Amazon Redshift и традиционные хранилища данных
За последние 12 лет облачная экосистема Amazon пережила поразительный рост. К 2020 году Amazon Web Services (AWS) зарегистрировала выручку в размере 44 миллиардов долларов, что вдвое превышает совокупный доход двух ее ключевых конкурентов в сфере облачных технологий: Google Cloud и Microsoft Azure. AWS Redshift – главный двигатель этого роста.
Облачное хранилище данных AWS Redshift, один из флагманских продуктов Amazon, кардинально меняет правила игры в отрасли. От непревзойденной производительности до неограниченной масштабируемости – число корпоративных клиентов, использующих Redshift, увеличивается с каждым днем. В этой статье мы рассмотрим мир Redshift, его мощные функции и почему так много компаний выбирают Redshift для хранения своих данных и аналитики.
Что такое AWS Redshift?
AWS Redshift – это облачный сервис для хранения данных петабайтного масштаба, одно из решений экосистемы данных Amazon. Платформа, основанная на PostgreSQL, интегрируется с большинством сторонних приложений за счет применения драйверов ODBC и JDBC.
Redshift обеспечивает невероятно высокую производительность за счет использования двух ключевых архитектурных элементов: столбчатого хранилища данных и массивно-параллельной обработки. В 2012 году Amazon инвестировал в поставщика хранилищ данных, ParAccel (сейчас куплен Actian), и использовал свою технологию параллельной обработки в Redshift. Решение быстро стало неотъемлемой частью ландшафта аналитики больших данных благодаря своей способности выполнять запросы на основе SQL в больших базах данных, в которых есть смесь структурированных, неструктурированных и полуструктурированных данных.
За последние пять лет Redshift стал одним из ведущих облачных решений благодаря своей непревзойденной способности предоставлять организациям бизнес-аналитику.
Чем Redshift превосходит традиционные хранилища данных?
Традиционно компании сталкивались с рядом проблем при настройке хранилищ данных. Во-первых, организация таких центров на территории компании дорогая и на ее запуск уйдут месяцы. Этот фактор требовал от руководства твердой бюджетной и стратегической уверенности. Во-вторых, через несколько месяцев или лет объем данных неизменно увеличивался, а это означало, что компаниям приходилось выбирать между инвестированием в новое оборудование или терпимостью к низкой производительности.
Облачное решение Redshift помогает компаниям решить эти проблемы. Создание кластера из консоли AWS занимает считанные минуты. Прием данных в Redshift выполняется простой командой COPY из Amazon S3 (Simple Storage Service) или DynamoDB. Кроме того, масштабируемая архитектура Redshift позволяет компаниям размещать динамический запрос на масштабирование инфраструктуры вверх или вниз по мере изменения требований.
Поскольку кластеры серверов полностью управляются AWS, Redshift избавляет нас от рутинных задач по администрированию баз данных. Сложные задачи, такие как шифрование данных, решаются легко с помощью встроенных функций безопасности Redshift. Платформа также выполняет непрерывное резервное копирование данных, устраняя риск потери данных или необходимость планирования оборудования для резервного копирования.
Учитывая, что Redshift является экономичным, надежным, масштабируемым и быстродействующим решением, компании, естественно, склоняются к такому варианту хранилища данных как услуги (DWaaS).
AWS Redshift – что под капотом?
Основная причина того, что Redshift стала одним из самых популярных решений для облачных хранилищ данных – это архитектурные элементы, лежащие в его основе. AWS фокусируется на постоянных инновациях, добавляя новые функции и предлагая расширения продуктов. Давайте рассмотрим несколько особенностей дизайна Redshift, которые изменили способ получения бизнес-информации.
Хранение данных в столбцах
Традиционные реляционные базы данных используют хранилище на основе строк. Это идеально подходит для тех случаев, когда применяются простые запросы и нужно обновлять определенные строки, например, в приложениях CRM и ERP.
База данных на основе строк будет хранить данные в таблице 1 в таком виде:
Зачем и когда переходить на Amazon Redshift
Многим компаниям необходимо принимать решения на основе данных, поступающих в режиме реального времени, и в то же время быстро внедрять решения.
возьмем случай Uber, Например. Основываясь на исторических и текущих данных, компания должна определить пиковые цены, куда направить водителей, какой маршрут выбрать, ожидаемый трафик и целый ряд данных.
Каждую минуту приходится принимать тысячи таких решений такой компании, как Uber, работающей по всему миру. Текущий поток данных и исторические данные должны обрабатываться для принятия этих решений и обеспечения бесперебойной работы. Эти экземпляры могут использовать Redshift в качестве технологии MPP для упрощения доступа к данным и их обработки.
Объединение нескольких источников данных
Бывают случаи, когда необходимо обработать структурированные, полуструктурированные и/или неструктурированные данные, чтобы получить представление. Традиционные инструменты бизнес-аналитики не способны обрабатывать разнообразные структуры данных из разных источников. Amazon Redshift — мощный инструмент в этих случаях использования.
бизнес-аналитика
С данными организации должно работать множество разных людей. Все они не обязательно являются специалистами по данным и не будут знакомы с инструментами программирования, используемыми инженерами.
Они могут рассчитывать на подробные отчеты и информационные панели с простым в использовании интерфейсом.
С помощью Redshift можно создавать высокофункциональные информационные панели и автоматическое создание отчетов. Его можно использовать с такими инструментами, как Amazon QuickSight а также сторонние инструменты, созданные партнерами AWS.
анализ журнала
Анализ поведения — мощный источник полезных идей. Он предоставляет информацию о том, как пользователь использует приложение, как он с ним взаимодействует, продолжительности использования, его кликах, данных датчиков и множестве других данных.
Данные можно собирать из различных источников, включая веб-приложения, используемые на настольных компьютерах, мобильных устройствах или планшетах, а также их можно агрегировать и анализировать, чтобы получить представление о поведении пользователей. Это объединение сложных наборов данных и вычислительных данных можно выполнить с помощью Redshift.
Redshift также можно использовать для традиционного хранения данных. Но такие решения, как озеро данных S3, вероятно, лучше подходят для этого. Redshift можно использовать для выполнения операций с данными в S3 и сохранения вывода в S3 или Redshift.
