Невозможно выполнить поиск по тексту в PDF-файле
Не удается выполнить поиск по тексту в PDF-файле после обновления Acrobat или Acrobat Reader до последней версии
Только в ОС Windows
В Acrobat или Acrobat Reader не удается выполнить поиск по тексту в PDF-файле с помощью инструмента «Найти» или «Расширенный поиск».
Применимо к версиям
- Acrobat (версия 2021.001.20135 | выпуск за 9 февраля 2021 г.)
- Acrobat Reader (версия 2021.001.20135 | выпуск за 9 февраля 2021 г.)
Решение 1. Обновление Acrobat или Acrobat Reader до последнего исправления
Обновите приложение Acrobat или Acrobat Reader. В последнем исправлении выпуска (21.001.20142) эта проблема устранена. Чтобы выполнить обновление прямо из приложения, откройте Acrobat или Acrobat Reader и выберите Справка > Проверка обновлений.
Если проблема не решена, обратитесь к решению 2 ниже.
Решение 2. Включение PDF-индексации с помощью ключа реестра bFallbackOnix32
Применимо в Windows (32-разрядная версия)
Обновите Acrobat и Acrobat Reader до версии 21.001.20142 или более поздней, а затем попробуйте выполнить шаги ниже.
Закройте Acrobat или Acrobat Reader, если приложение уже запущено.
Откройте редактор реестра: откройте меню Выполнить (кнопка меню Windows+R), введите regedit.exe в поле «Открыть» и затем нажмите ОК.
- Acrobat:
Путь: HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\Adobe\Adobe Acrobat\DC\FeatureState
Ключ: bFallbackOnix32
Тип: REG_DWORD
Значение: 1
Путь: HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\Adobe\Acrobat Reader\DC\FeatureState
Ключ: bFallbackOnix32
Тип: REG_DWORD
Значение: 1
PDF с возможностью поиска
Если в PDF-файлах, содержащих только изображения, имеется текст или PDF-файлы создаются на основе файлов изображений, содержащих текст, поиск по содержимому этих документов невозможен. Чтобы сделать возможным поиск по таким файлам, необходимо извлечь текст с помощью функции распознавания текста. PDF-документ с возможностью поиска представляет собой изображения страниц, а в отдельном слое содержит распознанный текст, каждый символ которого ссылается на соответствующий символ в изображении. Это обеспечивает возможность поиска по PDF-документу. PDF-документы с возможностью поиска особенно полезны для представления содержимого документов, которые необходимо заархивировать, в точности сохранив их исходный вид.
При установленном флажке PDF с возможностью поиска процесс оптического распознавания текста запускается только в том случае, если во входном файле не удается обнаружить доступный текстовый слой. Если таковой найден, он используется для создания обычного PDF-документа с возможностью поиска без оптического распознавания текста. Это происходит даже в том случае, если флажок PDF с возможностью поиска снят.
С помощью программы Create Assistant PDF-файлы, содержащие только изображения, и файлы изображений различных типов можно преобразовывать в PDF-документы с возможностью поиска.
Язык для распознавания текста можно указать в диалоговом окне Параметры преобразования PDF с поддержкой поиска.
Список поддерживаемых типов файлов см. в разделе Create Assistant.
В Create Assistant имеется отдельный профиль, который называется «PDF с возможностью поиска», однако для создания PDF-документов с возможностью поиска можно использовать и другие профили, установив флажок PDF с возможностью поиска.
Использование профиля «PDF с возможностью поиска» в Create Assistant
- В поле «Профиль» в Create Assistant выберите профиль PDFс возможностью поиска.
- Откройте один или несколько файлов, которые нужно преобразовать в PDF-файлы с возможностью поиска.
- Нажмите кнопку Профили, чтобы проверить параметры в диалоговом окне Профили PDF Create. Флажок PDF с возможностью поиска будет установлен автоматически. Сохраните его без изменений и при необходимости измените остальные параметры (например, параметры безопасности, водяного знака и т. д.).
