Библиотека Scikit-learn: как создать свой первый ML‑проект
Изучаем возможности Python-библиотеки для machine learning и пишем модель классификации цветов с помощью Scikit-learn.

Изображение: промоматериалы к фильму «Робот по имени Чаппи» / Columbia Pictures

Антон Яценко
Изучает Python, его библиотеки и занимается анализом данных. Любит путешествовать в горах.
Python-библиотеку Scikit-learn используют в data science для создания моделей машинного обучения. С помощью «Сайкит-лёрн» (именно так произносится название этой либы) автомобили ездят по городу на автопилоте, а ваш почтовый ящик фильтрует спам.
В этой статье мы собрали всё необходимое для старта работы с этой библиотекой: базовые теоретические понятия, примеры кода для основных алгоритмов и теоретические основы. Так что запускайте Google Colab или другую IDE и присоединяйтесь к нам.
Что такое Scikit-learn
Scikit-learn — популярная Python-библиотека для машинного обучения, которая была разработана в рамках проекта Google Summer of Code в 2007 году. Её цель — взаимодействие с числовыми и научными библиотеками Python: NumPy и SciPy. В библиотеке представлены различные алгоритмы классификации, регрессии и кластеризации, включая support vector machines, random forests, gradient boosting, k-means и DBSCAN.
Scikit-learn быстро набрала популярность и сегодня является одним из лучших вариантов для ML-разработки, что подтверждает статистика её использования в Kaggle-соревнованиях:
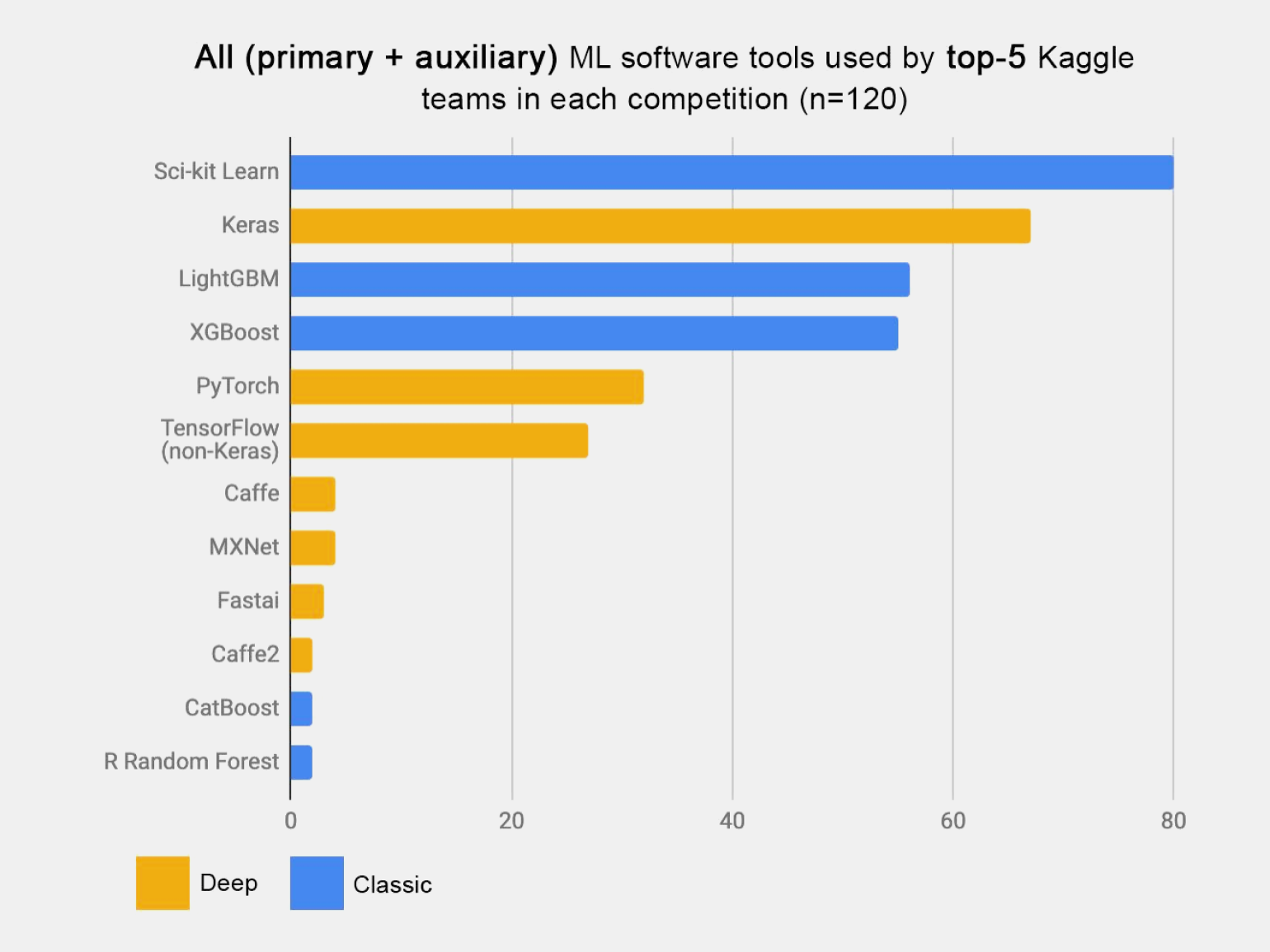
Почему она так популярна:
- большое комьюнити и подробная документация, облегчающая обучение и использование библиотеки на практике;
- самостоятельность для машинного обучения за счёт возможности работать с основными алгоритмами ML: регрессия, кластеризация, random forest и другими;
- лёгкая интеграция с другими библиотеками, используемыми в машинном обучении и data science в целом: Matplotlib и Plotly для построения графиков, NumPy для векторизации массивов, Pandas DataFrame, SciPy и другими;
- open-source-код и возможность использования в коммерческих проектах.
Как установить Scikit-learn
В машинном обучении для работы с кодом обычно используются специальные инструменты: Google Colab или Jupyter Notebook. Это IDE, специально созданные для работы с данными, позволяющие не писать отдельные приложения, а обрабатывать информацию пошагово.
В этой статье мы будем использовать Google Colab — облачное решение для работы с данными. Оно работает в браузере и доступно хоть на ноутбуке, хоть на планшете и даже на смартфоне.
