Natural language processing что это
NLP (Natural Language Processing, обработка естественного языка) — это направление в машинном обучении, посвященное распознаванию, генерации и обработке устной и письменной человеческой речи. Находится на стыке дисциплин искусственного интеллекта и лингвистики.

Освойте профессию «Data Scientist»
Инженеры-программисты разрабатывают механизмы, позволяющие взаимодействовать компьютерам и людям посредством естественного языка. Благодаря NLP компьютеры могут читать, интерпретировать, понимать человеческий язык, а также выдавать ответные результаты. Как правило, обработка основана на уровне интеллекта машины, расшифровывающего сообщения человека в значимую для нее информацию.
Процесс машинного понимания с применением алгоритмов обработки естественного языка может выглядеть так:
- Речь человека записывается аудио-устройством.
- Машина преобразует слова из аудио в письменный текст.
- Система NLP разбирает текст на составляющие, понимает контекст беседы и цели человека.
- С учетом результатов работы NLP машина определяет команду, которая должна быть выполнена.
Профессия / 24 месяца
Data Scientist
Дата-сайентисты решают поистине амбициозные задачи. Научитесь создавать искусственный интеллект, обучать нейронные сети, менять мир и при этом хорошо зарабатывать. Программа рассчитана на новичков и плавно введет вас в Data Science.

Кто использует NLP
Приложения NLP окружают нас повсюду. Это поиск в Google или Яндексе, машинный перевод, чат-боты, виртуальные ассистенты вроде Siri, Алисы, Салюта от Сбера и пр. NLP применяется в digital-рекламе, сфере безопасности и многих других.
Технологии NLP используют как в науке, так и для решения коммерческих бизнес-задач: например, для исследования искусственного интеллекта и способов его развития, а также создания «умных» систем, работающих с естественными человеческими языками, от поисковиков до музыкальных приложений.
Как устроена обработка языков
Раньше алгоритмам прописывали набор реакций на определенные слова и фразы, а для поиска использовалось сравнение. Это не распознавание и понимание текста, а реагирование на введенный набор символов. Такой алгоритм не смог бы увидеть разницы между столовой ложкой и школьной столовой.
NLP — другой подход. Алгоритмы обучают не только словам и их значениям, но и структуре фраз, внутренней логике языка, пониманию контекста. Чтобы понять, к чему относится слово «он» в предложении «человек носил костюм, и он был синий», машина должна иметь представление о свойствах понятий «человек» и «костюм». Чтобы научить этому компьютер, специалисты используют алгоритмы машинного обучения и методы анализа языка из фундаментальной лингвистики.

Курс для новичков «IT-специалист
с нуля» – разберемся, какая профессия вам подходит, и поможем вам ее освоить
Задачи NLP
Распознавание речи. Этим занимаются голосовые помощники приложений и операционных систем, «умные» колонки и другие подобные устройства. Также распознавание речи используется в чат-ботах, сервисах автоматического заказа, при автоматической генерации субтитров для видеороликов, голосовом вводе, управлении «умным» домом. Компьютер распознает, что сказал ему человек, и выполняет в соответствии с этим нужные действия.
Обработка текста. Человек может также общаться с компьютером посредством письменного текста. Например, через тех же чат-ботов и помощников. Некоторые программы работают одновременно и как голосовые, и как текстовые ассистенты. Пример — помощники в банковских приложениях. В этом случае программа обрабатывает полученный текст, распознает его или классифицирует. Затем она выполняет действия на основе данных, которые получила.
Извлечение информации. Из текста или речи можно извлечь конкретную информацию. Пример задачи — ответы на вопросы в поисковых системах. Алгоритм должен обработать массив входных данных и выделить из него ключевые элементы (слова), в соответствии с которыми будет найден актуальный ответ на поставленный вопрос. Для этого требуются алгоритмы, способные различать контекст и понятия в тексте.
Анализ информации. Это схожая с предыдущей задача, но цель — не получить конкретный ответ, а проанализировать имеющиеся данные по определенным критериям. Машины обрабатывают текст и определяют его эмоциональную окраску, тему, стиль, жанр и др. То же самое можно сказать про запись голоса.
Анализ информации часто используется в разных видах аналитики и в маркетинге. Например, можно отследить среднюю тональность отзывов и высказываний по заданному вопросу. Соцсети используют такие алгоритмы для поиска и блокировки вредоносного контента. В перспективе компьютер сможет отличать фейковые новости от реальных, устанавливать авторство текста. Также NLP применяется при сборе информации о пользователе для показа персонализированной рекламы или использования сведений для анализа рынка.

Станьте аналитиком данных и получите востребованную специальность
Генерация текста и речи. Противоположная распознаванию задача — генерация, или синтез. Алгоритм должен отреагировать на текст или речь пользователя. Это может быть ответ на вопрос, полезная информация или забавная фраза, но реплика должна быть по заданной теме. В системах распознавания речи предложения разбиваются на части. Далее, чтобы произнести определенную фразу, компьютер сохраняет их, преобразовывает и воспроизводит. Конечно, на границах «сшивки» могут возникать искажения, из-за чего голос часто звучит неестественно.
Генерация текста не ограничивается шаблонными ответами, заложенными в алгоритм. Для нее используют алгоритмы машинного обучения. «Говорящие» программы могут учиться на основе реальных данных. Можно добиться того, чтобы алгоритм писал стихи или рассказы с логичной структурой, но они обычно не очень осмысленные.
Автоматический пересказ. Это направление также подразумевает анализ информации, но здесь используется и распознавание, и синтез.Задача — обработать большой объем информации и сделать его краткий пересказ. Это бывает нужно в бизнесе или в науке, когда необходимо получить ключевые пункты большого набора данных.
Машинный перевод. Программы-переводчики тоже используют алгоритмы машинного обучения и NLP. С их использованием качество машинного перевода резко выросло, хотя до сих пор зависит от сложности языка и связано с его структурными особенностями. Разработчики стремятся к тому, чтобы машинный перевод стал более точным и мог дать адекватное представление о смысле оригинала во всех случаях.
Машинный перевод частично автоматизирует задачу профессиональных переводчиков: его используют для перевода шаблонных участков текста, например в технической документации.
Как обрабатывается текст
Алгоритмы не работают с «сырыми» данными. Большая часть процесса — подготовка текста или речи, преобразование их в вид, доступный для восприятия компьютером.
Очистка. Из текста удаляются бесполезные для машины данные. Это большинство знаков пунктуации, особые символы, скобки, теги и пр. Некоторые символы могут быть значимыми в конкретных случаях. Например, в тексте про экономику знаки валют несут смысл.
