Вы отправили слишком много запросов, поэтому ваш компьютер был заблокирован.
Для того, чтобы предотвратить автоматическое считывание информации с нашего сервиса, на Linguee допустимо лишь ограниченное количество запросов на каждого пользователя.
Пользователям, браузер которых поддерживает Javascript, доступно большее количество запросов, в отличие от пользователей, чей браузер не поддерживает Javascript. Попробуйте активировать Javascript в настройках вашего браузера, подождать несколько часов и снова воспользоваться нашим сервером.
Если же ваш компьютер является частью сети компьютеров, в которой большое количество пользователей одновременно пользуется Linguee,сообщитеоб этом нам.
Zabbix «High memory utilization»
С некоторого времени на одном из серверов с мониторингом Zabbix начал срабатывать триггер «High memory utilization».
На самом сервере 100 гигов памяти, занято всегда не больше 20. Причем сообщение выходит в нерабочее время, когда сервер по идее вообще не должен быть нагружен. Сервер виндовый, терминальный.
Также не до конца понятно, что означает сам триггер. На вики Заббикса это выражение просто не ищется. Залезла внутрь элемента данных. Ключ vm.memory.util, формула last(«vm.memory.size[used]») / last(«vm.memory.size[total]») * 100.
Судя по логике, используемая память сравнивается с общей, что и говорит о нагрузке сервера. Но дело в том, что сервер в принципе не использует больше 20% памяти.
В логах сервера тоже чисто.
Можете подсказать, в какую сторону копать, что именно смотреть, и, все-таки, о какой нагрузке говорит «High memory utilization»?
Memory Usage
Простое мини-приложение рабочего стола, показывающее уровень использования физической и виртуальной памяти. Данные показываются в процентном соотношении, в виде цветных полосок и в виде графиков, которые отображают историю использования памяти. Зеленая полоска отображает оперативную память, а синяя полоса показывает использование файла подкачки.
В настройках можно изменить цвет общего фона и выбрать тип графика. Нажав на гаджет, открывается окно «Диспетчер задач» для быстрого отключения приложений, которые загружают оперативную память.
Для тех, кто не знает.
Физическая память (RAM) — это оперативная память (те платы, которые установлены в вашем компьютере).
Виртуальная память — это файл подкачки, который система хранит на жестком диске компьютера.
Потребление ресурсов

Чтобы узнать, сколько программа потребляет ОЗУ и насколько эффективно загружает процессорные ядра, можно использовать методы, описанные ниже.
Во время работы программы
Предварительно необходимо выяснить, на каких именно узлах работает задача. Это делается командой ‘qstat -f XXXX‘, где XXXX — номер выполняющейся задачи. Выделенные задаче узлы будут отображаться в строке ‘exec_host’:
user01@clu:~> qstat -f 389182
. exec_host = cn225/0*4+cn226/0*4+cn227/0*4+cn228/0*4 .
В данном случае задача работает на узлах cn225, cn226, cn227 и cn228. ‘0*4’ означает, что на каждом узле выделено по 4 ядра.
Метод 1
Данный способ наиболее нагляден, но применим только в том случае, если вычислительный узел монопольно занят одной задачей.
Открыть веб-интерфейс Ganglia. В левом верхнем углу в поле ‘Choose a Source’ выбрать поле, соответствующее модели используемых узлов:
BL2x220c-G6 для 8-ядерных, с именами cn101-cn196
BL2x220c-G7 для 12-ядерных, с именами cn201-cn296
SL390s-G7 для узлов с GPU, sl001-sl012
В появившемся рядом поле ‘Choose a Node’ выбрать интересующий узел. Будет отображена статистика использования ресурсов за некоторое прошедшее время. В первую очередь надо обращать внимание на использование Memory и CPU. Например, из приведённой ниже картинки видно, что задача, запустившаяся около 14:36, достаточно быстро загрузила все ядра до 90% и стабильно держит нагрузку на этом уровне, а потребление оперативной памяти с момента запуска постепенно увеличивается, и на данный момент (15:15) составляет около 9 ГБ:
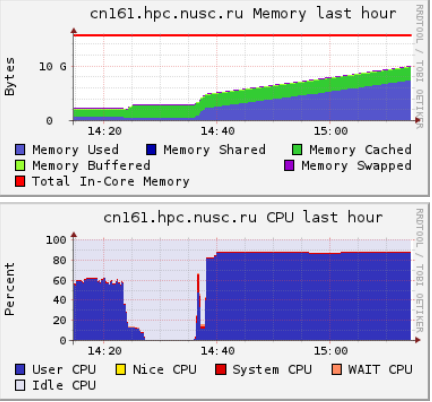
Для обновления графиков необходимо нажать кнопку ‘Get Fresh Data’ в правом верхнем углу.
