SSSE3 (Supplemental SSE3)

SSSE3 (Supplemental SSE3, то есть дополнительный SSE3) — это набор дополнительных инструкций процессора, разработанный компанией Intel в продолжение развития наборов команд SSE, SSE2 и SSE3.
По сути, это был четвертый по счету набор инструкций SSE и, по логике вещей, ему нужно бы было присвоить название SSE4. Но в Intel решили иначе, возможно, посчитав его лишь незначительным дополнением к предыдущему пакету.
На первых порах SSSE3 также назывался Merom New Instructions (MNI) по названию процессорного ядра, в котором Intel впервые намеревалась его использовать.
SSSE3 представляет собой набор из 16 новых команд, улучшающих работу с упакованными целыми. При этом, каждая из инструкций может использоваться процессором как для 64-битных, так и для 128-битных регистров. Поэтому в документации Intel речь идет не о 16, а о 32 командах SSSE3.
Инструкции SSSE3 необходимы для нормальной работы многих современных приложений, в частности программ распознавания речи, используемых алгоритм DNN (Deep Neural Network), и др.
Начало использование SSSE3 приходится на 2006 год (выход процессоров архитектуры Intel Core).
ПОДЕЛИТЬСЯ:

НАПИСАТЬ АВТОРУ
Похожие материалы

Технологии и инструкции, используемые в процессорах
Люди обычно оценивают процессор по количеству ядер, тактовой частоте, объему кэша и других показателях, редко обращая внимание на поддерживаемые им технологии.
Отдельные из этих технологий нужны только для решения специфических заданий и в «домашнем» компьютере вряд ли когда-нибудь понадобятся. Наличие же других является непременным условием работы программ, необходимых для повседневного использования.
Так, полюбившийся многим браузер Google Chrome не работает без поддержки процессором SSE2. Инструкции AVX могут в разы ускорить обработку фото- и видеоконтента. А недавно один мой знакомый на достаточно быстром Phenom II (6 ядер) не смог запустить игру Mafia 3, поскольку его процессор не поддерживает инструкции SSE4.2.
Если аббревиатуры SSE, MMX, AVX, SIMD вам ни о чем не говорят и вы хотели бы разобраться в этом вопросе, изложенная здесь информация станет неплохим подспорьем.

Таблица совместимости процессоров и материнских плат AMD
Одной из особенностей компьютеров на базе процессоров AMD, которой они выгодно отличаются от платформ Intel, является высокий уровень совместимости процессоров и материнских плат. У владельцев относительно не старых настольных систем на базе AMD есть высокие шансы безболезненно «прокачать» компьютер путем простой замены процессора на «камень» из более новой линейки или же флагман из предыдущей.
Если вы принадлежите к их числу и задались вопросом «апгрейда», эта небольшая табличка вам в помощь.

Сравнение процессоров
В таблицу можно одновременно добавить до 6 процессоров, выбрав их из списка (кнопка «Добавить процессор»). Всего доступно больше 2,5 тыс. процессоров Intel и AMD.
Пользователю предоставляется возможность в удобной форме сравнивать производительность процессоров в синтетических тестах, количество ядер, частоту, структуру и объем кэша, поддерживаемые типы оперативной памяти, скорость шины, а также другие их характеристики.
Дополнительные рекомендации по использованию таблицы можно найти внизу страницы.

Спецификации процессоров
В этой базе собраны подробные характеристики процессоров Intel и AMD. Она содержит спецификации около 2,7 тысяч десктопных, мобильных и серверных процессоров, начиная с первых Пентиумов и Атлонов и заканчивая последними моделями.
Информация систематизирована в алфавитном порядке и будет полезна всем, кто интересуется компьютерной техникой.

Таблица процессоров
Таблица содержит информацию о почти 2 тыс. процессоров и будет весьма полезной людям, интересующимся компьютерным «железом». Положение каждого процессора в таблице определяется уровнем его быстродействия в синтетических тестах (расположены по убыванию).
Есть фильтр, отбирающий процессоры по производителю, модели, сокету, количеству ядер, наличию встроенного видеоядра и другим параметрам.
Для получения подробной информации о любом процессоре достаточно нажать на его название.

Как проверить стабильность процессора
Проверка стабильности работы центрального процессора требуется не часто. Как правило, такая необходимость возникает при приобретении компьютера, разгоне процессора (оверлокинге), при возникновении сбоев в работе компьютера, а также в некоторых других случаях.
В статье описан порядок проверки процессора при помощи программы Prime95, которая, по мнению многих экспертов и оверлокеров, является лучшим средством для этих целей.

ПОКАЗАТЬ ЕЩЕ
Использование набора инструкций Intel SSSE3 для ускорения реализации алгоритма DNN в задачах распознавания речи, выполняемых на мобильных устройствах
За последние тридцать лет технологии распознавания речи серьёзно продвинулись вперед, начав свой путь в исследовательских лабораториях и дойдя до широкого круга потребителей. Эти технологии начинают играть важную роль в нашей жизни. Их можно встретить на рабочем месте, дома, в машине. Их используют в медицинских целях и в других сферах деятельности. Распознавание речи входит в топ-10 перспективных технологий мирового уровня.
