Учебник по Python. Обучение и сохранение модели Python с помощью T-SQL
В четвертой части этой серии руководств вы узнаете, как обучить модель машинного обучения с помощью пакетов Python scikit-learn и revoscalepy. Эти библиотеки Python устанавливаются в составе машинного обучения SQL Server.
Вы загрузите модули и вызовете необходимые функции для создания и обучения модели с помощью хранимой процедуры SQL Server. Для модели требуются функции данных, разработанные в предыдущих частях этой серии руководств. Наконец, вы сохраните обученную модель в таблице SQL Server.
Работая с этой статьей, вы узнаете о следующем.
- Создание и обучение модели с помощью хранимой процедуры SQL
- Сохранение обученной модели в таблице SQL
В первой части были установлены необходимые компоненты и восстановлена демонстрационная база данных.
Во второй части вы изучили образец данных и создали несколько графиков.
В третьей части вы узнали, как создавать функции из необработанных данных с помощью функции Transact-SQL. Затем вы вызвали эту функцию из хранимой процедуры, чтобы создать таблицу, содержащую значения характеристик.
Из пятой части вы узнаете, как ввести в эксплуатацию модели, которые были обучены и сохранены в соответствии с инструкциями в четвертой части.
Разделение примера данных на обучающий и проверочный наборы
- Создайте хранимую процедуру с именем PyTrainTestSplit, чтобы разделить данные в таблице nyctaxi_sample на две части: nyctaxi_sample_training и nyctaxi_sample_testing. Чтобы создать ее, выполните следующий код:
DROP PROCEDURE IF EXISTS PyTrainTestSplit; GO CREATE PROCEDURE [dbo].[PyTrainTestSplit] (@pct int) AS DROP TABLE IF EXISTS dbo.nyctaxi_sample_training SELECT * into nyctaxi_sample_training FROM nyctaxi_sample WHERE (ABS(CAST(BINARY_CHECKSUM(medallion,hack_license) as int)) % 100) < @pct DROP TABLE IF EXISTS dbo.nyctaxi_sample_testing SELECT * into nyctaxi_sample_testing FROM nyctaxi_sample WHERE (ABS(CAST(BINARY_CHECKSUM(medallion,hack_license) as int)) % 100) >@pct GO EXEC PyTrainTestSplit 60 GO Создание модели логистической регрессии
После подготовки данных их можно использовать для обучения модели. Для этого вызывается хранимая процедура, которая выполняет некоторый код Python, принимая таблицу обучающих данных в качестве входных данных. В этом руководстве вы создадите две модели. Обе модели будут использовать двоичную классификацию.
- Хранимая процедура PyTrainScikit создает модель прогнозирования чаевых с помощью пакета scikit-learn.
- Хранимая процедура TrainTipPredictionModelRxPy создает модель прогнозирования чаевых с помощью пакета revoscalepy.
Эта хранимая процедура использует указанные входные данные для создания и обучения модели логистической регрессии. Весь код Python упаковывается в системную хранимую процедуру sp_execute_external_script .
Чтобы упростить повторное обучение модели на основе новых данных, можно поместить вызов sp_execute_external_script в другую хранимую процедуру и передать ей новые обучающие данные в качестве параметра. В этом разделе описаны этапы этого действия.
PyTrainScikit
- В среде Среда Management Studio откройте новое окно Запрос и выполните приведенную ниже инструкцию, чтобы создать хранимую процедуру PyTrainScikit. Поскольку хранимая процедура уже включает в себя определение входных данных, указывать входной запрос не требуется.
