Как создать таблицу в postgresql
Вы можете создать таблицу, указав её имя и перечислив все имена столбцов и их типы:
CREATE TABLE weather ( city varchar(80), temp_lo int, -- минимальная температура дня temp_hi int, -- максимальная температура дня prcp real, -- уровень осадков date date );
Весь этот текст можно ввести в psql вместе с символами перевода строк. psql понимает, что команда продолжается до точки с запятой.
В командах SQL можно свободно использовать пробельные символы (пробелы, табуляции и переводы строк). Это значит, что вы можете ввести команду, выровняв её по-другому или даже уместив в одной строке. Два минуса ( « — » ) обозначают начало комментария. Всё, что идёт за ними до конца строки, игнорируется. SQL не чувствителен к регистру в ключевых словах и идентификаторах, за исключением идентификаторов, взятых в кавычки (в данном случае это не так).
varchar(80) определяет тип данных, допускающий хранение произвольных символьных строк длиной до 80 символов. int — обычный целочисленный тип. real — тип для хранения чисел с плавающей точкой одинарной точности. date — тип даты. (Да, столбец типа date также называется date . Это может быть удобно или вводить в заблуждение — как посмотреть.)
Postgres Pro поддерживает стандартные типы SQL : int , smallint , real , double precision , char( N ) , varchar( N ) , date , time , timestamp и interval , а также другие универсальные типы и богатый набор геометрических типов. Кроме того, Postgres Pro можно расширять, создавая набор собственных типов данных. Как следствие, имена типов не являются ключевыми словами в данной записи, кроме тех случаев, когда это требуется для реализации особых конструкций стандарта SQL .
Во втором примере мы сохраним в таблице города и их географическое положение:
CREATE TABLE cities ( name varchar(80), location point );
Здесь point — пример специфического типа данных Postgres Pro .
Наконец, следует сказать, что если вам больше не нужна какая-либо таблица, или вы хотите пересоздать её по-другому, вы можете удалить её, используя следующую команду:
DROP TABLE имя_таблицы;
| Пред. | Наверх | След. |
| 2.2. Основные понятия | Начало | 2.4. Добавление строк в таблицу |
Как создать таблицу в SQL (примеры с PostgreSQL и MySQL)

Умение создать таблицу — важный, даже можно сказать фундаментальный навык в работе с SQL.
В этом руководстве я покажу вам синтаксис инструкции CREATE TABLE на примерах с PostgreSQL и MySQL.
Базовый синтаксис CREATE TABLE
Вот синтаксис инструкции CREATE TABLE (букв. «создать таблицу»):
CREATE TABLE table_name( column1 data_type column_constraint, column2 data_type column_constraint, column3 data_type column_constraint, column4 data_type column_constraint, . etc );
Начинаем с самой инструкции CREATE TABLE. Сразу за ней идет имя таблицы, которую вы хотите создать.
Предположим, я хочу создать таблицу с информацией о преподавателях. Я могу написать следующий запрос:
CREATE TABLE teachers();
В скобках указывается дополнительная информация о столбцах таблицы. Если вы забудете скобки, то получите сообщение об ошибке:
CREATE TABLE teachers;

Точка с запятой после скобок сообщает о том, что это конец SQL-инструкции.
Движки хранения данных MySQL
Согласно документации MySQL, «Движки хранения данных — это компоненты MySQL, управляющие SQL-операциями для разных типов таблиц».
MySQL использует эти движки для осуществления CRUD-операций (создание, чтение, обновление и удаление данных) в базе данных.
В MySQL можно указать тип движка, который вы хотите использовать для вашей таблицы. Для этого используется предложение ENGINE. Если вы его опустите, будет применен дефолтный движок — InnoDB.
CREATE TABLE table_name( column1 data_type column_constraint, column2 data_type column_constraint, column3 data_type column_constraint, column4 data_type column_constraint, . etc )ENGINE=storage_engine;
От редакции Techrocks. Возможно, вам также будут интересны следующие статьи:
- Запросы SQL: руководство для начинающих
- Оператор UPDATE в SQL: разбираем на примерах
- Выражение CASE в SQL: объяснение на примерах
- Порядок выполнения SQL-операций
Что такое IF NOT EXISTS?
Вы можете добавить в запрос опциональное предложение IF NOT EXISTS. Оно нужно для проверки, не существует ли уже в базе данных та таблица, которую вы хотите создать. Это предложение можно поместить непосредственно перед именем таблицы.