Обзор
В результате исследований последних лет произошла смена основных алгоритмов распознавания речи. Так, прежде это были алгоритмы GMM (Gaussian Mixture Model) и HMM-GMM (Hidden Markov Model – Gaussian Mixture Model). От них произошёл переход к алгоритму DNN (Deep Neural Network). Работа этого алгоритма напоминает деятельность человеческого мозга. Здесь используются сложные вычисления и огромное количество данных.
Благодаря Интернету воспользоваться современными технологиями распознавания речи может любой владелец смартфона. К его услугам – бесчисленное множество серверов. А вот без Интернета службы распознавания речи в мобильных устройствах почти бесполезны. Они редко способны правильно понимать тех, кто пытается с ними «разговаривать».
Можно ли перенести реализацию алгоритма DNN с сервера на смартфон или планшет? Ответ на этот вопрос – да. Благодаря поддержке процессорами от Intel набора инструкций SSSE3, на мобильных устройствах можно пользоваться приложениями для распознавания речи, основанными на алгоритме DNN. При этом подключение к Интернету не требуется. В результате наших испытаний точность распознавания речи таким приложением составила более 80%. Это очень близко к тому, что достижимо при использовании серверных систем. В этом материале мы расскажем об алгоритме DNN и о том, как набор инструкций Intel SSSE3 способен помочь в ускорении расчётов, необходимых для реализации этого алгоритма.
Предварительные сведения
DNN (ГНС) – это сокращение от Deep Neural Network (Глубокая Нейронная Сеть). Это – сеть прямого распространения, содержащая множество скрытых слоёв. DNN находится на переднем крае современных технологий машинного обучения. Для этого алгоритма нашлось множество вариантов практического применения.
Глубокие нейронные сети имеют большое количество скрытых слоёв. При их обучении нужно модифицировать десятки миллионов параметров. Как результат, обучение таких сетей требует значительных затрат времени.
Распознавание речи – типичный пример применения DNN. Упрощённо, приложения для распознавания речи можно представить состоящими из акустической модели (acoustic model), языковой модель (language model) и подсистемы декодирования (decoding). Акустическая модель используется для моделирования распределения вероятностей вариантов произношения. Языковая модель применяется для моделирования связей между словами. На этапе декодирования используются две вышеописанные модели, речь преобразуется в текст. Нейронная сеть умеет моделировать любые словесные конструкции. В то время как глубокая нейронная сеть имеет более сильную способность к выделению существенных признаков данных, чем мелкая (shallow) сеть, она моделирует структуру человеческого мозга, и, таким образом, способна более точно «понять» характеристики вещей. В результате, в сравнении с другими методами, в такой нейронной сети можно более точно смоделировать акустические и языковые модели.

Области применения алгоритма DNN
Схема типичной глубокой нейронной сети
Обычно типичная глубокая нейронная сеть содержит множество линейных и нелинейных слоёв, которые накладываются друг на друга.

Четыре скрытых слоя в акустической модели, построенной на базе DNN
Сеть, схема которой здесь приведена, состоит из набора линейных слоёв. Каждый нейрон из предыдущего слоя связан с каждым нейроном из следующего. Связь входа сети с её выходом можно описать следующей формулой:
Y T = X T W T + B
X T – это вектор-строка, вход нейронной сети. В применении к распознаванию речи мы обычно помещаем 4 фрагмента данных для одновременной работы над ними, таким образом, создавая входную матрицу 4xM. W T и B это, соответственно, линейная матрица преобразования нейронной сети и вектор смещения. Обычно размерность такой сети очень велика, во всех слоях имеется одинаковое количество нейронов, то есть, сеть имеет квадратную форму.
Набор инструкций Intel SSSE3
Intel называет набор команд Supplemental Streaming SIMD Extensions 3, или, для краткости, просто SSSE3, расширением набора команд SSE3. Это – часть технологии SIMD, интегрированной в микропроцессоры Intel. Данная технология рассчитана на улучшение возможностей по обработке мультимедийных данных. Она предназначена для ускорения выполнения задач кодирования и декодирования информации и для ускорения проведения различных расчётов. Используя набор инструкций SSSE3, мы можем обрабатывать несколько потоков данных с помощью одной инструкции за один тактовый цикл. Это позволяет значительно повысить эффективность приложений. В частности, команды SSSE3 применимы к матричным вычислениям.
Для использования набора инструкций SSSE3 нужно подключить соответствующие заголовочные файлы SIMD:
#include //MMX #include //SSE #include //SSE2 #include //SSE3 #include //SSSE3 #include //SSSE4.1 #include //SSSE4.2 #include //AES #include //AVXЗаголовочный файл tmmintrin.h обеспечивает работу с SSSE3, ниже приведено описание функций, которые в нём определены.