DROP PROCEDURE IF EXISTS PyTrainScikit; GO CREATE PROCEDURE [dbo].[PyTrainScikit] (@trained_model varbinary(max) OUTPUT) AS BEGIN EXEC sp_execute_external_script @language = N'Python', @script = N' import numpy import pickle from sklearn.linear_model import LogisticRegression ##Create SciKit-Learn logistic regression model X = InputDataSet[["passenger_count", "trip_distance", "trip_time_in_secs", "direct_distance"]] y = numpy.ravel(InputDataSet[["tipped"]]) SKLalgo = LogisticRegression() logitObj = SKLalgo.fit(X, y) ##Serialize model trained_model = pickle.dumps(logitObj) ', @input_data_1 = N' select tipped, fare_amount, passenger_count, trip_time_in_secs, trip_distance, dbo.fnCalculateDistance(pickup_latitude, pickup_longitude, dropoff_latitude, dropoff_longitude) as direct_distance from nyctaxi_sample_training ', @input_data_1_name = N'InputDataSet', @params = N'@trained_model varbinary(max) OUTPUT', @trained_model = @trained_model OUTPUT; ; END; GO DECLARE @model VARBINARY(MAX); EXEC PyTrainScikit @model OUTPUT; INSERT INTO nyc_taxi_models (name, model) VALUES('SciKit_model', @model); Обработка данных и компоновка модели может занять несколько минут. Сообщения, которые должны передаваться в поток stdout Python, отображаются в окне Сообщения среды Среда Management Studio. Пример:
STDOUT message(s) from external script: C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\PYTHON_SERVICES\lib\site-packages\revoscalepy SciKit_model 0x800363736B6C6561726E2E6C696E6561. TrainTipPredictionModelRxPy
Эта хранимая процедура использует пакет Python revoscalepy. Он содержит объекты, преобразования и алгоритмы, аналогичные тем, которые содержатся в пакете RevoScaleR для языка R.
С помощью revoscalepy можно создавать удаленные контексты вычислений, перемещать данные между контекстами вычислений, преобразовывать данные и обучать прогнозные модели с помощью популярных алгоритмов, таких как логистическая и линейная регрессия, деревья принятия решений и др. Дополнительные сведения см. в статьях Модуль revoscalepy в SQL Server и Справочник по функции revoscalepy.
-
В среде Среда Management Studio откройте новое окно Запрос и выполните приведенную ниже инструкцию, чтобы создать хранимую процедуру TrainTipPredictionModelRxPy. Поскольку хранимая процедура уже включает в себя определение входных данных, указывать входной запрос не требуется.
DROP PROCEDURE IF EXISTS TrainTipPredictionModelRxPy; GO CREATE PROCEDURE [dbo].[TrainTipPredictionModelRxPy] (@trained_model varbinary(max) OUTPUT) AS BEGIN EXEC sp_execute_external_script @language = N'Python', @script = N' import numpy import pickle from revoscalepy.functions.RxLogit import rx_logit ## Create a logistic regression model using rx_logit function from revoscalepy package logitObj = rx_logit("tipped ~ passenger_count + trip_distance + trip_time_in_secs + direct_distance", data = InputDataSet); ## Serialize model trained_model = pickle.dumps(logitObj) ', @input_data_1 = N' select tipped, fare_amount, passenger_count, trip_time_in_secs, trip_distance, dbo.fnCalculateDistance(pickup_latitude, pickup_longitude, dropoff_latitude, dropoff_longitude) as direct_distance from nyctaxi_sample_training ', @input_data_1_name = N'InputDataSet', @params = N'@trained_model varbinary(max) OUTPUT', @trained_model = @trained_model OUTPUT; ; END; GO - Запрос SELECT применяет пользовательскую скалярную функцию fnCalculateDistance для вычисления прямого расстояния между местами посадки и высадки. Результаты выполнения запроса сохраняются во входной переменной Python по умолчанию InputDataset .
- Двоичная переменная tipped применяется в качестве столбца меток (результатов) и формируется модель с использованием следующих столбцов признаков: passenger_count, trip_distance, trip_time_in_secsи direct_distance.
- Обученная модель сериализуется и сохраняется в переменной Python logitObj . С помощью ключевого слова OUTPUT T-SQL можно добавить переменную в качестве выходных данных хранимой процедуры. На следующем шаге эта переменная используется для вставки двоичного кода модели в таблицу базы данных nyc_taxi_models. Этот механизм упрощает хранение и повторное использование моделей.
