Виды баз данных
В этой статье мы рассмотрим основные виды баз данных. На конкретных примерах выявим преимущества и недостатки каждой модели, изучим сценарии их применения.

В этой статье мы рассмотрим основные виды баз данных. На конкретных примерах выявим преимущества и недостатки каждой модели, изучим сценарии их применения.
Что такое база данных
База данных — это набор сведений об объектах, структурированный определенным образом. Обычно базы данных управляются специальным ПО, или системами управления базами данных (СУБД).
В зависимости от вида логическая структура базы данных может иметь различное описание. Это различие влияет на то, какая именно БД используется в разработке конкретного продукта или технологии.
Простейшие типы баз данных
К таким базам данных относятся БД, где хранятся данные с простой структурой: например, список разрешенных IP-адресов для доступа к сети, настройки окружения проекта, список подписчиков на рассылку компании и прочее. Они все еще широко распространены.
Текстовые файлы
Информация об объектах собирается в простых по структуре файлах различных форматов – txt, csv и др. Для разделения полей применяются пробелы, табуляция, запятые, точка с запятой и двоеточие.
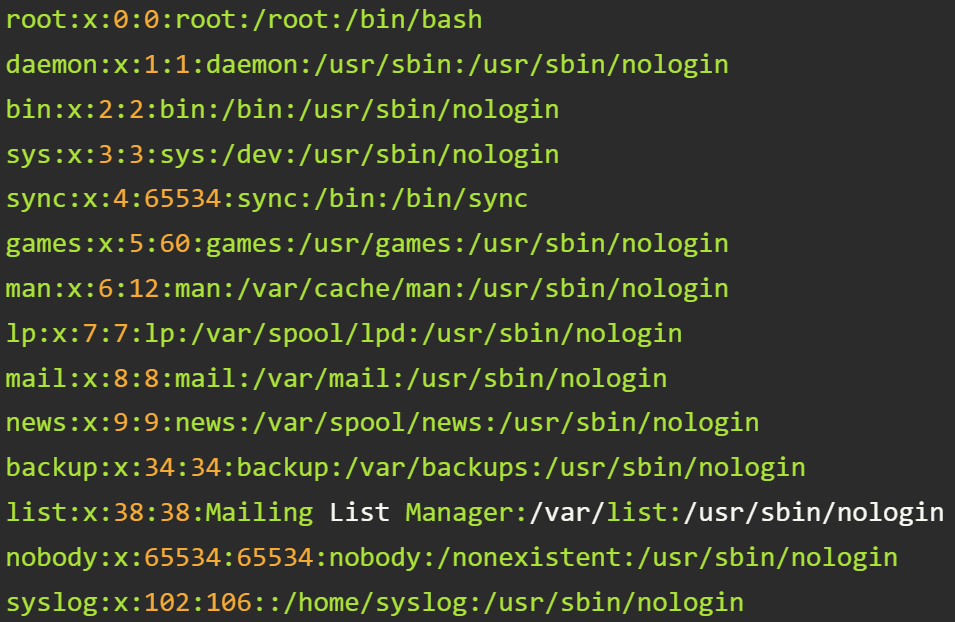
Примеры: etc/passwd и etc/fstab в Unix-подобных системах, csv-файлы, ini-файлы и др.
Особенности:
- Просто использовать. Для работы с файлами достаточно примитивного текстового редактора.
- Удобно работать с конфигурационными данными приложений (учетные данные, настройки подключения к удаленным серверам и устройствам, порты и пр.).
Ограничения:
- Сложно установить связи между компонентами данных.
- Не для всех типов информации.
Иерархические базы данных
В отличие от текстовых файлов здесь между хранимыми объектами устанавливаются связи. Объекты делятся на родителей (основные классы или категории объектов) и потомков (экземпляры этих классов или категорий). При этом у каждого потомка может быть не более одного родителя.
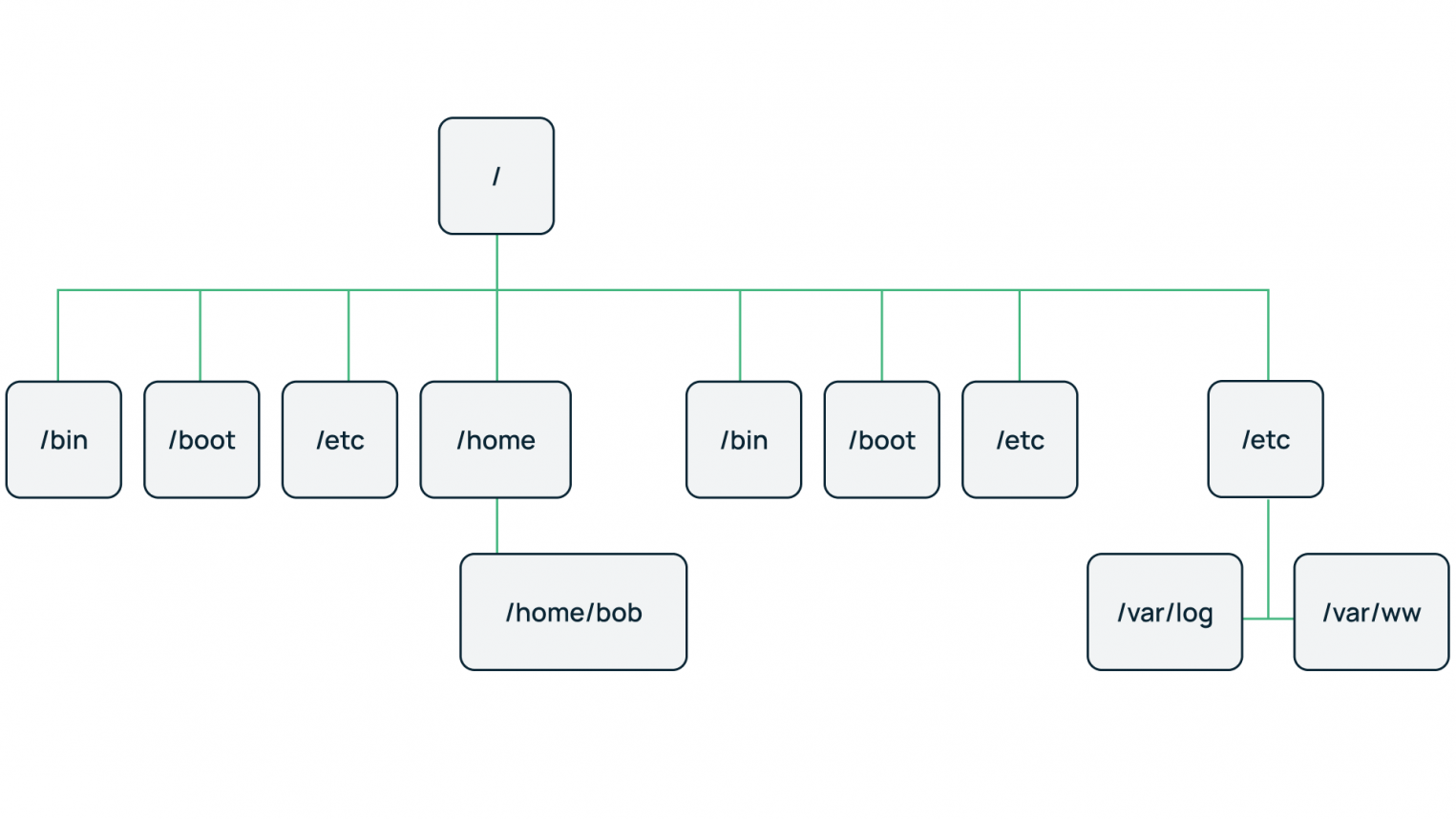
Графическим представлением такой базы данных является древовидная структура.
Примеры: Организация файловых систем; DNS и LDAP-соединения.
Особенности:
- Отношения между объектами реализованы в виде физических указателей. Например, в файловой системе путь к папке или файлу строится из имен корневых и вложенных каталогов;
- Моделирование отношений вложенности и подчиненности.
Ограничения: Технология иерархической организации не предполагает связи «многие-ко-многим», а значит, система хранения данных довольно ограничена.
Сетевые базы данных
Эта технология развивает иерархический подход за счет моделирования сложных отношений между объектами. Здесь потомки могут иметь более одного родителя, однако ограничения иерархического подхода сохраняются.
Пример: IDMS — специализированная СУБД для мейнфреймов.
Реляционные базы данных
Данный тип БД является старейшим: теоретические основы подхода заложены британским ученым Эдгаром Коддом в 1970 году. Здесь данные формируются в таблицы из строк и столбцов. В строках приводятся сведения об объектах (значения свойств), а в столбцах — сами свойства объектов (поля).
Нормализация
Сложные взаимоотношения объектов в реляционных БД моделируются с помощью внешних ключей – ссылок на другие таблицы. Это позволяет подходить к вопросу проектирования базы данных с позиций нормализации – минимизации избыточности при описании свойств объектов.
Например, если речь идет о меню ресторана, то у каждого блюда есть вес, цена, наименование, калорийность и категория, к которой оно относится — горячие закуски, холодные закуски, первые блюда, десерты, салаты и так далее. Связь между блюдами и категорией выполняется посредством ссылочного поля индекса категории в таблице блюд.
Такой подход позволяет:
- Минимизировать объем базы данных: не нужно каждому блюду прописывать название категории.
- Повысить целостность системы: в указанном примере все блюда привязаны к категориям меню. Добавление блюда без категории невозможно, равно как и указание в качестве ссылки индекса несуществующей категории.
- Упростить масштабирование: новые блюда могут быть добавлены в существующие категории. Также не исключается добавление новых категорий, привязка новых блюд к ним и перераспределение блюд по категориям.
- Повысить отказоустойчивость: за счет оптимальной организации схемы таблиц запросы на выборку и агрегацию будут работать с меньшим объемом данных, а значит, быстрее, чем без нормализации. При увеличении числа записей в таблицах со временем это позволит поддерживать положительный пользовательский опыт.