Преимущества использования Amazon Redshift
Самым очевидным преимуществом использования Amazon Redshift является экономичность для вашей организации. Это стоит лишь часть (примерно одну двадцатую) стоимости конкурентов, таких как Teradata и Oracle.
Помимо стоимости, есть еще несколько преимуществ, наиболее очевидными из которых являются:
- Скорость. Благодаря использованию технологии MPP скорость доставки больших наборов данных не имеет себе равных. Ни один другой поставщик облачных услуг не может сравниться по скорости и стоимости с AWS.
- шифрование данных. Amazon предлагает возможность шифрования данных для любой части операции Redshift. Вы, как пользователь, можете решить, какие операции требуют шифрования, а какие нет.
А, как мы знаем, шифрование данных обеспечивает дополнительный уровень безопасности.
- семейная оснастка. Redshift основан на PostgreSQL. Все запросы SQL работают с ним.
Кроме того, вы можете выбрать любые инструменты SQL, ETL и Business Intelligence (BI), с которыми вы знакомы. Нет необходимости использовать инструменты, предоставляемые Amazon.
- умная оптимизация. Для большого набора данных будет несколько способов запроса данных с одинаковыми параметрами. Различные команды будут иметь разные уровни использования данных.
AWS Redshift предоставляет инструменты и информацию для улучшения запросов. Он также предоставит советы по автоматическому улучшению базы данных.
- Автоматизация повторяющихся задач. В Redshift есть положения, с помощью которых вы можете автоматизировать задачи, которые необходимо выполнять снова и снова.
Это могут быть административные задачи, такие как создание ежедневных, еженедельных или ежемесячных отчетов. Это может быть аудит ресурсов и затрат. Это также могут быть регулярные задачи обслуживания для очистки данных.
- одновременное масштабирование. Amazon Redshift автоматически масштабируется для поддержки постоянно растущих одновременных рабочих нагрузок.
- Объем запроса. Технология MPP блистает в этом аспекте. Вы можете отправлять тысячи запросов к набору данных в любой момент времени.
Тем не менее, Redshift совсем не будет тормозить; он будет динамически распределять ресурсы обработки и памяти для обработки более высоких требований.
- Интеграция с АВС. Redshift хорошо работает с остальными инструментами AWS. Вы можете настроить интеграцию между всеми сервисами в соответствии с вашими потребностями и оптимальной конфигурацией.
- API красного смещения. Redshift имеет надежный API с обширной документацией. Его можно использовать для отправки запросов и результатов из bain с помощью инструментов API. API также можно использовать в программе Python для упрощения написания кода.
- безопасность. Облачная безопасность обеспечивается Amazon, а безопасность облачных приложений должна обеспечиваться пользователями.
Amazon обеспечивает контроль доступа, шифрование данных и виртуальное частное облако для обеспечения дополнительного уровня безопасности.
- Машинное обучение. Redshift использует машинное обучение для прогнозирования и анализа запросов. Это, в дополнение к MPP, позволяет Redshift работать быстрее, чем другие решения на рынке.
- Простое развертывание. Кластер Redshift можно развернуть в любой точке мира из любой точки мира за считанные минуты. Вы можете получить высокопроизводительное решение для хранения данных по цене, намного меньшей, чем у конкурентов, всего за несколько минут.
- Согласованное резервное копирование. Amazon автоматически создает резервные копии данных на регулярной основе. Это можно использовать для восстановления в случае сбоев, сбоев или повреждения. Резервные копии разбросаны по разным местам. Следовательно, это исключает риск отказа сайта в целом.
- АМС Аналитика. AWS предлагает множество аналитических инструментов. Все это может отлично работать с Redshift.
Amazon поддерживает интеграцию других аналитических инструментов с Redshift. Redshift имеет собственные возможности интеграции с аналитическими сервисами AWS.
- открытые форматы. Redshift поддерживает и может обеспечивать вывод данных во многих открытых форматах. Наиболее распространенными поддерживаемыми форматами являются форматы файлов Apache Parquet и Optimized Row Columnar (ORC).
- партнерская экосистема. AWS — один из старейших поставщиков облачных услуг. Многие клиенты полагаются на Amazon в плане своей инфраструктуры.
Кроме того, AWS имеет обширную сеть партнеров, которые создают сторонние приложения и предлагают услуги по внедрению. Что партнерская экосистема его также можно использовать, чтобы увидеть, сможете ли вы найти идеальное решение для внедрения для своего бизнеса.
Подведение
Собранные данные будут расти с каждым днем. Вот почему Redshift — это защита от растущих данных с возрастающей аналитической сложностью. Его можно использовать для создания инфраструктуры, которая просуществует в будущем.
Кроме того, Redshift обеспечивает лучшую в своем классе производительность за небольшую часть стоимости конкурентов. Это делает его ценным предложением для любой организации, которой необходимо работать с большими объемами данных.
Можем ли мы показать вам, что такое Amazon Redshift и как он работает? поговори с нами прямо сейчас подробнее и узнайте, как мы можем помочь вам внедрить это решение в вашей компании!
Вопросы и ответы по Amazon Redshift
Десятки тысяч клиентов ежедневно применяют возможности SQL-аналитики Amazon Redshift в облаке, обрабатывая эксабайты данных для получения ценной информации. Независимо от того, где хранятся ваши данные (в операционном хранилище данных, в сервисах потоковой обработки данных или в сторонних наборах данных), Amazon Redshift помогает вам получать безопасный доступ к данным, комбинировать и совместно использовать их при минимальном перемещении и копировании. Сервис Amazon Redshift глубоко интегрирован в сервисы баз данных, аналитики и машинного обучения AWS, чтобы применять подходы без извлечения, преобразования и загрузки данных или помочь вам обращаться к данным на месте для их анализа в режиме реального времени, построения моделей машинного обучения на SQL и применения аналитических функций Apache Spark к данным в Redshift. Amazon Redshift Serverless позволяет вашим инженерам, разработчикам, специалистам по обработке данных и аналитикам с легкостью приступить к работе и быстро масштабировать аналитику в среде, которой не требуется администрирование. Благодаря своему движку массово-параллельной обработки (MPP) и архитектуре, которая отделяет вычислительные ресурсы от ресурсов хранилищ для эффективного масштабирования, а также инновациям в области повышения производительности с использованием машинного обучения (например, AutoMaterialized Views), Amazon Redshift имеет все возможности для масштабирования и обеспечивает соотношение цены и производительности в 5 раз лучшее, чем другие облачные хранилища данных.
