# Программный стек ELK. Часть 1. Elasticsearch
Программный стек ELK — связка из нескольких приложений (Elasticsearch, Logstash, Kibana, Filebeat), позволяющая быстро собирать и обрабатывать всю информацию об обслуживаемой системе.
Elasticsearch — это ядро программного стека ELK, поисковый движок для работы с большими объёмами данных. Он позволяет осуществлять быстрый и эффективный поиск по всему объёму собранных данных. Для сбора системных логов в данной конфигурации стека используется FileBeat, передающий данные в фильтрационную систему Logstash, а для визуализации представляемых данных используется Kibana.
В данной серии инструкций мы рассмотрим установку и настройку всего программного стека ELK на VPS под управлением CentOS или Ubuntu.
Начнём с установки и первичной настройки Elasticsearch. Устанавливать Elasticsearch будем из официальных репозиториев разработчиков на подготовленный к работе VPS с CentOS 8 stream или Ubuntu 20.04. Все необходимые зависимости и дополнительные приложения будут установлены в процессе.
# Установка Elasticsearch
# CentOS
Устанавливать Elasticsearch будем из официального репозитория Elastic. Для этого сначала добавим GPG-ключ на сервер:
sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch После этого добавим репозиторий в список репозиториев, используемых dnf. Создадим в папке с репозиториями конфигурационный файл, содержащий все сведения о добавляемом источнике:
sudo vi /etc/yum.repos.d/elasticsearch.repo В открывшемся текстовом файле укажем основные параметры устанавливаемого репозитория:
[elasticsearch] name=Elasticsearch repository for 7.x packages baseurl=https://artifacts.elastic.co/packages/7.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=0 autorefresh=1 type=rpm-md Здесь мы указали имя, адрес, откуда устанавливать Elasticsearch, и gpg-ключ. В адресе установки мы указали 7.x — 7 версию. Если вы хотите установить более свежую версию, проверьте страницу доступных версий
(opens new window) и укажите номер версии, который хотите установить.
Теперь переходим к установке:
sudo dnf --enablerepo=elasticsearch install elasticsearch Эта команда добавит репозиторий Elasticsearch в список репозиториев, из которых возможна установка, и проверит доступность пакета Elasticsearch, после чего предложит установить его.
В процессе установки Elasticsearch установит дополнительные необходимые зависимости, в том числе необходимые для работы версии Open JDK и JVM.
После завершения установки можно добавить Elasticsearch в автозагрузку и запустить:
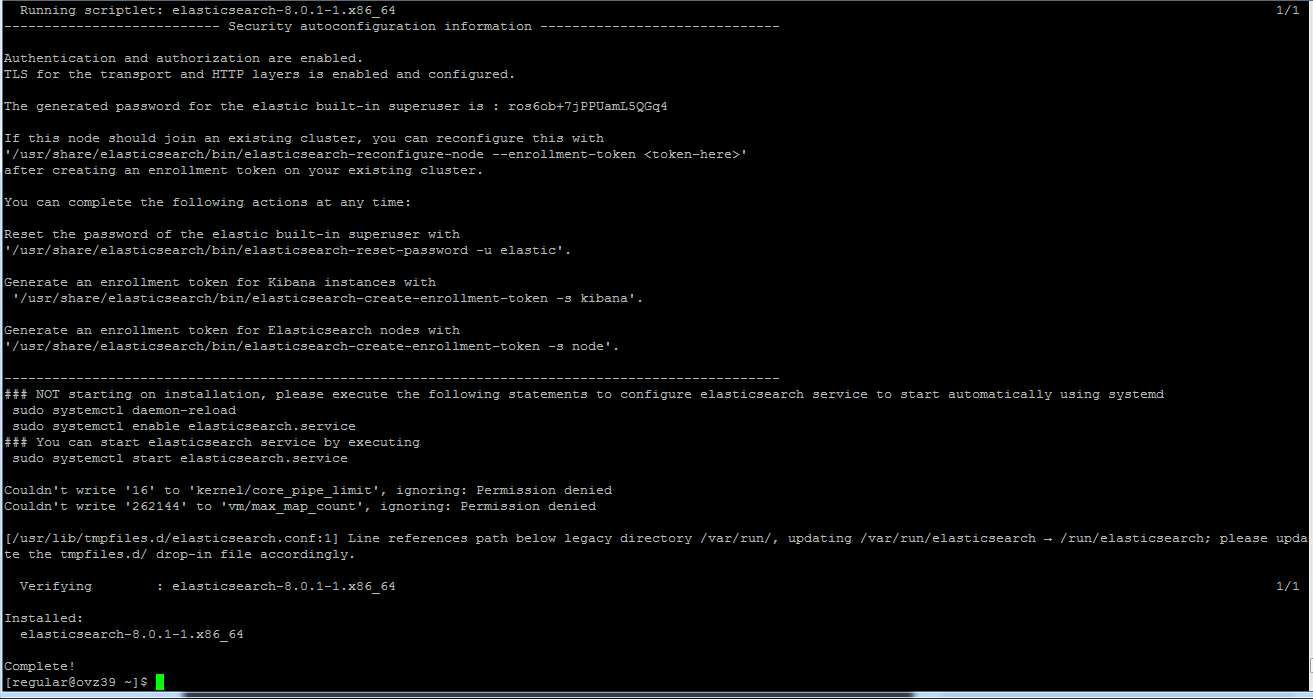
sudo systemctl daemon-reload sudo systemctl enable elasticsearch.service sudo systemctl start elasticsearch.service После этого проверим статус программы:
sudo systemctl status elasticsearch.service Вывод должен быть примерно таким:
# Ubuntu
Последовательность действий при установке Elasticsearch на Ubuntu будет примерно такой же, как и при установке на CentOS. Основное отличие — способ добавления репозитория.