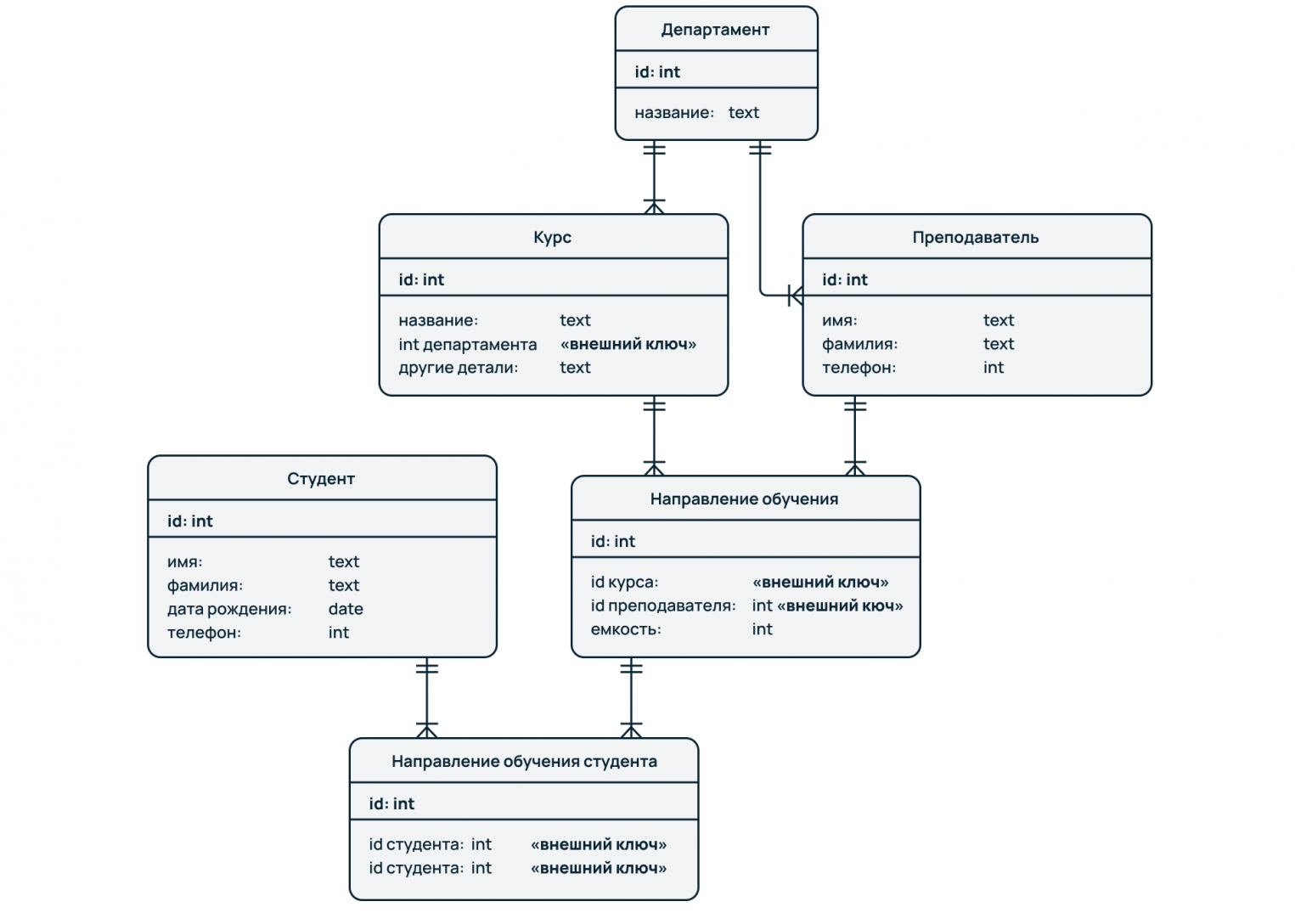
Наглядный пример моделирования сложных взаимоотношений в реляционных БД приведен на рисунке выше. Здесь мы видим модель базы данных учебного заведения, где есть следующие объекты: ученик, курс, преподаватель, отдел, направление обучения.
Связь преподавателя с отделом организована через секцию и курс (внешние ключи id курса и id преподавателя в таблице Секция, а также Отдел в таблице Курс). Связь ученика с направлением обучения реализована через таблицу Направление обучения студента (внешние ключи id студента и id направления обучения).
Таким образом, чтобы посчитать, например, количество студентов на курсе и детализировать статистику по преподавателям, необходимо написать запрос с присоединением учеников к направлению, курсу и преподавателям, сделав соответствующую группировку по преподавателям.
Язык запросов SQL
Запросы в реляционных базах данных формируют с помощью структурированного языка SQL. Его предложения позволяют:
- делать выборки,
- проводить агрегации и группировки,
- изменять и удалять данные,
- модифицировать структуру БД (создавать таблицы, поля),
- управлять доступом пользователей к тем или иным операциям и пр.
Денормализация
Помимо нормализации, в реляционных БД существует и обратный процесс — денормализация. Он направлен на перенос наиболее часто используемых полей из внешних таблиц во внутренние. Рассмотрим это на примере мессенджера.
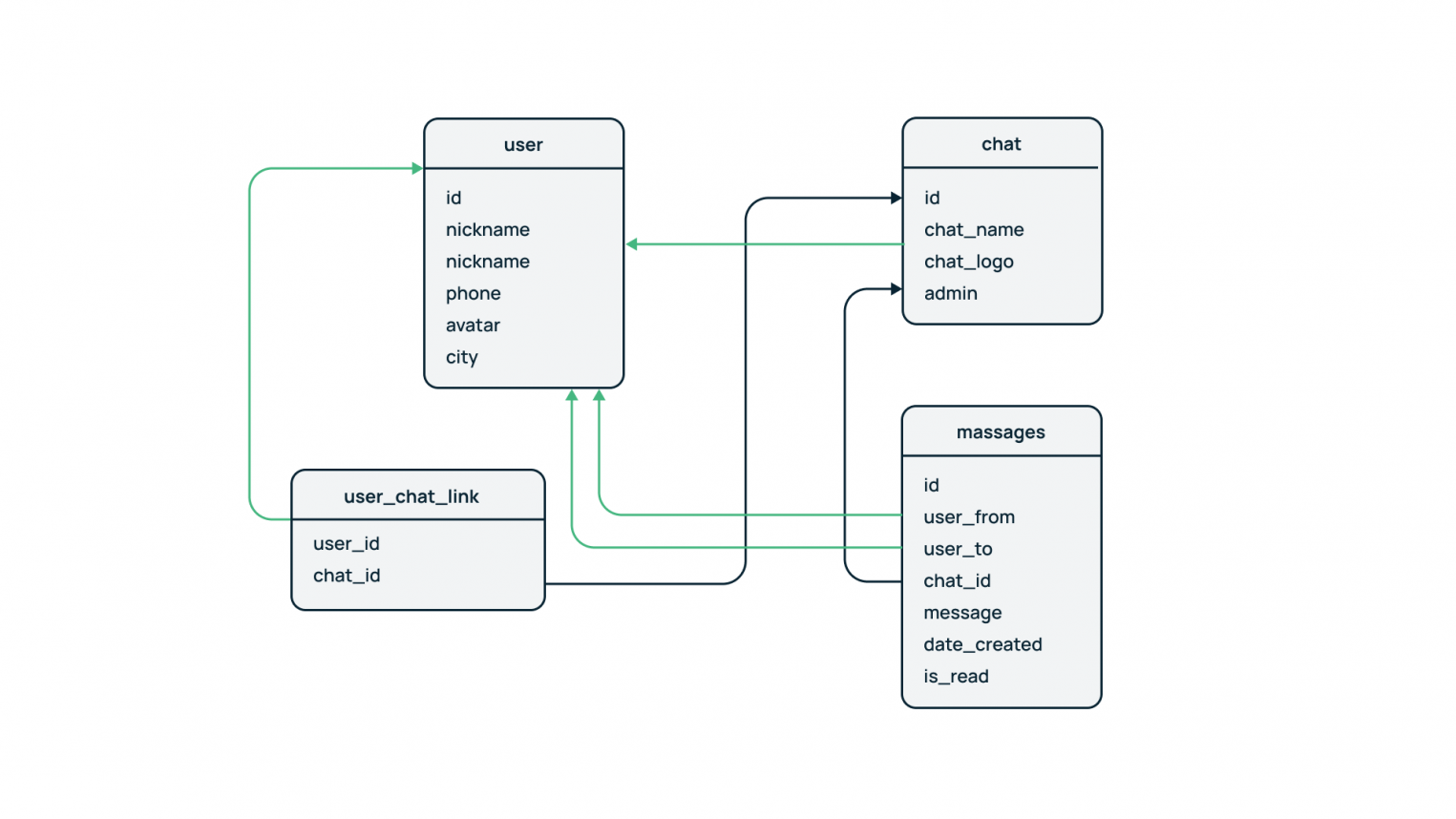
Пользователь (user) оставляет сообщения (messages) в чатах (chat). Структура данных такова, что сообщения связаны с пользователем и чатом через внешние ключи (user_from и user_to, а также chat_id в таблице сообщений; user_id и chat_id в таблице user_chat_link). Поскольку схема нормализована, то различные запросы на выборку, подсчет и агрегацию статистики по чатам, пользователям и сообщениям необходимо выполнять с помощью присоединения внешних таблиц.
На относительно небольших объемах данных эти запросы будут отрабатывать быстро, а с увеличением размера базы – замедляться. Причина кроется в механизме присоединения. Он основан на построчном сравнении двух и более таблиц по условию соединения — например, равенство chat_id в messages и id в chat. А это дает нагрузку на сервер базы данных, которая с ростом ее размера только увеличивается. Для оптимизации такого рода запросов и существует механизм денормализации.
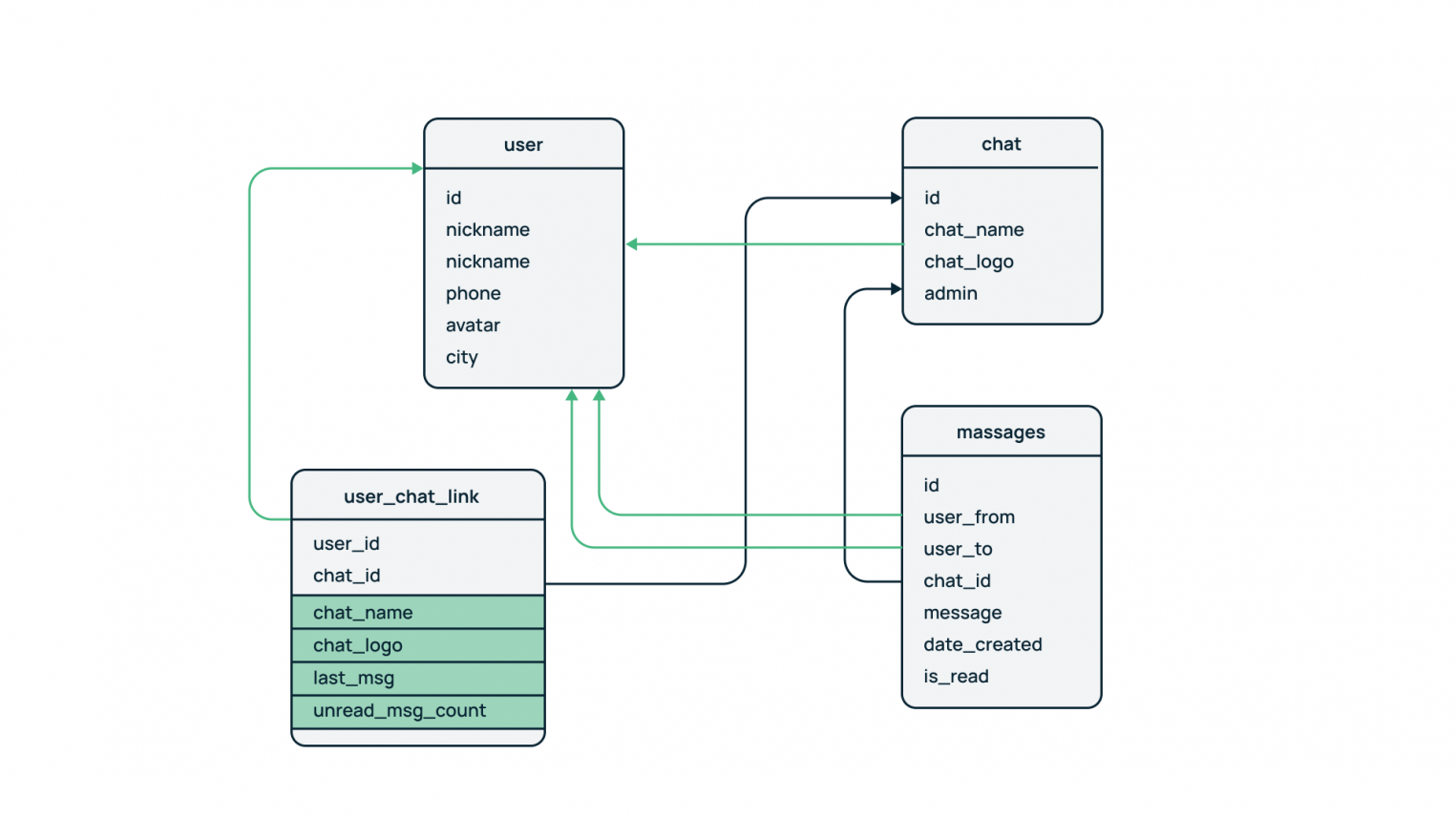
В таблицу связи пользователя и чата user_chat_link добавлены дублирующие поля имени чата (chat_name) и аватара (chat_logo). Также туда выводятся последнее сообщение (last_msg) и количество непрочитанных сообщений (unread_msg_count).
