. Этот параметр необратим, но стоит принять во внимание, будет ли большее количество операций ввода-вывода в секунду полезным для вашей рабочей нагрузки в будущем.
Не забудьте проверить и протестировать эти команды в тестовой среде, прежде чем использовать их в рабочей среде.
Дальнейшие действия
- Узнать больше о миграции базы данных PostgreSQL с помощью метода экспорта и импорта можно в статье Миграция базы данных PostgreSQL с помощью метода экспорта и импорта.
- Дополнительные сведения о переносе баз данных в службу «База данных Azure для PostgreSQL» см. в этой статье.
Как сделать дамп базы данных postgresql
Идея, стоящая за этим методом, заключается в генерации текстового файла с командами SQL, которые при выполнении на сервере пересоздадут базу данных в том же самом состоянии, в котором она была на момент выгрузки. Postgres Pro предоставляет для этой цели вспомогательную программу pg_dump . Простейшее применение этой программы выглядит так:
pg_dumpимя_базы>файл_дампа
Как видите, pg_dump записывает результаты своей работы в устройство стандартного вывода. Далее будет рассмотрено, чем это может быть полезно. В то время как вышеупомянутая команда создаёт текстовый файл, pg_dump может создать файлы и в других форматах, которые допускают параллельную обработку и более гибкое управление восстановлением объектов.
Программа pg_dump является для Postgres Pro обычным клиентским приложением (хотя и весьма умным). Это означает, что вы можете выполнять процедуру резервного копирования с любого удалённого компьютера, если имеете доступ к нужной базе данных. Но помните, что pg_dump не использует для своей работы какие-то специальные привилегии. В частности, ей обычно требуется доступ на чтение всех таблиц, которые вы хотите выгрузить, так что для копирования всей базы данных практически всегда её нужно запускать с правами суперпользователя СУБД. (Если у вас нет достаточных прав для резервного копирования всей базы данных, вы тем не менее можете сделать резервную копию той части базы, доступ к которой у вас есть, используя такие параметры, как -n схема или -t таблица .)
Указать, к какому серверу должна подключаться программа pg_dump , можно с помощью аргументов командной строки -h сервер и -p порт . По умолчанию в качестве сервера выбирается localhost или значение, указанное в переменной окружения PGHOST . Подобным образом, по умолчанию используется порт, заданный в переменной окружения PGPORT , а если она не задана, то порт, указанный по умолчанию при компиляции. (Для удобства при компиляции сервера обычно устанавливается то же значение по умолчанию.)
Как и любое другое клиентское приложение Postgres Pro , pg_dump по умолчанию будет подключаться к базе данных с именем пользователя, совпадающим с именем текущего пользователя операционной системы. Чтобы переопределить имя, либо добавьте параметр -U , либо установите переменную окружения PGUSER . Помните, что pg_dump подключается к серверу через обычные механизмы проверки подлинности клиента (которые описываются в Главе 19).
Важное преимущество pg_dump в сравнении с другими методами резервного копирования, описанными далее, состоит в том, что вывод pg_dump обычно можно загрузить в более новые версии Postgres Pro , в то время как резервная копия на уровне файловой системы и непрерывное архивирование жёстко зависят от версии сервера. Также, только метод с применением pg_dump будет работать при переносе базы данных на другую машинную архитектуру, например, при переносе с 32-битной на 64-битную версию сервера.
Дампы, создаваемые pg_dump , являются внутренне согласованными, то есть, дамп представляет собой снимок базы данных на момент начала запуска pg_dump . pg_dump не блокирует другие операции с базой данных во время своей работы. (Исключение составляют операции, которым нужна исключительная блокировка, как например, большинство форм команды ALTER TABLE .)
24.1.1. Восстановление дампа
Текстовые файлы, созданные pg_dump , предназначаются для последующего чтения программой psql . Общий вид команды для восстановления дампа:
psqlимя_базы<файл_дампа
где файл_дампа — это файл, содержащий вывод команды pg_dump . База данных, заданная параметром имя_базы , не будет создана данной командой, так что вы должны создать её сами из базы template0 перед запуском psql (например, с помощью команды createdb -T template0 имя_базы ). Программа psql принимает параметры, указывающие сервер, к которому осуществляется подключение, и имя пользователя, подобно pg_dump . За дополнительными сведениями обратитесь к справке по psql . Дампы, выгруженные не в текстовом формате, восстанавливаются утилитой pg_restore .
Перед восстановлением SQL-дампа все пользователи, которые владели объектами или имели права на объекты в выгруженной базе данных, должны уже существовать. Если их нет, при восстановлении будут ошибки пересоздания объектов с изначальными владельцами и/или правами. (Иногда это желаемый результат, но обычно нет).
По умолчанию, если происходит ошибка SQL, программа psql продолжает выполнение. Если же запустить psql с установленной переменной ON_ERROR_STOP , это поведение поменяется и psql завершится с кодом 3 в случае возникновения ошибки SQL:
psql --set ON_ERROR_STOP=onимя_базы<файл_дампа
В любом случае вы получите только частично восстановленную базу данных. В качестве альтернативы можно указать, что весь дамп должен быть восстановлен в одной транзакции, так что восстановление либо полностью выполнится, либо полностью отменится. Включить данный режим можно, передав psql аргумент -1 или —single-transaction . Выбирая этот режим, учтите, что даже незначительная ошибка может привести к откату восстановления, которое могло продолжаться несколько часов. Однако это всё же может быть предпочтительней, чем вручную вычищать сложную базу данных после частично восстановленного дампа.
Благодаря способности pg_dump и psql писать и читать каналы ввода/вывода, можно скопировать базу данных непосредственно с одного сервера на другой, например:
pg_dump -hhost1имя_базы| psql -hhost2имя_базы
Важно
Дампы, которые выдаёт pg_dump , содержат определения относительно template0 . Это означает, что любые языки, процедуры и т. п., добавленные в базу через template1 , pg_dump также выгрузит в дамп. Как следствие, если при восстановлении вы используете модифицированный template1 , вы должны создать пустую базу данных из template0 , как показано в примере выше.
После восстановления резервной копии имеет смысл запустить ANALYZE для каждой базы данных, чтобы оптимизатор запросов получил полезную статистику; за подробностями обратитесь к Подразделу 23.1.3 и Подразделу 23.1.6. Другие советы по эффективной загрузке больших объёмов данных в Postgres Pro вы можете найти в Разделе 14.4.
24.1.2. Использование pg_dumpall
Программа pg_dump выгружает только одну базу данных в один момент времени и не включает в дамп информацию о ролях и табличных пространствах (так как это информация уровня кластера, а не самой базы данных). Для удобства создания дампа всего содержимого кластера баз данных предоставляется программа pg_dumpall , которая делает резервную копию всех баз данных кластера, а также сохраняет данные уровня кластера, такие как роли и определения табличных пространств. Простое использование этой команды:
pg_dumpall > файл_дампа
Полученную копию можно восстановить с помощью psql :
psql -f файл_дампа postgres
(В принципе, здесь в качестве начальной базы данных можно указать имя любой существующей базы, но если вы загружаете дамп в пустой кластер, обычно нужно использовать postgres ). Восстанавливать дамп, который выдала pg_dumpall , всегда необходимо с правами суперпользователя, так как они требуются для восстановления информации о ролях и табличных пространствах. Если вы используете табличные пространства, убедитесь, что пути к табличным пространствам в дампе соответствуют новой среде.
pg_dumpall выдаёт команды, которые заново создают роли, табличные пространства и пустые базы данных, а затем вызывает для каждой базы pg_dump . Таким образом, хотя каждая база данных будет внутренне согласованной, состояние разных баз не будет синхронным.
Только глобальные данные кластера можно выгрузить, передав pg_dumpall ключ —globals-only . Это необходимо, чтобы полностью скопировать кластер, когда pg_dump выполняется для отдельных баз данных.
24.1.3. Управление большими базами данных
Некоторые операционные системы накладывают ограничение на максимальный размер файла, что приводит к проблемам при создании больших файлов с помощью pg_dump . К счастью, pg_dump может писать в стандартный вывод, так что вы можете использовать стандартные инструменты Unix для того, чтобы избежать потенциальных проблем. Вот несколько возможных методов:
Используйте сжатые дампы. Вы можете использовать предпочитаемую программу сжатия, например gzip :
pg_dumpимя_базы| gzip >имя_файла.gz
Затем загрузить сжатый дамп можно командой:
gunzip -cимя_файла.gz | psqlимя_базы
catимя_файла.gz | gunzip | psqlимя_базы
Используйте split . Команда split может разбивать выводимые данные на небольшие файлы, размер которых удовлетворяет ограничению нижележащей файловой системы. Например, чтобы получить части по 2 гигабайта:
pg_dumpимя_базы| split -b 2G -имя_файла
Восстановить их можно так:
catимя_файла* | psqlимя_базы
Использовать GNU split можно вместе с gzip :
pg_dump имя_базы | split -b 2G --filter='gzip > $FILE.gz'
Восстановить данные после такого разбиения можно с помощью команды zcat .
Используйте специальный формат дампа pg_dump . Если при сборке Postgres Pro была подключена библиотека zlib , дамп в специальном формате будет записываться в файл в сжатом виде. В таком формате размер файла дампа будет близок к размеру, полученному с применением gzip , но он лучше тем, что позволяет восстанавливать таблицы выборочно. Следующая команда выгружает базу данных в специальном формате:
pg_dump -Fcимя_базы>имя_файла
Дамп в специальном формате не является скриптом для psql и должен восстанавливаться с помощью команды pg_restore , например:
pg_restore -dимя_базыимя_файла
За подробностями обратитесь к справке по командам pg_dump и pg_restore .
Для очень больших баз данных может понадобиться сочетать split с одним из двух других методов.
Используйте возможность параллельной выгрузки в pg_dump . Чтобы ускорить выгрузку большой БД, вы можете использовать режим параллельной выгрузки в pg_dump . При этом одновременно будут выгружаться несколько таблиц. Управлять числом параллельных заданий позволяет параметр -j . Параллельная выгрузка поддерживается только для формата архива в каталоге.
pg_dump -jчисло-F d -fвыходной_каталогимя_базы
Вы также можете восстановить копию в параллельном режиме с помощью pg_restore -j . Это поддерживается для любого архива в формате каталога или специальном формате, даже если архив создавался не командой pg_dump -j .
| Пред. | Наверх | След. |
| Глава 24. Резервное копирование и восстановление | Начало | 24.2. Резервное копирование на уровне файлов |
Создание и импорт дампа БД PostgreSQL
Для создания дампа БД PostgreSQL следует использовать в консоли SSH команду следующего вида:
pg_dump -h hostname -U username -F format -f dumpfile dbname
- hostname — имя сервера БД;
- username — имя пользователя БД (совпадает с именем базы данных);
- format — формат дампа (может быть одной из трех букв: ‘с’ (custom — архив .tar.gz), ‘t’ (tar — tar-файл), ‘p’ (plain — текстовый файл). В команде букву надо указывать без кавычек.);
- dumpfile — имя создаваемого файла дампа;
- dbname — имя базы данных.