Препроцессинг. Дальше наступает большой этап предварительной обработки — препроцессинга. Это приведение информации к виду, в котором она более понятна алгоритму. Популярные методы препроцессинга:
- приведение символов к одному регистру, чтобы все слова были написаны с маленькой буквы;
- токенизация — разбиение текста на токены. Так называют отдельные компоненты — слова, предложения или фразы;
- тегирование частей речи — определение частей речи в каждом предложении для применения грамматических правил;
- лемматизация и стемминг — приведение слов к единой форме. Стемминг более грубый, он обрезает суффиксы и оставляет корни. Лемматизация — приведение слов к изначальным словоформам, часто с учетом контекста;
- удаление стоп-слов — артиклей, междометий и пр.;
- спелл-чекинг — автокоррекция слов, которые написаны неправильно.
Методы выбирают согласно задаче.
Векторизация. После предобработки на выходе получается набор подготовленных слов. Но алгоритмы работают с числовыми данными, а не с чистым текстом. Поэтому из входящей информации создают векторы — представляют ее как набор числовых значений.
Популярные варианты векторизации — «мешок слов» и «мешок N-грамм». В «мешке слов» слова кодируются в цифры. Учитывается только количество слова в тексте, а не их расположение и контекст. N-граммы — это группы из N слов. Алгоритм наполняет «мешок» не отдельными словами с их частотой, а группами по несколько слов, и это помогает определить контекст.
Применение алгоритмов машинного обучения. С помощью векторизации можно оценить, насколько часто в тексте встречаются слова. Но большинство актуальных задач сложнее, чем просто определение частоты — тут нужны продвинутые алгоритмы машинного обучения. В зависимости от типа конкретной задачи создается и настраивается своя отдельная модель.
Алгоритмы обрабатывают, анализируют и распознают входные данные, делают на их основе выводы. Это интересный и сложный процесс, в котором много математики и теории вероятностей.
Аналитик данных
Аналитики влияют на рост бизнеса. Они выясняют, какой товар и в какое время больше покупают. Считают юнит-экономику. Оценивают окупаемость рекламной кампании. Поэтому компании ищут и переманивают таких специалистов.

Статьи по теме:
Методы обработки естественного языка
![]()
В последнее десятилетие технологии искусственного интеллекта и машинной обработки естественной речи пережили скачок развития. В жизнь человека прочно вошли виртуальные ассистенты, способные на полноценный диалог. Всё это стало возможным благодаря методам автоматической обработки естественного языка.

Что такое обработка естественного языка
Natural Language Processing — область в науке, объединяющая два направления: гуманитарную лингвистику и инновационные технологии искусственного интеллекта. Задача NLP — создать условия для понимания компьютером смысла речи человека. Это непросто из-за особенностей предмета анализа:
- Язык наделён осмысленностью. Это не просто звуки и буквы, а способ передачи информации, которую нужно интерпретировать.
- Фразы произносятся с различными интонациями, акцентом, ударениями, бывает, что речь слишком быстрая, и некоторые слова « съедаются » . Люди понимают друг друга благодаря лингвистическому опыту и образному мышлению. Машинам же для понимания смысла необходима обработка множества параметров.
- Синтаксические, грамматические, лексические нюансы усложняют восприятие. Слова с одинаковым написанием и звучанием могут иметь разное значение: например, « стекло » может быть существительным и глаголом. Поэтому важно научить искусственный интеллект видеть смысловую связь.
- Любой язык богат жаргонизмами, неологизмами, профессиональной, фольклорной и другими видами лексики. Люди постоянно пополняют свой словарный запас. Машинные алгоритмы понимания речи тоже должны непрерывно обучаться.
Языковое общение — по-прежнему основной способ передачи и обработки информации для человека. По смыслу слов и интонации люди понимают намерения друг друга, а благодаря NLP этому научились и виртуальные ассистенты.
Так, Sber предлагает разработчикам приложений с виртуальными ассистентами Салют улучшить качество их взаимодействия с аудиторией. Для этого есть платформа для обработки запросов на естественном языке SmartNLP. Система определяет более 600 тематик, таких как медиа и видео, банковские сервисы, погода.
Навык постоянно совершенствуется благодаря тому, что каждый запрос пользователя проходит стадию предобработки текста. Исходные данные модифицируются и стандартизируются для дальнейшего использования ML-моделями:
- Применяется лемматизация и нормализация текста, чтобы привести слова к нормальной форме, исправляются ошибки, где нужно, буква « е » заменяется на « ё » .
- Определяются члены предложения и части речи для дальнейшей работы с входящими запросами.
- Выделяются именованные сущности, которые помогают собственной разработке Сбера — интентрекогнайзеру — понимать намерения пользователя. Эти сущности также могут использоваться внешними системами для работы с текстом. Сейчас выделяется более 30 сущностей, среди которых обозначения денежных знаков, локации и другие.
Намерение пользователя определяется двумя способами:
- Подход, основанный на правилах. Подойдёт для простых запросов, например о погоде или ближайшем магазине. По настроенным правилам система понимает намерение пользователя.
- С помощью текстового классификатора. Это глубокая модель машинного обучения, основанная на Roberta. В этом случае текст проходит через токенизацию, попадает в модель, и на выходе мы получаем нужный класс намерения пользователя.
В результате обработки сигналов от векторов система получает конкретные команды, по которым запускается навык в виртуальном ассистенте.
Современные инструменты работы с речью позволяют быстро обрабатывать поступающие обращения, искать нужную информацию, сохранять транскрипции видеовыступлений. Появляются новые способы применения технологии искусственного интеллекта и Natural Language Processing. Разрабатываются сервисы для внедрения машинной обработки естественного языка в собственные продукты, расширения функциональности существующих решений.
Основной технологией в направлении Natural Language Processing становится deep learning. Глубокое обучение возможно благодаря следующим предпосылкам:
- Для обучения моделей стали доступны суперкомпьютеры с большим количеством GPU.
- Разработчики накопили достаточно тренировочных данных для машинного обучения.
Алгоритмы глубокого обучения самостоятельно выделяют признаки из необработанных данных, поэтому NLP практически полностью автоматизирована и имеет высокую точность понимания речи.
Видеозвонки в SberJazz
Общайтесь с друзьями и близкими где бы вы ни были
Попробовать сейчас
Какие задачи сегодня может решать NLP?
В общем смысле задачи NLP-технологий распределяются по уровням:
- На сигнальном уровне нейросетевые системы могут распознавать и синтезировать устную и письменную речь — автоматическая запись бесед, транскрибация, речевая аналитика.
- На уровне слова возможен его морфологический разбор, приведение в соответствие с нормами — автоматическое исправление, проверка грамматики.
- При работе со словосочетаниями NLP позволяет выделять сущности, отдельные слова, тегировать части речи.
- В предложениях искусственный интеллект точно определяет точки, отличает конец предложения от сокращения слова.
- При анализе абзаца алгоритм распознает язык, эмоциональную окраску, выявит отношения между смысловыми единицами.