/*Горизонтальное сложение [с насыщением] упакованных слов, двойных слов, MM2/m (b) to MM1 (a).*/ //a=(a0, a1, a2, a3, a4, a5, a6, a7), b=(b0, b1, b2, b3, b4, b5, b6, b7) //then r0=a0+a1,r1=a2+a3,r2=a4+a5,r3=a6+a7,r4=b0+b1,r5=b2+b3,r6=b4+b5, r7=b6+b7 extern __m128i _mm_hadd_epi16 (__m128i a, __m128i b); //a=(a0, a1, a2, a3), b=(b0, b1, b2, b3) //then r0=a0+a1,r1=a2+a3,r2=b0+b1,r3=b2+b3 extern __m128i _mm_hadd_epi32 (__m128i a, __m128i b); //SATURATE_16(x) is ((x > 32767) ? 32767 : ((x < -32768) ? -32768 : x)) //a=(a0, a1, a2, a3, a4, a5, a6, a7), b=(b0, b1, b2, b3, b4, b5, b6, b7) //then r0=SATURATE_16(a0+a1), . r3=SATURATE_16(a6+a7), //r4=SATURATE_16(b0+b1), . r7=SATURATE_16(b6+b7) extern __m128i _mm_hadds_epi16 (__m128i a, __m128i b); //a=(a0, a1, a2, a3), b=(b0, b1, b2, b3) //then r0=a0+a1, r1=a2+a3, r2=b0+b1, r3=b2+b3 extern __m64 _mm_hadd_pi16 (__m64 a, __m64 b); //a=(a0, a1), b=(b0, b1), 则r0=a0+a1, r1=b0+b1 extern __m64 _mm_hadd_pi32 (__m64 a, __m64 b); //SATURATE_16(x) is ((x >32767) ? 32767 : ((x < -32768) ? -32768 : x)) //a=(a0, a1, a2, a3), b=(b0, b1, b2, b3) //then r0=SATURATE_16(a0+a1), r1=SATURATE_16(a2+a3), //r2=SATURATE_16(b0+b1), r3=SATURATE_16(b2+b3) extern __m64 _mm_hadds_pi16 (__m64 a, __m64 b); /*Горизонтальное вычитание [с насыщением] упакованных слов, двойных слов, MM2/m (b) from MM1 (a).*/ //a=(a0, a1, a2, a3, a4, a5, a6, a7), b=(b0, b1, b2, b3, b4, b5, b6, b7) //затем r0=a0-a1, r1=a2-a3, r2=a4-a5, r3=a6-a7, r4=b0-b1, r5=b2-b3, r6=b4-b5, r7=b6-b7 extern __m128i _mm_hsub_epi16 (__m128i a, __m128i b); //a=(a0, a1, a2, a3), b=(b0, b1, b2, b3) //then r0=a0-a1, r1=a2-a3, r2=b0-b1, r3=b2-b3 extern __m128i _mm_hsub_epi32 (__m128i a, __m128i b); //SATURATE_16(x) is ((x > 32767) ? 32767 : ((x < -32768) ? -32768 : x)) //a=(a0, a1, a2, a3, a4, a5, a6, a7), b=(b0, b1, b2, b3, b4, b5, b6, b7) //then r0=SATURATE_16(a0-a1), . r3=SATURATE_16(a6-a7), //r4=SATURATE_16(b0-b1), . r7=SATURATE_16(b6-b7) extern __m128i _mm_hsubs_epi16 (__m128i a, __m128i b); //a=(a0, a1, a2, a3), b=(b0, b1, b2, b3) //then r0=a0-a1, r1=a2-a3, r2=b0-b1, r3=b2-b3 extern __m64 _mm_hsub_pi16 (__m64 a, __m64 b); //a=(a0, a1), b=(b0, b1), 则r0=a0-a1, r1=b0-b1 extern __m64 _mm_hsub_pi32 (__m64 a, __m64 b); //SATURATE_16(x) is ((x >32767) ? 32767 : ((x < -32768) ? -32768 : x)) //a=(a0, a1, a2, a3), b=(b0, b1, b2, b3) //then r0=SATURATE_16(a0-a1), r1=SATURATE_16(a2-a3), //r2=SATURATE_16(b0-b1), r3=SATURATE_16(b2-b3) extern __m64 _mm_hsubs_pi16 (__m64 a, __m64 b); /*Умножение и сложение упакованных слов, MM2/m (b) to MM1 (a).*/ //SATURATE_16(x) is ((x > 32767) ? 32767 : ((x < -32768) ? -32768 : x)) //a=(a0, a1, a2, . a13, a14, a15), b=(b0, b1, b2, . b13, b14, b15) //then r0=SATURATE_16((a0*b0)+(a1*b1)), . r7=SATURATE_16((a14*b14)+(a15*b15)) //Параметр a содержит байты без знака. Параметр b содержит байты со знаком. extern __m128i _mm_maddubs_epi16 (__m128i a, __m128i b); //SATURATE_16(x) is ((x >32767) ? 32767 : ((x < -32768) ? -32768 : x)) //a=(a0, a1, a2, a3, a4, a5, a6, a7), b=(b0, b1, b2, b3, b4, b5, b6, b7) //then r0=SATURATE_16((a0*b0)+(a1*b1)), . r3=SATURATE_16((a6*b6)+(a7*b7)) //Параметр a содержит байты без знака. Параметр b содержит байты со знаком. extern __m64 _mm_maddubs_pi16 (__m64 a, __m64 b); /*Упакованное умножение старших элементов целых чисел с округлением и масштабированием, MM2/m (b) to MM1 (a).