Теперь для получения указанных выше полей и проведения аналитики по ним можно использовать таблицу user_chat_link без необходимости соединения с таблицей сообщений. Тем не менее, такой подход имеет ограничения.
За счет дополнительных полей оптимизируются запросы на чтение и агрегацию данных, однако ценой этого является вынужденная избыточность и усложнение бизнес-логики приложения. В частности, усложняется написание запросов изменения данных (update и delete), а также модификации структуры базы (create).
Использование денормализации должно быть тщательно осмыслено. Нужно быть уверенным в том, что нормализованная структура, оптимизированные запросы и правильно настроенные индексы более не способны удовлетворять критерию быстродействия.
Преимущества реляционного подхода:
- определение сложных отношений между объектами,
- нормализация и денормализация данных,
- структурированный язык запросов,
- богатая история развития и широкое распространение (основной инструмент при разработке различных приложений и сервисов).
Недостатки подхода: жесткая структура сведений об объектах.
Примеры: MySQL, MariaDB, PostgreSQL, SQLite и др.
NoSQL и нереляционные базы данных
Все преимущества и недостатки реляционных БД основаны на жесткой структуризации и типизации сведений об объектах. С одной стороны, можно оптимизировать хранение и индексирование данных за счет нормализации или же денормализации. С другой — сложно организовать хранение и обработку плохо структурированных (например, объекты кэша) или вовсе не структурированных данных (например, данные из нескольких источников).
Для борьбы с этими ограничениями было разработано семейство нереляционных БД. Рассмотрим их подробнее.
Базы данных «Ключ-значение»
Это простейшая разновидность нереляционных БД. Данные хранятся в виде словаря, где указателем выступает ключ.
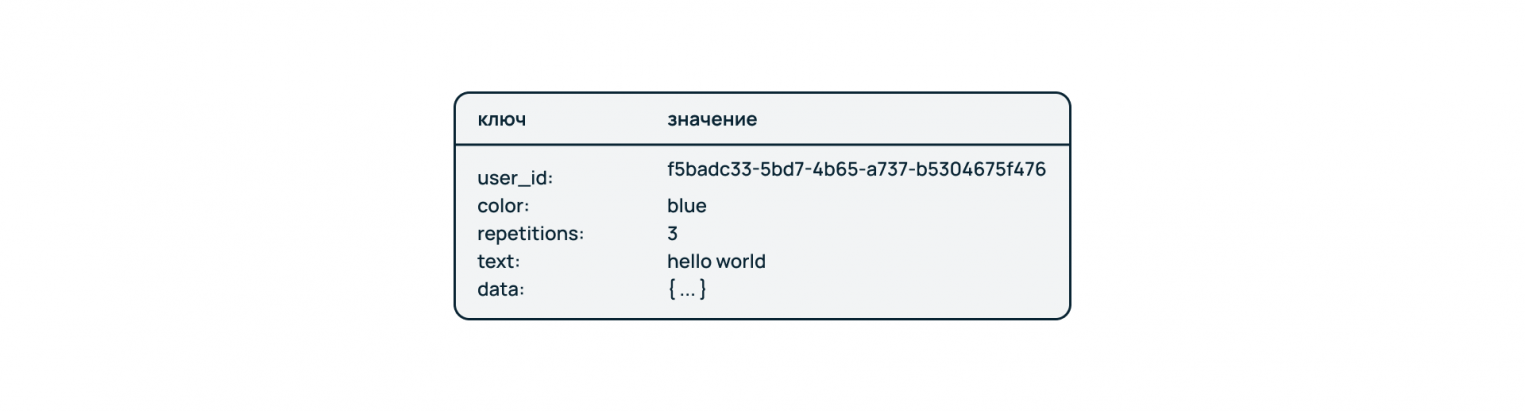
Особенности:
- Хранение и обработка разных по типу и содержанию данных: в одном хранилище под разными ключами могут находиться файлы, строки, текст, числа, JSON-объекты и другие типы данных.
- Высокая скорость доступа к данным за счет адресного хранения.
- Легкое масштабирование. Можно создать правила шардирования по определенным ключам – например, сессии пользователей разных сайтов хранятся в различных сегментах БД.
Ограничения: Поскольку подход не предполагает жесткой типизации и структуризации данных, то контроль их валидности, а также нейминг ключей отдаются на откуп разработчику.
Примеры: Amazon, DynamoDB, Redis, Riak, LevelDB, различные хранилища кэша – например, Memcached и пр.
Документоориентированные БД
В отличие от баз типа «Ключ-значение» данные здесь хранятся в структурированных форматах – XML, JSON, BSON. Тем не менее, сохраняется адресный доступ к данным по ключу. При этом содержимое документа может иметь различный набор свойств.
Например, каталог профилей пользователей: один в качестве предпочтений указал любимое блюдо, а другой – видеоигру. Поскольку эти сведения нельзя хранить в одном поле ввиду логической и структурной разобщенности, они записываются в отдельные свойства отдельных документов. При необходимости можно добавить в документы новые свойства, не нарушив при этом общей целостности данных.
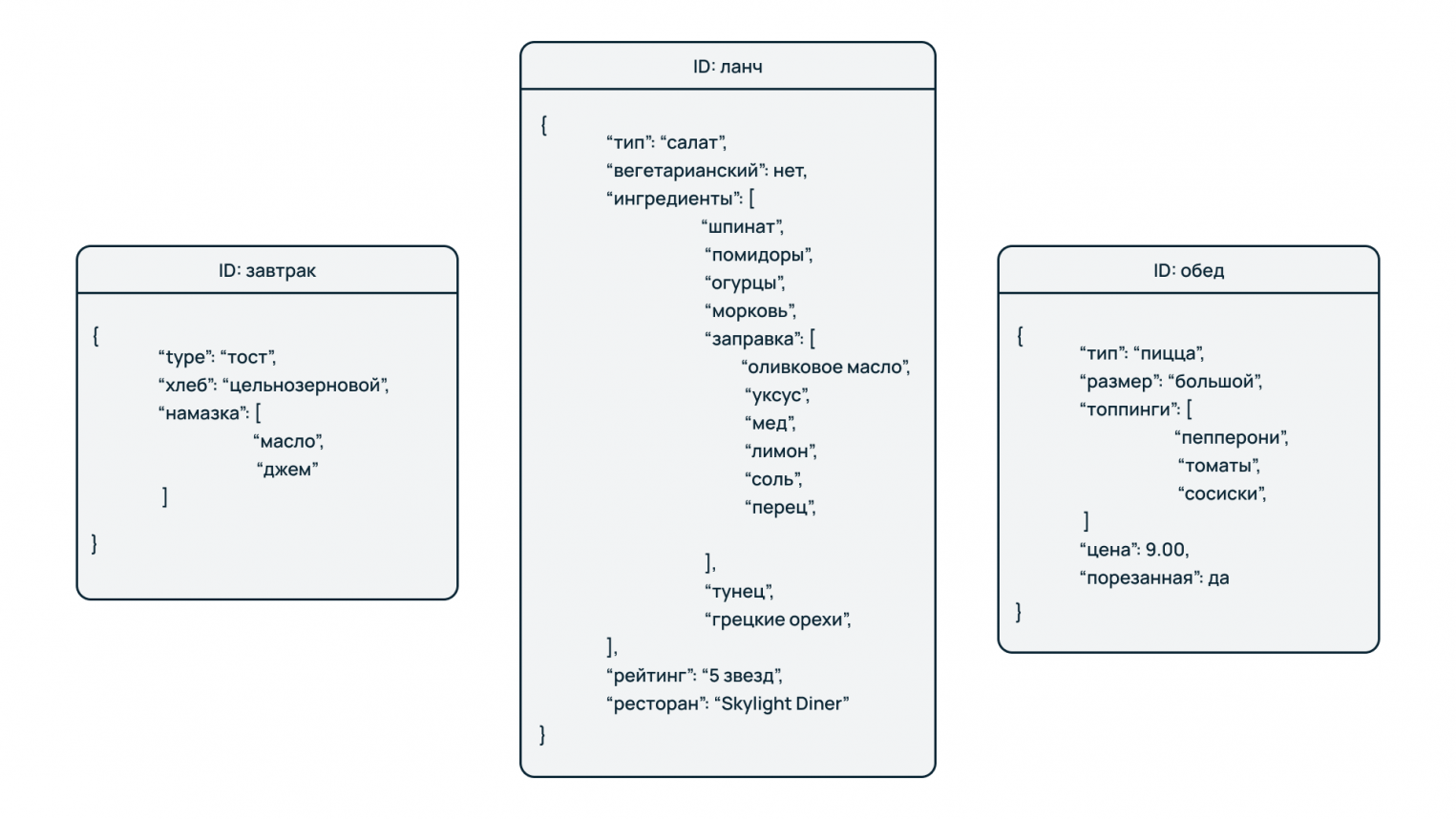
Особенности:
- хорошо подходят для быстрой разработки систем и сервисов, работающих с по-разному структурированными данными,
- легко масштабируются и меняют структуру при необходимости.
Примеры: MongoDB, RethinkDB, CouchDB, DocumentDB.
Графовые базы данных
Это семейство баз предназначено для моделирования сложных отношений с помощью теории графов, где связями выступают ребра графа, а сами объекты – это узлы или вершины.