- В объёмных документах система определит тематику, составит аннотацию или краткое изложение, перепишет текст другими словами без потери смысла.
- При работе с текстовым кластером Natural Language Processing устранит дубликаты, отыщет нужную информацию по меткам.
NLP используют в бизнесе, науке и других сферах для решения самых разных задач. Среди них можно выделить:
- Сегментирование и определение целевых категорий клиентов. Например, автоматический анализ текстовых сообщений пользователя в игре — метод прогноза и предотвращения его ухода.
- Поиск, разделение на категории отзывов и комментариев о работе.
- Алгоритмы классификации входящих обращений по содержанию.
- Автоматизация взаимодействия с клиентами.
- Способность нейросети создавать краткие изложения любых текстов, выделяя важное.
Рассмотрим подробнее несколько методов Natural Language Processing, которые активно применяются в различных отраслях.

Машинный перевод
Методы глубокого обучения сделали автоматический перевод не механическим, а таким, будто компьютер понимает смысл фраз на языке оригинала. Система не переводит каждое слово отдельно. Машинный интеллект анализирует смысл целой фразы или предложения, « видит » знаки препинания, части речи и их связь. Затем он переводит фразу на целевой язык.
Полученная при анализе и переводе информация сопоставляется, интерпретируется, после чего формируется результат — последовательность слов с тем же смыслом, но на другом языке. При этом алгоритм должен учитывать правила построения языков, согласование слов между собой, их место в предложении, правильно использовать роды, склонения, числа и так далее. Так работает модель перевода по правилам.
Другой способ — перевод по фразам — работает иначе. Система без дополнительных этапов анализа формирует несколько вариантов перевода и выбирает оптимальный на основе выученных вероятностей использования.
Подобные методы используют онлайн-переводчики, встроенные сервисы в различных приложениях. Компании могут применять технологию для взаимодействия с иностранными клиентами и контрагентами.
Голосовые помощники
В виртуальных ассистентах сочетаются два базовых решения:
- искусственный интеллект;
- машинное обучение.
Пользователь взаимодействует не с живым человеком, а с цифровым алгоритмом. Такой алгоритм должен не только анализировать полученные данные, но и предугадывать ход беседы, как реальный собеседник. Кроме того, система должна с высокой точностью выделять главное среди шума.
Для автоматической обработки прямой или записанной речи нужны специальные инструменты. Например, среди продуктов SberDevices есть платформа SaluteSpeech, с которой можно « научить » приложения понимать естественную речь человека и синтезировать голосовые ответы на запросы. Сервис позволяет создать собственного виртуального помощника, который внесёт вклад в продвижение и узнаваемость бренда.
Платформа SmartNLP от SberDevices предназначена для более точной работы ассистентов Салют. Технология помогает выбрать нужный навык ассистента для запуска, настроить алгоритм действий в случае возможных ошибок и задержек системы. К примеру, в момент ожидания ассистент может пообщаться с клиентом, развлечь интересной историей или объяснить, что произошло.
В этом важное отличие ассистентов от чат-ботов — ещё одного метода цифровизации бизнеса и автоматизации взаимодействия с клиентом. Их внедряют на сайты, в приложения, в мессенджеры. Бот может отвечать на типовые вопросы, принимать заявки, делать рассылки, информировать об изменениях и акциях.
В форме простого диалога с фразами-подсказками клиент оформит заказ, узнает его статус, запишется на приём. Бота можно наделить различными полномочиями — от деловых до развлекательных. С алгоритмом можно поиграть в города или устроить викторину. Взаимодействие возможно только текстом и строго по заданному сценарию.
SaluteBot от SberDevices интегрируется с омниканальной платформой Jivo, которая позволяет в едином пространстве обрабатывать обращения, поступающие со всех подключённых каналов. Чат-бот можно создать самостоятельно с помощью готовых шаблонов в zero-code- и low-code-конструкторах платформы Studio. Боты могут обрабатывать неограниченное количество запросов, поэтому способны решить проблему упущенных клиентов.
Анализ текстов
Есть много инструментов для анализа текста, основанных на технологиях машинного обучения и искусственного интеллекта. Они помогают оценивать тексты разных объёмов по специальным критериям. Одни предназначены для профессионального использования, другие помогают в обучении, в оценке работы сотрудников, в создании контента.
Популярные онлайн-сервисы могут:
- генерировать новые тексты по запросу;
- проверять уникальность и бороться с плагиатом;
- проводить семантический анализ текста для SEO;
- подбирать синонимы и рифмы;
- анализировать стилистическую чистоту текста;
- проверять грамматические ошибки;
- предварительно оценивать время прочтения;
- делать краткое изложение и выделять тезисы;
- переписывать тексты другими словами с сохранением общего смысла.
В линейке продуктов SberDevices есть сервисы работы с текстом Рерайтер и Суммаризатор.
Рерайтер автоматически создаёт уникальные рерайты исходников любого размера. Содержание не имеет значения, система может работать с научными статьями, художественными текстами, новостными заметками, постами для социальных сетей.
В сервис вводится текст, настраиваются параметры генерации, система создаёт несколько вариантов и выбирает из них лучший с точки зрения уникальности и соответствия первоначальному смыслу. Используемая нейросеть обучалась на объёмном пласте данных разной стилистики и жанров. В качестве базы для машинного обучения использовалась генеративная модель ruT5.
Суммаризатор позволяет выделить главные мысли и оформить их в виде кратких тезисов. Сервис актуален для людей, интересующихся наукой. Он позволяет быстро изучать объёмные научные работы.
Суммаризатор подойдёт также для работы с учебными материалами. Сокращение помогает создавать дайджесты новостей, изучать темы из письменных транскрипций лекций и семинаров.

Распознавание и синтез речи
Метод считается одним из самых популярных в NLP. Технология распознавания речи и голосового синтеза позволяет:
- озвучивать контент и интерфейсы;
- создавать субтитры;
- транскрибировать лекции и совещания;
- внедрять в продукты голосовое управление;
- создавать персонализированных виртуальных помощников;
- обрабатывать и анализировать голосовые записи;
- трансформировать телефонию, создавать IVR-меню, голосовые рассылки и обзвоны.
Платформа SaluteSpeech от Sber работает в двух направлениях:
- При распознавании речи искусственный интеллект может определять эмоции говорящего и знаки препинания. Сервис поймёт, где закончилась фраза, отфильтрует шумы. Правильно понимать прямую и записанную речь помогают специальные подсказки — хинты, которые ускоряют автоматическую реакцию системы.
- Синтез речи построен на уникальных моделях машинного обучения, которые могут решать даже узкие задачи, например правильно расставлять ударения и произносить букву « ё » . Знаний нейросети достаточно для того, чтобы без ошибок произносить термины, географические названия, большие числа и другие сложные речевые конструкции. Сервис позволяет подобрать тембр, настроение, манеру общения, мужское или женское звучание синтезируемой речи.
