Задача на питоне Все сразу
Заменил второй элемент списка на 17;
Добавил числа 4, 5 и 6 в конец списка;
Удалил первый элемент списка;
Удвоил список;
Вставил число 25 по индексу 3;
Вывел список, с помощью функции print()
сам код:
numbers = [8, 9, 10, 11]
Голосование за лучший ответ
numbers = [8, 9, 10, 11]
numbers[1] = 17
numbers += [4, 5, 6]
del numbers[0]
numbers *= 2
numbers.insert(3, 25)
print(*numbers)
Python. Урок 7. Работа со списками (list)


Одна из ключевых особенностей Python, благодаря которой он является таким популярным – это простота. Особенно подкупает простота работы с различными структурами данных – списками, кортежами, словарями и множествами. Сегодня мы рассмотрим работу со списками.
Что такое список (list) в Python?
Список (list) – это структура данных для хранения объектов различных типов. Если вы использовали другие языки программирования, то вам должно быть знакомо понятие массива. Так вот, список очень похож на массив, только, как было уже сказано выше, в нем можно хранить объекты различных типов. Размер списка не статичен, его можно изменять. Список по своей природе является изменяемым типом данных. Про типы данных можно подробно прочитать здесь . Переменная, определяемая как список, содержит ссылку на структуру в памяти, которая в свою очередь хранит ссылки на какие-либо другие объекты или структуры.
Как списки хранятся в памяти?
Как уже было сказано выше, список является изменяемым типом данных. При его создании в памяти резервируется область, которую можно условно назвать некоторым “контейнером”, в котором хранятся ссылки на другие элементы данных в памяти. В отличии от таких типов данных как число или строка, содержимое “контейнера” списка можно менять. Для того, чтобы лучше визуально представлять себе этот процесс взгляните на картинку ниже. Изначально был создан список содержащий ссылки на объекты 1 и 2, после операции a[1] = 3, вторая ссылка в списке стала указывать на объект 3.

Более подробно эти вопросы обсуждались в уроке 3 (Типы и модель данных).
Создание, изменение, удаление списков и работа с его элементами
Создать список можно одним из следующих способов.
>>> a = [] >>> type(a) >>> b = list() >>> type(b)
Также можно создать список с заранее заданным набором данных.
>>> a = [1, 2, 3] >>> type(a)
Если у вас уже есть список и вы хотите создать его копию, то можно воспользоваться следующим способом:
>>> a = [1, 3, 5, 7] >>> b = a[:] >>> print(a) [1, 3, 5, 7] >>> print(b) [1, 3, 5, 7]
или сделать это так:
>>> a = [1, 3, 5, 7] >>> b = list(a) >>> print(a) [1, 3, 5, 7] >>> print(b) [1, 3, 5, 7]
В случае, если вы выполните простое присвоение списков друг другу, то переменной b будет присвоена ссылка на тот же элемент данных в памяти, на который ссылается a, а не копия списка а. Т.е. если вы будете изменять список a, то и b тоже будет меняться.
>>> a = [1, 3, 5, 7] >>> b = a >>> print(a) [1, 3, 5, 7] >>> print(b) [1, 3, 5, 7] >>> a[1] = 10 >>> print(a) [1, 10, 5, 7] >>> print(b) [1, 10, 5, 7]
Добавление элемента в список осуществляется с помощью метода append().
>>> a = [] >>> a.append(3) >>> a.append("hello") >>> print(a) [3, 'hello']
Для удаления элемента из списка, в случае, если вы знаете его значение, используйте метод remove(x), при этом будет удалена первая ссылка на данный элемент.
>>> b = [2, 3, 5] >>> print(b) [2, 3, 5] >>> b.remove(3) >>> print(b) [2, 5]
Если необходимо удалить элемент по его индексу, воспользуйтесь командой del имя_списка[индекс].