- Нажмите кнопку Параметры, чтобы открыть диалоговое окно Параметры преобразования PDF с поддержкой поиска. Укажите язык исходного документа и закройте диалоговое окно. Нажмите кнопку «ОК», чтобы закрыть диалоговое окно «Профили PDF Create».
- Выберите инструмент Запустить создание PDF. Если выбрать несколько файлов с заданным параметром Создать PDF для каждого из входных документов и задать параметр сохранения Запросить имя файла, диалоговое окно «Сохранить как» будет появляться отдельно для каждого сгенерированного PDF-файла.
Чтобы создать PDF-документ с возможностью поиска с использованием других профилей, выполните указанные ниже действия.
- Выберите профиль в поле «Профиль» в Create Assistant и загрузите файлы.
- Нажмите кнопку Профили.
- В диалоговом окне Профили PDF Create установите флажок С возможностью поиска.
- Нажмите кнопку Параметры, чтобы открыть диалоговое окно Параметры преобразования PDF с поддержкой поиска. Выберите язык исходного документа и нажмите кнопку «ОК».
- В диалоговом окне Профили PDF Create проверьте и при необходимости измените другие параметры (например, параметры безопасности, водяного знака и т. д.). Нажмите кнопку «ОК» и запустите процесс создания, как описано выше.
Чтобы получить PDF-документ с возможностью поиска со сжатием MRC, необходимо установить оба флажка. В этом случае при нажатии кнопки Параметры будет открыто диалоговое окно Параметры преобразования MRC PDF с поддержкой поиска.
Программу Power PDF можно настроить так, чтобы при открытии PDF-файла только с изображениями или файла, который содержит только страницы с изображениями, она автоматически обнаруживала это («Файл» > «Параметры» > «Документ» > «Документы PDF с возможностью поиска»). Для этого снимите соответствующий флажок (по умолчанию он установлен). Если соответствующая функция включена, программа предлагает выбрать один из указанных ниже типов итогового документа.
- PDF с возможностью поиска. При этом будут сохранены оригинальные изображения страниц, их вид останется неизменным, но будет добавлен текстовый слой с возможностью поиска.
- Обычный PDF. Будет создан текст и сохранены рисунки, но исходные изображения страниц будут удалены.
- Форма PDF. Такое преобразование выполняется с помощью средства автозаполнения форм для создания активных элементов управления формы.
- PDF-файл. Файл остается без изменений.
Дополнительные сведения см. в разделе Редактирование PDF-документов.
В программе Power PDF можно преобразовать PDF-файл, представляющий собой изображение или содержащий только изображения, в PDF-файл с возможностью поиска с помощью команды PDF с возможностью поиска в разделе «Домой» > «Преобразование». Чтобы изменить параметры этого преобразования, выберите «Файл» > «Параметры» > «Документ» > «Документы PDF с возможностью поиска». Укажите, для каких страниц следует выполнять распознавание текста: для содержащих только изображения или для всех. В последнем случае все содержимое текстовых слоев, имеющееся в PDF-файле, будет заменено результатами распознавания. При выборе первого параметра оптическое распознавание будет выполняться, если текстовый слой присутствует, но непригоден из-за нестандартной кодировки. Полученный текст можно проверить, чтобы удалить ошибки, которые могли возникнуть при распознавании.
Почему не работает поиск по тексту в документе PDF?
Что делать, чтобы работал? Пробовала конвертировать в Word, получается абракадабра или вообще текст не отображается, остаются одни знаки препинания((((((((((((( . Помогите, пожалуйста, надо позарез просто!
Голосование за лучший ответ
дело в том что не всегда pdf делают из текста.. . иногда его делают из картинок (ну все равно что в ворд повставлять отсканированные картинки) — тогда оно и не ищет.. . потому что видит перед собой документ из набора изображений
АсельПрофи (797) 13 лет назад
а возможно ли его конвертировать так, чтобы текст нормально отображался?
Скорее всего текст в виде изображений или в кривых Решение — распознать файнреадером.