Попробуйте преобразование аудио в текст
Запишите голос и SaluteSpeech преобразует его в текст

Возможности платформы позволяют внедрить методы понимания естественной речи в свои продукты. Воспользоваться сервисом можно при работе над различными проектами в среде для разработчиков Studio от Sber. Тарификация посекундная и посимвольная, пользователи платят только за фактический результат.
NLP — перспективное направление развития искусственного интеллекта. Методы автоматической обработки естественного языка используют в рекламе, в информационных компаниях, в сфере безопасности. Крупные компании внедряют голосовое управление во внутреннее программное обеспечение.
Технология Natural Language Processing позволяет автоматизировать процессы, извлекать и анализировать большие объёмы информации. Растущий спрос даёт основание думать, что в ближайшие несколько лет NLP станет привычным инструментом в работе любой компании.
Продукты из этой статьи:
Обработка естественного языка
Обработка естественного языка (Natural Language Processing, NLP) — пересечение машинного обучения и математической лингвистики [1] , направленное на изучение методов анализа и синтеза естественного языка. Сегодня NLP применяется во многих сферах, в том числе в голосовых помощниках, автоматических переводах текста и фильтрации текста. Основными тремя направлениями являются: распознавание речи (Speech Recognition), понимание естественного языка (Natural Language Understanding [2] ) и генерация естественного языка (Natural Language Generation [3] ).
Задачи
| Определение: |
| Корпус — подобранная и обработанная по определённым правилам совокупность текстов, используемых в качестве базы для исследования языка. |
NLP решает большой набор задач, который можно разбить по уровням (в скобках). Среди этих задач, можно выделить следующие:
- Распознавание текста, речи, синтез речи (сигнал);
- Морфологический анализ, канонизация (слово);
- POS-тэгирование, распознавание именованных сущностей, выделение слов (словосочетание);
- Синтаксический разбор, токенизация предложений (предложение);
- Извлечение отношений, определение языка, анализ эмоциональной окраски (абзац);
- Аннотация документа, перевод, анализ тематики (документ);
- Дедубликация, информационный поиск (корпус).
Основные подходы
Предобработка текста
Предобработка текста переводит текст на естественном языке в формат удобный для дальнейшей работы. Предобработка состоит из различных этапов, которые могут отличаться в зависимости от задачи и реализации. Далее приведен один из возможных набор этапов:
- Перевод всех букв в тексте в нижний или верхний регистры;
- Удаление цифр (чисел) или замена на текстовый эквивалент (обычно используются регулярные выражения);
- Удаление пунктуации. Обычно реализуется как удаление из текста символов из заранее заданного набора;
- Удаление пробельных символов (whitespaces);
- Токенизация (обычно реализуется на основе регулярных выражений);
- Удаление стоп слов;
- Стемминг;
- Лемматизация;
- Векторизация.
Стемминг
Количество корректных словоформ, значения которых схожи, но написания отличаются суффиксами, приставками, окончаниями и прочим, очень велико, что усложняет создание словарей и дальнейшую обработку. Стемминг позволяет привести слово к его основной форме. Суть подхода в нахождении основы слова, для этого с конца и начала слова последовательно отрезаются его части. Правила отсекания для стеммера создаются заранее, и чаще всего представляют из себя регулярные выражения, что делает данный подход трудоемким, так как при подключении очередного языка нужны новые лингвистические исследования. Вторым недостатком подхода является возможная потеря информации при отрезании частей, например, мы можем потерять информацию о части речи.
Лемматизация
Данный подход является альтернативой стемминга. Основная идея в приведении слова к словарной форме — лемме. Например для русского языка:
- для существительных — именительный падеж, единственное число;
- для прилагательных — именительный падеж, единственное число, мужской род;
- для глаголов, причастий, деепричастий — глагол в инфинитиве несовершенного вида.
Векторизация
Основная статья: Векторное представление слов
Большинство математических моделей работают в векторных пространствах больших размерностей, поэтому необходимо отобразить текст в векторном пространстве. Основным походом является мешок слов (bag-of-words): для документа формируется вектор размерности словаря, для каждого слова выделяется своя размерность, для документа записывается признак насколько часто слово встречается в нем, получаем вектор. Наиболее распространенным методом для вычисления признака является TF-IDF [4] (TF — частота слова, term frequency, IDF — обратная частота документа, inverse document frequency). TF вычисляется, например, счетчиком вхождения слова. IDF обычно вычисляют как логарифм от числа документов в корпусе, разделённый на количество документов, где это слово представлено. Таким образом, если какое-то слово встретилось во всех документах корпуса, то такое слово не будет никуда добавлено. Плюсами мешка слов является простая реализация, однако данный метод теряет часть информации, например, порядок слов. Для уменьшения потери информации можно использовать мешок N-грамм (добавлять не только слова, но и словосочетания), или использовать методы векторных представлений слов это, например, позволяет снизить ошибку на словах с одинаковыми написаниями, но разными значениями.
Дедубликация
Так как количество схожих документов в большом корпусе может быть велико, необходимо избавляться от дубликатов. Так как каждый документ может быть представлен как вектор, то мы можем определить их близость, взяв косинус или другую метрику. Минусом является то, что для больших корпусов полный перебор по всем документам будет невозможен. Для оптимизации можно использовать локально-чувствительный хеш, который поместит близко похожие объекты.
Семантический анализ
Семантический (смысловой) анализ текста — выделение семантических отношений, формировании семантического представления. В общем случае семантическое представление является графом, семантической сетью, отражающим бинарные отношения между двумя узлами — смысловыми единицами текста. Глубина семантического анализа может быть разной, а в реальных системах чаще всего строится только лишь синтаксико-семантическое представление текста или отдельных предложений. Семантический анализ применяется в задачах анализа тональности текста [5] (Sentiment analysis), например, для автоматизированного определения положительности отзывов.
Распознавание именованных сущностей и извлечение отношений
Именованные сущности — объекты из текста, которые могут быть отнесены к одной из заранее заявленных категорий (например, организации, личности, адреса). Идентификация ссылок на подобные сущности в тексте является задачей распознавания именованных сущностей.
Станкевич Андрей Сергеевич — лауреат специальной премии корпорации IBM. Станкевич Андрей Сергеевич[личность] — лауреат специальной премии корпорации IBM[компания].
Определение семантических отношений между именованными сущностями или другими объектами текста, является задачей извлечения отношений. Примеры отношений: (автор,книга), (организация,главный_офис).
Эти два подхода применяются во многих задачах, например, извлечение синонимов из текста, автоматическом построении онтологий и реализованы во многих работающих системах, например, NELL [6] и Snowball [7] .