Начнём с добавления gpg-ключа:
curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - После этого добавим репозиторий в список репозиториев apt. Для этого можно воспользоваться любым текстовым редактором. Мы используем команду echo :
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list Обратите внимание, что в данном случае мы тоже устанавливаем 7 версию Elasticsearch.
После добавления репозитория в список источников apt обновим его и запустим установку:
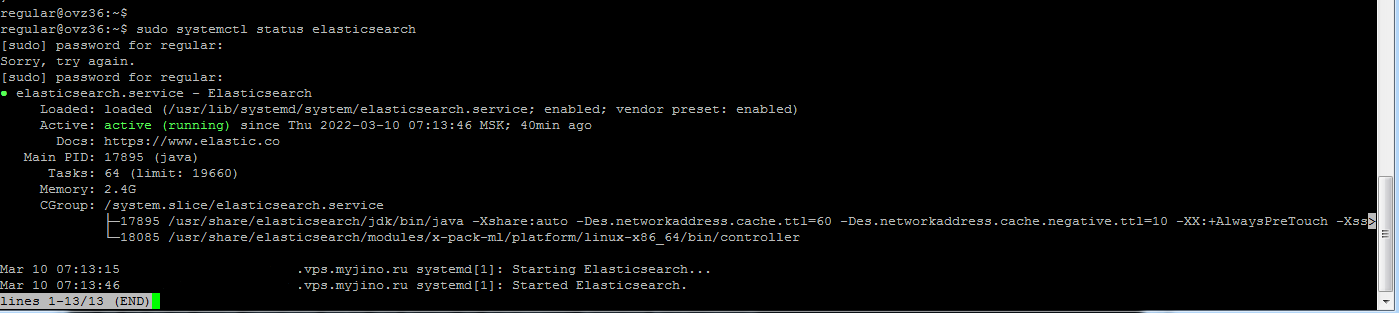
sudo apt update sudo apt install elasticsearch После завершения установки запустим Elasticsearch и проверим его статус, чтобы убедиться, что всё работает верно:
sudo systemctl enable elasticsearch sudo systemctl start elasticsearch sudo systemctl status elasticsearch Если установка прошла как положено, правильные зависимости установились и запустились, и сам Elasticsearch запустился без ошибок, то на экране появится примерно такое сообщение:
# Настройка Elasticsearch
Основные настройки Elasticsearch производятся через конфигурационный файл elasticsearch.yml , файл конфигурации виртуальной машины Java jvm.options и файл журнала Elasticsearch log4j2.properties .
На данном этапе нужно проверить сетевые настройки работы Elasticsearch. Для этого откроем основной конфигурационный файл:
sudo vi /etc/elasticsearch/elasticsearch.yml Найдём здесь блок Network , отвечающий за сетевое соединение Elasticsearch. В качестве хоста указан localhost с номером порта 9200. Оставим именно эти значения, потому что в нашем случае Elastcisearch будет работать только на внутренней машине, доступ к нему будет осуществляться из локальной сети сервера.
В этом же файле в разделе Paths указаны директории хранения логов работы программы и основных данных, с которыми будет работать Elasticsearch. Программный стек будет работать с большими объёмами данных, поэтому размещать их хранилище нужно там, где будет достаточно дискового пространства.
# Проверка работы Elasticsearch
После проверки сетевых настроек и статуса Elasticsearch (active, enabled) проверим непосредственный доступ к приложению.
Сначала проверим правильность его размещения на сервере. Посмотрим, какое приложение занимает порт 9200, указанный в качестве рабочего порта Elasticsearch:
sudo netstat -tulpn | grep 9200 # Output tcp6 0 0 127.0.0.1:9200 . * LISTEN 17895/java Как видим, порт 9200 локального адреса занят java — это виртуальная машина, на которой запущен Elasticsearch.
Теперь отправим к Elasticsearch curl-запрос:
curl -X GET 'http://localhost:9200' Результат выдачи должен быть примерно следующим:
# Output "name" : "localhost_name", "cluster_name" : "elasticsearch", "cluster_uuid" : "-JKGBFLLS5itNHDokWrPzQ", "version" : "number" : "7.17.1", "build_flavor" : "default", "build_type" : "deb", "build_hash" : "e5acb99f822233d62d6444ce45a4543dc1c8059a", "build_date" : "2022-02-23T22:20:54.153567231Z", "build_snapshot" : false, "lucene_version" : "8.11.1", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" >, "tagline" : "You Know, for Search" > Это означает, что Elasticsearch запущен и правильно функционирует, возвращая по запросу свои основные данные.
Теперь можно переходить к следующей части нашей инструкции, в которой мы будем устанавливать компонент для визуализации получаемых данных — Kibana.
© Джино, 2003–2022. «Джино» является зарегистрированным товарным знаком.
Лицензия на телематические услуги связи №150549 от 09.03.2017.
ElasticSearch и Kibana
К сожалению, просто обновить пакеты через yum или apt не достаточно — форматы данных в major-версиях отличаются, а автоматическое обновление данных при установке пакетов не предусмотрено.
- обновить ELK с 5.x до 5.6.16,
- после этого обновить индексы,
- затем обновить ELK до 6.8.0,
- снова обновить индексы,
- и наконец, обновить ELK до 7.1.1.
Обновлять индексы можно двумя путями:
- вручную с помощью прямых запросов к REST API через curl,
- через Веб-интерфейс, предварительно обновив x-pack для kibana и elasticsearch, чтобы в меню Management появился пункт Upgrade Assistant.
Мы выбрали второй вариант, как более наглядный.