DECLARE @model VARBINARY(MAX); EXEC TrainTipPredictionModelRxPy @model OUTPUT; INSERT INTO nyc_taxi_models (name, model) VALUES('revoscalepy_model', @model); Обработка данных и компоновка модели может занять некоторое время. Сообщения, которые должны передаваться в поток stdout Python, отображаются в окне Сообщения среды Среда Management Studio. Пример:
STDOUT message(s) from external script: C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\PYTHON_SERVICES\lib\site-packages\revoscalepy revoscalepy_model 0x8003637265766F7363616c. В следующей части этого учебника обученная модель будет использоваться для создания прогнозов.
Дальнейшие шаги
Работая с этой статьей, вы выполните следующие задачи:
- Создание и обучение модели с помощью хранимой процедуры SQL
- Обученная модель сохранена в таблице SQL
Rukovodstvo
статьи и идеи для разработчиков программного обеспечения и веб-разработчиков.
scikit-learn: Сохранение и восстановление моделей
Во многих случаях при работе с библиотекой scikit-learn [http://scikit-learn.org/stable/] вам необходимо сохранить свои модели прогнозов в файл, а затем восстановить их, чтобы повторно использовать вашу предыдущую работу. чтобы: протестировать вашу модель на новых данных, сравнить несколько моделей или что-то еще. Эта процедура сохранения также известна как сериализация объекта — представляет объект с потоком байтов, чтобы сохранить его на диске, отправить по сети или сохранить в базе данных, в то время как процедура восстановления
Время чтения: 7 мин.
Во многих случаях при работе с библиотекой scikit-learn вам необходимо сохранить свои модели прогнозов в файл, а затем восстановить их, чтобы повторно использовать вашу предыдущую работу для: тестирования вашей модели на новых данных, сравнения нескольких моделей или что-нибудь еще. Эта процедура сохранения также известна как сериализация объекта — представляет объект с потоком байтов, чтобы сохранить его на диске, отправить по сети или сохранить в базе данных, в то время как процедура восстановления известна как десериализация. В этой статье мы рассмотрим три возможных способа сделать это в Python и scikit-learn, каждый из которых имеет свои плюсы и минусы.
Инструменты для сохранения и восстановления моделей
Первый инструмент, который мы описываем, — это Pickle , стандартный инструмент Python для (де) сериализации объектов. После этого мы рассмотрим библиотеку Joblib, которая предлагает простую (де) сериализацию объектов, содержащих большие массивы данных, и, наконец, мы представляем ручной подход для сохранения и восстановления объектов в / из JSON (нотация объектов JavaScript). Ни один из этих подходов не представляет собой оптимального решения, но правильный выбор следует выбирать в соответствии с потребностями вашего проекта.
Инициализация модели
Для начала создадим одну модель scikit-learn. В нашем примере мы будем использовать модель логистической регрессии и набор данных Iris . Импортируем необходимые библиотеки, загрузим данные и разделим их на обучающий и тестовый наборы.
from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split # Load and split data data = load_iris() Xtrain, Xtest, Ytrain, Ytest = train_test_split(data.data, data.target, test_size=0.3, random_state=4)
Теперь давайте создадим модель с некоторыми параметрами, не заданными по умолчанию, и подгоним ее под данные обучения. Мы предполагаем, что вы ранее нашли оптимальные параметры модели, т. Е. Те, которые обеспечивают максимальную расчетную точность.
# Create a model model = LogisticRegression(C=0.1, max_iter=20, fit_intercept=True, n_jobs=3, solver='liblinear') model.fit(Xtrain, Ytrain)
И наша получившаяся модель:
LogisticRegression(C=0.1, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, max_iter=20, multi_class='ovr', n_jobs=3, penalty='l2', random_state=None, solver='liblinear', tol=0.0001, verbose=0, warm_start=False)
Используя fit метод, модель узнала ее коэффициенты , которые хранятся в model.coef_ . Цель состоит в том, чтобы сохранить параметры и коэффициенты модели в файл, чтобы вам не нужно было снова повторять шаги обучения модели и оптимизации параметров для новых данных.