Метод 2
Зайти на используемый узел с помощью команды ‘ssh‘:
user01@clu:~> ssh cn225
user01@cn225:~>
Подобным образом можно зайти только на тот узел, на котором уже выполняется Ваша программа, запущенная планировщиком. Если же зайти на какой-то другой узел, то ssh-сессия будет принудительно закрыта в течении нескольких секунд.
Запустить команду ‘top‘:
user01@cn225:~> top
top - 22:56:25 up 1 day, 10:06, 1 user, load average: 4.43, 4.44, 4.45 Tasks: 349 total, 5 running, 344 sleeping, 0 stopped, 0 zombie Cpu(s): 31.8%us, 0.4%sy, 0.0%ni, 67.6%id, 0.2%wa, 0.0%hi, 0.0%si, 0.0%st Mem: 24684348k total, 23334268k used, 1350080k free, 119680k buffers Swap: 33559776k total, 0k used, 33559776k free, 7100712k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 25415 user01 20 0 3835m 3.7g 15m R 101 15.6 293:43.08 fluent_mpi.13.0 25417 user01 20 0 3776m 3.6g 15m R 101 15.3 293:58.96 fluent_mpi.13.0 25416 user01 20 0 3945m 3.8g 15m R 99 16.0 294:04.56 fluent_mpi.13.0 25418 user01 20 0 3961m 3.8g 15m R 99 16.1 293:17.68 fluent_mpi.13.0 9300 root 20 0 27060 8316 1168 S 2 0.0 5:37.87 pbs_mom 1 root 20 0 1064 412 348 S 0 0.0 0:01.92 init 2 root 15 -5 0 0 0 S 0 0.0 0:00.02 kthreadd .
В данном случае видно, что:
Работают 4 процесса пользователя user01, каждый из которых потребляет около 3.7 ГБ ОЗУ (столбец RES) и полностью загружает одно ядро (столбец %CPU).
Всеми процессами (включая операционную систему) на узле суммарно используется 23334268 КБ ОЗУ из имеющихся 24684348 КБ.
Виртуальная память (SWAP) на узле не используется.
Полное потребление памяти, включая виртуальную, отображается в столбце VIRT
Если число в столбце RES не имеет суффикса g или m, то это значение в килобайтах.
Чтобы прервать работу утилиты top, необходимо нажать Ctrl-C
Использование GPU
При выполнении вычислений на графических сопроцессорах cтепень загруженности GPU и памяти видеокарты можно узнать с помощью утилиты ‘nvidia-smi‘. Для этого необходимо:
Определить используемый задачей узел и GPU.
Командой ‘ssh’ зайти с интерфейсного сервера на соответствующий узел и выполнить следующую команду, заменив ‘X’ на идентификатор нужного GPU (или нескольких GPU, через запятую):
nvidia-smi --query-gpu=utilization.gpu,utilization.memory,memory.free,memory.used --format=csv -i X
При использовании узлов в очереди teslaq в качестве идентификатора GPU можно использовать его порядковый номер (от 0 до 2), определяемый из имени виртуального узла. Например, если интересует нагрузка на GPU задачей с номером 3437445, запросившей два ngpus:
Чтобы узнать выделенные задаче виртуальные узлы, выполнить на интерфейсном сервере:
qstat -f 3437445|tr -d '\n'' ''\t'|sed 's/Hold_Types.*//'|sed 's/.*exec_vnode=//'|tr -d \(\)|tr + '\n'|sed 's/:.*//'|sort
Допустим, эта команда выведет:
sl003[0] sl003[2]
Т.е. задача иcпользует GPU с номерами 0 и 2 на узле sl003.