Каковы основные причины, по которым клиенты выбирают Amazon Redshift?
Тысячи клиентов выбирают Amazon Redshift, чтобы ускорить получение результатов, потому что это эффективная аналитическая система, которая тесно интегрируется с сервисами баз данных и машинного обучения, проста в использовании и может стать центральным сервисом, который удовлетворяет все их требования к аналитике. Amazon Redshift Serverless автоматически распределяет и масштабирует мощности хранилища данных, позволяя обеспечить высокую производительность для рабочих нагрузок с высокими и непредсказуемыми требованиями к ресурсам. Amazon Redshift отличается наилучшим соотношением цены и производительности при работе с разнообразными аналитическими рабочими нагрузками: панелями управления, разработкой приложений, совместным использованием данных, заданиями ETL (извлечение, преобразование, нагрузка) и некоторыми другими нагрузками. Учитывая то, что десятки тысяч клиентов используют аналитику для обработки от терабайтов до петабайтов данных, Amazon Redshift повышает производительность реальных рабочих нагрузок клиентов на основании телеметрии производительности парка и обеспечивает производительность, которая масштабируется в линейном соотношении с рабочей нагрузкой, не требуя при этом больших затрат. Инновации в области повышения производительности доступны клиентам без дополнительной платы. Amazon Redshift позволяет получить ценные сведения, выполняя интерактивный и прогностический анализ по всем данным во всех корпоративных базах данных, озерах данных, хранилищах данных, по потоковым данным и наборам данных сторонних организаций. Amazon Redshift поддерживает лучшую в отрасли систему безопасности с интеграцией управления идентификацией и федерацией для единого входа (SSO), многофакторной аутентификацией, контролем доступа на уровне столбцов, контролем доступа на основе ролей, Виртуальным частным облаком Amazon (Amazon VPC) и более быстрым изменением размера кластера.
Каким образом сервис Amazon Redshift упрощает управление хранилищем данных и аналитикой?
Управление Amazon Redshift полностью осуществляется платформой AWS, так что вам не придется беспокоиться о таких задачах по управлению хранилищем данных, как распределение оборудования, применение исправлений, настройка, конфигурирование, мониторинг узлов и дисков для восстановления после сбоев, а также резервное копирование. AWS управляет работами по настройке, эксплуатации и масштабированию хранилища данных от вашего имени, позволяя сосредоточиться на создании приложений. Amazon Redshift Serverless автоматически распределяет и масштабирует мощности хранилища данных, позволяя обеспечить высокую производительность для рабочих нагрузок с высокими и непредсказуемыми требованиями к ресурсам, а также оплачивать только реально используемые ресурсы. Amazon Redshift также поддерживает функцию автоматической настройки и дает рекомендации по управлению складом в Redshift Advisor. Чтобы обеспечить работу Redshift Spectrum, сервис Amazon Redshift управляет всей вычислительной инфраструктурой, балансировкой нагрузки, планированием, разработкой графика запросов к данным, хранящимся в Amazon S3, и выполнением этих запросов. Amazon Redshift обеспечивает аналитику всех ваших данных благодаря тесной интеграции с сервисами баз данных, обладающими такими характеристиками, как работа Amazon Aurora с Amazon Redshift без извлечения, преобразования и загрузки данных и федеративные запросы для доступа к данным на месте из таких операционных баз данных, как Amazon RDS и ваше озеро данных Amazon S3. Redshift обеспечивает ускоренное получение данных за счет автоматизированных конвейеров данных без кода, автоматизированных конвейеров данных, которые автоматически принимают потоковые данные или файлы Amazon S3. Кроме того, Redshift интегрирован с Обменом данными AWS, что позволяет пользователям находить сторонние наборы данных, подписываться на них и отправлять к ним запросы, а также комбинировать их со своими данными, чтобы получать комплексную аналитическую информацию. Благодаря встроенной интеграции с Amazon SageMaker клиенты могут прямо в своем хранилище данных создавать, обучать и компоновать модели машинного обучения на SQL. Amazon Redshift обеспечивает в 5 раз лучшее соотношение цены и производительности использования аналитических возможностей SQL, чем другие облачные хранилища данных.
Какие имеются варианты развертывания Amazon Redshift?
Amazon Redshift является полностью управляемым сервисом, который предоставляет распределенные и бессерверные варианты использования, что повышает эффективность использования и масштабирования аналитики без необходимости самостоятельно управлять хранилищем данных. Вы можете развернуть новый бессерверный адрес Amazon Redshift для автоматического предоставления хранилища данных за считанные секунды или же выбрать готовый вариант для прогнозируемых рабочих нагрузок.
Как начать работу с Amazon Redshift?
Вы можете всего за несколько действий в Консоли управления AWS начать отправлять запросы к данным. Вы можете использовать предварительно загруженные примеры данных, в том числе наборы данных для сравнительного тестирования TPC-H, TPC-DS и другие примеры запросов, которые позволят почти мгновенно начать работу. Чтобы начать работу с Amazon Redshift Serverless, щелкните «Начало работы с Amazon Redshift» и создайте запрос к данным. Начать работу можно здесь.
Как соотносится производительность Amazon Redshift с производительностью других хранилищ данных?
Результаты теста производительности TPC-DS показывают, что Amazon Redshift обеспечивает наилучшую производительность в стандартной конфигурации, даже для сравнительно небольшого набора данных размером 3 ТБ. Amazon Redshift обеспечивает в 5 раз лучшее соотношение цены и производительности, чем другие облачные хранилища данных. Это позволяет вам сразу же получить преимущество благодаря лучшему соотношению цены и производительности Amazon Redshift, причем без дополнительной настройки вручную. На основании телеметрии парка производительности мы также знаем, что большинство рабочих нагрузок используют краткие запросы (рабочие нагрузки, которые выполняются менее чем за секунду). Последние оценочные тестирования показали, что при этих рабочих нагрузках Amazon Redshift демонстрирует в 7 раз лучшее соотношение цены и производительности рабочих нагрузок с высоким уровнем параллельного выполнения и низкой задержкой, чем другие облачные хранилища данных. Подробнее см. здесь.