Для баз созданных до 16.09.2019 имя хоста будет выглядеть так: pg.sweb.ru; для баз данных, которые были созданы после 16.09.2019 имя хоста будет таким: pg2.sweb.ru. Для баз данных созданных после 24.04.2023 имя хоста будет таким: pg3.sweb.ru
После завершения задачи файл с именем dumpfile будет размещен в директории, из которой запускалась команда.
Пример создания дампа базы vh36sup в файл архива формата postgress. где custom — архив, в формате самого postgress:
pg_dump -h pg2.sweb.ru -U vh36sup -F c -f dump.tar.gz vhsup
Импорт дампа БД PostgreSQL
Для импорта необходимо использовать команду вида:
pg_restore -h hostname -U username -F format -d dbname dumpfile
Параметры аналогичные, за исключением того, что format может быть либо ‘c’, либо ‘t’.
Пример загрузки архива дампа dump.tar.gz в базу vhsup:
pg_restore -h pg2.sweb.ru -U vhsup -F c -d vhsup dump.tar.gz
Дампы представленные в виде текстового файла можно импортировать с помощью следующей команды:
cat dumpfile | psql -h hostname -U username dbname
Резервное копирование и восстановление PostgreSQL: pg_dump, pg_restore, wal-g
В этой статье мы разберем возможности встроенных и внешних инструментов PostgreSQL для резервного копирования логической схемы и данных.
Эта инструкция — часть курса «PostgreSQL для новичков».
Смотреть весь курс
Задача резервного копирования — одна из основных при сопровождении и поддержке PostgreSQL. Для резервного копирования логической схемы и данных можно использовать как встроенные инструменты СУБД, так и внешние. В этой статье мы разберем оба варианта.
Для начала подготовим сервер. Для демо-стенда закажем виртуальный сервер в Облачной платформе. Для этого откроем панель управления my.selectel.ru, перейдем в меню Облачная платформа и нажмем на кнопку Создать сервер.
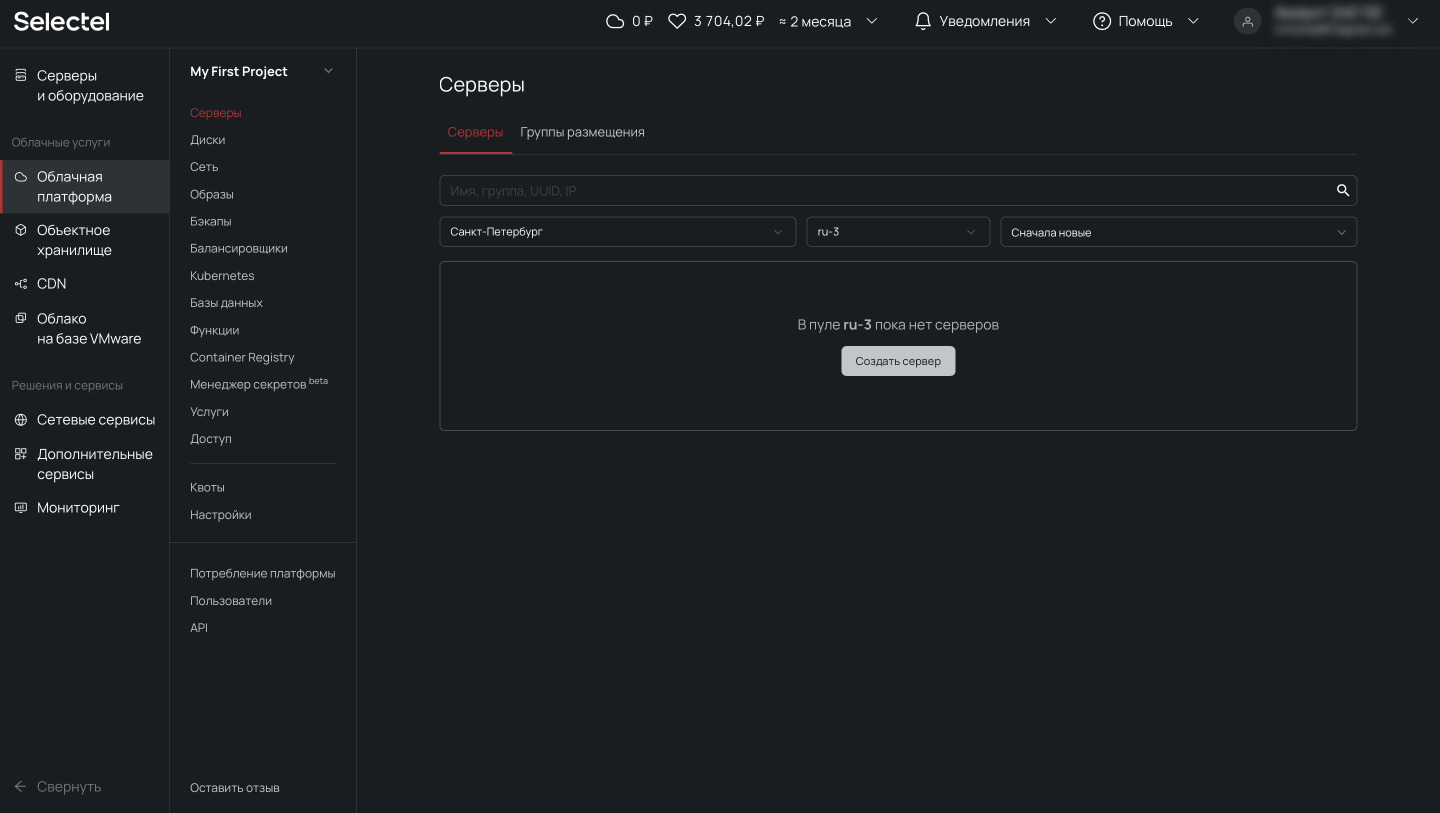
В статье будем использовать виртуальный сервер с конфигурацией 2 vCPU, 4 ГБ RAM и 10 ГБ HDD с операционной системой CentOS 8 Stream 64-bit.
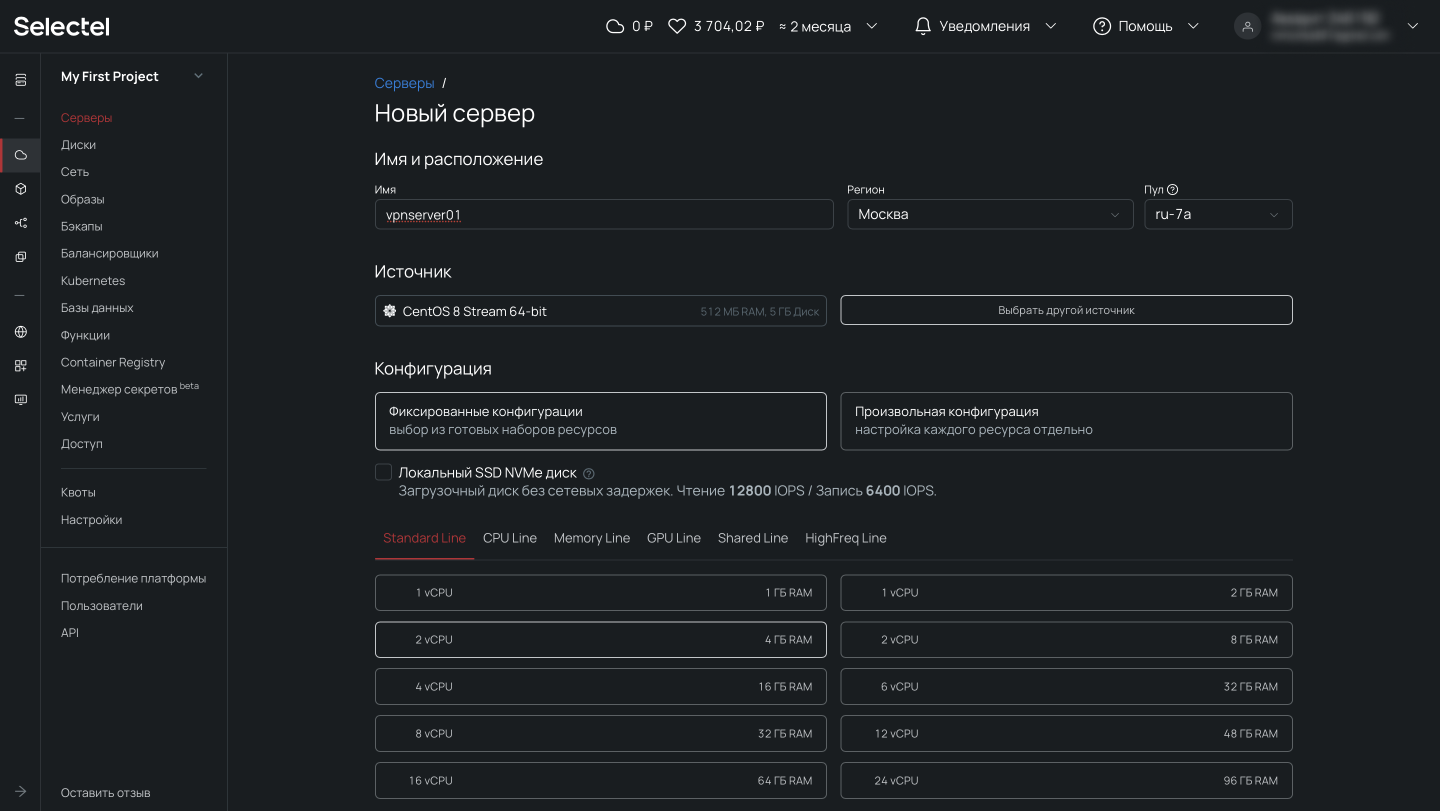
Теперь прокрутим представление ниже, где находятся настройки сети. Важно, чтобы у сервера был внешний плавающий IP-адрес для доступа извне.