Выполнить на интерфейсном сервере команду:
ssh sl003 nvidia-smi --query-gpu=utilization.gpu,utilization.memory,memory.free,memory.used --format=csv -i 0,2
При использовании очереди a6500g10q порядковый номер GPU не является уникальным идентификатором т.к. для каждой из работающих задач доступные GPU нумеруются последовательно, начиная с ноля. Вместо этого можно использовать идентификатор шины PCI:
Добавить в начало скрипта для qsub такую команду:
nvidia-smi --query-gpu=pci.bus_id --format=csv,noheader > $PBS_O_WORKDIR/$PBS_JOBID.id
В результате после запуска задачи в рабочей директории появится файл с именем вида ‘95054.vm-pbs.id’, содержащий что-то вроде ‘00000000:15:00.0’ (или несколько таких строк, если было запрошено несколько GPU).
Выполнить команду вида:
ssh a6500g10 nvidia-smi --query-gpu=utilization.gpu,utilization.memory,memory.free,memory.used --format=csv -i 00000000:15:00.0
В результате на экран будет выведено примерно такое:
utilization.gpu [%], utilization.memory [%], memory.free [MiB], memory.used [MiB] 33 %, 0 %, 1735 MiB, 30775 MiB
Обращаем внимание, что ‘utilization.memory’ — это интенсивность работы с памятью карты, а не степень её заполненности.
Может быть полезно выполнить ‘man mvidia-smi’ и изучить возможности утилиты. Например, можно запросить вывод статистики каждые 10 секунд, добавив команде параметр ‘-l 10’
После завершения программы
Выполнить команду ‘tracejob XXX‘, где ‘XXX’ — номер задачи. Эта команда анализирует логи PBS и выводит информацию, связанную с работой указанной задачи. По умолчанию обрабатываются данные только за последний день. Если задача закончилась несколько дней назад или Вы хотите получить данные, начиная с момента постановки задачи в очередь, то надо дополнительно указать параметр ‘-n ZZZ‘, где ‘ZZZ’ — количество дней, прошедших с данного момента, логи за которые должна проанализировать команда.
Пример: запрос информации по задаче с номером 482685 за два прошедших дня:
tracejob -n 2 482685
. 11/19/2013 06:05:04 A user=user01 group=users project=_pbs_project_default jobname=runs queue=bl2x220g7q ctime=1384777907 qtime=1384777907 etime=1384777907 start=1384777908 exec_host=cn263/0 exec_vnode=(cn263:mem=4194304kb:ncpus=1) Resource_List.mem=4gb Resource_List.ncpus=1 Resource_List.nodect=1 Resource_List.place=pack Resource_List.qlist=bl2x220g7q Resource_List.select=1:mem=4gb:ncpus=1:qlist=bl2x220g7q Resource_List.walltime=100:00:00 session=10647 end=1384815904 Exit_status=271 resources_used.cpupercent=98 resources_used.cput=10:33:16 resources_used.mem=1321292kb resources_used.ncpus=1 resources_used.vmem=2144544kb resources_used.walltime=10:33:17 run_count=1
Здесь видно, в частности, что задача:
Запросила 1 ядро (Resource_List.ncpus) и 4 ГБ ОЗУ (Resource_List.mem)
Но ОЗУ использовалась крайне неэффективно: resources_used.mem=1321292kb, т.е. примерно 1.26 ГБ из 4 ГБ запрошенных. Что означает, что 2.5 ГБ из зарезервированных PBS под эту задачу, не использовались и при этом были недоступны другим пользователям.
Время работы команды ‘tracejob’ зависит от временного интервала, за который запрашивается информация.
Если с момента завершения задачи прошло не очень много времени, то можно также открыть веб-интерфейс Ganglia и посмотреть на графики работы. Однако, чем больше прошло времени, тем сложнее будет по графикам определить период работы задачи.