Может ли кто-то рассказать подробнее об Amazon Redshift и помочь с подключением?
Да, специалисты Amazon Redshift готовы ответить на вопросы и обеспечить поддержку. Напишите нам, и мы свяжемся с вами в течение одного рабочего дня, чтобы рассказать, как AWS может помочь вашей организации.
Что такое управляемое хранилище Amazon Redshift?
Управляемое хранилище Amazon Redshift доступно с типами узлов RA3 и в бессерверной конфигурации. Оно позволяет масштабировать и оплачивать вычислительные ресурсы и хранилище независимо друг от друга. Поэтому размер кластера можно устанавливать в соответствии с потребностями задачи вычисления. Оно автоматически использует высокопроизводительное локальное хранилище на твердотельном накопителе в качестве кэша первого уровня 1 и использует такие средства оптимизации, как температура блока данных, время создания блоков данных и шаблоны рабочей нагрузки. Это обеспечивает высокую производительность при возможном автоматическом масштабировании хранилища в Amazon S3 без необходимости каких-либо действий.
Как использовать управляемое хранилище сервиса Amazon Redshift?
Если вы уже используете узлы Amazon Redshift Dense Storage или Dense Compute, с помощью эластичного изменения размера вы можете обновить существующие кластеры до нового вычислительного инстанса RA3. Amazon Redshift Serverless и кластеры на основе инстансов RA3 автоматически используют для хранения данных хранилище под управлением Redshift. Для использования этой возможности не требуется никаких действий, кроме применения Amazon Redshift Serverless или инстансов RA3.
Как из Redshift отправлять запросы на получение данных, хранящихся в озере данных AWS?
Amazon Redshift Spectrum – это возможность сервиса Amazon Redshift, которая позволяет выполнять запросы к вашему озеру данных в Amazon S3 без загрузки или выполнения ETL-операций. При отправке SQL-запроса он поступает на адрес Amazon Redshift, и этот сервис генерирует и оптимизирует план запроса. Amazon Redshift определяет, какие данные являются локальными, а какие находятся в Amazon S3, генерирует план минимизации объема данных S3, которые необходимо прочитать, и запрашивает исполнителей Amazon Redshift Spectrum из общего пула ресурсов, чтобы прочитать и обработать данные из Amazon S3.
Для каких случаев стоит рассмотреть возможность использования инстансов RA3?
Выбор типов узлов RA3 может быть правильным в следующих случаях.
- Если вам требуется гибко масштабировать и оплачивать вычислительные ресурсы отдельно от хранилища.
- Если вы используете запросы по малой части от общего объема данных.
- Если объем данных быстро растет или будет быстро расти.
- Если сам нужно гибко изменять размер кластера с учетом текущих потребностей.
По мере роста объема данных (до петабайтов) параллельно растет и объем принимаемых в Amazon Redshift данных. Возможно, вам уже нужен более экономичный способ анализа огромных данных.
Новые инстансы Amazon Redshift RA3 с управляемым хранилищем позволяют выбирать число узлов в зависимости от потребностей в производительности и оплачивать только реально используемый объем управляемого хранилища. Это позволяет вам гибко выбирать размер кластера RA3 в зависимости от объема ежедневно обрабатываемых данных, не повышая затраты на хранилище. Инстансы RA3 основаны на AWS Nitro System, используют высокопрозиводительные диски SSD для данных горячего уровня и Amazon S3 для данных холодного уровня, что позволяет получить простое в использовании экономичное хранилище с огромной производительностью для запросов.
Какую функцию можно использовать для аналитики на основании местоположения?
Amazon Redshift Spatial предоставляет возможности аналитики на основе местоположения для глубокого анализа ваших данных. Он без проблем интегрирует пространственные и деловые данные, позволяя выполнять по ним аналитику и принимать решения. Amazon Redshift получил в ноябре 2019 года встроенную поддержку обработки пространственных данных, для которой применяются полиморфный тип данных GEOMETRY и несколько важнейших пространственных функций SQL. Теперь мы поддерживаем тип данных GEOGRAPHY, а библиотека пространственных функций SQL выросла в размере до 80 функций. Мы поддерживаем все самые распространенные пространственные типы данных и стандарты, в том числе Shapefiles, GeoJSON, WKT, WKB, eWKT и eWKB. Подробную информацию вы найдете на странице документации или в учебном пособии по пространственным вычислениям в Amazon Redshift.
Какова поддержка SQL Athena по сравнению с Redshift и как мне выбрать между двумя этими сервисами?
Сервис Amazon Athena и бессерверный сервис Amazon Redshift решают разные задачи и предназначены для разных сценариев, хотя являются бессерверными и подходят для пользователей SQL.
Благодаря архитектуре массово-параллельной обработки (MPP), которая отделяет ресурсы хранилища от вычислительных ресурсов, и возможностям автоматической оптимизации на основе машинного обучения, хранилище данных, такое как Amazon Redshift, независимо от того, является ли оно серверным или выделенным, – это отличный выбор для клиентов, которым нужно наилучшее соотношение цены и производительности в любых масштабах для комплексных аналитических рабочих нагрузок, в том числе для бизнес-аналитики. Клиенты могут использовать Amazon Redshift как центральный компонент своей архитектуры данных с тесной интеграцией, чтобы получать доступ к данным на месте, либо получать или перемещать их в хранилище данных для высокопроизводительной аналитики, делая это без труда благодаря отсутствию необходимости извлекать, преобразовывать и загружать данные и применению методов, не требующих написания кода. Клиенты могут обращаться к данным, которые хранятся в Amazon S3, операционных базах данных, например Aurora и Amazon RDS, сторонних хранилищах данных за счет интеграции с Обменом данными AWS, а также комбинировать их с данными, которые находятся в хранилище данных Amazon Redshift для аналитики. Они могут легко приступить к использованию хранилищ данных и тренировать модели машинного обучения с использованием всех этих данных.