CREATE TABLE IF NOT EXISTS teachers();
Если такая таблица существует, новая не будет создана.
Если не указать IF NOT EXISTS и попытаться создать заново уже существующую таблицу, получите сообщение об ошибке.
В этом примере я создала таблицу teachers. Попытавшись создать такую же таблицу снова, я получила ошибку.
CREATE TABLE IF NOT EXISTS teachers(); CREATE TABLE teachers();

Как создавать столбцы в таблице
В инструкции CREATE TABLE, в круглых скобках после имени таблицы, перечисляются имена столбцов, которые вы хотите создать, а также их типы данных и ограничения.
В этом примере мы добавим в таблицу teachers четыре столбца: school_id, name, email и age. Имена столбцов разделяются запятыми.
CREATE TABLE teachers( school_id data_type column_constraint, name data_type column_constraint, email data_type column_constraint, age data_type column_constraint );
Согласно документации MySQL, «В MySQL установлено жесткое ограничение в 4096 столбцов на таблицу, но эффективный максимум может быть меньше. Реальный лимит количества столбцов зависит от нескольких факторов».
Впрочем, если вы работаете над маленькими личными проектами, маловероятно, что вам понадобится больше столбцов, чем это разрешено.
Согласно документации PostgreSQL, в этой СУБД установлен лимит в 1600 столбцов на таблицу. Так же, как и в MySQL, максимальное число столбцов может варьироваться в зависимости от количества места на диске или ограничений производительности.
Типы данных в SQL
При создании столбцов таблицы нужно указать их тип данных. Типы данных описывают значения, которые будут храниться в столбцах.
В SQL есть шесть популярных категорий типов данных:
- числа (int, float, serial, decimal)
- дата и время (timestamp, data, time)
- символы и строки (char, varchar, text)
- Unicode (ntext, nvarchar)
- бинарные данные (binary)
- смешанные (xml, table и др.)
Здесь мы не будем разбирать все типы, затронем только самые популярные. Полный список возможных типов данных можно посмотреть в документации: для PostgreSQL и для MySQL.
Что такое SERIAL и AUTO_INCREMENT?
В PostgreSQL тип данных SERIAL — это целое число, которое будет автоматически увеличиваться на единицу при каждом создании новой строки.
Мы можем указать тип данных SERIAL сразу после имени столбца school_id в нашей таблице teachers.
school_id SERIAL
В MySQL вместо SERIAL используется инструкция AUTO_INCREMENT. В примере ниже мы использовали ее с типом данных INT, представляющим целые числа.
school_id INT AUTO_INCREMENT
Если мы добавим в таблицу teachers пять строк и выведем содержимое столбца school_id, будут показаны числа 1, 2, 3, 4, 5. Число автоматически возрастает для каждой новой строки.

Что из себя представляет тип данных VARCHAR?
VARCHAR — это строковые данные переменной длины, где можно установить максимальную длину символов.
Ниже показан пример использования типа данных VARCHAR для столбцов name и email в таблице teachers. Здесь установлена максимальная длина в 30 символов.
name VARCHAR(30) column_constraint, email VARCHAR(30) column_constraint,
Ограничения столбцов
Ограничения — это правила, которые должны соблюдаться относительно данных в столбцах таблицы.
Вот список нескольких самых распространенных ограничений столбцов:
- PRIMARY KEY — если для столбца установлено это ограничение, данные в нем становятся уникальными идентификаторами строк в таблице
- FOREIGN KEY — этот ключ связывает данные в одной таблице с данными в другой
- UNIQUE — все значения в столбце должны быть уникальными
- NOT NULL — значения не могут быть NULL. NULL — это отсутствие значения
- CHECK — проверка значения на соответствие логическому выражению
Примеры PRIMARY и FOREIGN ключей
Давайте добавим ограничение PRIMARY KEY (первичный ключ) для столбца school_id в нашей таблице teachers.
В PostgreSQL код будет выглядеть так:
school_id SERIAL PRIMARY KEY
school_id INT AUTO_INCREMENT PRIMARY KEY
Первичный ключ может быть составным, т. е. строка может уникально идентифицироваться двумя столбцами. Чтобы установить PRIMARY KEY для нескольких столбцов, эту инструкцию нужно добавить сразу после создания самих столбцов:
CREATE TABLE table_name( column1 data_type column_constraint, column2 data_type column_constraint, column3 data_type column_constraint, column4 data_type column_constraint, . etc PRIMARY KEY (column1, column2) );
Если вы хотите связать одну таблицу с другой, следует использовать FOREIGN KEY (внешний ключ).