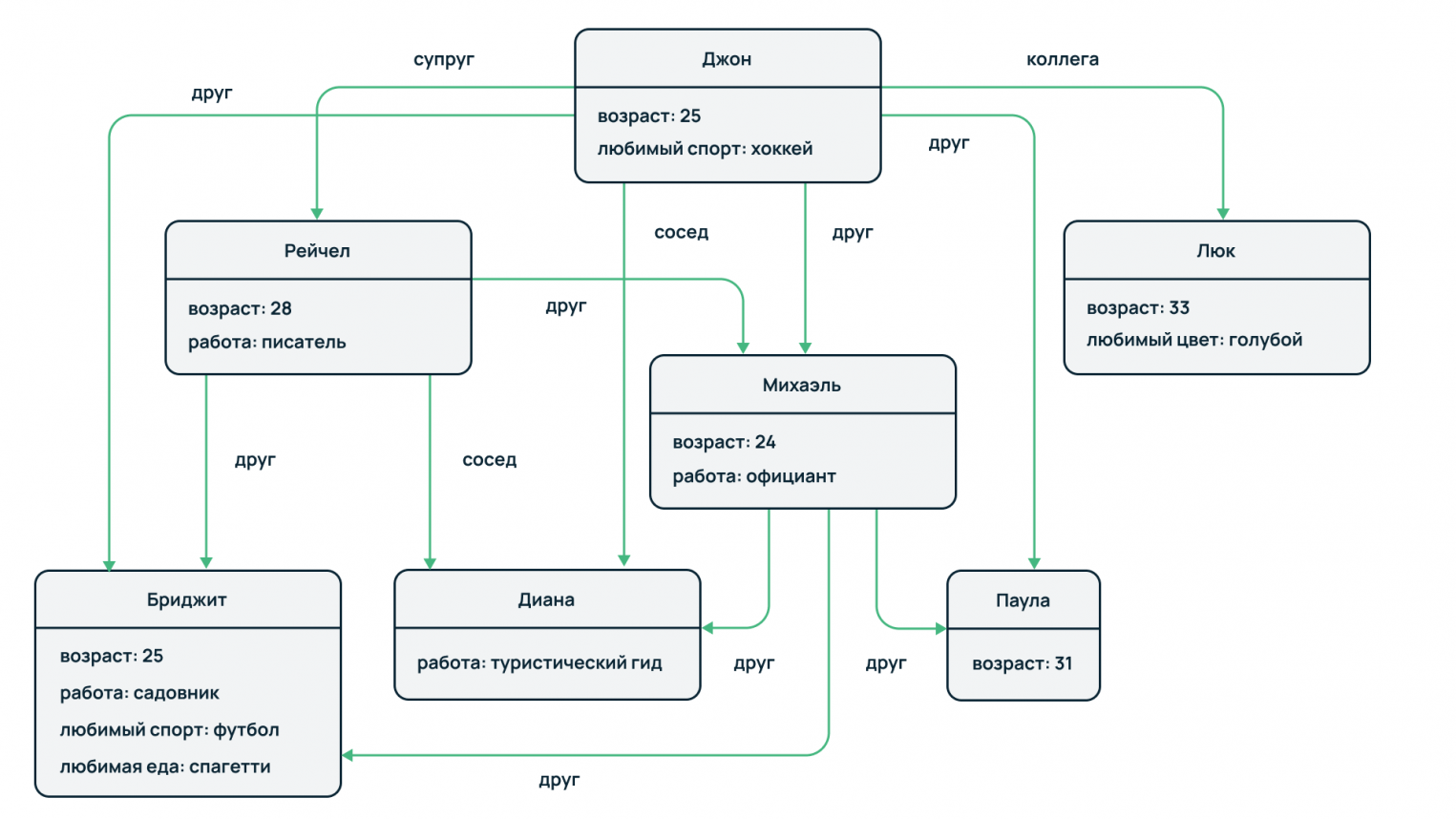
Такой подход может пригодиться при анализе профилей пользователей социальных сетей. Один пользователь подписан на обновления второго, другой пользователь подписан на определенное сообщество и так далее. Также технология может использоваться при анализе экономической активности контрагентов для выявления различных схем мошенничества. Например, можно отследить использование определенных счетов, карт или реквизитов контрагентов в различных операциях.
Особенности: высокая производительность, поскольку обход ребер и вершин значительно быстрее анализа множества внешних и внутренних таблиц и их соединения по условию отбора в реляционных БД.
Примеры: Neo4J, JanusGraph, Dgraph, OrientDB.
Колоночные базы данных
Как можно понять из названия, записи в таких базах хранятся не по строкам, а по столбцам (колонкам). Вместо таблиц здесь используются колоночные семейства. Они содержат ключи, указывающие на формат строки записи информации об объекте. Каждая строка имеет свой набор свойств, что позволяет хранить в рамках одного семейства разно структурированные данные.
Технология активно используется при построении аналитических систем и сервисов, работающих с большими объемами данных.
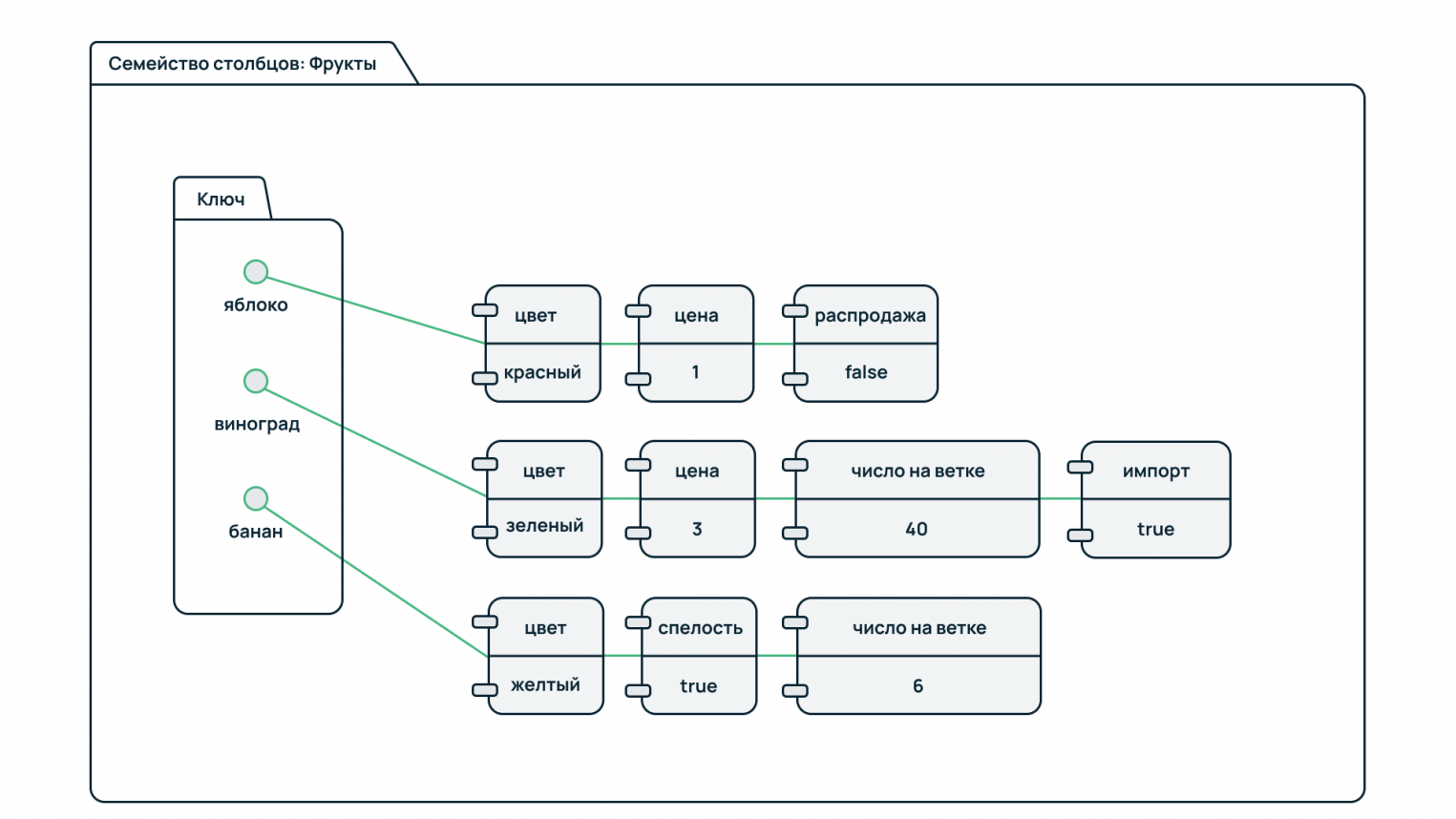
На рисунке приведен пример колоночного хранения информации о фруктах. Известно три типа фруктов: яблоки, виноград, бананы. Все они объединены в семейство фруктов.
У каждого фрукта индивидуальный набор свойств. Для яблок это цвет, цена и наличие. У винограда это цвет, цена, число ягод в связке и происхождение (импортный или нет). У бананов же это цвет, цена, число в связке и зрелость.
Чтобы получить детальную сводку по одному типу фруктов, достаточно в запросе указать его идентификатор. При этом можно построить аналитический запрос по общим для всего семейства признакам – например, посчитать число фруктов с группировкой по цвету, вычислить среднюю цену на все фрукты в магазине и т.д.
Особенности:
- С группировкой свойств по колонкам при запросе индексируется меньший объем данных, что обеспечивает высокую скорость его выполнения.
- Широкие возможности масштабирования и модификации структуры — так, при добавлении новых колонок не придется их жестко формализовывать, как в случае с реляционными базами.
Примеры: Cassandra, HBase, ClickHouse.
Базы данных временных рядов
Данный тип БД можно использовать при необходимости отслеживания исторической динамики по ряду показателей. Здесь данные группируются по временным меткам. Базы временных рядом чаще ориентированы на запись, чем на построение сложных аналитических запросов.