*/ //a=(a0, a1, a2, a3, a4, a5, a6, a7), b=(b0, b1, b2, b3, b4, b5, b6, b7) //then r0=INT16(((a0*b0)+0x4000) >> 15), . r7=INT16(((a7*b7)+0x4000) >> 15) extern __m128i _mm_mulhrs_epi16 (__m128i a, __m128i b); //a=(a0, a1, a2, a3), b=(b0, b1, b2, b3) //then r0=INT16(((a0*b0)+0x4000) >> 15), . r3=INT16(((a3*b3)+0x4000) >> 15) extern __m64 _mm_mulhrs_pi16 (__m64 a, __m64 b); /*Упакованная перестановка байтов MM2/m (b) by MM1 (a).*/ //SELECT(a, n) extracts the nth 8-bit parameter from a. The 0th 8-bit parameter //is the least significant 8-bits, b=(b0, b1, b2, . b13, b14, b15), b is mask //then r0 = (b0 & 0x80) ? 0 : SELECT(a, b0 & 0x0f), . //r15 = (b15 & 0x80) ? 0 : SELECT(a, b15 & 0x0f) extern __m128i _mm_shuffle_epi8 (__m128i a, __m128i b); //SELECT(a, n) extracts the nth 8-bit parameter from a. The 0th 8-bit parameter //is the least significant 8-bits, b=(b0, b1, . b7), b is mask //then r0= (b0 & 0x80) ? 0 : SELECT(a, b0 & 0x07). //r7=(b7 & 0x80) ? 0 : SELECT(a, b7 & 0x07) extern __m64 _mm_shuffle_pi8 (__m64 a, __m64 b); /*Знак упакованных байтов, слов, двойных слов, MM2/m (b) to MM1 (a).*/ //a=(a0, a1, a2, . a13, a14, a15), b=(b0, b1, b2, . b13, b14, b15) //then r0=(b0 < 0) ? -a0 : ((b0 == 0) ? 0 : a0), . //r15= (b15 < 0) ? -a15 : ((b15 == 0) ? 0 : a15) extern __m128i _mm_sign_epi8 (__m128i a, __m128i b); //a=(a0, a1, a2, a3, a4, a5, a6, a7), b=(b0, b1, b2, b3, b4, b5, b6, b7) //r0=(b0 < 0) ? -a0 : ((b0 == 0) ? 0 : a0), . //r7= (b7 < 0) ? -a7 : ((b7 == 0) ? 0 : a7) extern __m128i _mm_sign_epi16 (__m128i a, __m128i b); //a=(a0, a1, a2, a3), b=(b0, b1, b2, b3) //then r0=(b0 < 0) ? -a0 : ((b0 == 0) ? 0 : a0), . //r3= (b3 < 0) ? -a3 : ((b3 == 0) ? 0 : a3) extern __m128i _mm_sign_epi32 (__m128i a, __m128i b); //a=(a0, a1, a2, a3, a4, a5, a6, a7), b=(b0, b1, b2, b3, b4, b5, b6, b7) //then r0=(b0 < 0) ? -a0 : ((b0 == 0) ? 0 : a0), . //r7= (b7 < 0) ? -a7 : ((b7 == 0) ? 0 : a7) extern __m64 _mm_sign_pi8 (__m64 a, __m64 b); //a=(a0, a1, a2, a3), b=(b0, b1, b2, b3) //r0=(b0 < 0) ? -a0 : ((b0 == 0) ? 0 : a0), . //r3= (b3 < 0) ? -a3 : ((b3 == 0) ? 0 : a3) extern __m64 _mm_sign_pi16 (__m64 a, __m64 b); //a=(a0, a1), b=(b0, b1), 则r0=(b0 < 0) ? -a0 : ((b0 == 0) ? 0 : a0), //r1= (b1 < 0) ? -a1 : ((b1 == 0) ? 0 : a1) extern __m64 _mm_sign_pi32 (__m64 a, __m64 b); /*Упакованное выравнивание и сдвиг вправо на n*8 битов, MM2/m (b) to MM1 (a).*/ //n: константа, которая задаёт, на сколько байтов //вправо будет сдвинут промежуточный результат, //если n > 32, итоговое значение будет нулём. //CONCAT(a, b) это 256-битное беззнаковое промежуточное значение, //которое представляет собой объединение параметров a и b. //Результат – это промежуточное значение, сдвинутое вправо на n байт. //then r= (CONCAT(a, b) >> (n * 8)) & 0xffffffffffffffff extern __m128i _mm_alignr_epi8 (__m128i a, __m128i b, int n); //n: целочисленная константа, которая указывает, на сколько байтов вправо //нужно сдвинуть промежуточный результат. //Если n > 16, в результате получится ноль. //CONCAT(a, b) это 128-битное беззнаковое промежуточное значение, //которое представляет собой объединение параметров a и b. //Результирующие значения - правые 64 бита, полученные //после сдвига этого промежуточного результата вправо на n байтов. //then r = (CONCAT(a, b) >> (n * 8)) & 0xffffffff extern __m64 _mm_alignr_pi8 (__m64 a, __m64 b, int n); /*Абсолютное значение упакованных байтов, слов, двойных слов, MM2/m (b) to MM1 (a).