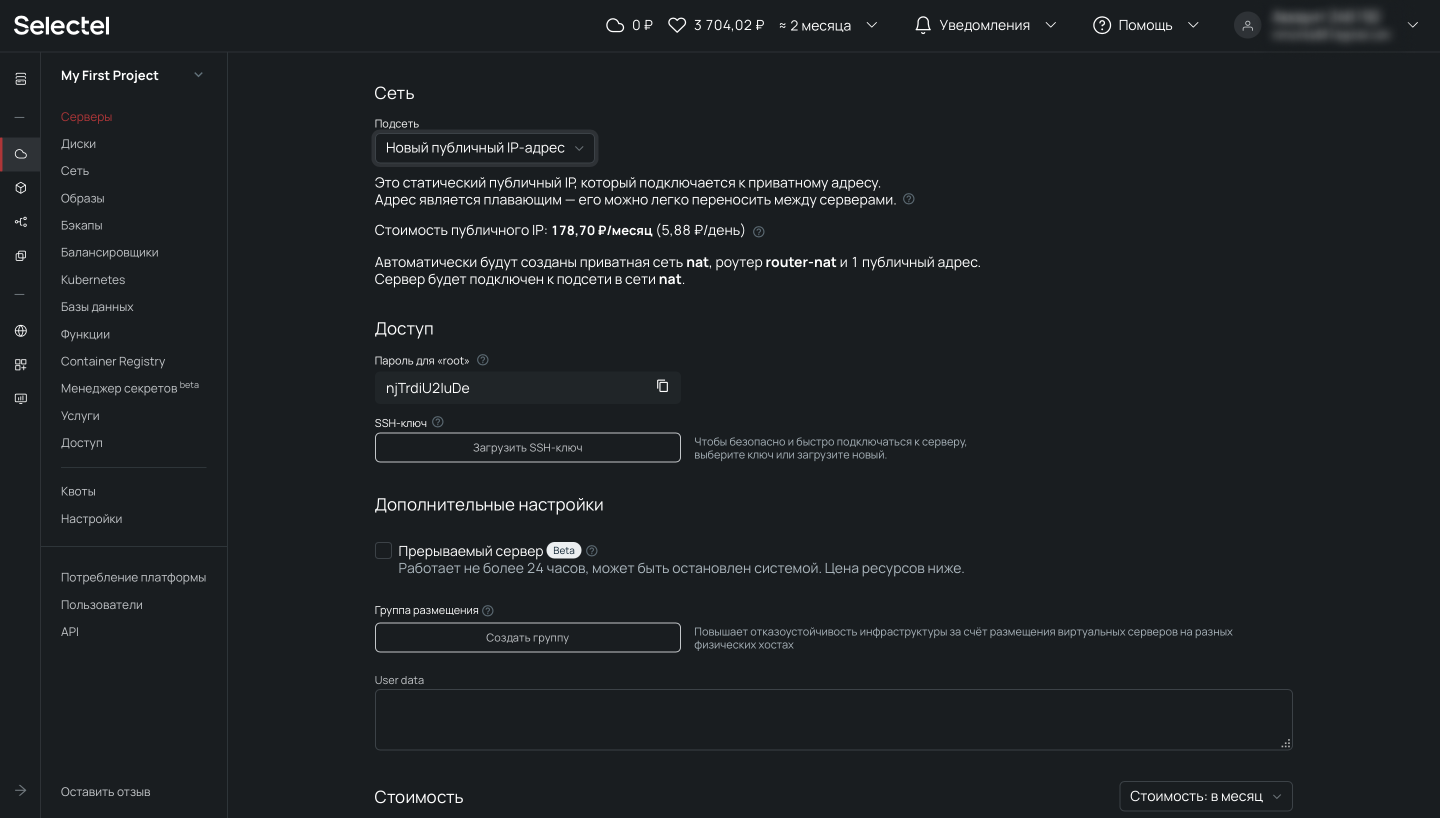
После выбора операционной системы, конфигурации сервера и выполнения сетевых настроек переходим к завершению заказа и нажимаем на кнопку Создать. Через несколько минут сервер будет готов.
Перед началом демонстрации возможностей резервного копирования, мы подготовили PostgreSQL. Для целей наполнения базы данных и создания непрерывного потока записи, развернули там Zabbix (некоторое время назад публиковали о нем статью).
Облачные базы данных Selectel
Доверьте нам развертывание и администрирование баз данных в облаке.
Создание резервных копий и восстановление из командной строки
В этом разделе мы расскажем как сделать дамп базы данных PostgreSQL в консоли при подключении по SSH, разберем синтаксис и покажем примеры использования утилит pg_dump, pg_dumpall, pg_restore, pg_basebackup и wal-g.
Утилита pg_dump
В PostgreSQL есть встроенный инструмент для создания резервных копий — утилита pg_dump. Утилита имеет простой синтаксис:
# pg_dump >
В простейшем случае достаточно указать имя базы данных, которую в дальнейшем нужно будет восстановить. Резервная копия создается следующей командой:
# pg_dump zabbix > /tmp/zabbix.dumpЕсли требуется авторизация под определенным пользователем, можно воспользоваться ключом -U:
# pg_dump -U zabbix -W zabbix > /tmp/zabbix.dump # pg dump u postgresКлюч -U определяет пользователя, а -W обязывает ввести пароль.
Чтобы сэкономить место на диске, можно сразу же сжимать дамп:
# pg_dump -U zabbix -W zabbix | gzip > /tmp/zabbix.gzРезервное копирование обычно выполняется по расписанию, например, ежедневно в 3 часа ночи. Нижеприведенный пример скрипта не только выполняет бэкап, но и удаляет все файлы старше 61 дня (за исключением 15-го числа месяца).
#!/bin/sh PATH=/etc:/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin PGPASSWORD=some_password export PGPASSWORD pathB=/mnt/backup dbUser=dbadmin database=zabbix find $pathB \( -name "*-1[^5].*" -o -name "*-[023]?.*" \) -ctime +61 -delete pg_dump -U $dbUser $database | gzip > $pathB/pgsql_$(date "+%Y-%m-%d").sql.gz unset PGPASSWORDЧтобы настроить регулярное выполнение, выполним следующую команду в планировщике crontab:
# crontab -e 3 0 * * * /etc/scripts/pgsql_dump.sh # postgres pg dumpЧтобы выполнить аналогичную команду на удаленном сервере, достаточно добавить ключ -h:
# pg_dump -h 192.168.56.101 zabbix > /tmp/zabbix.dumpКлюч -t задает таблицу, для которой нужно создать резервную копию:
# pg_dump -t history zabbix > /tmp/zabbix.dump # postgres dump tableПри помощи специальных ключей можно создавать резервные копии структуры данных или непосредственно данных:
# pg_dump --schema-only zabbix > /tmp/zabbix.dump # pg_dump --data-only zabbix > /tmp/zabbix.dumpУ утилиты pg_dump также есть ключи для сохранения дампа в другие форматы. Чтобы сохранить копию в виде бинарного файла используются ключи -Fc:
# pg_dump -Fc zabbix > /tmp/zabbix.bakЧтобы создать архив — -Ft:
# pg_dump -Ft zabbix > /tmp/zabbix.tarЧтобы сохранить в directory-формате — -Fd:
# pg_dump -Fd zabbix > /tmp/zabbix.dirРезервное копирование в виде каталогов позволяет выполнять процесс в многопоточном режиме.
Ниже мы перечислим возможные параметры утилиты pg_dump.
-d , —dbname=имя_бд — база данных, к которой выполняется подключение.
-h , —host=сервер — имя сервера.
-p , —port=порт — порт для подключения.
-U , —username=пользователь) — учетная запись, используемое для подключения.
-w, —no-password — деактивация требования ввода пароля.
-W, —password — активация требования ввода пароля.
—role=имя роли — роль, от имени которой генерируется резервная копия.
-a, —data-only — вывод только данных, вместо схемы объектов (DDL).
-b, —blobs — параметр добавляет в выгрузку большие объекты.
-c, —clean — добавление команд DROP перед командами CREATE в файл резервной копии.
-C, —create — генерация реквизитов для подключения к базе данных в файле резервной копии.
-E , —encoding=кодировка — определение кодировки резервной копии.
-f , —file=файл — задает имя файла, в который будет сохраняться вывод утилиты.
-F , —format=формат — параметр определяет формат резервной копии. Доступные форматы:
- p, plain) — формирует текстовый SQL-скрипт;
- c, custom) — формирует резервную копию в архивном формате;
- d, directory) — формирует копию в directory-формате;
- t, tar) — формирует копию в формате tar.
-j , —jobs=число_заданий — параметр активирует параллельную выгрузку для одновременной обработки нескольких таблиц (равной числу заданий). Работает только при выгрузке копии в формате directory.
-n , —schema=схема — выгрузка в файл копии только определенной схемы.
-N , —exclude-schema=схема — исключение из выгрузки определенных схем.
-o, —oids — добавляет в выгрузку идентификаторы объектов (OIDs) вместе с данными таблиц.
-O, —no-owner — деактивация создания команд, определяющих владельцев объектов в базе данных.
-s, —schema-only —добавление в выгрузку только схемы данных, без самих данных.
-S , —superuser=пользователь — учетная запись привилегированного пользователя, которая должна использоваться для отключения триггеров.
-t , —table=таблица — активация выгрузки определенной таблицы.
-T , —exclude-table=таблица —исключение из выгрузки определенной таблицы.
-v, —verbose — режим подробного логирования.
-V, —version — вывод версии pg_dump.
-Z 0..9, —compress=0..9 — установка уровня сжатия данных. 0 — сжатие выключено.
Утилита pg_dumpall
Утилита pg_dumpall реализует резервное копирование всего экземпляра (кластера или инстанса) базы данных без указания конкретной базы данных на инстансе. По принципу схожа с pg_dump. Добавим, что только утилиты pg_dump и pg_dumpall предоставляют возможность создания логической копии данных, остальные утилиты, рассматриваемые в этой статье, позволяют создавать только бинарные копии.
# pg_dumpall > /tmp/instance.bakЧтобы сразу сжать резервную копию экземпляра базы данных, нужно передать вывод на архиватор gzip:
# pg_dumpall | gzip > /tmp/instance.tar.gzНиже приведены параметры, с которыми может вызываться утилита pg_dumpall.
-d , —dbname=имя_бд — имя базы данных.
-h , —host=сервер — имя сервера.