>>> c = [3, 5, 1, 9, 6] >>> print(c) [3, 5, 1, 9, 6] >>> del c[2] >>> print(c) [3, 5, 9, 6]
Изменить значение элемента списка, зная его индекс, можно напрямую к нему обратившись.
>>> d = [2, 4, 9] >>> print(d) [2, 4, 9] >>> d[1] = 17 >>> print(d) [2, 17, 9]
Очистить список можно просто заново его проинициализировав, так как будто вы его вновь создаете. Для получения доступа к элементу списка укажите индекс этого элемента в квадратных скобках.
>>> a = [3, 5, 7, 10, 3, 2, 6, 0] >>> a[2] 7
Можно использовать отрицательные индексы, в таком случае счет будет идти с конца, например для доступа к последнему элементу списка можно использовать вот такую команду:
>>> a[-1] 0
Для получения из списка некоторого подсписка в определенном диапазоне индексов, укажите начальный и конечный индекс в квадратных скобках, разделив их двоеточием.
>>> a[1:4] [5, 7, 10]
Методы списков
list.append(x)
Добавляет элемент в конец списка. Ту же операцию можно сделать так a[len(a):] = [x].
>>> a = [1, 2] >>> a.append(3) >>> print(a) [1, 2, 3]
list.extend(L)
Расширяет существующий список за счет добавления всех элементов из списка L. Эквивалентно команде a[len(a):] = L.
>>> a = [1, 2] >>> b = [3, 4] >>> a.extend(b) >>> print(a) [1, 2, 3, 4]
list.insert(i, x)
Вставить элемент x в позицию i. Первый аргумент – индекс элемента после которого будет вставлен элемент x.
>>> a = [1, 2] >>> a.insert(0, 5) >>> print(a) [5, 1, 2] >>> a.insert(len(a), 9) >>> print(a) [5, 1, 2, 9]
list.remove(x)
Удаляет первое вхождение элемента x из списка.
>>> a = [1, 2, 3] >>> a.remove(1) >>> print(a) [2, 3]
Удаляет элемент из позиции i и возвращает его. Если использовать метод без аргумента, то будет удален последний элемент из списка.
>>> a = [1, 2, 3, 4, 5] >>> print(a.pop(2)) 3 >>> print(a.pop()) 5 >>> print(a) [1, 2, 4]
list.clear()
Удаляет все элементы из списка. Эквивалентно del a[:].
>>> a = [1, 2, 3, 4, 5] >>> print(a) [1, 2, 3, 4, 5] >>> a.clear() >>> print(a) []
list.index(x[, start[, end]])
Возвращает индекс элемента.
>>> a = [1, 2, 3, 4, 5] >>> a.index(4) 3
list.count(x)
Возвращает количество вхождений элемента x в список.
>>> a=[1, 2, 2, 3, 3] >>> print(a.count(2)) 2
list.sort(key=None, reverse=False)
Сортирует элементы в списке по возрастанию. Для сортировки в обратном порядке используйте флаг reverse=True. Дополнительные возможности открывает параметр key, за более подробной информацией обратитесь к документации.
>>> a = [1, 4, 2, 8, 1] >>> a.sort() >>> print(a) [1, 1, 2, 4, 8]
list.reverse()
Изменяет порядок расположения элементов в списке на обратный.
>>> a = [1, 3, 5, 7] >>> a.reverse() >>> print(a) [7, 5, 3, 1]
list.copy()
Возвращает копию списка. Эквивалентно a[:].