Как починить поиск в русском PDF
Начинающий пользователь Help+Manual, пишущий документацию на русском языке, рано или поздно сталкивается с ситуацией, когда в созданном PDF-документе не работает поиск. Русский текст отображается корректно, но после копирования вставляется из буфера кракозябрами. В этой статье я расскажу, как это исправить и почему так получается.
Настройки по инструкции разработчика
Чтобы в PDF документах на русском языке, сгенерированных Help+Manual, корректно работал поиск, задайте следующие настройки:
- В языковых настройках проекта Configuration \ Common Properties \ Language Settings выберите русский язык и русскую кодировку. Это нужно для корректной работы Help+Manual с кириллицей.
- В параметрах публикации Configuration \ Publishing Options \ Adobe PDF \ Fonts Embedding включите внедрение шрифтов. Используйте режимы:
- Embed CID Fonts (обеспечивает максимальное качества текста при увеличении);
- Embed Type3 fonts (выберите, если поиск не заработал с предыдущим режимом; работает всегда, но качество текста при увеличении будет ниже).
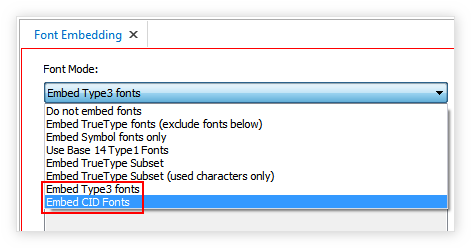
- Проверьте список исключений Do NOT embed these fonts. Он должен быть пустым. Все шрифты, использованные для оформления текста на русском языке, должны быть внедрены в документ*.
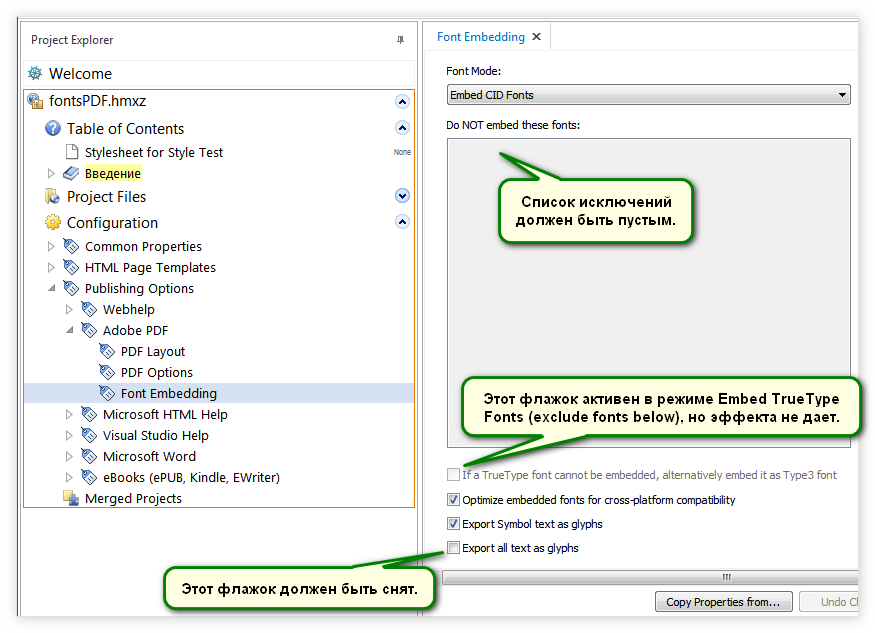
- В нижней части окна проверьте флажок Export all text as glyphs (Экспортировать весь текст как глифы). Он должен быть снят.
- В настройках Help+Manual View \ Program Options \ PDF Export проверьте драйвер принтера, используемый для генерации PDF**.
Дополнительная информация
*1. Разработчики формата PDF в документации указывают, что поиск в pdf-файлах, содержащих Кириллицу, должен работать и без внедрения шрифтов:
**2. В моей практике проблему поиска в русских PDF помогал решить только правильно выбранный режим внедрения шрифтов. Но этот пункт есть в инструкции разработчика по наладке поиска в PDF-документах с Кириллицей. Полный текст инструкции можно посмотреть на форуме поддержки.