Использование N-грамм
| Определение: |
| N-грамма — последовательность из [math]n[/math] элементов. |
В NLP N-граммы используются для построения вероятностных моделей, задач схожести текстов, категоризации текста и языка.
Построив N-граммную модель можно определить вероятность употребления заданной фразы в тексте. N-граммная модель рассчитывает вероятность последнего слова N-граммы, если известны все предыдущие, при этом полагается, что вероятность появления каждого слова зависит только от предыдущих слов.
Использование N-грамм применяется в задаче выявления плагиата. Текст разбивается на несколько фрагментов, представленных N-граммами. Сравнение N-грамм друг с другом позволяет определить степень сходства документов. Аналогичным способом можно решать задачу исправления орфографических ошибок, подбирая слова кандидаты для замены.
Частеречная разметка
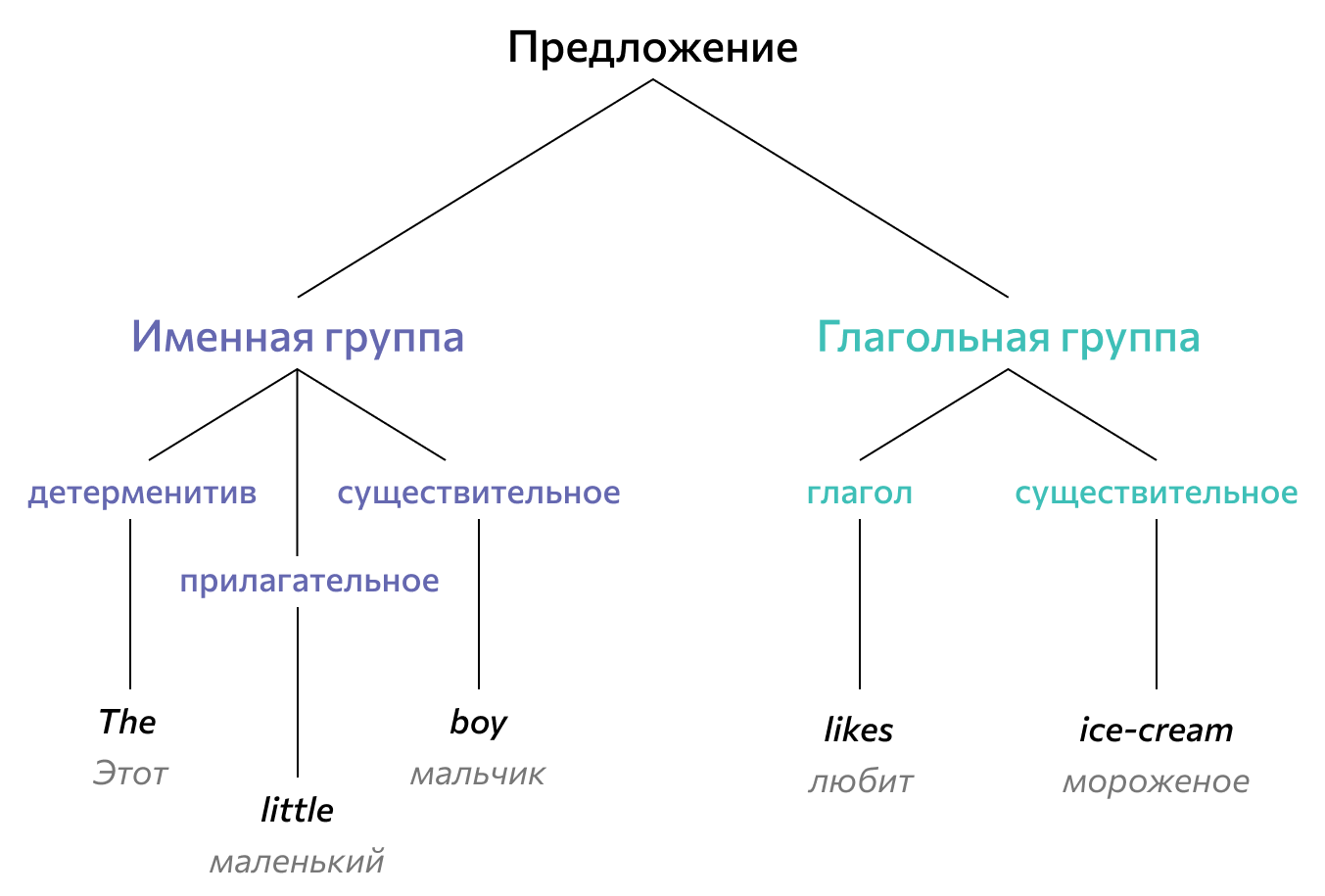
Частеречная разметка (POS-тэгирование, англ. part-of-speech tagging) используется в NLP для определения части речи и грамматических характеристик слов в тексте с приписыванием им соответствующих тегов. Модель необходима, когда значение слова зависит от контекста. Например, в предложениях «Столовая ложка» и «Школьная столовая» слово «столовая» имеет разные части речи. POS-тэгирование позволяет сопоставить слову в тексте специальный тэг на основе его значения и контекста.
Алгоритмы частеречной разметки делятся на несколько групп:
- Стохастический метод. Такой метод имеет два похожих друг на друга подхода. Первый подход основывается на частоте встречаемости слова с конкретным тэгом: если определенное слово встречается чаще всего с тэгом «существительное», то скорее всего и сейчас оно будет иметь такой тэг. Второй вариант использует n-граммы — анализируя входную последовательность, алгоритм высчитывает вероятность, что в данном контексте будет определенный тэг. В конце просчета вероятностей выбирается тэг, который имеет наибольшую вероятность. Библиотека TextBlob [8] в своей основе использует стохастический метод.
- Основанные на правилах. Метод основан на заранее известных правилах. Алгоритм состоит из двух стадий. Сначала расставляются потенциальные тэги всем словам на основе словаря или по какому-либо другому принципу. Далее, если у какого-нибудь слова оказалось несколько тэгов, правильный тэг выбирается на основе рукописных правил. Правил должно быть много, чтобы решить все возникшие неопределенности и учесть все случаи. Например, правило: слова длиной меньше трех символов являются частицами, местоимениями или предлогами. Однако такое правило не учитывает некоторые короткие слова из других частей речи. В библиотеке NLTK [9] используется данный метод.
- С использованием скрытой марковской модели. Пусть в нашей Марковской модели тэги будут скрытыми состояниями, которые производят наблюдаемое событие — слова. С математической точки зрения, мы хотим найти такую последовательность тэгов (C), которая будет максимизировать условную вероятность [math]P(C|W)[/math] , где [math]C = C_1, C_2, \dots C_T[/math] и [math]W = W_1, W_2, \dots W_T[/math] . Воспользовавшись формулой Байеса получим, что максимизировать необходимо следующее выражение: [math]p(C_1, C_2, \dots C_T) \cdot p(W_1, W_2, \dots W_T | C_1, C_2, \dots C_T)[/math] . Библиотека spaCy [10] основана на скрытой марковской модели.