Amazon Athena хорошо подходит для интерактивной аналитики и исследования данных в вашем озере данных или в любом другом источнике данных с использованием расширяемой сети коннекторов (включает в себя более 30 готовых коннекторов для приложений и локальных или других облачных аналитических систем) без необходимости заботиться о получении или обработке данных. Сервис Amazon Athena создан на основе движков и платформ с открытым исходным кодом, таких как Spark, Presto и Apache Iceberg, что дает клиентам гибкость, так как они могут использовать либо Python, либо SQL, либо работать над открытыми форматами данных. Если клиентам требуется интерактивная аналитика на основе платформ и форматов данных с открытым исходным кодом, то Amazon Athena – это отличная стартовая точка.
тут блог

Общественные обязательства интроверта.
Сообщения на ИТ тематику, но не обязательно.
О Redshift
О ClickHouse я уже рассказывал. А о Redshift как-то позабыл. Вспомнил, когда пришлось рассказывать о них на конференции. Здесь — краткий пересказ.
Redshift — это аналитическая база данных, живущая в облаке AWS. Это проприетарная БД. Вы не можете её запустить где-то локально в Докере. Только в Амазоне.
Redshift — не оригинальная разработка Амазона. Это продукт компании ParAccel. Они лет шесть пилили свою уникальную аналитическую БД на основе PostgreSQL 8. И в 2011 году выпустили ParAccel Analytic Database. В 2012 этот продукт адаптировал Амазон под своё облако. В публичную эксплуатацию Redshift вышел в начале 2013. А мы на проекте начали его использовать в начале 2020. Redshift к этому моменту явно был зрелым продуктом.
Я думал, ClickHouse значительно моложе. Но нет, он моложе лишь на годик. ClickHouse использовался в Яндекс.Метрике уже в 2012.
Redshift, как и ClickHouse, — колоночная СУБД. То есть она хранит данные не по строкам, как тот же Postgres, а по колонкам. В результате, так как в одной колонке присутствуют однородные данные, данные получается эффективно сжимать при хранении на диске. Очень эффективно. В частности, этим колоночные БД хороши.
Redshift — распределённая БД. Кластер Redshift состоит из нескольких узлов, расположенных в одном регионе AWS. На каждом узле запущено несколько слайсов (slices) — процессов БД. Как правило, по числу ядер CPU.
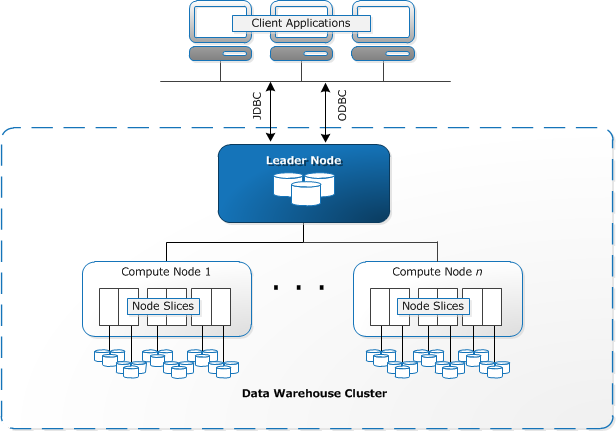
Redshift, как и ClickHouse, — поддерживает SQL. Слава богу, никакой поддержки конкретных стандартов SQL не декларируется. И правильно, SQL в этих колоночных БД весьма специфичный.
Redshift позиционируется как БД для операционной аналитики в реальном времени. Того, что называется OLAP (Online analytical processing) и BI (Business intelligence). Куча данных забивается в большую БД с поддержкой SQL. Аналитик эти данные как-то вертит. А потом всё грохается. Очень похоже на типичный юзкейс для Redshift.
Redshift поддерживает SQL. И этот SQL на 70% совпадает с SQL PostgreSQL 8. Что неудивительно.
В Redshift есть транзакции. С единственным уровнем изоляции serializable . Сделано это через read-write lock на уровне таблиц. Что, с одной стороны, — хорошо. Потому что это действительно честные транзакции. А с другой стороны — плохо. Ибо порождает серьёзные проблемы с производительностью конкурентных запросов. Даже сам уровень конкурентности в кластере Redshift (размер очереди транзакций) не может превышать пятидесяти.
В ClickHouse, напомню, вообще нет транзакций. Все асинхронно и eventually. Также в ClickHouse нет честных (с немедленным эффектом) UPDATE и DELETE . Впрочем, существующего ALTER DELETE вполне достаточно, чтобы удовлетворить GDPR.
На вход в Redshift у нас на проекте поступают данные из бид-реквестов OpenRTB. Метка времени, айдишники, цены, множители. Порядка 19 колонок сейчас. Плюс ещё разнообразные уведомления, которые вставляются в ещё 11 таблиц. Порядка 300 тысяч запросов в минуту.
В ClickHouse, на другом проекте, мы складываем DNS запросы. Их на порядок меньше — порядка 30 тысяч в минуту.
Из Redshiftа мы извлекаем в основном отчёты. Сколько всего, в штуках и в деньгах, было потрачено. С группировкой по разным параметрам и временным интервалам. Тут встречаются джойны с несколькими другими таблицами. Чтобы прилепить сюда и курсы валют, и наличие разных уведомлений. И ещё извлекаем немного статистики по входящим запросам, например, общий размер аудитории. Ну и делаем совершенно произвольные запросы в Redshift для проверки соответствия данных в разных системах. RTB — это есть взаимодействие множества разных систем. И часто нужно сверять данные.
В итоге мы в Redshift имеем, в той самой большой таблице с бид-реквестами, больше 7 миллиардов записей. И то, мы храним данные лишь где-то за последний месяц. Это порядка 370 гигабайт на диске. Всё это умещается в кластер из 4 не самых больших узлов типа dc2.large , с 2 vCPU и 15 гигабайтами памяти на борту каждого. И стоит это удовольствие порядка $850 в месяц. Недёшево.