При работе с Google Colab или Jupyter Notebook устанавливать Python и Scikit-learn не понадобится — язык программирования и библиотека уже доступны «из коробки». Но если вы решили писать код в другой IDE, например в Visual Studio Code, то сначала установите Python, а затем Scikit-learn через терминал:

Датасеты хранятся в Scikit-learn не в привычных для аналитиков данных DataFrame, а в Bunch — специальном словаре с расширением .data. В нашем случае это массивы setosa, versicolor, virginica и другие.
Для удобства работы можно импортировать Pandas и сохранить информацию в табличном виде:
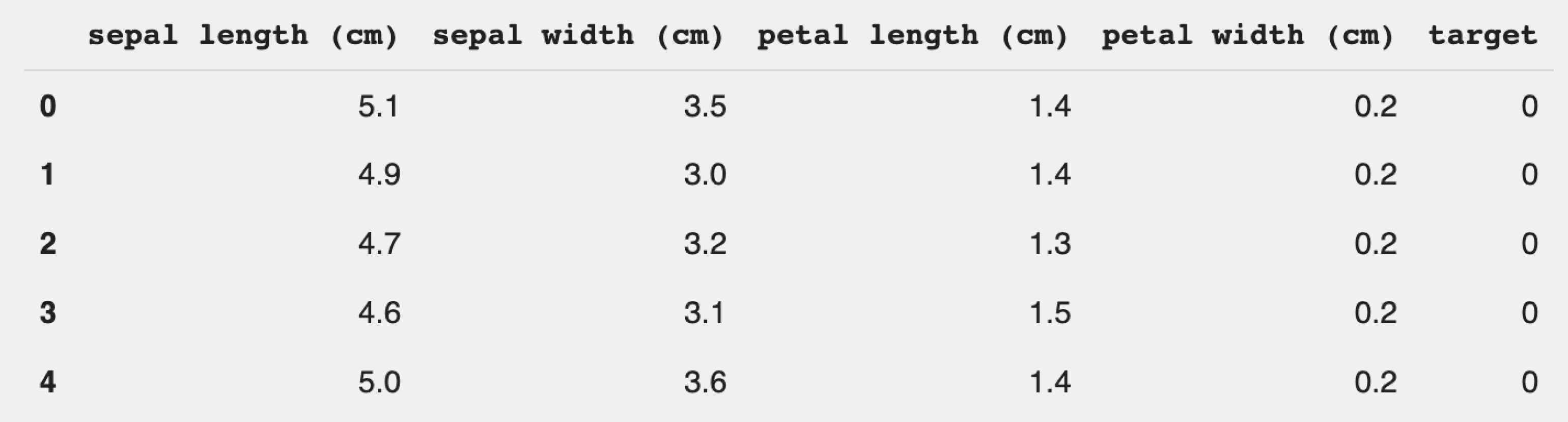
Используем этот датасет для классической задачи машинного обучения — классификации. Для начала разберёмся в самих данных и поймём, что содержится в этом наборе данных.
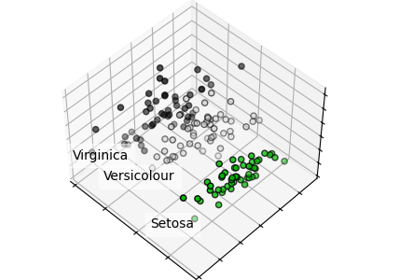
Что содержится в датасете с ирисами?
Данные включают в себя информацию о 150 образцах трёх видов ирисов. В первом столбце представлена длина чашелистика, во втором — ширина чашелистика, в третьем — длина лепестка, в четвёртом — ширина лепестка. В зависимости от этих значений мы можем разделить цветки на три разных вида: setosa, versicolor, virginica, различающиеся шириной и высотой лепестков и чашелистиков.
Этот набор данных отлично подходит для классических задач контролируемого обучения, то есть обучения на размеченных данных. Входными переменными являются длина и ширина чашелистика и длина и ширина лепестка; каждая строка представляет собой один экземпляр или наблюдение. Выходной переменной является Iris setosa, Iris versicolor или Iris virginica, то есть название вида.
Посмотрим ещё раз на наш датасет:
В столбце target указан вид, к которому относится цветок: setosa (0), versicolor (1), virginica (2). Но работать с ним неудобно, так как нам проще работать с названиями видов. Поэтому добавим столбец с указанием вида растения:
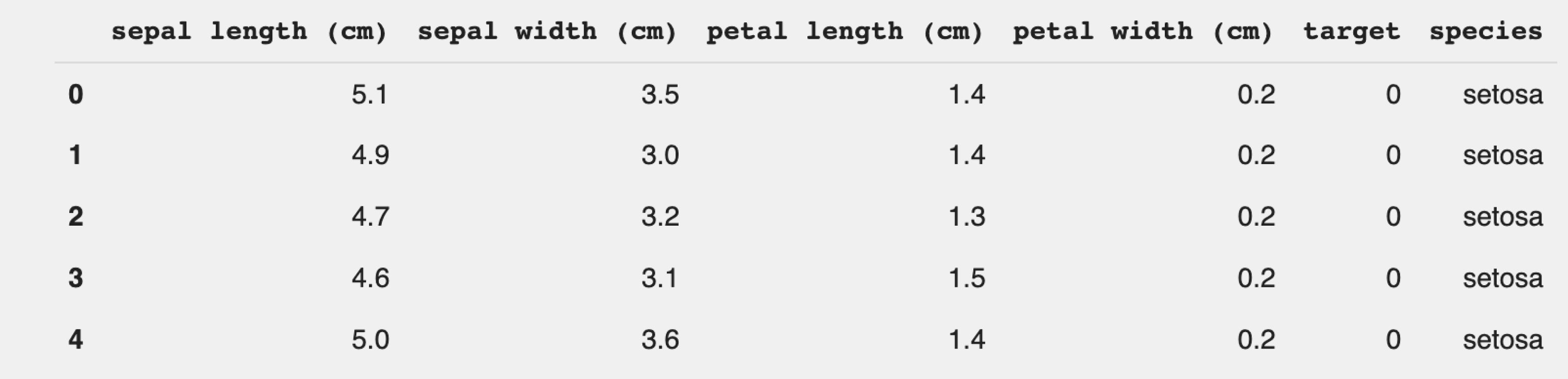
Отлично. Всё получилось.