POS-тэгирование является неотъемлемой частью обработки естественного языка. Без частеречной разметки становится невозможным дальнейший анализ текста из-за возникновения неопределенностей в значениях слов. Данный алгоритм используется при решении таких задач как перевод на другой язык, определение смысла текста, проверка на пунктуационные и речевые ошибки. Также можно автоматизировать процесс определения хештегов у постов и статей, выделяя существительные в приведенном тексте.
Благодаря частому использованию POS-тэгирования на практике, существует много встроенных библиотек с готовыми реализациями. Например, NLTK, scikit-learn [11] , spaCy, TextBlob, HunPOS [12] , Standford POS Tagger [13] и другие. Примеры использования некоторых библиотек:
- TextBlob (стохастический метод):
from textblob import TextBlob text = ("The quick brown fox jumps over the lazy dog") blob_object = TextBlob(text) print(blob_object.tags) output: [('The', 'DT'), ('quick', 'JJ'), ('brown', 'JJ'), ('fox', 'NN'), ('jumps', 'VBZ'), ('over', 'IN'), ('the', 'DT'), ('lazy', 'JJ'), ('dog', 'NN')]
- NLTK (основанный на правилах):
import nltk from nltk.tokenize import word_tokenize text = word_tokenize("Hello welcome to the world of to learn Categorizing and POS Tagging with NLTK and Python") nltk.pos_tag(text) output: [('Hello', 'NNP'), ('welcome', 'NN'), ('to', 'TO'), ('the', 'DT'), ('world', 'NN'), ('of', 'IN'), ('to', 'TO'), ('learn', 'VB'), ('Categorizing', 'NNP'), ('and', 'CC'), ('POS', 'NNP'), ('Tagging', 'NNP'), ('with', 'IN'), ('NLTK', 'NNP'), ('and', 'CC'), ('Python', 'NNP')]
- spaCy (с использованием скрытой марковской модели):
import spacy nlp = spacy.load("en_core_web_sm") doc = nlp("The quick brown fox jumps over the lazy dog") for token in doc: print((token.text, token.pos_)) output: [('The', 'DT'), ('quick', 'JJ'), ('brown', 'JJ'), ('fox', 'NN'), ('jumps', 'NNS'), ('over', 'IN'), ('the', 'DT'), ('lazy', 'JJ'), ('dog', 'NN')]
from os.path import expanduser home = expanduser("~") from nltk.tag.hunpos import HunposTagger _path_to_bin = home + '/hunpos-1.0-linux/hunpos-tag' _path_to_model = home + '/hunpos-1.0-linux/en_wsj.model' ht = HunposTagger(path_to_model=_path_to_model, path_to_bin=_path_to_bin) text = "The quick brown fox jumps over the lazy dog" ht.tag(text.split()) output: [('The', 'DT'), ('quick', 'JJ'), ('brown', 'JJ'), ('fox', 'NN'), ('jumps', 'NNS'), ('over', 'IN'), ('the', 'DT'), ('lazy', 'JJ'), ('dog', 'NN')]
- Stanford POS tagger
from os.path import expanduser home = expanduser("~") from nltk.tag.stanford import POSTagger _path_to_model = home + '/stanford-postagger/models/english-bidirectional-distsim.tagger' _path_to_jar = home + '/stanford-postagger/stanford-postagger.jar' st = POSTagger(path_to_model=_path_to_model, path_to_jar=_path_to_jar) text = "The quick brown fox jumps over the lazy dog" st.tag(text.split()) output: [('The', 'DT'), ('quick', 'JJ'), ('brown', 'JJ'), ('fox', 'NN'), ('jumps', 'VBZ'), ('over', 'IN'), ('the', 'DT'), ('lazy', 'JJ'), ('dog', 'NN')]
Библиотеки для NLP
NLTK (Natural Language ToolKit) [14]
Пакет библиотек и программ для символьной и статистической обработки естественного языка, написанных на Python и разработанных по методологии SCRUM. Содержит графические представления и примеры данных. Поддерживает работу с множеством языков, в том числе, русским.
- Наиболее известная и многофункциональная библиотека для NLP;
- Большое количество сторонних расширений;
- Быстрая токенизация предложений;
- Поддерживается множество языков.
- Медленная;
- Сложная в изучении и использовании;
- Работает со строками;
- Не использует нейронные сети;
- Нет встроенных векторов слов.
spaCy [15]
Библиотека, разработанная по методологии SCRUM на языке Cypthon, позиционируется как самая быстрая NLP библиотека. Имеет множество возможностей, в том числе, разбор зависимостей на основе меток, распознавание именованных сущностей, пометка частей речи, векторы расстановки слов. Не поддерживает русский язык.
- Самая быстрая библиотека для NLP;
- Простая в изучении и использовании;
- Работает с объектами, а не строками;
- Есть встроенные вектора слов;
- Использует нейронные сети для тренировки моделей.
- Менее гибкая по сравнению с NLTK;
- Токенизация предложений медленнее, чем в NLTK;
- Поддерживает маленькое количество языков.
scikit-learn [16]
Библиотека scikit-learn разработана по методологии SCRUM и предоставляет реализацию целого ряда алгоритмов для обучения с учителем и обучения без учителя через интерфейс для Python. Построена поверх SciPy. Ориентирована в первую очередь на моделирование данных, имеет достаточно функций, чтобы использоваться для NLP в связке с другими библиотеками.
- Большое количество алгоритмов для построения моделей;
- Содержит функции для работы с Bag-of-Words моделью;
- Хорошая документация.
- Плохой препроцессинг, что вынуждает использовать ее в связке с другой библиотекой (например, NLTK);
- Не использует нейронные сети для препроцессинга текста.
gensim [17]
Python библиотека, разработанная по методологии SCRUM, для моделирования, тематического моделирования документов и извлечения подобия для больших корпусов. В gensim реализованы популярные NLP алгоритмы, например, word2vec. Большинство реализаций могут использовать несколько ядер.
- Работает с большими датасетами;
- Поддерживает глубокое обучение;
- word2vec, tf-idf vectorization, document2vec.
- Заточена под модели без учителя;
- Не содержит достаточного функционала, необходимого для NLP, что вынуждает использовать ее вместе с другими библиотеками.
Балто-славянские языки имеют сложную морфологию, что может ухудшить качество обработки текста, а также ограничить использование ряда библиотек. Для работы со специфичной русской морфологией можно использовать, например, морфологический анализатор pymorphy2 [18] и библиотеку для поиска и извлечения именованных сущностей Natasha [19]
Примеры использования NLTK
- Разбиение на предложения:
text = "Предложение. Предложение, которое содержит запятую. Восклицательный знак! Вопрос?" sents = nltk.sent_tokenize(text) print(sents) output: ['Предложение.', 'Предложение, которое содержит запятую.', 'Восклицательный знак!', 'Вопрос?']