-p , —port=порт — TCP-порт, на который принимаются подключения.
-U , —username=пользователь — имя пользователя для подключения.
-w, —no-password — деактивация требования ввода пароля.
-W, —password — активация требования ввода пароля.
—role= — роль, от имени которой генерируется резервная копия.
-a, —data-only — создание резервной копии без схемы данных.
-c, —clean — добавление операторов DROP перед операторами CREATE.
-f , —file=имя_файла — активация направления вывода в указанный файл.
-g, —globals-only — выгрузка глобальных объектов без баз данных.
-o, —oids — выгрузка идентификаторов объектов (OIDs) вместе с данными таблиц.
-O, —no-owner — деактивация генерации команд, устанавливающих принадлежность объектов, как в исходной базе данных.
-r, —roles-only — выгрузка только ролей без баз данных и табличных пространств.
-s, —schema-only — выгрузка только схемы без самих данных.
-S , —superuser=имя_пользователя — привилегированный пользователь, используемый для отключения триггеров.
-t, —tablespaces-only — выгрузка табличных пространства без баз данных и ролей.
-v, —verbose — режим подробного логирования.
-V (—version — вывод версии утилиты pg_dumpall.
Утилита pg_restore
Утилита позволяет восстанавливать данные из резервных копий. Например, чтобы восстановить только определенную БД (в нашем примере zabbix), нужно запустить эту утилиту с параметром -d:
# pg_restore -d zabbix /tmp/zabbix.bakЧтобы этой же утилитой восстановить определенную таблицу, нужно использовать ее с параметром -t:
# pg_restore -a -t history /tmp/zabbix.bakТакже утилитой pg_restore можно восстановить данные из бинарного или архивного файла. Соответственно:
# pg_restore -Fc zabbix.bak # pg_restore -Ft zabbix.tarПри восстановлении можно одновременно создать новую базу:
# pg_restore -Ft -С zabbix.tarВосстановить данные из дампа также возможно при помощи psql:
# psql zabbix < /tmp/zabbix.dumpЕсли для подключения нужно авторизоваться, вводим следующую команду:
# psql -U zabbix -W zabbix < /tmp/zabbix.dumpНиже приведен синтаксис утилиты pg_restore.
-h , —host=сервер — имя сервера, на котором работает база данных.
-p , —port=порт — TCP-порт, через база данных принимает подключения.
-U , —username=пользователь — имя пользователя для подключения..
-w, —no-password — деактивация требования ввода пароля.
-W, —password — активация требования ввода пароля.
—role=имя роли — роль, от имени которой выполняется восстановление резервная копия.
— расположение восстанавливаемых данных.
-a, —data-only — восстановление данных без схемы.
-c, —clean — добавление операторов DROP перед операторами CREATE.
-C, —create — создание базы данных перед запуском процесса восстановления.
-d , —dbname=имя_бд — имя целевой базы данных.
-e, —exit-on-error — завершение работы в случае возникновения ошибки при выполнении SQL-команд.
-f , —file=имя_файла — файл для вывода сгенерированного скрипта.
-F , —format=формат — формат резервной копии. Допустимые форматы:
- p, plain — формирует текстовый SQL-скрипт;
- c, custom — формирует резервную копию в архивном формате;
- d, directory — формирует копию в directory-формате;
- t, tar — формирует копию в формате tar.
-I , —index=индекс — восстановление только заданного индекса.
-j , —jobs=число-заданий — запуск самых длительных операций в нескольких параллельных потоках.
-l, —list) — активация вывода содержимого архива.
-L , —use-list=файл-список — восстановление из архива элементов, перечисленных в файле-списке в соответствующем порядке.
-n , —schema=схема — восстановление объектов в указанной схеме.
-O, —no-owner — деактивация генерации команд, устанавливающих владение объектами по образцу исходной базы данных.
-P <имя-функции(тип-аргумента[, …])>, —function=имя-функции(тип-аргумента[, …]) — восстановление только указанной функции.
-s, —schema-only — восстановление только схемы без самих данных.
-S , —superuser=пользователь — учетная запись привилегированного пользователя, используемая для отключения триггеров.
-t , —table=таблица — восстановление определенной таблицы.
-T , —trigger=триггер — восстановление конкретного триггера.
-v, —verbose — режим подробного логирования.
-V, —version — вывод версии утилиты pg_restore.
Утилита pg_basebackup
Утилитой pg_basebackup можно выполнять резервное копирования работающего кластера баз данных PostgreSQL. Результирующий бинарный файл можно использовать для репликации или восстановления на определенный момент в прошлом. Утилита создает резервную копию всего экземпляра базы данных и не дает возможности создавать слепки данных отдельных сущностей. Подключение pg_basebackup к PostgreSQL выполняется при помощи протокола репликации с полномочиями суперпользователя или с правом REPLICATION.
Для выполнения резервного копирования локальной базы данных достаточно передать утилите pg_basebackup параметр -D, обозначающий директорию, в которой будет сохранена резервная копия:
# pg_basebackup -D /tmpЧтобы создать сжатые файлы из табличных пространств, добавим параметры -Ft и -z:
# pg_basebackup -D /tmp -Ft -z То же самое, но со сжатием bzip2 и для экземпляра базы с общим табличным пространством:
# pg_basebackup -D /tmp -Ft | bzip2 > backup.tar.bz2Ниже приведен синтаксис утилиты pg_basebackup.
-d , —dbname=строка_подключения — определение базы данных в виде строки для подключения.
-h , —host=сервер — имя сервера с базой данных.
-p , —port=порт — TCP-порт, через база данных принимает подключения.
-s , —status-interval=интервал — количество секунд между отправками статусных пакетов.
-U , —username=пользователь — установка имени пользователя для подключения.
-w, —no-password — отключение запроса на ввод пароля.
-W, —password — принудительный запрос пароля.
-V, —version — вывод версии утилиты pg_basebackup.
-?, —help — вывод справки по утилите pg_basebackup.
-D каталог, —pgdata=каталог — директория записи данных.
-F , —format=формат — формат вывода. Допустимые варианты:
- p, plain — значение для записи выводимых данных в текстовые файлы;
- t, tar — значение, указывающее на необходимость записи в целевую директорию в формате tar.
-r , —max-rate=скорость_передачи — предельная скорость передачи данных в Кб/с.
-R, —write-recovery-conf — записать минимальный файл recovery.conf в директорию вывода.
-S , —slot=имя_слота — задание слота репликации при использовании WAL в режиме потоковой передачи.
-T , —tablespace-mapping=каталог_1=каталог_2 — активация миграции табличного пространства из одного каталога в другой каталог при копировании.
—xlogdir=каталог_xlog — директория хранения журналов транзакций.
-X , —xlog-method=метод — активация вывода файлов журналов транзакций WAL в резервную копию на основе следующих методов:
- f, fetch — включение режима сбора файлов журналов транзакций при окончании процесса копирования;
- s, stream — включение передачи журнала транзакций в процессе создания резервной копии.
-z, —gzip — активация gzip-сжатия результирующего tar-файла.
-Z , —compress=уровень — определение уровня сжатия механизмом gzip.
-c , —checkpoint=fast|spread — активация режима реперных точек.
-l , —label=метка — установка метки резервной копии.
-P, —progress — активация в вывод отчета о прогрессе.
-v, —verbose — режим подробного логирования.
Утилита wal-g
Wal-g — утилита для резервного копирования и восстановления базы данных PostgreSQL. При помощи wal-g можно выполнять сохранение резервных копий на хранилищах S3 или просто на файловой системе. Ниже мы разберем установку, настройку и работу с утилитой. Покажем как выполнить резервное копирование в Объектное хранилище S3 от Selectel.