3. Я пользуюсь Help+Manual с 2005 года, начиная с версии 4. С проблемой поиска в русских PDF-файлах сталкивался только в приложениях Adobe. В других бесплатных программах для просмотра PDF-файлов (например, STDU PDF Viewer и Foxit PDF Reader) поиск текста на русском языке всегда работал корректно. Русский текст также корректно копировался и вставлялся.
В чем причина
Новое — это хорошо забытое старое. Проблема с поиском в русских PDF была в Help&Manual 4 и 5. Решалась она аналогичным образом. И нет ничего удивительного, что версии 7 и 8 ее унаследовали.
Дело в том, что в Help&Manual начиная с версии 3 для генерации PDF-файлов используется компонент wPDF от компании WPCubed GmbH (Мюнхен).
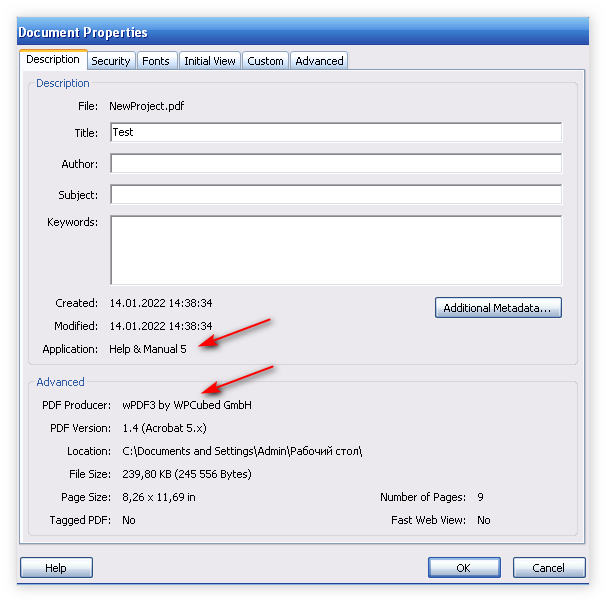
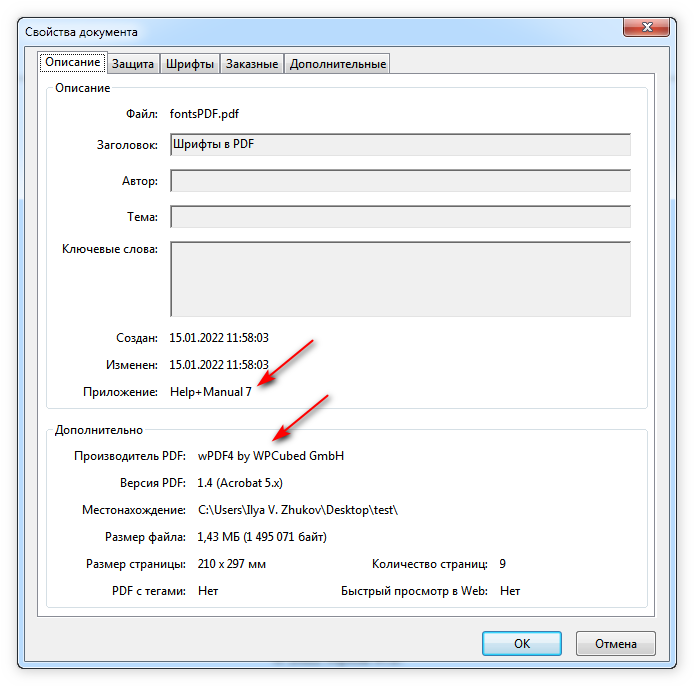
Дальше можно строить только предложения, начиная с кодовой таблицы и неюникодных шрифтов, которые могли использоваться для генерации PDF с русским текстом. Думаю, что у ребят из Мюнхена в списке задач вряд ли есть проблема с кодировкой в русских PDF, поэтому ограничусь приведенным выше решением.