ClickHouse другого проекта на обычных виртуалках умещается на 6 узлах о 8 гигабайтах памяти на каждом. За $240 в месяц. И это за 195 гигабайт живых данных. За полгода. В два раза меньше данных за в три раза меньше денег. Тоже недёшево.
Типы данных. В Redshift они обычные SQLные, унаследованные от PostgreSQL. Даже какой-то GEOMETRY завезли. А вот ARRAY почему-то нет. Из-за отсутствия ARRAY нам приходится хранить чуть больше строк, чем можно было бы.
ClickHouse на типы данных побогаче. Тут совершенно не следуют SQL традиции, в том числе и в их наименовании. Есть enumы. Есть сложные типы, вроде тех же массивов, кортежей и даже что-то типа объектов (вложенные типы вроде мапы). Из целочисленных мне нравится UInt256 . Буду мутить с блокчейнами, буду его использовать. Ибо в Ethereum везде сплошной uint256 .
Redshift и ClickHouse умеют здорово сжимать данные. Это одно из важных преимуществ колоночных БД. Из универсальных поддерживаются весьма эффективные и модерновые алгоритмы сжатия: LZO и ZSTD. В ClickHouse можно задать уровень сжатия.
Гораздо более интересны специализированные алгоритмы. BYTEDICT превращает строки в enumы, которых в Redshift нет. Если у вас не более 256 уникальных значений, на каждую запись будет отведён лишь один байт. Плюс словарь значений, конечно же. MOSTLY8 , MOSTLY16 , MOSTLY32 хранит целочисленные значения более короткими числами, чем предусмотрено в обычном SQL от Postgres.
Плохо то, что по умолчанию Redshift предлагает вовсе не самые оптимальные алгоритмы сжатия. Вероятно, потому, что новые алгоритмы добавлялись позднее, и они не хотели ломать обратную совместимость. И даже ANALYZE COMPRESSION недостаточно вникает в структуру данных, и тоже предлагает не самый лучший вариант.
На практике лучше всего сжимает ZSTD , и строки, и вещественные числа. Для целых чисел, в зависимости от диапазона значений, стоит выбрать какой-нибудь MOSTLY* . Для строк, которые на самом деле enum, обязательно выбирайте BYTEDICT . И да, sort key сжимать нельзя.
В Redshift тщательно выбирайте алгоритм сжатия сразу при создании таблицы. Поменять его потом может оказаться не так уж и просто. В худшем случае придётся создавать, копировать и переименовывать колонки.
Собственно, о sort key. Во всех колоночных БД нет привычных индексов, которые можно почти в любой момент создать по любым колонкам. Есть лишь два ключа. DISTSTYLE/DISTKEY в Redshift, и аналогичный по смыслу PARTITION BY в ClickHouse — отвечают за физическое распределение записей. И SORTKEY и ORDER BY — ключ сортировки.
DISTSTYLE в Redshift отвечает за то, как строки будут распределяться между узлами кластера (точнее, слайсами). AUTO — БД сама решит (не надо так делать). EVEN — строки будут размазаны псевдослучайно-равномерно. ALL — данная таблица будет присутствовать на каждом узле кластера, что может быть полезно для небольших таблиц-справочников. KEY — распределение по DISTKEY , явно выбранной колонке. Строки с одинаковыми значениями в этой колонке будут располагаться в одном слайсе. Это полезно для эффективного джойна по этой колонке.
К сожалению, DISTKEY может указывать лишь на одну колонку. Если такой удобной колонки, по которой можно всё джойнить, у вас нет, придётся довольствоваться DISTSTYLE EVEN .
PARTITION BY в ClickHouse хоть и похож по сути, имеет совершенно другой смысл. Это выражение, по которому записи в таблице будут объединяться в партиции. На каждом узле кластера. Произвольное выражение, но в первых версиях ClickHouse ключ партицирования всегда неявно соответствовал toYYYYMM(eventDate) , то есть год и месяц колонки типа Date . Партиции в ClickHouse можно очень быстро отцепить, удалить, перенести на другой узел и прицепить там.
Ключ сортировки в обеих БД это именно что ключ сортировки. Данные на диске будут отсортированы именно по этому ключу. Этот ключ может быть составным, из нескольких колонок. Соответственно, поиск по любому префиксу этого ключа будет значительно быстрее. Поэтому ключ сортировки крайне желательно включать в условие WHERE любого запроса. Иначе БД будет вынуждена просканировать всю таблицу, что, очевидно, медленнее. Впрочем, помните, что это колоночная БД. Чем меньше колонок участвует в запросе, тем быстрее. Просканировать одну колонку, в общем-то, не так уж и долго.
В ClickHouse, кроме того, индекс по ключу сортировки — разреженный. Это значит, что в индексе хранится адрес не каждой строки, а, допустим, каждой восьмитысячной строки. Это значительно уменьшает размер самого индекса. Но снижает эффективность запросов, которым нужно извлечь лишь несколько строк.
О, внешние БД. К Redshift и ClickHouse можно подключать внешние таблицы или даже целые базы данных. Из PostgreSQL или MySQL. Или даже из произвольных БД, доступных через JDBC или ODBC, в случае ClickHouse. И к этим внешним таблицам можно будет делать джойны. Может быть очень удобно хранить там длинные справочники, например.
Redshift, кроме того, может делать запросы напрямую к файлам, которые хранятся в S3. Это называется Redshift Spectrum. Это могут быть как «простые текстовые» файлы, типа CSV, так и более сложные форматы вроде JSON, или даже специальные форматы, хранящие данные в колонках, такие как Parquet. То есть вы просто складываете правильные файлы правильным образом в S3, а потом делаете SQL запросы по ним из Redshift.
А ещё Redshift может загружать и выгружать данные в/из кучи разных источников. Это делается командами COPY (загрузка) и UNLOAD (выгрузка). Можно загружать/выгружать из того же S3, из DynamoDB, из EMR (Elastic Map Reduce, то есть из разных хадупов), и даже с удалённого сервера по SSH.