*/ //a=(a0, a1, a2, . a13, a14, a15) //then r0 = (a0 < 0) ? -a0 : a0, . r15 = (a15 < 0) ? -a15 : a15 extern __m128i _mm_abs_epi8 (__m128i a); //a=(a0, a1, a2, a3, a4, a5, a6, a7) //then r0 = (a0 < 0) ? -a0 : a0, . r7 = (a7 < 0) ? -a7 : a7 extern __m128i _mm_abs_epi16 (__m128i a); //a=(a0, a1, a2, a3) //then r0 = (a0 < 0) ? -a0 : a0, . r3 = (a3 < 0) ? -a3 : a3 extern __m128i _mm_abs_epi32 (__m128i a); //a=(a0, a1, a2, a3, a4, a5, a6, a7) //then r0 = (a0 < 0) ? -a0 : a0, . r7 = (a7 < 0) ? -a7 : a7 extern __m64 _mm_abs_pi8 (__m64 a); //a=(a0, a1, a2, a3) //then r0 = (a0 < 0) ? -a0 : a0, . r3 = (a3 < 0) ? -a3 : a3 extern __m64 _mm_abs_pi16 (__m64 a); //a=(a0, a1), then r0 = (a0 < 0) ? -a0 : a0, r1 = (a1 < 0) ? -a1 : a1 extern __m64 _mm_abs_pi32 (__m64 a);Определения структур данных __m64 и __m128 находятся в заголовочном файле для MMX (mmintrin.h) и SSE (xmmintrin.h).
typedef union __declspec(intrin_type) _CRT_ALIGN(8) __m64 < unsigned __int64 m64_u64; float m64_f32[2]; __int8 m64_i8[8]; __int16 m64_i16[4]; __int32 m64_i32[2]; __int64 m64_i64; unsigned __int8 m64_u8[8]; unsigned __int16 m64_u16[4]; unsigned __int32 m64_u32[2]; >__m64; typedef union __declspec(intrin_type) _CRT_ALIGN(16) __m128 < float m128_f32[4]; unsigned __int64 m128_u64[2]; __int8 m128_i8[16]; __int16 m128_i16[8]; __int32 m128_i32[4]; __int64 m128_i64[2]; unsigned __int8 m128_u8[16]; unsigned __int16 m128_u16[8]; unsigned __int32 m128_u32[4]; >__m128; Пример: использование функций SSSE3 для ускорения вычислений, примеряющихся в алгоритме DNN
Здесь мы рассмотрим пару функций. На их примере будет показано, как SSSE3 используется для ускорения расчётов при реализации алгоритма DNN.
__m128i _mm_maddubs_epi16 (__m128i a, __m128i b) Сложение с насыщением
Эта функция очень важна при выполнении матричных вычислений в алгоритме DNN. Параметр – это 128-битный регистр (register), который используется для хранения 16-ти целых чисел без знака (8-ми битных). Параметр b – это целое со знаком, тоже 8-ми битное. Возвращаемый результат – это 8 16-битных целых чисел со знаком. Эта функция отлично подходит для выполнения матричных вычислений:
r0 := SATURATE_16((a0*b0) + (a1*b1)) r1 := SATURATE_16((a2*b2) + (a3*b3)) … r7 := SATURATE_16((a14*b14) + (a15*b15))__m128i _mm_hadd_epi32 (__m128i a, __m128i b) Сложение смежных элементов
Эту функцию можно назвать функцией, которая выполняет попарное сложение. Параметры a и b – это 128-битные регистры, которые хранят по 4 целых 32-битных числа со знаком. В соответствии с обычной операцией по сложению соответствующих элементов в двух векторах, команда выполняет сложение смежных элементов входного вектора:
r0 := a0 + a1 r1 := a2 + a3 r2 := b0 + b1 r3 := b2 + b3Предположим, у нас есть задача вычислений на векторах, типичная для реализации DNN.
Имеются пять векторов: a1, b1, b2, b3, b4. Вектор a1 – это одномерный массив из 16-ти целых чисел типа signed char. Векторы b1, b2, b3, b4 – массивы целых чисел из 16 элементов каждый типа unsigned char. Нам нужно получить скалярные произведения a1*b1, a1*b2, a1*b3, a1*b4 результат надо сохранить в виде 32-битного целого числа со знаком.
Если мы воспользуемся обычным для программирования на C подходом, то код для решения этой задачи будет выглядеть так:
unsigned char b1[16],b2[16],b3[16],b4[16]; signed char a1[16]; int c[4],i; // //Инициализация b1,b2,b3,b4 и a1, c инициализируется нулями // for(i=0;i
Предположим, что за один тактовый цикл можно выполнить одну операцию умножения и одну операцию сложения. Получаем – 64 тактовых цикла на выполнение расчётов.