>>> a = [1, 7, 9] >>> b = a.copy() >>> print(a) [1, 7, 9] >>> print(b) [1, 7, 9] >>> b[0] = 8 >>> print(a) [1, 7, 9] >>> print(b) [8, 7, 9]
List Comprehensions
List Comprehensions чаще всего на русский язык переводят как абстракция списков или списковое включение, является частью синтаксиса языка, которая предоставляет простой способ построения списков. Проще всего работу list comprehensions показать на примере. Допустим вам необходимо создать список целых чисел от 0 до n, где n предварительно задается. Классический способ решения данной задачи выглядел бы так:
>>> n = int(input()) 7 >>> a=[] >>> for i in range(n): a.append(i) >>> print(a) [0, 1, 2, 3, 4, 5, 6]
Использование list comprehensions позволяет сделать это значительно проще:
>>> n = int(input()) 7 >>> a = [i for i in range(n)] >>> print(a) [0, 1, 2, 3, 4, 5, 6]
или вообще вот так, в случае если вам не нужно больше использовать n:
>>> a = [i for i in range(int(input()))] 7 >>> print(a) [0, 1, 2, 3, 4, 5, 6]
List Comprehensions как обработчик списков
В языке Python есть две очень мощные функции для работы с коллекциями: map и filter . Они позволяют использовать функциональный стиль программирования, не прибегая к помощи циклов, для работы с такими типами как list , tuple , set , dict и т.п. Списковое включение позволяет обойтись без этих функций. Приведем несколько примеров для того, чтобы понять о чем идет речь.
Пример с заменой функции map .
Пусть у нас есть список и нужно получить на базе него новый, который содержит элементы первого, возведенные в квадрат. Решим эту задачу с использованием циклов:
>>> a = [1, 2, 3, 4, 5, 6, 7] >>> b = [] >>> for i in a: b.append(i**2) >>> print('a = <>\nb = <>'.format(a, b)) a = [1, 2, 3, 4, 5, 6, 7] b = [1, 4, 9, 16, 25, 36, 49]
Та же задача, решенная с использованием map , будет выглядеть так:
>>> a = [1, 2, 3, 4, 5, 6, 7] >>> b = list(map(lambda x: x**2, a)) >>> print('a = <>\nb = <>'.format(a, b)) a = [1, 2, 3, 4, 5, 6, 7] b = [1, 4, 9, 16, 25, 36, 49]
В данном случае применена lambda -функция, о том, что это такое и как ее использовать можете прочитать здесь.
Через списковое включение эта задача будет решена так:
>>> a = [1, 2, 3, 4, 5, 6, 7] >>> b = [i**2 for i in a] >>> print('a = <>\nb = <>'.format(a, b)) a = [1, 2, 3, 4, 5, 6, 7] b = [1, 4, 9, 16, 25, 36, 49]
Пример с заменой функции filter .
Построим на базе существующего списка новый, состоящий только из четных чисел:
>>> a = [1, 2, 3, 4, 5, 6, 7] >>> b = [] >>> for i in a: if i%2 == 0: b.append(i) >>> print('a = <>\nb = <>'.format(a, b)) a = [1, 2, 3, 4, 5, 6, 7] b = [2, 4, 6]
Решим эту задачу с использованием filter :
>>> a = [1, 2, 3, 4, 5, 6, 7] >>> b = list(filter(lambda x: x % 2 == 0, a)) >>> print('a = <>\nb = <>'.format(a, b)) a = [1, 2, 3, 4, 5, 6, 7] b = [2, 4, 6]
Решение через списковое включение:
>>> a = [1, 2, 3, 4, 5, 6, 7] >>> b = [i for i in a if i % 2 == 0] >>> print('a = <>\nb = <>'.format(a, b)) a = [1, 2, 3, 4, 5, 6, 7] b = [2, 4, 6]
Слайсы / Срезы
Слайсы (срезы) являются очень мощной составляющей Python , которая позволяет быстро и лаконично решать задачи выборки элементов из списка. Выше уже был пример использования слайсов, здесь разберем более подробно работу с ними. Создадим список для экспериментов:
>>> a = [i for i in range(10)]
Слайс задается тройкой чисел, разделенных запятой: start:stop:step . Start – позиция с которой нужно начать выборку, stop – конечная позиция, step – шаг. При этом необходимо помнить, что выборка не включает элемент определяемый stop .