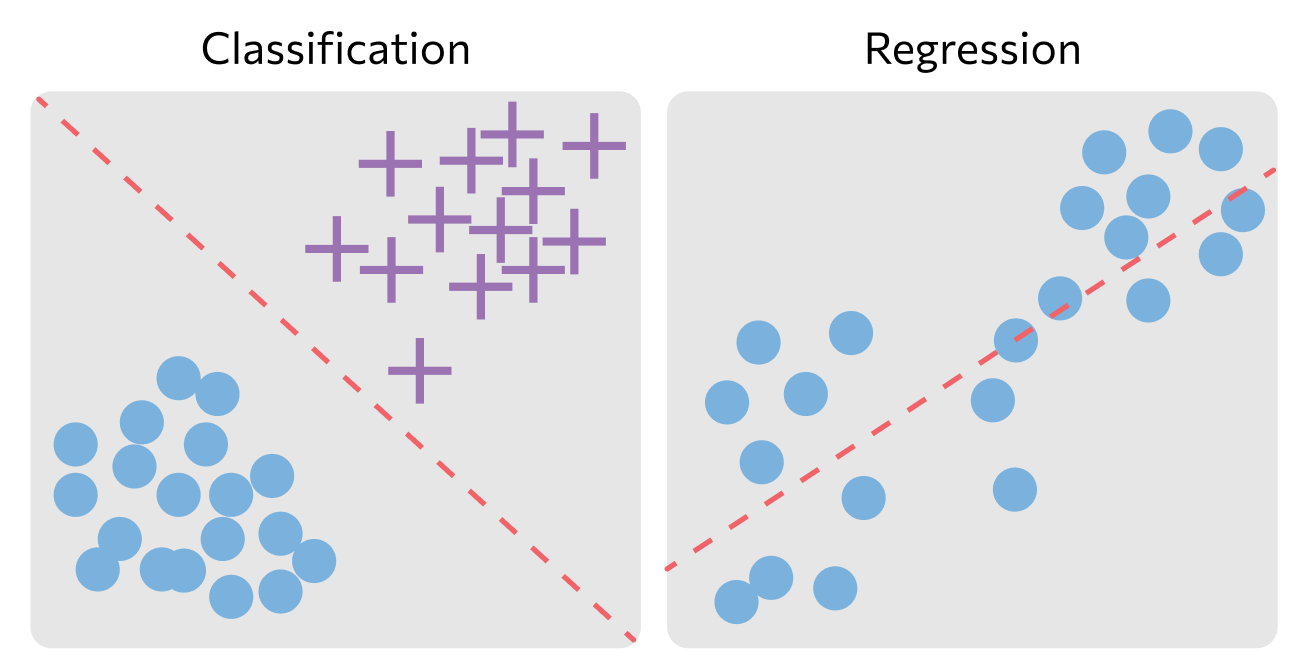
Классификация в машинном обучении
Классификация используется для разделения переменных или каких-то объектов по категориям. Как правило, это всегда обучение с учителем, то есть на выходе должны быть размеченные данные с признаками и сами категории, которые будут использоваться для разделения. Один из примеров работы классификации — спам-фильтры в почтовом ящике.
Посмотрим, как классификация работает на практике, — приготовьтесь, часть терминологии из сферы работы с данными довольно сложна для понимания, и мы предполагаем, что с ней вы уже немного знакомы.
Шаг 1. Смотрим на распределение данных
Прежде чем приступать к написанию алгоритма классификации, посмотрим на то, как сейчас распределены образцы по своим параметрам — воспользуемся библиотекой Matplotlib и построим график распределения образцов по размерам чашелистика:
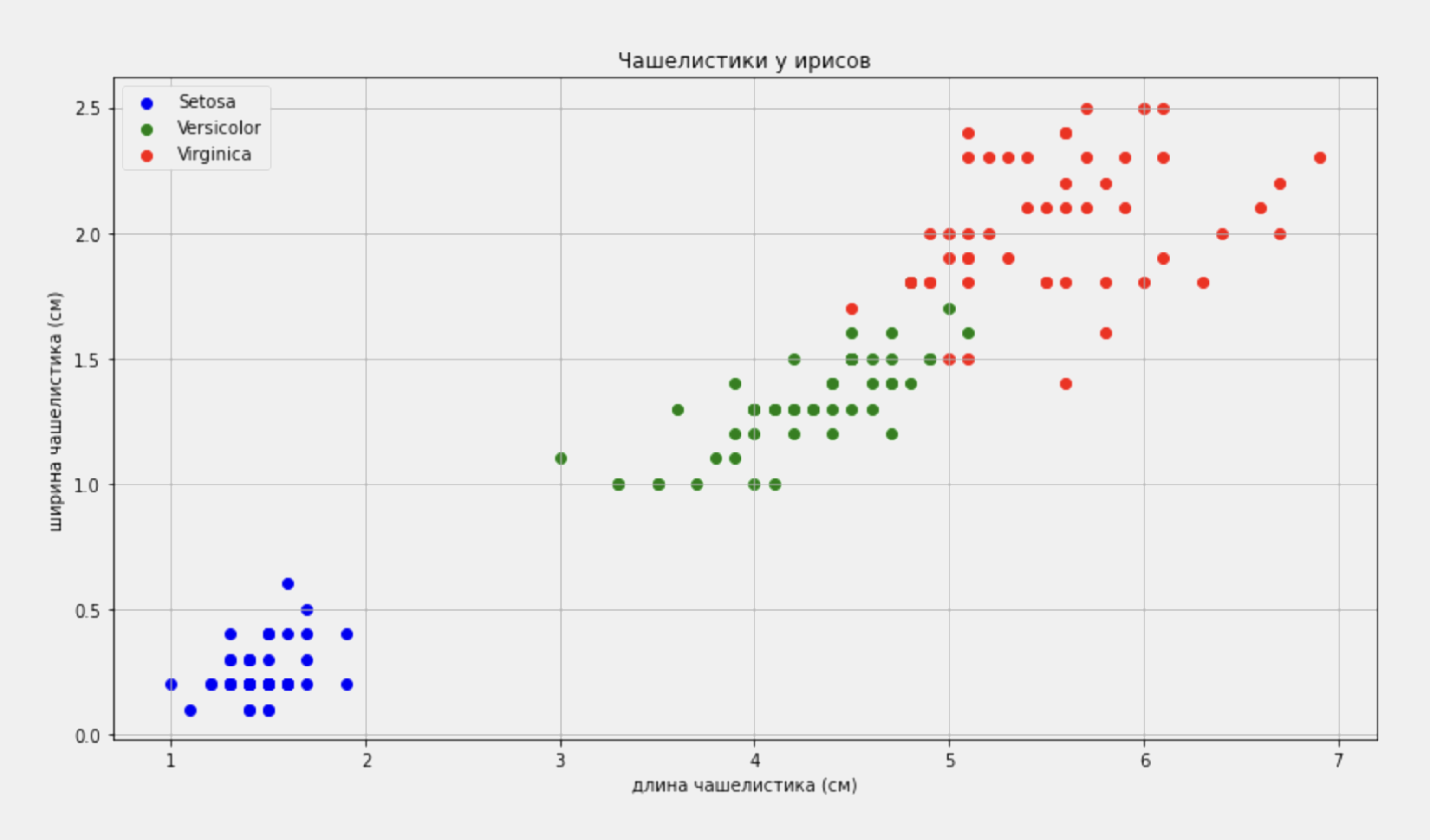
Хорошо заметно, что виды отличаются друг от друга размером чашелистиков. Например, у ирисов virginica они крупнее, чем у ирисов versicolor и setosa. То есть эти характеристики можно использовать для различения видов между собой. Попробуем научить этому компьютер.