Теперь воспользуемся набором инструкций SSSE3 для решений той же задачи.
register __m128i a1,b1,b2,b3,b4,c,d1,d2,d3,d4; //Инициализация a1, b1, b2, b3 и b4, c инициализируется нулями // d1 = _mm_maddubs_epi16(a1,b1); d1 = _mm_add_epi32(_mm_srai_epi32(_mm_unpacklo_epi16(d1, d1), 16), _mm_srai_epi32(_mm_unpackhi_epi16(d1, d1), 16)); d2 = _mm_maddubs_epi16(a1,b2); d2 = _mm_add_epi32(_mm_srai_epi32(_mm_unpacklo_epi16(d2, d2), 16), _mm_srai_epi32(_mm_unpackhi_epi16(d2, d2), 16)); d3 = _mm_hadd_epi32(d1, d2); d1 = _mm_maddubs_epi16(a1,b3); d1 = _mm_add_epi32(_mm_srai_epi32(_mm_unpacklo_epi16(d1, d1), 16), _mm_srai_epi32(_mm_unpackhi_epi16(d1, d1), 16)); d2 = _mm_maddubs_epi16(a1,b4); d2 = _mm_add_epi32(_mm_srai_epi32(_mm_unpacklo_epi16(d2, d2), 16), _mm_srai_epi32(_mm_unpackhi_epi16(d2, d2), 16)); d4 = _mm_hadd_epi32(d1, d2); c = _mm_hadd_epi32(d3, d4);Результат мы сохраняем в 128-битном регистре (с), в котором помещаются 4 целых числа. Учитывая конвейерную обработку данных, на вычисления уйдёт 12 или 13 тактовых циклов. Если сравнить эти данные, получится следующее:
| Вариант реализации | Тактовые циклы процессора | Выигрыш |
| Обычное программирование на C | 64 | — |
| Использование SSSE3 | 13 | ~500% |
Сравнительное тестирование
Проведем эксперимент, взяв за основу вышеприведенный код. Создадим две функции, которые выполняют одни и те же вычисления разными способами. Одна из них, в итоге, возвращает сумму элементов целочисленного массива c, вторая – сумму 32-битных целочисленных элементов 128-битного регистра с. Инициализация переменных производится при каждом вызове функций. Всего осуществляется по 10000000 вызовов каждой из функций, тест работает в фоновом потоке.
Интерфейс приложения для тестирования производительности
Вот какие результаты даёт испытание release-версии приложения на планшете Asus Fonepad 8 с CPU Intel Atom Z3530. На устройстве установлена Android 5.0.
Сравнение скорости выполнения кода, написанного с использованием и без использования SSSE3
| № | Использование SSSE3, мс. | Использование обычного C, мс. |
| 1 | 547 | 3781 |
| 2 | 507 | 3723 |
| 3 | 528 | 3762 |
| 4 | 517 | 3731 |
| 5 | 531 | 3755 |
| 6 | 517 | 3769 |
| 7 | 502 | 3752 |
| 8 | 529 | 3750 |
| 9 | 514 | 3745 |
| 10 | 510 | 3721 |
| Среднее | 520.2 | 3748.9 |
В результате оказывается, что код, реализующий вычисления с использованием инструкций SSSE3 выполняется, в среднем, в 7.2 раза быстрее, чем обычный.
Исходный код проекта, который можно импортировать в Android Studio, можно найти здесь.
Итоги
Как известно, при распознавании речи с помощью глубокой нейронной сети проводится множество матричных вычислений. Если эти вычисления оптимизировать, можно достичь наилучшей, чем когда-либо, производительности на платформе IA. Мы работаем совместно с компанией ISV Unisound, которая предоставляет сервисы распознавания речи в Китае. Unisound удалось достичь прироста производительности в 10% при использовании ПО, основанного на DNN, на ARM-устройствах.
DNN в наши дни становится основным алгоритмом для распознавания речи. Его, в частности, используют такие службы, как Google Now, Baidu Voice, Tencent Wechat, iFlytek Speech Service, Unisound Speech Service и многие другие. В то же время, имеется набор инструкций SSSE3, способный помочь в оптимизации расчётов, на которых строится процесс распознавания речи. Если везде, где используется DNN, реализуют подобную оптимизацию, это повысит качество распознавания речи и позволит полнее раскрыть возможности платформы IA.
- Блог компании Intel
- Алгоритмы
- Разработка под Android
Какие процессоры поддерживают SSSE3
SSE или Streaming SIMD Extensions — это набор инструкций процессора для обработки большого количества данных. Технология постоянно развивается, поэтому есть несколько её версий. Без поддержки SSE2 на компьютере не будут работать большинство современных программ, например, браузеры Google Chrome. Инструкции SSE3 используются больше в приложениях для обработки графики. Эта технология была придумана в Intel, однако сейчас поддерживается также в процессорах AMD, так как стала стандартом.
SSSE3 или Superimplemental SSE 3 — это следующая версия расширения SSE3, вместо того, чтобы увеличивать цифру версии, разработчики просто добавили ещё одну букву S. В этой версии было добавлено 32 новых инструкции в основном, это математика и другие операции с данными. Этот набор инструкций ещё не так важен для работы операционной системы в целом, но необходим для работы программ распознавания речи и некоторых современных игр. Давайте разберемся какие процессоры поддерживают SSSE3, а также как определить поддерживает ли ваш процессор эту технологию.