Обновление до 5.6.16
- Останавливаем ElasticSearch и Kibana:
systemctl stop kibana systemctl stop elasticsearch [elasticsearch-2.x] name=Elasticsearch repository for 2.x packages baseurl=http://packages.elastic.co/elasticsearch/2.x/centos gpgcheck=1 gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch enabled=0 [elasticsearch-5.x] name=Elasticsearch repository for 5.x packages baseurl=https://artifacts.elastic.co/packages/5.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 autorefresh=1 type=rpm-md [elasticsearch-6.x] name=Elasticsearch repository for 6.x packages baseurl=https://artifacts.elastic.co/packages/6.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=0 autorefresh=1 type=rpm-md [elasticsearch-7.x] name=Elasticsearch repository for 7.x packages baseurl=https://artifacts.elastic.co/packages/7.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=0 autorefresh=1 type=rpm-md $ yum update -y kibana elasticsearch logstash $ yum info elasticsearch . Installed Packages Name : elasticsearch Arch : noarch Version : 5.6.16 . $ yum info kibana . Installed Packages Name : kibana Arch : noarch Version : 5.6.16 . Обновление x-pack plugin:
- Проверяем что плагин установлен:
$ /usr/share/elasticsearch/bin/elasticsearch-plugin list x-pack $ /usr/share/kibana/bin/kibana-plugin list x-pack@5.6.12$ /usr/share/elasticsearch/bin/elasticsearch-plugin remove x-pack $ /usr/share/kibana/bin/kibana-plugin remove x-pack$ /usr/share/elasticsearch/bin/elasticsearch-plugin install x-pack $ /usr/share/kibana/bin/kibana-plugin install x-packНастройка x-pack:
- Если у вас отключена авторизация внутри elk, то необходимо отключить авторизацию в x-pack:
$ grep ^xpack.security /etc/elasticsearch/elasticsearch.yml xpack.security.enabled: false xpack.security.authc.accept_default_password: true$ grep ^path.data: /etc/elasticsearch/elasticsearch.yml path.data: /var/lib/elasticsearch$ grep ^path.logs: /etc/elasticsearch/elasticsearch.yml path.logs: /var/log/elasticsearchЗапуск и проверка 5.6.16:
- Теперь можно запустить elasticsearch и kibana:
$ systemctl start kibana $ systemctl start elasticsearchОбновление до 6.8.0:
- Останавливаем сервисы:
$ systemctl stop kibana $ systemctl stop elasticsearch$ yum update -y kibana elasticsearch logstash$ yum info elasticsearch . Installed Packages Name : elasticsearch Arch : noarch Version : 6.8.0 . $ yum info kibana . Installed Packages Name : kibana Arch : noarch Version : 6.8.0 . x-pack:
- Снова удаляем старую версию из ElasticSearch:
$ /usr/share/elasticsearch/bin/elasticsearch-plugin list ES_PATH_CONF must be set to the configuration path $ export ES_PATH_CONF=/etc/elasticsearch $ /usr/share/elasticsearch/bin/elasticsearch-plugin list x-pack WARNING: plugin [x-pack] was built for Elasticsearch version 5.6.16 but version 6.8.0 is required $ /usr/share/elasticsearch/bin/elasticsearch-plugin remove x-pack -> removing [x-pack]. -> preserving plugin config files [/etc/elasticsearch/x-pack] in case of upgrade; use --purge if not needed $ /usr/share/kibana/bin/kibana-plugin list x-pack@5.6.16 $ /usr/share/kibana/bin/kibana-plugin remove x-pack Removing x-pack. Plugin removal complete$ /usr/share/kibana/bin/kibana-plugin install x-pack Plugin installation was unsuccessful due to error "Kibana now contains X-Pack by default, there is no longer any need to install it as it is already present."Запуск и проверка 6.8.0:
- Запускаем ElasticSearch и получаем первую ошибку:
$ systemctl start elasticsearch $ journalctl -u elasticsearch -f . Jun 12 18:17:48 elk.cdnnow.ru systemd[1]: Started Elasticsearch. Jun 12 18:17:48 elk.cdnnow.ru systemd[1]: elasticsearch.service: main process exited, code=exited, status=1/FAILURE Jun 12 18:17:48 elk.cdnnow.ru systemd[1]: Unit elasticsearch.service entered failed state. Jun 12 18:17:48 elk.cdnnow.ru systemd[1]: elasticsearch.service failed.$ sudo -u elasticsearch -H /usr/share/elasticsearch/bin/elasticsearch -p /var/run/elasticsearch/elasticsearch.pid --quiet /usr/share/elasticsearch/bin/elasticsearch-env: line 71: /etc/sysconfig/elasticsearch: Permission denied$ ls -l /etc/sysconfig/elasticsearch* -rw-rw---- 1 root root 2.5K Sep 27 2017 elasticsearch -rw-rw---- 1 root elasticsearch 1.6K May 15 23:13 elasticsearch.rpmnewmv -f /etc/sysconfig/elasticsearch.rpmnew /etc/sysconfig/elasticsearchmv -f /etc/elasticsearch/log4j2.properties.rpmnew /etc/elasticsearch/log4j2.properties[2019-06-12T15:28:50,865][WARN ][o.e.b.JNANatives ] [unknown] Unable to lock JVM Memory: error=12, reason=Cannot allocate memory [2019-06-12T15:28:50,867][WARN ][o.e.b.JNANatives ] [unknown] This can result in part of the JVM being swapped out. [2019-06-12T15:28:50,867][WARN ][o.e.b.JNANatives ] [unknown] Increase RLIMIT_MEMLOCK, soft limit: 65536, hard limit: 65536 [2019-06-12T15:28:50,867][WARN ][o.e.b.JNANatives ] [unknown] These can be adjusted by modifying /etc/security/limits.conf, for example: # allow user 'elasticsearch' mlockall elasticsearch soft memlock unlimited elasticsearch hard memlock unlimited [2019-06-12T15:28:50,867][WARN ][o.e.b.JNANatives ] [unknown] If you are logged in interactively, you will have to re-login for the new limits to take effect. elasticsearch soft memlock unlimited elasticsearch hard memlock unlimited$ systemctl restart elasticsearch $ systemctl start kibanaУстраняем проблемы:
- Открываем https://domain/app/kibana#/management/elasticsearch/upgrade_assistant
- Исправляем все ошибки.