>>> # Получить копию списка >>> a[:] [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> # Получить первые пять элементов списка >>> a[0:5] [0, 1, 2, 3, 4] >>> # Получить элементы с 3-го по 7-ой >>> a[2:7] [2, 3, 4, 5, 6] >>> # Взять из списка элементы с шагом 2 >>> a[::2] [0, 2, 4, 6, 8] >>> # Взять из списка элементы со 2-го по 8-ой с шагом 2 >>> a[1:8:2] [1, 3, 5, 7]
Слайсы можно сконструировать заранее, а потом уже использовать по мере необходимости. Это возможно сделать, в виду того, что слайс – это объект класса slice . Ниже приведен пример, демонстрирующий эту функциональность:
>>> s = slice(0, 5, 1) >>> a[s] [0, 1, 2, 3, 4] >>> s = slice(1, 8, 2) >>> a[s] [1, 3, 5, 7]
Типо “List Comprehensions”… в генераторном режиме
Есть ещё одни способ создания списков, который похож на списковое включение, но результатом работы является не объект класса list , а генератор. Подробно про генераторы написано в “ Уроке 15. Итераторы и генераторы“.
Предварительно импортируем модуль sys , он нам понадобится:
>>> import sys
Создадим список, используя списковое включение :
>>> a = [i for i in range(10)]
проверим тип переменной a:
>>> type(a)
и посмотрим сколько она занимает памяти в байтах:
>>> sys.getsizeof(a) 192
Для создания объекта-генератора, используется синтаксис такой же как и для спискового включения, только вместо квадратных скобок используются круглые:
>>> b = (i for i in range(10)) >>> type(b) >>> sys.getsizeof(b) 120
Обратите внимание, что тип этого объекта ‘generator’ , и в памяти он занимает места меньше, чем список, это объясняется тем, что в первом случае в памяти хранится весь набор чисел от 0 до 9, а во втором функция, которая будет нам генерировать числа от 0 до 9. Для наших примеров разница в размере не существенна, рассмотрим вариант с 10000 элементами:
>>> c = [i for i in range(10000)] >>> sys.getsizeof(c) 87624 >>> d = (i for i in range(10000)) >>> sys.getsizeof(d) 120
Сейчас уже разница существенна, как вы уже поняли, размер генератора в данном случае не будет зависеть от количества чисел, которые он должен создать.
Если вы решаете задачу обхода списка, то принципиальной разницы между списком и генератором не будет:
>>> for val in a: print(val, end=' ') 0 1 2 3 4 5 6 7 8 9 >>> for val in b: print(val, end=' ') 0 1 2 3 4 5 6 7 8 9
Но с генератором нельзя работать также как и со списком: нельзя обратиться к элементу по индексу и т.п.
P.S.
Если вам интересна тема анализа данных, то мы рекомендуем ознакомиться с библиотекой Pandas. На нашем сайте вы можете найти вводные уроки по этой теме. Все уроки по библиотеке Pandas собраны в книге “Pandas. Работа с данными”.
Раздел: Python Уроки по Python Метки: Python, Уроки Python
Python. Урок 7. Работа со списками (list) : 53 комментария
- навруз 17.12.2017 там ошибка
Изменить значение элемента списка, зная его индекс, можно напрямую к нему обратившись. >>> d = [2, 4, 9]
>>> print(d)
[2, 4, 9]
>>> d[1] = 17 индекс указан первый, следовательно должен измениться первый элемент.
>>> print(d)
[2, 17, 9] а тут изменен второй элемент. Вывод должен выглядеть так [17, 4, 9] Если я не
ошибаюсь)))
- writer 18.12.2017 В Python элементы списка нумеруются с нуля. Поэтому в списке [2, 4, 9], элемент с индексом 1 – это 4, и если мы сделаем присваивание d[1] = 17, то поменяем средний элемент в списке, так как это показано в примере!
Удачи!