Модуль рассола
В следующих нескольких строках кода модель, которую мы создали на предыдущем шаге, сохраняется в файл, а затем загружается как новый объект с именем pickled_model . Затем загруженная модель используется для расчета показателя точности и прогнозирования результатов на новых невидимых (тестовых) данных.
import pickle # # Create your model here (same as above) # # Save to file in the current working directory pkl_filename = "pickle_model.pkl" with open(pkl_filename, 'wb') as file: pickle.dump(model, file) # Load from file with open(pkl_filename, 'rb') as file: pickle_model = pickle.load(file) # Calculate the accuracy score and predict target values score = pickle_model.score(Xtest, Ytest) print("Test score: %".format(100 * score)) Ypredict = pickle_model.predict(Xtest)
Выполнение этого кода должно дать ваш результат и сохранить модель через Pickle:
$ python save_model_pickle.py Test score: 91.11 %
Самое замечательное в использовании Pickle для сохранения и восстановления наших моделей обучения заключается в том, что это быстро
-
вы можете сделать это в двух строках кода. Это полезно, если вы оптимизировали параметры модели на обучающих данных, поэтому вам не нужно повторять этот шаг снова. В любом случае, он не сохраняет результаты тестов или какие-либо данные. Тем не менее, вы можете сделать это, сохранив кортеж или список из нескольких объектов (и запомните, какой объект куда идет) следующим образом: tuple_objects = (model, Xtrain, Ytrain, score)
Save tuple
pickle.dump(tuple_objects, open(“tuple_model.pkl”, ‘wb’))
Restore tuple
Модуль Joblib
Библиотека Joblib предназначена для замены Pickle для объектов, содержащих большие данные. Повторим процедуру сохранения и восстановления, как и в случае с Pickle.
from sklearn.externals import joblib # Save to file in the current working directory joblib_file = "joblib_model.pkl" joblib.dump(model, joblib_file) # Load from file joblib_model = joblib.load(joblib_file) # Calculate the accuracy and predictions score = joblib_model.score(Xtest, Ytest) print("Test score: %".format(100 * score)) Ypredict = pickle_model.predict(Xtest) $ python save_model_joblib.py Test score: 91.11 %
Как видно из примера, библиотека Joblib предлагает немного более простой рабочий процесс по сравнению с Pickle. В то время как Pickle требует передачи файлового объекта в качестве аргумента, Joblib работает как с файловыми объектами, так и с строковыми именами файлов. Если ваша модель содержит большие массивы данных, каждый массив будет храниться в отдельном файле, но процедура сохранения и восстановления останется прежней. Joblib также поддерживает различные методы сжатия, такие как zlib, gzip, bz2, а также различные уровни сжатия.
Ручное сохранение и восстановление в JSON
В зависимости от вашего проекта, Pickle и Joblib часто оказываются неподходящими решениями. Некоторые из этих причин обсуждаются позже в разделе « Проблемы совместимости ». В любом случае, когда вы хотите иметь полный контроль над процессом сохранения и восстановления, лучший способ — создать свои собственные функции вручную.
Ниже показан пример сохранения и восстановления объектов вручную с помощью JSON. Этот подход позволяет нам выбрать данные, которые необходимо сохранить, такие как параметры модели, коэффициенты, данные обучения и все, что нам нужно.
Поскольку мы хотим сохранить все эти данные в одном объекте, один из возможных способов сделать это — создать новый класс, наследующий от класса модели, которым в нашем примере является LogisticRegression . Новый класс, названный MyLogReg , затем реализует методы save_json и load_json для сохранения и восстановления в / из файла JSON соответственно.