Шаг 2. Используем правильные модули для классификации
Нам не придётся писать алгоритм классификации с нуля. В библиотеке Scikit-learn есть множество готовых алгоритмов — надо только выбрать правильный.
В случае с ирисами воспользуемся логистической регрессией. Прежде чем приступить к этому, разделим датасет на два набора данных: тренировочный, который будем использовать для обучения алгоритма, и тестовый — для проверки точности его работы. Для этого воспользуемся стандартным методом train_test_split.
Важно, что логистическая регрессия не работает с датафреймами Pandas. Поэтому дополнительно импортируем NumPy и преобразуем датафрейм в NumPy-массивы.

Мы видим, что на выходе получили массив, содержащий значения от 0 до 2, которые соответствуют видам ирисов. Повторим для тестовой выборки:
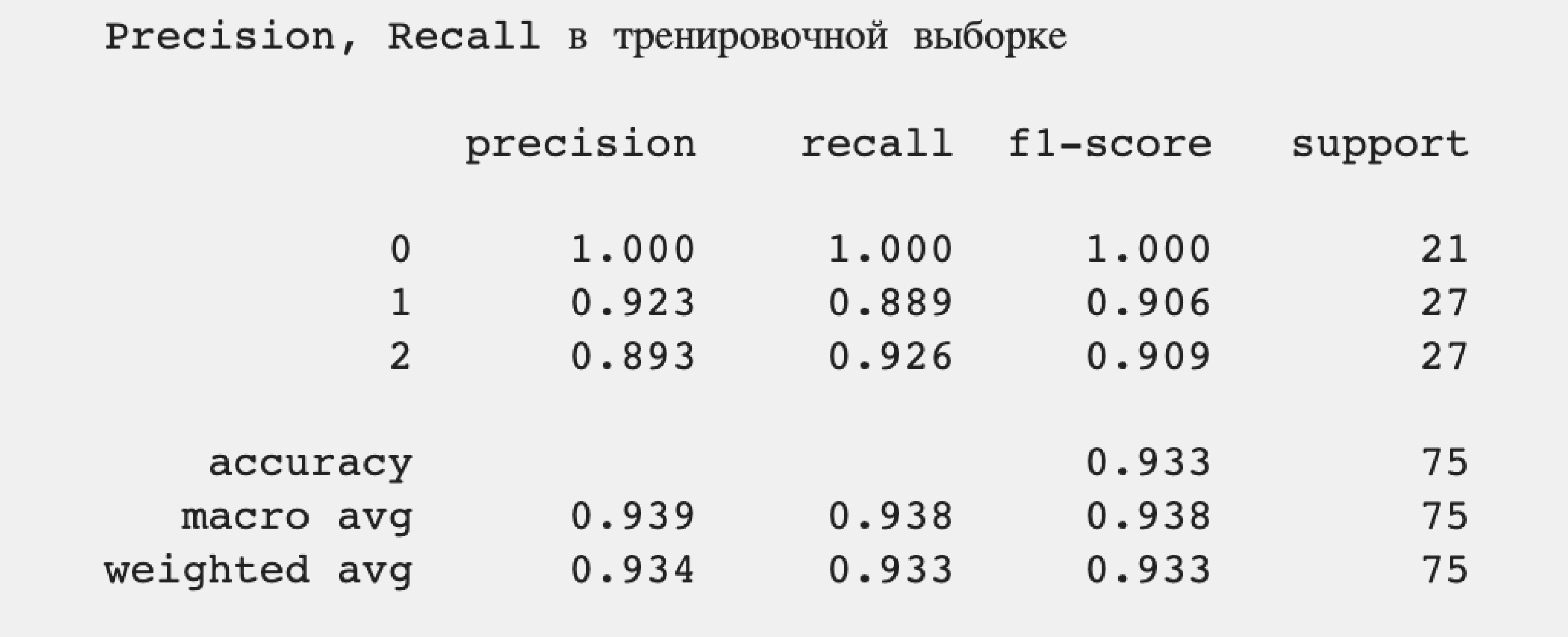
Точность (precision) в среднем равна 0,939, то есть 93,9%, что довольно хорошо для небольшого количества образцов. Полнота (recall) также равна 0,938, то есть алгоритм в 93,8% случаев правильно понимает принадлежность конкретного образца, пропуская их в оставшихся 6,2% случаев.