А в ClickHouse есть словари. Это наборы ключей и связанных значений, которые хранятся (как правило) в памяти узлов и могут загружаться и обновляться из внешних источников. Опять-таки, идеальное решение для справочников (не сильно больших).
И Redshift, и ClickHouse — распределённые системы. А значит, они могут масштабироваться.
В Redshift всё сводится к изменению размеров и характеристик кластера. А сам кластер всегда живёт в одном регионе AWS. Можно менять количество и размеры узлов, а также управлять размером хранилища.
В простейшем случае кластер Redshift может состоять из одного узла. Впрочем, даже самый маленький узелочек будем вам стоить $160 в месяц. В single-node кластере действительно лишь один инстанс. Тут нет лидера. Несколько другая архитектура получается. Поэтому добавить ещё узлов без простоя не получится.
А в multi-node кластере, помимо узлов, которые хранят и обрабатывают данные, появляется ещё leader node. Через него проходят все запросы, и он ещё высчитывает некоторые финальные агрегаты.
Узлы можно выбирать разных размеров. И есть ещё два разных типа. DC2 узлы хранят данные исключительно на локальных SSD дисках. Больше узлов — больше места для данных в кластере. А RA3 узлы могут прозрачно вытеснять данные во внешнее хранилище. Снова S3. В этом случае объём хранилища почти не ограничен. А вы платите столько, сколько храните.
В ClickHouse всё ближе к NoSQL. Здесь кластер — это шарды реплик. Данные разбиваются на шарды. Причём Кликхаусу почти пофигу, как вы разбиваете данные. Можно просто прямо вставлять в тот шард, куда удобнее, например, ближе географически. Когда будут делаться запросы, всё равно будут опрошены все шарды. А сами шарды могут быть разных размеров и производительности. Только вот время выполнения запроса будет определяться скоростью самого медленного шарда.
А сами шарды могут состоять из нескольких реплик. Причём наличие реплик ускоряет и чтение, и запись. Поскольку репликация асинхронная, а писать можно в любую реплику. Другие реплики просто рано или поздно подсосут себе отсутствующие данные.
Redshift для общения по сети использует протокол PostgreSQL 8. Поэтому все инструменты работы с Postgres могут к нему подключиться (но не все они будут одинаково полезны в отношении Redshift).
У ClickHouse есть аж два сетевых протокола. Свой бинарный протокол, который используется для общения узлов кластера между собой, а также в родном CLI клиенте clickhouse-client . И HTTP протокол. Запросы можно засылать прямо curl ом.
JDBC драйвер. К Redshift можно подключиться и Postgres драйвером. Только последние версии этого драйвера ругаются ворнингами, что PostgreSQL 8 — это слишком старая версия сервера, которая скоро перестанет поддерживаться.
А ещё у Redshift есть свои JDBC драйвера. Аж двух версий. Версии 1.x крайне не рекомендую к использованию. Они глючат. А версии 2.x — открыты, и проблем с ними не замечено.
У ClickHouse свой JDBC драйвер. Он, почему-то, подключается через HTTP. Он работает.
Материализованные представления. Они есть и там и там. Нам они очень понравилось в ClickHouse. Потому что там их можно использовать вместе со -State агрегатными функциями и движком AggregatingMergeTree. В результате у вас получаются автоматически обновляемые агрегаты, сворачивающие исходные данные в несколько раз. При этом сами исходные данные можно потом и удалить (когда партиция заполнится).
В Redshift materialized views самые обычные. И их нужно руками обновлять командой REFRESH MATERIALIZED VIEW .
Самое интересное. Как вставлять 300k строк в минуту. В Redshift пришлось знатно помучиться.
Мама же учила вас всегда использовать prepared statement? Ну хотя бы для того, чтобы избежать SQL инъекций. Так вот, у разработчиков Redshift, ну или как минимум у разработчиков её JDBC драйвера, были другие мамы. Использовать PreparedStatement для быстрой вставки в Redshift у вас не получится. Не знаю почему, но каждый INSERT через PreparedStatement занимает не менее двух секунд. И батчи не помогают. Так что забываем про правильную вставку.
Рекомендуемый способ быстрой вставки в Redshift — это multi-row insert. Это когда в одном выражении INSERT вы указываете сразу много строк для вставки. Как-то так: INSERT INTO. VALUES (. ), (. ), . . Такую строку придётся собрать самостоятельно. И она может быть длиной до 16 мегабайт. Да, пришлось сделать это руками. Хорошо, что во входных данных нет произвольного пользовательского ввода, только цифры да айдишники, можно надеяться, что примитивного экранирования будет достаточно.
Но даже этого недостаточно для 300k вставок в минуту. Ещё более рекомендуемый способ — делать COPY из S3. То есть вы буквально пишете в S3 файлы. Например, |-separated, с разделителем в виде символа «|». Такой формат предполагает Redshift по умолчанию. Файлов должно быть больше, чем слайсов в кластере Redshift. А потом делаете COPY . И эта единственная команда COPY за те же самые две секунды всасывает все эти данные. Магия. Они называют это массивно-параллельной обработкой. Каждый слайс обрабатывает часть всех файлов. Именно поэтому файлов должно быть много.
Да, это очень странно. Но да, через S3 уже можно вставить 300k записей в минуту.
Хотя мы уже думаем, что, раз уж эти данные уже есть в S3, и, на самом деле, эти данные нужны не сильно часто, они не входят в те постоянные отчёты, что делают пользователи, может, пусть они и лежат в S3. А запросы, если понадобится, можно делать и через Redshift Spectrum.
В ClickHouse проблем со вставкой нет. Батчи JDBC, и PreparedStatement работают прекрасно. Рекомендуются батчи не менее 1000 строк и вставка не чаще раза в секунду.
Конечно, остаётся проблема того, как этот самый батч создать. Его же надо где-то накопить. В памяти, в очереди. Где-то надо. И, как всегда, есть риск либо потерять какой-нибудь кусок данных, либо вставить более одного раза.
SQL в Redshift скучен. Самый обычный SQL. Хотя вполне нормально поддерживаются common table expression (CTE). Те самые запросы с WITH . Это радует.