Создадим пользователя для облачного хранилища, учетные данные которого будем потом использовать для сохранения резервной копии. Перейдем в меню Пользователи и нажмем кнопку Создать пользователя:
Дополнительную информацию можно получить в нашей Базе знаний. Первую часть логина изменить нельзя — это идентификатор пользователя в панели управления. Вторая часть логина задается произвольно. Например, 123456_wal-g:
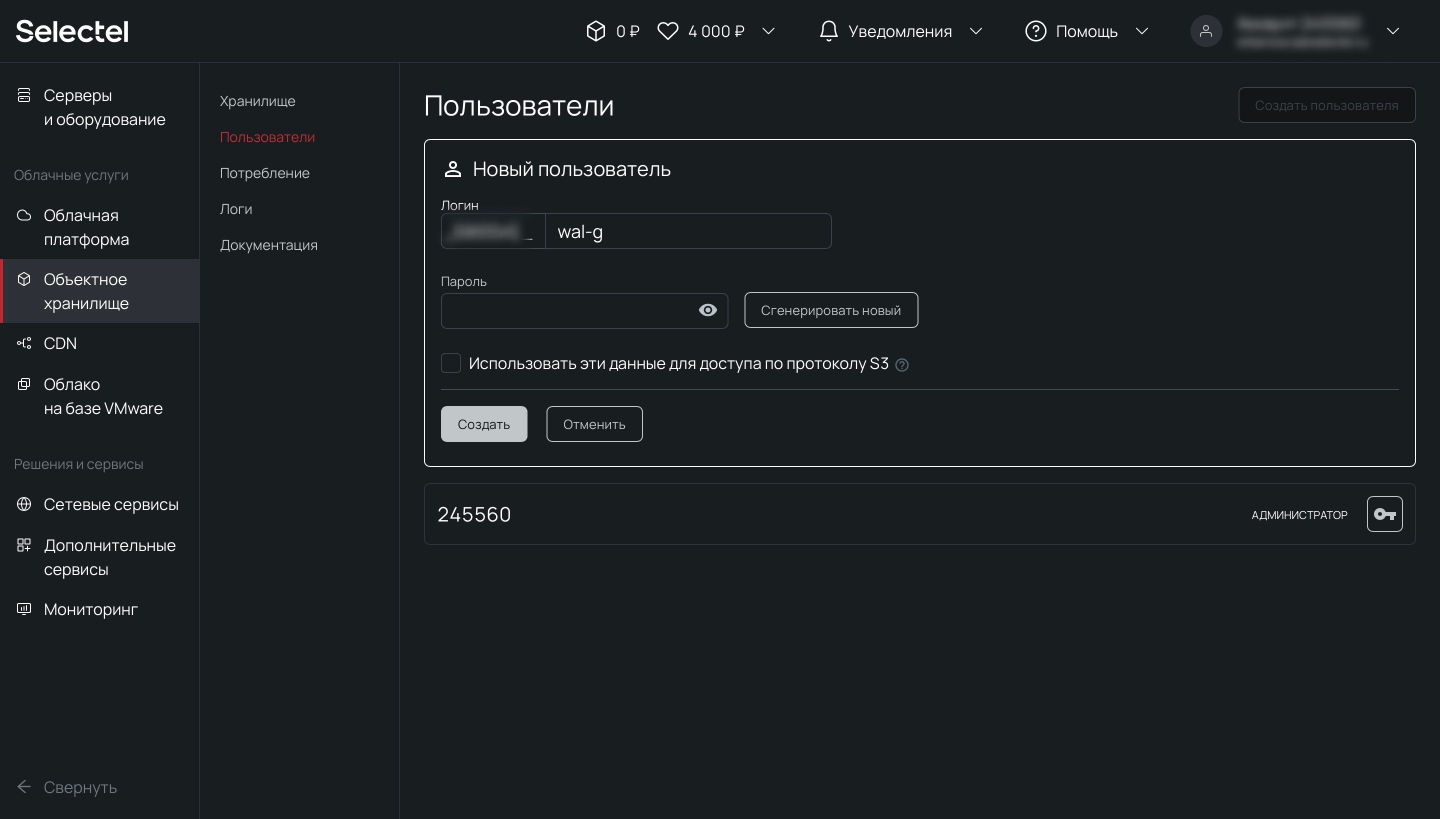
Теперь перейдем к установке wal-g. Скачаем готовый установочный пакет из репозитория на github.com, распакуем и скопируем папку содержающую исполняемые файлы:
# cd /tmp # curl -L "https://github.com/wal-g/wal-g/releases/download/v0.2.19/wal-g.linux-amd64.tar.gz" -o "wal-g.linux-amd64.tar.gz # tar -xzf wal-g.linux-amd64.tar.gz # mv wal-g /usr/local/bin/Заполним конфигурационный файл wal-g и изменим его владельца на учетную запись postgres:
# cat > /var/lib/pgsql/.walg.json EOF # chown postgres: /var/lib/pgsql/.walg.jsonДалее настроим автоматизированное создание резервных копий в PostgreSQL и перезагрузим процессы базы данных:
# echo "wal_level=replica" >> /var/lib/pgsql/data/postgresql.conf # echo "archive_mode=on" >> /var/lib/pgsql/data/postgresql.conf # echo "archive_command='/usr/local/bin/wal-g wal-push \"%p\" >> /var/log/postgresql/archive_command.log 2>&1' " >> /var/lib/pgsql/data/postgresql.conf # echo “archive_timeout=60” >> /var/lib/pgsql/data/postgresql.conf # echo "restore_command='/usr/local/bin/wal-g wal-fetch \"%f\" \"%p\" >> /var/log/postgresql/restore_command.log 2>&1' " >> /var/lib/pgsql/data/postgresql.conf # killall -s HUP postgresТеперь проверим корректность проведения настроек и загрузим резервную копию в хранилище:
# su - postgres -c '/usr/local/bin/wal-g backup-push /var/lib/pgsql/data'После выполнения процесса резервного копирования, в созданном контейнере появится директория с резервными копиями баз данных:
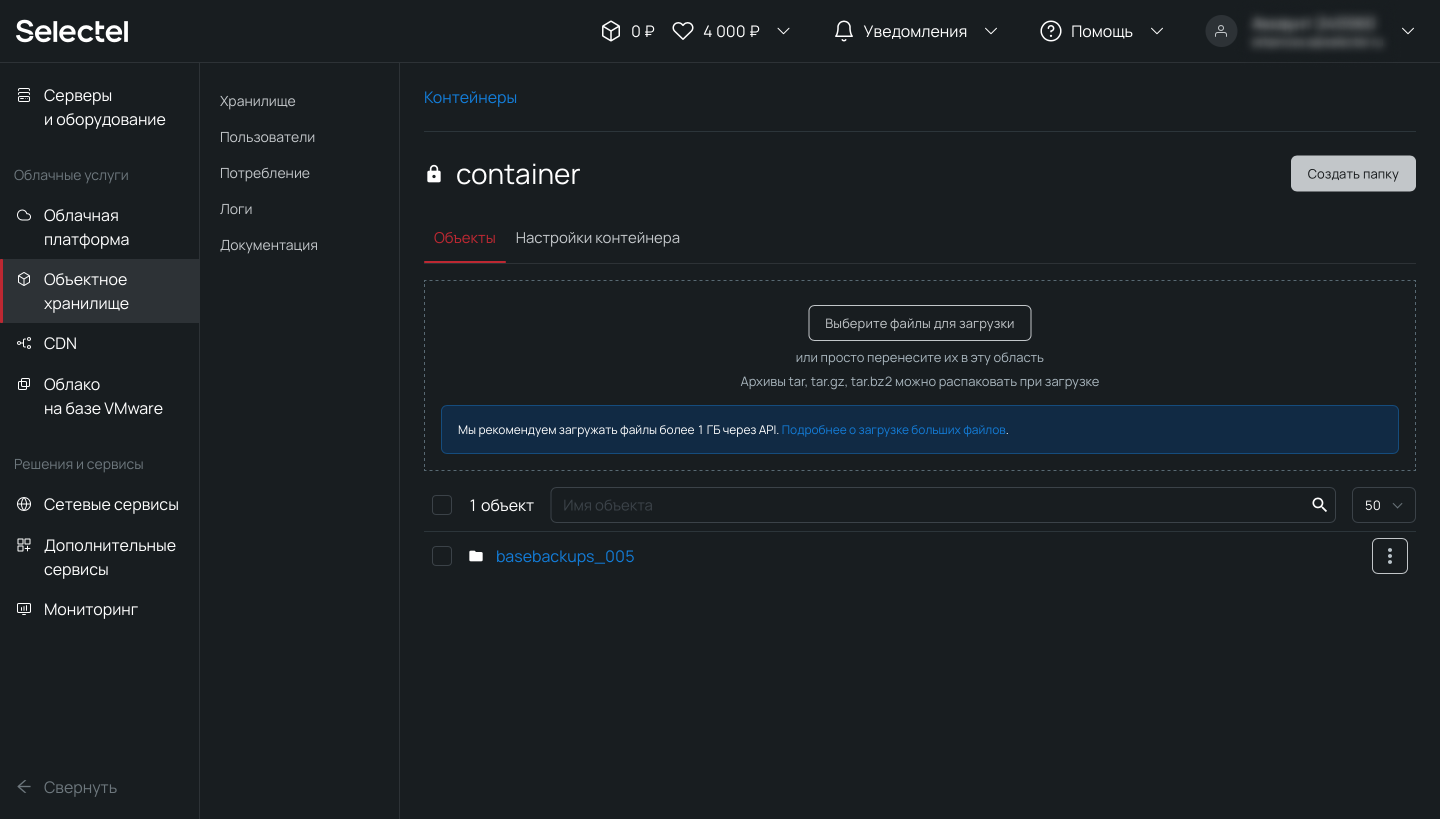
Такой процесс в продакшене может выполняться при помощи планировщика заданий на регулярной основе.
Утилита pgAdmin
Управлять созданием резервных копий возможно также и в графическом интерфейсе. Для этого мы будем использовать утилиту pgAdmin (в примере — работа с утилитой на локальном устройстве, но то же самое можно сделать на сервере). Актуальную версию для Windows или другой поддерживаемой ОС можно свободно скачать с официального сайта.
После скачивания утилиту нужно установить и запустить. Она работает в виде веб-приложения через браузер.
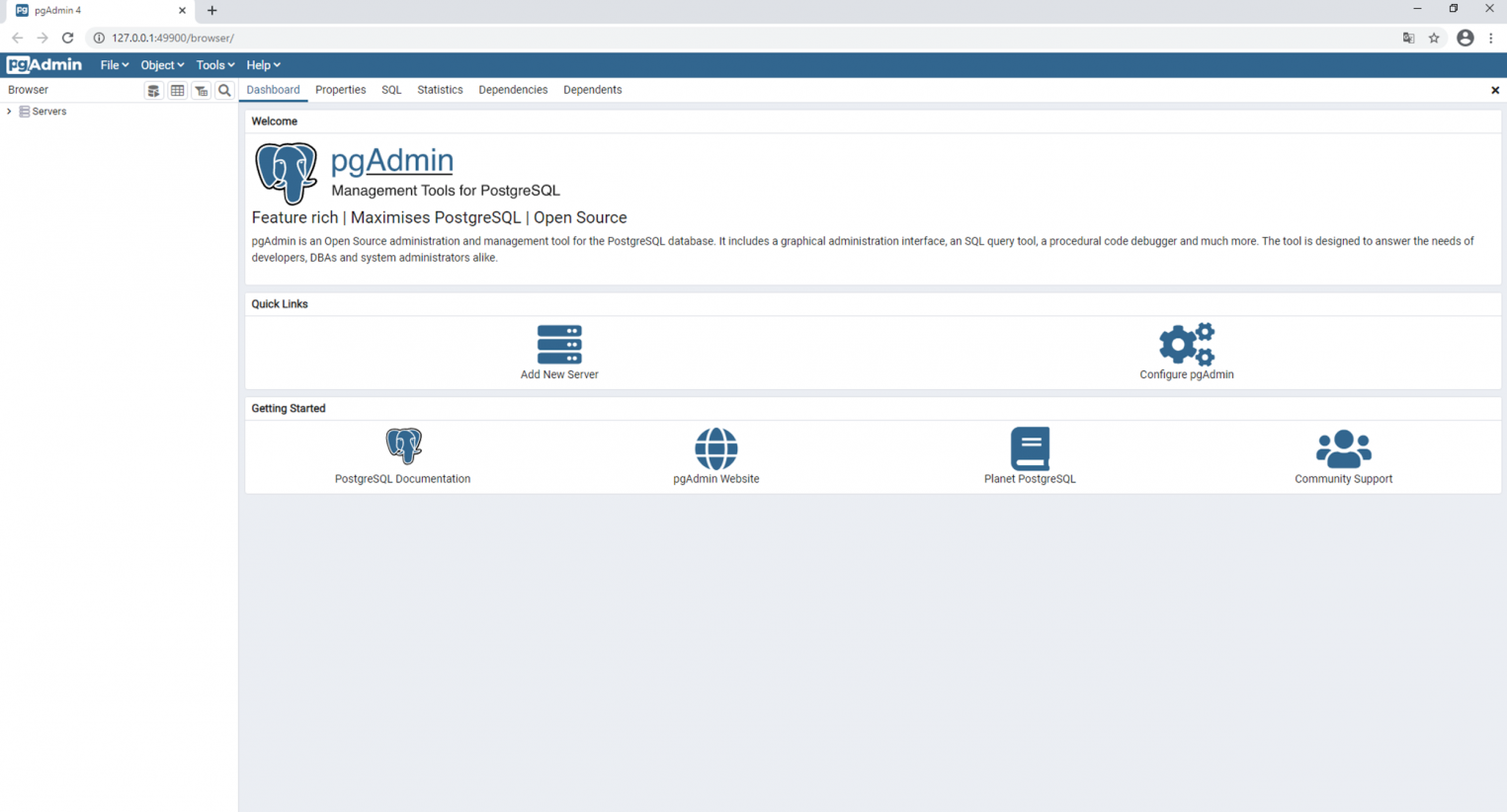
После добавления сервера с базой данных, в интерфейсе появляется возможность создания резервной копии. Аналогичным образом здесь же можно выполнить восстановление из резервной копии.