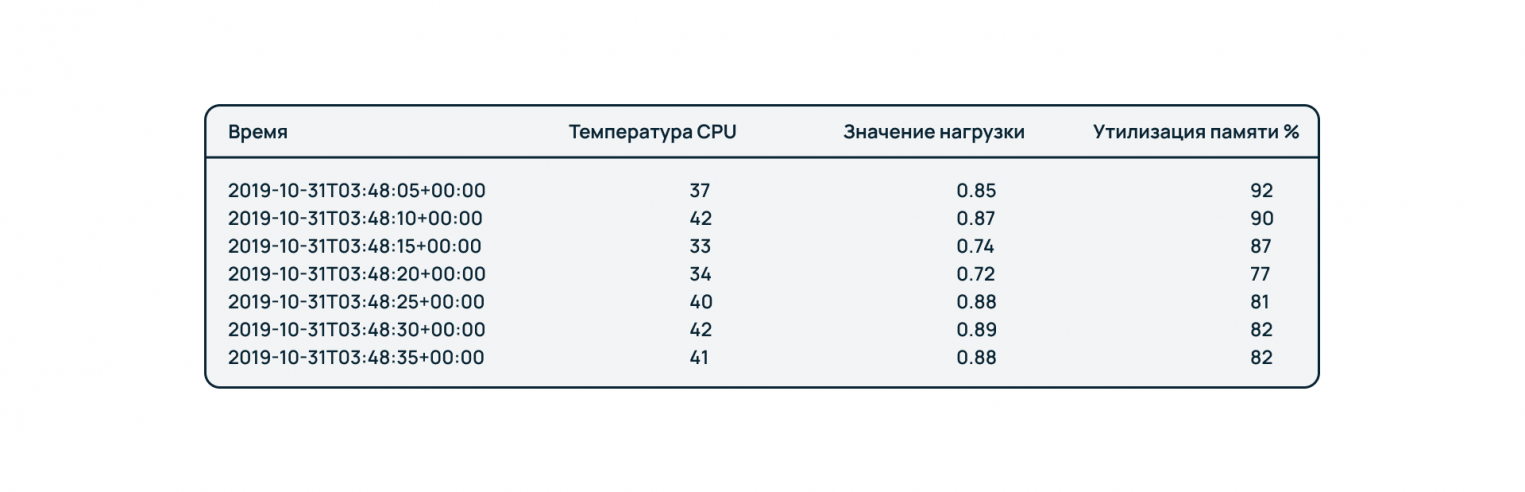
На рисунке выше приведен пример использования такой БД для отслеживания состояния ПК во времени по ряду показателей – температуре процессора, загрузке системы и потреблению оперативной памяти.
Особенности: Можно обрабатывать постоянный поток входных данных.
Ограничения: Производительность зависит от объема поступающей информации, количества отслеживаемых метрик, а также временного лага между записью новых данных и запросами на чтение
Примеры БД: OpenTSDB, Prometheus, InfluxDB, TimescaleDB
Комбинированные базы
Эта разновидность баз совмещает в себе SQL- и NoSQL-подходы к организации хранения и обработки данных. Этот класс баз включает в себя NewSQL и многомодельные решения. Рассмотрим их подробнее.
Базы данных NewSQL
Данный тип решений для хранения информации стремится обеспечить компромисс между масштабируемостью и согласованностью при сохранении реляционного подхода.
Термин предложил в 2011 году аналитик компании 451 Group Мэтью Аслет. Он отмечал высокую потребность в таких системах для сфер, работающих с критическими данными, — здравоохранение, FinTech и пр. Характерными признаками этих решений являются: использование алгоритмов обеспечения консенсуса (алгоритм Paxos, Raft и др.), шардирование и заточка под горизонтальное масштабирование.
Особенности:
- широкие возможности масштабирования,
- высокая производительность и доступность данных.
Ограничения: Высокие требования к аппаратным ресурсам разработчиков. Но если разрабатываемый продукт является высоконагруженной системой, то применение такой БД имеет смысл.
Примеры баз такого типа: MemSQL, VoltDB, Spanner и др.
Многомодельные базы
Такие БД сочетают в себе несколько подходов к организации данных одновременно. Это обеспечивает функциональное разнообразие при разработке систем с их использованием.
Особенности:
- возможность в одном запросе работать с данными, хранящимися в разных типах баз, не нарушая при этом согласованности;
- обширные возможности масштабирования за счет легкой интеграции новых моделей баз данных в существующую инфраструктуру проекта.
Пример решения данного типа: ArangoDB.
Базы данных в Selectel
В Selectel вы можете запустить готовые облачные базы данных — поддерживаем такие СУБД, как PostgreSQL (в том числе для 1С:Предприятие), MySQL, Redis, TimescaleDB.
Облачные базы данных позволяют исключить работу с инфраструктурой: поднять нужное количество нод можно за несколько минут в панели управления компании. Решение отказоустойчивое и легко масштабируется. На экстренный случай создаются резервные копии для отката состояния базы на срок до семи дней.
Большинство рутинных операций по системному администрированию (настройка, конфигурация, обслуживание и обеспечение безопасности) выполняются специалистами Selectel.
Запустите свою базу данных в облаке
Быстрое развертывание самых популярных реляционных и NoSQl-баз данных.
Заключение
В данной статье мы рассмотрели 11 видов баз данных. Каждый имеет свои особенности и ограничения. Решение о выборе того или иного вида необходимо принимать с учетом:
- сложности хранимых данных и взаимосвязей между ними,
- производительности операций чтения/записи и модификации структуры БД на планируемом объеме данных,
- опыта команды разработки,
- стадии жизненного цикла разрабатываемого продукта (производите ли вы доработку действующего решения либо создаете что-то принципиально новое, каковы ваши текущие и перспективные ресурсные возможности).
Автор: Роман Андреев.
Что такое База Данных (БД)
База данных — это место для хранения данных. Используется в том числе в клиент-серверной архитектуре. Это все интернет-магазины, сайты кинотеатров или авиабилетов. Вы делаете заказ, а система сохраняет ваши данные в базе.

В этот статье я на простых примерах расскажу, что такое база данных и как она выглядит. А потом поясню некоторые термины из конкретной (реляционной) базы. Те, с которыми вы почти наверняка столкнетесь на работе.
Статья рассчитана на начинающих тестировщиков или аналитиков, то есть тех, кто будет работать с базой, но не на супер-глубоком уровне. Она для тех, кто только входит в мир ИТ, и многого не знает. Она объясняет, что это за звено в клиент-серверной архитектуре такое, и зачем оно нужно.
Что такое база данных
База данных — хранилище, куда приложение складывает свои данные. Если приложение небольшое, отдельная база не нужна. Но потом это становится удобнее и выгоднее с точки зрения памяти.
Катя решила открыть свой магазинчик. Она нашла хорошую марку обуви, которую «днем с огнем» не сыскать в ее городе. Заказала оптовую партию и стала потихоньку распродавать через знакомых. Пришлось освободить половину шкафа под коробки, но вроде всё поместилось.

Обувь хорошая, в розницу заказывать в других местах невыгодно — и вот уже у Кати есть постоянные клиенты, которые приводят друзей. Как только какая-то пара заканчивается, Катя делает новый заказ.
Но покупатели хотят новинок, разных размеров. Да и самих покупателей становится все больше и больше. В шкаф коробки уже не влезают!

Теперь, если покупатель просит определенную пару, Катьке сложно её найти. Пока коробок было мало, она помнила наизусть, где что лежит. А теперь уже нет, да и все попытки организовать систему провалились. Места мало, да и детки любят с коробками поиграть.

Тогда Катька решила арендовать складское помещение. И вот теперь красота! Не надо теснить своих домашних, дома чисто и свободно! И на складе место есть, появилась система — тут босоножки, тут сапоги.

Чем больше объемы производства, тем больше нужно места. Если в начале пути склад не нужен, всё поместится дома, то потом это будет оправданно.
То же самое и в приложениях. Если приложение маленькое, то все данные можно хранить в памяти. Но учтите, что это память на вашем компьютере, вашем телефоне. И чем больше данных туда пихать, тем медленнее будет работать программа.
Место в памяти ограничено. Поэтому когда данных много, их нужно куда-то сложить. Можно писать в файлики, а можно сохранять информацию в базу данных (сокращенно БД). Выбор за вами. А точнее, за вашим разработчиком.
Как она выглядит
Да примерно как excel-табличка! Есть колонки с заголовками, и информация внутри:
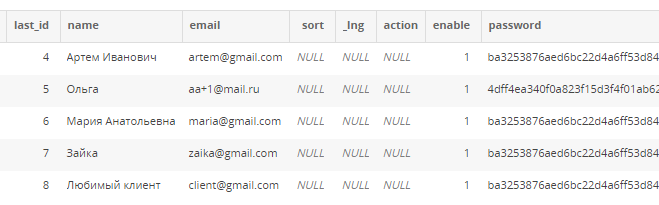
Это называется реляционная база данных — набор таблиц, хранящихся в одном пространстве.
Что за пространство? Ну вот представьте, что вы храните все данные в excel. Можно запихать всю-всю-всю информацию в одну огро-о-о-о-мную таблицу, но это неудобно. Обычно табличек несколько: тут информация по клиентам, там по заказам, а тут по адресам. Эти таблицы удобно хранить в одном месте, поэтому кладем их в отдельную папочку:
Так вот пространство внутри базы данных — это та же самая папочка в винде. Место, куда мы сложили свои таблички, чтобы они все были в одном месте.
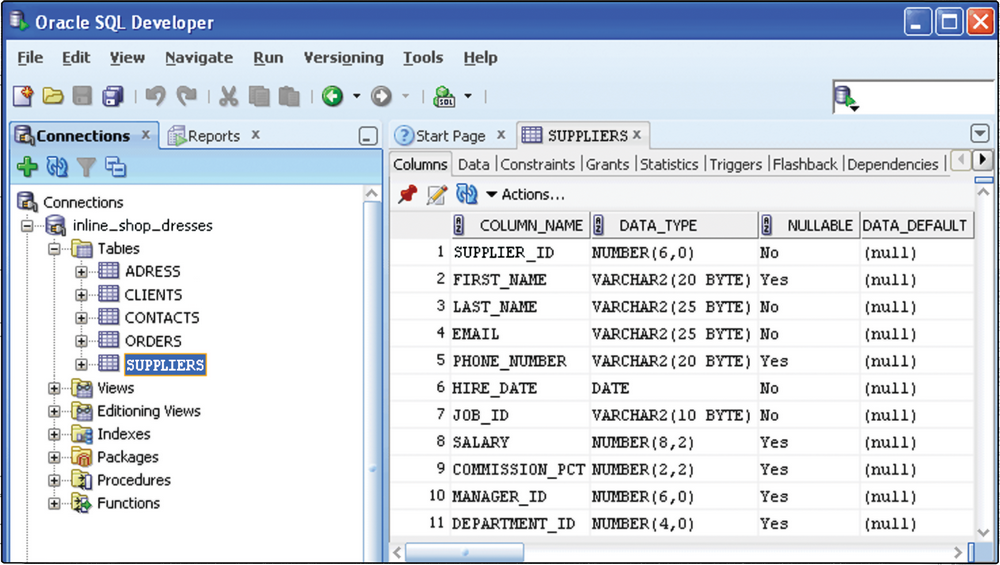
Цель та же — выделить отдельное место, чтобы у вас не была одна большая свалка:
- заходишь в папку в винде → видишь файлики только из этой папки
- заходишь в пространство → видишь только те таблицы, которые в нем есть
Хранение данных в виде табличек — это не единственно возможный вариант. Вот вам для примера запись из таблицы в системе Users. Там используется MongoDB база данных, она не реляционная. Поэтому вместо таблички «словно в excel» каждая запись хранится в виде объекта, вот так:
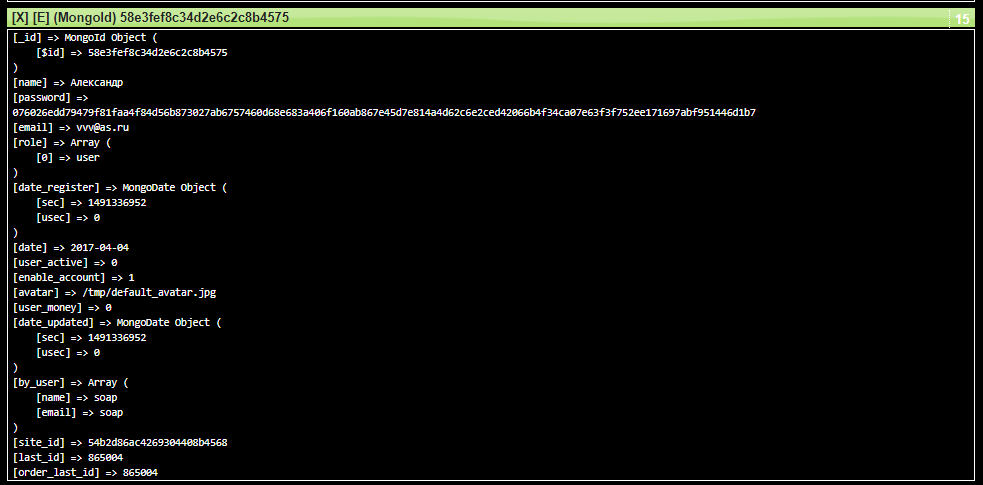
А еще есть файловые базы — когда у вас вся информация хранится в файликах. Да-да, простых текстовых файликах!