Допустим, у нас есть таблица district_employees с первичным ключом district_id. Вот как будет выглядеть код в PostgreSQL:
CREATE TABLE district_employees( district_id SERIAL PRIMARY KEY, employee_name VARCHAR(30) NOT NULL, PRIMARY KEY(district_id) );
В таблице teachers мы можем установить связь с таблицей district_employees при помощи внешнего ключа:
district_id INT REFERENCES district_employees(district_id),
CREATE TABLE teachers( school_id SERIAL PRIMARY KEY, district_id INT REFERENCES district_employees(district_id), column1 data_type column_constraint, column2 data_type column_constraint, column3 data_type column_constraint, column4 data_type column_constraint, . etc );
Примеры NOT NULL, CHECK и UNIQUE
Если бы нам нужно было обеспечить отсутствие значений NULL в столбцах, мы могли бы прописать ограничение NOT NULL.
name VARCHAR(30) NOT NULL
При помощи ограничения CHECK можно гарантировать, что все учителя в таблице будут старше 18 лет. CHECK проверяет значение на соответствие логическому выражению.
Если одно из значений не соответствует условию, мы получим сообщение об ошибке.

Ограничение UNIQUE мы можем использовать, чтобы обеспечить уникальность всех электронных адресов.
email VARCHAR(30) UNIQUE
Вот так выглядит наша таблица teachers в итоге:

Полный код в PostgreSQL:
CREATE TABLE teachers( school_id SERIAL PRIMARY KEY, name VARCHAR(30) NOT NULL, email VARCHAR(30) UNIQUE, age INT CHECK(age >= 18) );
CREATE TABLE teachers( school_id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(30) NOT NULL, email VARCHAR(30) UNIQUE, age INT CHECK(age >= 18) );
Надеюсь, эта статья была вам полезна!
Создание таблиц — Основы реляционных баз данных
В этом уроке мы поработаем с таблицами: будем создавать их, добавлять, модифицировать и удалять данные. Также разберем типы данных таблицы.
Создание базы данных
Прежде чем создать таблицу, создадим базу данных hexlet с помощью SQL (если вы еще этого не сделали). Для этого подключитесь к СУБД через psql . При этом не указывайте базу данных, чтобы подключиться к базе по умолчанию. Далее выполните следующие запросы:
DROP DATABASE hexlet; CREATE DATABASE hexlet; В примере выше два SQL запроса:
- DROP DATABASE hexlet — удаляет базу данных с именем hexlet
- CREATE DATABASE hexlet — создает базу данных с таким же именем
Базовые правила построения запросов:
- Каждый запрос должен заканчиваться точкой с запятой. Иначе psql будет думать, что вы продолжаете вводить команды
- Регистр не важен. Можно было написать drop database hexlet; . По традиции принято использовать верхний регистр для ключевых слов самого SQL. Это позволяет визуально разделять структуру запроса от данных внутри него. Последнее в примере — это имя базы данных, которое может быть произвольным
Если подключиться к той же базе данных, которую вы хотите удалить или пересоздать, то во время попытки удаления СУБД будет ругаться, что к базе есть активное соединение — ваше соединение. Поэтому важно подключиться к любой другой базе данных.
Команды createdb и createuser , которые мы разобрали в прошлых уроках, выполняют SQL-запросы внутри СУБД. Их сделали ради удобства первоначальной настройки, и чтобы использовать в скриптах автоматизации.
SQL поддерживает комментарии — строчка, которая начинается с двух дефисов. Комментарии игнорируются СУБД при построении запросов:
hexlet=> -- i am comment hexlet=> Нам удалось создать базу данных hexlet , поэтому можно переходить к созданию таблицы.
Создание таблиц
Таблица создается с помощью запроса CREATE TABLE :
-- Это один запрос, хоть и многострочный. -- Описание запроса заканчивается символом ; CREATE TABLE courses ( name varchar(255), slug varchar(255), lessons_count integer, body text ); Чтобы создать таблицу, необходимо указать ее имя, набор полей и их типы. В примере выше названия полей — это name , slug , lessons_count и body , а varchar(255) , integer и text — их типы.
Типы данных
У каждого поля в PostgreSQL определенный тип, который задается на этапе создания таблицы. Это значит, что значением этого поля могут быть только определенные данные. Если поле имеет числовой тип, то в него невозможно вставить строку, и наоборот. База данных выдаст ошибку при попытке выполнить подобный запрос.
