Data Engineer

Data Engineer работает в сфере информационной инженерии, занимается доставкой, хранением и обработкой данных. Профессия имеет ярко выраженные технические черты, подойдет для тех, кто увлекается информационными технологиями. Кстати, недавно центр профориентации ПрофГид разработал точный тест на профориентацию, который сам расскажет, какие профессии вам подходят, даст заключение о вашем типе личности и интеллекте.
Краткое описание
Появление Big Data изменило стратегию работы с данными. Data Analyst и Scientist занимаются анализом и извлечением данных из огромных массивов, а Data Engineer специализируется на разработке структуры для Big Data и других типов данных. Работа связана с большим количеством профессиональных компетенций, но она популярна из-за достойного уровня оплаты труда и колоссальной востребованности на кадровом рынке.
Как узнать, подходит ли вам профессия «Data Engineer»?

Data Engineer востребован везде, где есть обилие источников данных, работа с которыми вместе с тем является нетривиальной задачей. Профессия очень распространена, потому что необходимость в правильном сборе и хранении данных увеличилась вслед за развитием предиктивной аналитики (предиктивная, или прогнозная, предсказательная, аналитика – класс методов анализа больших данных, которые используются для прогнозирования поведения объектов и субъектов с целью принятия оптимальных решений. – Прим. ред.), для работы которой необходимы чистые данные. Потому что чем меньше в исходных данных дефектов, тем лучше модель будет выявлять закономерности.

Никита Васильев
Senior Data Engineer, Inno.tech
Читайте также

Особенности профессии
Data Engineer занимается извлечением, последующим преобразованием, загрузкой и обработкой данных. Нередко Data Engineer и Data Scientist путают, однако это разные профессии. Первый специалист – гуру Big Data и безупречно знает программирование, второму нет равных в работах, связанных с аналитическими процессами и алгоритмами. Data Engineer – профессиональный программист, он пишет код, без которого невозможно построить пайплайн данных.

Черная пятница в Skillbox: месяц инвестиций в себя!
Получи скидку, курс в подарок и гарантию трудоустройства, чтобы стать востребованным специалистом.

Мечтаешь создать свою игру?
Воплоти мечту в реальность вместе с XYZ School!
Data Engineer в первую очередь автоматизирует и в дальнейшем поддерживает извлечение данных (Extract) их преобразование (Transform) из различных источников, таких как сырые логи в JSON, таблицы в базах данных, файлы в сетевых каталогах и так далее. Затем сохраняет (Load) их в том виде, в котором ими будут пользоваться конечные потребители. Это могут быть Data Scientists (DS), Data Analyst, Buisness analyst и так далее. А весь процесс получил аббревиатурное название ETL (Extract, Transform, Load).
Во вторую очередь обязанность Data Engineer – это формирование различных фреймворков для работы с данными и анализа их качества, которые упрощают порог вхождения, а также гарантируют, что все данные будут консистентны. Также часто в требованиях к вакансии можно встретить выкатку моделей DS в продакшен, то есть в целевое использование.
Технологии, с которыми работает Data Engineer, зависят от того, какие из них необходимы в компании. В основном это различные базы данных, инструменты ETL, а из языков программирования популярны Python и Scala.

Никита Васильев
Senior Data Engineer, Inno.tech
Data Engineers востребованы во всех сферах бизнеса, например, в банковском секторе, который имеет тысячи хранилищ информации с данными, касающимися клиентов, транзакций и других финансовых операций. Конкуренция в сфере информационной инженерии невысокая, как утверждают российские HR-специалисты. Сейчас отечественный рынок испытывает потребность в опытных Data Engineers, поэтому работу долго искать не придется.

НОВОГОДНЯЯ РАСПРОДАЖА SKILLBOX
При покупке курса со скидкой до 60% выберите второй курс в подарок.

Скидки 70% и подарки на сумму до 260 000 ₽
Покупаете один курс — получаете два. Год английского от Skyeng +1 профессия в подарок.
Новогодняя акция! Скидки до 60% и «Тайный Санта»
Всеми любимый «Тайный Санта» здесь: те, кто приобрел у нас курс, получат курс в подарок и смогут подарить мини-курс своему другу.
Плюсы и минусы профессии
Плюсы
- Должность Data Engineer высокооплачиваемая.
- Работодатели заинтересованы в опытных Data Engineer, поэтому много возможностей устроиться в крупную отечественную или зарубежную компанию.
- Работа достаточно интересная.
- Привыкший работать в режиме многозадачности Data Engineer может реализовать свой потенциал в смежных сферах деятельности.
Минусы
- Многие компании заинтересованы в Data Engineer, но четких требований и списка должностных обязанностей для таких специалистов нет – это порождает недопонимание между работодателями и кандидатами на трудоустройство или даже уже нанятыми сотрудниками.
Важные личные качества
Data Engineer – ответственный и очень педантичный специалист, которому надо уметь трудиться в формате многозадачности. Работа с данными требует внимательности, развитого технического мышления, аналитических способностей. Data Engineer нужно умееть работать в команде.
Обучение на Data Engineer
Профессия новая, и пока требования к уровню образования размыты. Конечно, хорошей базой будет вузовская подготовка по направлениям, связанным с программной инженерией. После окончания университета или института, скорее всего, придется продолжить обучение на отечественных и зарубежных курсах.
Лучшие вузы для Data Engineer
- МГТУ им. Н. Э. Баумана.
- НИЯУ МИФИ.
- РТУ МИРЭА.
- НИУ ВШЭ.
- КубГТУ.

Курсы
GeekUniversity
На факультете Data Engineering можно освоить профессию с нуля. Программа рассчитана на низкий порог вхождения, обучение позволяет будущим Data Engineering приобрести год опыта. Курс разработан в содружестве с онлайн-университетом Mail.ru Group. Первые полгода студенты обучаются бесплатно, дальнейшая стоимость составляет 4 990 руб. в месяц. Выпускники получают сертификат и диплом о профессиональной переподготовке.
Кто такие дата-инженеры, и как ими становятся?
И снова здравствуйте! Заголовок статьи говорит сам о себе. В преддверии старта курса «Data Engineer» предлагаем разобраться в том, кто же такие дата-инженеры. В статье очень много полезных ссылок. Приятного прочтения.

Простое руководство о том, как поймать волну Data Engineering и не дать ей затянуть вас в пучину.
Складывается впечатление, что в наши дни каждый хочет стать дата-саентистом (Data Scientist). Но как насчет Data Engineering (инжиниринга данных)? По сути, это своего рода гибрид дата-аналитика и дата-саентиста; дата-инженер обычно отвечает за управление рабочими процессами, конвейерами обработки и ETL-процессами. Ввиду важности этих функций, в настоящее время это очередной популярный профессиональный жаргонизм, который активно набирает обороты.
Высокая зарплата и огромный спрос — это лишь малая часть того, что делает эту работу чрезвычайно привлекательной! Если вы хотите пополнить ряды героев, никогда не поздно начать учиться. В этом посте я собрал всю необходимую информацию, чтобы помочь вам сделать первые шаги.
Итак, начнем!
Что такое Data Engineering?
Честно говоря, нет лучшего объяснения, чем это:
«Ученый может открыть новую звезду, но не может ее создать. Ему придется просить инженера сделать это за него.»
–Гордон Линдсей Глегг
Таким образом, роль дата-инженера достаточно весома.
Из названия следует, что инженерия данных связана с данными, а именно с их доставкой, хранением и обработкой. Соответственно, основная задача инженеров — обеспечить надежную инфраструктуру для данных. Если мы посмотрим на ИИ-иерархию потребностей, инженерия данных занимает первые 2–3 этапа: сбор, перемещение и хранение, подготовка данных.

Чем занимается инженер данных?
С появлением больших данных сфера ответственности резко изменилась. Если раньше эти эксперты писали большие SQL-запросы и перегоняли данные с помощью таких инструментов, как Informatica ETL, Pentaho ETL, Talend, то теперь требования к дата-инженерам повысились.
Большинство компаний с открытыми вакансиями на должность дата-инженера предъявляют следующие требования:
- Отличное знание SQL и Python.
- Опыт работы с облачными платформами, в частности Amazon Web Services.
- Предпочтительно знание Java/Scala.
- Хорошее понимание баз данных SQL и NoSQL (моделирование данных, хранение данных).
Список используемых в этом случае инструментов может отличаться, все зависит от объема этих данных, скорости их поступления и неоднородности. Большинство компаний вообще не сталкиваются с большими данными, поэтому в качестве централизованного хранилища, так называемого хранилища данных, можно использовать базу данных SQL (PostgreSQL, MySQL и т. д.) с небольшим набором скриптов, которые направляют данные в хранилище.
IT-гиганты, такие как Google, Amazon, Facebook или Dropbox, предъявляют более высокие требования: знание Python, Java или Scala.
- Опыт работы с большими данными: Hadoop, Spark, Kafka.
- Знание алгоритмов и структур данных.
- Понимание основ распределенных систем.
- Опыт работы с инструментами визуализации данных, такими как Tableau или ElasticSearch, будет большим плюсом.
Дата-инженеры Vs. дата-саентисты

Ладно, это было простое и забавное сравнение (ничего личного), но на самом деле все намного сложнее.
Во-первых, вы должны знать, что существует достаточно много неясности в разграничении ролей и навыков дата-саентиста и дата-инженера. То есть, вы легко можете быть озадачены тем, какие все-таки навыки необходимы для успешного дата-инженера. Конечно, есть определенные навыки, которые накладываются на обе роли. Но также есть целый ряд диаметрально противоположных навыков.
Наука о данных — это серьезное дело, но мы движется к миру с функциональной дата саенс, где практикующие способны делать свою собственную аналитику. Чтобы задействовать конвейеры данных и интегрированные структуры данных, вам нужны инженеры данных, а не ученые.
Является ли дата-инженер более востребованным, чем дата-саентист?
— Да, потому что прежде чем вы сможете приготовить морковный пирог, вам нужно сначала собрать, очистить и запастись морковью!
Дата-инженер разбирается в программировании лучше, чем любой дата-саентист, но когда дело доходит до статистики, все с точностью до наоборот.
Но вот преимущество дата-инженера: без него/нее ценность модели-прототипа, чаще всего состоящей из фрагмента кода ужасного качества в файле Python, полученной от дата-саентиста и каким-то образом дающей результат, стремится к нулю.
Без дата-инженера этот код никогда не станет проектом, и никакая бизнес-проблема не будет эффективно решена. Инженер данных пытается превратить это все в продукт.
Основные сведения, которые должен знать дата-инженер

Итак, если эта работа пробуждает в вас свет и вы полны энтузиазма — вы способны научиться этому, вы можете овладеть всеми необходимыми навыками и стать настоящей рок-звездой в области разработки данных. И, да, вы можете осуществить это даже без навыков программирования или других технических знаний. Это сложно, но возможно!
Каковы первые шаги?
Вы должны иметь общее представление о том, что есть что.
Прежде всего, Data Engineering относится к информатике. Конкретне — вы должны понимать эффективные алгоритмы и структуры данных. Во-вторых, поскольку дата-инженеры работают с данными, необходимо понимание принципов работы баз данных и структур, лежащих в их основе.
Например, обычные B-tree SQL базы данных основаны на структуре данных B-Tree, а также, в современных распределенных репозиториях, LSM-Tree и других модификациях хеш-таблиц.
* Эти шаги основаны на замечательной статье Адиля Хаштамова. Итак, если вы знаете русский язык, поддержите этого автора и прочитайте его пост.
1. Алгоритмы и структуры данных
Использование правильной структуры данных может значительно улучшить производительность алгоритма. В идеале, мы все должны изучать структуры данных и алгоритмы в наших школах, но это редко когда-либо освещается. Во всяком случае, ознакомится никогда не поздно.
Итак, вот мои любимые бесплатные курсы для изучения структур данных и алгоритмов:
- От простых к сложным: Структуры Данных(Udemy)
- Алгоритмы, Часть I (Coursera)
- Алгоритмы, Часть II (Coursera)
- Чтобы улучшить свои навыки, используйте Leetcode.
- Введение в системы баз данных.
- Продвинутые системы баз данных.
Вся наша жизнь — это данные. И для того, чтобы извлечь эти данные из базы данных, вам нужно «говорить» с ними на одном языке.
SQL (Structured Query Language — язык структурированных запросов) является языком общения в области данных. Независимо от того, что кто-то говорит, SQL жил, жив и будет жить еще очень долго.
Если вы долгое время находились в разработке, вы, вероятно, заметили, что слухи о скорой смерти SQL появляются периодически. Язык был разработан в начале 70-х годов и до сих пор пользуется огромной популярностью среди аналитиков, разработчиков и просто энтузиастов.
Без знания SQL в инженерии данных делать нечего, так как вам неизбежно придется создавать запросы для извлечения данных. Все современные хранилища больших данных поддерживают SQL:
- Amazon Redshift
- HP Vertica
- Oracle
- SQL Server
Для анализа большого слоя данных, хранящихся в распределенных системах, таких как HDFS, были изобретены механизмы SQL: Apache Hive, Impala и т. д. Видите, он не собирается никуда уходить.
Как выучить SQL? Просто делай это на практике.
Для этого я бы порекомендовал ознакомиться с отличным учебником, который, кстати, бесплатный, от Mode Analytics.
- Средний уровень SQL
- Объединение данных в SQL
3. Программирование на Python и Java/Scala
Почему стоит изучать язык программирования Python, я уже писал в статье Python vs R. Выбор лучшего инструмента для AI, ML и Data Science. Что касается Java и Scala, большинство инструментов для хранения и обработки огромных объемов данных написаны на этих языках. Например:
- Apache Kafka (Scala)
- Hadoop, HDFS (Java)
- Apache Spark (Scala)
- Apache Cassandra (Java)
- HBase (Java)
- Apache Hive (Java)
Чтобы погрузиться в язык Scala, вы можете прочитать Программирование в Scala от автора языка. Также компания Twitter опубликовала хорошее вводное руководство — Scala School.
Что касается Python, я считаю Fluent Python лучшей книгой среднего уровня.
4. Инструменты для работы с большими данными
Вот список самых популярных инструментов в мире больших данных:
- Apache Spark
- Apache Kafka
- Apache Hadoop (HDFS, HBase, Hive)
- Apache Cassandra
- Введением в Hadoop может служить Полное руководство по освоению Hadoop (бесплатно).
- Наиболее полное руководство по Apache Spark для меня — Spark: полное руководство.

Знание хотя бы одной облачной платформы находится в списке базовых требований, предъявляемым к соискателям на должность дата-инженера. Работодатели отдают предпочтение Amazon Web Services, на втором месте — облачная платформа Google, и замыкает тройку лидеров Microsoft Azure.
Вы должны хорошо ориентироваться в Amazon EC2, AWS Lambda, Amazon S3, DynamoDB.
6. Распределенные системы
Работа с большими данными подразумевает наличие кластеров независимо работающих компьютеров, связь между которыми осуществляется по сети. Чем больше кластер, тем больше вероятность отказа его узлов-членов. Чтобы стать крутым экспертом в области данных, вам необходимо вникнуть в проблемы и существующие решения для распределенных систем. Эта область старая и сложная.
Эндрю Таненбаум считается пионером в этой области. Для тех, кто не боится теории, я рекомендую его книгу «Распределенные системы», для начинающих она может показаться сложной, но это действительно поможет вам отточить свои навыки.
Я считаю «Проектирование приложений с интенсивным использованием данных» под авторством Мартина Клеппманна лучшей вводной книгой. Кстати, у Мартина есть замечательный блог. Его работа поможет систематизировать знания о построении современной инфраструктуры для хранения и обработки больших данных.
Для тех, кто любит смотреть видео, на Youtube есть курс Распределенные компьютерные системы.
7. Конвейеры данных

Конвейеры данных — это то, без чего вы не можете жить в качестве дата-инженера.
Большую часть времени дата-инженер строит так называемую пайплайн дату, то есть создает процесс доставки данных из одного места в другое. Это могут быть пользовательские сценарии, которые идут к API внешнего сервиса или делают SQL-запрос, дополняют данные и помещают их в централизованное хранилище (хранилище данных) или хранилище неструктурированных данных (озера данных).
Подводя итог: основной чеклист дата-инженера

Подытожим — необходимо хорошее понимание следующего:
- Информационные системы;
- Разработка программного обеспечения (Agile, DevOps, Design Techniques, SOA);
- Распределенные системы и параллельное программирование;
- Основы баз данных — планирование, проектирование, эксплуатация и устранение неисправностей;
- Проектирование экспериментов — A/B-тесты для доказательства концепций, определения надежности, производительности систем, а также для разработки надежных путей для оперативного предоставления хороших решений.
И, наконец, последнее, но очень важное, что я хочу сказать.
Путь становления Data Engineering не так прост, как может показаться. Он не прощает, фрустрирует, и вы должны быть готовы к этому. Некоторые моменты в этом путешествии могут подтолкнуть вас все бросить. Но это настоящий труд и учебный процесс.
Просто не приукрашивайте его с самого начала. Весь смысл путешествия в том, чтобы узнать как можно больше и быть готовым к новым вызовам.
Вот отличная картинка, с которой я столкнулся, которая хорошо иллюстрирует этот момент:

И да, не забудьте избегать выгорания и отдыхать. Это тоже очень важно. Удачи!
Как вам статья, друзья? Приглашаем на бесплатный вебинар, который состоится уже сегодня в 20.00. В рамках вебинара обсудим, как построить эффективную и масштабируемую систему обработки данных для небольшой компании или стартапа с минимальными затратами. В качестве практики познакомимся с инструментами обработки данных Google Cloud. До встречи!
- Data Engineering
- Data Science
- Big Data
- Data
- Towards Data Science
- Блог компании OTUS
- Big Data
- Хранение данных
- Data Engineering
Кто такой Data Engineer и как им стать


Максим Керемет Эксперт в Data Engineering.
Дата-инженер (Data Engineer) — это человек, который организует потоки загрузки и обрабатывает данные. Простыми словами, это инженер данных, который занимается тем, чтобы данные в компьютерах компании правильно передвигались и хранились, как книги на полках библиотеки. Это помогает другим людям легче находить и использовать эти данные для принятия решений и работы. Как он это делает, что для этого нужно уметь, и насколько такая деятельность востребована, разбираемся с дата-инженером X5 Retail Group Максимом Кереметом.

Освойте профессию «Data Scientist» на курсе с МГУ
Data Scientist с нуля до PRO
Освойте профессию Data Scientist с нуля до уровня PRO на углубленном курсе совместно с академиком РАН из МГУ. Изучите продвинутую математику с азов, получите реальный опыт на практических проектах и начните работать удаленно из любой точки мира.

25 месяцев
Data Scientist с нуля до PRO
Создавайте ML-модели и работайте с нейронными сетями
6 224 ₽/мес 11 317 ₽/мес

Что делает дата-инженер?
Дата-инженер участвует в начальной и финальной стадиях анализа данных, обеспечивает их работу на инфраструктуре компании. Он занимается ETL-процессами, то есть обрабатывает данные: достает (extract) их из сырых источников, трансформирует (transform) и загружает (load). После предварительной обработки, очистки от повторов, ошибок, ненужных уточнений, он автоматизирует выполнение скриптов и, если нужно, настраивает мониторинги, алерты (сигналы о том, что в моделях что-то пошло не так), задает расписание, по которому сервис или программа будут работать с данными (шедуллит). Задачи в компаниях могут отличаться: где-то инженер только обрабатывает данные, а где-то выполняет и программистскую работу: внедряет новые модели и переучивает старые. Помимо сбора и обработки инженер данных организует хранение данных. Для этого он строит архитектуру хранилищ – базы данных с таблицами, в которых они разбиты по смыслу. Дата-сайентистам это облегчает доступ к обработанным наборам данных (признакам), с помощью хранилища проще и быстрее масштабировать модели.

Чем дата-инженер отличается от дата-сайентиста?
Задачи дата-сайентиста и дата-инженера находятся на разных этапах работы с данными. Дата-сайентист – это исследователь, который придумывает, как решить задачу бизнеса. Например, прогнозирует, когда покупатель придет в магазин в следующий раз. Он готовит дата-сет, извлекает признаки, экспериментирует с моделями, делает пилотный запуск модели. Для того, чтобы дата-сайентисту было с чем экспериментировать, дата-инженер готовит данные. Они обычно скрыты в хранилищах. Когда модель готова, дата-инженер масштабирует успешные решения на гораздо бОльшие объемы чем тренировочный датасет Модель также нужно периодически обновлять: делать отчеты, чтобы бизнес мог ежедневно использовать этот труд, по мере необходимости обновлять признаки. Этим тоже занимается дата-инженер.
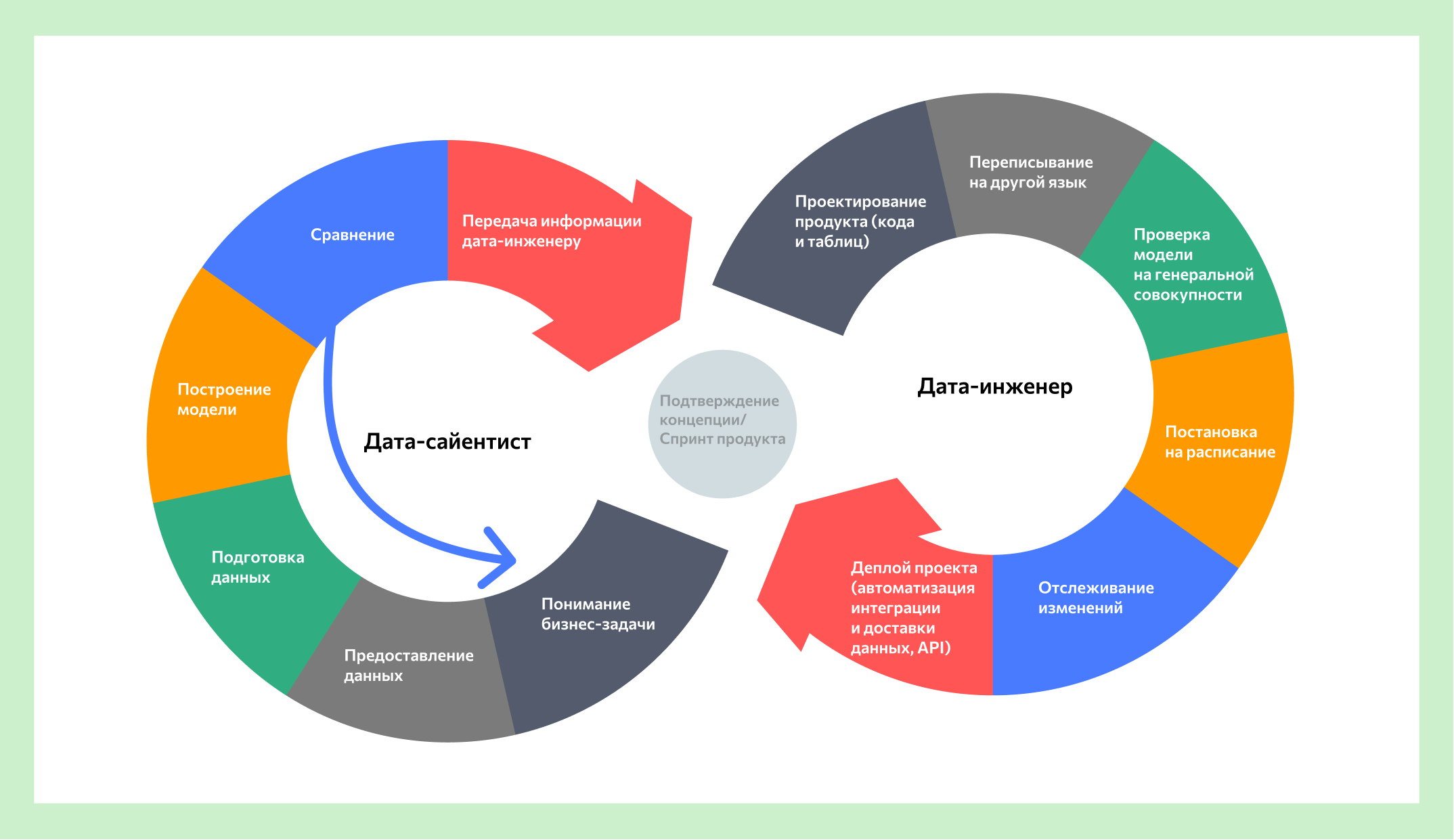

Станьте дата-сайентистом на курсе с МГУ и решайте амбициозные задачи с помощью нейросетей
Где он нужен
- регулярно собирает данные приложения с устройств пользователей,
- собирает данные логов сервера, которые относятся к пользователю,
- создает точку API, которая отразит историю событий любого пользователя.
Для этого необходимо создать пайплайн (процесс сбора, трансформации и загрузки в базу данных), который в реальном времени сможет собрать логи приложений и сервера, проанализировать их и соотнести с конкретным пользователем. Проанализированные логи дата-инженер собирает в базу данных так, чтобы их можно было без труда запросить по API.
Насколько это востребовано
Из-за того, что данные растут в геометрической прогрессии, компании придумывают новые, более эффективные способы работы с ними. Для этого им нужны не только мощные платформы для хранения, но и сотрудники, которые оптимизируют процессы, поставляют уже подготовленные данные, ускоряя дальнейшую работу дата-сайентистов. Поэтому спрос на специалистов в этой сфере только увеличивается, а зарплаты в этом направлении – одни из самых высоких в IT.
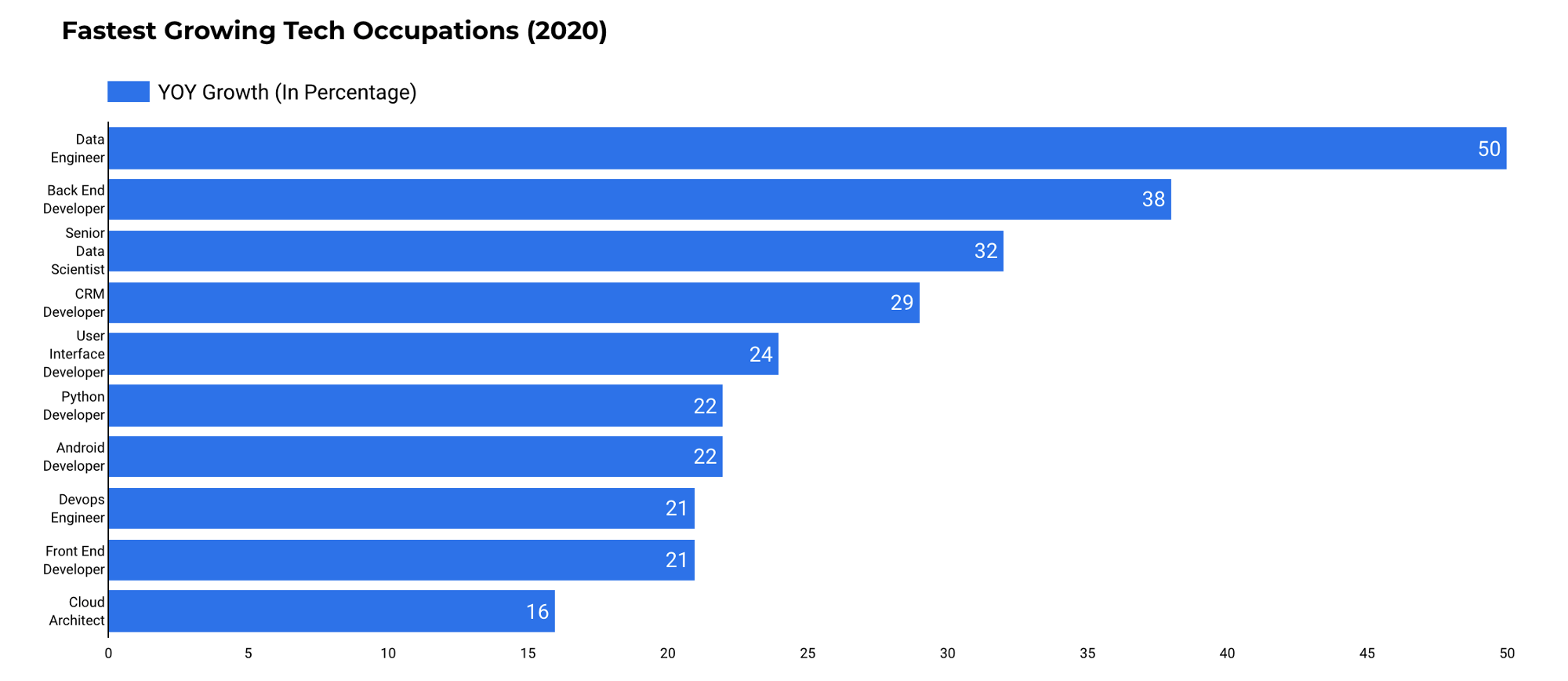
Согласно отчету DICE о технических вакансиях за 2020 год количество вакансий дата-инженера выросло на 50% по сравнению в 2019 годом. Это самый большой показатель среди других профессий.
Сколько получает дата-инженер
Зарплаты зависят от уровня: в среднем джуниоры получают 100-150 тыс. руб, миддл-специалисты 150-250 тыс. руб, а синьор-профессионалы 250-300 тыс. руб, основываясь на данных из сообщества ODS.
Что ему нужно знать
По мнению Максима Керемета, на российском рынке дата-инженер – это человек, который может все по чуть-чуть: и программировать, и работать с базами данных, и провести несложную аналитику (построить дашборд в Power BI или Tableau), и самостоятельно написать приложение, которое может работать.
Традиционно дата-инженер работает с таблицами, поэтому ему необходимо знать, как писать SQL-запросы, разбираться в видах баз данных. В основном он сталкивается с реляционными (наборы данных, связанных между собой по значению) и колоночными (данные связаны не по строкам, а по колонкам) базами данных.
Наиболее популярная система управления реляционной БД – PostgreSQL, для колоночных – ClickHouse, он быстрый и используется для аналитики и логирования событий.
Дата-инженер должен хорошо знать Python: он умеет читать таблицы из источников на компьютере, понимает язык на уровне базовых структур, ООП. Python также нужен для того, чтобы писать веб-сервисы, чтобы в дальнейшем работать с продуктивизацией моделей. Кроме того, с помощью языка можно разрабатывать новые сервисы и модели, которые отслеживают стабильность уже работающих программ.
Плюсом будет знание Scala — язык эффективен в промышленных масштабах, когда становится важна скорость обработки данных. В этом Python уступает.
Нужно владеть инструментами экосистемы Hadoop (система управления базами данных Hive или фреймворк Spark) – они помогают работать с большими данными, которые невозможно обрабатывать на одном локальном компьютере из-за объемов и производительности. Для них используются кластерные машины с более мощными показателями.
Чтобы запускать уже готовые сервисы, не требующие доработки, на разных компьютерах, дата-инженеру нужно уметь использовать Docker. Он «упаковывает» сервис, написанный на локальном компьютере, в контейнер, и его можно воспроизводить на компьютере коллеги или кластерной машине.
А для автоматизации работы в команде дата-инженер использует GitLab.

Откуда приходят в дата-инженеры
- Из аналитики вне IT. Когда хочется автоматизировать и улучшить работу с таблицами и отчетами.
- Из аналитики в IT. Если уже знакомы с Python на базовом уровне и хочется развиваться в техническом направлении, научиться программировать.
Максим Керемет добавляет: «Можно переквалифицироваться из дата-сайентиста, если хочется больше развиваться с точки зрения программирования и построить какой-то сервис или продукт. Кроме того, если надоело постоянно выполнять разные ситуативные задачи и хочется сконцентрироваться на среднесрочных проектах на несколько месяцев, дата-инженер — хороший вариант».
Плюсы и минусы профессии
Плюсы:
- Высокие зарплаты.
- Дефицит специалистов не только в России, но и за рубежом. Из-за того, что компании только начинают понимать ценность таких сотрудников, вакансия редкая, а значит и конкуренция низкая.
- Широкое поле для развития в разных технических направлениях. «С навыками дата-инженера можно уйти в MLOps (введение моделей в продакшн). Можно статьDevOps– организовывать работу сервисов. Можно перейти в менеджмент: руководителем группы аналитиков или разработчиков и прокачивать софт-скиллы».
Минусы:
- К профессии нет четких и универсальных требований. В вакансиях компании часто взваливают на дата-инженера обязанности коллег дата-сайентистов или аналитиков. Максим поделился своим опытом работы в небольшом стартапе: «Из-за того, что компания маленькая, нет организационных процессов, СЕО мог позвонить мне в девять вечера. И чем больше я делал, тем больше на меня сваливалось. Я шел работать на Python, делать сервисы, работать с разными видами баз данных, а по факту два месяца писал SQL-запросы».
- Во время найма не всегда проверяют нужные навыки. Максим обратил внимание на закономерность: «Довольно распространенная практика, что людей тестируют на то, что не показывает их компетенцию. Проверяют знания алгоритмических задач, теории вероятности, которые проходят в техническом университете на первых курсах. Количество задач, которые ты решил по матстату и терверу не показывают, насколько ты умеешь ориентироваться в бизнес-представлениях, общаться с другими людьми, придумывать решение задачи и писать код».
Как начать
Новичкам без бэкграунда в IT попасть в профессию сложно, так как она требует серьезной технической подготовки: нужно писать хотя бы на Python, владеть инструментами автоматизации.
Для специалиста в этой области важны знания алгоритмов и структур данных. Алгоритмические задачи хорошо выстраивают мышление, знание синтаксиса языка и его возможностей. Алгоритмы данных можно изучить на бесплатном курсе на Coursera.
Кроме того, на Coursera можно познакомиться с базовыми понятиями, научиться строить пайплайны (выстраивать весь ETL-процесс переноса данных из одного места в другое), разобраться в том, что такое базы данных и как устроены системы облачных хранилищ.
Можно попробовать самостоятельно определить траекторию обучения, ориентируясь на Road map профессии. C ее помощью удобно систематизировать, какими навыками вы уже овладели, а какие нужно подтянуть или выучить с нуля.
Полезные ссылки:
- сабреддит про популярные вопросы профессии;
- митап DE or DIE, где обсуждают технические вопросы;
- сообщество в Telegram «Data Engineers»;
- Data Engineering Podcast, где к каждому выпуску прикладывают ссылки на обсуждаемые инструменты и кейсы.
Либо можно пройти полноценный курс по Data Engineering. На нем есть главное – практика, благодаря которой вы сможете не просто в теории разобраться с программами и продуктами, которыми используют в профессии, но отработать технологии на реальных задачах и применить их в проекте.
Data scientist, data analyst, data engineer

Некоторые считают, что data scientist, дата-аналитик и дата-инженер занимаются одним и тем же. На самом деле все не так просто. У каждого из них — свои задачи и функции, которые могут пересекаться.
Вместе с Ольгой Матевой, Analyst в Preply, Максимом Натальчишиным, Data Engineer в AutoDoc, и Виталием Радченко, Data Scientist в YouScan, рассказываем, в чем различие позиций и может ли один человек совмещать компетенции.
Кто за что отвечает
Дата-аналитик — позиция для тех, кто хочет начать работать с данными. Технические навыки важны, но главное — знание статистических методов.

Ольга: «Дата-аналитики ищут инсайты в данных , создают визуализации и дают ответы на запросы от бизнеса (например, какую метрику лучше использовать для этого функционала). В работе аналитиков больше коммуникации, чем в работе инженеров и специалистов по data science.
Ключевые навыки дата-аналитика:
- знание языков Python/R, математики/статистики, SQL,
- опыт работы с платформами для аналитики и визуализаций Tableau/Power BI
- любовь к цифрам и усидчивость. Часто нужно довольно долго копать, чтобы найти что-то интересное.
- способность решать проблемы, искать новые идеи и решения.
- коммуникабельность (важны и коммуникация в команде, и правильная подача результатов анализа)».
Data scientist чаще работает с большими массивами данных. Он ищет в них закономерности, строит прогнозные модели, создает рекомендательные алгоритмы. Также data scientist может визуализировать данные.

Виталий: «Data scientist должен подстроиться под определенную задачу и решить ее. Если нужно, он может совмещать и компетенции дата-аналитика, и компетенции дата-инженера. Но это не значит, что data scientist справится лучше дата-инженера с задачей оптимизации пайплайна или найдет аномалии в данных быстрее дата-аналитика.
Сложнее всего для data scientist собрать качественные данные. Почти всегда качество данных — это определяющий критерий, без которого техническая часть не имеет смысла.
Ключевые навыки data scientist’а:
- умение анализировать. Нужно проанализировать задачу перед ее выполнением, подумать над тем, какие данные нужны и как их лучше всего собрать. После сбора данных нужно оценить их качество, потом — качество моделей и вероятность их использования в реальном мире. На каждом этапе можно допустить ошибку. Поэтому нужно анализировать промежуточные результаты. Иначе вы рискуете не заметить ошибку и потратить время зря, обнаружив ее в финале.
- способность учиться от задачи к задаче, чтобы предыдущий опыт помогал вам справляться с новыми вызовами быстрее».
Кроме этого, data scientist должен иметь опыт программирования на Python, уметь работать с SQL, создавать визуализации данных и обладать хотя бы базовыми знаниями в области machine learning.