А в ClickHouse есть несколько уникальных плюшек. Можно считать агрегаты не по всем строкам, а по некоторому подмножеству строк, приближённые агрегаты, с помощью SAMPLE . Можно оптимизировать выполнение запроса, сначала анализируя только колонки с условиями выборки, а лишь затем извлекая данные из остальных колонок, с помощью PREWHERE . Можно сразу формировать строку «итого» при группировке, с помощью WITH TOTALS .
В ClickHouse встроено громадное количество всяких разных интересных функций агрегации. Разнообразные квантили, стандартные отклонения и прочие прелести на радость статистикам.
Redshift из коробки не выходит за рамки обычных для SQL агрегатов. Но тут можно писать UDF (user defined functions). На SQL или Python. Или даже запускаемые на Lambda. Также можно писать хранимые процедуры на PL/pgSQL. Интересно, существуют ли библиотеки статистических функций, чтобы хоть чуть-чуть приблизиться к ClickHouse?
Ну и, наконец, проблемы.
Не используйте JDBC драйвер для Redshift версии 1.x. У нас он приводил к зависаниям на пару минут при каждом открытии подключения к Redshift. Только при запуске внутри AWS. Только если в classpath при этом присутствовал и драйвер PostgreSQL. Этот же драйвер периодически вызывал странные ошибки в DataGrip. То колонки с таймстампами не отображаются. То вообще не получается стянуть схему БД. С драйвером версии 2.x проблем не замечено.
С конкурентностью у Redshift всё плохо. Транзакции сделаны через блокировку на уровне таблиц. А это значит, что те самые вставки кучи строк и тяжёлые выборки по одним и тем же таблицам нужно делать в один поток. Серьёзно, мы пытались вставлять и делать выборки в несколько потоков. В лучшем случае это нисколько не ускоряет их выполнение. В худшем случае можно словить дедлоки. Которые в худшем случае лечатся ребутом кластера. Вроде как можно поиграть с очередями запросов. Но что-то я сомневаюсь, что это как-то существенно изменит ситуацию.
У ClickHouse, кстати, всё в точности наоборот. Все операции асинхронны. Параллельная вставка лишь увеличивает (до определённого момента) общую производительность. Конкуренция идёт, как обычно, за CPU, память и дисковый ввод-вывод. Пока всего этого хватает, параллельные запросы друг другу не мешают. Но нет транзакций.
Redshift может внезапно сожрать весь диск. Как я понимаю, каждый подзапрос на самом деле создаёт временную таблицу, куда записываются результаты подзапроса. На диск. Если вы будете неаккуратны, попытаетесь извлечь слишком много строк, или слишком много колонок, в слишком большом количестве подзапросов. То вы легко случайно за несколько минут сможете занять места в два раза больше, чем у вас уже хранится в кластере. И всё. Пока операции не отменятся из-за нехватки места на диске, и это самое место не освободится, весь кластер будет стоять колом.
Redshift хоть и поддерживает SQL, но не все комбинации, которые можно выразить в SQL, в нём допустимы. Например, он очень не любит подзапросы в сочетании с внешними соединениями. Или просто слишком большое количество подзапросов. Вы просто пишете запрос, слегка его усложняете, и получаете красивую ошибку, которая объясняет ничего: [0A000] ERROR: This type of correlated subquery pattern is not supported yet .
Ситуация усугубляется ещё тем, что вы не можете поднять Redshift где-нибудь локально в Докере. Для локальных экспериментов предлагают использовать PostgreSQL. Ну так хитрый запрос без проблем выполняется в Postgres. А вот в Redshift, внезапно, отказывается работать.
Между тем, ClickHouse без проблем можно запустить локально. Open source и всё такое. Запускаете один узел в Docker, и вперёд.
Ну и последняя мелочь. В Redshift нет и намёка на разнообразные collation. Есть лишь два: CASE_SENSITIVE и CASE_INSENSITIVE . Что бы это ни значило. Опять вопиющее расхождение с PostgreSQL.
С ClickHouse проблем было меньше. Больше всего доставлял ZooKeeper. Он нужен для работы реплик. В нём узлы кластера хранят информацию о том, какой узел какие куски данных содержит. И какие, соответственно, нужно скопировать. ZooKeeper — это часть Hadoop, написан на Java. И, если его неправильно приготовить, он будет падать, глючить и жрать диск своими снапшотами и логами.
А ещё ClickHouse не поддерживается популярными инструментами управления миграциями БД. Видимо, потому, что в ClickHouse нет транзакций, и эти инструменты не могут надёжно сохранить метаданные о миграциях в самом ClickHouse. Впрочем, на практике схемы в ClickHouse меняются очень редко. Не сильно сложно руками держать несколько идемпотентных SQL скриптов для воссоздания схемы БД с нуля.
Ну и ClickHouse, к сожалению, ещё не поддерживается как managed сервис в популярных среди западных заказчиков облаках. Он есть только в Yandex.Cloud. Только из-за этого мы не смогли воткнуть ClickHouse в тот самый проект, куда воткнули Redshift. Заказчик настаивал на максимальном использовании managed сервисов в AWS.
На самом деле, Redshift и ClickHouse действительно очень похожи. Оба могут хранить очень много данных. Оба очень эффективно сжимают эти данные на диске. Оба позволяют быстро вставлять много строк.
Разница есть в транзакциях. В Redshift они строго serializable. В ClickHouse их нет. В конкурентности. Redshift, из-за блокировок на уровне таблиц, очень не любит конкурентные запросы на одни и те же таблицы. И в скорости ответа. От Redshift очень сложно добиться ответа быстрее, чем через пару секунд. А ClickHouse вполне может отвечать за сотню-другую миллисекунд.
Ну и подход к масштабируемости у них разный. Redshift хоть и может вырасти до большого кластера из десятков узлов, всё равно будет жить лишь в одном регионе. Его типичный вариант использования — загрузить много данных, чтобы их повертеть аналитиком в одиночестве.
А с ClickHouse можно построить географически распределённый кластер. Можно добиться локальности данных — иметь узел кластера в том регионе, где данные генерируются, для быстрой вставки.
P.P.S. Извините, что почти нет картинок. Но и в официальных документациях их тоже почти нет 🙁