-- Выполняем запрос на вставку передавая в lessons_count строку вместо числа ERROR: invalid input syntax for type integer: "wrong value" В PostgreSQL встроено много различных типов данных, но на практике используются не все. Ниже мы разбираем только самые популярные типы.
Строки
Для строк в базах данных в основном используются два типа:
- varchar — для строк с ограничением максимальной длины
- text — для строк без ограничения. Как правило, это полноценные тексты
В базах данных нельзя оставить первый тип без указания длины. Это связано с производительностью и эффективностью. Данные в базах данных физически хранятся на дисках в файлах. Быстрый доступ к этим данным возможен только тогда, когда у данных фиксированный размер. Это позволяет быстро перемещаться по ним и считать смещения.
Если размер данных не известен, то придется просматривать весь файл в поисках нужного значения. Чтобы избежать подобной ситуации, тип text хранится отдельно. Это тоже негативно влияет на скорость, но уже не так сильно. Если размер строки известен или он меньше какого-то значения, то предпочтительнее использовать varchar.
| Имя | Описание |
|---|---|
| character varying(n), varchar(n) | строка ограниченной переменной длины |
| text | строка неограниченной переменной длины |
- varchar. Полное название типа character varying (varchar может использоваться как псевдоним). Размер строки с таким типом указывается в скобках после названия типа, например, varchar(10). Это значит, что в поле с таким типом можно записать строку длиной до 10 символов.
- text. Не требует указания размера и может содержать текст произвольной длины
Пример создания таблицы с такими типами:
CREATE TABLE blog_posts ( name varchar(80), body text ); Числа
Для чисел в основном используются два типа данных: integer и bigint. Какой конкретно указывать тип, зависит от потенциального потолка значения. Ниже указаны диапазоны, допустимые в рамках этих типов:
| Имя | Описание | Диапазон |
|---|---|---|
| integer | типичный выбор для целых чисел | -2147483648 .. +2147483647 |
| bigint | целое в большом диапазоне | -9223372036854775808 .. 9223372036854775807 |
Пример создания таблицы с такими типами:
CREATE TABLE users ( id bigint, age integer ); Даты
Типы для хранения дат отличаются друг от друга очень сильно, в первую очередь по решаемой задаче. Нам надо хранить день без конкретного времени? Это тип date. Нужно конкретный момент времени, тогда timestamp. Просто время без даты? Тогда time.
| Имя | Описание | Наименьшее значение | Наибольшее значение | Точность |
|---|---|---|---|---|
| timestamp | дата и время (без часового пояса) | 4713 до н. э. | 294276 н. э. | 1 микросекунда |
| date | дата (без времени суток) | 4713 до н. э. | 5874897 н. э. | 1 день |
| time | время суток (без даты) | 00:00:00 | 24:00:00 | 1 микросекунда |
Пример создания таблицы с такими типами:
CREATE TABLE events ( start_date date, -- имя поля может называться как тип данных time time, updated_at timestamp, created_at timestamp ); Хорошей практикой считается добавление и заполнение полей created_at и updated_at в каждую таблицу базы данных. С их помощью всегда можно узнать, когда запись создалась и обновилась.
Значения даты и времени принимаются практически в любом известном формате. Вот несколько примеров того, как можно задавать дату:
| Пример | Описание |
|---|---|
| 1999-01-08 | ISO 8601 (рекомендуемый формат) |
| January 8, 1999 |
Логический тип
Содержит всего два значения: true и false . Этот тип используется для флагов:
| Имя | Описание |
|---|---|
| boolean | true или false (истина или ложь) |
Пример создания таблицы с такими типами:
CREATE TABLE blog_posts ( -- флаг: опубликован? published boolean ); Состояние «true» может задаваться следующими значениями:
Для состояния «false» можно использовать следующие варианты:
Помимо типов данных для реальных значений, в базе существует специальное значение NULL , чтобы обозначать пустоту. Оно используется, когда у конкретного поля нет значения. Тип поля при этом не важен. Подробнее с NULL мы разберемся в следующих уроках.
Анализ структуры базы данных
Чтобы исследовать структуру таблиц в визуальном режиме, используется PgAdmin:
SQL для анализа структуры базы данных не существует. Если вы хотите посмотреть список таблиц и их структуру в базе данных, то придется использовать команды самого psql :
Просмотр списка таблиц базы данных hexlet
hexlet=> \d List of relations Schema | Name | Type | Owner --------+------------+-------+--------- public | courses | table | vagrant public | events | table | vagrant public | blog_posts | table | vagrant Здесь мы видим список таблиц в базе данных hexlet. Все что здесь отображается, было создано в этом уроке выше.