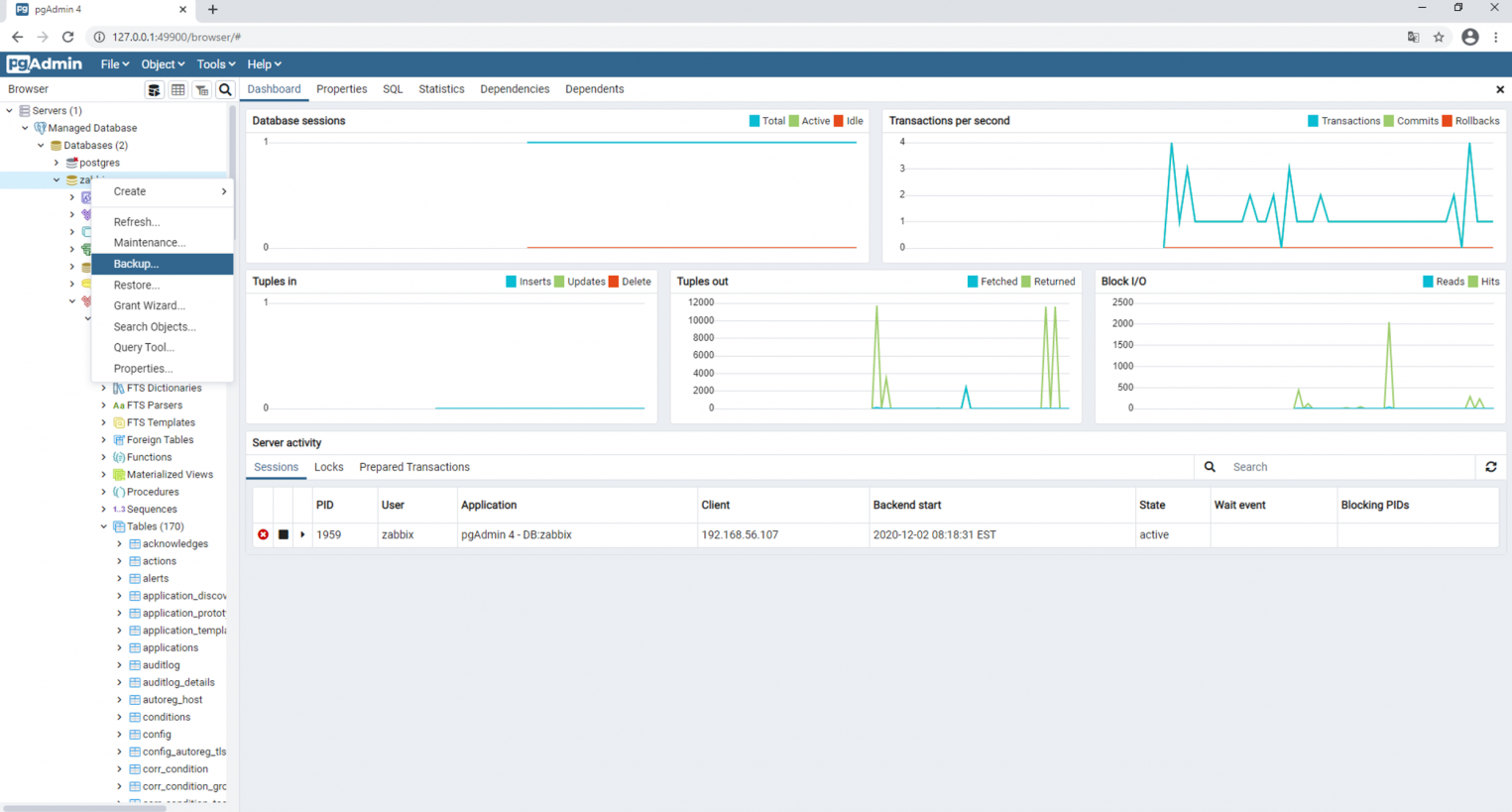
После выполнения команды Backup резервная копия сохраняется в заранее определенную директорию.
Работа с облачной базой данных в панели управления Selectel
В облачной платформе Selectel есть возможность создавать управляемые базы данных (Managed Databases). Такие БД разворачиваются в несколько кликов мыши, однако, их основные преимущества — автоматическое резервное копирование, отказоустойчивость, быстрое масштабирование и управление различными характеристиками из графического интерфейса. Ниже мы создадим экземпляр управляемой базы данных, создадим резервную копию базы данных на виртуальном сервере и восстановим ее в управляемую базу данных.
Чтобы создать управляемую базу данных, перейдем в меню Базы данных и нажмем кнопку Создать кластер:
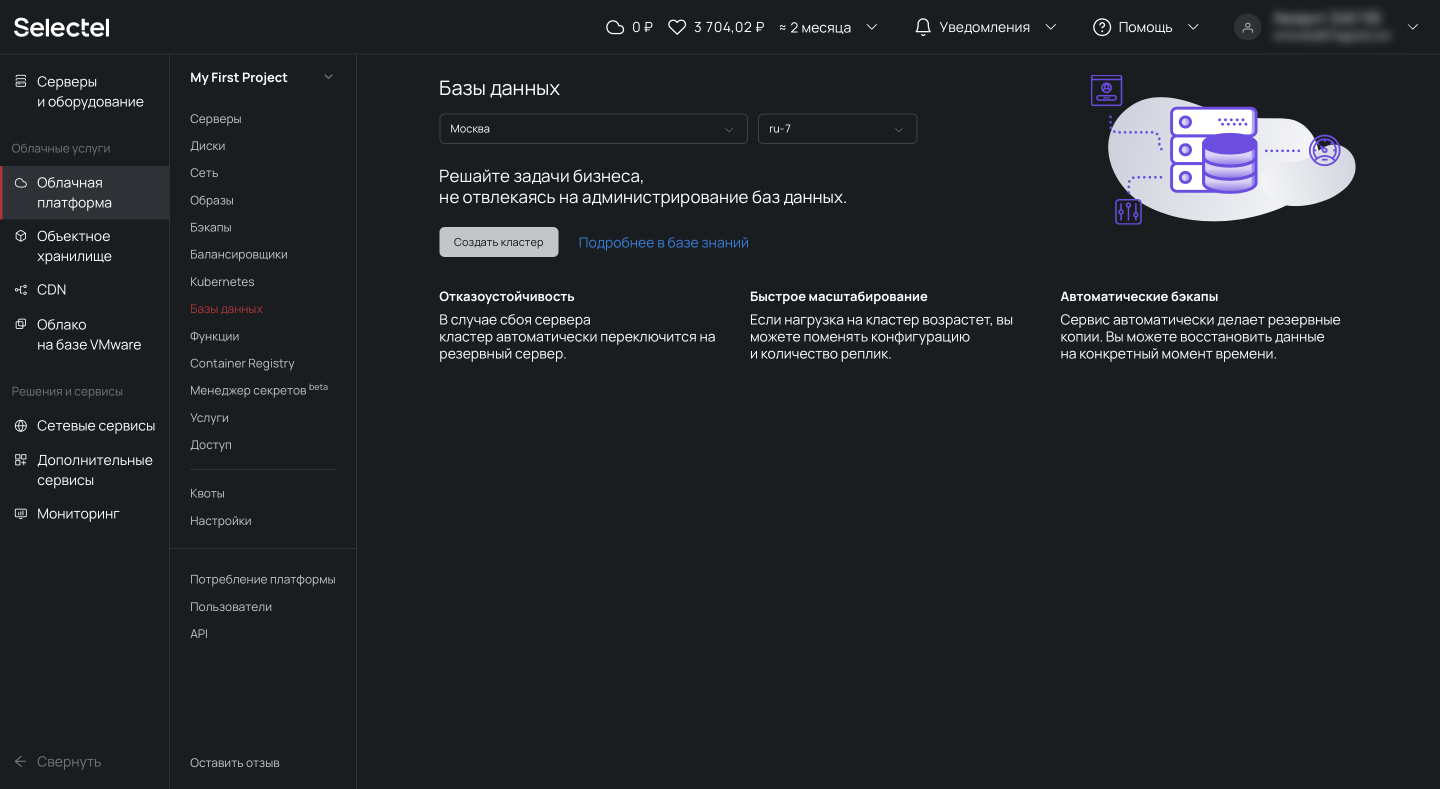
Появится форма создания кластера. Здесь можно выбрать версию PostgreSQL, конфигурацию кластера, настройки сети, режим пулинга и размер пула.