Для простоты мы сохраним только три параметра модели и данные обучения. Некоторые дополнительные данные, которые мы могли бы сохранить с помощью этого подхода, — это, например, оценка перекрестной проверки обучающего набора, тестовые данные, оценка точности тестовых данных и т. Д.
import json import numpy as np class MyLogReg(LogisticRegression): # Override the class constructor def __init__(self, C=1.0, solver='liblinear', max_iter=100, X_train=None, Y_train=None): LogisticRegression.__init__(self, C=C, solver=solver, max_iter=max_iter) self.X_train = X_train self.Y_train = Y_train # A method for saving object data to JSON file def save_json(self, filepath): dict_ = <> dict_['C'] = self.C dict_['max_iter'] = self.max_iter dict_['solver'] = self.solver dict_['X_train'] = self.X_train.tolist() if self.X_train is not None else 'None' dict_['Y_train'] = self.Y_train.tolist() if self.Y_train is not None else 'None' # Creat json and save to file json_txt = json.dumps(dict_, indent=4) with open(filepath, 'w') as file: file.write(json_txt) # A method for loading data from JSON file def load_json(self, filepath): with open(filepath, 'r') as file: dict_ = json.load(file) self.C = dict_['C'] self.max_iter = dict_['max_iter'] self.solver = dict_['solver'] self.X_train = np.asarray(dict_['X_train']) if dict_['X_train'] != 'None' else None self.Y_train = np.asarray(dict_['Y_train']) if dict_['Y_train'] != 'None' else None
Теперь попробуем класс MyLogReg Сначала мы создаем объект mylogreg , передаем ему обучающие данные и сохраняем в файл. Затем мы создаем новый объект json_mylogreg и вызываем load_json для загрузки данных из файла.
filepath = "mylogreg.json" # Create a model and train it mylogreg = MyLogReg(X_train=Xtrain, Y_train=Ytrain) mylogreg.save_json(filepath) # Create a new object and load its data from JSON file json_mylogreg = MyLogReg() json_mylogreg.load_json(filepath) json_mylogreg
Распечатав новый объект, мы сможем увидеть наши параметры и данные обучения по мере необходимости.
MyLogReg(C=1.0, X_train=array([[ 4.3, 3. , 1.1, 0.1], [ 5.7, 4.4, 1.5, 0.4], . [ 7.2, 3. , 5.8, 1.6], [ 7.7, 2.8, 6.7, 2. ]]), Y_train=array([0, 0, . 2, 2]), class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1, penalty='l2', random_state=None, solver='liblinear', tol=0.0001, verbose=0, warm_start=False)
Поскольку сериализация данных с использованием JSON фактически сохраняет объект в строковом формате, а не в потоке байтов, файл mylogreg.json можно открывать и изменять с помощью текстового редактора. Хотя этот подход был бы удобен для разработчика, он менее безопасен, поскольку злоумышленник может просматривать и изменять содержимое файла JSON. Более того, этот подход больше подходит для объектов с небольшим количеством переменных экземпляра, таких как модели scikit-learn, потому что любое добавление новых переменных требует изменений в методах сохранения и восстановления.
Проблемы совместимости
Хотя некоторые из плюсов и минусов каждого инструмента до сих пор были рассмотрены в тексте, вероятно, самым большим недостатком инструментов Pickle и Joblib является их совместимость с различными моделями и версиями Python.
Совместимость версий Python. В документации к обоим инструментам указано, что не рекомендуется (де) сериализовать объекты в разных версиях Python, хотя это может работать при изменении второстепенных версий.
Совместимость модели. Одна из наиболее частых ошибок — сохранение модели с помощью Pickle или Joblib, а затем изменение модели перед попыткой восстановления из файла. Внутренняя структура модели должна оставаться неизменной между сохранением и перезагрузкой.
Последняя проблема с Pickle и Joblib связана с безопасностью. Оба инструмента могут содержать вредоносный код, поэтому не рекомендуется восстанавливать данные из ненадежных или непроверенных источников.