- Проблема: Number of open shards exceeds cluster soft limit. There are [6115] open shards in this cluster, but the cluster is limited to [1000] per data node, for [1000] maximum.
- Решение — повысили лимит до 20000:
$ grep shards /etc/elasticsearch/elasticsearch.yml . cluster.max_shards_per_node: 20000 . $ cat /etc/elasticsearch/elasticsearch.yml . discovery.zen.ping.unicast.hosts: ["127.0.0.1"] . Реиндексация!
- Перед тем, как нажимать Reindex, рекомендуется удалить все ненужные индексы.
- В процессе реиндекса индексы будут переходить в состояние read-only и данные поступать не будут.
- Необходимо убедиться в том что на диске с индексами есть свободное место:
- Новые индексы создаются путём переноса данных из старых индексов.
- Например: если старый индекс занимал 10 гигабайт, для нового индекса понадобится примерно 8 гигабайт места.
- Если одновременно запустить reindex большого количества индексов, то места может не хватить.
Обновление пакетов до 7.1.1:
- Останавливаем сервисы:
$ systemctl stop kibana $ systemctl stop elasticsearch$ yum update -y kibana elasticsearch logstash$ yum info elasticsearch . Installed Packages Name : elasticsearch Arch : noarch Version : 7.1.1 . $ yum info kibana . Installed Packages Name : kibana Arch : noarch Version : 7.1.1 .Финальный запуск и проверка:
- Запускаем сервисы:
$ systemctl start elasticsearch $ systemctl start kibana"message":"Status changed from yellow to red - Validation Failed: 1: this action would add [2] total shards, but this cluster currently has [3060]/[1000] maximum shards open;: [index_creation_exception] failed to create index [.kibana_8]"curl -X PUT localhost:9200/_cluster/settings -H "Content-Type: application/json" -d ' < "persistent": < "cluster.max_shards_per_node": "10000" >>'Подпишитесь на новые статьи:
Спасибо за Вашу заявку! В скором времени наш менеджер свяжется с Вами.
Установка и настройка Elasticsearch в Ubuntu 18.04

Elasticsearch — это платформа для распределенного поиска и анализа данных в режиме реального времени. Она пользуется популярностью благодаря удобству в использовании, наличию мощных характеристик и возможности масштабирования.
Эта статья расскажет вам о том, как установить Elasticsearch, настроить платформу под ваш вариант использования, обеспечить безопасность установки и начать работу с вашим сервером Elasticsearch.
Предварительные требования
Для работы с этим обучающим руководством вам потребуется следующее:
- Сервер Ubuntu 18.04 с 4 ГБ оперативной памяти и 2 процессорами, настроенный пользователем sudo без прав root. Вы можете это сделать, воспользовавшись рекомендациями по Начальной настройке сервера с Ubuntu 18.04
- Установленный OpenJDK 11
В этом обучающем модуле мы будем использовать минимальное количество процессоров и оперативной памяти, необходимое для работы с Elasticsearch. Обратите внимание, что требования сервера Elasticsearch к количеству процессоров, оперативной памяти и хранению данных зависят от ожидаемого объема журналов.
Шаг 1 — Установка и настройка Elasticsearch
Компоненты Elasticsearch отсутствуют в репозиториях пакетов Ubuntu по умолчанию. Однако их можно установить с помощью APT после добавления списка источников пакетов Elastic.
Все пакеты подписаны ключом подписи Elasticsearch для защиты вашей системы от поддельных пакетов. Ваш диспетчер пакетов будет считать надежными пакеты, для которых проведена аутентификация с помощью ключа. На этом шаге вы импортируете открытый ключ Elasticsearch GPG и добавите список источников пакетов Elastic для установки Elasticsearch.
Для начала используйте cURL, инструмент командной строки для передачи данных с помощью URL, для импорта открытого ключа Elasticsearch GPG в APT. Обратите внимание, что мы используем аргументы -fsSL для подавления всех текущих и возможных ошибок (кроме сбоя сервера), а также, чтобы разрешить cURL подать запрос на другой локации при переадресации. Выведите результаты команды cURL в программу apt-key, которая добавит открытый ключ GPG в APT.
Затем добавьте список источников Elastic в каталог sources.list.d , где APT будет искать новые источники:
Затем обновите списки пакетов, чтобы APT мог прочитать новый источник Elastic:
Установите Elasticsearch с помощью следующей команды:
Теперь система Elasticsearch установлена и готова к настройке.
Шаг 2 — Настройка Elasticsearch
Для настройки Elasticsearch мы отредактируем файлы конфигурации. В Elasticsearch имеется три файла конфигурации:
- elasticsearch.yml для настройки Elasticsearch, главный файл конфигурации
- jvm.options для настройки виртуальной машины Elasticsearch Java Virtual Machine (JVM)
- log4j2.properties для настройки журнала Elasticsearch
Для целей настоящего обучающего модуля нас интересует файл elasticsearch.yml , где хранится большая часть параметров конфигурации. Этот файл находится в каталоге /etc/elasticsearch .
Используйте предпочитаемый текстовый редактор для изменения файла конфигурации Elasticsearch. Мы будем использовать nano :
Примечание. Файл конфигурации Elasticsearch представлен в формате YAM. Это означает, что нам нужно сохранить формат отступов. Не добавляйте никакие дополнительные пробелы при редактировании этого файла.