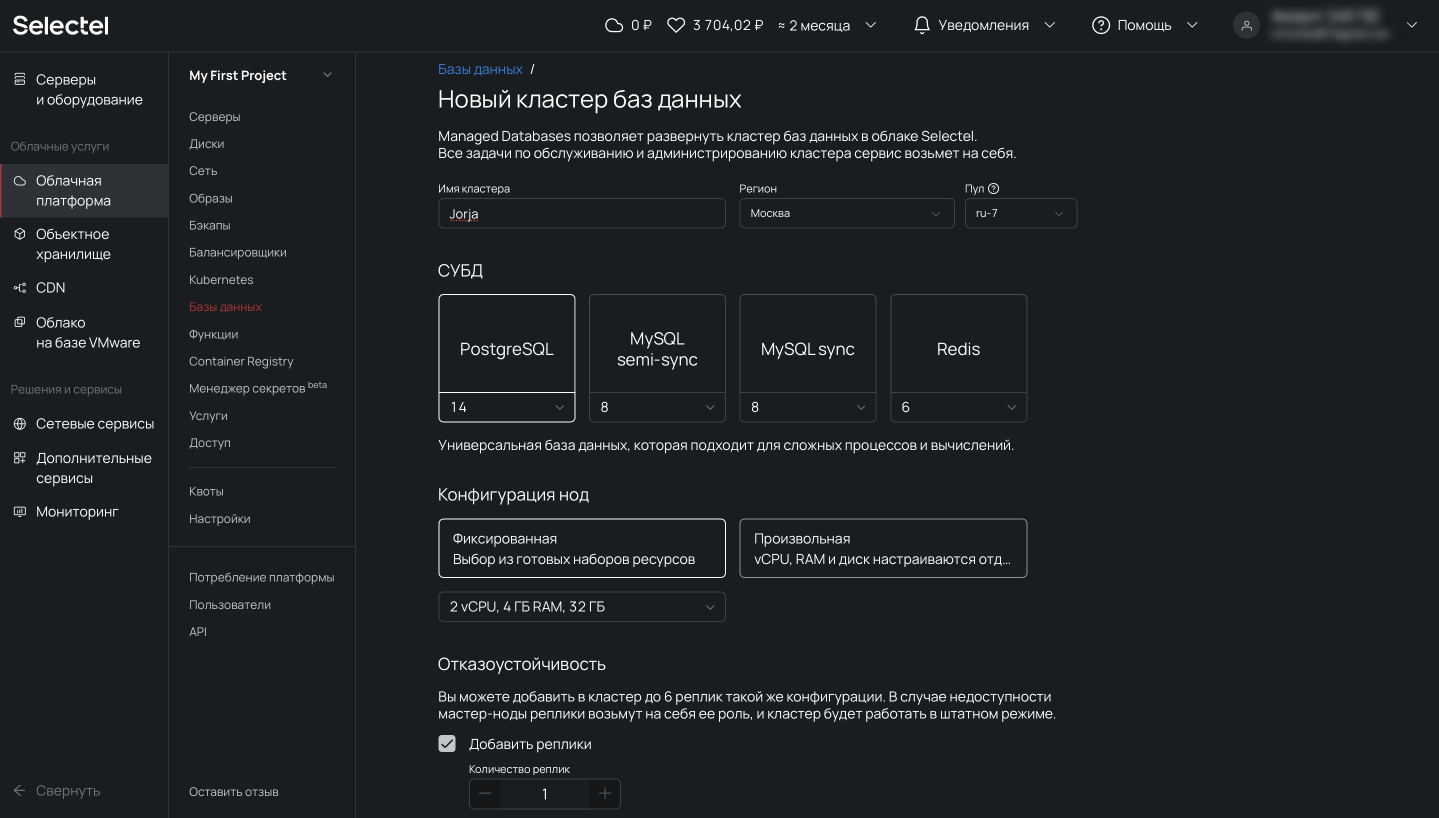
Обращаем внимание на блок Резервные копии, в котором указаны частота резервного копирования, время и срок хранения выгрузок. Под капотом используется механизм wal-g, о котором мы писали выше.
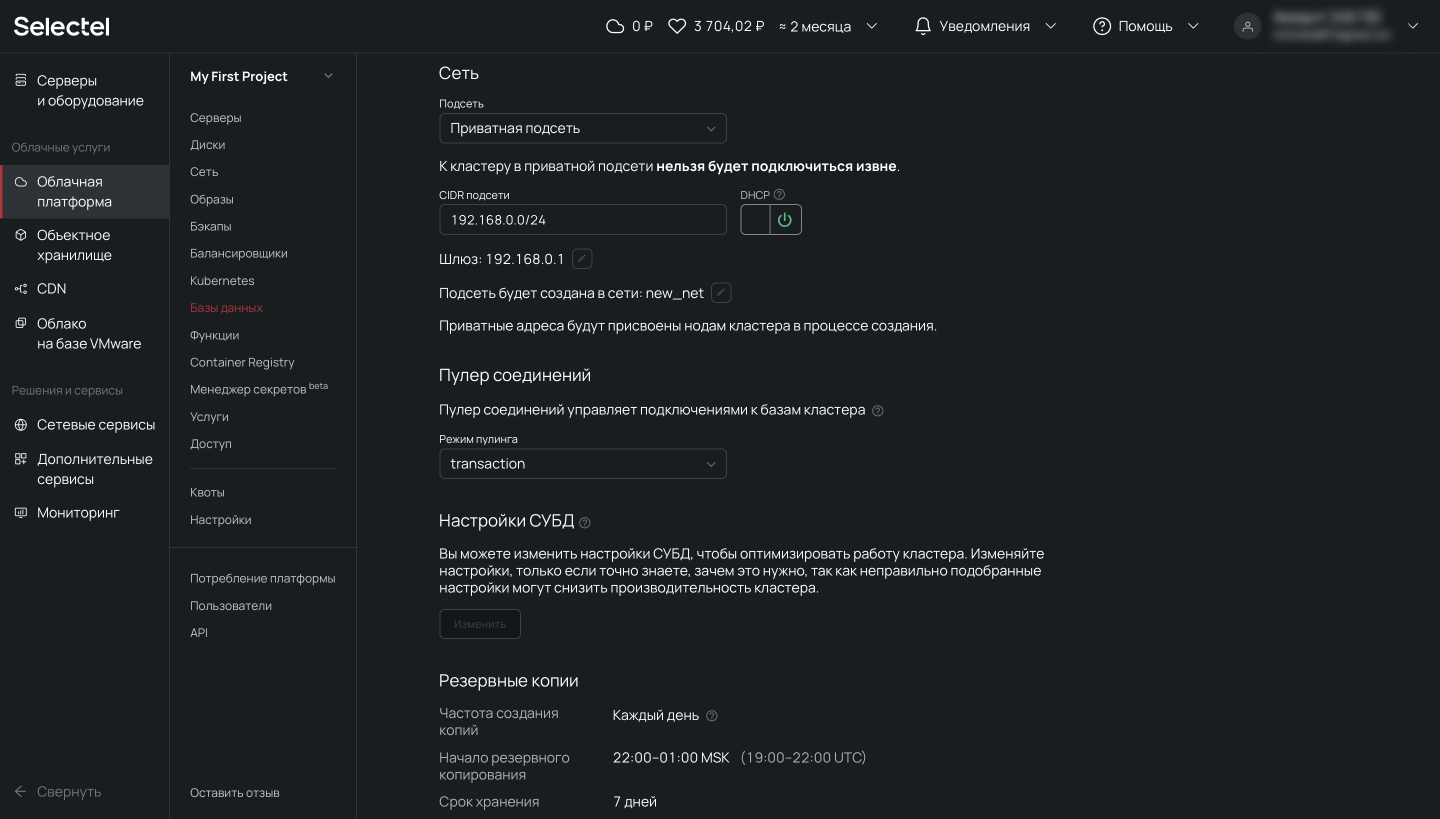
Автоматическое создание резервных копий отключить нельзя.
Следующий шаг — создание пользователя, от имени которого мы позже будем обращаться к базе данных. Для этого перейдем на вкладку Пользователи и нажмем на кнопку Создать пользователя.
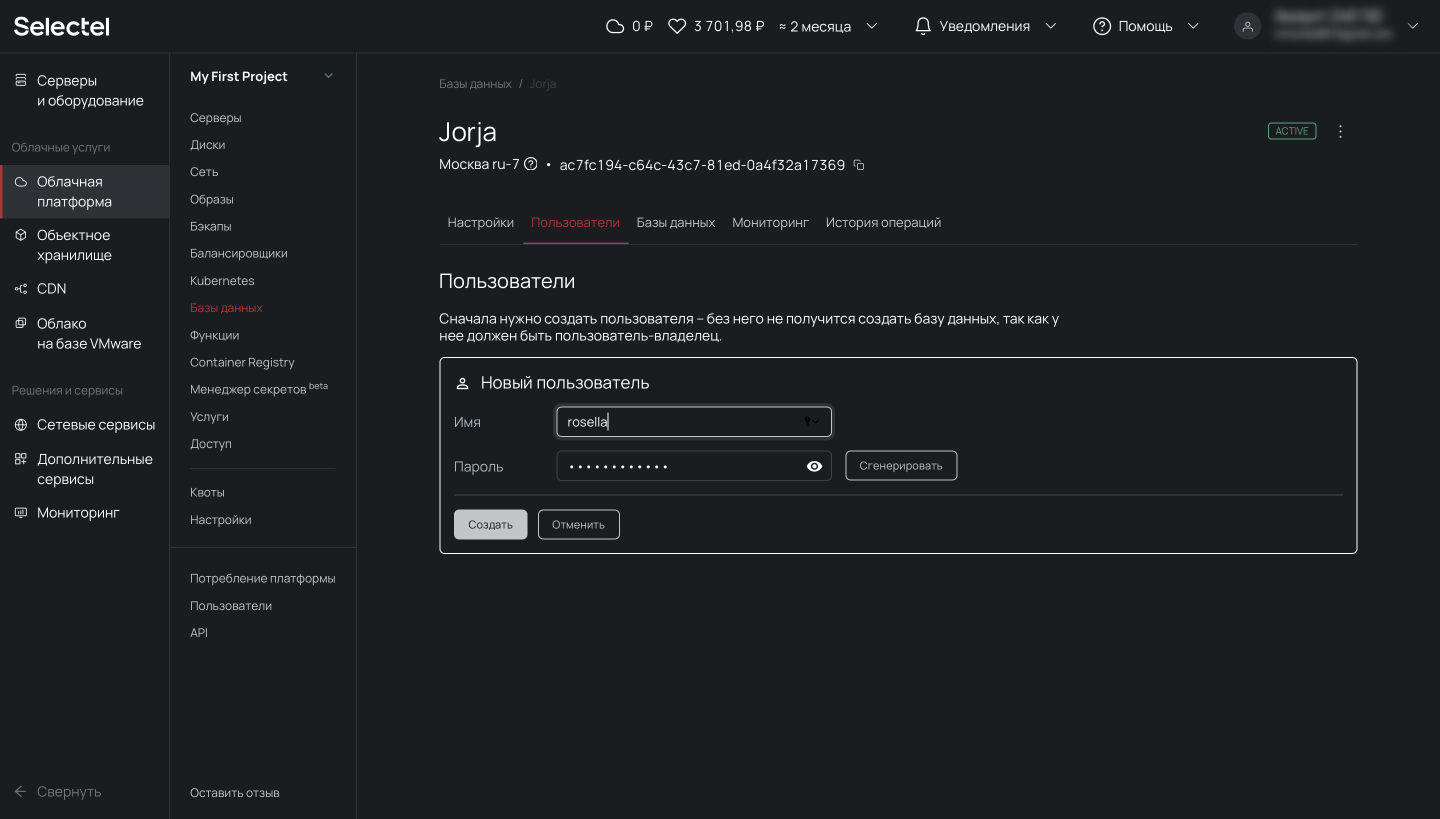
После этого появится приглашение ввести имя пользователя и пароль. После ввода этих данных нажимаем Сохранить.