- навруз 20.12.2017 ой спасибо за обьяснение)) изивиняюсь за ложные обвинения и невнимательность)))
- writer 20.12.2017 Пожалуйста! Спасибо вам за интерес к блогу)))
Python map(): все, что вы хотели знать, но боялись спросить не так
Разобрали на примерах, как работает Python map(), в чем ее преимущество перед классическими циклами и какие у нее бывают применения-фишки.
Когда только-только начинаешь писать код на Python, разобраться, какому объекту уделять больше внимания, непросто. Если вы приступили к программированию и тоже хотите узнать больше про map() — своеобразную звезду языка, эта статья поможет.
Из документации
Мэппинг — это функция, которая применяет другую функцию к итерируемому объекту. Ее цель в том числе — приведение входных данных к нужной форме, чтобы потом их уменьшала reduce() .
Описание функции в документации.
Знающие подметят, что эта пара образует название MapReduce, и да, действительно, эта модель распределенных вычислений для больших объемов данных вовсю использует мэппинг + редукцию.
Рефакторим код с циклом
Представьте, что у нас есть функция my_funс() :
def my_funс(x): return х*2 Она умножает аргумент на два. А вот наш список ls :
ls = [1, 2, 3, 4, 5, 6, 7, 8, 9] Вместо классического, но затратного for loop :
i = 0 while i Можно применить мэппинг, чтобы удвоить все элементы ls один за другим:
r = map(my_funс, ls) # Заметили, что скобок у my_func нет? Посмотрим, как выглядит r:
>>> print(r) . Интерпретатор отдает ссылку на объект в памяти, но r по сути является итератором (то есть вычислений еще не проводилось!). Лишь при преобразовании r в список удвоение запустится:
>>> list(г) . [2, 4, 6, 7, 10, 12, 14, 16, 18] Скрытые возможности
Давайте посмотрим, что еще умеет эта замечательная функция. Она действительно способна облегчить нам жизнь в неожиданных ситуациях.
Строки тоже итерируются
map() использует «дочернюю» функцию на любом объекте, где применим цикл for . Мы можем применять ее к любому итерируемому объекту, даже к strings:
my_string = 'TProger' Импортируем модуль string , чтобы использовать метод capwords() — приведение к верхнему регистру:
import string Преобразуем все буквы в заглавные:
>>> list(map(string.capwords, my_string) . ['T', 'P', 'R', 'O', 'G', 'E', 'R'] map() + лямбды
Мы можем комбинировать мэппинг с безымянными функциями, чтобы код стал еще короче:
list(map(lambda x: x * x, ls)) Возведя все элементы списка ls в квадрат, мы получим такой результат:
[1, 4, 9, 16, 25, 36, 49, 64, 81] self() для обращения объекта к себе
Посмотрите на функцию ниже:
class Foo(): def __init__(self): self.factor = 2 def multiply(self, num): return num * self.factor def show(self, ls): print(list(map(self.multiply, ls))) В данном случае self позволяет перемножить элементы списка на 2:
>>> f = Foo() >>> f.show([1,2,3]) . [2, 4, 6] Загонка пользовательского ввода
Сотрудничество map() , input() и list() позволит поместить весь пользовательский текст в список. Это может пригодиться при расчете эмоциональной окраски текста, ведь слова предстоит потом возвращать к исходной форме:
>>> arr = list(map(str, input().split())) >>> print(arr) >>> Это предложение про ввод . ['Это', 'предложение', 'про', 'ввод'] Недостатки map()
Помните ссылку на итератор из первого раздела?
К недостаткам map() , так же как и в случае с filter() , можно отнести «ленивую оценку» (Lazy Evaluation). Создатели языка сделали немало в 3-й версии, чтобы улучшить производительность языка, и потому вместо обработанного объекта по умолчанию нам возвращается ссылка на итератор. Пока мы не обернем ее в list() или другой метод, обработка функцией-дочкой еще не произошла.