Выводы
В этом посте мы описали три инструмента для сохранения и восстановления моделей scikit-learn. Библиотеки Pickle и Joblib быстры и просты в использовании, но имеют проблемы совместимости с разными версиями Python и изменениями в модели обучения. С другой стороны, ручной подход сложнее реализовать, и его необходимо модифицировать при любых изменениях в структуре модели, но с другой стороны, он может быть легко адаптирован к различным потребностям и не имеет проблем с совместимостью.
Licensed under CC BY-NC-SA 4.0
9.1. Python конкретные сериализации ¶
После обучения модели scikit-learn желательно иметь способ сохранить модель для будущего использования без необходимости повторного обучения. В следующих разделах дается несколько советов о том, как сохранить модель scikit-learn.
Можно сохранить модель в scikit-learn, используя встроенную модель сохраняемости Python, а именно pickle :
>>> from sklearn import svm >>> from sklearn import datasets >>> clf = svm.SVC() >>> X, y= datasets.load_iris(return_X_y=True) >>> clf.fit(X, y) SVC() >>> import pickle >>> s = pickle.dumps(clf) >>> clf2 = pickle.loads(s) >>> clf2.predict(X[0:1]) array([0]) >>> y[0] 0
В конкретном случае scikit-learn может быть лучше использовать замену pickle ( dump & load ) в joblib , которая более эффективна для объектов, которые несут большие массивы numpy внутри, как это часто бывает для встроенных оценщиков scikit-learn, но может только рассол на диск, а не на строку:
>>> from joblib import dump, load >>> dump(clf, 'filename.joblib')
Позже вы можете загрузить обратно маринованную модель (возможно, в другом процессе Python) с помощью:
>>> clf = load('filename.joblib')
dump и load функции также принимают файловые объекты вместо имен файлов. Более подробную информацию о сохранении данных с помощью Joblib можно найти здесь .
9.1.1. Ограничения безопасности и ремонтопригодности
pickle (и с расширением joblib) имеет некоторые проблемы, связанные с ремонтопригодностью и безопасностью. Из-за этого,
- Никогда не извлекайте ненадежные данные, так как это может привести к запуску вредоносного кода при загрузке.
- Хотя модели, сохраненные с использованием одной версии scikit-learn, могут загружаться в других версиях, это полностью не поддерживается и не рекомендуется. Также следует иметь в виду, что операции, выполняемые с такими данными, могут давать разные и неожиданные результаты.
Чтобы перестроить аналогичную модель с будущими версиями scikit-learn, необходимо сохранить дополнительные метаданные вместе с маринованной моделью:
- Обучающие данные, например ссылка на неизменяемый снимок
- Исходный код Python, используемый для создания модели
- Версии scikit-learn и их зависимости
- Оценка перекрестной проверки, полученная на данных обучения
Это должно позволить проверить, что оценка перекрестной проверки находится в том же диапазоне, что и раньше.
За некоторыми исключениями, маринованные модели должны быть переносимы между архитектурами, предполагая, что используются одни и те же версии зависимостей и Python. Если вы столкнулись с непереносимым оценщиком, откройте вопрос на GitHub. Готовые модели часто развертываются в производственной среде с использованием контейнеров, таких как Docker, чтобы заморозить среду и зависимости.
Если вы хотите узнать больше об этих проблемах и изучить другие возможные методы сериализации, обратитесь к докладу Алекса Гейнора .
Если вы хотите помочь проекту с переводом, то можно обращаться по следующему адресу support@scikit-learn.ru
© 2007 — 2020, scikit-learn developers (BSD License).
Создание компонента модели Python
В этой статье описывается компонент в конструкторе Машинного обучения Azure.
Узнайте, как использовать компонент создания модели Python для создания необученной модели из скрипта Python. Вы можете создать модель на основе любого учащегося, включенного в пакет Python в среде конструктора Машинного обучения Azure.