Проверим теперь алгоритм на тестовой выборке:
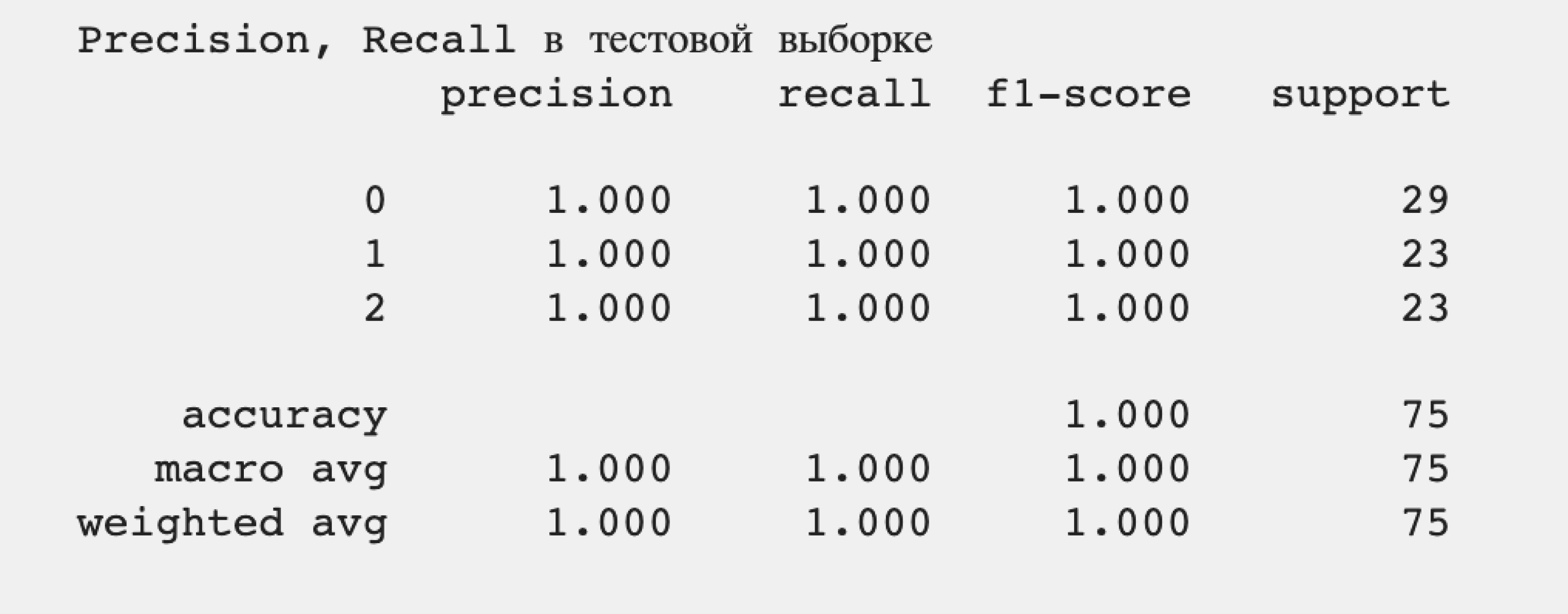
100% точность определения. Наша модель классификации правильно определяет все подвиды ирисов на основе длины и ширины чашелистиков, не допуская ложноположительных и ложноотрицательных результатов.
Что дальше?
Библиотека Scikit-learn имеет подробную официальную документацию, которая содержит подробную информацию об особенностях работы с ней и примеры кода для различных вариантов алгоритмов машинного обучения. Для глубокого погружения в работу с библиотекой лучше подойдут специализированные книги:
- «Прикладное машинное обучение с помощью Scikit-Learn, Keras и TensorFlow. Концепции, инструменты и техники для создания интеллектуальных систем» Жерона Орельена;
- Learning scikit-learn. Machine Learning in Python Рауля Гарреты;
- Scikit-learn Cookbook Трента Хаука.
Читайте также:
- Что такое Machine Learning и стоит ли его изучать
- Тест: а нейросети точно так могут?
- Библиотека TensorFlow: пишем нейросеть и изучаем принципы машинного обучения
scikit-learn
Прогнозирование атрибута с непрерывным значением связанного с объектом.
Применение: Ответ на лекарство, Отток клиентов. Алгоритмы: SVR, k-ближайшего соседа, случайный лес, узнать больше…
Кластеризация
Автоматическая группировка похожих объектов в наборы.
Применение: Сегментация клиентов, Группировка экспериментальных результатов Алгоритмы: k-среднее, спектральная кластеризация, сдвиг среднего значения, узнать больше…
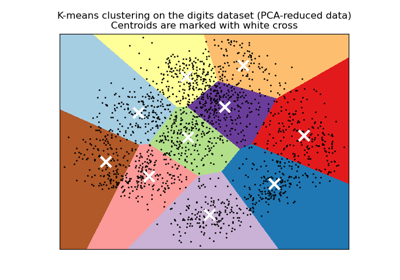
Понижение размерности
Понижение числа случайных переменных для анализа.
Применение: Визуализация, Увеличение эффективности Алгоритмы: k-среднее, выборка признаков, не отрицательная матричная факторизация, узнать больше…
Выбор модели
Сравнение, валидация и выбор параметров и моделей.
Применение: Улучшение точности через настройку параметров Алгоритмы: таблица поиска, Крос валидация, метрики, узнать больше…
Препроцессинг
Извлечение признаков и нормализация
Применение: Преобразование входных данных, таких как текст для применения алгоритмов машинного обучения Алгоритмы: Препроцессинг, Извлечение признаков, узнать больше…
Руководство по Scikit-learn для машинного обучения
Scikit-learn – одна из самых полезных библиотек Python для машинного обучения. Все концепции машинного обучения, которые мы изучаем теоретически, могут быть реализованы с помощью библиотеки Scikit-learn в Python. В этой статье я покажу вам работу Scikit-learn в машинном обучении с использованием Python.
Что такое Scikit-learn?
Scikit-learn – это библиотека Python, которая является одной из самых полезных библиотек Python для машинного обучения. Она включает все алгоритмы и инструменты, которые нужны для задач классификации, регрессии и кластеризации. Она также включает все методы оценки производительности модели машинного обучения.
Ниже представлены некоторые из преимуществ использования Scikit-learn для машинного обучения:
- Пользоваться очень просто.
- Предоставляет очень эффективные инструменты для прогнозной аналитики.
- Легко доступна для всех.
- Построена на библиотеках Numpy, sciPy и matplotlib в Python.
- Как и язык программирования Python, также имеет открытый исходный код и может использоваться в коммерческих целях.
Многие компании используют Scikit-learn в своих моделях машинного обучения. J.P. Morgan и Spotify входят в число известных пользователей этой системы. В J.P. Morgan инструментарий Scikit-learn широко используется во всех приложениях банка для задач классификации и прогнозной аналитики. В Spotify Scikit-learn используется для генерации музыкальных рекомендаций, чтобы обеспечить лучший пользовательский опыт.