Файл elasticsearch.yml предоставляет варианты конфигурации для вашего кластера, узла, пути, памяти, сети, обнаружения и шлюза. Большинство из этих вариантов уже настроены в файле, но вы можете изменить их в соответствии с вашими потребностями. В нашем случае для демонстрации односерверной конфигурации мы будем регулировать настройки только для хоста сети.
Elasticsearch прослушивает весь трафик порта 9200 . По желанию вы можете ограничить внешний доступ к вашему экземпляру Elasticsearch, чтобы посторонние не смогли прочесть ваши данные или отключить ваш кластер Elasticsearch через [REST API] (https://en.wikipedia.org/wiki/Representational_state_transfer). Для ограничения доступа и повышения безопасности найдите строку с указанием network.host , уберите с нее значок комментария и замените значение на localhost , чтобы она выглядела следующим образом:
/etc/elasticsearch/elasticsearch.yml
. . . # ---------------------------------- Network ----------------------------------- # # Set the bind address to a specific IP (IPv4 or IPv6): # network.host: localhost . . .Мы указали localhost , и теперь Elasticsearch прослушивает все интерфейсы и связанные IP-адреса. Если вы хотите, чтобы прослушивался только конкретный интерфейс, вы можете указать его IP-адрес вместо localhost . Сохраните и закройте elasticsearch.yml . Если вы используете nano , вы можете сделать это, нажав CTRL+X , затем Y , а затем ENTER .
Это минимальные настройки, с которыми вы можете начинать использовать Elasticsearch. Теперь вы можете запустить Elasticsearch в первый раз.
Запустите службу Elasticsearch с помощью systemctl . Запуск Elasticsearch может занять некоторое время. В другом случае вы можете увидеть сообщение об ошибке подключения.
Затем запустите следующую команду, чтобы активировать Elasticsearch при каждой загрузке сервера:
Мы включили Elasticsearch при запуске и теперь перейдем к следующему шагу для обсуждения вопросов безопасности.
Шаг 3 — Защита Elasticsearch
По умолчанию любой пользователь, который имеет доступ к HTTP API может контролировать Elasticsearch. Это не всегда связано с риском для безопасности, так как Elasticsearch прослушивает только циклический интерфейс (имеется в виду 127.0.0.1 ), доступ к которому только локальный. Таким образом, невозможно получить публичный доступ к серверу, и, пока все пользователи сервера являются проверенными, вопрос безопасности не будет для вас серьезной проблемой.
Если вам потребуется разрешить удаленный доступ к HTTP API, вы можете ограничить открытость сети с помощью настроек брандмауэра Ubuntu по умолчанию, UFW. Этот брандмауэр уже должен быть активирован, если вы выполнили все предварительные шаги по Начальной настройке сервера с Ubuntu 18.04.
Теперь мы настроим брандмауэр для доступа к порту Elasticsearch HTTP API по умолчанию (TCP 9200) для надежного удаленного хоста. Как правило, это сервер, который вы используете при настройке на одном сервере, например 198.51.100.0 . Для доступа введите следующую команду:
После этого вы можете активировать UFW с помощью команды:
В заключение проверьте статус UFW с помощью следующей команды:
Если вы правильно задали правила, результат должен выглядеть так:
OutputStatus: active To Action From -- ------ ---- 9200 ALLOW 198.51.100.0 22 ALLOW Anywhere 22 (v6) ALLOW Anywhere (v6)Теперь UFW должен быть активирован и настроен на защиту порта Elasticsearch 9200.
Если вы хотите инвестировать в дополнительную защиту, Elasticsearch предлагает к покупке платный плагин Shield.
Шаг 4 — Тестирование Elasticsearch
Сейчас система Elasticsearch должна работать на порту 9200 Вы можете протестировать ее с помощью cURL и запроса GET.
Вы должны увидеть следующий ответ:
Output< "node.name" : "My First Node", "cluster.name" : "mycluster1", "version" : < "number" : "2.3.1", "build_hash" : "bd980929010aef404e7cb0843e61d0665269fc39", "build_timestamp" : "2020-04-04T12:25:05Z", "build_snapshot" : false, "lucene_version" : "5.5.0" >, "tagline" : "You Know, for Search" >Если вы получите ответ, аналогичный вышеуказанному, значит Elasticsearch работает корректно. Если нет, убедитесь, что вы правильно выполнили инструкции по установке и дали время системе Elasticsearch для полного запуска.
Для более тщательной проверки Elasticsearch выполните следующую команду:
В выводе для команды, указанной выше, вы можете проверить все текущие настройки для узла, кластера, путей приложения, модулей и т.д.
Шаг 5 — Использование Elasticsearch
Чтобы начать использовать Elasticsearch, в первую очередь нужно добавить некоторые данные. Elasticsearch использует RESTful API, который соответствует обычным командам CRUD: create, read, update и delete. Для работы мы снова используем команду cURL.
Ваша первая запись может выглядеть так:
Вы должны получить следующий ответ:
Output,"_seq_no":1,"_primary_term":1>С помощью cURL мы отправили запрос HTTP POST на сервер Elasticsearch. URI запроса — /tutorial/helloworld/1 с несколькими параметрами:
- tutorial — это индекс данных в Elasticsearch.
- helloworld — это тип.
- 1 — это ID нашей записи по индексу и типу.
Вы можете получить эту первую запись по запросу HTTP GET.
Вывод должен выглядеть следующим образом:
Output>Для изменения существующей записи вы можете использовать запрос HTTP PUT.
Elasticsearch должна признать успешное изменение следующим образом:
Output< "_index" : "tutorial", "_type" : "helloworld", "_id" : "1", "_version" : 2, "_shards" : < "total" : 2, "successful" : 1, "failed" : 0 >, "created" : false >В примере, представленном выше, мы изменили message первой записи на “Hello, People!”. При этом номер версии автоматически увеличился до 2 .