В первом столбце видим новое для нас понятие — schema. Это пространство имен, которое позволяет группировать таблицы в различных ситуациях. На практике эта возможность используется редко, поэтому мы не обращаем на нее внимание. По умолчанию все таблицы публикуются в общей схеме public, которую можно не указывать.
Просмотр структуры таблицы courses
hexlet=> \d courses # public - обозначает схему по умолчанию Table "public.courses" Column | Type | Modifiers ---------------+------------------------+----------- name | character varying(255) | slug | character varying(255) | lessons_count | integer | body | text | В этом выводе показана структура таблицы courses. Здесь мы видим все имена полей и их типы.
Кроме перечисленных полезными могут оказаться следующие команды:
- \l — список всех баз данных
- \dt — список всех таблиц
- \? — вывод справки
Удаление таблиц
Чтобы удалить таблицу, выполняется запрос DROP :
DROP TABLE courses; Будьте внимательны, так как удаление таблицы приводит к безвозвратной потере данных.
Открыть доступ
Курсы программирования для новичков и опытных разработчиков. Начните обучение бесплатно
- 130 курсов, 2000+ часов теории
- 1000 практических заданий в браузере
- 360 000 студентов
Наши выпускники работают в компаниях:
SQL-Ex blog

Создание базы данных и таблиц в PostgreSQL: Изучение PostgreSQL с Grant Fritchey
Добавил Sergey Moiseenko on Среда, 10 августа. 2022
У вас есть локально работающий экземпляр PostgreSQL. Что дальше? Создание резервных копий. Но прежде мне нужно создать базу данных и пару таблиц, чтобы было что архивировать.
- Мне нравится Azure Data Studio. С ней легко работать. Она быстрая. Она чистая. Она имеет плагины для выполнения различных вещей.
- Например, она очень хорошо подключается к GitHub, поэтому вы можете легко держать разрабатываемые коды на GitHub.
- Мне просто более комфортно работать над кодом с выделенным инструментом, а не просто выполняя его из командной строки.
- Я не хочу описывать каждый отдельный имеющийся метод, поэтому я должен был выбрать один. И я его выбрал.
Создание базы данных
Команда создания базы данных очень простая:
CREATE DATABASE postgrelearning;
Да, это очень легко.
Давайте еще немного поговорим об этом. Поскольку я знаю SQL Server, я собираюсь сравнивать, как делать что-то там и здесь. В SQL Server у вас есть системная база данных model, используемая как шаблон при создании новой базы данных. В PostgreSQL происходит то же самое, но база данных называется template1. template1 работает очень похоже на model. Вы можете добавлять объекты в template1, и они будут автоматически присутствовать в новой базе данных, которую вы создаете.
Однако в PostgreSQL происходит больше. Давайте взглянем на мой список баз данных:
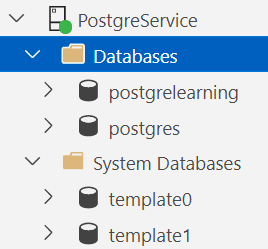
Есть еще база данных template0. Что это? Ну, в случае если вы совершенно запутаетесь с template1, template0 будет служить базовым уровнем. Кроме того, когда вы восстанавливаете базу данных, PostgreSQL использует template0 для запуска этого процесса.
А что насчет базы данных postgres? Она встроена в PostgreSQL по умолчанию, чтобы всегда можно было подключиться к базе данных.
Команда CREATE DATABASE имеет много опций, которые вы можете найти в документации. Одна из наиболее интересных для меня связана с указанием шаблонной базы данных. Вы можете выполнить, например, такую команду CREATE DATABASE:
CREATE DATABASE templatetest WITH template = postgrelearning;
И да. Вы можете указать другую базу данных в качестве шаблона. Однако:

Вы можете использовать базу данных в качестве шаблона, только если к этой базе данных нет никаких подключений.
Имеется несколько других опций от определения владельца базы данных, локали, коллации и т.д.. Я не буду здесь их рассматривать.