Руководство по Scikit-learn с использованием Python
Библиотека Scikit-learn на Python очень проста в использовании для всех задач машинного обучения. Если вы работаете с приложениями, которые имеют дело с классификацией, регрессией или кластеризацией, то большая часть работы будет реализована только с использованием этой библиотеки. Теперь я расскажу вам, как работать с библиотекой Scikit-learn в Python для машинного обучения.
Использование этой библиотеки обычно начинается с разделения набора данных на обучающий и тестовый наборы. Вот как вы можете разделить свои данные:
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0)
Затем нам нужно обработать данные, чтобы они соответствовали модели машинного обучения. Здесь нам обычно нужно масштабировать данные, что можно сделать с помощью стандартизации и нормализации. Ниже приведен способ обработки данных scikit-learn:
from sklearn.preprocessing import StandardScaler scaler = StandardScaler().fit(x_train) scaler.transform(x_train) scaler.transform(x_test) from sklearn.preprocessing import Normalizer scaler = Normalizer().fit(x_train) scaler.transform(x_train) scaler.transform(x_test)
В качестве следующего шага нам нужно подогнать данные к модели. Ниже представлена реализация обучения некоторых из наиболее распространенных алгоритмов машинного обучения:
from sklearn.linear_model import LinearRegression from sklearn.svm import SVC from sklearn.naive_bayes import GaussianNB from sklearn import neighbors from sklearn.decomposition import PCA from sklearn.cluster import KMeans lr = LinearRegression(normalize=True) lr.fit(x_train, y_train) knn = neighbors.KNeighborsClassifier(n_neighbors=5) knn.fit(x_train, y_train) svc = SVC(kernel='linear') svc.fit(x_train, y_train) k_means = KMeans(n_clusters=3, random_state=0) k_means.fit(x_train) pca = PCA(n_components=0.95) pca.fit_transform(x_train)
Следующий шаг – сделать прогнозы на тестовой выборке:
y_pred = lr.predict(x_test) ypred = k_means.predict(x_test) y_pred = knn.predict_proba(x_test)
Последний шаг – определить, как модель машинного обучения работала на тестовой выборке. Ниже приведен метод, предоставляемый библиотекой Scikit-learn для оценки производительности моделей машинного обучения для задач классификации, регрессии и кластеризации:
# Classification from sklearn.metrics import accuracy_score accuracy_score(y_test, y_pred) # Regression from sklearn.metrics import mean_absolute_error mean_absolute_error(y_test,y_pred) # Clustering from sklearn.metrics import adjusted_rand_score adjusted_rand_score(y_test,y_pred)
Резюме
Это – быстрый обзор методов, предоставляемых библиотекой Scikit-learn в Python для машинного обучения. В этой библиотеке так много функций, что невозможно описать их все в одной статье. Все методы, предоставляемые scikit-learn, можно изучить здесь, среди нескольких других библиотек и моделей для машинного обучения. Надеюсь, вам понравилась эта статья о Scikit-библиотеке для машинного обучения с использованием Python.
Scikit-learn
Scikit-learn (sklearn) — это один из наиболее широко используемых пакетов Python для Data Science и Machine Learning. Он содержит функции и алгоритмы для машинного обучения: классификации, прогнозирования или разбивки данных на группы. Sklearn написана на языках Python, C, C++ и Cython.


Освойте профессию «Data Scientist»
Зачем нужна Scikit-learn
Первый релиз библиотеки вышел в 2007 году. Ее используют программисты, которые работают в Data Science и Machine Learning. Они используют библиотеку при построении моделей для обучения как с учителем, так и без.
- в рекомендательных системах: например, реклама на основе ваших ранее проявленных интересов или сервис музыки с «умными» рекомендациями;
- для распознавание текста и изображений;
- для предсказания поведения пользователей, финансовых колебаний и других прогнозируемых явлений на основе существующих данных;
- для классификации данных и автоматического построения метрик в бизнес-анализе;
- при распределении и обработке результатов исследований — научных, медицинских и других.
Это только часть возможных вариантов применения Scikit-learn в бизнесе. Машинное обучение используется в десятках сфер, перечислить все просто не получится.
Профессия / 24 месяца
Data Scientist
Дата-сайентисты решают поистине амбициозные задачи. Научитесь создавать искусственный интеллект, обучать нейронные сети, менять мир и при этом хорошо зарабатывать. Программа рассчитана на новичков и плавно введет вас в Data Science.

Зависимости Scikit-learn
Scikit-learn основана на других библиотеках, которые тоже применяются в машинном обучении, анализе данных, компьютерном зрении и смежных сферах.
- NumPy — библиотека для работы с многомерными массивами числовых данных и со сложными математическими операциями.
- SciPy — набор продвинутых математических и научных функций. Основана на NumPy, но глубже и функциональнее.
- Matplotlib — библиотека для визуализации и построения графиков. Поддерживает двумерные и трехмерные построения.
- Pandas — библиотека для обработки данных, анализа и манипуляций с ними.
- SymPy — библиотека для работы с символьной математикой.
- IPython — интерактивная консоль для более удобной работы с библиотеками. Среди ее возможностей — автодополнение фраз, подсветка кода, поддержка визуализации данных и многое другое.
Какие задачи решает библиотека
Препроцессинг. Термин «препроцессинг» (preprocessing) означает предварительную обработку данных. Они приводятся к виду, необходимому для подачи на вход какому-либо алгоритму. Например, изображения подгоняются под один размер и цветовую схему. Из данных извлекаются ключевые признаки, по которым будет обучаться модель, и также приводятся к нужному формату.
Уменьшение размерности. Часто в данных содержится избыточная информация. Например, некоторые признаки можно получить из каких-либо других. Чтобы сделать дальнейший анализ эффективнее, размерность выборки уменьшают — так, чтобы сохранить максимум полезных данных. Для этого используются специальные методы, например метод главных компонент.
Обнаружение аномалий. Алгоритмы «отсекают» из набора данных ошибочные или странные записи, которые только добавляют в результат лишние погрешности. Это нужно, чтобы анализ и обучение работали точнее.
Выбор датасета. Если необходимо познакомиться с библиотекой, можно воспользоваться одним из готовых учебных наборов. Они тоже есть в библиотеке.
Выбор модели. Функции и алгоритмы помогают оценить эффективность разных моделей для решения задачи. Их можно сравнивать друг с другом, проводить валидацию результатов, выбирать более точные. Это нужно для улучшения качества обучения.