Возможно, вы заметили дополнительный аргумент pretty в представленном выше запросе. Он обеспечивает удобный для восприятия человеком формат, и вы можете для написания каждого поля данных использовать новый ряд. Вы также можете “приукрасить” ваши результаты при получении данных, чтобы получить более читабельный вывод, путем введения следующей команды.
Теперь ответ отформатирован так, чтобы синтаксис был удобен для человека:
Output< "_index" : "tutorial", "_type" : "helloworld", "_id" : "1", "_version" : 2, "found" : true, "_source" : < "message" : "Hello, People!" >>Мы добавили и запросили данные в Elasticsearch. Информацию о других операциях можно найти в документации API.
Заключение
Вы установили, настроили и начали использовать Elasticsearch. С момента первоначального выпуска Elasticsearch команда Elastic разработала три дополнительных инструмента, Logstash, Kabana и Beats, предназначенные для использования совместно с Elasticsearch в составе комплекса Elastic. Вместе эти инструменты обеспечивают возможность поиска, анализа и визуализации журналов в любом формате, сгенерированных любым источником, посредством практики, называемой централизованным ведением журнала. Чтобы познакомиться с использованием комплекса Elastic в Ubuntu 18.04, воспользуйтесь нашим руководством Установка Elasticsearch, Logstash и Kibana (комплекс Elastic) в Ubuntu 18.04.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
Основы Elasticsearch
Elasticsearch — поисковый движок с json rest api, использующий Lucene и написанный на Java. Описание всех преимуществ этого движка доступно на официальном сайте. Далее по тексту будем называть Elasticsearch как ES.
Подобные движки используются при сложном поиске по базе документов. Например, поиск с учетом морфологии языка или поиск по geo координатам.
В этой статье я расскажу про основы ES на примере индексации постов блога. Покажу как фильтровать, сортировать и искать документы.
Чтобы не зависеть от операционной системы, все запросы к ES я буду делать с помощью CURL. Также есть плагин для google chrome под названием sense.
По тексту расставлены ссылки на документацию и другие источники. В конце размещены ссылки для быстрого доступа к документации. Определения незнакомых терминов можно прочитать в глоссарии.
Установка ES
Для этого нам сначала потребуется Java. Разработчики рекомендуют установить версии Java новее, чем Java 8 update 20 или Java 7 update 55.
Дистрибутив ES доступен на сайте разработчика. После распаковки архива нужно запустить bin/elasticsearch . Также доступны пакеты для apt и yum. Есть официальный image для docker. Подробнее об установке.
После установки и запуска проверим работоспособность:
# для удобства запомним адрес в переменную #export ES_URL=$(docker-machine ip dev):9200 export ES_URL=localhost:9200 curl -X GET $ES_URLНам придет приблизительно такой ответ:
< "name" : "Heimdall", "cluster_name" : "elasticsearch", "version" : < "number" : "2.2.1", "build_hash" : "d045fc29d1932bce18b2e65ab8b297fbf6cd41a1", "build_timestamp" : "2016-03-09T09:38:54Z", "build_snapshot" : false, "lucene_version" : "5.4.1" >, "tagline" : "You Know, for Search" >Индексация
Добавим пост в ES:
# Добавим документ c id 1 типа post в индекс blog. # ?pretty указывает, что вывод должен быть человеко-читаемым. curl -XPUT "$ES_URL/blog/post/1?pretty" -d' < "title": "Веселые котята", "content": "Смешная история про котят
", "tags": [ "котята", "смешная история" ], "published_at": "2014-09-12T20:44:42+00:00" >'
< "_index" : "blog", "_type" : "post", "_id" : "1", "_version" : 1, "_shards" : < "total" : 2, "successful" : 1, "failed" : 0 >, "created" : false >ES автоматически создал индекс blog и тип post. Можно провести условную аналогию: индекс — это база данных, а тип — таблица в этой БД. Каждый тип имеет свою схему — mapping, также как и реляционная таблица. Mapping генерируется автоматически при индексации документа:
# Получим mapping всех типов индекса blog curl -XGET "$ES_URL/blog/_mapping?pretty"В ответе сервера я добавил в комментариях значения полей проиндексированного документа:
< "blog" : < "mappings" : < "post" : < "properties" : < /* "content": "Смешная история про котят
", */ "content" : < "type" : "string" >, /* "published_at": "2014-09-12T20:44:42+00:00" */ "published_at" : < "type" : "date", "format" : "strict_date_optional_time||epoch_millis" >, /* "tags": ["котята", "смешная история"] */ "tags" : < "type" : "string" >, /* "title": "Веселые котята" */ "title" : < "type" : "string" >> > > > >
Стоит отметить, что ES не делает различий между одиночным значением и массивом значений. Например, поле title содержит просто заголовок, а поле tags — массив строк, хотя они представлены в mapping одинаково.
Позднее мы поговорим о маппинге более подобно.Запросы
Извлечение документа по его id:
# извлечем документ с id 1 типа post из индекса blog curl -XGET "$ES_URL/blog/post/1?pretty"< "_index" : "blog", "_type" : "post", "_id" : "1", "_version" : 1, "found" : true, "_source" : < "title" : "Веселые котята", "content" : "Смешная история про котят
", "tags" : [ "котята", "смешная история" ], "published_at" : "2014-09-12T20:44:42+00:00" > >
В ответе появились новые ключи: _version и _source . Вообще, все ключи, начинающиеся с _ относятся к служебным.
Ключ _version показывает версию документа. Он нужен для работы механизма оптимистических блокировок. Например, мы хотим изменить документ, имеющий версию 1. Мы отправляем измененный документ и указываем, что это правка документа с версией 1. Если кто-то другой тоже редактировал документ с версией 1 и отправил изменения раньше нас, то ES не примет наши изменения, т.к. он хранит документ с версией 2.