Использование виртуальной памяти
В случае, если необходимо использовать больше ОЗУ, чем имеется у компьютера, операционная система сохраняет данные из каких-то неиспользуемых в данный момент областей оперативной памяти на жесткий диск в специальный файл (файл подкачки) или специальный раздел диска, обобщённо называемые ‘swap’ (английское ‘обмен’). Освободившаяся оперативная память используется по назначению. В случае, если потребуются данные, перенесённые в swap, то происходит аналогичная операция — часть данных из ОЗУ переносится на диск, а нужные данные с диска возвращаются в оперативную память. Подобный метод позволяет операционной системе и программам работать так, как будто на компьютере больше оперативной памяти, чем на самом деле. Поэтому такая память называется виртуальной.
К сожалению, скорость передачи данных у жесткого диска существенно меньше, чем у микросхем оперативной памяти. Поэтому интенсивное использование swap сильно замедляет работу.
Рассмотрим типичные графики, полученные при помощи системы Ganglia с сервера, на котором работает задача, потребившая всю оперативную память (обозначена на первом графике синим) и интенсивно использующая swap (фиолетовый):
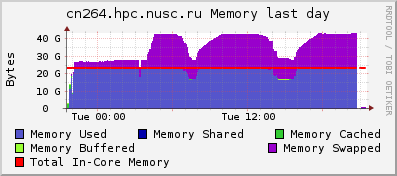
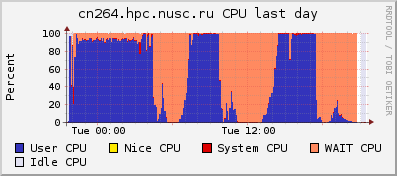
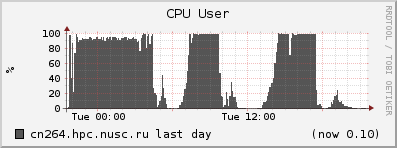
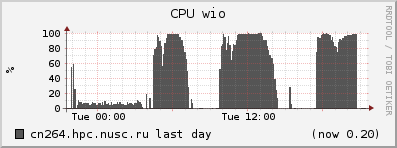
Видно, что в те моменты, когда потребление swap увеличивается, процессор вместо выполнения прикладных задач (‘User CPU’, загрузка процессора пользовательскими программами) простаивает в ожидании данных (‘Wait CPU’ и ‘CPU wio’; wio = wait in/out, ожидание ввода/вывода). То есть данная программа почти половину времени не работает, а ждёт обмена данными с жёстким диском. И если бы у сервера было больше оперативной памяти, программа работала бы почти в два раза быстрее.
Поэтому рекомендуется отслеживать потребление памяти вашими задачами и при необходимости что-то менять:
В случае, если программа пишется вами, в первую очередь надо подумать об оптимизации кода с целью уменьшения потребления ОЗУ.
Если известно, что при распараллеливании задачи каждый процесс, загружающий одно ядро, требует определённое количество ОЗУ и оно больше, чем имеется у сервера, то может иметь смысл занимать сервер полностью, но задействовать не все ядра. Например: у сервера 12 ядер и 24 ГБ ОЗУ, т.е. 2 ГБ на ядро; а задаче необходимо 3 ГБ на процесс. В таком случае можно занять сервер полностью (запросить 12 ядер) но задействовать только 24/3 = 8 ядер, запустив 8 процессов. Хотя более правильным будет позапускать задачу с использованием разного количества ядер и найти компромиссный вариант, обеспечивающий максимальное использование процессора.
Перенести запуск задач на сервера другого типа, имеющие больше ОЗУ либо больше ОЗУ на одно ядро.
Следует однако отметить, что само по себе использование виртуальной памяти и количество данных, находящихся в swap, не критичны для быстродействия. Если данные просто перенеслись на диск и долгое время никому не требовались, то и больших задержек не возникло. Гораздо важнее интенсивность работы с swap — как часто происходят обращения к жёсткому диску для чтения или записи. К сожалению, количества таких обращений на графиках Ganglia нет.
Ниже приведены графики задачи, которой использование виртуальной памяти не вредит — хотя в swap находится уже 24 ГБ данных, процессор всё равно загружен на 90%. Другое дело, что виртуальная память не бесконечна и если она закончится, то такая задача прервётся. Скорее всего, для такой задачи будет более правильным сразу сохранять в файл полученные результаты и освобождать память.