Это неплохо на малых оборотах, но на практике, где данные весьма разнообразны, без просмотра результата вероятность ошибок на проде увеличивается: мы просто не увидим потенциальных проблем.
Заключение
map() по праву считается воплощением декларативной природы Python. Акцент делается на применении функций, а не на изменении состояния объекта. Функция не манипулирует данными за пределами своей области действия, а лишь создает их видоизмененные экземпляры.
Если вы хотите знать больше не только про map() и reduce(), но еще и про одну участницу трио — filter(), обратитесь к этой статье.
Списковое включение (List comprehension) в Python
Python, несмотря на свою относительную молодость, постоянно развивается и стремится максимально походить на обычный текст (чтобы не только компьютеру было удобно работать с кодом, но и программисту). Одна из фишек языка, которой комфортно пользоваться – List comprehension. В русском языке есть 2 варианта перевода: списковое включение или генератор списка. Выбирайте тот, что вам удобнее.
Списковое включение – это некий синтаксический сахар, позволяющий упростить генерацию последовательностей (списков, множеств, словарей, генераторов). Никто не заставляет его использовать в своем коде. Но если вы считаете себя (или стремитесь к этому) профессионалом, вы обязаны знать эту конструкцию.
Поначалу list comprehension может показаться сложным, но как только вы освоите эту возможность, то без проблем будете с ней работать.
1. Способы формирования списков
- при помощи циклов;
- при помощи функции map() ;
- при помощи list comprehension.
1.1. Использование цикла For
Наиболее удобным является цикл for (тем не менее, никто не мешает применять цикл while , если вам хочется лишней головной боли). Последовательность действий такова:
- Предсоздаем пустой список.
- Обходим список, в котором требуется произвести ряд преобразований, или осуществляем требуемое количество итераций цикла при помощи функцииrange().
- Добавляем в пустой список новые значения / элементы с помощью метода append() .
Пример 1. Генерация списка кубов для чисел от 0 до 9 с использованием функции range()
s = [] # Создаем пустой список for i in range(10): # Осуществляем 10 итераций - от 0 до 9 s.append(i ** 3) # Добавляем к списку куб каждого числа print(s) # [0, 1, 8, 27, 64, 125, 216, 343, 512, 729]
Пример 2. Генерация списка заглавных букв из слова «Парашют»
# Так как строка является итерируемым объектом, то по ней можно пройтись в цикле. word = 'Парашют' # Начальное слово s = [] # Создаем пустой список for i in word.upper(): # Проходимся по каждой букве в слове s.append(i) # Приводим все буквы к верхнему регистру print(s) # ['П', 'А', 'Р', 'А', 'Ш', 'Ю', 'Т']
1.2. Использование функции map()
Этот способ переводит нас в область функционального программирования. Многие начинающие программисты боятся сталкиваться с этой темой. Понимать суть метода нужно, ведь вы можете встретить его в чужом скрипте.
Следует учесть, что map() возвращает не список, а итератор. Чтобы преобразовать его в список, нужно использовать функцию list() . Для получения итератора нужно задать функцию (которая применится к каждому элементу изначального списка) и сам список.
Читайте также
Лямбда функции в Python
Рассказываем, что такое лямбда функции и зачем они нужны, как их создать и использовать внутри как обычных функций, так и служебных: filter, map, reduce
Передают функцию без ее вызова (круглые скобки ставить не нужно). Можно и безымянную функцию создать внутри map() при помощи lambda . Рассмотрим примеры, так будет понятнее.