- Токенизация:
from nltk.tokenize import RegexpTokenizer sent = "В этом предложении есть много слов, мы их разделим." tokenizer = RegexpTokenizer(r'\w+') print(tokenizer.tokenize(sent)) output: ['В', 'этом', 'предложении', 'есть', 'много', 'слов', 'мы', 'их', 'разделим']
from nltk import word_tokenize sent = "В этом предложении есть много слов, мы их разделим." print(word_tokenize(sent)) output: ['В', 'этом', 'предложении', 'есть', 'много', 'слов', ',', 'мы', 'их', 'разделим', '.']
- Стоп слова:
from nltk.corpus import stopwords stop_words=set(stopwords.words('english')) print(stop_words) output:
- Стемминг и лемматизация:
from nltk.stem.porter import PorterStemmer porter_stemmer = PorterStemmer() print(porter_stemmer.stem("crying")) output: cri
from nltk.stem.lancaster import LancasterStemmer lancaster_stemmer = LancasterStemmer() print(lancaster_stemmer.stem("crying")) output: cry
from nltk.stem import SnowballStemmer snowball_stemmer = SnowballStemmer("english") print(snowball_stemmer.stem("crying")) output: cri
from nltk.stem import WordNetLemmatizer wordnet_lemmatizer = WordNetLemmatizer() print(wordnet_lemmatizer.lemmatize("came", pos="v")) output: come
Пример кода на языке Scala
См. также
Что такое обработка естественного языка (NLP)?
Обработка естественного языка (NLP) – это технология машинного обучения, которая дает компьютерам возможность интерпретировать, манипулировать и понимать человеческий язык. Сегодня организации имеют большие объемы голосовых и текстовых данных из различных каналов связи, таких как электронные письма, текстовые сообщения, новостные ленты социальных сетей, видео, аудио и многое другое. Они используют программное обеспечение NLP для автоматической обработки этих данных, анализа намерений или настроений в сообщении и реагирования на человеческое общение в режиме реального времени.
Почему NLP играет такую важную роль?
Обработка естественного языка (NLP) имеет решающее значение для полного и эффективного анализа текстовых и речевых данных. Таким образом можно преодолевать различия в диалектах, сленге и грамматических нарушениях, типичных для повседневных разговоров.
Компании используют этот метод для нескольких автоматизированных задач, таких как:
• Обработка, анализ и архивирование больших документов
• Анализ отзывов клиентов или записей колл-центра
• Запуск чат-ботов для автоматизированного обслуживания клиентов
• Ответы на вопросы «кто, что, когда и где»
• Классификация и извлечение текста
Вы также можете интегрировать NLP в приложения, ориентированные на клиента, чтобы более эффективно общаться с клиентами. Например, чат-бот анализирует и сортирует запросы клиентов, автоматически отвечая на распространенные вопросы и перенаправляя сложные запросы в службу поддержки. Эта автоматизация помогает снизить затраты, избавить агентов от необходимости тратить время на избыточные запросы, а также она повышает удовлетворенность клиентов.
Каковы сценарии использования NLP для бизнеса?
Компании используют программное обеспечение и инструменты обработки естественного языка (NLP) для эффективного и точного упрощения, автоматизации и оптимизации операций. Ниже мы приводим несколько примеров использования.
Скрытие конфиденциальных данных
Компании в страховом, юридическом и медицинском секторах обрабатывают, сортируют и извлекают большие объемы конфиденциальных документов, таких как медицинские карты, финансовые данные и личные данные. Вместо проверки вручную компании используют технологию NLP для редактирования личной информации и защиты конфиденциальных данных. Например, Chisel AI помогает страховым компаниям извлекать номера полисов, даты истечения срока действия и другие личные атрибуты клиентов из неструктурированных документов с помощью Amazon Comprehend.
Взаимодействие с клиентами
Технологии NLP позволяют чат-ботам и голосовым ботам быть более похожими на людей при общении с клиентами. Компании используют чат-ботов для масштабирования возможностей и качества обслуживания клиентов при минимальных эксплуатационных расходах. Компания PubNub, которая создает программное обеспечение для чат-ботов, использует Amazon Comprehend для внедрения локализованных функций чата для своих клиентов по всему миру. T-Mobile использует NLP для определения конкретных ключевых слов в текстовых сообщениях клиентов и предоставления персонализированных рекомендаций. Университет штата Оклахома внедряет чат-бот для вопросов и ответов для решения вопросов студентов с использованием технологии машинного обучения.
Маркетологи используют инструменты NLP, такие как Amazon Comprehend и Amazon Lex, чтобы получить образованное представление о том, что клиенты думают о продукте или сервисе компании. Сканируя определенные фразы, они могут оценить настроение и эмоции клиента в письменных отзывах. Например, Success KPI предоставляет решения для обработки естественного языка, которые помогают компаниям сосредоточиться на целевых областях анализа тональности и помогают контакт-центрам получать полезную информацию из аналитики звонков.
Как работает NLP?
Обработка естественного языка (NLP) сочетает в себе компьютерную лингвистику, машинное обучение и модели глубокого обучения для обработки человеческого языка.
Компьютерная лингвистика – это наука о понимании и построении моделей человеческого языка с помощью компьютеров и программных инструментов. Исследователи используют методы компьютерной лингвистики, такие как синтаксический и семантический анализ, для создания платформ, помогающих машинам понимать разговорный человеческий язык. Такие инструменты, как переводчики языков, синтезаторы текста в речь и программное обеспечение для распознавания речи, основаны на компьютерной лингвистике.
Машинное обучение – это технология, которая обучает компьютер с помощью выборочных данных для повышения его эффективности. Человеческий язык имеет несколько особенностей, таких как сарказм, метафоры, вариации в структуре предложений, а также исключения из грамматики и употребления, на изучение которых у людей уходят годы. Программисты используют методы машинного обучения, чтобы научить приложения NLP распознавать и точно понимать эти функции с самого начала.
Глубокое обучение – это особая область машинного обучения, которая учит компьютеры учиться и мыслить как люди. Это включает нейронную сеть, состоящую из узлов обработки данных, структурированных так, чтобы напоминать человеческий мозг. С помощью глубокого обучения компьютеры распознают, классифицируют и сопоставляют сложные закономерности во входных данных.
Этапы внедрения NLP
Как правило, внедрение NLP начинается со сбора и подготовки неструктурированных текстовых или речевых данных из таких источников, как облачные хранилища данных, опросы, электронные письма или внутренние приложения бизнес-процессов.
Программное обеспечение NLP использует методы предварительной обработки, такие как токенизация, стемминг, лемматизация и удаление стоп-слов, для подготовки данных для различных приложений.