Ключ _source содержит тот документ, который мы индексировали. ES не использует это значение для поисковых операций, т.к. для поиска используются индексы. Для экономии места ES хранит сжатый исходный документ. Если нам нужен только id, а не весь исходный документ, то можно отключить хранение исходника.
Если нам не нужна дополнительная информация, можно получить только содержимое _source:
curl -XGET "$ES_URL/blog/post/1/_source?pretty"< "title" : "Веселые котята", "content" : "Смешная история про котят
", "tags" : [ "котята", "смешная история" ], "published_at" : "2014-09-12T20:44:42+00:00" >
Также можно выбрать только определенные поля:
# извлечем только поле title curl -XGET "$ES_URL/blog/post/1?_source=title&pretty"Давайте проиндексируем еще несколько постов и выполним более сложные запросы.
curl -XPUT "$ES_URL/blog/post/2" -d' < "title": "Веселые щенки", "content": "Смешная история про щенков
", "tags": [ "щенки", "смешная история" ], "published_at": "2014-08-12T20:44:42+00:00" >'
curl -XPUT "$ES_URL/blog/post/3" -d' < "title": "Как у меня появился котенок", "content": "Душераздирающая история про бедного котенка с улицы
", "tags": [ "котята" ], "published_at": "2014-07-21T20:44:42+00:00" >'
Сортировка
# найдем последний пост по дате публикации и извлечем поля title и published_at curl -XGET "$ES_URL/blog/post/_search?pretty" -d' < "size": 1, "_source": ["title", "published_at"], "sort": [] >'< "took" : 8, "timed_out" : false, "_shards" : < "total" : 5, "successful" : 5, "failed" : 0 >, "hits" : < "total" : 3, "max_score" : null, "hits" : [ < "_index" : "blog", "_type" : "post", "_id" : "1", "_score" : null, "_source" : < "title" : "Веселые котята", "published_at" : "2014-09-12T20:44:42+00:00" >, "sort" : [ 1410554682000 ] > ] > >Мы выбрали последний пост. size ограничивает кол-во документов в выдаче. total показывает общее число документов, подходящих под запрос. sort в выдаче содержит массив целых чисел, по которым производится сортировка. Т.е. дата преобразовалась в целое число. Подробнее о сортировке можно прочитать в документации.
Фильтры и запросы
ES с версии 2 не различает фильты и запросы, вместо этого вводится понятие контекстов.
Контекст запроса отличается от контекста фильтра тем, что запрос генерирует _score и не кэшируется. Что такое _score я покажу позже.Фильтрация по дате
Используем запрос range в контексте filter:
# получим посты, опубликованные 1ого сентября или позже curl -XGET "$ES_URL/blog/post/_search?pretty" -d' < "filter": < "range": < "published_at": < "gte": "2014-09-01" >> > >'Фильтрация по тегам
Используем term query для поиска id документов, содержащих заданное слово:
# найдем все документы, в поле tags которых есть элемент 'котята' curl -XGET "$ES_URL/blog/post/_search?pretty" -d' < "_source": [ "title", "tags" ], "filter": < "term": < "tags": "котята" >> >'< "took" : 9, "timed_out" : false, "_shards" : < "total" : 5, "successful" : 5, "failed" : 0 >, "hits" : < "total" : 2, "max_score" : 1.0, "hits" : [ < "_index" : "blog", "_type" : "post", "_id" : "1", "_score" : 1.0, "_source" : < "title" : "Веселые котята", "tags" : [ "котята", "смешная история" ] >>, < "_index" : "blog", "_type" : "post", "_id" : "3", "_score" : 1.0, "_source" : < "title" : "Как у меня появился котенок", "tags" : [ "котята" ] >> ] > >Полнотекстовый поиск
Три наших документа содержат в поле content следующее:
-
Смешная история про котят
-
Смешная история про щенков
-
Душераздирающая история про бедного котенка с улицы
Используем match query для поиска id документов, содержащих заданное слово:
# source: false означает, что не нужно извлекать _source найденных документов curl -XGET "$ES_URL/blog/post/_search?pretty" -d' < "_source": false, "query": < "match": < "content": "история" >> >'< "took" : 13, "timed_out" : false, "_shards" : < "total" : 5, "successful" : 5, "failed" : 0 >, "hits" : < "total" : 3, "max_score" : 0.11506981, "hits" : [ < "_index" : "blog", "_type" : "post", "_id" : "2", "_score" : 0.11506981 >, < "_index" : "blog", "_type" : "post", "_id" : "1", "_score" : 0.11506981 >, < "_index" : "blog", "_type" : "post", "_id" : "3", "_score" : 0.095891505 >] > >Однако, если искать «истории» в поле контент, то мы ничего не найдем, т.к. в индексе содержатся только оригинальные слова, а не их основы. Для того чтобы сделать качественный поиск, нужно настроить анализатор.
Поле _score показывает релевантность. Если запрос выпоняется в filter context, то значение _score всегда будет равно 1, что означает полное соответствие фильтру.
Анализаторы
Анализаторы нужны, чтобы преобразовать исходный текст в набор токенов.
Анализаторы состоят из одного Tokenizer и нескольких необязательных TokenFilters. Tokenizer может предшествовать нескольким CharFilters. Tokenizer разбивают исходную строку на токены, например, по пробелам и символам пунктуации. TokenFilter может изменять токены, удалять или добавлять новые, например, оставлять только основу слова, убирать предлоги, добавлять синонимы. CharFilter — изменяет исходную строку целиком, например, вырезает html теги.В ES есть несколько стандартных анализаторов. Например, анализатор russian.