Регрессия. Это прогнозирование показателей по уже имеющимся данным, которые могут принимать бесконечное количество разных значений. Эти показатели должны быть связаны с каким-либо объектом, т.е. быть его атрибутами. Например, прогноз числа пользователей на сайте в разные дни — это задача регрессии.
Классификация. Классификация — прогнозирование показателя с конечным количеством значений. Более простое определение — прогнозирование категории, к которой относится объект. Распознавание жанра текста или объектов на картинке — это задачи классификации.
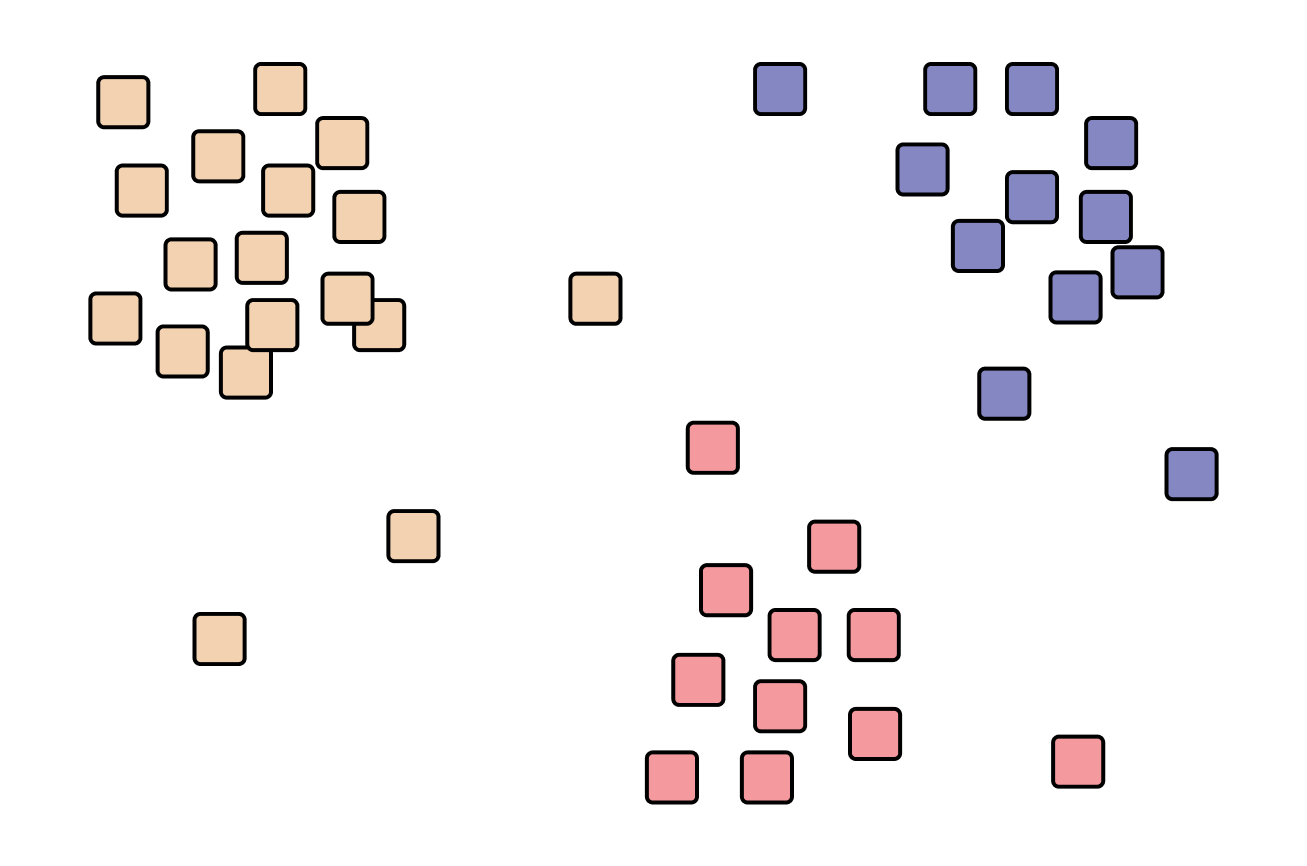
Кластеризация. Это распределение данных из датасета по большим группам — кластерам, т. е. их группировка. Похожие объекты объединяются в классы. Критерии, по которым определяется схожесть, зависят от модели и условий задачи.

Станьте дата-сайентистом и решайте амбициозные задачи с помощью нейросетей
Модели машинного обучения
Линейные. Модели с линейной зависимостью одних значений от других. Позволяют строить разделяющие плоскости или аппроксимировать результаты и использовать линейную регрессию.
Метрические. Предугадывают свойства объекта на основе его соседей. Относятся к так называемому ленивому обучению.
Деревья решений. Это древовидные модели, состоящие из наборов правил. Они принимают решения на основе входных условий.