Пользователь создан и отображается в списке пользователей.
Теперь создадим базу данных. Для этого перейдем на вкладку Базы данных и нажмем на кнопку Создать базу данных.
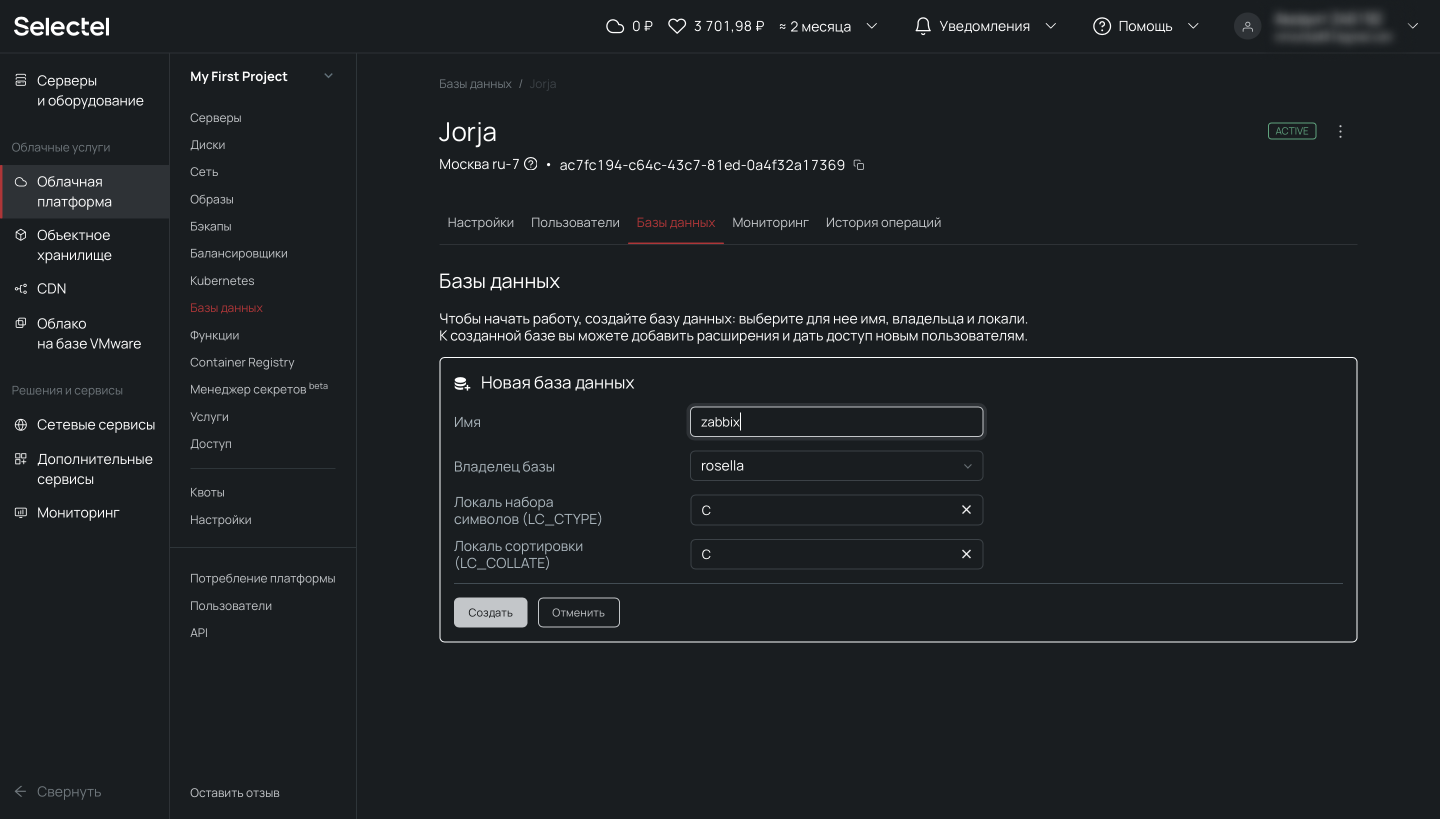
Заполняем необходимые поля и нажимаем кнопку Сохранить.
База данных создана и отображается в списке баз данных.
Теперь проверим возможность подключения. Для этого откроем консоль и вводим реквизиты:
# psql "host=192.168.0.3 \ port=6432 \ user=rosella \ dbname=zabbix \ sslmode=disable"В консоли должно появиться приглашение к вводу SQL-запроса или других управляющих команд.

Выполним резервное копирование при помощи команды pg_dump:
# pg_dump zabbix > /tmp/zabbix.dumpИ следом резервное восстановление в созданную управляемую базу данных:
# psql -h 192.168.0.3 -U rosella -d zabbix < /tmp/zabbix.dumpВ результате выполнения команды выше мы восстановили резервную копию в управляемую базу данных.
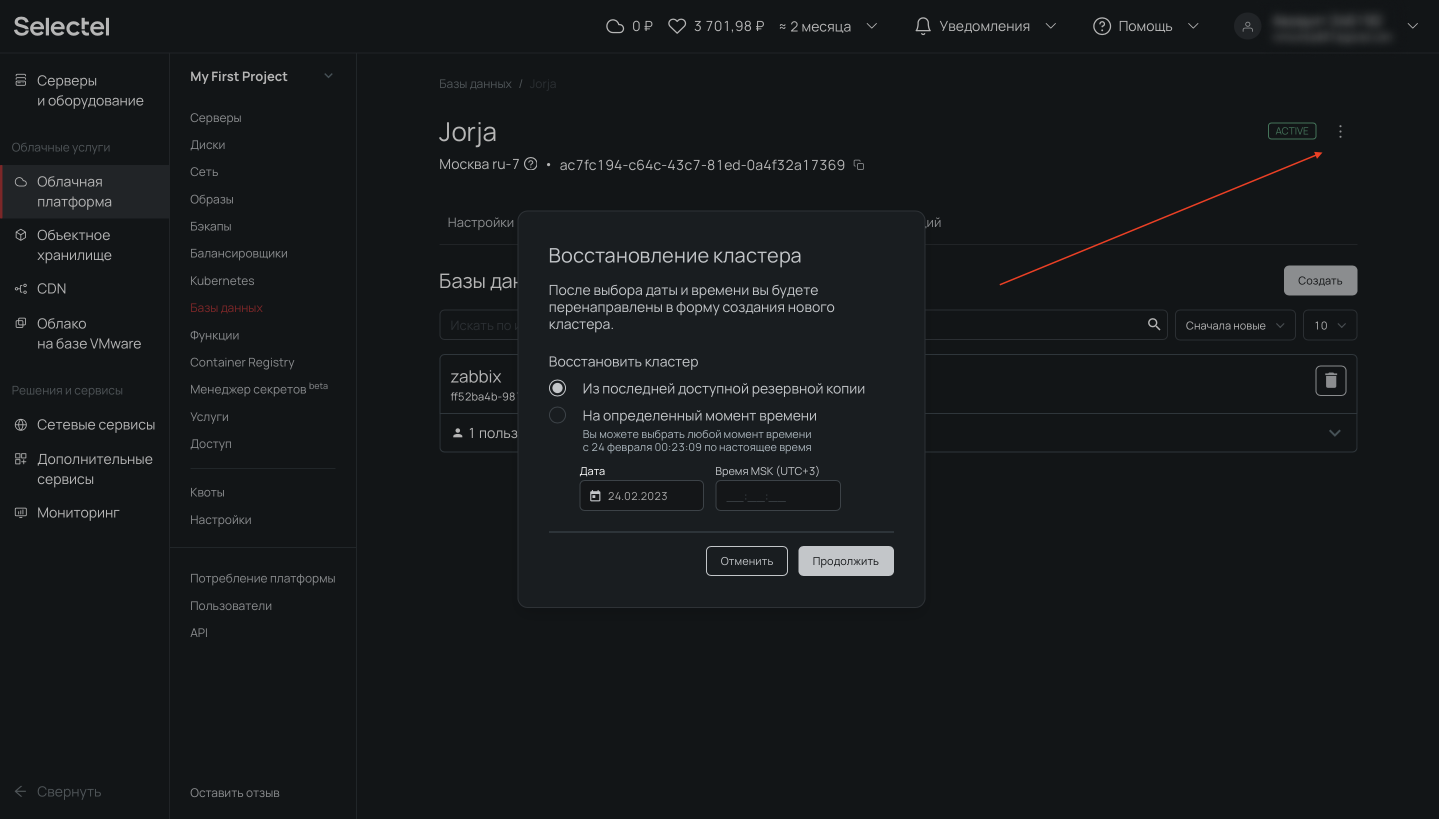
Чтобы воспользоваться восстановлением из резервной копии, которая автоматически создается на платформе Selectel, необходимо нажать на символ с тремя точками. В открывшемся меню нужно нажать на опцию Восстановить. После этого появится модальное окно, в котором можно выбрать резервную копию, а также дату и время, на которое нужно восстановить базу данных. Это так называемый Point-in-Time Recovery из WAL-файлов.
Услуга «Управляемые базы данных в облаке» позволяет перенести существующий кластер PostgreSQL на сервис управляемых баз данных бесшовно и без простоя, обратившись в техническую поддержку. Инженеры Selectel готовы помочь с переносом, а также проконсультировать по всем связанным с этим процессом вопросам.
Заключение
Мы рассмотрели возможности выполнения резервного копирования и показали отличия утилит pg_dump, pg_dumpall, pg_restore, pg_basebackup и wal-g. Вы увидели как можно создать управляемую базу данных, чтобы переложить часть административных задач на облачного провайдера.
Узнать подробнее об управляемых базах данных можно в документации Selectel.
Как настроить репликацию в PostgreSQL