Почитать о разных видах баз данных можно в википедии. Я не буду в этой статье углубляться в эту тему, потому что моя задача — объяснить «что это вообще такое» для ребят, которые базу в глаза не видели. А на работе они скорее всего столкнутся именно с реляционной базой данных, поэтому о ней и речь.
Да, базы бывают разные. Классификацию можно изучить, можно выучить. Но по факту от начинающего тестировщика обычно нужно уметь достать информацию из реляционной БД («обычно» != «всегда», если что).
Как получить информацию из базы
Нужно записать свой запрос в понятном для базы виде — на SQL. SQL (Structured Query Language) — язык общения с базой данных. В нем есть ключевые слова, которые помогут вам сделать выборку:
- select — выбери мне такие-то колонки.
- from — из такой-то таблицы базы.
- where — такую-то информацию.
Например, я хочу получить информацию по клиенту «Назина Ольга». Составляю в уме ТЗ:
Дай мне информацию по клиенту, у которого ФИО = «Назина Ольга»Переделываю в SQL:
select * from clients where name = 'Назина Ольга';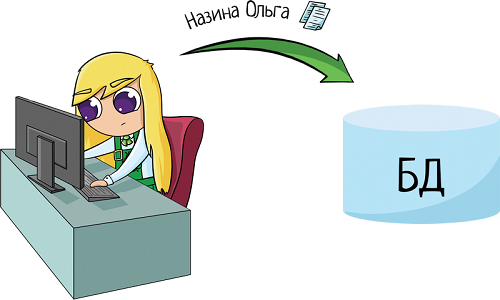
В дословном переводе:
select -- выбери мне * -- все колонки (можно выбирать конкретные, а можно сразу все) from clients -- из таблицы clients where name = 'Назина Ольга'; -- где поле name имеет значение 'Назина Ольга'См также:
Комментарии в Oracle/PLSQL — мой перевод остается работающим запросом, потому что я убрала «лишнее» в комментарии
Если бы у меня была не база данных, а простые excel-файлики, то же действие было бы:
- Открыть файл с нужными данными (clients)
- Поставить фильтр на колонку «ФИО» — «Назина Ольга».
То есть нам в любом случае надо знать название таблицы, где лежат данные, и название колонки, по которой фильтруем. Это не что-то страшное, что есть только в базе данных. То же самое есть в простом экселе.
Бывают запросы и сложнее — когда надо достать данные не из одной таблицы, а из разных. В базе это будет выглядеть даже лучше, чем в эксельке. В экселе вам нужно открыть 1-2-3 таблицы и смотреть в каждую. Неудобно.
А в базе данных вы внутри запроса SQL указываете, какие колонки из каких таблиц вам нужны. И результат запроса их отрисовывает. Скажем, мы хотим увидеть заказ, который сделал клиент, ФИО клиента, и его номер телефона. И всё это в разных таблицах! А мы написали запрос и увидели то, что нам надо:
id_order
order (таблица order)
fio (таблица client)
phone (таблица contacts)
И пусть в таблице клиентов у нас будет 30 колонок, а в таблице заказов 50, в результате выборки мы видим ровно 4 запрошенные. Удобно, ничего лишнего!
Конечно, написать такой запрос будет немного сложнее обычного селекта. Это уже select join, почитать о нем можно тут. И я рекомендую вам его изучить, потому что он входит в «базовое знание sql», которое требуется на собеседованиях.
Результаты выборки можно группировать, сортировать — это следующий уровень сложности. См раздел «статьи и книги по теме» для получения большей информации.
Как связать данные между собой
Вот например, у нас есть интернет-магазин по доставке пиццы. Так выглядит его база данных:
- В таблице «client» лежат данные по клиентам: ФИО, пол, дата рождения и т.д.
last_name
first_name
birthdate
VIP
- В таблице «orders» лежат данные по заказам. Что заказали (пиццу, суши, роллы), когда, насколько довольны доставкой?
order
addr
date
time
Роллы «Филадельфия» и «Канада»
Студеный пр-д, д 10
Пицца 35 см, роллы комбо 1
Пицца с сосиками по краям
Комбо набор 3, обед №4
Но как понять, где чей был заказ? Сколько раз заказывал Вася, а сколько Алина?
Тут есть несколько вариантов:
1. Запихать все данные в одну таблицу: тут и заказы, и информация по клиентам. В целом удобно, открыл табличку и сразу видишь — ага, это Васин заказ, а это Машин.
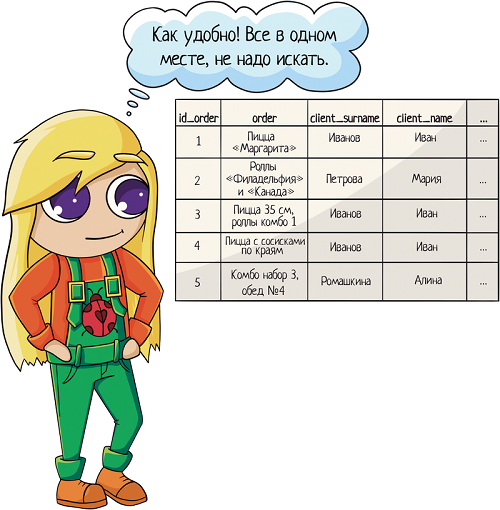
- Таблица все растет и растет, в итоге получается просто огромной! А когда данных много, легкость чтения пропадает, придется листать до нужной колонки.
- Поиск будет работать медленнее. Чем меньше информации в таблице, тем быстрее поиск. Когда у нас много строк, количество колонок становится существенным.
- Много дублей — один человек может сделать хоть сотню заказов. И вся информация по нему будет продублирована сто раз. Неоптимальненько!
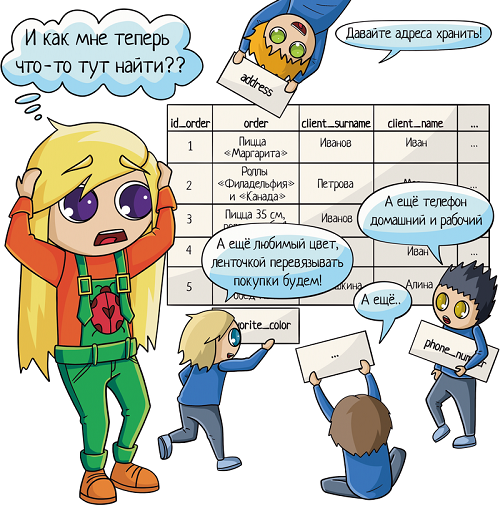
Чтобы избежать дублей, таблицы принято разделять:
- Клиенты отдельно
- Заказы отдельно
- Новые объекты отдельно
Но надо при этом их как-то связать между собой, мы ведь всё еще хотим знать, чей конкретно был заказ. Для связи таблиц используется foreign key, внешний ключ.
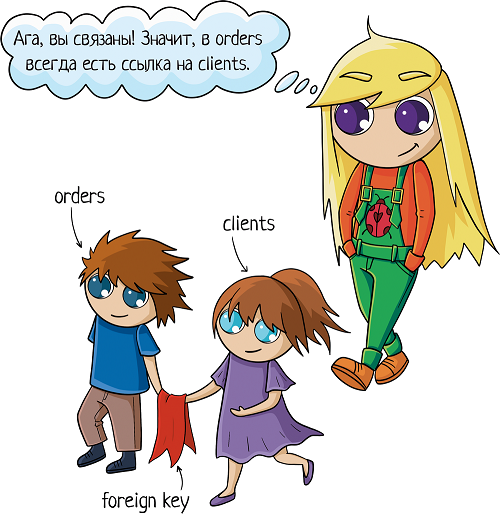
Нам надо у заказа сделать отметку о клиенте. Значит, таблица «orders» будет ссылаться на таблицу «clients». Ключ можно поставить на любую колонку таблицы (в некоторых базах колонка должна быть уникальной, сначала её нужно такой указать). Какую бы выбрать?
Можно ссылаться на имя. А что, миленько, в таблице заказов будем сразу имя видеть! Но минуточку. А если у нас два клиента Ивана? Или три Маши? Десять Саш. Ну вы поняли =) И как тогда разобраться, где какой клиент? Не подходит!
Можно вешать foreign key на несколько колонок. Например, на фамилию + имя, или фамилию + имя + отчество. Но ведь и ФИО бывают неуникальные! Что тогда? Можно добавить в связку дату рождения. Тогда шанс ошибиться будет минимален, хотя и такие ребята существуют. И чем больше клиентов у вас будет, тем больше шанс встретить дубликат.

А можно не усложнять! Вместо того, чтобы делать внешний ключ на 10 колонок, лучше создать в таблице клиентов primary key, первичный ключ. Первичный ключ отвечает за то, чтобы каждое значение в поле было уникальным, никаких дублей. При попытке добавить в таблицу запись с неуникальным первичным ключом получаешь ошибку:
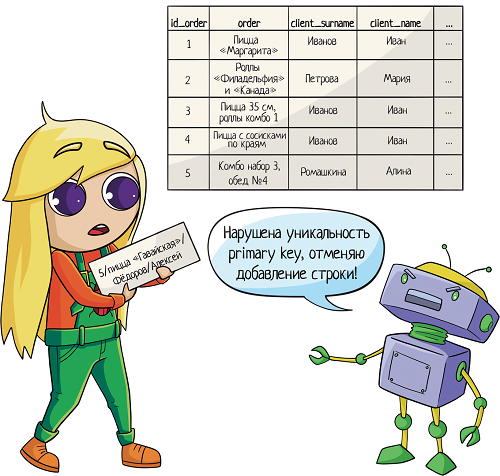
Вот на него и нужно ссылаться! Обычно таким ключом является ID, идентификатор записи. Его можно сделать автоинкрементальным — это значит, что он генерируется сам по алгоритму «прошлое значение + 1».