Какие процессоры поддерживают SSSE3 и SSE4
Расширение SSSE3 появилось в 2006 году, следовательно все современные процессоры эту технологию поддерживают. Все процессоры с архитектурой x64 поддерживают версию расширения SSE2.
Что касается SSE3, то поддержка начинается её поддерживают такие процессоры, и все выпущенные после них:
- Intel Pentium 4 архитектуры Prescott;
- AMD Athlon 64 ревизии E;
- AMD Phenom.
Более новое расширение SSSE3 поддерживается в этих линейках процессоров и более новых:
- Intel Core 2 Duo;
- Intel Core i7;
- Intel Core i5;
- Intel Core i3;
- Intel Atom;
- AMD Bulldozer;
- AMD Bobcat;
- AMD Ryzen.
Расширение SSE4.1 вышло немного позже и поддерживается начиная с этих моделей:
- Intel Core 2 начиная с архитектуры Penryn;
- Intel Core i7 начиная с Nehalem;
- Intel Atom начиная с Silvermont;
- AMD Bulldozer, Jaguar.
Набор инструкций SSE4.2 появился весной 2007 года и поддерживается всеми процессорами, что и SSE4.1 кроме Intel Core 2. Естественно, что процессоры, которые поддерживают более свежую версию SSE, поддерживают и предыдущие.
Надеюсь, мне удалось ответить на вопрос какие процессоры поддерживают технологию sse3 ssse3 и sse4, а также для каких программ они подходят.
Как узнать поддерживает ли процессор SSSE3
Самый простой способ посмотреть какую версию SSE поддерживает ваш процессор, воспользоваться утилитой CPU-Z. Запустите программу и на первой же вкладке, в разделе Instructions вы можете увидеть всё расширения инструкций, которые поддерживает процессор.
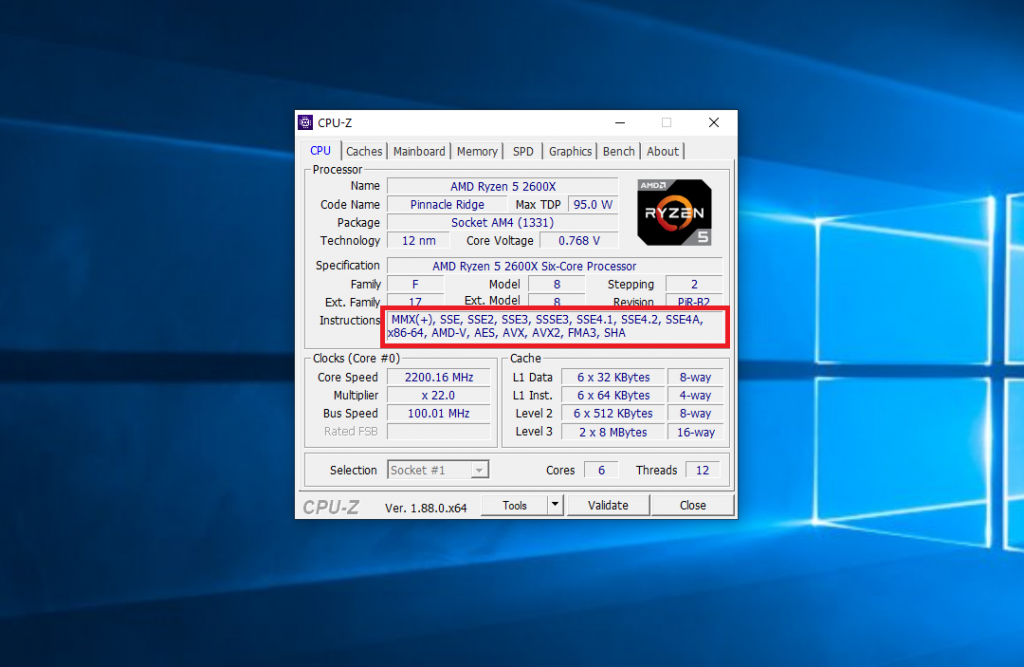
Выводы
Согласно статистике от Steam 100% процессоров пользователей поддерживают инструкции SSE2 и SSE3. Набор SSSE3 поддерживает 97.24% процессоров, а SSE4.1 и SSE4.2 — 95,8 и 94,6% соответственно. Поэтому скорее всего, ваш процессор поддерживает все необходимые инструкции, если он был выпущен позже 2008 года.
SSSE3 - SSSE3
Дополнительные расширения SIMD для потоковой передачи 3 (SSSE3 или SSE3S ) - это SIMD набор инструкций, созданный Intel и являющийся четвертой версией технологии SSE.
- 1 История
- 2 Функциональность
- 3 ЦП с SSSE3
- 4 Новые инструкции
- 5 См. Также
- 6 Ссылки
- 7 Внешние ссылки
История
SSSE3 был впервые представлен с процессорами Intel на основе микроархитектуры Core 26 июня 2006 года с процессорами Woodcrest Xeon.