Пример 3. Генерация списка остатков от деления чисел на 5
def mod5(x): # Создаем функцию, которая возвращает return x % 5 # остаток от деления на 5 s = [5, 7, 11, 20] # Исходный список print(list(map(mod5, s))) # [0, 2, 1, 0] - список остатков
Пример 4. Генерация списков целочисленного деления на 7 с использованием лямбда-функции
s = [7, 22, 49, 701] # Исходный список чисел n = list(map(lambda x: x // 7, s)) # Новый список целочисленного деления на 7 print(n) # [1, 3, 7, 100]
1.3. Использование генератора списка
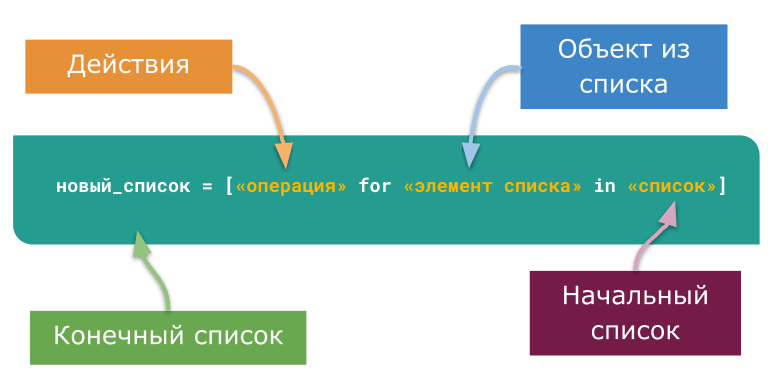
List comprehension – элегантный способ создавать списки в стиле языка Python. Стоит один раз освоить – и вы всегда будете им пользоваться, где это уместно.
Общая структура выражения:
новый_список = [«операция» for «элемент списка» in «список»]
Здесь есть 3 элемента:
– операция подразумевает некие действия, которые вы собираетесь применить к каждому элементу списка;
– элемент списка – каждый отдельный объект списка;
– список – последовательность, элементы которой вы планируете подвергнуть операции (это не обязательно должен быть list , подойдет любой итерируемый объект).
Имеется начальный список цен на изделия. Сегодня на них дана скидка 10 %. Составим новый l ist с учетом удешевления стоимости.
Пример 5. Генерация списков цен на товары с учетом скидок
old_prices = [120, 550, 410, 990] # Исходный список цен на товары в рублях discount = 0.15 # Скидка в 15 % new_prices = [int(product * (1 - discount)) for product in old_prices] # Вычисляем новые цены (без учета копеек) print(new_prices) # [102, 467, 348, 841]
Код выглядит компактным и понятным.
2. Причины использовать list comprehension
Списковые включения считаются более «пайтонообразными», нежели циклы или функция map() для генерации списков. В других популярных языках программирования вы не встретите такой конструкции.
Их можно использовать не только в качестве «создателей» списков, но и для фильтрации данных. Зачастую (но не всегда – об этом будет сказано дальше) list comprehension проще понимать и читать в чужом коде (да и в своем, когда вы вернетесь к нему через некоторое время).
Вам не обязательно создавать пустой список, цикл, чтобы сформировать новую последовательность. Все это делается в одном единственном выражении.
3. Применение условий при генерировании списков
При наличии некого начального набора данных нам может понадобиться не просто сделать какие-то однотипные операции над элементами, но и отфильтровать их. В циклах для этого применяются условия. Радует то, что условия можно внедрять и в списковые включения. Они не столь очевидны, поэтому попробуем разобраться.
3.1. Условие в конце включения
новый_список = [«операция» for «элемент списка» in «список» if «условие»]
Такой вариант использования условий позволяет отсечь часть элементов итератора. Новый список будет короче первоначального. По сути, к той же конструкции, которая приведена выше, добавляется условие if .
Пример 6. Получение списка из чисел, которые делятся на 11 без остатка
numbers = [121, 544, 111, 99, 77] # Исходный список чисел number11 = [num for num in numbers if num % 11 == 0] # Выбираем только те числа, которые делятся на 11 print(number11) # [121, 99, 77]
В результате мы получаем только те элементы, которые делятся на 11 без остатка. Следует обратить внимание, что условие может быть только одно (т. е. здесь невозможно использовать elif , else или другие if , как мы могли бы сделать в циклах).