Например, у нас гостиница для котиков. Это когда хозяева едут в отпуск, а котика оставить не с кем — оставляем в гостинице!
Есть таблица постояльцев:
Типы данных в MySQL
В этой инструкции рассказываем про основные типы данных в MySQL и даем советы, где лучше использовать тот или иной тип.
Эта инструкция — часть курса «MySQL для новичков».
Смотреть весь курс
Введение
При создании таблиц в MySQL для каждого столбца нужно указывать тип данных. Он определяет, какие данные там могут храниться, как будут обрабатываться и сколько места будут занимать. В MySQL все типы данных делятся на несколько классов: числовые типы, символьные, дата/время и так далее. В каждом классе есть несколько типов данных, которые внешне могут быть похожи, но их поведение или принципы хранения отличаются. Важно выбрать правильный тип сразу при создании таблицы, потому что потом готовую структуру и приложения будет сложней переделать.
В этой статье мы расскажем об основных типах данных в MySQL и дадим советы, где лучше использовать тот или иной тип.
Возможности MySQL в «Облачных базах данных»
Числовые типы
Используются для хранения чисел. Бывают целочисленными, с плавающей точкой и с фиксированной точкой.
Целые числа
Хранят только целые числа, без дробной части. Делятся на signed (со знаком) и unsigned (без знака). Типы singed позволяют хранить как положительные, так и отрицательные значения. Типы unsigned хранят только положительные числа, но зато диапазон значений больше. Это может быть полезно в случаях, когда хранимые значения заведомо не могут быть отрицательным. Например, количество товара или идентификатор записи в таблице.
| Тип | Размер (байт) | Диапазон signed | Диапазон unsigned |
| TINYINT | 1 | -128 … 127 | 0 … 255 |
| SMALLINT | 2 | -3 2768 … 32 767 | 0 … 65 535 |
| MEDIUMINT | 3 | -8 388 608 … 8388607 | 0 … 16 777 215 |
| INT | 4 | 2 147 483 648 … 2 147 483 647 | 0 … 42 94 967 295 |
| BIGINT | 8 | -2 63 … 2 63 -1 | 0 … 2 64 -1 |
Числа с плавающей точкой
Хранят приблизительные значения. Не резервируют определенное количество бит для целочисленной или дробной частей. Поэтому у всех значений в таблице количество до и после запятой будет разным.
| Тип | Размер (байт) | Диапазон |
| FLOAT | 4 | -3.402823466E+38 … -1.175494351E-38 и 1.175494351E-38 … 3.402823466E+38 |
| DOUBLE | 8 | -1.7976931348623157E+308 … -2.2250738585072014E-308 и2.2250738585072014E-308 … 1.7976931348623157E+308 |
До версии MySQL 8.0.17 эти типы данных поддерживали диапазон unsigned, но он работал не так, как с целыми числами. Беззнаковый диапазон просто запрещал сохранять отрицательные значения, при этом максимальное значение не увеличивалось. Начиная с версии 8.0.17, использование unsigned не рекомендуется и считается устаревшим. В будущих версиях MySQL поддержку беззнакового диапазона для этого типа данных могут вовсе удалить.
Числа с фиксированной точкой
Эти типы данных используются для сохранения заданной точности. Такие числа резервируют определенное количество бит для целочисленной и дробной частей. Независимо от того, насколько большое или маленькое число, оно всегда будет использовать одно и то же количество бит для сохранения каждой части. Эти типы данных подходят для случаев, когда важна точность, например, деньги.
В MySQL для хранения чисел с фиксированной точкой используются типы DECIMAL(M,D) и NUMERIC(M,D), но по факту это синонимы. Можно использовать любой из этих типов, результат будет одинаковым. В таких столбцах максимально можно хранить до 65 чисел вместе с целочисленной и дробной частями.
Символьные (строковые)
Символьные типы используются для хранения текстов. Есть два основных типа: CHAR и VARCHAR. С точки зрения пользователя они выглядят похоже, но MySQL хранит и обрабатывает их по-разному.
- CHAR хранит строку фиксированной длины до 255 символов. Если длина вставляемой записи меньше, то MySQL автоматически дополняет значение пробелами. Например, если мы указали тип CHAR(10) и сохранили строку «Привет», то по факту в БД будет храниться строка «Привет » (обратите внимание на четыре пробела в конце строки).
Кажется, что это лишняя трата места. Но если во всех ваших записях хранятся строки примерно одной длины, то тип CHAR будет очень производительным. Например, его можно использовать для хранения хешей, у которых длина всегда одинакова.
- VARCHAR хранит строки переменной длины до 65 535 символов. Причем в памяти хранится именно та длина, которая была указана при создании. VARCHAR занимает меньше места, чем CHAR, но подвержен фрагментации и из-за этого может проигрывать в скорости обработки данных.
Текстовые и бинарные
Текстовые (TEXT) и бинарные (BLOB) типы данных используются для хранения больших объемов текста или двоичных данных. Эти типы похожи, но отличаются по способу хранения и обработки внутри MySQL.
- BLOB обрабатывается как двоичные данные. В нем не хранится набор символов, а операции сортировки и сравнения основаны на числовых значениях байтов.
- TEXT обрабатывается как символьные строки. В нем хранится именно набор символов, а значения сортируются и сравниваются на основе сопоставления набора символов..
Текстовые типы отлично подходят для хранения больших текстов: статей, докладов и так далее. А бинарные типы могут хранить любые файлы или мультимедиа-контент.
| Тип | Размер (байт) | Макс. размер символов |
| TINYTEXT / TINYBLOB | 255 | 255 |
| TEXT / BLOB | 65 535 | 65 535 |
| MEDIUMTEXT / MEDIUMBLOB | 16 777 215 | 2 24 -1 |
| LONGTEXT / LONGBLOB | 4 294 967 295 | 2 32 -1 |
Кажется, что типы TINYTEXT и TEXT похожи на CHAR и VARCHAR. Но разница в том, что MySQL не умеет индексировать текстовые и бинарные типы и не может использовать индексы для сортировки.
Дата/время
Типы данных, которые позволяют работать с датой и временем.
| Тип | Размер (байт) | Описание |
| DATE | 3 | Только дата в формате YYYY-MM-DD. Допустимые значения от 1000-01-01 до 9999-12-31 |
| DATETIME | 8 | Дата и время в формате YYYY-MM-DD HH:MM:SS. Допустимые значения от 1000-01-01 00:00:00 до 9999-12-31 23:59:59 |
| TIMESTAMP | 4 | Дата и время. Хранится в виде количества секунд, прошедших с 1 января 1970 года по гринвичу. Занимает в два раза меньше места, чем тип DATETIME. Но при этом диапазон ограничен значениями от 1970-01-01 00:00:01 до 2038-01-09 03:14:07 |
| TIME | 3 | Только время в формате HH:MM:SS. Допустимые значения от 00:00:00 до 23:59:59 |
| YEAR(N) | 1 | Только год в формате YYYY или YY. Допустимые значения от 1901 до 2155 или от 70 до 69 (1970 — 2069) |
JSON
Это относительно новый тип данных, который появился в MySQL версии 5.7.8. Он позволяет нативно хранить и обрабатывать данные в JSON-формате.
В отличие от хранения объектов в виде текста, в использовании специального типа данных есть несколько преимуществ:
- Валидация JSON-объектов. Если попытаться сохранить неправильный JSON, MySQL сгенерирует ошибку.
- Возможность нативно работать с JSON, выбирать и обновлять только отдельные части объектов, а не весь объект целиком.
- MySQL сохраняет тип JSON в специальном внутреннем формате. Такой способ более производительный, чем работа с JSON в виде строки.
Составные типы
Строковые типы данных, которые могут хранить значения только из заранее определенного списка. Несмотря на то, что список значений состоит из строк, в самих таблицах хранятся только числа, которые ассоциированы со справочником возможных значений. Поэтому они занимают мало места.
- ENUM может хранить только одно значение из списка, занимает 1-2 байта.
- SET может хранить одновременно до 64 значений из списка, занимает от 1 до 8 байт.
Заключение
Мы рассмотрели основные типы данных и полей в MySQL, объяснили разницу между схожими типами. Теперь вы можете создавать свои структуры БД, используя полученные знания.
Создание базы данных в MySQL
Типы данных SQL: какие бывают и как с ними работать
Что это такое? Типы данных SQL необходимы для организации работы всей базы. В таблице каждый столбец обязан иметь имя и указание на информацию, которая в нем содержится. Это определяет как язык, на котором написана БД, будет взаимодействовать с наполнением таблицы.
Какие бывают? В каждой конкретной СУБД существуют свои типы данных. Более того, в некоторых системах они могут иметь одинаковое название, но разные функции, поэтому всегда важно знакомиться с документацией до начала работы.
В статье рассказывается:
- Задачи типов данных в SQL
- Виды типов данных SQL
- Хранение типов данных SQL
- Преобразование типов данных
Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.
Бесплатно от Geekbrains
Задачи типов данных в SQL
Для начала определим, о каких данных мы говорим? В данной статье речь пойдёт о типе данных, которые любая переменная или столбец могут хранить в MS SQL Server.
Когда мы создаём любую таблицу или переменную, мы указываем имя, а также тип данных, которые будут храниться.
Тип данных таблицы SQL, которые будут храниться в столбце или в переменной, необходимо определять заранее. Это ограничит пользователя от возможности ввести любые неожиданные или недействительные данные.
Как наиболее эффективно использовать память? Для начала назначьте соответствующий тип данных переменной или столбцу, в котором будет выделяться тот объём, который необходим системной памяти для данных столбца SQL.
MS SQL обеспечивает широкую категорию типов данных, которая соответствует потребностям конкретного пользователя: например, двоичные изображения, дата и др.
В качестве иллюстрации можно взять простую страницу регистрации приложения web-сайта. Мы имеем три поля ввода: Имя, Фамилия, Контактный номер.
Узнай, какие ИТ — профессии
входят в ТОП-30 с доходом
от 210 000 ₽/мес
Павел Симонов
Исполнительный директор Geekbrains
Команда GeekBrains совместно с международными специалистами по развитию карьеры подготовили материалы, которые помогут вам начать путь к профессии мечты.
Подборка содержит только самые востребованные и высокооплачиваемые специальности и направления в IT-сфере. 86% наших учеников с помощью данных материалов определились с карьерной целью на ближайшее будущее!
Скачивайте и используйте уже сегодня:

Павел Симонов
Исполнительный директор Geekbrains
Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда
Подборка 50+ бесплатных нейросетей для упрощения работы и увеличения заработка
Только проверенные нейросети с доступом из России и свободным использованием
ТОП-100 площадок для поиска работы от GeekBrains
Список проверенных ресурсов реальных вакансий с доходом от 210 000 ₽
Получить подборку бесплатно
Уже скачали 25504
Обратите внимание, что в режиме реального времени:
- поля «Имя» и «Фамилия» всегда будут буквенными;
- поле «Контактный номер» всегда будет числовым.
Таким образом, «Имя» и «Фамилия» надо указать как символ, а «Контактный номер» – как целое число.