SSSE3 упоминается под кодовыми именами Tejas New Instructions (TNI) или Merom New Instructions (MNI) для первых разработок процессоров, предназначенных для его поддержки.
Функциональные возможности
SSSE3 содержит 16 новых дискретных инструкций. Каждая инструкция может воздействовать на 64-битные регистры MMX или 128-битные XMM. Поэтому в материалах Intel упоминаются 32 новые инструкции. В их число входят:
- Двенадцать инструкций, которые выполняют операции горизонтального сложения или вычитания.
- Шесть инструкций, оценивающих абсолютные значения.
- Две инструкции, которые выполняют операции умножения и сложения и ускоряют вычисление точки
- Две инструкции, которые ускоряют операции упакованного целочисленного умножения и создают целочисленные значения с масштабированием.
- Две инструкции, которые выполняют побайтовое перемешивание на месте в соответствии со вторым операндом управления перемешиванием.
- Шесть инструкций, которые инвертируют упакованные целые числа в целевом операнде, если знаки соответствующего элемента в исходном операнде меньше нуля.
- Две инструкции, выравнивающие данные из композиции двух операндов.
ЦП с SSSE3
- AMD :
- "Cat" процессоры с низким энергопотреблением
- на базе Bobcat процессоры
- на базе Jaguar процессоры и более новые
- на базе Puma процессоры и более новые
- процессоры на базе Bulldozer
- процессоры на базе Piledriver rs
- на базе Steamroller процессоры
- на базе Excavator процессоры и более новые
- Xeon 5100 Series
- Xeon 5300 Series
- Xeon 5400 Series
- Xeon 3000 Series
- Core 2 Duo
- Core 2 Extreme
- Core 2 Quad
- Core i7
- Core i5
- Core i3
- Pentium Dual Core (если поддерживается 64-разрядная версия; Allendale и далее)
- Celeron 4xx Sequence Conroe-L
- Celeron Dual Core E1200
- Серия Celeron M 500
- Atom
- Nano
Новинка инструкции
В таблице ниже satsw (X) (читается как «насыщение до знакового слова») принимает целое число X со знаком и преобразует его в -32768, если оно меньше -32768, в +32767 если он больше 32767, и в противном случае оставляет его без изменений. Как правило, для архитектуры Intel байты составляют 8 бит, слова - 16 бит, а двойные слова - 32 бита; «регистр» относится к векторному регистру MMX или XMM.
PSIGNB, PSIGNW, PSIGND Packed Sign Отменяет элементы регистра байтов, слов или двойных слов, если знак соответствующих элементов другого регистра отрицательный. PABSB, PABSW, PABSD Упакованное абсолютное значение Заполните элементы регистра байтов, слов или двойных слов абсолютными значениями элементов другого регистра PALIGNR Packed Align Right берет два регистра, объединяет их значения и извлекает секцию длины регистра из смещения, заданного непосредственным значением, закодированным в инструкции. PSHUFB Packed Shuffle Bytes принимает регистры байтов A = [a 0a1a2. ] и B = [b 0b1b2. ] и заменяет A на [a b0ab1ab2. ]; за исключением того, что он заменяет i-ю запись на 0, если установлен верхний бит b i. PMULHRSW Packed Multiply High with Round and Scale обрабатывает 16-битные слова в регистрах A и B как 16-битные числа со знаком с фиксированной точкой в диапазоне от -1,00000000 до +0,99996948. (например, 0x4000 обрабатывается как +0,5, а 0xA000 как -0,75), и умножьте их вместе с правильным округлением. PMADDUBSW Умножение и сложение упакованных байтов со знаком и без знака Возьмите байты в регистрах A и B, умножьте их вместе, сложите пары, выполните насыщение со знаком и сохраните. Т.е. [a0 a1 a2…] pmaddubsw [b0 b1 b2…] = [satsw (a0b0 + a1b1) satsw (a2b2 + a3b3)…] PHSUBW, PHSUBD Упакованное горизонтальное вычитание (слова или двойные слова) принимает регистры A = [a0 a1 a2…] и B = [b0 b1 b2…] и выводит [a0 − a1 a2 − a3… b0 − b1 b2 − b3…] PHSUBSW Упакованные слова горизонтального вычитания и насыщения как PHSUBW, но выводят [satsw (a0-a1) satsw (a2-a3)… satsw (b0-b1) satsw (b2-b3)…] PHADDW, PHADDD Упакованное горизонтальное сложение (слова или двойные слова) принимает регистры A = [a0 a1 a2…] и B = [b0 b1 b2…] и выводит [a0 + a1 a2 + a3… b0 + b1 b2 + b3…] PHADDSW Упакованные слова горизонтального добавления и насыщения как PHADDW, но выводит [satsw (a0 + a1) satsw (a2 + a3) … Satsw (b0 + b1) satsw (b2 + b3)…] См. Также
Ссылки
Внешние ссылки
- Технические характеристики Core 2 Mobile
- Официальный документ Intel, в котором признается существование SSSE3 и описывается SSE4
- В документация по набору структур, в которой перечислены функции инструкций SSSE3
- "Cat" процессоры с низким энергопотреблением