Если вам нужно избавиться от базы данных, это делается тоже простой командой:
DROP DATABASE templatetest;
Эта команда удалит всю базу данных. Однако вы не можете иметь подключение к базе данных, когда ее удаляете. Как и в случае CREATE, DROP имеет некоторые опции. Например, вы можете написать такую команду:
DROP DATABASE IF EXISTS templatetest;
Это устранит ошибку, если вы пытаетесь удалить несуществующую базу данных. Вы также можете удалить используемую базу данных:
DROP DATABASE IF EXISTS templatetest WITH (FORCE);
Это опасно, конечно. Всегда проявляйте крайнюю осторожность при использовании этой команды. Я всегда избегаю ее использования, поскольку достаточно один раз промахнуться, и вы удалите производственную базу.
Еще одно. Используя ADS, мы можете быстро легко переключаться между базами данных в окне запроса. Однако, кажется, нет способа сделать это исключительно на SQL. Вы управляете соединением с помощью используемого инструмента.
Создание таблицы
Когда у нас есть база данных, чтобы было с чем работать, начнем с использования синтаксиса CREATE TABLE для получения таблицы. Если вы уже знакомы с реляционными СУБД, то это весьма большая статья (посмотрите по ссылке на документацию). Я собираюсь пока придерживаться простого варианта, и не залезать глубоко в кроличью нору. В дальнейшем можно будет в это углубиться.
Вот первый пример:
CREATE TABLE TableTest1
(ID int NOT NULL,
SomeValue varchar(50) NOT NULL,
AnotherValue varchar(30) NULL);
Базовый синтаксис узнаваем, если вы пришли с SQL Server. В ADS результаты выглядят так:
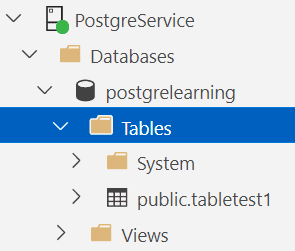
Код не включает схему, поэтому используется схема по умолчанию — public. Я предпочитаю определять схему, привязывать к ней таблицы, а не использовать схему по умолчанию. Собрание всего в определенной схеме или схемах значительно упрощает процесс блокировки.
Конечно, чтобы создать таблицы для реального тестирования, нужно сделать пример немного более сложным. Давайте начнем со схемы:
CREATE SCHEMA hsr;
Теперь создадим пару таблиц с первичными и внешними ключами:
CREATE TABLE hsr.radiobrand
(radiobrandid int PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY,
radiobranddesc varchar(50) NOT NULL);
CREATE TABLE hsr.radio
(radioid int PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY,
radioname varchar(50) NOT NULL,
radiobrandid int REFERENCES hsr.RadioBrand NOT NULL);
Как и в SQL Server, синтаксис для поддержки создания ключей использует ALTER, а также CREATE. Имеется также синтаксис для создания табличных ограничений, который, если вы создаете составной ключ или используя его как составной ключ, должны использовать вместо приведенного. Вы могли бы так создать таблицу hsr.radio этим способом:
CREATE TABLE hsr.radio
(radioid int NOT NULL GENERATED BY DEFAULT AS IDENTITY,
radioname varchar(50) NOT NULL,
radiobrandid int NOT NULL,
CONSTRAINT radiopk PRIMARY KEY (radioid),
FOREIGN KEY (radiobrandid) REFERENCES hsr.RadioBrand(radiobrandid));
Определение IDENTITY для столбца должно оставаться на месте, поскольку это свойство столбца. Однако вы могли бы создать первичный и внешние ключи отдельно от определений столбца. В целях согласованности я бы, вероятно использовал второй синтаксический вариант, а не первый. Тогда весь код будет выглядеть единообразно, а не только ограничения, которые имеют составные ключи.
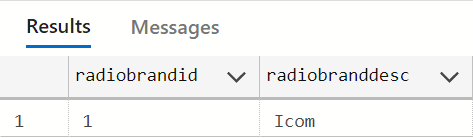
Вы можете провести небольшой тест:
insert into hsr.radiobrand
(radiobranddesc)
VALUES
('Icom');
SELECT radiobrandid,
radiobranddesc
FROM hsr.radiobrand;
Заключение
Теперь у нас есть база данных и пара таблиц с данными. Пока PostgreSQL мало чем отличается от SQL Server. Не идентичны, конечно, но очень похожи. Мы увидим более значительные различия по мере продвижения вглубь. Возможность определить более одной шаблонной базы данных — изящный трюк. Остальное было ожидаемо.
В следующий раз мы действительно собираемся заняться резервным копированием и восстановлением.
Обратные ссылки
Нет обратных ссылок
Комментарии
Показывать комментарии Как список | Древовидной структурой
Автор не разрешил комментировать эту запись