После создания модели вы можете использовать Модель обучения для обучения модели на наборе данных, как и любой другой учащийся в Машинном обучении Azure. Обученную модель можно передать в Модель оценки, чтобы делать прогнозы. Затем вы можете сохранить обученную модель и опубликовать рабочий процесс скоринга как веб-службу.
В настоящее время невозможно подключить этот компонент к модулю Настройки гиперпараметров модели или передать результаты оценки модели Python в Анализ модели. Если вам нужно настроить гиперпараметры или оценить модель, вы можете написать собственный сценарий Python с помощью компонента Выполнение сценария Python.
Настройка компонента
Использование этого компонента требует среднего или экспертного знания Python. Компонент поддерживает использование любого учащегося, включенного в пакеты Python, уже установленные в Машинное обучение Azure. См. список предустановленных пакетов Python в разделе Выполнение сценария Python.
Будьте очень осторожны при написании сценария и убедитесь, что нет синтаксических ошибок, таких как использование необъявленного объекта или неимпортированного компонента.
Также обратите особое внимание на список предустановленных компонентов в Выполнение сценария Python. Импортируйте только предварительно установленные компоненты. Пожалуйста, не устанавливайте в этот скрипт дополнительные пакеты, такие как «pip install xgboost», иначе будут возникать ошибки при чтении моделей в последующих компонентах.
В этой статье показано, как использовать Создание модели Python с простым конвейером. Вот схема конвейера:
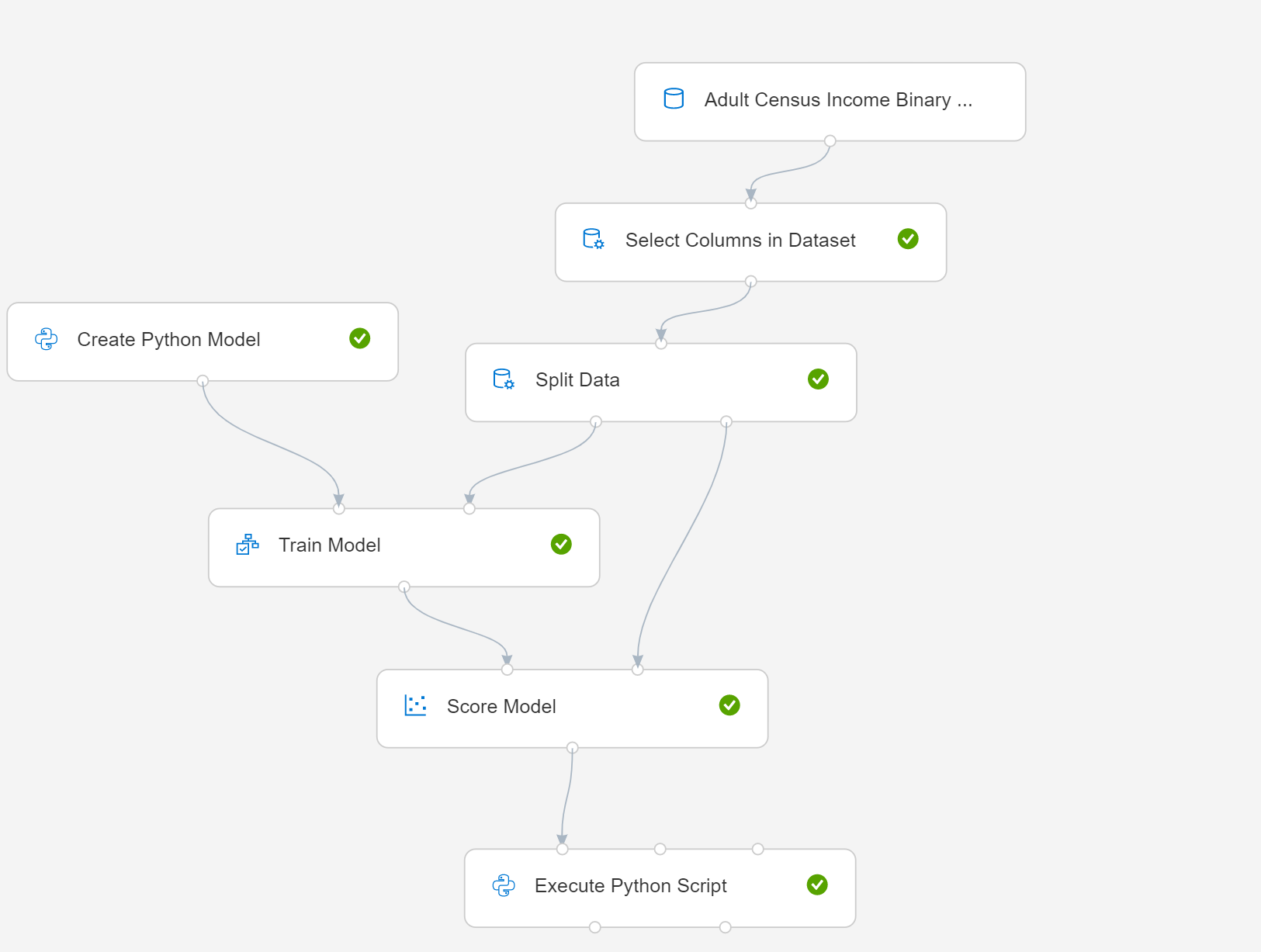
- Выберите Создать модель Python и отредактируйте сценарий, чтобы реализовать процесс моделирования или управления данными. Вы можете основывать модель на любом учащемся, включенном в пакет Python в среде машинного обучения Azure.
Обратите особое внимание на комментарии в образце кода сценария и убедитесь, что ваш сценарий строго соответствует требованиям, включая имя класса, методы, а также подпись метода. Нарушение приведет к исключениям. Создание модели Python поддерживает только создание модели на основе sklearn путем обучения с помощью модели обучения.
В следующем примере кода наивного байесовского классификатора с двумя классами используется популярный пакет sklearn:
# The script MUST define a class named Azure Machine LearningModel. # This class MUST at least define the following three methods: # __init__: in which self.model must be assigned, # train: which trains self.model, the two input arguments must be pandas DataFrame, # predict: which generates prediction result, the input argument and the prediction result MUST be pandas DataFrame. # The signatures (method names and argument names) of all these methods MUST be exactly the same as the following example. # Please do not install extra packages such as "pip install xgboost" in this script, # otherwise errors will be raised when reading models in down-stream components. import pandas as pd from sklearn.naive_bayes import GaussianNB class AzureMLModel: def __init__(self): self.model = GaussianNB() self.feature_column_names = list() def train(self, df_train, df_label): # self.feature_column_names records the column names used for training. # It is recommended to set this attribute before training so that the # feature columns used in predict and train methods have the same names. self.feature_column_names = df_train.columns.tolist() self.model.fit(df_train, df_label) def predict(self, df): # The feature columns used for prediction MUST have the same names as the ones for training. # The name of score column ("Scored Labels" in this case) MUST be different from any other columns in input data. return pd.DataFrame( )
- Подключите только что созданный компонент Создания модели Python для Модели обучения и Модели оценки.
- Если вам нужно оценить модель, добавьте компонент Выполнить скрипт Python и отредактируйте скрипт Python. Следующий сценарий представляет собой пример кода оценки:
# The script MUST contain a function named azureml_main # which is the entry point for this component. # imports up here can be used to import pandas as pd # The entry point function MUST have two input arguments: # Param: a pandas.DataFrame # Param: a pandas.DataFrame def azureml_main(dataframe1 = None, dataframe2 = None): from sklearn.metrics import accuracy_score, precision_score, recall_score, roc_auc_score, roc_curve import pandas as pd import numpy as np scores = dataframe1.ix[:, ("income", "Scored Labels", "probabilities")] ytrue = np.array([0 if val == '
Дальнейшие действия
Ознакомьтесь с набором доступных компонентов для Машинного обучения Azure.