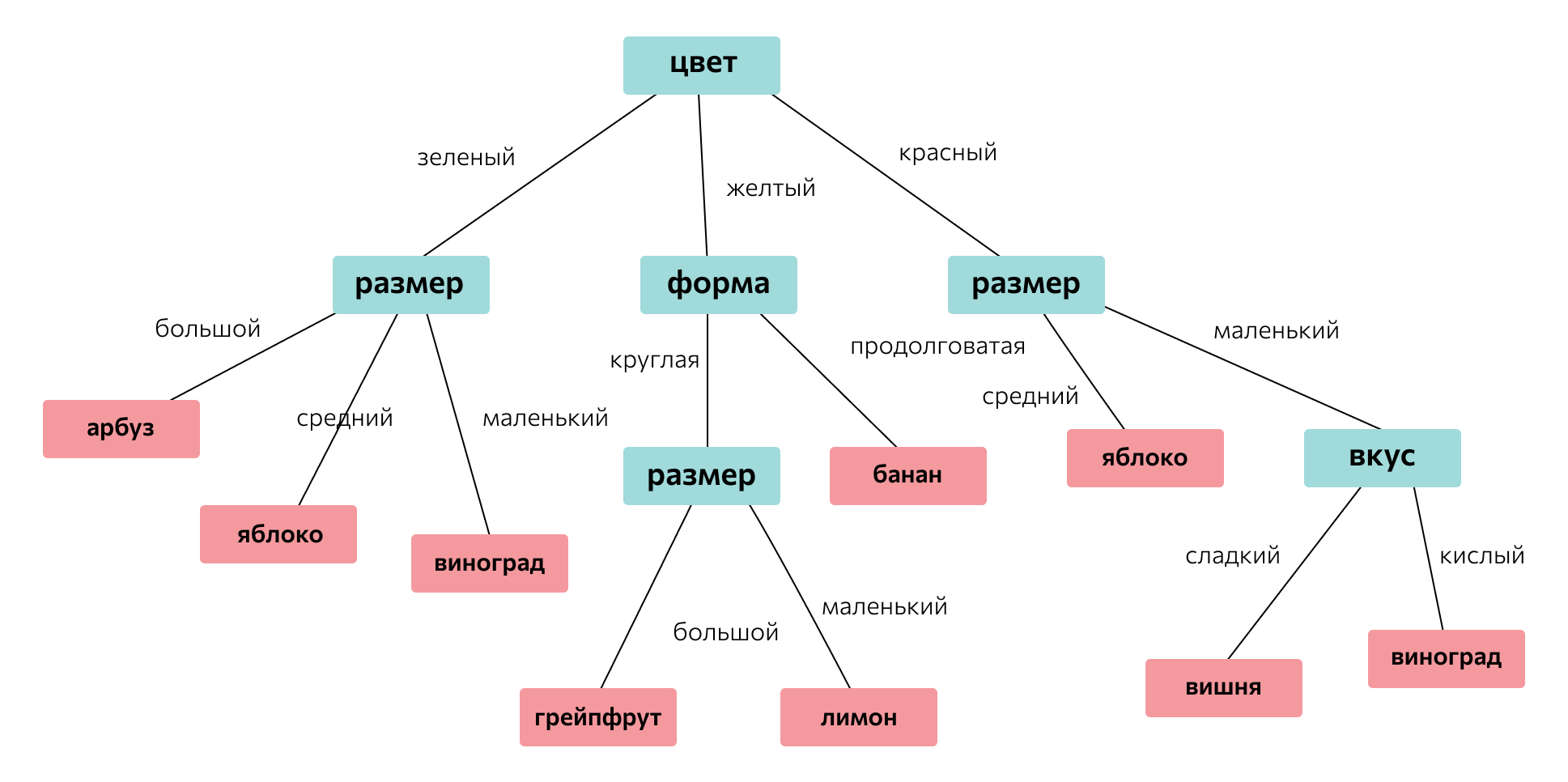
Ансамблевые. Методы, которые используют множество деревьев решений.
Нейросети. Модели, структура которых основана на биологических нейронных сетях, когда нейроны соединены между собой синапсами. Нейрон — вычислительная единица, синапс — путь для передачи информации от одного нейрона к другому. Такая модель самообучается с учетом предыдущего опыта и с каждым разом совершает все меньше ошибок.
Наивный Байес. Модели прогнозирования на основе теоремы Байеса (теорема из теории вероятностей).
Кросс-валидация. Метод многократного обучения, для которого используется датасет целиком. Для каждого шага валидация происходит с одной из частей датасета. Этот метод разбивает данные на несколько секций и обучает несколько алгоритмов на этих секциях.
Это только малая часть возможностей для примера. В библиотеку входят такие популярные методы, как PCA (метод главных компонент, один из основных способов уменьшить размерность данных с минимальными потерями информации), SVM (метод опорных векторов, набор схожих алгоритмов обучения с учителем, использующихся для задач классификации и регрессионного анализа) и другие.
Преимущества Scikit-learn
Многофункциональность. У Scikit-learn много возможностей, начиная с подготовки данных и заканчивая визуализацией результата. Она уже связана со многими технологиями, которыми пользуются в сфере машинного обучения, поэтому библиотеки достаточно для большинства задач, которые встают перед начинающим специалистом по Data Science. Это почти универсальное решение для машинного обучения.
Большое количество алгоритмов. В Scikit-learn входит огромный набор методов и алгоритмов, которые нужны для прогнозирования, кластеризации, распознавания и т.д. Их не нужно писать с нуля — для каждого есть своя функция. Достаточно подать на вход необходимые данные. Для типовых задач есть готовые решения, вплоть до учебных датасетов и подготовленных моделей.
Удобство использования. Связь с другими библиотеками, понятные названия функций и простой синтаксис делают работу удобной и простой.
Бесплатный доступ. Scikit-learn бесплатная и имеет открытый исходный код. Это значит, что любой разработчик может его посмотреть. Sklearn распространяется по свободной лицензии BSD: библиотеку можно использовать и в коммерческих проектах, и в бесплатном ПО. Репозиторий на сервисе GitHub открыт для всех желающих.
Кросс-платформенность. Библиотека Scikit-learn поддерживается операционными системами Linux, Windows и macOS, как и сам Python.
Широкое комьюнити. Специалисты по Data Science активно пишут туториалы, гайды и вспомогательные материалы. Получить информацию легко. А если есть вопросы — можно задать их на специализированном ресурсе и получить ответы от комьюнити.
Популярность. Sklearn используют в ряде крупных проектов: международные сервисы Spotify и Booking, мобильный оператор «Билайн», Газпромбанк, платформа поиска вакансий HeadHunter и т.д. Специалисту по машинному обучению, который владеет Scikit-learn, легко найти работу, в том числе в большой компании.
Недостатки Scikit-learn
Отсутствие ряда возможностей. В Sklearn мало инструментов для построения нейронных сетей. А также меньше возможностей для машинного обучения без учителя, чем для обучения с учителем. Поэтому для некоторых задач одной Scikit-learn будет недостаточно, несмотря на ее обширность.
Обилие зависимостей. Глубокая связь с другими библиотеками — одновременно и плюс, и минус. Конечно, удобнее выстраивать работу с несколькими инструментами одновременно, такой подход расширяет функциональность. Но еще это значит, что для работы с Scikit-learn нужно разбираться в ее зависимостях и желательно уметь пользоваться всеми связанными инструментами. Это повышает порог входа для новичков.
Сложность в изучении. Data Science — сложная отрасль. Нужно хорошо разбираться не только в программировании, но и в математике, алгоритмах прогнозирования и кластеризации. Необходима глубокая теоретическая база. Несмотря на то что сами модели не нужно строить с нуля, разработчик должен понимать, как они работают.
Data Scientist
Дата-сайентисты решают поистине амбициозные задачи. Научитесь создавать искусственный интеллект, обучать нейронные сети, менять мир и при этом хорошо зарабатывать. Программа рассчитана на новичков и плавно введет вас в Data Science.

Статьи по теме: