Результаты моделей машинного обучения
В этой статье рассматриваются матрицы ошибок, проблемы классификации и точность в моделях машинного обучения (ML). Целью является улучшение понимания точности в результатах прогнозирования в ML. Целевые аудитории включают инженеров, аналитиков и руководителей, желающих расширить свои знания и навыки в области обработки и анализа данных.
Матрица ошибок
После того, как контролируемая система ML обучена по набору исторических данных, она тестируется с использованием данных, которые можно исключить из процесса обучения. Таким образом можно сравнить прогнозы из обученной модели с фактическими значениями. Матрица ошибок предоставляет средство оценки успешности решения задачи классификации и мест возникновения ошибок (то есть, когда она «путается»).
Например, ваша цель — предсказать, является ли домашнее животное собакой или кошкой, на основе некоторых физических и поведенческих атрибутов. Если имеется тестовый набор данных, содержащий 30 собак и 20 кошек, то матрица ошибок может быть похожа на следующую иллюстрацию.

Числа в зеленых ячейках представляют собой правильные прогнозы. Как можно видеть, модель правильно прогнозируется более высокий процент фактических кошек. Общую точность модели легко рассчитать. В данном случае это 42 ÷ 50 или 0,84.
Классификаторы по нескольким классам в матрице ошибок
Большинство дискуссий о матрице ошибок сосредоточено на двоичных классификаторах, как в предыдущем примере. Этот случай представляет собой особый случай, когда могут учитываться другие показатели, такие как чувствительность и отзыв.
Далее будет рассмотрена проблема классификации для финансового сценария, имеющая три состояния. Модель прогнозирует, будет ли накладная клиента оплачена вовремя, поздно или очень поздно. Например, из 100 тестовых накладных, 50 оплачиваются вовремя, 35 — с опозданием, а 15 — с очень большим опозданием. В этом случае модель может создать матрицу ошибок, которая напоминает следующий рисунок.
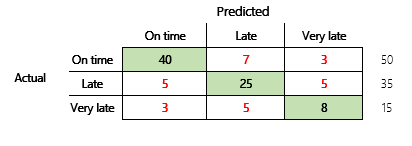
]
Матрица ошибок предоставляет значительно больше информации, чем простая метрика точности. Однако ее по-прежнему довольно легко понять. Матрица ошибок сообщает, имеется ли сбалансированный набор данных, в котором выходные классы имеют похожее количество. В случае с несколькими классами она показывает, насколько может ошибаться прогнозирование, когда выходные классы являются порядковыми, как в предыдущем примере о платежах клиентов.
Точность модели
У различных показателей точности имеется преимущество измерения качества модели.
Так как точность является простой метрикой для понимания, она является хорошей отправной точкой для объяснения модели другим людям, особенно пользователем модели, не являющихся специалистами в области обработки данных. Понимание статистики не требуется, чтобы понять точность модели. При наличии матрицы ошибок она предоставляет дальнейшее понимание эффективности модели.
Однако для более глубокого понимания необходимо отметить несколько проблем, связанных с точностью. Полезность метрики зависит от контекста проблемы. Вопрос, который часто возникает в связи с эффективностью модели, — «Насколько хороша модель?» Однако ответ на этот вопрос необязательно прост. Рассмотрим следующую матрицу ошибок (модель 2).
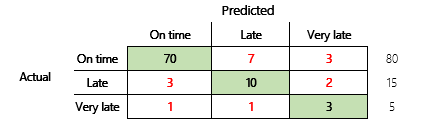
Быстрый расчет показывает, что точность этой модели составляет (70 + 10 + 3) ÷ 100 или 0,83. На поверхности этот результат кажется более подходящим, чем результат для предыдущей модели с несколькими классами (модель 1), имеющей точность 0,73. Но лучше ли это?
Чтобы начать рассмотрение этого вопроса, необходимо оценить точность наивного предположения. При проблемы классификации простая догадка всегда будет спрогнозировать самый распространенный класс. Для модели 1 эта догадка будет иметь значение «вовремя», и это приведет к точности 0,50. Догадка для модели 2 также будет «вовремя», и это приведет к точности 0,80. Поскольку модель 1 улучшает наивную догадку на 0,73 – 0,50 = 0,23, в то время как модель 2 улучшает наивную догадку на 0,83 – 0,80 = 0,03, модель 1 является лучшей моделью, даже если она имеет меньшую точность. Расчет показывает, что эффективная оценка качества модели требует большего количества контекста, чем значение точности.
Стоит отметить еще один аспект. Рассмотрим ситуацию, в которой медицинские тесты используются для обнаружения болезни у пациентов. Эта проблема является проблемой двоичной классификации, когда положительный результат указывает на то, что пациент болен. В этом случае необходимо подумать о влиянии следующих ошибок:
- Ложный положительный результат, когда тест говорит о том, что пациент болен, но на самом деле пациент здоров.
- Ложный отрицательный результат, когда тест говорит о том, что пациент здоров, но на самом деле пациент болен.
Очевидно, что эти типы ошибок нежелательны, но что хуже? Опять, это зависит от ситуации. В случае опасной для жизни болезни, требующей быстрого лечения, приоритет имеет минимизация ложных отрицательных результатов (за которыми желательно следуют дополнительные тесты). В других, менее критических случаях, создатели моделей могут минимизировать ложные положительные результаты. В любом случае разумным заключением является то, что для эффективного определения качества модели необходимо иметь большее количество сведений, чем дает метрика точности.
Рекомендации
Точность — важное средство для общения со специалистами в экспертной области, знакомых со статистикой. Однако, чтобы сделать информацию полезной, очень важно, чтобы дополнительный контекст был одновременно представлен со значением точности.
Для сценария прогнозирования платежей можно настроить цель для модели ML, которая включает факторы в различном поведении платежей. Цель состоит в том, что модель должна быть улучшена относительно наивной догадки путем уменьшения количества неправильных ответов не менее чем на 50 процентов. Другими словами, требуется целевая точность, которая находится между точностью наивной догадки и 100 процентами.
В следующей таблице этот принцип обобщен для матриц ошибок, рассмотренных в этой статье.
| Модель | Наивное предположение | Цель | Точность модели | Цель достигнута? |
|---|---|---|---|---|
| Модель 1 | 0.50 | 0.75 | 0.73 | Почти. Эта модель значительно лучше догадки. |
| Модель 2 | 0.80 | 0.90 | 0.83 | Нет. Необходимо улучшить. |
Точность F1классификации
Последнее, что будет рассмотрено в этой статье, — это более сложная мера производительности ML-процесса классификации, которая называется точностью F1.
Прежде чем можно будет определить точность F1, должны быть введены две дополнительные метрики: точность и отзыв. Точность показывает, сколько общего количества прогнозов, указанных как положительные, правильно назначено. Эта метрика также называется положительным прогнозируемым значением. Отзыв — это общее число фактических положительных случаев, которые были спрогнозированы правильно. Эта метрика также известна как чувствительность.

В матрице ошибок на предыдущем рисунке эти показатели рассчитываются следующим образом:
- Точность = TP ÷ (TP + FP)
- Отзыв = TP ÷ (TP + FN)
Мера F1 сочетает точность и отзыв. Результатом является среднее гармоническое двух значений. Она вычисляется следующим образом:
- F1 = 2 × (Точность × Отзыв) ÷ (Точность + Отзыв)
Рассмотрим конкретный пример. Ранее в этой статье был приведен пример модели, которая прогнозирует, является ли животное собакой или кошкой. Здесь повторяется это изображение.
Здесь приведены результаты, если «Собака» используется как положительный ответ.
- Точность = 24 ÷ (24 + 2) = 0,9231
- Отзыв = 24 ÷ (24 + 6) = 0,8
- F1 = 2 × (0,9231 × 0,8) ÷ (0,9231 + 0,8) = 0,8572
Как можно видеть, значение F1 находится между значениями точности и отзыва.
Хотя точность F1 не так проста в понимании, она добавляет нюансы к базовому числу точности. Она также может помочь в несбалансированном наборе данных, так как будет показано в следующем обсуждении.
В разделе Точность модели данной статьи сравниваются следующие две матрицы ошибок. Даже несмотря на то, что первая модель имела меньшую точность, она была признана более полезной моделью, поскольку она показала более значительное улучшение по сравнению с предположением по умолчанию для времени оплаты.
Давайте посмотрим, как эти две модели сравниваются при использовании оценки F1. Оценка F1 учитывает точность и отзыв для каждого состояния, а вычисление макроса F1 затем усредняет оценку F1 по всем состояниям для определения общего показателя F1. Имеются другие варианты F1, но очень важно рассмотреть версию макроса с учетом того, что все три состояния учитываются одинаково.
Для упрощения вычислений образцы массивов создавались в соответствии с фактическими и прогнозируемыми значениями. Эти массивы использовали библиотеку показателей sklearn в Python для расчета значений. Вот результат.
| Модель | Наивное предположение | Точность | Макрос F1 |
|---|---|---|---|
| Модель 1 | 0.5 | 0.73 | 0.67 |
| Модель 2 | 0.80 | 0.83 | 0.66 |
Для получения более подробной информации о том, как выполняется этот расчет, здесь приведен отчет о классификации sklearn.metrics для модели 1. Три состояния, «Вовремя», «Поздно» и «Очень поздно», представлены строками, которые имеют метку 1, 2 и 3 соответственно. Среднее макроса — это просто среднее значение столбца «оценка-f1».
| точность | отзыв | оценка-f1 | |
|---|---|---|---|
| 1 | 0.83 | 0.80 | 0.82 |
| 2 | 0.68 | 0.71 | 0.69 |
| 3 | 0.50 | 0.50 | 0.50 |
Как показывают эти результаты, две модели имеют почти одинаковые результаты точности макросов F1. В этом и многих других случаях точность F1 обеспечивает лучший индикатор возможности модели. Для точности, интерпретация результатов требует понимания того, что наиболее важно для учета в модели.
Матрица ошибок (Error matrix)
Матрица ошибок представляет собой способ визуализации для оценки качества классификаторов. Обычно используется в машинном обучении с учителем как для бинарной, так и для многоклассовой классификации.
В случае бинарной классификации матрица ошибок представляет собой таблицу, состоящую из двух строк и двух столбцов, при этом строки соответствуют фактическим классам, а столбцы — предсказанным.
В процессе обучения классификатор делает предсказания на обучающих примерах, для которых метка класса известна. При этом он допускает ошибки I и II рода. Если предсказанный класс соответствует фактическому, то исход классификации считается истинным, а в противном случае — ложным. Примеры положительного и отрицательного классов, для которых исход предсказания истинный, называются истинноположительными (true-positive, TP) и истинноотрицательными (true-negative, TN) соответственно. Очевидно, что это правильно классифицированные примеры.
Примеры положительного и отрицательного классов, для которых исход предсказания является ложным, называются ложноположительными (false-positive, FP) и ложноотрицательными (false-negative, FN) соответственно. Считается, что на этих примерах классификатор допустил ошибку.
Тогда результаты работы бинарного классификатора могут быть представлены в матрице ошибок следующим образом.
| P+N | Положительный (предсказано) | Отрицательный (предсказано) |
|---|---|---|
| Положительный (факт) | TP | FP |
| Отрицательный (факт) | FN | TN |
Если ячейка матрицы ошибок расположена на пересечении строки и столбца для одного и того же класса (т.е. элемент на главной диагонали), то она соответствует истинным классификациям, и в ней ставится число правильно отсортированных примеров для соответствующего класса. Если столбец и строка, на пересечении которых расположена ячейка, относятся к разным классам, то в ней окажется число ошибочно определенных примеров.
По результатам, представленным в матрице ошибок, могут вычисляться меры качества модели бинарной классификации.
Меткость (Accuracy, ACC или Overall classification rate, OCR ) — доля правильно классифицированных примеров:
A C C = T P + T N T P + T N + F P + F N .
Точность (Precision) — отношение числа истинноположительных классификаций к общему числу положительных классификаций. Данная величина также известна как positive predictive value (PPV) или положительное прогностическое значение:
P r = P P V = T P T P + F P .
Полнота (Recall) — доля истинноположительных примеров (TPR — true positive rate). Упоминается еще как чувствительность. Определяется как число истинноположительных классификаций относительно общего числа положительных примеров:
R e = T P R = T P T P + F N .
Полноту можно рассматривать как способность бинарного классификатора обнаруживать определенный класс.
Специфичность — доля истинноотрицательных (True Negative Rate — TNR) классификаций в общем числе отрицательных классификаций:
S p = T N R = T N T N + F P .
Данная величина показывает, насколько хорошо модель классифицирует отрицательные примеры.
Точностью отрицательного прогноза — доля верно классифицированных отрицательных примеров (Negative predictive value — NPV) от общего числа примеров классифицированных как отрицательные:
N P V = T N T N + F N .
False positive rate (FPR или Fall-out) — доля неверно классифицированных положительных примеров от общего количества отрицательных:
F P R = 1 − T N R = F P F P + T N .
False negative rate (FNR) — доля неверно классифицированных отрицательных примеров от общего количества положительных примеров:
F N R = 1 − T P R = F N F N + T P .
F1-мера объединяет в себе информацию о точности и полноте, поэтому позволяет находить баланс между ними:
F 1 = 2 ⋅ P P V ⋅ T P R P P V + T P R = 2 ⋅ T P 2 ⋅ T P + F P + F N .
Матрица ошибок может применяться и для многоклассовой классификации. В этом случае число строк и столбцов в ней будет равно числу классов. Однако в этом случае понятия отрицательного и положительного классов в том виде, в котором они были сформулированы для бинарной модели, не работают. Поэтому в ячейках матрицы ставятся не величины TP, FP, TN и FN, а количества классифицированных соответствующим образом примеров.
| Класс 1 (предсказано) | Класс 2 (предсказано) | Класс 3 (предсказано) |
|---|---|---|
| Класс 1 (факт) | 20 | 15 |
| Класс 2 (факт) | 10 | |
| Класс 3 (факт) | 5 | 50 |
Числа, стоящие в ячейках на пересечении строк и столбцов для одноимённых классов (когда предсказанный класс соответствует фактическому) определяют число правильно классифицированных примеров. Очевидно, что такие ячейки будут располагаться на главной диагонали матрицы ([20, 10, 50]). Ячейки, расположенные вне нее будут содержать количества ошибочно классифицированных примеров.
Если некоторые ячейки матрицы остались пустыми, это указывает на отсутствие ошибок модели в соответствующих комбинациях фактических и предсказанных классов. В них можно внести нулевые значения.
Матрица ошибок для многоклассовой классификации также позволяет наглядно представлять результаты работы классификатора и оценивать его качество. Например, по ней просто вычислить точность модели как отношение суммы чисел по главной диагонали матрицы к общему числу элементов в ней, или ошибку, как отношение суммы чисел вне главной диагонали к общему числу элементов.
Узнать подробнее, какие меры качества моделей бинарной классификации вычисляются с использованием матрицы ошибок, можно в статье «Метрики качества моделей бинарной классификации».
Что такое матрица ошибок и зачем она нужна: пример расчета стоимости ошибки прогнозирования

Поскольку в бизнесе поиск баланса между спросом и предложением напрямую конвертируется в деньги, возникает вопрос, насколько выгодно применение методов Machine Learning для решения этой задачи. С целью сопоставления предсказаний и реальности в Data Science используется матрица ошибок (confusion matrix) – таблица с 4 различными комбинациями прогнозируемых и фактических значений.
Поскольку в бизнесе поиск баланса между спросом и предложением напрямую конвертируется в деньги, возникает вопрос, насколько выгодно применение методов Machine Learning для решения этой задачи. С целью сопоставления предсказаний и реальности в Data Science используется матрица ошибок (confusion matrix) – таблица с 4 различными комбинациями прогнозируемых и фактических значений. Прогнозируемые значения описываются как положительные и отрицательные, а фактические – как истинные и ложные [6]. Вообще матрица ошибок используется для оценки точности моделей в задачах классификации. Но прогнозирование и распознавание образов можно рассматривать как частный случай этой проблемы, поэтому confusion matrix актуальна и для измерения точности предсказаний. Важно, что матрица ошибок позволяет оценить эффективность прогноза не только в качественном, но и в количественном выражении, т.е. измерить стоимость ошибки в деньгах. Например, каковы будут расходы на удержание пользователя, если машинное обучение предсказало, что он перестанет приносить компании пользу [7]? Аналогичный вопрос по предсказанию оттока (Churn Rate) актуален и в HR-сфере для удержания ключевых сотрудников, мотивация которых снижается. Впрочем, матрица ошибок может использоваться не только в рамках применения Machine Learning. По сути, этот метод оценки стоимости прогноза является универсальным аналитическим инструментом.
| Реальность | ||
| Прогноз | + | — |
| + | True Positive (истинно-положительное решение): прогноз совпал с реальностью, результат положительный произошел, как и было предсказано ML-моделью | False Positive (ложноположительное решение): ошибка 1-го рода, ML-модель предсказала положительный результат, а на самом деле он отрицательный |
| — | False Negative (ложноотрицательное решение): ошибка 2-го рода – ML-модель предсказала отрицательный результат, но на самом деле он положительный | True Negative (истинно-отрицательное решение): результат отрицательный, ML-прогноз совпал с реальностью |

С математической точки зрения оценить точность ML-модели можно с помощью следующих метрик [8]:
- Точность – сколько всего результатов было предсказано верно;
- Доля ошибок;
- Полнота – сколько истинных результатов было предсказано верно;
- F-мера, которая позволяет сравнить 2 модели, одновременно оценив полноту и точность. Здесь используется среднее гармоническое вместо среднего арифметического, сглаживая расчеты за счет исключения экстремальных значений.
В количественном выражении это будет выглядеть так:

Метрики оценки качества прогноза: полнота, точность, F-мера
Рассмотрим матрицу ошибок на практическом примере для задачи прогнозирования спроса на скоропортящуюся продукцию, которая должна быть продана конечному пользователю в течение суток. Например, букеты цветов, продающиеся по цене k рублей при закупочной стоимости в p рублей. Предположим, с помощью Machine Learning было предложена 2 варианта:
- Положительный прогноз (+), что по цене kбудут полностью раскуплены все цветы в количестве n букетов.
- Отрицательный прогноз (+), что по цене kбудут полностью раскуплены не все цветы, останется m не проданных букетов.
Соответственно, матрица ошибок для этого случая будет выглядеть следующим образом:
| Прогноз | Реальность | |
| Проданы все букеты цветов | Остались не проданные m букетов | |
| +: Проданы все n букетов по k рублей c ценой закупки p | True Positive: прогноз совпал с реальностью, все закупленные n букетов проданы Выручка = n*kЗатраты = n*pПрибыль = n*(k-p)Стоимость ошибки = 0 | False Positive: ошибка 1-го рода, ML-модель предсказала, что будет n продаж, а на самом деле их было (n-m), осталось m не проданных букетов, которые пропали и не вернули затраты на их покупку Выручка = (n-m)*kЗатраты = n*pПрибыль = n*(k-p) – m*kСтоимость ошибки = m*p |
| —: Остались не проданные m букетов c ценой закупки p | False Negative: ошибка 2-го рода – ML-модель предсказала, что n букетов не будет продано, поэтому закупили (n-m) букетов, но спрос был на n букетов. Эффект недополученной прибыли Выручка = (n-m)*kЗатраты = (n-m)*pПрибыль = (n-m)*(k-p)Стоимость ошибки = m*k | True Negative: ML-прогноз совпал с реальностью, было раскуплено (n-m) букетов по цене k, сколько и было изначально закуплено по цене p Выручка = (n-m)*kЗатраты = (n-m)*pПрибыль = (n-m)*(k-p)Стоимость ошибки = 0 |
Таким образом, с помощью confusion matrix можно измерить эффективность прогноза в денежном выражении, что весьма актуально для практического бизнес-приложения Machine Learning. Впрочем, отметим еще раз, что данный метод предварительной оценки будущих сценариев можно использовать и вне сферы Data Science, оценивая риски и перспективы в рамках классического бизнес-анализа.
Матрица ошибок (Confusion matrix)
Пусть дана выборка x i > ( i = 1 , … , N , y i > — метка класса i-го объекта, y i ∈ < 1 , 2 , … , C >\in \> ), каждый объект которой относится к одному из C классов и классификатор a , который эти классы предсказывает. Матрицей ошибок для такого классификатора называется следующая матрица: M = < m i j >i , j = 0 C , m i j = ∑ k = 0 N I [ a ( x k ) = j ] I [ y k = i ] \>_^,~m_=\sum _^\mathbb [a(x_)=j]\mathbb [y_=i]> .
Такая матрица показывает сколько объектов класса i были распознаны как объекты класса j .
Случай бинарной классификации [ ]
| a ( x ) = 1 | TP | FP |
| a ( x ) = − 1 | FN | TN |
В случае бинарной классификации метка класса y принимает значение + 1 (положительный класс) или − 1 (отрицательный). Вводятся 4 величины, соответствующие элементам матрицы ошибок:
- True positive (TP). T P = ∑ i = 0 n [ a ( x i ) = + 1 ] [ y i = + 1 ] ^[a(x_)=+1][y_=+1]>
- True negative (TN). T N = ∑ i = 0 n [ a ( x i ) = − 1 ] [ y i = − 1 ] ^[a(x_)=-1][y_=-1]>
- False positive (FP). F P = ∑ i = 0 n [ a ( x i ) = + 1 ] [ y i = − 1 ] ^[a(x_)=+1][y_=-1]>
- False negative (FN). F N = ∑ i = 0 n [ a ( x i ) = − 1 ] [ y i = + 1 ] ^[a(x_)=-1][y_=+1]>
P означает что классификатор определяет класс объекта как положительный (N — отрицательный). T — значит что класс предсказан правильно (соответственно F — неправильно).
Ахтунг! Не путать с матрицей штрафов.
Точность, полнота, F мера. [ ]
F = 2 ∗ p r e c i s i o n ∗ r e c a l l p r e c i s i o n + r e c a l l >>