Воспользуемся api и посмотрим, как анализаторы standard и russian преобразуют строку «Веселые истории про котят»:
# используем анализатор standard # обязательно нужно перекодировать не ASCII символы curl -XGET "$ES_URL/_analyze?pretty&analyzer=standard&text=%D0%92%D0%B5%D1%81%D0%B5%D0%BB%D1%8B%D0%B5%20%D0%B8%D1%81%D1%82%D0%BE%D1%80%D0%B8%D0%B8%20%D0%BF%D1%80%D0%BE%20%D0%BA%D0%BE%D1%82%D1%8F%D1%82"< "tokens" : [ < "token" : "веселые", "start_offset" : 0, "end_offset" : 7, "type" : "", "position" : 0 >, < "token" : "истории", "start_offset" : 8, "end_offset" : 15, "type" : "", "position" : 1 >, < "token" : "про", "start_offset" : 16, "end_offset" : 19, "type" : "", "position" : 2 >, < "token" : "котят", "start_offset" : 20, "end_offset" : 25, "type" : "", "position" : 3 > ] ># используем анализатор russian curl -XGET "$ES_URL/_analyze?pretty&analyzer=russian&text=%D0%92%D0%B5%D1%81%D0%B5%D0%BB%D1%8B%D0%B5%20%D0%B8%D1%81%D1%82%D0%BE%D1%80%D0%B8%D0%B8%20%D0%BF%D1%80%D0%BE%20%D0%BA%D0%BE%D1%82%D1%8F%D1%82"< "tokens" : [ < "token" : "весел", "start_offset" : 0, "end_offset" : 7, "type" : "", "position" : 0 >, < "token" : "истор", "start_offset" : 8, "end_offset" : 15, "type" : "", "position" : 1 >, < "token" : "кот", "start_offset" : 20, "end_offset" : 25, "type" : "", "position" : 3 > ] >Стандартный анализатор разбил строку по пробелам и перевел все в нижний регистр, анализатор russian — убрал не значимые слова, перевел в нижний регистр и оставил основу слов.
Посмотрим, какие Tokenizer, TokenFilters, CharFilters использует анализатор russian:
< "filter": < "russian_stop": < "type": "stop", "stopwords": "_russian_" >, "russian_keywords": < "type": "keyword_marker", "keywords": [] >, "russian_stemmer": < "type": "stemmer", "language": "russian" >>, "analyzer": < "russian": < "tokenizer": "standard", /* TokenFilters */ "filter": [ "lowercase", "russian_stop", "russian_keywords", "russian_stemmer" ] /* CharFilters отсутствуют */ >> >Опишем свой анализатор на основе russian, который будет вырезать html теги. Назовем его default, т.к. анализатор с таким именем будет использоваться по умолчанию.
< "filter": < "ru_stop": < "type": "stop", "stopwords": "_russian_" >, "ru_stemmer": < "type": "stemmer", "language": "russian" >>, "analyzer": < "default": < /* добавляем удаление html тегов */ "char_filter": ["html_strip"], "tokenizer": "standard", "filter": [ "lowercase", "ru_stop", "ru_stemmer" ] >> >Сначала из исходной строки удалятся все html теги, потом ее разобьет на токены tokenizer standard, полученные токены перейдут в нижний регистр, удалятся незначимые слова и от оставшихся токенов останется основа слова.
Создание индекса
Выше мы описали default анализатор. Он будет применяться ко всем строковым полям. Наш пост содержит массив тегов, соответственно, теги тоже будут обработаны анализатором. Т.к. мы ищем посты по точному соответствию тегу, то необходимо отключить анализ для поля tags.
Создадим индекс blog2 с анализатором и маппингом, в котором отключен анализ поля tags:
curl -XPOST "$ES_URL/blog2" -d' < "settings": < "analysis": < "filter": < "ru_stop": < "type": "stop", "stopwords": "_russian_" >, "ru_stemmer": < "type": "stemmer", "language": "russian" >>, "analyzer": < "default": < "char_filter": [ "html_strip" ], "tokenizer": "standard", "filter": [ "lowercase", "ru_stop", "ru_stemmer" ] >> > >, "mappings": < "post": < "properties": < "content": < "type": "string" >, "published_at": < "type": "date" >, "tags": < "type": "string", "index": "not_analyzed" >, "title": < "type": "string" >> > > >'Добавим те же 3 поста в этот индекс (blog2). Я опущу этот процесс, т.к. он аналогичен добавлению документов в индекс blog.
Полнотекстовый поиск с поддержкой выражений
Познакомимся с еще одним типом запросов:
# найдем документы, в которых встречается слово 'истории' # query -> simple_query_string -> query содержит поисковый запрос # поле title имеет приоритет 3 # поле tags имеет приоритет 2 # поле content имеет приоритет 1 # приоритет используется при ранжировании результатов curl -XPOST "$ES_URL/blog2/post/_search?pretty" -d' < "query": < "simple_query_string": < "query": "истории", "fields": [ "title^3", "tags^2", "content" ] >> >'Т.к. мы используем анализатор с русским стеммингом, то этот запрос вернет все документы, хотя в них встречается только слово ‘история’.
Запрос может содержать специальные символы, например:
"\"fried eggs\" +(eggplant | potato) -frittata"+ signifies AND operation | signifies OR operation - negates a single token " wraps a number of tokens to signify a phrase for searching * at the end of a term signifies a prefix query ( and ) signify precedence ~N after a word signifies edit distance (fuzziness) ~N after a phrase signifies slop amount# найдем документы без слова 'щенки' curl -XPOST "$ES_URL/blog2/post/_search?pretty" -d' < "query": < "simple_query_string": < "query": "-щенки", "fields": [ "title^3", "tags^2", "content" ] >> >' # получим 2 поста про котиковСсылки
Если интересны подобные статьи-уроки, есть идеи новых статей или есть предложения о сотрудничестве, то буду рад сообщению в личку или на почту m.kuzmin+habr@darkleaf.ru.