3.2. Условие в начале включения
Если требуется не фильтрация данных по какому-то критерию, а изменение типа операции над элементами последовательности, условия могут использоваться в начале генератора списков.
Общий вид конструкции:
новый_список = [«операция» if «условие» for «элемент списка» in «список»]
В отличие от предыдущего типа условий, здесь оно может дополняться вариантом else (но elif и тут невозможен).
Пример 7. Генерирование списка, в котором будут отмечены английские и неанглийские буквы
Представим задачу: нам дают строку, в которой могут присутствовать буквы любых алфавитов. И вот мы захотели составить новый список, где напротив каждой буквы будет отмечено, является ли она английской или нет.
Приступаем. Из модуля string импортирован объект ascii_letters , в котором содержатся только буквы английского алфавита:
ascii_letters = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
Можно, конечно, и самим сделать строку со всеми этими символами, но зачем? В Python есть данная реализация. Следует избегать излишних строк кода, если разработчики уже нам помогли.
Пример 7. Генерирование списка, в котором будут отмечены английские и неанглийские буквы
from string import ascii_letters letters = 'hыtφтrцзqπ' # набор букв из разных алфавитов # Разграничиваем буквы на английские и не английские is_eng = [f'-ДА' if letter in ascii_letters else f'-НЕТ' for letter in letters] print(is_eng) # ['h-ДА', 'ы-НЕТ', 't-ДА', 'φ-НЕТ', 'т-НЕТ', 'r-ДА', 'ц-НЕТ', 'з-НЕТ', 'q-ДА', 'π-НЕТ']
В итоге мы получили желаемый список.
4. Сложные списковые включения
Циклы могут иметь несколько уровней вложенности, что относится и к генераторам списков. И вот здесь скрывается одна засада, о которой будет сказано в самом конце. А пока рассмотрим несколько примеров.
Пример 8. Приведение «многомерного» объекта к «одномерному»
# Представим список из слов, который мы хотим привести к сплошному списку из букв. # Реализация представлена ниже. words = ['Я', 'изучаю', 'Python'] # Список слов letters = [letter for word in words for letter in word] # Двойная итерация: по словам и по буквам print(letters) # ['Я', 'и', 'з', 'у', 'ч', 'а', 'ю', 'P', 'y', 't', 'h', 'o', 'n']
Пример 9. Генерация таблицы умножения от 1 до 5
# Списковые включения могут генерировать список списков. # Попробуем сформировать таблицу умножения чисел от 1 до 5. table = [[x * y for x in range(1, 6)] for y in range(1, 6)] print(table) [[1, 2, 3, 4, 5], [2, 4, 6, 8, 10], [3, 6, 9, 12, 15], [4, 8, 12, 16, 20], [5, 10, 15, 20, 25]]
Все получилось, но выглядит конструкция страшновато.
Читайте также
Задачник по Python. Тема 4. Работа со списками
Решаем задачи и отвечаем на вопросы по теме "Списки": работаем с типом данных list
Программирование на Python. Урок 2. Типы данных
Разбираем типы данных в Python: списки, кортежи, словари, множества и т. д. Рассматриваем часто используемые способы ввода-вывода данных. Решаем задачи.
5. Ограничения на применение списка включений
Хоть генераторы списков и выглядят красивыми, когда небольшие, они начинают становиться громоздкими по мере роста «мерности» и сложности.
Так как мы пишем код для людей, желательно стремиться к его максимальной читабельности. С приведенными в примере 8 и 9 ситуациями не следует частить. Никто вам не запрещает устроить хоть тройное вложение, но, поверьте, через несколько недель вы не сумеете разобраться в написанном, а что уж говорить о других людях.
Также, list comprehension даже теоретически не везде можно применить. Это касается вопроса замены циклов со множеством условий. Например, если бы задача с буквами разных алфавитов стояла иначе (напротив каждой буквы указать язык, к которому она принадлежит: русский, английский или греческий), мы бы никак не смогли воспользоваться генераторами списков.