Каждое поле имеет определённый тип данных. Это могут быть числовые данные, буквенные, формат даты и др.
У разных типов данных будут различные требования к памяти. Для того чтобы память использовалась эффективно, определяйте переменную или столбец с типом данных, которые будут храниться в нём.
Виды типов данных SQL
Строковые типы данных
К этому типы относят имена, названия, адреса и другие данные, которые выражаются словами. Строковые типы – самые распространённые.
Независимо от типа строки, её всегда заключают в одинарные кавычки. Все строковые типы условно делятся на две группы: переменной и фиксированной длины.
У строк с переменной длиной есть ограничение по максимальному размеру поля данной СУБД, но нет ограничений «сверху». В некоторых типах встречается «нижняя граница» – минимальное количество символов. В целом, возможны разные по длине значения, и необходимости ставить дополнительные пробелы при этом нет.
Длину строк фиксированной длины определяют заранее, на этапе определения таблицы. В качестве примера можно привести поля, хранящие номера телефонов. Для них выделяют одиннадцать символов, а остальные знаки просто не сохраняются. Если же пользователь не до конца заполнит поле, СУБД автоматически завершит строку, добавив пробелы.
Определение фиксированной длины повышает производительность: получение, изменение и сортировка данных реализуется намного быстрее, когда в СУБД заложено конкретное количество символов на строку. Индексирование столбцов тоже увеличивает скорость работы: в некоторых СУБД оно возможно только в случае определения фиксированной длины строки.
Для вас подарок! В свободном доступе до 14.01 —>
Скачайте ТОП-10
бесплатных нейросетей
для программирования
Помогут писать код быстрее на 25%
Чтобы получить подарок, заполните информацию в открывшемся окне
Перечислим основные строковые типы данных:
- CHAR – фиксированная длина строки. В процессе создания таблицы определяется точное значение – от 1 до 225 символов;
- NCHAR – одна из разновидностей CHAR, которая поддерживает Unicode или многобайтовые символы
- TEXT (она же LONG, VARCHAR или MEMO) – строки переменной длинны
- NVARCHAR – подвид TEXT, которые поддерживает Unicode или многобайтовые символы
Давайте разберёмся, почему не стоит хранить в числовых форматах номера документов, домов и телефонов.
Есть несколько причин. Во-первых, строковые форматы являются более экономичным способом хранить данные в БД. Во-вторых, в числовом типе данных удаляются все нули в начале значения: они считываются как неинформативные и, следовательно, лишние. При этом номера документов вполне могут начинаться с нулей: например, 0006382. После переработки данные просто станут некорректными.
Дарим скидку от 60%
на курсы от GeekBrains до 14 января
Уже через 9 месяцев сможете устроиться на работу с доходом от 150 000 рублей
Выбирайте числовой формат, когда вам необходимо производить операции сложения или вычитания полей, вычислять среднее значение столбца, находить максимальные значения.
Числовые типы данных
Этот тип данных обеспечивает возможность не только хранить числа, но и производить математические операции и прочие логические действия.
Числа отличаются от строк тем, что без кавычек помещаются в БД. Типы отличаются друг от друга размерами диапазонов значений. Чем меньше допустимый диапазон, тем меньше он требует места для хранения введённого числа.
Только до 11.01
Скачай подборку материалов, чтобы гарантированно найти работу в IT за 14 дней
Список документов:

ТОП-100 площадок для поиска работы от GeekBrains
20 профессий 2023 года, с доходом от 150 000 рублей
Чек-лист «Как успешно пройти собеседование»
Чтобы зарегистрироваться на бесплатный интенсив и получить в подарок подборку файлов от GeekBrains, заполните информацию в открывшемся окне
Некоторые типы хранят исключительно целые числа, а другие могут содержать принимающие дроби.
Названия могут отличаться в зависимости от конкретной СУБД; актуальные заголовки проверяйте в документации. Примерно опишем варианты:
- NUMBER или FLOAT – числа с плавающими точками;
- NUMERIC или DECIMAL – числа с фиксированными или плавающими точками;
- BIT – одноразрядное значение, которое используют для битовых флагов: 0 или 1;
- REAL – 4-байтовые числа с плавающими точками;
- INTEGER или INT – целые 4-байтовые числа, у которых диапазон значений варьируется от -2147483648 до 2147483647;
- TINYINT – целые 1-байтовые числа в диапазоне от 0 до 255;
- SMALLINT – целые 2-байтовые числа в диапазоне от -32768 до 32767.
В некоторых СУБД денежный тип данных выделен в отдельную категорию. Он может относиться к типу DECIMAL, но обладать более удобным для денежных значений диапазоном. Его называют MONEY или CURRENCY.
Типы данных, включающие обозначение даты и времени
То или иное обозначение времени и даты включено во всех СУБД. Они, как и числовые форматы, отличаются друг от друга степенью точности и допустимым диапазоном. Варианты:
- DATE – дата;
- TIME – время;
- TIMESTAMP или DATETIME – дата и время;
- SMALLDATETIME – дата и время с точностью до минуты.
Бывают и более точные форматы, мы привели лишь самые популярные.
Бинарные типы данных
Этот тип данных обеспечивает содержание любых данных в бинарном виде. Это может быть графика, текст, медиа или двоичный код. На самом деле, бинарные типы используют довольно редко, поскольку они плохо совместимы в формате разных СУБД. И всё же порой они упрощают работу, так что приведём основные:
- BINARY – данные в двоичном виде в диапазоне от 255 до 8000 байт;
- RAW – данные фиксированной длинны в двоичном виде в диапазоне до 255 байт;
- LONG RAW – данные переменной длины в двоичном виде в диапазоне до 2Гбайт;
- VARBINARY – данные переменной длины в двоичном виде в диапазоне до 8000 байт или до 255 байт в зависимости от реализации.
Хранение типов данных SQL
Расскажем о двух вариантах хранения, которые позволяют хранить объекты LOB, экономя дисковое пространство.
Хранение данных типа FILESTREAM
LOB – большие объекты – хранятся в SQL Server с помощью типа данных MAX или VARBINARY. BLOB — большие двоичные объекты – хранятся в базе данных . Из-за этого могут возникать проблемы с производительностью, когда вы пытаетесь сохранить видео- или аудиофайлы. Во избежание нарушения работы такие данные сохраняют во внешних файлах за пределами базы данных.
Объекты LOB хранятся в файловой системе NTFS. Этот тип хранения позволяет данным, хранящимся вне базы, управляться базой. Основные характеристики:
- возможность хранения данных FILESTREAM при помощи инструкций CREATE TABLE, а в процессе работы с этими данными используются инструкции для модификации данных (DELETE, UPDATE, SELECT и INSERT);
- обеспечение для данных типа FILESTREAM того же уровня безопасности, что и у данных, которые хранятся внутри базы.
Разреженные столбцы (sparsecolumns)
Этот вариант хранения преследует совершенно иную цель.
Если тип FILESTREAM хранит объекты LOB вне базы данных, то разреженные столбцы минимизируют дисковое пространство, которое занимает база данных.
Это обеспечивает оптимизацию хранения столбцов, у которых большинство значений равняется null. Когда вы используете разреженные столбцы для хранения значений null, вам не требуется дисковое пространство. При этом для хранения значений, которые отличаются от null, потребуется дополнительные байты (от 2 до 4). Поэтому разреженные столбцы рекомендуются к использованию только тогда, когда вы ожидаете сэкономить не менее 20% дискового пространства.
Популярные статьи





Разреженные столбцы определяют так же, как и другие столбцы таблицы, а значит, обращаются к ним аналогично. При обращении к разреженному столбцу используйте инструкции DELETE, UPDATE , SELECT и INSERT так же, как и при работе с обычными столбцами.
Но всё же есть и отличие: когда вы создаёте разреженные столбцы, применяйте аргумент SPARSE, чтобы определить конкретный столбец разреженным.
Вот пример того, как это сделать:
имя_столбца тип_данных SPARSE
Разреженные столбцы таблицы при необходимости можно группировать в наборы столбцов. Это альтернативный способ хранения значений во всех разреженных столбцах таблицы.
Значение NULL
«Null» является одним из специальных значений, которые присваивают ячейкам таблиц. Его применяют в тех случаях, когда информация неприменима или совсем неизвестна. Приведём пример, если вы не знаете домашний номер телефона клиента, вы находите столбец home_telephone и присваиваете соответствующей ячейке значение null.
Важно понимать, что когда значение любой переменной арифметического действия равно null, результат его вычисления тоже будет обозначен как null.
Откройте для себя захватывающий мир IT! Обучайтесь со скидкой до 61% и получайте современную профессию с гарантией трудоустройства. Первый месяц – бесплатно. Выбирайте программу прямо сейчас и станьте востребованным специалистом.
Поэтому, если у вас есть унарная арифметическая операция, в которой значение выражения A равняется null, действие +A или -A будет возвращать null.
Бинарные выражения будут действовать так же. Когда A и B равняется null, результат любых операций (умножение, деление, деление по модулю, сложения, вычитания) этих операндов будет тоже обозначен как null.
Когда в выражении содержится операция сравнения, а значение одного или обоих операндов равняется null, результат действия снова будет null.
Обратите внимание, что значение 0, пустой строки и null не должны быть одинаковыми. Значение null всегда отличается от всех остальных значений.
Значение null сохраняется в столбцах таблицы только тогда, когда это явно разрешается определением данного столбца. При этом значения null недоступны для столбца, если в его определении напрямую указано «NOT NULL».
Когда для столбца с каким-либо типом данных не указано напрямую NULL или NOT NULL, мы присваиваем следующие значения:
- NULL, когда значение параметров ANSI_NULL_DFLT_ON в инструкции SET равняется on.
- NOT NULL, когда значение параметров ANSI_NULL_DFLT_OFF в инструкции SET равняется on.
Если вы не активируете инструкцию set, столбец будет автоматически определяться как NOT NULL. При этом столбцы типа TIMESTAMP не могут иметь значение null ни при каких обстоятельствах.
Преобразование типов данных
Часто возникает необходимость конвертации значений одного типа в значение другого. Как же изменить тип данных в SQL?
Для выполнения конвертирования числа в символьные данные используют специализированную функцию STR. Чтобы выполнить другие преобразования, SQL Server содержит универсальные функции CAST и CONVERT, которые позволяют преобразовывать значения одного типа в значения другого типа. Эти функции взаимозаменяемы. Приведём пример:
CAST(выражение AS тип_данных) CONVERT(тип_данных[(длина)], выражение [,стиль])
Существует аргумент «стиль», который делает возможным управление стилями представления значений некоторых типов данных (нецелочисленные, дата и время, денежные).
DECLARE @d DATETIME DECLARE @s CHAR(8) SET @s=’29.10.01’ SET @d=CAST(@s AS DATETIME)2.3.
В данной статье мы постарались описать основные типы данных, которые традиционно используются в SQL. Однако важно помнить, что в разных проектах заголовки и точные характеристики типов могут отличаться. Обращайте внимание на ваши требования и подбирайте тип, позволяющий их реализовать.