Ниже приведено описание этих методов.
- Токенизация разбивает предложение на отдельные единицы слов или фраз.
- Стемминг и лемматизация упрощают слова до их корневой формы. Например, эти процессы превращают «начало» в «старт».
- Удаление стоп-слов гарантирует, что слова, которые не добавляют значимого смысла предложению, такие как «для» и «с», будут удалены.
Исследователи используют предварительно обработанные данные и машинное обучение для тренировки моделей NLP, чтобы выполнять конкретные приложения на основе предоставленной текстовой информации. Обучение алгоритмов NLP требует предоставления программного обеспечения большими выборками данных для повышения их точности.
Развертывание и вывод
Затем специалисты по машинному обучению развертывают модель или интегрируют ее в существующую производственную среду. Модель NLP получает входные данные и прогнозирует выходные данные для конкретного сценария использования, для которого она предназначена. Приложение NLP можно запустить на живых данных и получить требуемый результат.
Что такое задачи NLP?
Методы обработки естественного языка (NLP), или задачи NLP, разбивают человеческий текст или речь на более мелкие части, которые компьютерные программы могут легко понять. Общие возможности обработки и анализа текста в NLP приведены ниже.
Маркировка частей речи
Это процесс, при котором программное обеспечение NLP помечает отдельные слова в предложении в соответствии с контекстуальными обычаями, такими как существительные, глаголы, прилагательные или наречия. Это помогает компьютеру понять, как слова формируют значимые отношения друг с другом.
Некоторые слова могут иметь разные значения при использовании в разных сценариях. Например, слово «замок» в разных предложениях означает разные вещи.
- Замок – это средневековое строение.
- Люди используют замок, чтобы закрыть что-либо.
Устраняя неоднозначность смысла слов, программное обеспечение NLP определяет предполагаемое значение слова, обучая его языковую модель или ссылаясь на словарные определения.
Распознавание речи превращает голосовые данные в текст. Процесс включает в себя разбиение слов на более мелкие части и понимание акцентов, оскорблений, интонаций и неправильного использования грамматики в повседневном разговоре. Ключевым применением распознавания речи является транскрипция, которую можно выполнить с помощью сервисов преобразования речи в текст, таких как Amazon Transcribe.
Программное обеспечение для машинного перевода использует обработку естественного языка для преобразования текста или речи с одного языка на другой с сохранением контекстуальной точности. Сервис AWS, поддерживающий машинный перевод, – Amazon Translate.
Распознавание наименований сущностей
Этот процесс определяет уникальные имена людей, мест, событий, компаний и многого другого. Программное обеспечение NLP использует распознавание именованных сущностей для определения отношений между различными сущностями в предложении.
Рассмотрим следующий пример: «Джейн отправилась в отпуск во Францию, где она побаловала себя блюдами местной кухни».
Программное обеспечение NLP выберет «Джейн» и «Франция» в качестве особых субъектов в предложении. Это может быть дополнительно расширено с помощью разрешения совместных ссылок, определяющего, используются ли разные слова для описания одного и того же субъекта. В приведенном выше примере и «Джейн», и «она» указали на одного и того же человека.
Анализ тональности текста
Анализ тональности – это основанный на искусственном интеллекте подход к интерпретации эмоций, передаваемых текстовыми данными. Программа NLP анализирует текст на наличие слов или фраз, которые показывают неудовлетворенность, счастье, сомнения, сожаление и другие скрытые эмоции.
Каковы подходы к обработке естественного языка?
Ниже мы приводим некоторые общие подходы к обработке естественного языка (NLP).
Контролируемая обработка естественного языка (NLP)
Во время контролируемой обработки естественного языка программное обеспечение обучается с помощью набора маркированных или известных входов и выходов. Программа сначала обрабатывает большие объемы известных данных и учится получать правильные выходные данные из любого неизвестного ввода. Например, компании обучают инструменты NLP категоризации документов в соответствии с конкретными этикетками.
Неконтролируемая обработка естественного языка (NLP)
Неконтролируемая обработка естественного языка использует статистическую языковую модель для прогнозирования закономерности, которая возникает при подаче немаркированного ввода. Например, функция автозаполнения в текстовых сообщениях предлагает релевантные слова, которые имеют смысл для предложения, отслеживая ответ пользователя.
Понимание естественных языков
Понимание естественного языка (NLU) – это подмножество NLP, которое фокусируется на анализе значения предложений. NLU позволяет программе находить похожие значения в разных предложениях или обрабатывать слова, которые имеют разные значения.
Генерация естественного языка
Генерация естественного языка (NLG) направлена на создание разговорного текста, как это делают люди, на основе определенных ключевых слов или тем. Например, интеллектуальный чат-бот с возможностями NLG может общаться с клиентами так же, как и сотрудники службы поддержки клиентов.
Как AWS может помочь в решении задач NLP?
AWS предоставляет самый широкий и полный набор сервисов искусственного интеллекта (ИИ) и машинного обучения (МО) для клиентов любого уровня квалификации. Эти сервисы подключены к полному набору источников данных.
Для клиентов, которым не хватает навыков машинного обучения, которым требуется ускорить вывод на рынок или которые хотят добавить интеллект в существующий процесс либо приложение, AWS предлагает ряд языковых сервисов на основе МО. Это позволяет компаниям легко добавлять интеллектуальные функции в свои приложения искусственного интеллекта с помощью предварительно обученных API для работы с речью, транскрипцией, переводом, анализом текста и функциями чат-ботов.
Вот список языковых сервисов на основе AWS МО:
- Amazon Comprehend помогает находить ценную информацию и взаимосвязи в тексте.
- Amazon Transcribe выполняет автоматическое распознавание речи.
- Amazon Translate свободно переводит текст.
- Amazon Polly превращает текст в речь с естественным звучанием.
- Amazon Lex помогает создавать чат-ботов для взаимодействия с клиентами.
- Amazon Kendra выполняет интеллектуальный поиск корпоративных систем, чтобы быстро найти нужный контент.
Клиентам, которые хотят создать стандартное решение для обработки естественного языка (NLP) в своем бизнесе, рекомендуется обратить внимание на Amazon SageMaker. SageMaker упрощает подготовку данных, создание, обучение и развертывание моделей машинного обучения для любого сценария использования с полностью управляемой инфраструктурой, инструментами и рабочими процессами, включая предложения без кода для бизнес-аналитики.
Используя Hugging Face в Amazon SageMaker, вы можете развертывать и точно настраивать предварительно обученные модели от Hugging Face, поставщика моделей NLP с открытым исходным кодом, известного как Transformers. Это сокращает время, необходимое для настройки и использования этих моделей NLP, с недель до минут.
Создайте аккаунт AWS и начните работу с NLP уже сегодня.